Downloaded 277 times





















































































The document outlines the methodology for sizing MongoDB clusters, emphasizing the importance of understanding IOPS, query processing, and the working set for optimal server configuration. It provides a step-by-step approach to estimating requirements, including the number of shards, server specifications, and monthly costs for cloud services. Additionally, practical examples and simplified models are discussed to facilitate accurate sizing decisions for large-scale applications.
Presentation introduction by Jay Runkel and agenda outlining the main topics including sizing objectives, IOPS, methodology, and examples.
Explanation of key questions to consider in cluster sizing: sharding needs, server sizes, costs, data capacity, query support, and latency requirements.
Introduction of a case study involving 'PlanetDollar' requiring analytics on events generated by their mobile app.
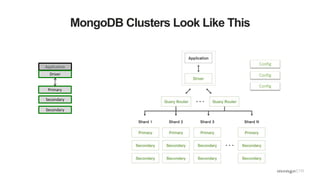
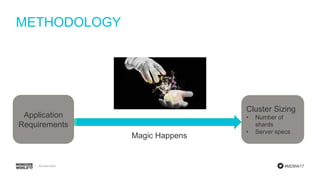
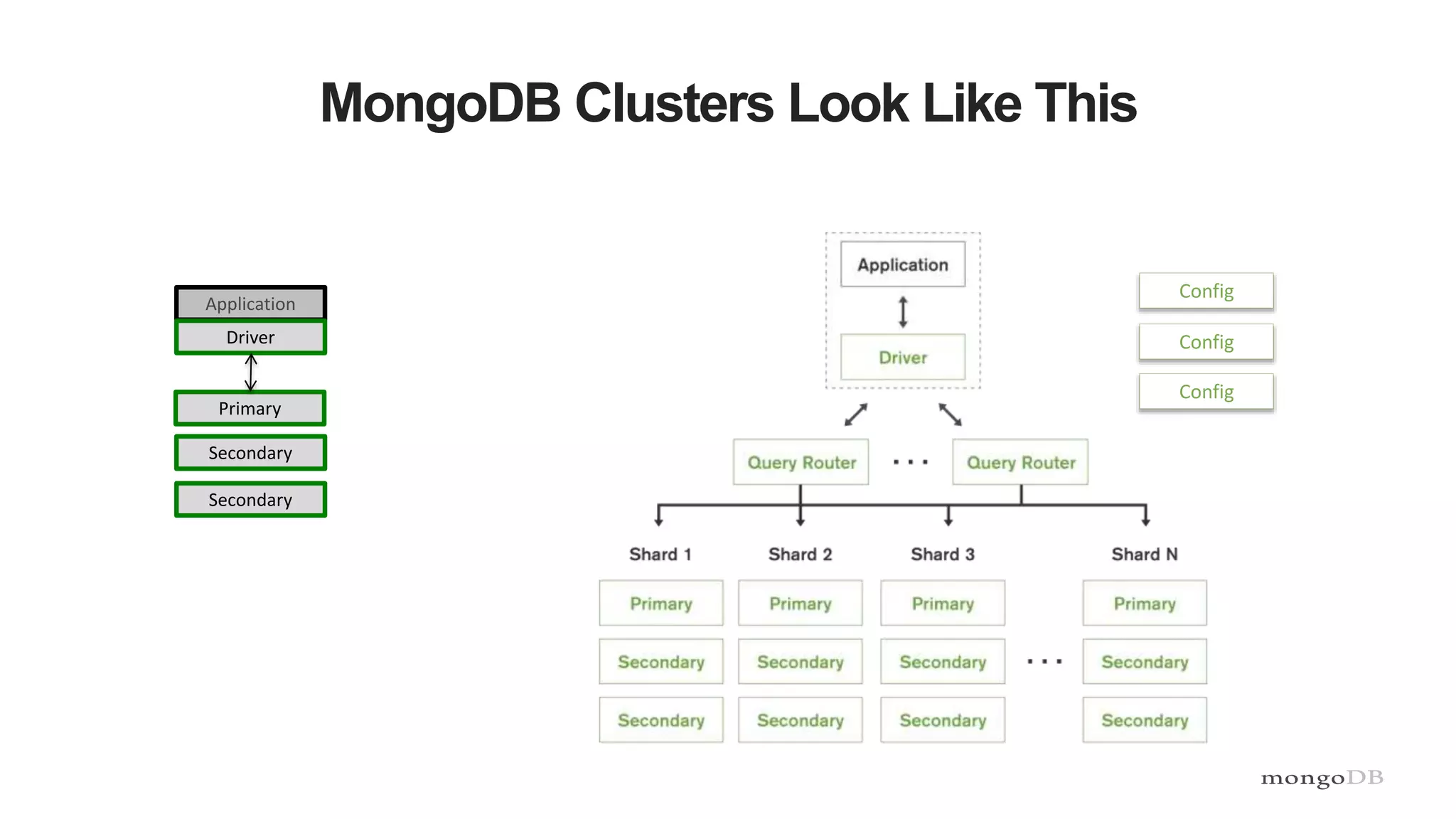
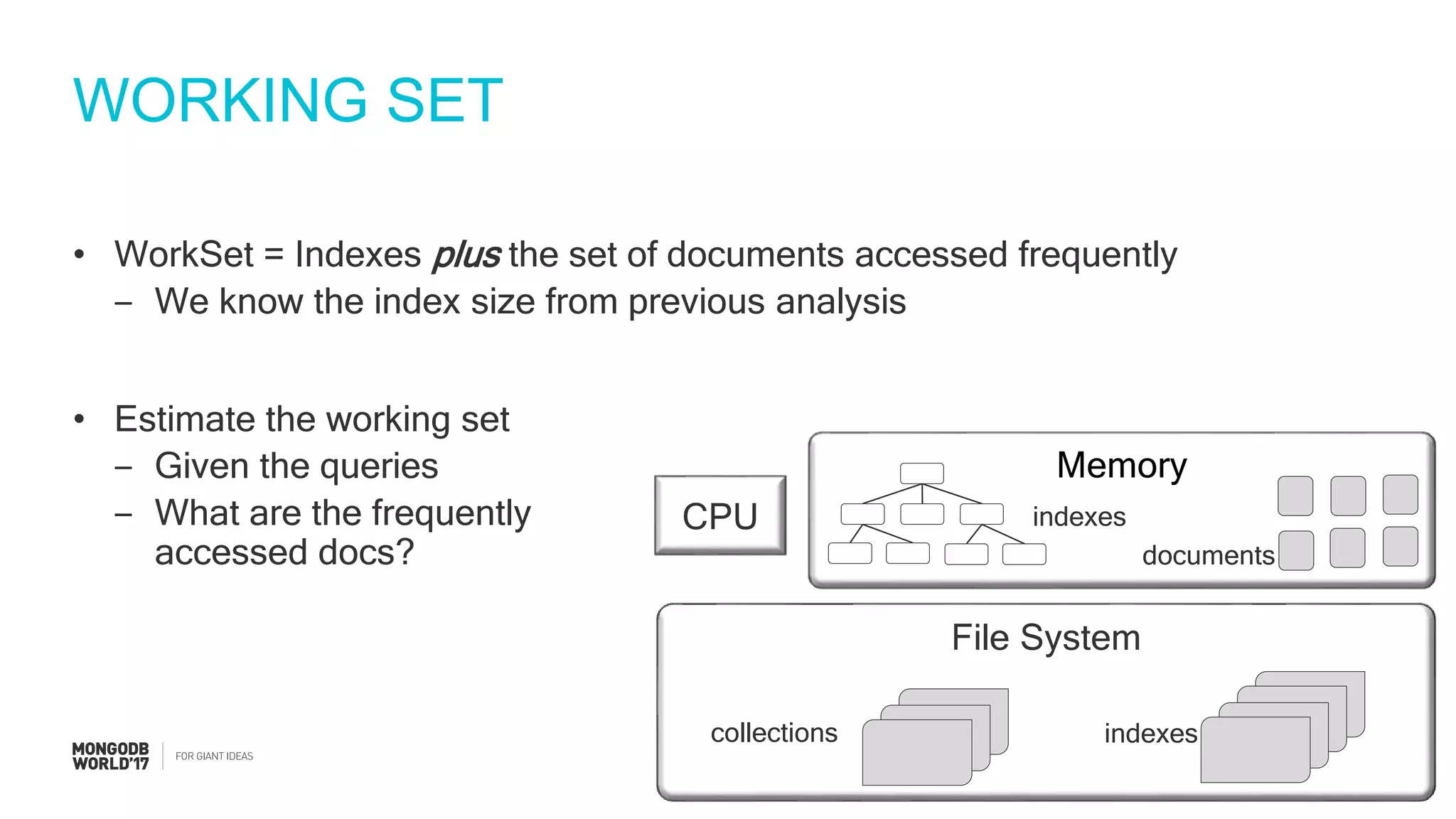
Visual representation of MongoDB clusters and components of sizing, including number of shards and server specifications.
