Rhishma Pandey (PUR077BCT067)
SanjeebKarki(PUR077BCT072)
Sunil Khilinge (PUR077BCT087)
Yukesh Katuwal(PUR077BCT094)
Team Supervisor:Assi.Prof. Rajnish Rajbahak
AAKAR.AI-
FINE TUNING STABLE DIFFUSION
MODEL TO GENERATE IMAGES
Tribhuvan University
Institute of Engineering
Purwanchal Campus
पुर्वाञ्चल क्याम्पस
PRESENTED BY : PRESENTED TO :
DEPARTMENT OF ELECTRONICS
AND COMPUTER ENGINEERING
2.
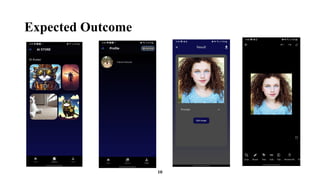
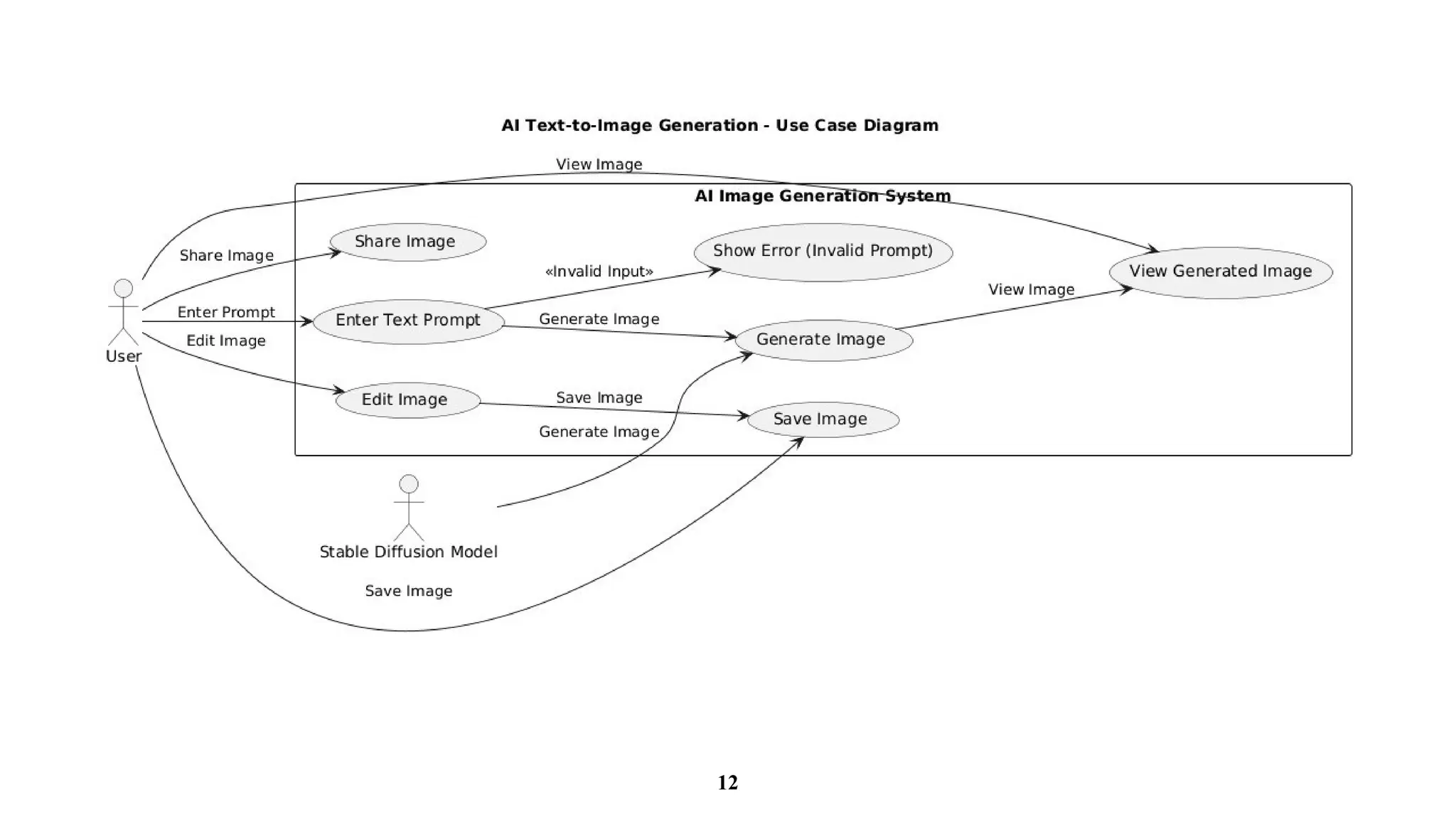
Introduction
The Stable DiffusionModel represents a significant advancement in the realm of AI image
generation, drawing upon the foundational principles of diffusion processes and stochastic
differential equations. This model enhances the capabilities of existing generative modeling
techniques by building upon earlier architectures such as Variational Autoencoders (VAEs) and
Generative Adversarial Networks (GANs).
