Downloaded 177 times




























![Flexible Schema
RDBMS
MongoDB
{
_id :
ObjectId("4c4ba5e5e8aabf3"),
employee_name: "Dunham, Justin",
department : "Marketing",
title : "Product Manager, Web",
report_up: "Neray, Graham",
pay_band: “C",
benefits : [
{ type : "Health",
plan : "PPO Plus" },
{ type :
"Dental",
plan : "Standard" }
]
}](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-37-320.jpg)











![Logical operators
// Find documents using OR
> db.user.find(
{$or : [ { name : “Sheldon“ },
{ mail : amy@bigbang.com }
]
})
// Find documents using AND
> db.user.find(
{$and : [ { name : “Sheldon“ },
{ mail : amy@bigbang.com }
]
})](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-61-320.jpg)



![Adding to arrays
// Adding a array
> db.user.update( {name : “Sheldon“ },
{ $set : {enemies :
[ { name : “Wil Wheaton“ },
{ name : “Barry Kripke“ }
]
}})
// Adding a value to the array
> db.user.update( { name : “Sheldon“},
{ $push : {enemies :
{ name : “Leslie Winkle“}
}})](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-66-320.jpg)








![What can be indexed?
// Multiple fields (Compound Key Indexes)
> db.recipes.ensureIndex({
main_ingredient: 1,
calories: -1
})
// Arrays with values (Multikey Indexes)
{
name: 'Chicken Noodle Soup’,
ingredients : ['chicken', 'noodles']
}
> db.recipes.ensureIndex({ ingredients: 1 })](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-82-320.jpg)





![Geospatial Index
// Add longitude and altitude
{
name: ‚codecentric Frankfurt’,
loc: [ 50.11678, 8.67206]
}
// Index the 2D coordinates
> db.locations.ensureIndex( { loc : '2d' } )
// Find locations near codecentric Frankfurt
> db.locations.find({
loc: { $near: [ 50.1, 8.7 ] }
})](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-88-320.jpg)















![Indices with low selectivity
// The following field has only few distinct values
> db.collection.distinct('status’)
[ 'new', 'processed' ]
// A index on this field is not the best idea…
> db.collection.ensureIndex({ status: 1 })
> db.collection.find({ status: 'new' })
// Better use a adequate compound index with other fields
> db.collection.ensureIndex({ status: 1, created_at: -1 })
> db.collection.find(
{ status: 'new' }
).sort({ created_at: -1 })](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-105-320.jpg)

![Negations & Indices
// Negations can not make use of indices
> db.things.ensureIndex({ x: 1 })
// e.g. queries using not equal
> db.things.find({ x: { $ne: 3 } })
// …or queries with not in
> db.things.find({ x: { $nin: [2, 3, 4 ] } })
// …or queries with the $not operator
> db.people.find({ name: { $not: 'John Doe' } })](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-107-320.jpg)





![Word Count: Reduce
INPUT
{
MongoDB
uses
MapReduce
}
MAPPER
GROUP/SORT
REDUCER
(doc1,
“…“)
(a, [1, 1])
(is, [1, 1])
(map, [1])
{
There is a
map phase
}
(doc2,
“…“)
(mapreduce, [1])
(mongodb, [1])
(phase, [1, 1])
{
There is a
reduce
phase
}
(doc3,
“…“)
(reduce, [1])
(there, [1, 1])
(uses, [1])
OUTPUT](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-116-320.jpg)
![Word Count: Result
INPUT
{
MongoDB
uses
MapReduce
}
MAPPER
GROUP/SORT
REDUCER
OUTPUT
(doc1,
“…“)
(a, [1, 1])
(is, [1, 1])
(map, [1])
a: 2
is: 2
map: 1
{
There is a
map phase
}
(doc2,
“…“)
(mapreduce, [1])
(mongodb, [1])
(phase, [1, 1])
mapreduce: 1
mongodb: 1
phase: 2
{
There is a
reduce
phase
}
(doc3,
“…“)
(reduce, [1])
(there, [1, 1])
(uses, [1])
reduce: 1
there: 2
uses: 1](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-117-320.jpg)
![Word Count: In a nutshell
INPUT
{
MongoDB
uses
MapReduce
}
MAPPER
GROUP/SORT
(doc1,
“…“)
REDUCER
(a, [1, 1])
(is, [1, 1])
(map, [1])
OUTPUT
a: 2
is: 2
map: 1
map()
reduce()
Transforms one keyvalue-pair in 0–N keyvalue-pairs
Reduces 0-N keyvalue-pairs into one
key-value-pair](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-118-320.jpg)













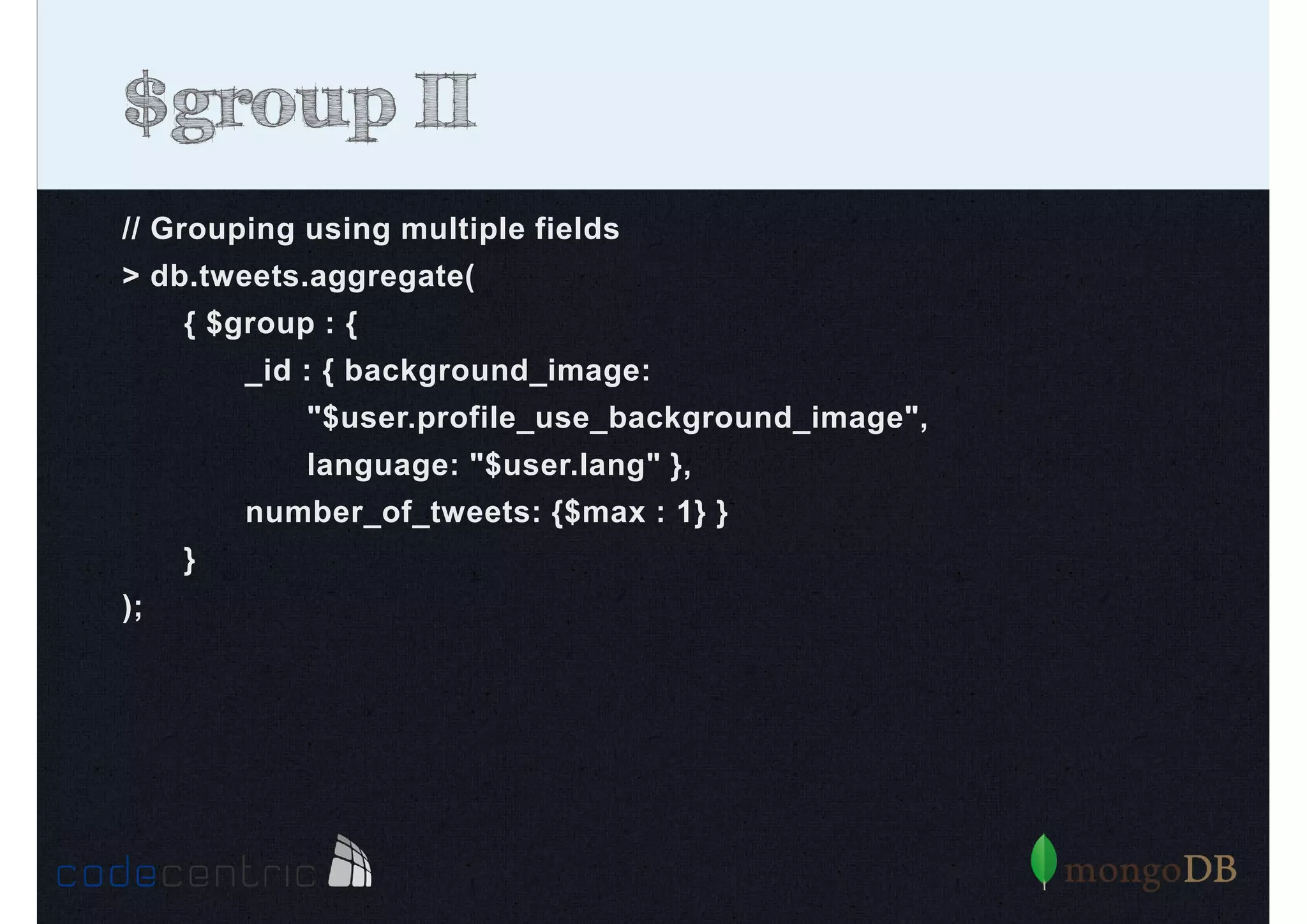
![$project II
// Rename a field
> db.tweets.aggregate(
{ $project : {_id: 0, content_of_tweet : "$text"} },
);
// Add a calculated field
> db.tweets.aggregate(
{ $project : {_id: 0, content_of_tweet : "$text", number_of_friends :
{$add: ["$user.friends_count", 10]} } },
);](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-144-320.jpg)
![$project III
// Add a subdocument
> db.tweets.aggregate(
{ $project : {_id: 0,
content_of_tweet : "$text",
user : {
name : "$user.name",
number_of_friends : {$add: ["$user.friends_count", 10]}
}
} } );](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-145-320.jpg)


![$unwind II
// Resulting document without $unwind
{
„content_of_tweet" : "RT @Philanthropy: How should
nonprofit groups measure their social-media efforts? A
new podcast from @afine http://ht.ly/2yFlS",
„mentioned_users" : [
"Philanthropy",
"Allison Fine"
]
}](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-151-320.jpg)






![Example: Online shopping
{
cust_id: “sheldon1",
ord_date:
ISODate("2013-04-018T19:38:11.102Z"),
status: ‘purchased',
price: 105,69,
items:
[ { sku: “nobel_price_replica",
qty: 3, price: 29,90 },
{ sku: “wheaton_voodoo_doll",
qty: 1, price: 15,99 } ]
}](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-159-320.jpg)
![Count all orders
SQL
MongoDB Aggregation
SELECT COUNT(*) AS
count FROM orders
db.orders.aggregate( [ {
$group: { _id: null,
count: { $sum: 1 } }
}])](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-160-320.jpg)
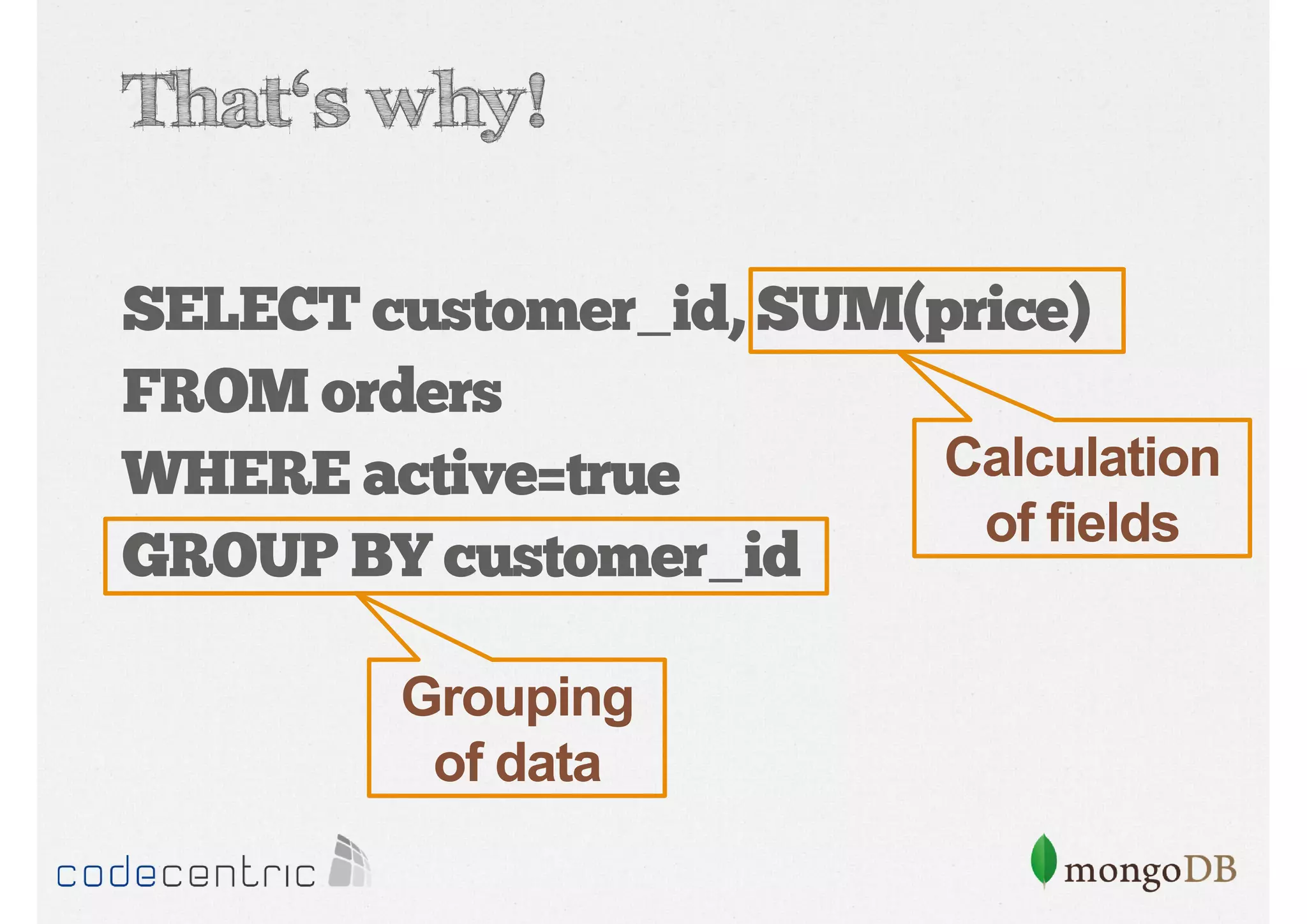
![Average order price per customer
SQL
MongoDB Aggregation
SELECT cust_id, SUM(price)
AS total FROM orders
GROUP BY cust_id ORDER
BY total
db.orders.aggregate( [ {
$group: { _id: "$cust_id",
total: { $sum: "$price" } } },
{ $sort: { total: 1 }
}])](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-161-320.jpg)
![Sum up all orders over 250$
SQL
MongoDB Aggregation
SELECT cust_id, SUM(price) as db.orders.aggregate( [ {
$match: { status: 'A' } },
total
{ $group: { _id: "$cust_id",
FROM orders
WHERE status = ‘purchased'
total: { $sum: "$price" } } },
GROUP BY cust_id
{ $match: { total: { $gt: 250
HAVING total > 250
}}}])](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-162-320.jpg)






![Configuration I
> conf = {
_id : "mySet",
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-176-320.jpg)
![Configuration II
> conf = {
_id : "mySet”,
members : [
Primary data center
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-177-320.jpg)
![Configuration III
> conf = {
_id : "mySet”,
members : [
Secondary data center
(Default priority = 1)
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-178-320.jpg)
![Configuration IV
> conf = {
_id : "mySet”,
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
Analytical data e.g. for
Hadoop, Storm, BI, …
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-179-320.jpg)
![Configuration V
> conf = {
_id : "mySet”,
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)
Back-up node](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-180-320.jpg)



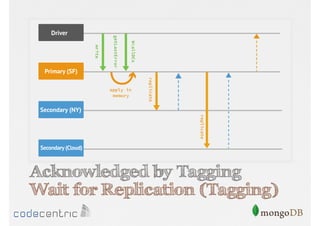
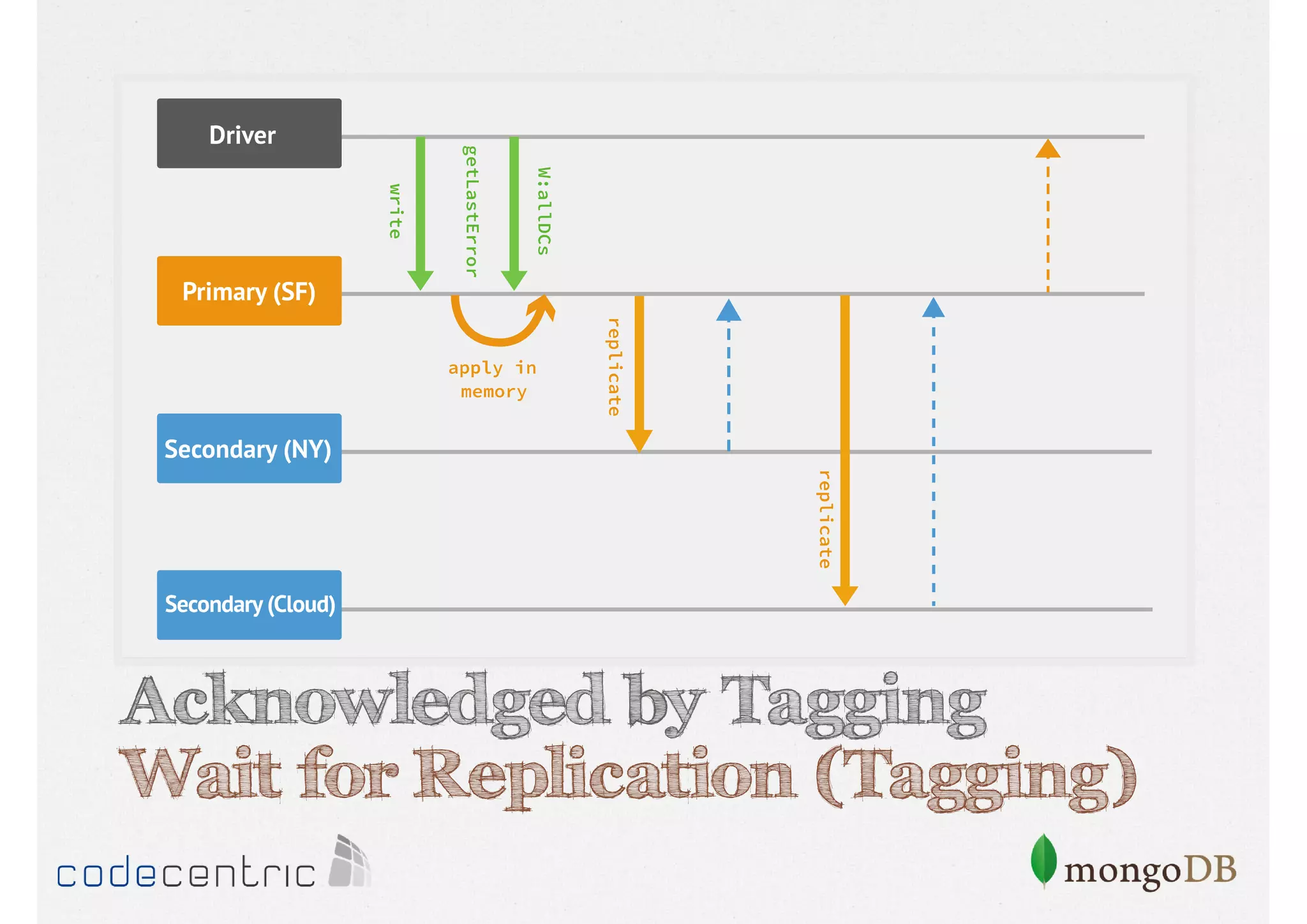
![Tagging - Example
{
_id : "mySet",
members : [
{_id : 0, host : "A", tags : {"dc": "ny"}},
{_id : 1, host : "B", tags : {"dc": "ny"}},
{_id : 2, host : "C", tags : {"dc": "sf"}},
{_id : 3, host : "D", tags : {"dc": "sf"}},
{_id : 4, host : "E", tags : {"dc": "cloud"}}],
settings : {
getLastErrorModes : {
allDCs : {"dc" : 3},
someDCs : {"dc" : 2}} }
}
> db.blogs.insert({...})
> db.runCommand({getLastError : 1, w : "someDCs"})](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-190-320.jpg)


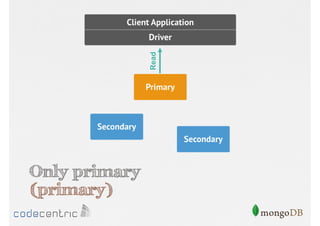
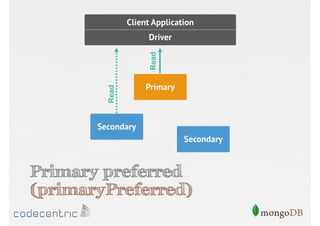

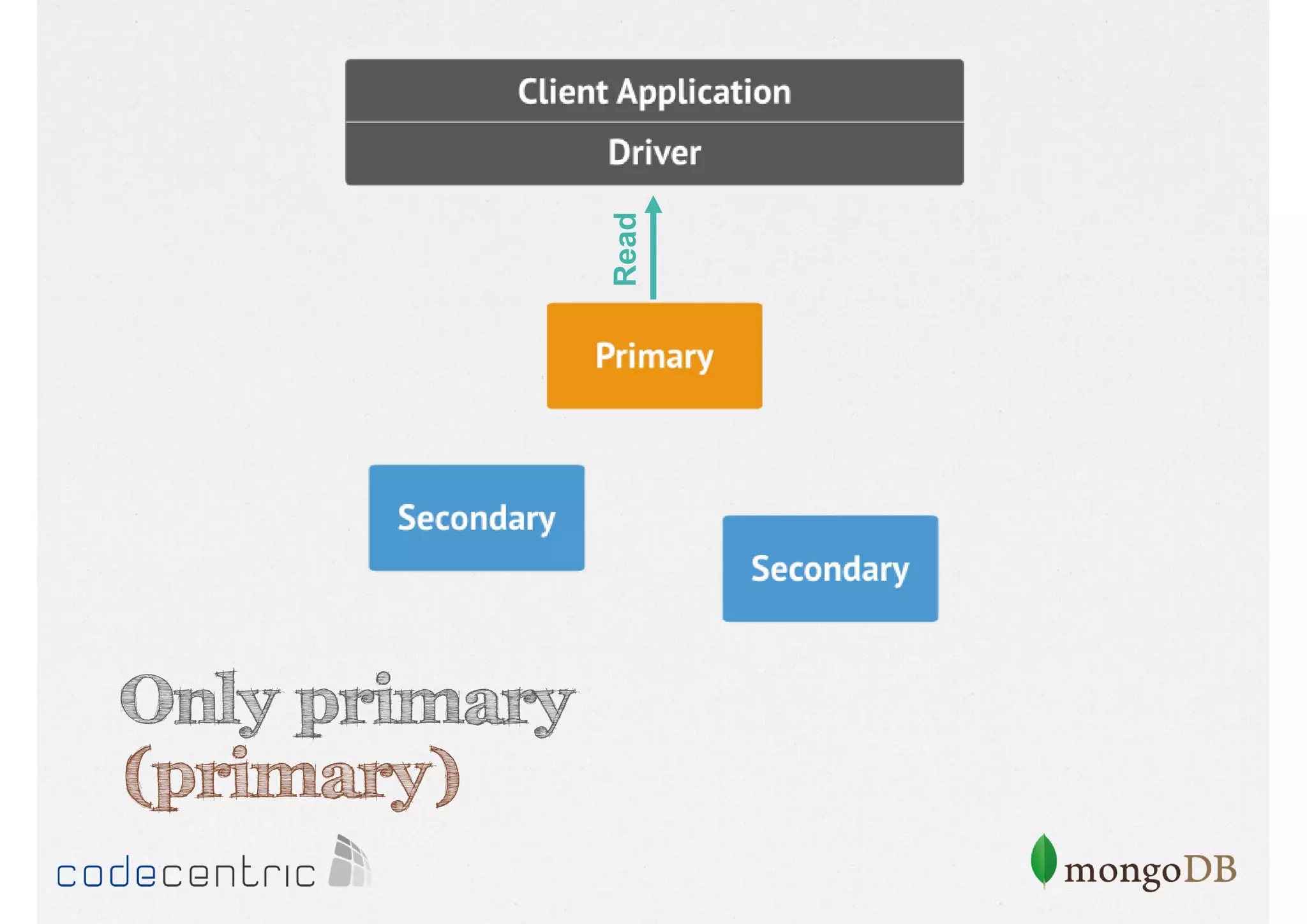
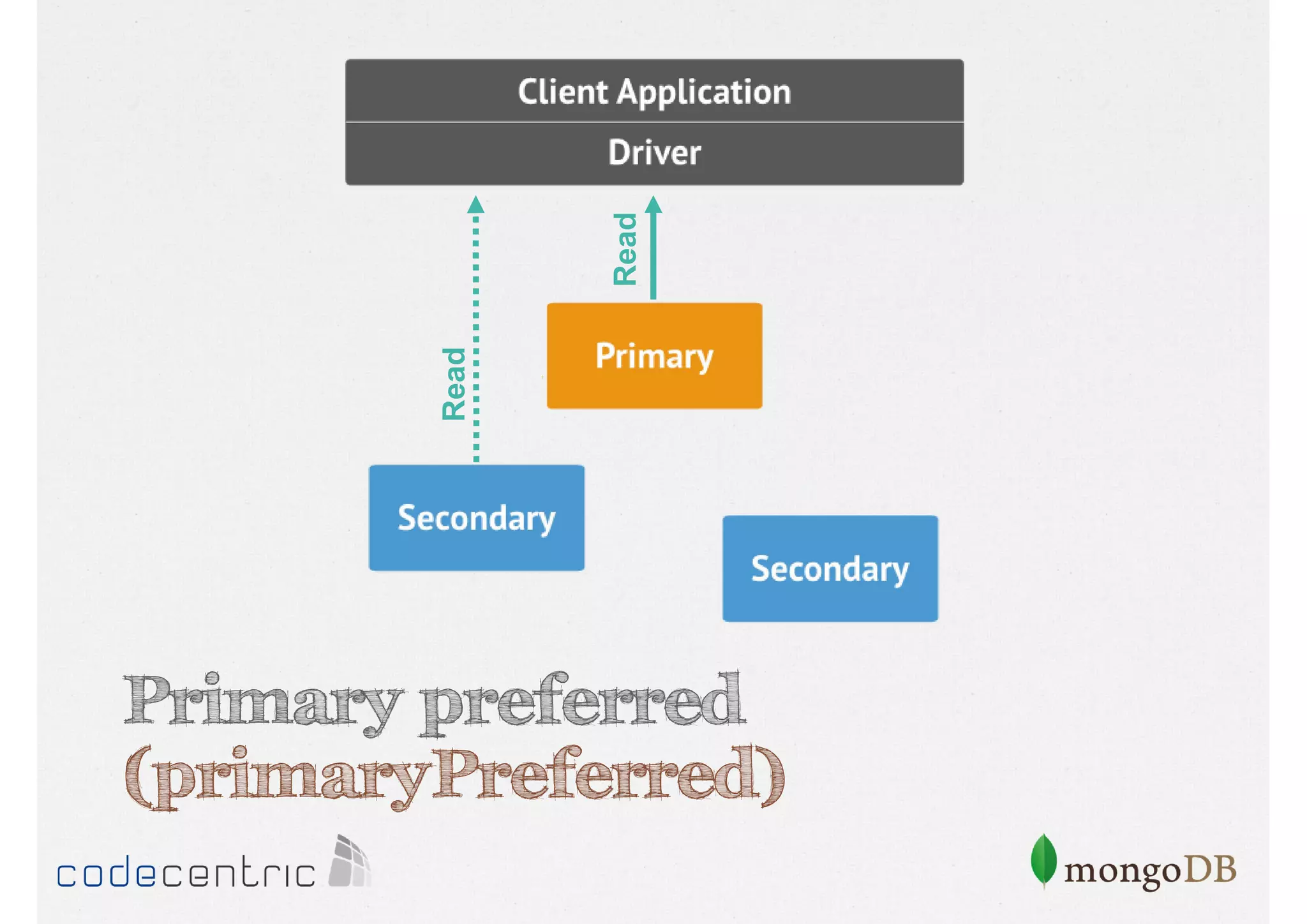
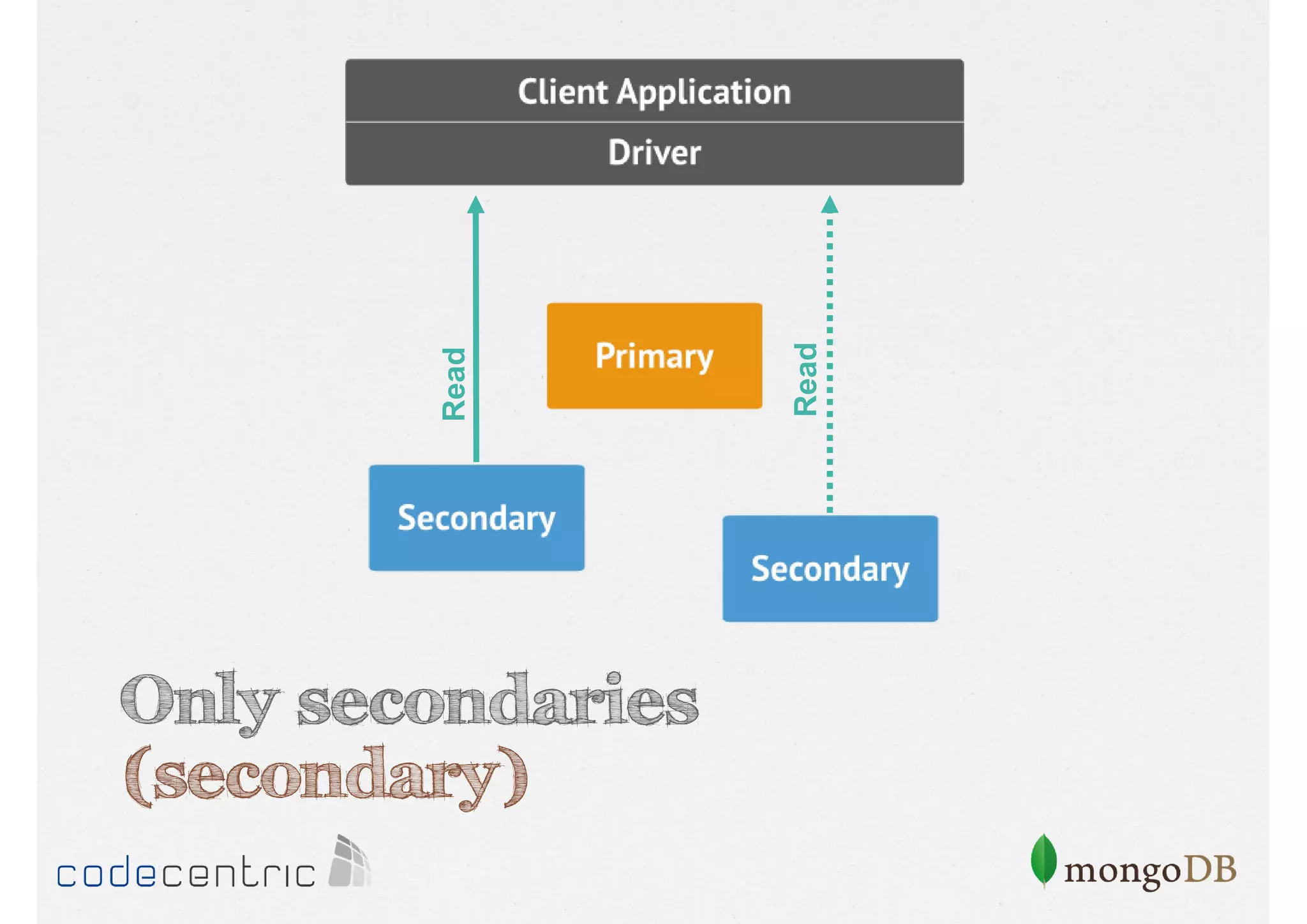
![Configure the Read Concern
// Only primary
> cursor.setReadPref( “primary" )
// Primary preferred
> cursor.setReadPref( “primaryPreferred" )
…
// Only secondaries with tagging
> cursor.setReadPref( “secondary“, [ rack : 2 ] )
Read Concern must be configured
before using the cursor to read data!](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-200-320.jpg)


















![Check configuration
// Check if the shard has been added
> db.runCommand({ listShards:1 })
{ "shards" :
[ { "_id”: "shard0000”, "host”: ”<hostname>:27018” } ],
"ok" : 1
}](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/85/MongoDB-for-Coder-Training-Coding-Serbia-2013-234-320.jpg)











































![Flexible Schema
RDBMS
MongoDB
{
_id :
ObjectId("4c4ba5e5e8aabf3"),
employee_name: "Dunham, Justin",
department : "Marketing",
title : "Product Manager, Web",
report_up: "Neray, Graham",
pay_band: “C",
benefits : [
{ type : "Health",
plan : "PPO Plus" },
{ type :
"Dental",
plan : "Standard" }
]
}](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-37-2048.jpg)












![Logical operators
// Find documents using OR
> db.user.find(
{$or : [ { name : “Sheldon“ },
{ mail : amy@bigbang.com }
]
})
// Find documents using AND
> db.user.find(
{$and : [ { name : “Sheldon“ },
{ mail : amy@bigbang.com }
]
})](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-61-2048.jpg)


![Adding to arrays
// Adding a array
> db.user.update( {name : “Sheldon“ },
{ $set : {enemies :
[ { name : “Wil Wheaton“ },
{ name : “Barry Kripke“ }
]
}})
// Adding a value to the array
> db.user.update( { name : “Sheldon“},
{ $push : {enemies :
{ name : “Leslie Winkle“}
}})](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-66-2048.jpg)








![What can be indexed?
// Multiple fields (Compound Key Indexes)
> db.recipes.ensureIndex({
main_ingredient: 1,
calories: -1
})
// Arrays with values (Multikey Indexes)
{
name: 'Chicken Noodle Soup’,
ingredients : ['chicken', 'noodles']
}
> db.recipes.ensureIndex({ ingredients: 1 })](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-82-2048.jpg)





![Geospatial Index
// Add longitude and altitude
{
name: ‚codecentric Frankfurt’,
loc: [ 50.11678, 8.67206]
}
// Index the 2D coordinates
> db.locations.ensureIndex( { loc : '2d' } )
// Find locations near codecentric Frankfurt
> db.locations.find({
loc: { $near: [ 50.1, 8.7 ] }
})](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-88-2048.jpg)















![Indices with low selectivity
// The following field has only few distinct values
> db.collection.distinct('status’)
[ 'new', 'processed' ]
// A index on this field is not the best idea…
> db.collection.ensureIndex({ status: 1 })
> db.collection.find({ status: 'new' })
// Better use a adequate compound index with other fields
> db.collection.ensureIndex({ status: 1, created_at: -1 })
> db.collection.find(
{ status: 'new' }
).sort({ created_at: -1 })](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-105-2048.jpg)

![Negations & Indices
// Negations can not make use of indices
> db.things.ensureIndex({ x: 1 })
// e.g. queries using not equal
> db.things.find({ x: { $ne: 3 } })
// …or queries with not in
> db.things.find({ x: { $nin: [2, 3, 4 ] } })
// …or queries with the $not operator
> db.people.find({ name: { $not: 'John Doe' } })](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-107-2048.jpg)





![Word Count: Reduce
INPUT
{
MongoDB
uses
MapReduce
}
MAPPER
GROUP/SORT
REDUCER
(doc1,
“…“)
(a, [1, 1])
(is, [1, 1])
(map, [1])
{
There is a
map phase
}
(doc2,
“…“)
(mapreduce, [1])
(mongodb, [1])
(phase, [1, 1])
{
There is a
reduce
phase
}
(doc3,
“…“)
(reduce, [1])
(there, [1, 1])
(uses, [1])
OUTPUT](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-116-2048.jpg)
![Word Count: Result
INPUT
{
MongoDB
uses
MapReduce
}
MAPPER
GROUP/SORT
REDUCER
OUTPUT
(doc1,
“…“)
(a, [1, 1])
(is, [1, 1])
(map, [1])
a: 2
is: 2
map: 1
{
There is a
map phase
}
(doc2,
“…“)
(mapreduce, [1])
(mongodb, [1])
(phase, [1, 1])
mapreduce: 1
mongodb: 1
phase: 2
{
There is a
reduce
phase
}
(doc3,
“…“)
(reduce, [1])
(there, [1, 1])
(uses, [1])
reduce: 1
there: 2
uses: 1](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-117-2048.jpg)
![Word Count: In a nutshell
INPUT
{
MongoDB
uses
MapReduce
}
MAPPER
GROUP/SORT
(doc1,
“…“)
REDUCER
(a, [1, 1])
(is, [1, 1])
(map, [1])
OUTPUT
a: 2
is: 2
map: 1
map()
reduce()
Transforms one keyvalue-pair in 0–N keyvalue-pairs
Reduces 0-N keyvalue-pairs into one
key-value-pair](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-118-2048.jpg)













![$project II
// Rename a field
> db.tweets.aggregate(
{ $project : {_id: 0, content_of_tweet : "$text"} },
);
// Add a calculated field
> db.tweets.aggregate(
{ $project : {_id: 0, content_of_tweet : "$text", number_of_friends :
{$add: ["$user.friends_count", 10]} } },
);](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-144-2048.jpg)
![$project III
// Add a subdocument
> db.tweets.aggregate(
{ $project : {_id: 0,
content_of_tweet : "$text",
user : {
name : "$user.name",
number_of_friends : {$add: ["$user.friends_count", 10]}
}
} } );](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-145-2048.jpg)


![$unwind II
// Resulting document without $unwind
{
„content_of_tweet" : "RT @Philanthropy: How should
nonprofit groups measure their social-media efforts? A
new podcast from @afine http://ht.ly/2yFlS",
„mentioned_users" : [
"Philanthropy",
"Allison Fine"
]
}](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-151-2048.jpg)






![Example: Online shopping
{
cust_id: “sheldon1",
ord_date:
ISODate("2013-04-018T19:38:11.102Z"),
status: ‘purchased',
price: 105,69,
items:
[ { sku: “nobel_price_replica",
qty: 3, price: 29,90 },
{ sku: “wheaton_voodoo_doll",
qty: 1, price: 15,99 } ]
}](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-159-2048.jpg)
![Count all orders
SQL
MongoDB Aggregation
SELECT COUNT(*) AS
count FROM orders
db.orders.aggregate( [ {
$group: { _id: null,
count: { $sum: 1 } }
}])](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-160-2048.jpg)
![Average order price per customer
SQL
MongoDB Aggregation
SELECT cust_id, SUM(price)
AS total FROM orders
GROUP BY cust_id ORDER
BY total
db.orders.aggregate( [ {
$group: { _id: "$cust_id",
total: { $sum: "$price" } } },
{ $sort: { total: 1 }
}])](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-161-2048.jpg)
![Sum up all orders over 250$
SQL
MongoDB Aggregation
SELECT cust_id, SUM(price) as db.orders.aggregate( [ {
$match: { status: 'A' } },
total
{ $group: { _id: "$cust_id",
FROM orders
WHERE status = ‘purchased'
total: { $sum: "$price" } } },
GROUP BY cust_id
{ $match: { total: { $gt: 250
HAVING total > 250
}}}])](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-162-2048.jpg)






![Configuration I
> conf = {
_id : "mySet",
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-176-2048.jpg)
![Configuration II
> conf = {
_id : "mySet”,
members : [
Primary data center
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-177-2048.jpg)
![Configuration III
> conf = {
_id : "mySet”,
members : [
Secondary data center
(Default priority = 1)
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-178-2048.jpg)
![Configuration IV
> conf = {
_id : "mySet”,
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
Analytical data e.g. for
Hadoop, Storm, BI, …
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-179-2048.jpg)
![Configuration V
> conf = {
_id : "mySet”,
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)
Back-up node](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-180-2048.jpg)



![Tagging - Example
{
_id : "mySet",
members : [
{_id : 0, host : "A", tags : {"dc": "ny"}},
{_id : 1, host : "B", tags : {"dc": "ny"}},
{_id : 2, host : "C", tags : {"dc": "sf"}},
{_id : 3, host : "D", tags : {"dc": "sf"}},
{_id : 4, host : "E", tags : {"dc": "cloud"}}],
settings : {
getLastErrorModes : {
allDCs : {"dc" : 3},
someDCs : {"dc" : 2}} }
}
> db.blogs.insert({...})
> db.runCommand({getLastError : 1, w : "someDCs"})](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-190-2048.jpg)



![Configure the Read Concern
// Only primary
> cursor.setReadPref( “primary" )
// Primary preferred
> cursor.setReadPref( “primaryPreferred" )
…
// Only secondaries with tagging
> cursor.setReadPref( “secondary“, [ rack : 2 ] )
Read Concern must be configured
before using the cursor to read data!](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-200-2048.jpg)



















![Check configuration
// Check if the shard has been added
> db.runCommand({ listShards:1 })
{ "shards" :
[ { "_id”: "shard0000”, "host”: ”<hostname>:27018” } ],
"ok" : 1
}](https://image.slidesharecdn.com/mongodbtrainingcodingserbia2013-131020110328-phpapp01/75/MongoDB-for-Coder-Training-Coding-Serbia-2013-234-2048.jpg)










