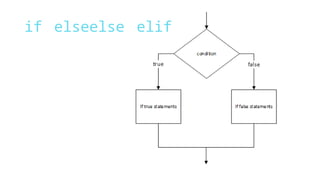
Python, invented by Guido van Rossum in the early 90s, has been open-sourced from the beginning and gained popularity, being used by Google. The document outlines naming rules, assignment, arrays, and introduces the Natural Language Toolkit (nltk) for NLP, covering tokenization, stop word removal, and stemming. Examples illustrate these processes and the importance of stemming in information retrieval.





![Array
• array = [2, 54, 5, 7, 8, 9]
• list1 = list() #empty list](https://image.slidesharecdn.com/lecture-250120154739-9e1a746c/85/Python-computer-science-technology-pptx-7-320.jpg)




![Stop Word Removal
• from nltk.corpus import stopwords
• from nltk.tokenize import word_tokenize
• example_sent = """early symptoms of the coronavirus"""
• stop_words = set(stopwords.words('english'))
• word_tokens = word_tokenize(example_sent)
• filtered_sentence = [w for w in word_tokens if not w in stop_words]](https://image.slidesharecdn.com/lecture-250120154739-9e1a746c/85/Python-computer-science-technology-pptx-12-320.jpg)
![Stop Word Removal
• filtered_sentence = []
• for w in word_tokens:
• if w not in stop_words:
• filtered_sentence.append(w)
• print(word_tokens)
• print(filtered_sentence)](https://image.slidesharecdn.com/lecture-250120154739-9e1a746c/85/Python-computer-science-technology-pptx-13-320.jpg)






![Array
• array = [2, 54, 5, 7, 8, 9]
• list1 = list() #empty list](https://image.slidesharecdn.com/lecture-250120154739-9e1a746c/75/Python-computer-science-technology-pptx-7-2048.jpg)




![Stop Word Removal
• from nltk.corpus import stopwords
• from nltk.tokenize import word_tokenize
• example_sent = """early symptoms of the coronavirus"""
• stop_words = set(stopwords.words('english'))
• word_tokens = word_tokenize(example_sent)
• filtered_sentence = [w for w in word_tokens if not w in stop_words]](https://image.slidesharecdn.com/lecture-250120154739-9e1a746c/75/Python-computer-science-technology-pptx-12-2048.jpg)
![Stop Word Removal
• filtered_sentence = []
• for w in word_tokens:
• if w not in stop_words:
• filtered_sentence.append(w)
• print(word_tokens)
• print(filtered_sentence)](https://image.slidesharecdn.com/lecture-250120154739-9e1a746c/75/Python-computer-science-technology-pptx-13-2048.jpg)













































![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





![Matrix and determinant URT [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/matrixanddeterminanturtautosaved-251018190340-9e6a6deb-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




