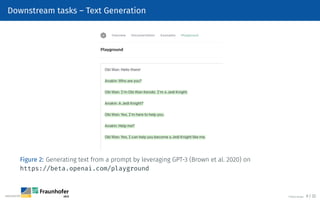
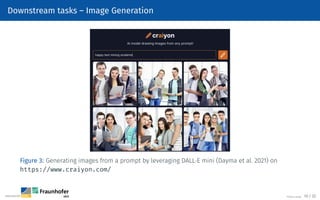
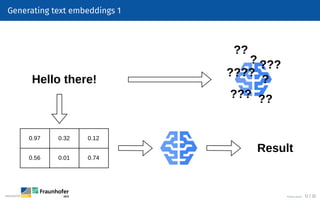
The document provides an overview of natural language processing (NLP), defining it as a field that enables computers to understand and analyze human language. It outlines the typical NLP workflow, including data gathering, text preprocessing, and various downstream tasks like classification and text generation. Additional sections detail specific preprocessing techniques such as tokenization, stemming, and lemmatization, as well as resources for starting NLP projects using Python.










![Text preprocessing – Word Tokenization
Word tokenization describes the process of splitting a sentence (or any text)
into words.
Here, we mainly look for spaces and have to take care of punctuation marks.
1 from nltk.tokenize import word_tokenize
2 s = '''Good muffins cost $3.88nin New York. Please buy me two of
them.nnThanks.'''
3 word_tokenize(s)
4 ['Good', 'muffins', 'cost', '$', '3.88', 'in', 'New', 'York', '.', '
Please', 'buy', 'me', 'two', 'of', 'them', '.', 'Thanks', '.']
Listing 1: Example from the nltk documentation
©Tobias Deußer 16 / 32](https://image.slidesharecdn.com/am4tmws22practice01nlpbasics-240110140908-205d0e21/85/AM4TM_WS22_Practice_01_NLP_Basics-pdf-17-320.jpg)
![Text preprocessing – Subword Tokenization
Modern NLP approaches (e.g. Transformers like BERT) tokenize the input a
step further, splitting unknown (i.e., not in the vocabulary) words into
meaningful subwords, but preserving frequently used words.
1 from transformers import BertTokenizer
2 tokenizer = BertTokenizer.from_pretrained(bert-base-uncased)
3 tokenizer.tokenize('''Don't you love wasting GPU capacity by training
transformer models for your Advanced Method in Text Mining course?'''
)
4 ['don', ', 't', 'you', 'love', 'wasting', 'gp', '##u', 'capacity', 'by'
, 'training', 'transform', '##er', 'models', 'for', 'your', 'advanced'
, 'method', 'in', 'text', 'mining', 'course', '?']
Listing 2: Example using the BertTokenizer from the transformer package
©Tobias Deußer 17 / 32](https://image.slidesharecdn.com/am4tmws22practice01nlpbasics-240110140908-205d0e21/85/AM4TM_WS22_Practice_01_NLP_Basics-pdf-18-320.jpg)

![Text preprocessing – Stop Words Removal 1
Stop words are the most common (like articles, prepositions, pronouns,
conjunctions, etc) and often do not add that much information to a sentence
1 from nltk.corpus import stopwords
2 stopwords.words(english)
3 ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', you
're, you've, you'll, you'd, 'your', 'yours', 'yourself', '
yourselves', 'he', 'him', 'his', 'himself', 'she', she's, 'her', '
hers', 'herself', 'it', it's, 'its', 'itself', 'they', 'them', '
their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this'
, 'that', that'll, 'these', 'those', 'am', 'is', 'are', 'was', 'were
', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does'
, 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because
', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', '
against', 'between', 'into', 'through', 'during', 'before', 'after', '
above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off',
'over', 'under', 'again', 'further', 'then', 'once', 'here', ...]
