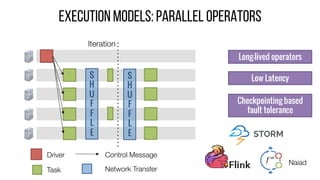
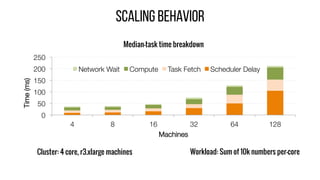
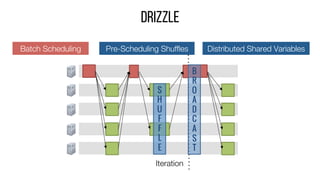
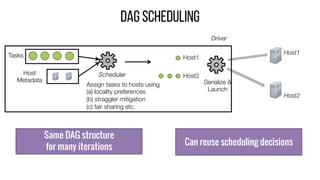
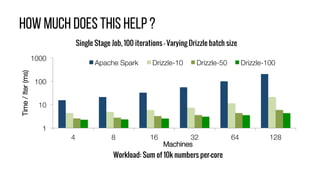
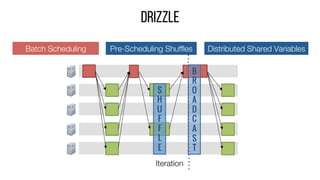
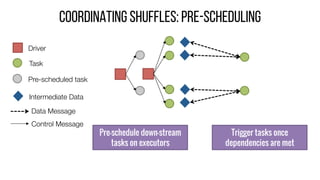
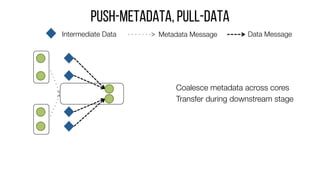
