Download as PDF, PPTX



![Python
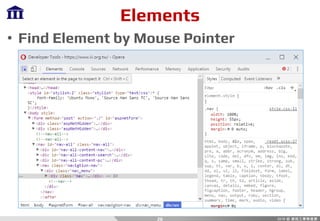
• Entry
if __name__ == '__main__':
# do something
• Method
def main ():
# do something
• Package
import [package]
import [package] as [alias]
• Format
'%s' % ([parameters ...])
4
demo01.py
demo02.py
demo03.py](https://image.slidesharecdn.com/crawler-180810205620/85/Python-Crawler-4-320.jpg)
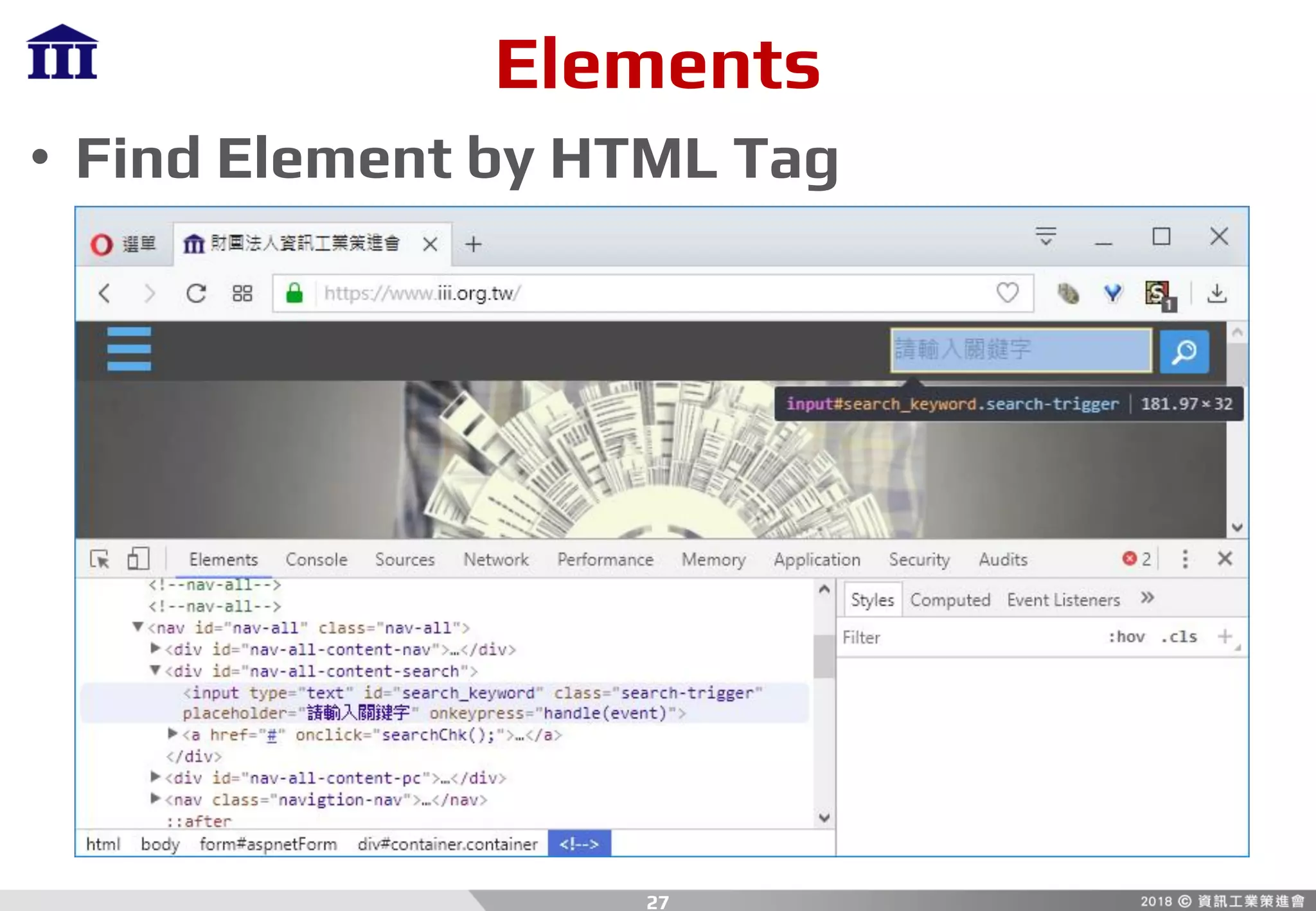
![Python
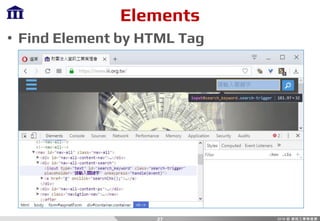
• If … Else …
