TEXT-TO-IMAGE GENERATION USING STABLE DIFFUSION.pptx
1.
TEXT-TO-IMAGE GENERATION USING
STABLEDIFFUSION
Under the supervision of
Dr. P Chandra Shaker Reddy sir
Professor
School of CS &AL
NAME
HALL TICKET
NUMBER
P. Harsha Vardhan Reddy 2103A52180
D. Saketh Reddy 2103A52178
E. Sai Krishna Reddy 2103A52014
T. Deekshitha Rao 2103A52179
E. Swapna 2103A52044
2.
INTRODUCTION
One of themost evocative applications of artificial
intelligence is text-to-image generation. It transforms
textual descriptions into realistic images concerning the
context. Among many approaches to this problem,
Stable Diffusion is one because of its efficiency and
scalability in producing high-quality images.
Built on the principles of diffusion probabilistic models,
Stable Diffusion is an innovative generative model that
exemplifies the current pinnacle of AI-driven creativity.
Stable Diffusion essentially works through a stepwise
process of converting noise into coherent data (images)
based on a textual input prompt.
3.
EXISTING SYSTEM
Limitations:
Currenttext-to-image models, such as DALL-E and Imagen, rely on semantic priors but
cannot reconstruct specific subjects from reference images.
Such models could output variations of the content of image representations but fail to
produce high-fidelity representations of specific subjects in novel contexts.
Language drift: models make associations between the class name and the instance itself
too strong, making diversity in generated results weak.
Capabilities:
Semantic priors are very strong and allow the model to generate diverse instances of
general classes ("dog," "car") by textual description; though.
They can synthesize visually good and coherent images, they are not personalized.
4.
PROPOSED
SYSTEM
Objective:
Stable Diffusion (v1-5):
A pre-trained text-to-image diffusion model
(runwayml/stable-diffusion-v1-5) known for
its ability to generate visually appealing
images from descriptive textual input.
Pre-trained on a large dataset (e.g., LAION-
5B), the model understands diverse textual
prompts and can render corresponding visuals
with remarkable detail.