1
3.
Objectives
• Utilize fine-tunedtransformer-based models to generate high-quality, context aware images for
various creative projects, such as movie posters and marketing materials.
• Offer customization tools for users to adjust style, composition, and other image elements,
allowing for tailored visuals that align with specific project needs.
• Enable users to generate customized product mockups and promotional images for e-commerce,
providing high-quality visuals for marketing and sales without the need for a graphic designer
• Integrate the AI platform into the fashion industry for generating clothing de signs, outfit
combinations, and fashion concept art, helping designers and brands visualize new collections.
2
4.
Literature Review
Text-to-image generationhas gained significant attention with the advancement of deep learning models,
particularly generative adversarial networks (GANs) and diffusion models. Early approaches, such as StackGAN
and AttnGAN, utilized GAN-based architectures to generate images from textual descriptions, focusing on
improving coherence and fine-grained details. More recent developments, like DALL·E and Stable Diffusion,
leverage transformer-based architectures and diffusion processes to achieve higher fidelity and semantic
alignment between text and images. These models incorporate large-scale datasets and extensive training
techniques to enhance creativity, realism, and diversity in image generation. Despite significant progress,
challenges remain in accurately capturing complex descriptions, maintaining consistency in generated images,
and reducing biases present in training data. Ongoing research focuses on improving control mechanisms,
reducing computational costs, and integrating user feedback for better adaptability
3
5.
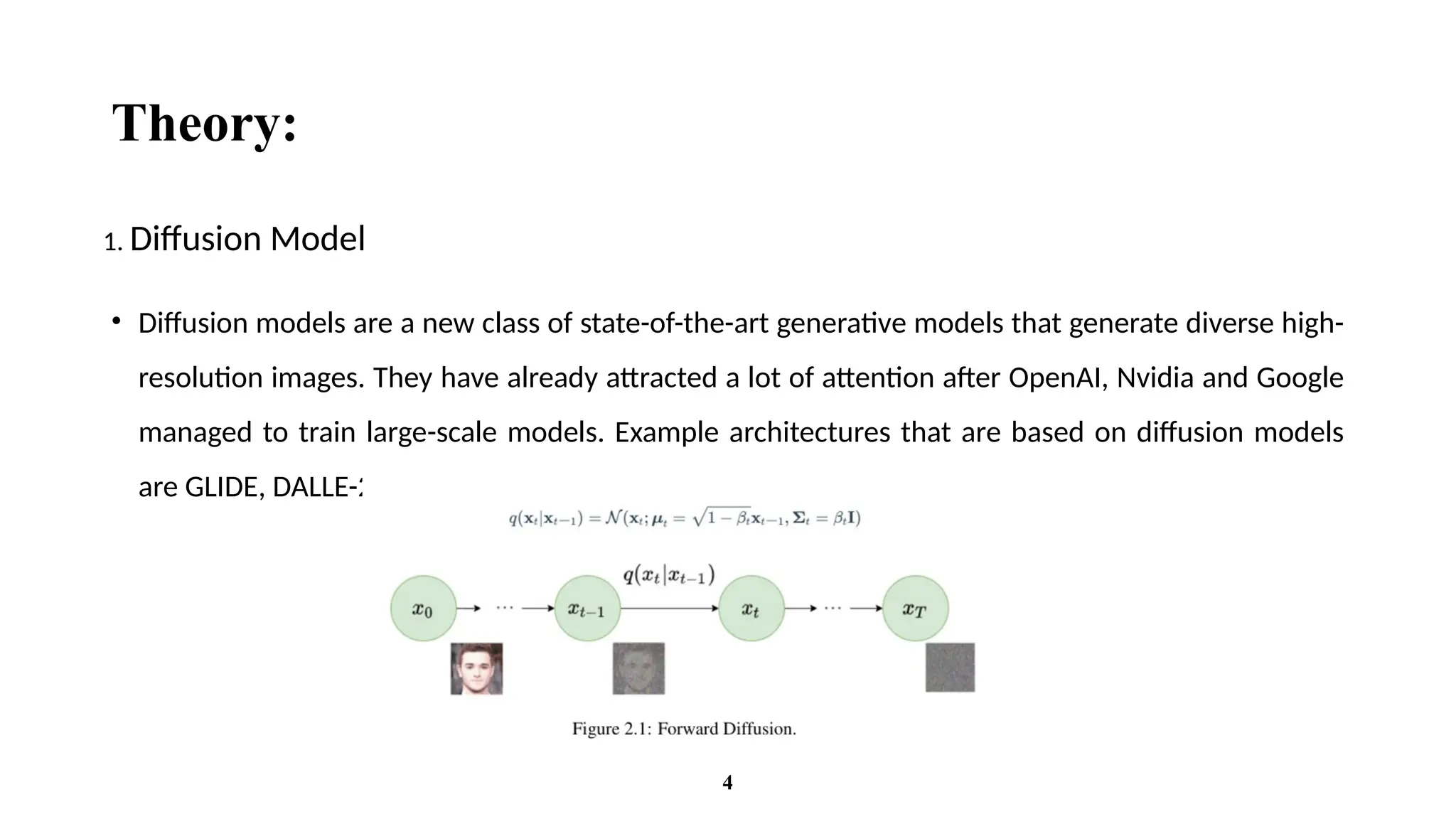
Theory:
• Diffusion modelsare a new class of state-of-the-art generative models that generate diverse high-
resolution images. They have already attracted a lot of attention after OpenAI, Nvidia and Google
managed to train large-scale models. Example architectures that are based on diffusion models
are GLIDE, DALLE-2, Imagen, and the full open source stable diffusion.
4
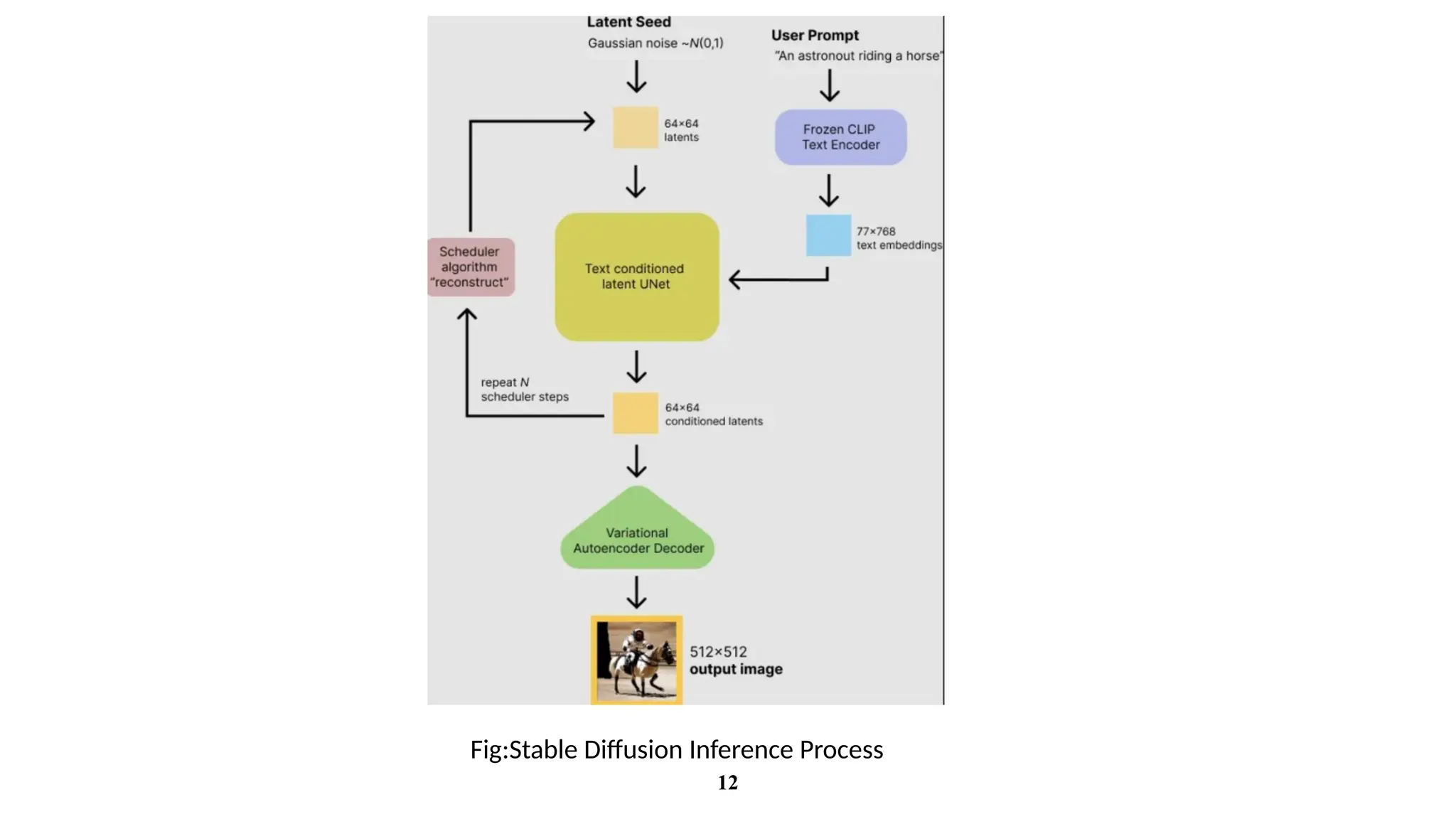
1. Diffusion Model
12
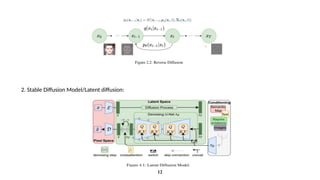
