














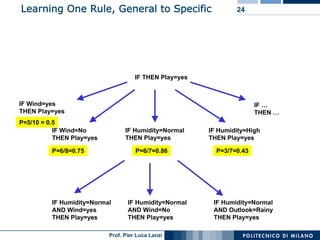
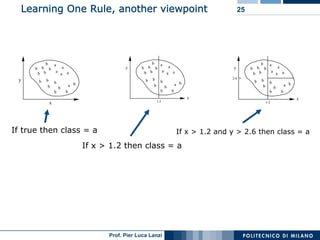
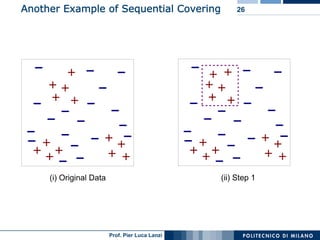
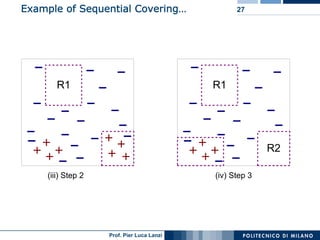























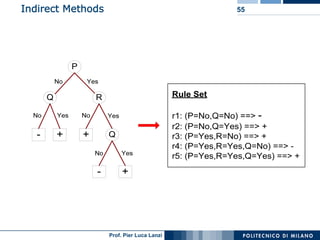


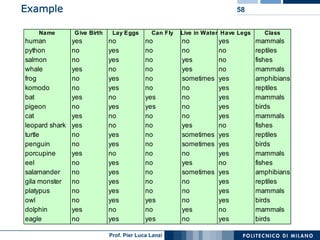
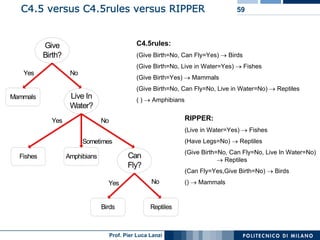
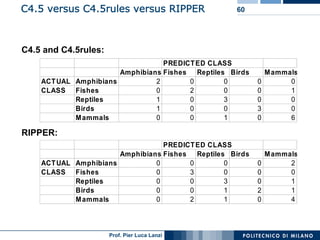