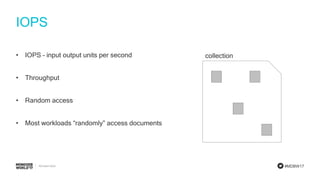
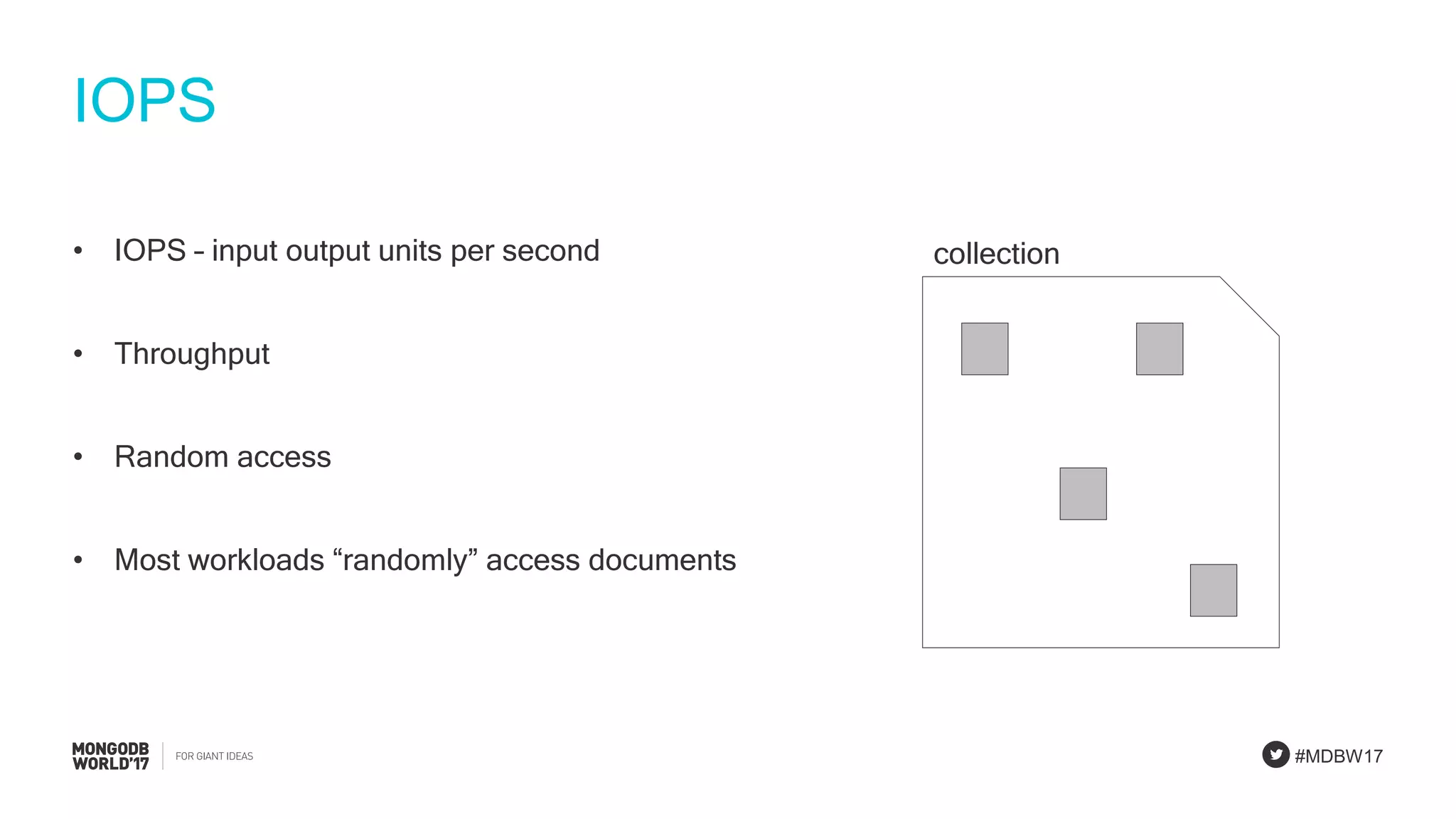
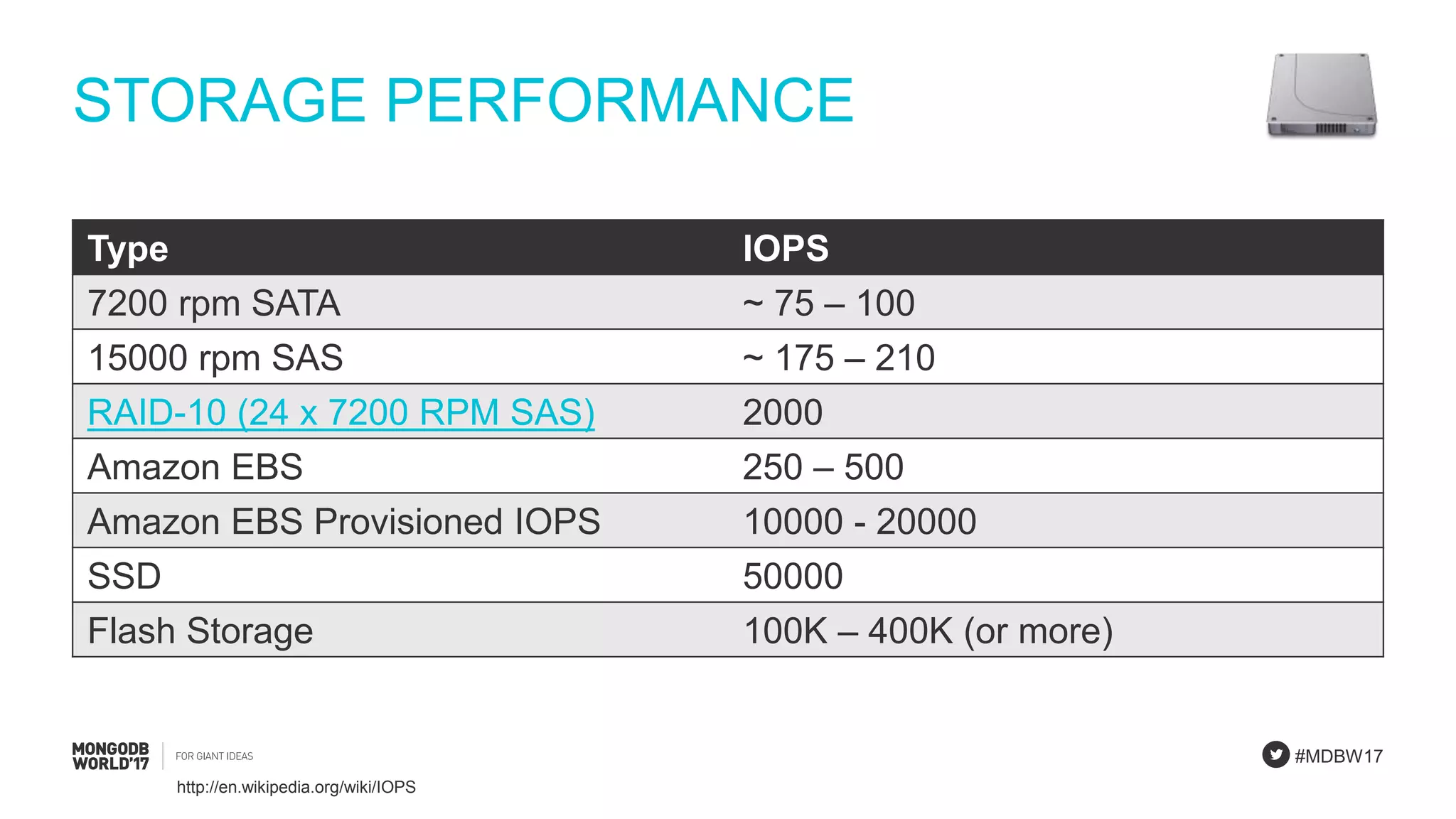
Focus on IOPS, query processing, and the importance of building prototypes and running performance tests.
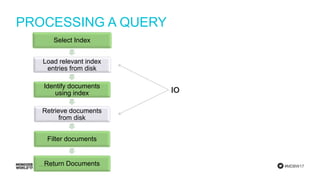
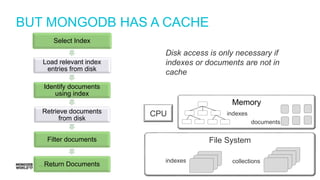
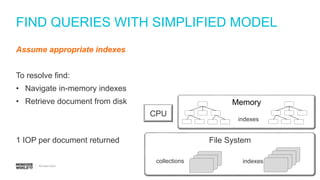