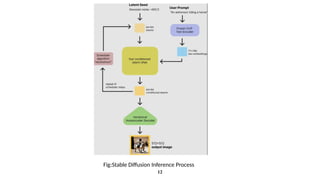
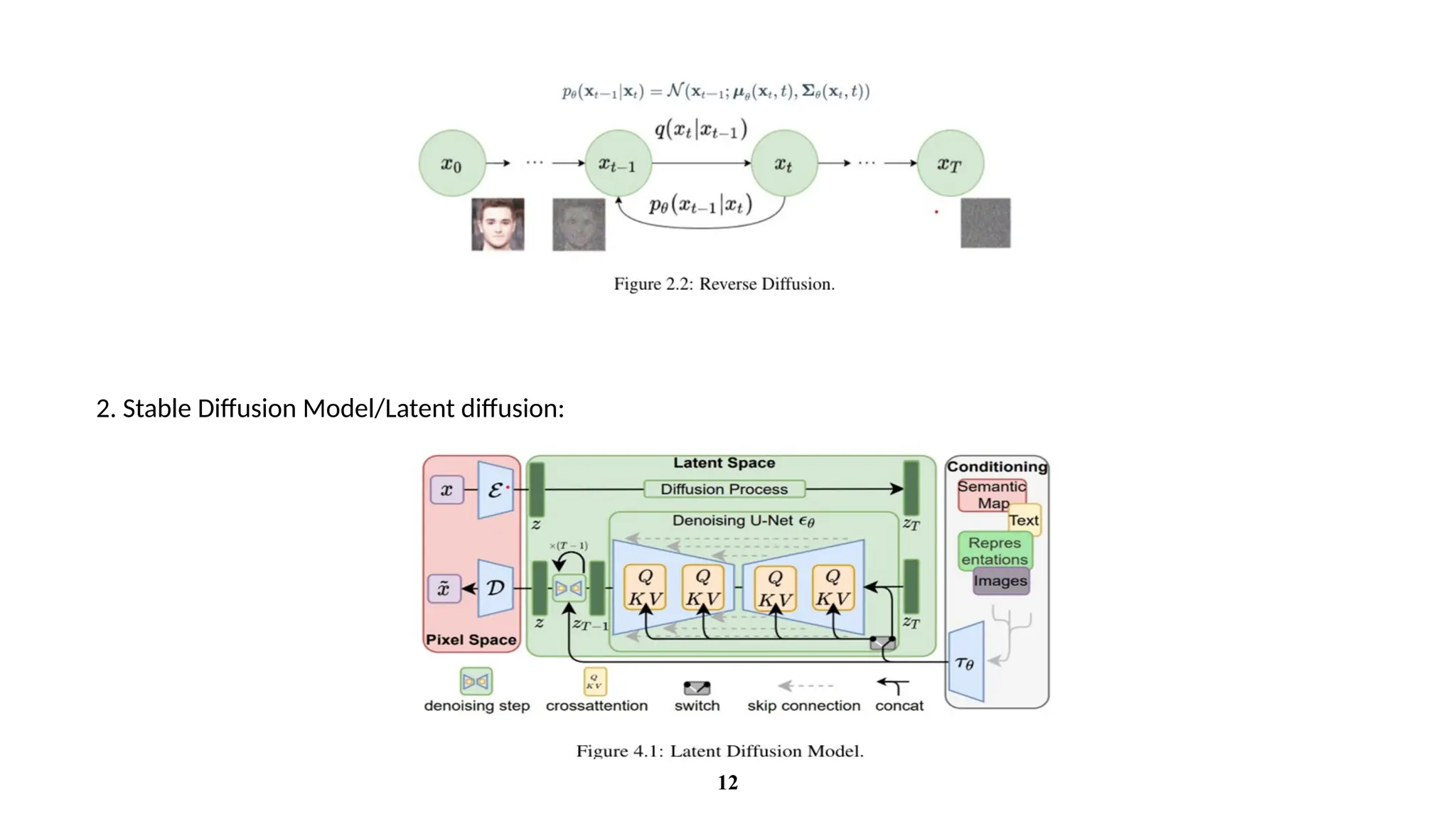
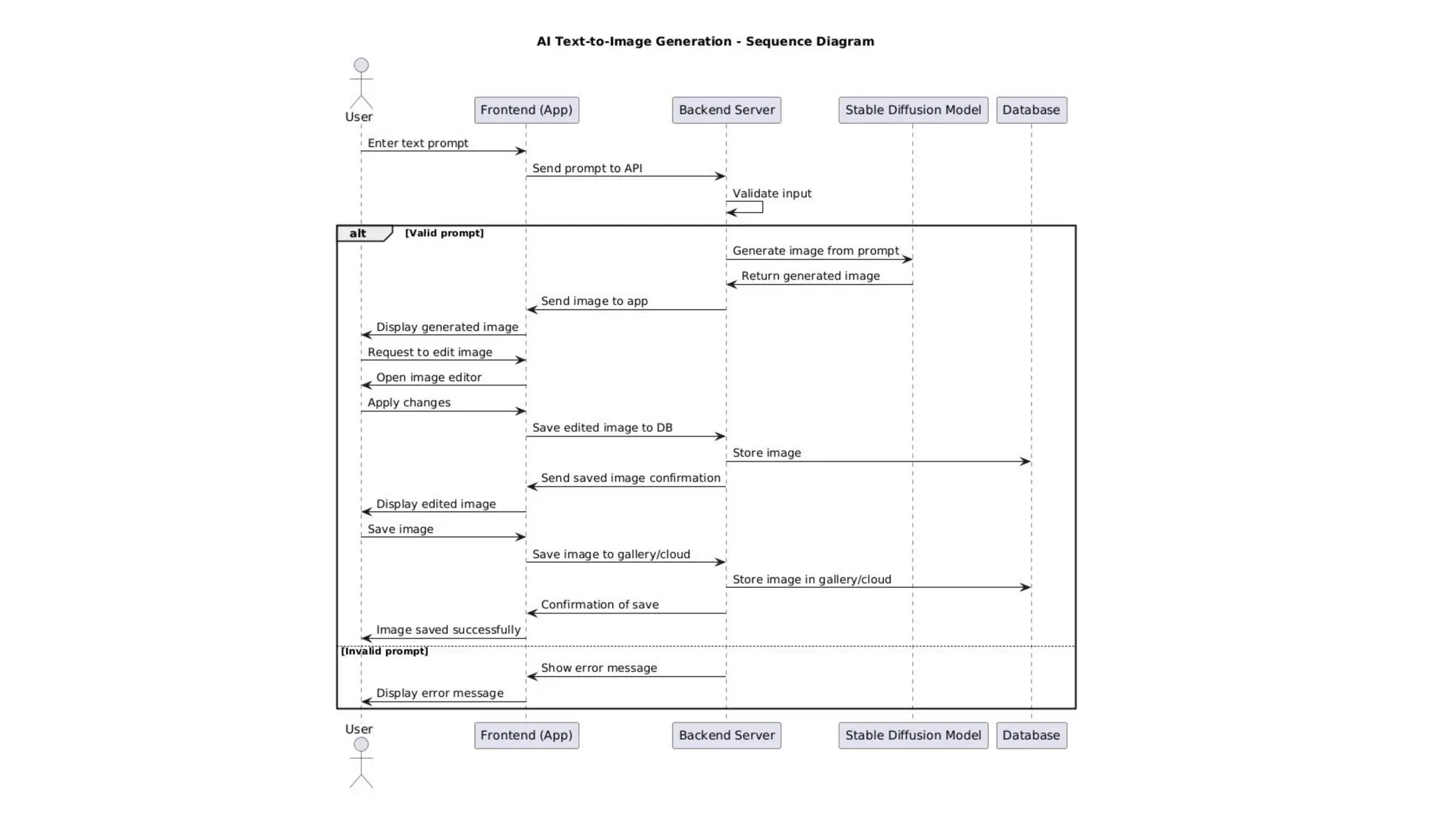
a. The Text-Encoder(e.g., CLIP’s Text Encoder)
The Text Encoder is responsible for transforming the input text prompt into a set of embeddings, which are
then used as guidance for the image generation process.
b. The Autoencoder (VAE):
The Variational Autoencoder (VAE) is a crucial part of the latent diffusion model. It consists of two
components: the encoder and the decoder. The VAE is responsible for converting high-dimensional images
into a lower-dimensional latent representation and then reconstructing the image from this latent space.
c. The Unet
The UNet is responsible for the denoising of the noisy latents during the reverse diffusion process. It takes
