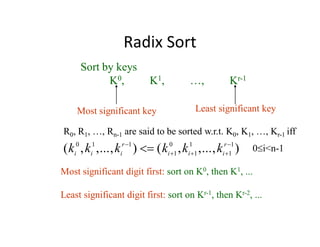
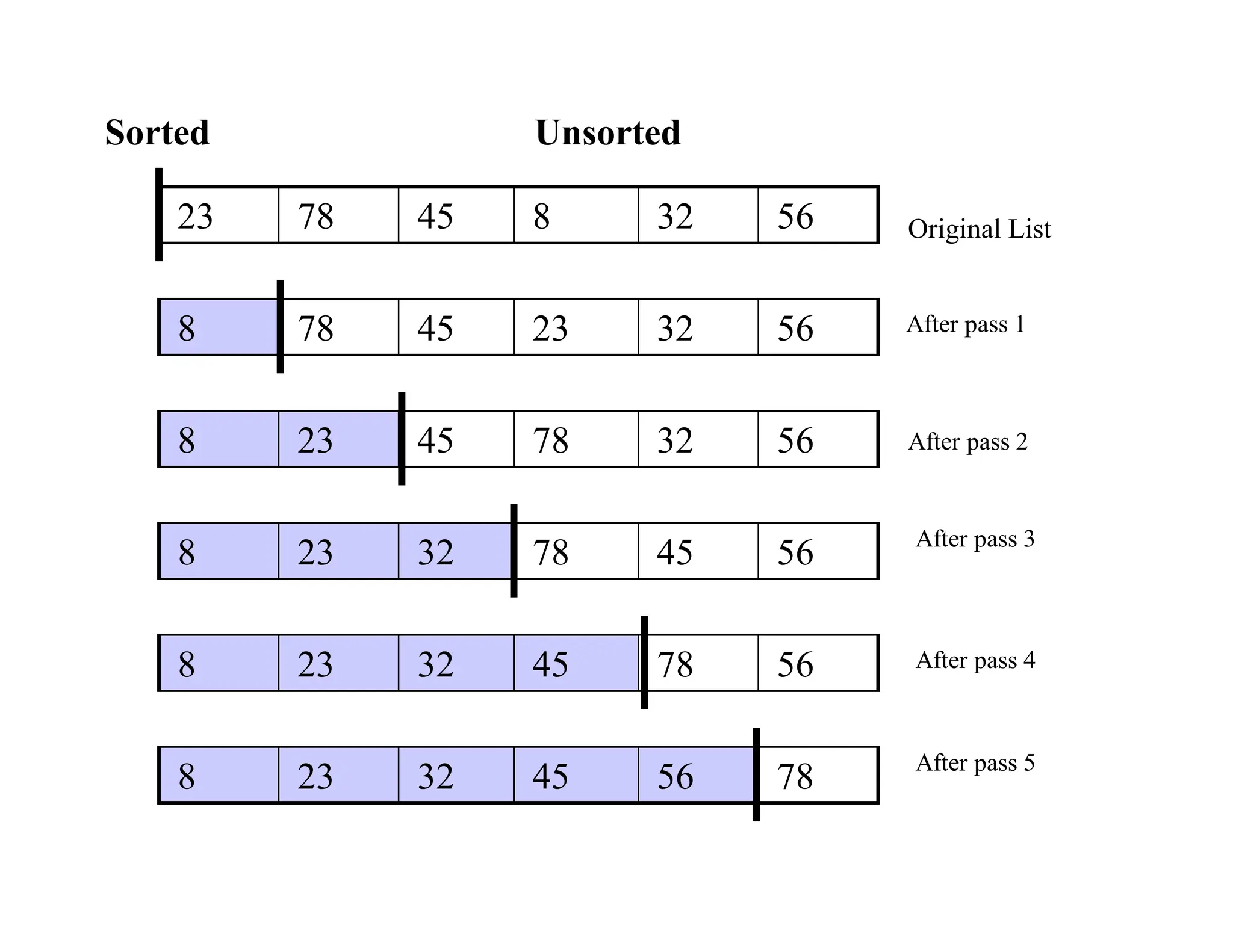
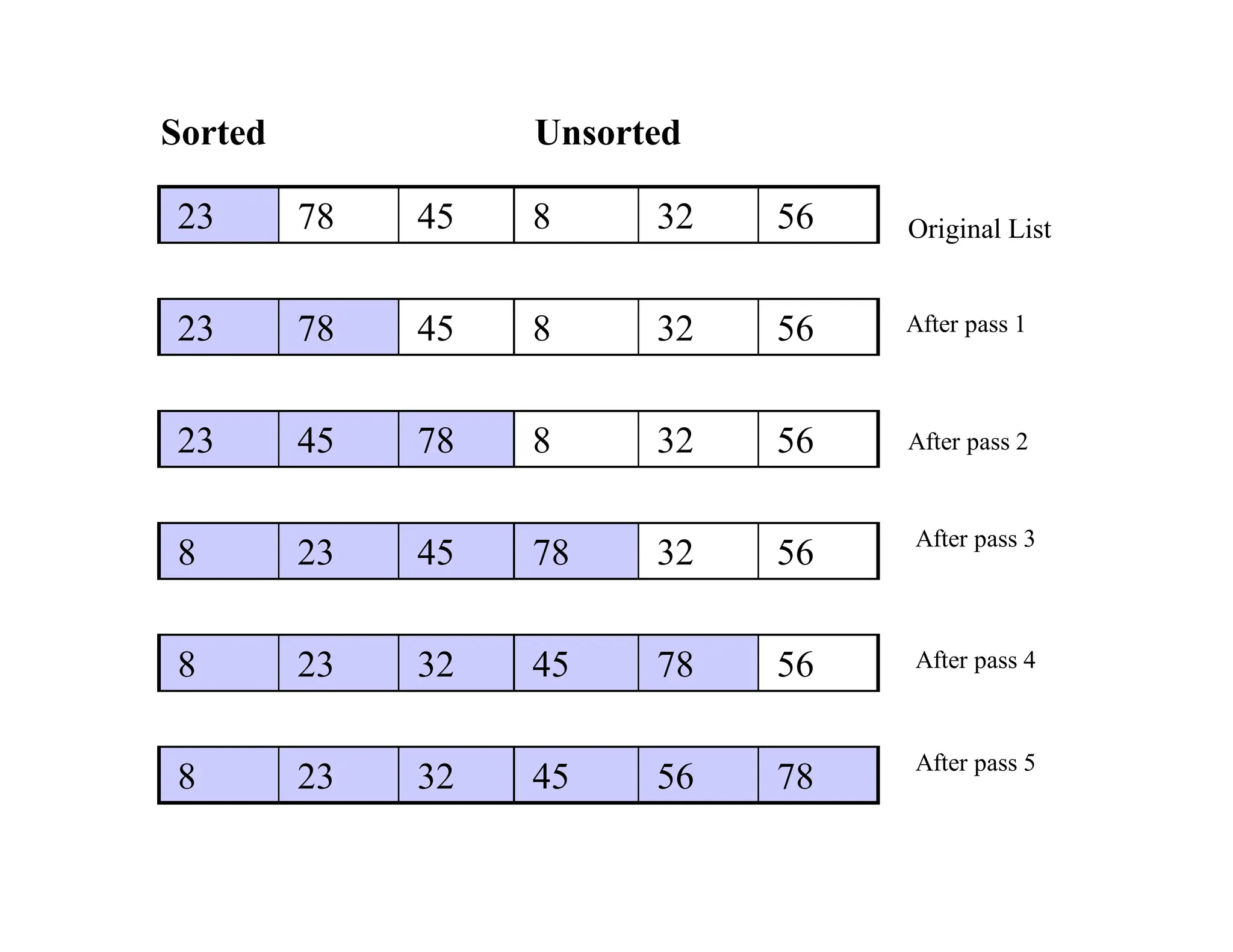
The document discusses various sorting algorithms, including selection sort, insertion sort, bubble sort, mergesort, and quicksort, outlining their procedures and efficiency. Each algorithm is analyzed in terms of key comparisons and moves, with performance characterized in best, worst, and average cases, often represented as O(n²) for simpler algorithms. The document emphasizes the necessity of efficient sorting techniques for organizing data, particularly focusing on internal sorting algorithms.