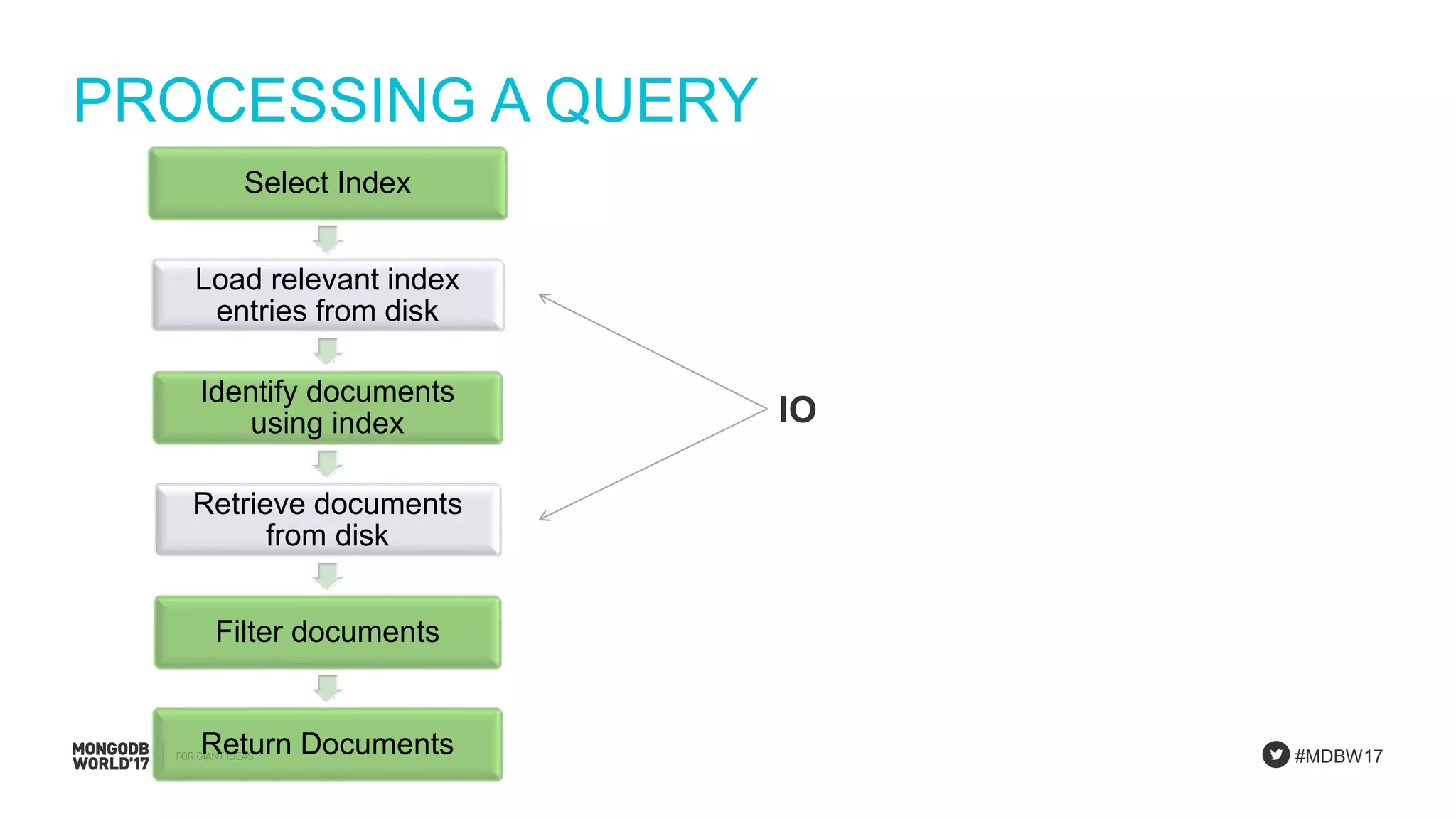
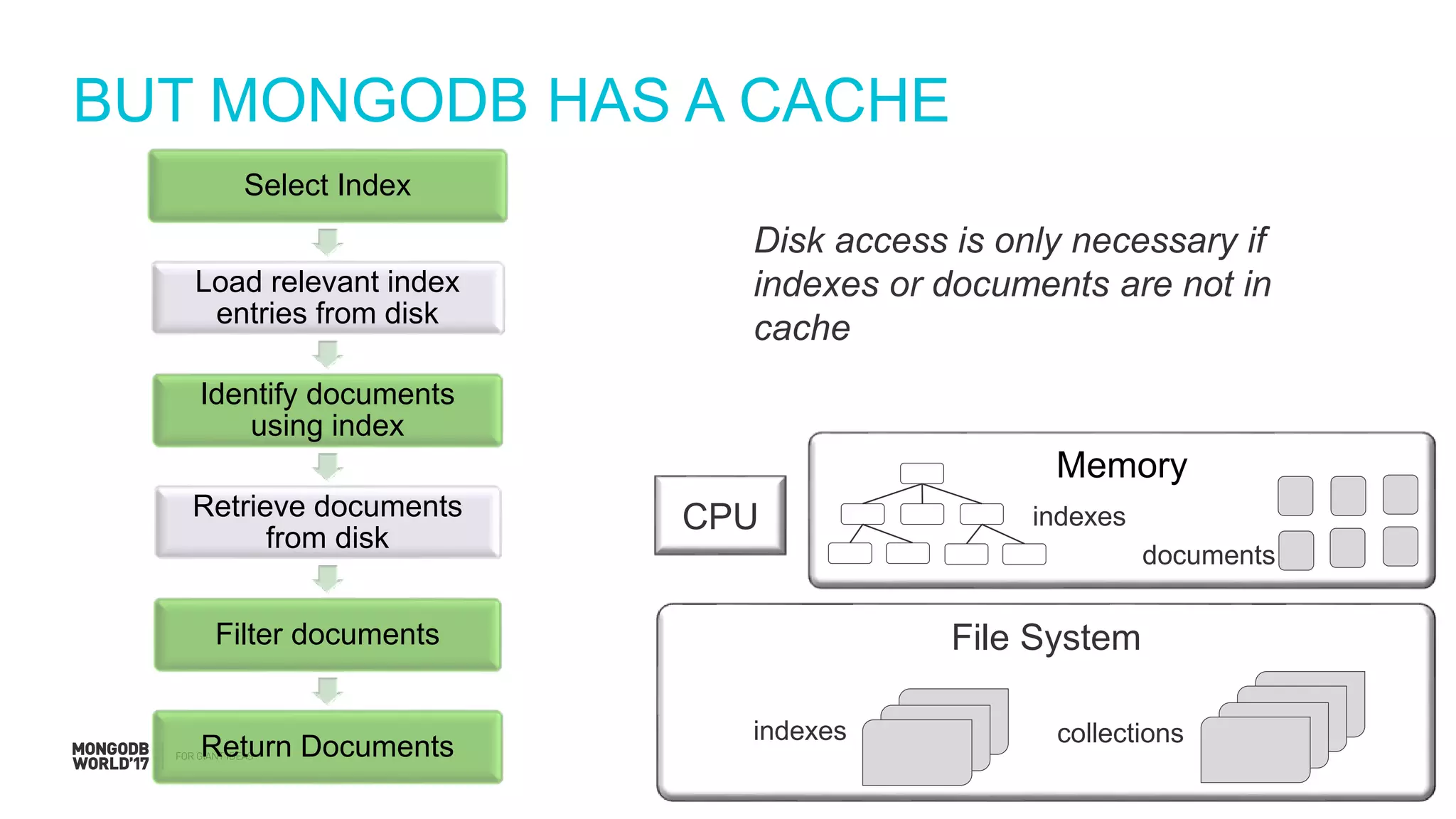
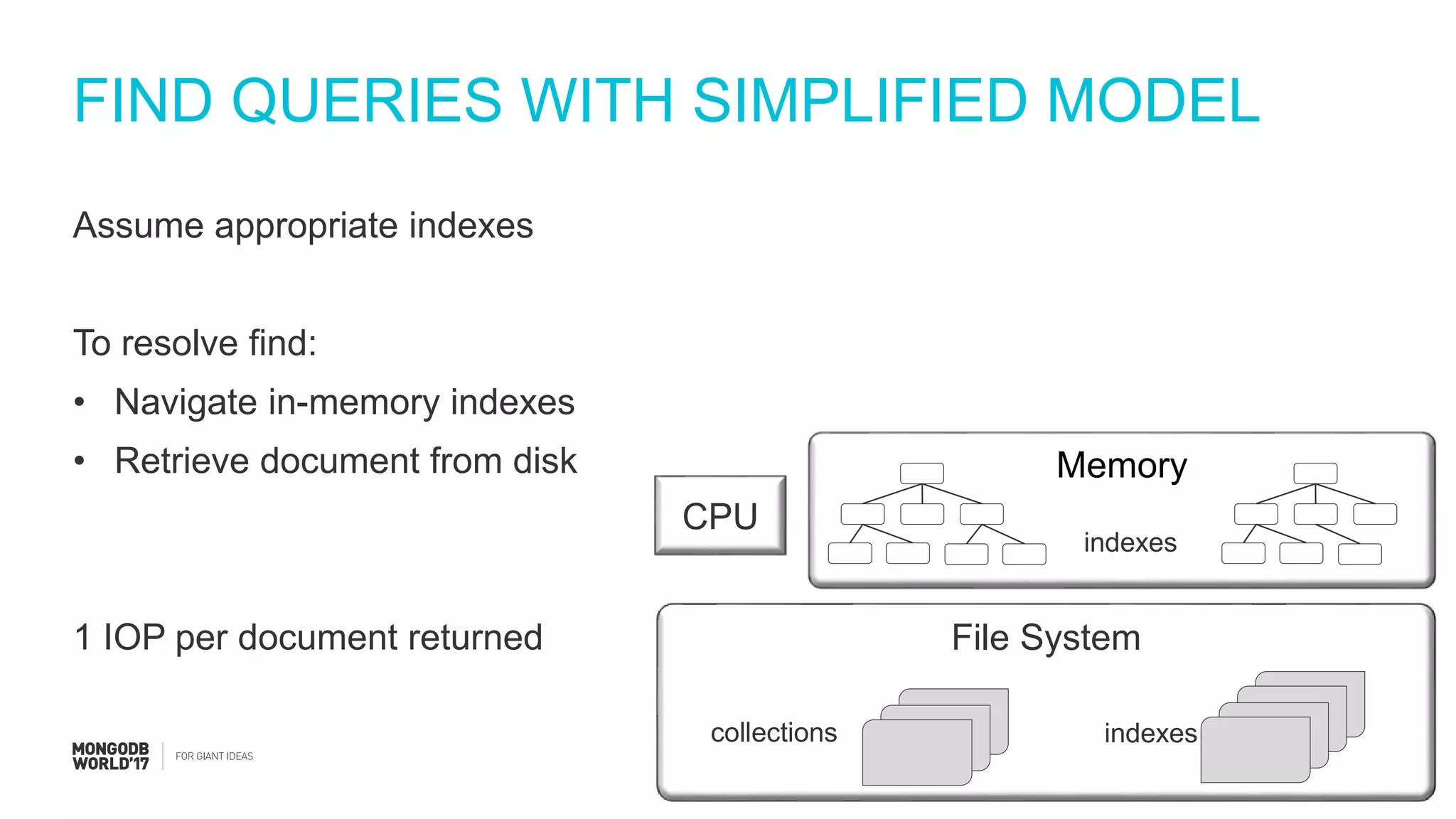
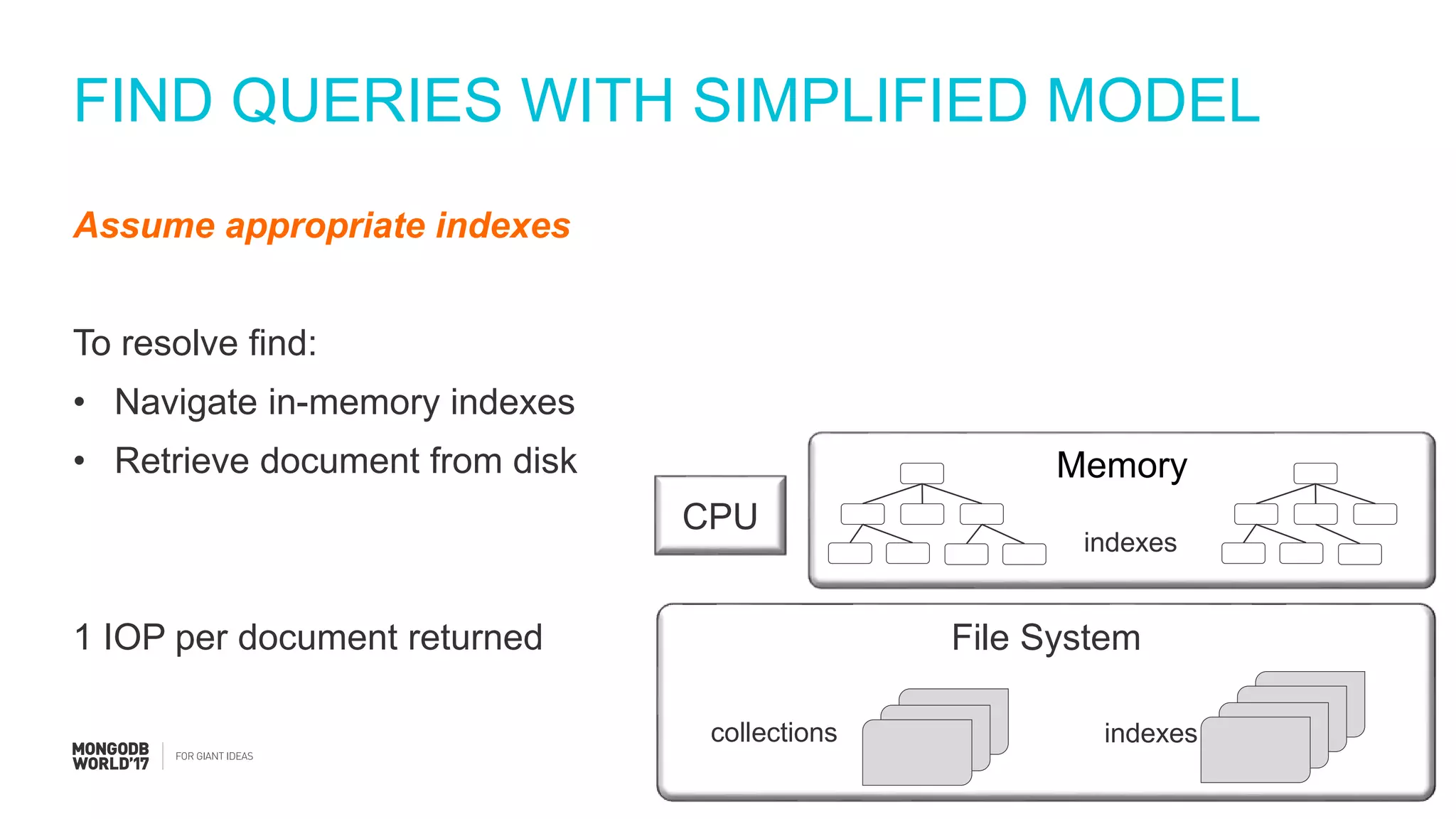
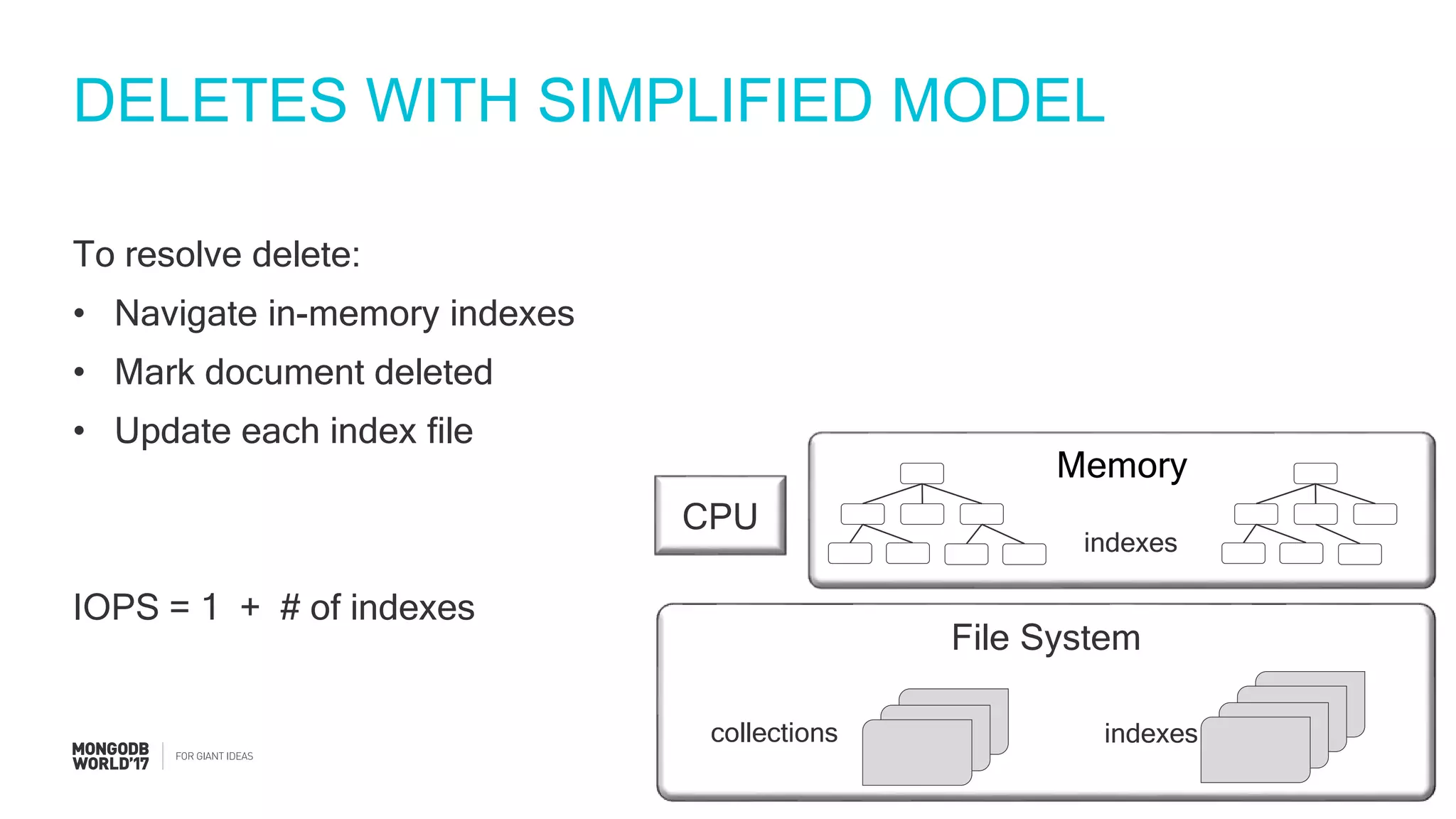
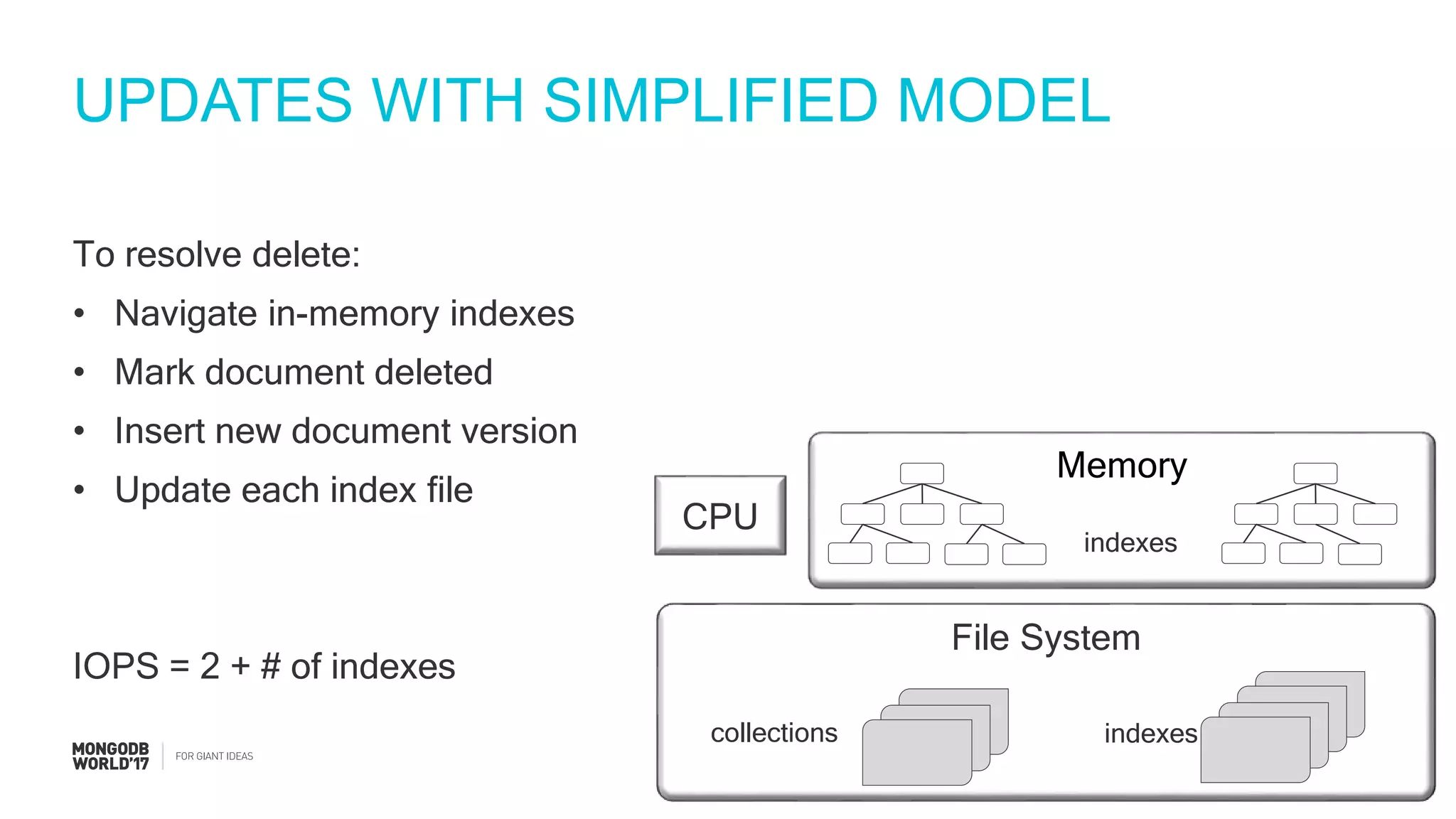
Detailed steps of query processing and impact of caching on I/O requirements as part of sizing considerations.
