





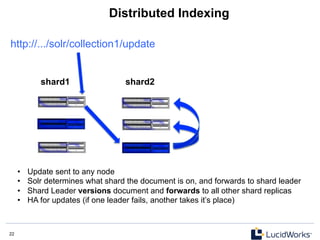
![9 9
Add and Retrieve document
$ curl http://localhost:8983/solr/update -H 'Content-type:application/json' -d '
[
{ "id" : "book1",
"title" : "American Gods",
"author" : "Neil Gaiman"
}
]'
$ curl http://localhost:8983/solr/get?id=book1
{
"doc":
{
"id"
:
"book1",
"author":
"Neil
Gaiman",
"title"
:
"American
Gods",
"_version_":
1410390803582287872
}
}
Note: no type of “commit”
is necessary to retrieve
documents via /get
(real-time get)](https://image.slidesharecdn.com/solr4nosqlsearchserver2013-130530202025-phpapp02/85/Solr4-nosql-search_server_2013-9-320.jpg)
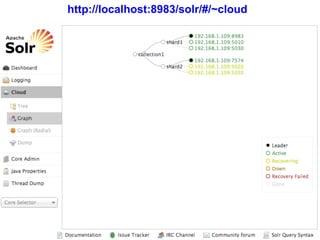
![10 10
Simplified JSON Delete Syntax
• Singe delete-by-id
{"delete":”book1"}
• Multiple delete-by-id
{"delete":[”book1”,”book2”,”book3”]}
• Delete with optimistic concurrency
{"delete":{"id":”book1",
"_version_":123456789}}