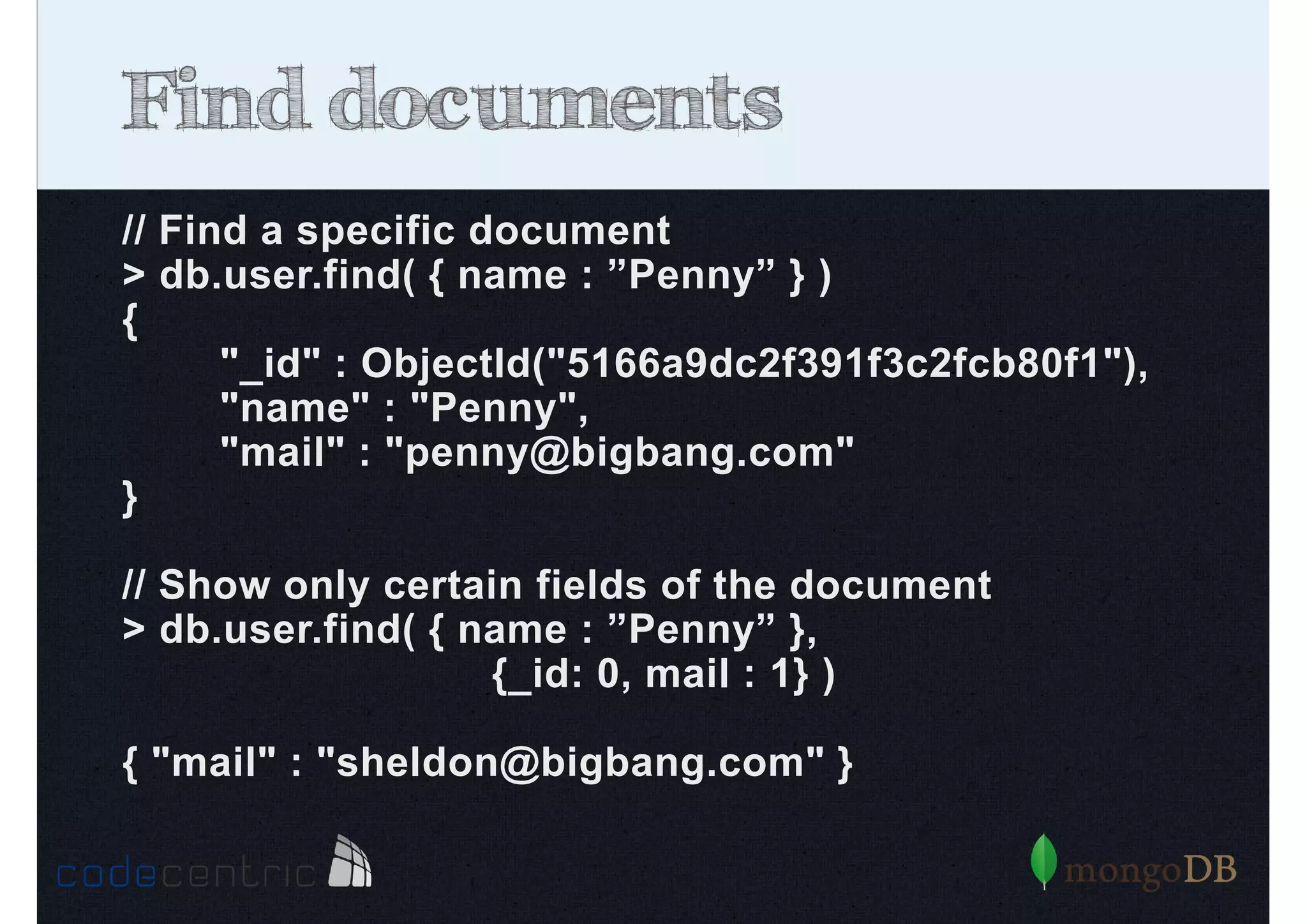
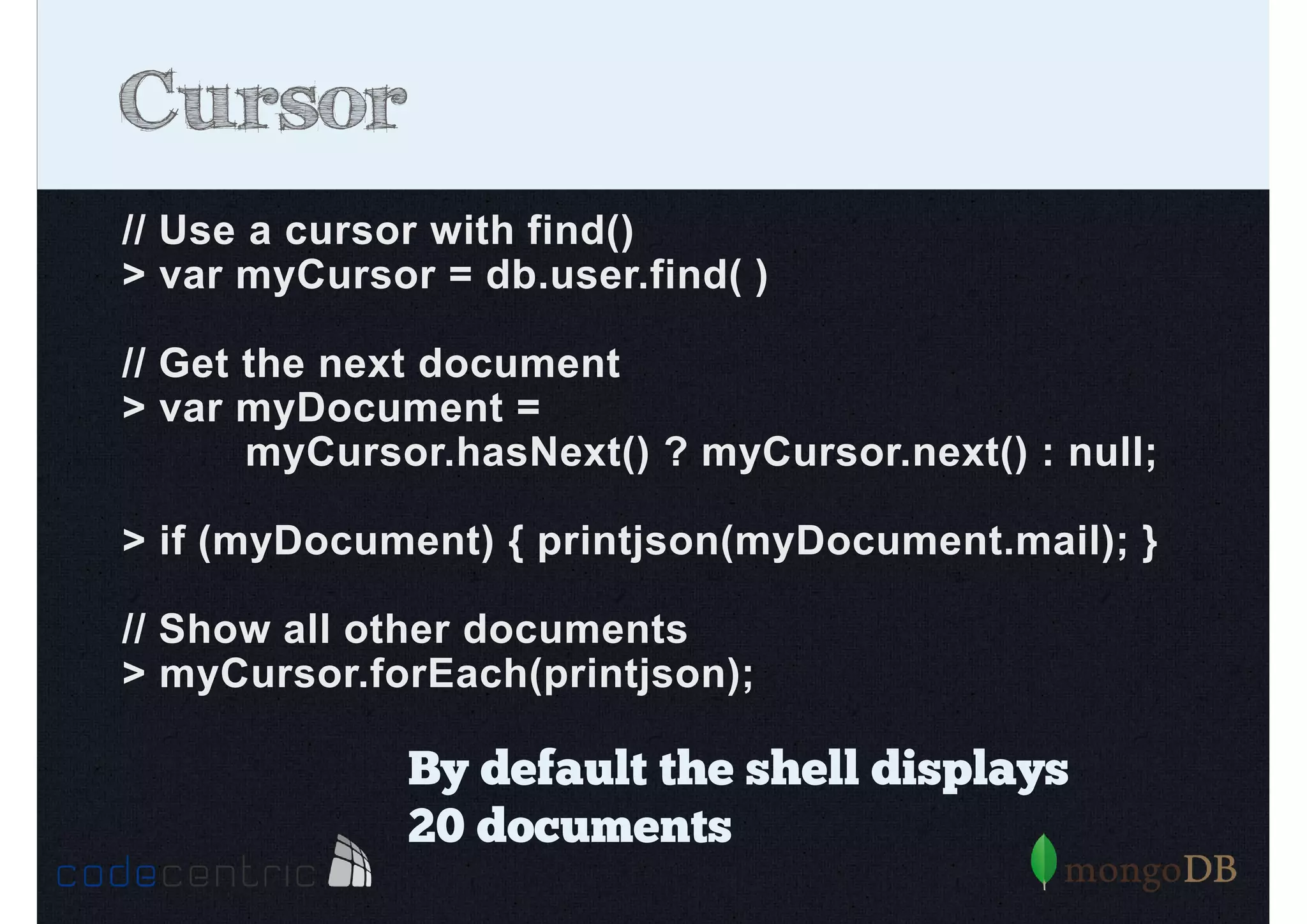
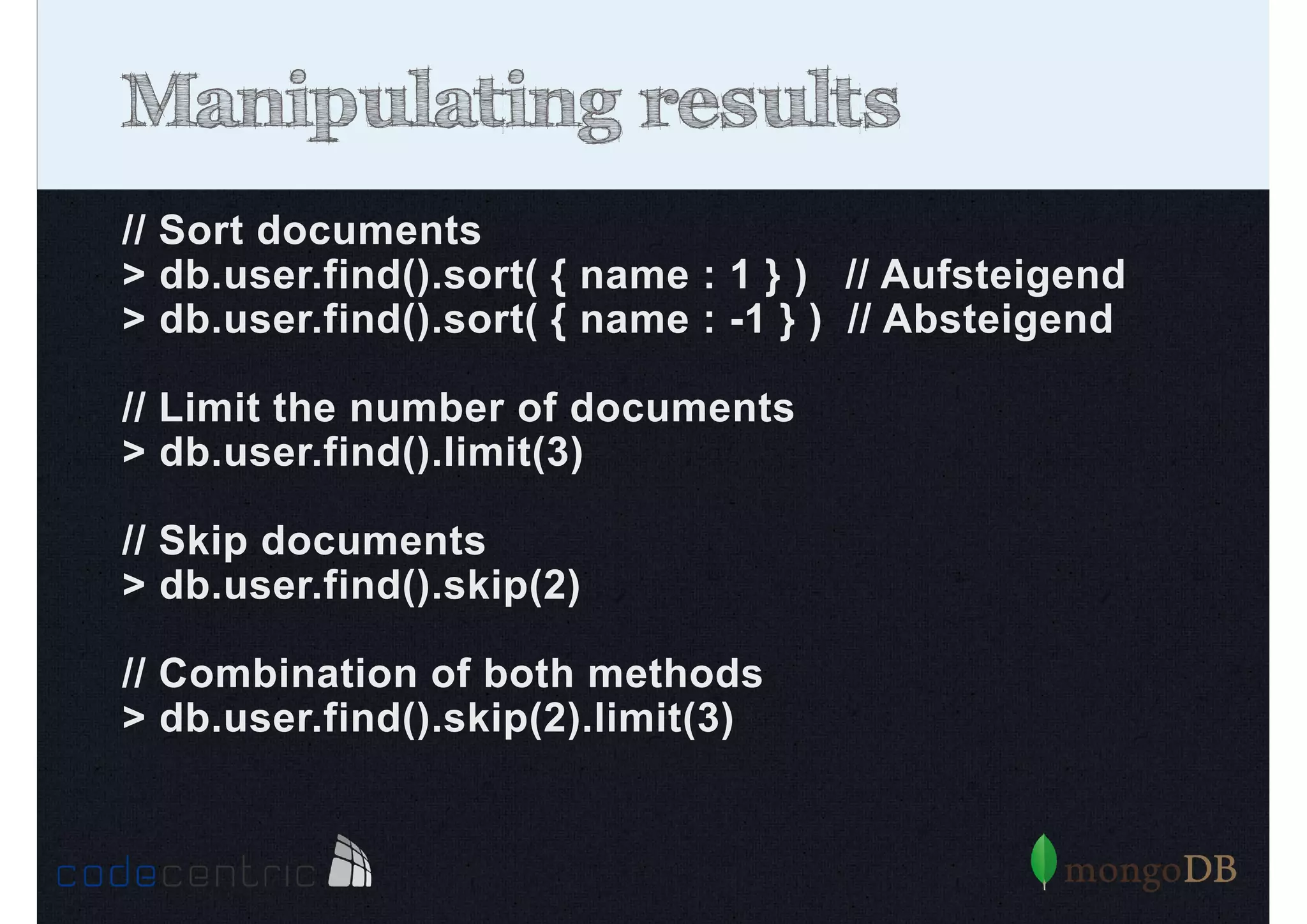
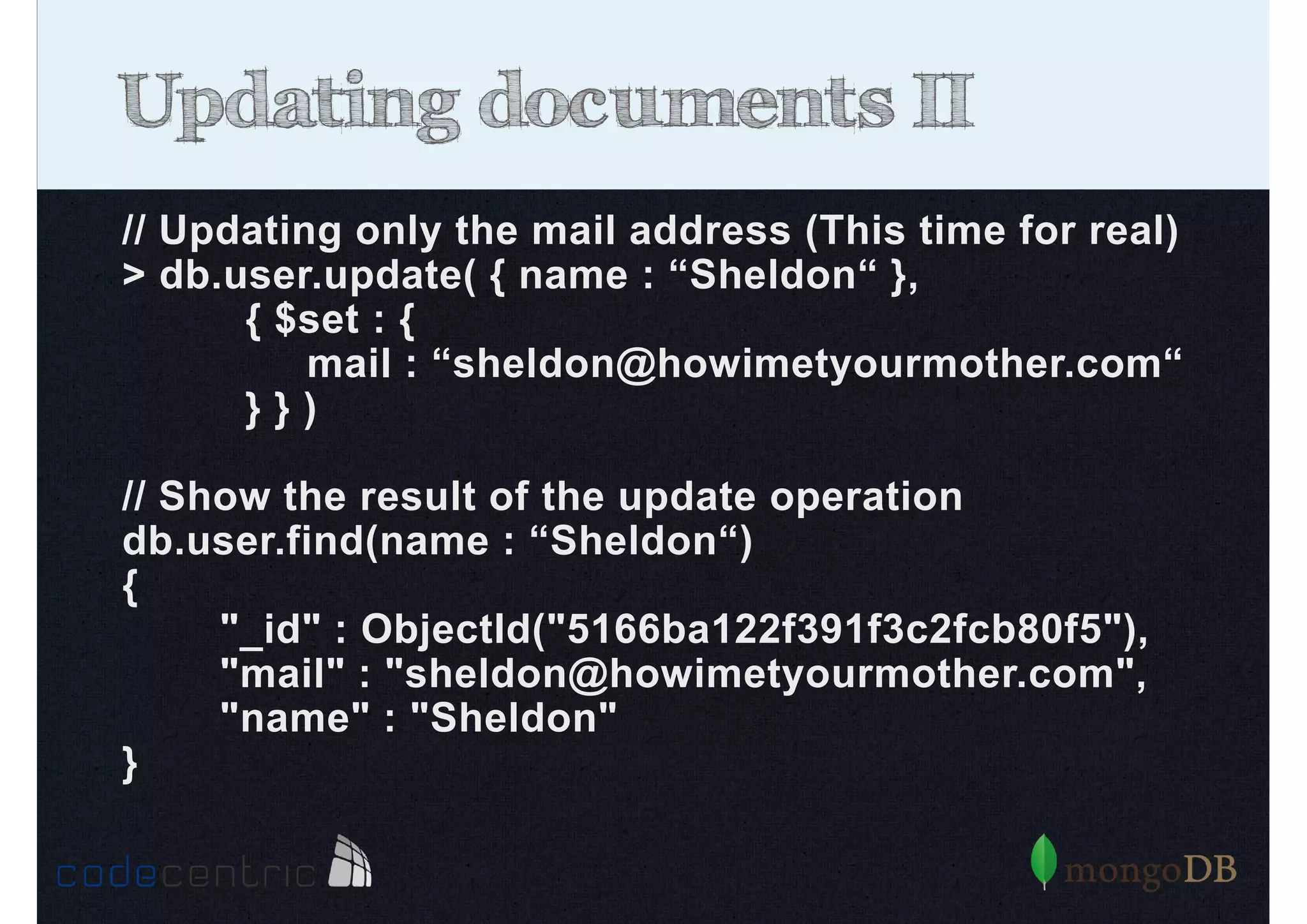
The document provides an extensive overview of MongoDB, covering its functionality, advantages, and core concepts such as data manipulation, indexing, and scalability. It discusses the architecture of MongoDB, the differences between ACID and BASE consistency models, and various operations like creating, reading, updating, and deleting documents across different scenarios. Additionally, it touches on performance optimization through indexing and highlights the importance of managing indices for querying efficiency.
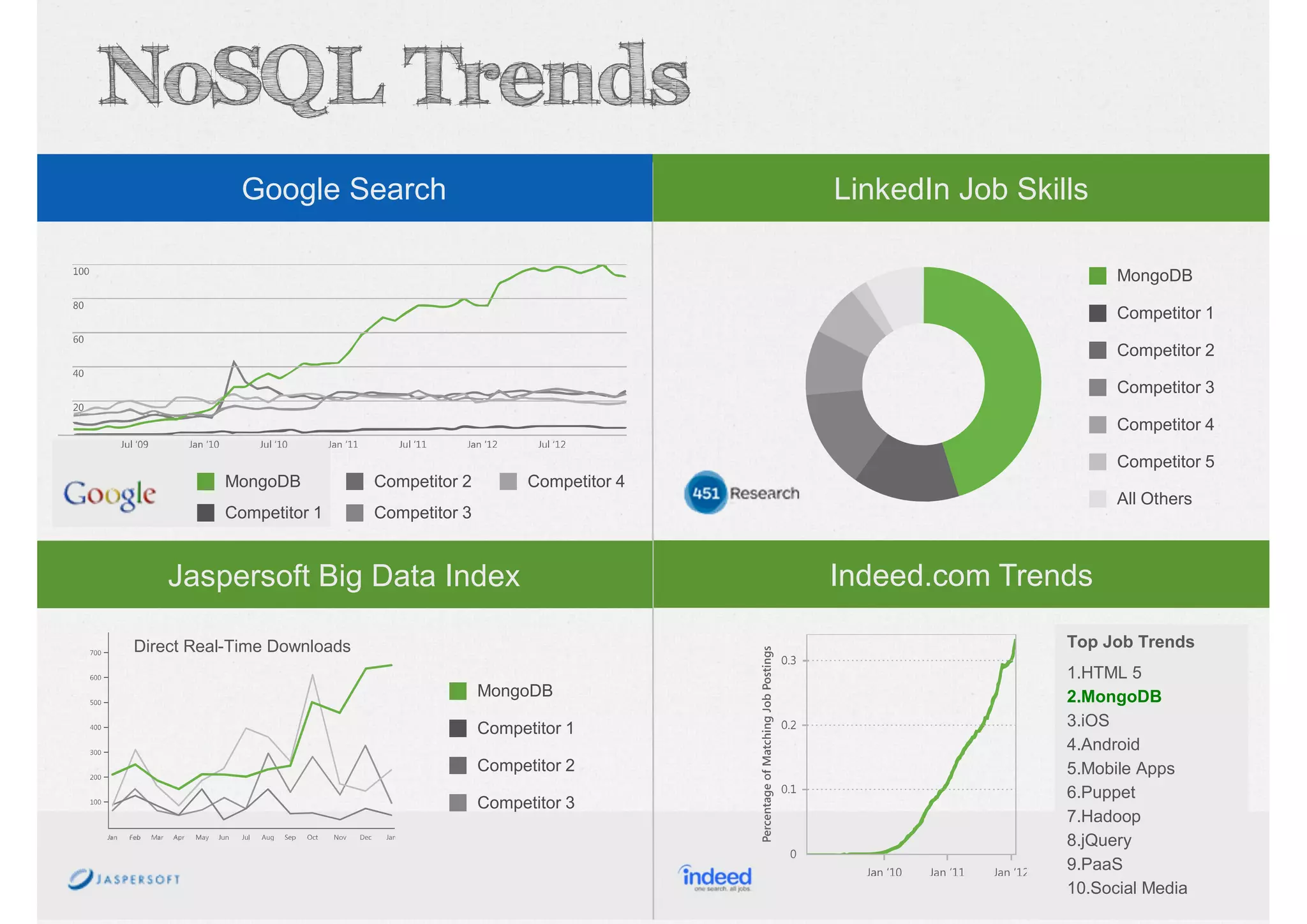
Introduction to the training session on MongoDB, covering agenda items including NoSQL, CRUD operations, indexing, and data aggregation.
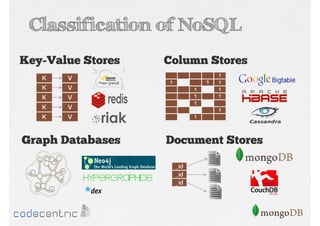
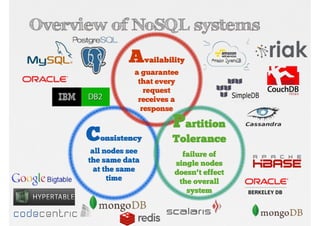
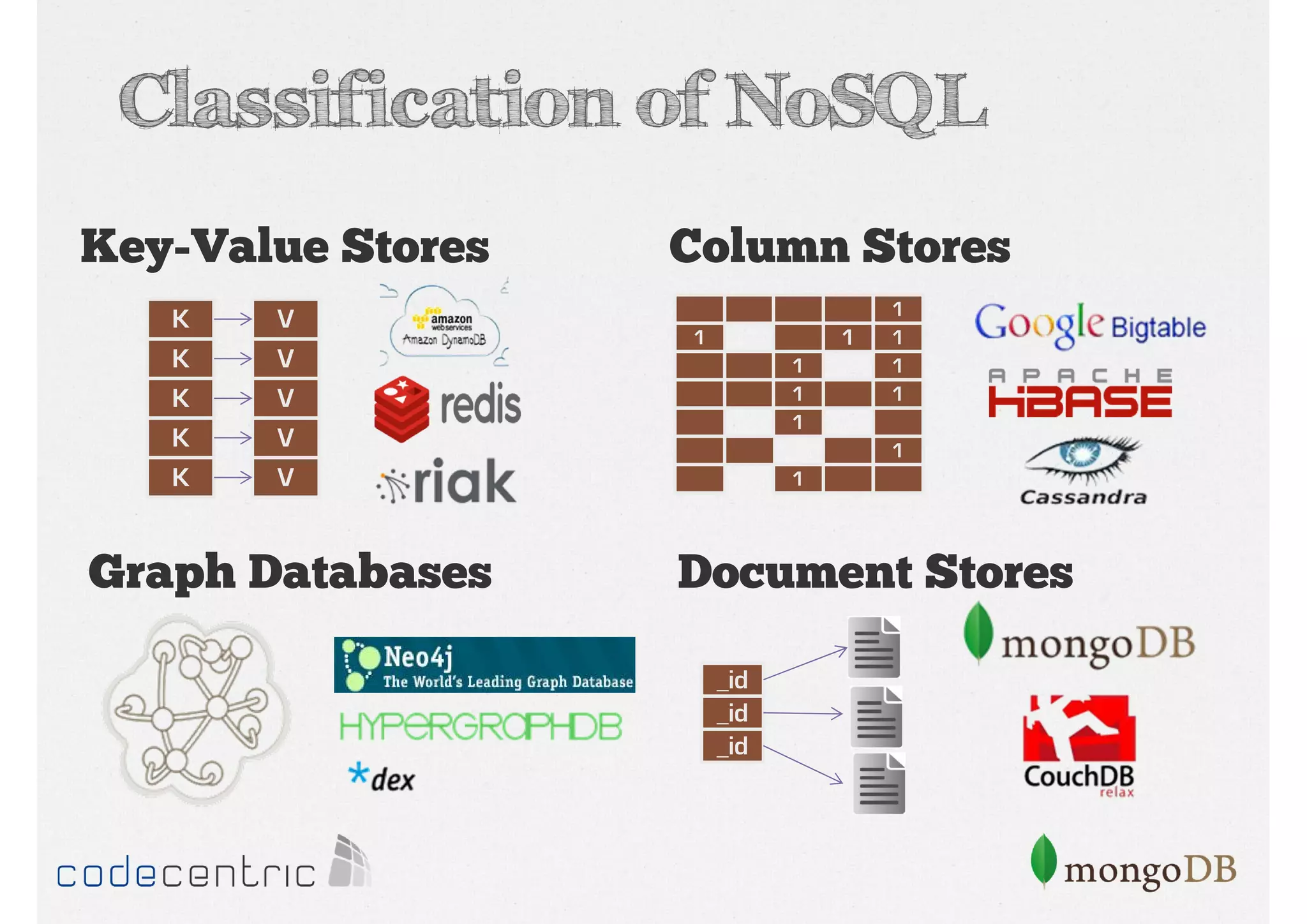
Explaining NoSQL classifications (Key-Value, Document, Column, Graph) and Big Data’s 3 V’s - Volume, Velocity, Variety.
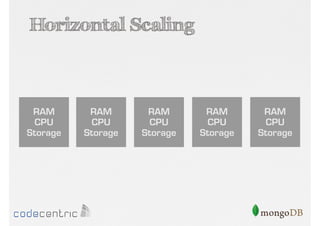
Discussion on scaling strategies: vertical scaling (RAM, CPU, storage) and horizontal scaling, emphasizing how they differ and their operational implications.
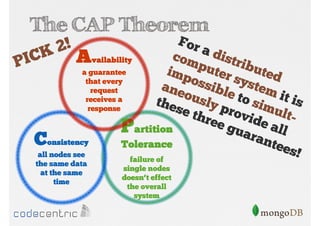
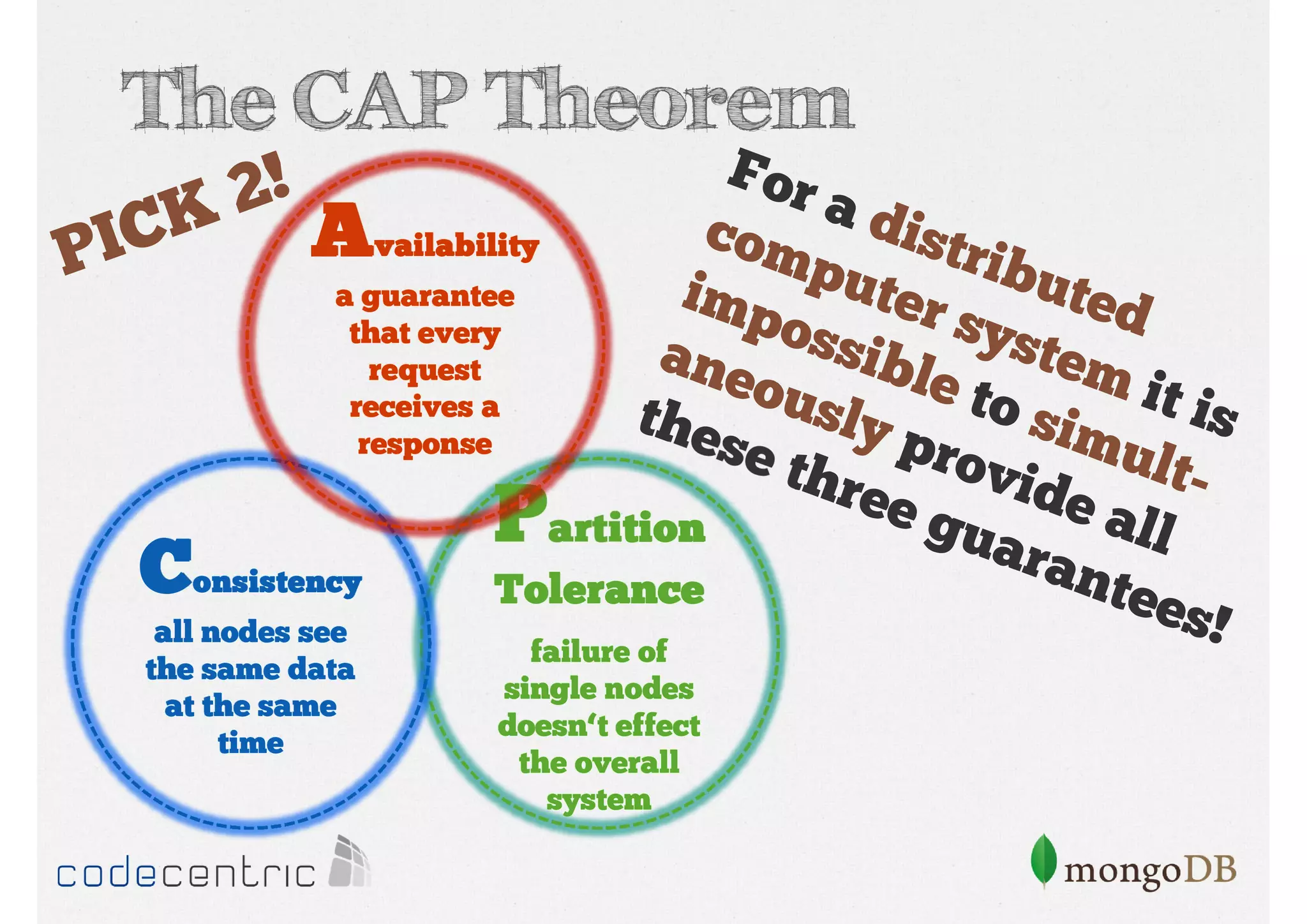
