Download as PDF, PPTX





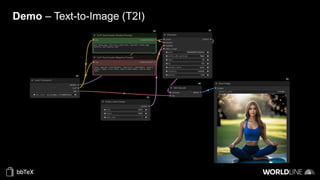

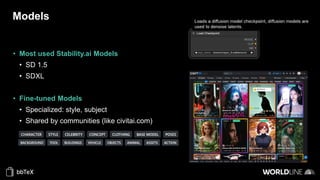
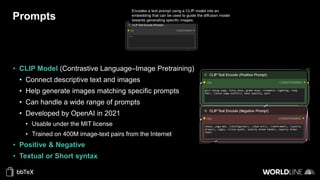

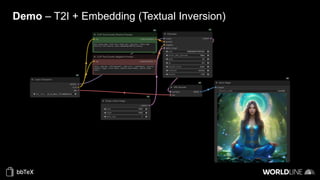


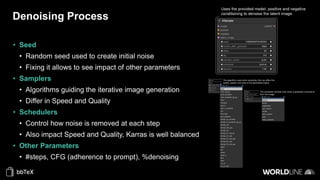



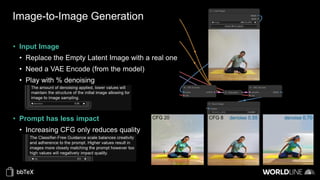

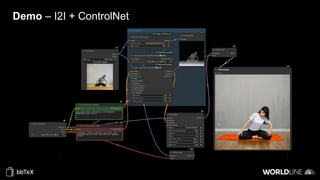

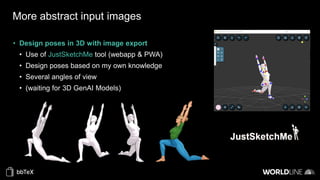
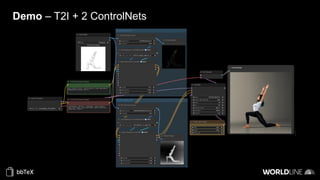


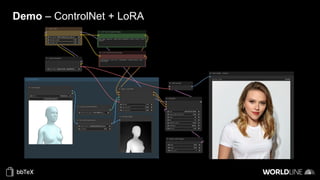
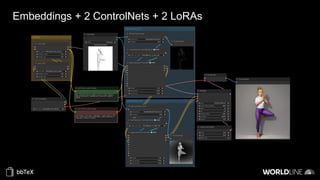



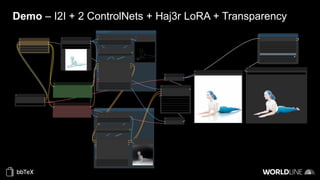

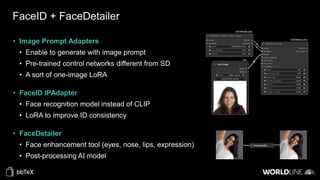
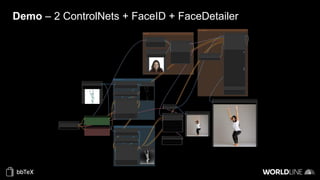