if [condition]:
# do something
else:
# do something
• For Loop
for item in list:
# do something
• Array Slice
array[start:end]
5](https://image.slidesharecdn.com/crawler-180810205620/85/Python-Crawler-5-320.jpg)
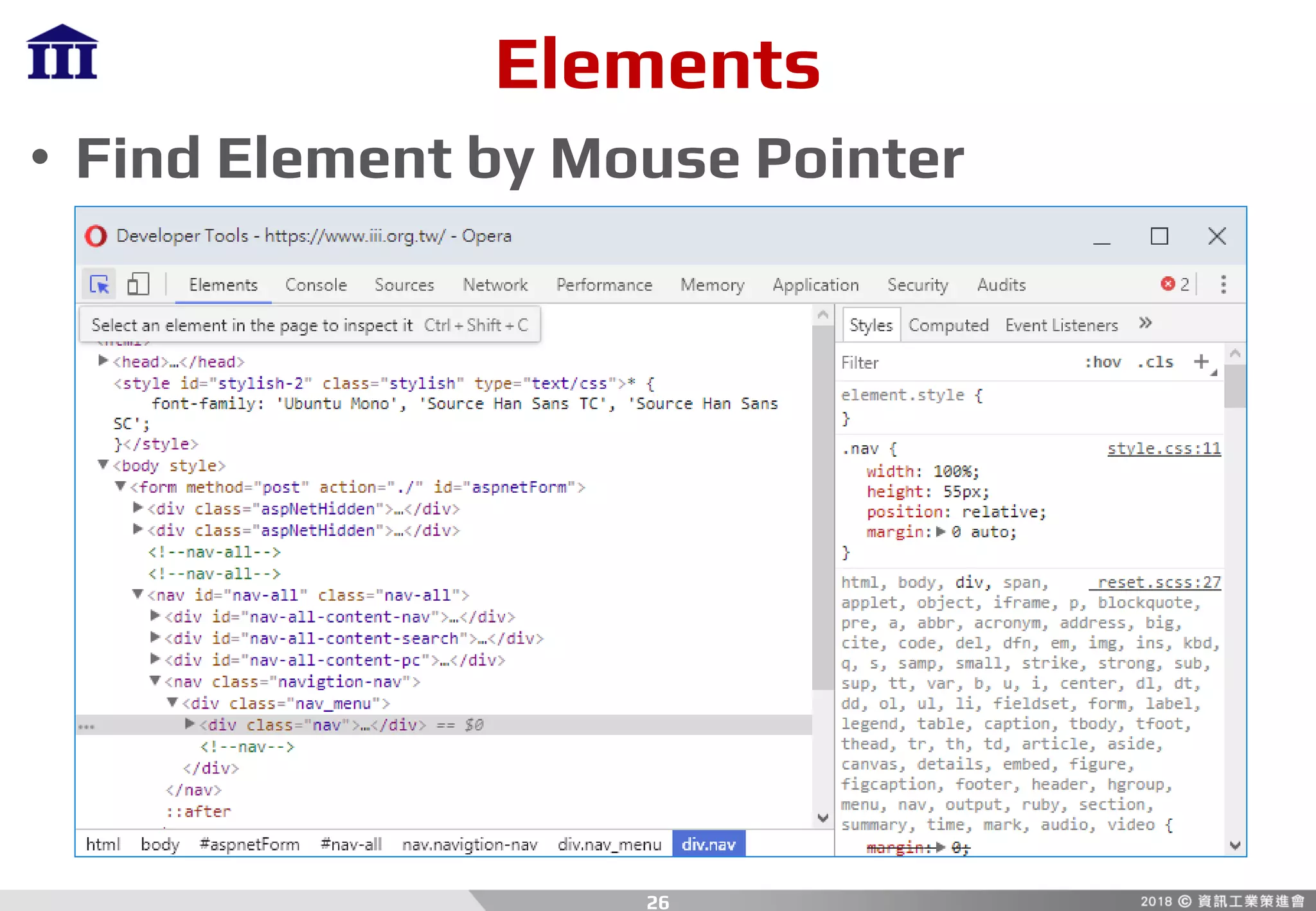
![Python
• Array Creation From For Loop
– Object
[item.attr for item in array]
– Dictionary
[item[key] for item in array]
6
demo04.py](https://image.slidesharecdn.com/crawler-180810205620/85/Python-Crawler-6-320.jpg)









