

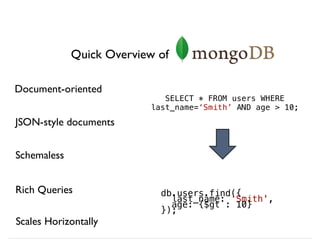




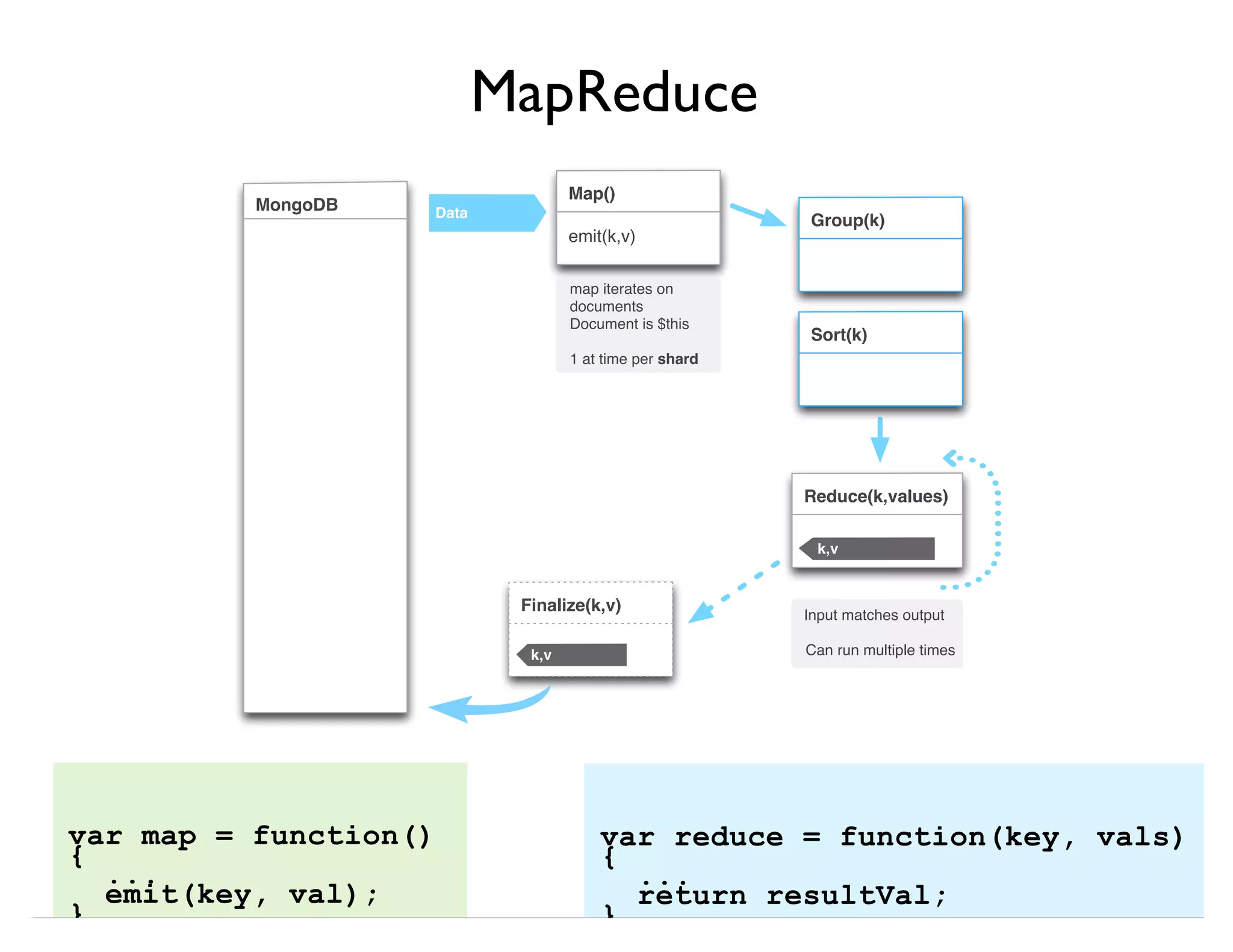
![db.article.aggregate(
{ $project : {author : 1, tags : 1}},
{ $unwind : "$tags" },
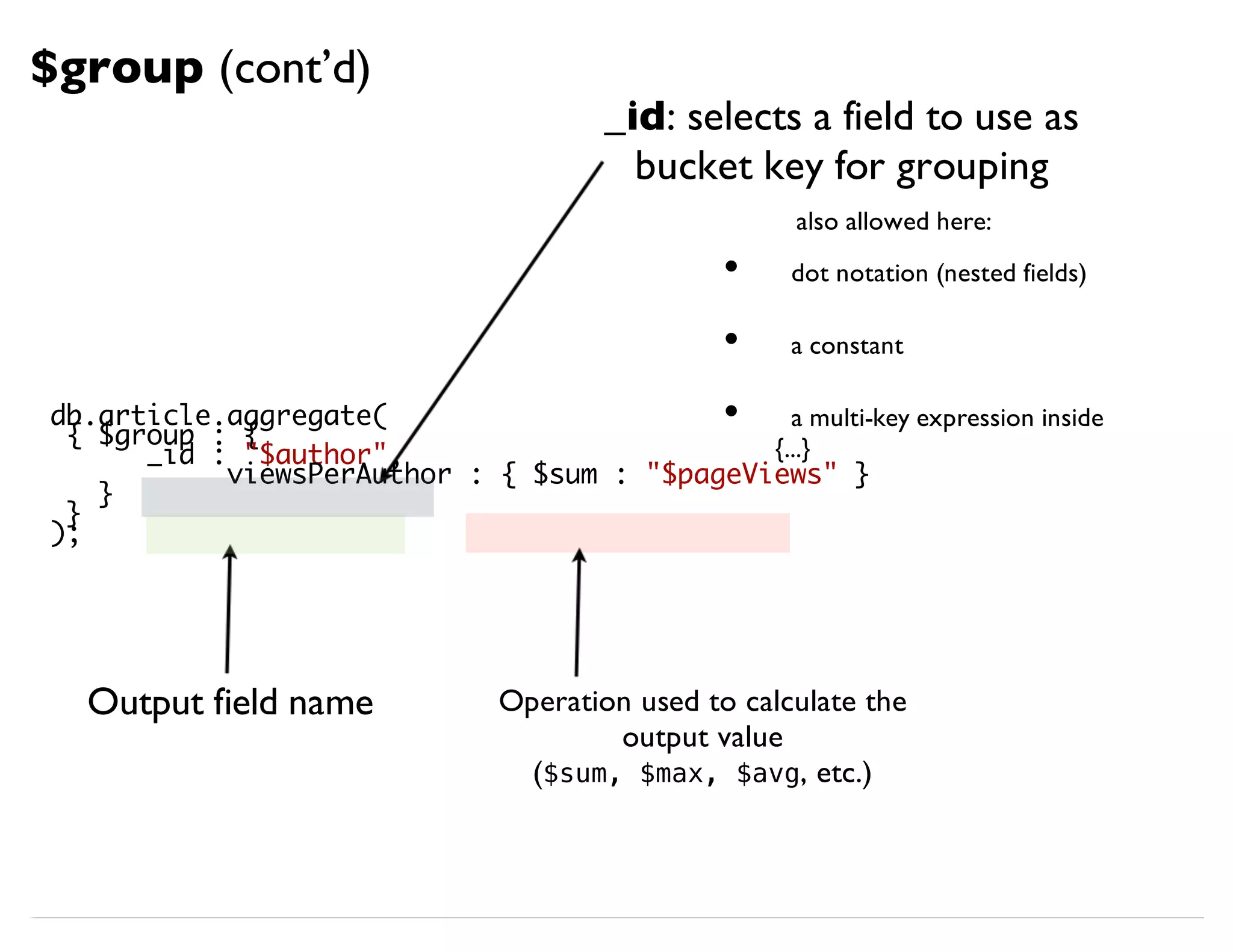
{ $group : {
_id : “$tags”,
authors : { $addToSet:"$author"}
}}
);
New Helper
Method:
.aggregate()
Operator
pipeline
db.runCommand({
aggregate : "article",
pipeline : [ {$op1, $op2, ...} ]
}](https://image.slidesharecdn.com/mongodb-aggregation-130611150658-phpapp01/85/MongoDB-Aggregation-Framework-11-320.jpg)
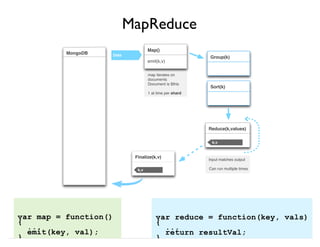