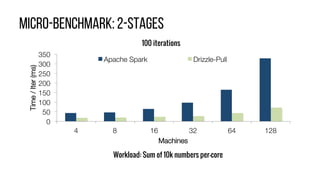
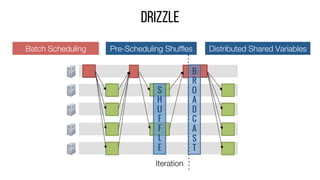
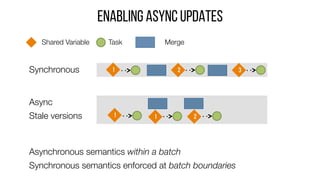
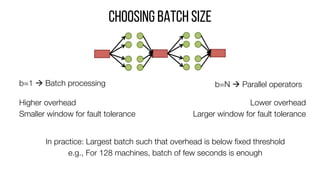
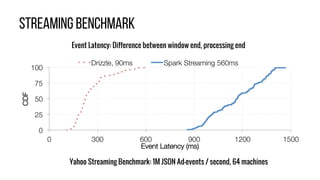
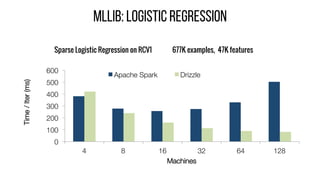
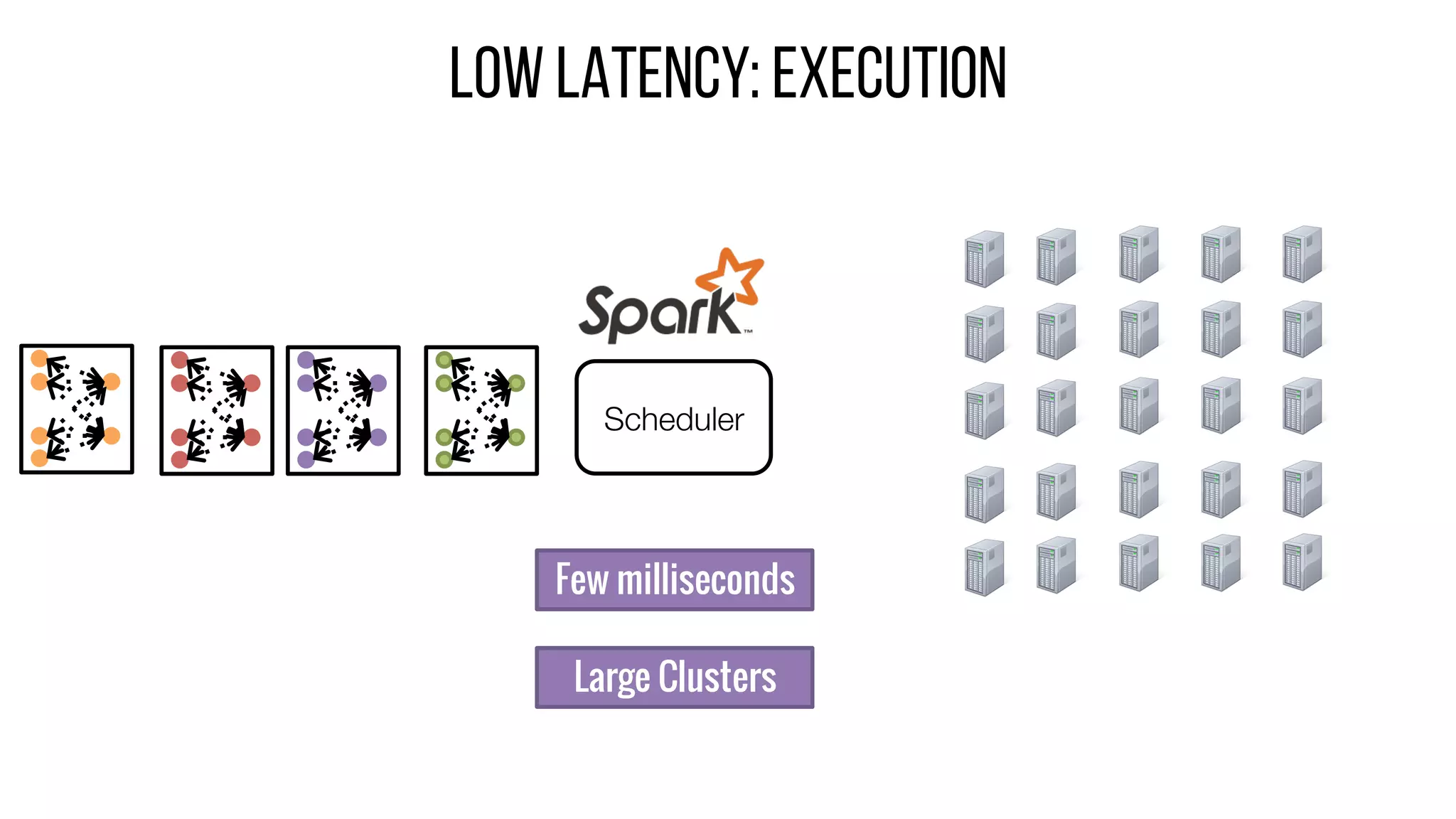
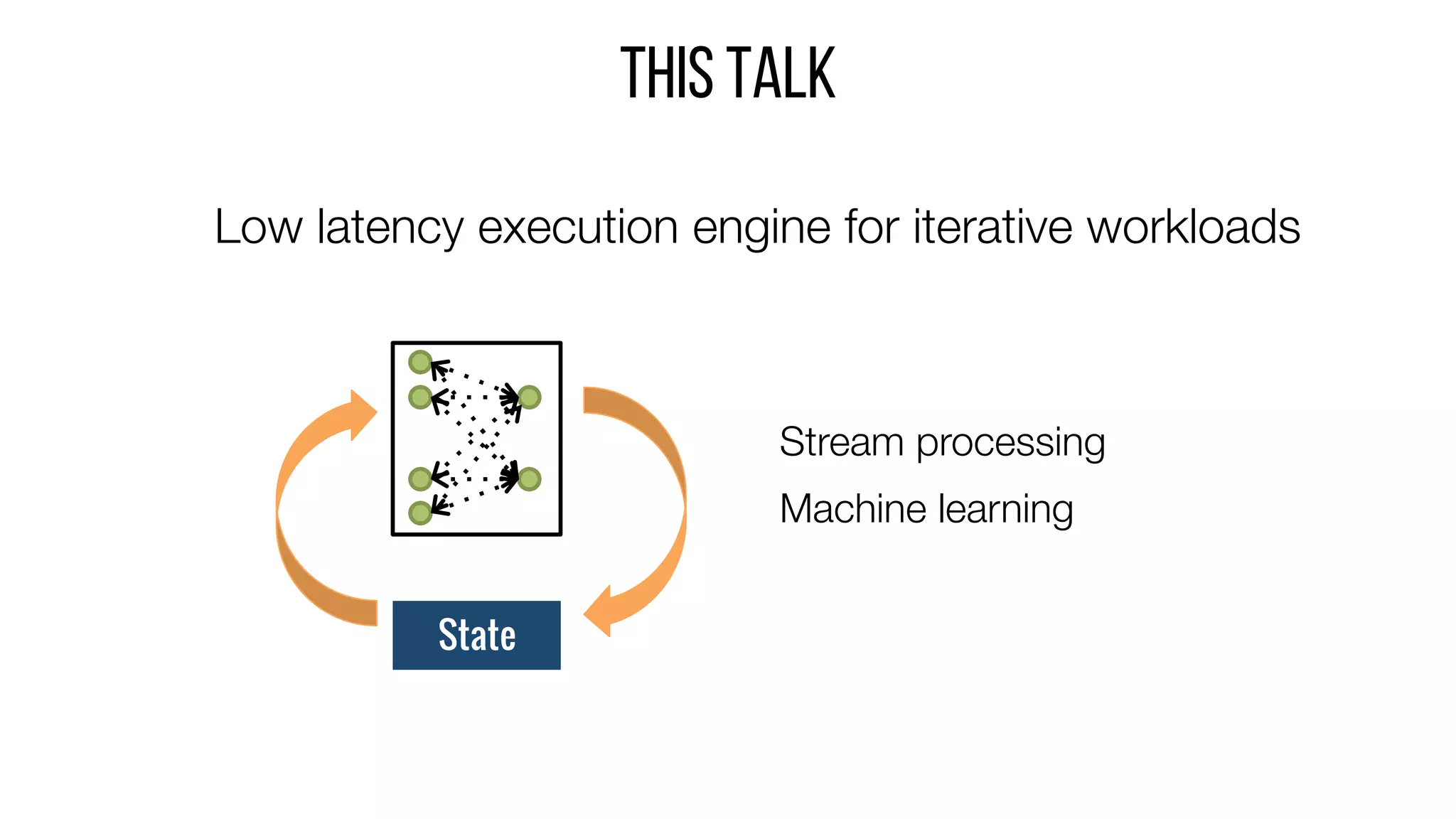
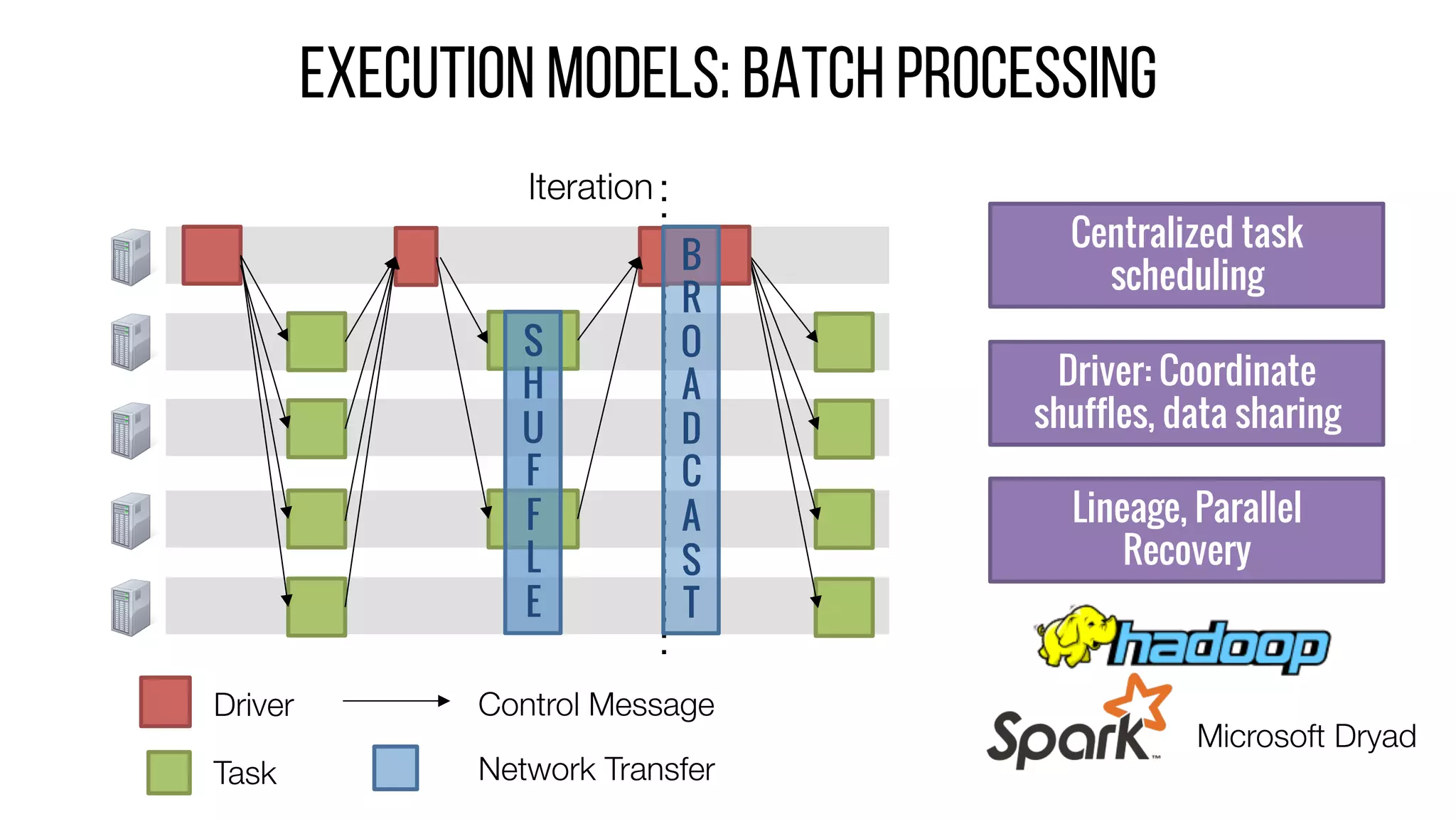
