Downloaded 202 times





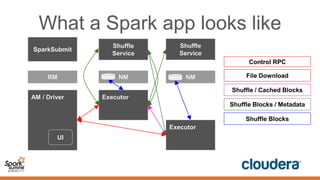






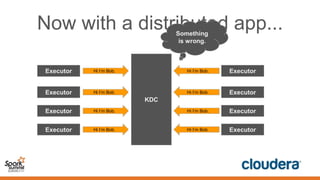
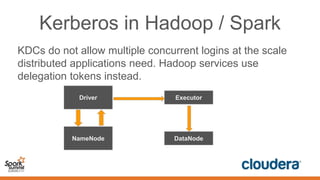










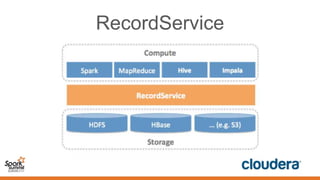

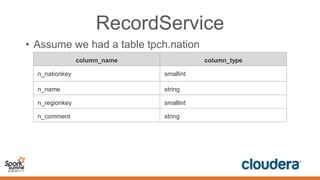













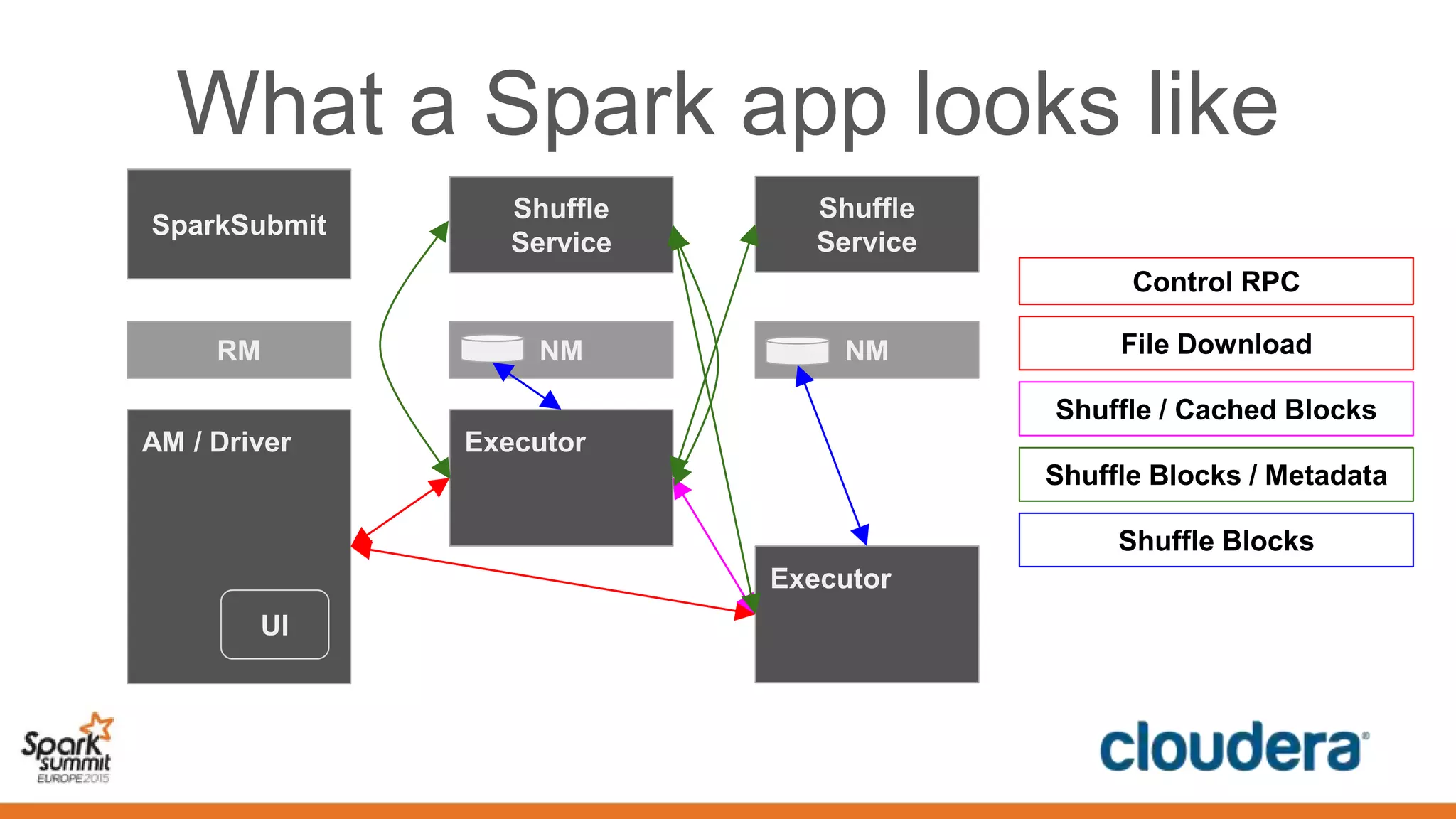