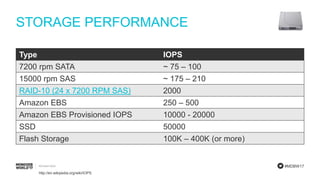
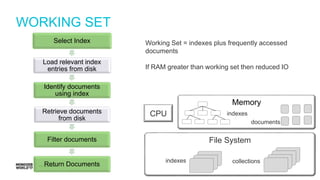
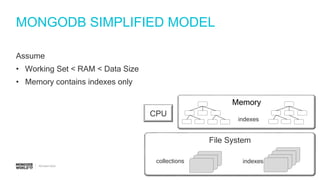
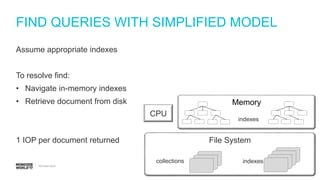
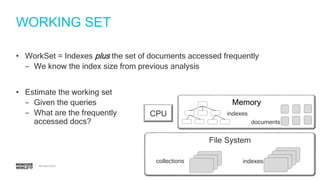
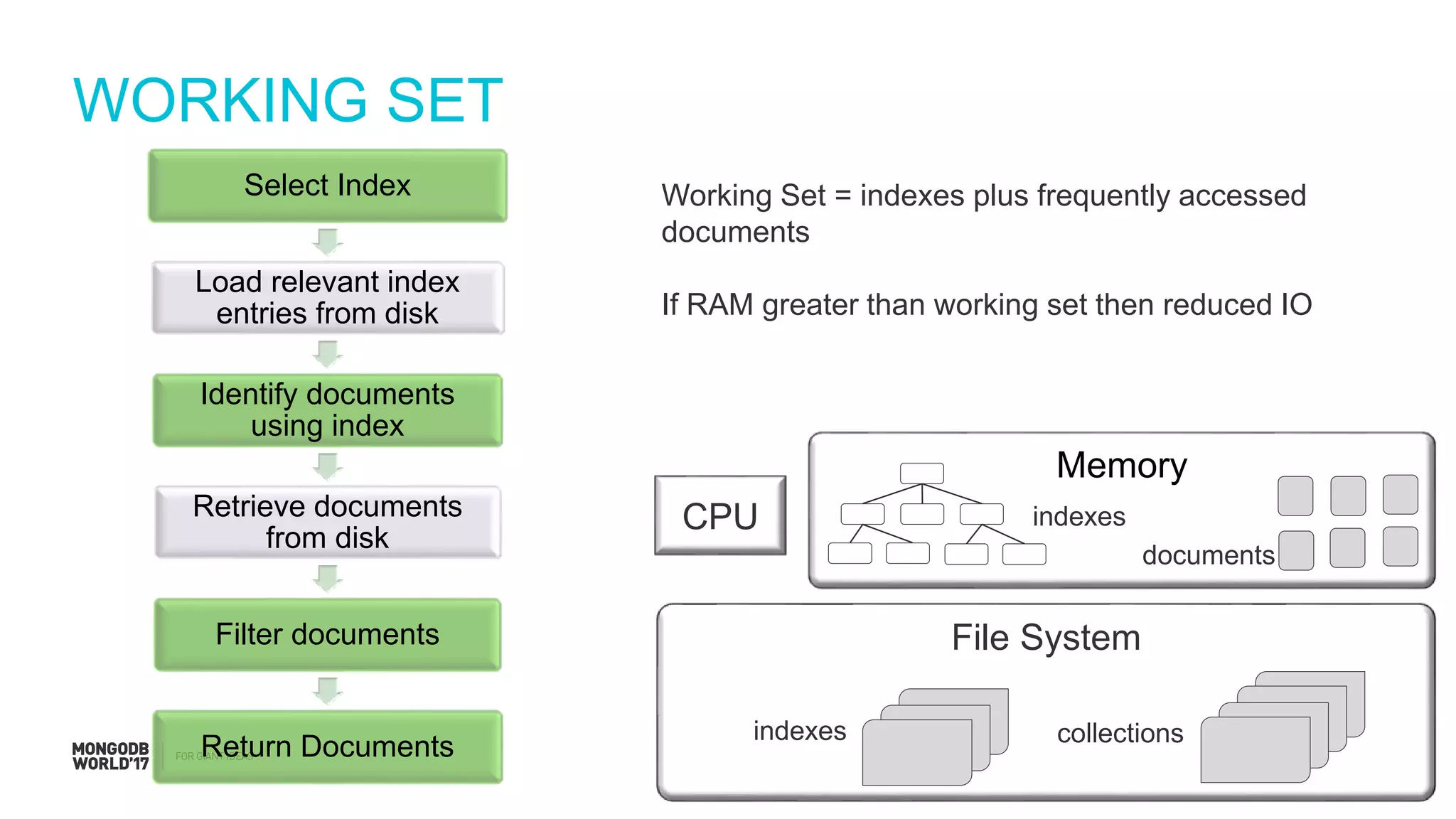
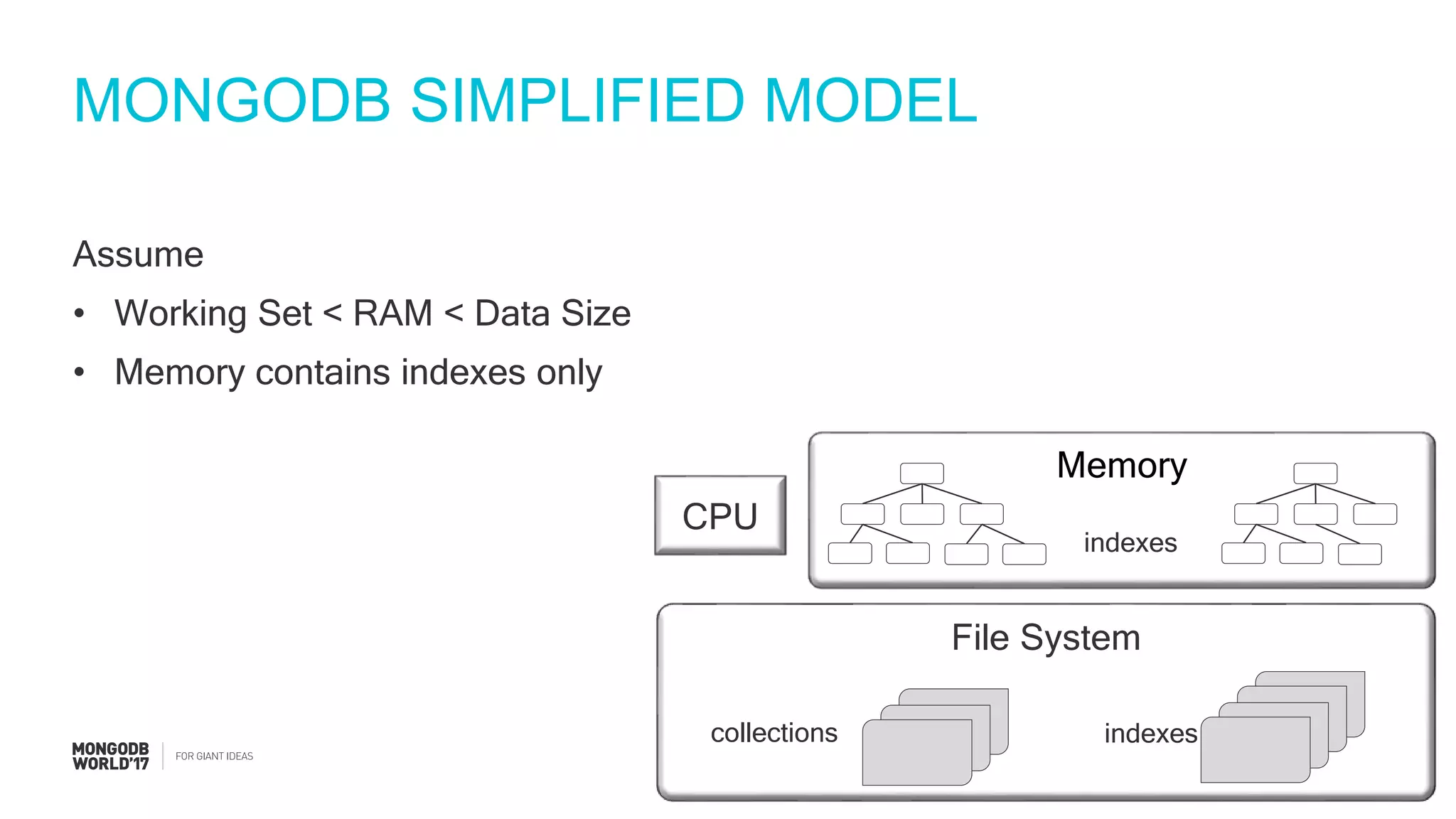