5.
PROPOSED
SYSTEM
Key Innovations
Fine-tunepre-trained text-to-image models by using a unique
identifier associated with the prompt.
Utilize class-specific knowledge already encoded in the model to
produce diverse and high-fidelity renditions.
Prevents language drift by keeping the total class diversity while
preserving the specificity of the topic.
It ensures that the produced images are contextually diverse yet keep
the core features of the subject under focus.
Applications
Subject Recontextualization: Align specific subjects with completely
different contexts (for instance, a dog in space).
Artistic Rendering: Generate artistic renderings of subjects but
keeping their respective features intact.
Text-Guided View Synthesis: Generate images of subjects in other
views, poses, and lighting conditions.
6.
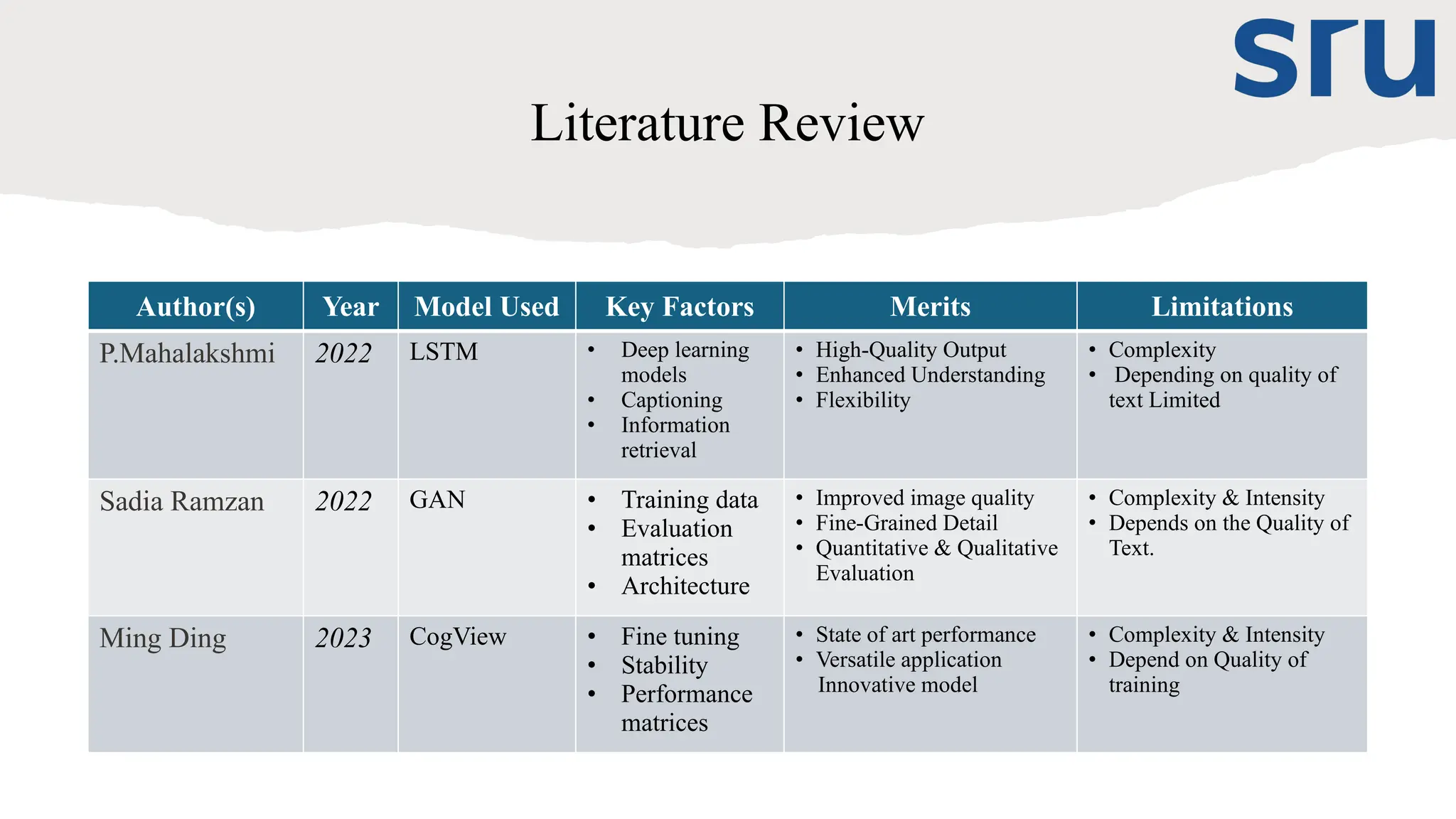
Literature Review
Author(s) YearModel Used Key Factors Merits Limitations
P.Mahalakshmi 2022 LSTM • Deep learning
models
• Captioning
• Information
retrieval
• High-Quality Output
• Enhanced Understanding
• Flexibility
• Complexity
• Depending on quality of
text Limited
Sadia Ramzan 2022 GAN • Training data
• Evaluation
matrices
• Architecture
• Improved image quality
• Fine-Grained Detail
• Quantitative & Qualitative
Evaluation
• Complexity & Intensity
• Depends on the Quality of
Text.
Ming Ding 2023 CogView • Fine tuning
• Stability
• Performance
matrices
• State of art performance
• Versatile application
Innovative model
• Complexity & Intensity
• Depend on Quality of
training
DESIGN
Software Requirements:
OperatingSystem: Windows 11, Linux,
or macOS.
Programming Language: Python 3.8 or
later.
Integrated Development Environment
(IDE): Jupyter Notebook, Google Colab
Pro, or VS Code.
Libraries: PyTorch, Transformers,
Hugging Face Diffusers, NumPy, Pillow,
Matplotlib, Scikit-learn, Gradio (for
Interface).
9.
DESIGN
Hardware Requirements:
Processor(CPU): 2 x 64-bit, 3.0 GHz quad-core CPUs
or better.
Graphics Processing Unit (GPU): NVIDIA GPU with
CUDA support (e.g., NVIDIA RTX 2060 or better).
Memory (RAM): Minimum 16 GB.