![Selection Sort (cont.)
void selectionSort( int a[], int n) {
for (int i = 0; i < n-1; i++) {
int min = i;
for (int j = i+1; j < n; j++)
if (a[j] < a[min]) min = j;
int tmp = a[i];
a[i] = a[min];
a[min] = tmp;
}
}](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-6-320.jpg)



![Insertion Sort Algorithm
void insertionSort(int a[], int n)
{
for (int i = 1; i < n; i++)
{
int tmp = a[i];
for (int j=i; j>0 && tmp < a[j-1]; j--)
a[j] = a[j-1];
a[j] = tmp;
}
}](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-11-320.jpg)



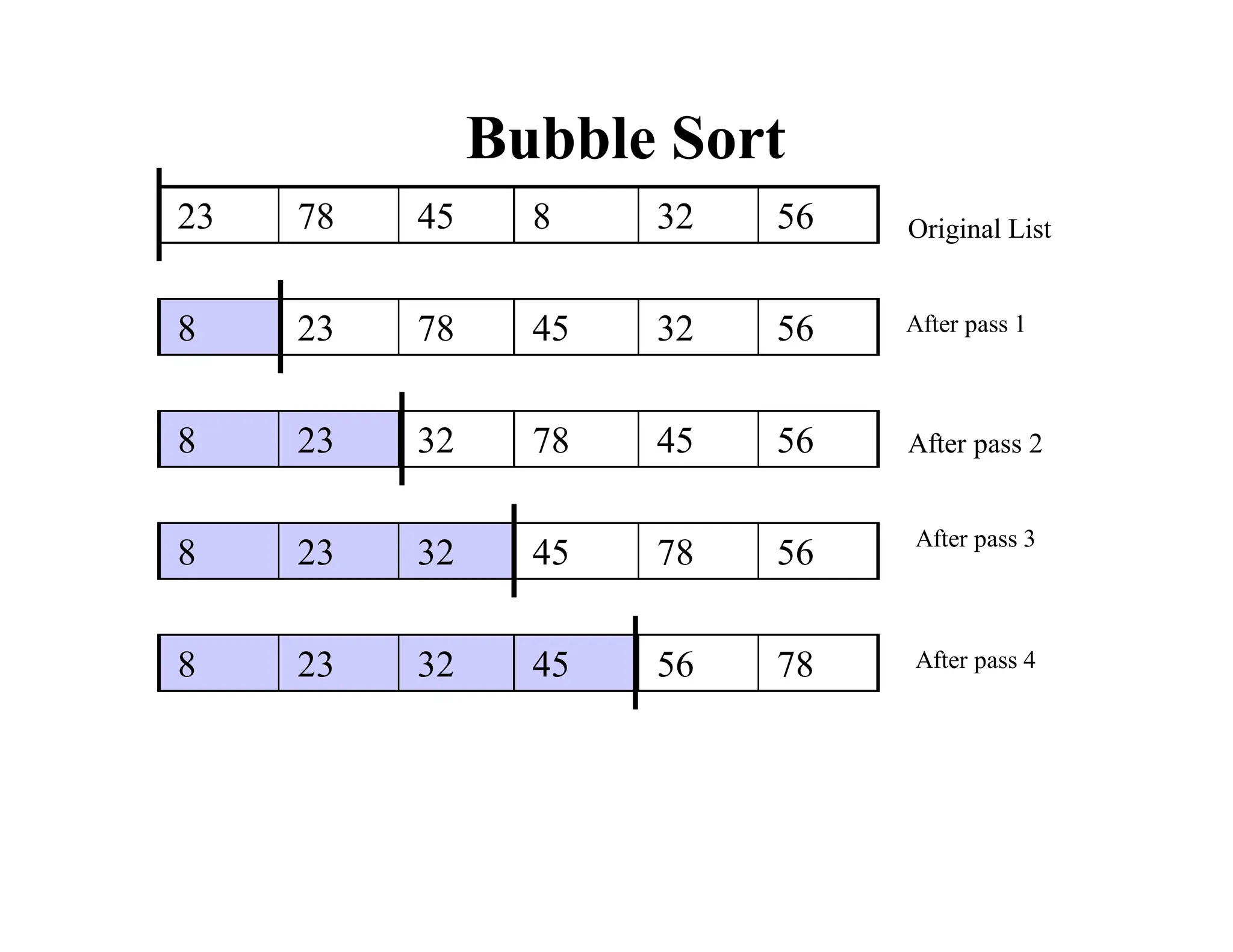
![Bubble Sort Algorithm
void bubleSort(int a[], int n)
{
bool sorted = false;
int last = n-1;
for (int i = 0; (i < last) && !sorted; i++){
sorted = true;
for (int j=last; j > i; j--)
if (a[j-1] > a[j]{
int temp=a[j];
a[j]=a[j-1];
a[j-1]=temp;
sorted = false; // signal exchange
}
}
}](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-15-320.jpg)