Steps to estimate IOPS using a simplified model, including assumptions about RAM and working set.
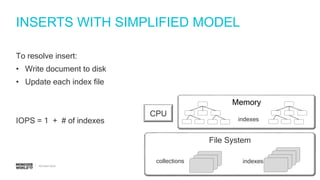
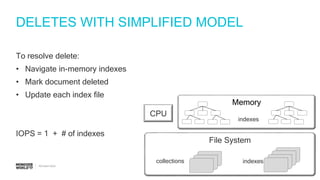
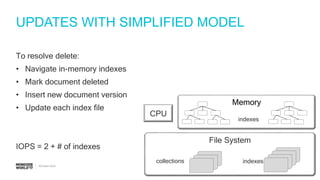
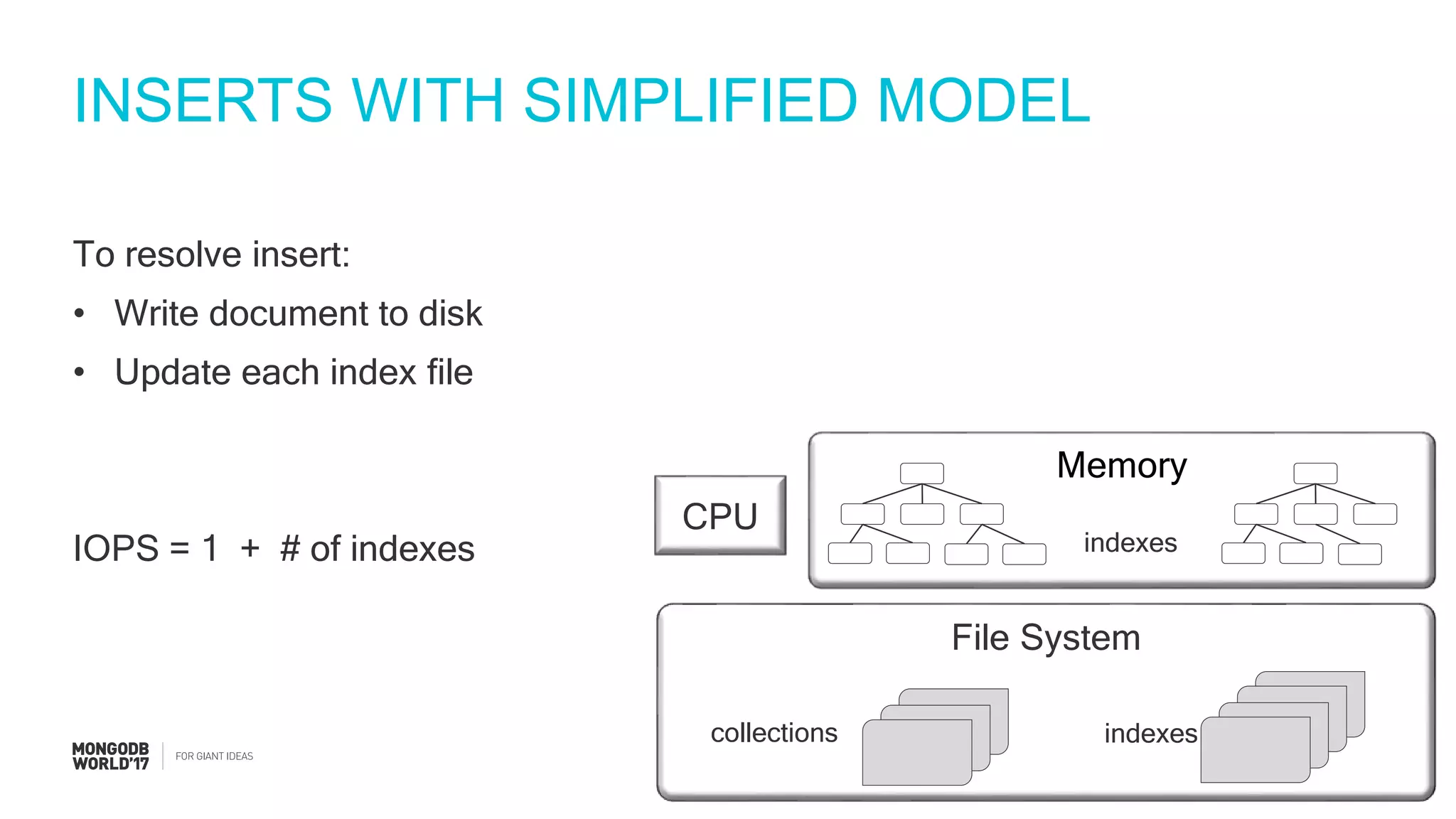
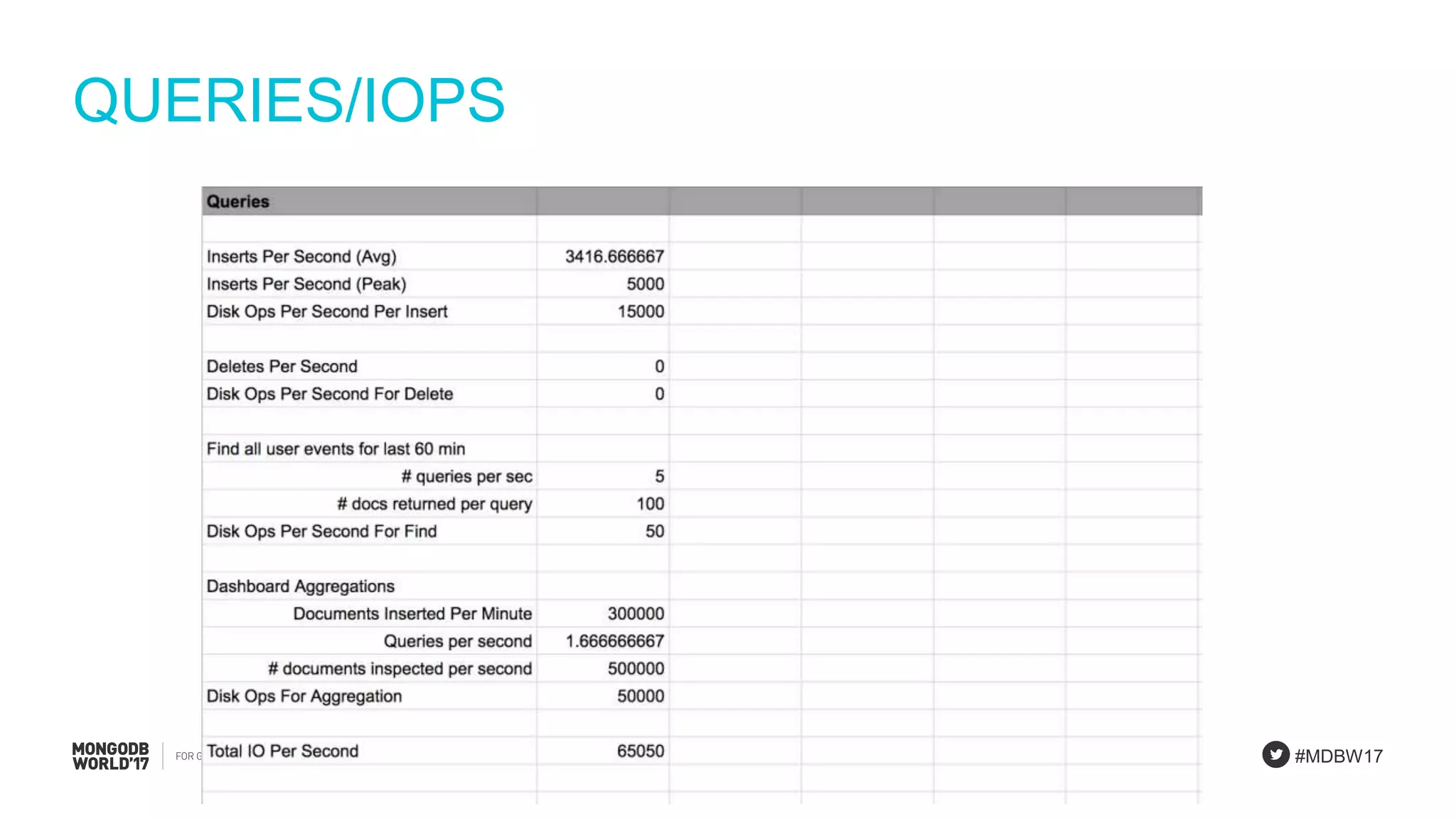
IOPS calculations for inserts, deletes, and updates involving index updates with MongoDB.
