This document provides an overview of machine learning using support vector machines (SVM). It first defines machine learning as a field that allows computers to learn without explicit programming. It then describes the main types of machine learning: supervised learning using labelled training data, unsupervised learning to find hidden patterns in unlabelled data, and reinforcement learning to maximize rewards. SVM is introduced as a classification algorithm that finds the optimal separating hyperplane between classes with the largest margin. Kernels are discussed as functions that enable SVMs to operate in high-dimensional implicit feature spaces without explicitly computing coordinates.
What is MachineLearning?
• Machine learning is the subfield of computer science that “gives computers the ability
to learn without being explicitly programmed”.
• Tom M. Mitchell provided a widely quoted, more formal definition: “A computer
program is said to learn from experience E with respect to some class of tasks T and
performance measure P if its performance at tasks in T, as measured by P, improves
with experience E.”
3.
Types of MachineLearning
• Supervised Learning
Inferring a function from labelled training data. A supervised learning algorithm
analyses the training data (a list of input and their correct output) and produces
an appropriate function, which can be used for mapping new examples.
• Unsupervised Learning
Inferring a function to describe hidden structure from unlabelled data. No labels
are given to the learning algorithm, leaving it on its own to find structure in its
input.
• Reinforcement Learning
Concerned with how software agents ought to take actions in an environment so
as to maximize some notion of cumulative reward.
4.
Types of SupervisedLearning
• Regression
In a regression problem, we are trying to predict results within a continuous
output, meaning that we are trying to map input variables to some continuous
function. For example, predicting housing prices where the output is a real
number.
• Classification
In a classification problem, we are instead trying to predict results in a discrete
output. In other words, we are trying to map input variables into discrete
categories. For example, predicting whether a particular email is spam or not.
5.
Machine Learning Toolsand Techniques
• Linear Regression
Here the predicted function is of linear degree. It’s the most common type of
regression as it usually fits most of the regression problems. It uses minimization
of its Cost Function using Gradient Descent, etc. for its working. Linear
regression can be single variable or multivariate. Higher degree regression
technique is called Polynomial Regression.
• Logistic Regression
This technique is used for classification problems. Here, the predicted function
has a discrete range. It can be considered as a modified form of Linear Regression
which uses Sigmoid function for its task.
6.
• Neural Network
Thistool can be used both for regression as well as for classification. It consists of one
or more layers of computational units between the input and output for modelling
the problem using Backpropagation Algorithm. For complex problems with many
features to model, neural network provide efficient solution compared to other
techniques.
• Support Vector Machine
While Neural Network outputs the probability by which a particular input is close to
the output, SVM is a non-probabilistic binary linear classifier. It has the ability to
linearly separate the classes by a large margin. Add to it the Kernel, and SVM
becomes one of the most powerful classifier capable of handling infinite dimensional
feature vectors.
7.
Support Vector Machine
TheHypothesis function for an SVM is same as that of logistic regression:
ℎ 𝜃 𝑥 =
1
1 + 𝑒−𝜃 𝑇 𝑥
The difference lies in the Cost Function:
𝐽 𝜃 = 𝐶
𝑖=1
𝑚
[𝑦 𝑖 𝑐𝑜𝑠𝑡1(𝜃 𝑇 𝑥(𝑖)) + 1 − 𝑦 𝑖 𝑐𝑜𝑠𝑡0(𝜃 𝑇 𝑥(𝑖))]
8.
Where 𝑐𝑜𝑠𝑡0 and𝑐𝑜𝑠𝑡1 are defined as
𝑐𝑜𝑠𝑡0 𝑧 =
0, 𝑖𝑓 𝑧 ≤ −1
𝑧 + 1, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
𝑐𝑜𝑠𝑡1 𝑧 =
0, 𝑖𝑓 𝑧 ≥ 1
−𝑧 + 1, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒
Thus the learned parameter vector is obtained as:
𝜃 = min
𝜃
𝐽(𝜃) +
1
2
𝑖=1
𝑛
𝜃𝑗
2
where the minimization functionality can be obtained via Gradient Descent, Conjugate
gradient, BFGS, L-BFGS, etc. and the second term is for Regularization to prevent Overfitting.
9.
Kernel
• A Kernelis a “similarity function” that we provide to a machine learning algorithm,
most commonly, an SVM. It takes two inputs and outputs how similar they are. The
means by which this similarity is determined differentiates one kernel function from
another. It is a shortcut that helps us do certain calculation faster which otherwise
would involve computations in higher dimensional space. Examples include Gaussian
Kernel, String Kernel, Chi-Squared Kernel, Histogram Intersection Kernel, etc.
• Kernel methods owe their name to the use of kernel functions, which enable them to
operate in a high-dimensional, implicit feature space without ever computing the
coordinates of the data in that space, but rather by simply computing the inner
products between the images of all pairs of data in the feature space. This operation is
often computationally cheaper than the explicit computation of the coordinates. This
approach is called the "kernel trick".
10.
SVM Intuition
• Wehave 2 colours of balls on the table that we want to separate.
11.
• We geta stick and put it on the table, this works
pretty well right?
12.
• Some villaincomes and places more balls on the
table, it kind of works but one of the balls is on the
wrong side and there is probably a better place to put
the stick now.
13.
• SVMs tryto put the stick in the best possible place by
having as big a gap on either side of the stick as
possible.
14.
• Now whenthe villain returns the stick is still in a
pretty good spot.
15.
• There isanother trick in the SVM toolbox that is even
more important. Say the villain has seen how good
you are with a stick so he gives you a new challenge.
16.
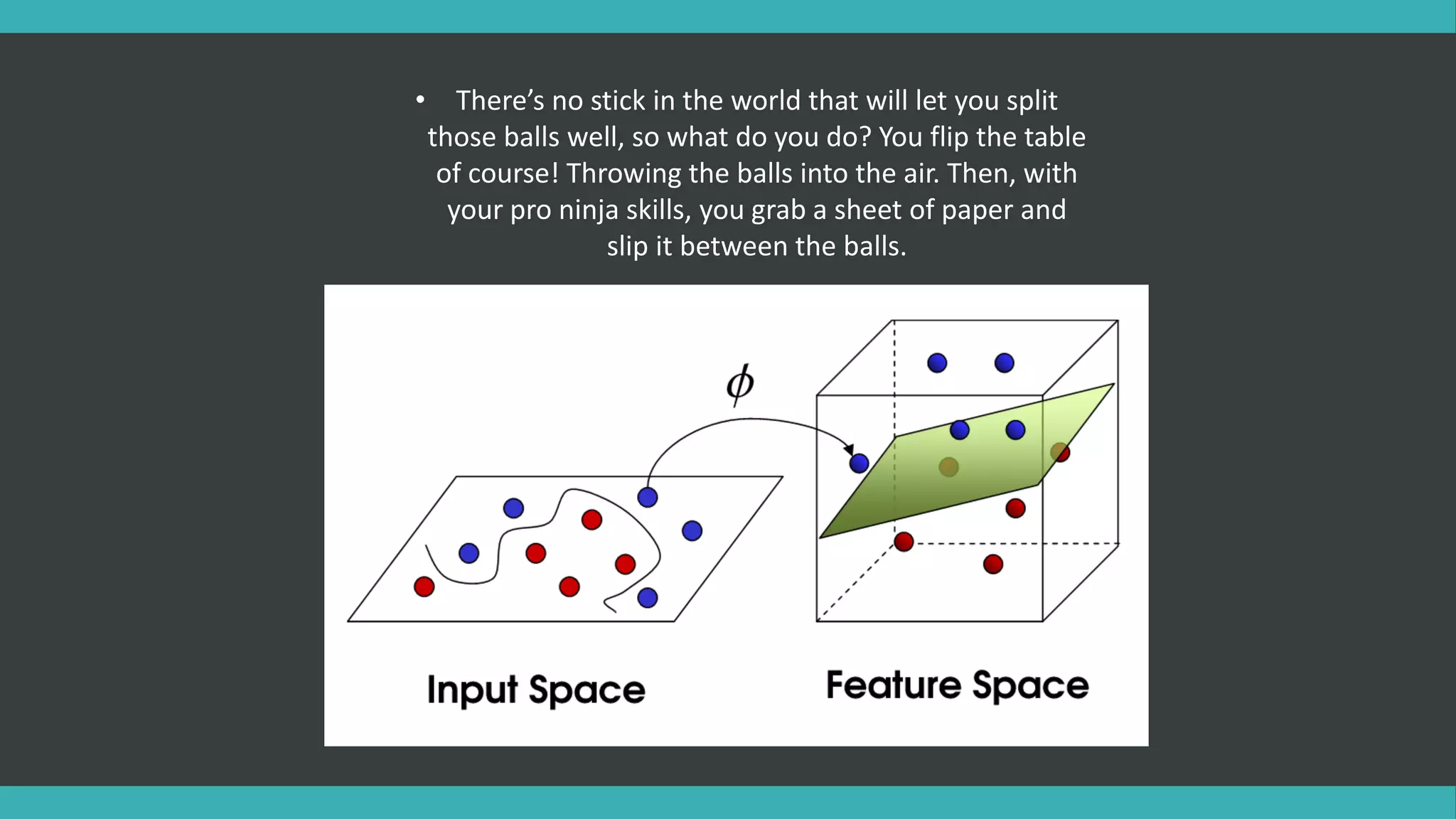
• There’s nostick in the world that will let you split
those balls well, so what do you do? You flip the table
of course! Throwing the balls into the air. Then, with
your pro ninja skills, you grab a sheet of paper and
slip it between the balls.
17.
• Now, lookingat the balls from where the villain is
standing, they balls will look split by some curvy line.
18.
“The balls canbe considered as data, the stick a classifier,
the biggest gap trick an optimization, flipping the table
kernelling and the piece of paper a hyperplane”