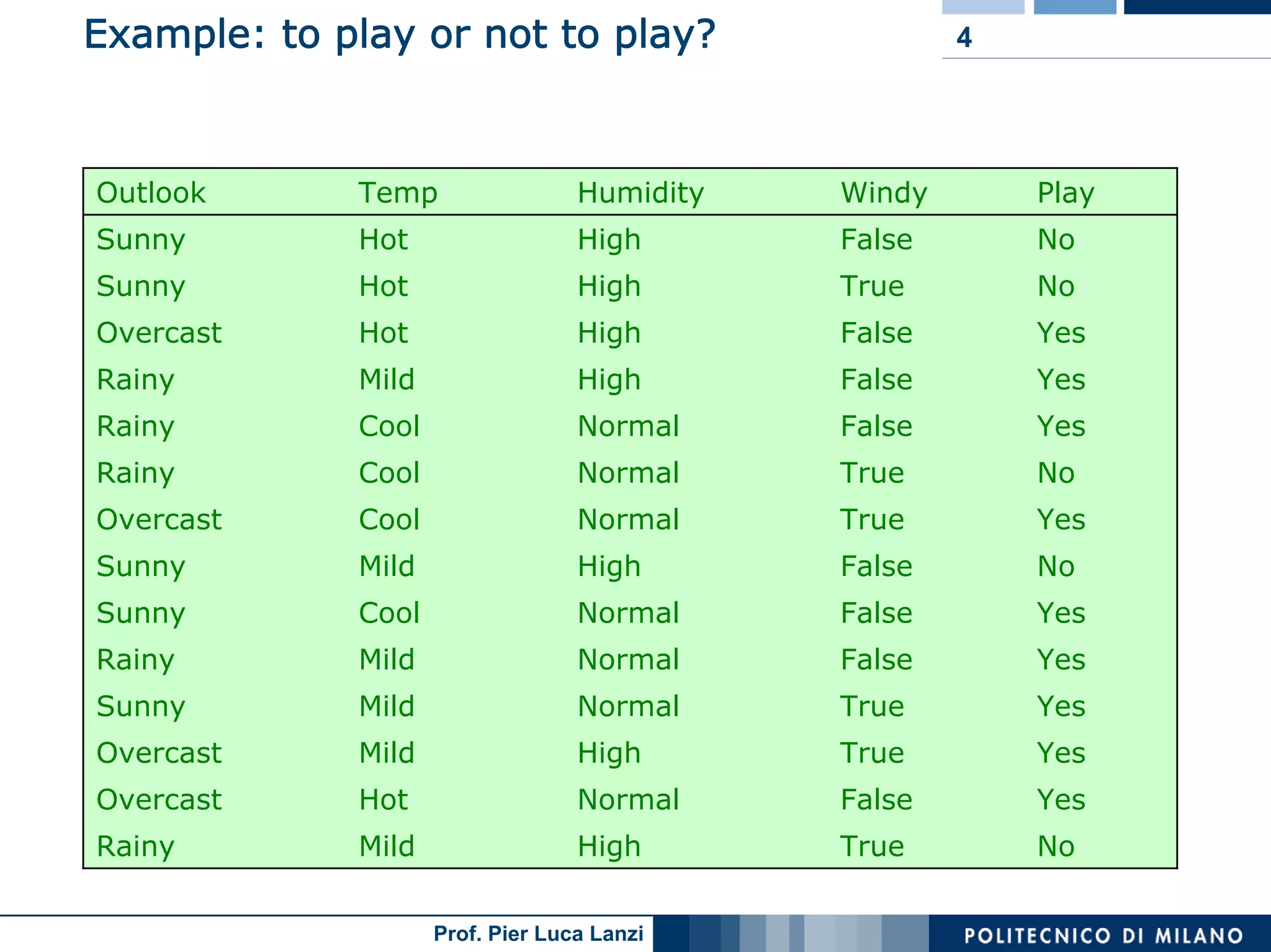

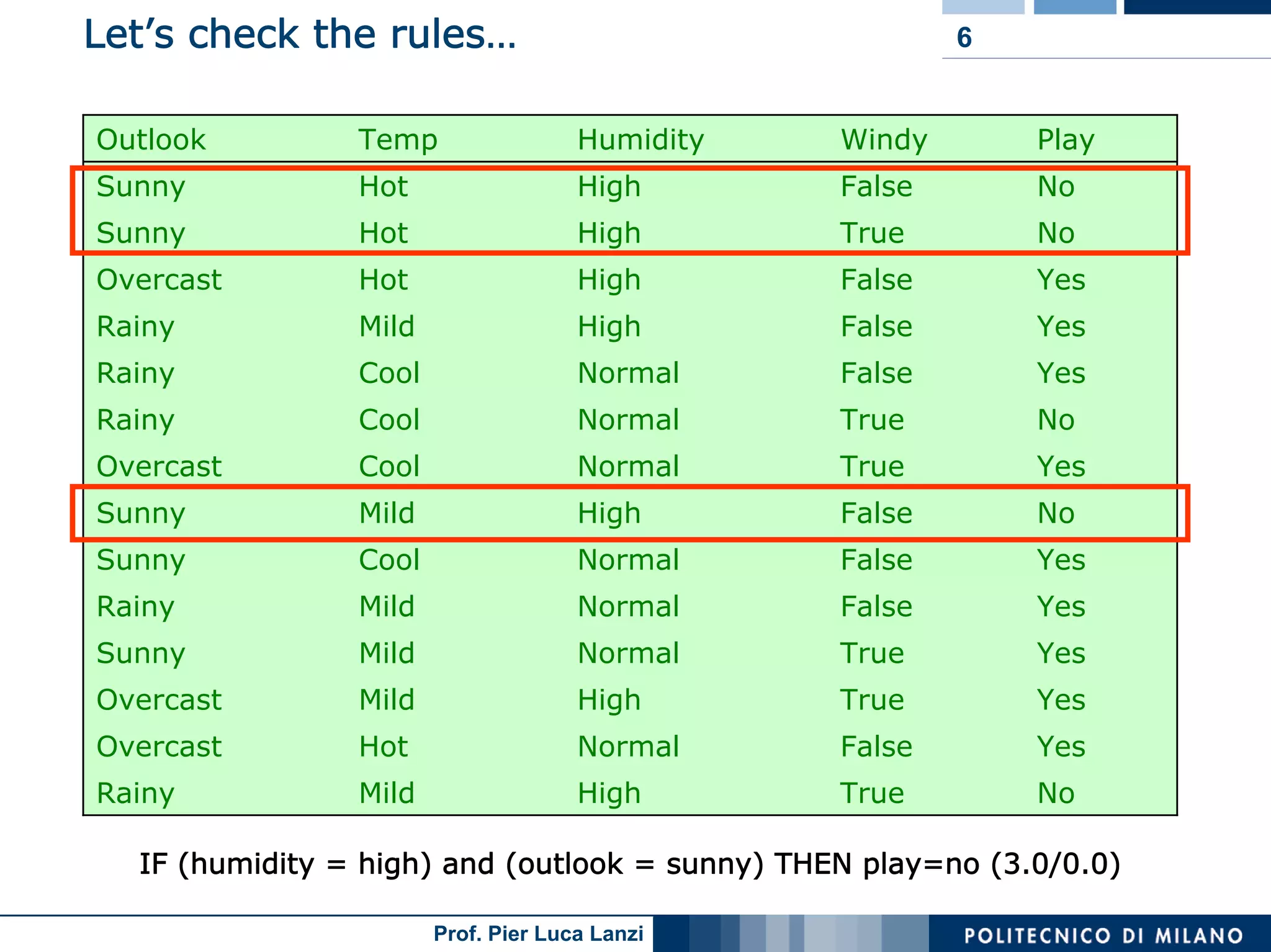
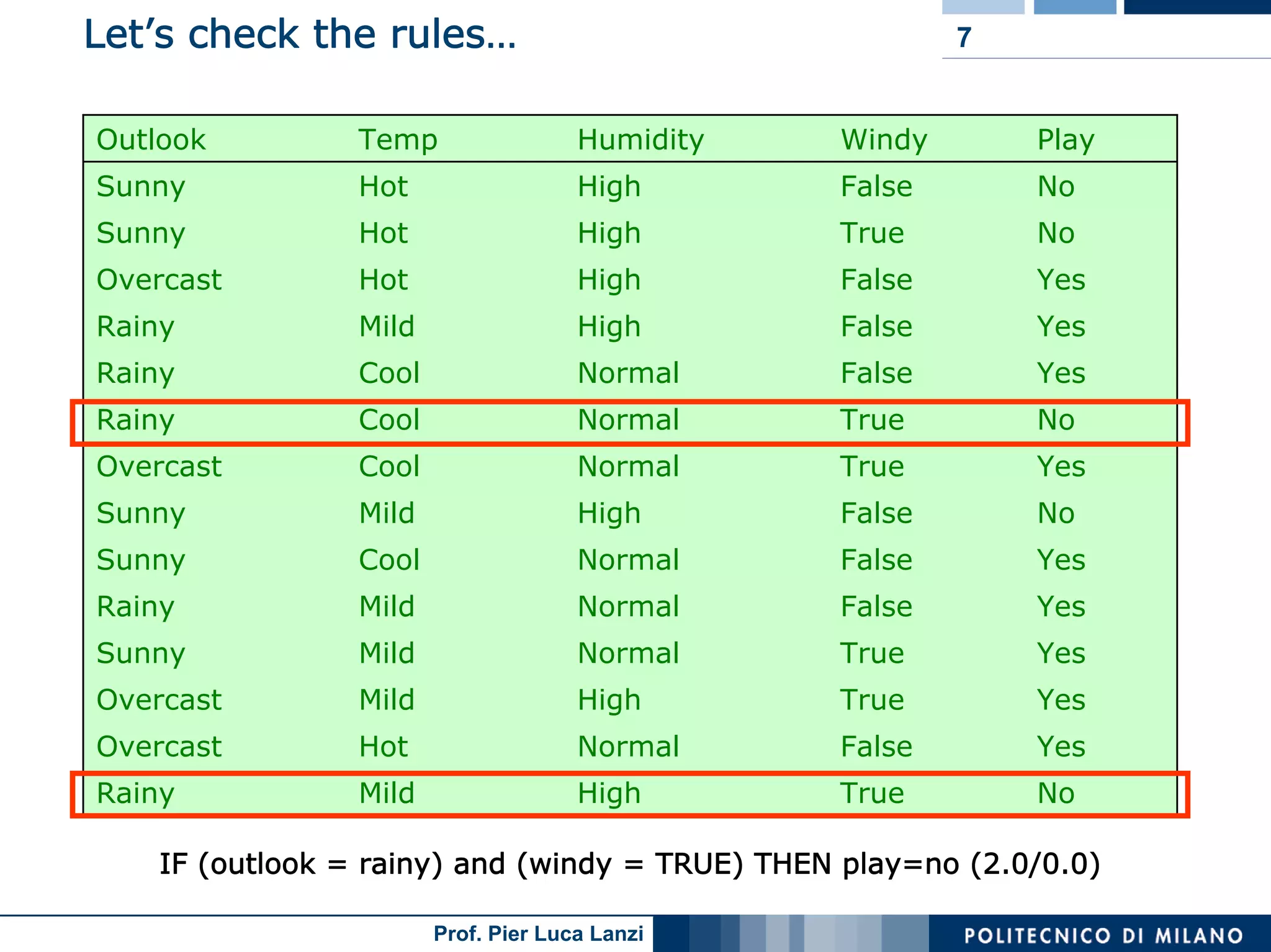
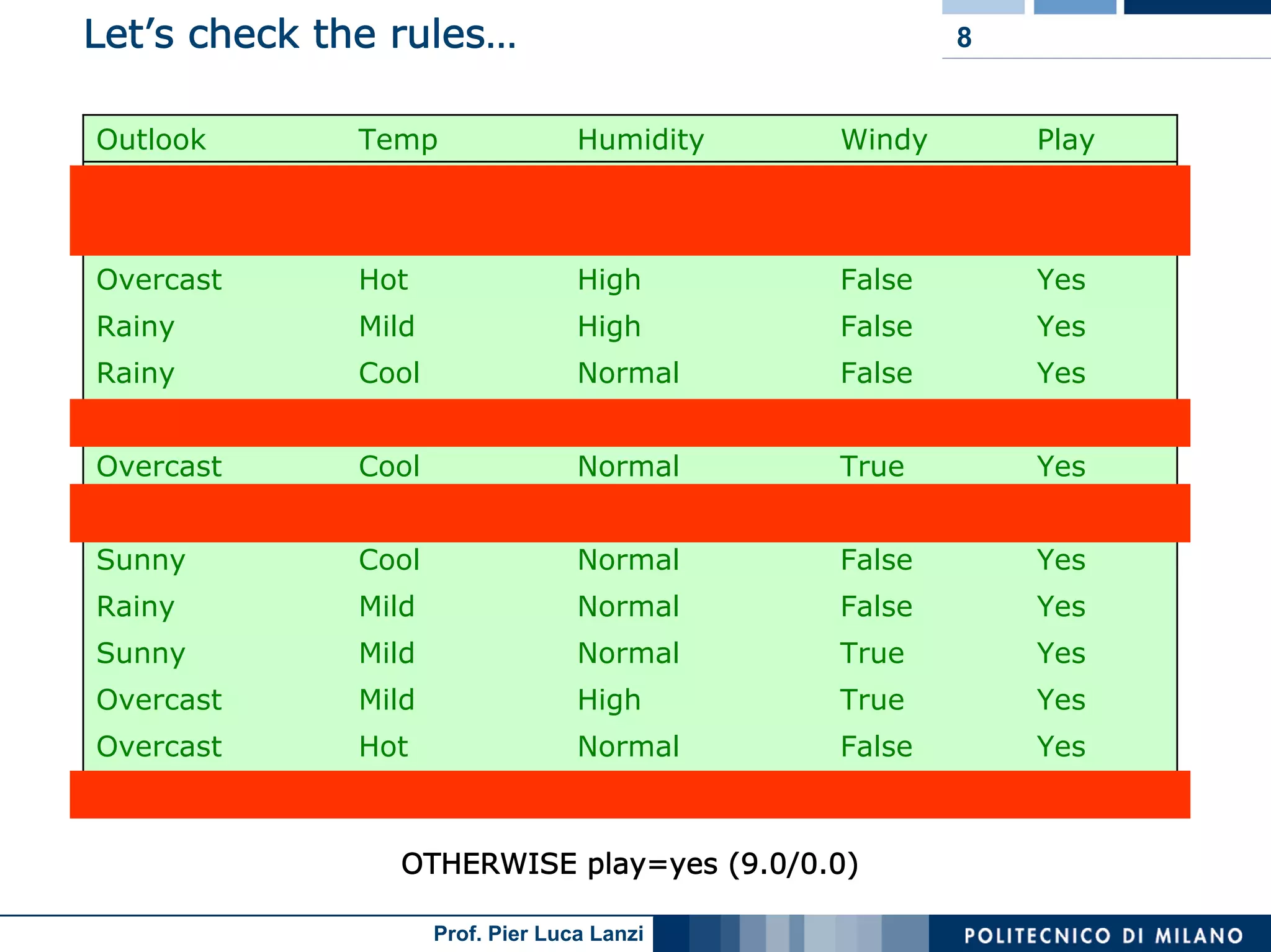