![{
"result" : [
{ "_id" : "art", "authors" : [ "bill", "bob" ] },
{ "_id" : "sports", "authors" : [ "jane", "bob" ] },
{ "_id" : "food", "authors" : [ "jane", "bob" ] },
{ "_id" : "science", "authors" : [ "jane", "bill", "bob" ] }
],
"ok" : 1
}
Output Document Looks like this:
result: array of pipeline
output
ok: 1 for success, 0
otherwise](https://image.slidesharecdn.com/mongodb-aggregation-130611150658-phpapp01/85/MongoDB-Aggregation-Framework-12-320.jpg)



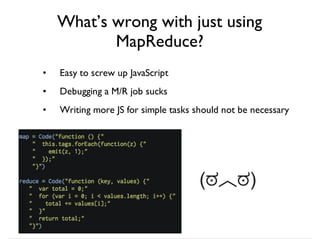
![$unwind
{
"_id" : ObjectId("4f...146"),
"author" : "bob",
"tags" :[ "fun","good","awesome"]
}
explode the “tags” array with:
{ $unwind : ”$tags” }
{ _id : ObjectId("4f...146"), author : "bob", tags:"fun"},
{ _id : ObjectId("4f...146"), author : "bob", tags:"good"},
{ _id : ObjectId("4f...146"), author : "bob", tags:"awesome"}
produces output:
Produce a new document for
each value in an input array](https://image.slidesharecdn.com/mongodb-aggregation-130611150658-phpapp01/85/MongoDB-Aggregation-Framework-16-320.jpg)

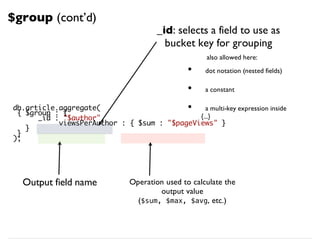