noisy latents as input and predicts the noise that should be subtracted from the latents
Components of Stable Diffusion:
12
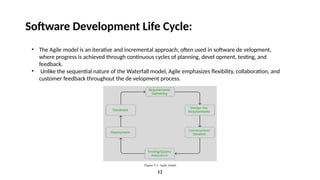
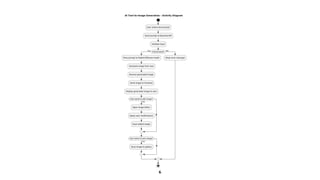
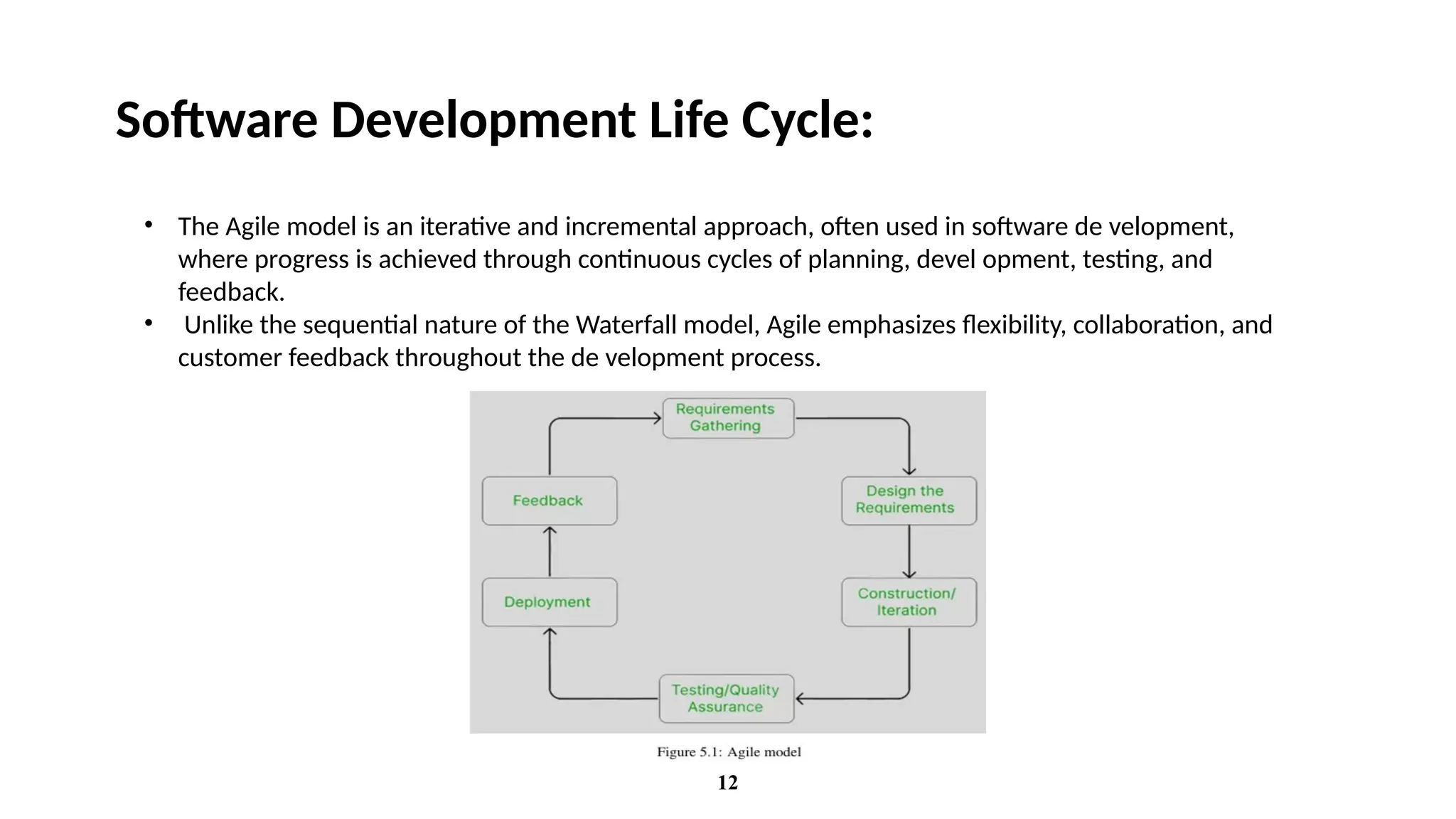
Software Development LifeCycle:
• The Agile model is an iterative and incremental approach, often used in software de velopment,
where progress is achieved through continuous cycles of planning, devel opment, testing, and
feedback.
• Unlike the sequential nature of the Waterfall model, Agile emphasizes flexibility, collaboration, and
customer feedback throughout the de velopment process.
References:
[1] R. Rombach,A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, ”High Resolution
Image Synthesis with Latent Diffusion Models,” in Proceedings of the Conference
on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 1-10.
[2] S. Correya and A. N. Amrutha, ”Text to Image Conversion using Stable Dif
fusion,” Indian Journal of Data Mining (IJDM), vol. 4, no. 1, pp. 15-28, May 2024.
[3] L. Zhang, A. Rao, and M. Agrawala, ”Adding Conditional Control to Text-to-
Image Diffusion Models,” Stanford University, 2023.
[4] N. Ruiz, Y. Pritch, Y. Li, M. Rubinstein, V. Jampani, and K. Aberman,
”DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject Driven
Generation,” Google Research, Boston University.
11
19.
References:
[5] J. Smith,A. Doe, and R. Martin, ”A Survey on Text-to-Image Generation:
Methods and Applications,” *Journal of Artificial Intelligence Research*, vol. 35, pp.
105-120, 2023.