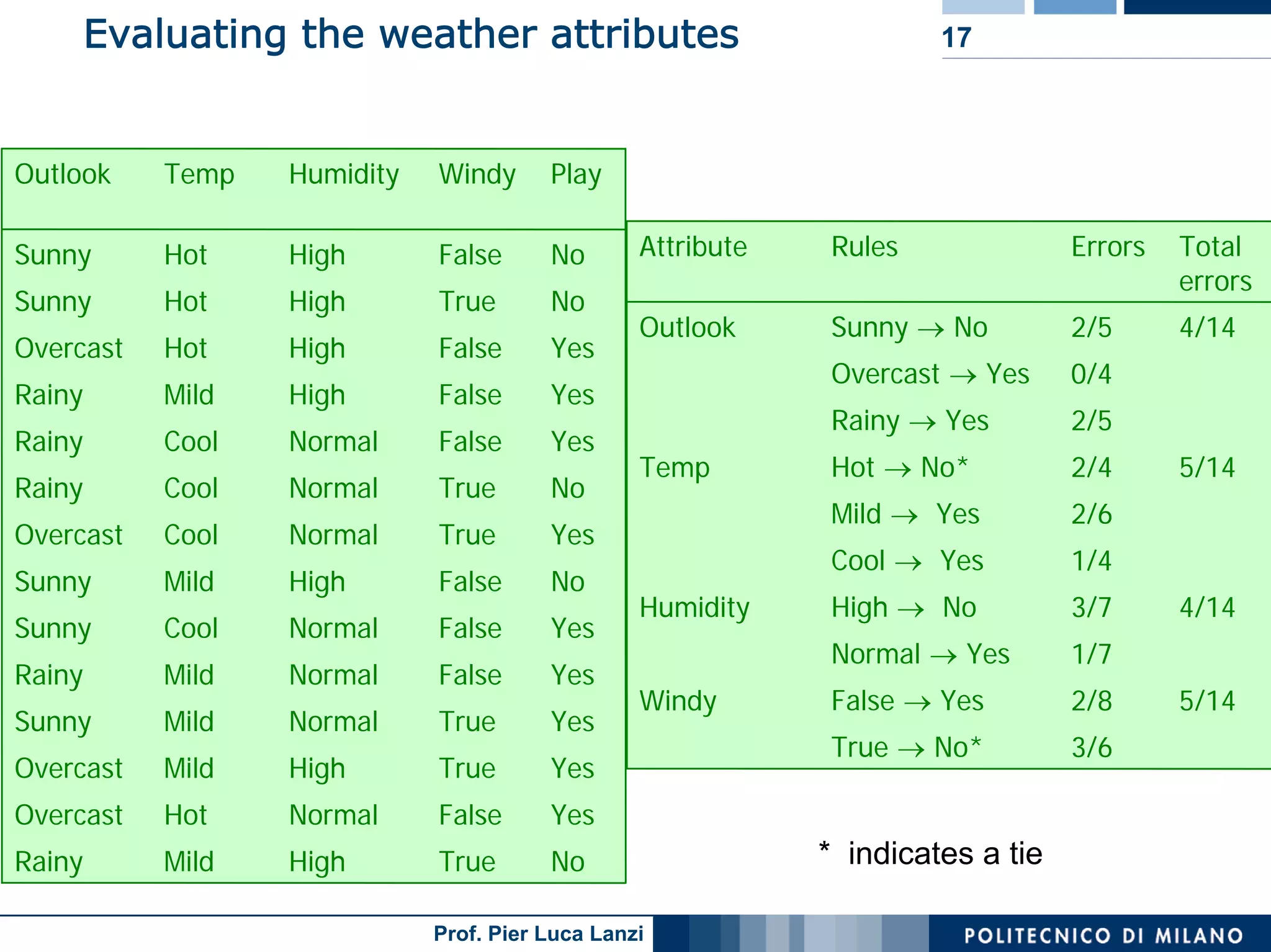
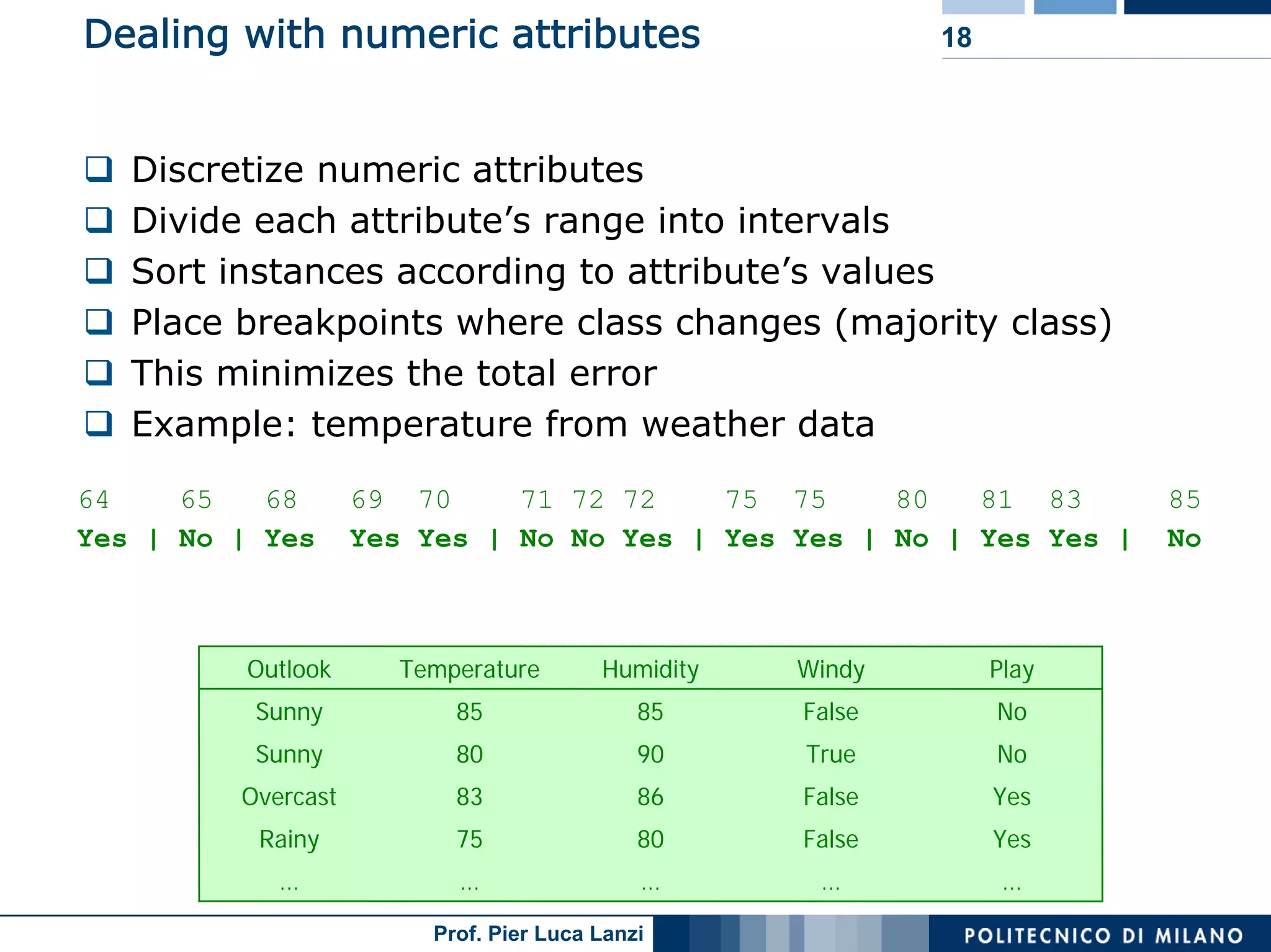