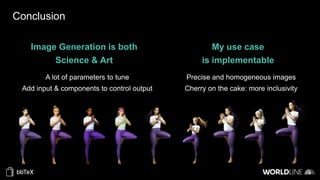



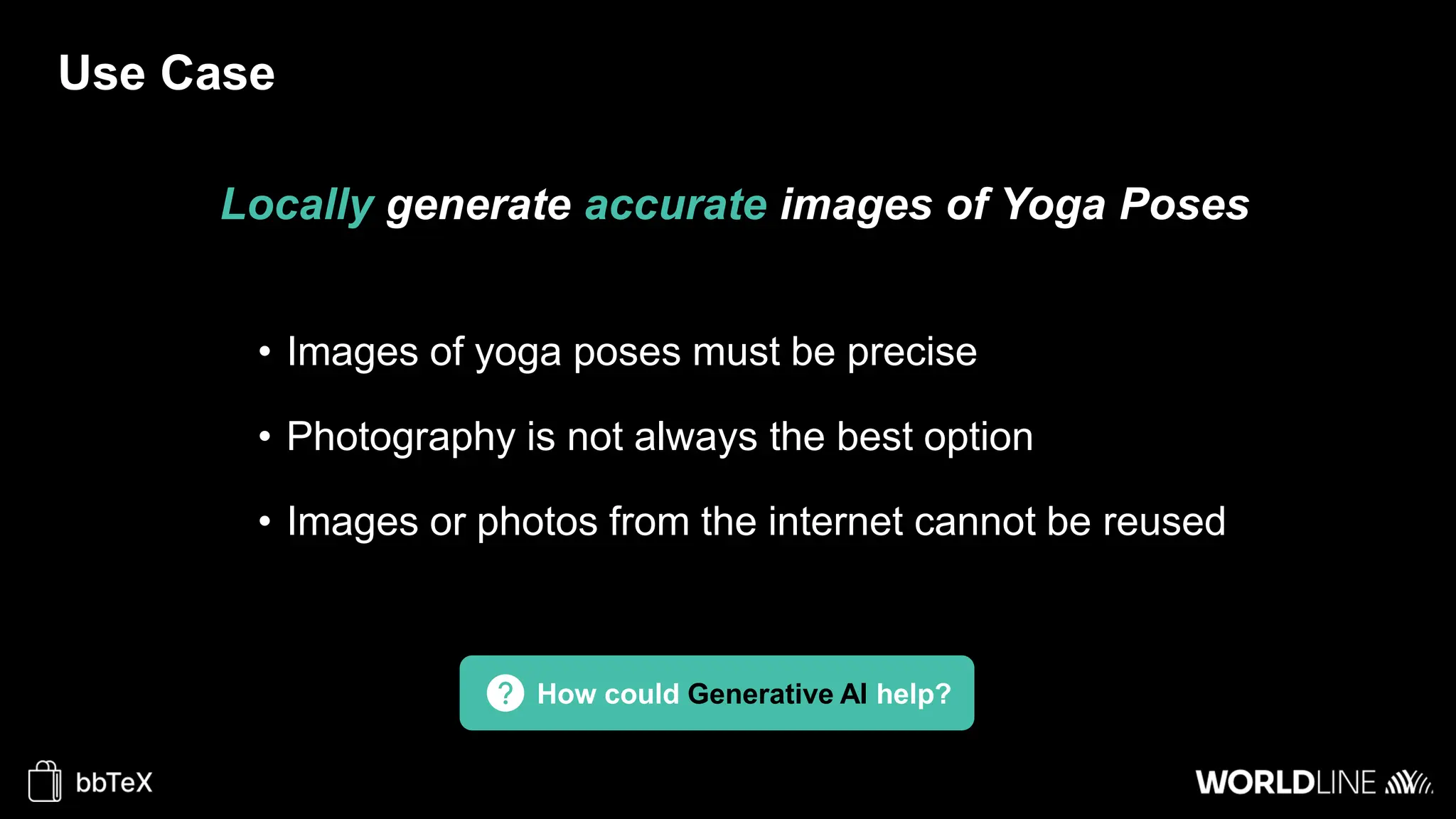




