Downloaded 32 times

![Agenda
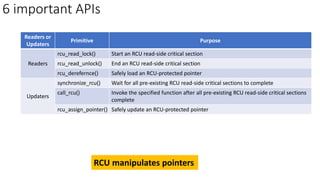
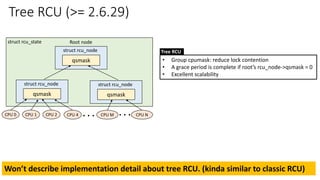
• [Overview] rwlock (reader-writer spinlock) vs RCU
• RCU Implementation Overview
✓High-level overview
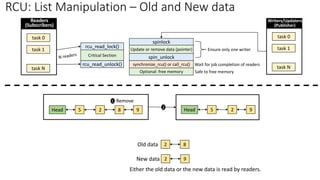
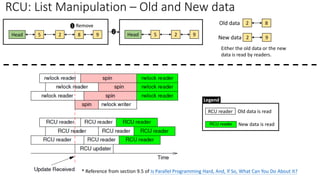
✓RCU: List Manipulation – Old and New data
✓Reader/Writer synchronization: six basic APIs
➢Reader
➢ rcu_read_lock() & rcu_read_unlock()
➢ rcu_dereference()
➢Writer
➢ rcu_assign_pointer()
➢ synchronize_rcu() & call_rcu()
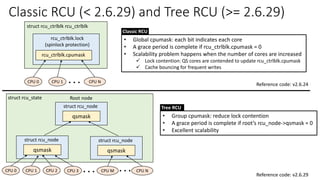
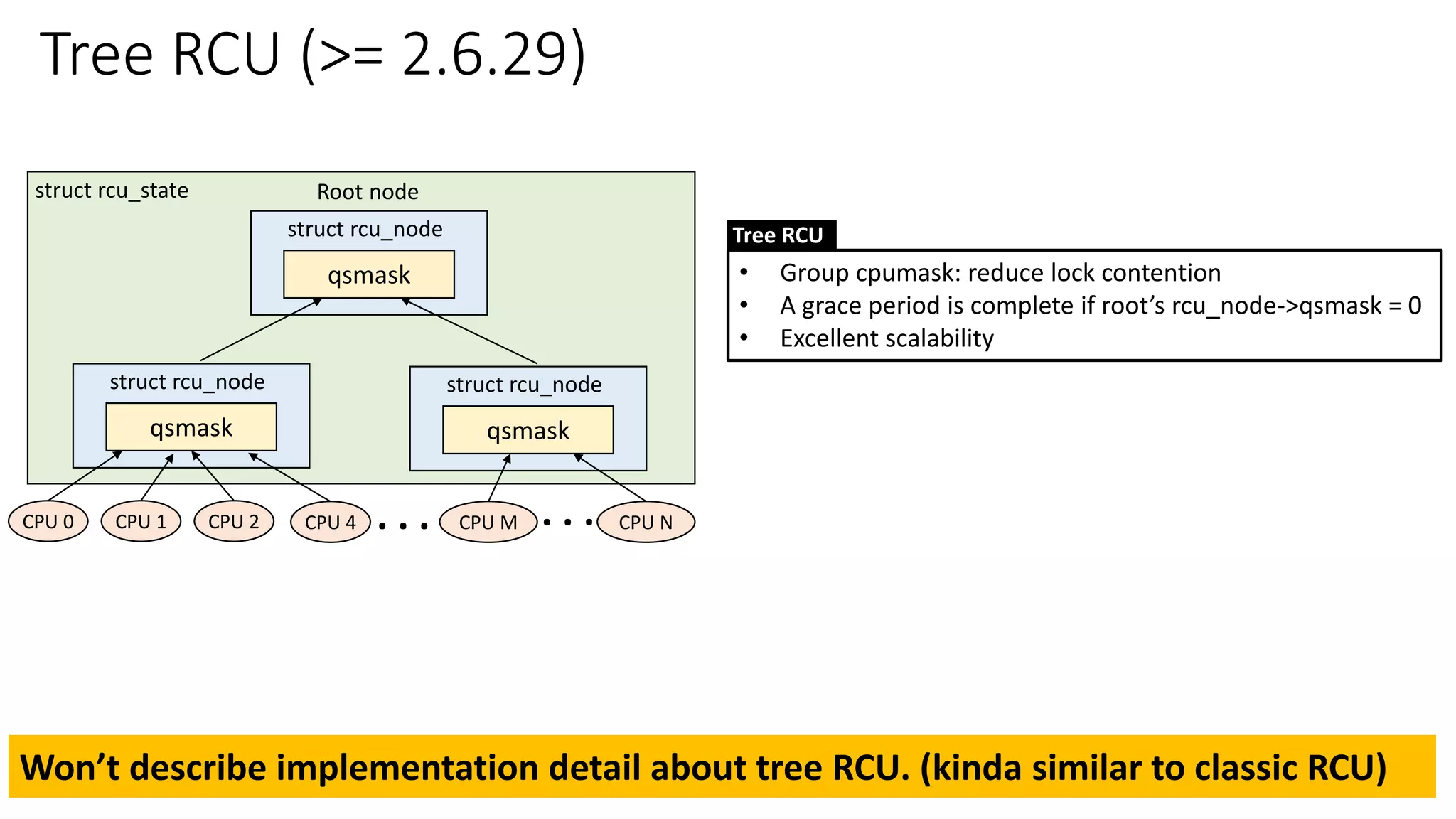
• Classic RCU vs Tree RCU
• RCU Flavors
• RCU Usage Summary & RCU Case Study](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-2-320.jpg)
![task 0
task 1
task N read_unlock()
read_lock()
Critical Section
write_unlock()
write_lock()
Readers
Critical Section
[Overview] rwlock (reader-writer spinlock) vs RCU
rcu_read_unlock()
rcu_read_lock()
Critical Section
synchronize_rcu() or call_rcu()
spin_unlock
spinlock
Update or remove data (pointer)
Optional: free memory
Ensure only one writer
Wait for job completion of readers
Deferred destruction: Safe to free memory
task 0
task 1
task N
Readers
(Subscribers)
task 0
task 1
task N
Writers
task 0
task 1
task N
Writers/Updaters
(Publisher)
rwlock_t
1. Mutual exclusion between reader and writer
2. Writer might be starved
1. RCU is a non-blocking synchronization mechanism: No mutual exclusion between readers and a writer
2. No specific *lock* data structure](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-3-320.jpg)
![[Overview] rwlock (reader-writer spinlock) vs RCU
* Reference from section 9.5 of Is Parallel Programming Hard, And, If So, What Can You Do About It?
How does RCU achieve concurrent readers and one writer?
(No mutual exclusion between readers and one writer)
rwlock
• Mutual exclusion between reader and writer
• Writer might be starved
RCU
• A non-blocking synchronization mechanism
• No specific *lock* data structure](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-4-320.jpg)
![Agenda
• [Overview] rwlock (reader-writer spinlock) vs RCU
• RCU Implementation Overview
✓High-level overview
✓RCU: List Manipulation – Old and New data
✓Reader/Writer synchronization: six basic APIs
➢Reader
➢ rcu_read_lock() & rcu_read_unlock()
➢ rcu_dereference()
➢Writer
➢ rcu_assign_pointer()
➢ synchronize_rcu() & call_rcu()
• Classic RCU vs Tree RCU
• RCU Flavors
• RCU Usage Summary & RCU Case Study](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-5-320.jpg)
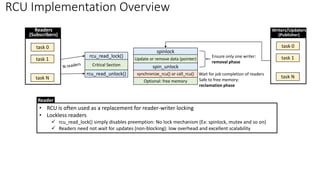
![RCU Implementation Overview
rcu_read_unlock()
rcu_read_lock()
Critical Section
synchronize_rcu() or call_rcu()
spin_unlock
spinlock
Update or remove data (pointer)
Optional: free memory
Ensure only one writer:
removal phase
Wait for job completion of readers
Safe to free memory:
reclamation phase
task 0
task 1
task N
Readers
(Subscribers)
task 0
task 1
task N
Writers/Updaters
(Publisher)
• [Writer] Waiting for readers
✓ Removal phase: remove references to data items (possibly by replacing them with references to new versions of these
data items)
➢ Can run concurrently with readers: readers see either the old or the new version of the data structure rather than
a partially updated reference.
✓ synchronize_rcu() and call_rcu(): wait for readers exiting critical section
✓ Block or register a callback that is invoked after active readers have completed.
✓ Reclamation phase: reclaim data items.
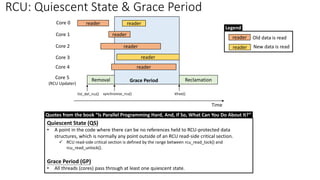
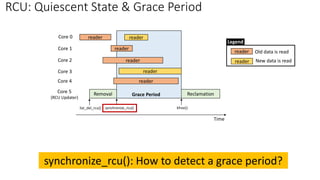
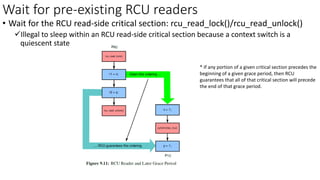
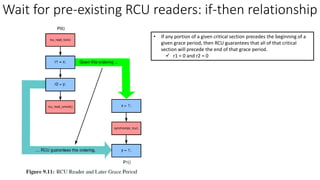
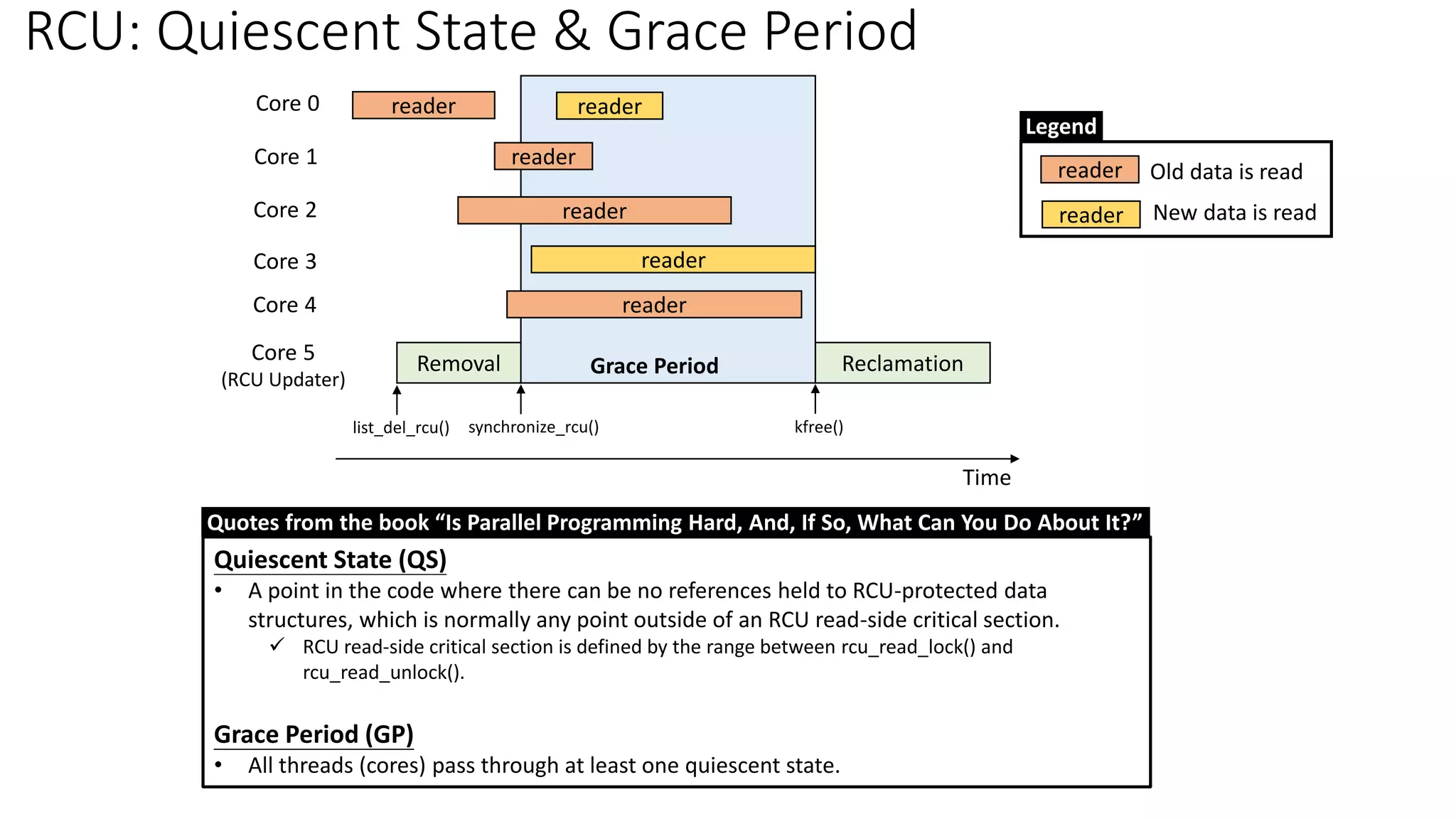
• Quiescent State (QS): [per-core] The time after pre-existing readers are done
✓ Context switch: a valid quiescent state
• Grace Period (GP): All cores have passed through the quiescent state → Complete a grace period
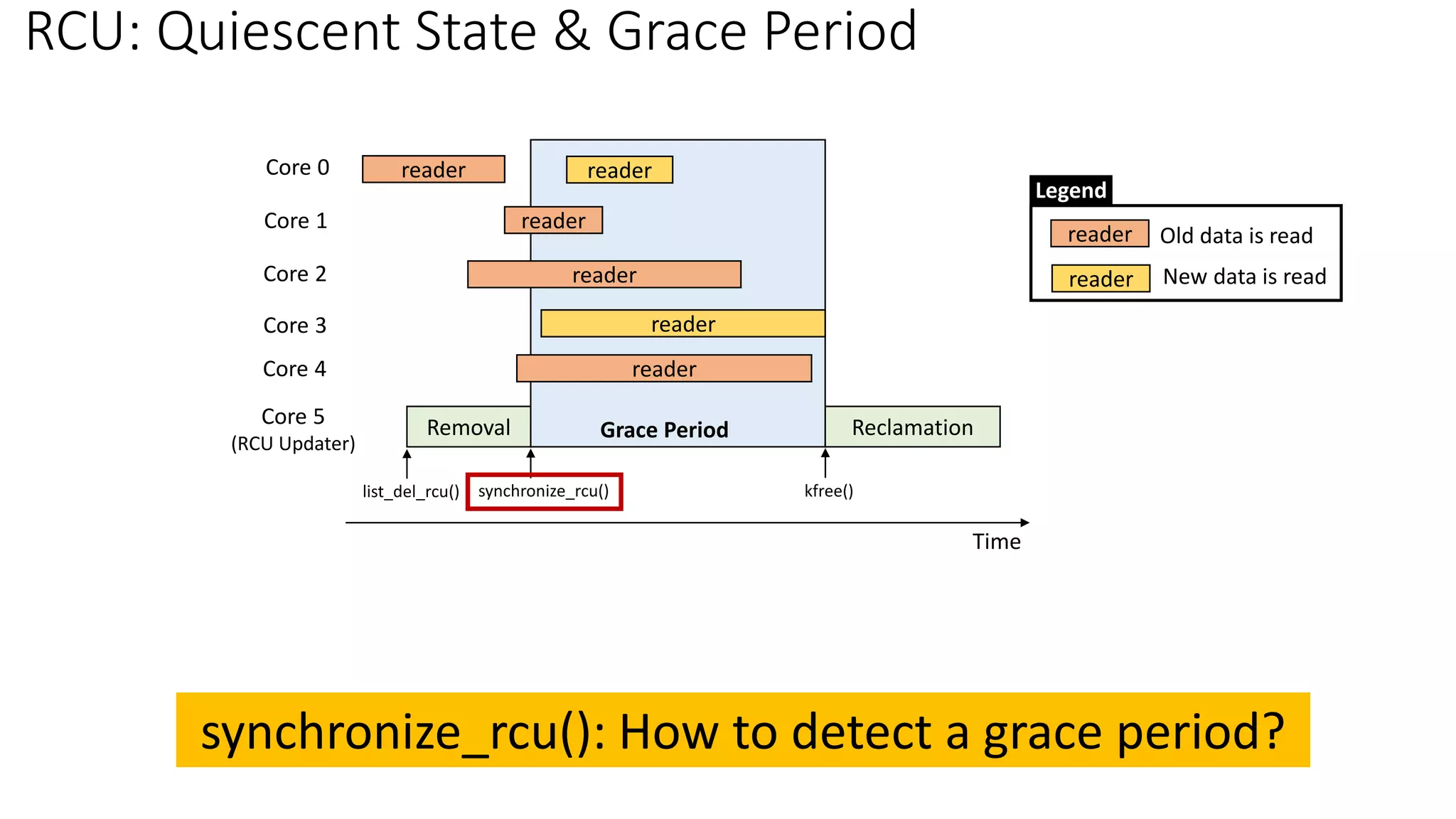
Typical RCU Update Sequence](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-8-320.jpg)