• Delete by Query
{"delete":{”query":”tag:category1”}}](https://image.slidesharecdn.com/solr4nosqlsearchserver2013-130530202025-phpapp02/85/Solr4-nosql-search_server_2013-10-320.jpg)
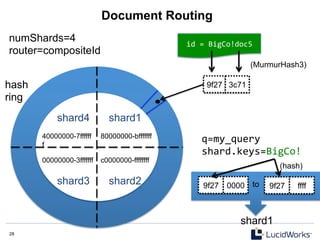
![11 11
Atomic Updates
$
curl
http://localhost:8983/solr/update
-‐H
'Content-‐type:application/json'
-‐d
'
[
{"id"
:
"book1",
"pubyear_i"
:
{
"add"
:
2001
},
"ISBN_s"
:
{
"add"
:
"0-‐380-‐97365-‐1"}
}
]'
$
curl
http://localhost:8983/solr/update
-‐H
'Content-‐type:application/json'
-‐d
'
[
{"id"
:
"book1",
"copies_i"
:
{
"inc"
:
1},
"cat"
:
{
"add"
:
"fantasy"},
"ISBN_s"
:
{
"set"
:
"0-‐380-‐97365-‐0"}
"remove_s"
:
{
"set"
:
null
}
}
]'](https://image.slidesharecdn.com/solr4nosqlsearchserver2013-130530202025-phpapp02/85/Solr4-nosql-search_server_2013-11-320.jpg)

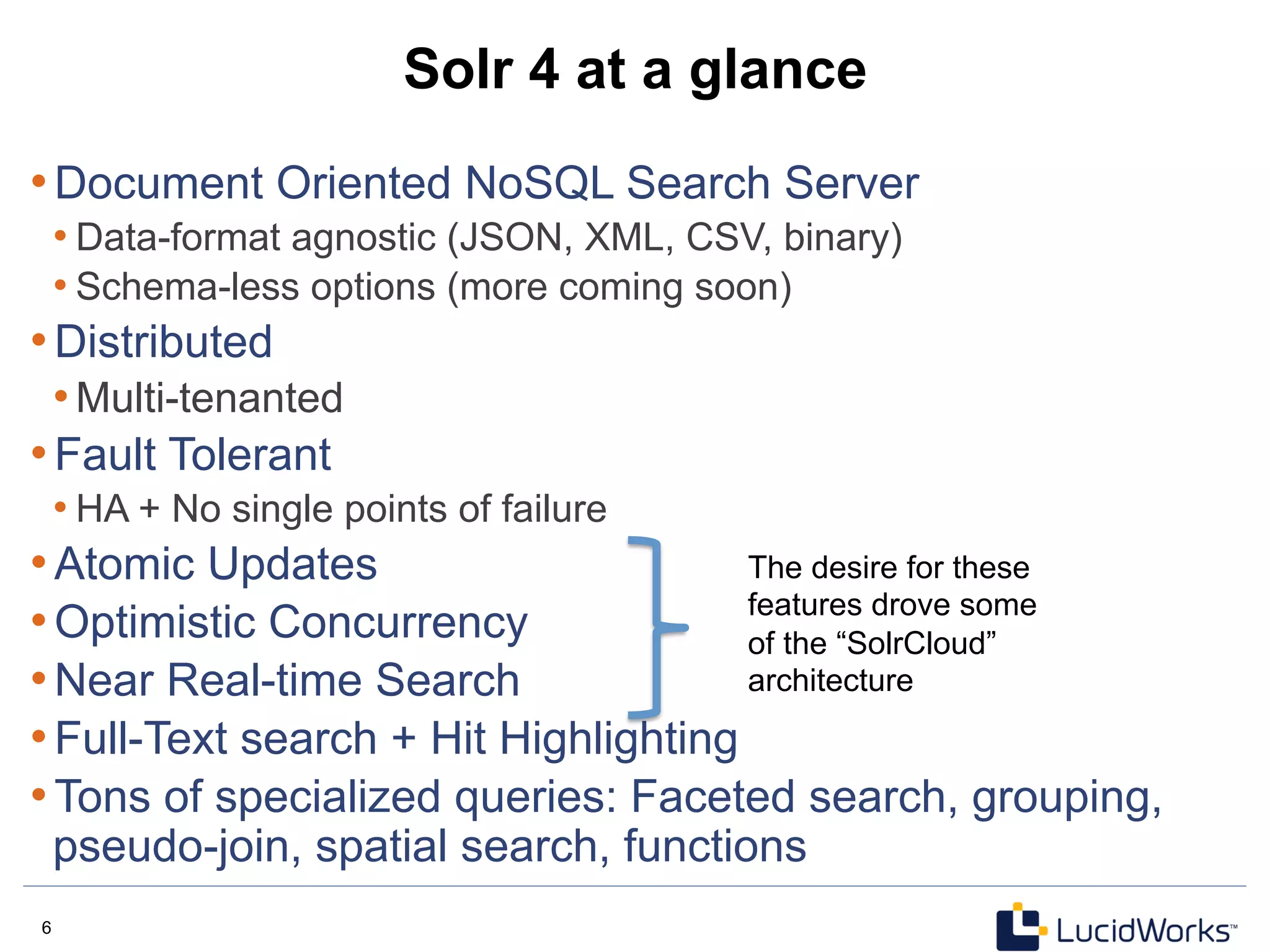
![14 14
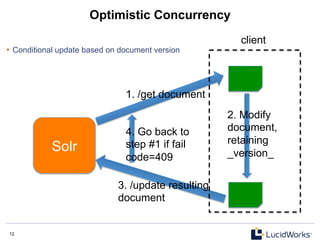