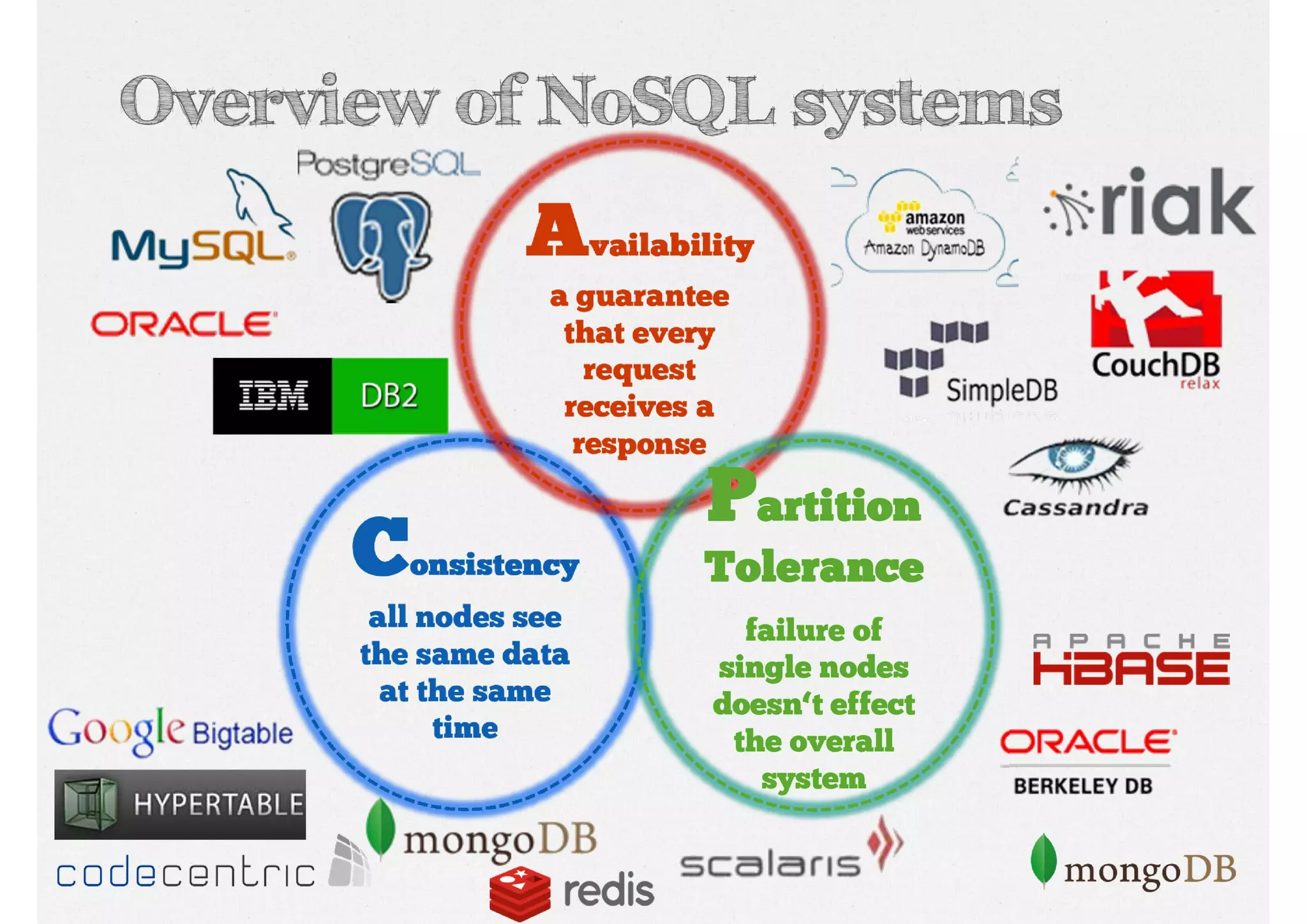
Introduces CAP Theorem components—Consistency, Availability, Partition Tolerance—highlighting trade-offs in distributed systems and ACID vs BASE models.
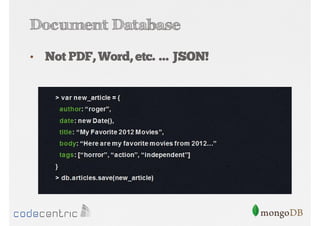
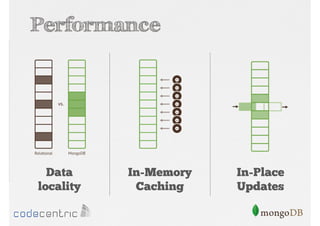
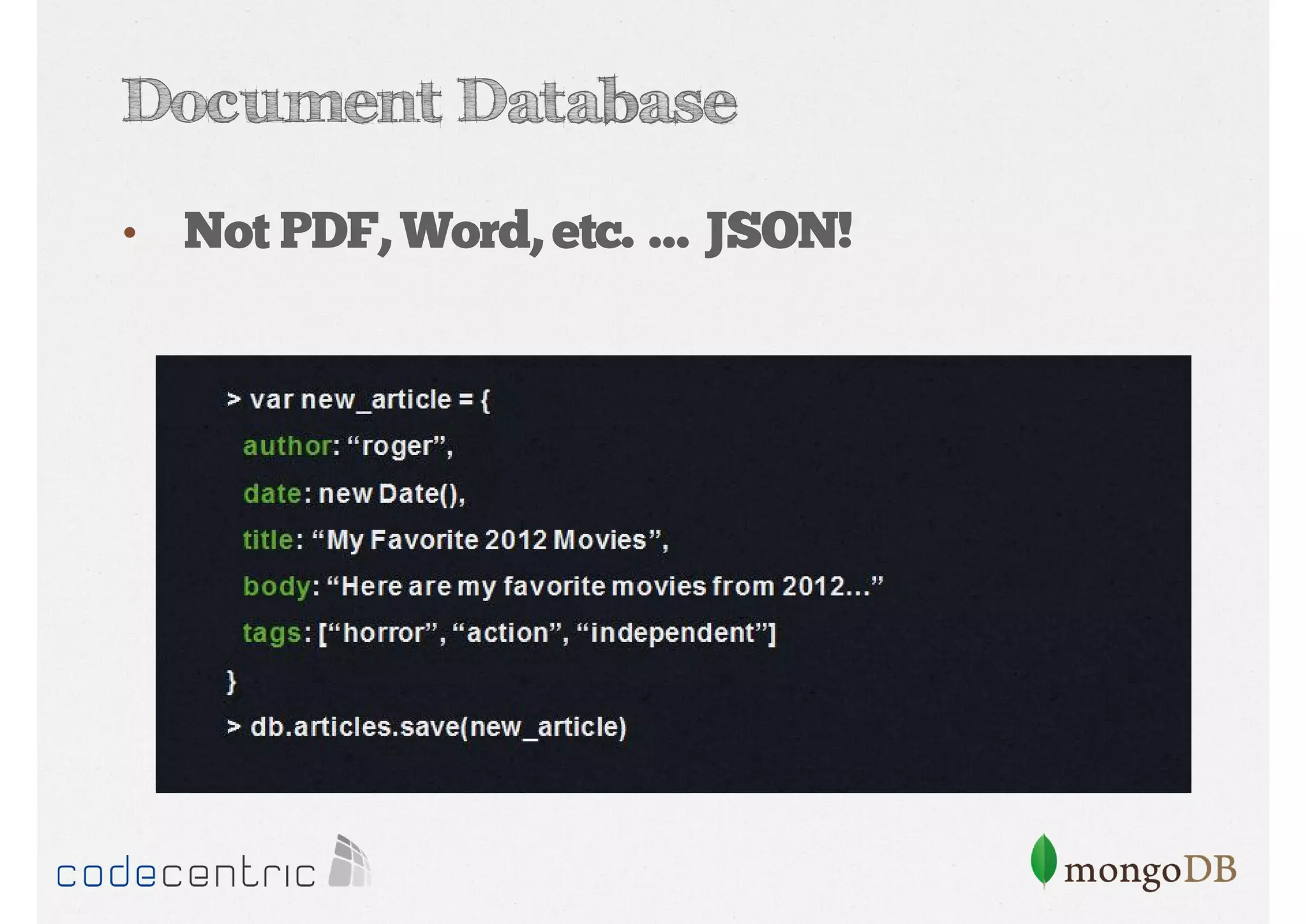
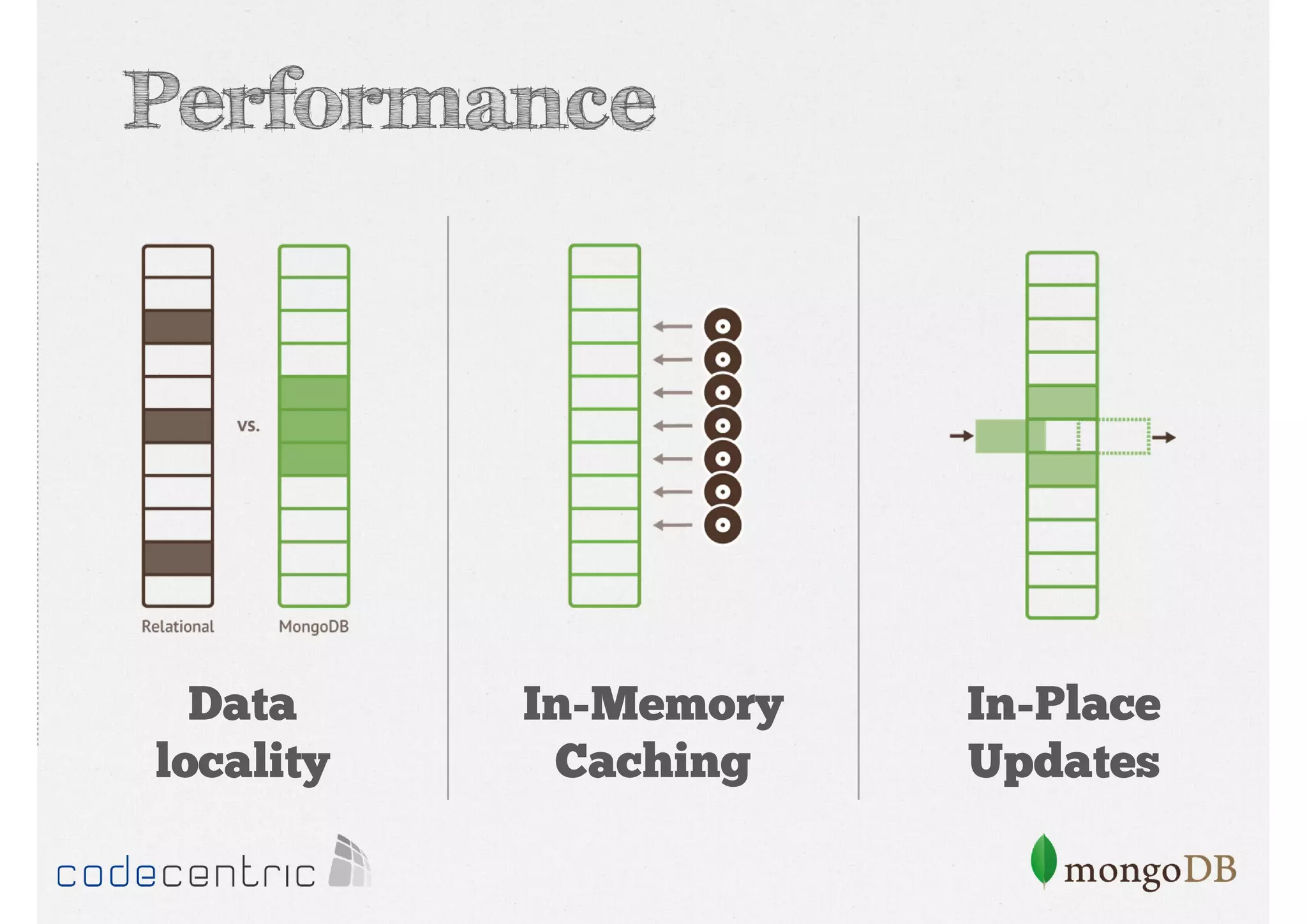
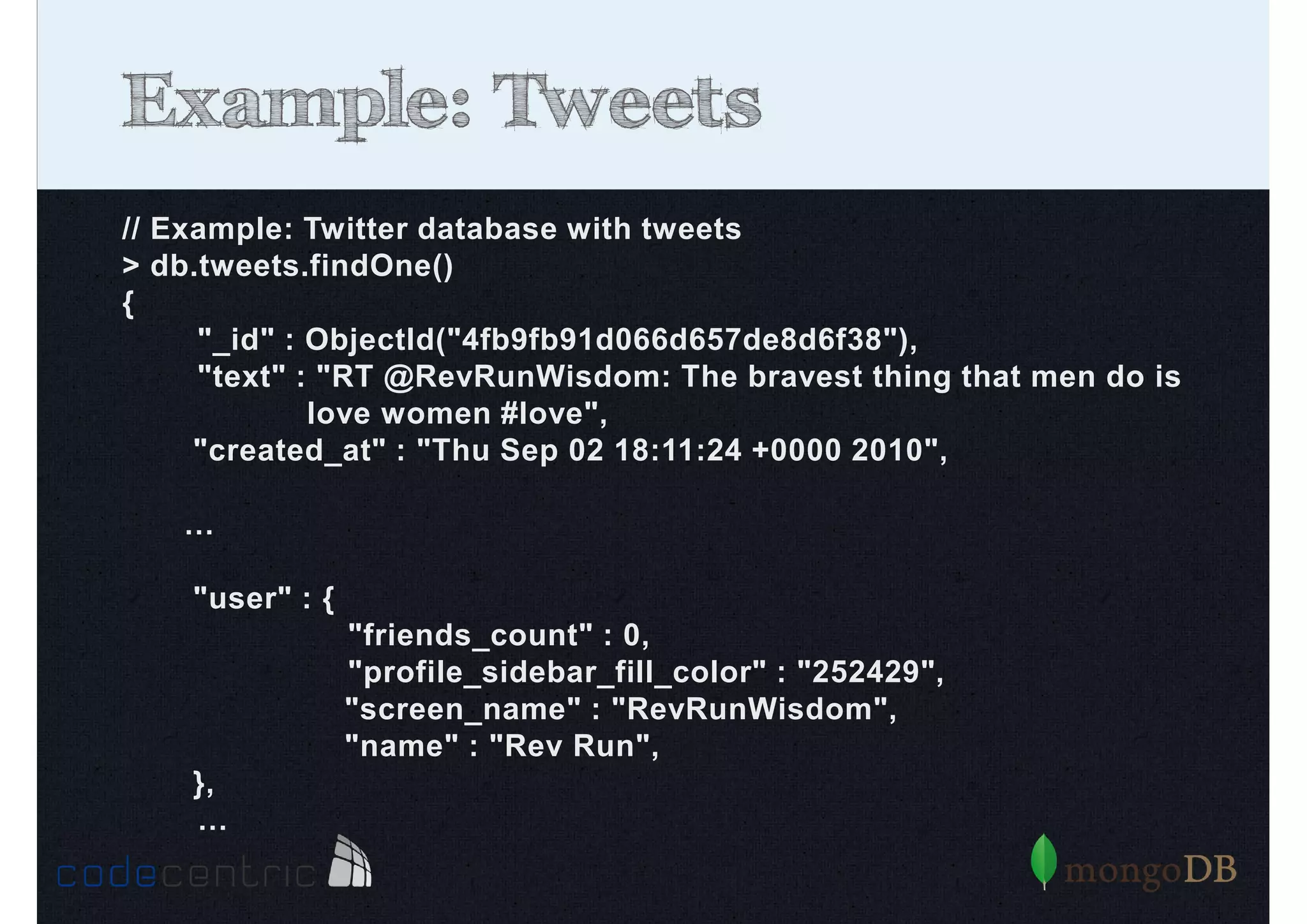
Overview of MongoDB: document database, performance, flexible schema, scalability, high availability, with examples of data structure.
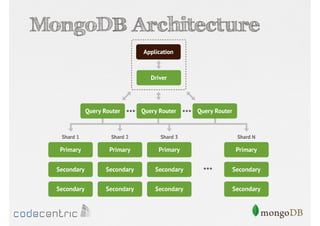
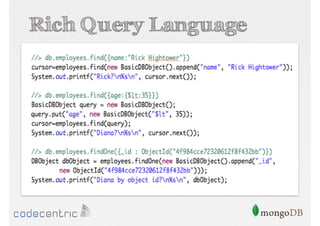
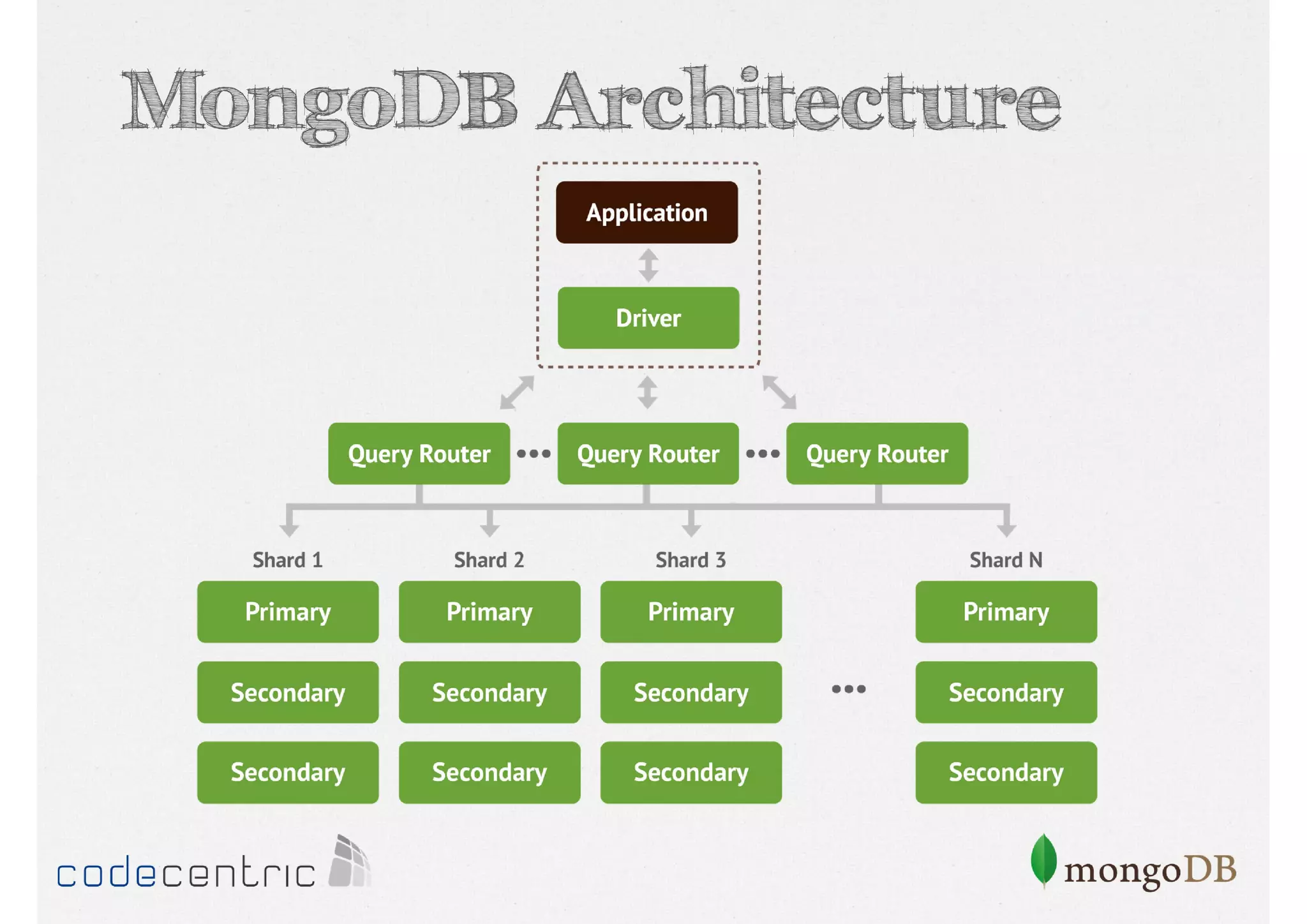
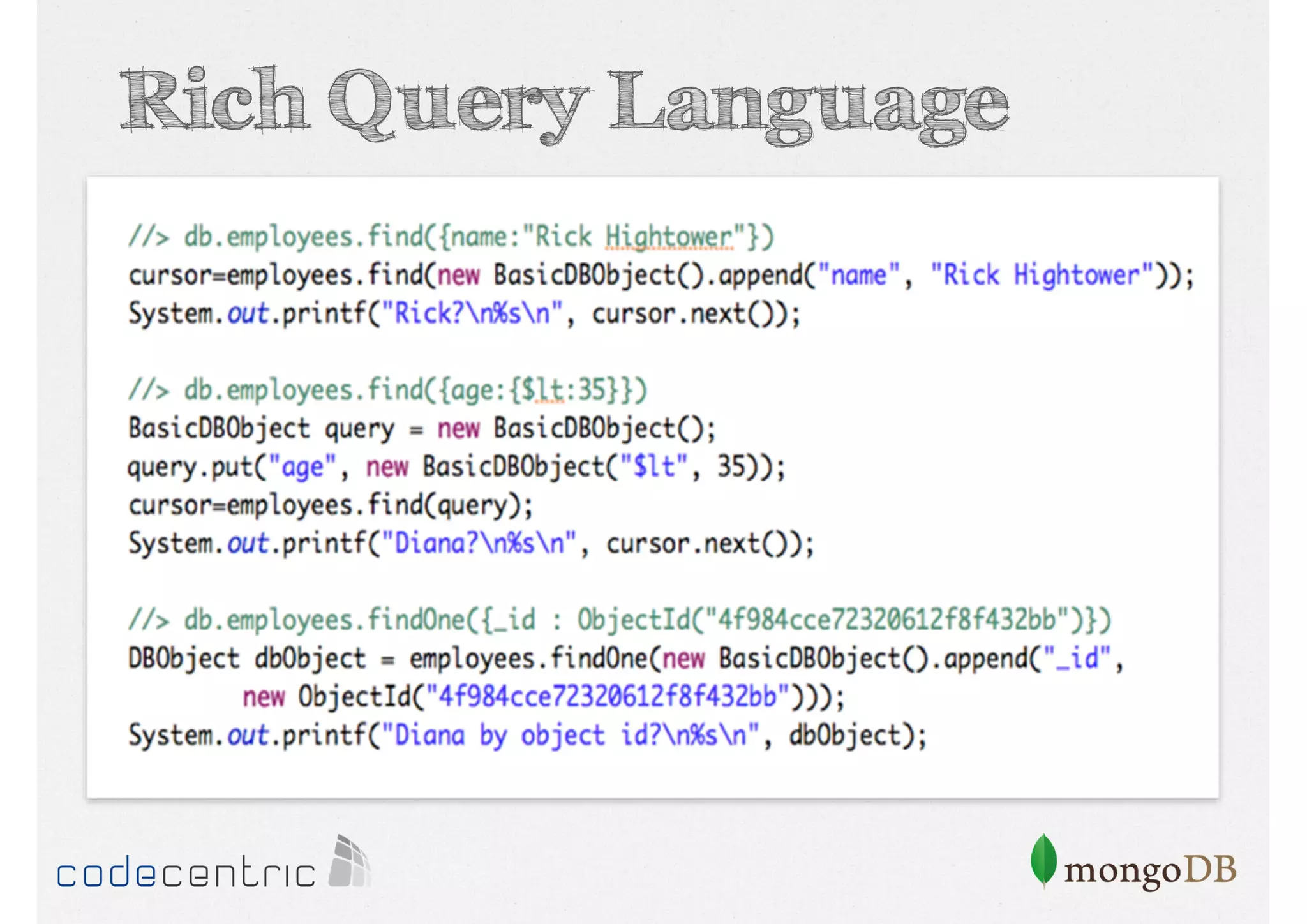
Overview of MongoDB architecture details and query capabilities, including rich query language and aggregation framework.
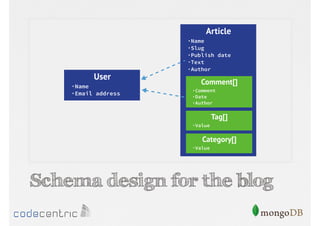
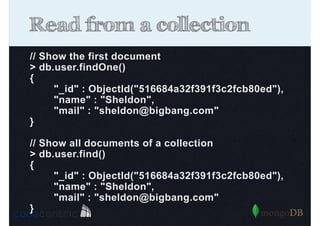
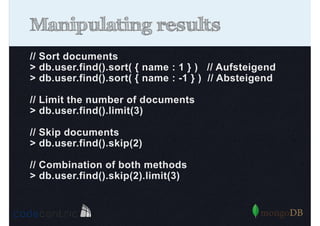
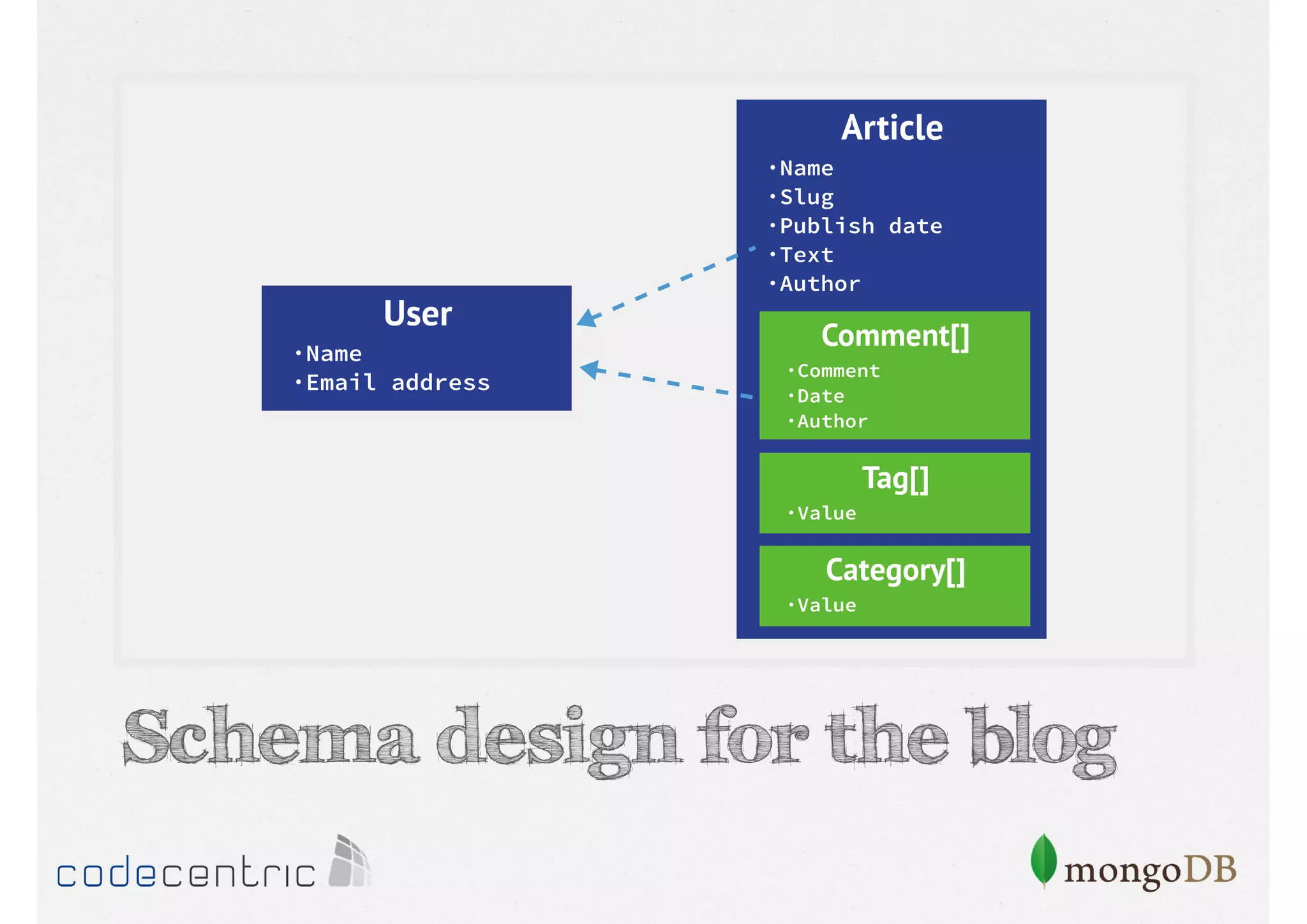
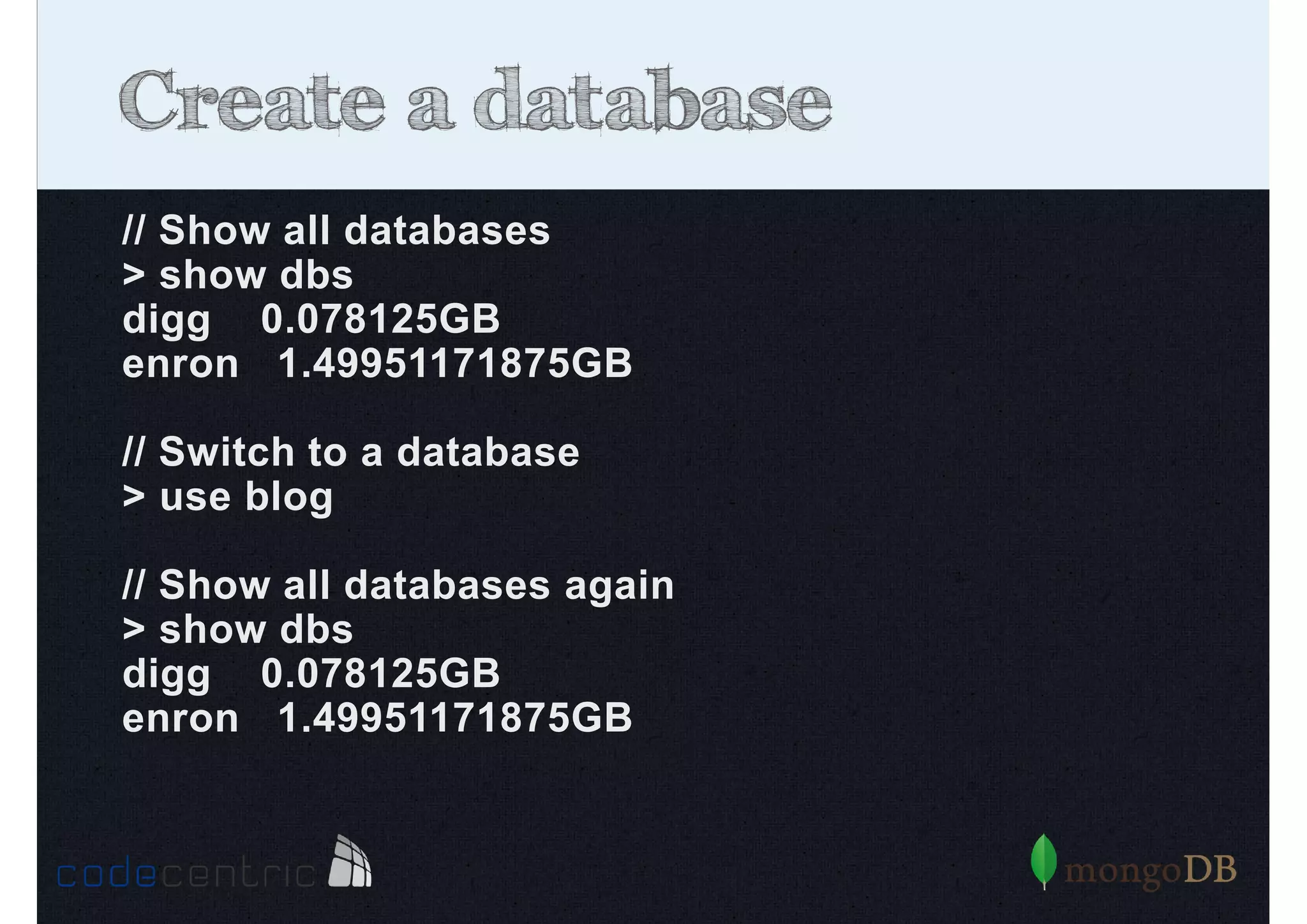
Describes how to manipulate data in MongoDB: terminology comparisons, basic commands to create collections and databases.
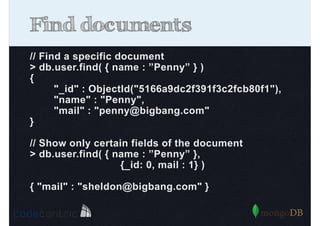
Details on updating and deleting documents in MongoDB, including modifications to documents and document arrays.
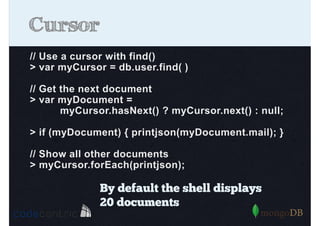
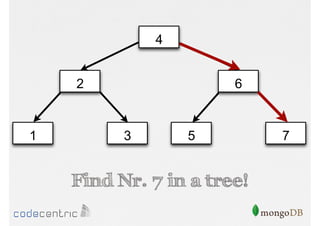
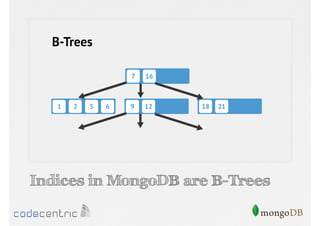