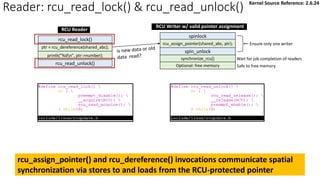
![RCU Spatial/Temporal Synchronization
5,25 9,81
curconfig
Address Space
rcu_read_lock();
mcp = rcu_dereference(curconfig);
*cur_a = mcp->a; (5)
*cur_b = mcp->b; (25)
rcu_read_unlock();
mcp = kmalloc(…);
rcu_assign_pointer(curconfig, mcp);
synchronize_rcu();
…
…
kfree(old_mcp);
rcu_read_lock();
mcp = rcu_dereference(curconfig);
*cur_a = mcp->a; (9)
*cur_b = mcp->b; (81)
rcu_read_unlock();
Grace
Period
Readers
Readers
• Temporal Synchronization
✓ [Reader] rcu_read_lock() / rcu_read_unlock()
✓ [Writer/Update] synchronize_rcu() / call_rcu()
• Spatial Synchronization
• [Reader] rcu_dereference()
• [Writer/Update] rcu_assign_pointer()
Reference: Is Parallel Programming Hard, And, If So, What Can You Do About It?
Time](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-14-320.jpg)
![RCU Spatial/Temporal Synchronization
5,25 9,81
curconfig
Address Space
rcu_read_lock();
mcp = rcu_dereference(curconfig);
*cur_a = mcp->a; (5)
*cur_b = mcp->b; (25)
rcu_read_unlock();
mcp = kmalloc(…);
rcu_assign_pointer(curconfig, mcp);
synchronize_rcu();
…
…
kfree(old_mcp);
rcu_read_lock();
mcp = rcu_dereference(curconfig);
*cur_a = mcp->a; (9)
*cur_b = mcp->b; (81)
rcu_read_unlock();
Grace
Period
Readers
Readers
RCU combines temporal and spatial synchronization in order to approximate
reader-writer locking
• Temporal Synchronization
✓ [Reader] rcu_read_lock() / rcu_read_unlock()
✓ [Writer/Update] synchronize_rcu() / call_rcu()
• Spatial Synchronization
• [Reader] rcu_dereference()
• [Writer/Update] rcu_assign_pointer()](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-15-320.jpg)
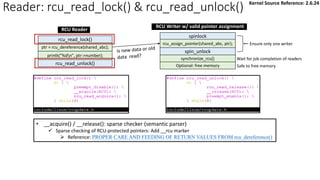
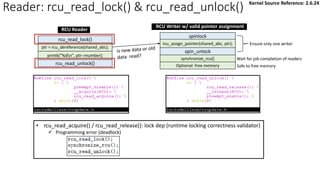
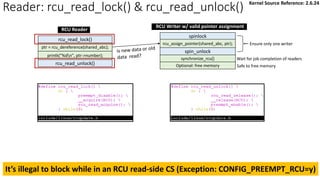
![Reader: rcu_read_lock() & rcu_read_unlock():
rcu_read_unlock()
rcu_read_lock()
ptr = rcu_dereference(shared_abc);
synchronize_rcu()
spin_unlock
spinlock
rcu_assign_pointer(shared_abc, ptr);
Optional: free memory
Ensure only one writer
Wait for job completion of readers
Safe to free memory
printk("%dn", ptr->number);
RCU Reader
RCU Writer w/ valid pointer assignment
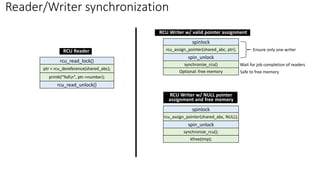
✓ Simply disable/enable preemption when entering/exiting RCU critical section
• [Why] A QS is detected by a context switch.
Kernel Source Reference: 2.6.24](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-16-320.jpg)


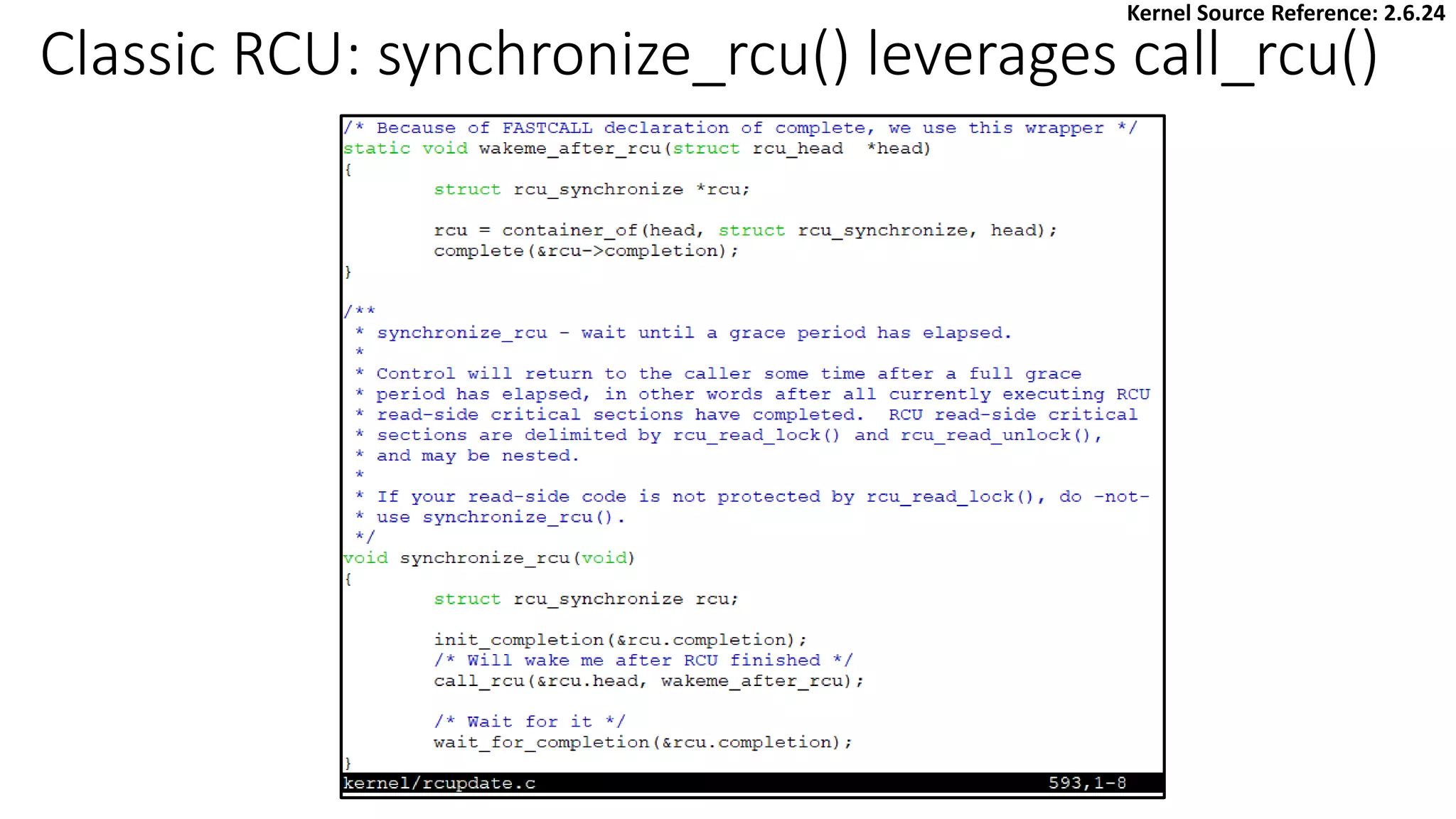
![Writer: synchronize_rcu() & call_rcu()
synchronize_rcu() or call_rcu()
spin_unlock
spinlock
rcu_assign_pointer(shared_abc, ptr);
Optional: free memory
RCU Writer
• Mark the end of updater code and the beginning of reclaimer code
• [Synchronous] synchronize_rcu()
✓ Block until all pre-existing RCU read-side critical sections on all CPUs have completed
✓ leverages call_rcu()
• [Asynchronous] call_rcu()
✓ Queue a callback for invocation after a grace period
✓ [Scenario]
➢ It’s illegal to block RCU updater
➢ Update-side performance is critically important
[Updater] Ensure only one writer: removal phase
Wait for job completion of readers
[Reclaimer] Safe to free memory: reclamation phase](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-23-320.jpg)



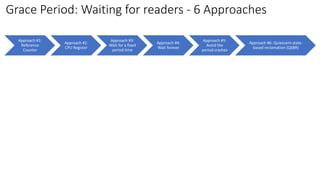



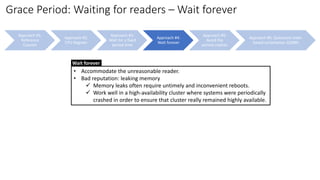

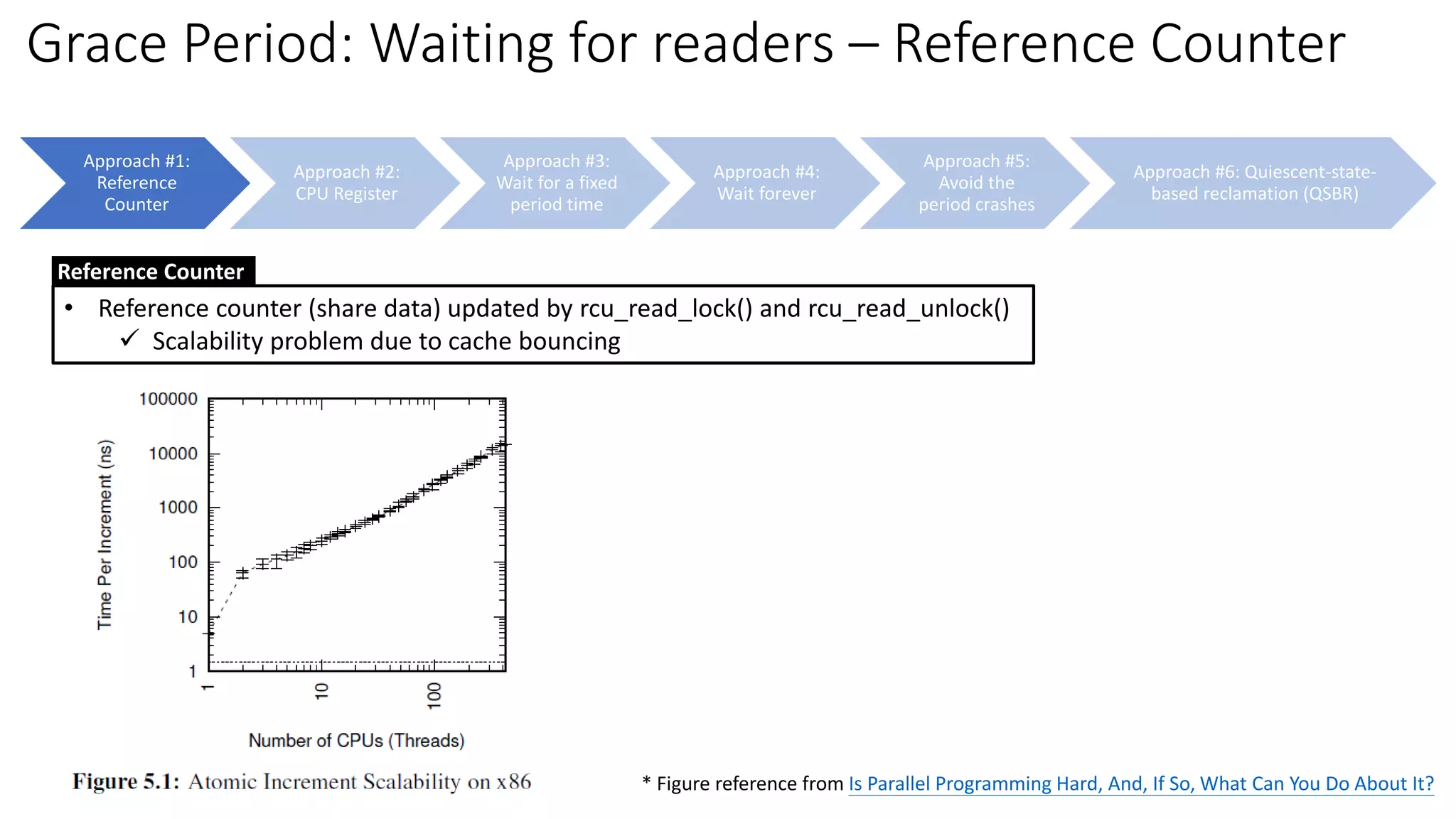
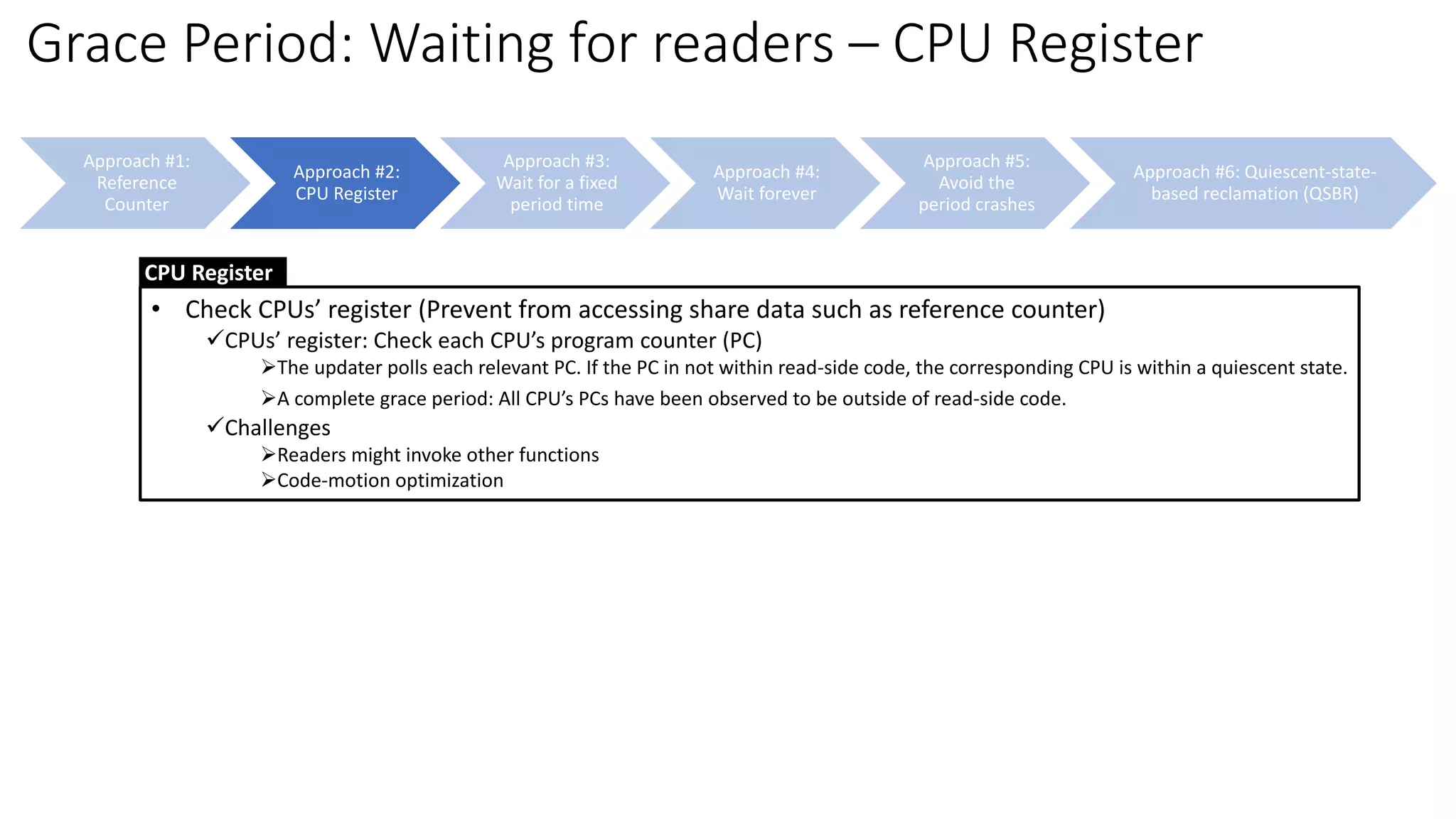
![Approach #1:
Reference
Counter
Approach #2:
CPU Register
Approach #3:
Wait for a fixed
period time
Approach #4:
Wait forever
Approach #5:
Avoid the
period crashes
Approach #6: Quiescent-state-
based reclamation (QSBR)
Grace Period: Waiting for readers – QSBR
• Numerous applications already have states (termed quiescent states) that
can be reached only after all pre-existing readers are done.
✓ Transaction-processing application: the time between a pair of successive
transactions might be a quiescent state.
✓ Non-preemptive OS kernel: Context switch can be a quiescent state.
✓ [Non-preemptive OS kernel] RCU reader must be prohibited from blocking
while referencing a global data.
QSBR](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-36-320.jpg)
![* Reference from Is Parallel Programming Hard, And, If So, What Can You Do About It?
Grace Period: Waiting for readers – QSBR
[Concept] Implementation for non-preemptive Linux kernel
* [Not production quality] sched_setaffinity() function causes the
current thread to execute on the specified CPU, which forces the
destination CPU to execute a context switch.](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-37-320.jpg)
![[Concept] QSBR: non-production and non-preemptible
implementation
Force the destination CPU to execution switch: Completion of RCU reader
Reference: Page #142 of Is Parallel Programming Hard, And, If So, What Can You Do About It?
synchronize_rcu()
rcu_read_lock() & rcu_read_unlock() → disable/enable preemption](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-38-320.jpg)
![Agenda
• [Overview] rwlock (reader-writer spinlock) vs RCU
• RCU Implementation Overview
✓High-level overview
✓RCU: List Manipulation – Old and New data
✓Reader/Writer synchronization: five basic APIs
➢Reader
➢ rcu_read_lock() & rcu_read_unlock()
➢ rcu_dereference()
➢Writer
➢ rcu_assign_pointer()
➢ synchronize_rcu() & call_rcu()
• Classic RCU vs Tree RCU
✓Will discuss implementation details about classic RCU *only*
• RCU Flavors
• RCU Usage Summary & RCU Case Study](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-39-320.jpg)
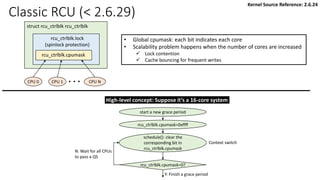