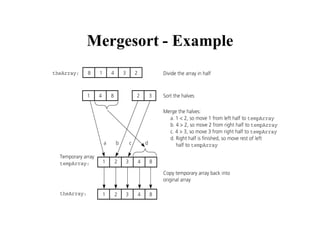
![Merge
const int MAX_SIZE = maximum-number-of-items-in-array;
void merge(int theArray[], int first, int mid, int last) {
int tempArray[MAX_SIZE]; // temporary array
int first1 = first; // beginning of first subarray
int last1 = mid; // end of first subarray
int first2 = mid + 1; // beginning of second subarray
int last2 = last; // end of second subarray
int index = first1; // next available location in tempArray
for ( ; (first1 <= last1) && (first2 <= last2); ++index) {
if (theArray[first1] < theArray[first2]) {
tempArray[index] = theArray[first1];
++first1;
}
else {
tempArray[index] = theArray[first2];
++first2;
} }](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-19-320.jpg)
![Merge (cont.)
// finish off the first subarray, if necessary
for (; first1 <= last1; ++first1, ++index)
tempArray[index] = theArray[first1];
// finish off the second subarray, if necessary
for (; first2 <= last2; ++first2, ++index)
tempArray[index] = theArray[first2];
// copy the result back into the original array
for (index = first; index <= last; ++index)
theArray[index] = tempArray[index];
} // end merge](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-20-320.jpg)
![Mergesort
void mergesort(int theArray[], int first, int last) {
if (first < last) {
int mid = (first + last)/2; // index of midpoint
mergesort(theArray, first, mid);
mergesort(theArray, mid+1, last);
// merge the two halves
merge(theArray, first, mid, last);
}
} // end mergesort](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-21-320.jpg)
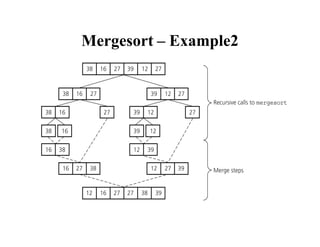

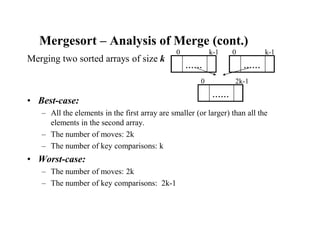
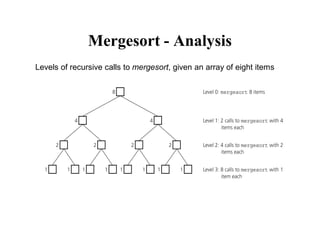
![Mergesort – Recurrence Relation
T(n) = 2 T(n/2) + cn
= 2 [2 T(n/4) + cn/2] + cn
= 4 T(n/4) + 2cn
= 4 [2 T(n/8) + cn/4] + 2cn
= 8 T(n/8) + 3cn
…
…
= 2k T(n/2k) + kcn
We know that T(1) = 1
Putting n/2k = 1, we get n = 2k OR log2 n = k
Hence,
T(n)=nT(1)+cn log2n = n + cn log2n = O(log n)](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-27-320.jpg)



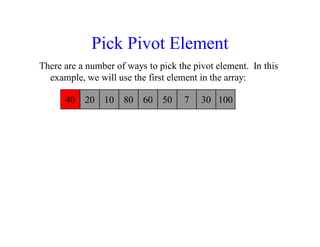

![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-33-320.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-34-320.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-35-320.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-36-320.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-37-320.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-38-320.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-39-320.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-40-320.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-41-320.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-42-320.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-43-320.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-44-320.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-45-320.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-46-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-47-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-48-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-49-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-50-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-51-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-52-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-53-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-54-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-55-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-56-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
7 20 10 30 40 50 60 80 100
pivot_index = 4
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-57-320.jpg)
![Partition Result
7 20 10 30 40 50 60 80 100
[0] [1] [2] [3] [4] [5] [6] [7] [8]
<= data[pivot] > data[pivot]](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-58-320.jpg)
![Recursion: Quicksort Sub-arrays
7 20 10 30 40 50 60 80 100
[0] [1] [2] [3] [4] [5] [6] [7] [8]
<= data[pivot] > data[pivot]](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-59-320.jpg)