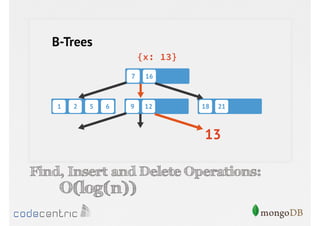
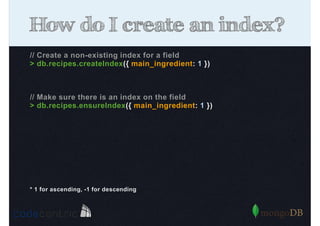
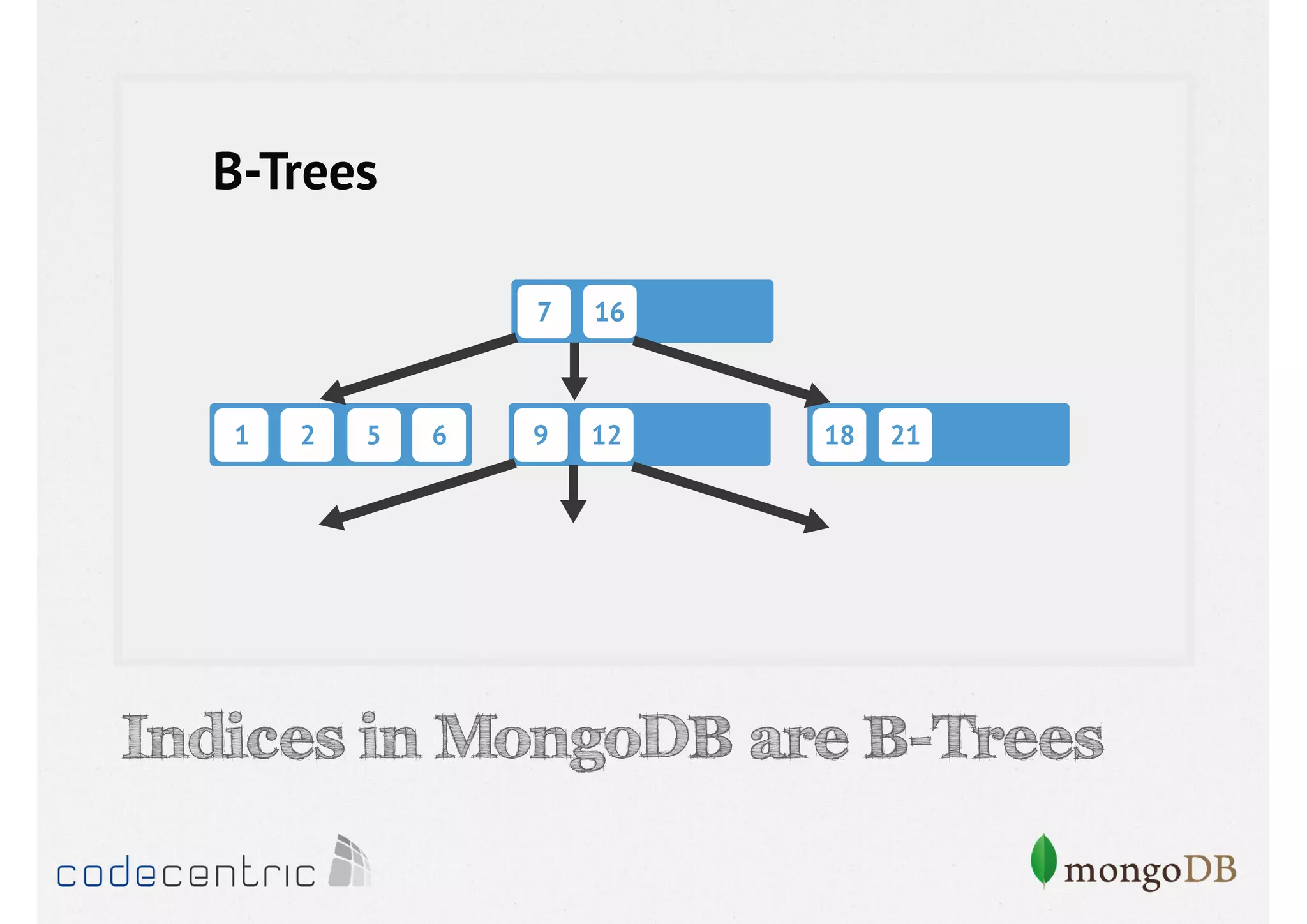
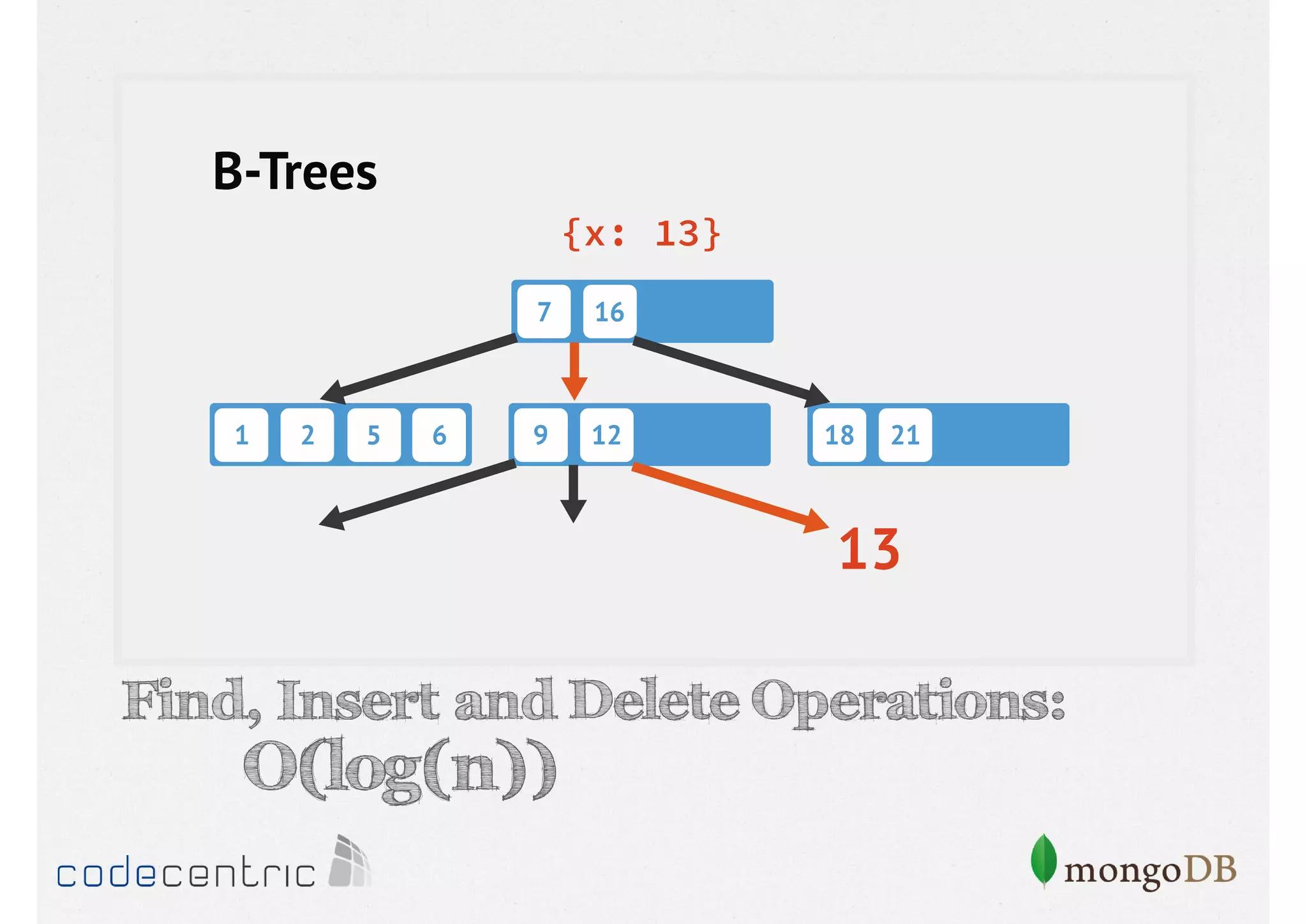
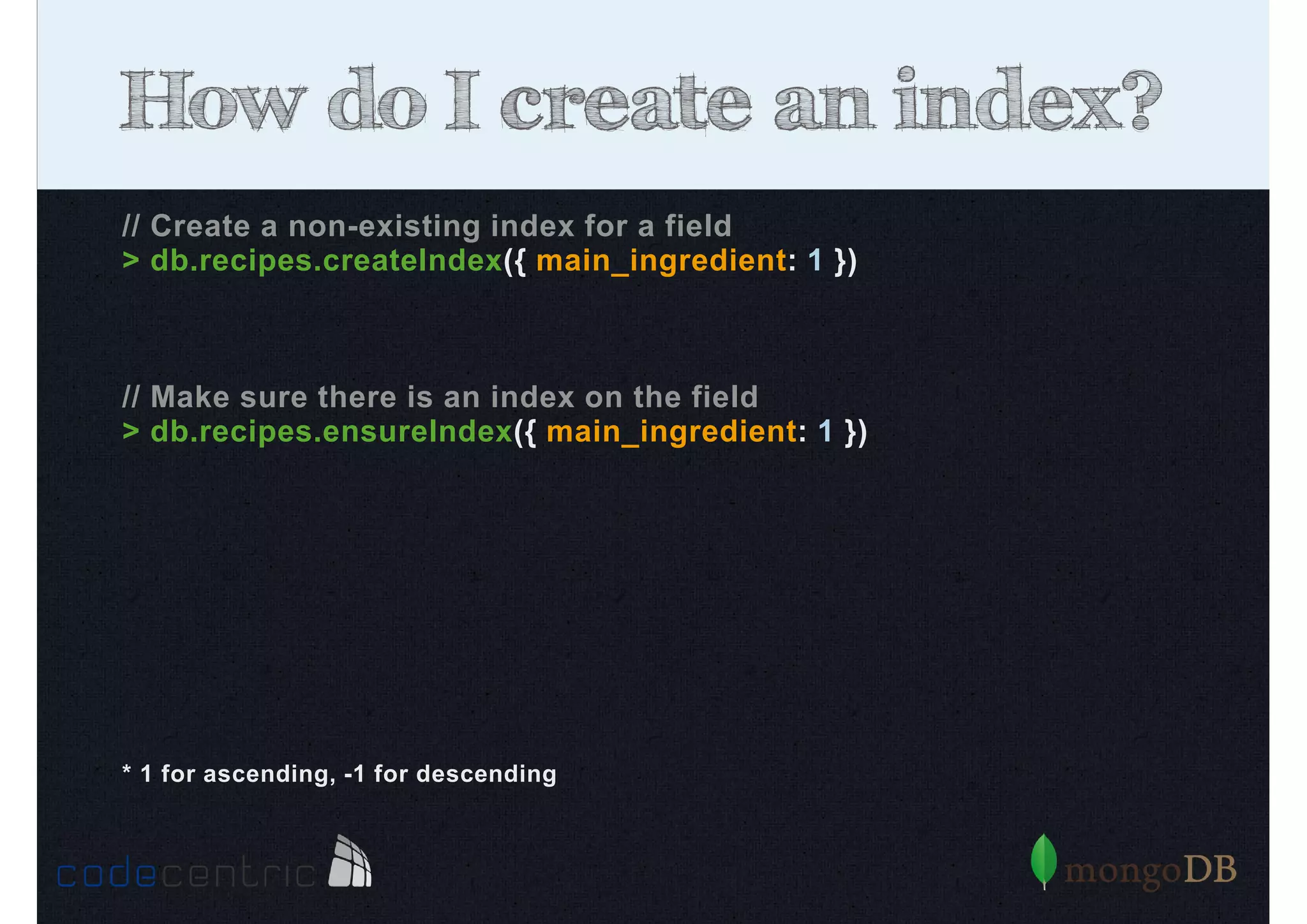
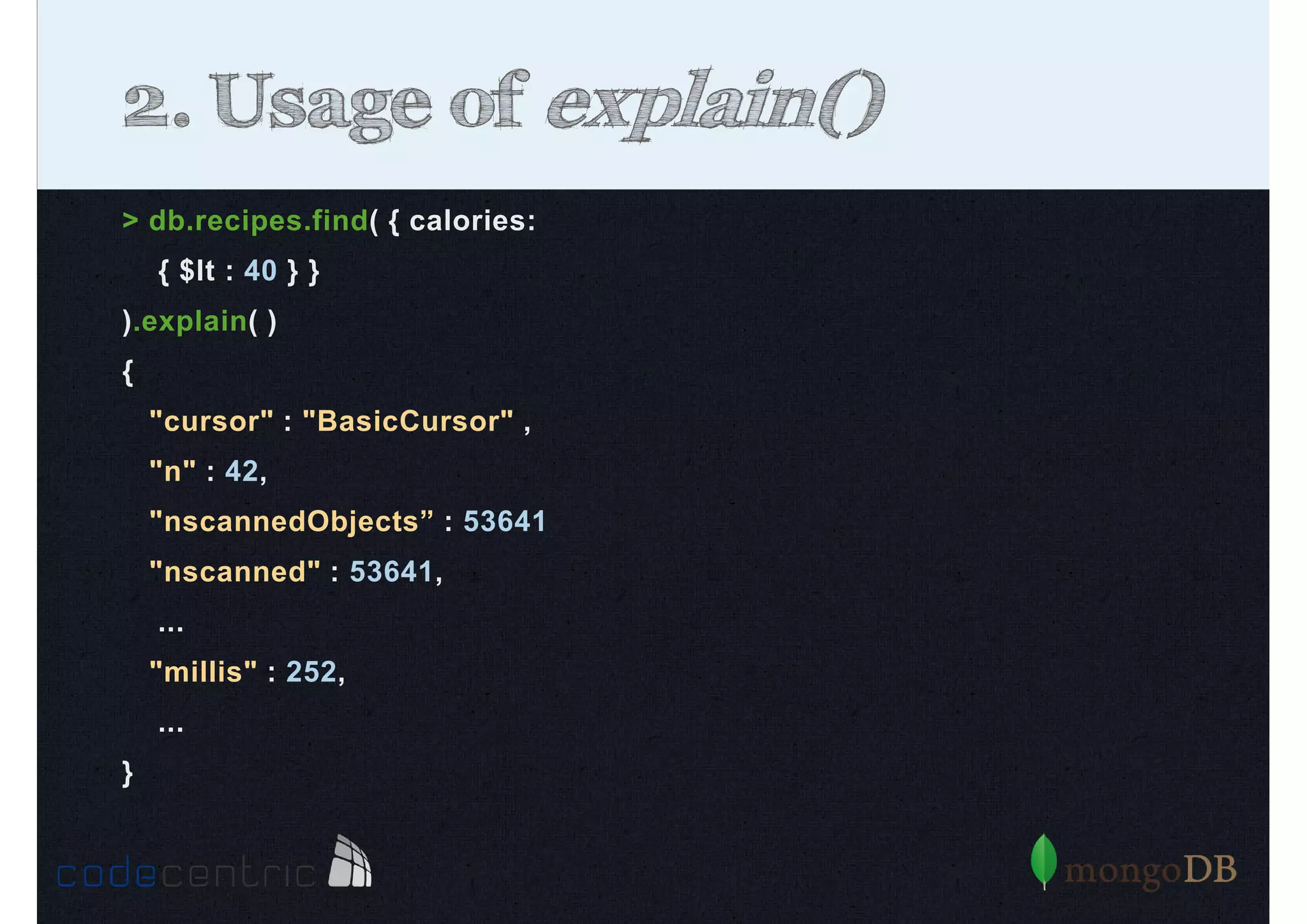
Introduction to indexing concepts, creation of indices, types of indices (unique, sparse, geospatial), and how they improve query performance.
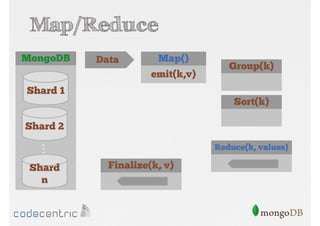
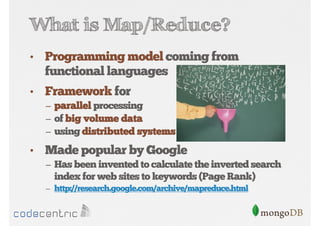
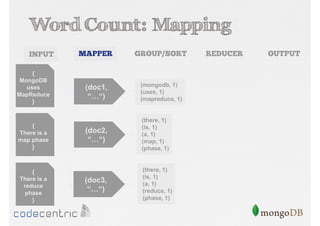
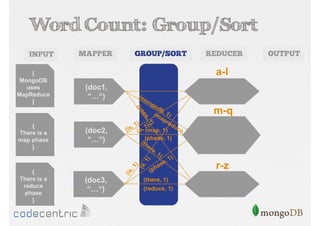
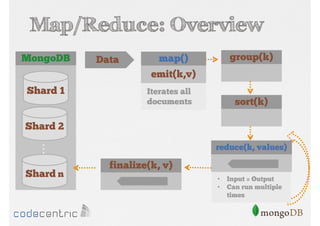
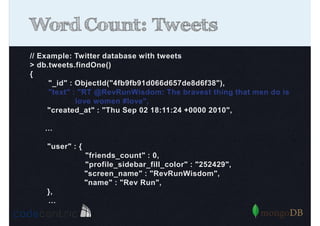
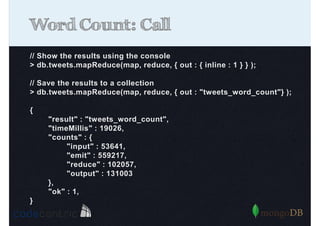
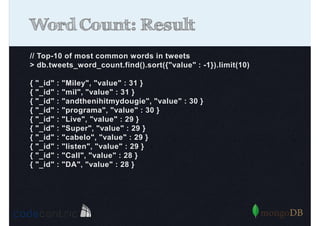
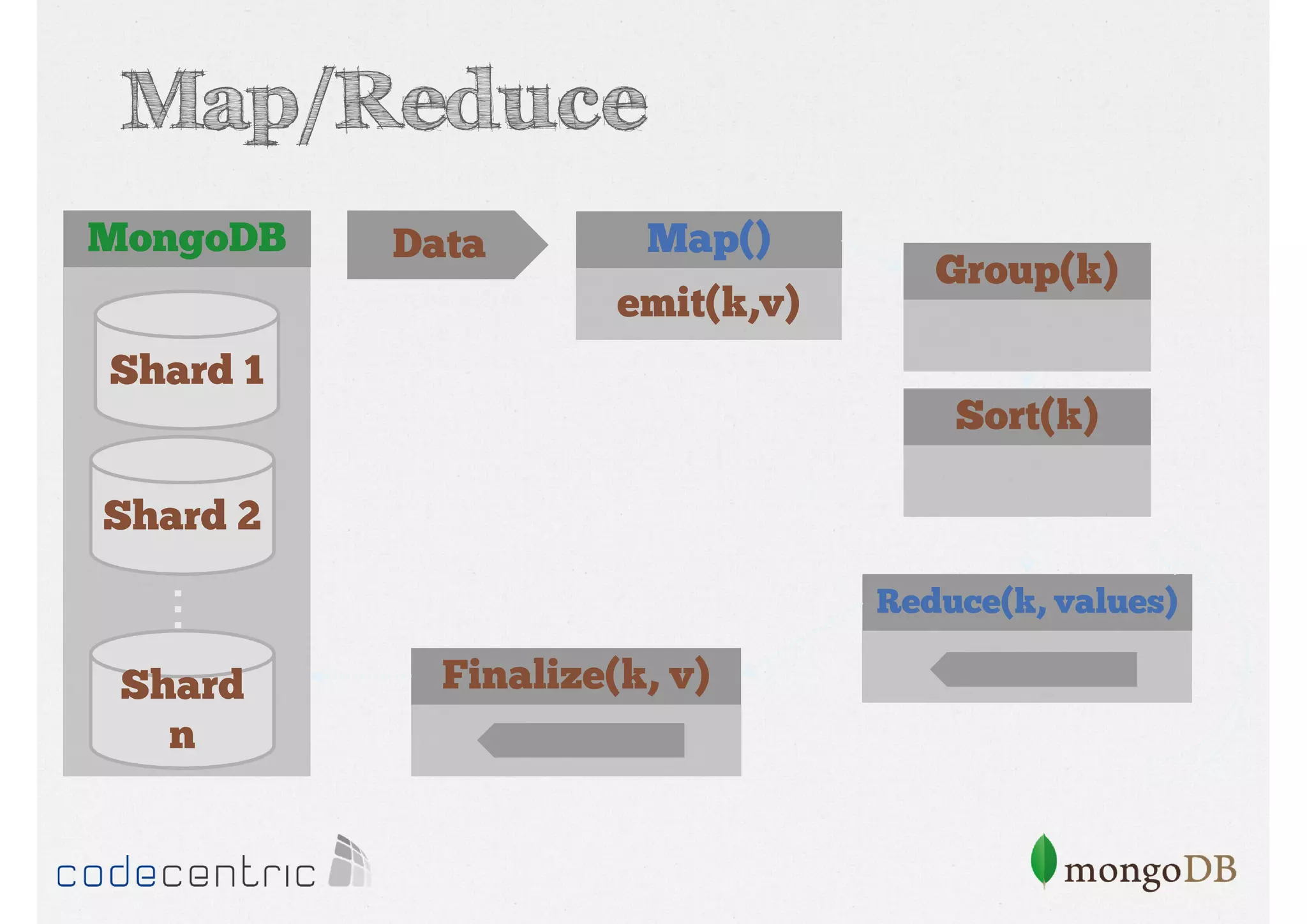
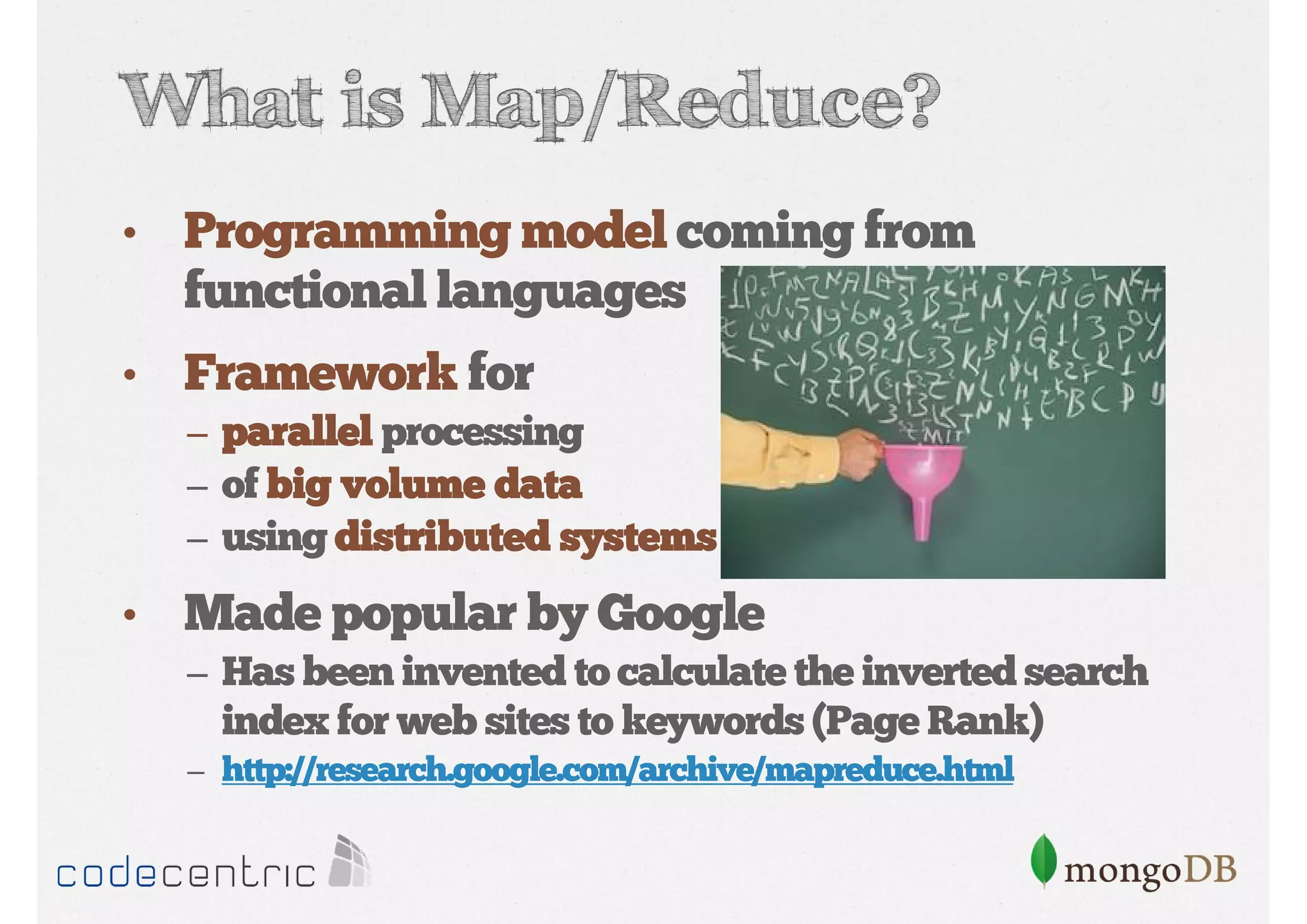
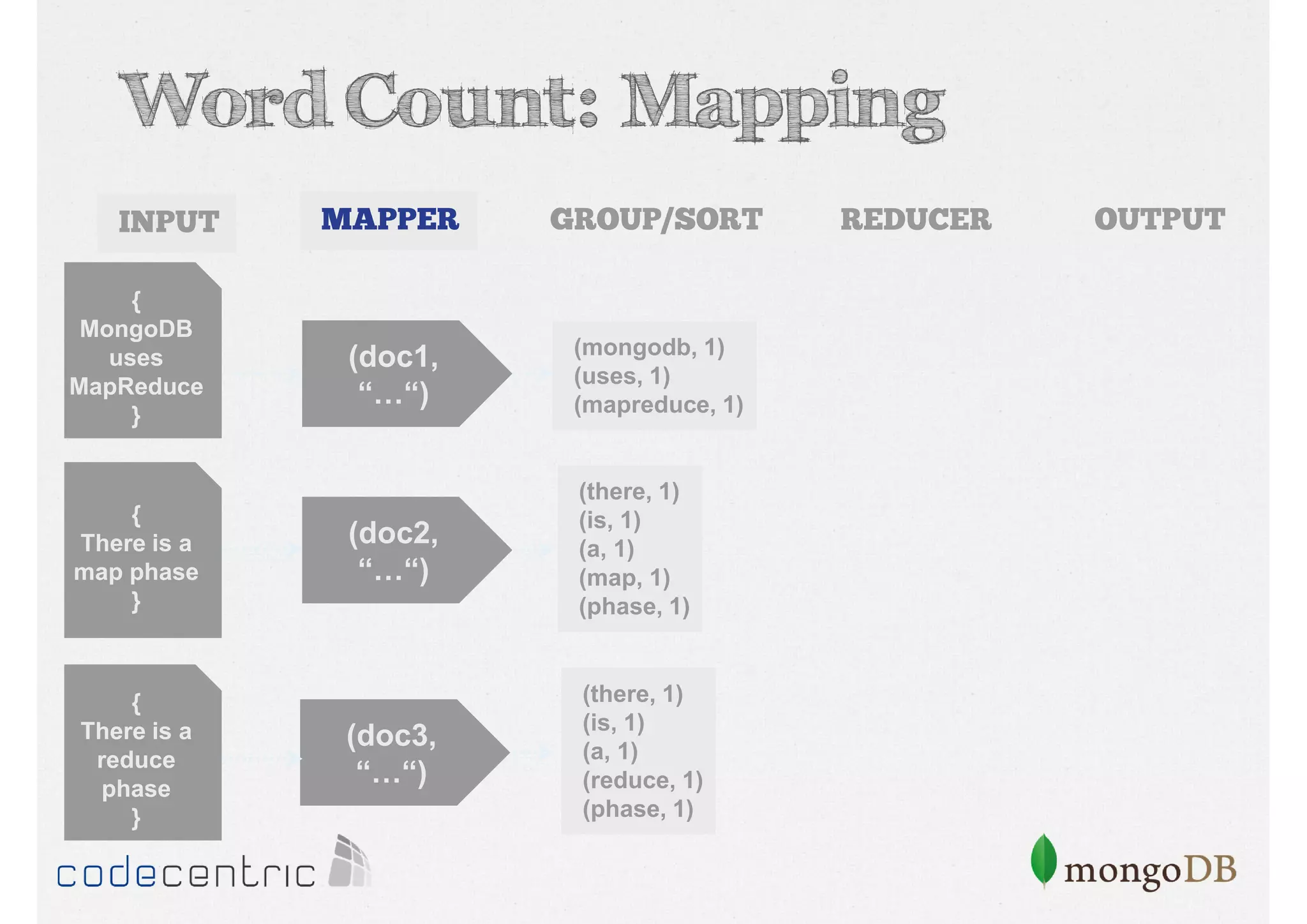
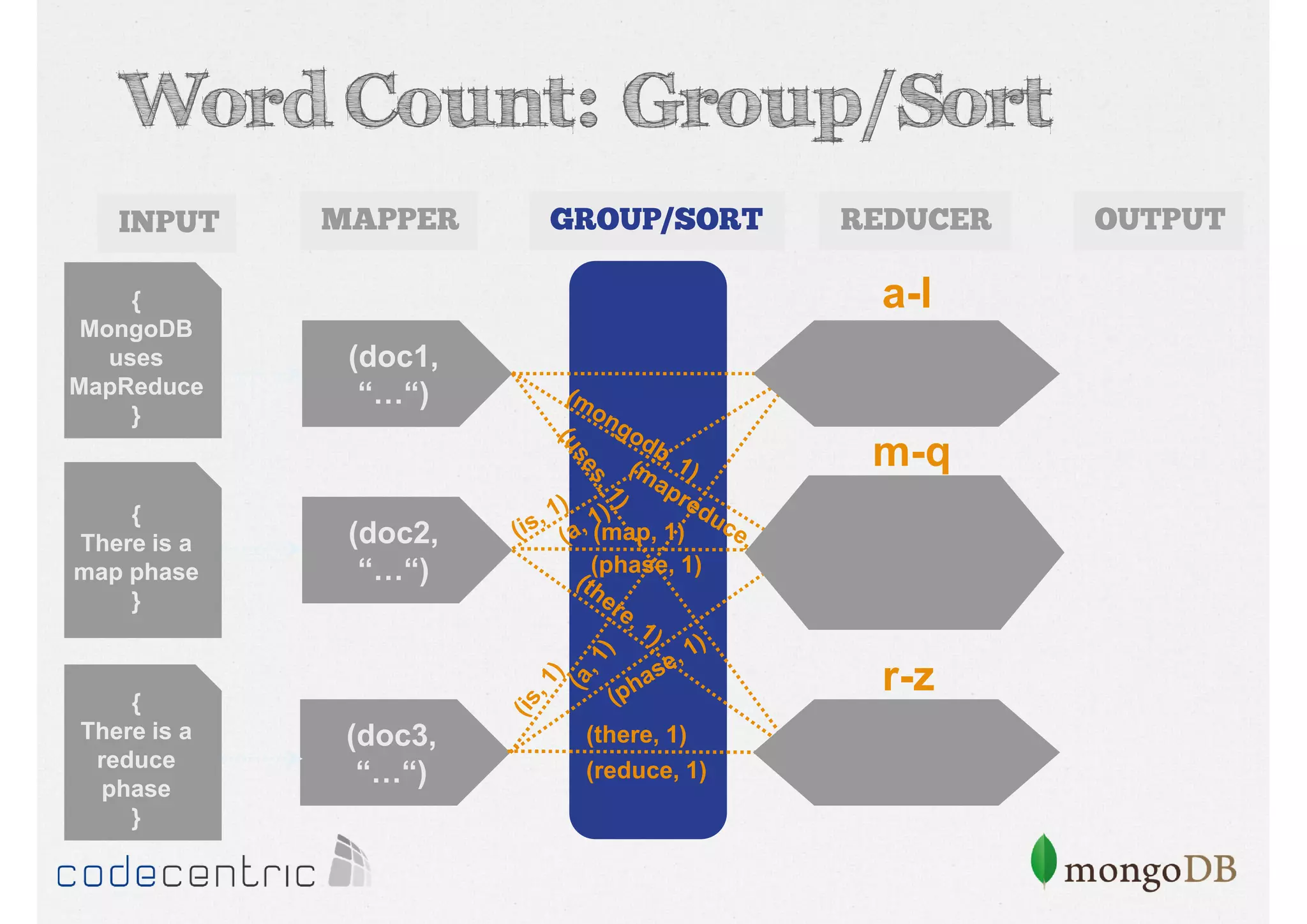
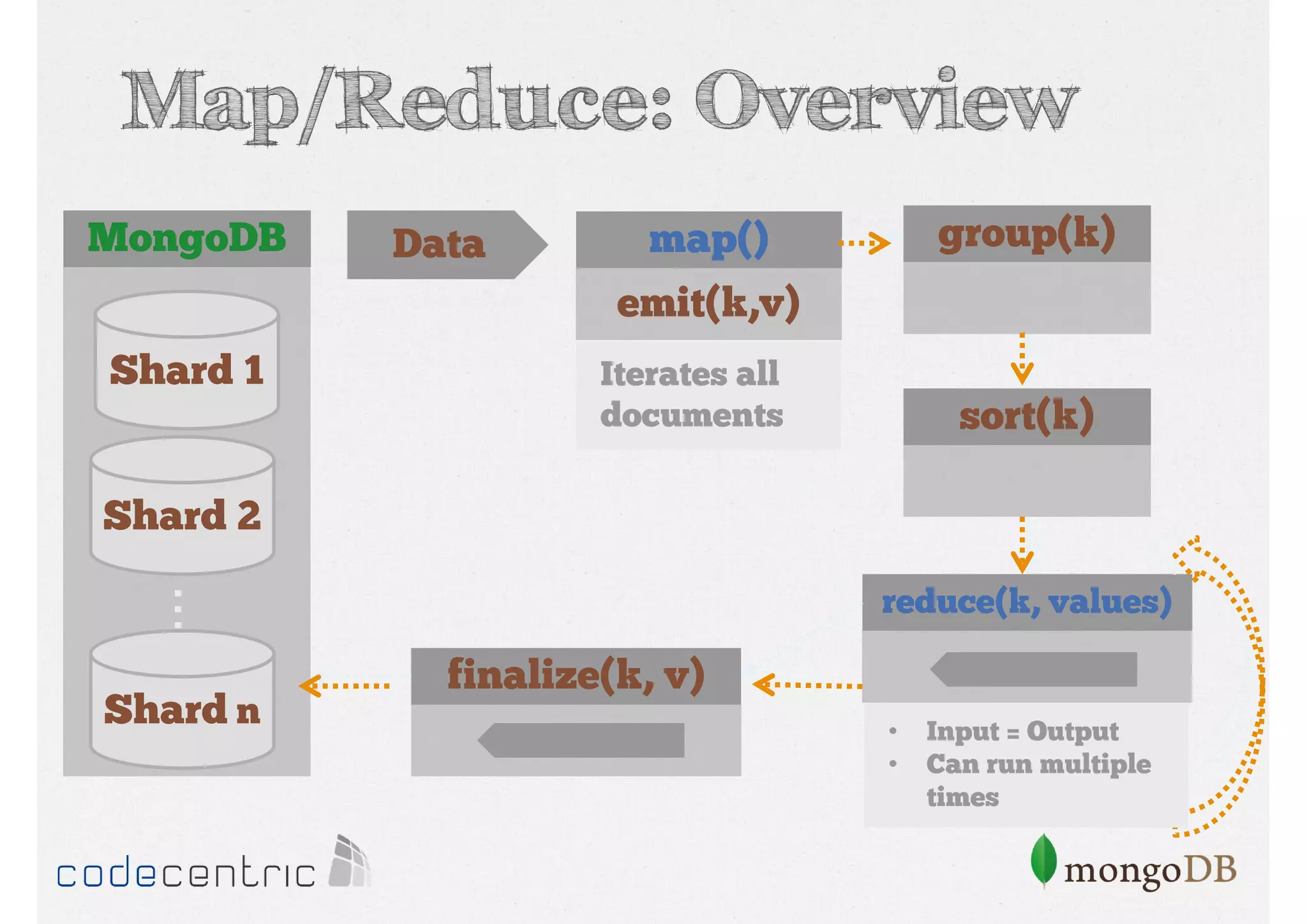
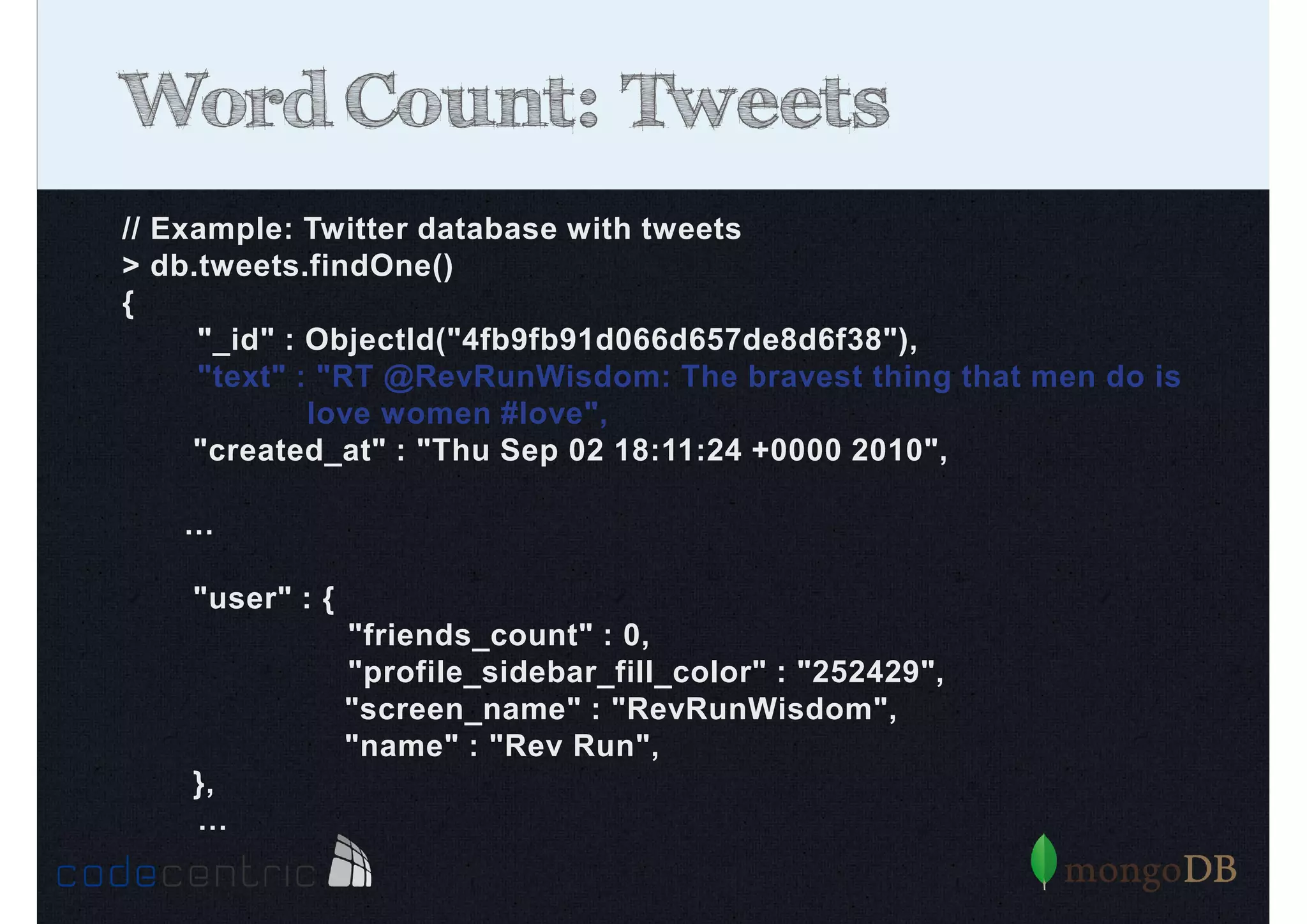
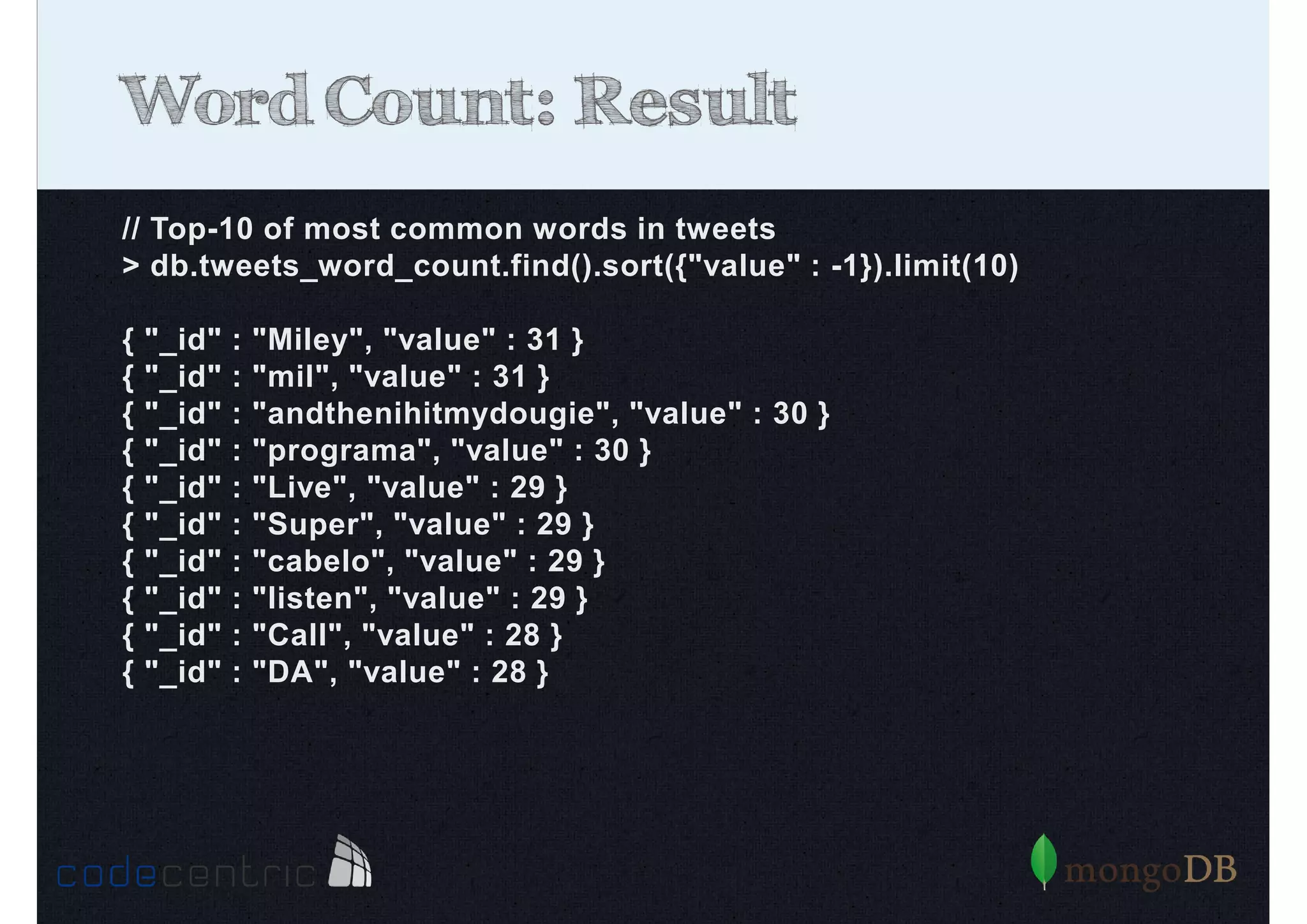
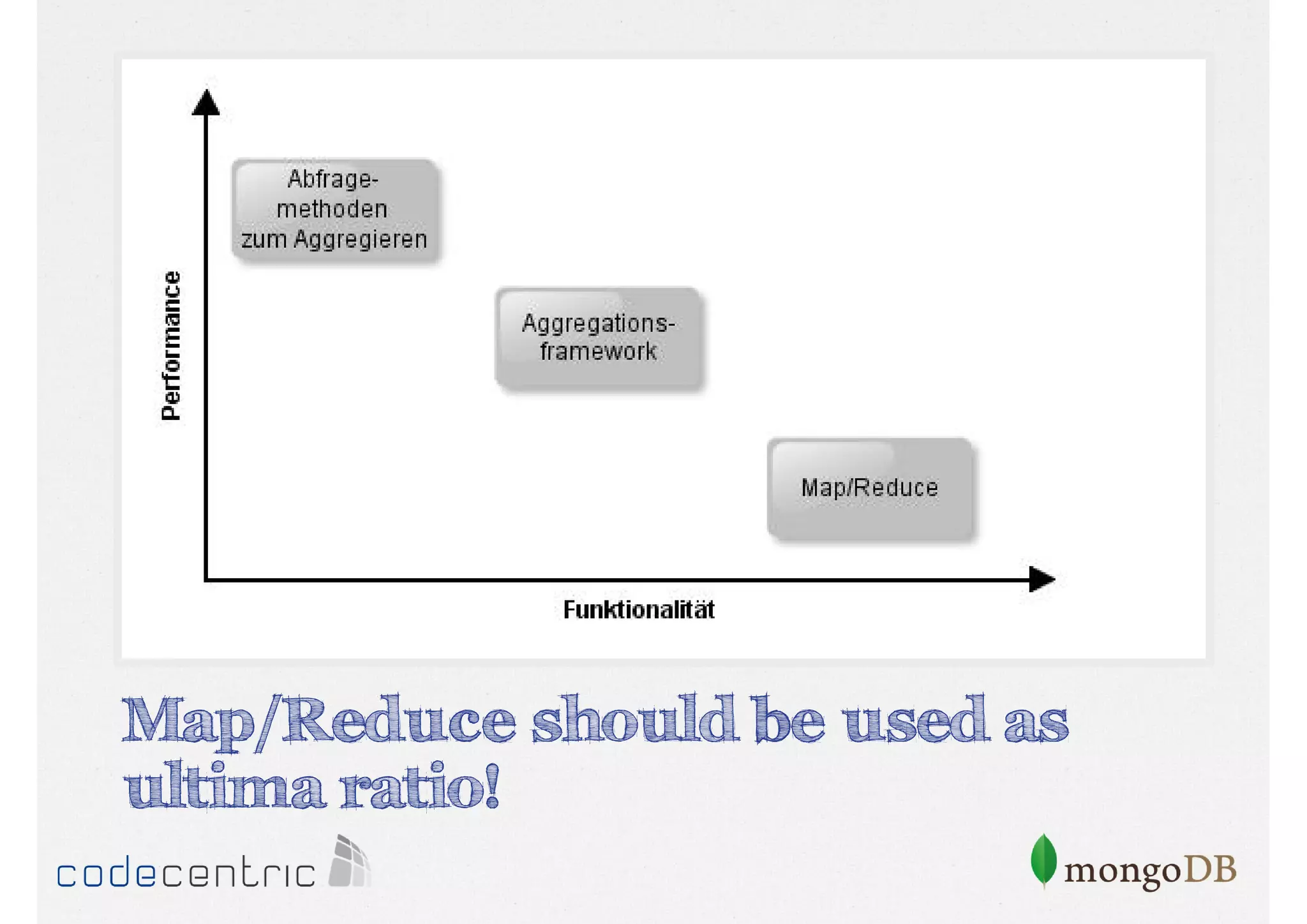
Explains Map/Reduce as a programming model for processing big data, highlighting its operation through the word count example.
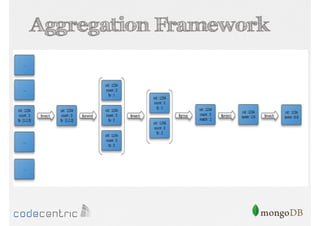
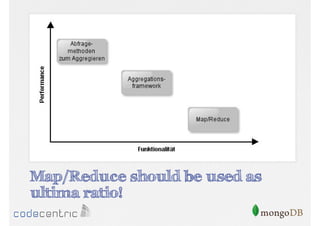
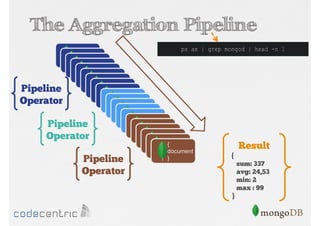
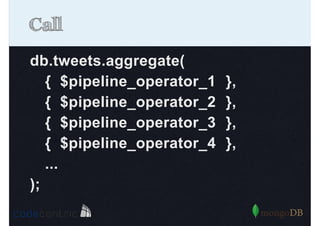
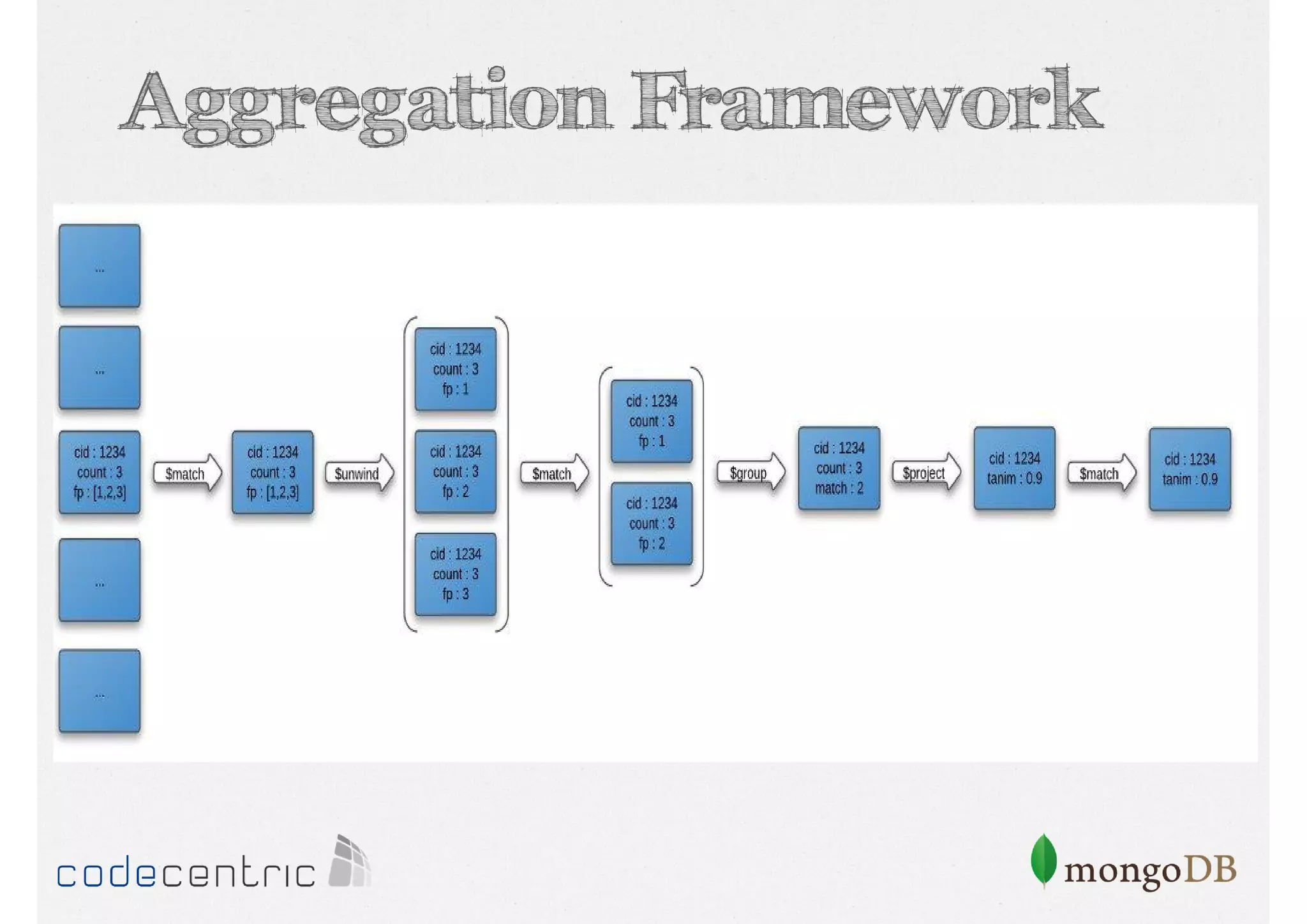