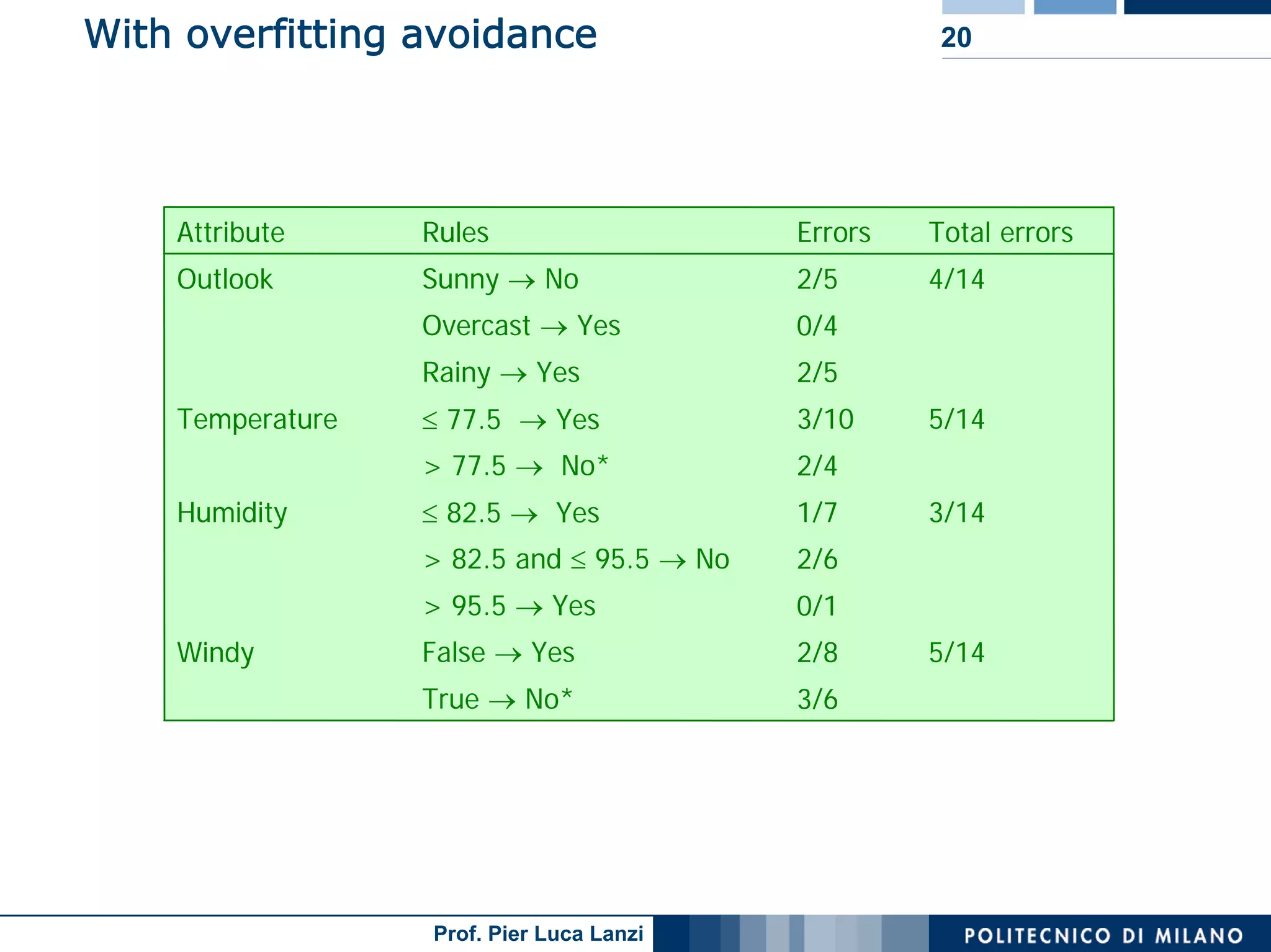



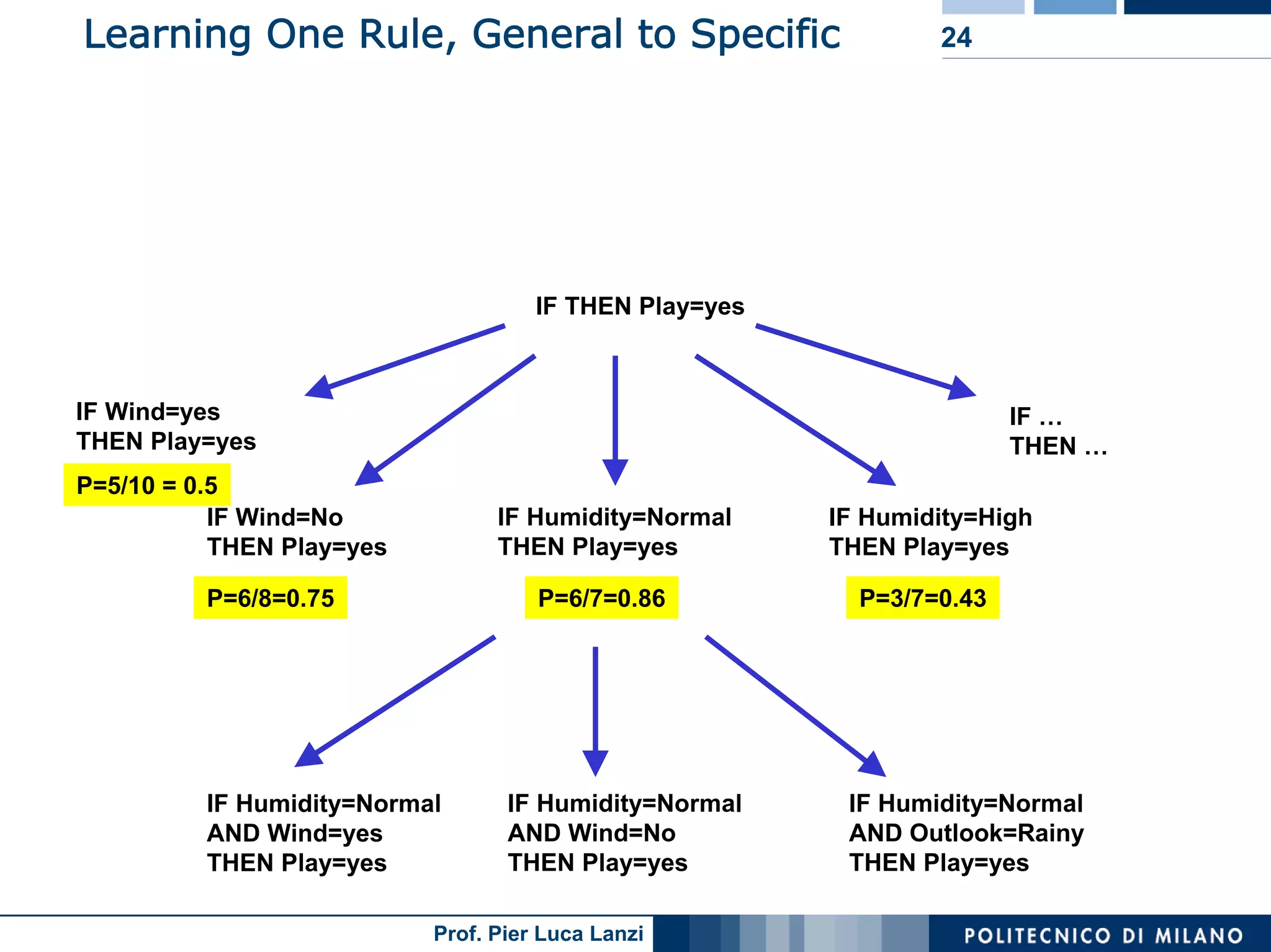