[6] H. Liu, X. Wang, and T. Zhang, ”Optimizing Latent Diffusion Models for Real-Time
Image Generation,” in *Proceedings of the International Confer ence on Machine
Learning (ICML)*, 2024, pp. 45-57.
[7] Y. Choi, K. Lee, and S. Kim, ”Improving Fine-Tuning Strategies for Dif fusion
Models in Creative Applications,” *Journal of Computer Graphics*, vol. 12, no. 4,
pp. 78-90, Dec. 2023
11











![References:
[1] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, ”High Resolution
Image Synthesis with Latent Diffusion Models,” in Proceedings of the Conference
on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 1-10.
[2] S. Correya and A. N. Amrutha, ”Text to Image Conversion using Stable Dif
fusion,” Indian Journal of Data Mining (IJDM), vol. 4, no. 1, pp. 15-28, May 2024.
[3] L. Zhang, A. Rao, and M. Agrawala, ”Adding Conditional Control to Text-to-
Image Diffusion Models,” Stanford University, 2023.
[4] N. Ruiz, Y. Pritch, Y. Li, M. Rubinstein, V. Jampani, and K. Aberman,
”DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject Driven
Generation,” Google Research, Boston University.
11](https://image.slidesharecdn.com/midterm-250720102110-a6ed26be/85/Mid_term_present_in_engineering_done-pptx-18-320.jpg)
![References:
[5] J. Smith, A. Doe, and R. Martin, ”A Survey on Text-to-Image Generation:
Methods and Applications,” *Journal of Artificial Intelligence Research*, vol. 35, pp.
105-120, 2023.
[6] H. Liu, X. Wang, and T. Zhang, ”Optimizing Latent Diffusion Models for Real-Time
Image Generation,” in *Proceedings of the International Confer ence on Machine
Learning (ICML)*, 2024, pp. 45-57.
[7] Y. Choi, K. Lee, and S. Kim, ”Improving Fine-Tuning Strategies for Dif fusion
Models in Creative Applications,” *Journal of Computer Graphics*, vol. 12, no. 4,
pp. 78-90, Dec. 2023
11](https://image.slidesharecdn.com/midterm-250720102110-a6ed26be/85/Mid_term_present_in_engineering_done-pptx-19-320.jpg)











![References:
[1] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, ”High Resolution
Image Synthesis with Latent Diffusion Models,” in Proceedings of the Conference
on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 1-10.
[2] S. Correya and A. N. Amrutha, ”Text to Image Conversion using Stable Dif
fusion,” Indian Journal of Data Mining (IJDM), vol. 4, no. 1, pp. 15-28, May 2024.
[3] L. Zhang, A. Rao, and M. Agrawala, ”Adding Conditional Control to Text-to-
Image Diffusion Models,” Stanford University, 2023.
[4] N. Ruiz, Y. Pritch, Y. Li, M. Rubinstein, V. Jampani, and K. Aberman,
”DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject Driven
Generation,” Google Research, Boston University.
11](https://image.slidesharecdn.com/midterm-250720102110-a6ed26be/75/Mid_term_present_in_engineering_done-pptx-18-2048.jpg)
![References:
[5] J. Smith, A. Doe, and R. Martin, ”A Survey on Text-to-Image Generation:
Methods and Applications,” *Journal of Artificial Intelligence Research*, vol. 35, pp.
105-120, 2023.
[6] H. Liu, X. Wang, and T. Zhang, ”Optimizing Latent Diffusion Models for Real-Time
Image Generation,” in *Proceedings of the International Confer ence on Machine
Learning (ICML)*, 2024, pp. 45-57.
[7] Y. Choi, K. Lee, and S. Kim, ”Improving Fine-Tuning Strategies for Dif fusion
Models in Creative Applications,” *Journal of Computer Graphics*, vol. 12, no. 4,
pp. 78-90, Dec. 2023
11](https://image.slidesharecdn.com/midterm-250720102110-a6ed26be/75/Mid_term_present_in_engineering_done-pptx-19-2048.jpg)

















