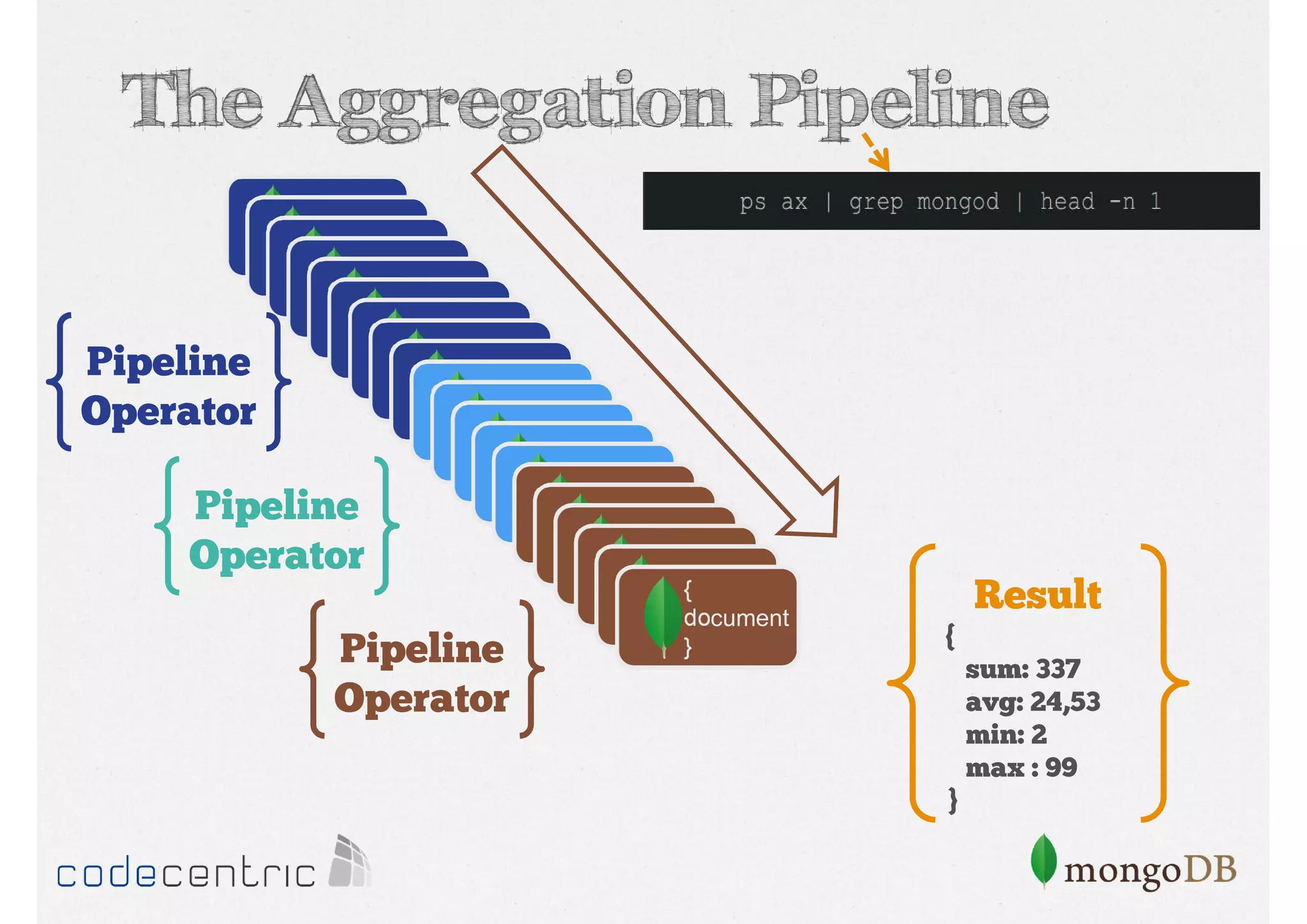
Introduction to the Aggregation Framework for efficient data processing, highlighting features and the pipeline concept.
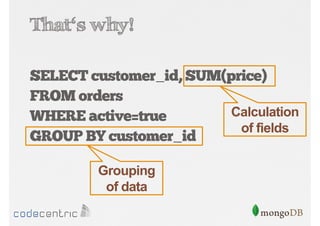
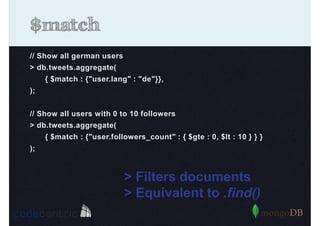
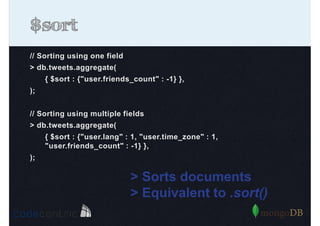
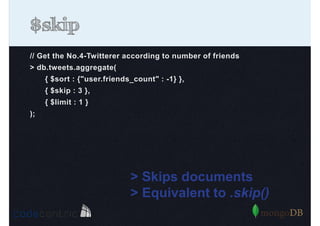
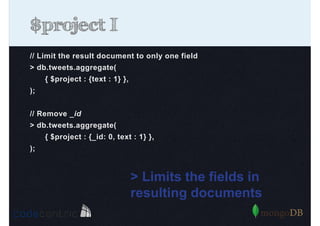
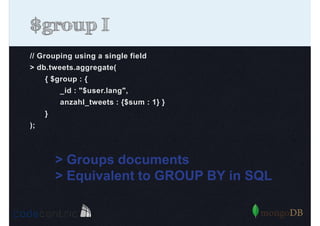
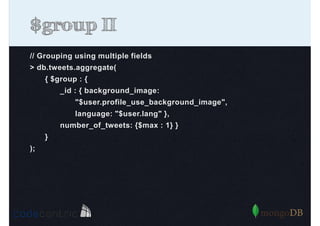
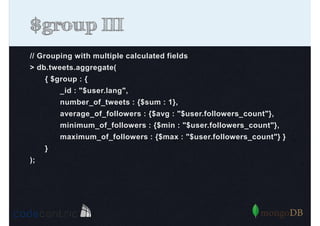
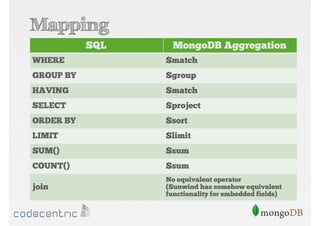
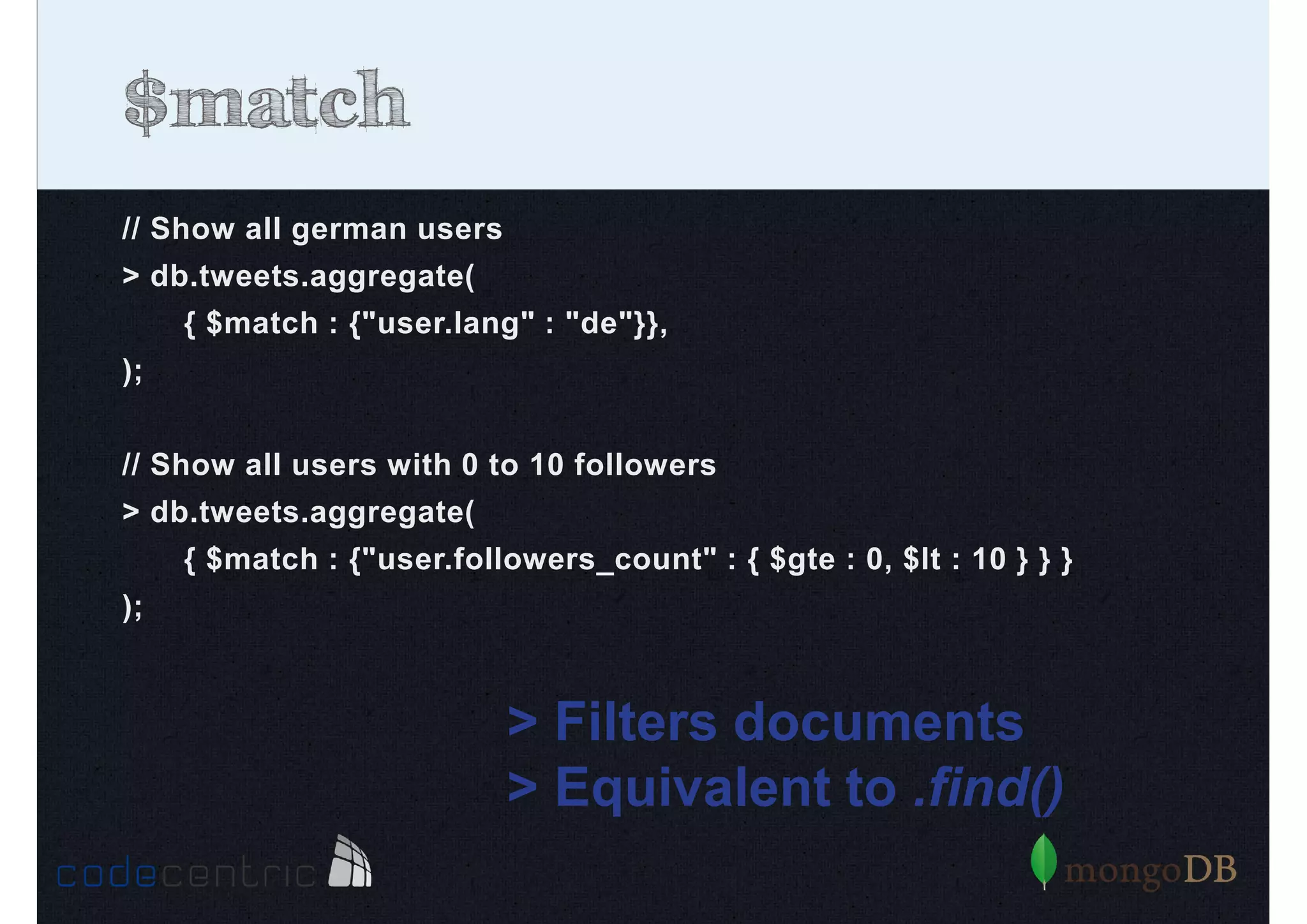
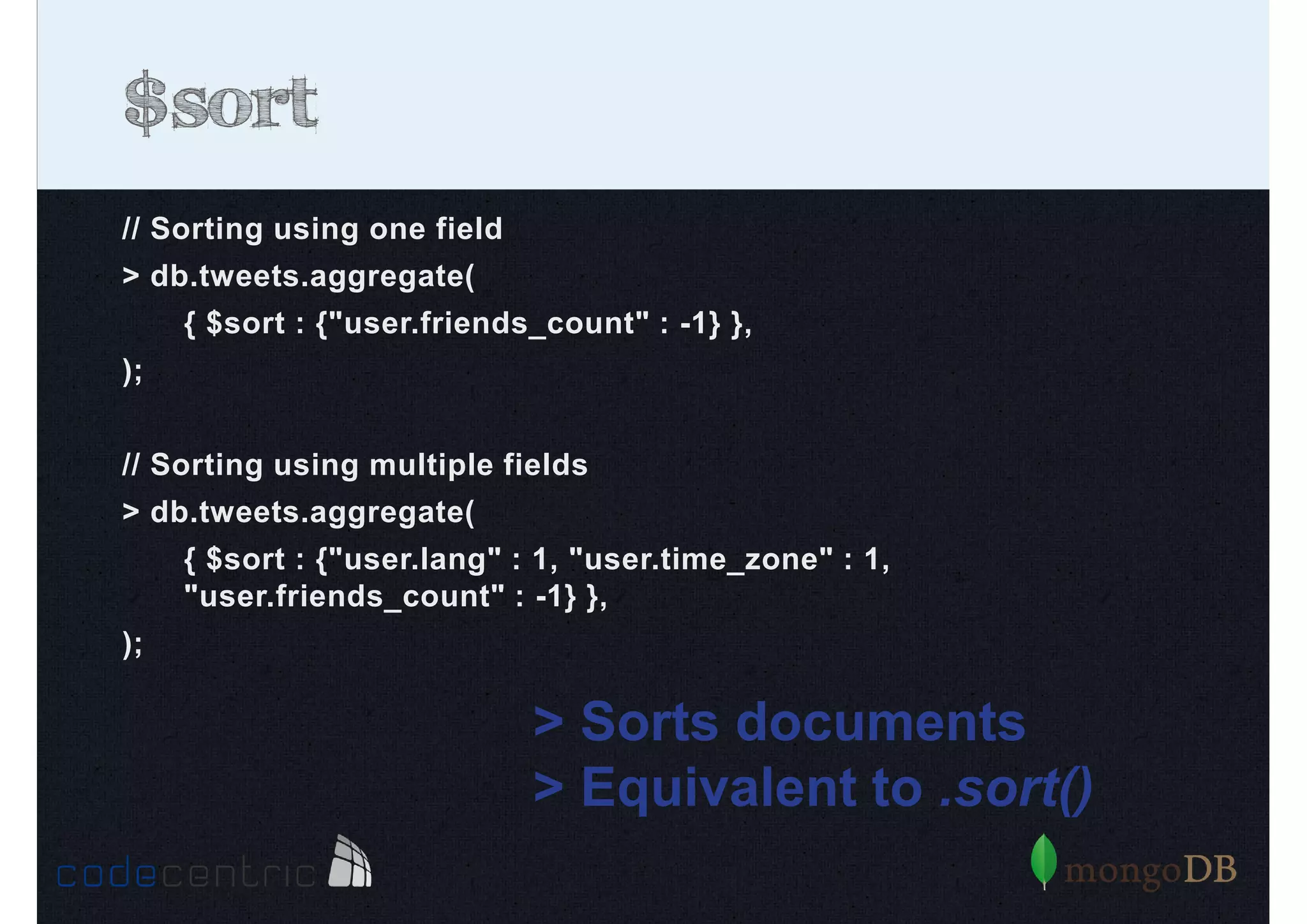
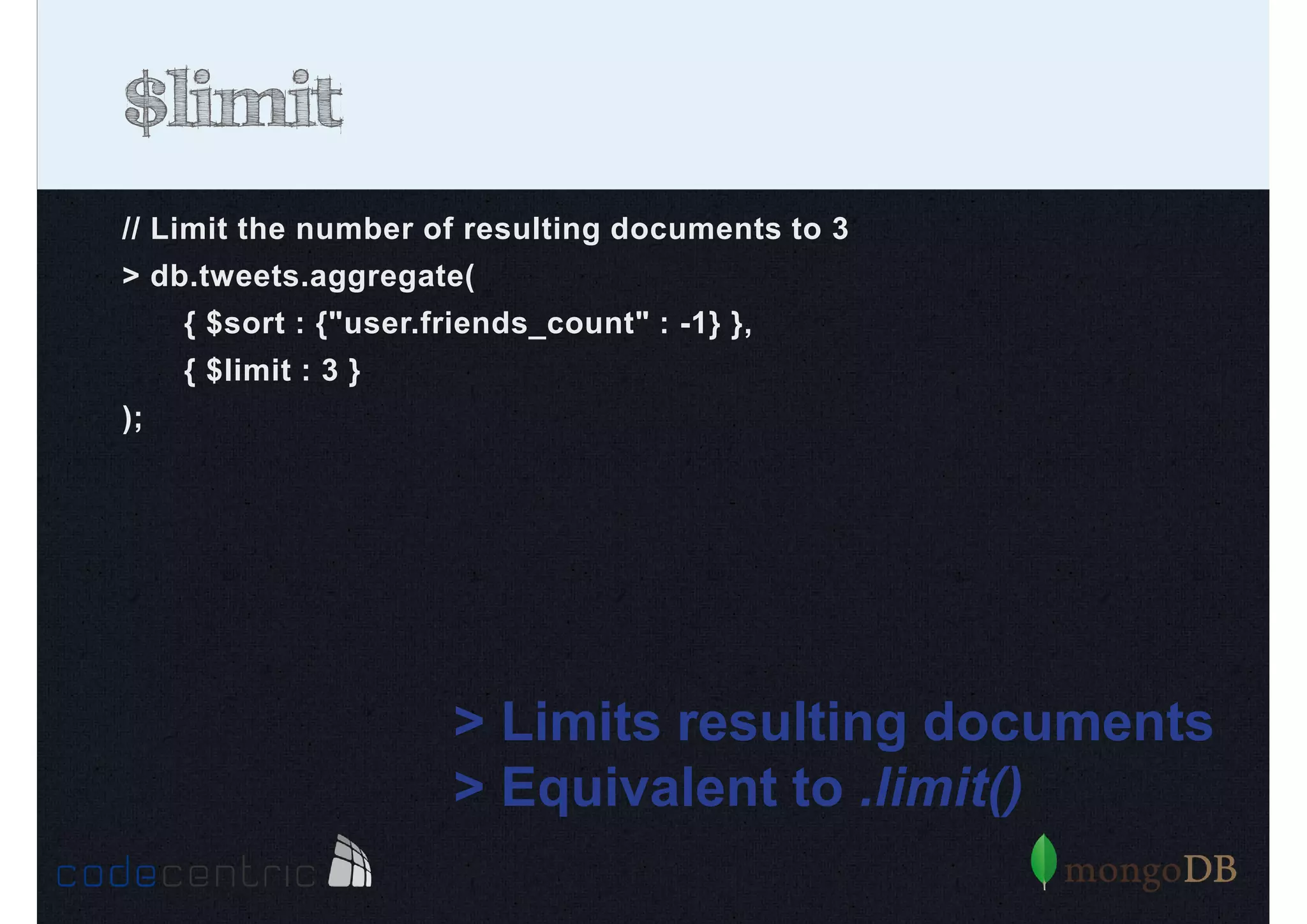
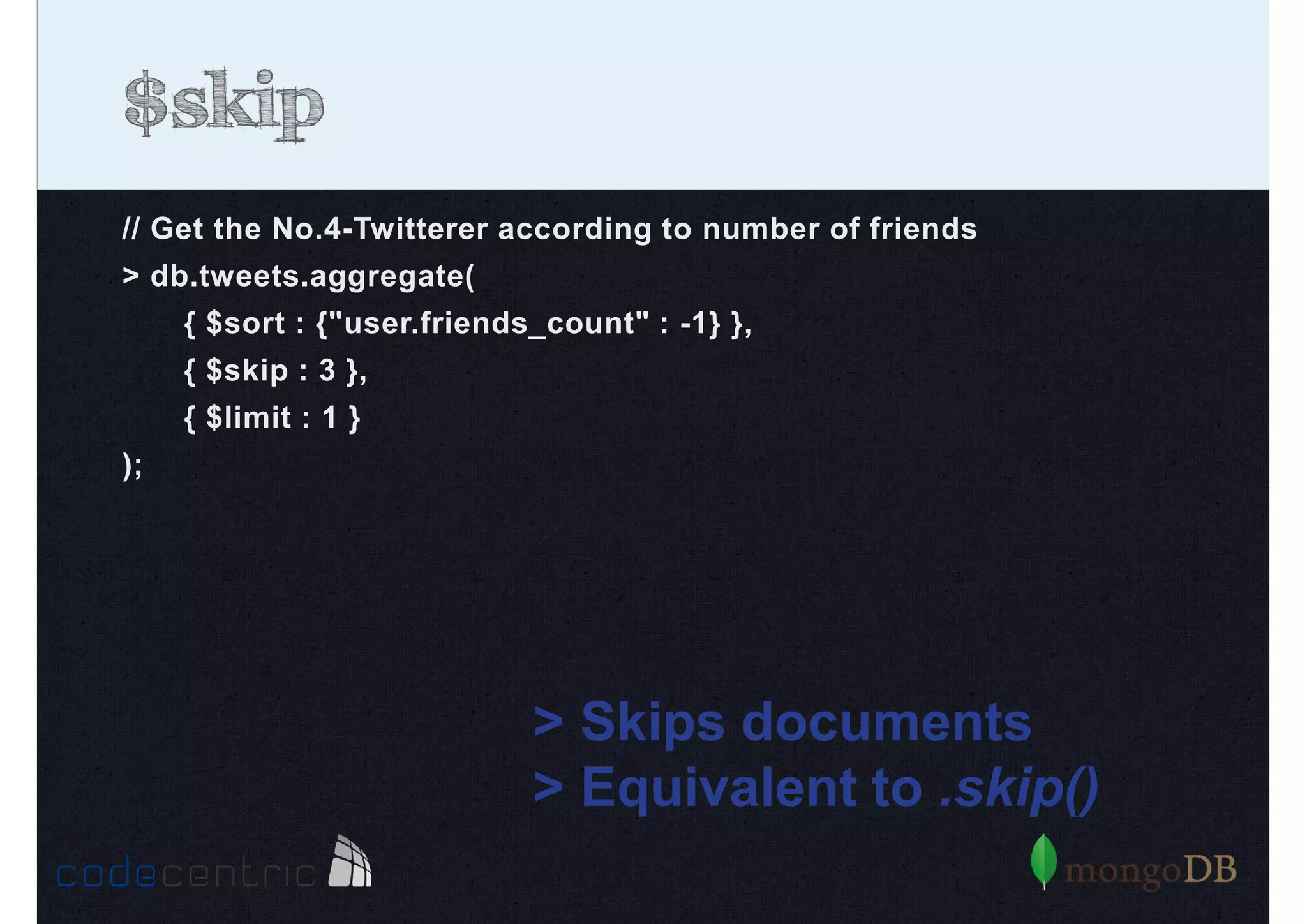
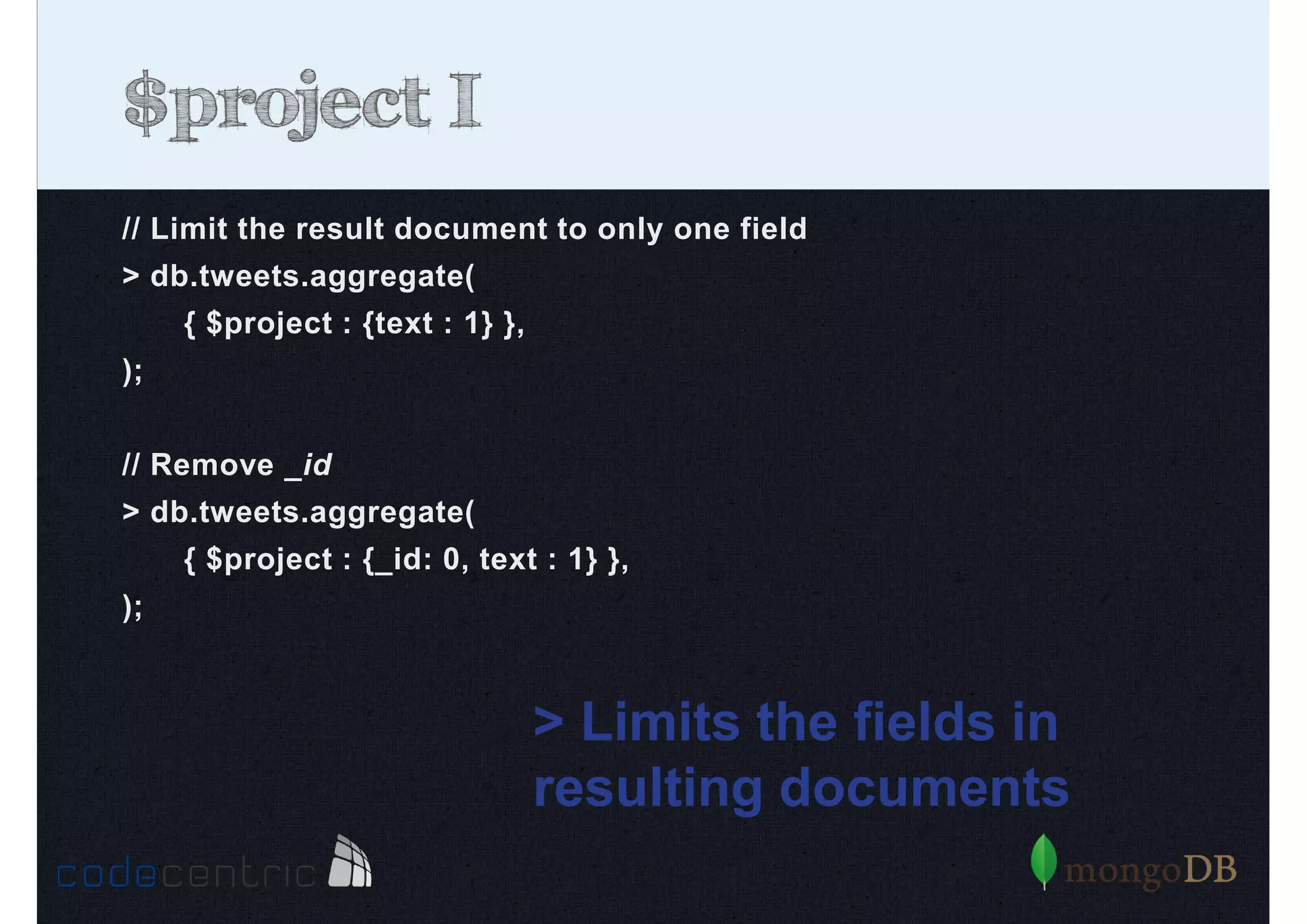
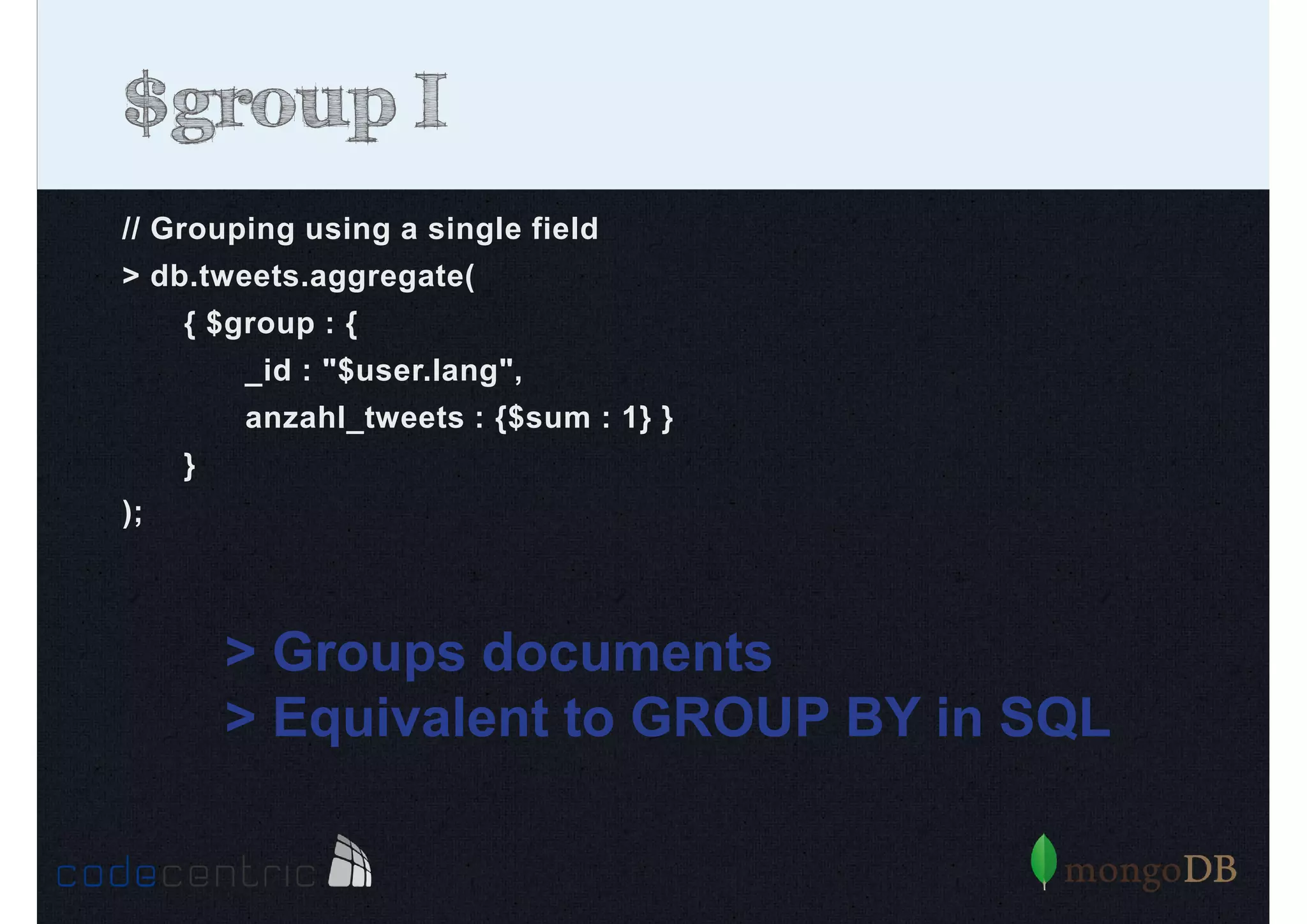
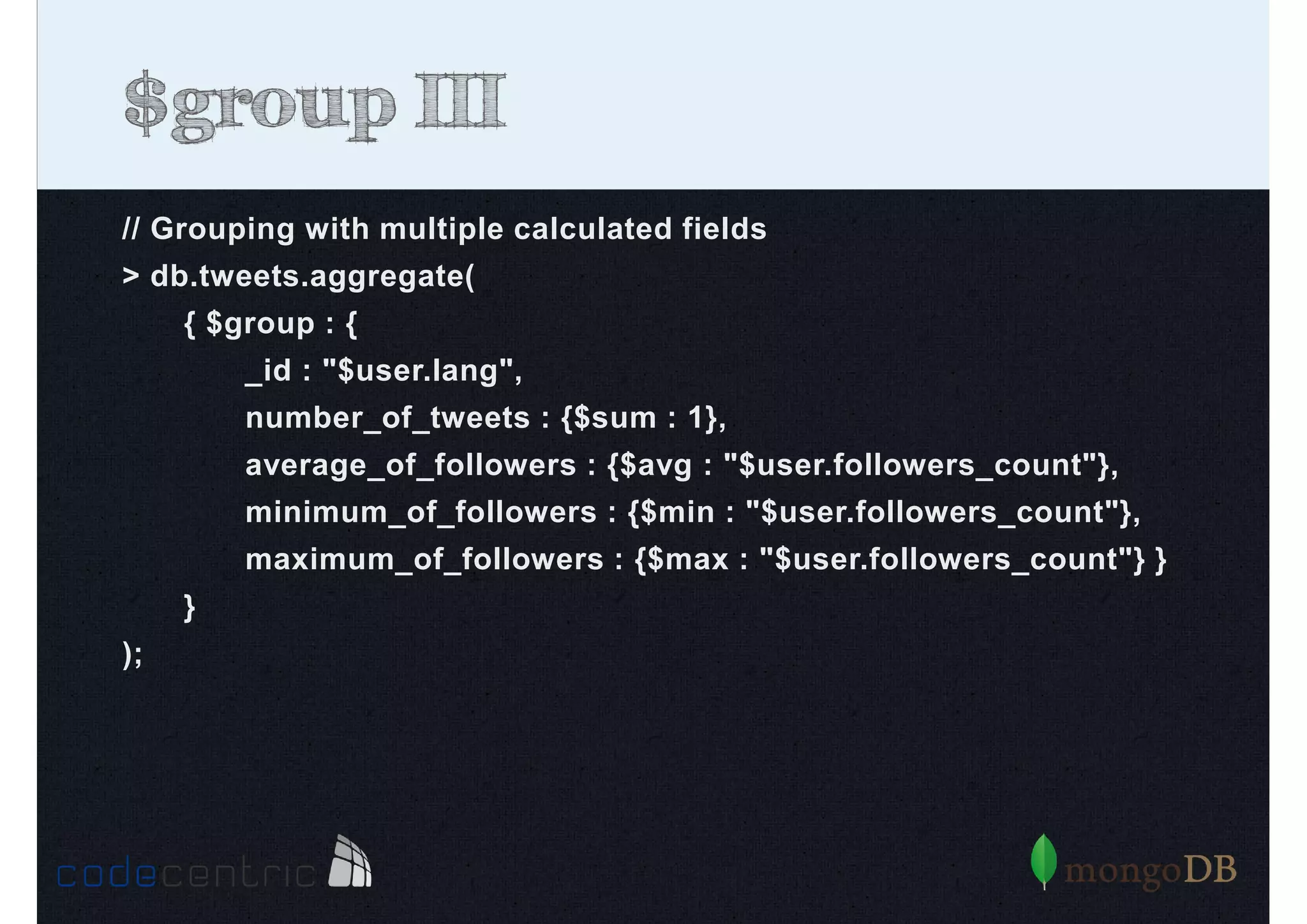
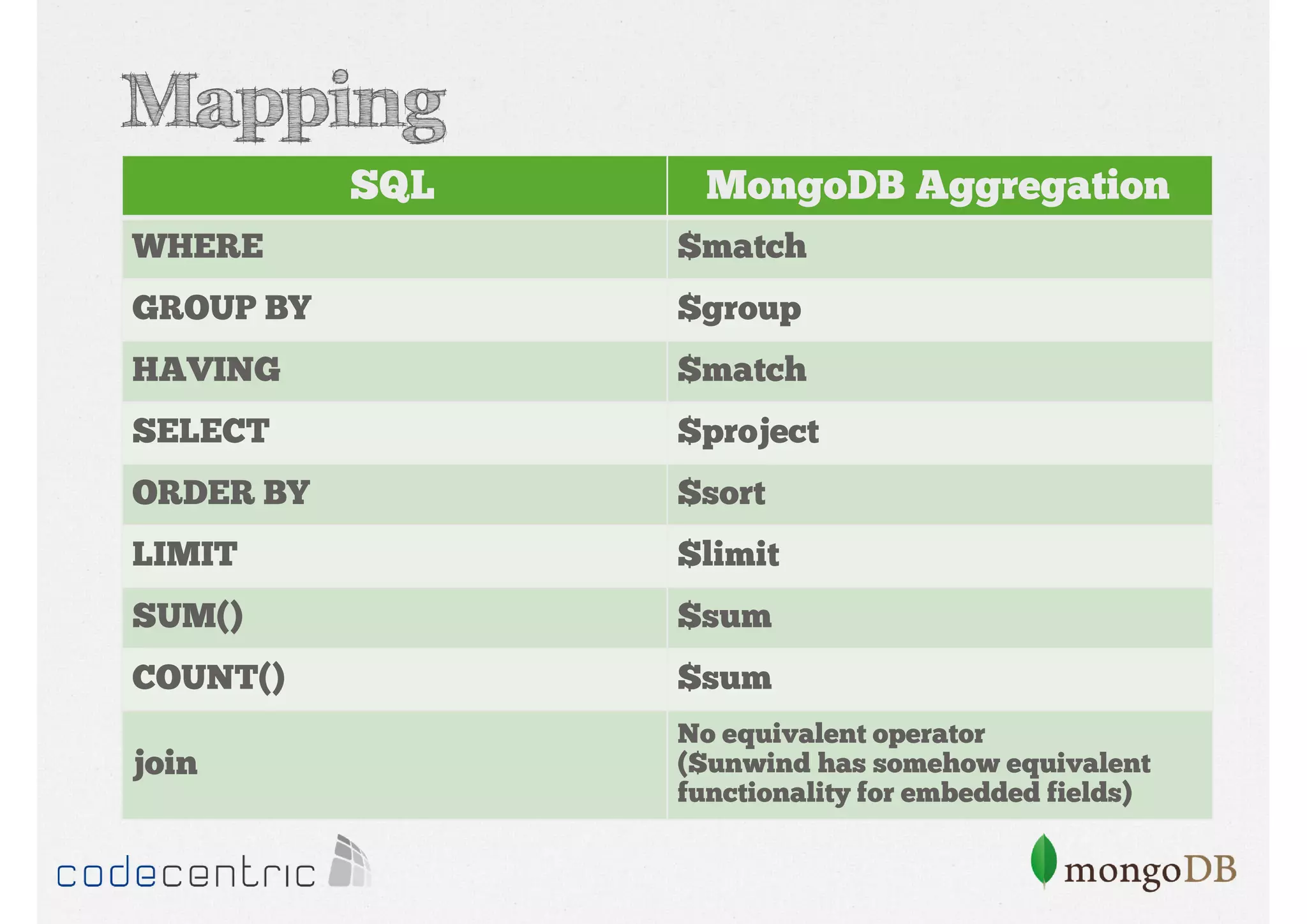
Detailed analysis of pipeline operators such as $match, $sort, $project, and $group for effective data aggregation.
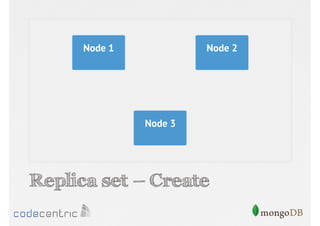
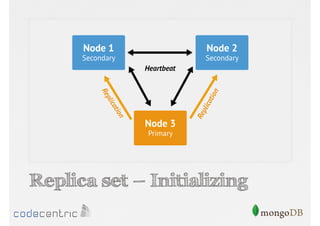
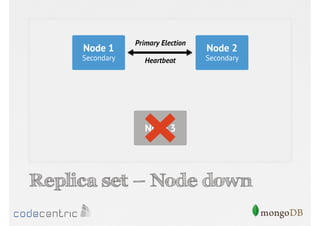
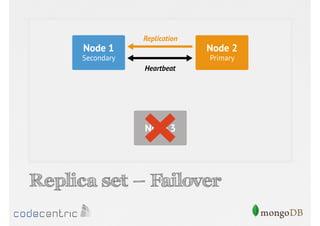
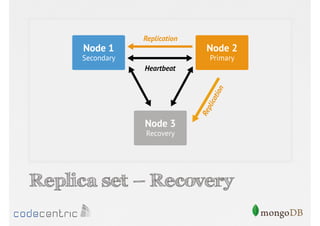
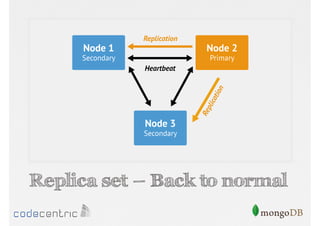
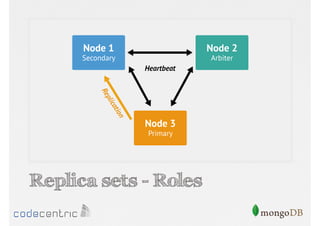
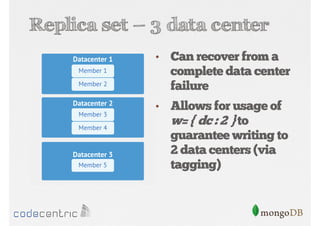
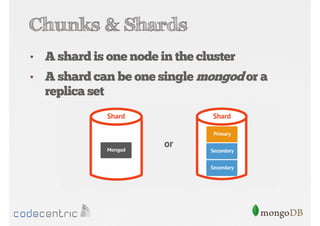
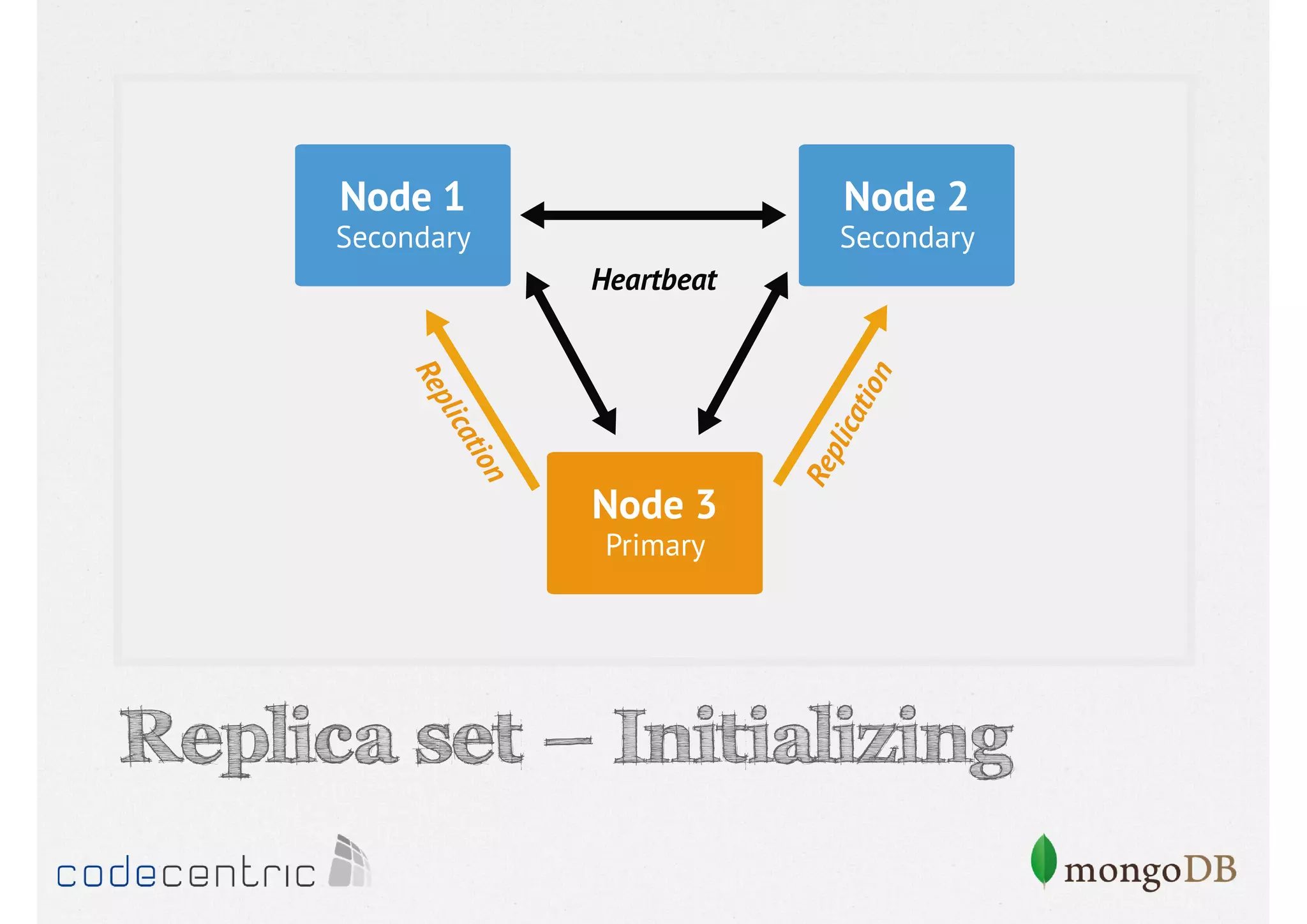