Storage: Minimum 50 GB free (preferably SSD for
faster access).
Input Devices: Standard Windows or Mac Keyboard,
Mouse.
Display: Full HD Monitor or better.
10.
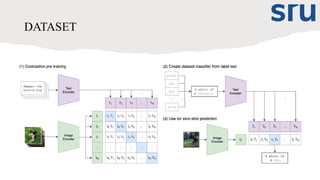
DATASET
The Stable Diffusionmodel was trained using LAION-5B, a publicly available large-scale
dataset containing image-text pairs. It is one of the largest datasets designed for text-to-image
and image-to-text model training. “LAION 5B" is also sometimes referred to as "LAION-
5B“.
Large-Scale Artificial Intelligence Open Network 5 Billion dataset", or simply “The LAION
dataset essentially signifying a massive, open-source collection of 5.85 billion image-text
pairs used for training AI models, particularly in the field of image generation.
"LAION-2B-en" is sometimes used to refer to the English subset of LAION 5B which
contains around 2.3 billion image-text pairs.
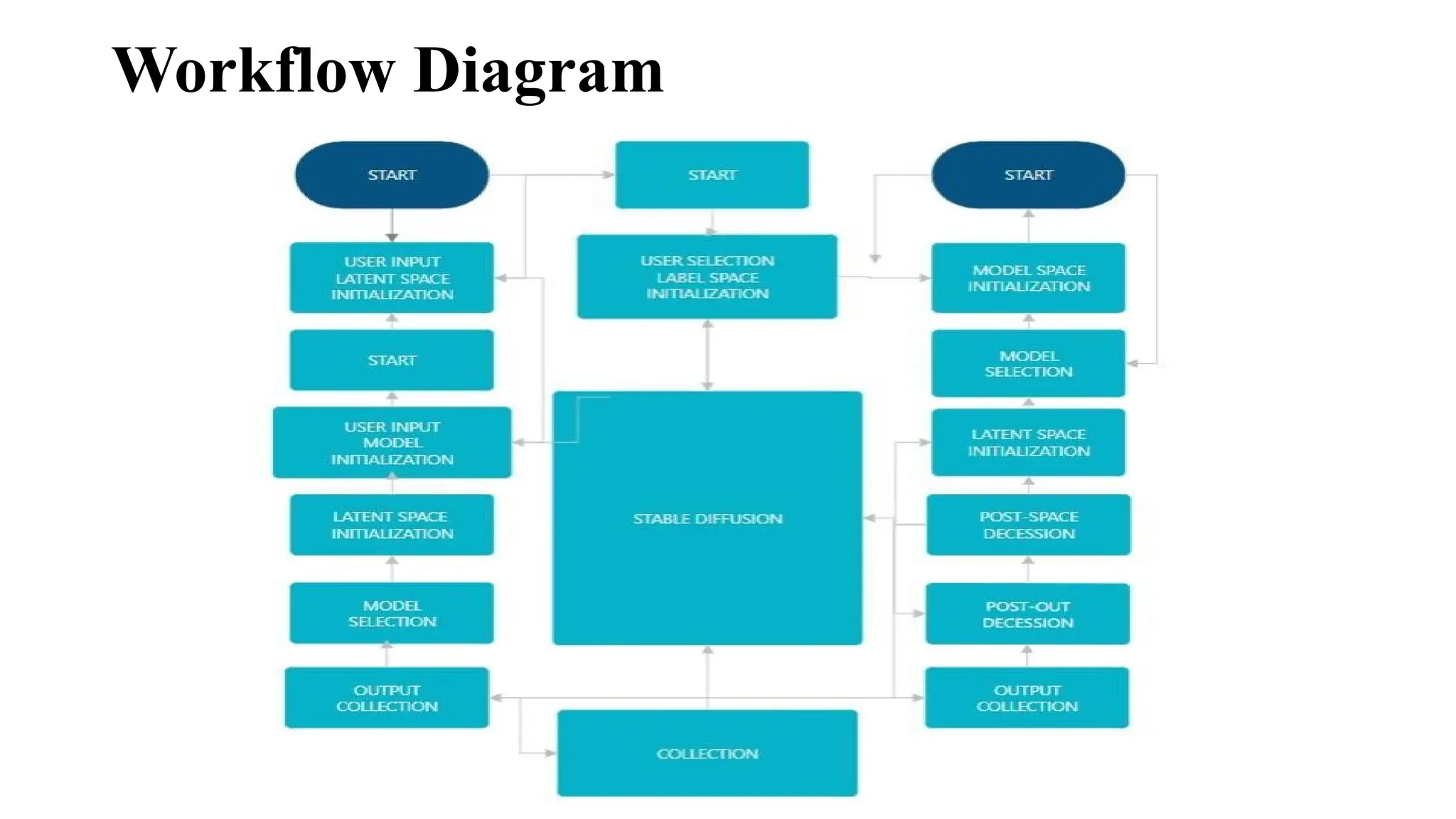
STABLE
DIFFUSION
Stable Diffusion operateson a stepwise process of converting
noise into coherent data (images) based on a textual input prompt.