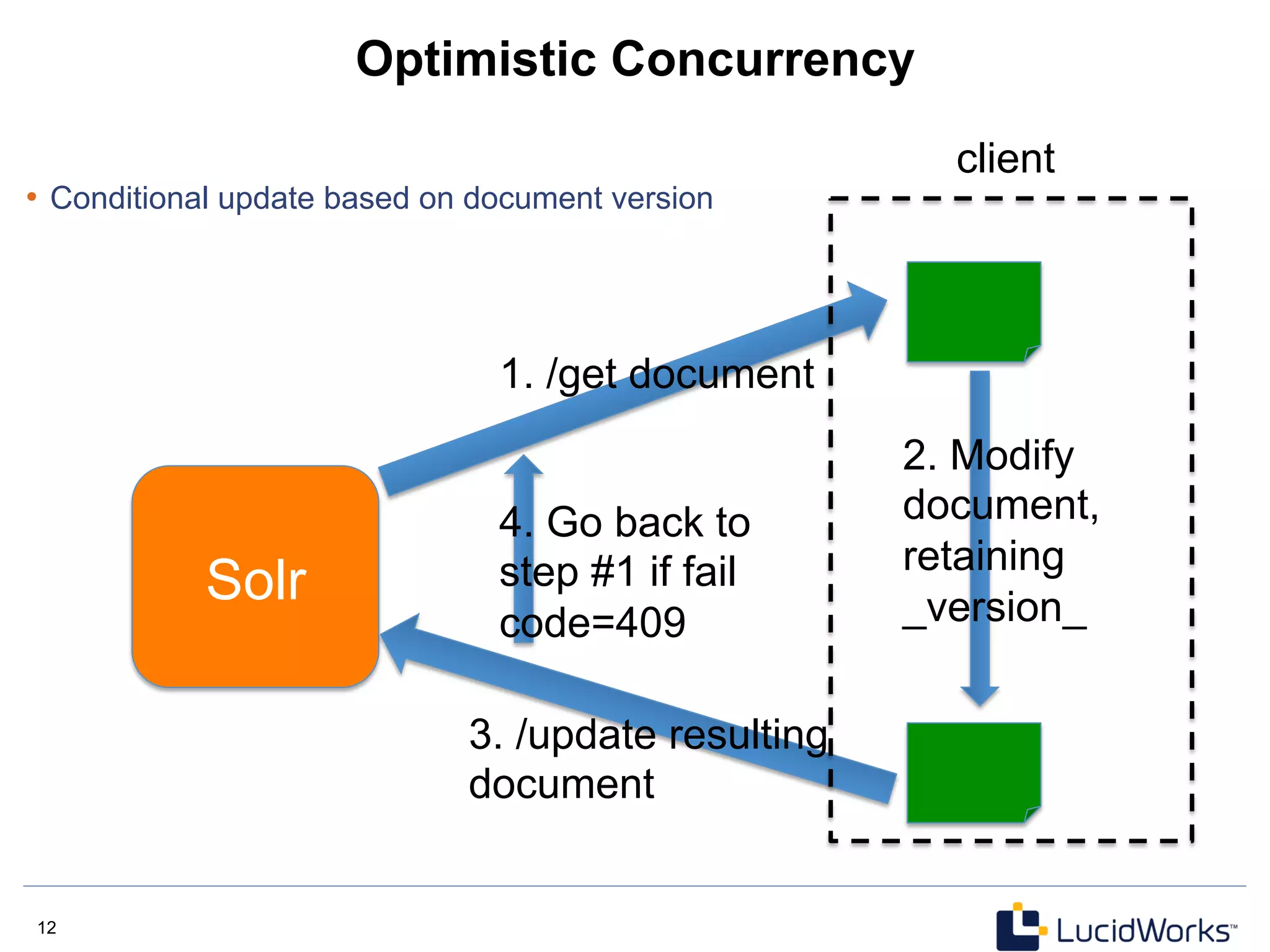
Optimistic Concurrency Example
$
curl
http://localhost:8983/solr/update
-‐H
'Content-‐type:application/json'
-‐d
'
[
{
"id":"book2",
"title":["Neuromancer"],
"author":"William
Gibson",
"copiesIn_i":6,
"copiesOut_i":4,
"_version_":123456789
}
]'
$
curl
http://localhost:8983/solr/get?id=book2
{
"doc”
:
{
"id":"book2",
"title":["Neuromancer"],
"author":"William
Gibson",
"copiesIn_i":7,
"copiesOut_i":3,
"_version_":123456789
}}
curl http://localhost:8983/solr/update?_version_=123456789 -H 'Content-type:application/json'
-d […]
Get the document
Modify and resubmit, using
the same _version_
Alternately, specify
the _version_ as a
request parameter](https://image.slidesharecdn.com/solr4nosqlsearchserver2013-130530202025-phpapp02/85/Solr4-nosql-search_server_2013-14-320.jpg)
![15 15
Optimistic Concurrency Errors