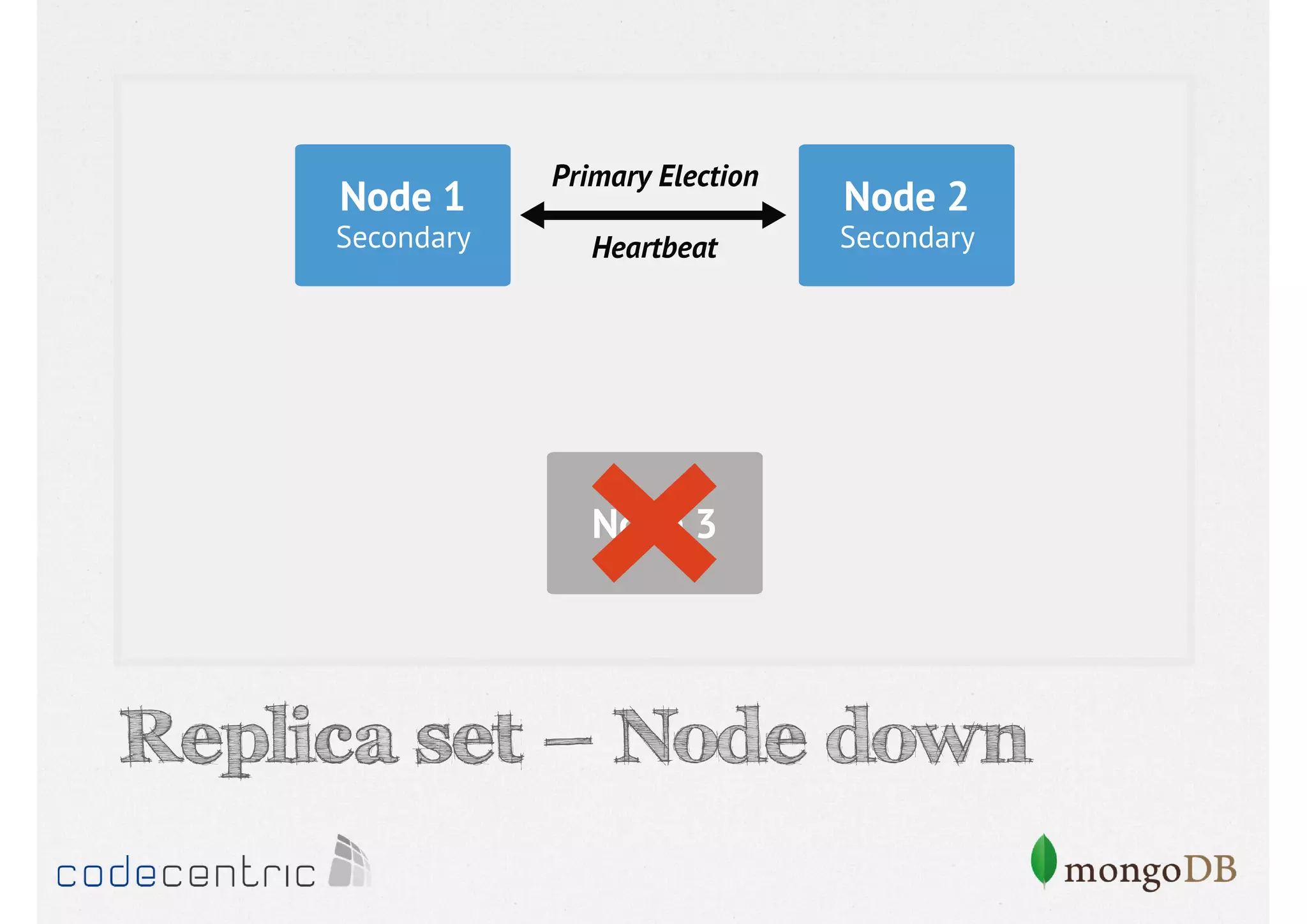
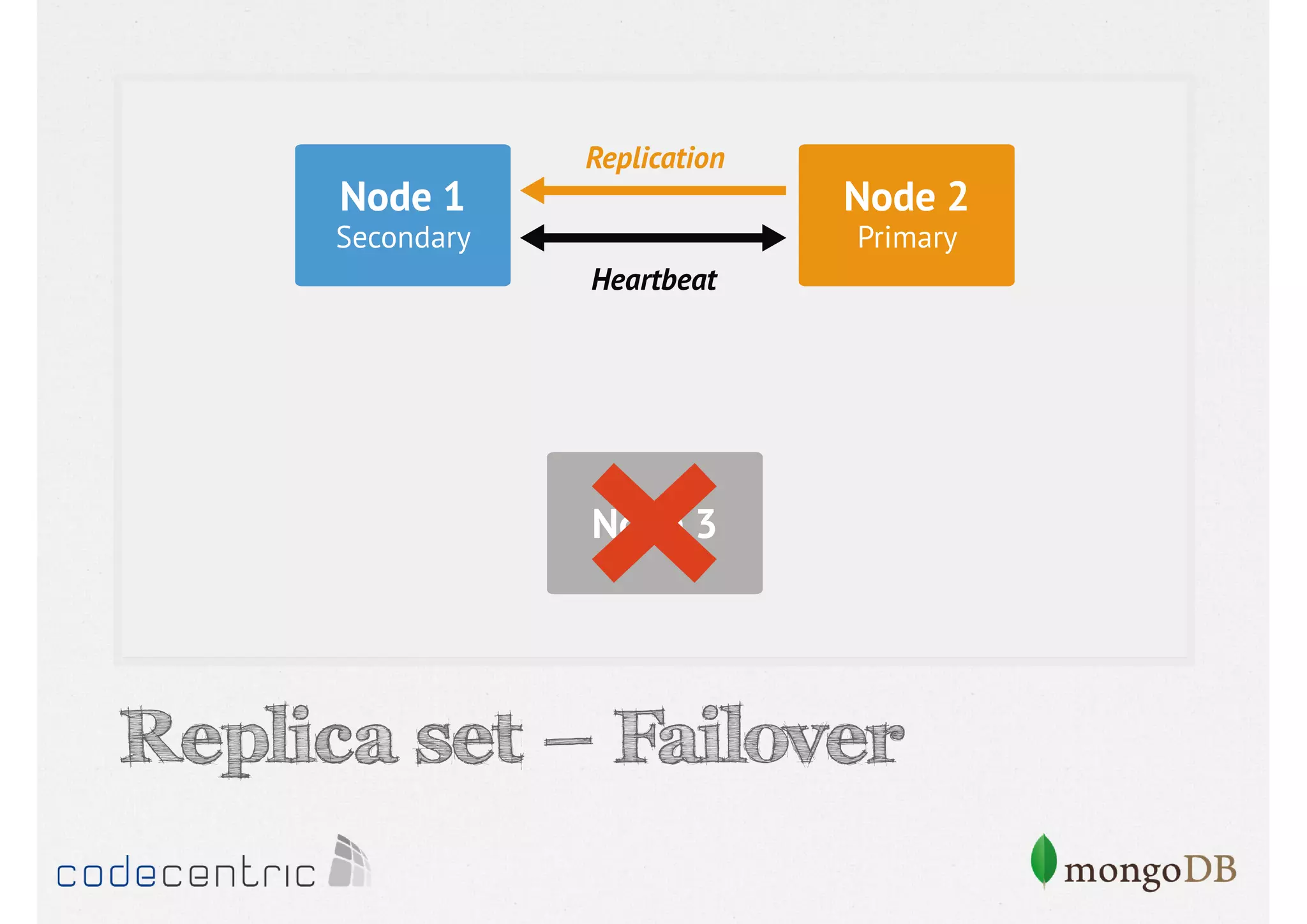
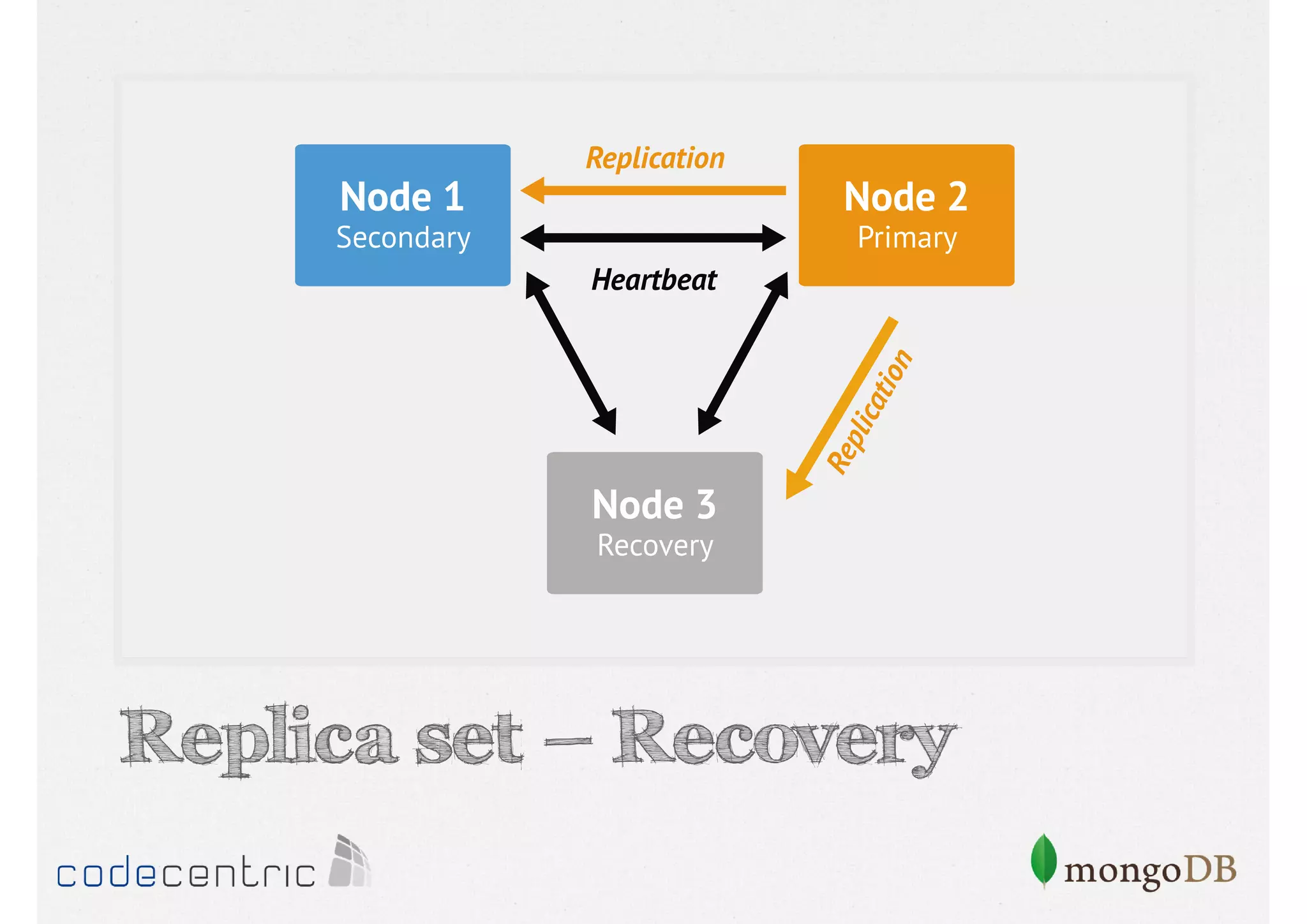
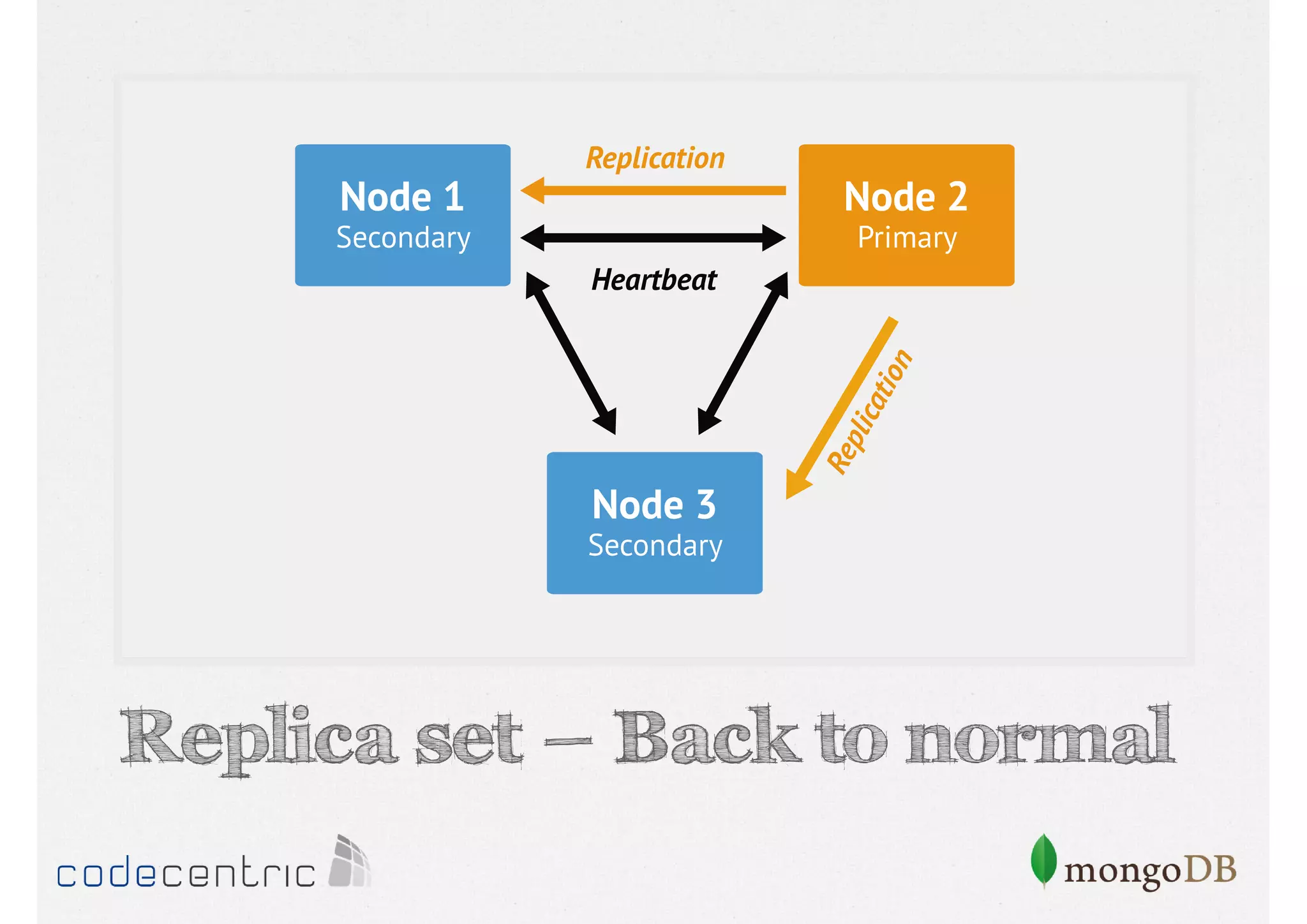
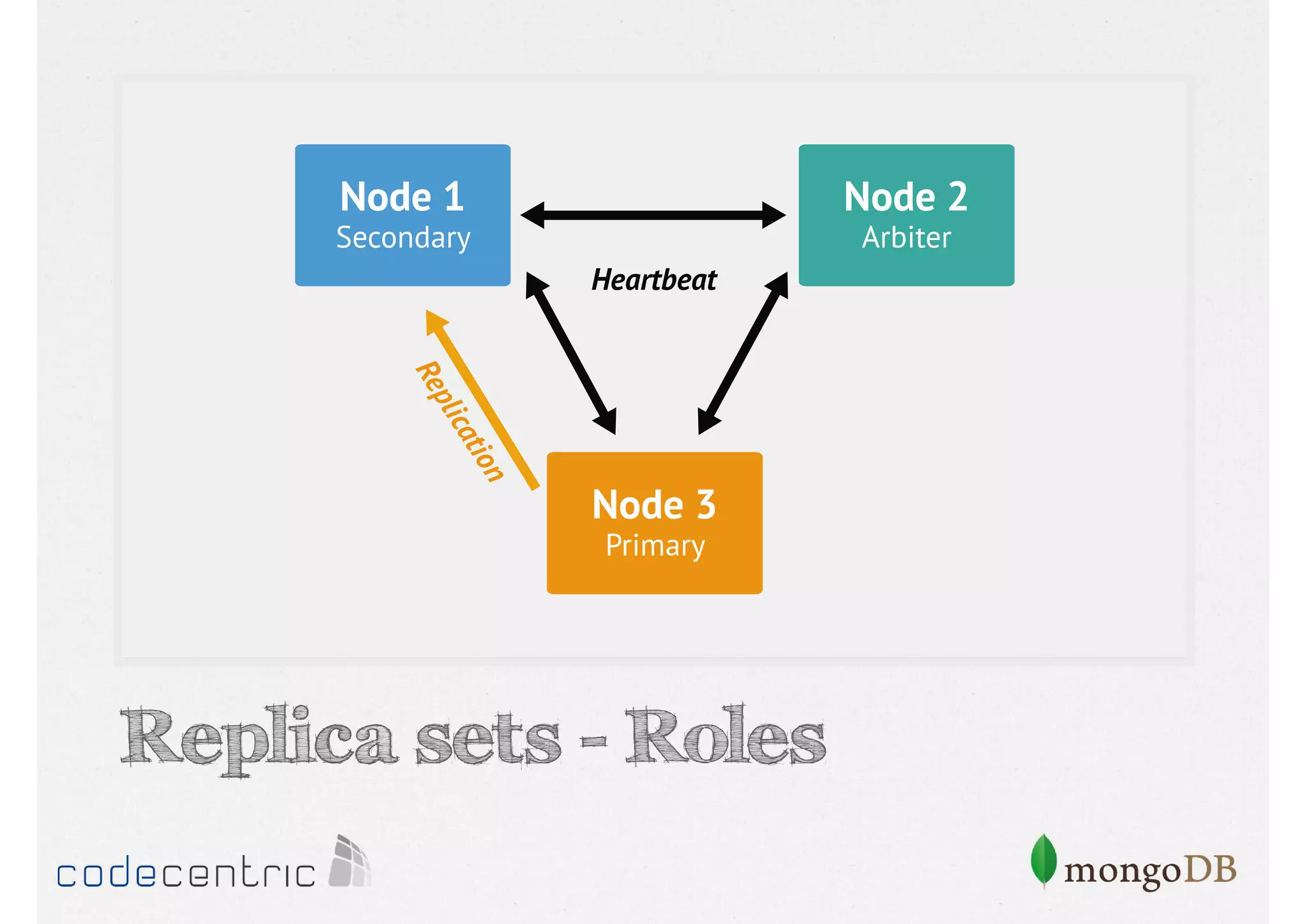
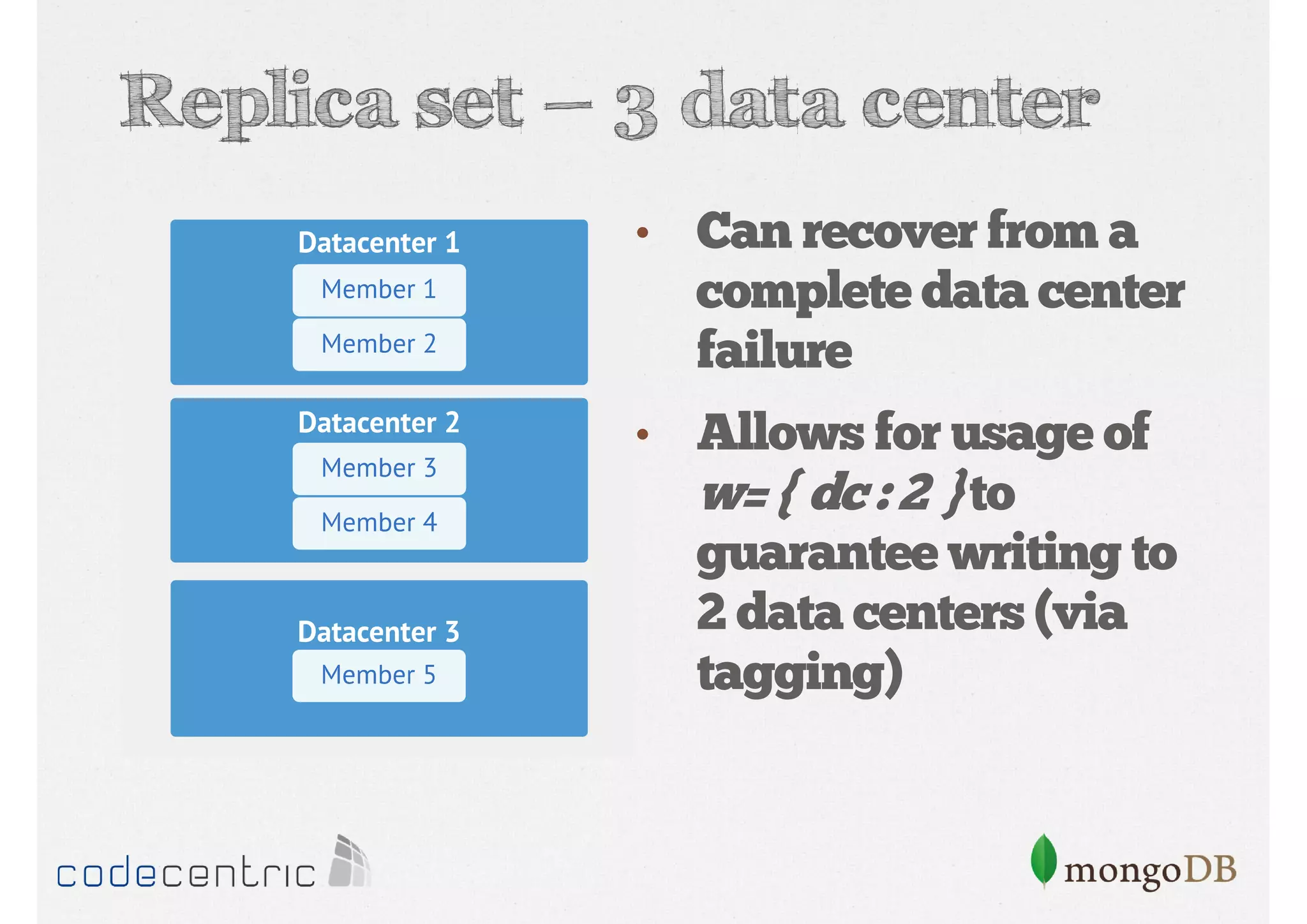
Discusses the importance of data replication in MongoDB for high availability and outlines the processes of setting up replica sets.
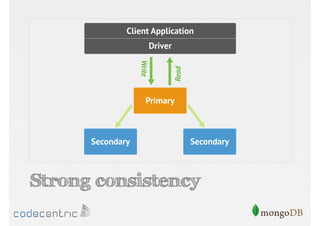
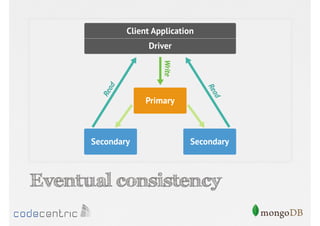
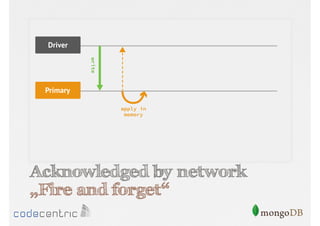
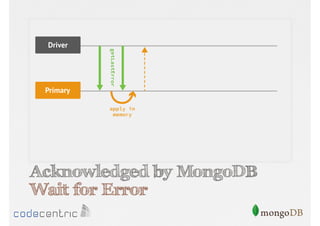
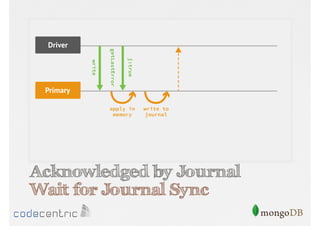
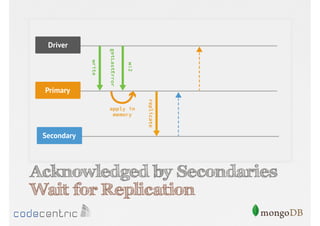
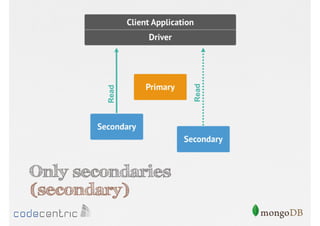
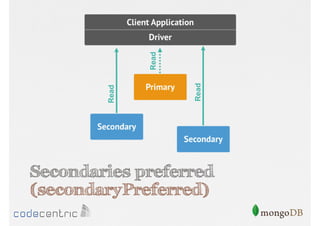
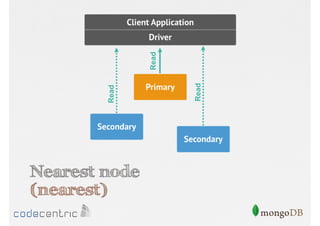
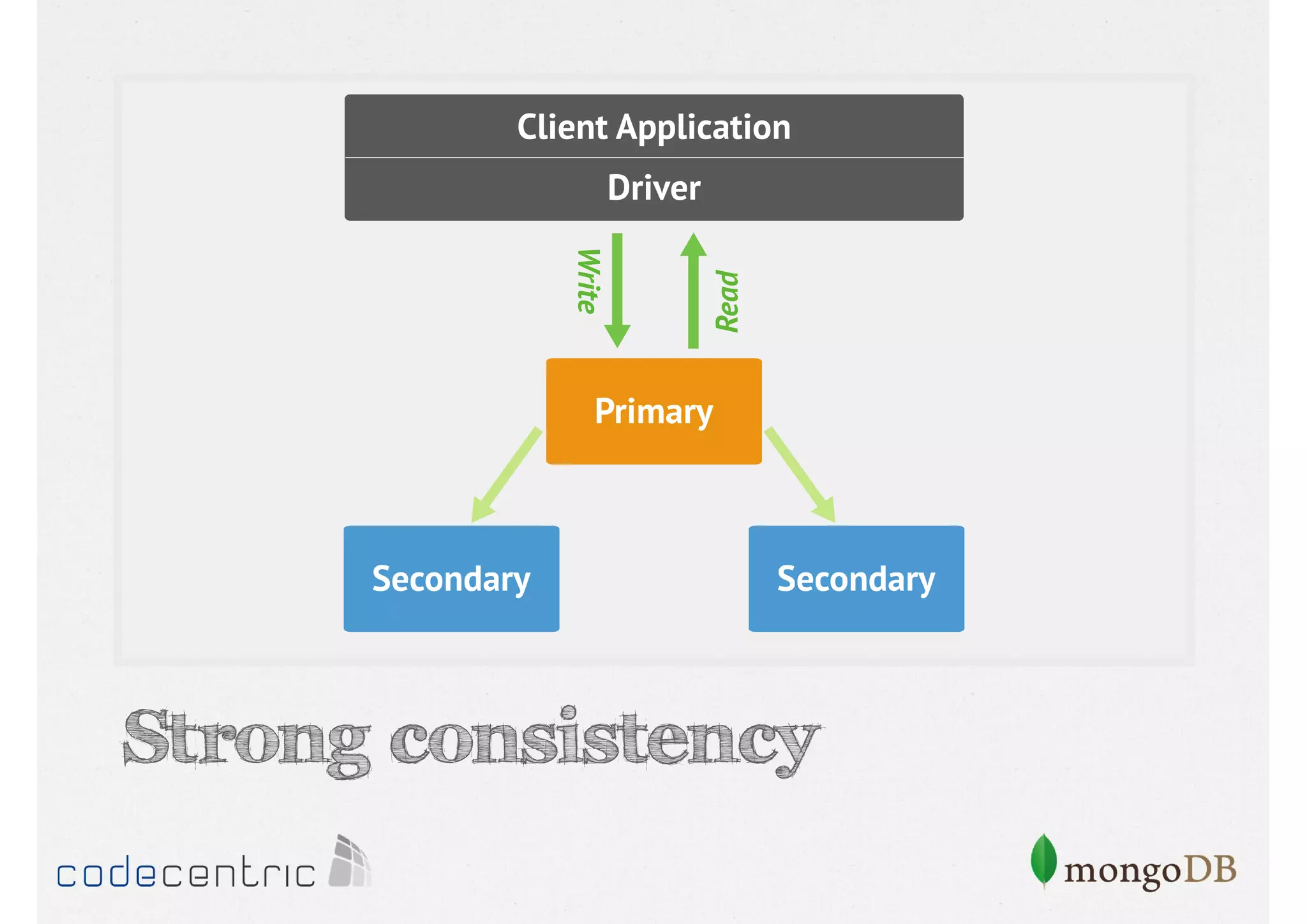
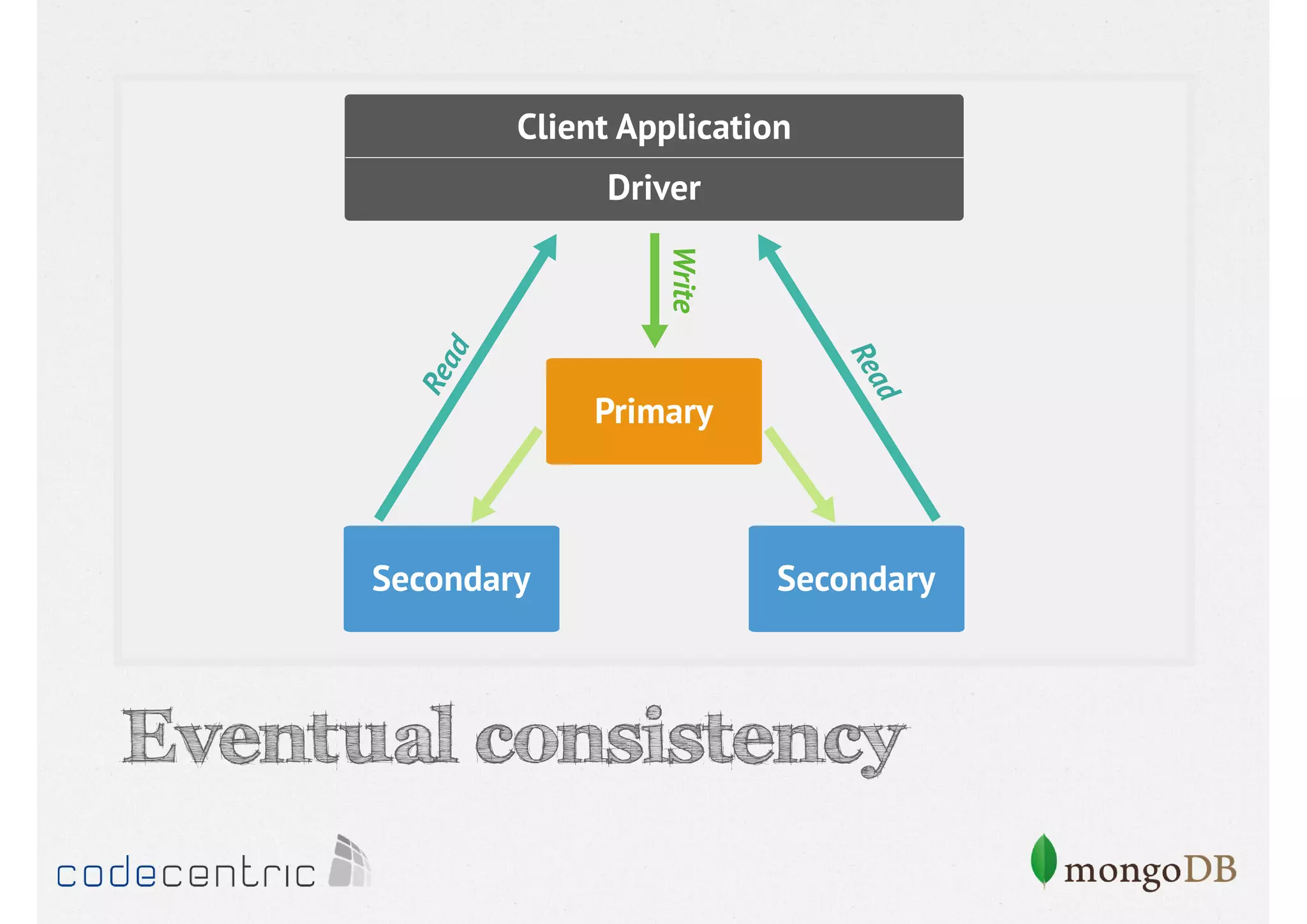
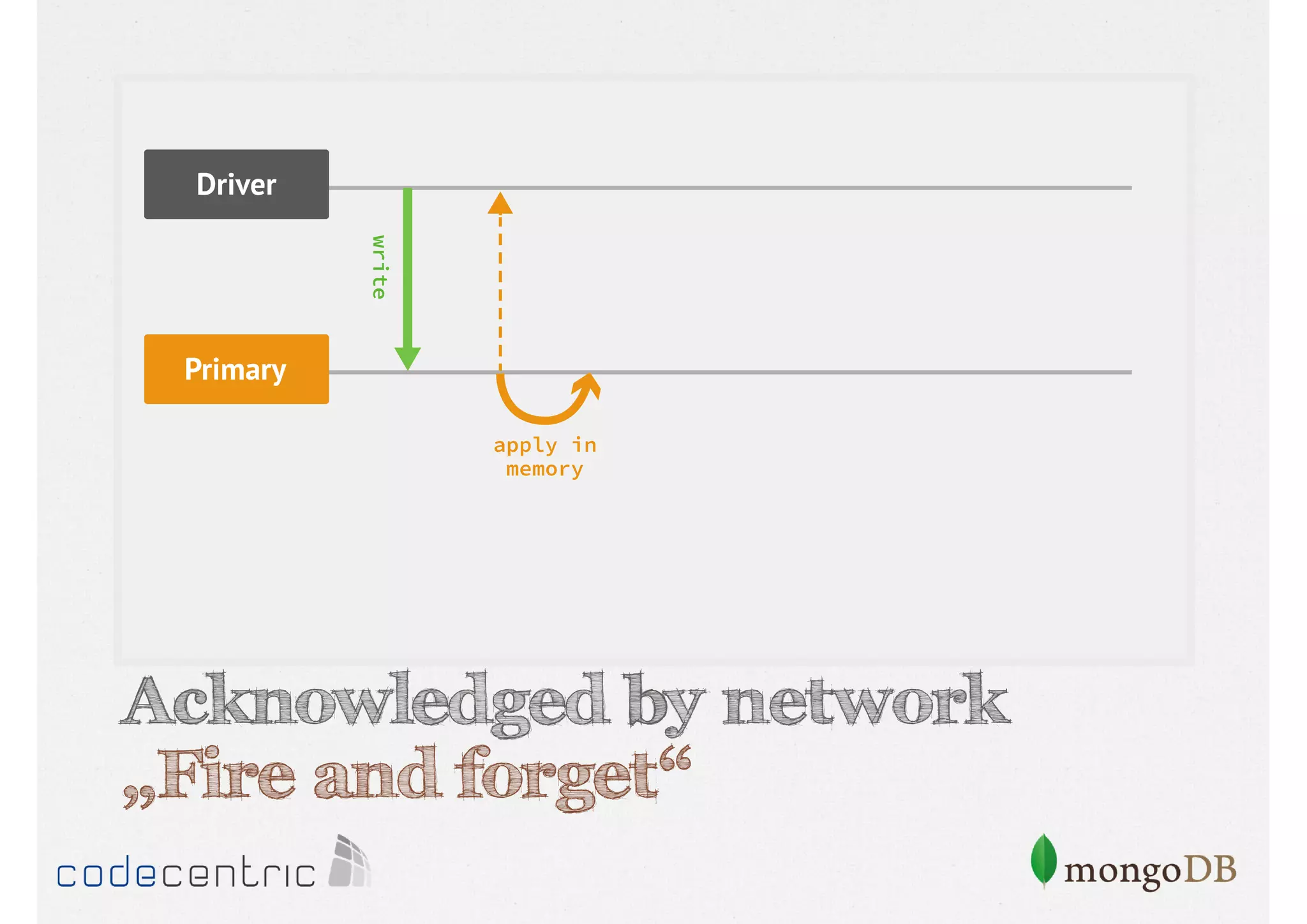
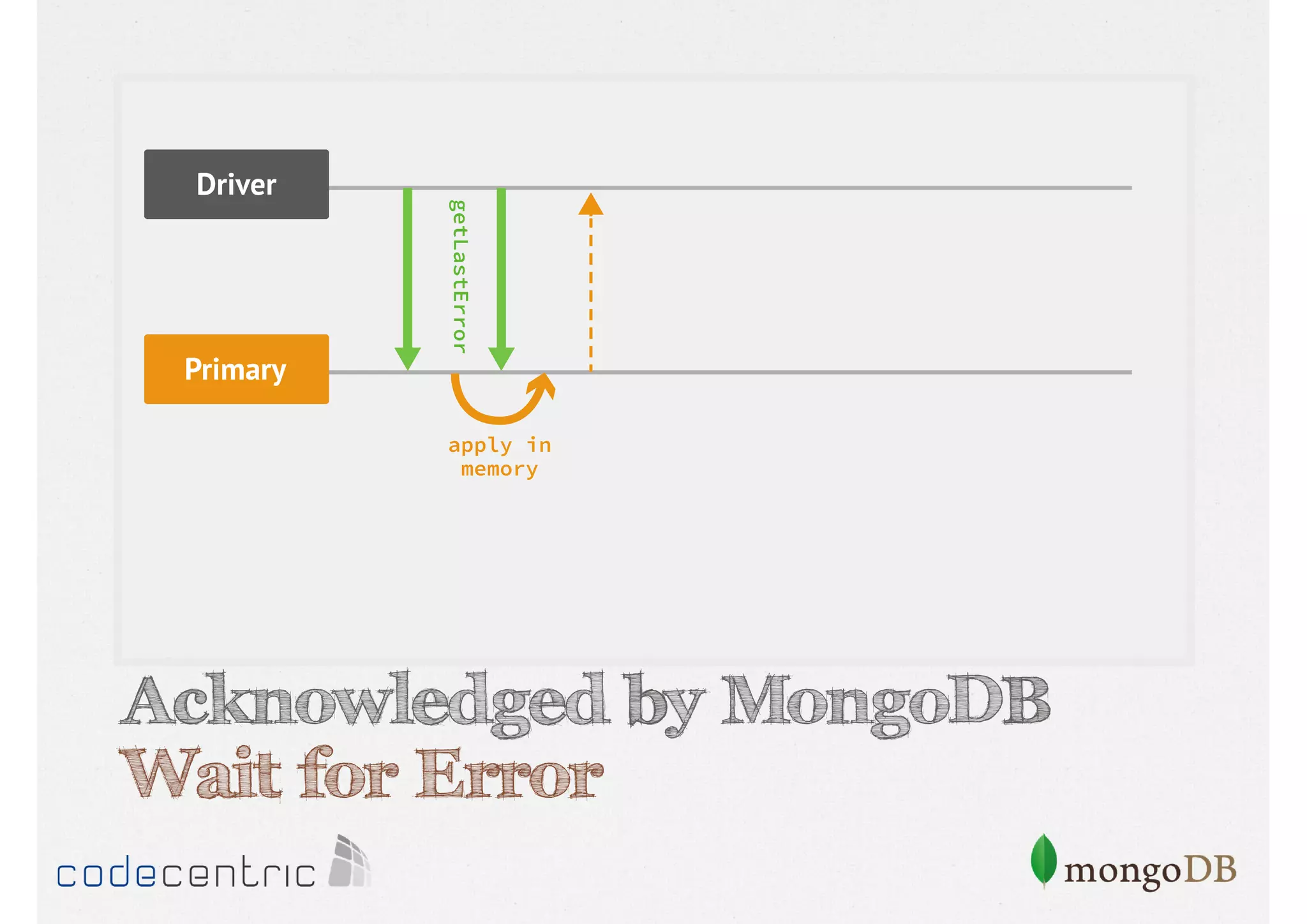
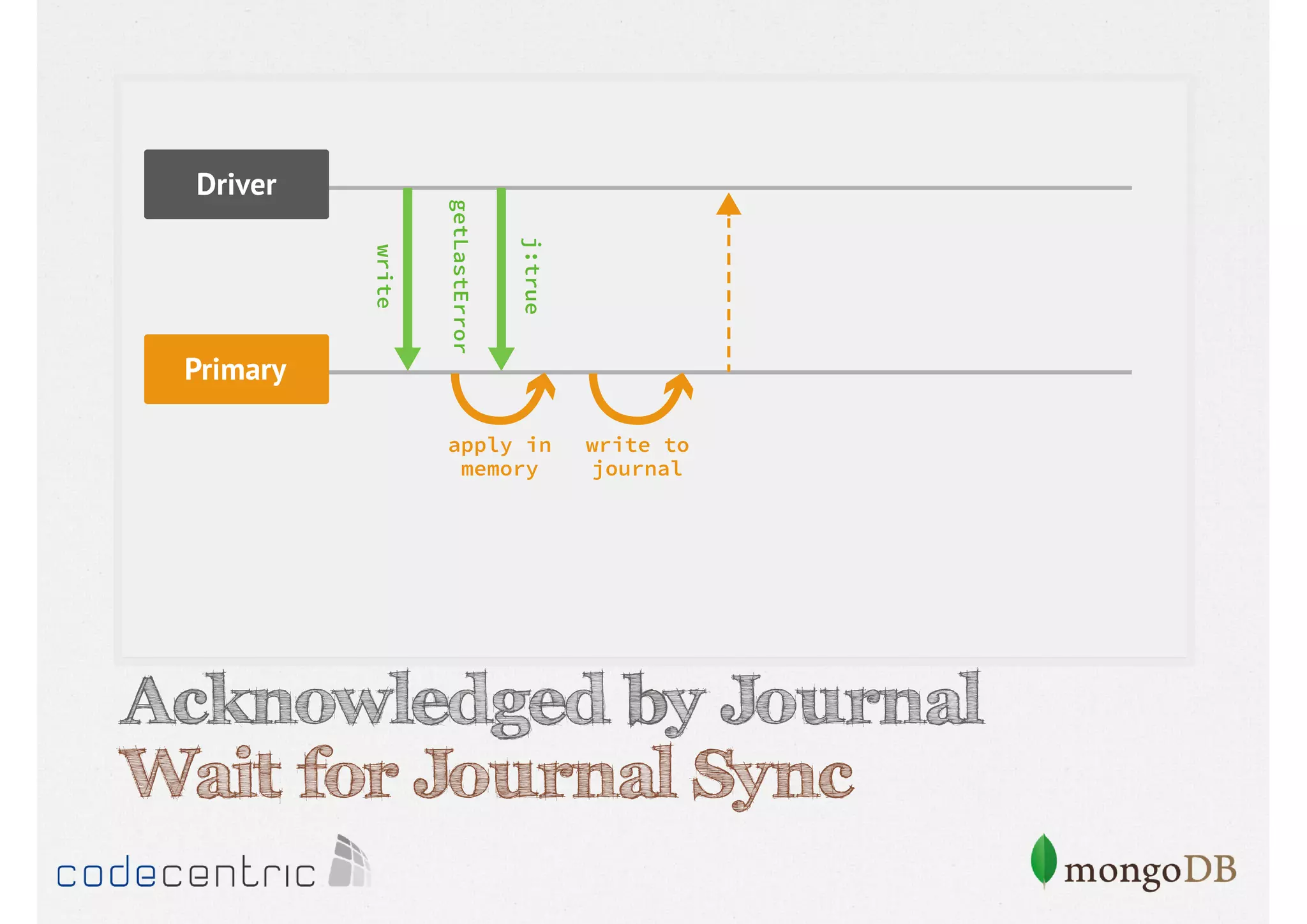
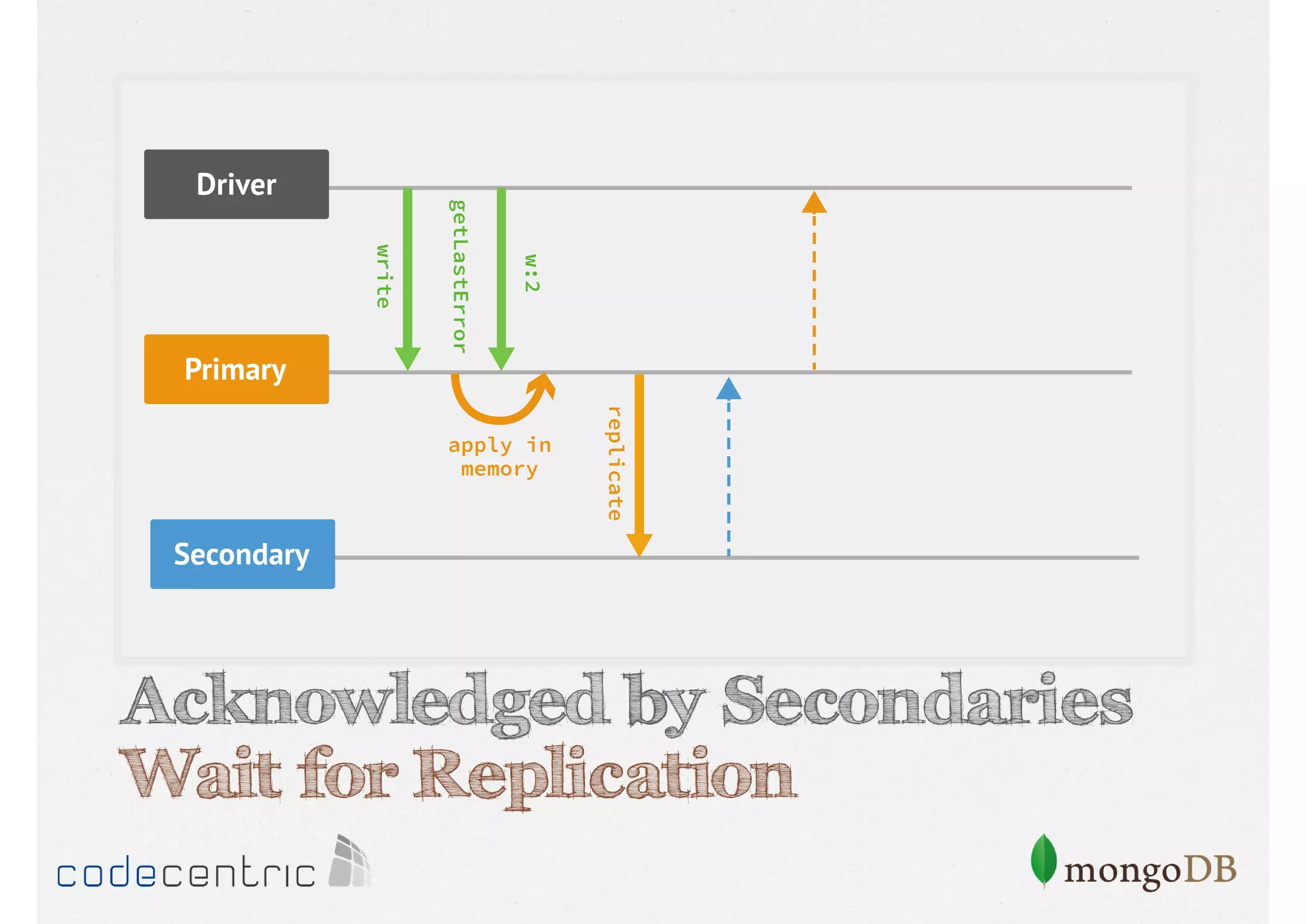
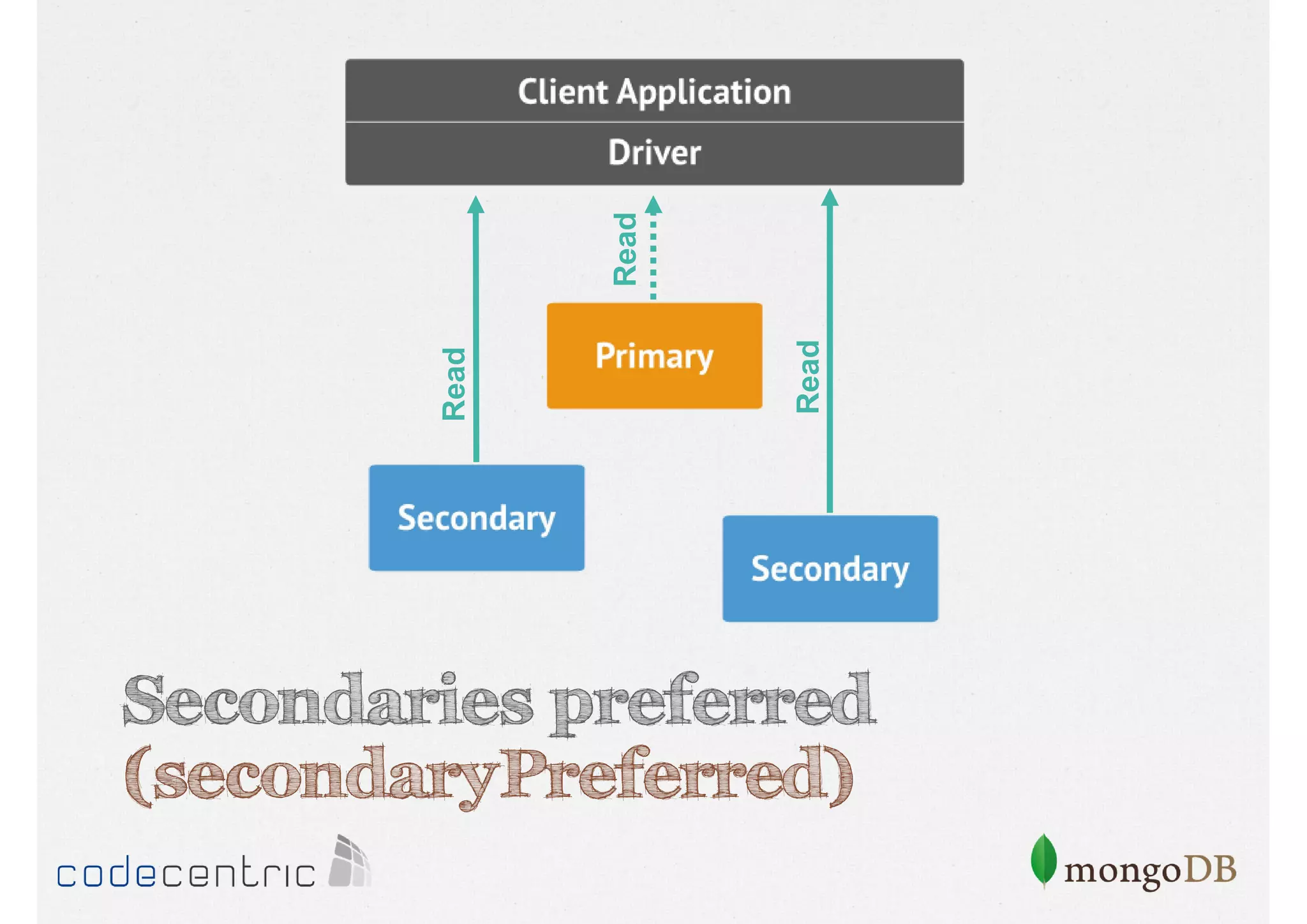
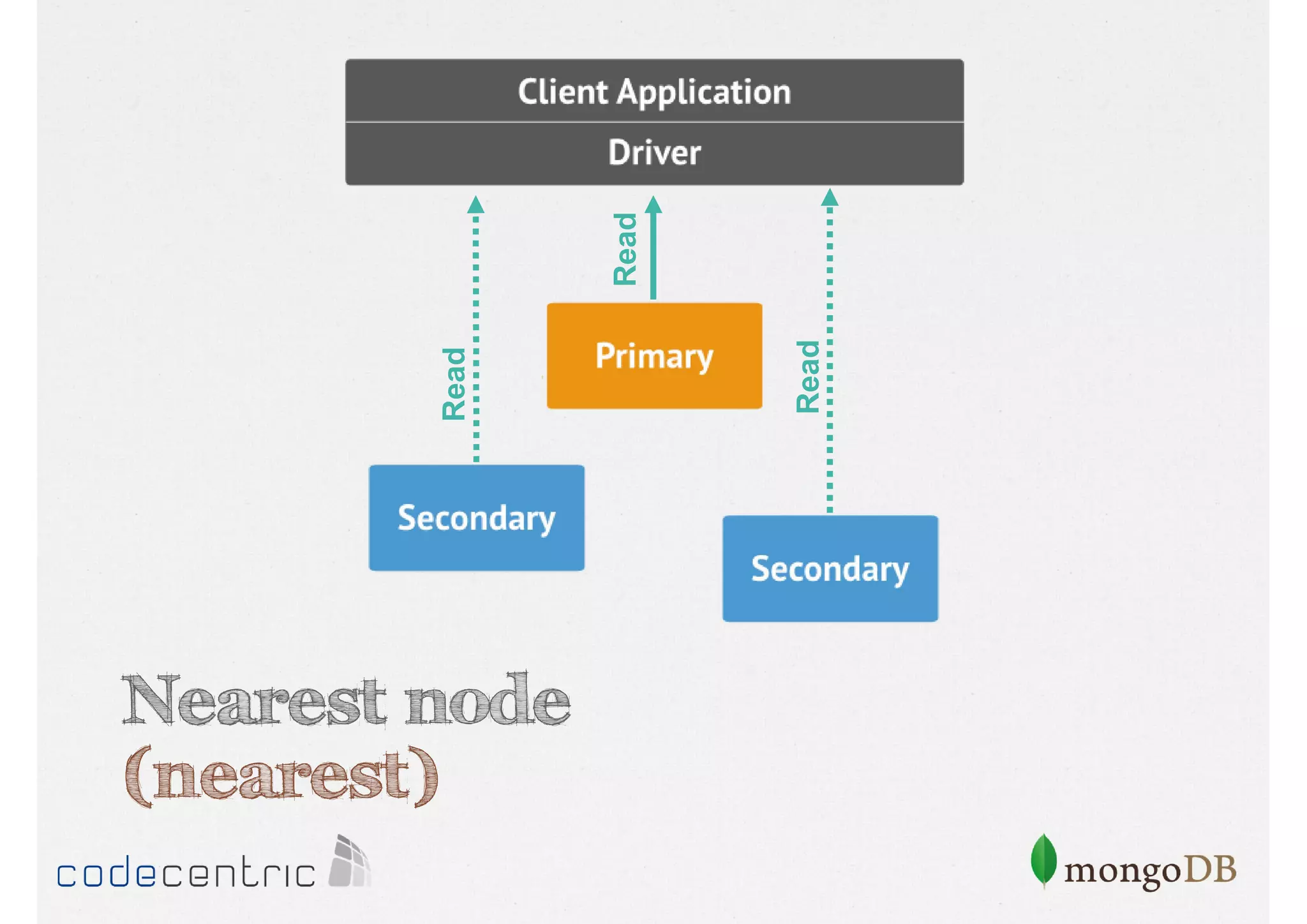
Focuses on data consistency levels in replication, different write concerns, and mechanisms for ensuring data reliability in replicas.
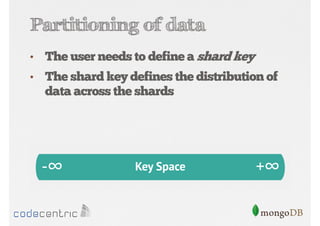
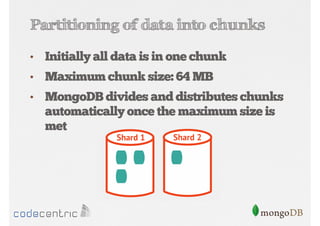
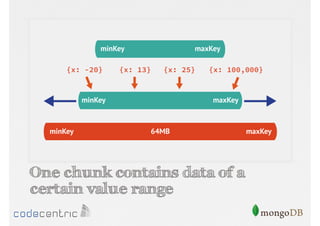
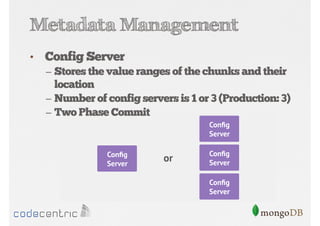
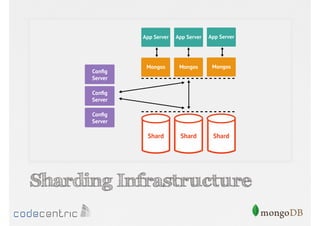