![Quicksort: Worst Case
• Assume first element is chosen as pivot.
• Assume we get array that is already in
order:
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-64-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-65-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-66-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-67-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-68-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-69-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-70-320.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
> data[pivot]
<= data[pivot]](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-71-320.jpg)
![Improved Pivot Selection
Pick median value of three elements from data array:
data[0], data[n/2], and data[n-1].
Use this median value as pivot.
However selection of median value takes O(n) time.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-72-320.jpg)

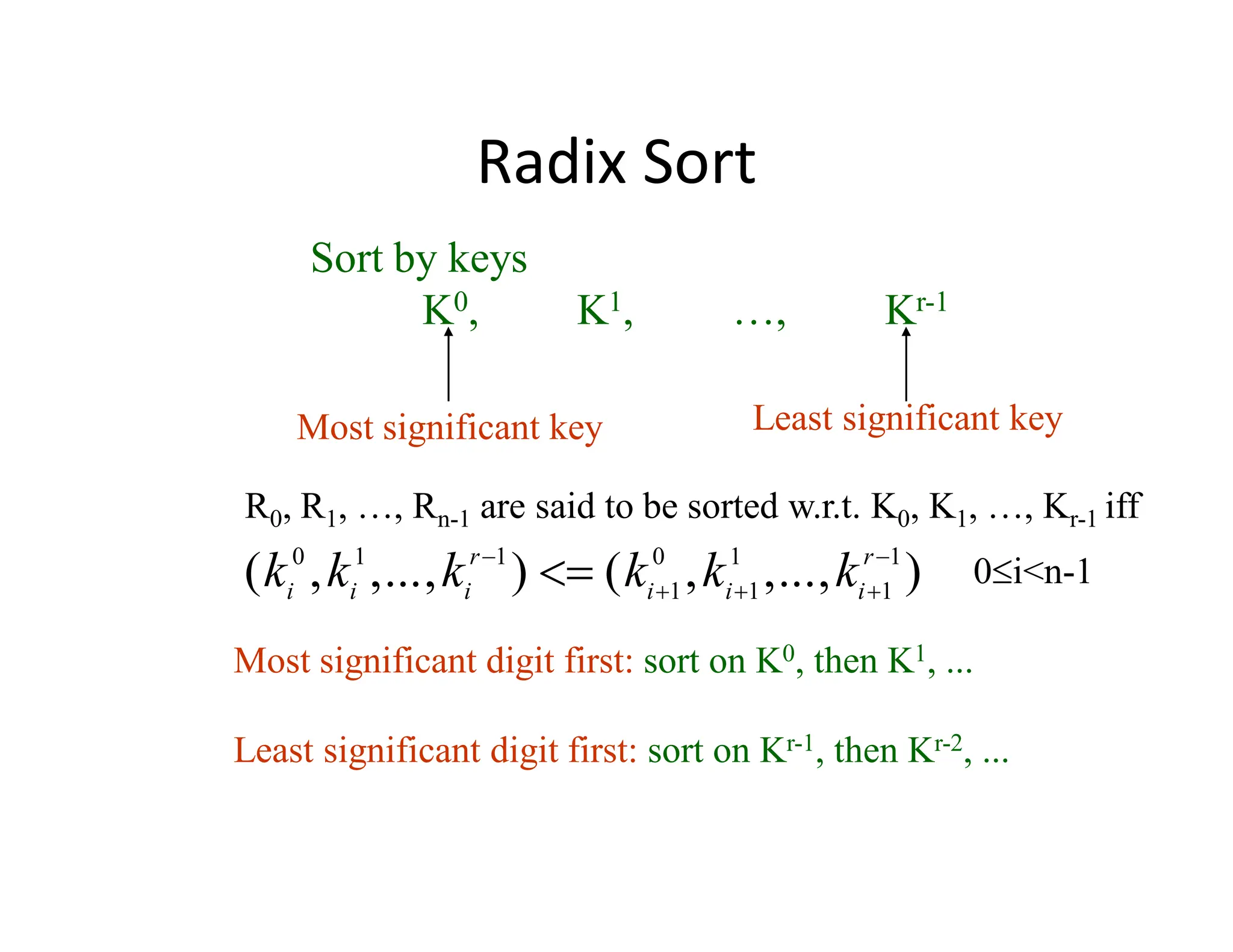
![Example for LSD Radix Sort
front[0] NULL rear[0]
front[1] 271 NULL rear[1]
front[2] NULL rear[2]
front[3] 93 33 NULL rear[3]
front[4] 984 NULL rear[4]
front[5] 55 NULL rear[5]
front[6] 306 NULL rear[6]
front[7] NULL rear[7]
front[8] 208 NULL rear[8]
front[9] 179 859 9 NULL rear[9]
179, 208, 306, 93, 859, 984, 55, 9, 271, 33
271, 93, 33, 984, 55, 306, 208, 179, 859, 9 After the first pass
Sort
by
digit
concatenate
d (digit) = 3, r (radix) = 10 ascending order](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-75-320.jpg)
![306 208 9 null
null
null
33 null
null
55 859 null
null
271 179 null
984 null
93 null
rear[0]
rear[1]
rear[2]
rear[3]
rear[4]
rear[5]
rear[6]
rear[7]
rear[8]
rear[9]
front[0]
front[1]
front[2]
front[3]
front[4]
front[5]
front[6]
front[7]
front[8]
front[9]
306, 208, 9, 33, 55, 859, 271, 179, 984, 93 (second pass)](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-76-320.jpg)
![9 33 55
306 null
null
null
859 null
984 null
rear[0]
rear[1]
rear[2]
rear[3]
rear[4]
rear[5]
rear[6]
rear[7]
rear[8]
rear[9]
front[0]
front[1]
front[2]
front[3]
front[4]
front[5]
front[6]
front[7]
front[8]
front[9]
9, 33, 55, 93, 179, 208, 271, 306, 859, 984 (third pass)
93 null
179 null
208 271 null
null
null](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/85/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-77-320.jpg)