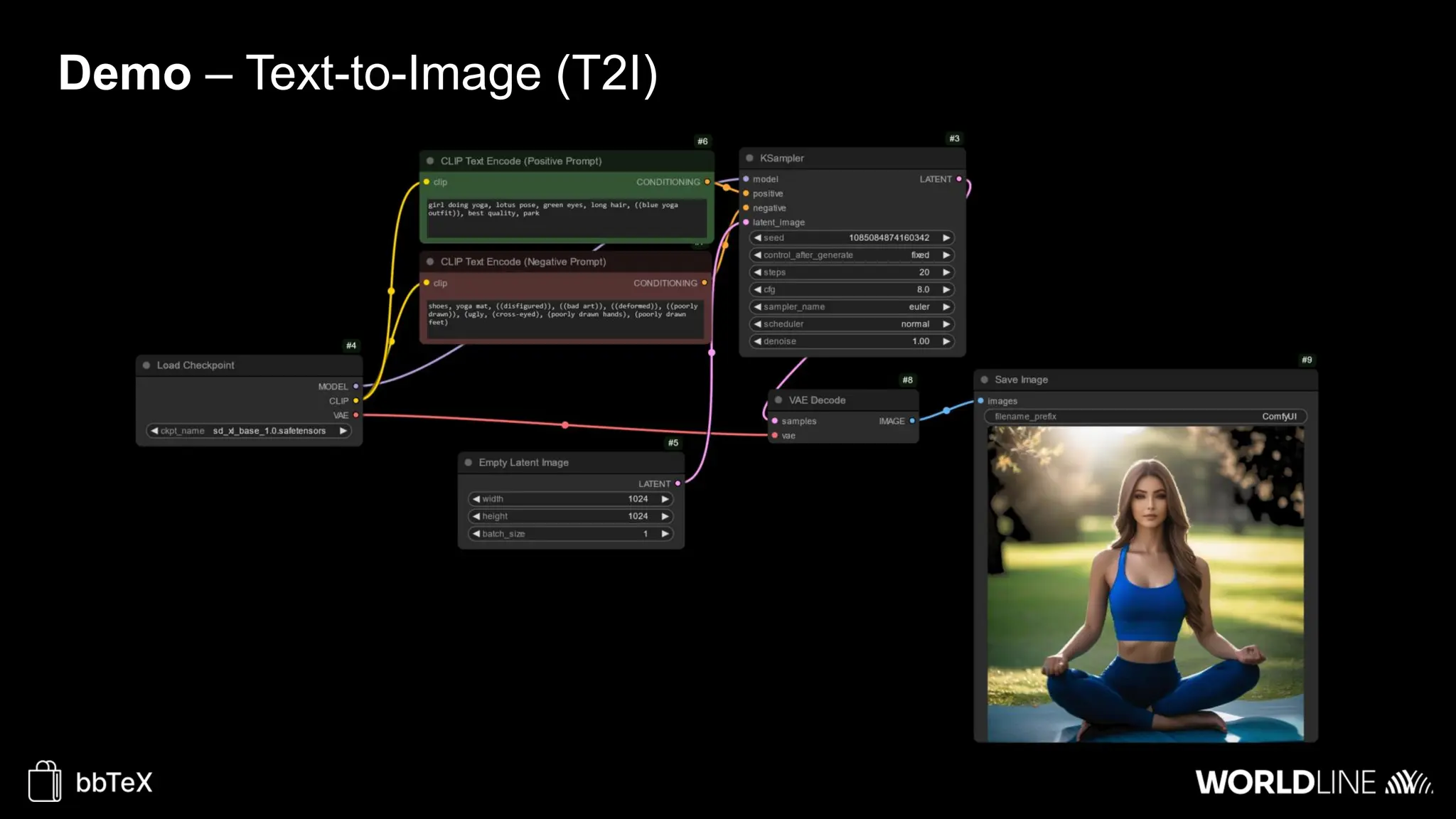

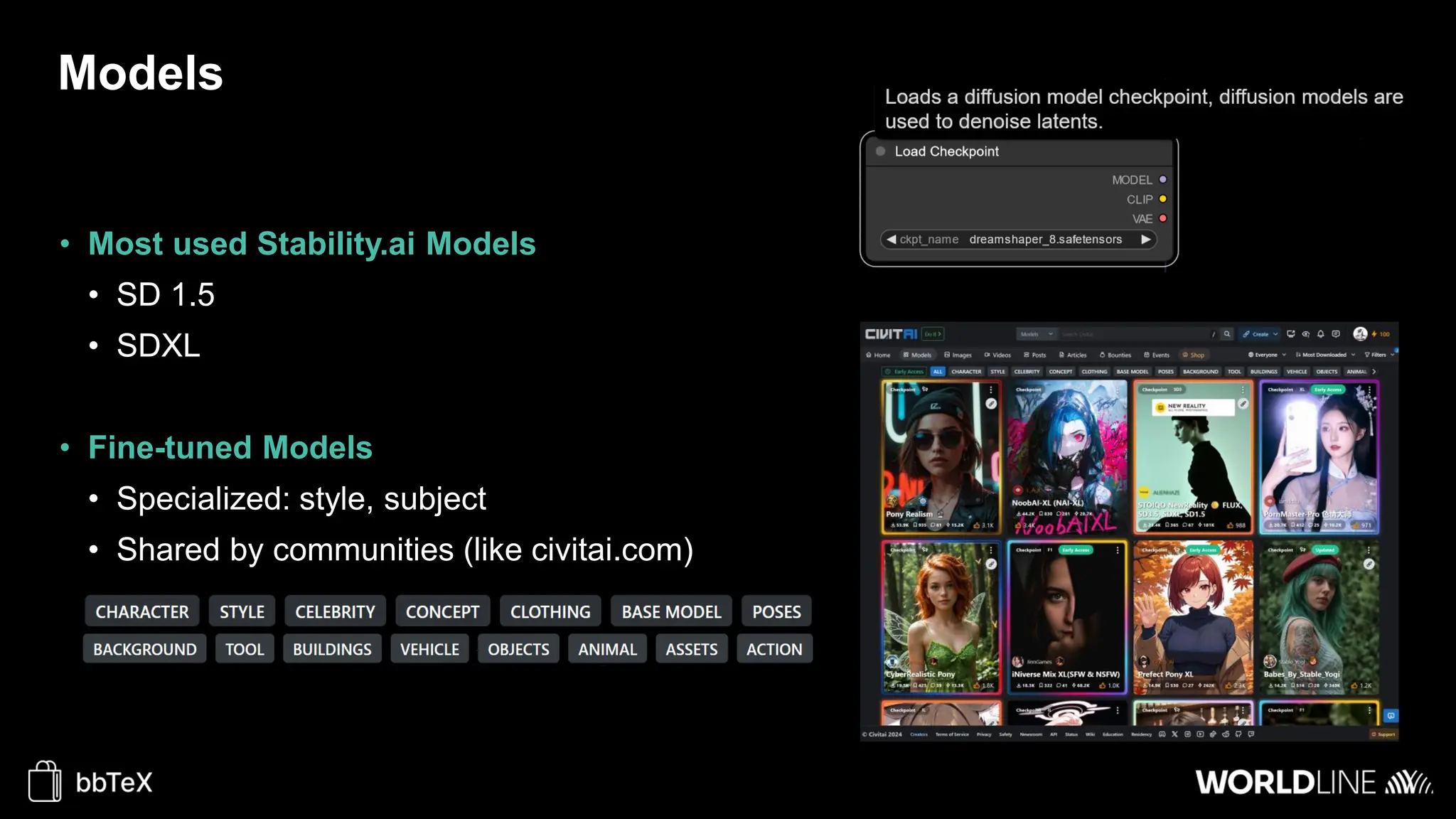
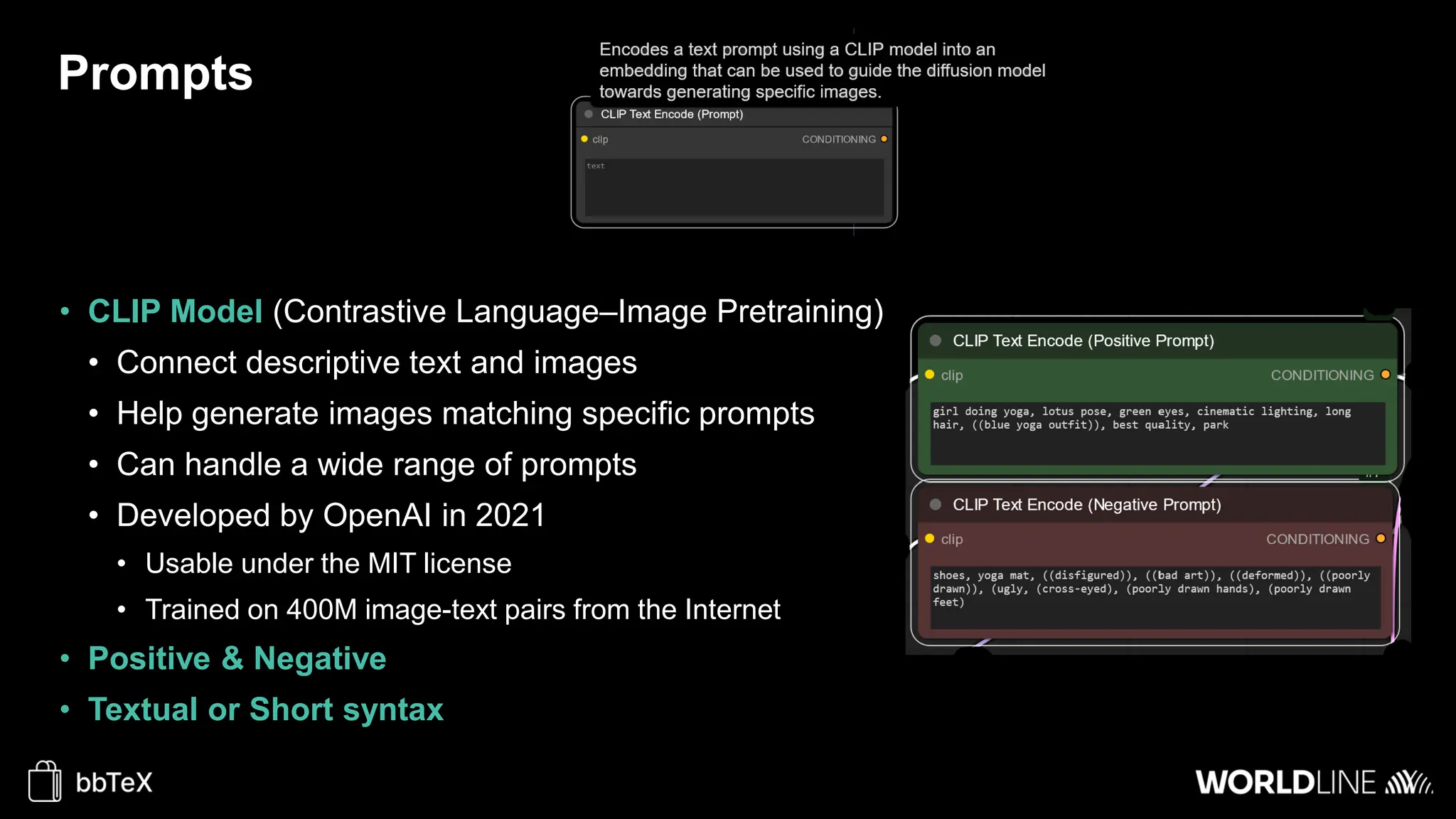