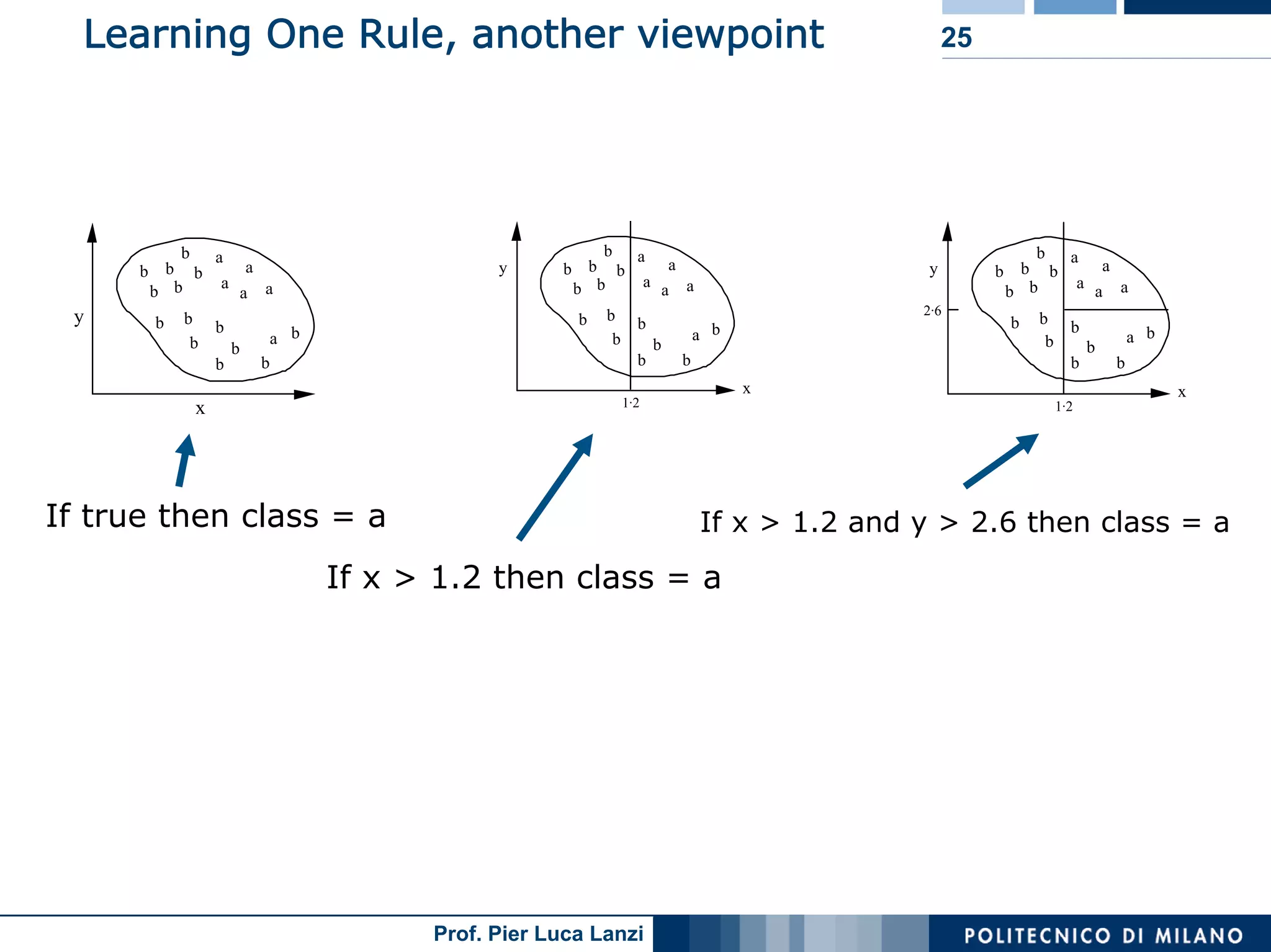
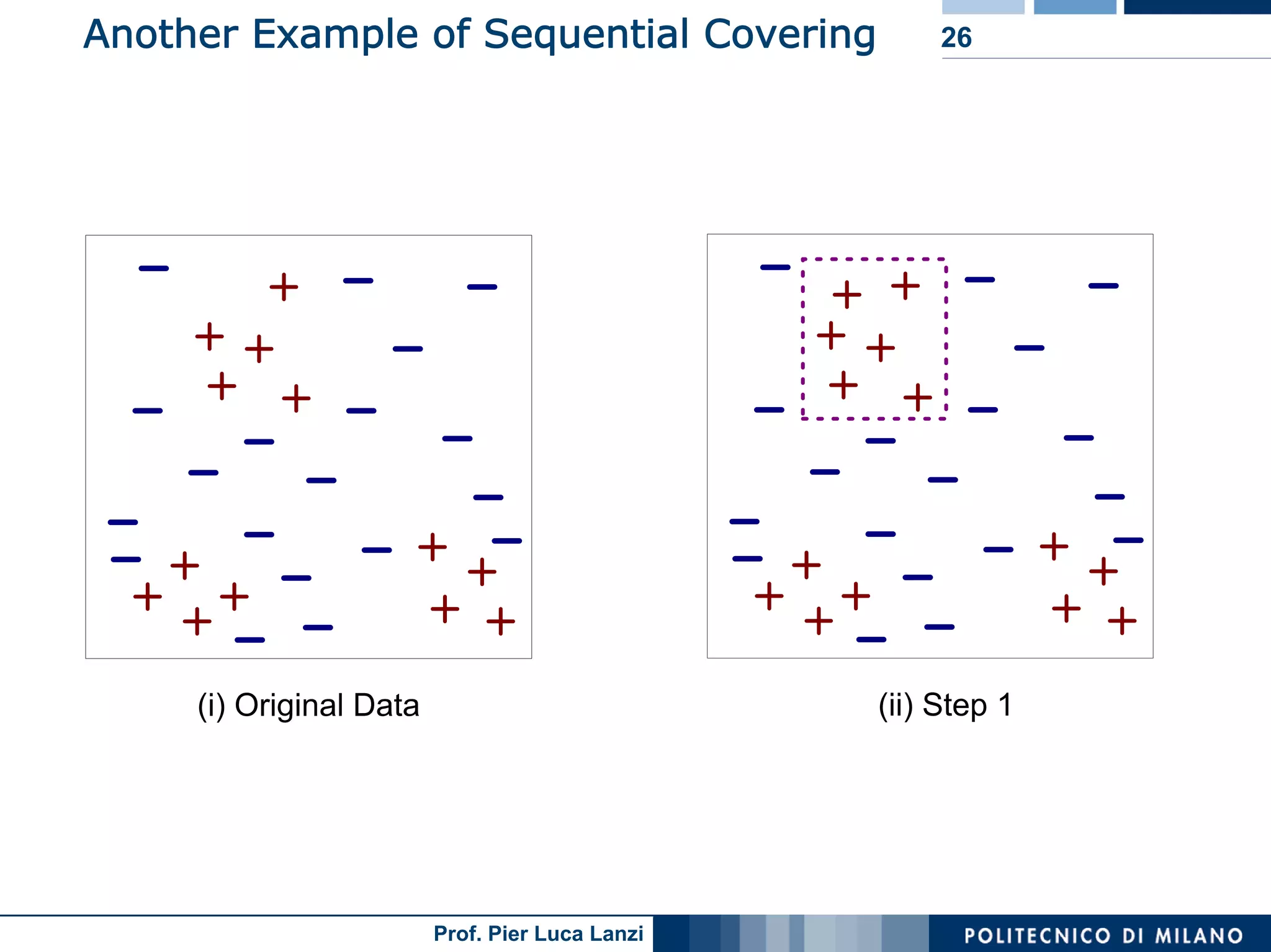
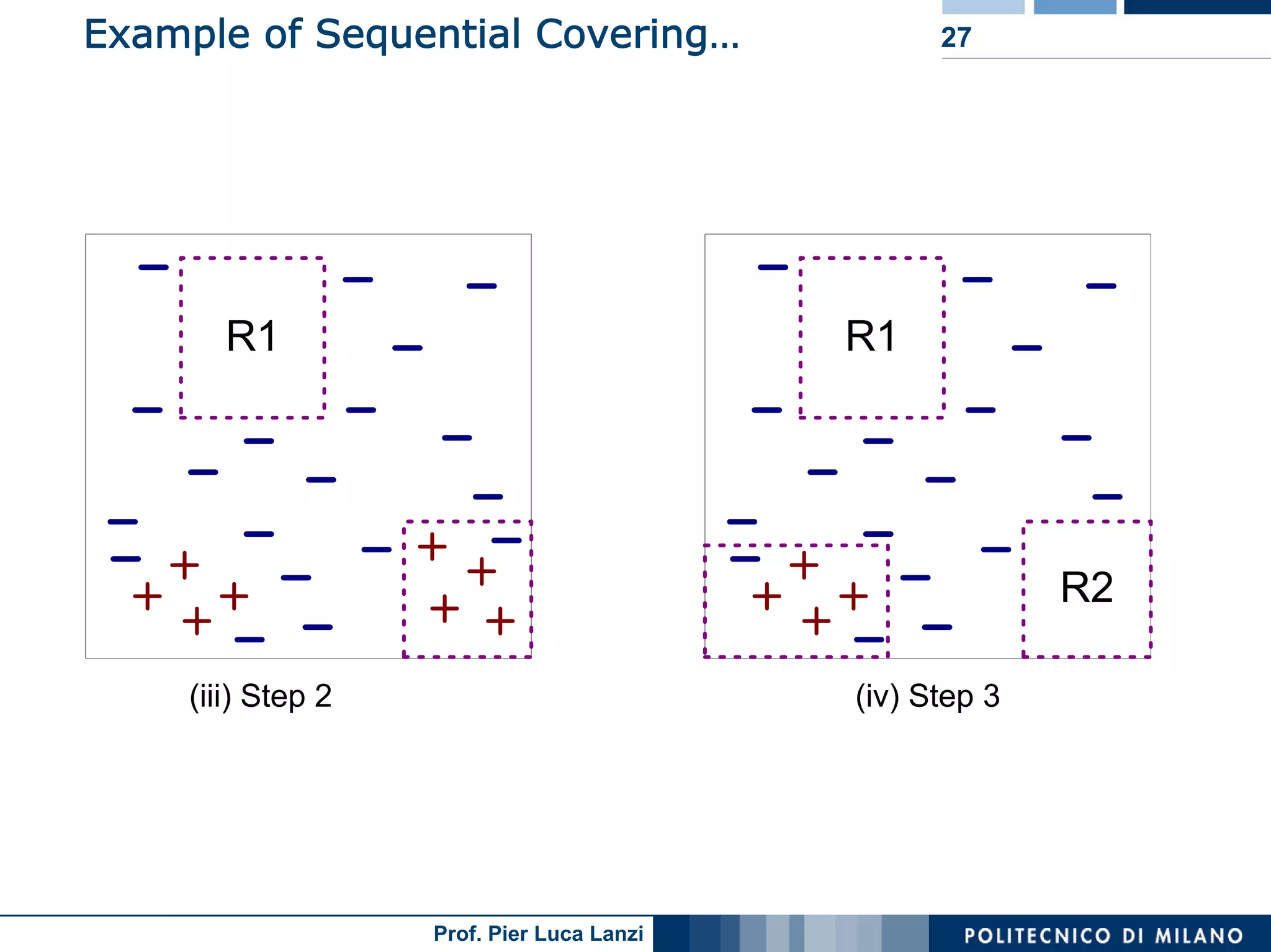