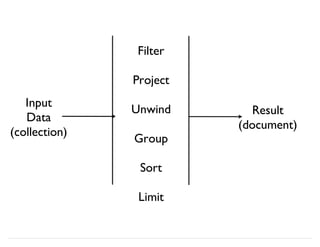
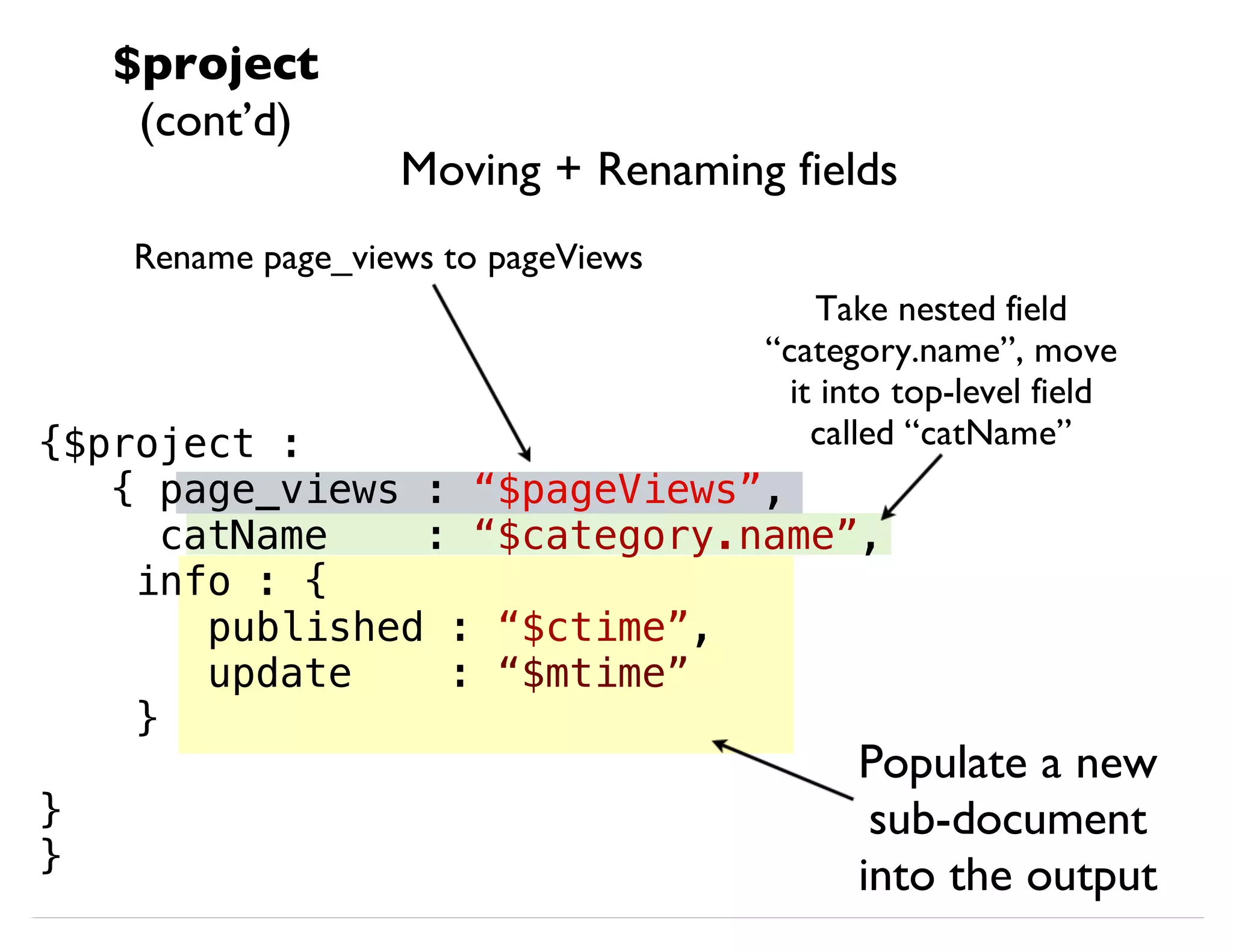
![db.article.aggregate(
{ $project : {
name : 1,
age_fixed : { $add:["$age", 2] }
}}
);
Building a Computed Field
Output
(computed field) Operands
Expression
$project
(cont’d)](https://image.slidesharecdn.com/mongodb-aggregation-130611150658-phpapp01/85/MongoDB-Aggregation-Framework-27-320.jpg)
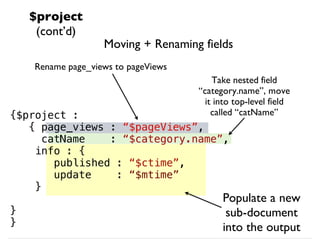
![Example: $sort → $limit → $project→
$group
MongoDB:
SQL:
English: Of the most recent 1000 blog posts, how many
were posted within each calendar year?