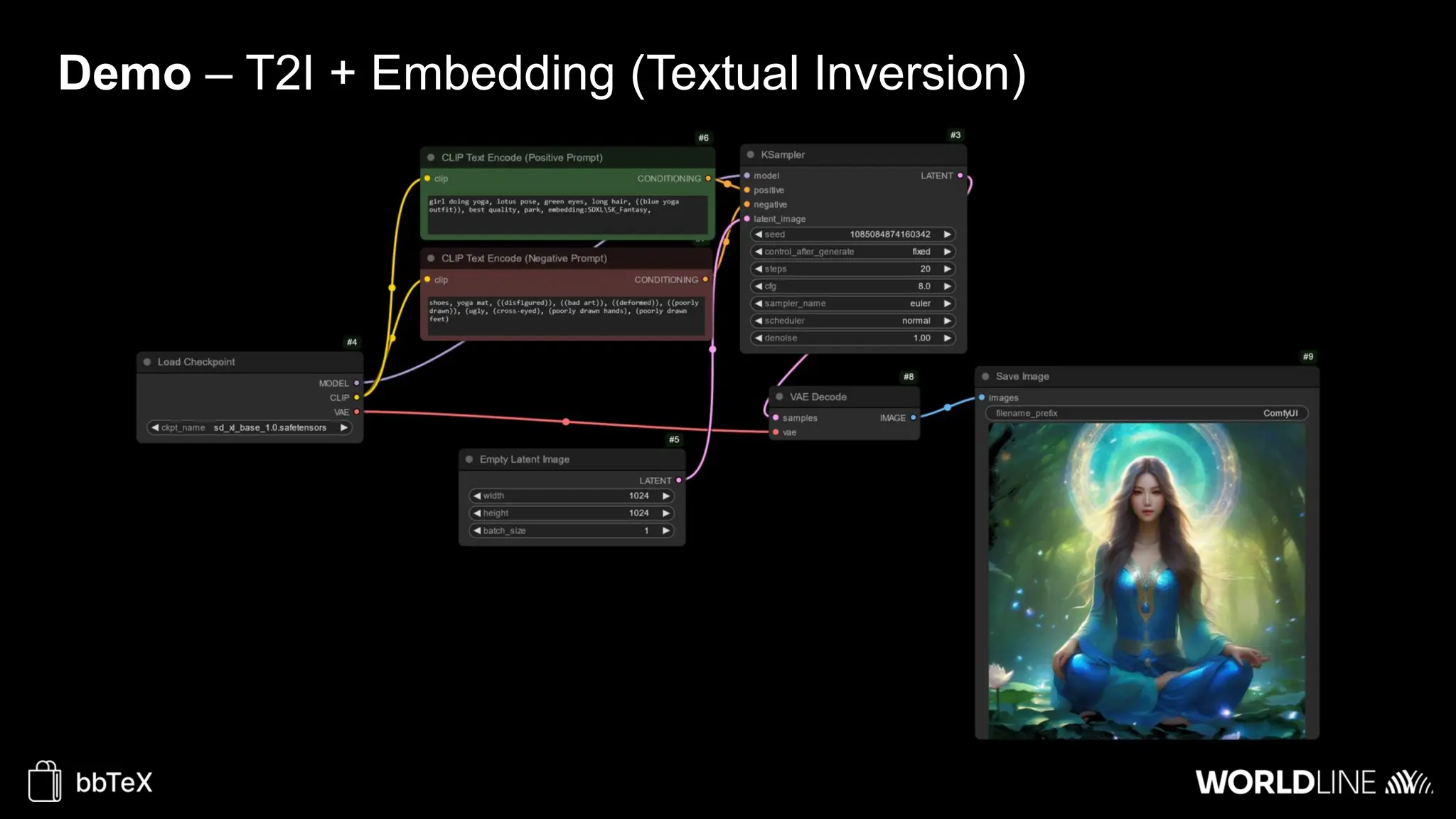


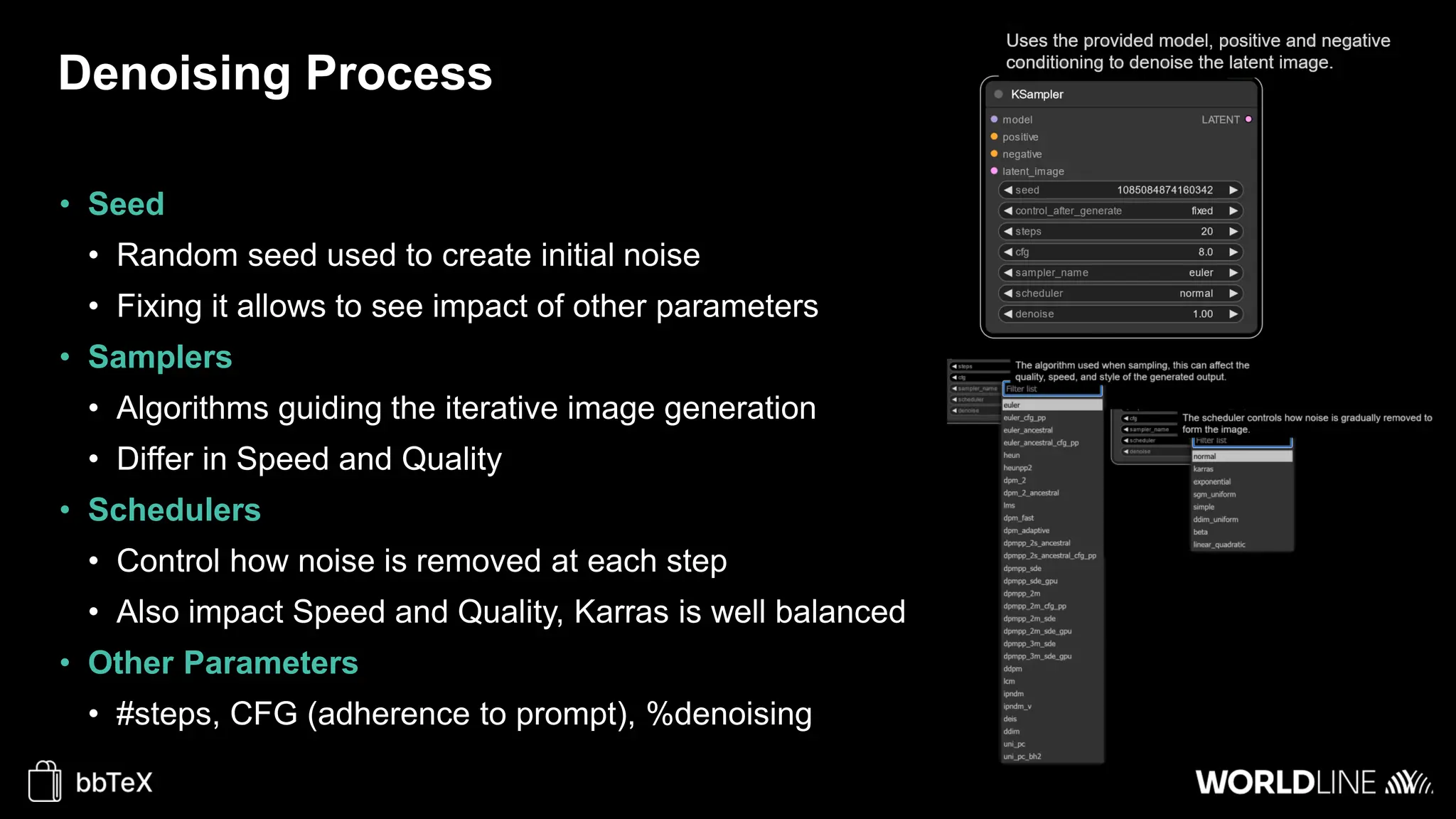


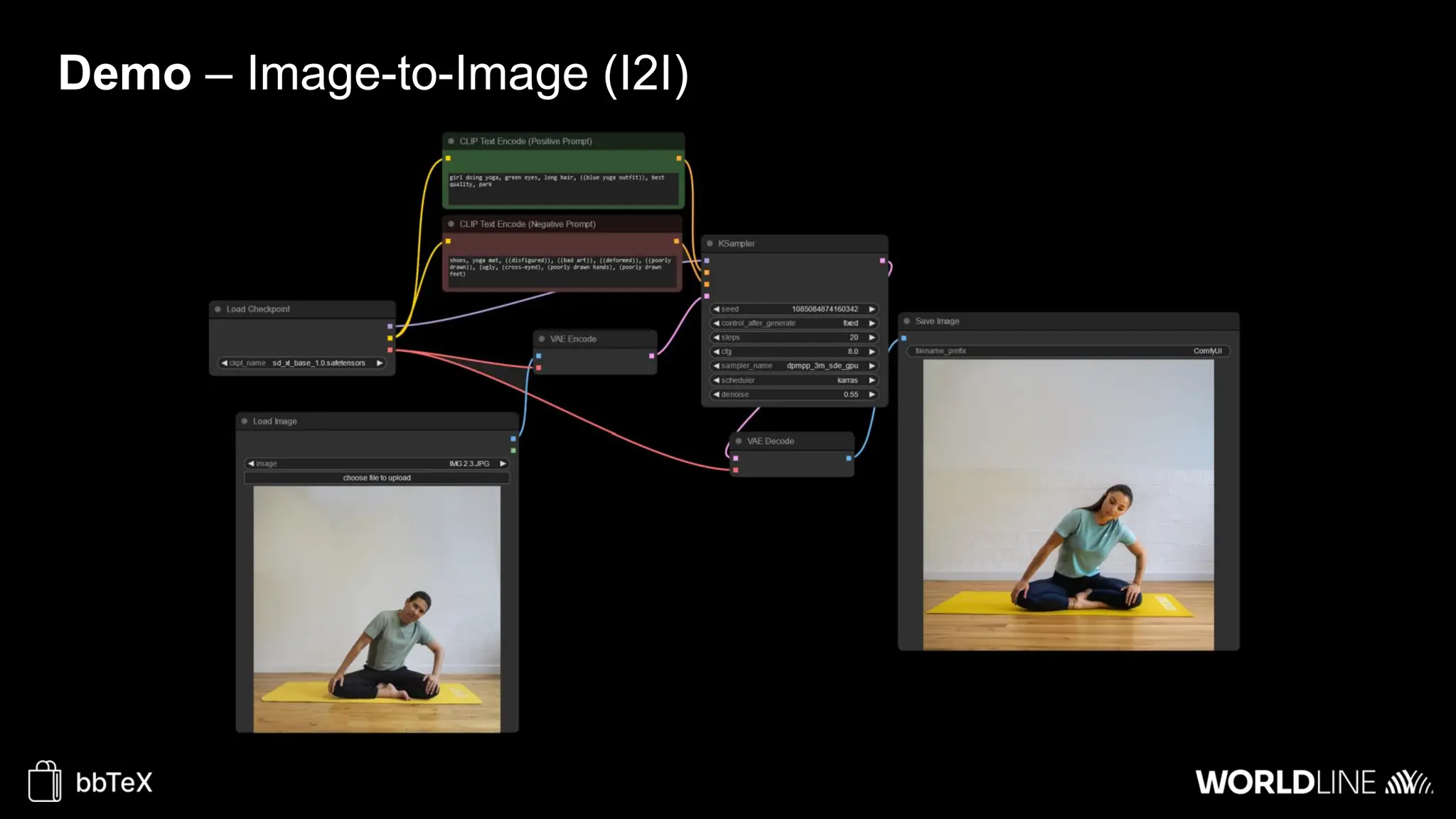
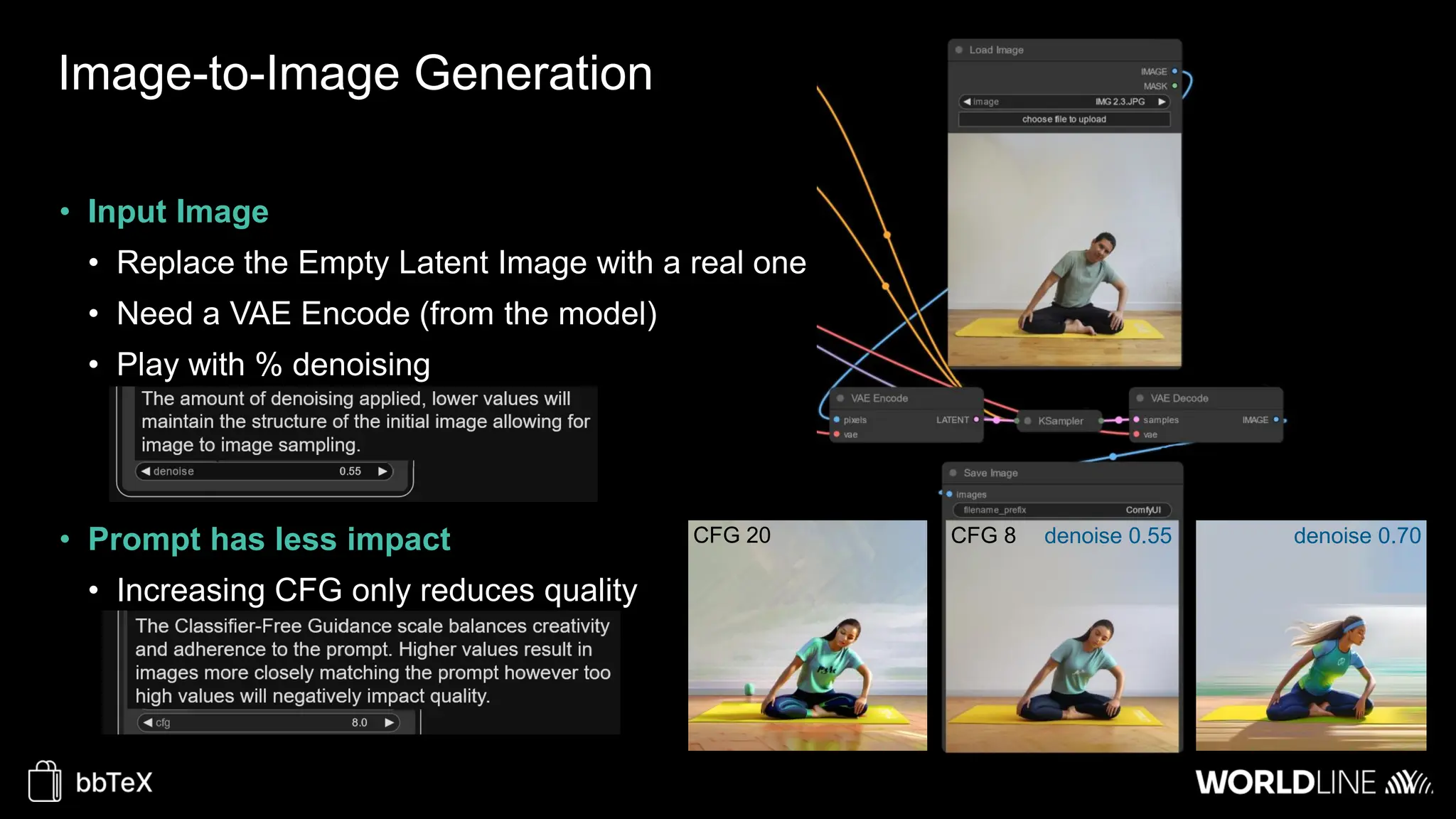