![Selection Sort (cont.)
void selectionSort( int a[], int n) {
for (int i = 0; i < n-1; i++) {
int min = i;
for (int j = i+1; j < n; j++)
if (a[j] < a[min]) min = j;
int tmp = a[i];
a[i] = a[min];
a[min] = tmp;
}
}](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-6-2048.jpg)



![Insertion Sort Algorithm
void insertionSort(int a[], int n)
{
for (int i = 1; i < n; i++)
{
int tmp = a[i];
for (int j=i; j>0 && tmp < a[j-1]; j--)
a[j] = a[j-1];
a[j] = tmp;
}
}](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-11-2048.jpg)


![Bubble Sort Algorithm
void bubleSort(int a[], int n)
{
bool sorted = false;
int last = n-1;
for (int i = 0; (i < last) && !sorted; i++){
sorted = true;
for (int j=last; j > i; j--)
if (a[j-1] > a[j]{
int temp=a[j];
a[j]=a[j-1];
a[j-1]=temp;
sorted = false; // signal exchange
}
}
}](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-15-2048.jpg)


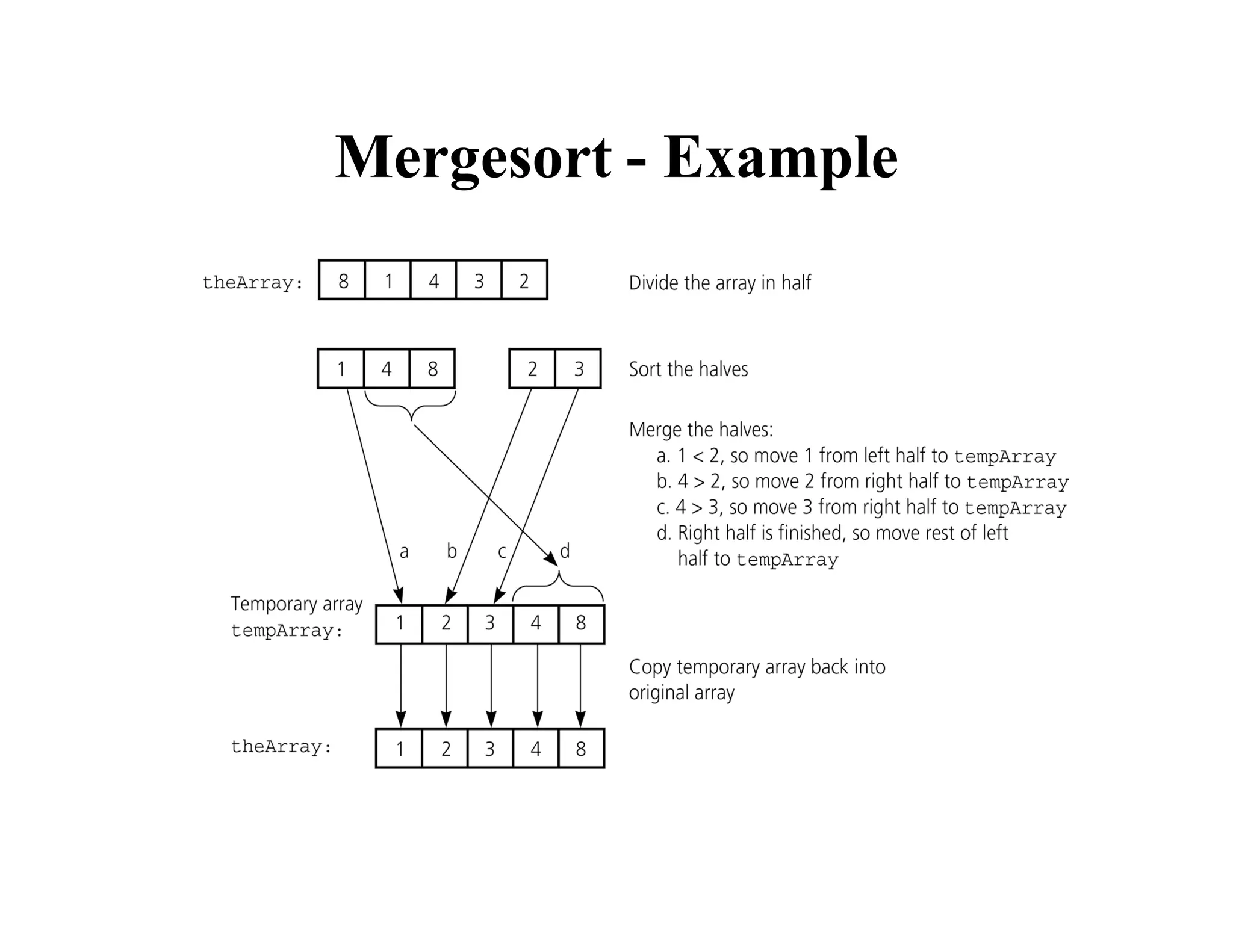
![Merge
const int MAX_SIZE = maximum-number-of-items-in-array;
void merge(int theArray[], int first, int mid, int last) {
int tempArray[MAX_SIZE]; // temporary array
int first1 = first; // beginning of first subarray
int last1 = mid; // end of first subarray
int first2 = mid + 1; // beginning of second subarray
int last2 = last; // end of second subarray