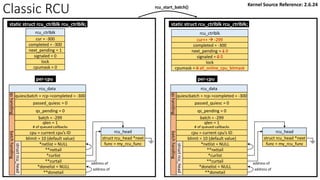
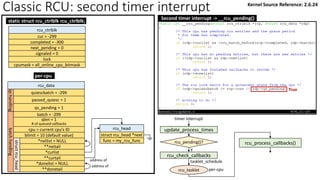
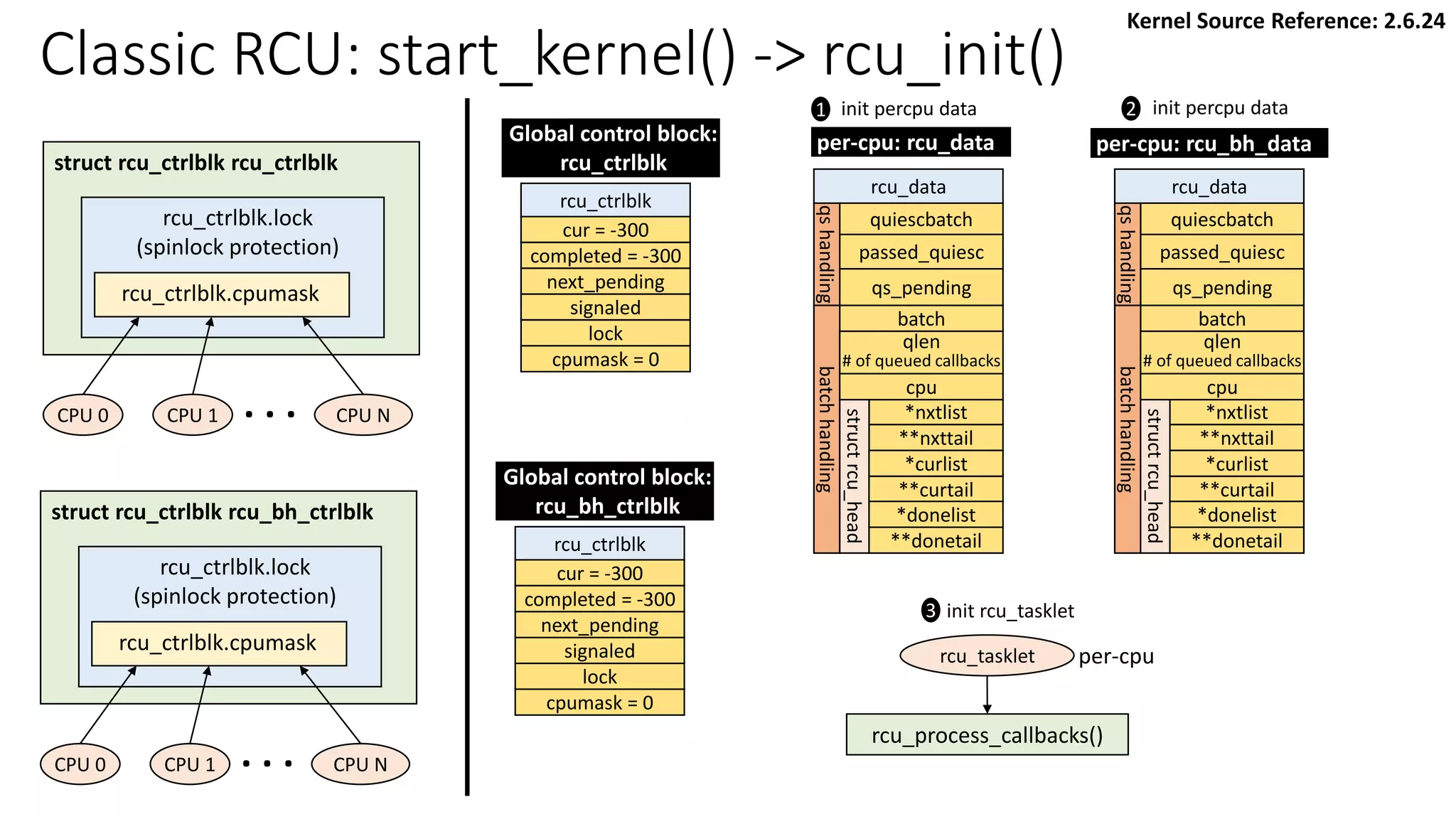
![rcu_ctrlblk
cur = -300
completed = -300
next_pending = 0
signaled = 0
lock
cpumask = 0
[Global control block]
static struct rcu_ctrlblk rcu_ctrlblk;
per-cpu variable initialized by rcu_init_percpu_data()
rcu_data
quiescbatch = rcp->completed = -300
passed_quiesc = 0
qs_pending = 0
batch = 0
*nxtlist = NULL
**nxttail
qs
handling
batch
handling
struct
rcu_head
*curlist = NULL
**curtail
*donelist = NULL
**donetail
qlen = 0
# of queued callbacks
cpu = current cpu’s ID
blimit = 10 (default value)
address of
address of
address of
Kernel Source Reference: 2.6.24
Classic RCU: start_kernel() -> rcu_init(): show “rcu_ctrlblk” only](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-44-320.jpg)