![Built-in
• Regular Expression
– Expressions
1. Range
[Start-End]
[0-9], [a-z], [A-Z], [a-zA-Z], [0-9a-zA-Z], ...
20
demo12.py](https://image.slidesharecdn.com/crawler-180810205620/85/Python-Crawler-20-320.jpg)

![Built-in
• Regular Expression
– Expressions
1. Numbers
d = [0-9]
2. Words
w = [a-zA-Z0-9] (ANSI)
w = [a-zA-Z0-9] + Non-ANSI Characters (UTF-8)
3. Spaces, Tabs, …
s
22
demo12.py](https://image.slidesharecdn.com/crawler-180810205620/85/Python-Crawler-22-320.jpg)







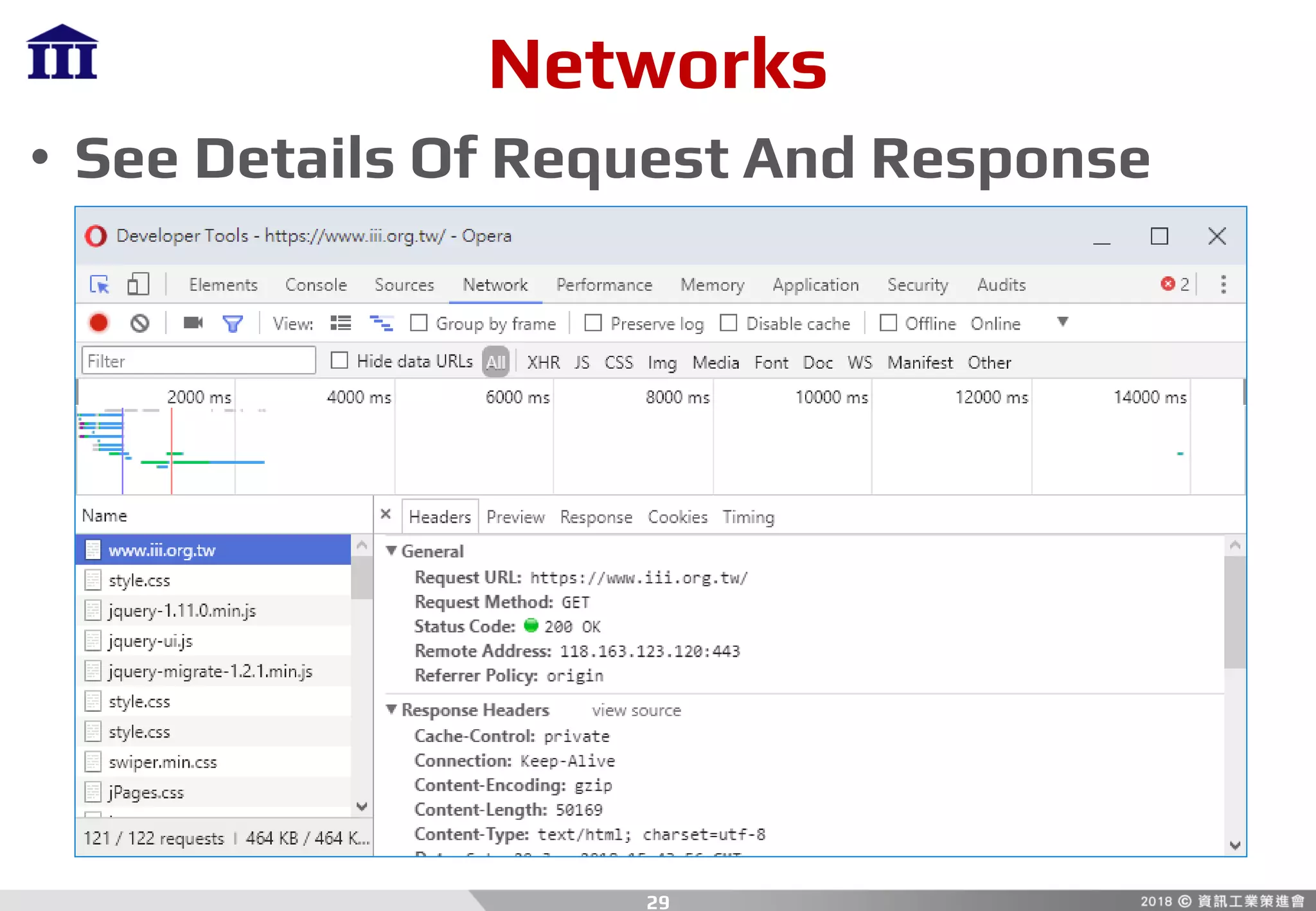
![Packages
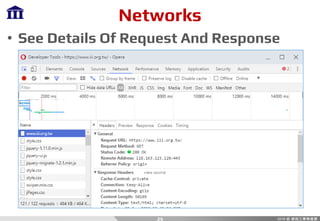
• Requests
– Response
1. Status Code
response.status_code
2. Headers
response.headers[<str:name>]
3. Cookies
response.cookies[<str:name>]
35
demo14.py](https://image.slidesharecdn.com/crawler-180810205620/85/Python-Crawler-35-320.jpg)