Listing 3: Stop Words from the NLTK package
©Tobias Deußer 19 / 32](https://image.slidesharecdn.com/am4tmws22practice01nlpbasics-240110140908-205d0e21/85/AM4TM_WS22_Practice_01_NLP_Basics-pdf-20-320.jpg)
![Text preprocessing – Stop Words Removal 2
But there are issues with this …
1 from nltk.corpus import stopwords
2 sentence = The dish was not tasty at all
3 [word for word in sentence.split() if word.lower() not in stopwords.
words(english)]
4 ['dish', 'tasty']
Listing 4: Removing “unimportant” words
©Tobias Deußer 20 / 32](https://image.slidesharecdn.com/am4tmws22practice01nlpbasics-240110140908-205d0e21/85/AM4TM_WS22_Practice_01_NLP_Basics-pdf-21-320.jpg)

![Text preprocessing – Stemming 2
Overstemming – When the algorithm stems words to the same root even
though are unrelated
Understemming – The opposite
1 from nltk.stem.porter import PorterStemmer
2 stemmer = PorterStemmer()
3 words_to_be_stemmed = [liked, birds, itemization, universal,
university, universe, alumnus, alumni]
4 [stemmer.stem(word) for word in words_to_be_stemmed]
5 ['like', 'bird', 'item', 'univers', 'univers', 'univers', 'alumnu', '
alumni']
Listing 5: Examples of correct and incorrect stemming