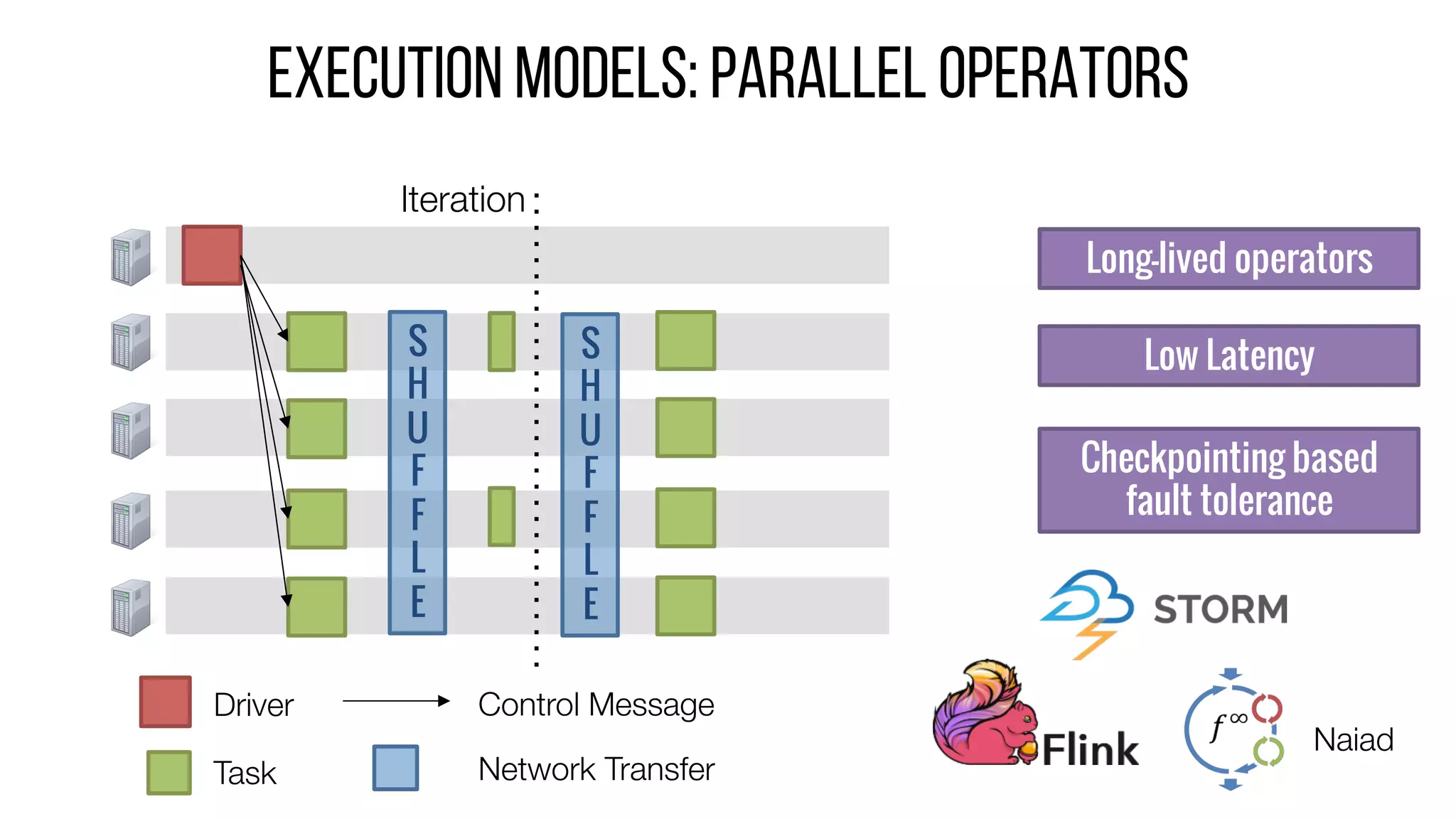
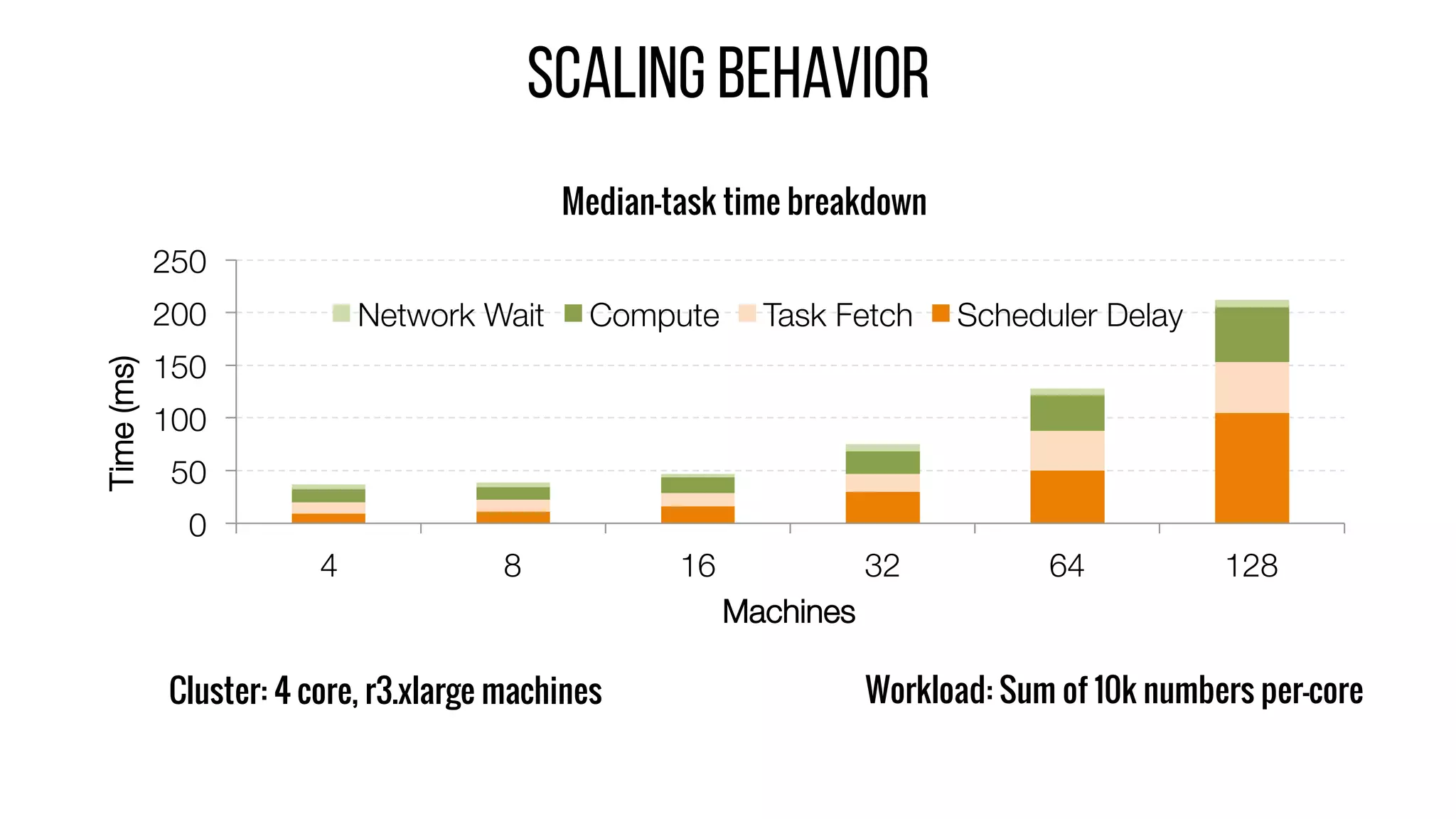
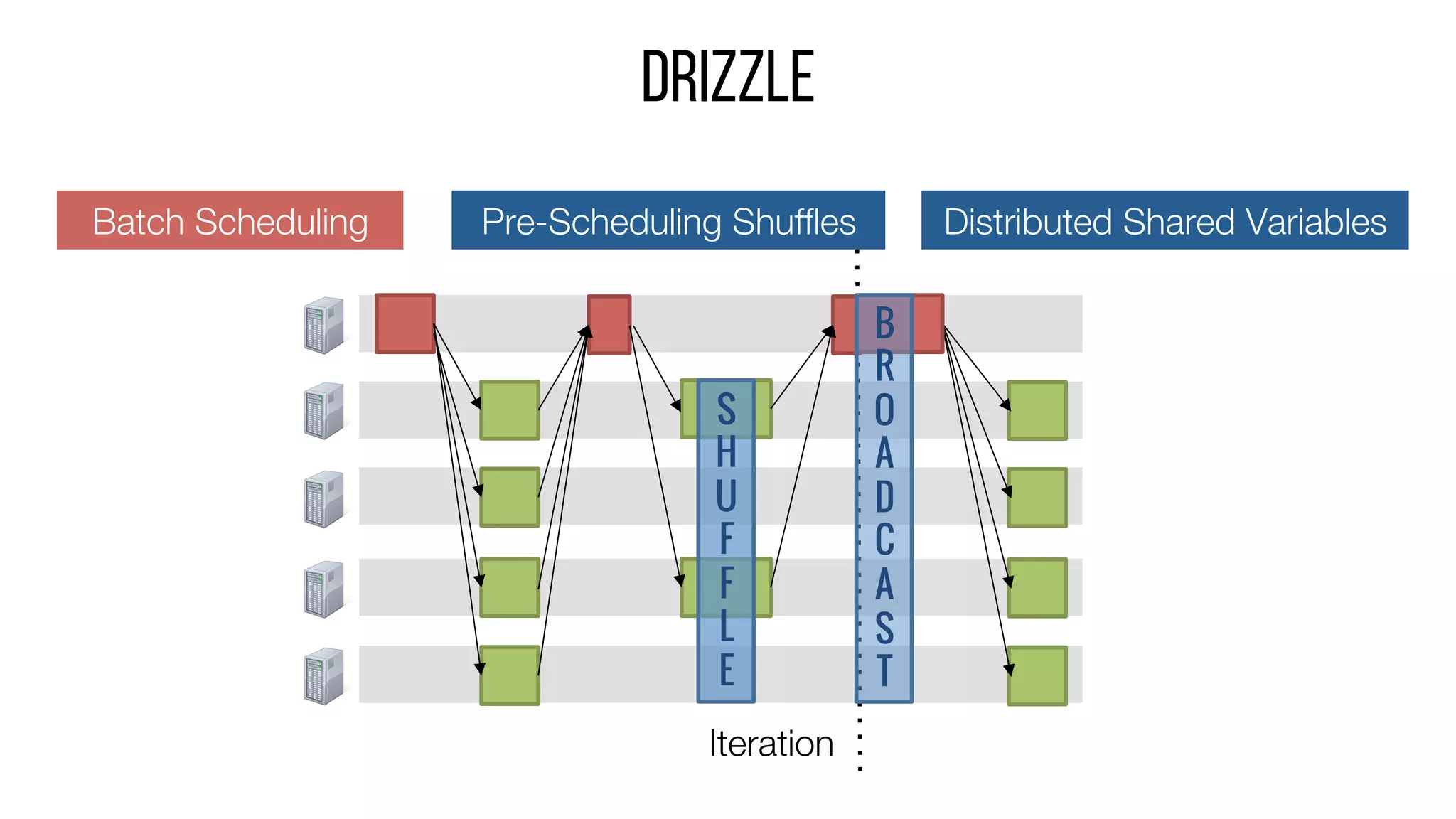
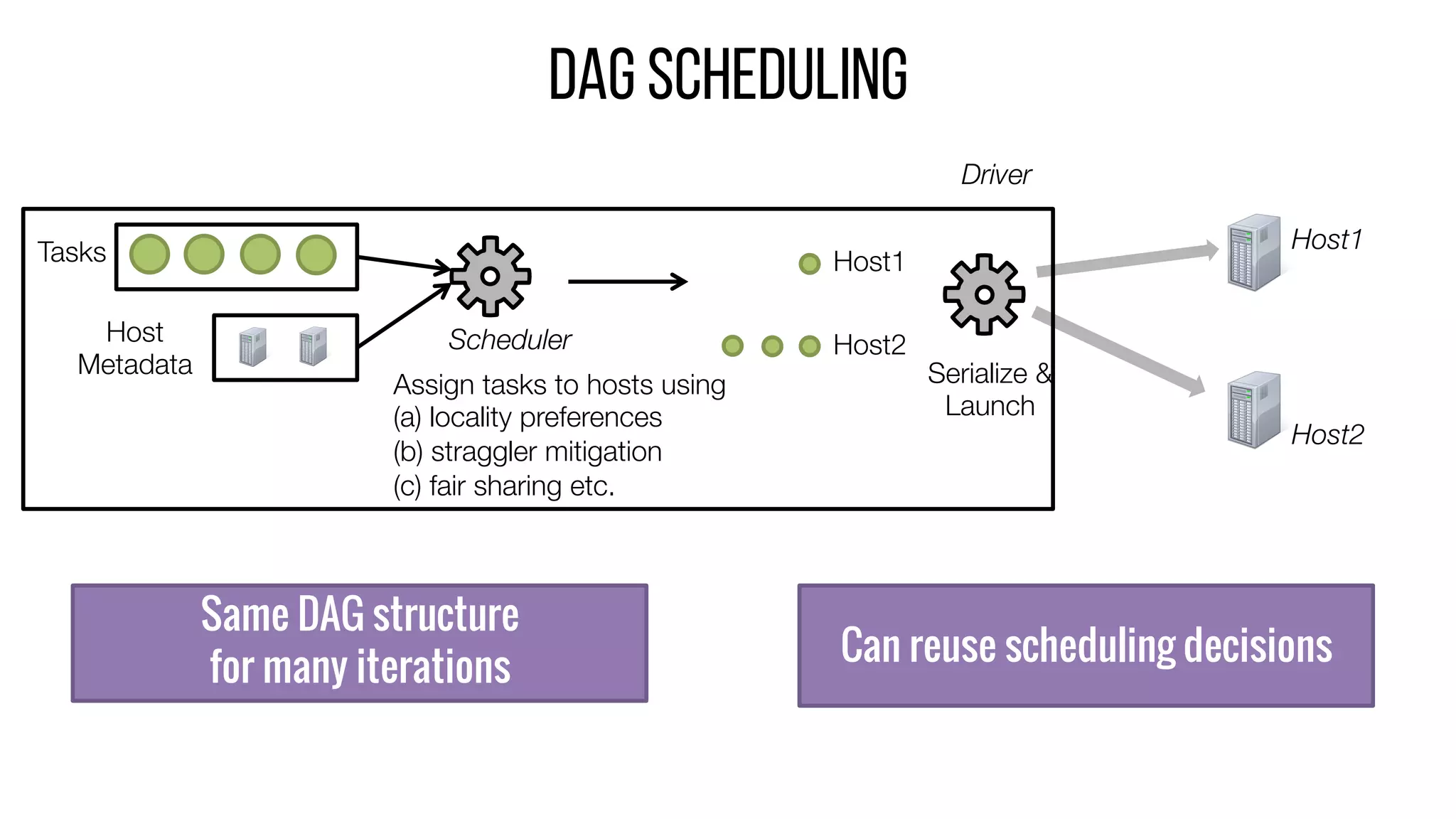
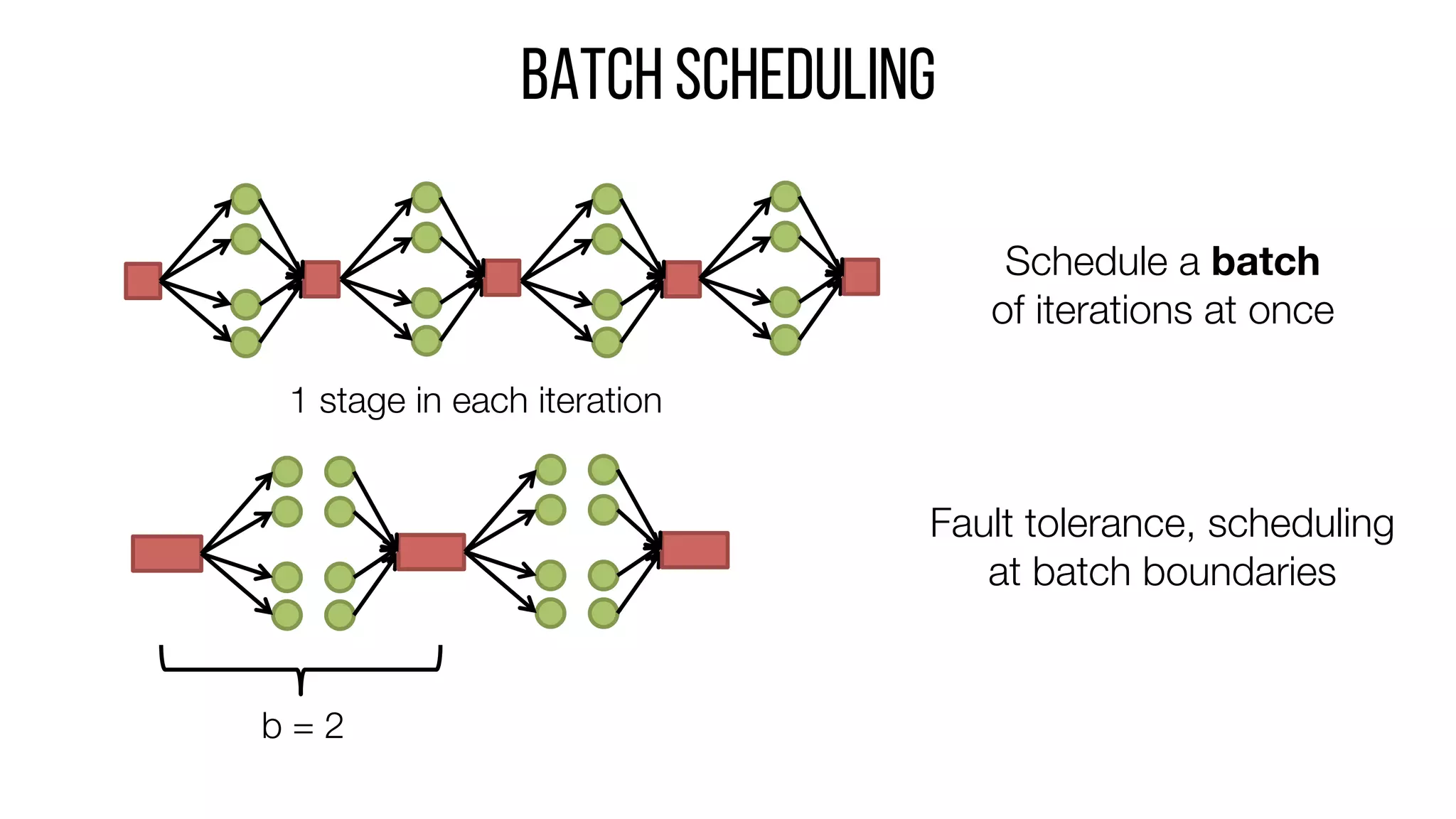
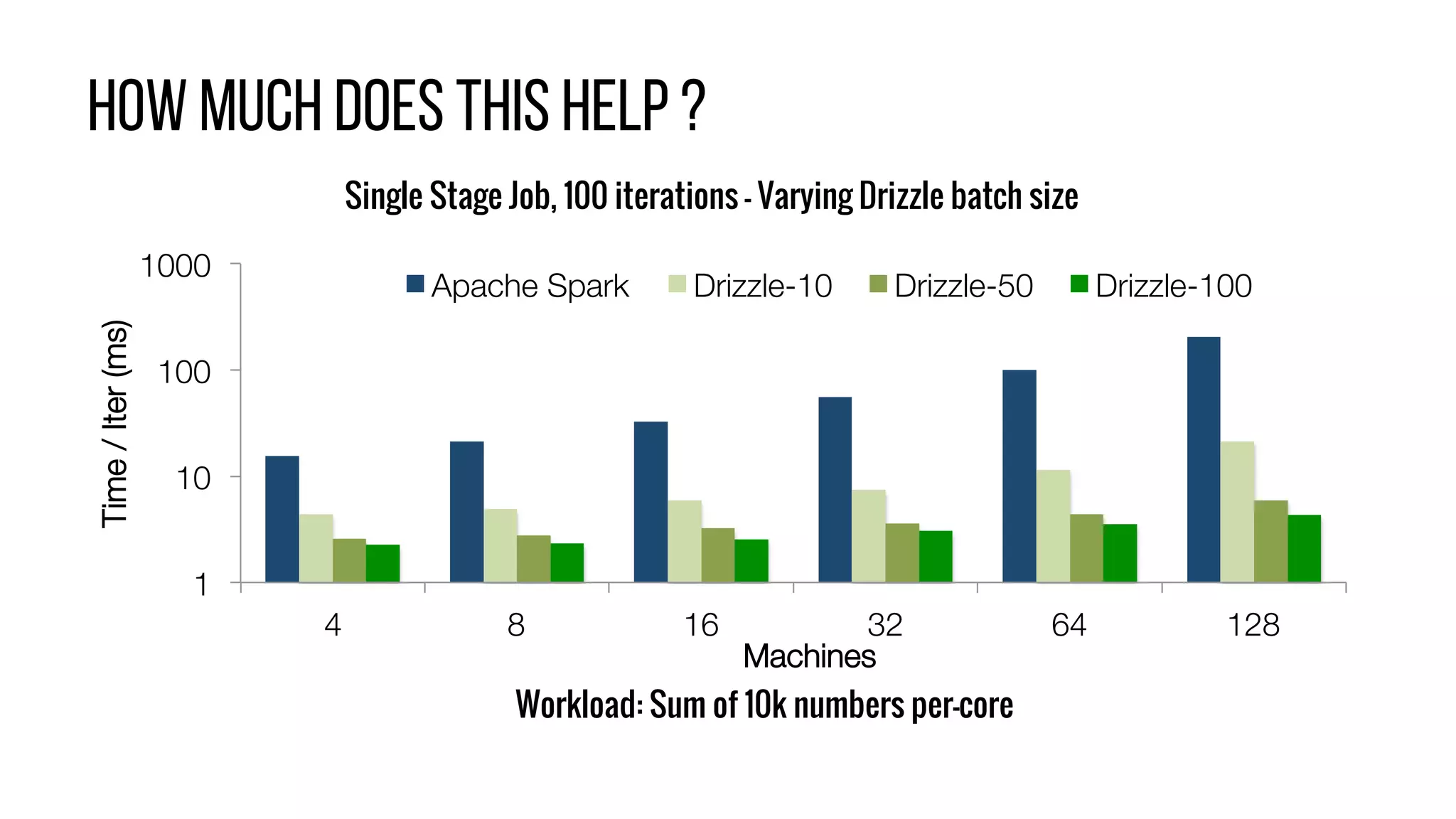
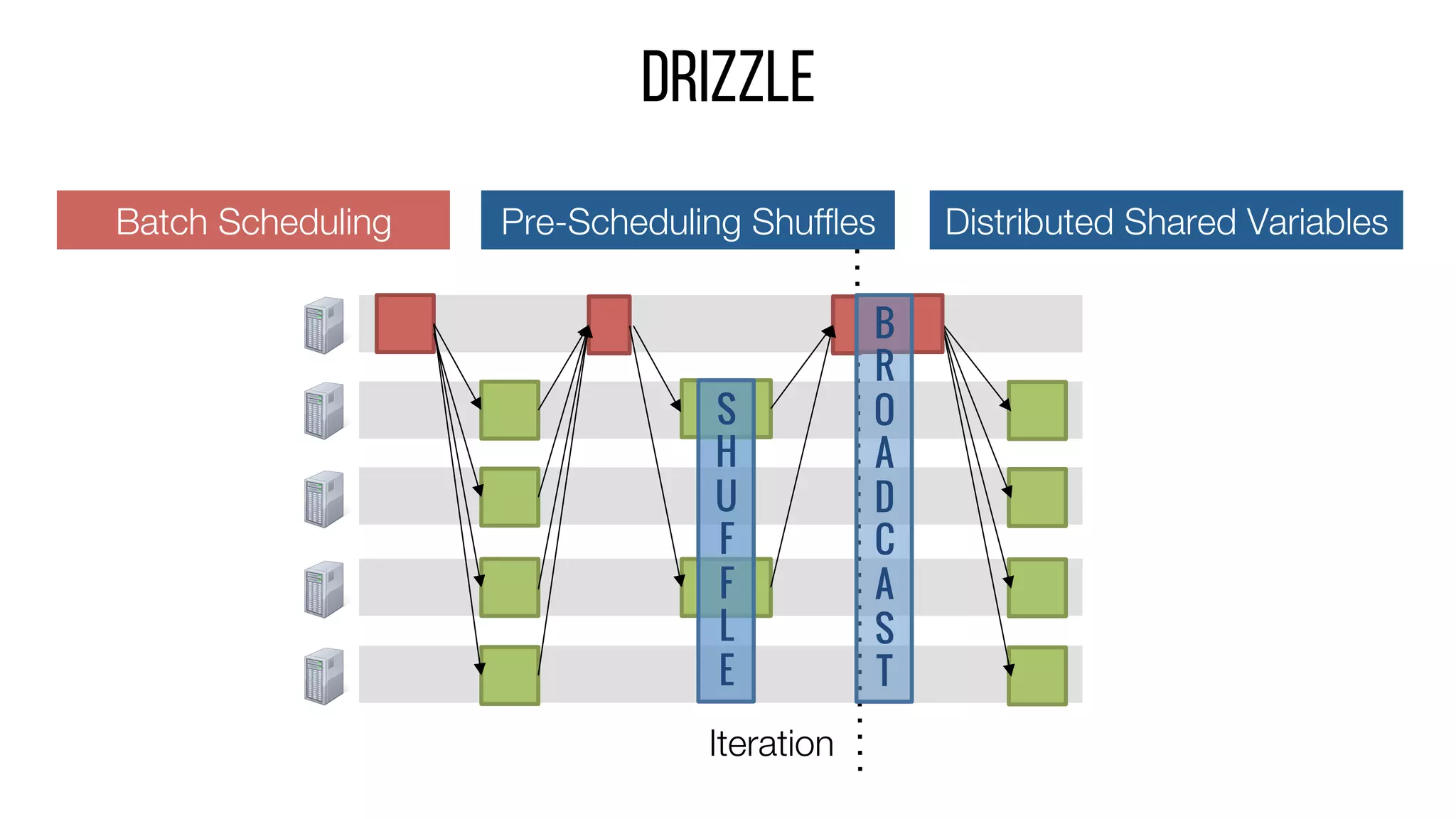
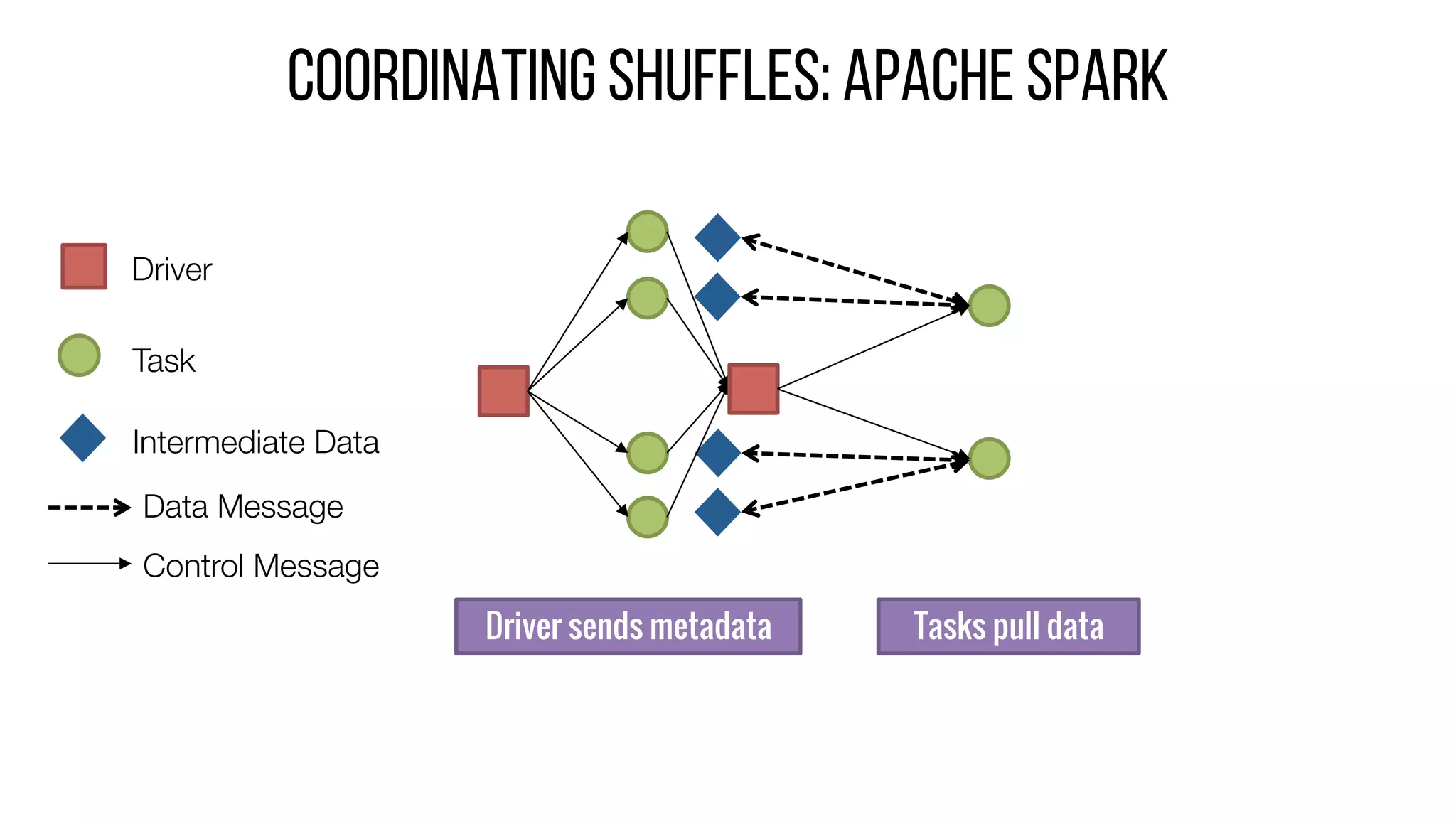