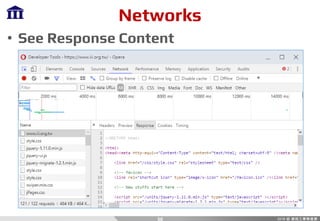
![Packages
• PyQuery
– Find
p = d(<str:expression>)
– Element To HTML
p.html()
– Extract Text From Element
p.text()
– Get Value From Element Attribute
val = p.attr[<str:name>]
38
demo15.py](https://image.slidesharecdn.com/crawler-180810205620/85/Python-Crawler-38-320.jpg)



















![Python
• Entry
if __name__ == '__main__':
# do something
• Method
def main ():
# do something
• Package
import [package]
import [package] as [alias]
• Format
'%s' % ([parameters ...])
4
demo01.py
demo02.py
demo03.py](https://image.slidesharecdn.com/crawler-180810205620/75/Python-Crawler-4-2048.jpg)
![Python
• If … Else …
if [condition]:
# do something
else:
# do something
• For Loop
for item in list:
# do something
• Array Slice
array[start:end]
5](https://image.slidesharecdn.com/crawler-180810205620/75/Python-Crawler-5-2048.jpg)
![Python
• Array Creation From For Loop
– Object
[item.attr for item in array]
– Dictionary
[item[key] for item in array]
6
demo04.py](https://image.slidesharecdn.com/crawler-180810205620/75/Python-Crawler-6-2048.jpg)









![Built-in
• Regular Expression
– Expressions
1. Range
[Start-End]
[0-9], [a-z], [A-Z], [a-zA-Z], [0-9a-zA-Z], ...
20
demo12.py](https://image.slidesharecdn.com/crawler-180810205620/75/Python-Crawler-20-2048.jpg)

![Built-in
• Regular Expression
– Expressions
1. Numbers
d = [0-9]
2. Words
w = [a-zA-Z0-9] (ANSI)
w = [a-zA-Z0-9] + Non-ANSI Characters (UTF-8)
3. Spaces, Tabs, …
s
22
demo12.py](https://image.slidesharecdn.com/crawler-180810205620/75/Python-Crawler-22-2048.jpg)