©Tobias Deußer 22 / 32](https://image.slidesharecdn.com/am4tmws22practice01nlpbasics-240110140908-205d0e21/85/AM4TM_WS22_Practice_01_NLP_Basics-pdf-23-320.jpg)












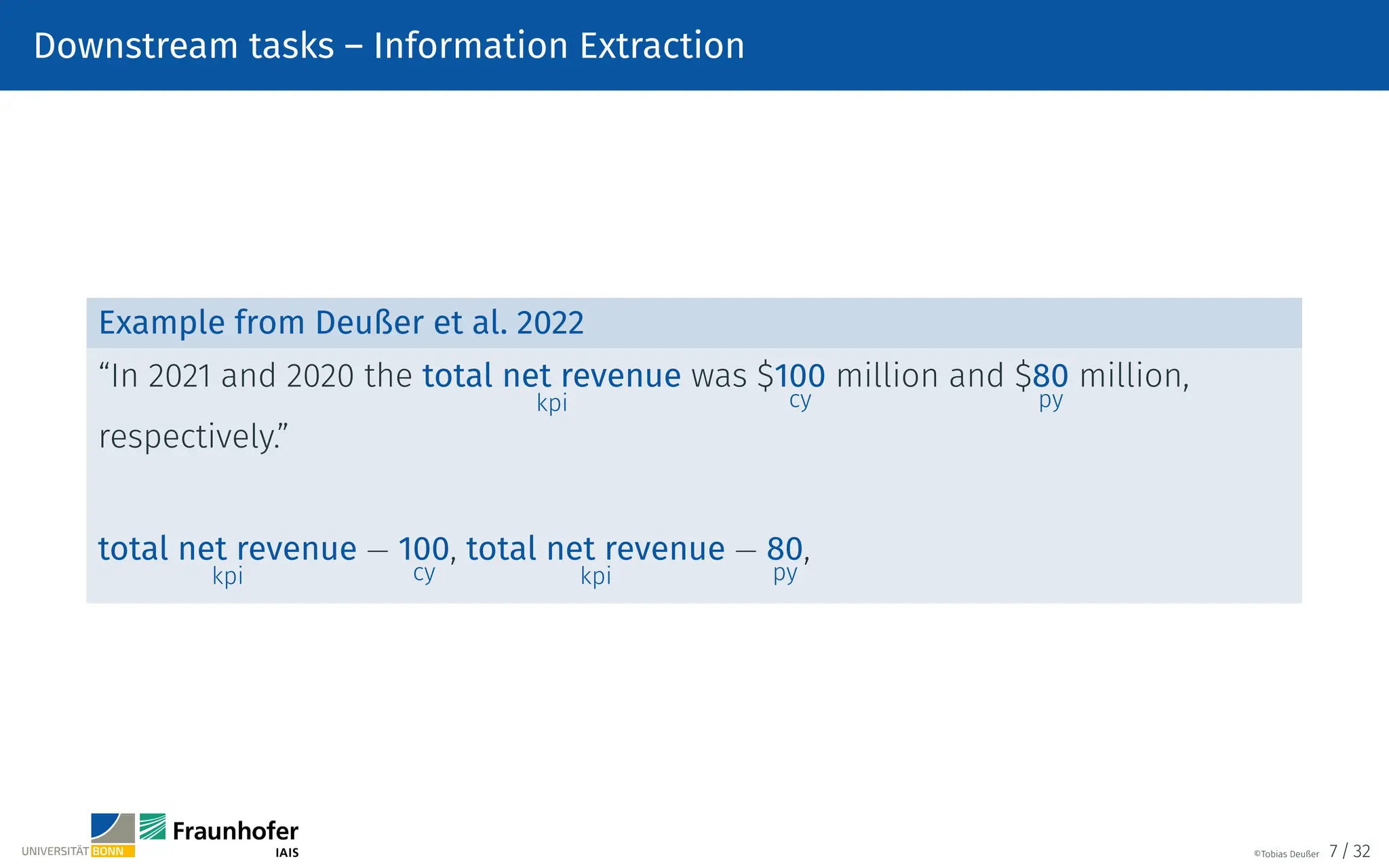

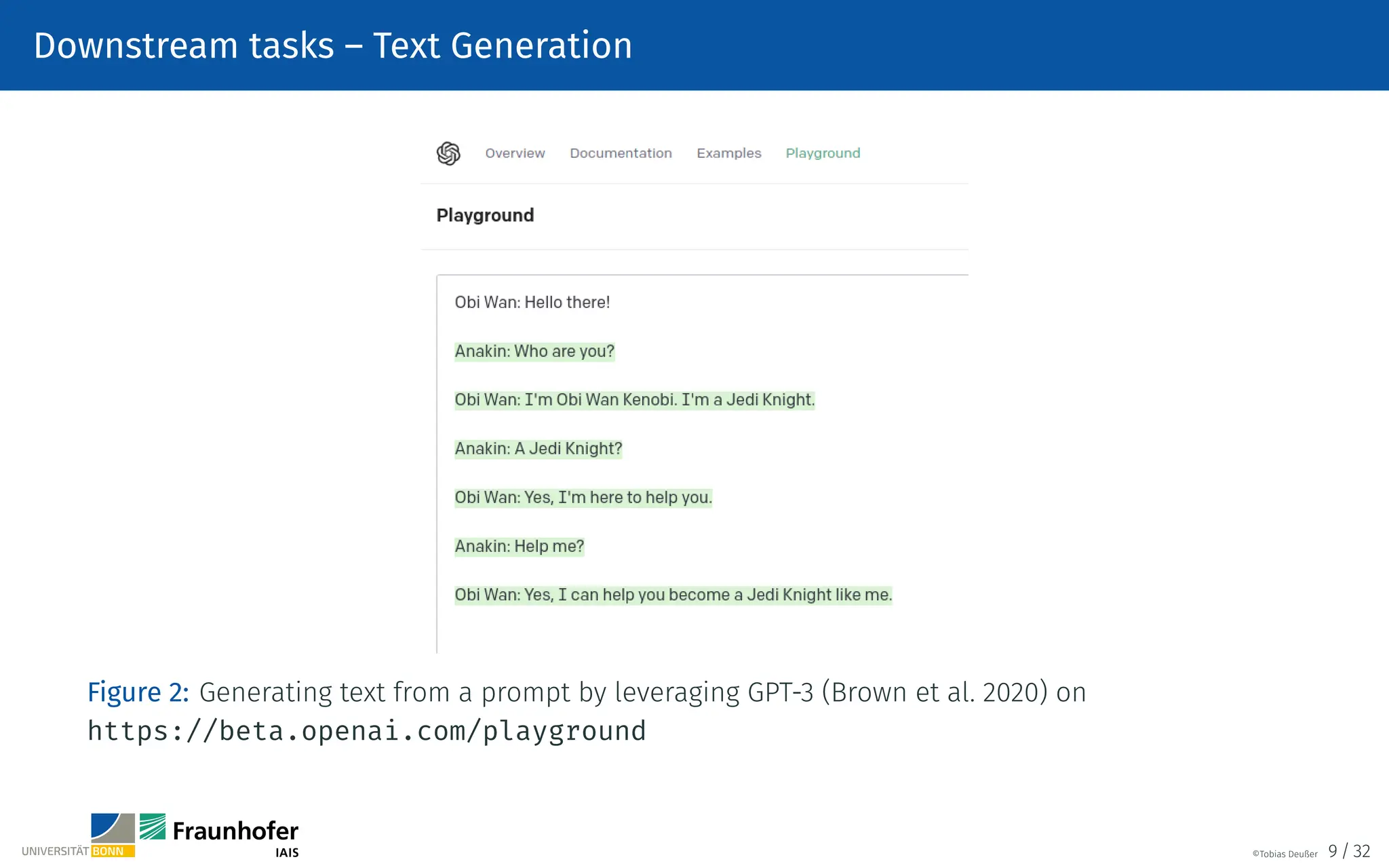
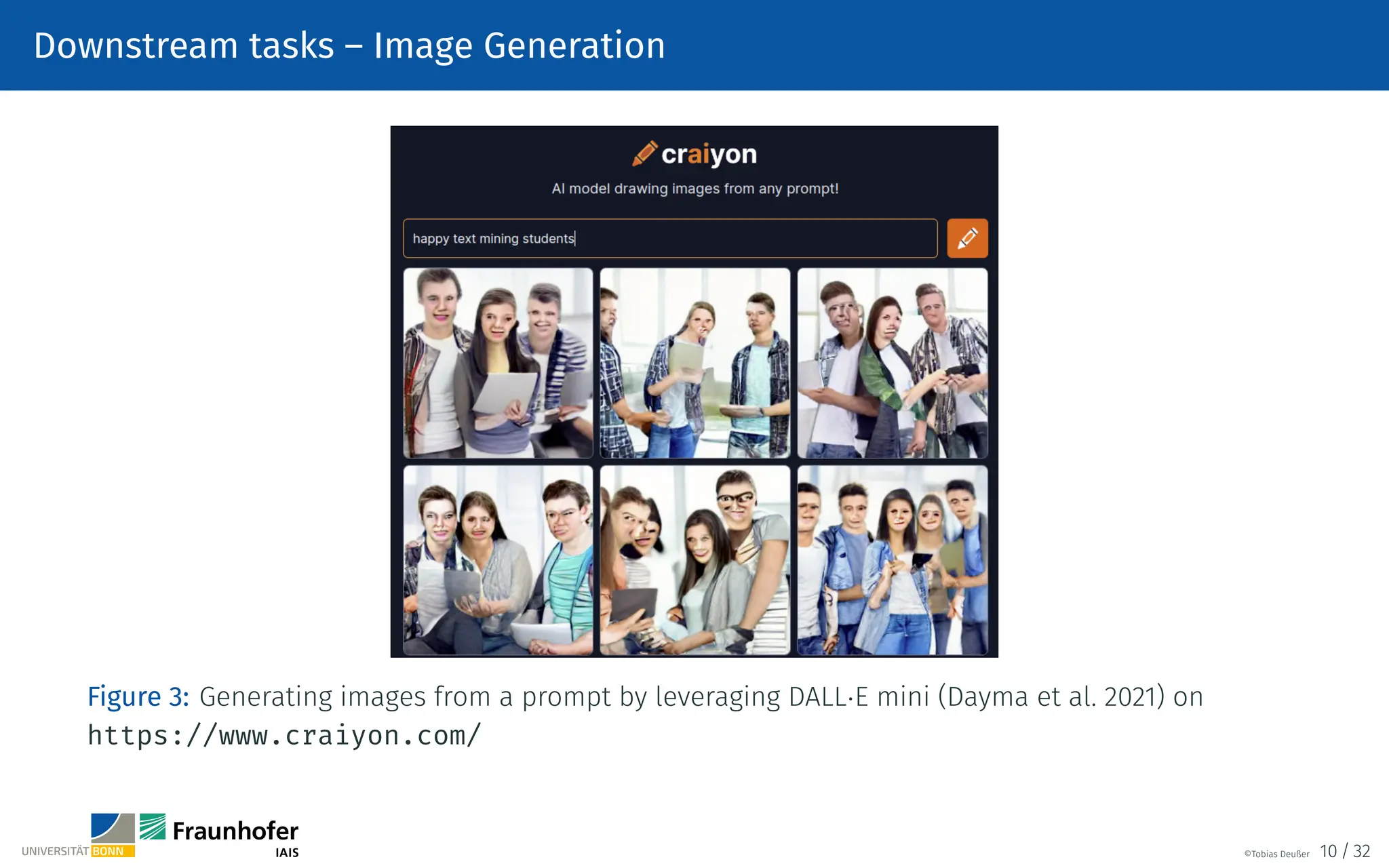

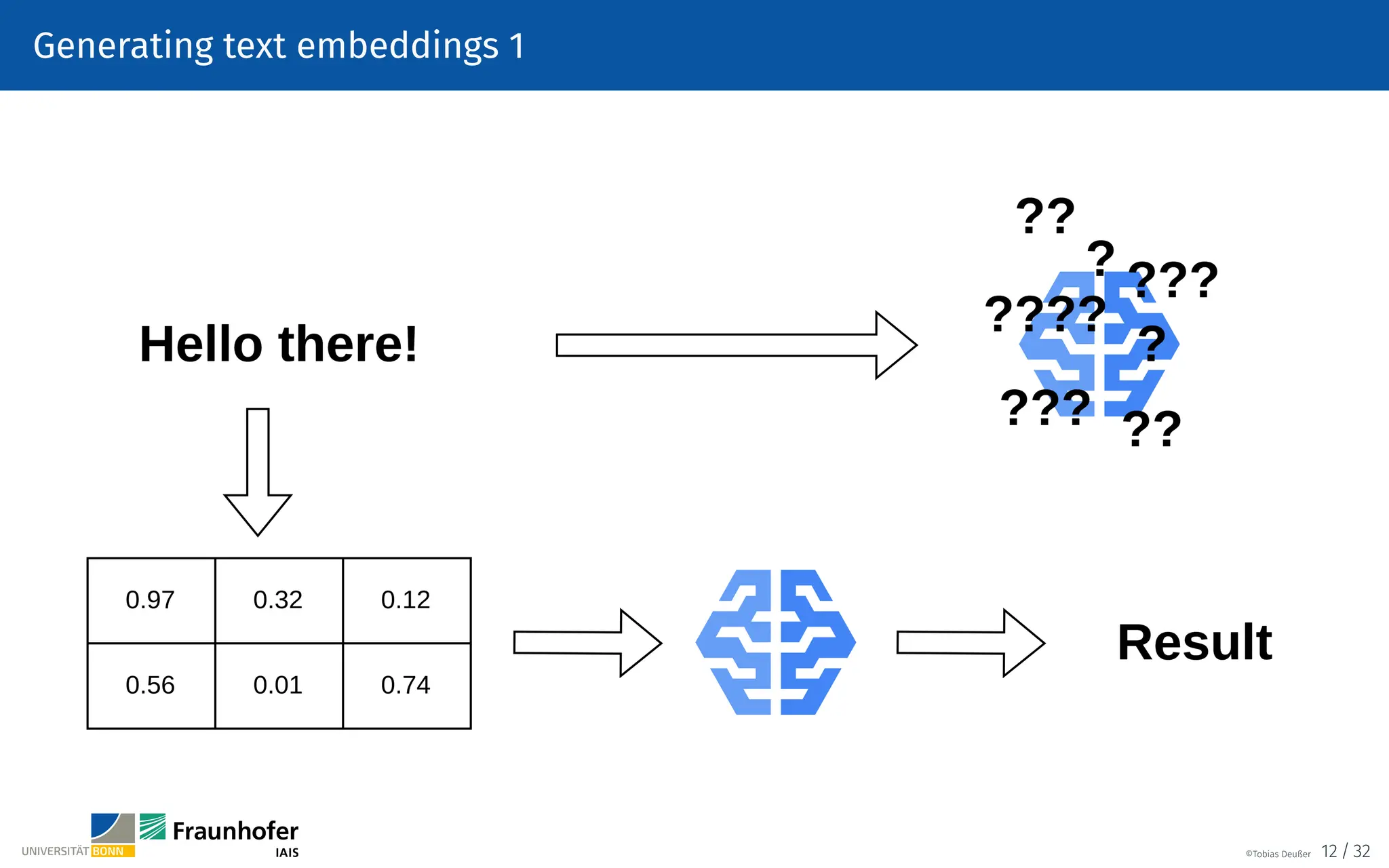



![Text preprocessing – Word Tokenization
Word tokenization describes the process of splitting a sentence (or any text)
into words.