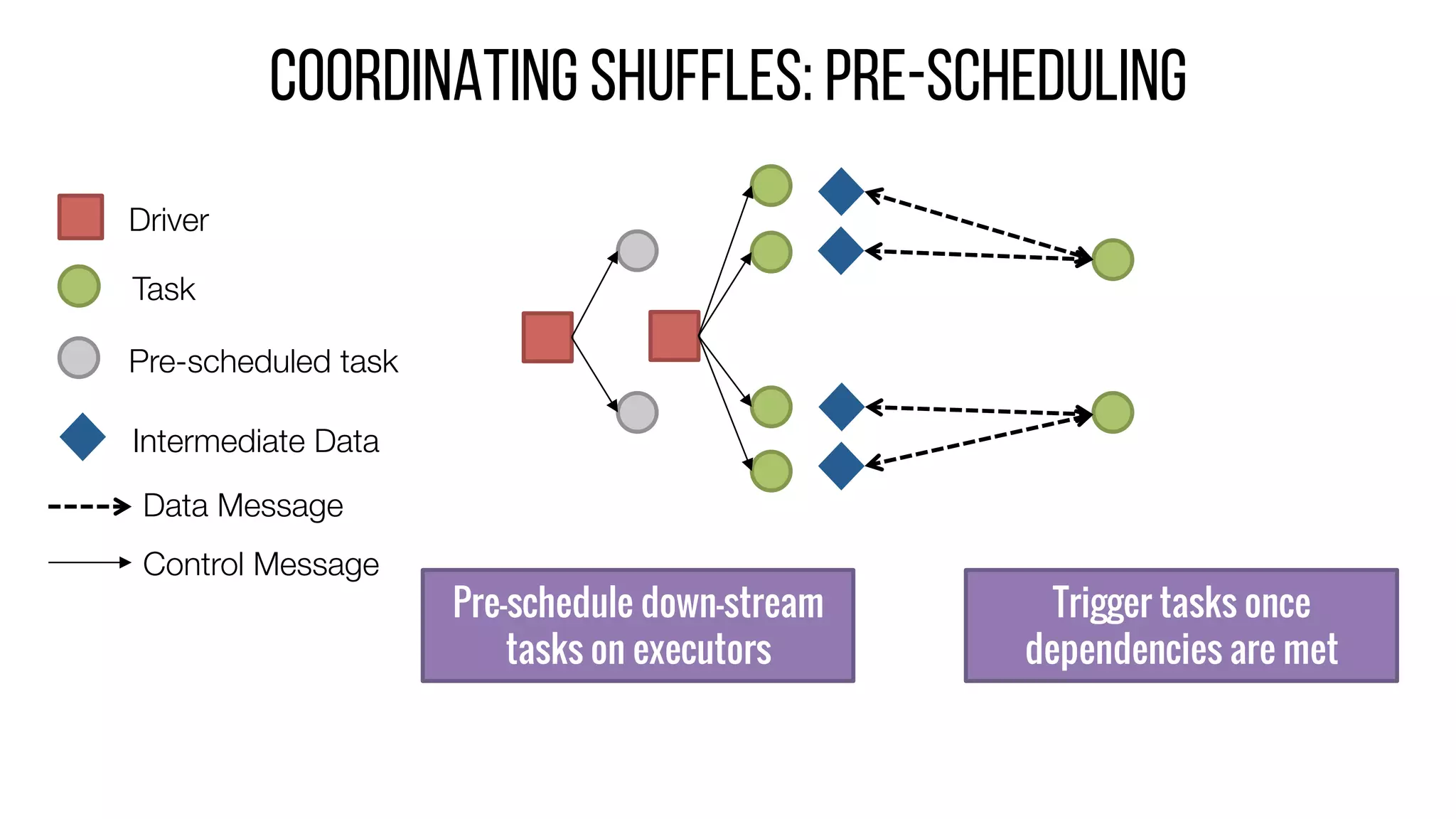
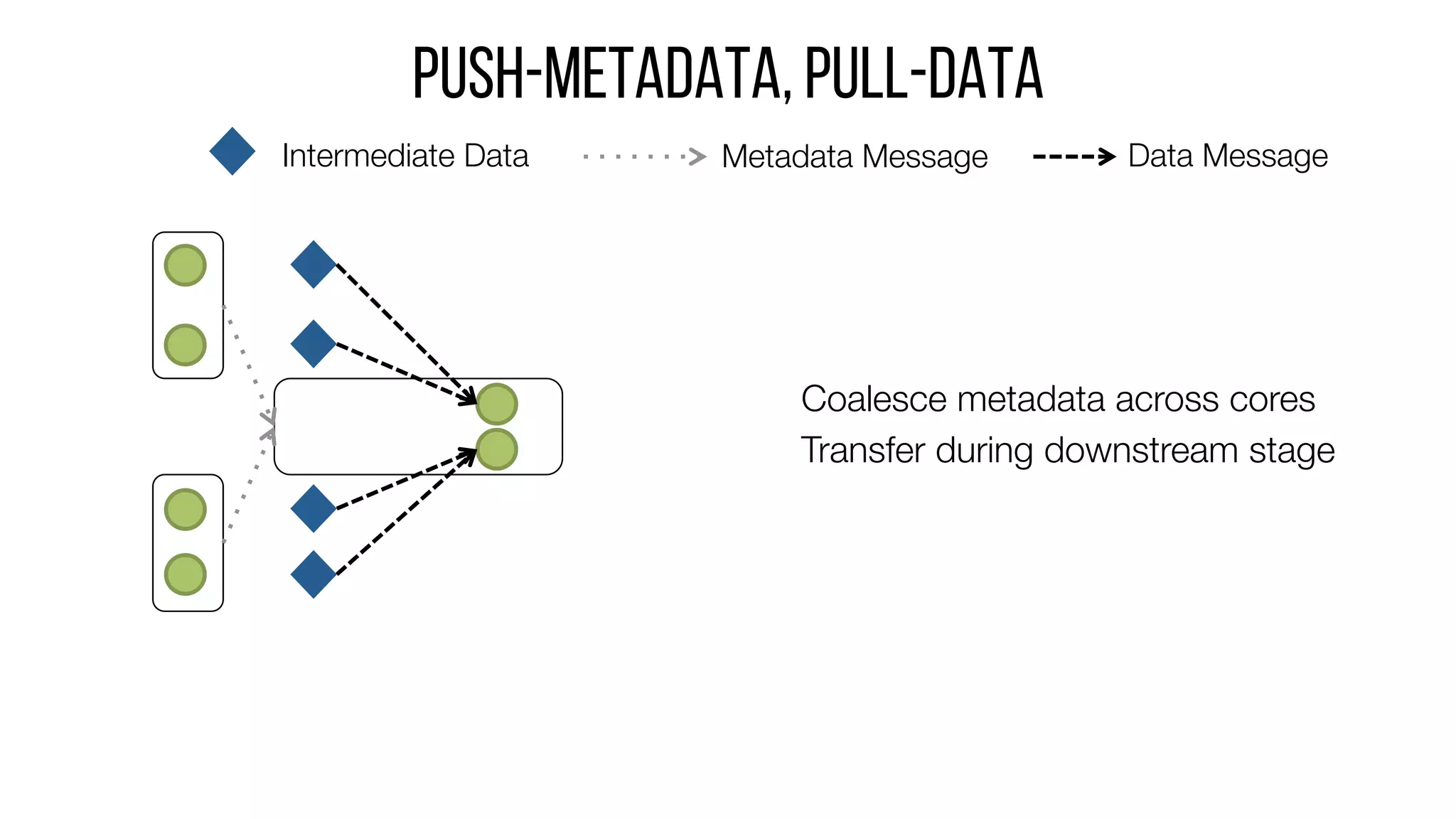
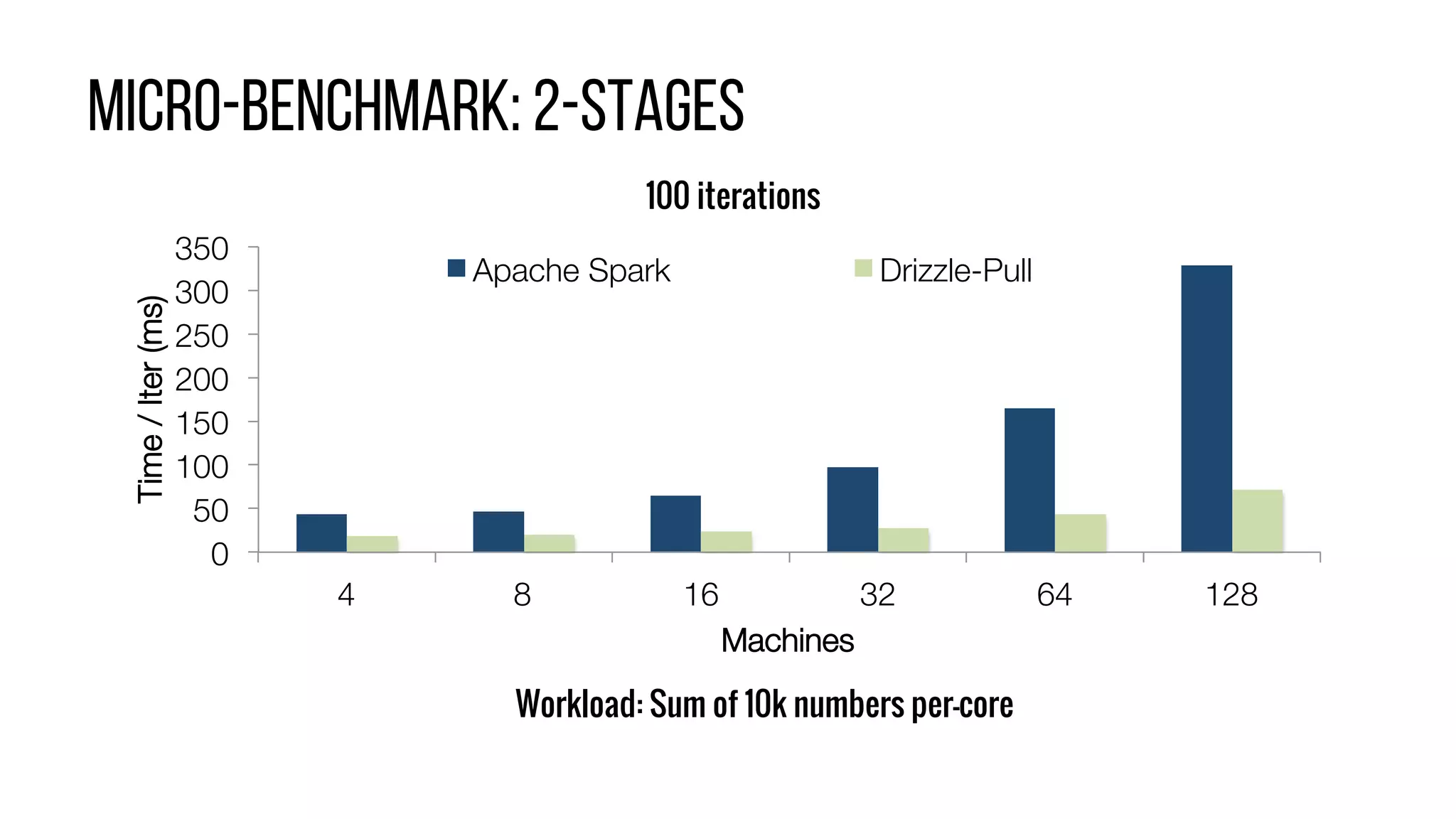
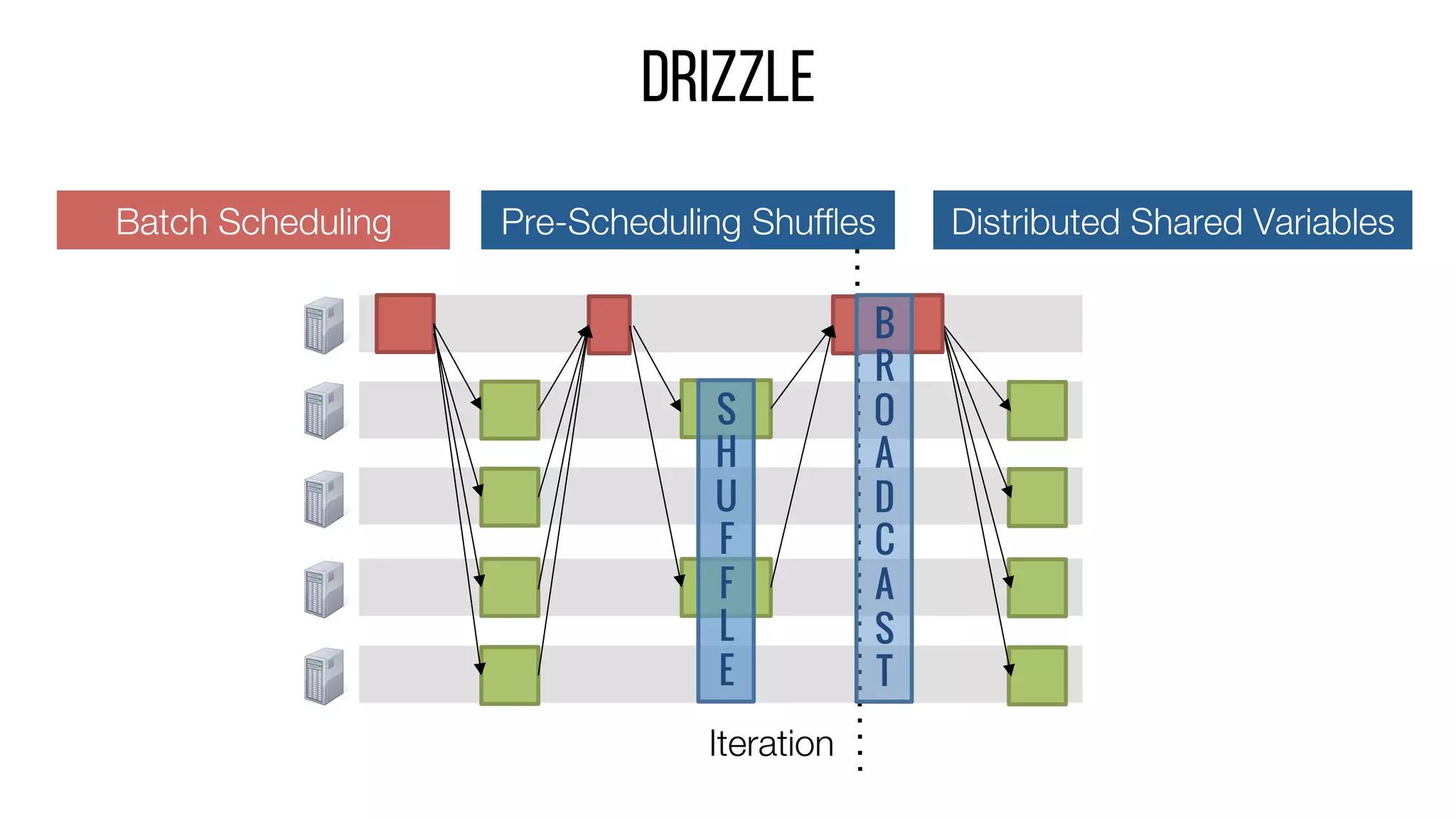
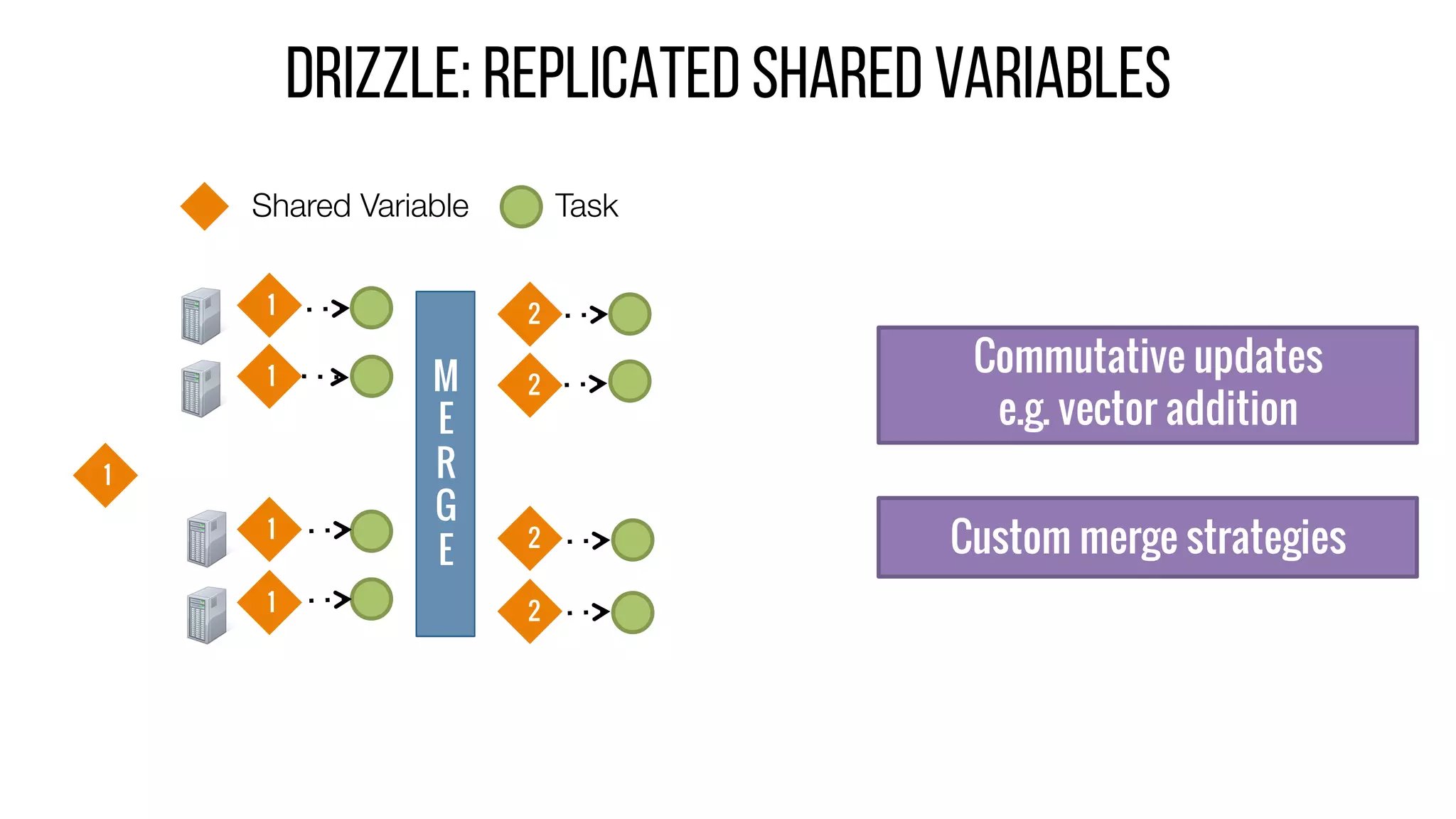
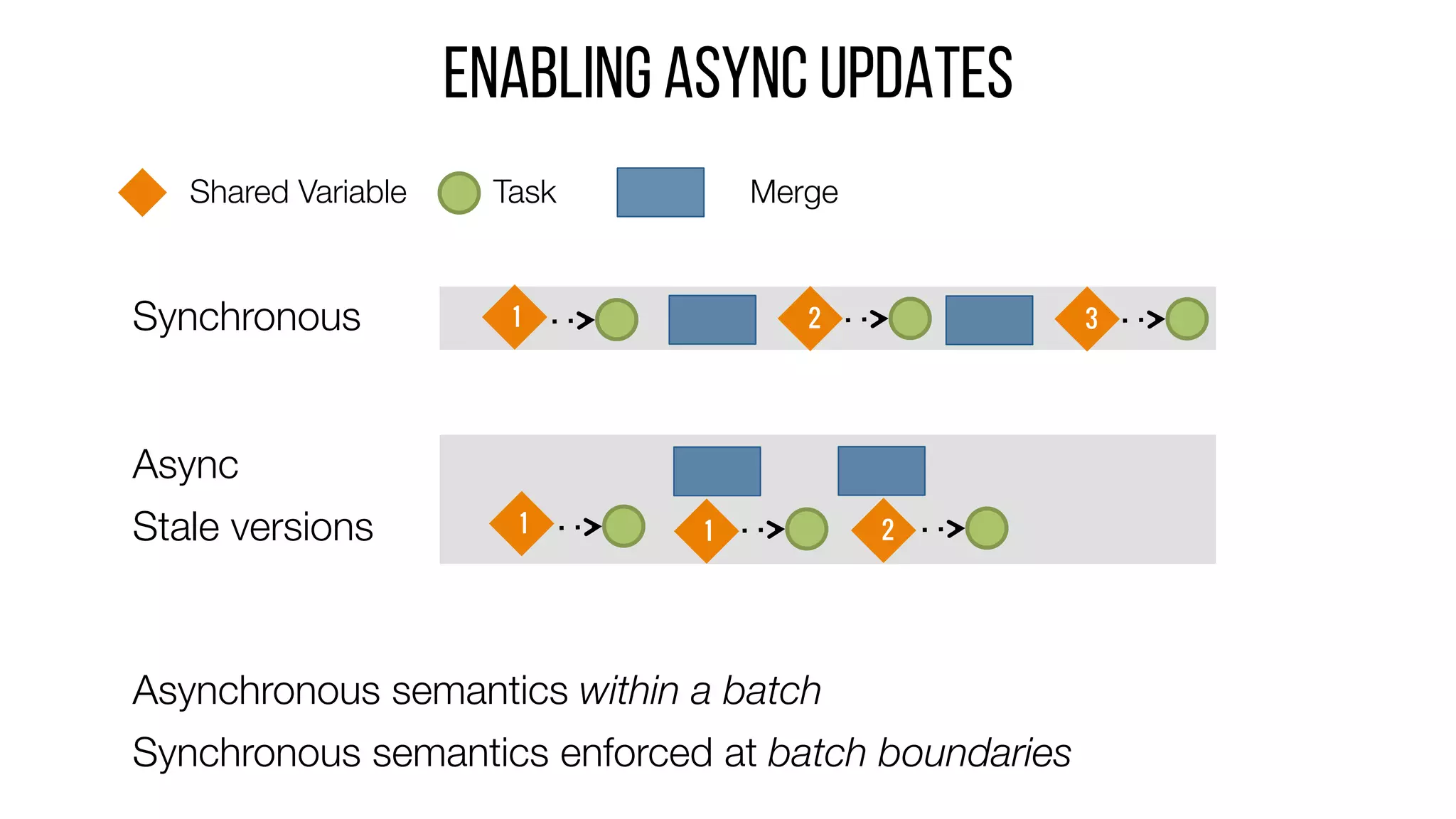
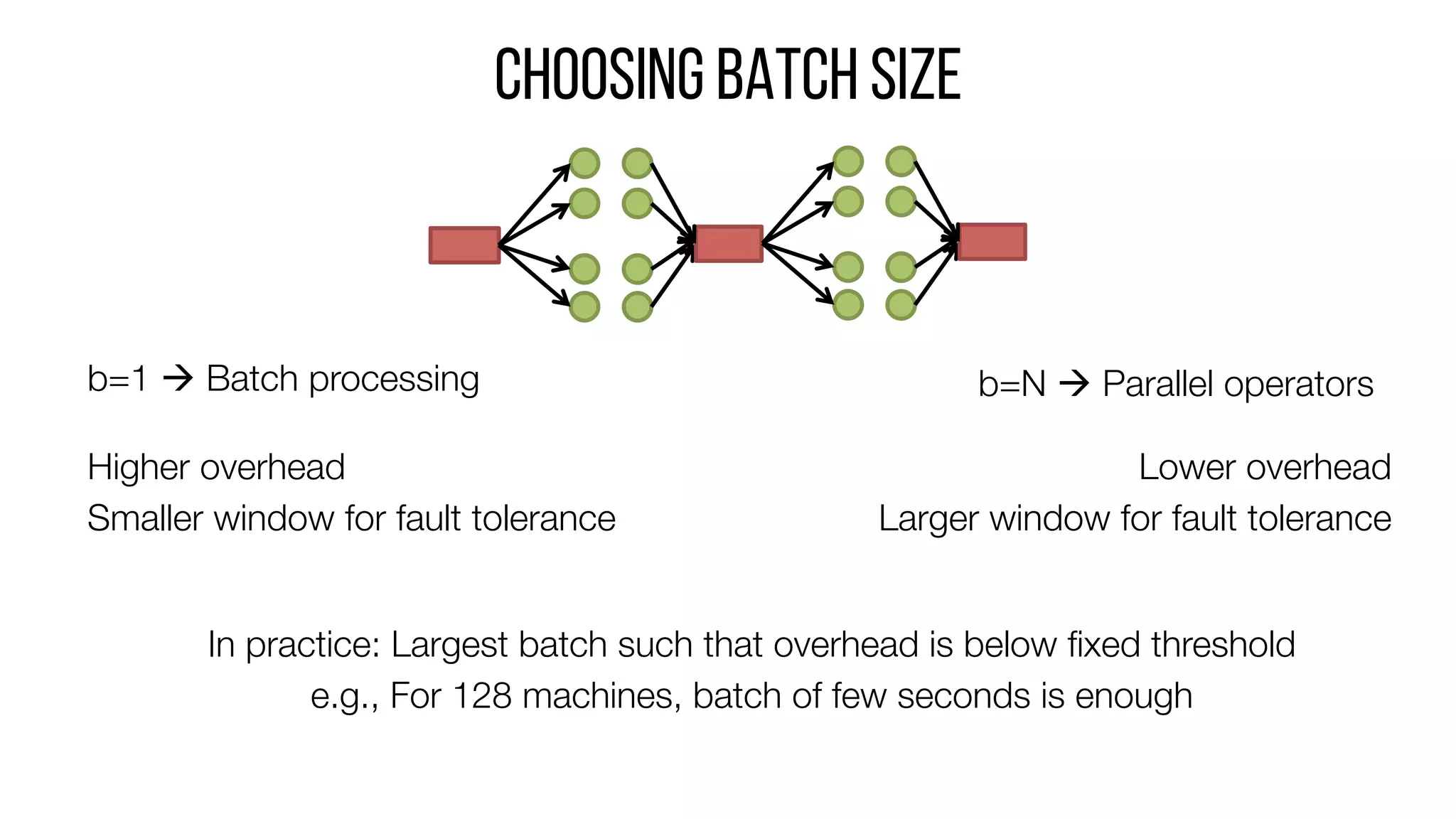
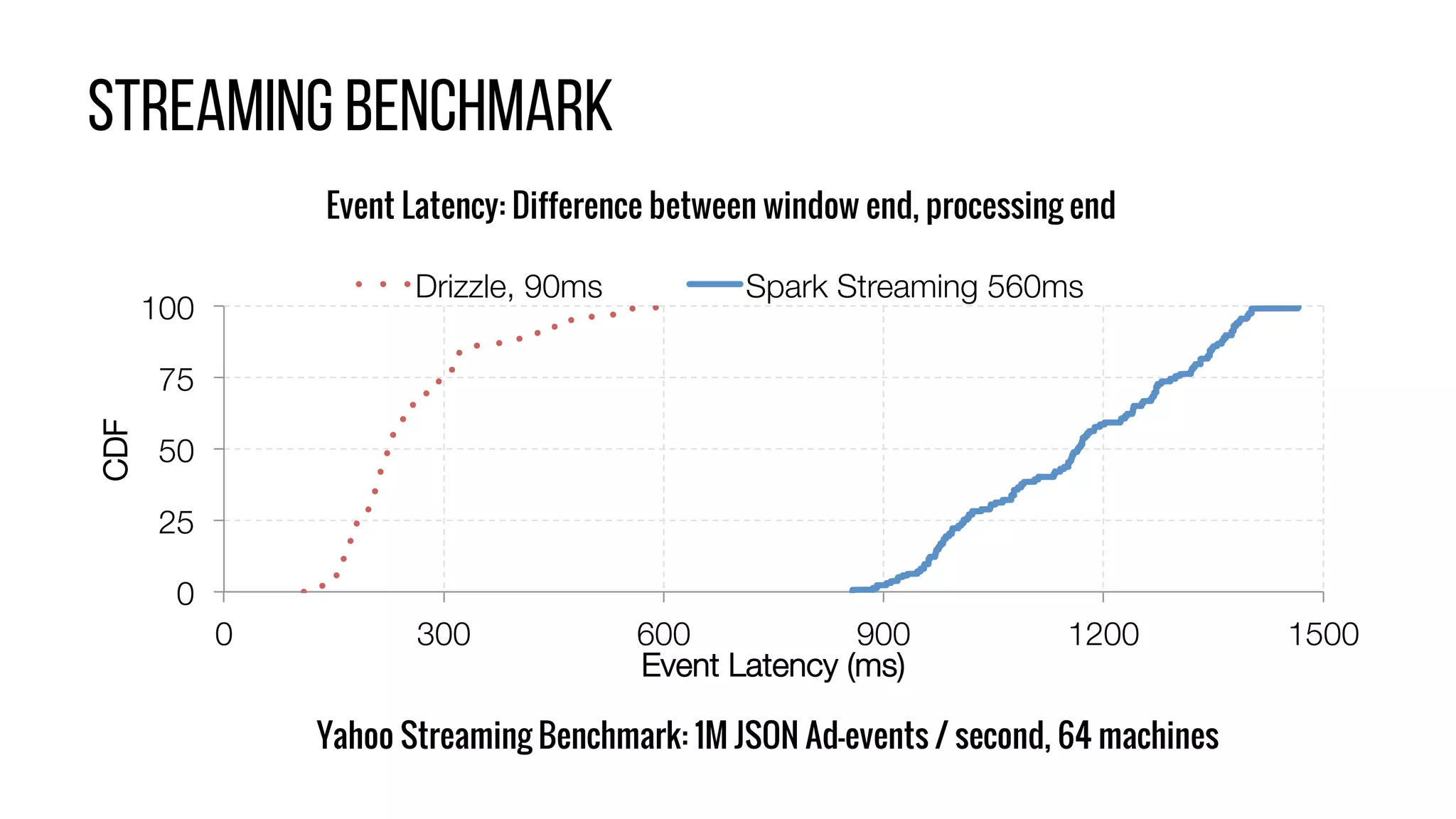