int index = first1; // next available location in tempArray
for ( ; (first1 <= last1) && (first2 <= last2); ++index) {
if (theArray[first1] < theArray[first2]) {
tempArray[index] = theArray[first1];
++first1;
}
else {
tempArray[index] = theArray[first2];
++first2;
} }](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-19-2048.jpg)
![Merge (cont.)
// finish off the first subarray, if necessary
for (; first1 <= last1; ++first1, ++index)
tempArray[index] = theArray[first1];
// finish off the second subarray, if necessary
for (; first2 <= last2; ++first2, ++index)
tempArray[index] = theArray[first2];
// copy the result back into the original array
for (index = first; index <= last; ++index)
theArray[index] = tempArray[index];
} // end merge](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-20-2048.jpg)
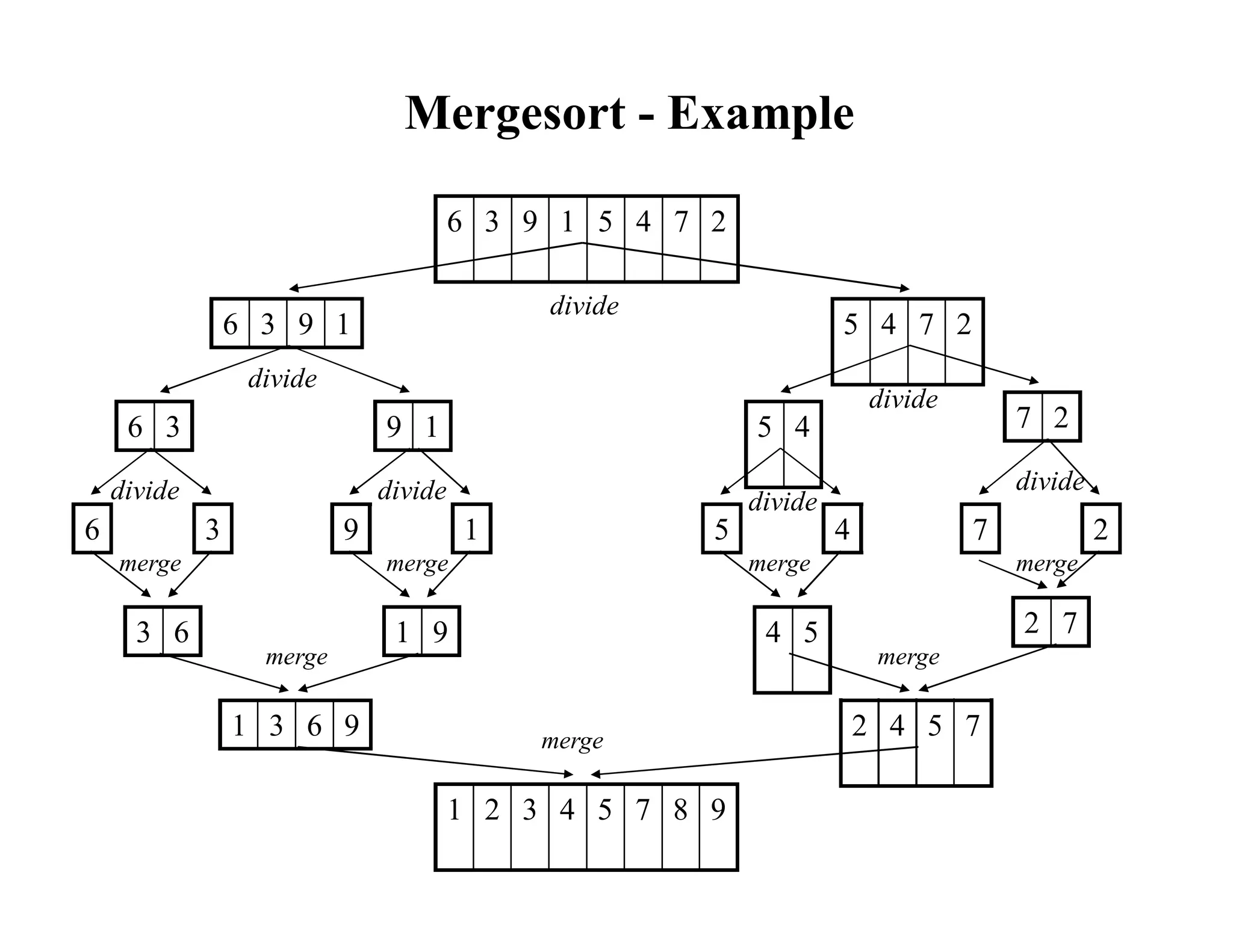
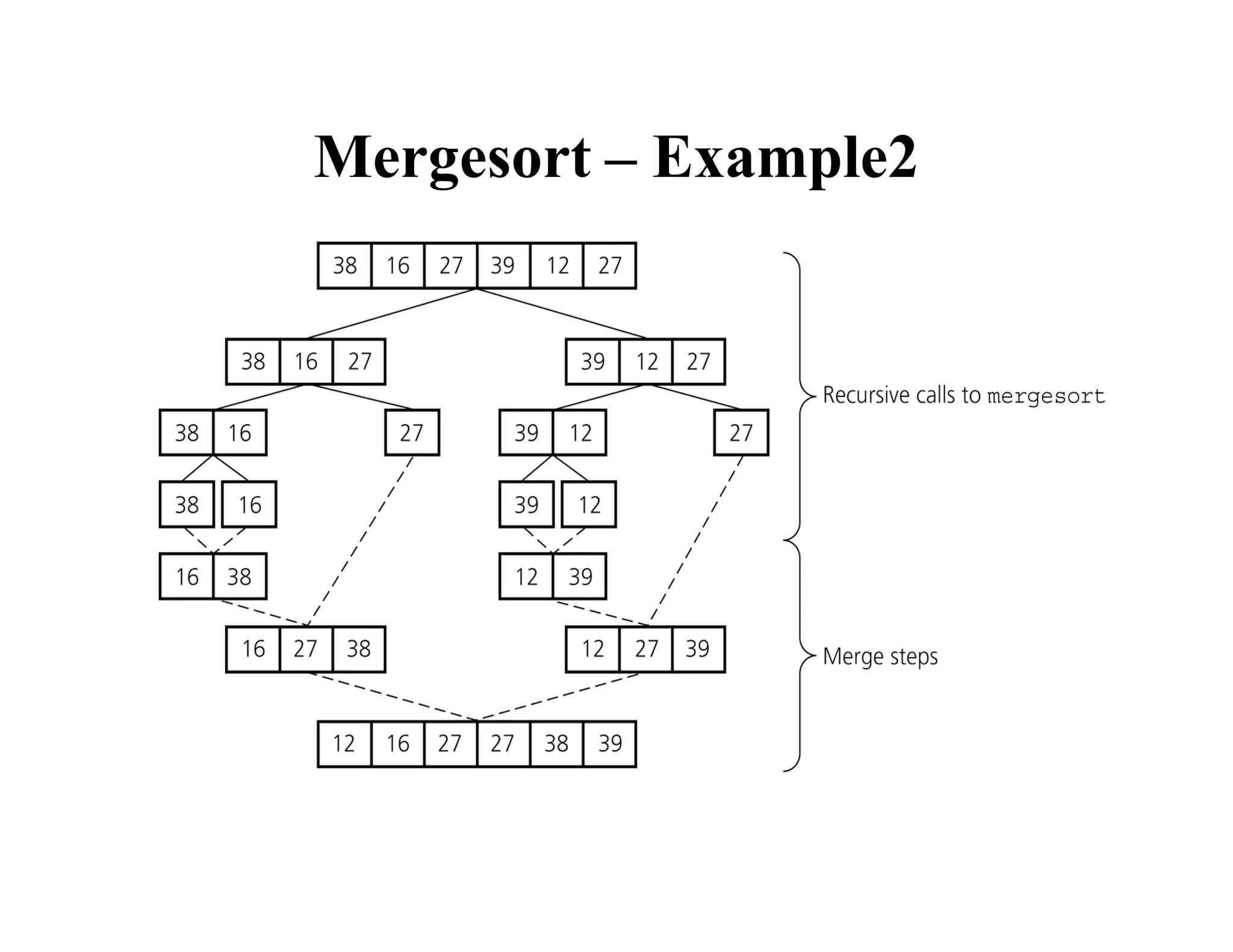
![Mergesort
void mergesort(int theArray[], int first, int last) {
if (first < last) {
int mid = (first + last)/2; // index of midpoint
mergesort(theArray, first, mid);
mergesort(theArray, mid+1, last);
// merge the two halves
merge(theArray, first, mid, last);
}
} // end mergesort](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-21-2048.jpg)