Discussion on the limitations of simplified models and the need to account for factors like working sets and checkpoints.
Overview of estimating total requirements including RAM, CPU, and Disk Space, followed by iterative methodology for sizing.
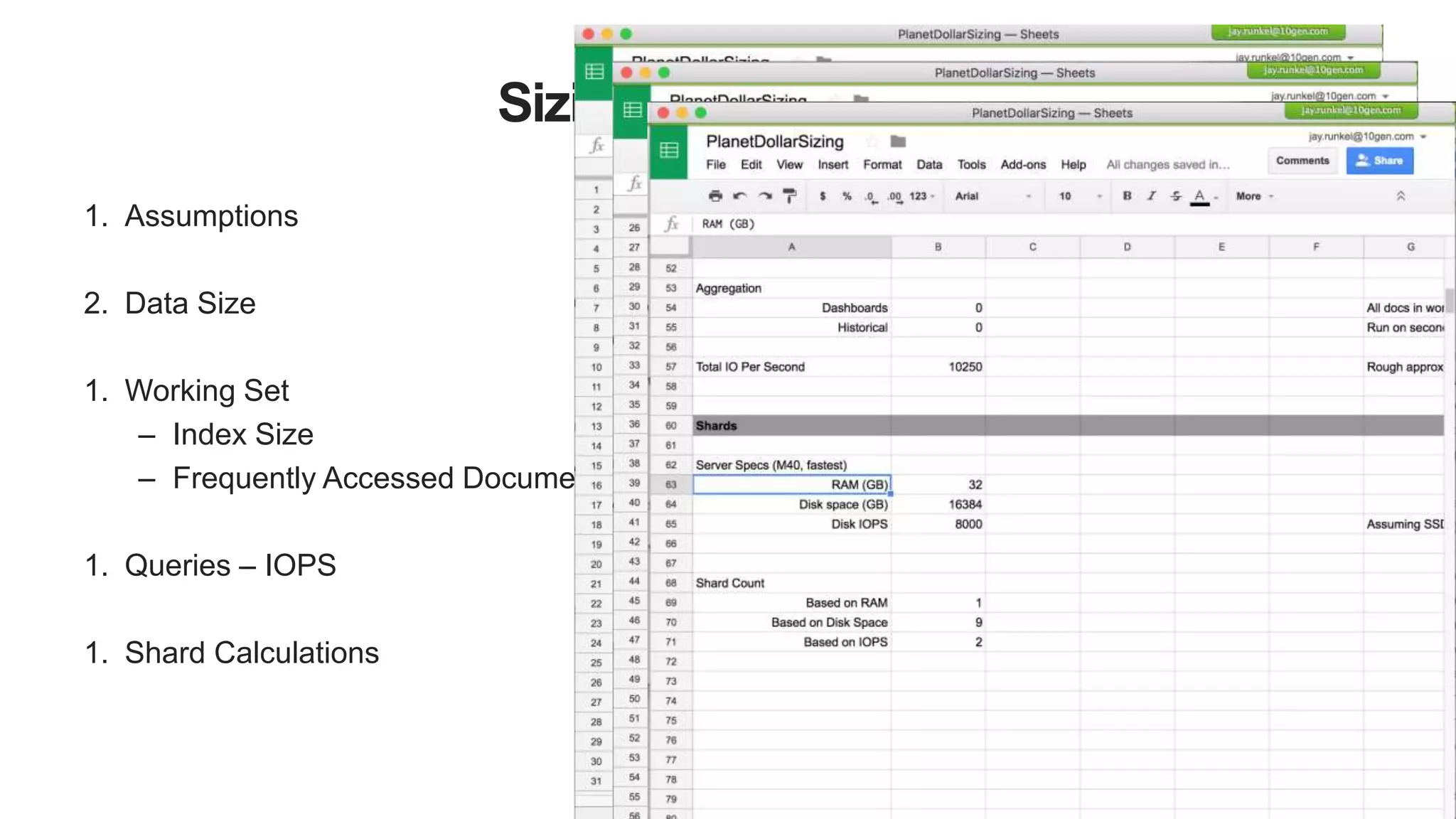