SELECT YEAR(pub_time) as pub_year,
COUNT(*) FROM
(SELECT pub_time FROM posts ORDER BY
pub_time desc)
GROUP BY pub_year;
db.test.aggregate(
{$sort : {pub_time: -1}},
{$limit : 1000},
{$project:{pub_year:{$year:["$pub_time"]}}},
{$group: {_id:"$pub_year", num_year:{$sum:1}}}
)](https://image.slidesharecdn.com/mongodb-aggregation-130611150658-phpapp01/85/MongoDB-Aggregation-Framework-29-320.jpg)






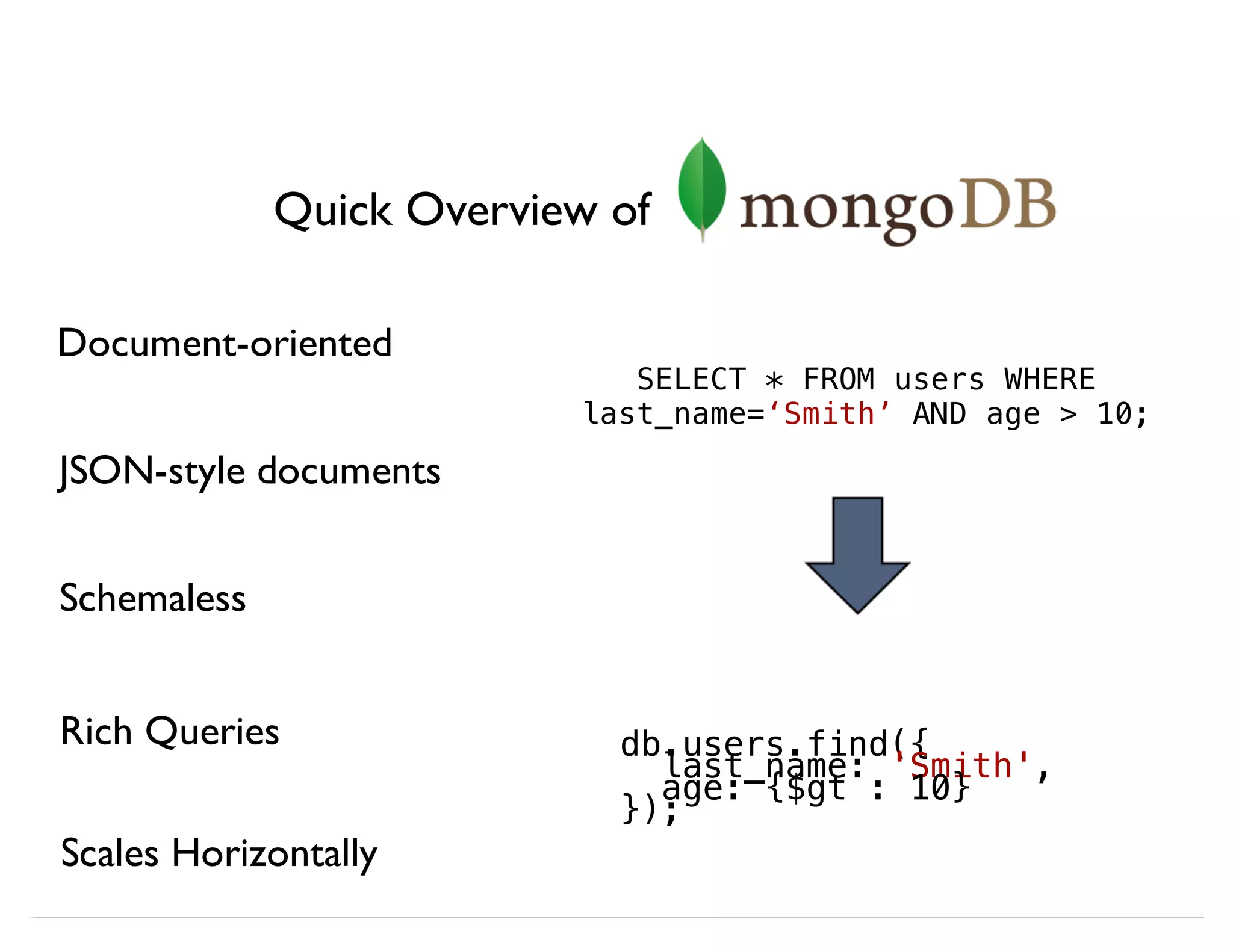





![db.article.aggregate(
{ $project : {author : 1, tags : 1}},
{ $unwind : "$tags" },
{ $group : {
_id : “$tags”,
authors : { $addToSet:"$author"}
}}
);
New Helper
Method:
.aggregate()
Operator
pipeline
db.runCommand({
aggregate : "article",
pipeline : [ {$op1, $op2, ...} ]
}](https://image.slidesharecdn.com/mongodb-aggregation-130611150658-phpapp01/75/MongoDB-Aggregation-Framework-11-2048.jpg)
![{
"result" : [
{ "_id" : "art", "authors" : [ "bill", "bob" ] },
{ "_id" : "sports", "authors" : [ "jane", "bob" ] },
{ "_id" : "food", "authors" : [ "jane", "bob" ] },
{ "_id" : "science", "authors" : [ "jane", "bill", "bob" ] }
],
"ok" : 1
}
Output Document Looks like this:
result: array of pipeline
output
ok: 1 for success, 0
otherwise](https://image.slidesharecdn.com/mongodb-aggregation-130611150658-phpapp01/75/MongoDB-Aggregation-Framework-12-2048.jpg)



![$unwind
{
"_id" : ObjectId("4f...146"),
"author" : "bob",
"tags" :[ "fun","good","awesome"]
}
explode the “tags” array with:
{ $unwind : ”$tags” }
{ _id : ObjectId("4f...146"), author : "bob", tags:"fun"},
{ _id : ObjectId("4f...146"), author : "bob", tags:"good"},
{ _id : ObjectId("4f...146"), author : "bob", tags:"awesome"}