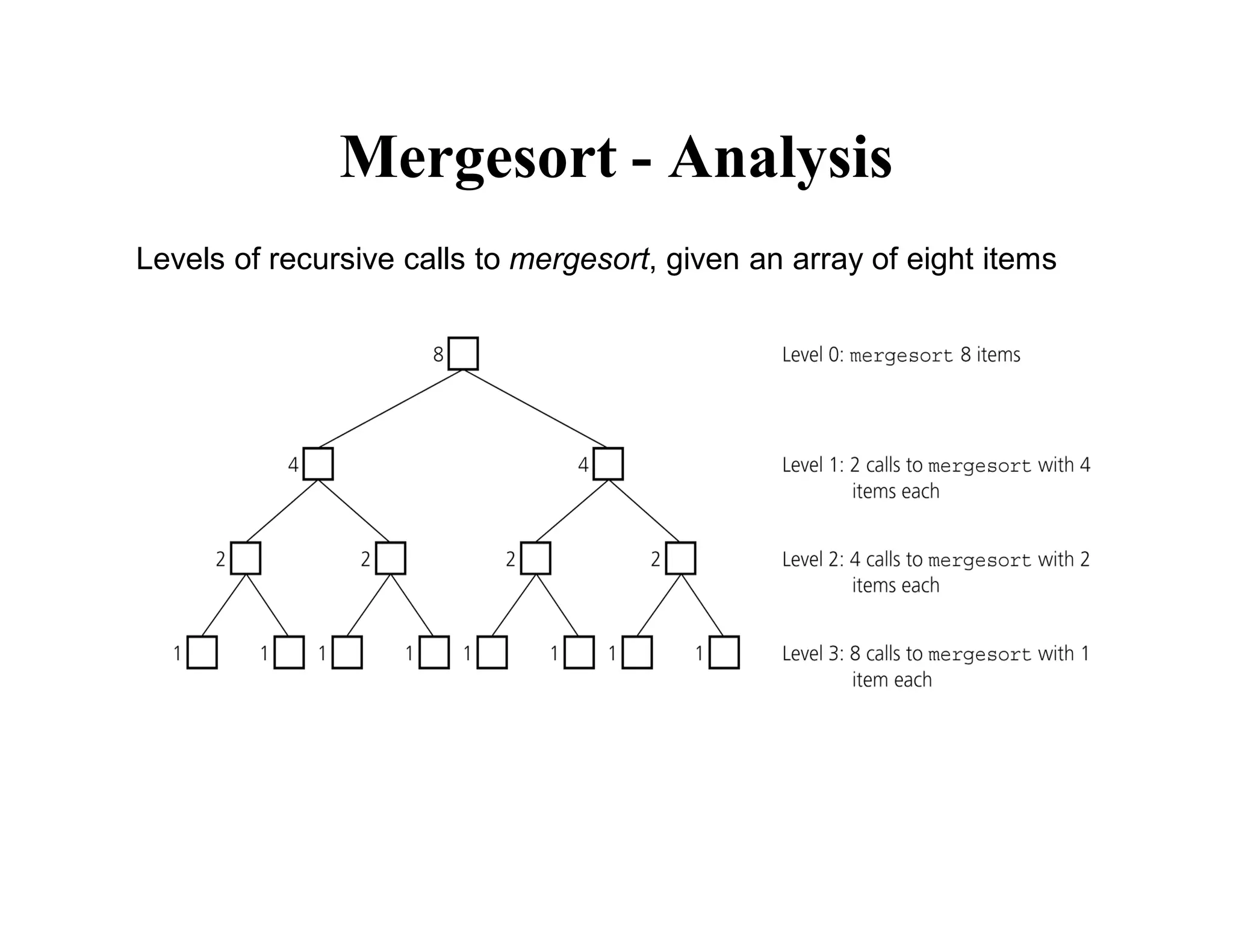
![Mergesort – Recurrence Relation
T(n) = 2 T(n/2) + cn
= 2 [2 T(n/4) + cn/2] + cn
= 4 T(n/4) + 2cn
= 4 [2 T(n/8) + cn/4] + 2cn
= 8 T(n/8) + 3cn
…
…
= 2k T(n/2k) + kcn
We know that T(1) = 1
Putting n/2k = 1, we get n = 2k OR log2 n = k
Hence,
T(n)=nT(1)+cn log2n = n + cn log2n = O(log n)](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-27-2048.jpg)