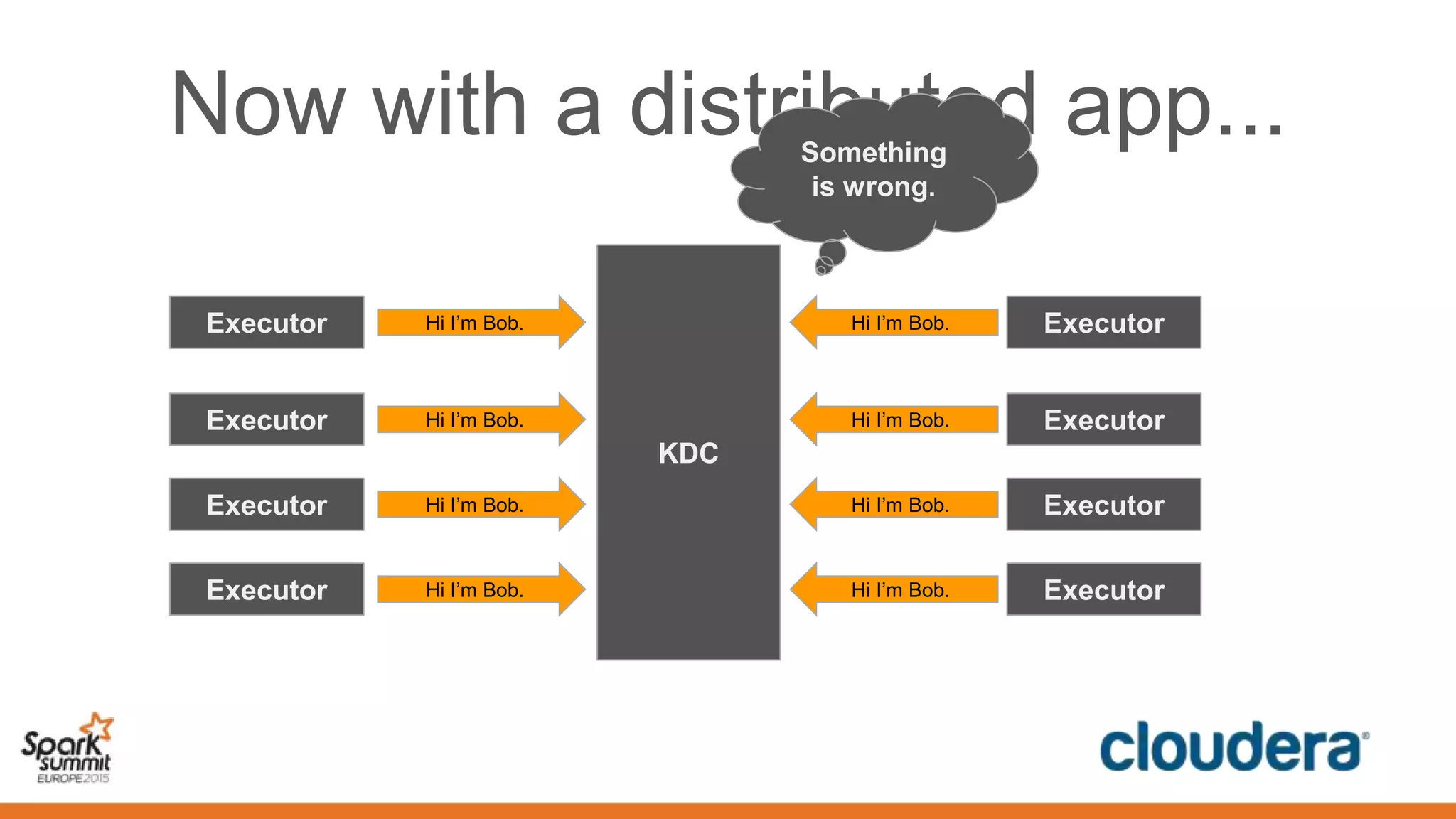











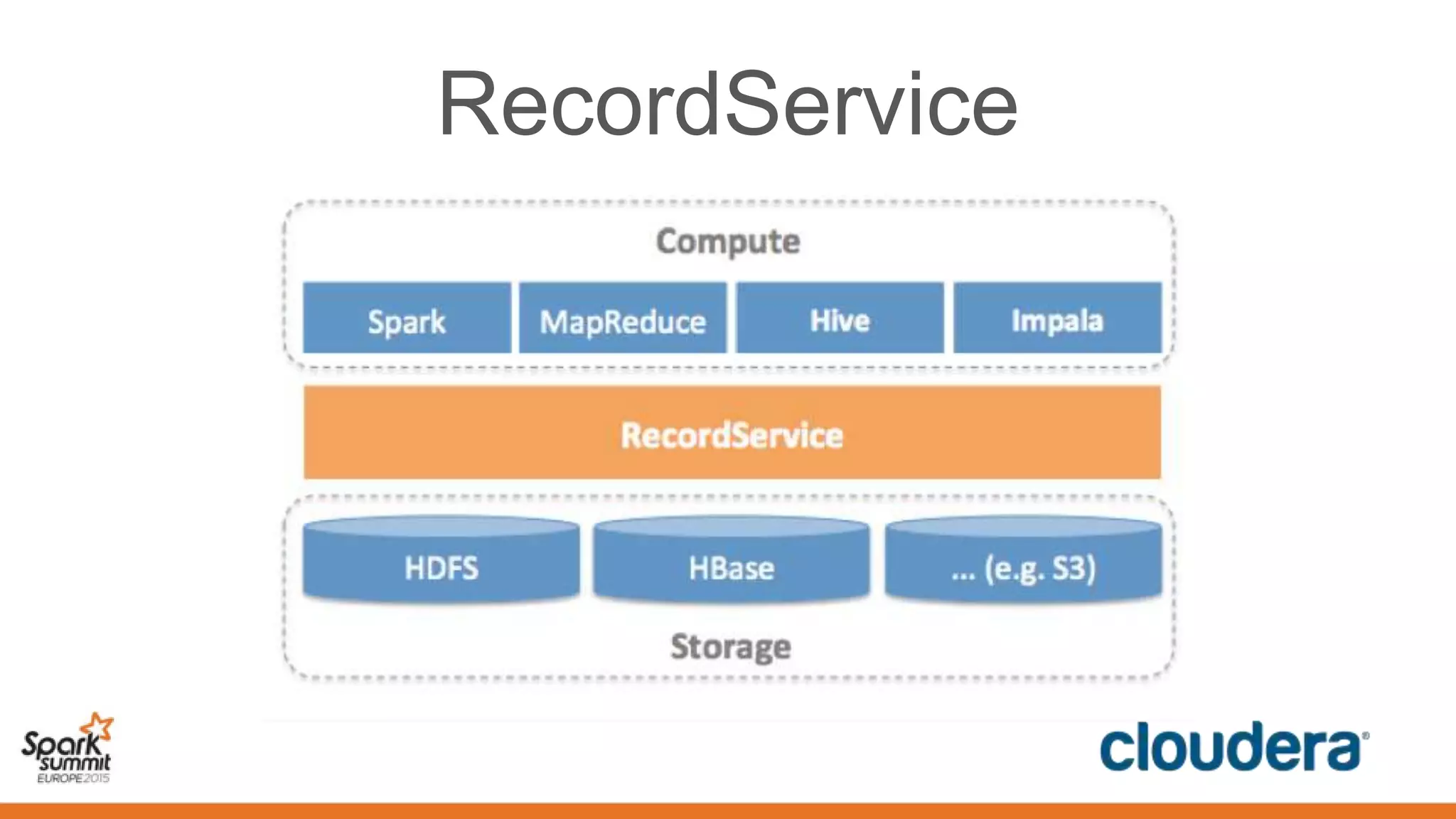

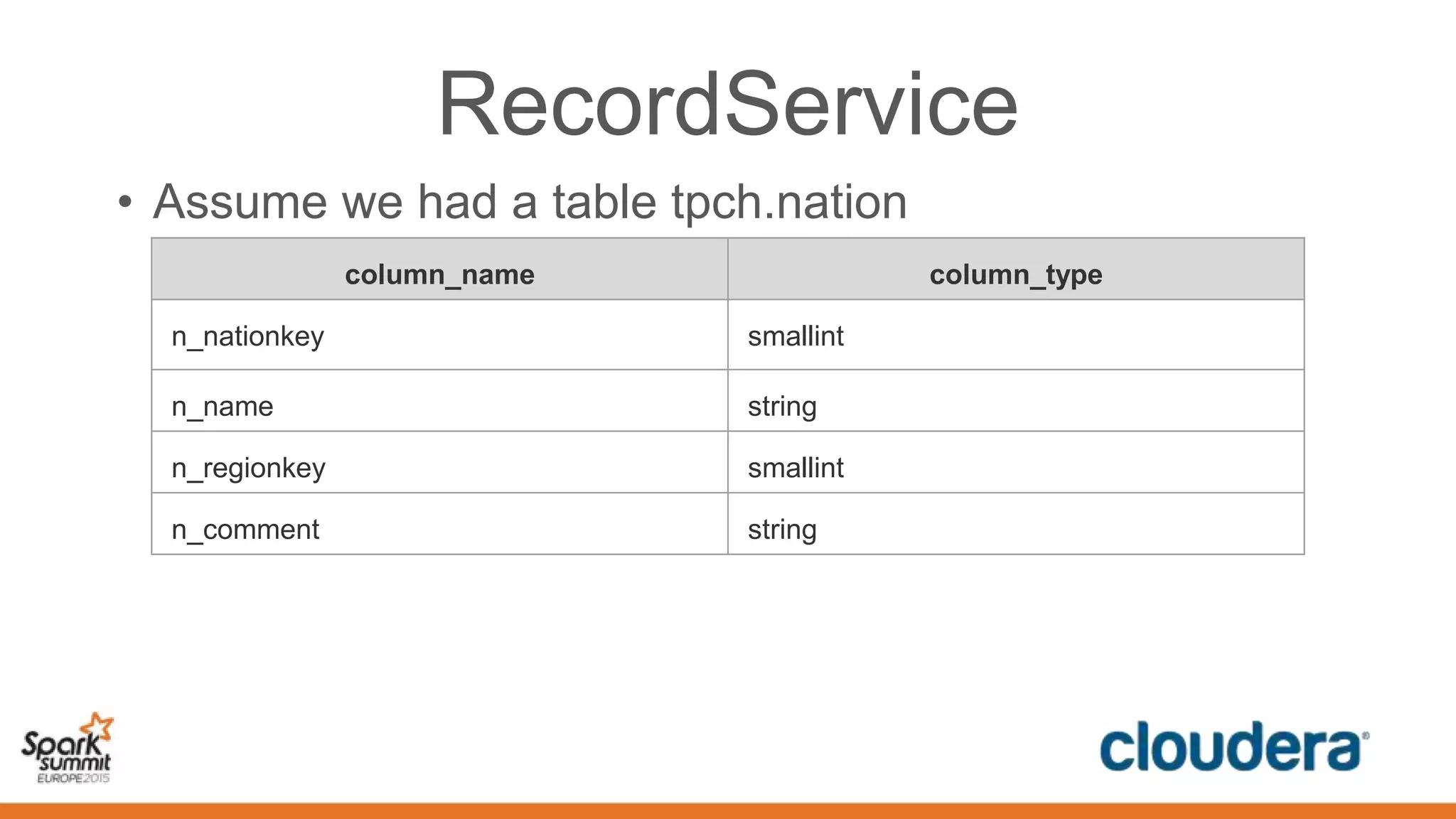









This document discusses securing Spark applications. It covers encryption, authentication, and authorization. Encryption protects data in transit using SASL or SSL. Authentication uses Kerberos to identify users. Authorization controls data access using Apache Sentry and the Sentry HDFS plugin, though a future RecordService aims to provide unified authorization. Securing Spark leverages existing Hadoop security but more integration work remains.























![[AKIBA.AWS] VPCをネットワーク図で理解してみる](https://cdn.slidesharecdn.com/ss_thumbnails/akibaaws5vpc-design-180419110936-thumbnail.jpg?width=600ounds&width=560&fit=bounds)































