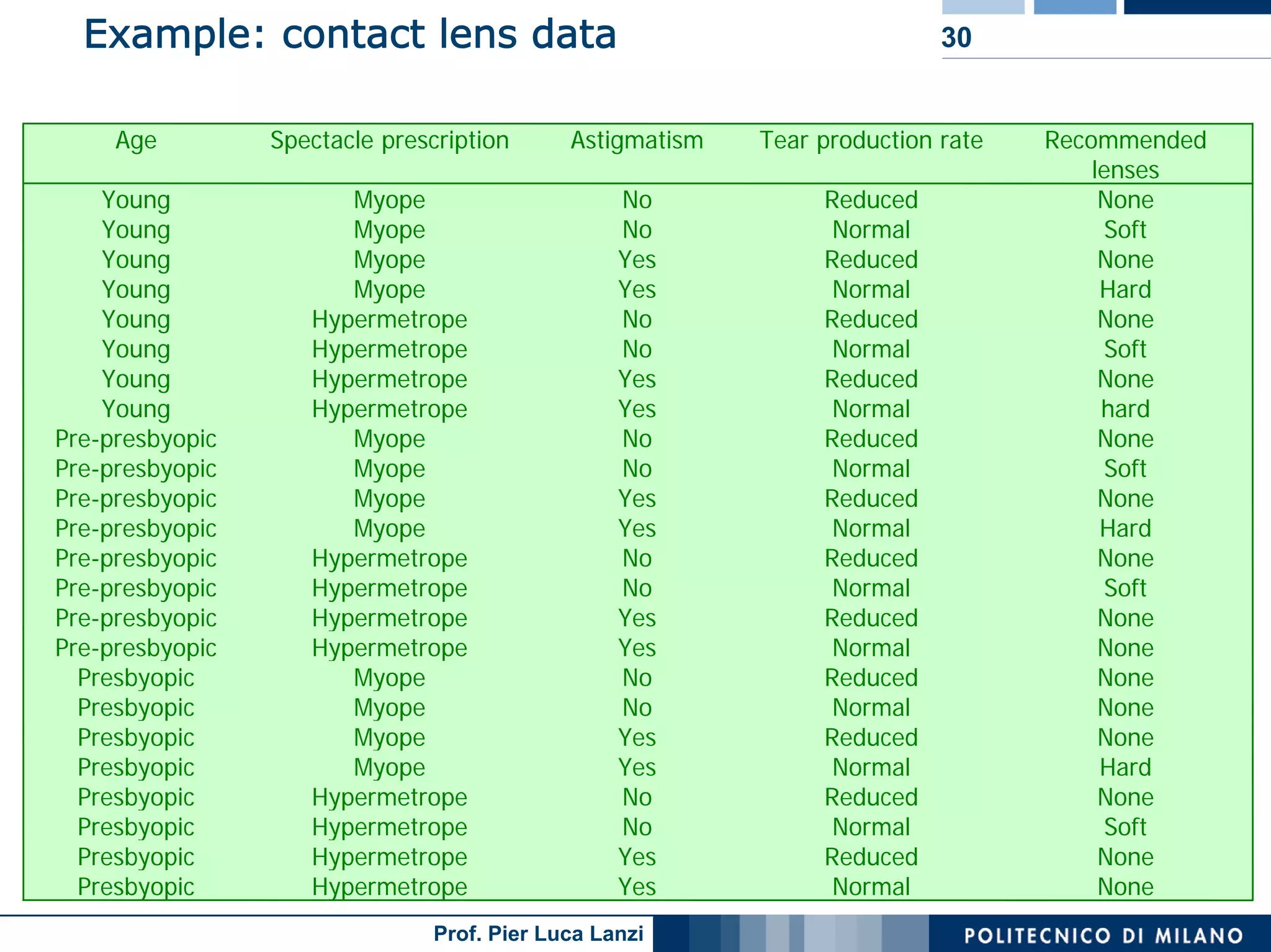
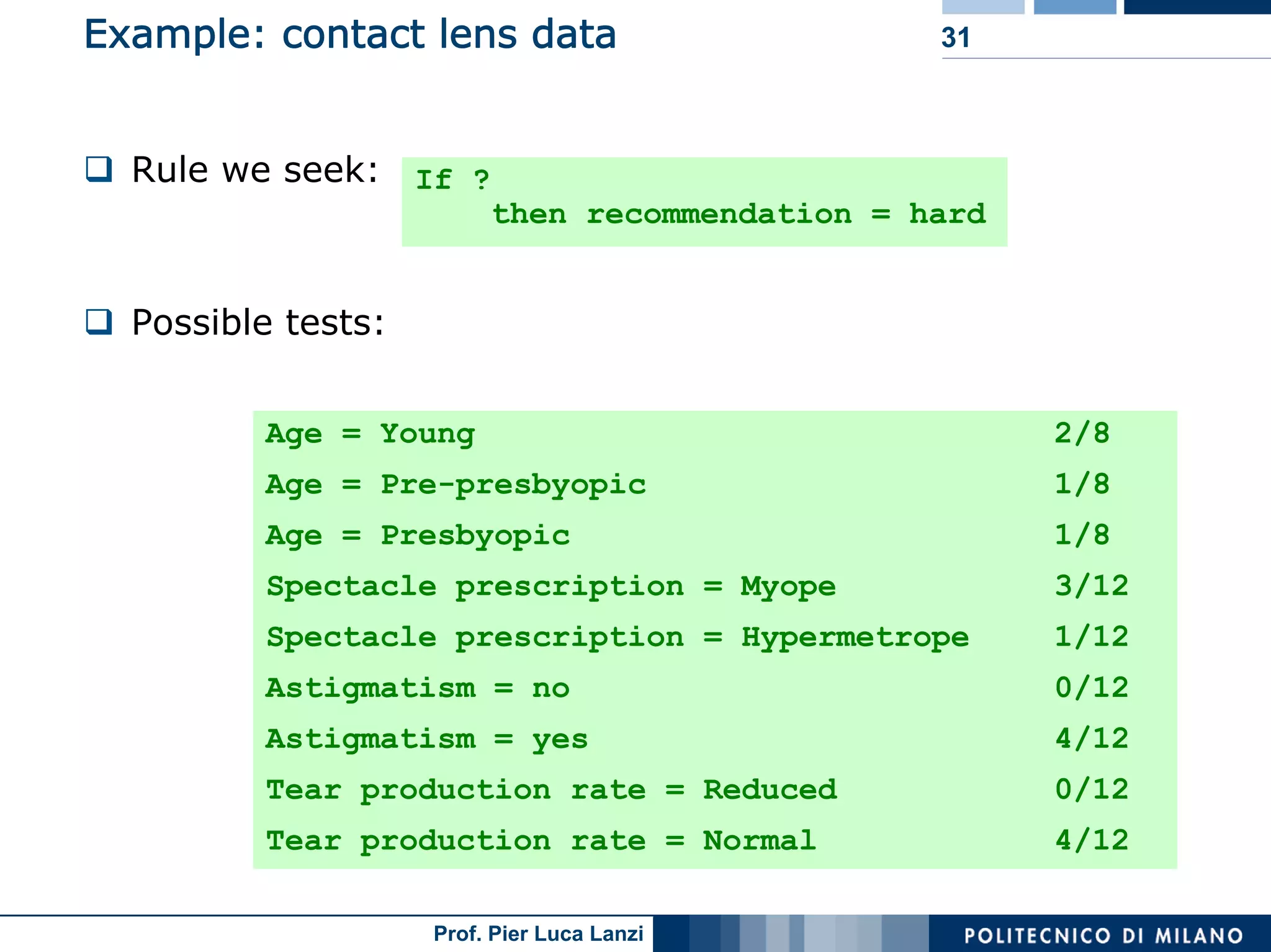
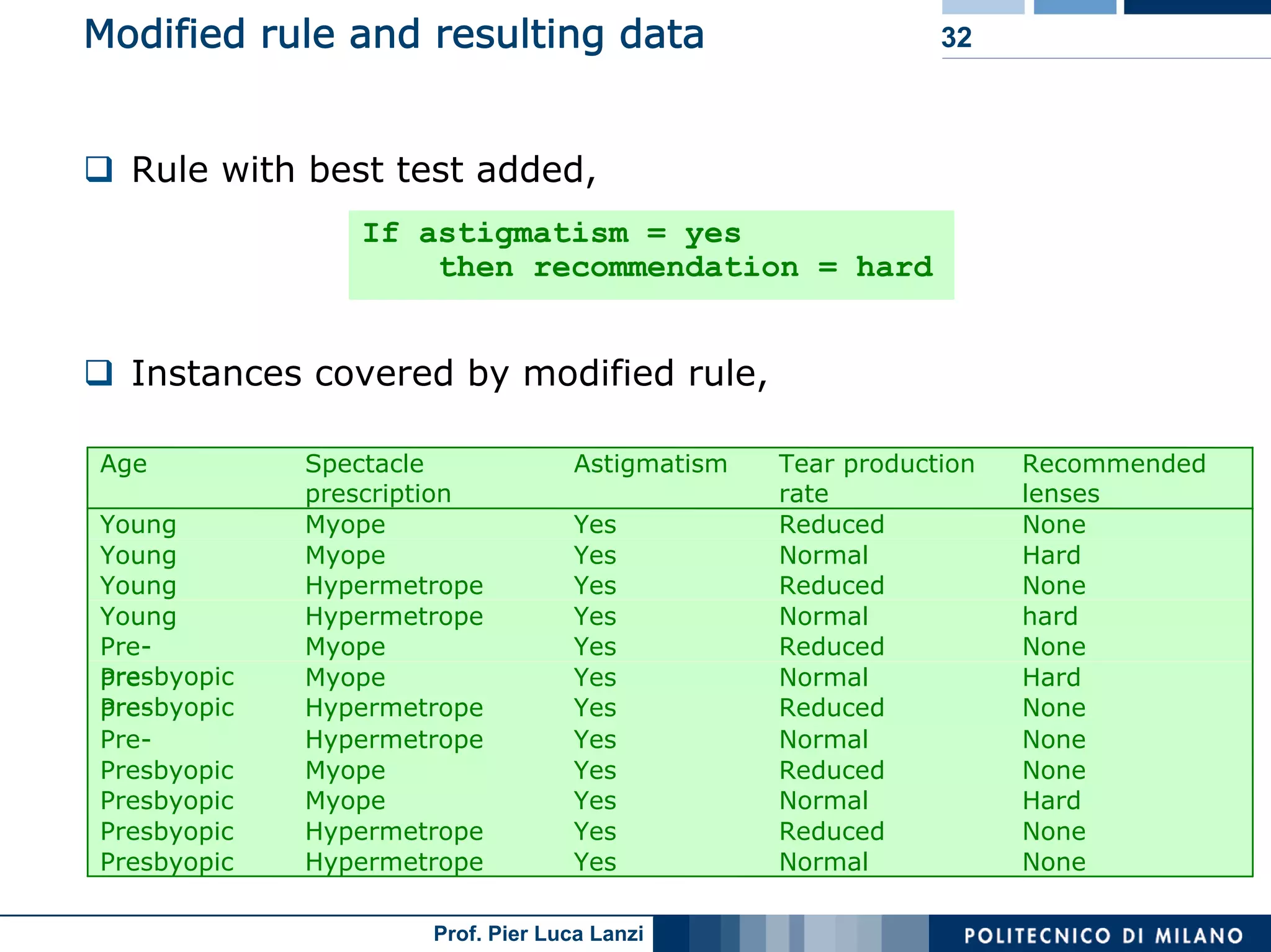