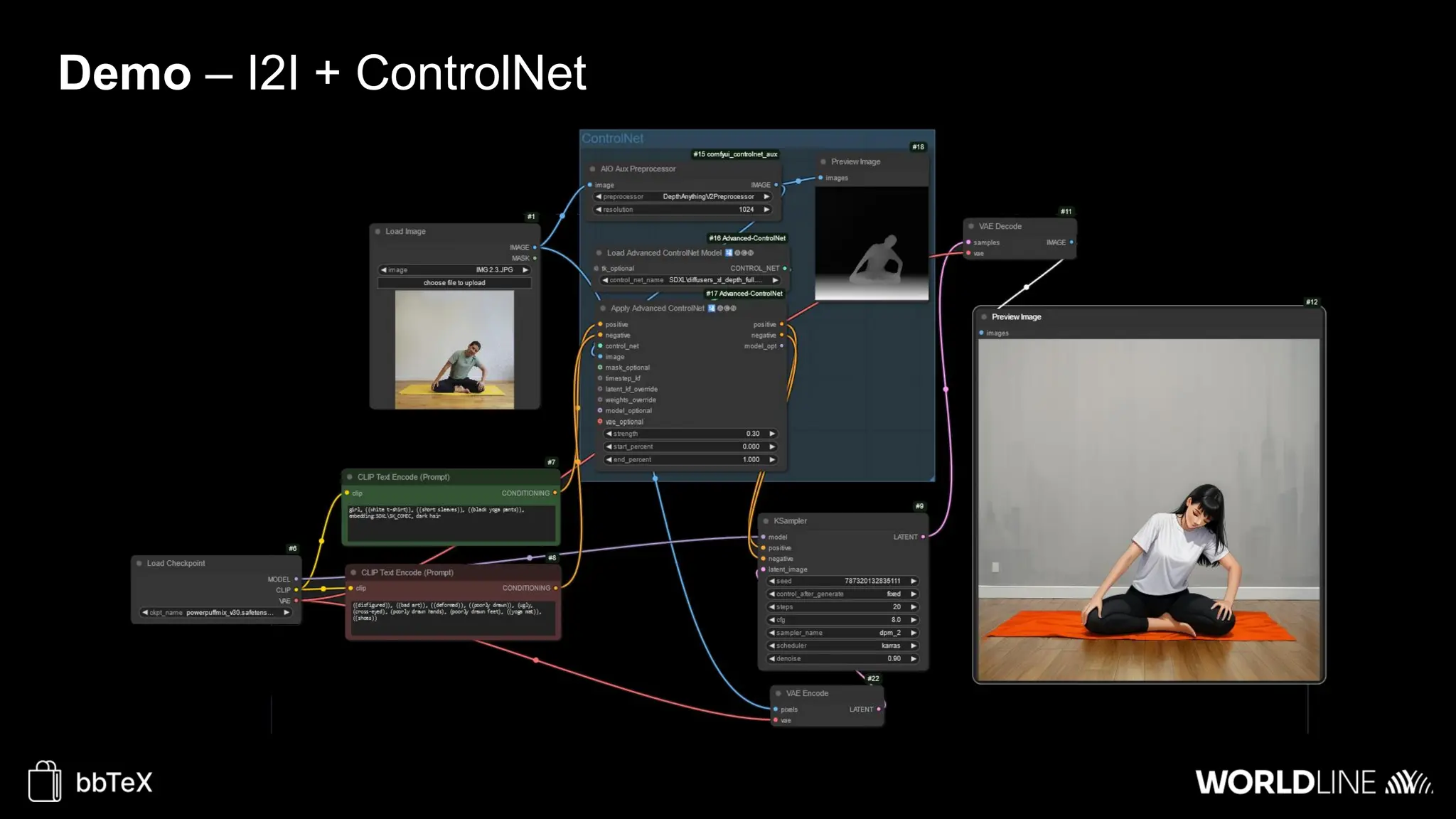

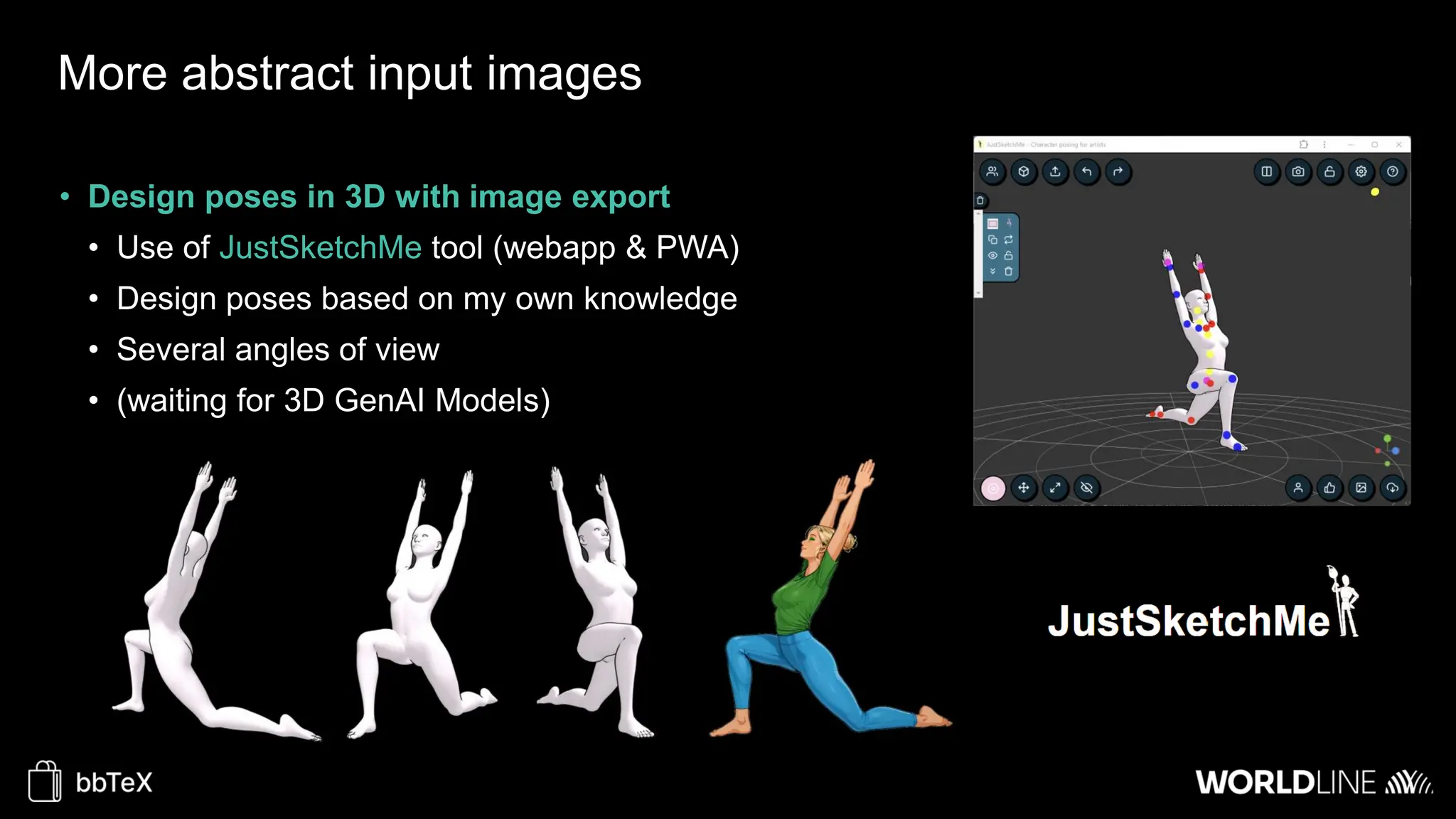
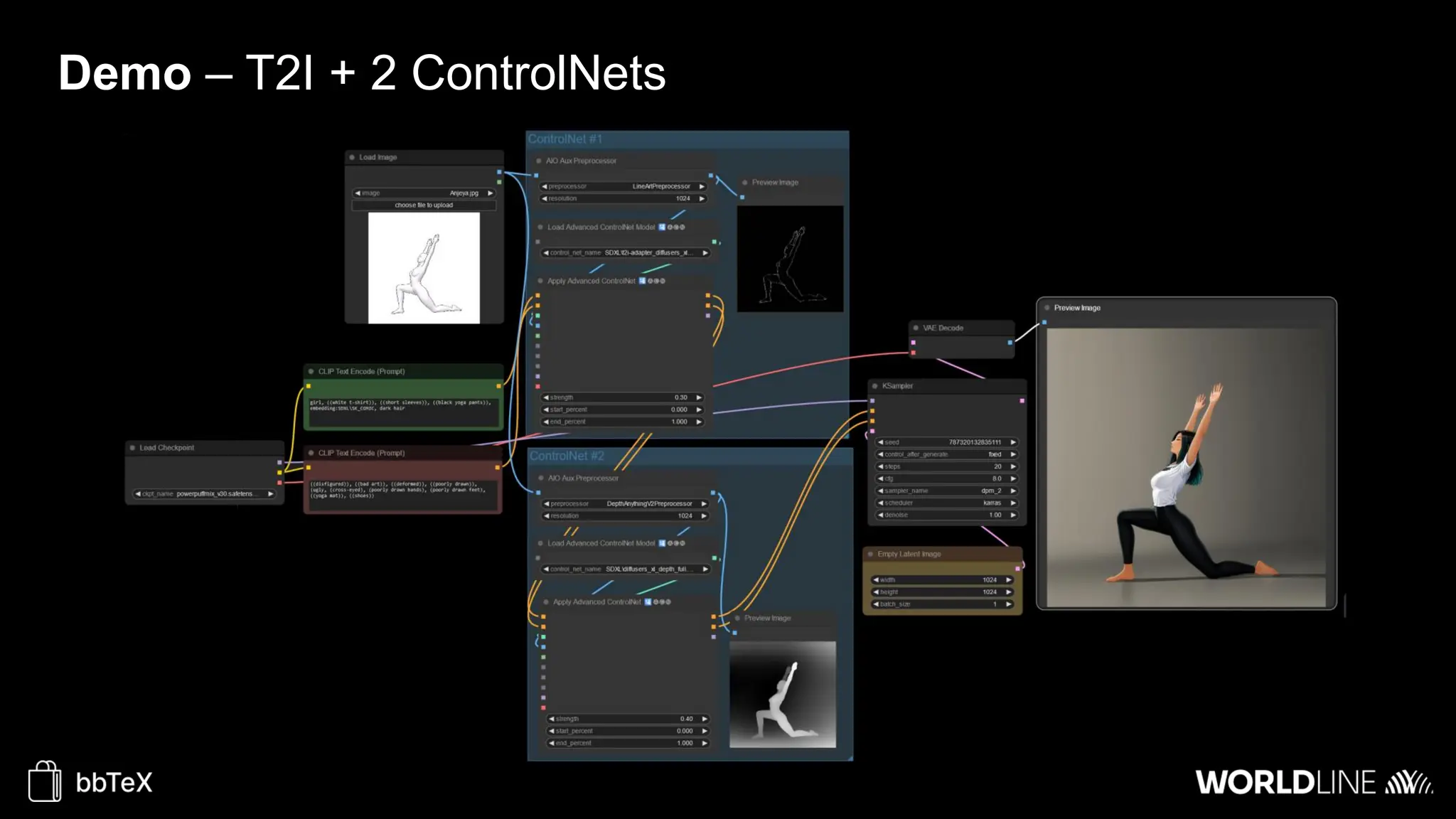