![Support Vector Machine
The Hypothesis function for an SVM is same as that of logistic regression:
ℎ 𝜃 𝑥 =
1
1 + 𝑒−𝜃 𝑇 𝑥
The difference lies in the Cost Function:
𝐽 𝜃 = 𝐶
𝑖=1
𝑚
[𝑦 𝑖 𝑐𝑜𝑠𝑡1(𝜃 𝑇 𝑥(𝑖)) + 1 − 𝑦 𝑖 𝑐𝑜𝑠𝑡0(𝜃 𝑇 𝑥(𝑖))]](https://image.slidesharecdn.com/seminarsvm-170309063314/85/Machine-Learning-using-Support-Vector-Machine-7-320.jpg)


















![Support Vector Machine
The Hypothesis function for an SVM is same as that of logistic regression:
ℎ 𝜃 𝑥 =
1
1 + 𝑒−𝜃 𝑇 𝑥
The difference lies in the Cost Function:
𝐽 𝜃 = 𝐶
𝑖=1
𝑚
[𝑦 𝑖 𝑐𝑜𝑠𝑡1(𝜃 𝑇 𝑥(𝑖)) + 1 − 𝑦 𝑖 𝑐𝑜𝑠𝑡0(𝜃 𝑇 𝑥(𝑖))]](https://image.slidesharecdn.com/seminarsvm-170309063314/75/Machine-Learning-using-Support-Vector-Machine-7-2048.jpg)











![[PR12] You Only Look Once (YOLO): Unified Real-Time Object Detection](https://cdn.slidesharecdn.com/ss_thumbnails/yolo-170616085751-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
















































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





