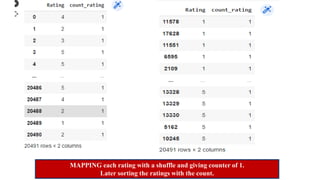
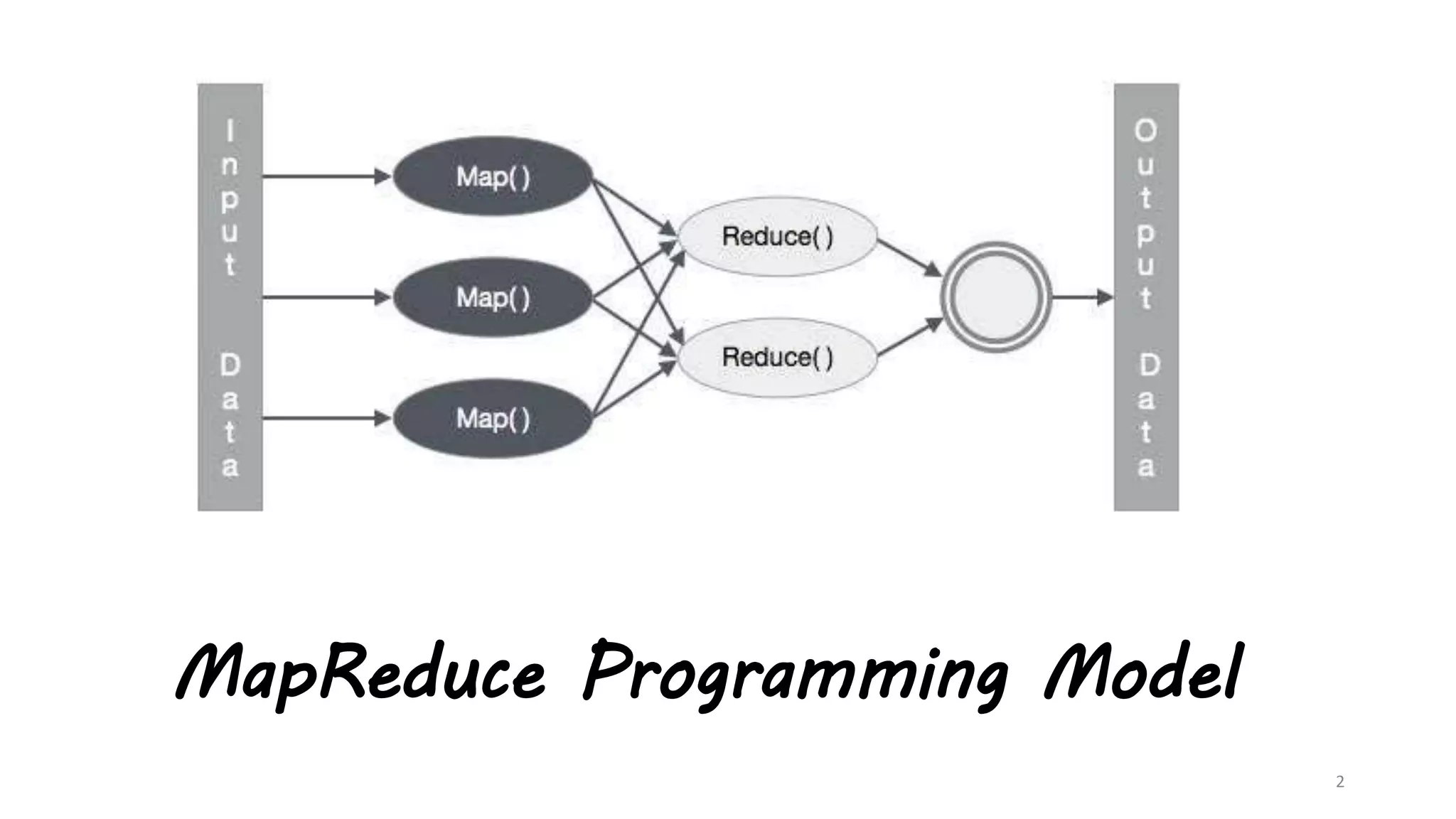
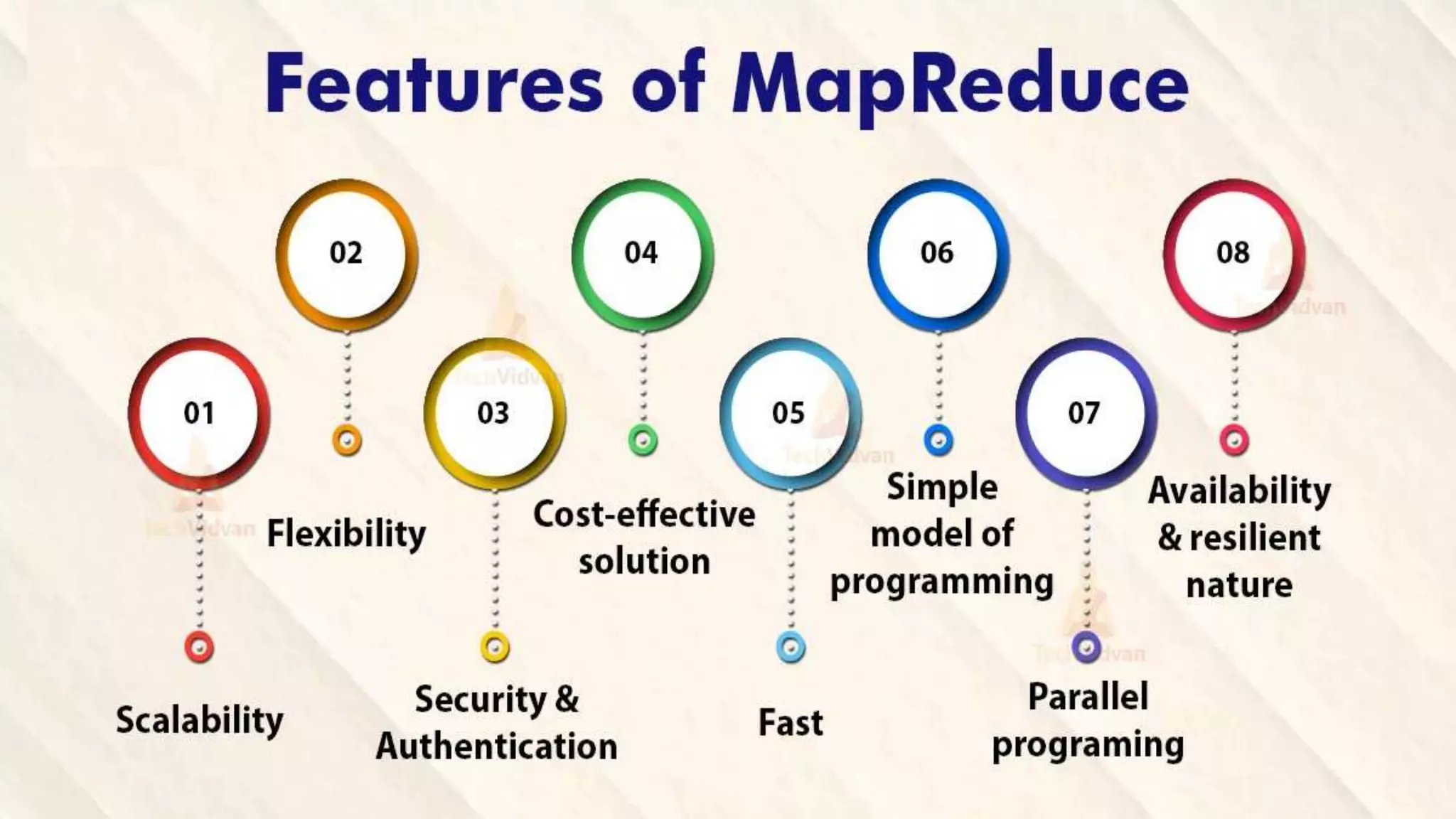
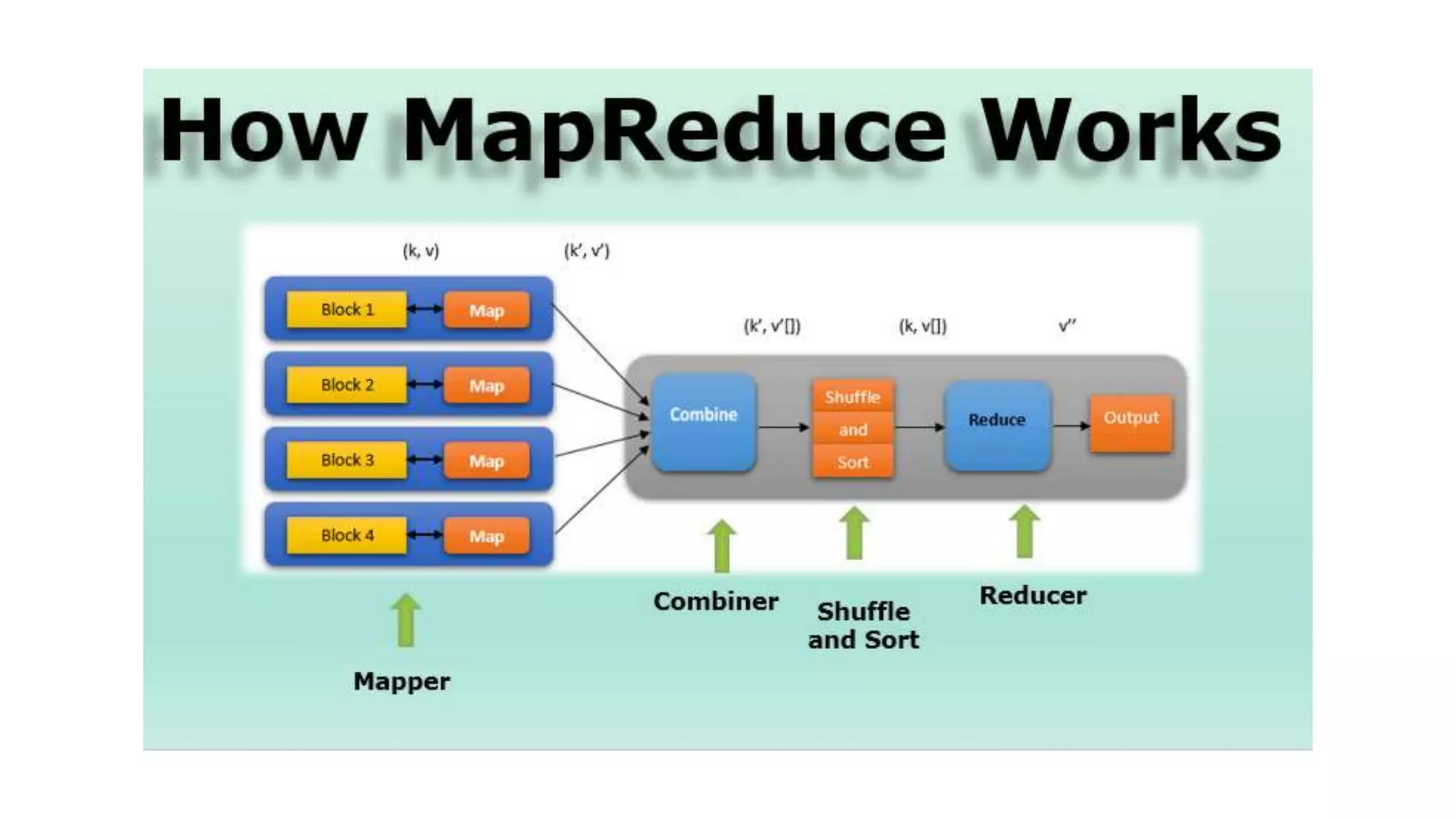