The approach involves:
• Diffusion Process: Initially, a noisy latent representation of an
image is generated.
• Denoising Process: Through iterative steps, noise is gradually
reduced, conditioned on the input text prompt. This process
employs a pre-trained U-Net architecture for denoising, guided
by the prompt embeddings.
• Text-Conditioning: The model integrates embeddings from a
text encoder, typically based on Transformers like CLIP
(Contrastive Language–Image Pre-training), ensuring the
generated image aligns with the semantic content of the
prompt.
13.
STABLE
DIFFUSION
Latent diffusion isthe research on top of which Stable
Diffusion was built. It was proposed in High-
Resolution Image Synthesis with Latent
Diffusion Models
There are three main components in latent diffusion:
• Autoencoder
• U-Net
• Text Encoder
14.
AUTOENCODER
An autoencoder isdesigned to learn a
compressed version of the input image. A
Variational Autoencoder consists of two
main parts i.e. an encoder and a decoder.
The encoder's task is to compress the
image into a latent form, and then the
decoder uses this latent representation to
recreate the original image.
15.
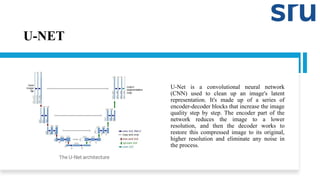
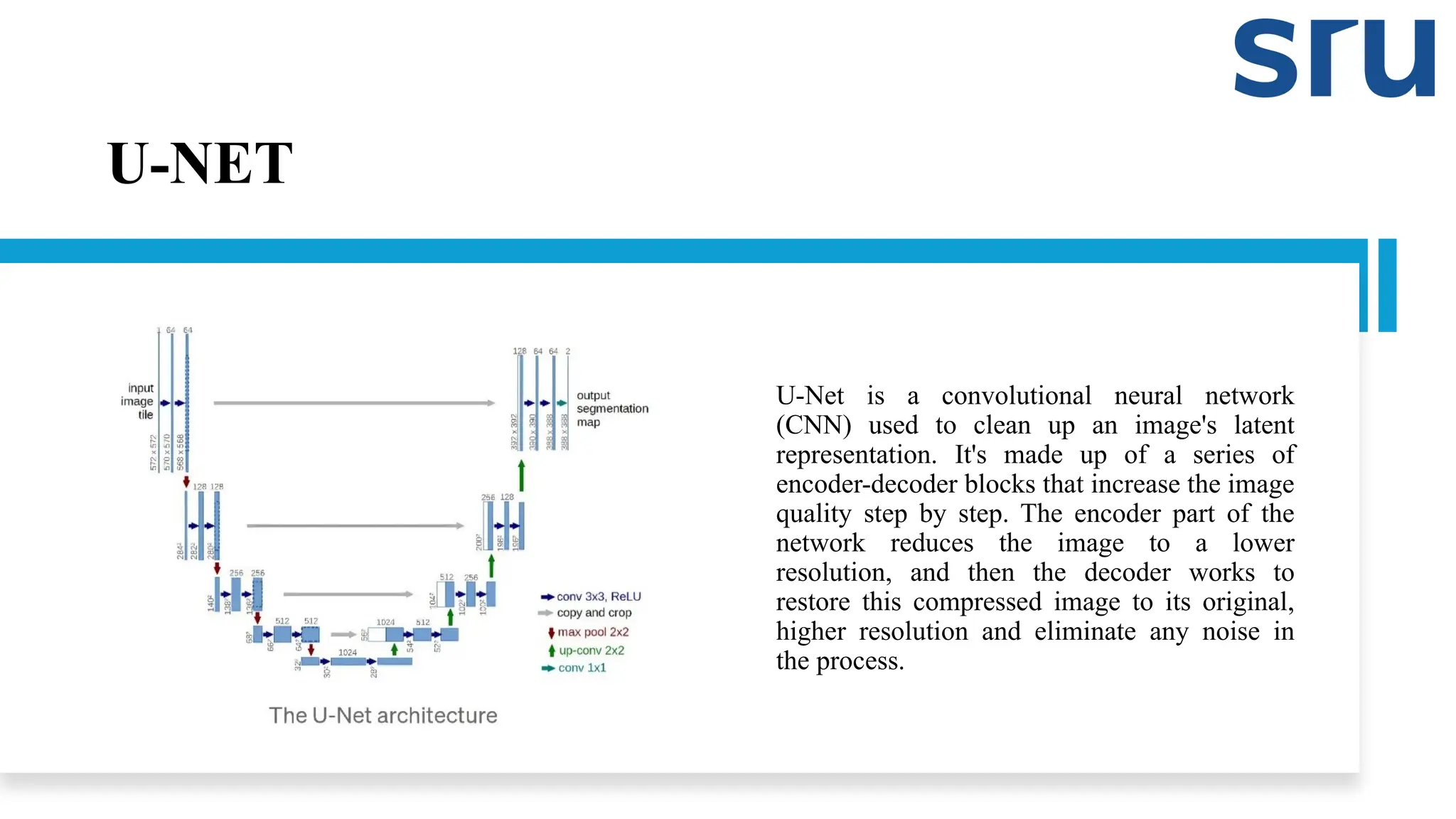
U-NET
U-Net is aconvolutional neural network
(CNN) used to clean up an image's latent
representation. It's made up of a series of
encoder-decoder blocks that increase the image
quality step by step. The encoder part of the
network reduces the image to a lower
resolution, and then the decoder works to
restore this compressed image to its original,
higher resolution and eliminate any noise in
the process.
16.
TEXT ENCODER
The jobof the text encoder is to convert text
prompts into a latent form. Typically, this is