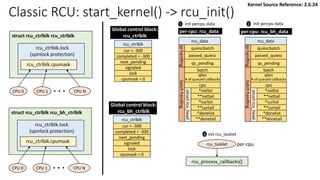
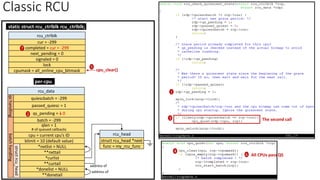
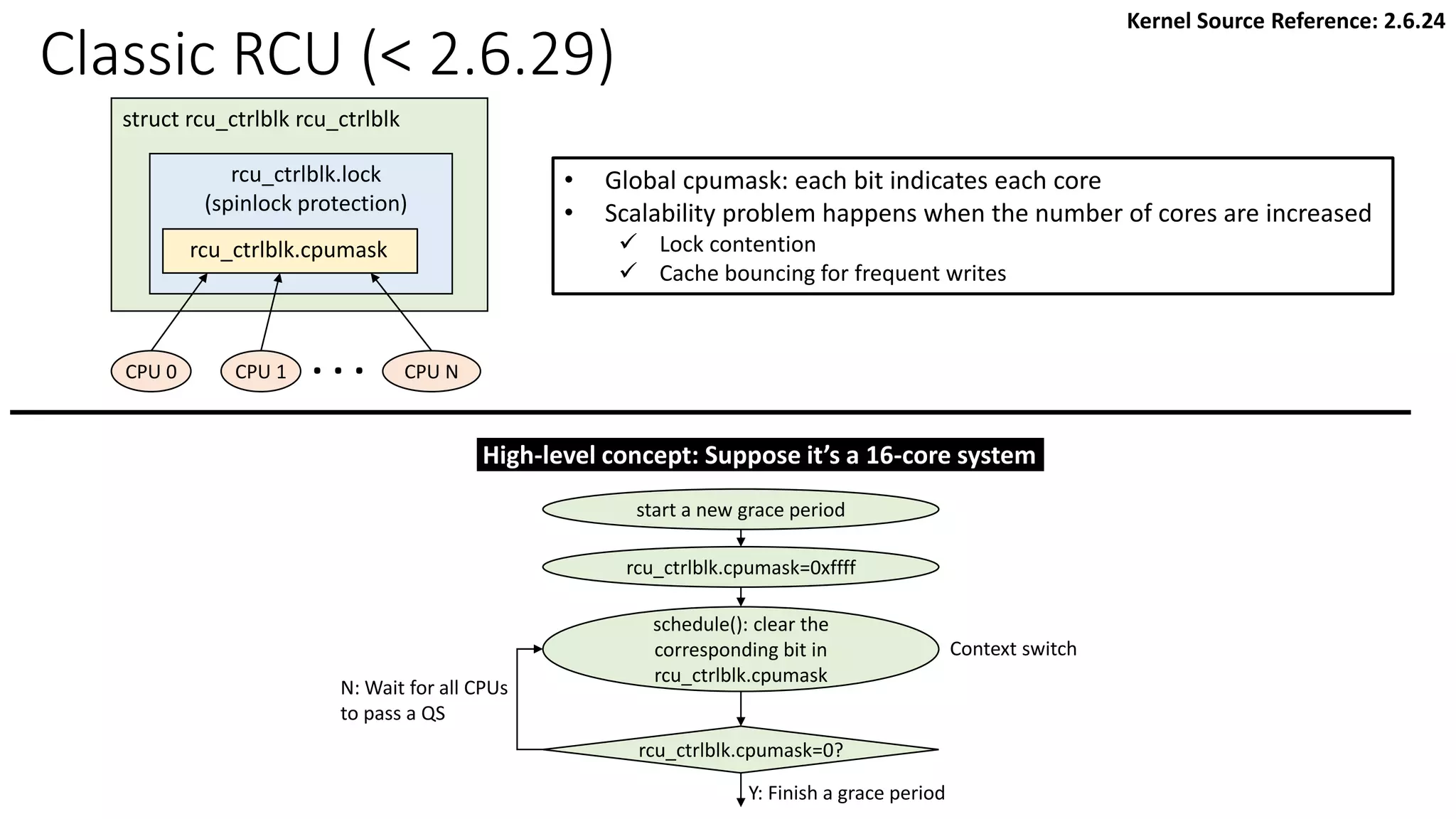
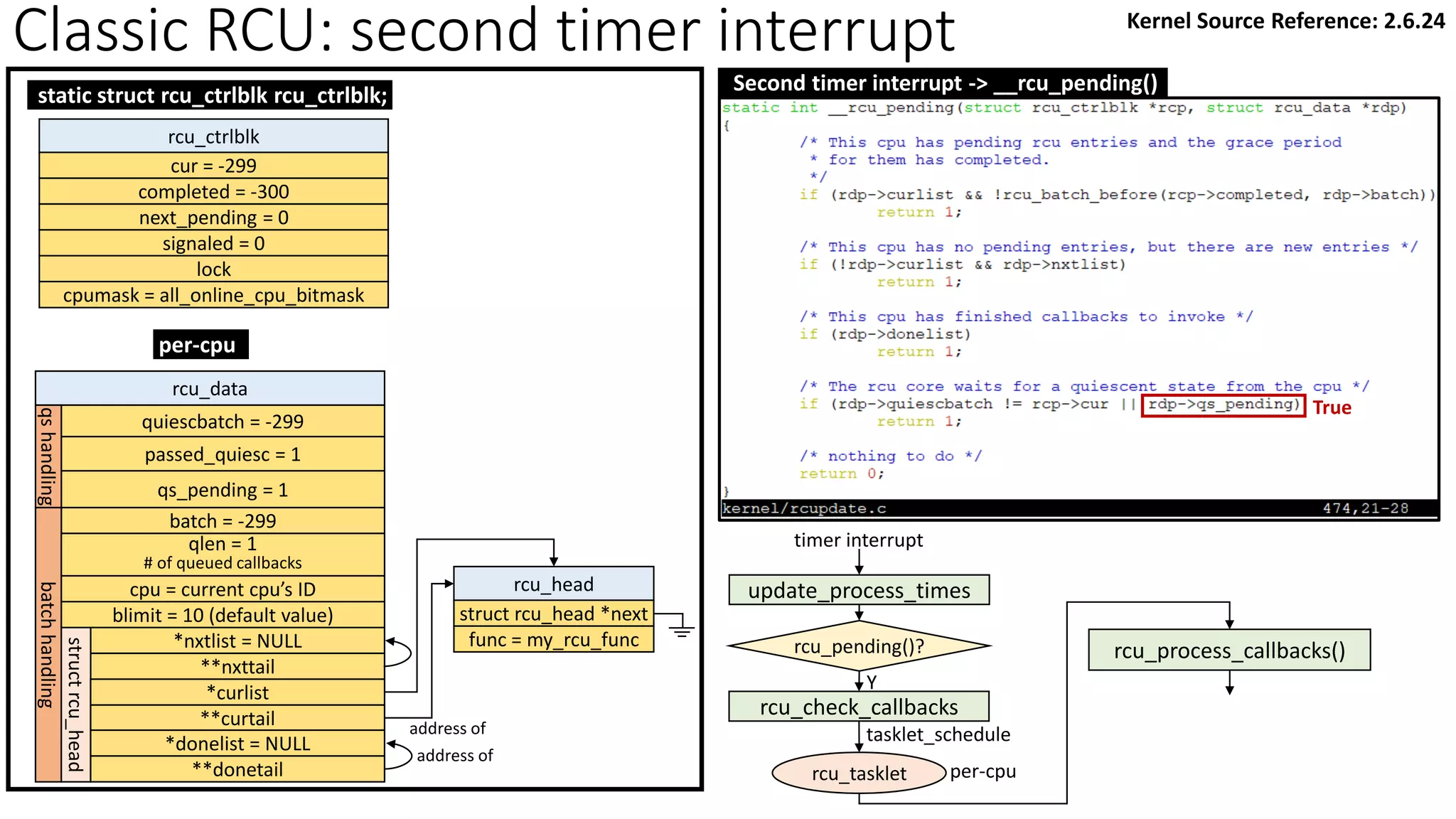
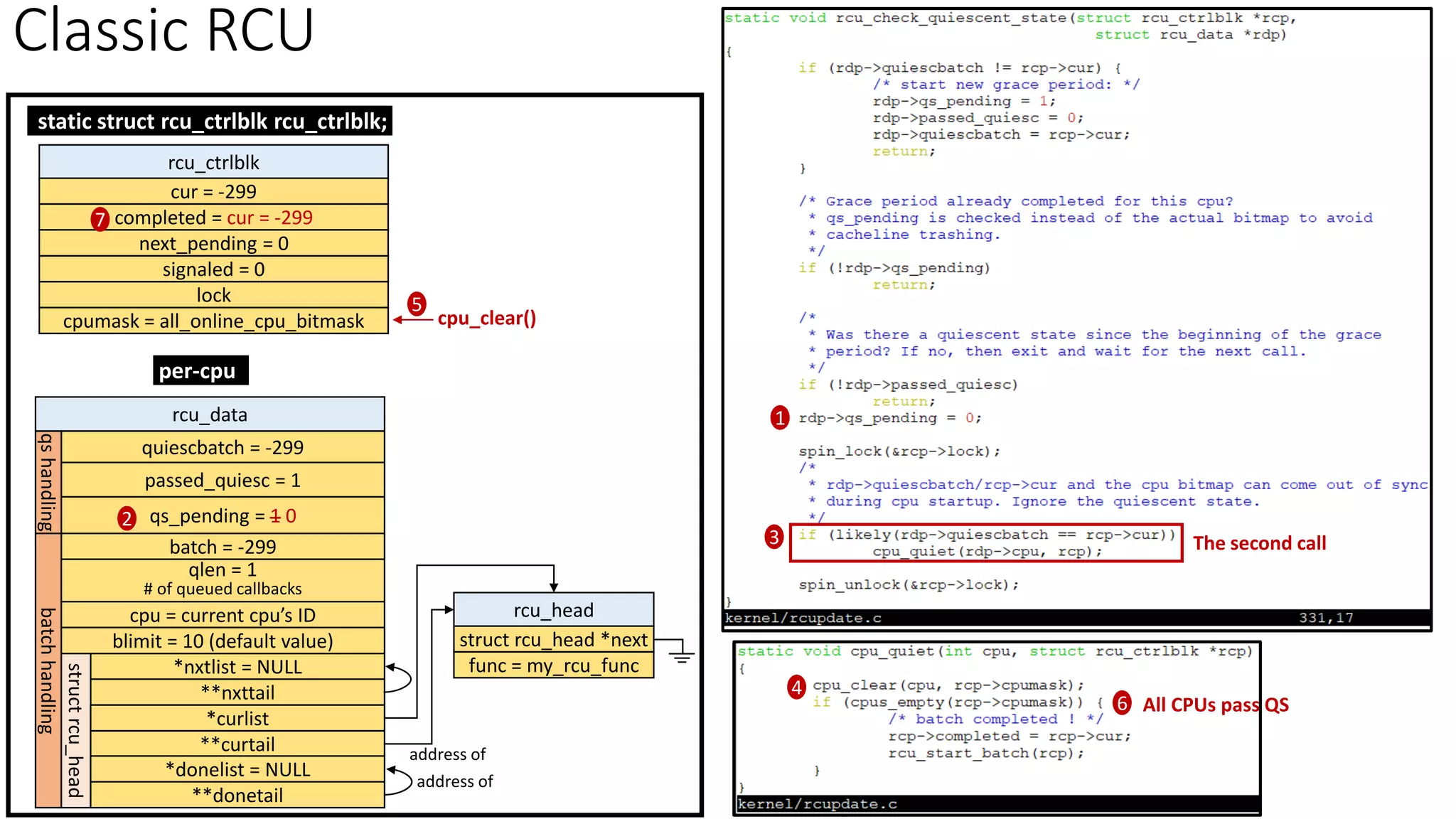
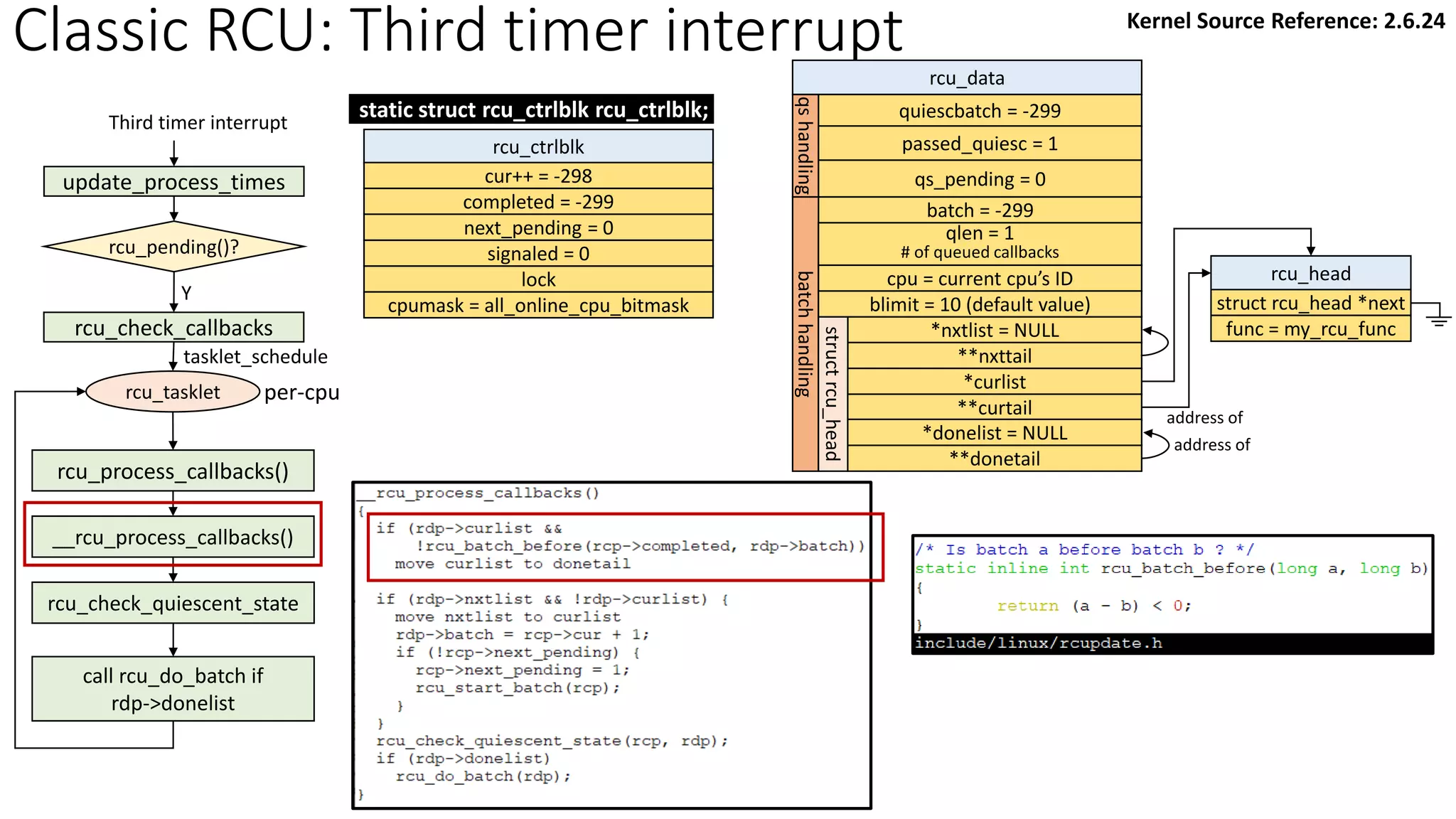
![Classic RCU: Check if a CPU passes a QS
rcu_check_callbacks
update_process_times
rcu_pending()?
Y
timer interrupt
Kernel Source Reference: 2.6.24
rcu_qsctr_inc
schedule
Timer interrupt Scheduler: context switch
[Note] “rcu_data.passed_quiesc = 1” does not clear the corresponding rcu_ctrlblk.cpumask
directly. More checks are performed. See later slides.](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-48-320.jpg)
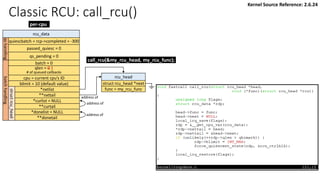
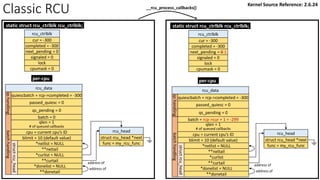
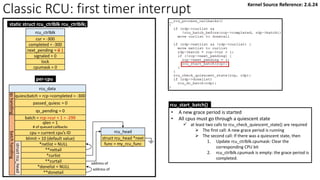
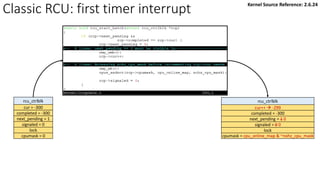
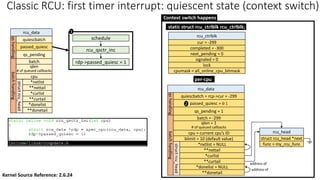
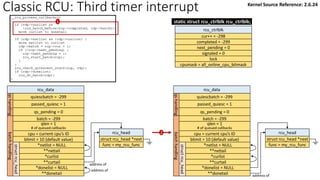
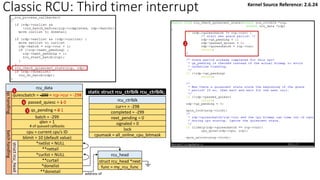
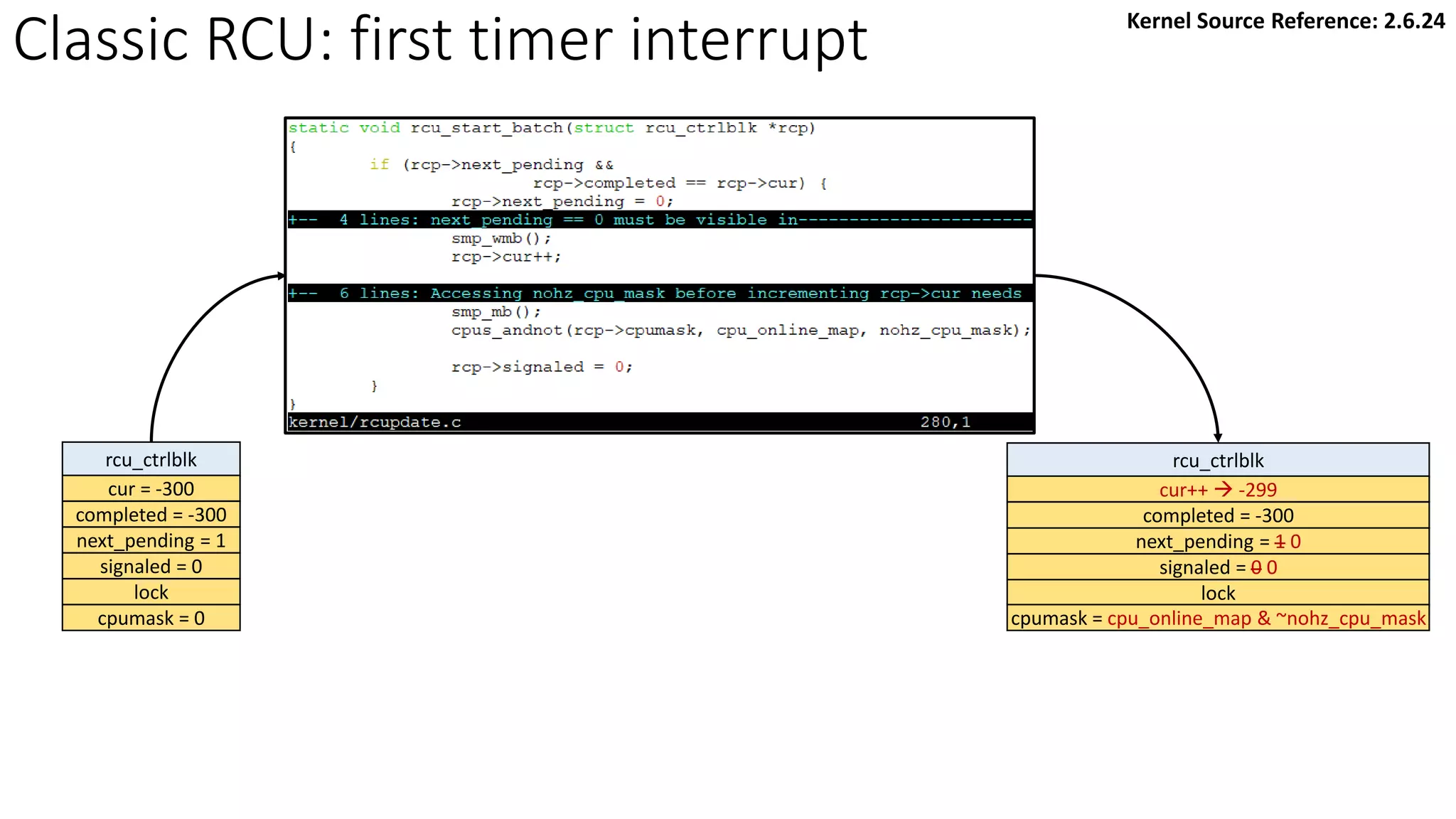
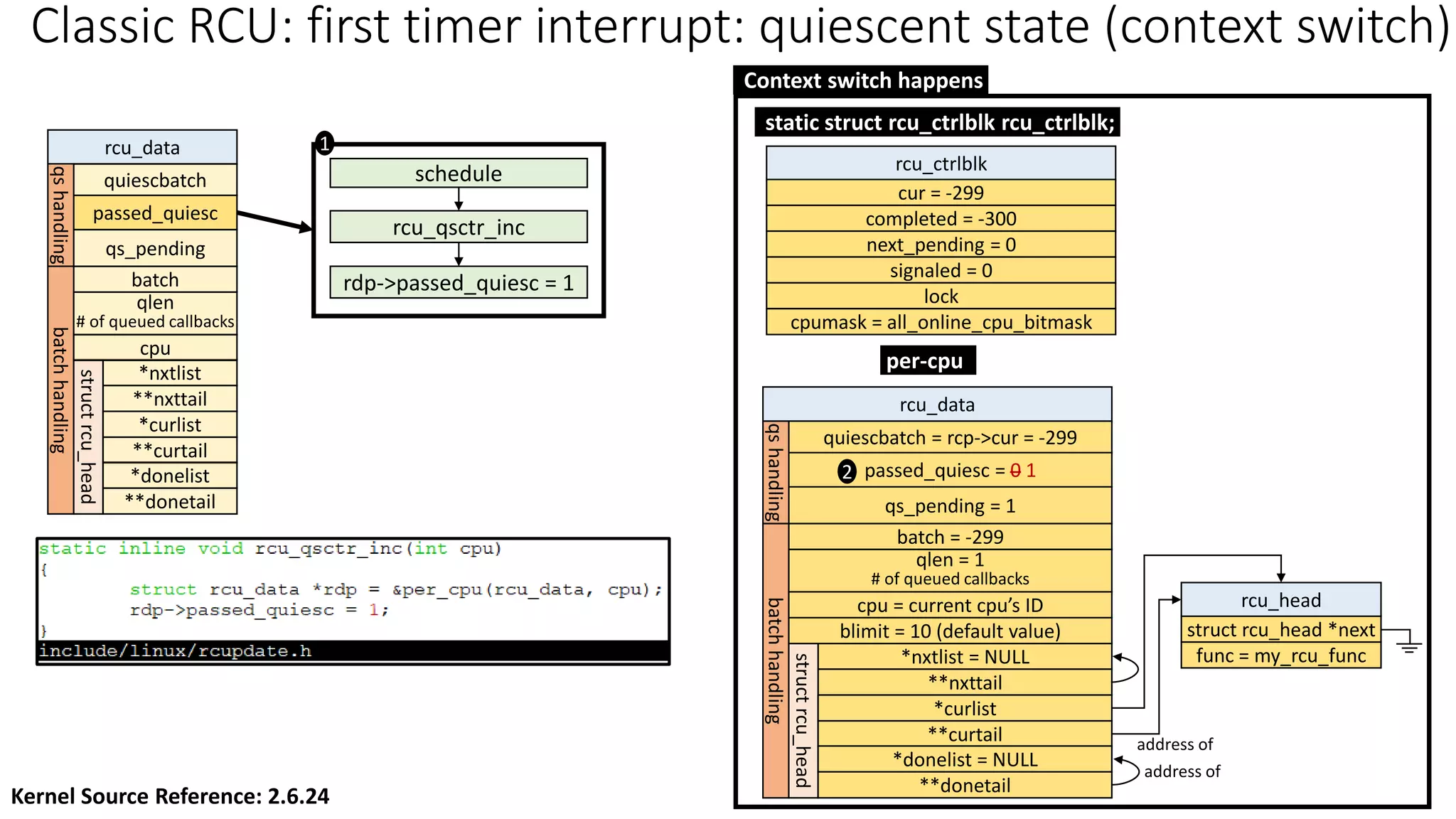
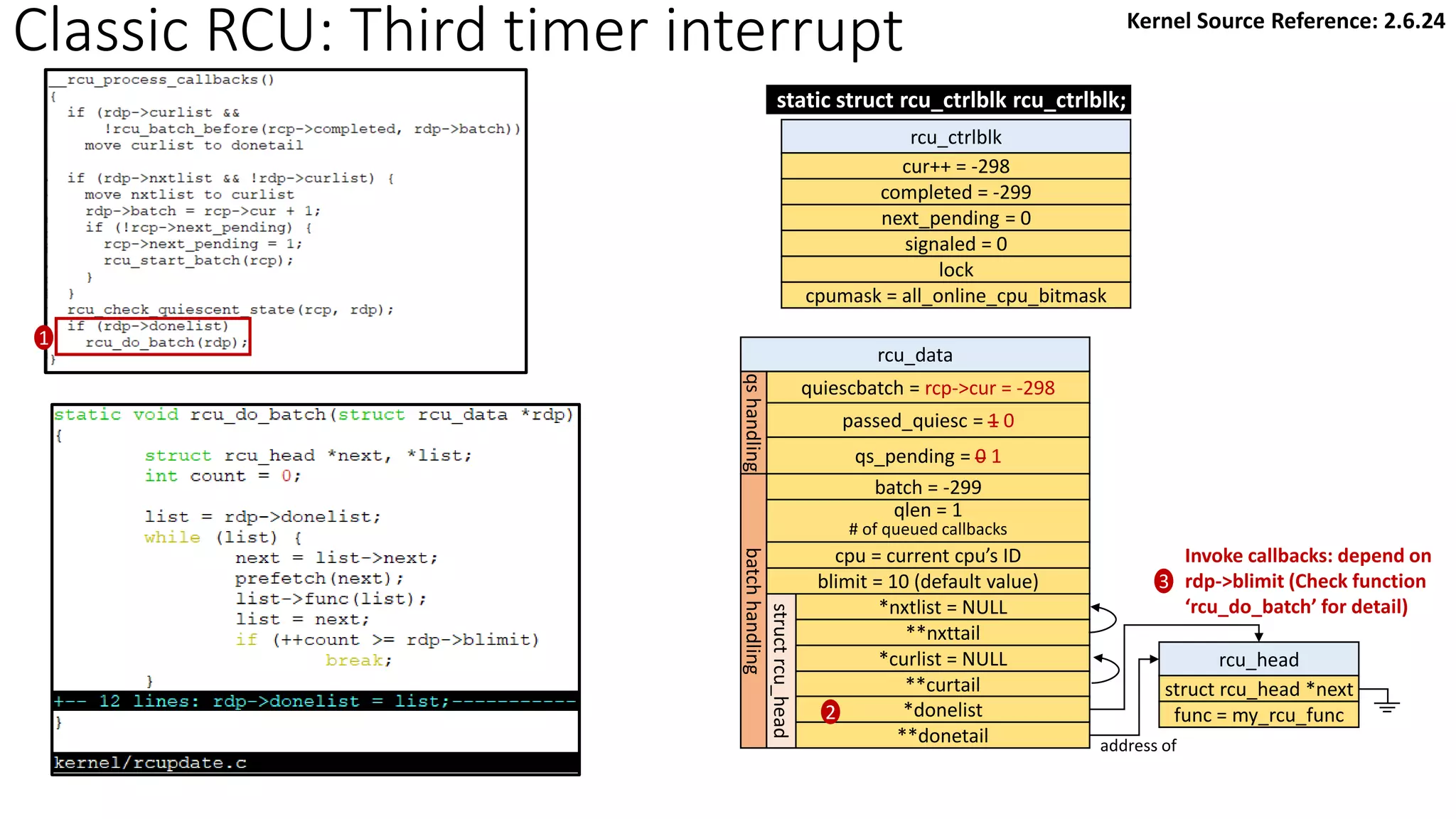
![Classic RCU: first timer interrupt
rcu_tasklet per-cpu
rcu_process_callbacks()
rcu_check_callbacks
tasklet_schedule
update_process_times
rcu_pending()?
Y
timer interrupt
__rcu_process_callbacks()
rcu_check_quiescent_state
call rcu_do_batch if
rdp->donelist
rcu_ctrlblk
cur = -300
completed = -300
next_pending = 0
signaled = 0
lock
cpumask = 0
[Global control block]
static struct rcu_ctrlblk rcu_ctrlblk;
per-cpu
rcu_data
quiescbatch = rcp->completed = -300
passed_quiesc = 0
qs_pending = 0
batch = 0
*nxtlist
**nxttail
qs
handling
batch
handling
struct
rcu_head
*curlist = NULL
**curtail
*donelist = NULL
**donetail
qlen = 1
# of queued callbacks
cpu = current cpu’s ID
blimit = 10 (default value)
rcu_head
struct rcu_head *next
func = my_rcu_func
address of
address of
address of
Manipulation
Kernel Source Reference: 2.6.24](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-49-320.jpg)