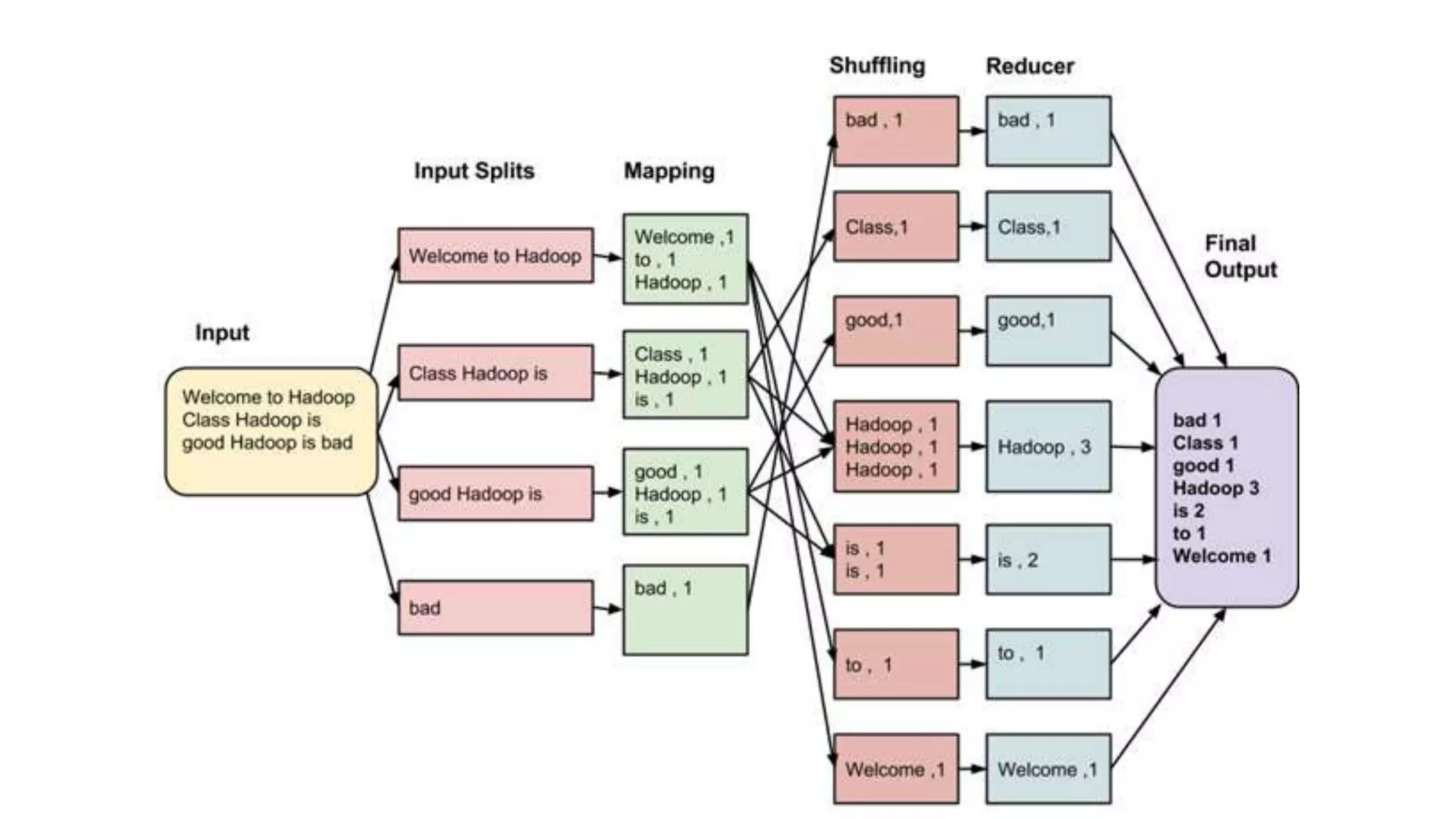
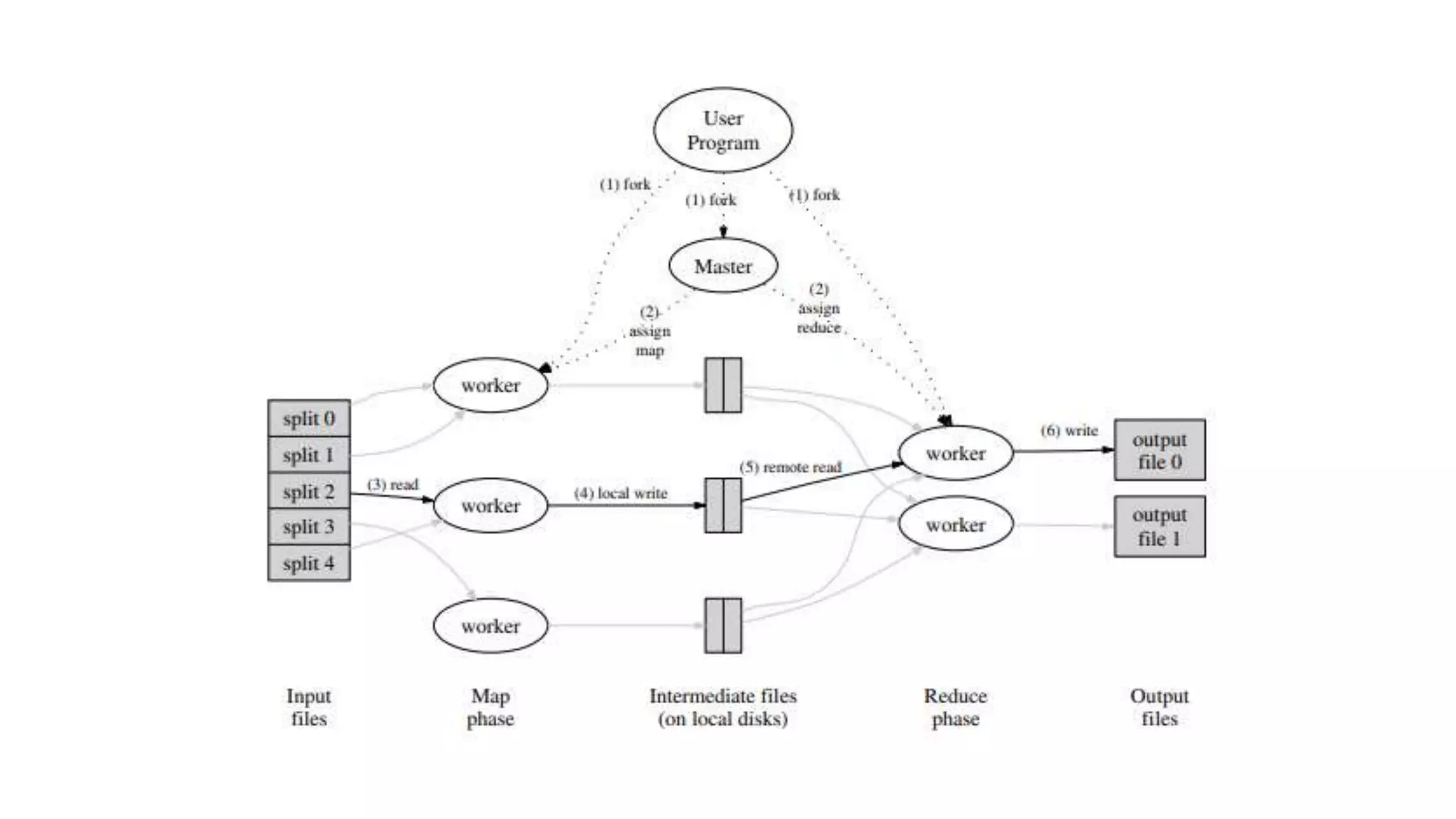
The document explains the MapReduce programming model developed by Google for processing large data sets on clusters of computers. It describes the framework's function, benefits, and workflow, including input splits, mapping, shuffling, sorting, and reducing. The document also outlines various implementations and advantages of MapReduce while noting its limitations.

































































































![Matrix and determinant URT [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/matrixanddeterminanturtautosaved-251018190340-9e6a6deb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