achieved using a transformer-based model,
such as the Text Encoder from CLIP, which
takes a series of input tokens and transforms
them into a sequence of
latent text embeddings.
17.
User
interface
Gradio is anopen-source Python library that simplifies
building User Interfaces (UIs) for machine learning
(ML) models, APIs, or any Python functions. It allows
developers to create interactive interfaces quickly,
which can be used to test, showcase, or deploy models.
In the provided code, Gradio serves as the UI layer for
generating images using the Stable Diffusion model.
18.
Advantages of Gradio
•Rapid Prototyping: Ideal for quickly building interfaces to test and debug ML
models.
• Collaboration: Shareable links allow users or stakeholders to interact with the
model remotely.
• Flexibility: Supports various input/output types (text, image, audio, or video).
• Open Source: Freely available and well-documented for easy integration.
19.
CONCLUSION
The project prioritizesaccessibility and considerations for ethics. It is computationally
efficient and user friendly, thus easily accessible to the individual and even to small
organizations. Additionally, safeguards against misuse include watermarking and input
validation, assuring responsible deployment of AI and avoiding unfairness and other forms of
harm.
It can generate contextual and diverse outputs while keeping the results realistic; this ability is
usually well beyond the capabilities of a generic model. With ethical implications and user-
centric design combined, this project stands as a power gap between generic text-to-image
systems and personalized content creation. The innovation opens doors to more progress in
personalized AI, which empowers users with previously unseen levels of creativity and
functionality.