produces output:
Produce a new document for
each value in an input array](https://image.slidesharecdn.com/mongodb-aggregation-130611150658-phpapp01/75/MongoDB-Aggregation-Framework-16-2048.jpg)








![db.article.aggregate(
{ $project : {
name : 1,
age_fixed : { $add:["$age", 2] }
}}
);
Building a Computed Field
Output
(computed field) Operands
Expression
$project
(cont’d)](https://image.slidesharecdn.com/mongodb-aggregation-130611150658-phpapp01/75/MongoDB-Aggregation-Framework-27-2048.jpg)
![Example: $sort → $limit → $project→
$group
MongoDB:
SQL:
English: Of the most recent 1000 blog posts, how many
were posted within each calendar year?
SELECT YEAR(pub_time) as pub_year,
COUNT(*) FROM
(SELECT pub_time FROM posts ORDER BY
pub_time desc)
GROUP BY pub_year;
db.test.aggregate(
{$sort : {pub_time: -1}},
{$limit : 1000},
{$project:{pub_year:{$year:["$pub_time"]}}},
{$group: {_id:"$pub_year", num_year:{$sum:1}}}
)](https://image.slidesharecdn.com/mongodb-aggregation-130611150658-phpapp01/75/MongoDB-Aggregation-Framework-29-2048.jpg)





The document provides an overview of MongoDB's aggregation framework, highlighting its advantages over traditional map/reduce methods for data aggregation and querying. It details various pipeline operators such as $match, $unwind, and $group, along with examples of usage and syntax. The framework allows for efficient data manipulation and eliminates the need for extensive JavaScript coding, offering declarative operations directly in the database.










































































