![Agenda
• [Overview] rwlock (reader-writer spinlock) vs RCU
• RCU Implementation Overview
✓High-level overview
✓RCU: List Manipulation – Old and New data
✓Reader/Writer synchronization: five basic APIs
➢Reader
➢ rcu_read_lock() & rcu_read_unlock()
➢ rcu_dereference()
➢Writer
➢ rcu_assign_pointer()
➢ synchronize_rcu() & call_rcu()
• Classic RCU vs Tree RCU
• RCU Flavors
• RCU Usage Summary & RCU Case Study](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-65-320.jpg)



![• Before preemptible RCU, context switch is a quiescent state
✓ [A complete grace period] Need to wait for all pre-existing interrupt and NMI handler
• [CONFIG_PREEMPTION=n]
✓ Vanilla RCU and RCU-sched grace period waits for pre-existing interrupt and NMI handlers
✓ Vanilla RCU and RCU-sched have identical implementations
• [CONFIG_PREEMPTION=Y] for RCU-sched
✓ Preemptible RCU does not need to wait for pre-existing interrupt and NMI handler.
✓ The code outside of an RCU read-side critical section → a QS
✓ rcu_read_lock_sched() → disable preemption
✓ rcu_read_unlock_sched() → re-enable preemption
✓ A preemption attempt during the RCU-sched read-side critical section:
✓ rcu_read_unlock_sched() will enter the scheduler
• Reader RCU APIs
✓ rcu_read_lock_sched() / rcu_read_unlock_sched()
✓ preempt_disable() / preempt_enable()
✓ local_irq_save() / local_irq_restore()
✓ hardirq enter / hardirq exit
✓ NMI enter / NMI exit
✓ rcu_dereference_sched()
• Writer: No change
RCU Flavors: Sched Flavor (Historical)](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-69-320.jpg)




![Agenda
• [Overview] rwlock (reader-writer spinlock) vs RCU
• RCU Implementation Overview
✓High-level overview
✓RCU: List Manipulation – Old and New data
✓Reader/Writer synchronization: five basic APIs
➢Reader
➢ rcu_read_lock() & rcu_read_unlock()
➢ rcu_dereference()
➢Writer
➢ rcu_assign_pointer()
➢ synchronize_rcu() & call_rcu()
• Classic RCU vs Tree RCU
• RCU Flavors
• RCU Usage Summary & RCU Case Study](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-74-320.jpg)




![RCU (Read-Copy-Update)
• Non-blocking synchronization
✓Deadlock Immunity: RCU read-side primitives do not block, spin or even do
backwards branches → execution time is deterministic.
➢Exception (programming error):
➢Immunity to priority inversion
◼ Low-priority RCU readers cannot prevent a high-priority RCU updater from acquiring the
update-side lock
◼ A low-priority RCU updater cannot prevent high-priority RCU readers from entering read-side
critical section
➢[-rt kernel] RCU is susceptible to priority inversion scenarios:
➢ A High-priority process blocked waiting for an RCU grace period to elapse can be blocked by
low-priority RCU readers. --> Solve by RCU priority boosting.
➢ [RCU priority boosting] Require rcu_read_unclock() do deboosting, which entails acquiring
scheduler locks.
➢ Need to avoid deadlocks within the scheduler and RCU: v5.15 kernel requires RCU to
avoid invoking the scheduler while holding any of RCU’s locks
➢ rcu_read_unlock() is not always lockless when RCU priority boosting is enabled.](https://image.slidesharecdn.com/rcu-230525071116-f4256278/85/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-84-320.jpg)



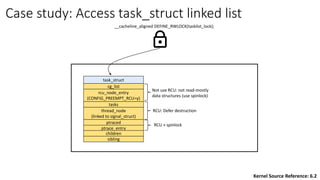

![Agenda
• [Overview] rwlock (reader-writer spinlock) vs RCU
• RCU Implementation Overview
✓High-level overview
✓RCU: List Manipulation – Old and New data
✓Reader/Writer synchronization: six basic APIs
➢Reader
➢ rcu_read_lock() & rcu_read_unlock()
➢ rcu_dereference()
➢Writer
➢ rcu_assign_pointer()
➢ synchronize_rcu() & call_rcu()
• Classic RCU vs Tree RCU
• RCU Flavors
• RCU Usage Summary & RCU Case Study](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-2-2048.jpg)
![task 0
task 1
task N read_unlock()
read_lock()
Critical Section
write_unlock()
write_lock()
Readers
Critical Section
[Overview] rwlock (reader-writer spinlock) vs RCU
rcu_read_unlock()
rcu_read_lock()
Critical Section
synchronize_rcu() or call_rcu()
spin_unlock
spinlock
Update or remove data (pointer)
Optional: free memory
Ensure only one writer
Wait for job completion of readers
Deferred destruction: Safe to free memory
task 0
task 1
task N
Readers
(Subscribers)
task 0
task 1
task N
Writers
task 0
task 1
task N
Writers/Updaters
(Publisher)
rwlock_t
1. Mutual exclusion between reader and writer
2. Writer might be starved
1. RCU is a non-blocking synchronization mechanism: No mutual exclusion between readers and a writer
2. No specific *lock* data structure](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-3-2048.jpg)
![[Overview] rwlock (reader-writer spinlock) vs RCU
* Reference from section 9.5 of Is Parallel Programming Hard, And, If So, What Can You Do About It?
How does RCU achieve concurrent readers and one writer?
(No mutual exclusion between readers and one writer)
rwlock
• Mutual exclusion between reader and writer
• Writer might be starved
RCU
• A non-blocking synchronization mechanism
• No specific *lock* data structure](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-4-2048.jpg)
![Agenda
• [Overview] rwlock (reader-writer spinlock) vs RCU
• RCU Implementation Overview
✓High-level overview
✓RCU: List Manipulation – Old and New data
✓Reader/Writer synchronization: six basic APIs
➢Reader
➢ rcu_read_lock() & rcu_read_unlock()
➢ rcu_dereference()
➢Writer
➢ rcu_assign_pointer()
➢ synchronize_rcu() & call_rcu()
• Classic RCU vs Tree RCU
• RCU Flavors
• RCU Usage Summary & RCU Case Study](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-5-2048.jpg)


![RCU Implementation Overview
rcu_read_unlock()
rcu_read_lock()
Critical Section
synchronize_rcu() or call_rcu()
spin_unlock
spinlock
Update or remove data (pointer)
Optional: free memory
Ensure only one writer:
removal phase
Wait for job completion of readers
Safe to free memory:
reclamation phase
task 0
task 1
task N
Readers
(Subscribers)
task 0
task 1
task N
Writers/Updaters
(Publisher)
• [Writer] Waiting for readers
✓ Removal phase: remove references to data items (possibly by replacing them with references to new versions of these
data items)
➢ Can run concurrently with readers: readers see either the old or the new version of the data structure rather than
a partially updated reference.
✓ synchronize_rcu() and call_rcu(): wait for readers exiting critical section
✓ Block or register a callback that is invoked after active readers have completed.
✓ Reclamation phase: reclaim data items.
• Quiescent State (QS): [per-core] The time after pre-existing readers are done
✓ Context switch: a valid quiescent state
• Grace Period (GP): All cores have passed through the quiescent state → Complete a grace period
Typical RCU Update Sequence](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-8-2048.jpg)