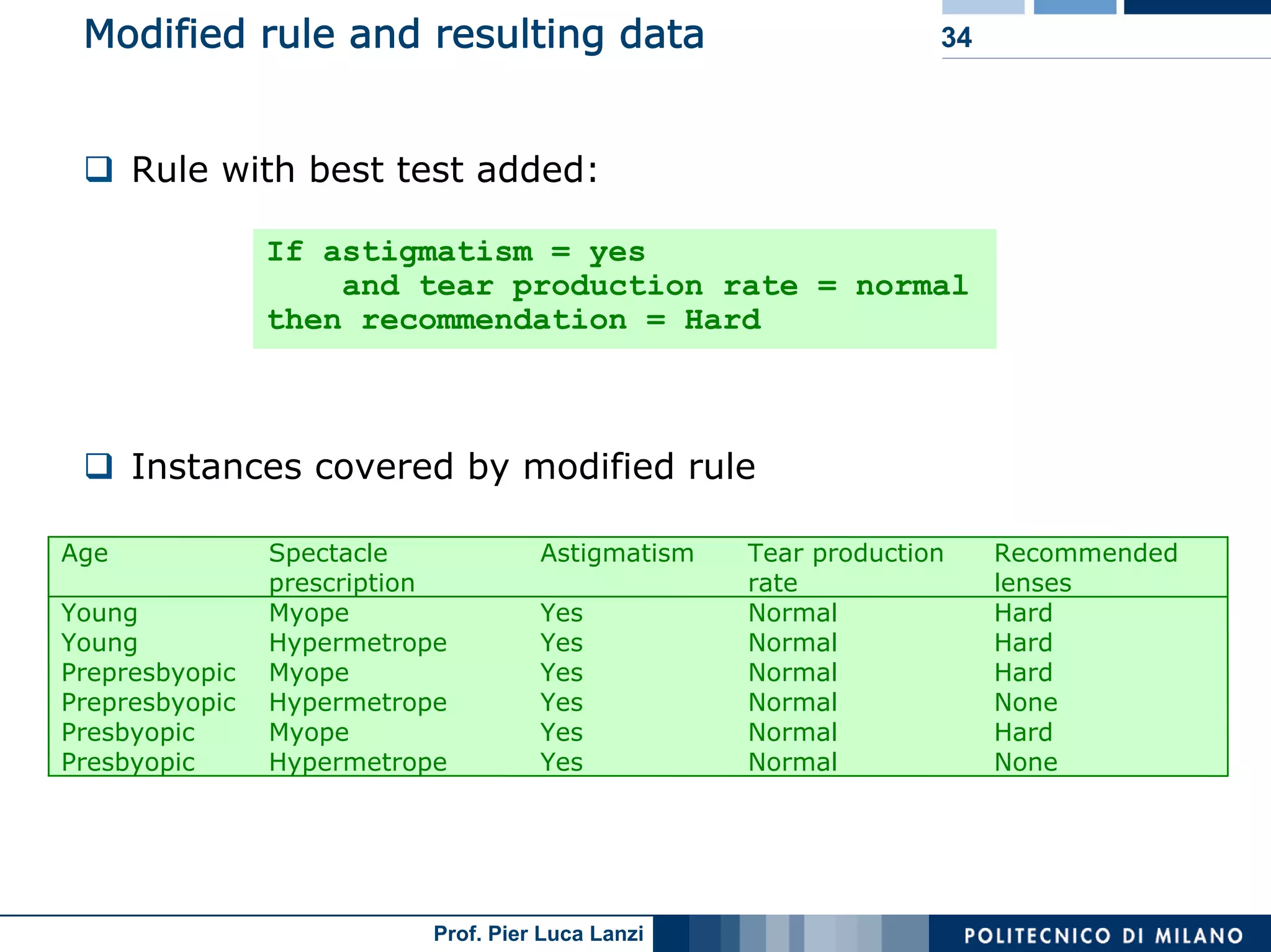


















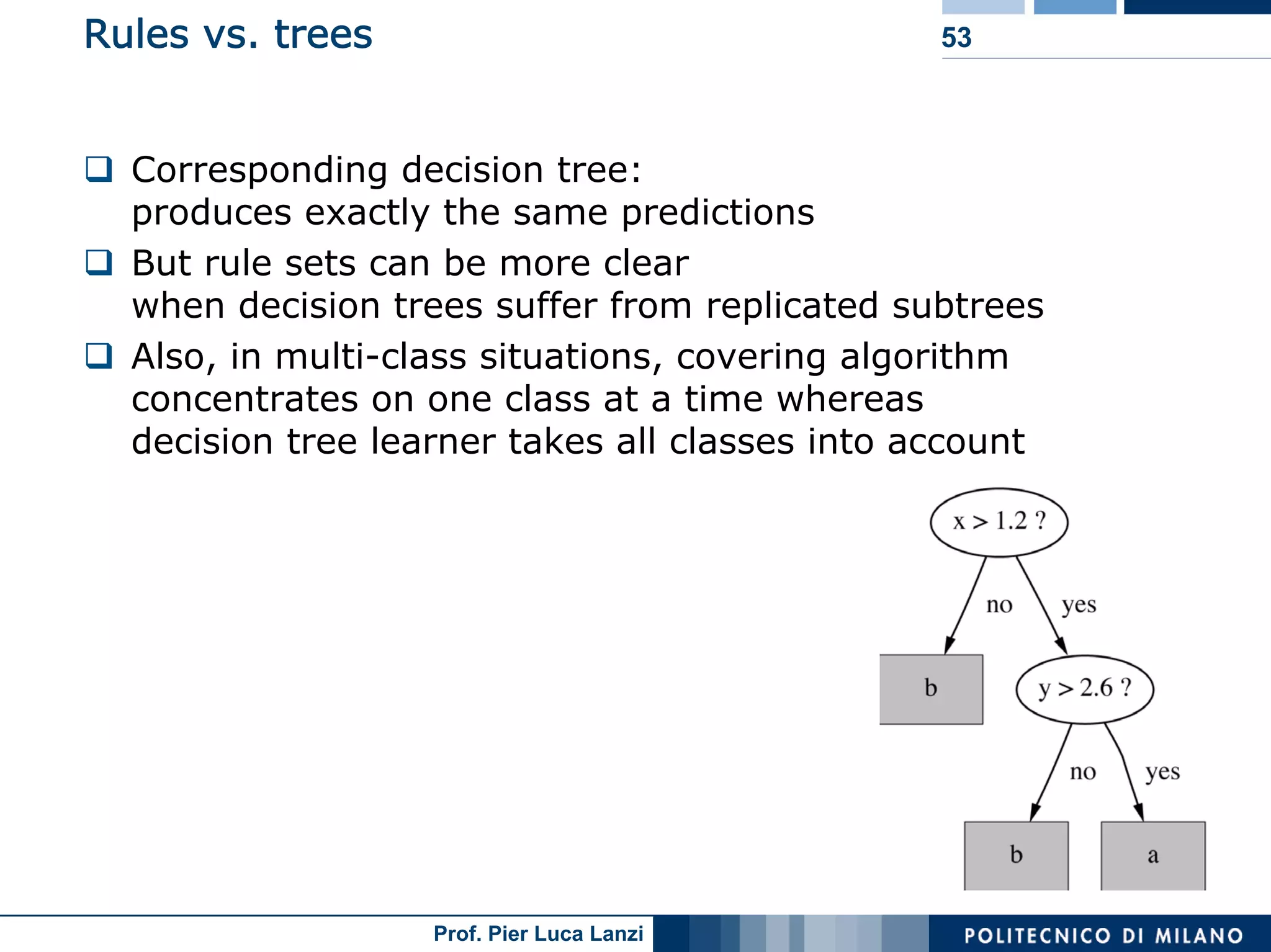

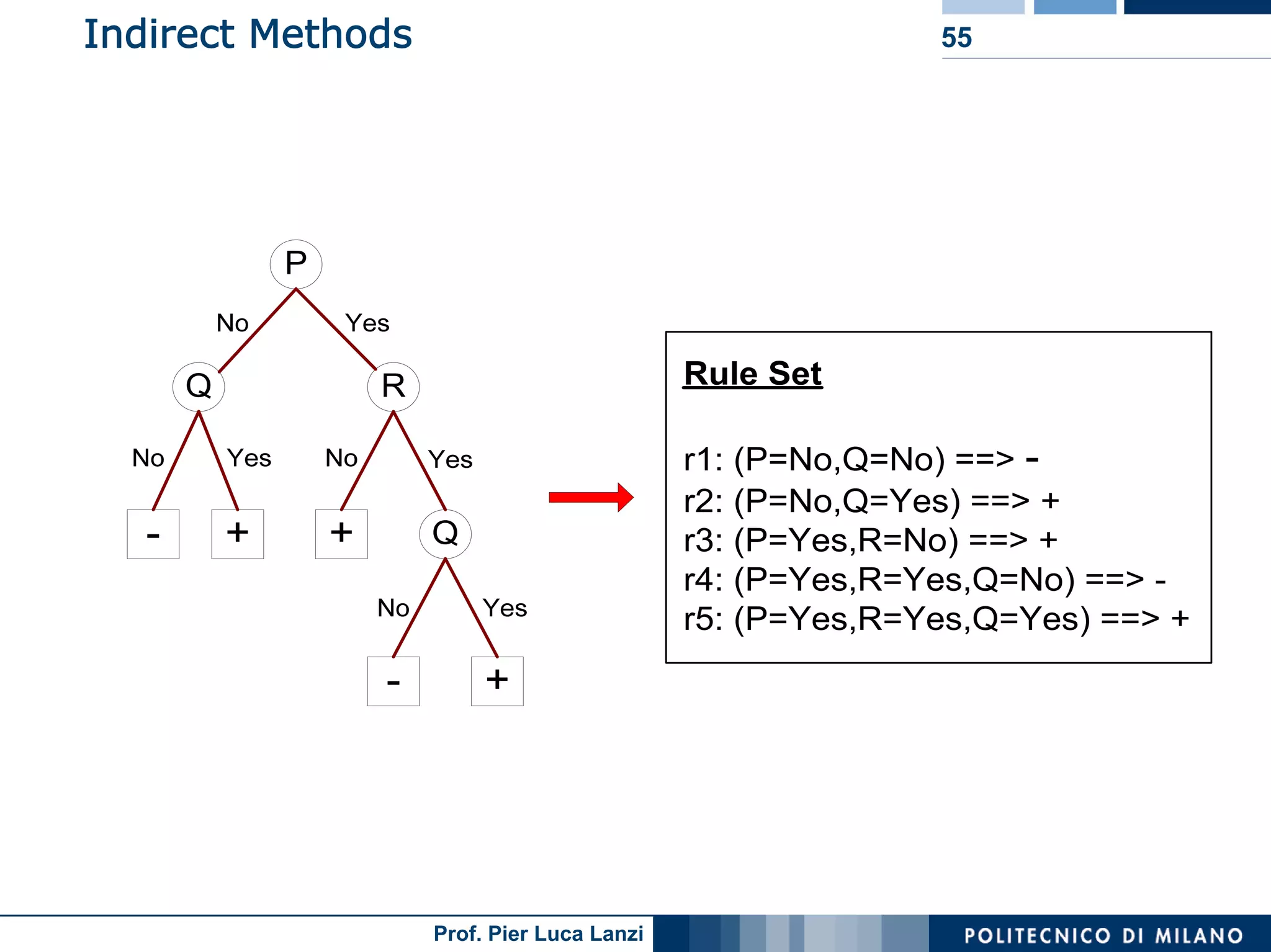


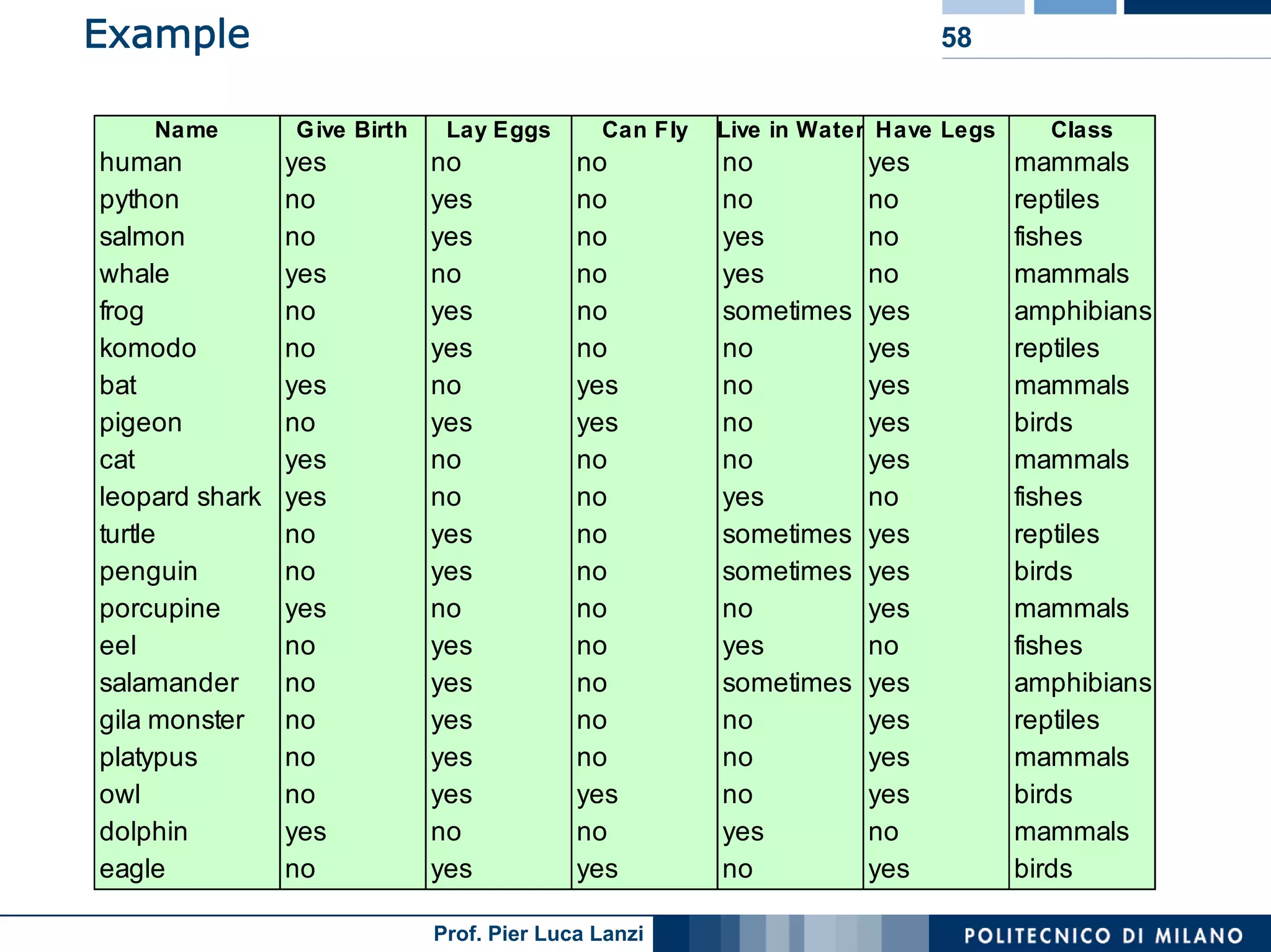
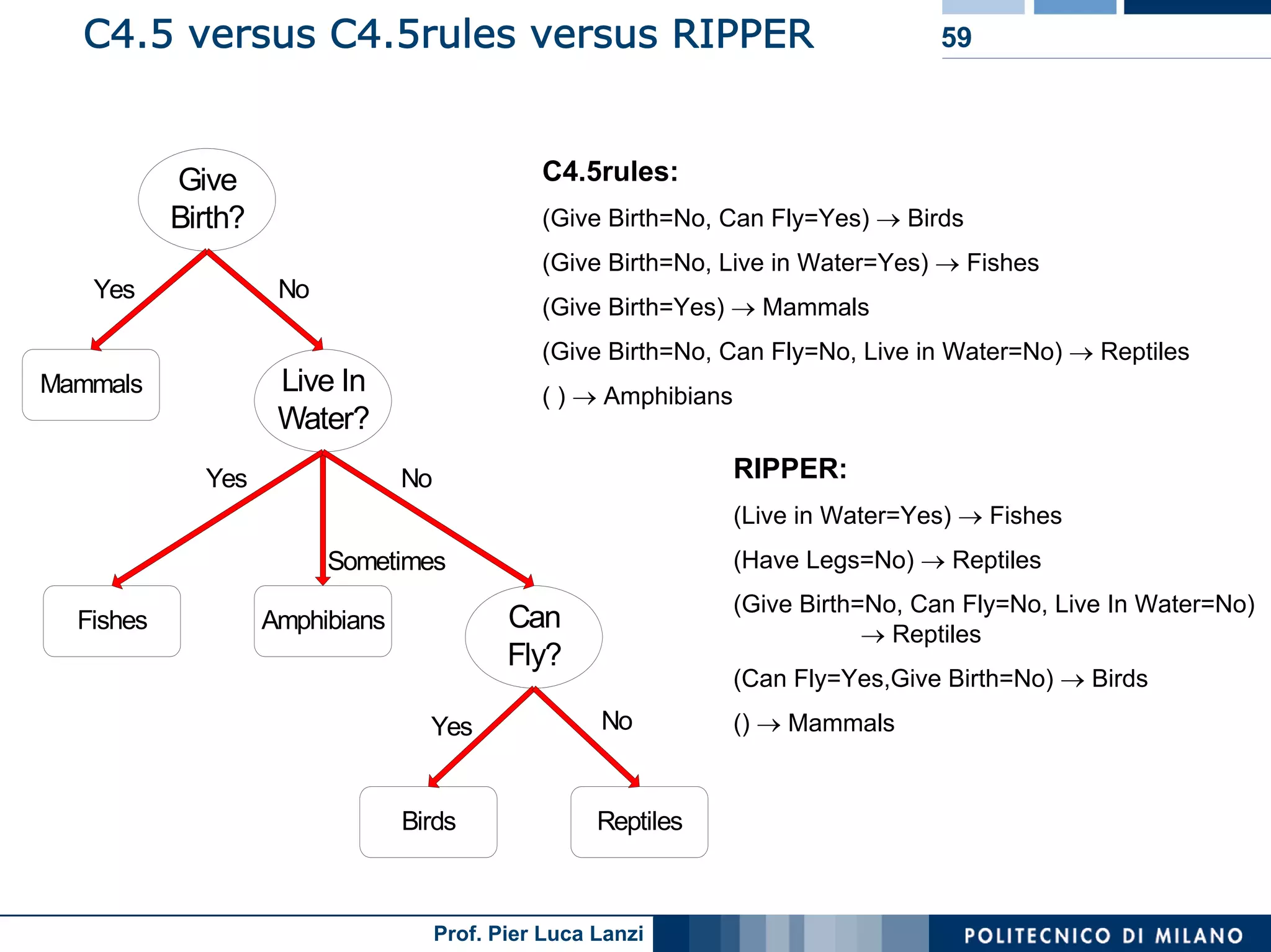
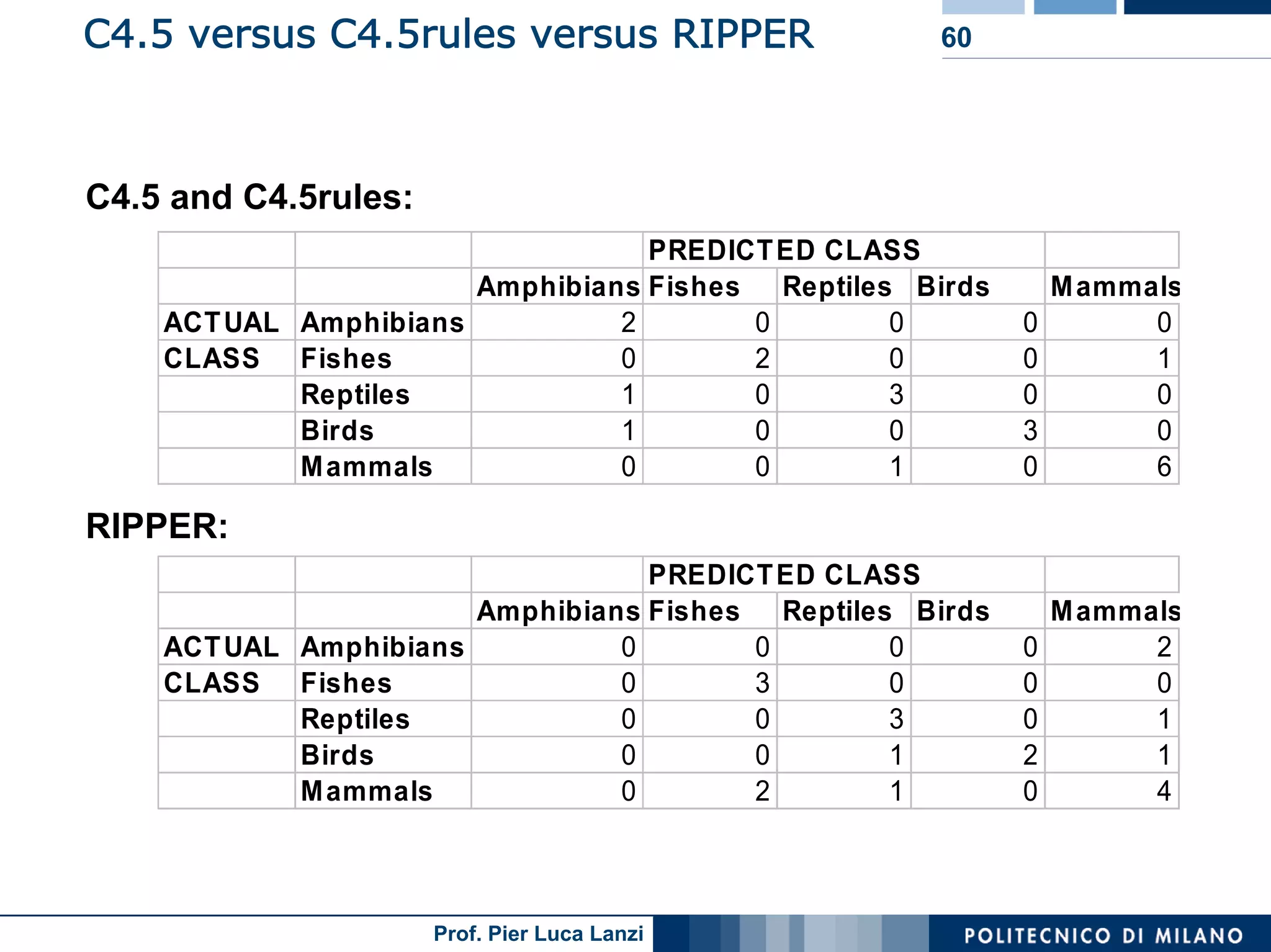


The document outlines classification rules in machine learning and data mining, providing methods and examples of rule formation, such as the OneRule algorithm and sequential covering algorithms. It discusses the importance of if-then rules for classification, how to evaluate their performance using coverage and accuracy, and various approaches for rule learning, including direct and indirect methods. Challenges like overfitting and noise sensitivity in attribute assessment are addressed, alongside practical applications such as weather data and contact lens recommendations.



































![Big Data [sorry] & Data Science: What Does a Data Scientist Do?](https://cdn.slidesharecdn.com/ss_thumbnails/dslatcloudmsevent20130125-130126065651-phpapp01-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




























