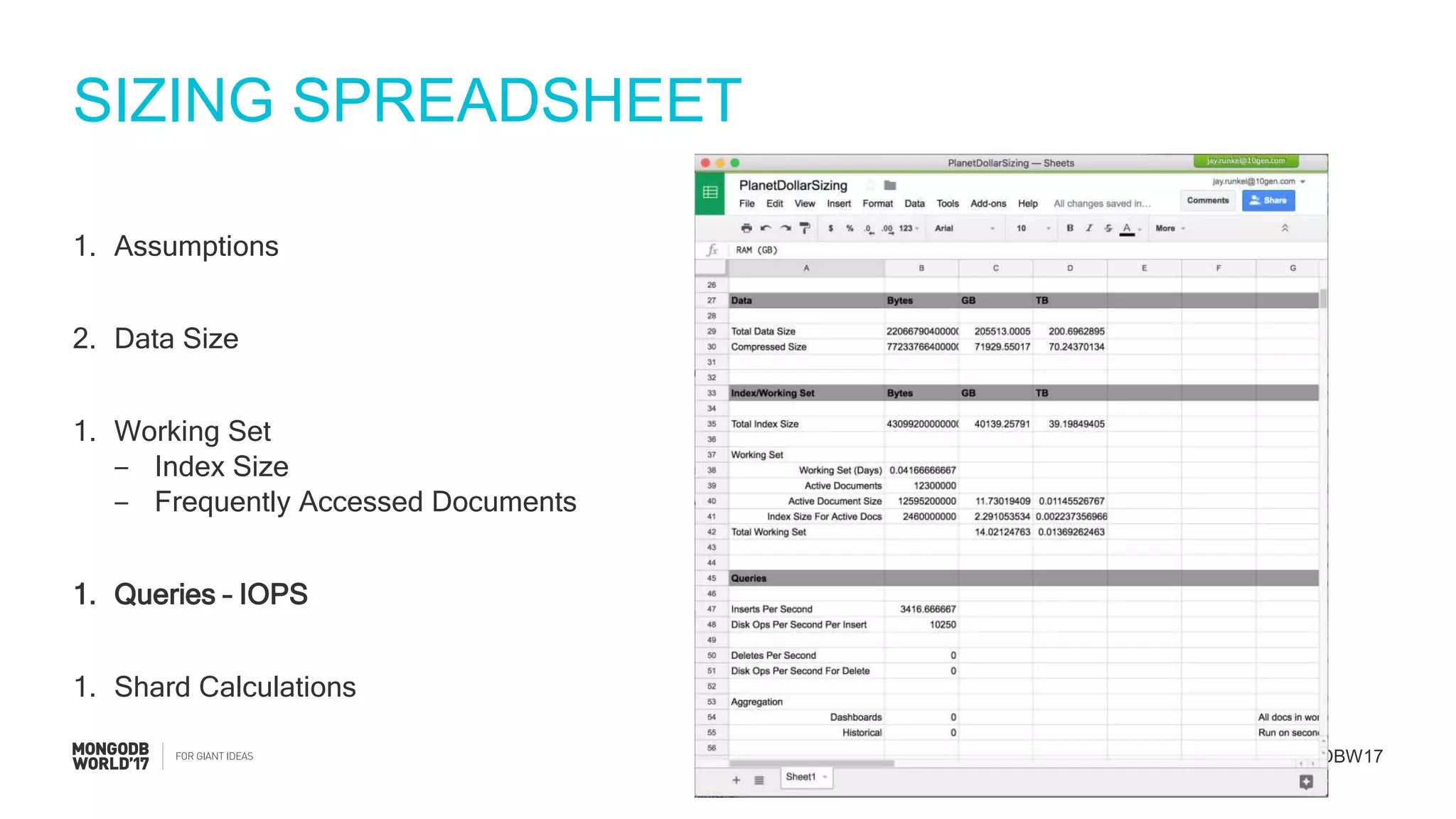
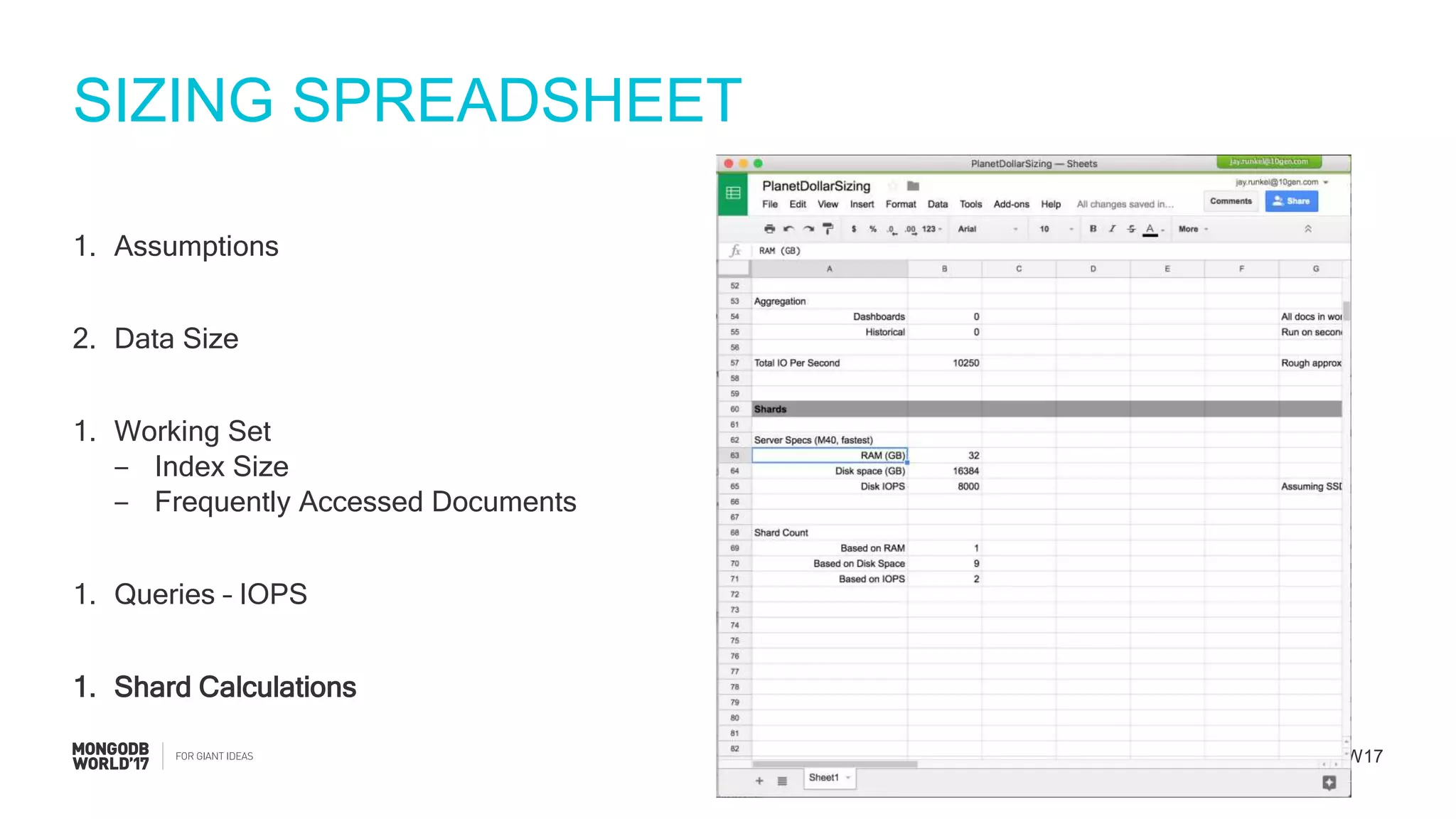
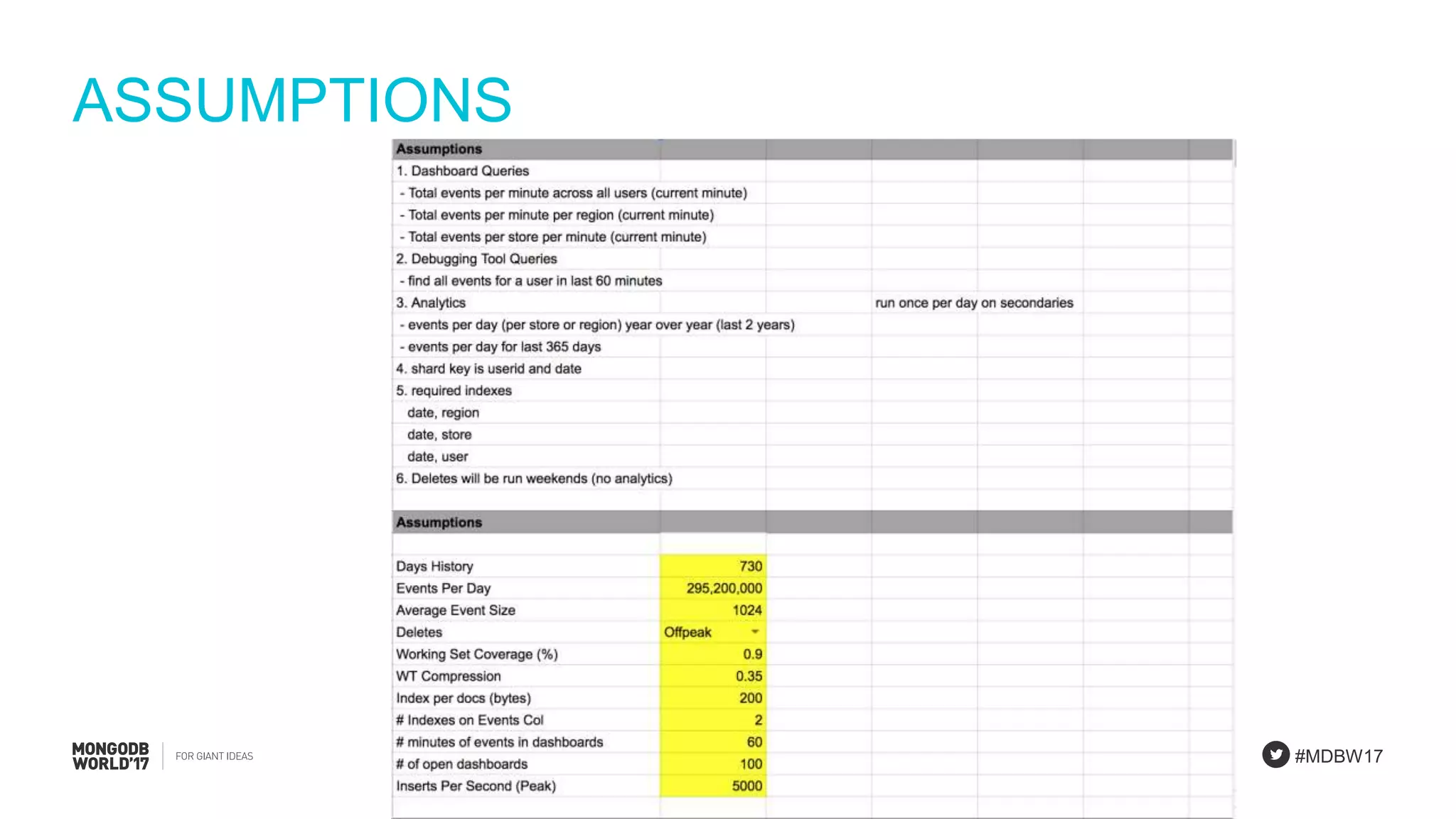
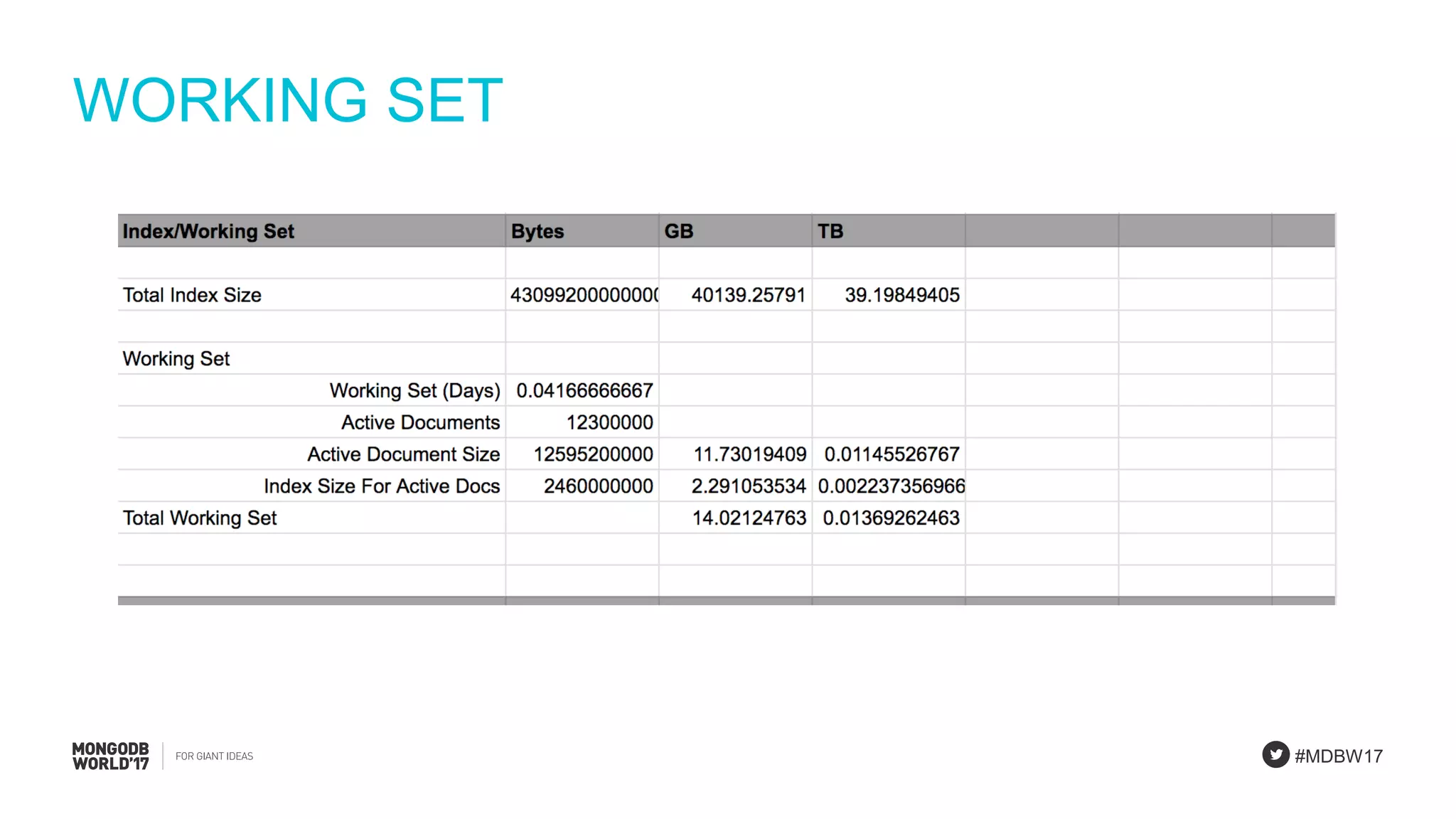
Details on using a sizing spreadsheet covering assumptions, collection analysis, working set, and queries.
