This document discusses various natural language processing (NLP) techniques available in the Natural Language Toolkit (NLTK) library. It covers topics like tokenization, part-of-speech tagging, parsing, and natural language generation. Code examples are provided to demonstrate how to use NLTK for tasks like tokenizing text, POS tagging, and simulating simple dialog with a chatbot. A variety of NLTK functions, corpora, and objects are introduced to facilitate common NLP tasks.







![10
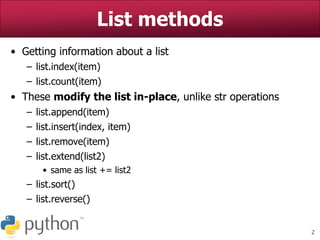
Tokenization (cont.)
• How do we split his speech into tokens?
>>> martysSpeech.split()
['You', 'know', 'what', 'I', 'hate?', 'Anybody',
'who', 'drives', 'an', 'S.U.V.', "I'd", 'really',
'like', 'to', 'find', 'Mr.', 'It-Costs-Me-100-
Dollars-To-Gas-Up', 'and', 'kick', 'him',
'square', 'in', 'the', 'teeth.', 'Booyah.', 'Be',
'like,', "I'm", 'Marty', 'Stepp,', 'the', 'best',
'ever.', 'Booyah!']
• Now, how often does he use the word "booyah"?
>>> martysSpeech.split().count("booyah")
0
>>> # What the!](https://image.slidesharecdn.com/nltkpythonbasicnaturallanguageprocessing-220823130955-30b583c0/85/NLTK-Python-Basic-Natural-Language-Processing-ppt-10-320.jpg)


![13
Part-of-speech (POS) tagging
• Exercise: most frequent proper noun in the Penn Treebank?
– Try:
• nltk.corpus.treebank
• Python's dir() to list attributes of an object
– Example:
>>> dir("hello world!")
[..., 'capitalize', 'center', 'count',
'decode', 'encode', 'endswith', 'expandtabs',
'find', 'index', 'isalnum', 'isalpha',
'isdigit', 'islower', 'isspace', 'istitle',
'isupper', 'join', 'ljust', 'lower', ...]](https://image.slidesharecdn.com/nltkpythonbasicnaturallanguageprocessing-220823130955-30b583c0/85/NLTK-Python-Basic-Natural-Language-Processing-ppt-13-320.jpg)
![14
Tuples
• tagged_words() gives us a list of tuples
– tuple: the same thing as a list, but you can't change it
– in this case, the tuples are a (word, tag) pairs
>>> # Get the (word, tag) pair at list index 0
...
>>> pair = nltk.corpus.treebank.tagged_words()[0]
>>> pair
('Pierre', 'NNP')
>>> word = pair[0]
>>> tag = pair[1]
>>> print word, tag
Pierre NNP
>>> word, tag = pair # or unpack in 1 line!
>>> print word, tag
Pierre NNP](https://image.slidesharecdn.com/nltkpythonbasicnaturallanguageprocessing-220823130955-30b583c0/85/NLTK-Python-Basic-Natural-Language-Processing-ppt-14-320.jpg)
![15
POS tagging (cont.)
• How do we tag plain sentences?
– A NLTK tagger needs a list of tagged sentences to train on
• We'll use nltk.corpus.treebank.tagged_sents()
– Then it is ready to tag any input! (but how well?)
– Try these tagger objects:
• nltk.UnigramTagger(tagged_sentences)
• nltk.TrigramTagger(tagged_sentences)
– Call the tagger's tag(tokens) method
>>> tagger = nltk.UnigramTagger(tagged_sentences)
>>> result = tagger.tag(tokens)
>>> result
[('You', 'PRP'), ('know', 'VB'), ('what', 'WP'),
('I', 'PRP'), ('hate', None), ('?', '.'), ...]](https://image.slidesharecdn.com/nltkpythonbasicnaturallanguageprocessing-220823130955-30b583c0/85/NLTK-Python-Basic-Natural-Language-Processing-ppt-15-320.jpg)











![10
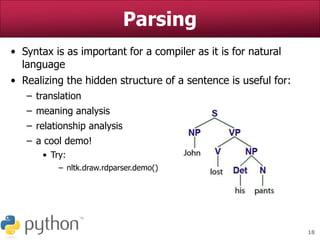
Tokenization (cont.)
• How do we split his speech into tokens?
>>> martysSpeech.split()
['You', 'know', 'what', 'I', 'hate?', 'Anybody',
'who', 'drives', 'an', 'S.U.V.', "I'd", 'really',
'like', 'to', 'find', 'Mr.', 'It-Costs-Me-100-
Dollars-To-Gas-Up', 'and', 'kick', 'him',
'square', 'in', 'the', 'teeth.', 'Booyah.', 'Be',
'like,', "I'm", 'Marty', 'Stepp,', 'the', 'best',
'ever.', 'Booyah!']
• Now, how often does he use the word "booyah"?
>>> martysSpeech.split().count("booyah")
0
>>> # What the!](https://image.slidesharecdn.com/nltkpythonbasicnaturallanguageprocessing-220823130955-30b583c0/75/NLTK-Python-Basic-Natural-Language-Processing-ppt-10-2048.jpg)


![13
Part-of-speech (POS) tagging
• Exercise: most frequent proper noun in the Penn Treebank?
– Try:
• nltk.corpus.treebank
• Python's dir() to list attributes of an object
– Example:
>>> dir("hello world!")
[..., 'capitalize', 'center', 'count',
'decode', 'encode', 'endswith', 'expandtabs',
'find', 'index', 'isalnum', 'isalpha',
'isdigit', 'islower', 'isspace', 'istitle',
'isupper', 'join', 'ljust', 'lower', ...]](https://image.slidesharecdn.com/nltkpythonbasicnaturallanguageprocessing-220823130955-30b583c0/75/NLTK-Python-Basic-Natural-Language-Processing-ppt-13-2048.jpg)
![14
Tuples
• tagged_words() gives us a list of tuples
– tuple: the same thing as a list, but you can't change it
– in this case, the tuples are a (word, tag) pairs
>>> # Get the (word, tag) pair at list index 0
...
>>> pair = nltk.corpus.treebank.tagged_words()[0]
>>> pair
('Pierre', 'NNP')
>>> word = pair[0]
>>> tag = pair[1]
>>> print word, tag
Pierre NNP
>>> word, tag = pair # or unpack in 1 line!
>>> print word, tag
Pierre NNP](https://image.slidesharecdn.com/nltkpythonbasicnaturallanguageprocessing-220823130955-30b583c0/75/NLTK-Python-Basic-Natural-Language-Processing-ppt-14-2048.jpg)
![15
POS tagging (cont.)
• How do we tag plain sentences?
– A NLTK tagger needs a list of tagged sentences to train on
• We'll use nltk.corpus.treebank.tagged_sents()
– Then it is ready to tag any input! (but how well?)
– Try these tagger objects:
• nltk.UnigramTagger(tagged_sentences)
• nltk.TrigramTagger(tagged_sentences)
– Call the tagger's tag(tokens) method
>>> tagger = nltk.UnigramTagger(tagged_sentences)
>>> result = tagger.tag(tokens)
>>> result
[('You', 'PRP'), ('know', 'VB'), ('what', 'WP'),
('I', 'PRP'), ('hate', None), ('?', '.'), ...]](https://image.slidesharecdn.com/nltkpythonbasicnaturallanguageprocessing-220823130955-30b583c0/75/NLTK-Python-Basic-Natural-Language-Processing-ppt-15-2048.jpg)


















































![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