• HTTP Code 409 (Conflict) returned on version mismatch
$ curl -i http://localhost:8983/solr/update -H 'Content-type:application/json' -d '
[{"id":"book1", "author":"Mr Bean", "_version_":54321}]'
HTTP/1.1
409
Conflict
Content-‐Type:
text/plain;charset=UTF-‐8
Transfer-‐Encoding:
chunked
{
"responseHeader":{
"status":409,
"QTime":1},
"error":{
"msg":"version
conflict
for
book1
expected=12345
actual=1408814192853516288",
"code":409}}](https://image.slidesharecdn.com/solr4nosqlsearchserver2013-130530202025-phpapp02/85/Solr4-nosql-search_server_2013-15-320.jpg)

















![9 9
Add and Retrieve document
$ curl http://localhost:8983/solr/update -H 'Content-type:application/json' -d '
[
{ "id" : "book1",
"title" : "American Gods",
"author" : "Neil Gaiman"
}
]'
$ curl http://localhost:8983/solr/get?id=book1
{
"doc":
{
"id"
:
"book1",
"author":
"Neil
Gaiman",
"title"
:
"American
Gods",
"_version_":
1410390803582287872
}
}
Note: no type of “commit”
is necessary to retrieve
documents via /get
(real-time get)](https://image.slidesharecdn.com/solr4nosqlsearchserver2013-130530202025-phpapp02/75/Solr4-nosql-search_server_2013-9-2048.jpg)
![10 10
Simplified JSON Delete Syntax
• Singe delete-by-id
{"delete":”book1"}
• Multiple delete-by-id
{"delete":[”book1”,”book2”,”book3”]}
• Delete with optimistic concurrency
{"delete":{"id":”book1",
"_version_":123456789}}
• Delete by Query
{"delete":{”query":”tag:category1”}}](https://image.slidesharecdn.com/solr4nosqlsearchserver2013-130530202025-phpapp02/75/Solr4-nosql-search_server_2013-10-2048.jpg)
![11 11
Atomic Updates
$
curl
http://localhost:8983/solr/update
-‐H
'Content-‐type:application/json'
-‐d
'
[
{"id"
:
"book1",
"pubyear_i"
:
{
"add"
:
2001
},
"ISBN_s"
:
{
"add"
:
"0-‐380-‐97365-‐1"}
