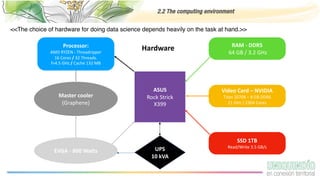
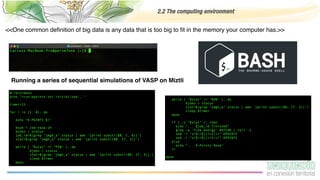
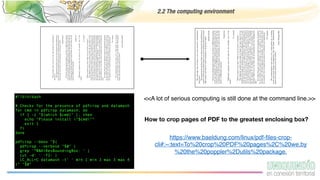
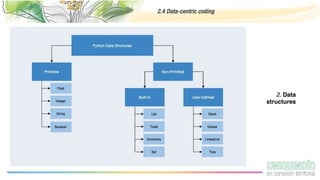
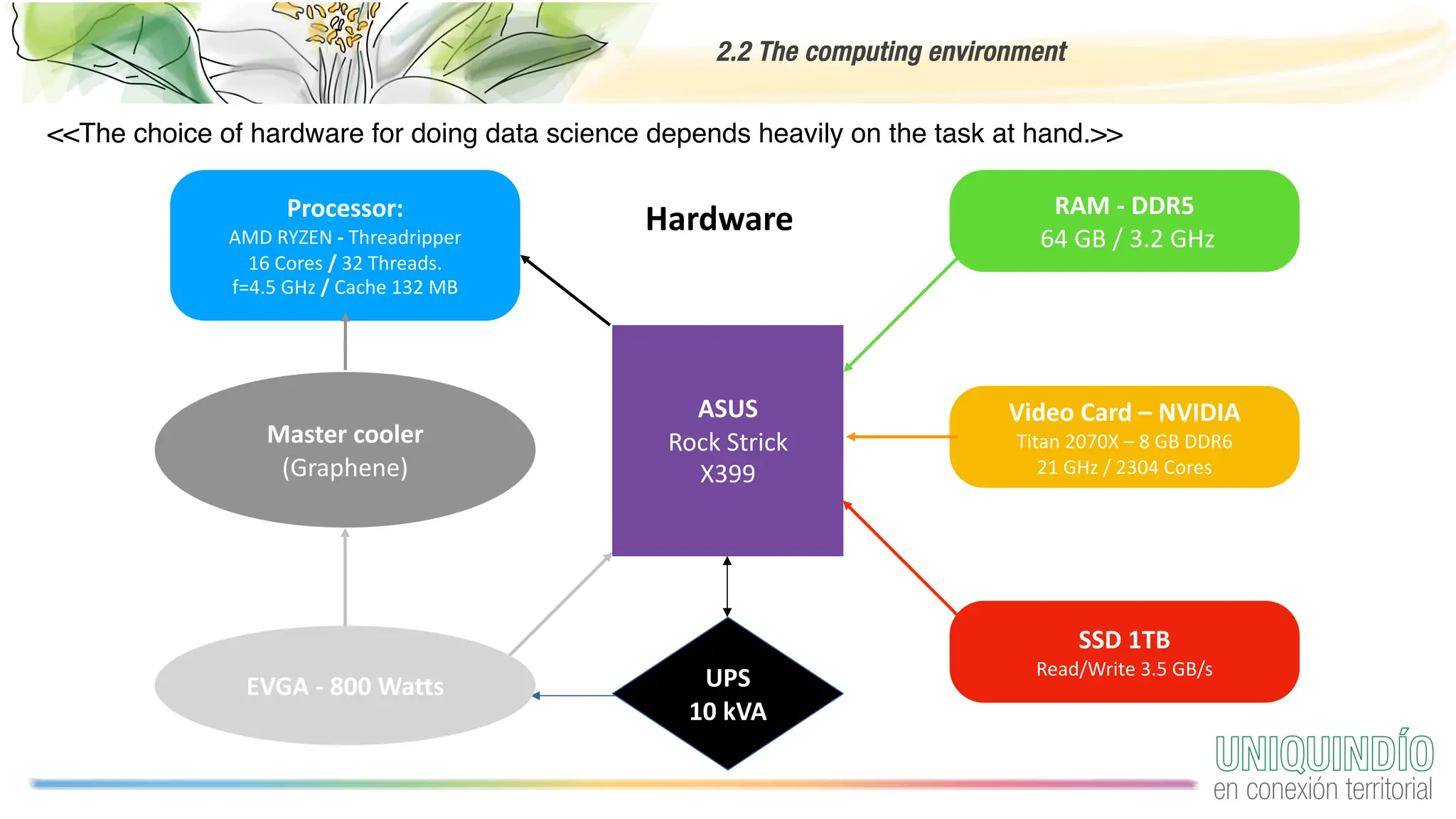