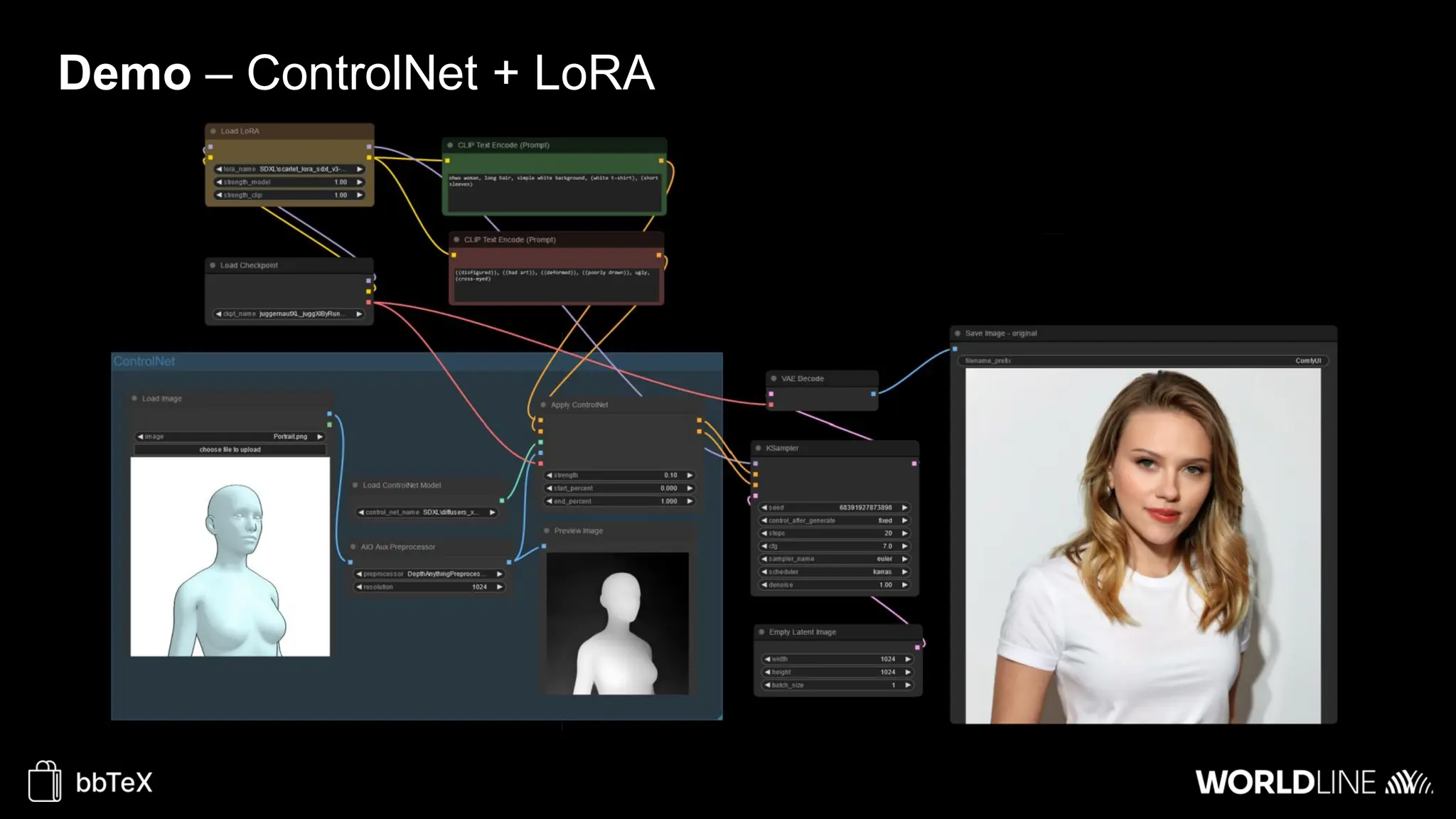
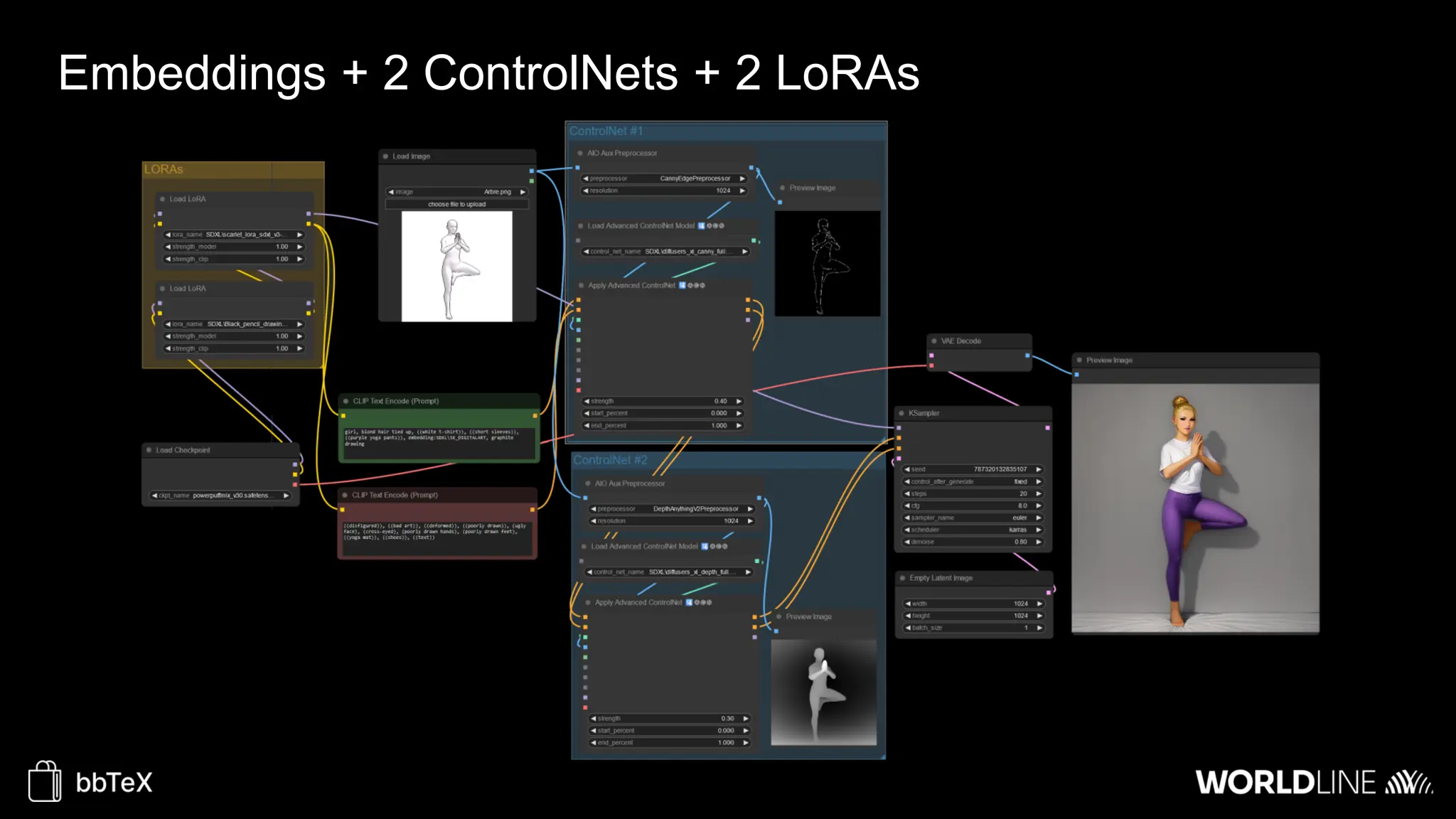