![Packages
• Requests
– Response
1. Status Code
response.status_code
2. Headers
response.headers[<str:name>]
3. Cookies
response.cookies[<str:name>]
35
demo14.py](https://image.slidesharecdn.com/crawler-180810205620/75/Python-Crawler-35-2048.jpg)
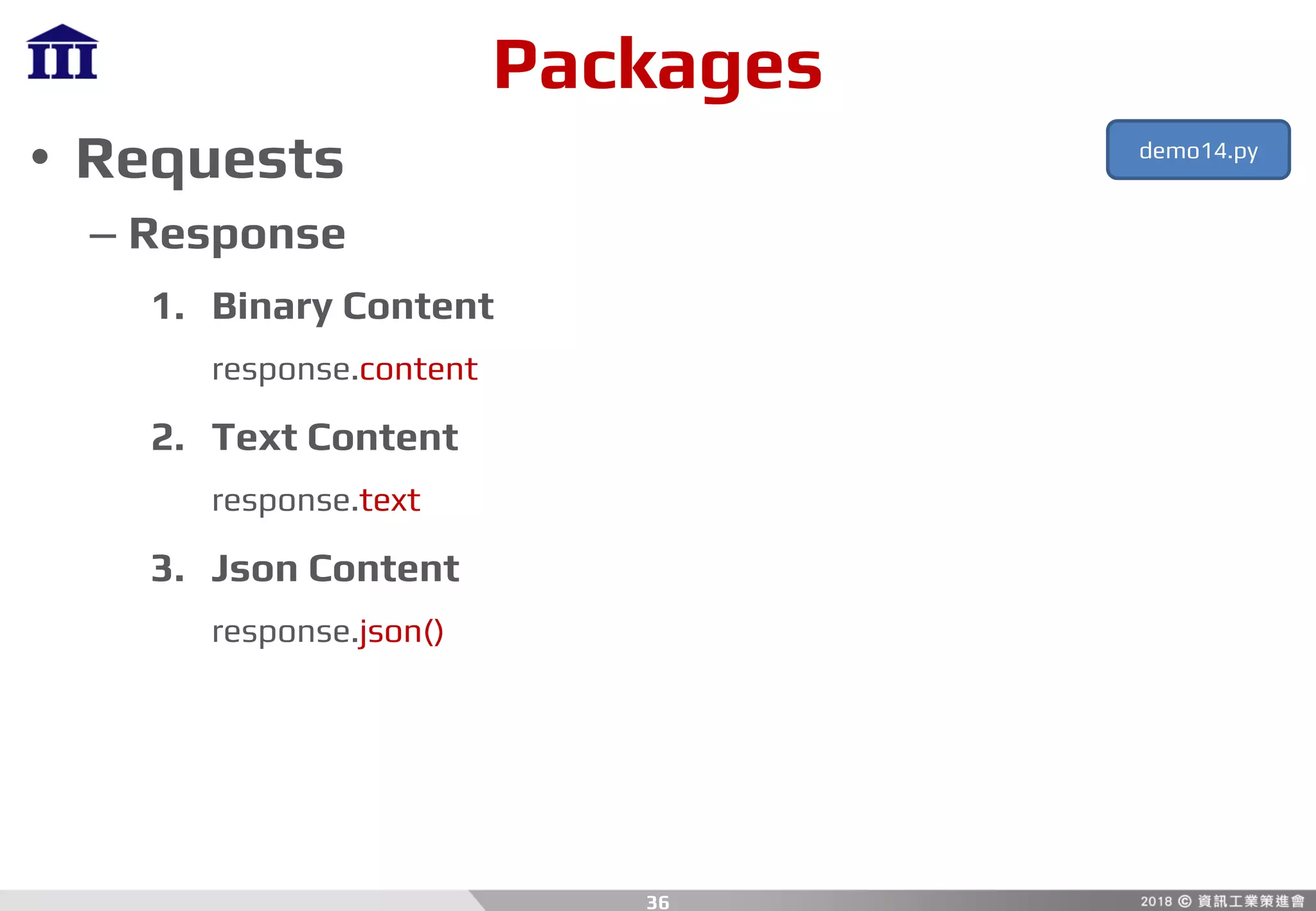

![Packages
• PyQuery
– Find
p = d(<str:expression>)
– Element To HTML
p.html()
– Extract Text From Element
p.text()
– Get Value From Element Attribute
val = p.attr[<str:name>]
38
demo15.py](https://image.slidesharecdn.com/crawler-180810205620/75/Python-Crawler-38-2048.jpg)

















This document provides an overview of Python web crawling from beginner to intermediate level. It introduces Python basics like conditional statements, loops, arrays and dictionaries. It also covers built-in modules for handling JSON, XML, URLs, regular expressions. Popular web crawling packages like Requests, PyQuery, Beautiful Soup are demonstrated. Selenium for controlling browsers is explained. The document contains code examples and suggests hands-on workshops on scraping news sites and social media pages.































































