Downloaded 45 times
















![Creating Drink Nodes
namespace :export
do
require 'csv'
task :generate_drink_nodes => :environment do
CSV.open("drink_nodes.csv", "wb", { :col_sep => "t" }) do |csv|
csv << ["name:string:drink_name_index", "type:label", "name"]
Drink.all.each do |drink|
csv << [drink.name, "Drink", drink.name]
end
end
end
end
17](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/85/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-17-320.jpg)
![Running the Script
• Make sure all nodes, relationships deleted from Neo4j
–
MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r
• Stop your Neo4j server before importing
• Run the import command (per the binary batch
importer we downloaded earlier):
–
./import.sh ~/neo4j-community-2.0/data/graph.db user_nodes.csv
18](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/85/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-18-320.jpg)

![Creating User Nodes
CSV.open("user_nodes.csv", "wb", { :col_sep => "t" }) do |csv|
csv << ["username:string:user_username_index",
"type:label",
"first_name",
"last_name"]
User.all.each do |user|
csv << [user.username, "User", user.first_name, user.last_name]
end
20](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/85/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-20-320.jpg)

![User to User Relationships
CSV.open("user_rels.csv", "wb", { :col_sep => "t" }) do |csv|
csv << ["username:string:user_username_index",
"username:string:user_username_index",
"type"]
User.all.each do |user|
user.following.each do |other_user|
csv << [user.username, other_user.username, "FOLLOWS"]
end
user.followers.each do |other_user|
csv << [other_user.username, user.username, "FOLLOWS"]
end
end
end
22](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/85/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-22-320.jpg)

![User to Drink Relationships
CSV.open("user_drink_rels.csv", "wb", { :col_sep => "t" }) do |csv|
csv <<
["username:string:user_username_index", "name:string:drink_name_index", "type"]
User.all.each do |user|
user.liked_drinks.each do |drink|
csv << [user.username, drink.name, "LIKED"]
end
user.disliked_drinks.each do |drink|
csv << [user.username, drink.name, "DISLIKED"]
end
user.drink_journal_entries.each do |entry|
csv << [user.username, entry.drink.name, "JOURNALED"]
end
end
end
24](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/85/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-24-320.jpg)
![Test Your Data
• Test with some cypher queries
– cheat sheet: http://docs.neo4j.org/refcard/2.0
– ex:
MATCH(n:User)-[r:FOLLOWS]-(o) WHERE
n.username='nickTribeca' RETURN n, r limit 50
• Note: you must limit your results or else the Data
Browser will become too slow to use
25](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/85/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-25-320.jpg)

















![Creating Drink Nodes
namespace :export
do
require 'csv'
task :generate_drink_nodes => :environment do
CSV.open("drink_nodes.csv", "wb", { :col_sep => "t" }) do |csv|
csv << ["name:string:drink_name_index", "type:label", "name"]
Drink.all.each do |drink|
csv << [drink.name, "Drink", drink.name]
end
end
end
end
17](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/75/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-17-2048.jpg)
![Running the Script
• Make sure all nodes, relationships deleted from Neo4j
–
MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r
• Stop your Neo4j server before importing
• Run the import command (per the binary batch
importer we downloaded earlier):
–
./import.sh ~/neo4j-community-2.0/data/graph.db user_nodes.csv
18](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/75/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-18-2048.jpg)

![Creating User Nodes
CSV.open("user_nodes.csv", "wb", { :col_sep => "t" }) do |csv|
csv << ["username:string:user_username_index",
"type:label",
"first_name",
"last_name"]
User.all.each do |user|
csv << [user.username, "User", user.first_name, user.last_name]
end
20](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/75/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-20-2048.jpg)

![User to User Relationships
CSV.open("user_rels.csv", "wb", { :col_sep => "t" }) do |csv|
csv << ["username:string:user_username_index",
"username:string:user_username_index",
"type"]
User.all.each do |user|
user.following.each do |other_user|
csv << [user.username, other_user.username, "FOLLOWS"]
end
user.followers.each do |other_user|
csv << [other_user.username, user.username, "FOLLOWS"]
end
end
end
22](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/75/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-22-2048.jpg)

![User to Drink Relationships
CSV.open("user_drink_rels.csv", "wb", { :col_sep => "t" }) do |csv|
csv <<
["username:string:user_username_index", "name:string:drink_name_index", "type"]
User.all.each do |user|
user.liked_drinks.each do |drink|
csv << [user.username, drink.name, "LIKED"]
end
user.disliked_drinks.each do |drink|
csv << [user.username, drink.name, "DISLIKED"]
end
user.drink_journal_entries.each do |entry|
csv << [user.username, entry.drink.name, "JOURNALED"]
end
end
end
24](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/75/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-24-2048.jpg)
![Test Your Data
• Test with some cypher queries
– cheat sheet: http://docs.neo4j.org/refcard/2.0
– ex:
MATCH(n:User)-[r:FOLLOWS]-(o) WHERE
n.username='nickTribeca' RETURN n, r limit 50
• Note: you must limit your results or else the Data
Browser will become too slow to use
25](https://image.slidesharecdn.com/nycneo4jmeetup4slides-140218090221-phpapp01/75/Migrating-from-MongoDB-to-Neo4j-Lessons-Learned-25-2048.jpg)