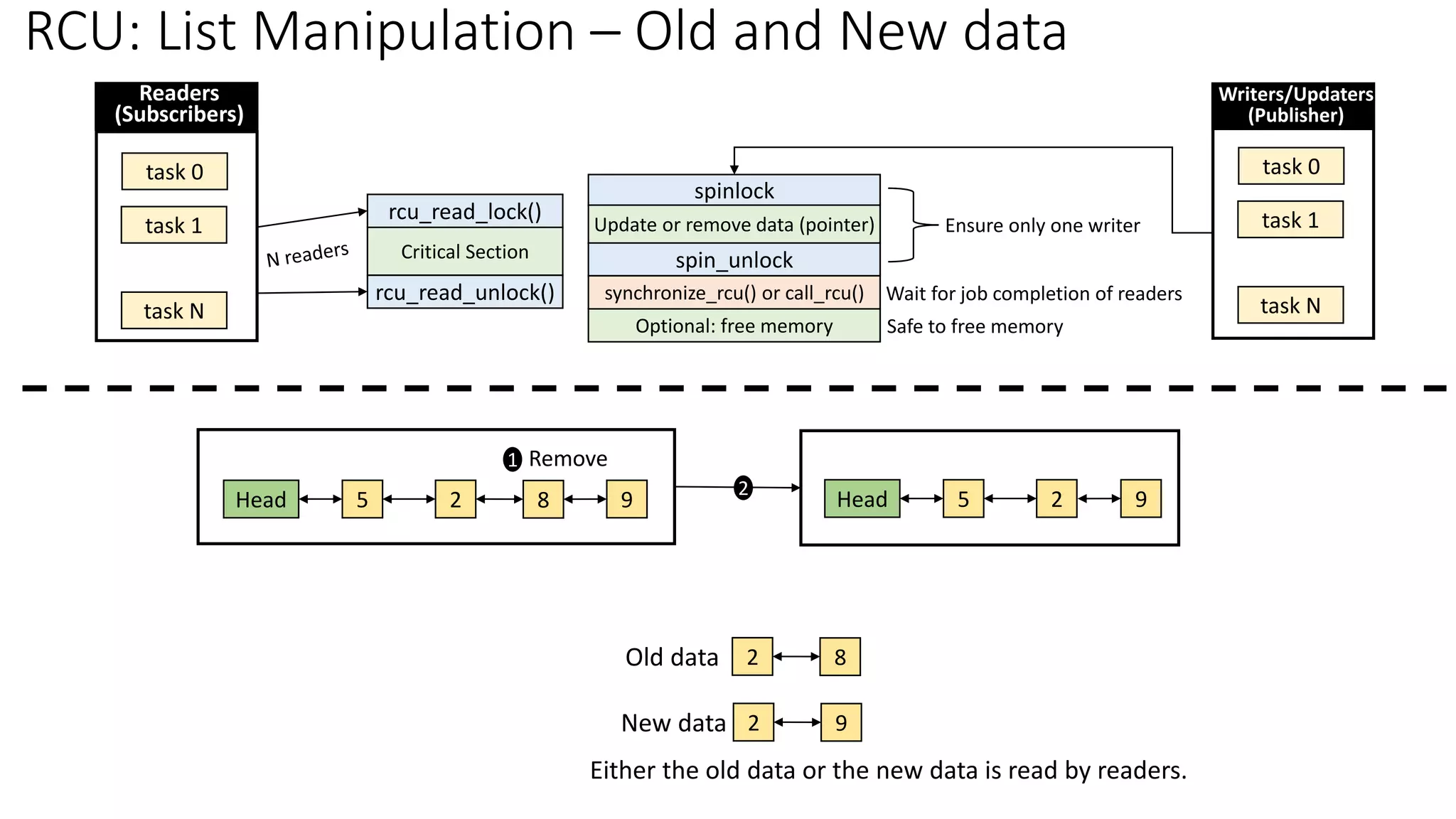
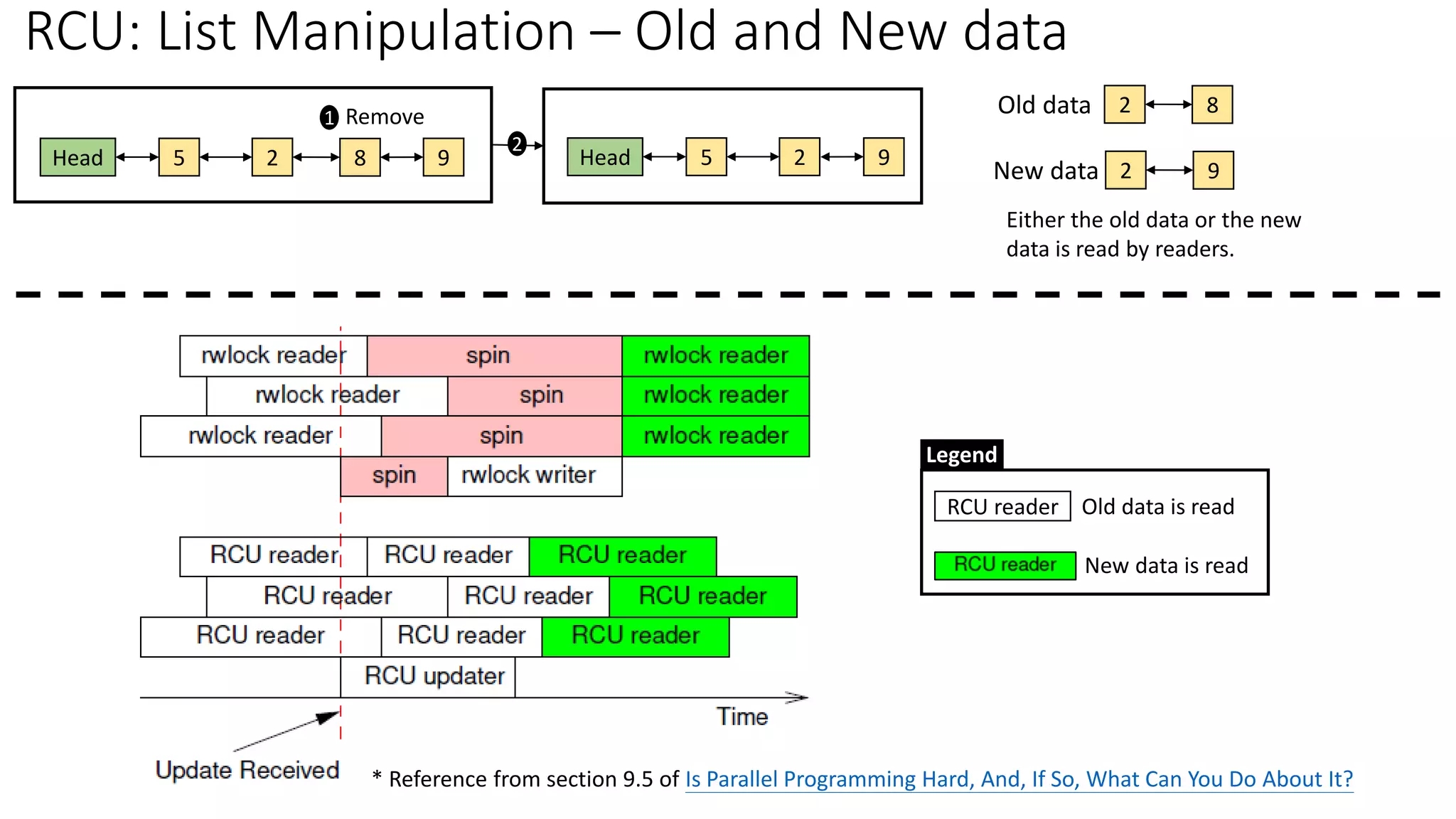


![RCU Spatial/Temporal Synchronization
5,25 9,81
curconfig
Address Space
rcu_read_lock();
mcp = rcu_dereference(curconfig);
*cur_a = mcp->a; (5)
*cur_b = mcp->b; (25)
rcu_read_unlock();
mcp = kmalloc(…);
rcu_assign_pointer(curconfig, mcp);
synchronize_rcu();
…
…
kfree(old_mcp);
rcu_read_lock();
mcp = rcu_dereference(curconfig);
*cur_a = mcp->a; (9)
*cur_b = mcp->b; (81)
rcu_read_unlock();
Grace
Period
Readers
Readers
• Temporal Synchronization
✓ [Reader] rcu_read_lock() / rcu_read_unlock()
✓ [Writer/Update] synchronize_rcu() / call_rcu()
• Spatial Synchronization
• [Reader] rcu_dereference()
• [Writer/Update] rcu_assign_pointer()
Reference: Is Parallel Programming Hard, And, If So, What Can You Do About It?
Time](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-14-2048.jpg)
![RCU Spatial/Temporal Synchronization
5,25 9,81
curconfig
Address Space
rcu_read_lock();
mcp = rcu_dereference(curconfig);
*cur_a = mcp->a; (5)
*cur_b = mcp->b; (25)
rcu_read_unlock();
mcp = kmalloc(…);
rcu_assign_pointer(curconfig, mcp);
synchronize_rcu();
…
…
kfree(old_mcp);
rcu_read_lock();
mcp = rcu_dereference(curconfig);
*cur_a = mcp->a; (9)
*cur_b = mcp->b; (81)
rcu_read_unlock();
Grace
Period
Readers
Readers
RCU combines temporal and spatial synchronization in order to approximate
reader-writer locking
• Temporal Synchronization
✓ [Reader] rcu_read_lock() / rcu_read_unlock()
✓ [Writer/Update] synchronize_rcu() / call_rcu()
• Spatial Synchronization
• [Reader] rcu_dereference()
• [Writer/Update] rcu_assign_pointer()](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-15-2048.jpg)
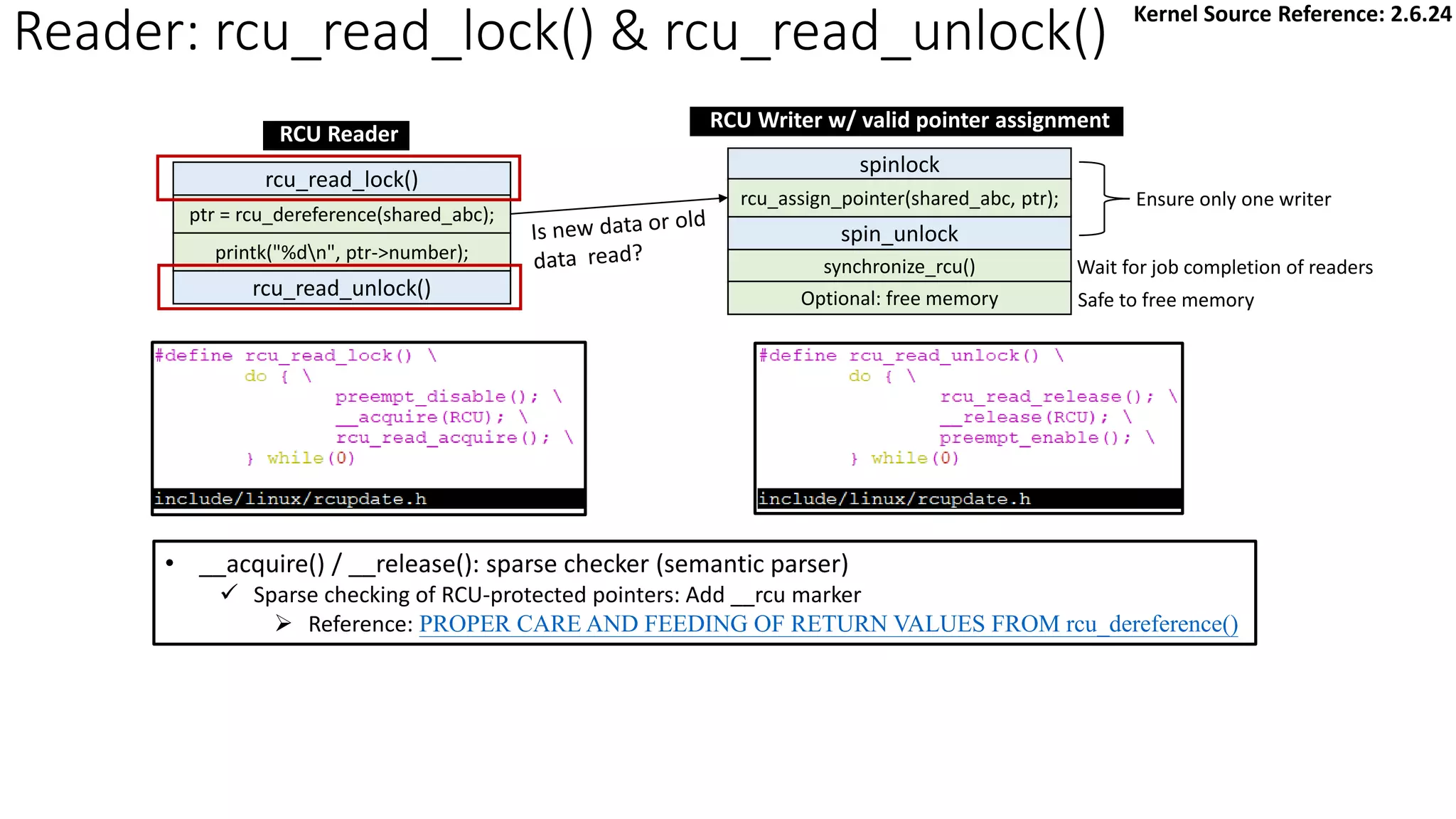
![Reader: rcu_read_lock() & rcu_read_unlock():
rcu_read_unlock()
rcu_read_lock()
ptr = rcu_dereference(shared_abc);
synchronize_rcu()
spin_unlock
spinlock
rcu_assign_pointer(shared_abc, ptr);
Optional: free memory
Ensure only one writer
Wait for job completion of readers
Safe to free memory
printk("%dn", ptr->number);
RCU Reader
RCU Writer w/ valid pointer assignment
✓ Simply disable/enable preemption when entering/exiting RCU critical section
• [Why] A QS is detected by a context switch.
Kernel Source Reference: 2.6.24](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-16-2048.jpg)





![Writer: synchronize_rcu() & call_rcu()
synchronize_rcu() or call_rcu()
spin_unlock
spinlock
rcu_assign_pointer(shared_abc, ptr);
Optional: free memory
RCU Writer
• Mark the end of updater code and the beginning of reclaimer code
• [Synchronous] synchronize_rcu()
✓ Block until all pre-existing RCU read-side critical sections on all CPUs have completed
✓ leverages call_rcu()
• [Asynchronous] call_rcu()
✓ Queue a callback for invocation after a grace period
✓ [Scenario]
➢ It’s illegal to block RCU updater
➢ Update-side performance is critically important
[Updater] Ensure only one writer: removal phase
Wait for job completion of readers
[Reclaimer] Safe to free memory: reclamation phase](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-23-2048.jpg)






![Approach #1:
Reference
Counter
Approach #2:
CPU Register
Approach #3:
Wait for a fixed
period time
Approach #4:
Wait forever
Approach #5:
Avoid the
period crashes
Approach #6: Quiescent-state-
based reclamation (QSBR)
Grace Period: Waiting for readers – QSBR
• Numerous applications already have states (termed quiescent states) that
can be reached only after all pre-existing readers are done.
✓ Transaction-processing application: the time between a pair of successive
transactions might be a quiescent state.
✓ Non-preemptive OS kernel: Context switch can be a quiescent state.
✓ [Non-preemptive OS kernel] RCU reader must be prohibited from blocking
while referencing a global data.
QSBR](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-36-2048.jpg)
![* Reference from Is Parallel Programming Hard, And, If So, What Can You Do About It?
Grace Period: Waiting for readers – QSBR
[Concept] Implementation for non-preemptive Linux kernel
* [Not production quality] sched_setaffinity() function causes the
current thread to execute on the specified CPU, which forces the
destination CPU to execute a context switch.](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-37-2048.jpg)
![[Concept] QSBR: non-production and non-preemptible
implementation
Force the destination CPU to execution switch: Completion of RCU reader
Reference: Page #142 of Is Parallel Programming Hard, And, If So, What Can You Do About It?
synchronize_rcu()
rcu_read_lock() & rcu_read_unlock() → disable/enable preemption](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-38-2048.jpg)
![Agenda
• [Overview] rwlock (reader-writer spinlock) vs RCU
• RCU Implementation Overview
✓High-level overview
✓RCU: List Manipulation – Old and New data
✓Reader/Writer synchronization: five basic APIs
➢Reader
➢ rcu_read_lock() & rcu_read_unlock()
➢ rcu_dereference()
➢Writer
➢ rcu_assign_pointer()
➢ synchronize_rcu() & call_rcu()
• Classic RCU vs Tree RCU
✓Will discuss implementation details about classic RCU *only*
• RCU Flavors
• RCU Usage Summary & RCU Case Study](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-39-2048.jpg)