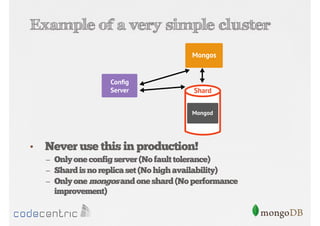
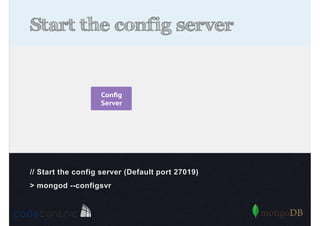
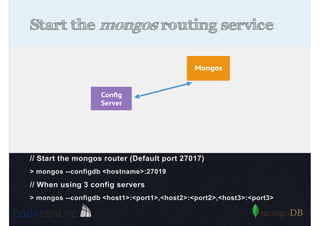
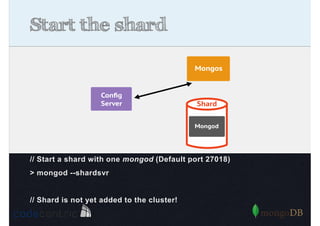
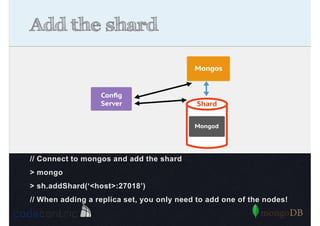
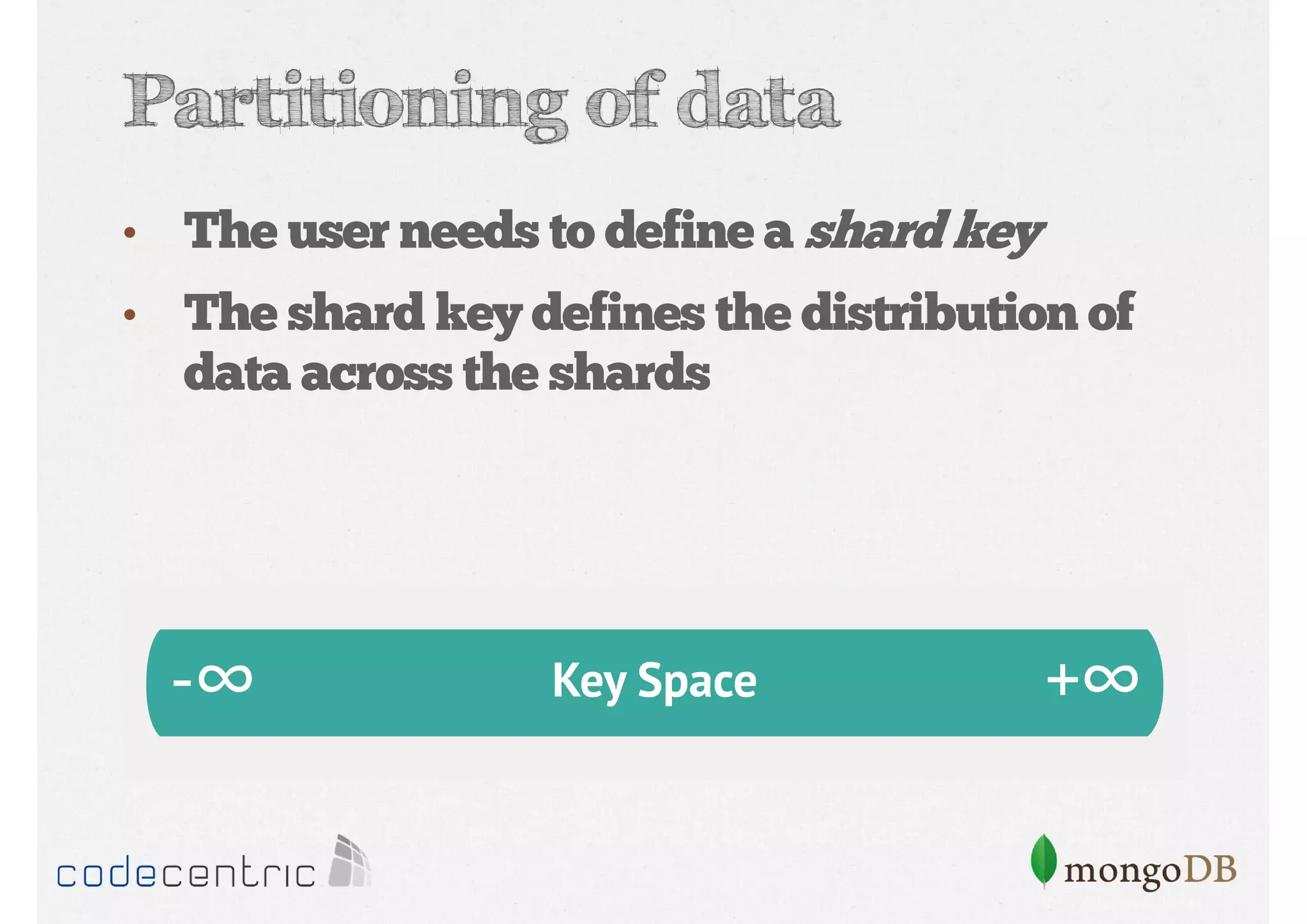
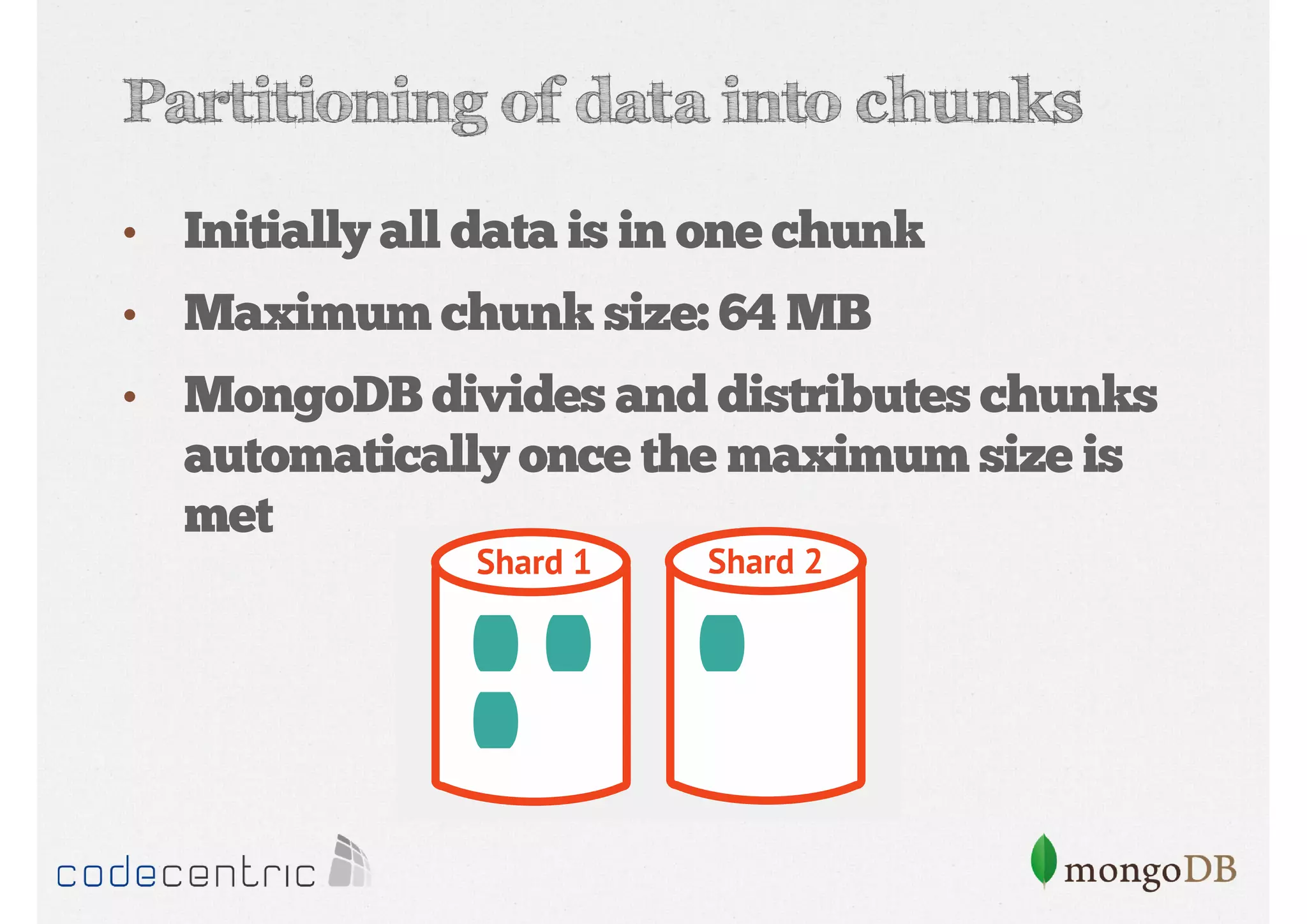
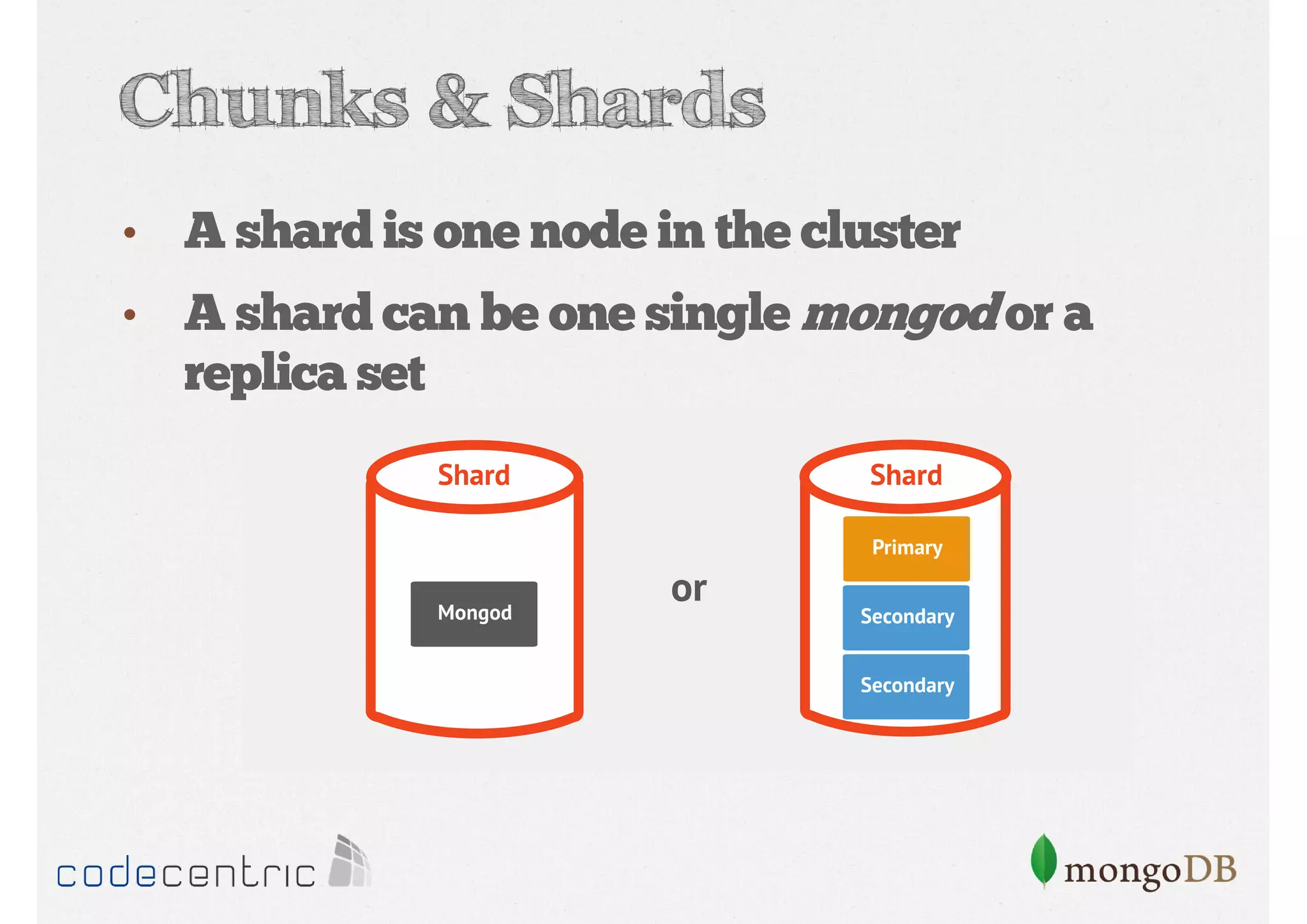
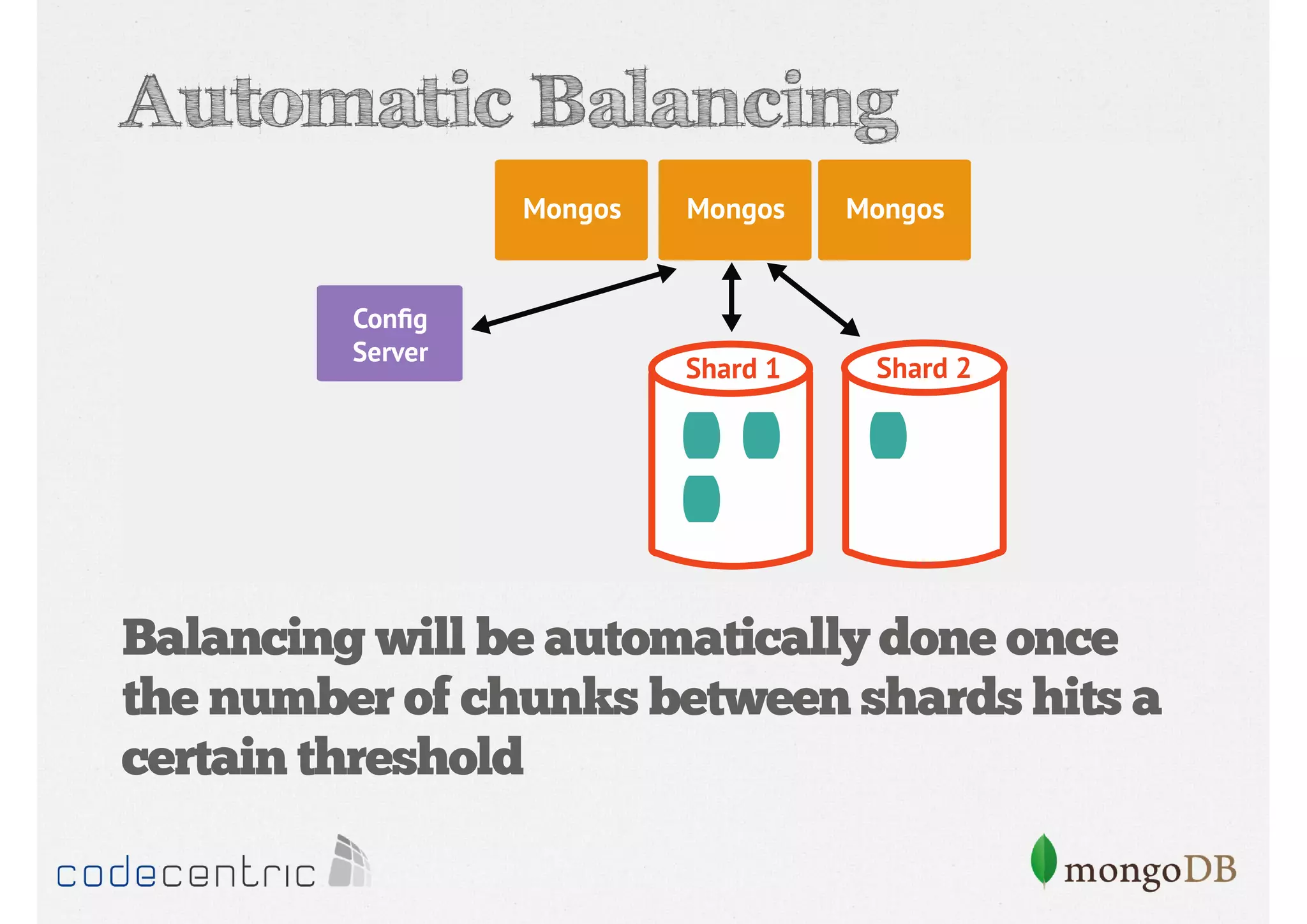
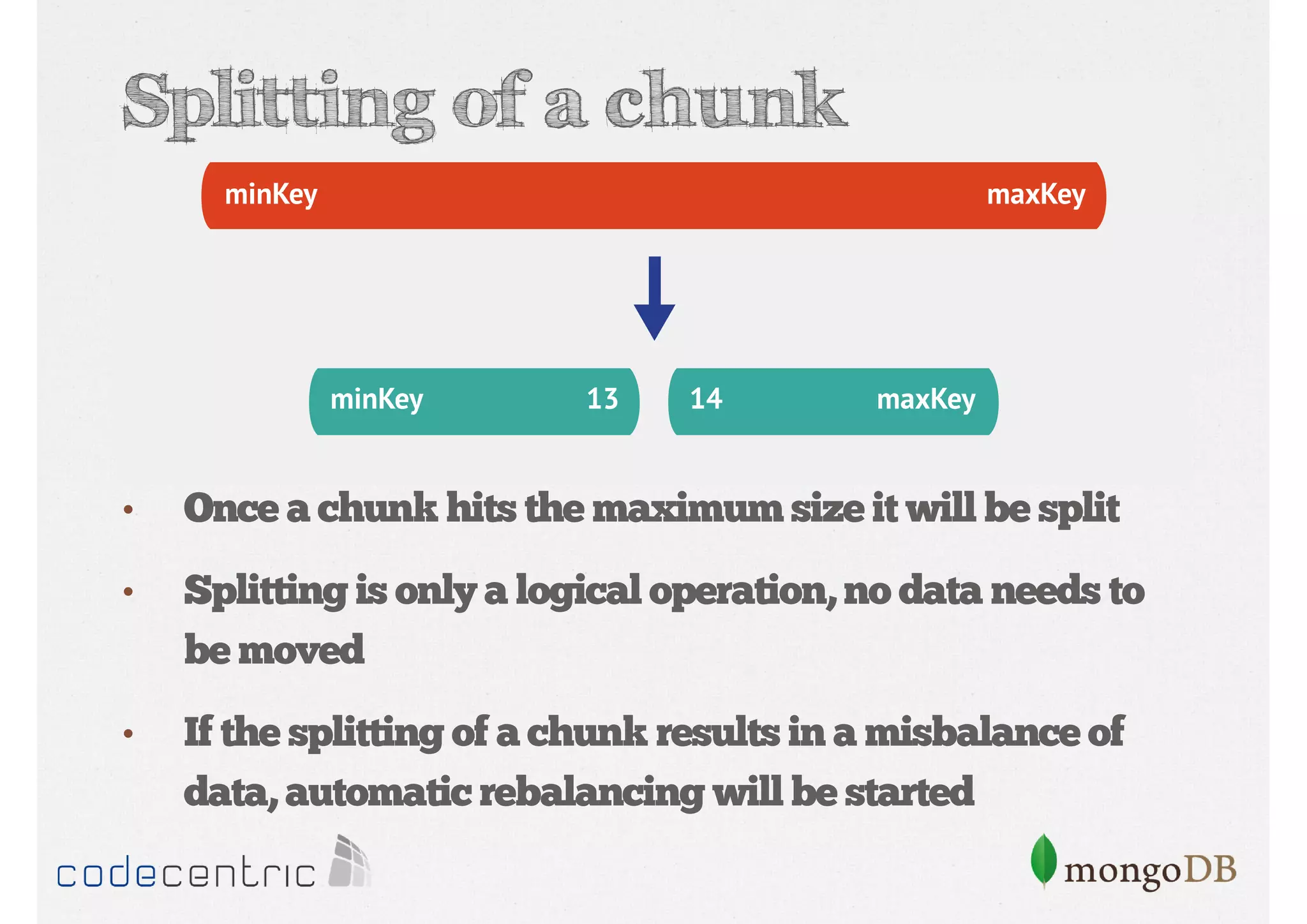
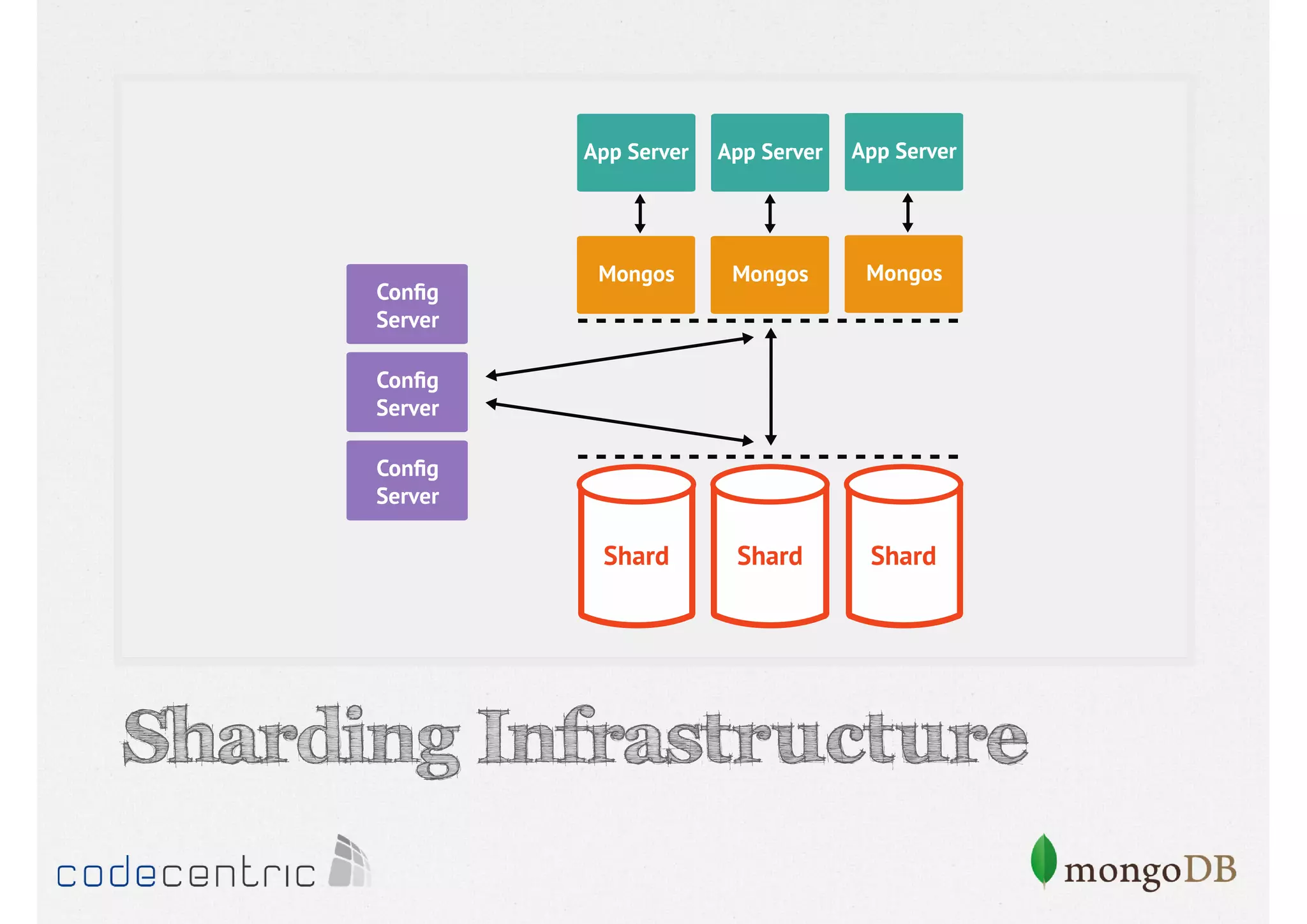
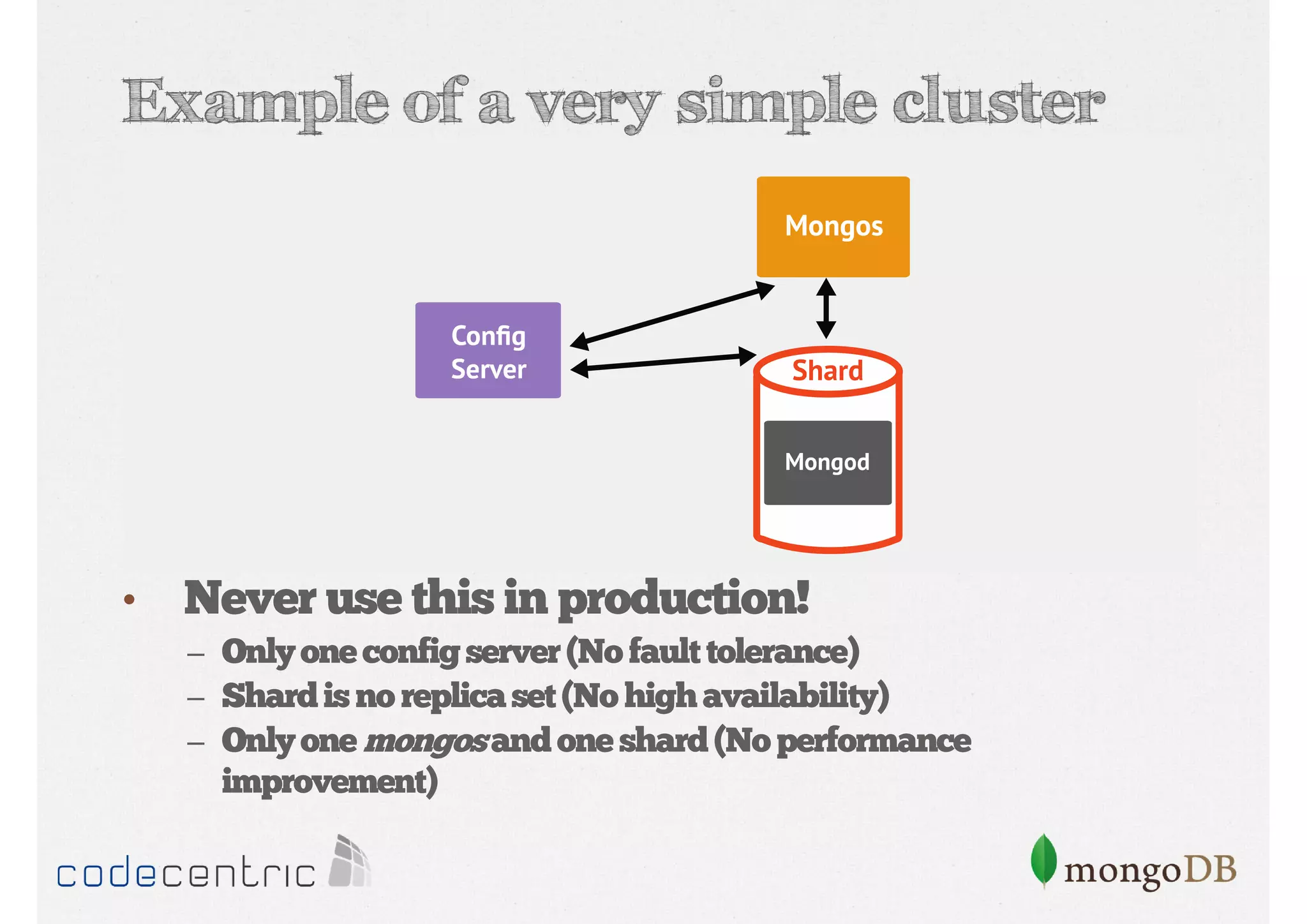
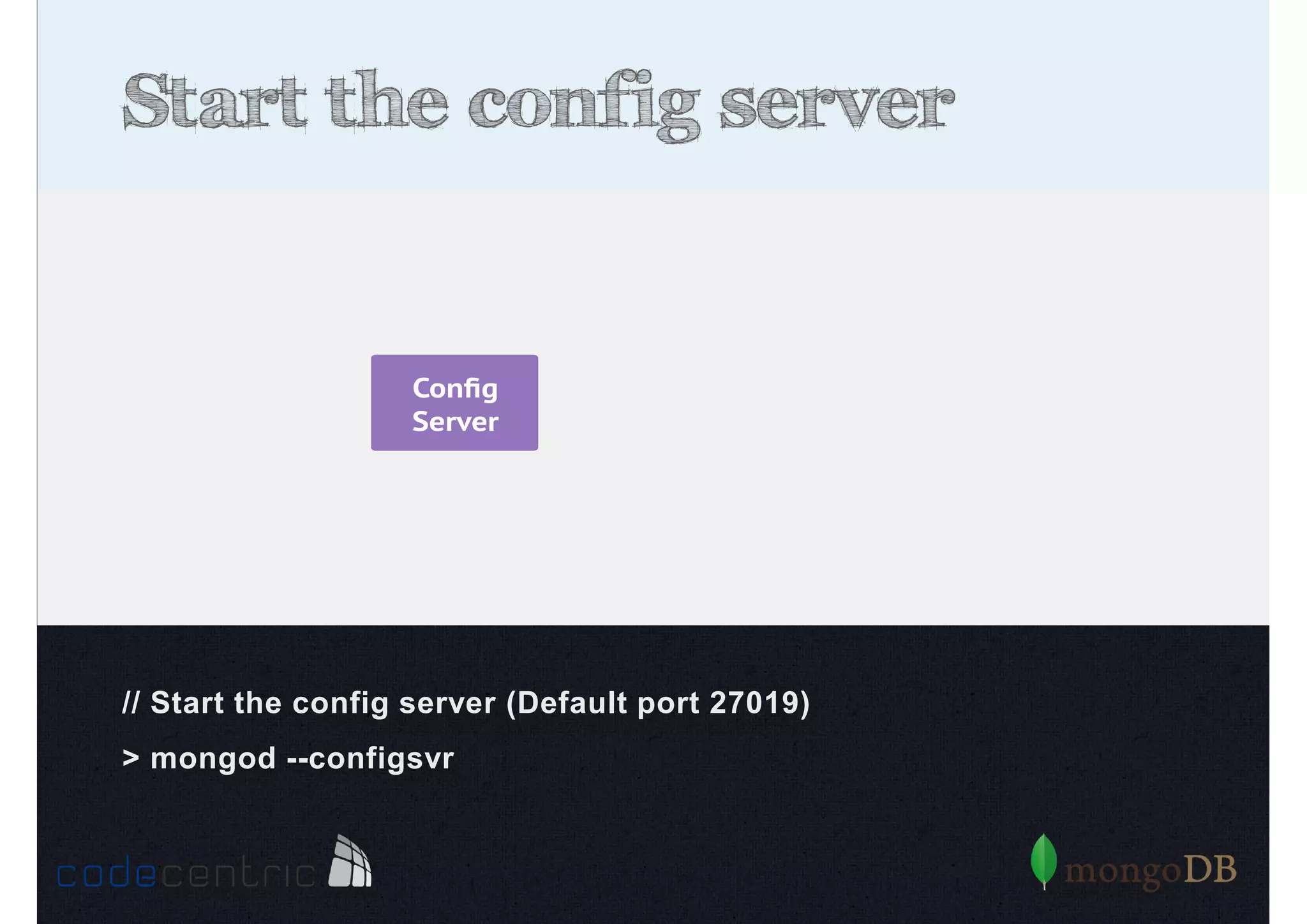
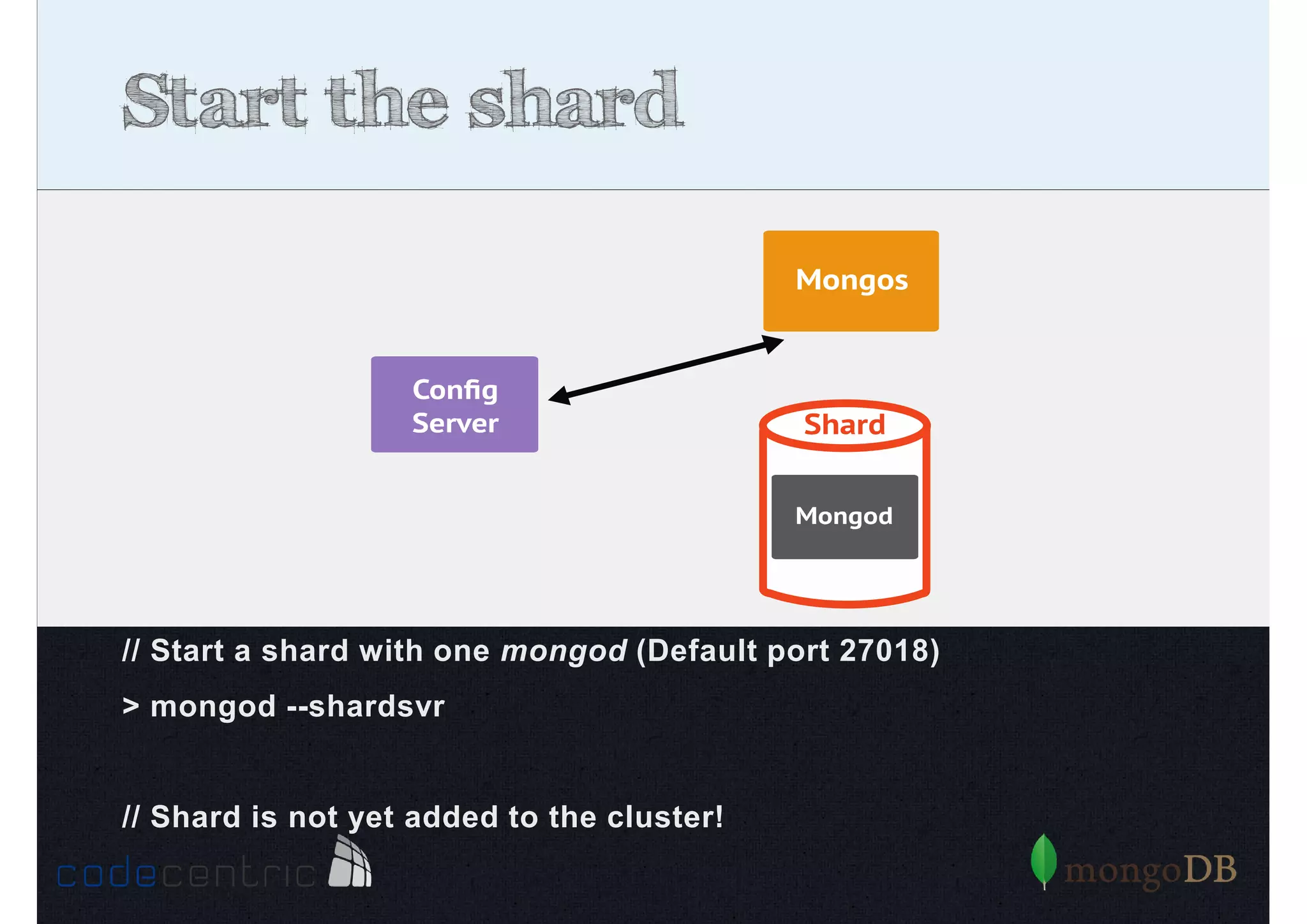
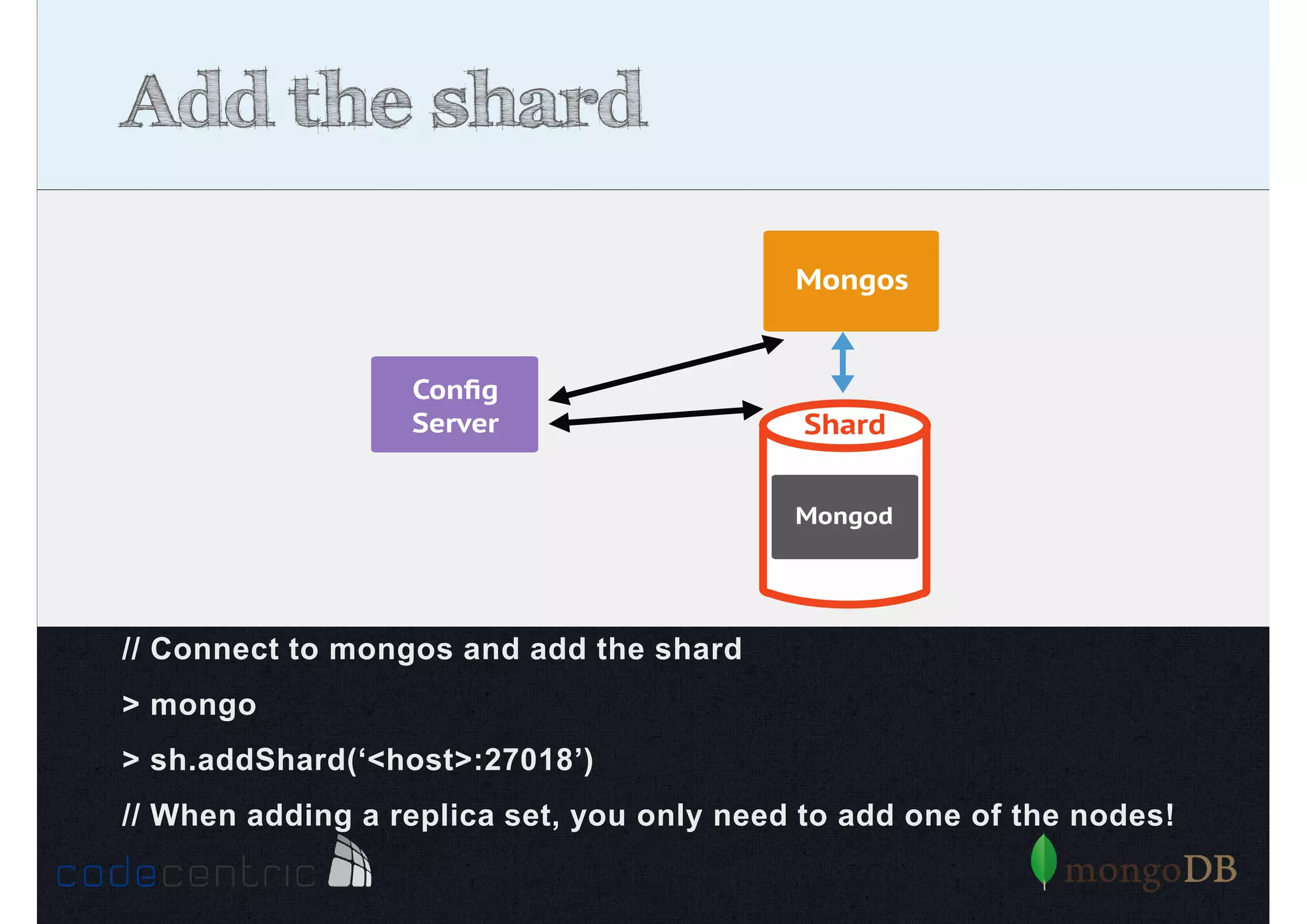
Explains sharding as a method for processing large datasets by partitioning data across multiple servers to enhance performance.
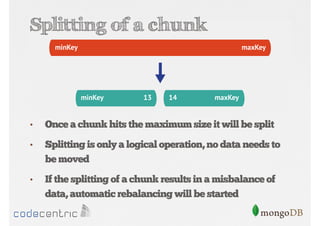
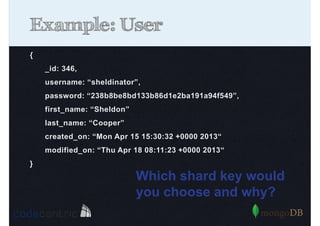
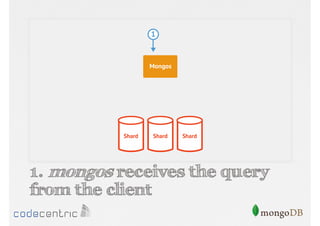
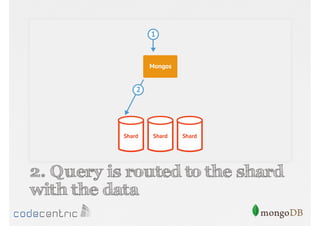
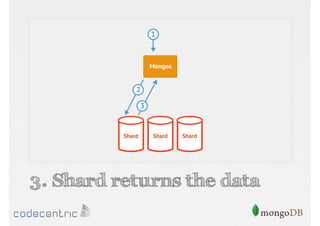
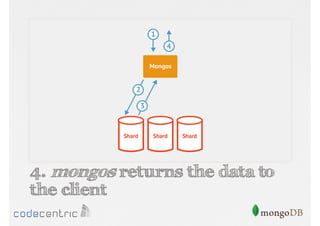
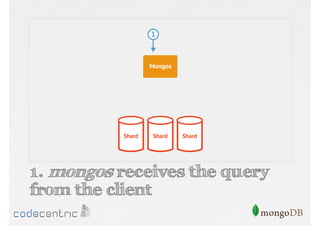
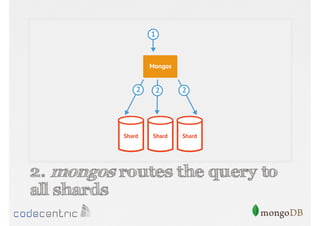
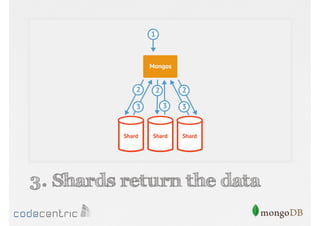
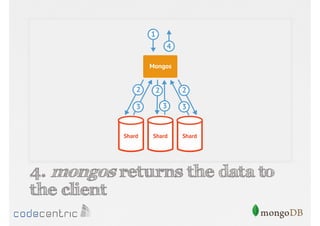
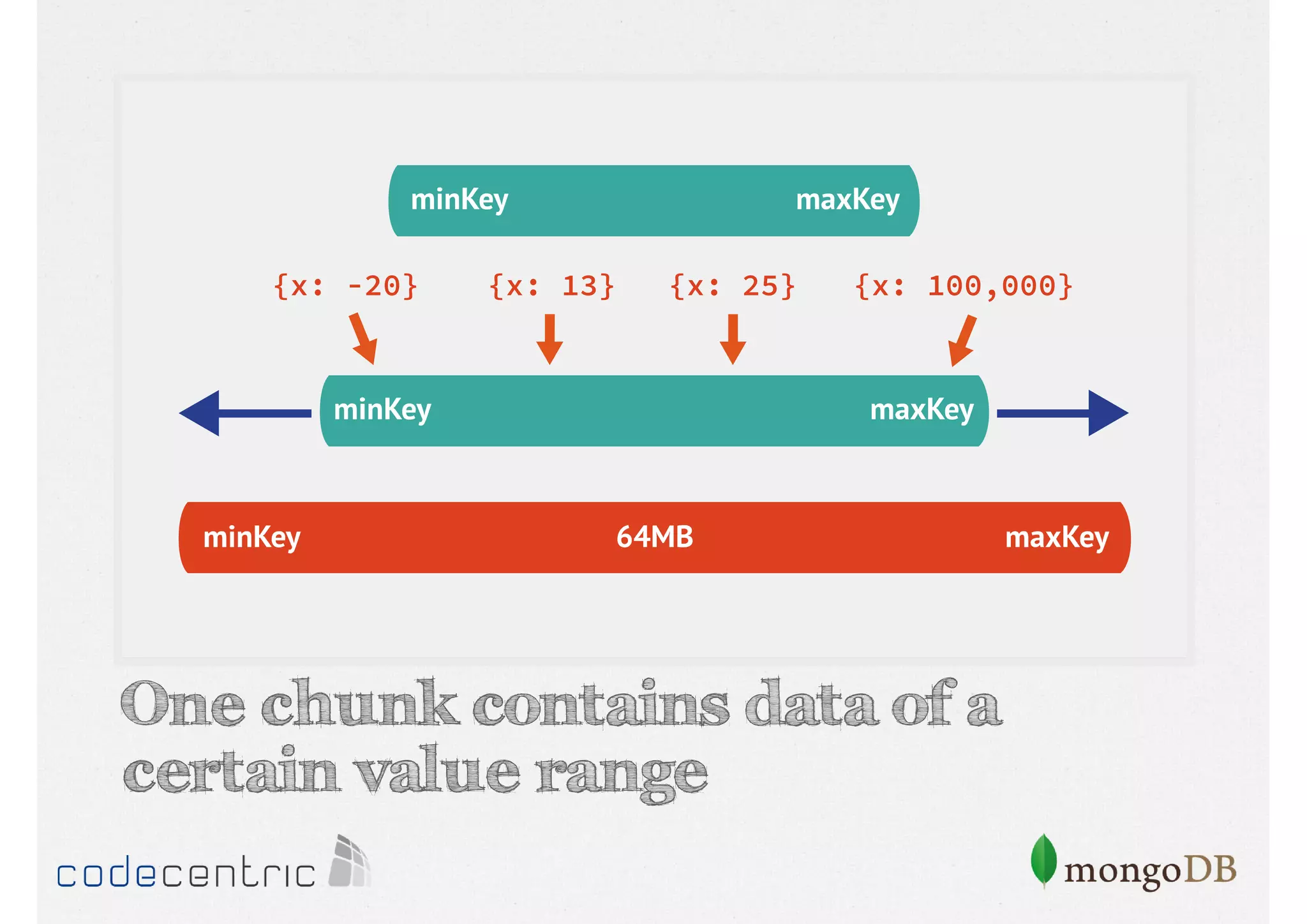
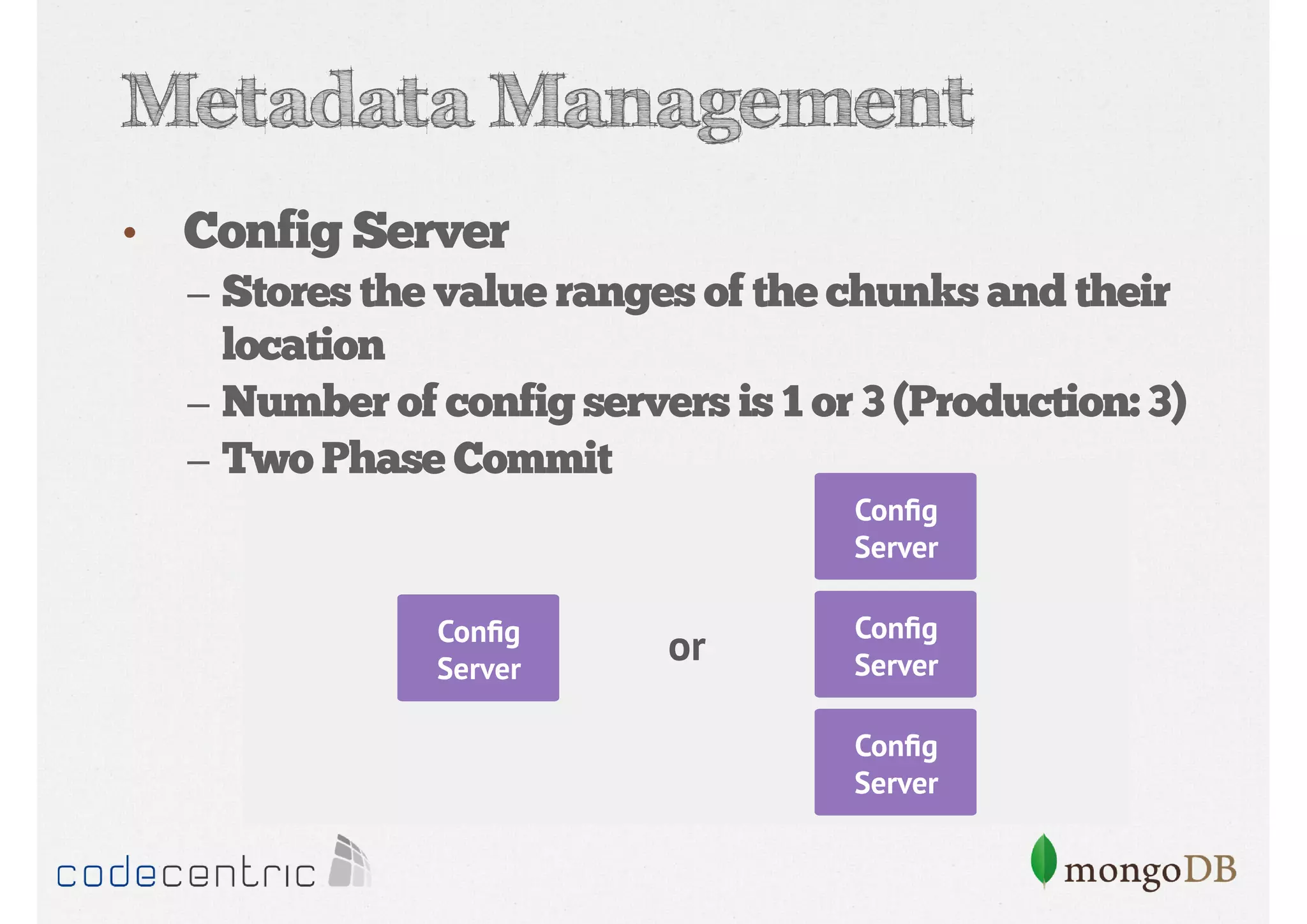
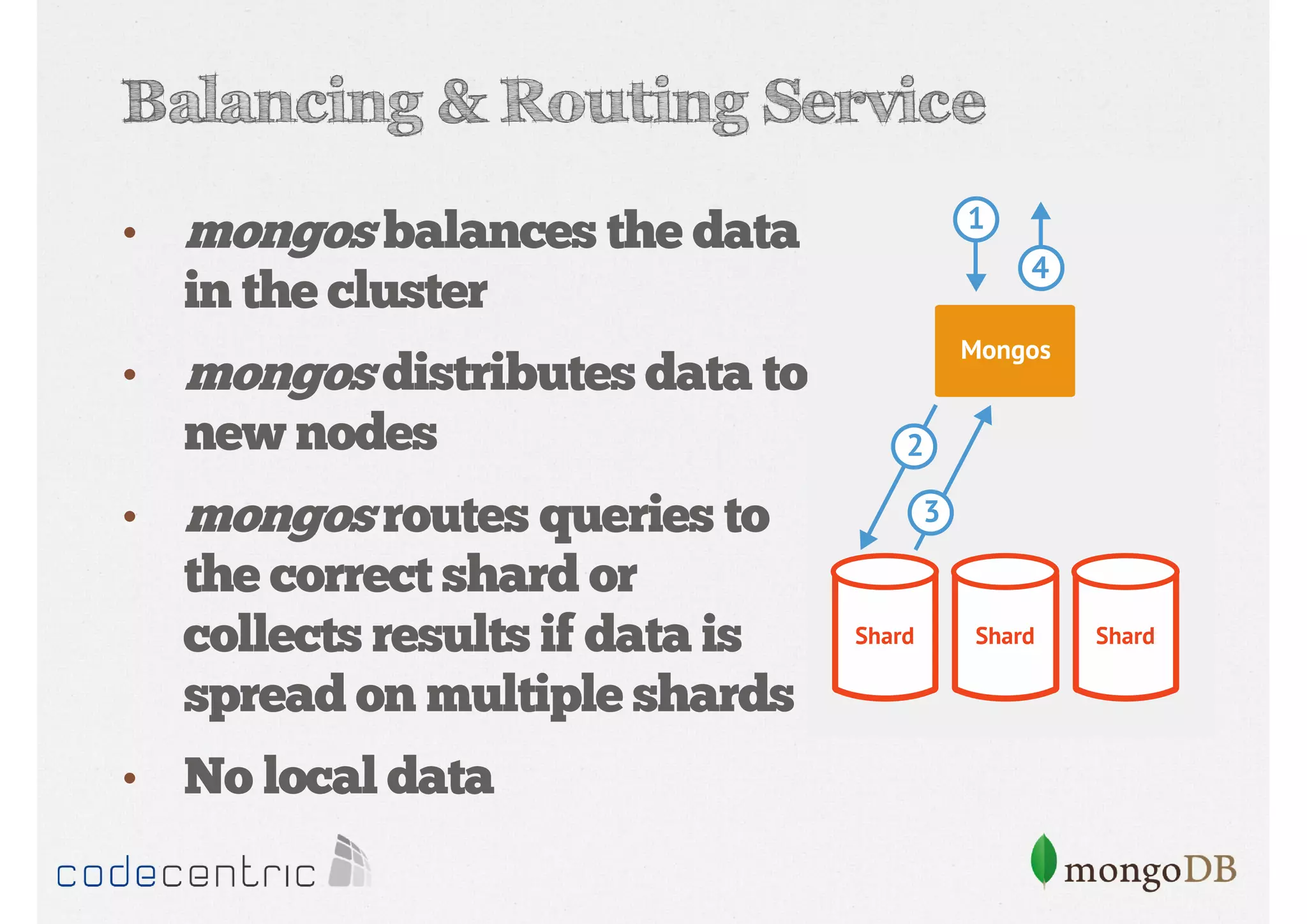
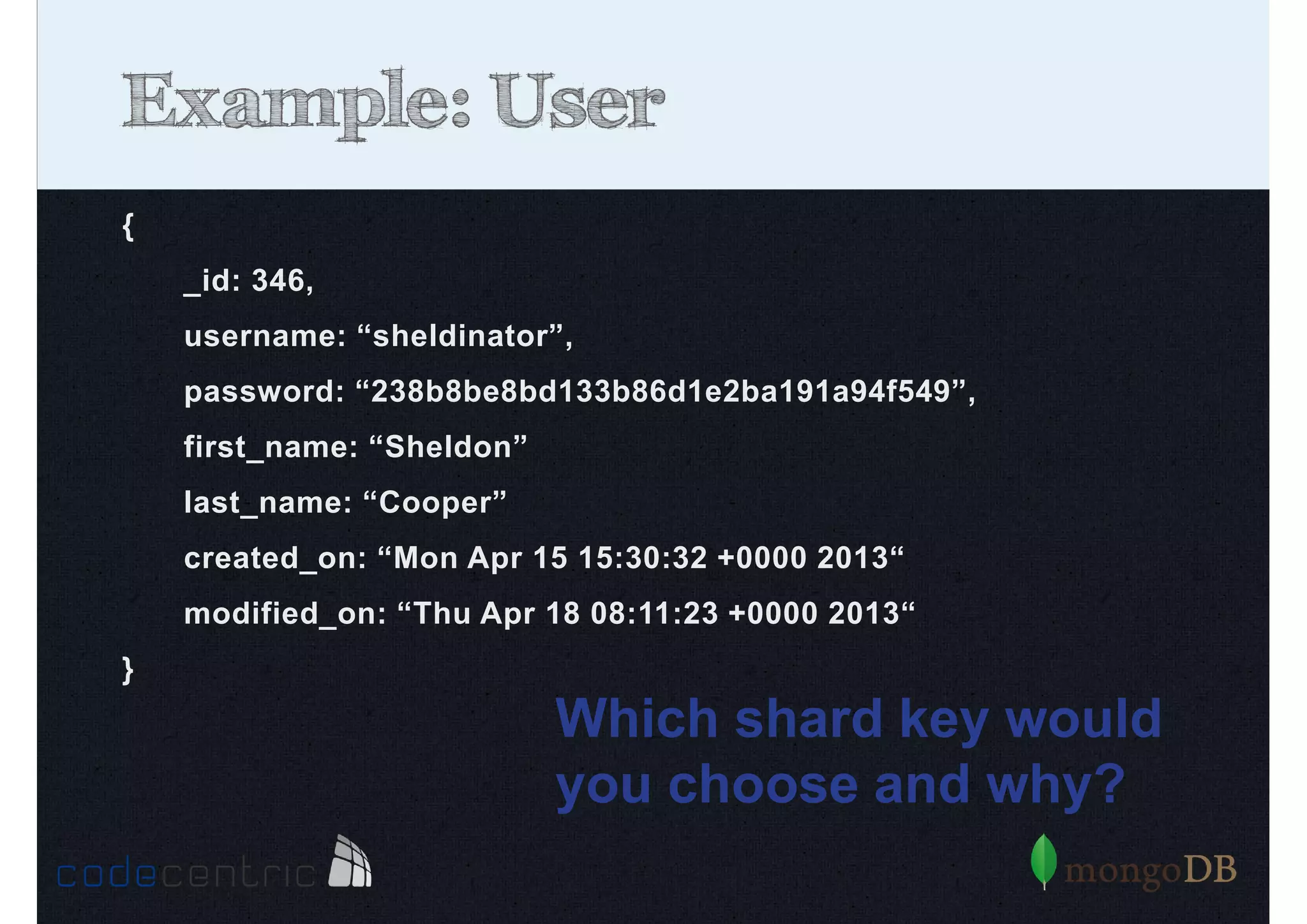
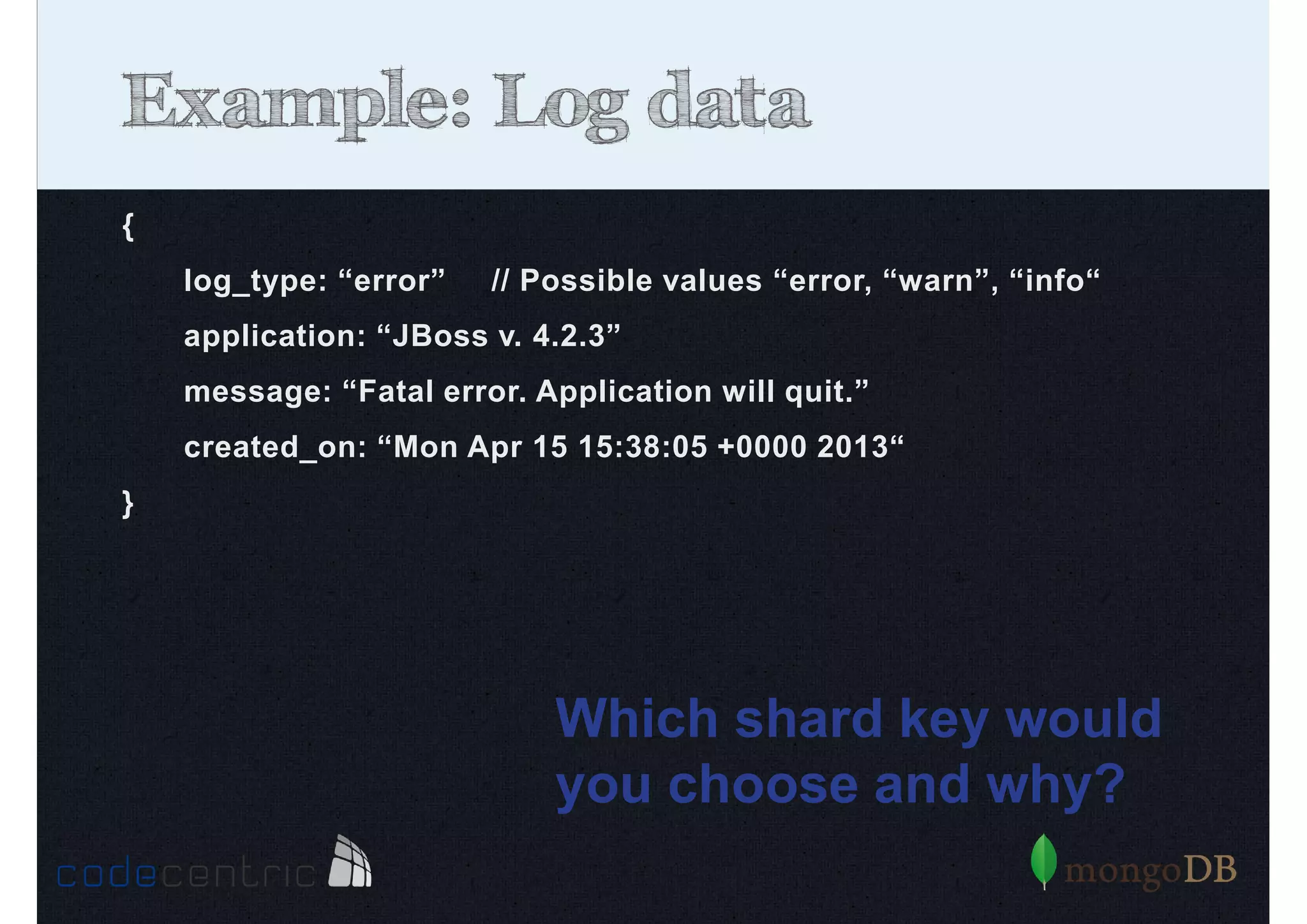
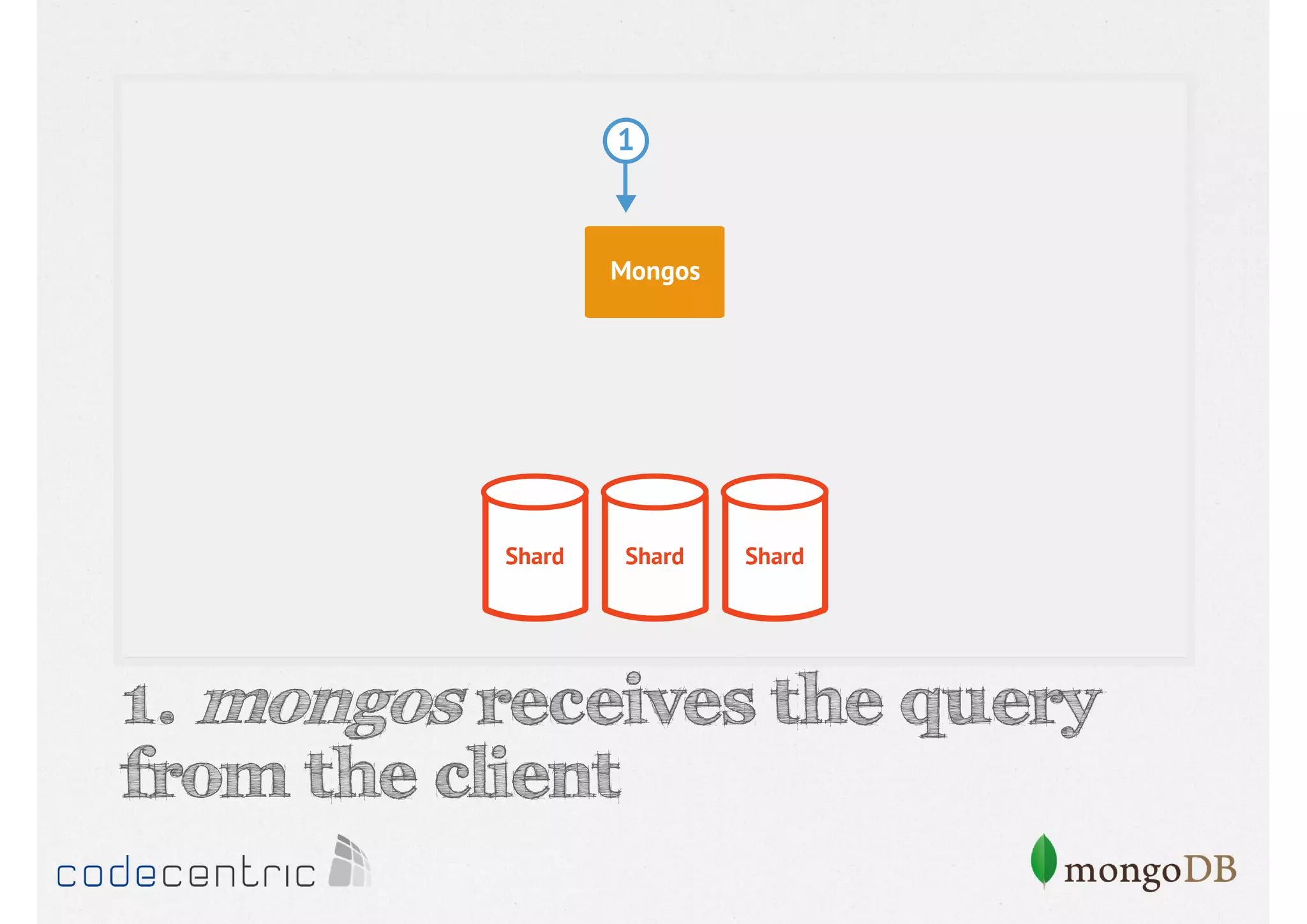