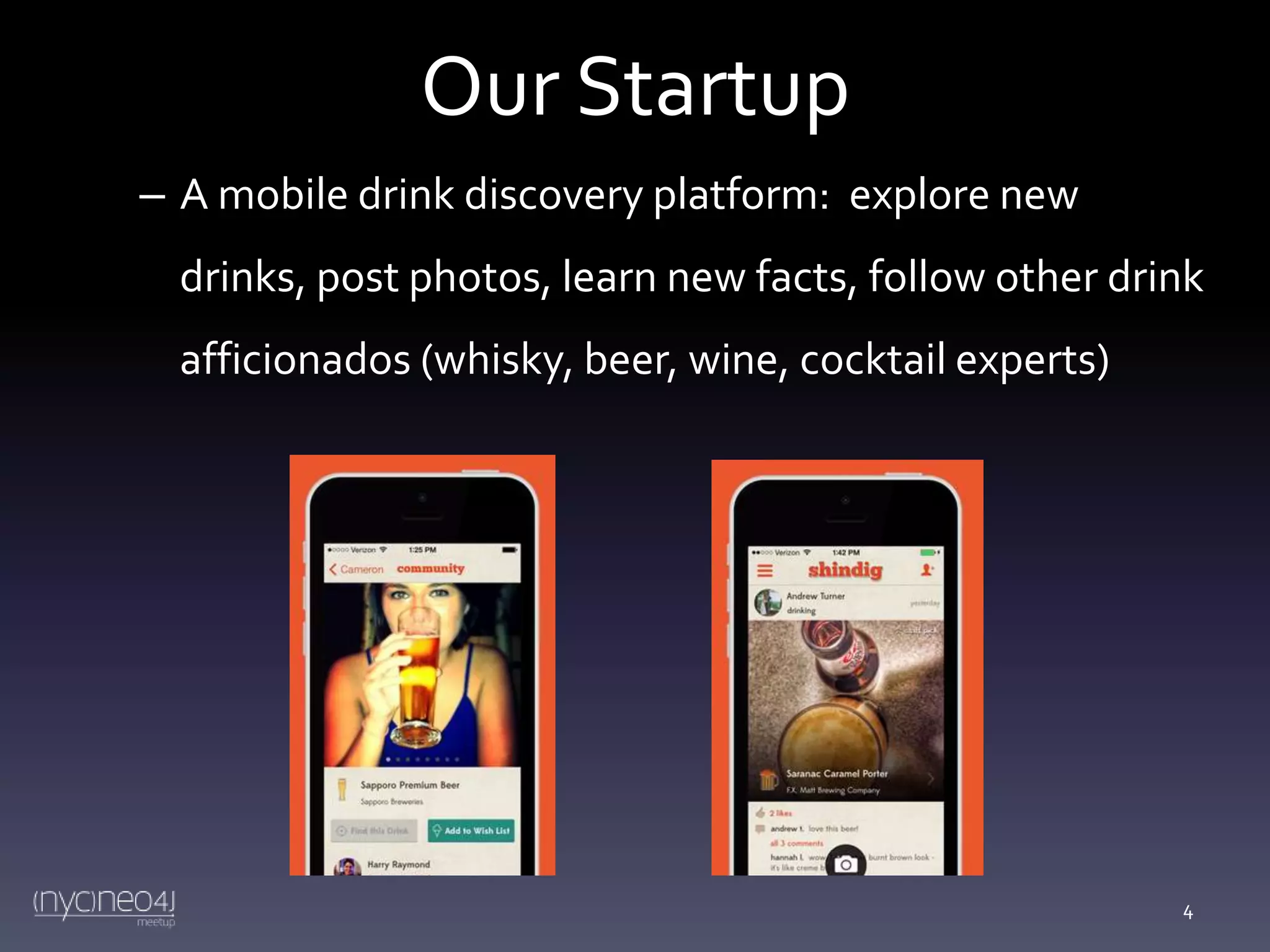
The document outlines a meetup discussing the migration from MongoDB to Neo4j, featuring an agenda that includes introductions, a case study, and group discussions on experiences with these databases. It details the startup's transition, motivations for change, evaluation methods, findings on performance improvements, and a tutorial on using the batch importer for data migration. Participants shared insights on data modeling, query optimization, and database management strategies.



































































