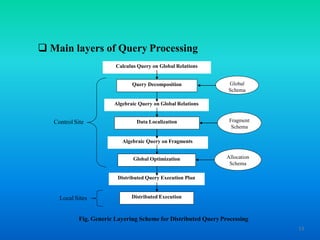
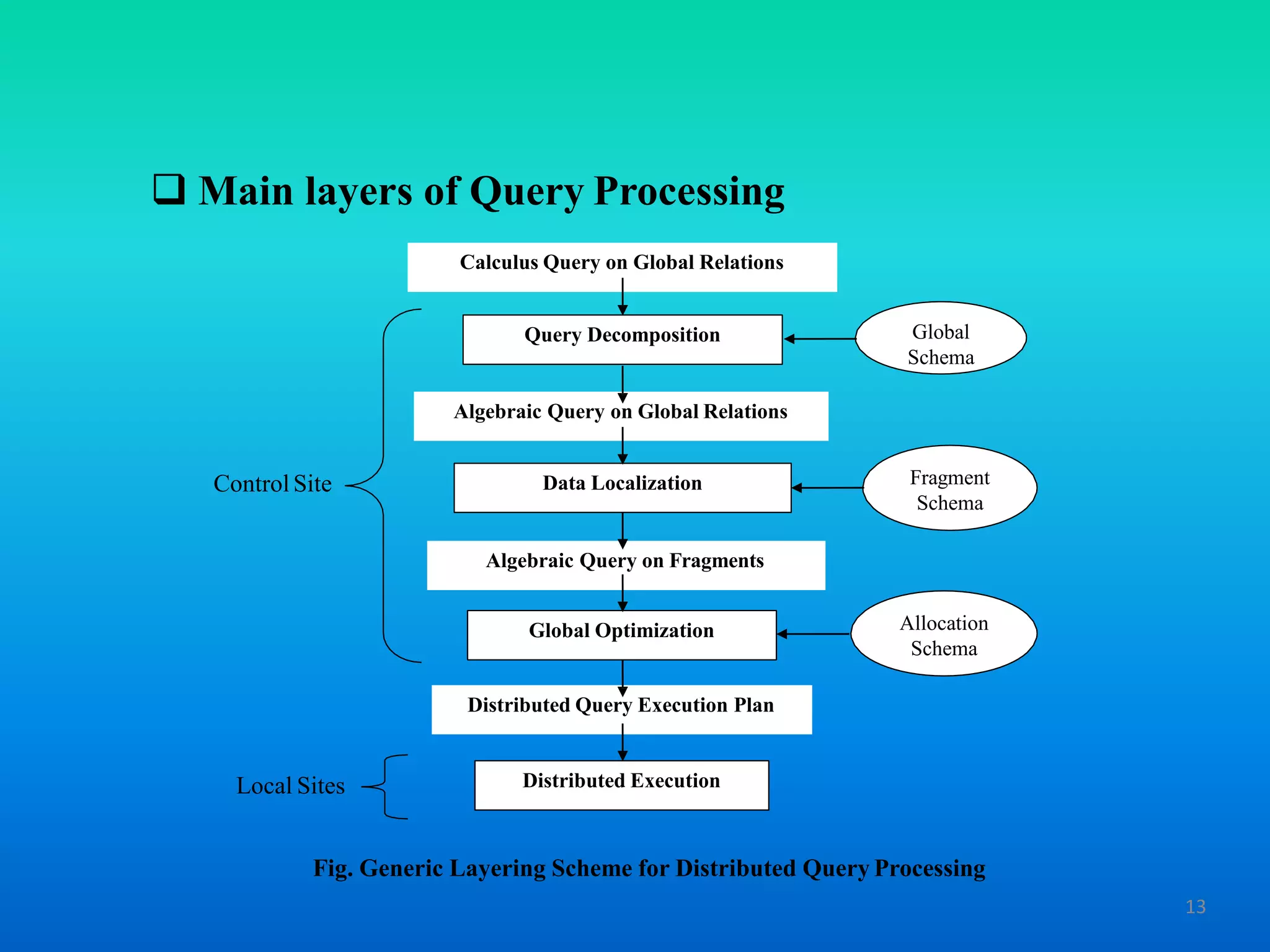
The document discusses query processing in distributed database systems, outlining the definition of queries, the role and functions of query processors, and key challenges such as query optimization. It describes the main layers of the query processing framework, including query decomposition, data localization, global query optimization, and distributed execution. Additionally, the document highlights the characteristics of query processors, such as the input language and optimization strategies.