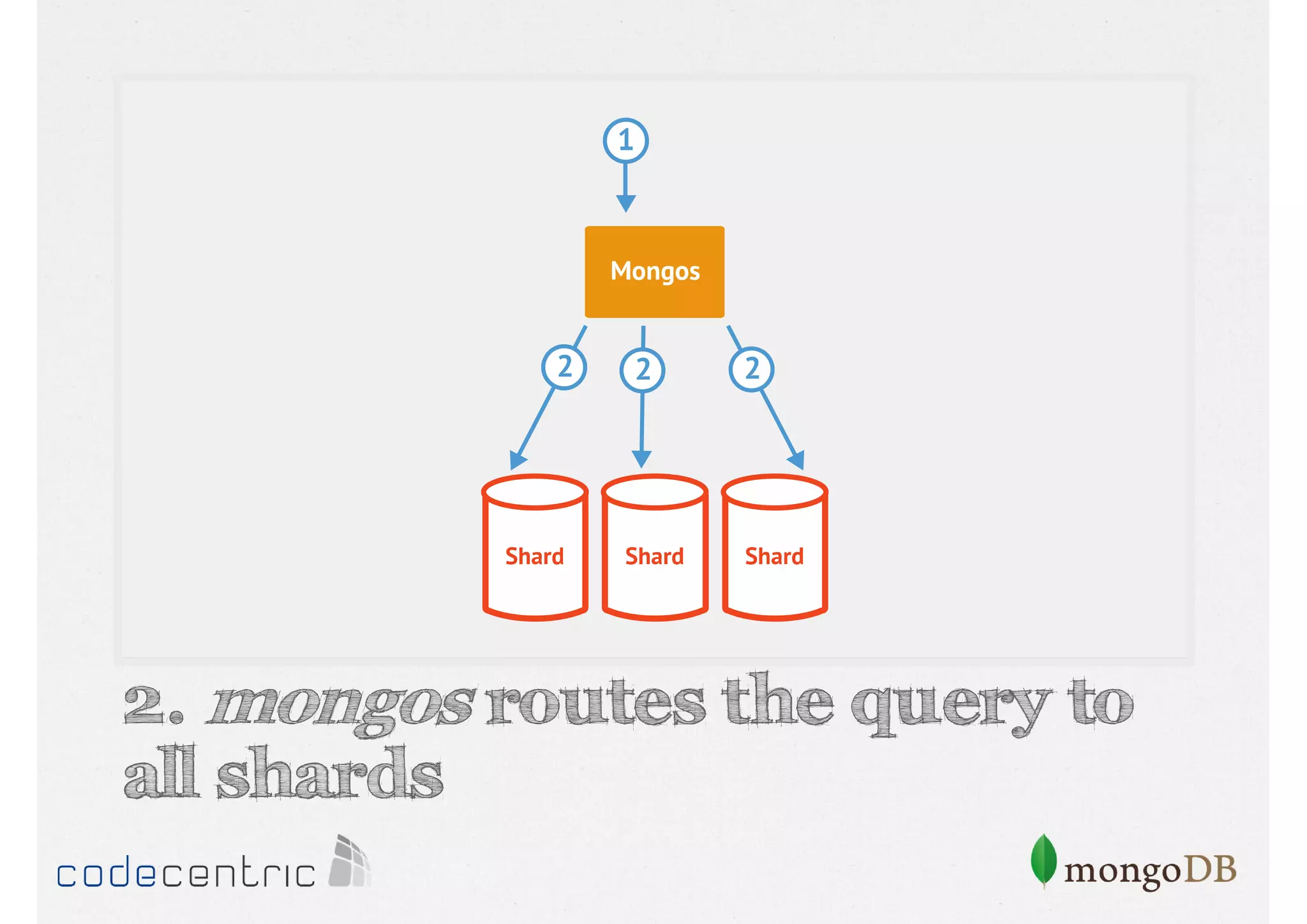
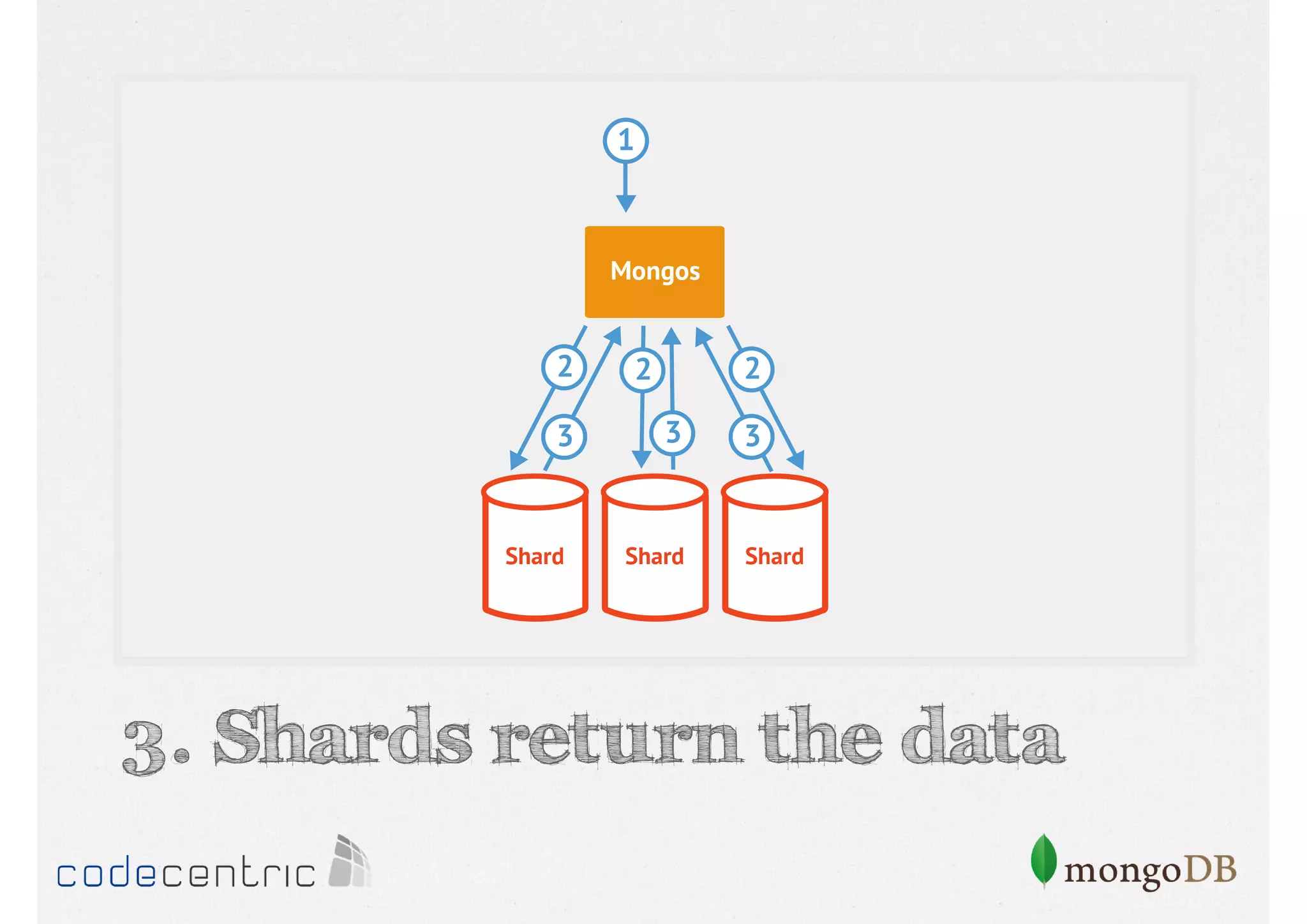
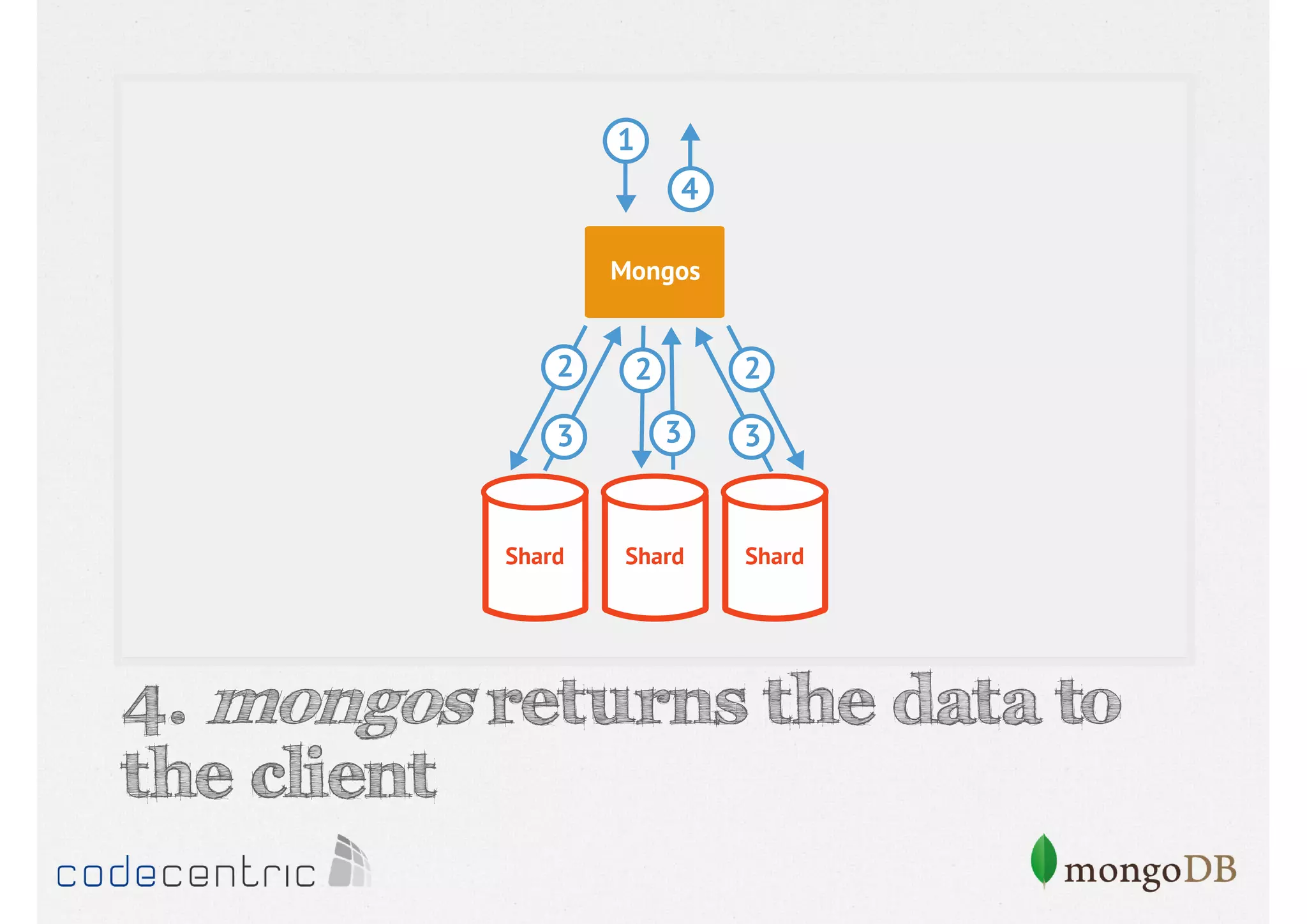
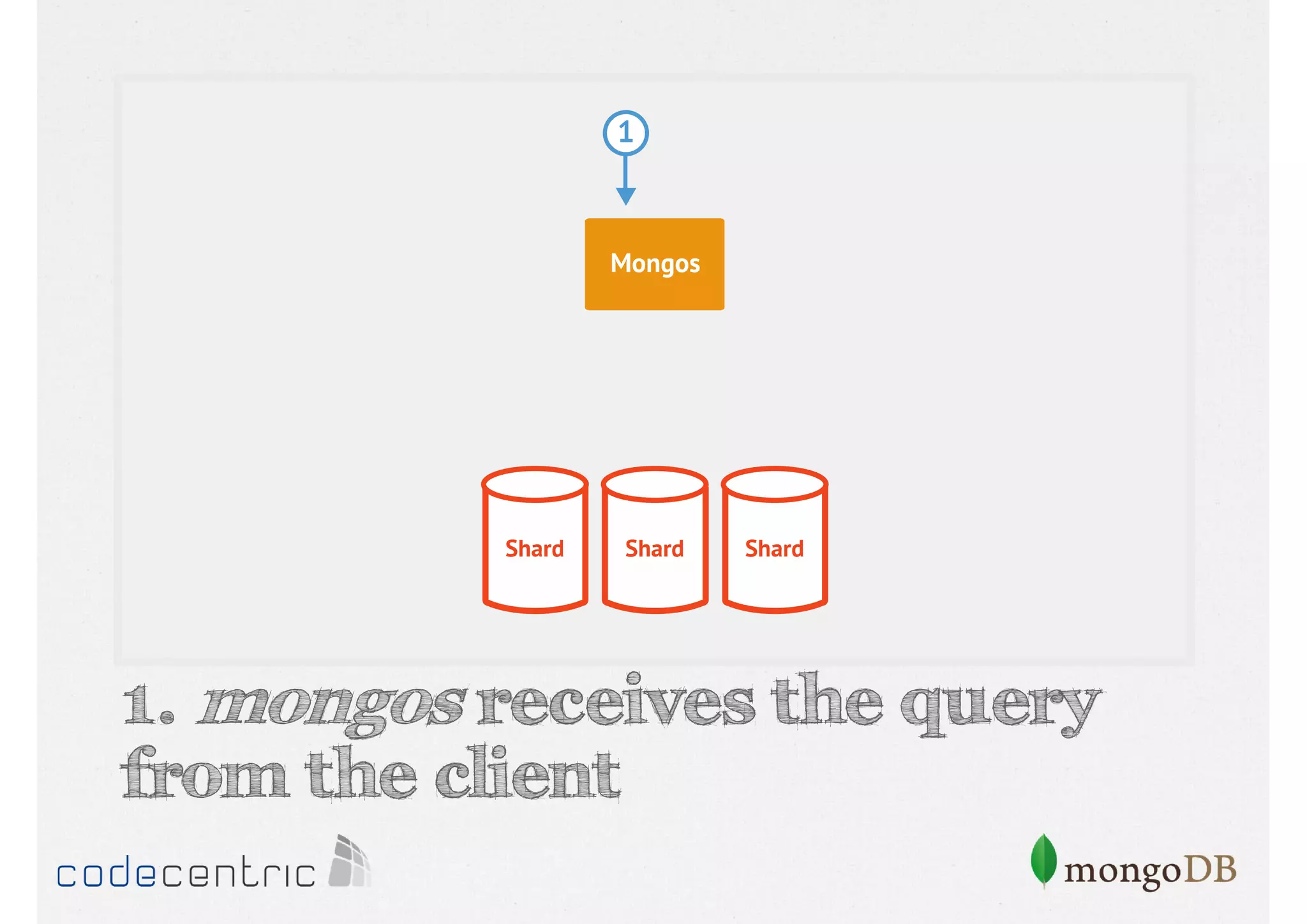
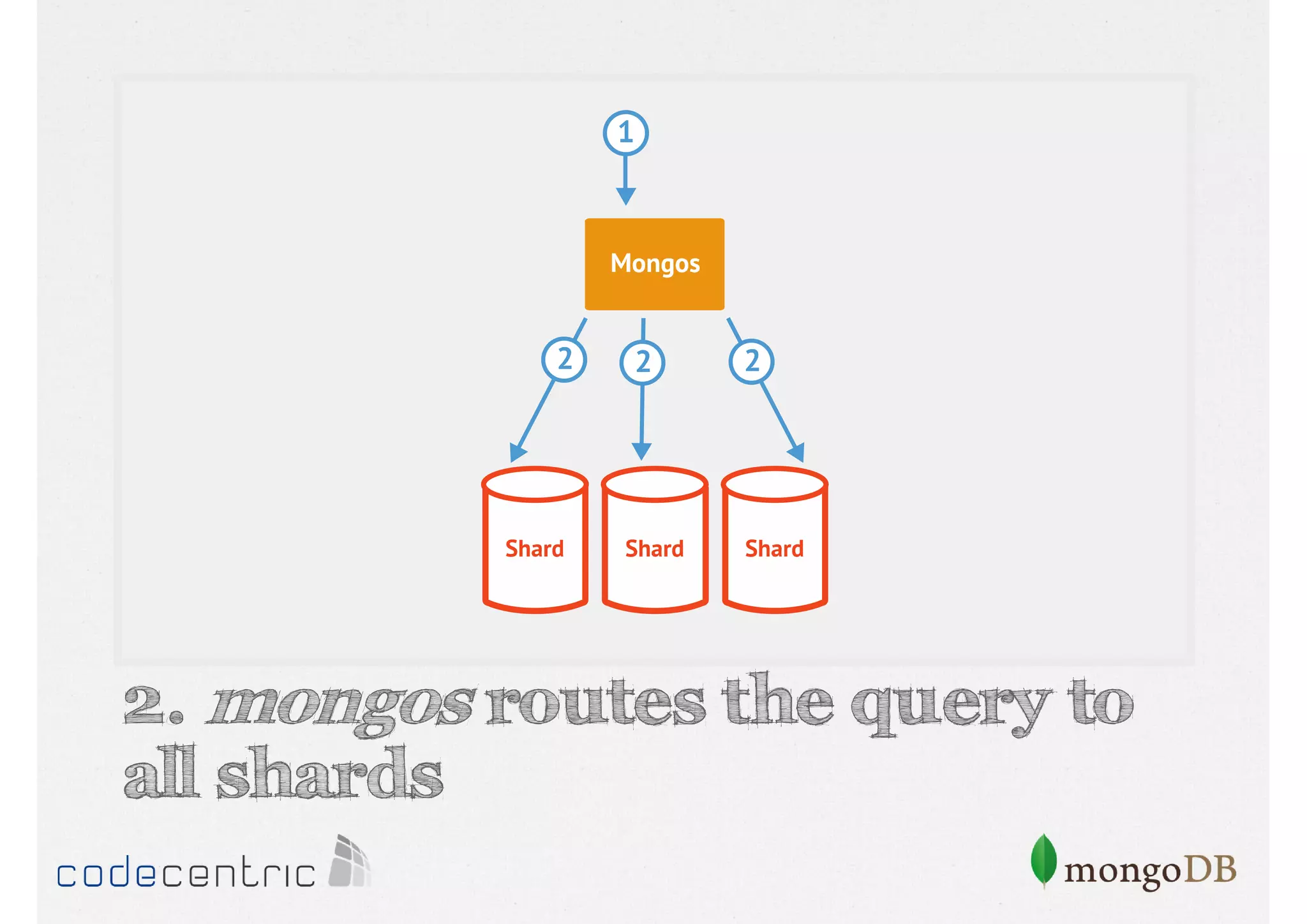
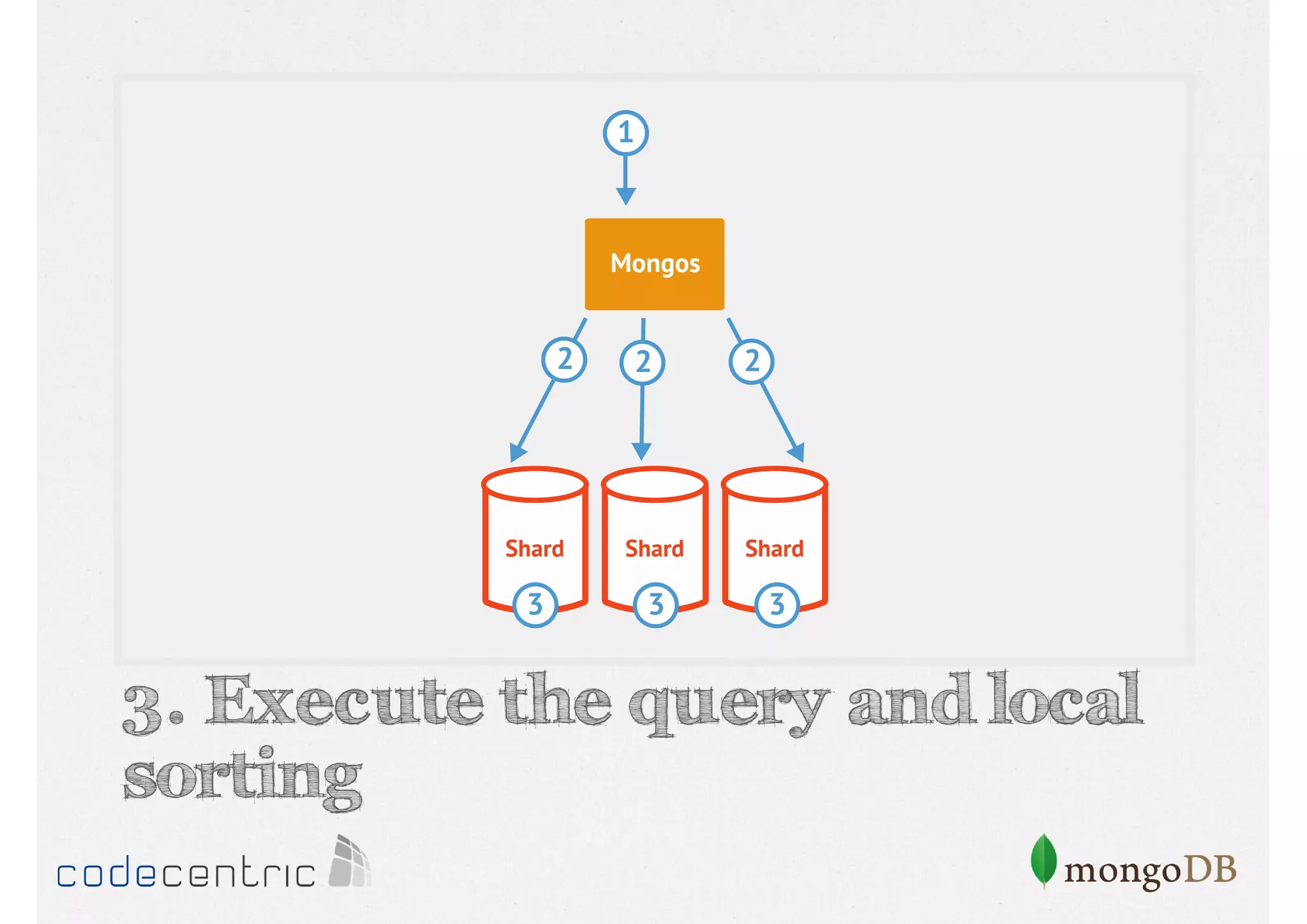
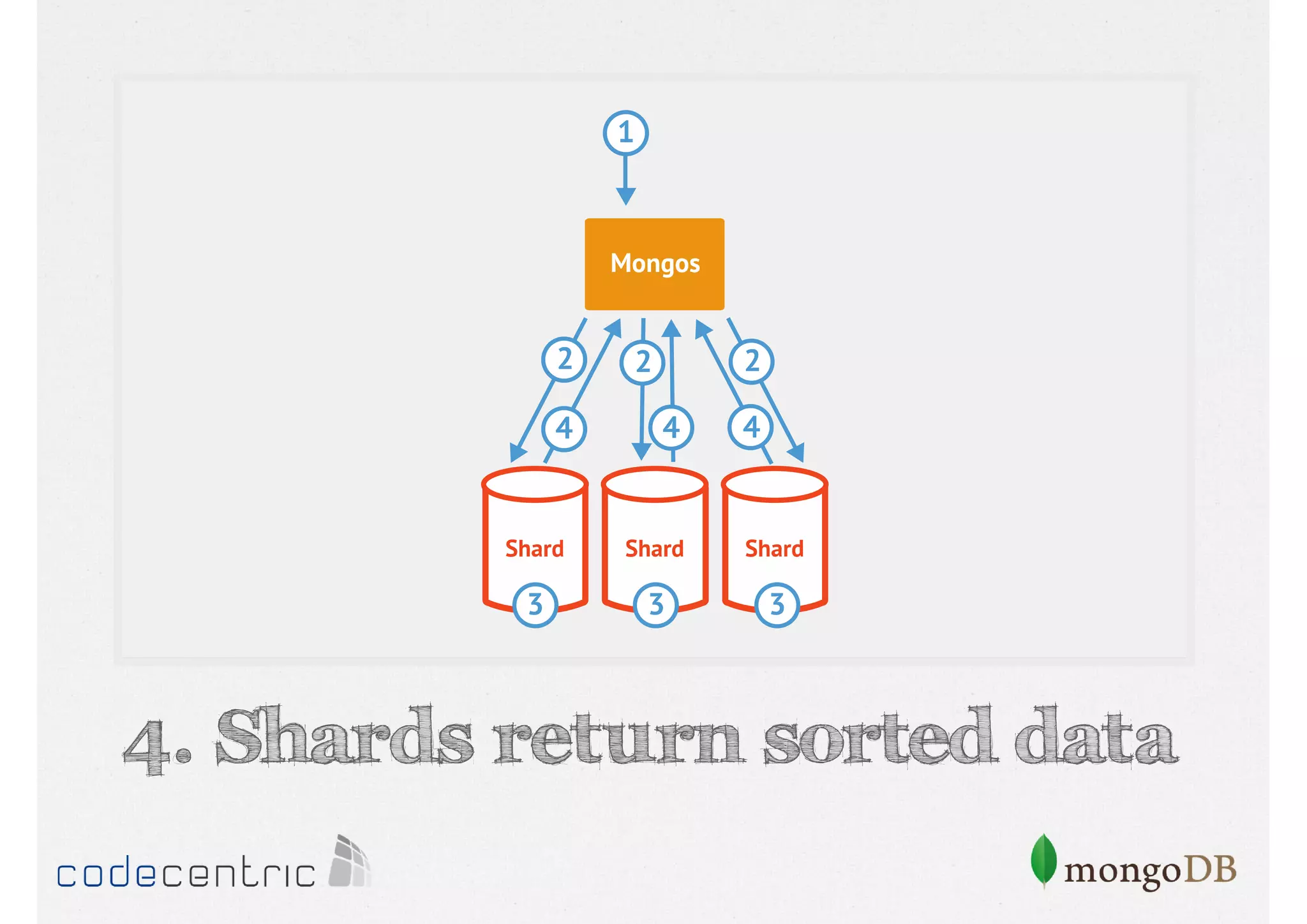
Details on shard key selection, query routing in sharding, and considerations for managing data distribution across shards.
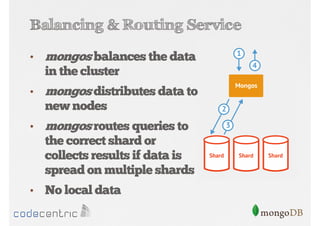
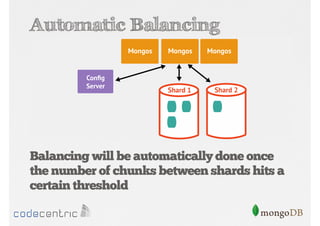
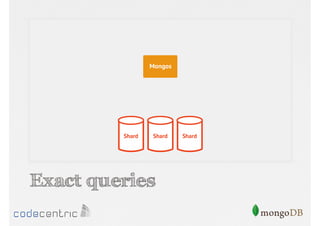
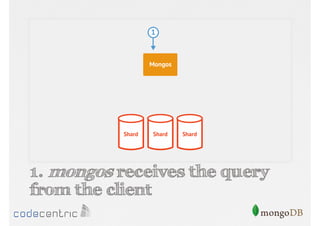
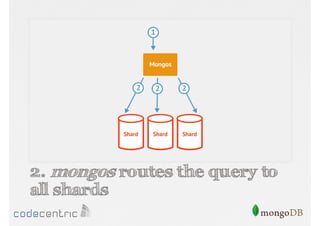
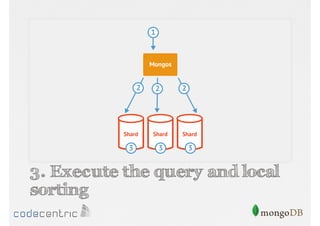
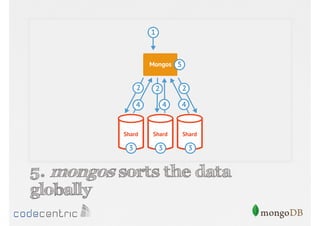
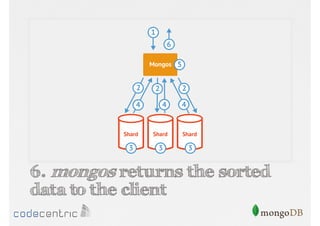
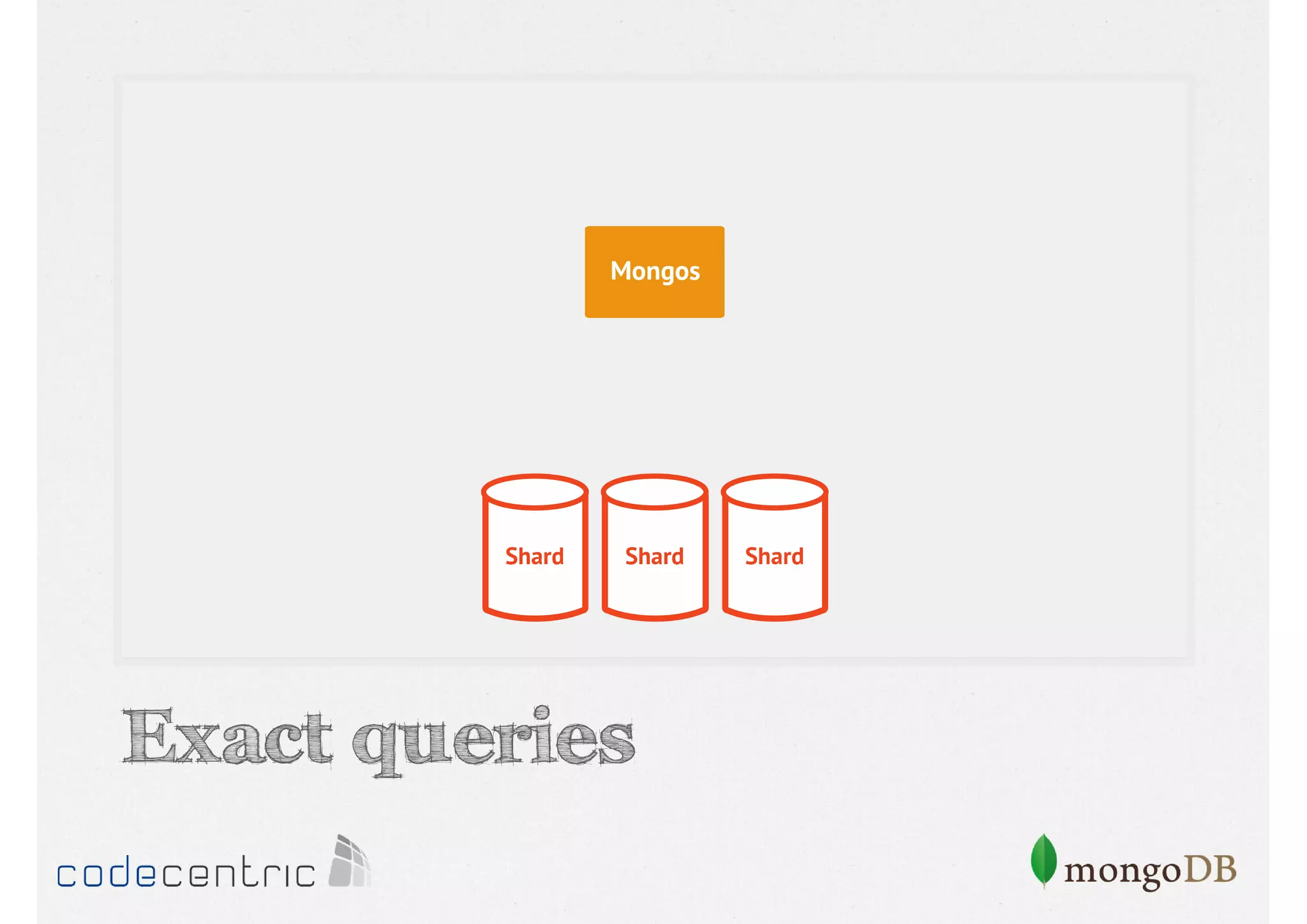
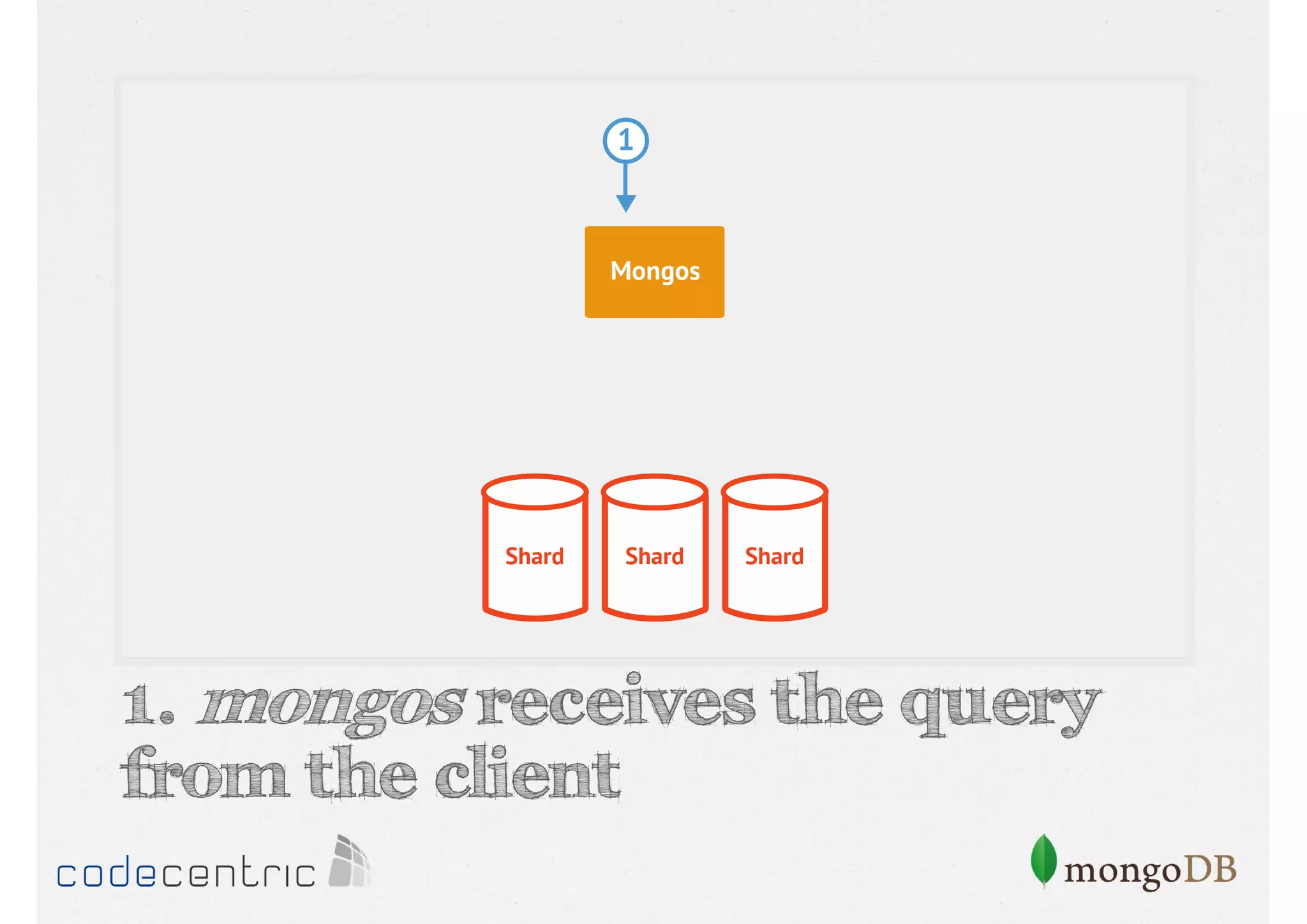
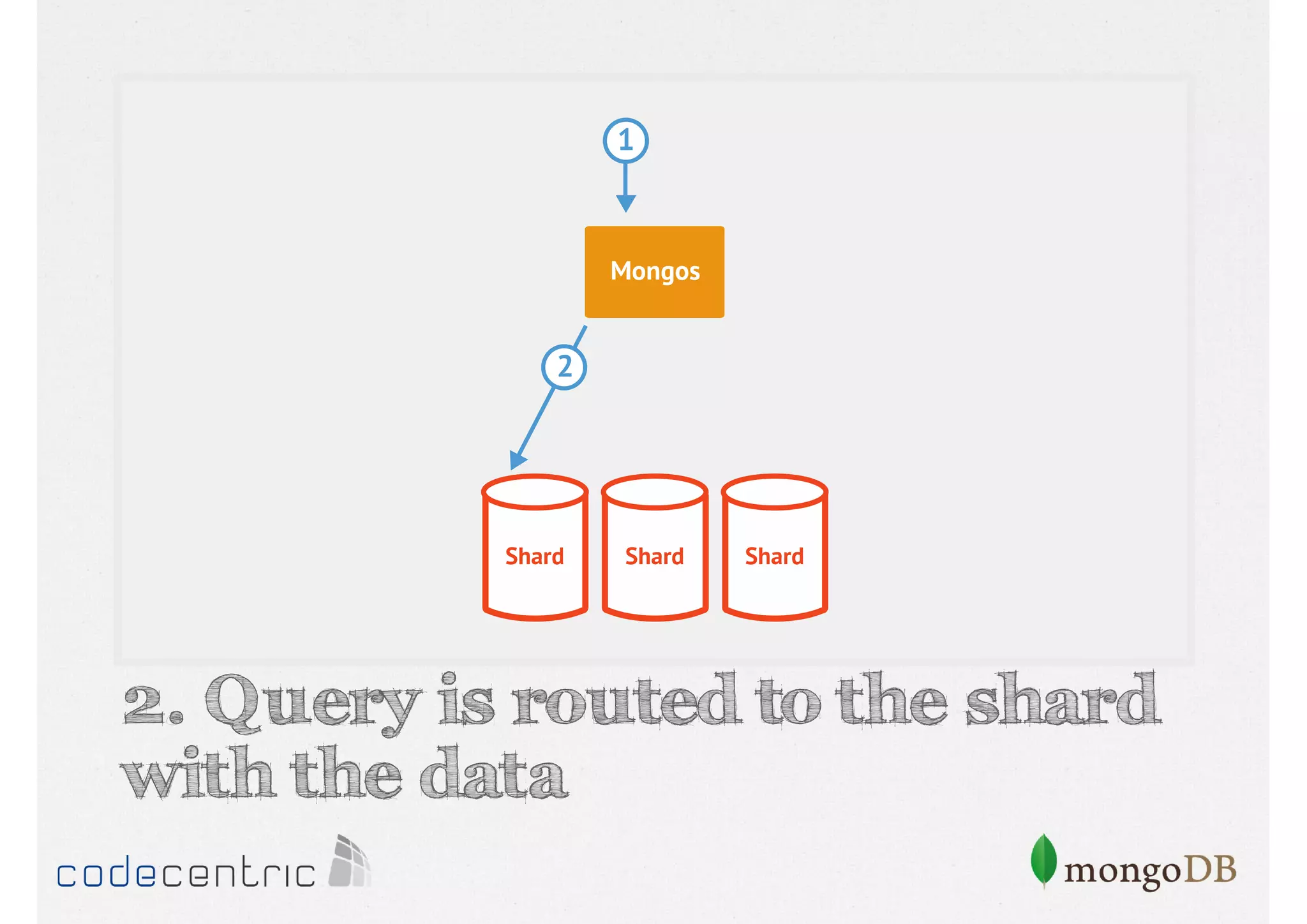
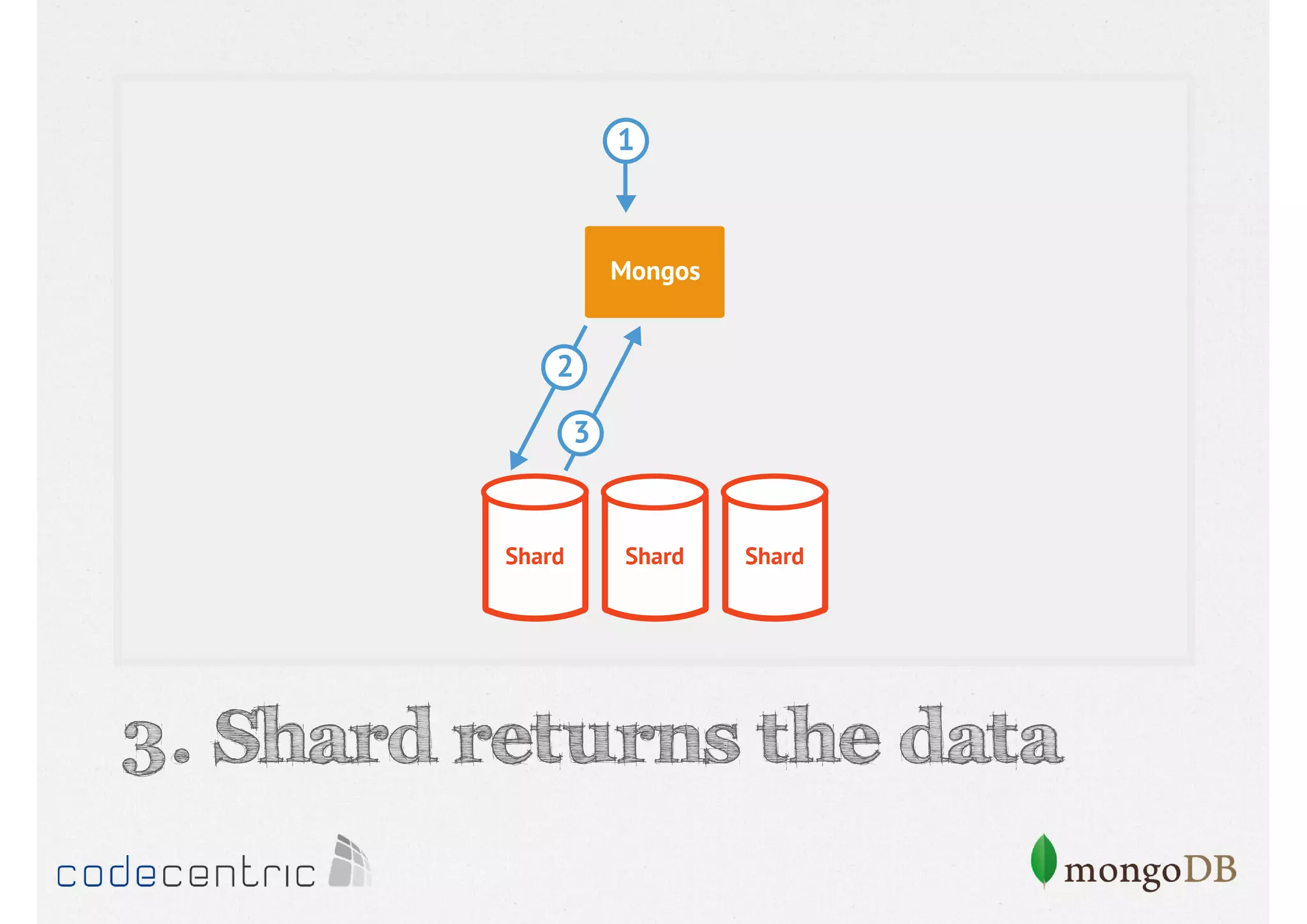
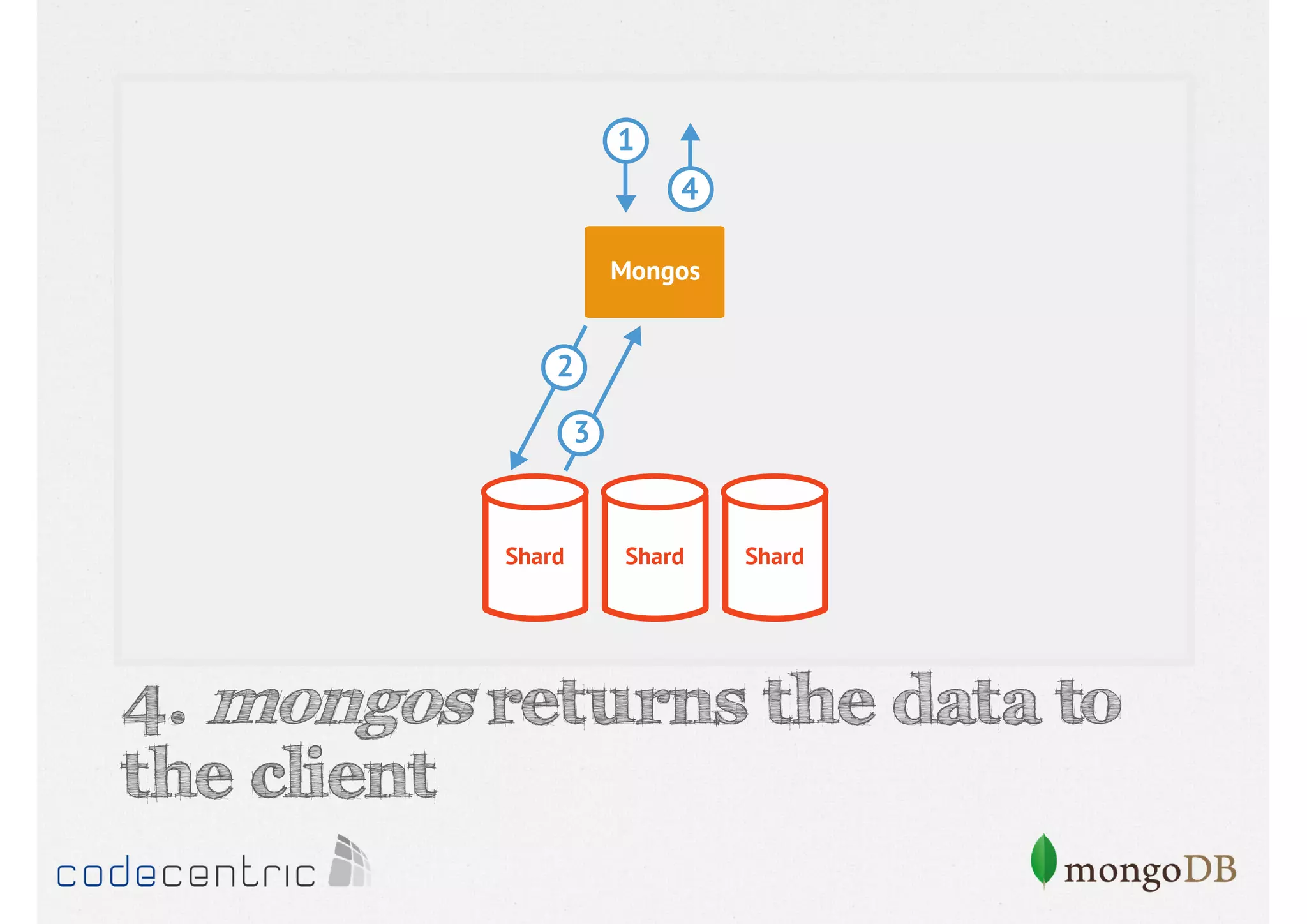
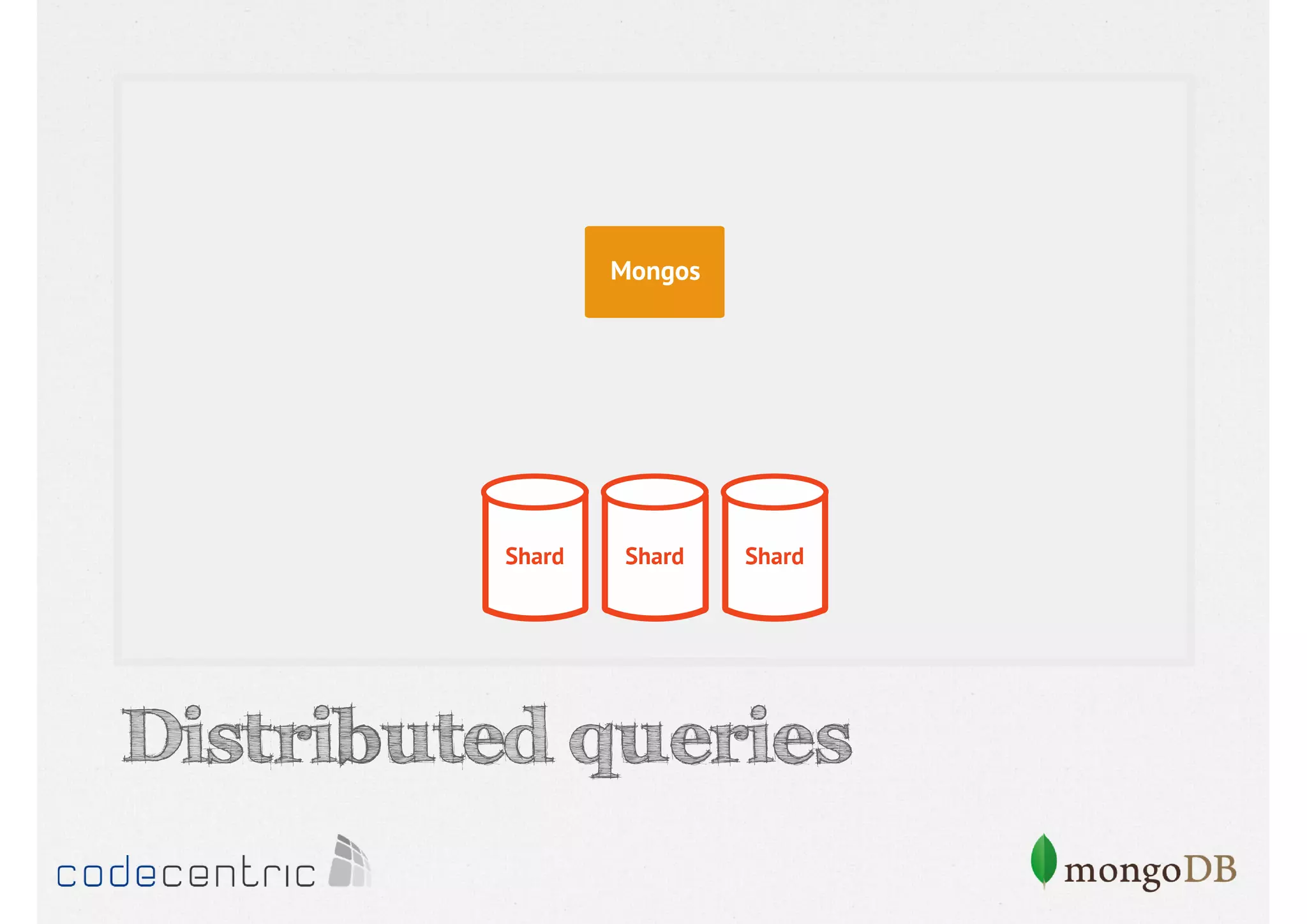
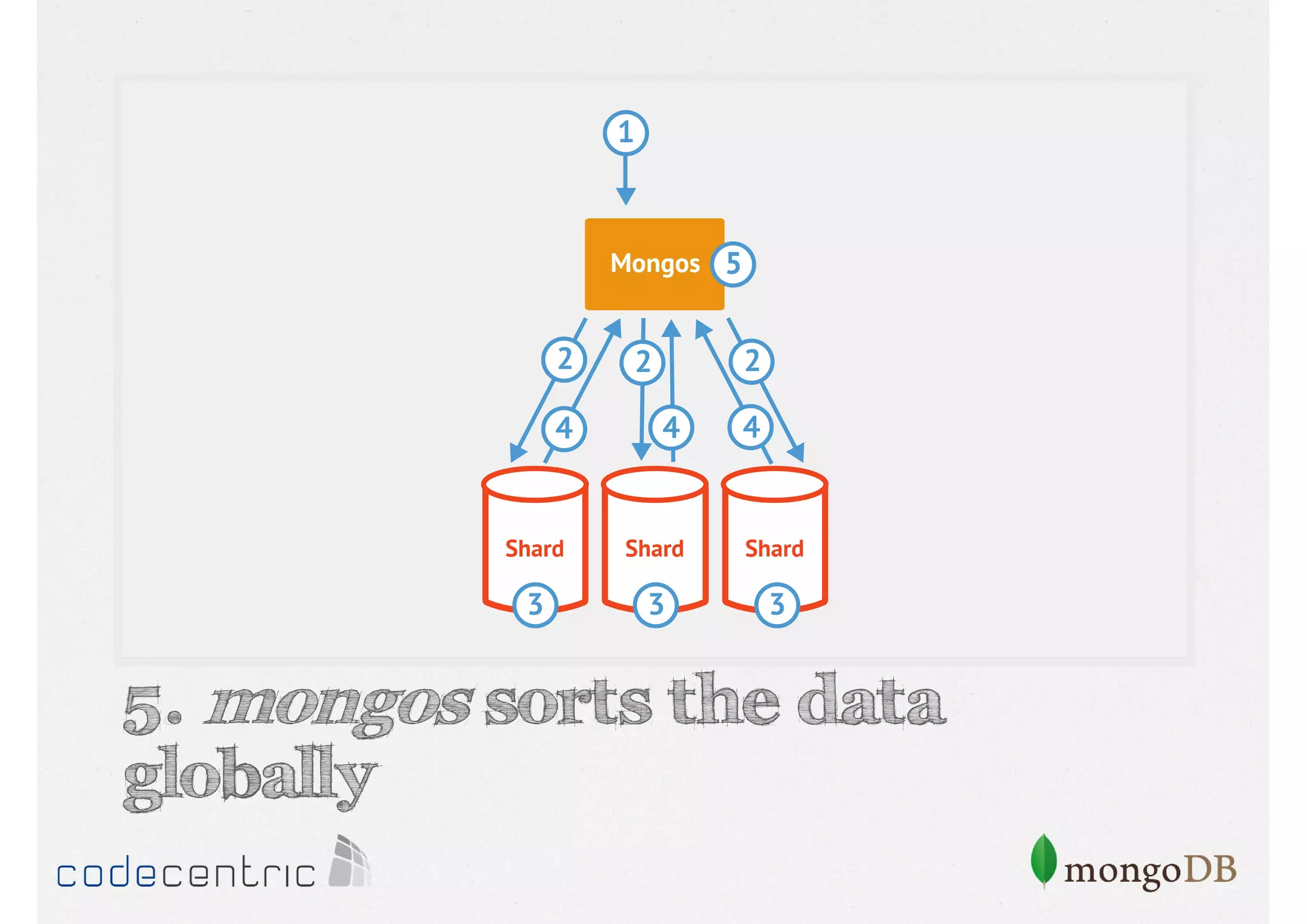
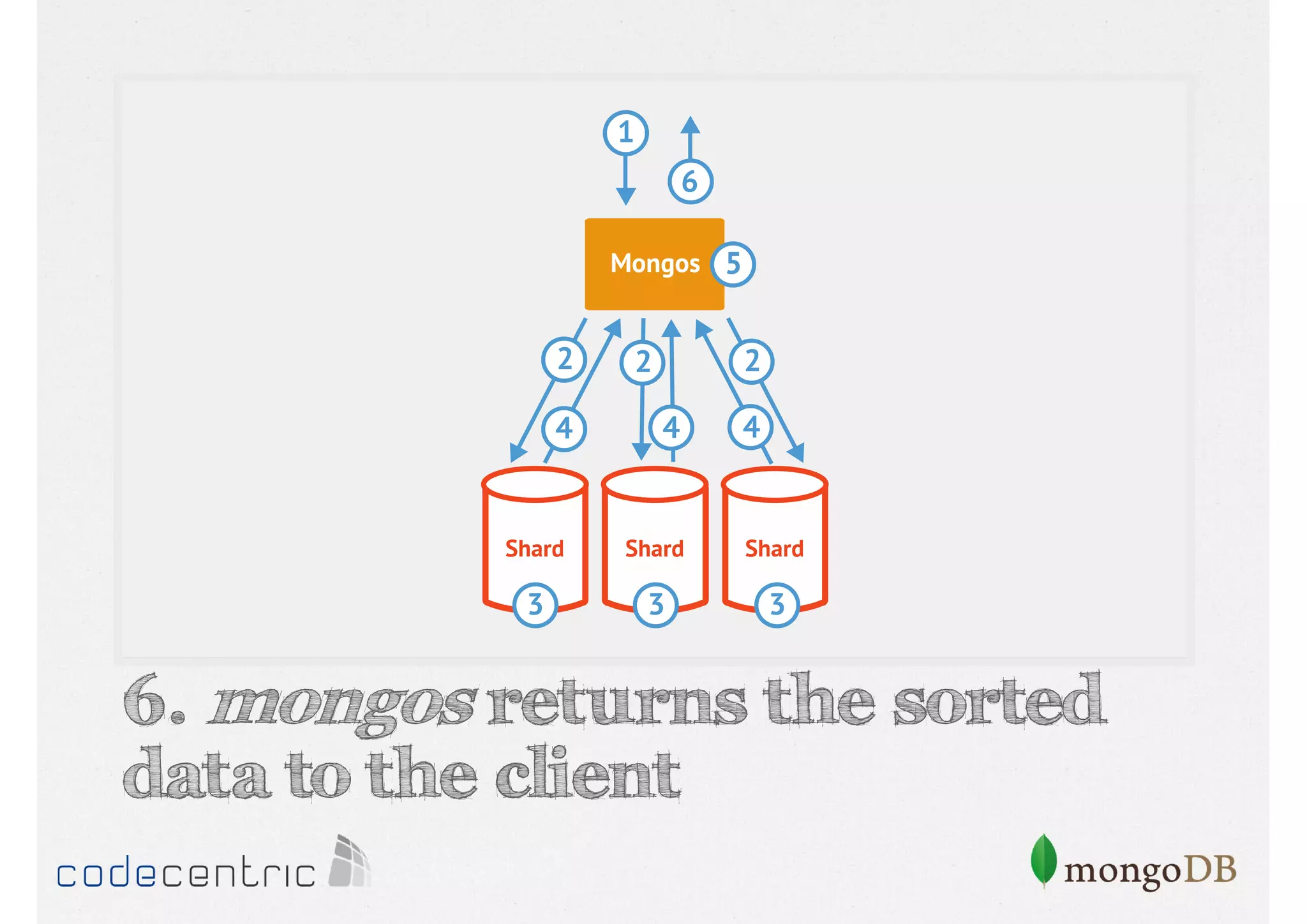
Describes handling both exact and distributed queries in a sharded environment and the mechanisms to manage them effectively.
Encouragement to further engage with MongoDB education resources for deeper knowledge.











































































