![rcu_ctrlblk
cur = -300
completed = -300
next_pending = 0
signaled = 0
lock
cpumask = 0
[Global control block]
static struct rcu_ctrlblk rcu_ctrlblk;
per-cpu variable initialized by rcu_init_percpu_data()
rcu_data
quiescbatch = rcp->completed = -300
passed_quiesc = 0
qs_pending = 0
batch = 0
*nxtlist = NULL
**nxttail
qs
handling
batch
handling
struct
rcu_head
*curlist = NULL
**curtail
*donelist = NULL
**donetail
qlen = 0
# of queued callbacks
cpu = current cpu’s ID
blimit = 10 (default value)
address of
address of
address of
Kernel Source Reference: 2.6.24
Classic RCU: start_kernel() -> rcu_init(): show “rcu_ctrlblk” only](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-44-2048.jpg)
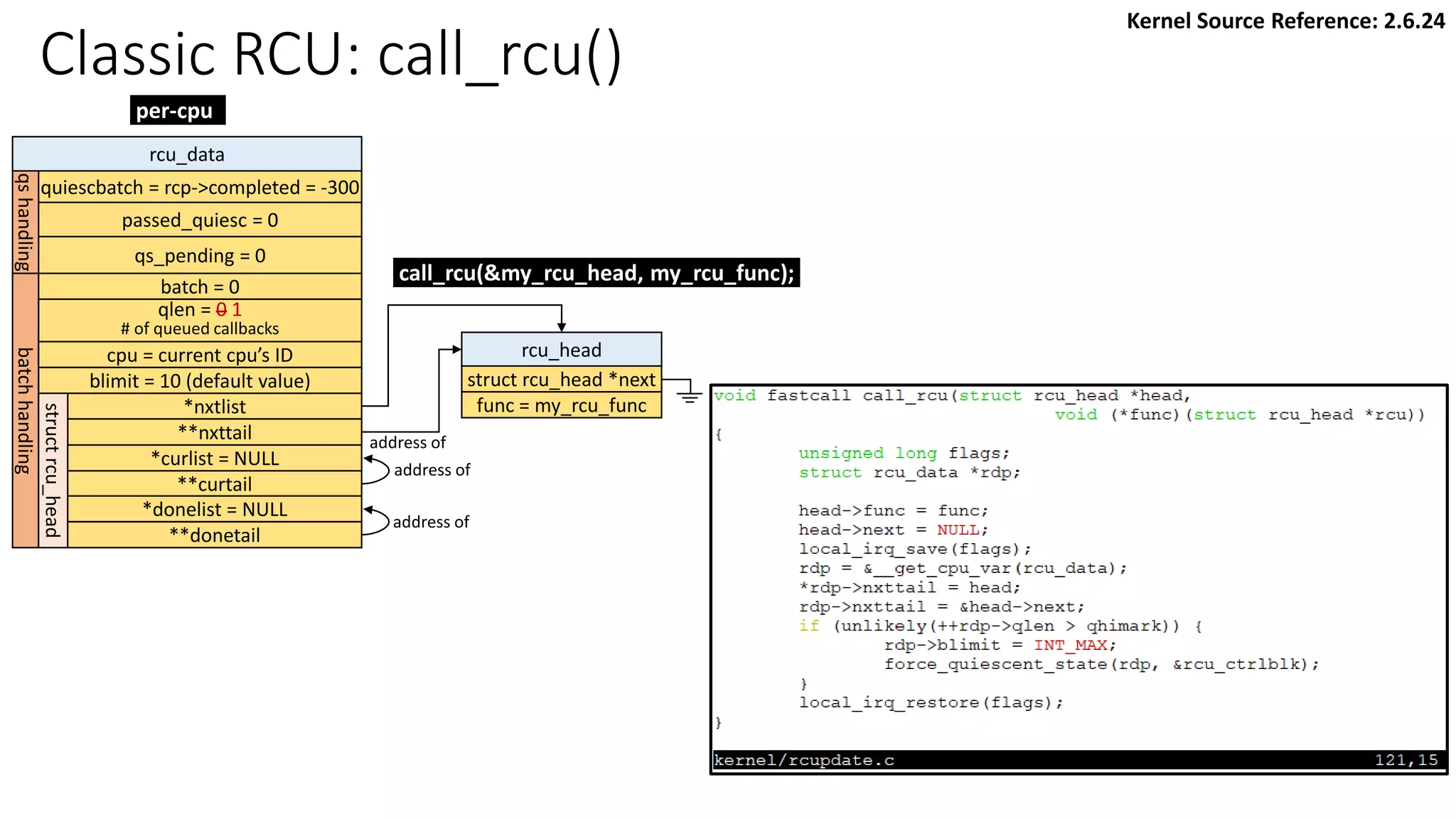

![Classic RCU: Check if a CPU passes a QS
rcu_check_callbacks
update_process_times
rcu_pending()?
Y
timer interrupt
Kernel Source Reference: 2.6.24
rcu_qsctr_inc
schedule
Timer interrupt Scheduler: context switch
[Note] “rcu_data.passed_quiesc = 1” does not clear the corresponding rcu_ctrlblk.cpumask
directly. More checks are performed. See later slides.](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-48-2048.jpg)
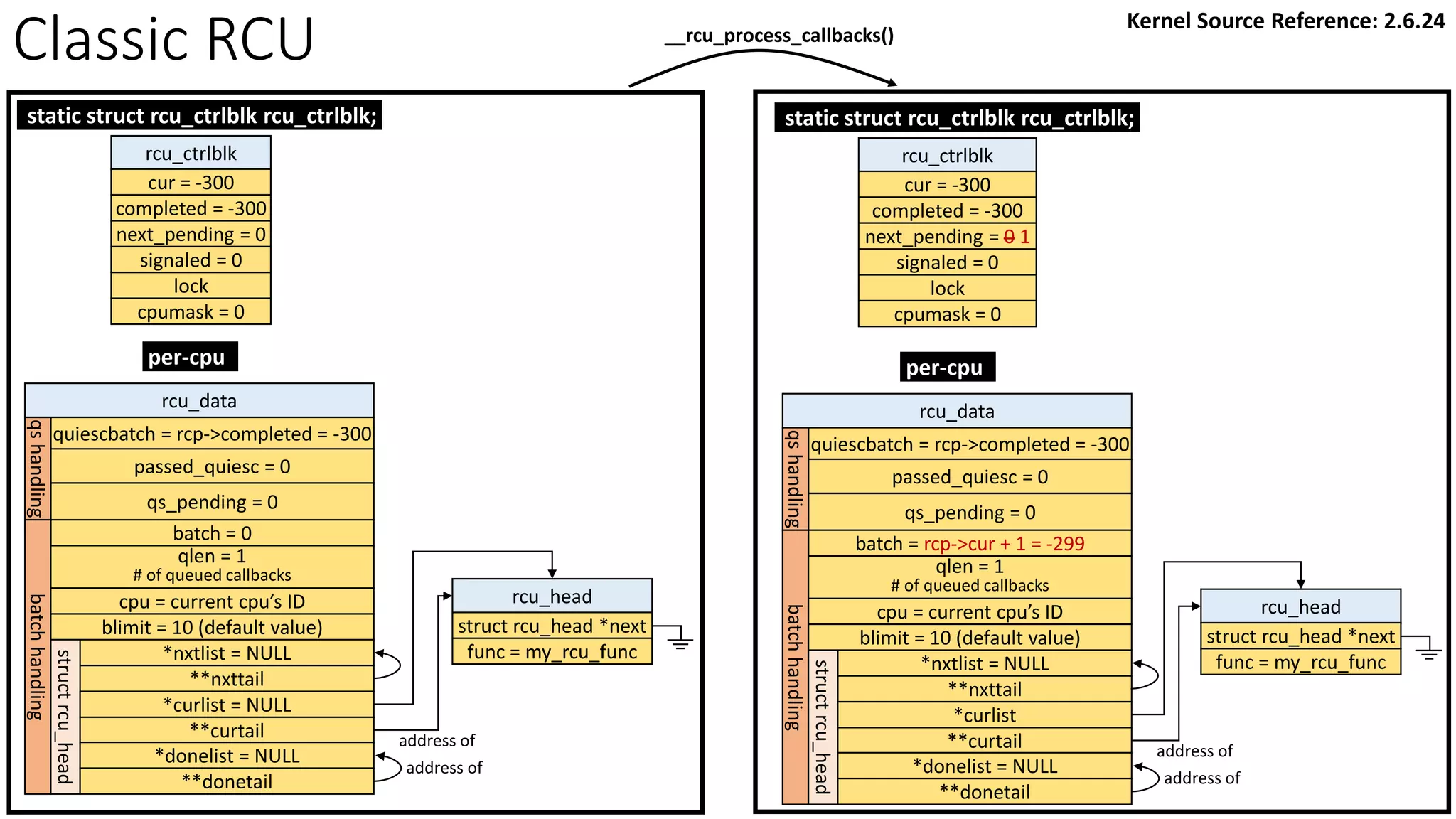
![Classic RCU: first timer interrupt
rcu_tasklet per-cpu
rcu_process_callbacks()
rcu_check_callbacks
tasklet_schedule
update_process_times
rcu_pending()?
Y
timer interrupt
__rcu_process_callbacks()
rcu_check_quiescent_state
call rcu_do_batch if
rdp->donelist
rcu_ctrlblk
cur = -300
completed = -300
next_pending = 0
signaled = 0
lock
cpumask = 0
[Global control block]
static struct rcu_ctrlblk rcu_ctrlblk;
per-cpu
rcu_data
quiescbatch = rcp->completed = -300
passed_quiesc = 0
qs_pending = 0
batch = 0
*nxtlist
**nxttail
qs
handling
batch
handling
struct
rcu_head
*curlist = NULL
**curtail
*donelist = NULL
**donetail
qlen = 1
# of queued callbacks
cpu = current cpu’s ID
blimit = 10 (default value)
rcu_head
struct rcu_head *next
func = my_rcu_func
address of
address of
address of
Manipulation
Kernel Source Reference: 2.6.24](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-49-2048.jpg)







![Agenda
• [Overview] rwlock (reader-writer spinlock) vs RCU
• RCU Implementation Overview
✓High-level overview
✓RCU: List Manipulation – Old and New data
✓Reader/Writer synchronization: five basic APIs
➢Reader
➢ rcu_read_lock() & rcu_read_unlock()
➢ rcu_dereference()
➢Writer
➢ rcu_assign_pointer()
➢ synchronize_rcu() & call_rcu()
• Classic RCU vs Tree RCU
• RCU Flavors
• RCU Usage Summary & RCU Case Study](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-65-2048.jpg)



![• Before preemptible RCU, context switch is a quiescent state
✓ [A complete grace period] Need to wait for all pre-existing interrupt and NMI handler
• [CONFIG_PREEMPTION=n]
✓ Vanilla RCU and RCU-sched grace period waits for pre-existing interrupt and NMI handlers
✓ Vanilla RCU and RCU-sched have identical implementations
• [CONFIG_PREEMPTION=Y] for RCU-sched
✓ Preemptible RCU does not need to wait for pre-existing interrupt and NMI handler.
✓ The code outside of an RCU read-side critical section → a QS
✓ rcu_read_lock_sched() → disable preemption
✓ rcu_read_unlock_sched() → re-enable preemption
✓ A preemption attempt during the RCU-sched read-side critical section:
✓ rcu_read_unlock_sched() will enter the scheduler
• Reader RCU APIs
✓ rcu_read_lock_sched() / rcu_read_unlock_sched()
✓ preempt_disable() / preempt_enable()
✓ local_irq_save() / local_irq_restore()
✓ hardirq enter / hardirq exit
✓ NMI enter / NMI exit
✓ rcu_dereference_sched()
• Writer: No change
RCU Flavors: Sched Flavor (Historical)](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-69-2048.jpg)




![Agenda
• [Overview] rwlock (reader-writer spinlock) vs RCU
• RCU Implementation Overview
✓High-level overview
✓RCU: List Manipulation – Old and New data
✓Reader/Writer synchronization: five basic APIs
➢Reader
➢ rcu_read_lock() & rcu_read_unlock()
➢ rcu_dereference()
➢Writer
➢ rcu_assign_pointer()
➢ synchronize_rcu() & call_rcu()
• Classic RCU vs Tree RCU
• RCU Flavors
• RCU Usage Summary & RCU Case Study](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-74-2048.jpg)




![RCU (Read-Copy-Update)
• Non-blocking synchronization
✓Deadlock Immunity: RCU read-side primitives do not block, spin or even do
backwards branches → execution time is deterministic.
➢Exception (programming error):
➢Immunity to priority inversion
◼ Low-priority RCU readers cannot prevent a high-priority RCU updater from acquiring the
update-side lock
◼ A low-priority RCU updater cannot prevent high-priority RCU readers from entering read-side
critical section
➢[-rt kernel] RCU is susceptible to priority inversion scenarios:
➢ A High-priority process blocked waiting for an RCU grace period to elapse can be blocked by
low-priority RCU readers. --> Solve by RCU priority boosting.
➢ [RCU priority boosting] Require rcu_read_unclock() do deboosting, which entails acquiring
scheduler locks.
➢ Need to avoid deadlocks within the scheduler and RCU: v5.15 kernel requires RCU to
avoid invoking the scheduler while holding any of RCU’s locks
➢ rcu_read_unlock() is not always lockless when RCU priority boosting is enabled.](https://image.slidesharecdn.com/rcu-230525071116-f4256278/75/Linux-Synchronization-Mechanism-RCU-Read-Copy-Update-84-2048.jpg)