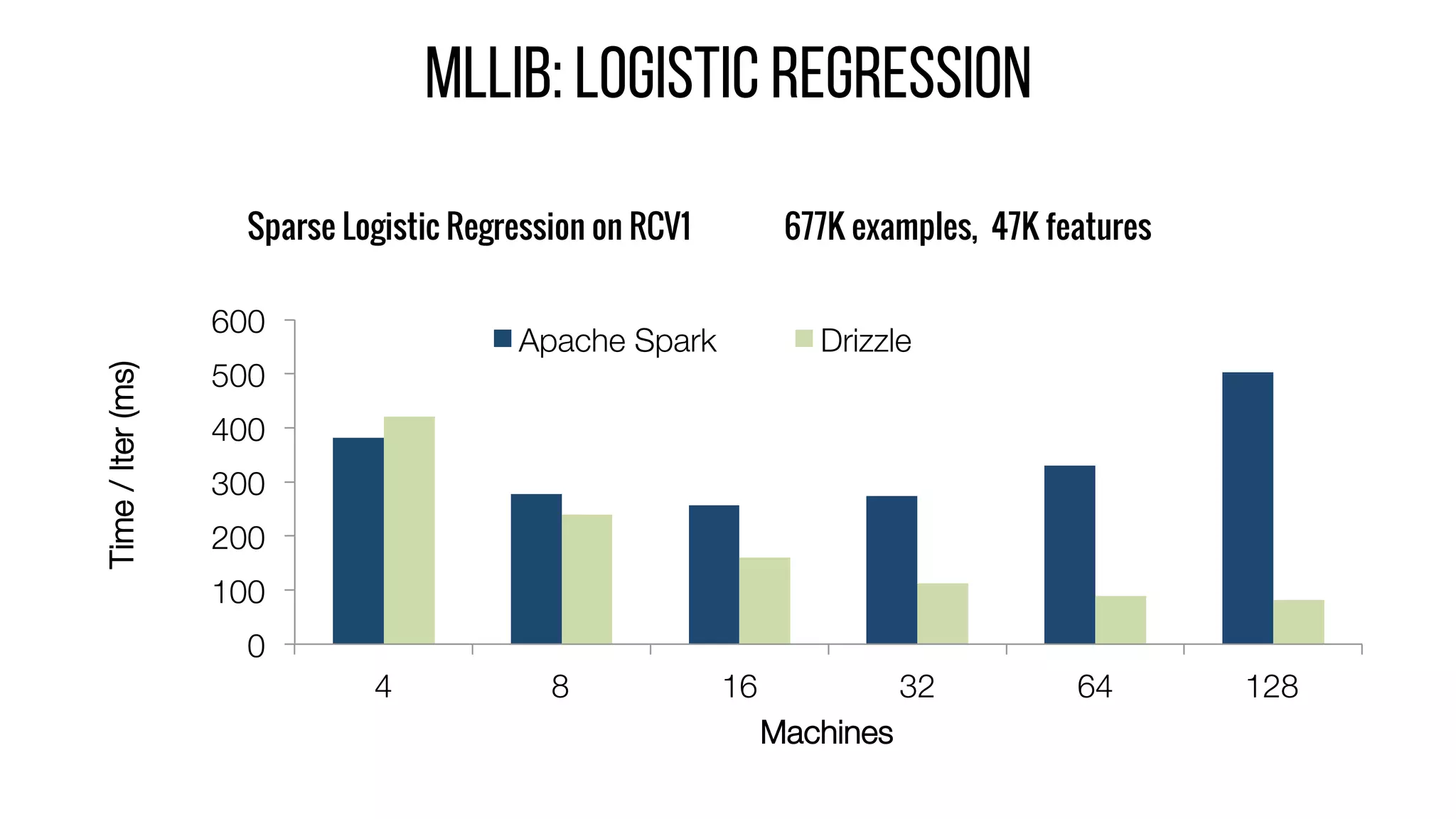
This document describes Drizzle, a low latency execution engine for Apache Spark. It addresses the high overheads of Spark's centralized scheduling model by decoupling execution from scheduling through batch scheduling and pre-scheduling of shuffles. Microbenchmarks show Drizzle achieves milliseconds latency for iterative workloads compared to hundreds of milliseconds for Spark. End-to-end experiments show Drizzle improves latency for streaming and machine learning workloads like logistic regression. The authors are working on automatic batch tuning and an open source release of Drizzle.












![USING DRIZZLE API
DAGScheduler.scala
def runJob(
rdd: RDD[T],
func: Iterator[T] => U)
Internal
def runBatchJob(
rdds: Seq[RDD[T]],
funcs: Seq[Iterator[T] => U])](https://image.slidesharecdn.com/1ppandavendataraman-160614191233/85/Low-Latency-Execution-For-Apache-Spark-28-320.jpg)














![USING DRIZZLE API
DAGScheduler.scala
def runJob(
rdd: RDD[T],
func: Iterator[T] => U)
Internal
def runBatchJob(
rdds: Seq[RDD[T]],
funcs: Seq[Iterator[T] => U])](https://image.slidesharecdn.com/1ppandavendataraman-160614191233/75/Low-Latency-Execution-For-Apache-Spark-28-2048.jpg)















































































![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)