}
]'
$
curl
http://localhost:8983/solr/update
-‐H
'Content-‐type:application/json'
-‐d
'
[
{"id"
:
"book1",
"copies_i"
:
{
"inc"
:
1},
"cat"
:
{
"add"
:
"fantasy"},
"ISBN_s"
:
{
"set"
:
"0-‐380-‐97365-‐0"}
"remove_s"
:
{
"set"
:
null
}
}
]'](https://image.slidesharecdn.com/solr4nosqlsearchserver2013-130530202025-phpapp02/75/Solr4-nosql-search_server_2013-11-2048.jpg)

![14 14
Optimistic Concurrency Example
$
curl
http://localhost:8983/solr/update
-‐H
'Content-‐type:application/json'
-‐d
'
[
{
"id":"book2",
"title":["Neuromancer"],
"author":"William
Gibson",
"copiesIn_i":6,
"copiesOut_i":4,
"_version_":123456789
}
]'
$
curl
http://localhost:8983/solr/get?id=book2
{
"doc”
:
{
"id":"book2",
"title":["Neuromancer"],
"author":"William
Gibson",
"copiesIn_i":7,
"copiesOut_i":3,
"_version_":123456789
}}
curl http://localhost:8983/solr/update?_version_=123456789 -H 'Content-type:application/json'