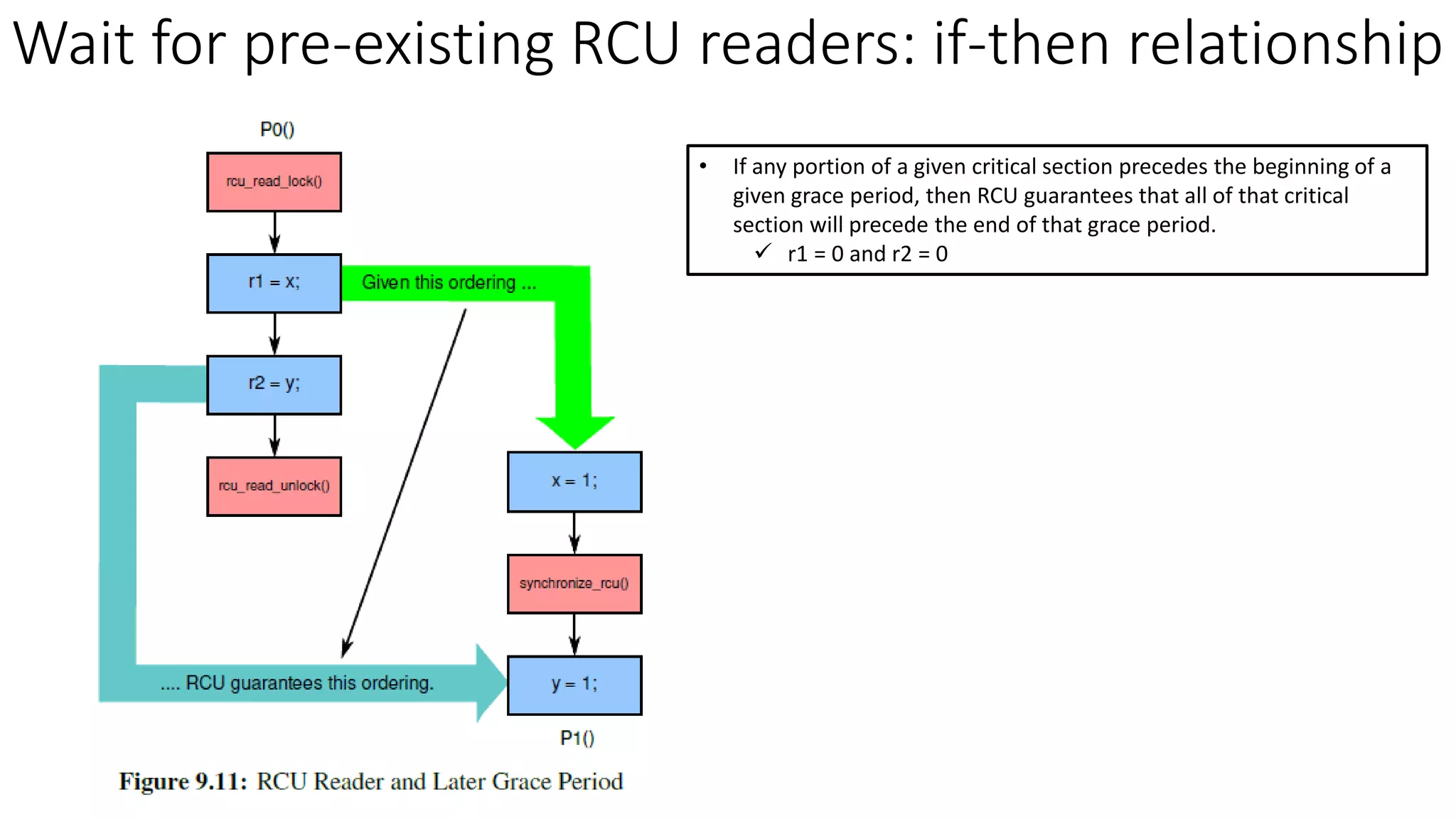
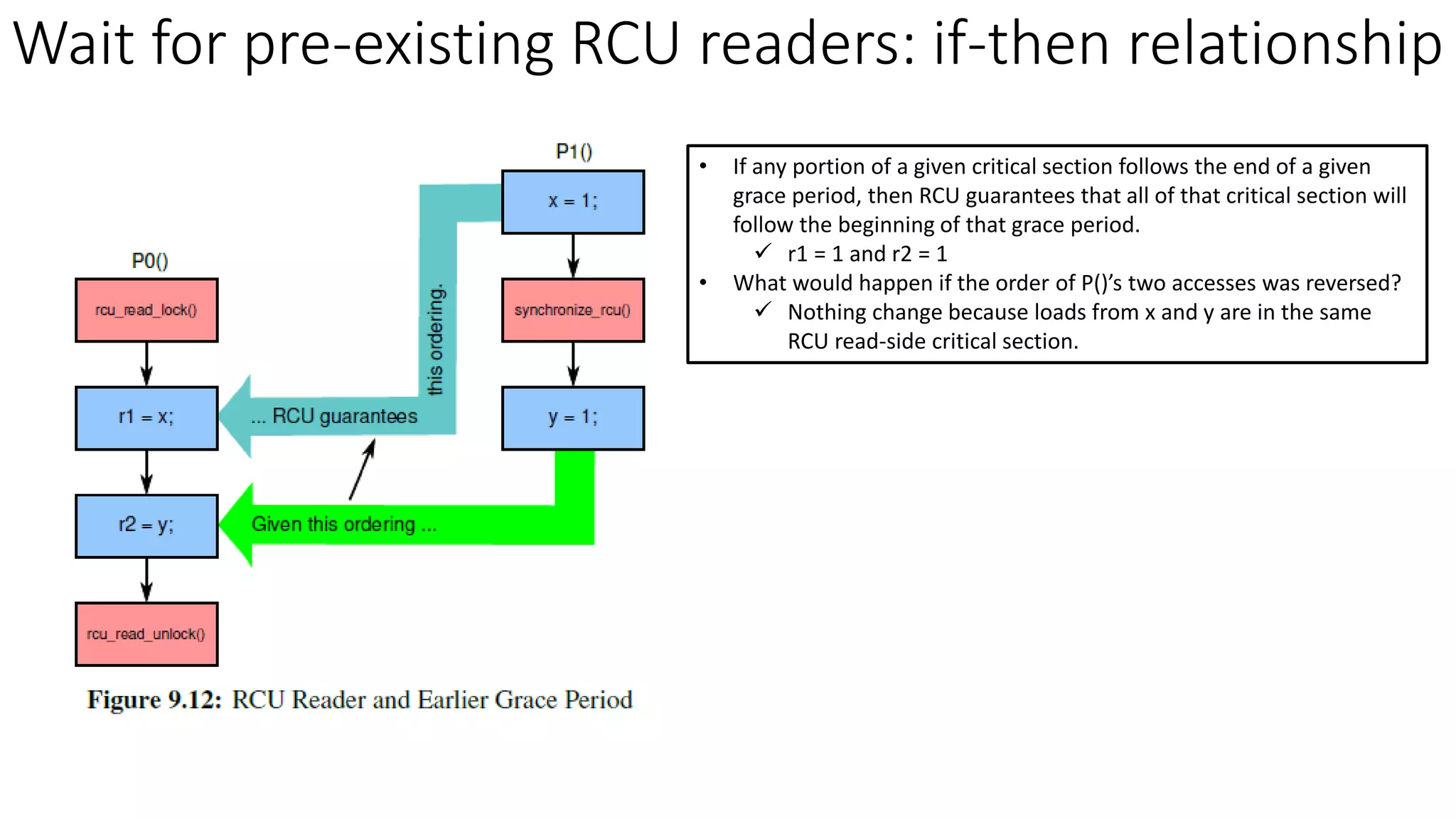
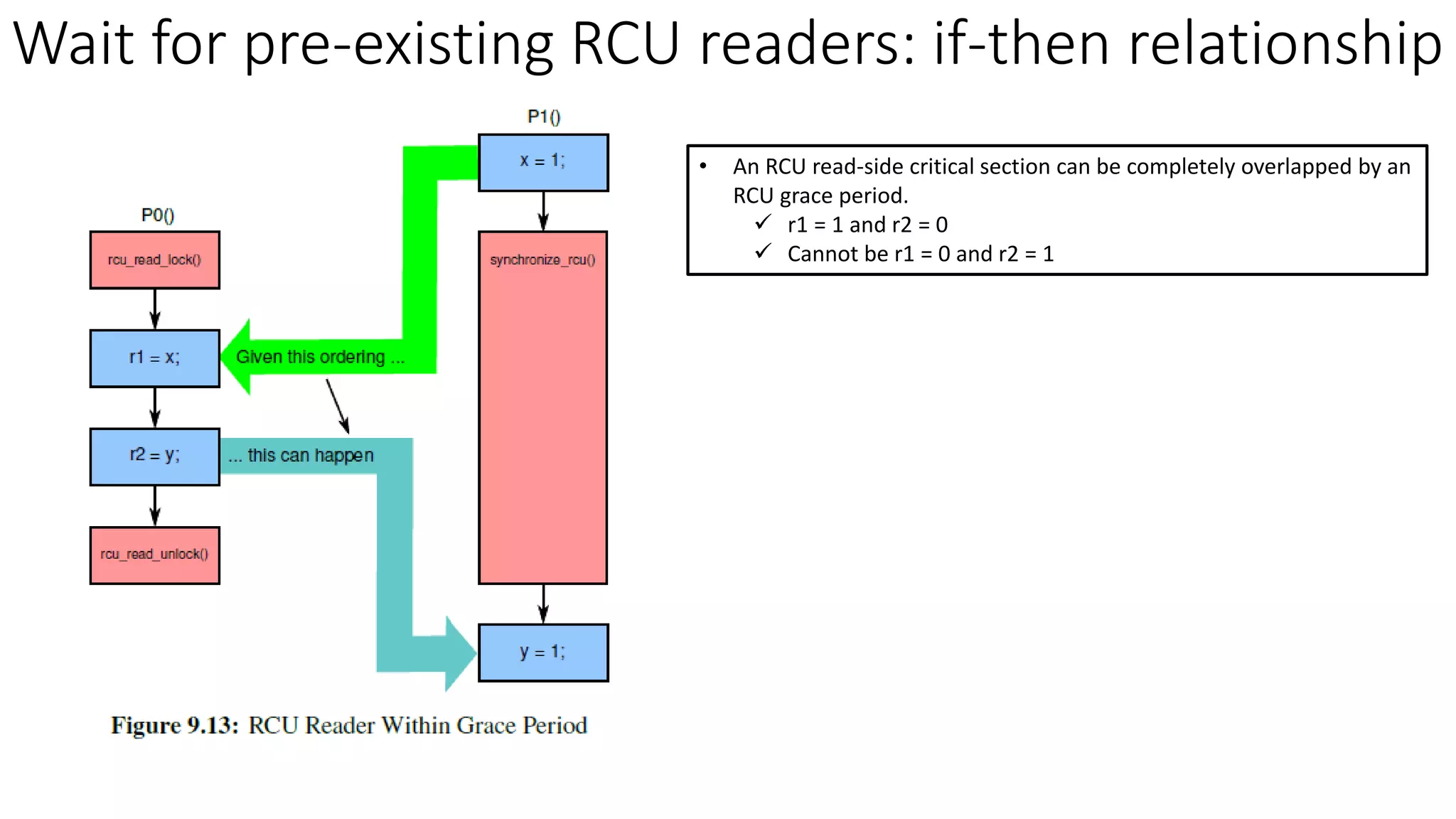
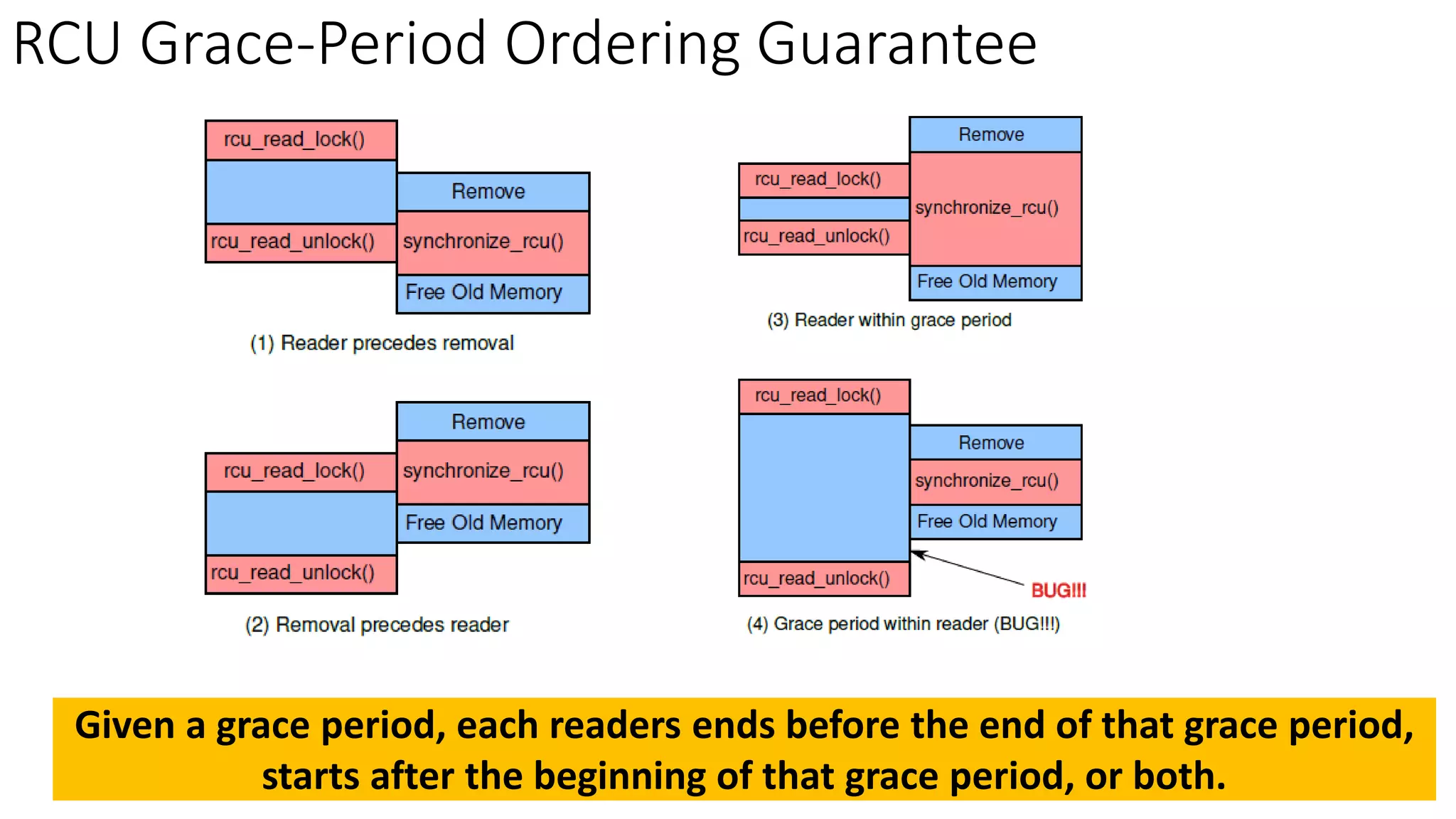



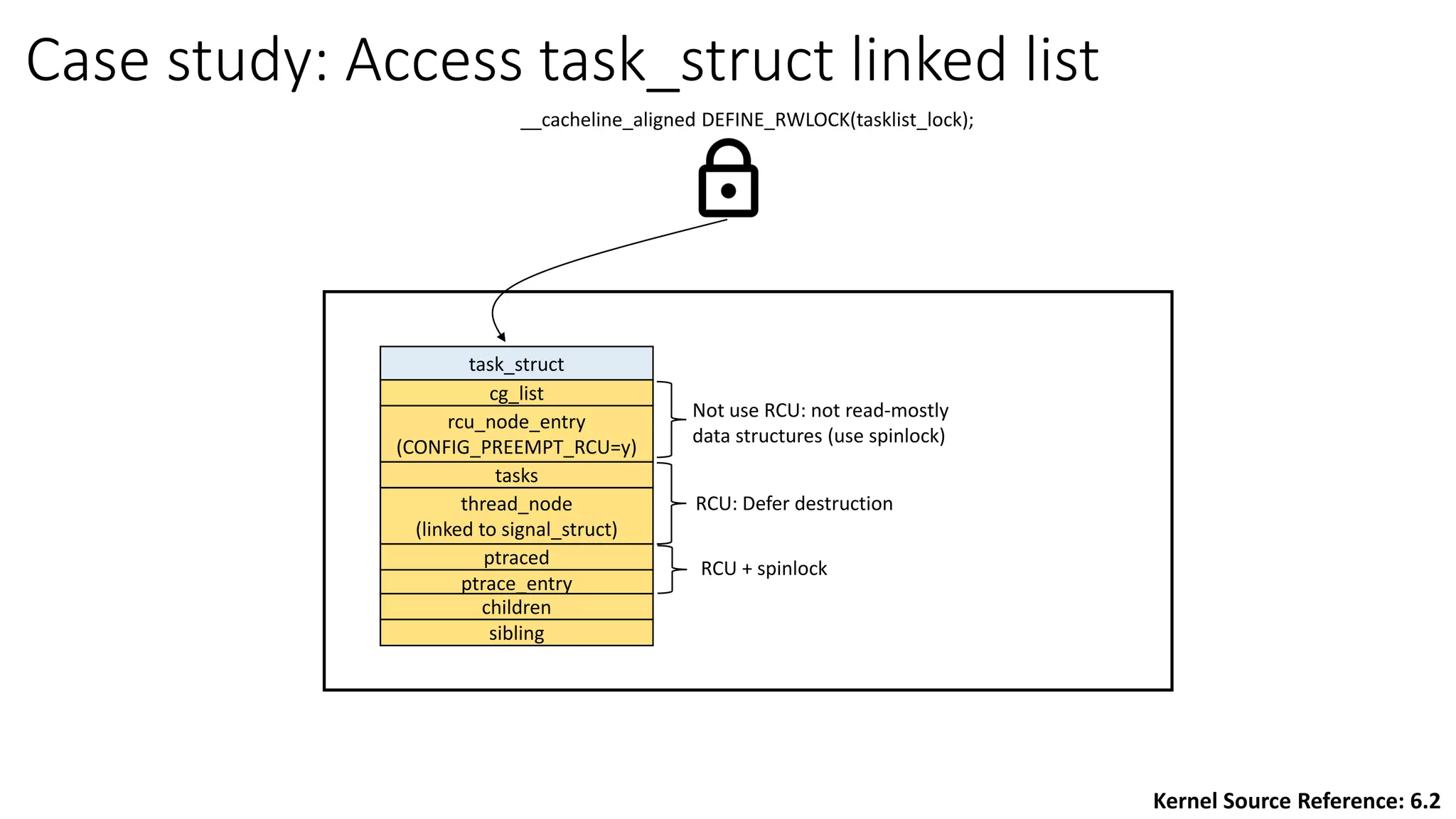

RCU (Read-Copy-Update) is a synchronization mechanism that allows for lock-free reads with concurrent updates. It achieves this through a combination of temporal and spatial synchronization. Temporal synchronization uses rcu_read_lock() and rcu_read_unlock() for readers, and synchronize_rcu() or call_rcu() for updaters. Spatial synchronization uses rcu_dereference() for readers to safely load pointers, and rcu_assign_pointer() for updaters to safely update pointers. RCU guarantees that readers will either see the old or new version of data, but not a partially updated version.



































