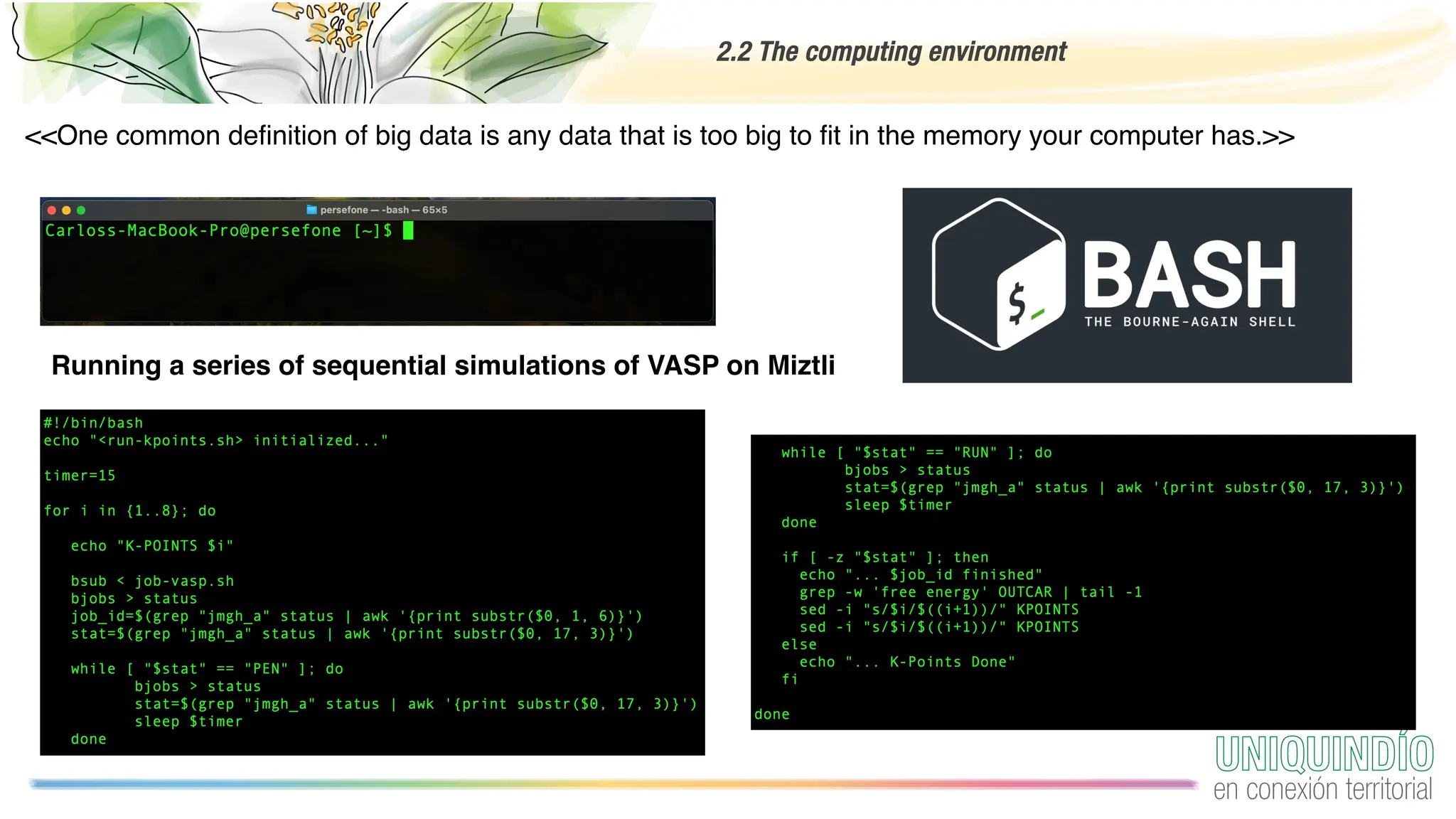
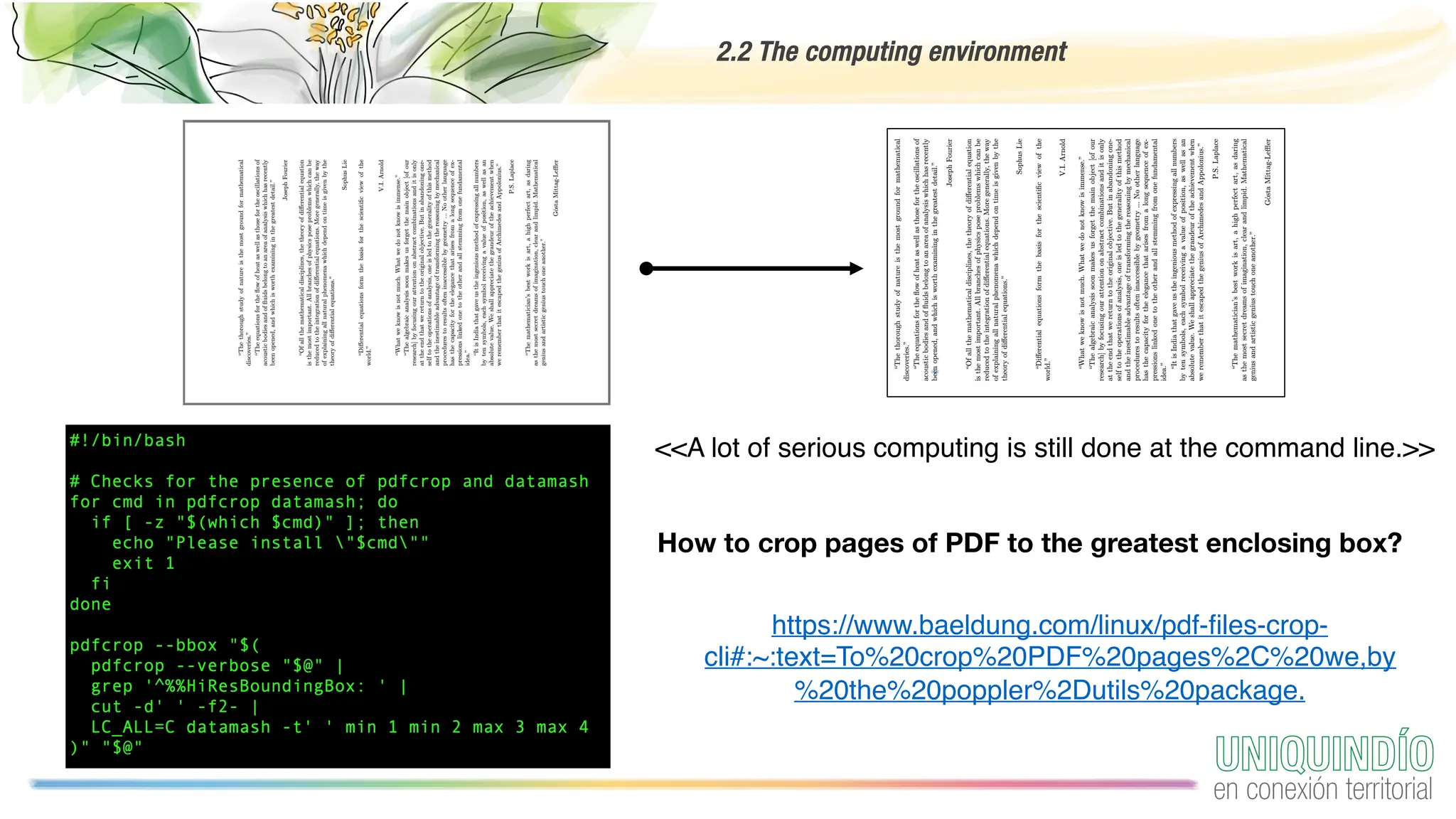
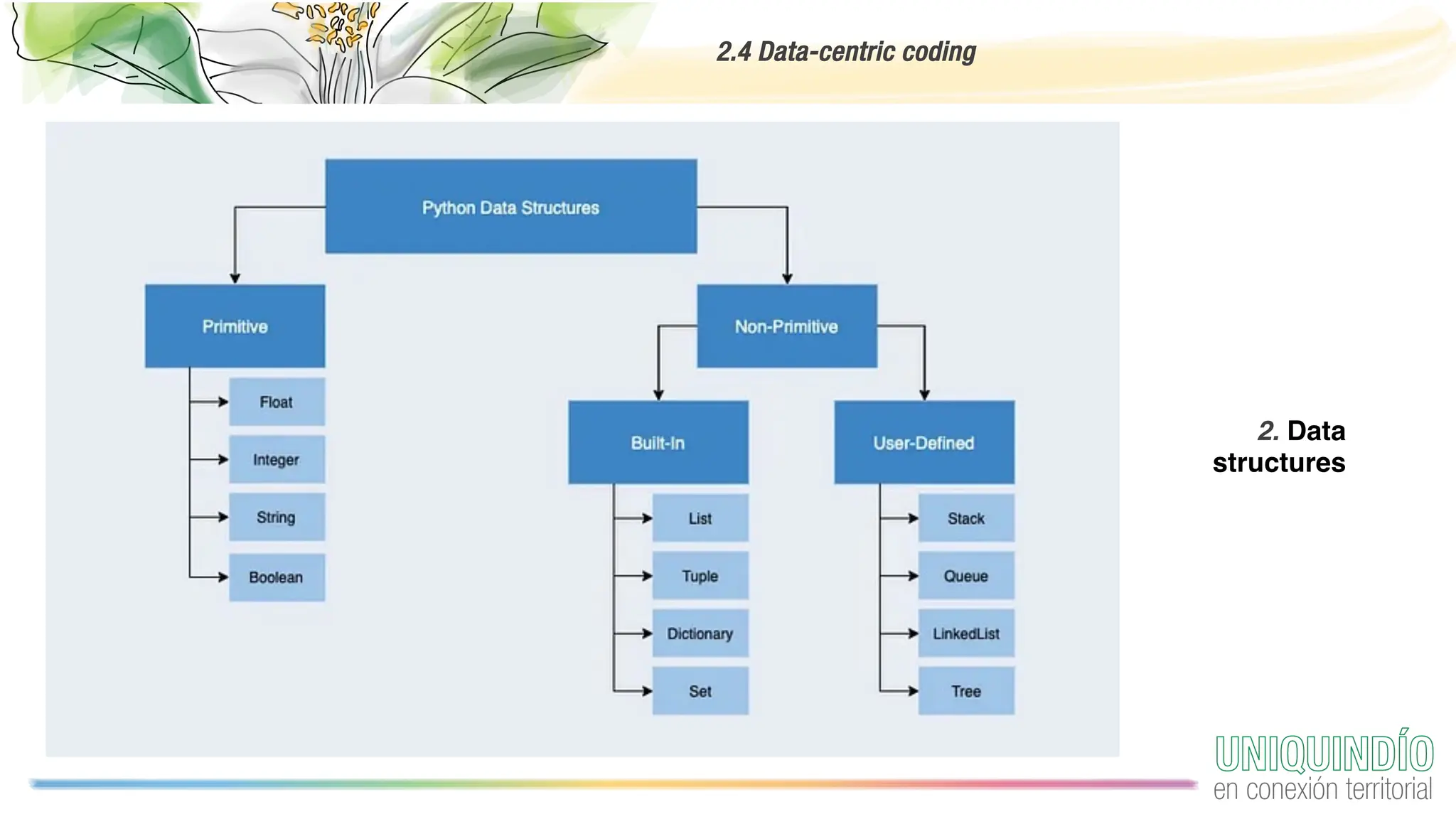
The document provides an overview of programming with data, focusing on the importance of computing in data science and best practices for coding. It discusses the computing environment, essential coding practices, data-centric coding techniques, and cleaning data, highlighting tools such as Python, Pandas, and libraries for exploratory data analysis. Additionally, it emphasizes the significance of reproducible projects and offers tips for acquiring and managing data.