Here, we mainly look for spaces and have to take care of punctuation marks.
1 from nltk.tokenize import word_tokenize
2 s = '''Good muffins cost $3.88nin New York. Please buy me two of
them.nnThanks.'''
3 word_tokenize(s)
4 ['Good', 'muffins', 'cost', '$', '3.88', 'in', 'New', 'York', '.', '
Please', 'buy', 'me', 'two', 'of', 'them', '.', 'Thanks', '.']
Listing 1: Example from the nltk documentation
©Tobias Deußer 16 / 32](https://image.slidesharecdn.com/am4tmws22practice01nlpbasics-240110140908-205d0e21/75/AM4TM_WS22_Practice_01_NLP_Basics-pdf-17-2048.jpg)
![Text preprocessing – Subword Tokenization
Modern NLP approaches (e.g. Transformers like BERT) tokenize the input a
step further, splitting unknown (i.e., not in the vocabulary) words into
meaningful subwords, but preserving frequently used words.
1 from transformers import BertTokenizer
2 tokenizer = BertTokenizer.from_pretrained(bert-base-uncased)
3 tokenizer.tokenize('''Don't you love wasting GPU capacity by training
transformer models for your Advanced Method in Text Mining course?'''
)
4 ['don', ', 't', 'you', 'love', 'wasting', 'gp', '##u', 'capacity', 'by'
, 'training', 'transform', '##er', 'models', 'for', 'your', 'advanced'
, 'method', 'in', 'text', 'mining', 'course', '?']
Listing 2: Example using the BertTokenizer from the transformer package
©Tobias Deußer 17 / 32](https://image.slidesharecdn.com/am4tmws22practice01nlpbasics-240110140908-205d0e21/75/AM4TM_WS22_Practice_01_NLP_Basics-pdf-18-2048.jpg)

![Text preprocessing – Stop Words Removal 1
Stop words are the most common (like articles, prepositions, pronouns,
conjunctions, etc) and often do not add that much information to a sentence
1 from nltk.corpus import stopwords
2 stopwords.words(english)
3 ['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', you
're, you've, you'll, you'd, 'your', 'yours', 'yourself', '
yourselves', 'he', 'him', 'his', 'himself', 'she', she's, 'her', '
hers', 'herself', 'it', it's, 'its', 'itself', 'they', 'them', '
their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this'
, 'that', that'll, 'these', 'those', 'am', 'is', 'are', 'was', 'were
', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does'
, 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because
', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', '
against', 'between', 'into', 'through', 'during', 'before', 'after', '
above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off',
'over', 'under', 'again', 'further', 'then', 'once', 'here', ...]
Listing 3: Stop Words from the NLTK package
©Tobias Deußer 19 / 32](https://image.slidesharecdn.com/am4tmws22practice01nlpbasics-240110140908-205d0e21/75/AM4TM_WS22_Practice_01_NLP_Basics-pdf-20-2048.jpg)
![Text preprocessing – Stop Words Removal 2
But there are issues with this …
1 from nltk.corpus import stopwords
2 sentence = The dish was not tasty at all
3 [word for word in sentence.split() if word.lower() not in stopwords.
words(english)]
4 ['dish', 'tasty']
Listing 4: Removing “unimportant” words
©Tobias Deußer 20 / 32](https://image.slidesharecdn.com/am4tmws22practice01nlpbasics-240110140908-205d0e21/75/AM4TM_WS22_Practice_01_NLP_Basics-pdf-21-2048.jpg)

![Text preprocessing – Stemming 2
Overstemming – When the algorithm stems words to the same root even
though are unrelated
Understemming – The opposite
1 from nltk.stem.porter import PorterStemmer
2 stemmer = PorterStemmer()
3 words_to_be_stemmed = [liked, birds, itemization, universal,
university, universe, alumnus, alumni]
4 [stemmer.stem(word) for word in words_to_be_stemmed]
5 ['like', 'bird', 'item', 'univers', 'univers', 'univers', 'alumnu', '
alumni']
Listing 5: Examples of correct and incorrect stemming
©Tobias Deußer 22 / 32](https://image.slidesharecdn.com/am4tmws22practice01nlpbasics-240110140908-205d0e21/75/AM4TM_WS22_Practice_01_NLP_Basics-pdf-23-2048.jpg)