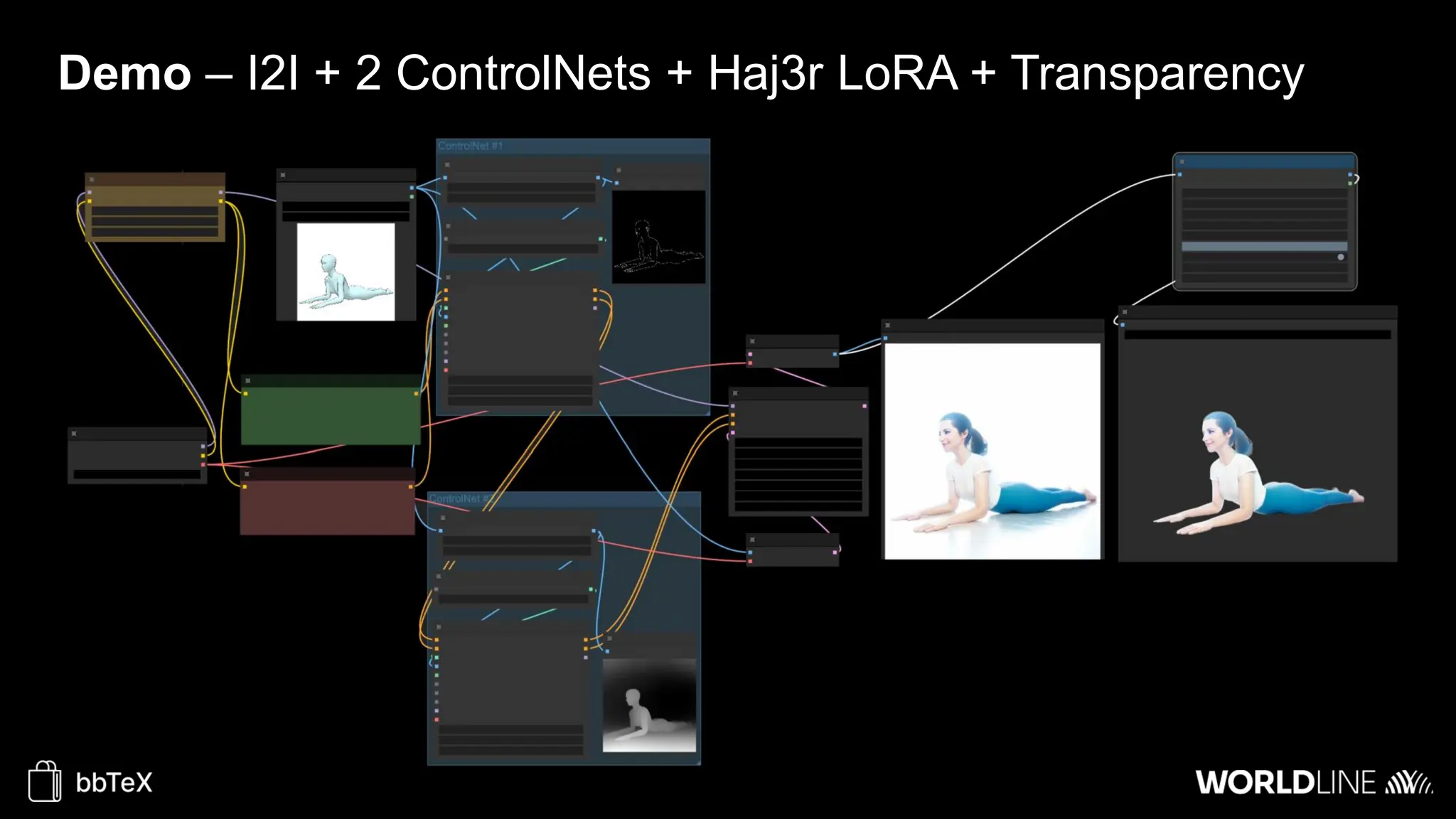

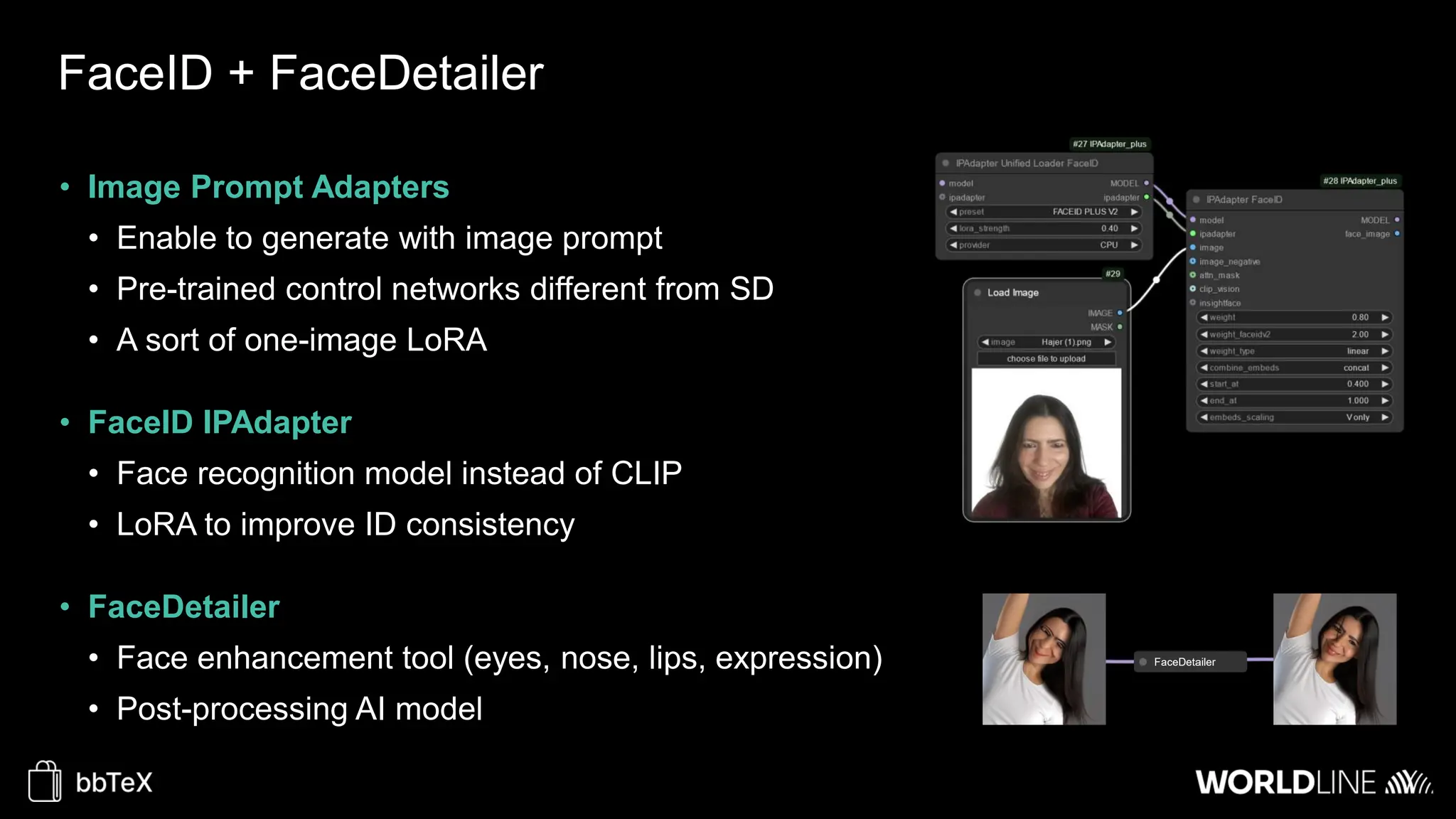
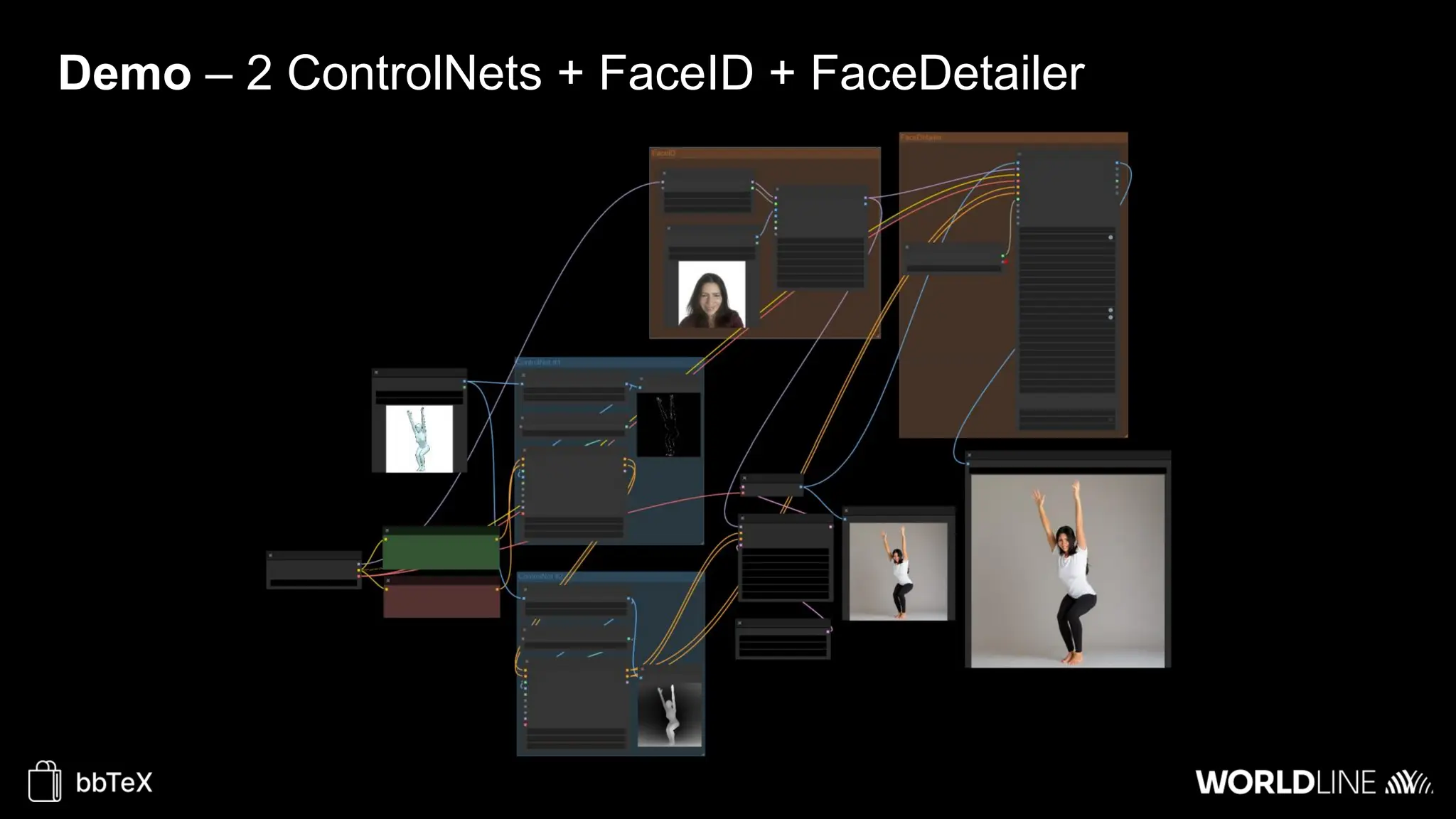




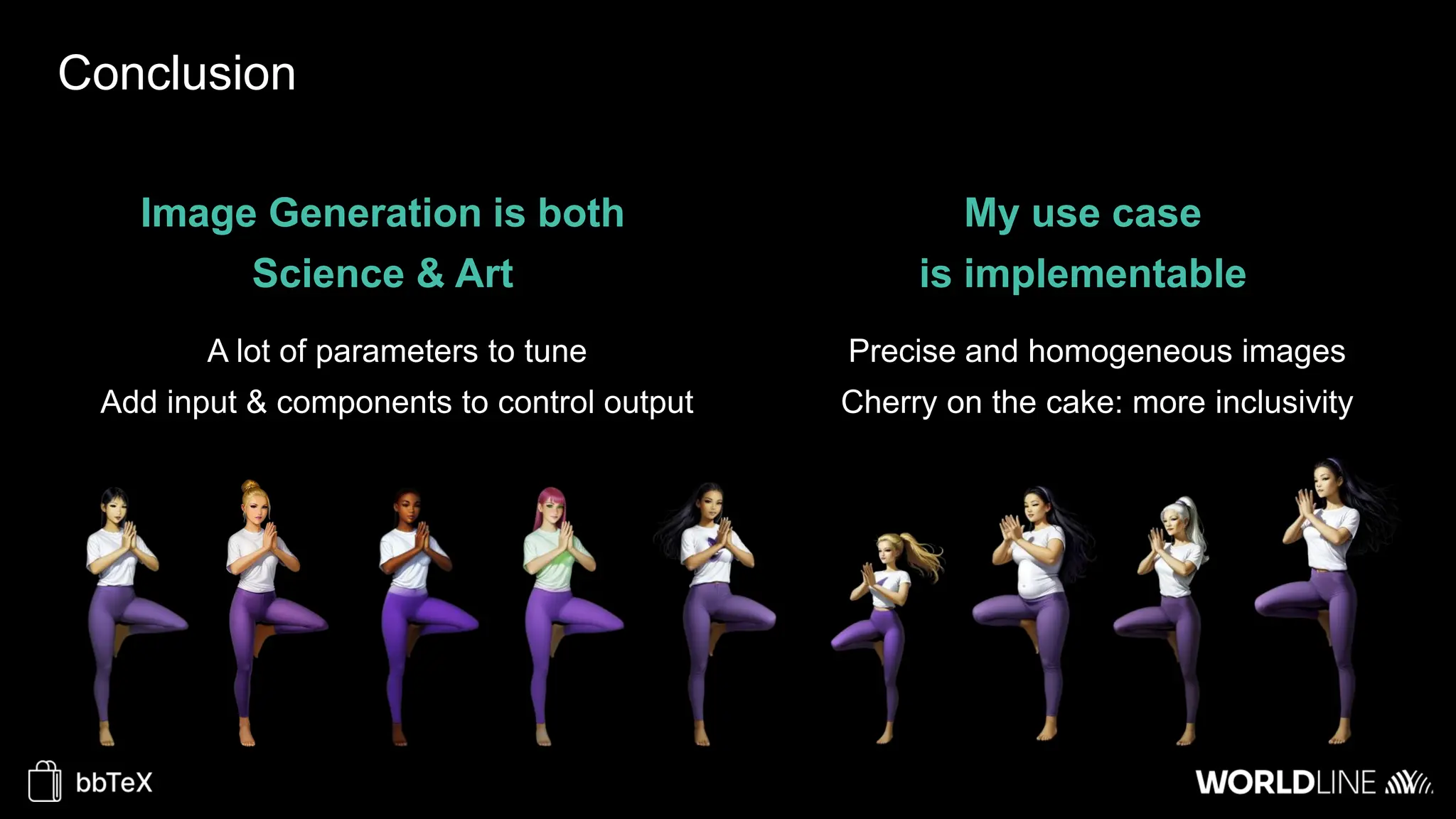



The document discusses the use of stable diffusion for generating precise images of yoga poses through generative AI technology. It highlights various tools, models, and community-driven resources that enable text-to-image and image-to-image generation, including complex customization with control nets and embeddings. The conclusion emphasizes that image generation merges science and art, aiming for inclusivity and precision in the representation of yoga postures.






![[DSC Europe 23] Alexander Kovalchuk - Finetuning Stable Diffusion with low-ra...](https://cdn.slidesharecdn.com/ss_thumbnails/alexanderkovalchukprioritet-finetuningstablediffusionwithlow-rankadaptationtechniques-231129092115-9b99f60b-thumbnail.jpg?width=600ounds&width=560&fit=bounds)














































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)