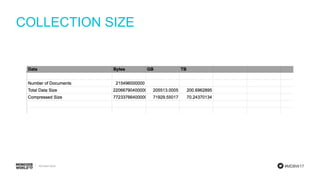
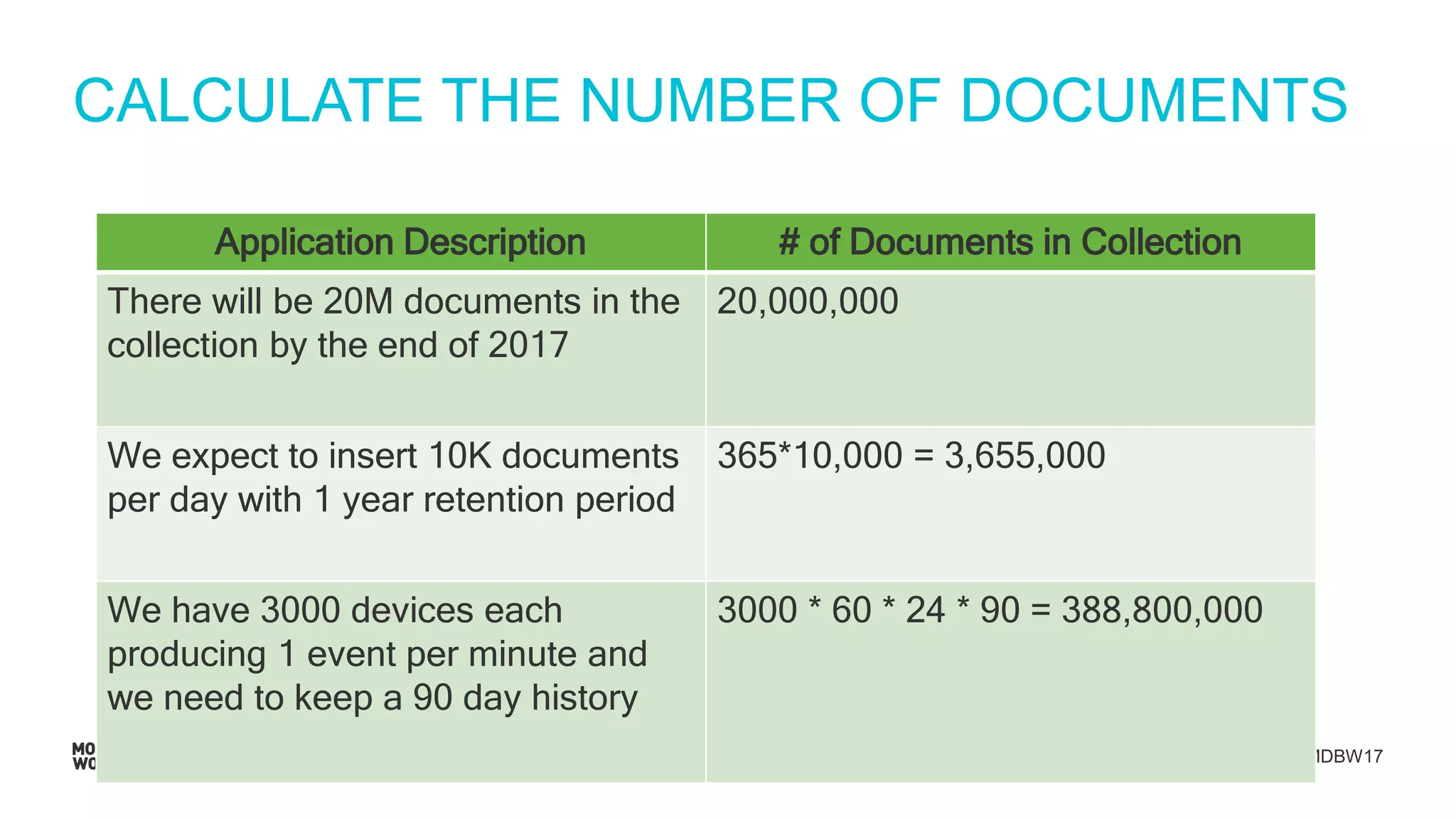
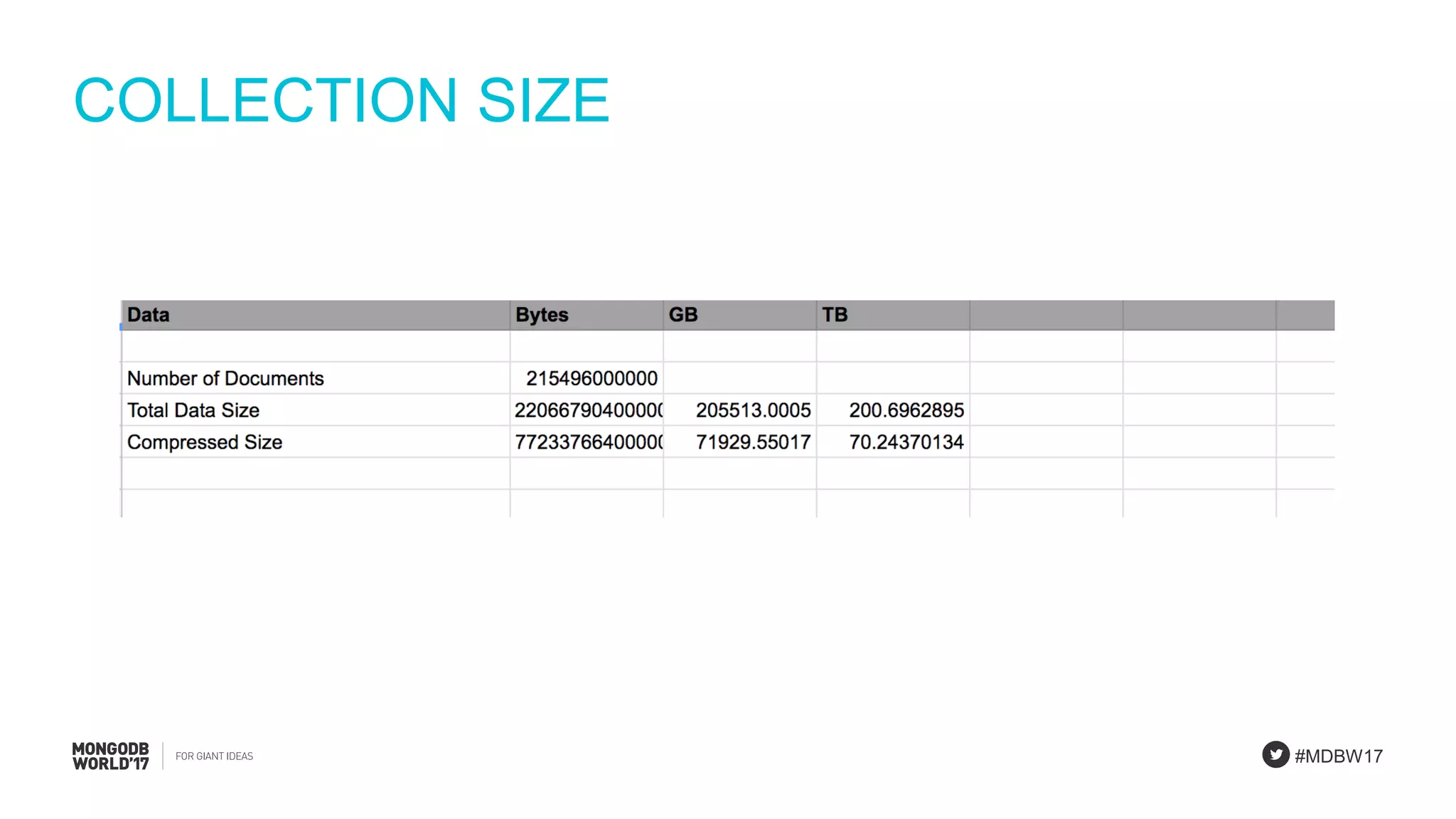
Demonstration of calculations for the number of documents required, data size, and IOPS for event processing.
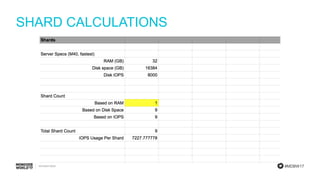
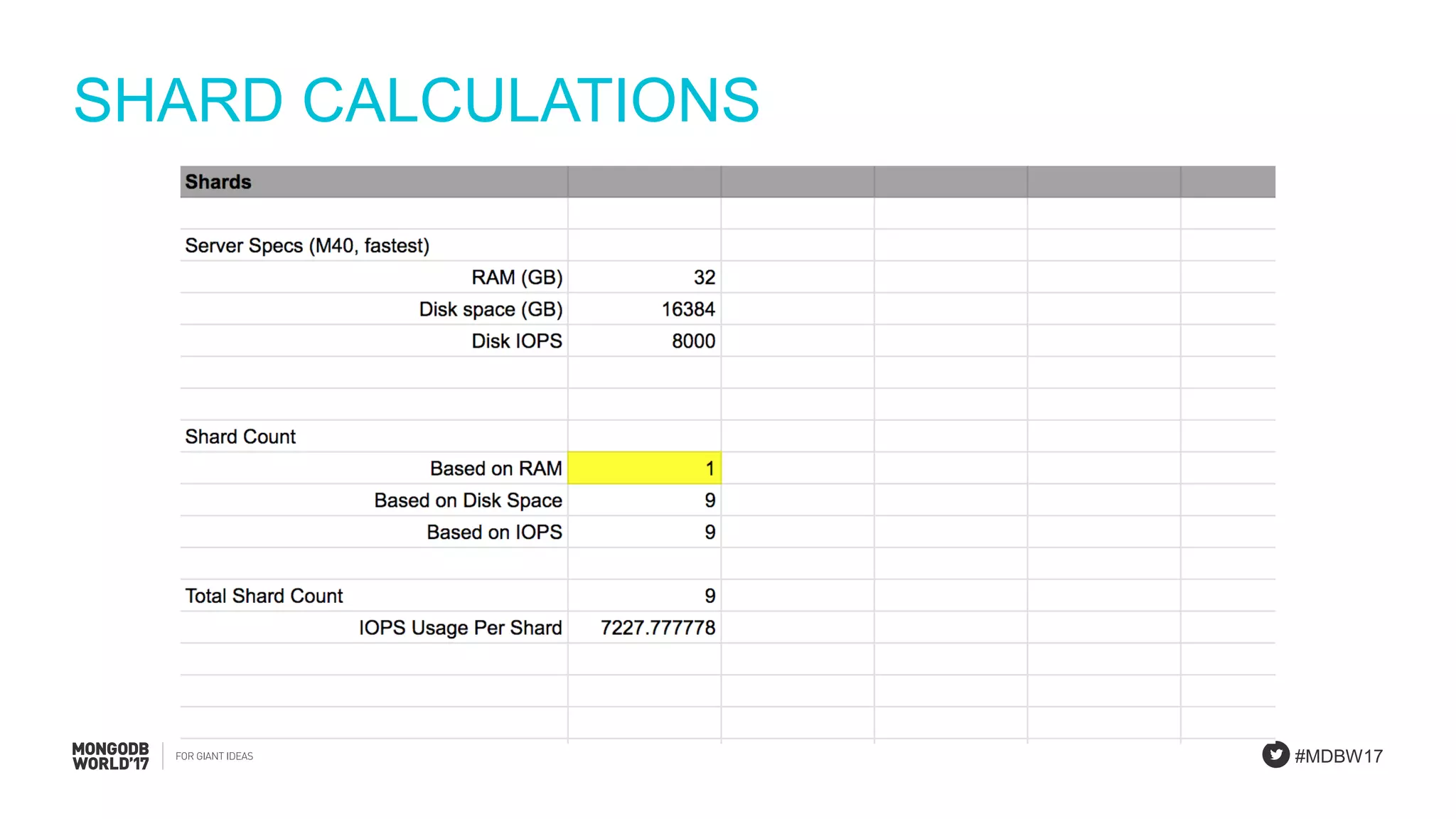
Final calculations for RAM, disk space, and required IOPS per shard to summarize the sizing process.
Final remarks on assumptions, collection size, working set, queries, and shard calculations necessary for the PlanetDollar case.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=600ounds&width=560&fit=bounds)





















![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)