-d […]
Get the document
Modify and resubmit, using
the same _version_
Alternately, specify
the _version_ as a
request parameter](https://image.slidesharecdn.com/solr4nosqlsearchserver2013-130530202025-phpapp02/75/Solr4-nosql-search_server_2013-14-2048.jpg)
![15 15
Optimistic Concurrency Errors
• HTTP Code 409 (Conflict) returned on version mismatch
$ curl -i http://localhost:8983/solr/update -H 'Content-type:application/json' -d '
[{"id":"book1", "author":"Mr Bean", "_version_":54321}]'
HTTP/1.1
409
Conflict
Content-‐Type:
text/plain;charset=UTF-‐8
Transfer-‐Encoding:
chunked
{
"responseHeader":{
"status":409,
"QTime":1},
"error":{
"msg":"version
conflict
for
book1
expected=12345
actual=1408814192853516288",
"code":409}}](https://image.slidesharecdn.com/solr4nosqlsearchserver2013-130530202025-phpapp02/75/Solr4-nosql-search_server_2013-15-2048.jpg)





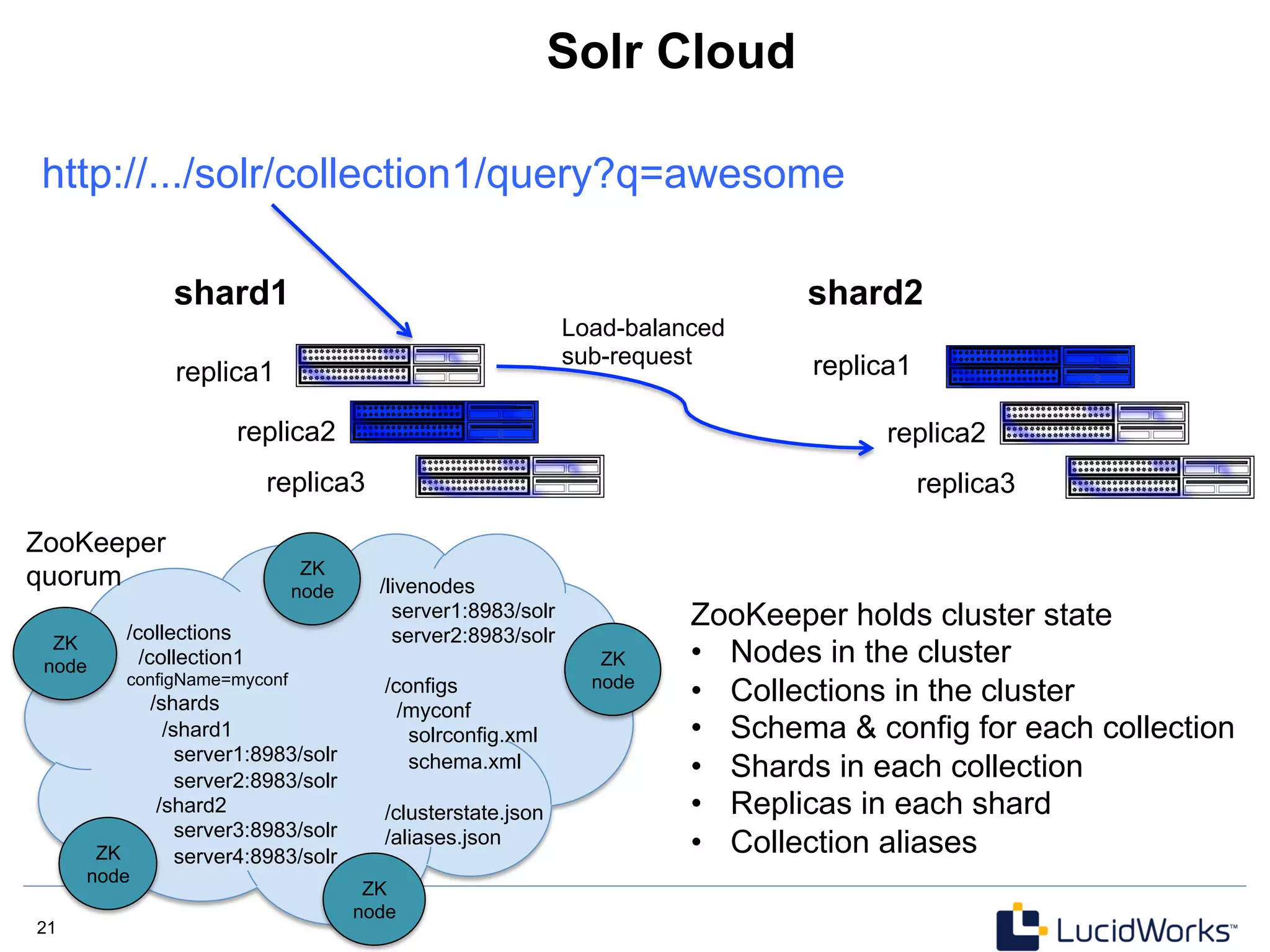
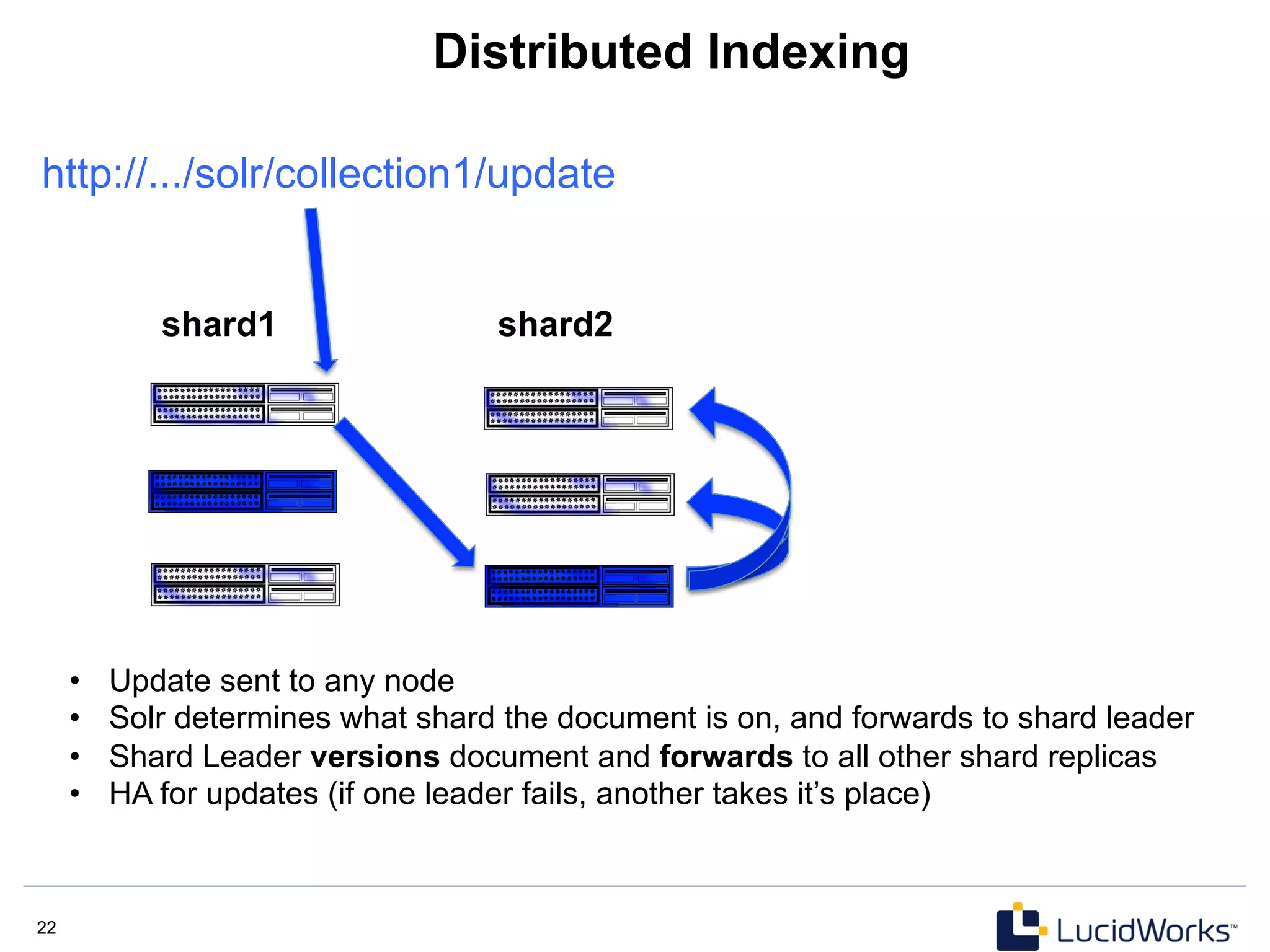

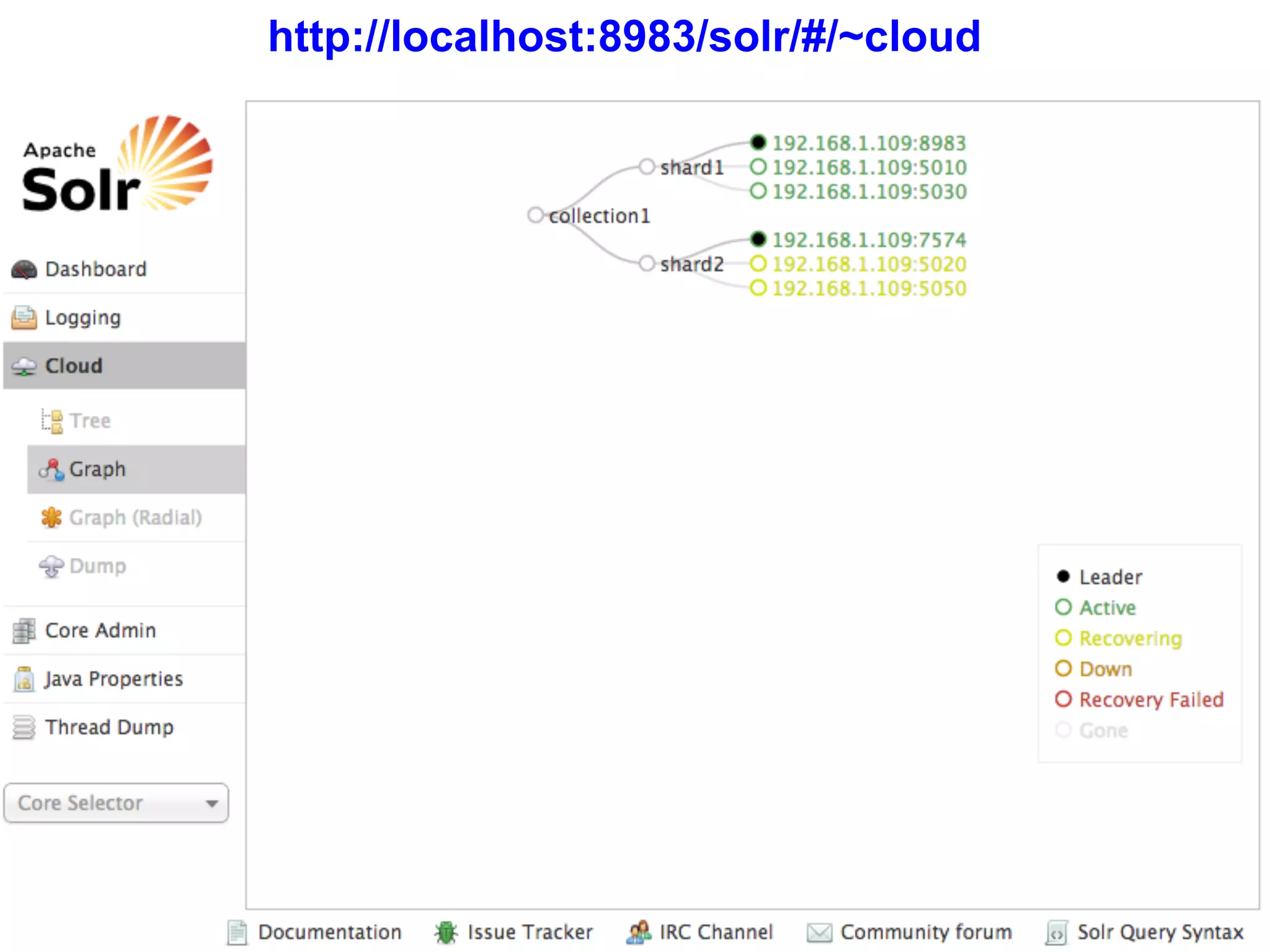




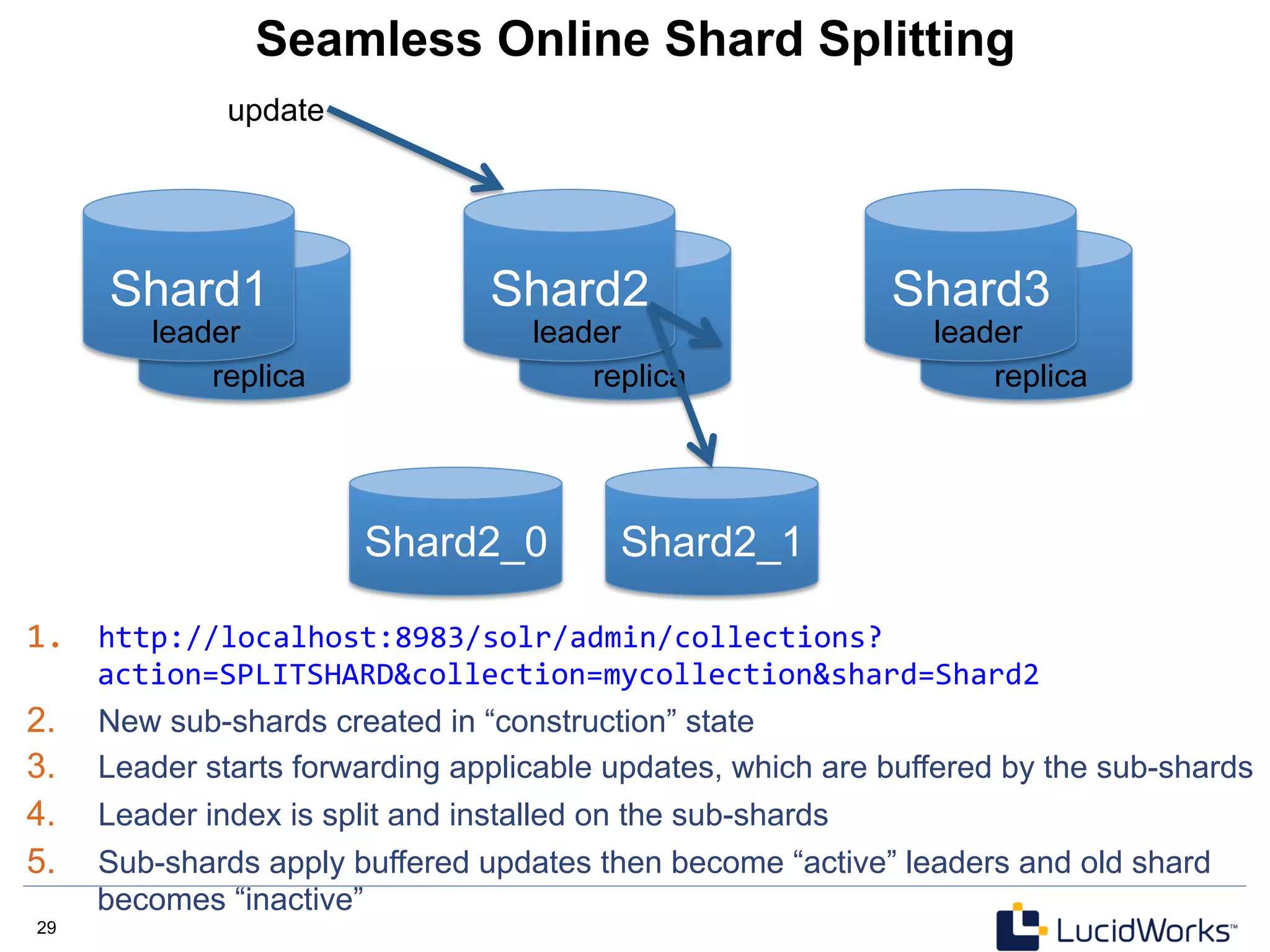


The document discusses Solr 4, an open source search platform built on Apache Lucene. Some key points: - Solr 4 is a NoSQL search server that provides distributed indexing, fault tolerance, and real-time search capabilities. - Solr Cloud is Solr's distributed architecture which uses Zookeeper for coordination to provide features like automatic sharding and replication of indexes across multiple servers. - The document outlines Solr 4's capabilities including schema-less options, atomic updates, optimistic concurrency, and a REST API for managing the schema dynamically.











































































