![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-33-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-34-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-35-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-36-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-37-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-38-2048.jpg)
![40 20 10 80 60 50 7 30 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-39-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-40-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-41-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-42-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-43-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-44-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-45-2048.jpg)
![40 20 10 30 60 50 7 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index
1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-46-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-47-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-48-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-49-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-50-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-51-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-52-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-53-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-54-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-55-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
40 20 10 30 7 50 60 80 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-56-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
7 20 10 30 40 50 60 80 100
pivot_index = 4
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-57-2048.jpg)
![Partition Result
7 20 10 30 40 50 60 80 100
[0] [1] [2] [3] [4] [5] [6] [7] [8]
<= data[pivot] > data[pivot]](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-58-2048.jpg)
![Recursion: Quicksort Sub-arrays
7 20 10 30 40 50 60 80 100
[0] [1] [2] [3] [4] [5] [6] [7] [8]
<= data[pivot] > data[pivot]](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-59-2048.jpg)




![Quicksort: Worst Case
• Assume first element is chosen as pivot.
• Assume we get array that is already in
order:
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-64-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-65-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-66-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-67-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-68-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-69-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
too_big_index too_small_index](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-70-2048.jpg)
![1. While data[too_big_index] <= data[pivot]
++too_big_index
2. While data[too_small_index] > data[pivot]
--too_small_index
3. If too_big_index < too_small_index
swap data[too_big_index] and data[too_small_index]
4. While too_small_index > too_big_index, go to 1.
5. Swap data[too_small_index] and data[pivot_index]
2 4 10 12 13 50 57 63 100
pivot_index = 0
[0] [1] [2] [3] [4] [5] [6] [7] [8]
> data[pivot]
<= data[pivot]](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-71-2048.jpg)
![Improved Pivot Selection
Pick median value of three elements from data array:
data[0], data[n/2], and data[n-1].
Use this median value as pivot.
However selection of median value takes O(n) time.](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-72-2048.jpg)

![Example for LSD Radix Sort
front[0] NULL rear[0]
front[1] 271 NULL rear[1]
front[2] NULL rear[2]
front[3] 93 33 NULL rear[3]
front[4] 984 NULL rear[4]
front[5] 55 NULL rear[5]
front[6] 306 NULL rear[6]
front[7] NULL rear[7]
front[8] 208 NULL rear[8]
front[9] 179 859 9 NULL rear[9]
179, 208, 306, 93, 859, 984, 55, 9, 271, 33
271, 93, 33, 984, 55, 306, 208, 179, 859, 9 After the first pass
Sort
by
digit
concatenate
d (digit) = 3, r (radix) = 10 ascending order](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-75-2048.jpg)
![306 208 9 null
null
null
33 null
null
55 859 null
null
271 179 null
984 null
93 null
rear[0]
rear[1]
rear[2]
rear[3]
rear[4]
rear[5]
rear[6]
rear[7]
rear[8]
rear[9]
front[0]
front[1]
front[2]
front[3]
front[4]
front[5]
front[6]
front[7]
front[8]
front[9]
306, 208, 9, 33, 55, 859, 271, 179, 984, 93 (second pass)](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-76-2048.jpg)
![9 33 55
306 null
null
null
859 null
984 null
rear[0]
rear[1]
rear[2]
rear[3]
rear[4]
rear[5]
rear[6]
rear[7]
rear[8]
rear[9]
front[0]
front[1]
front[2]
front[3]
front[4]
front[5]
front[6]
front[7]
front[8]
front[9]
9, 33, 55, 93, 179, 208, 271, 306, 859, 984 (third pass)
93 null
179 null
208 271 null
null
null](https://image.slidesharecdn.com/ds10-241017200916-fc74ca9d/75/Sorting-algorithms-bubble-sort-to-merge-sort-pdf-77-2048.jpg)















![UNIT V Searching Sorting Hashing Techniques [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unitvsearchingsortinghashingtechniquesautosaved-241014040608-74caa0f6-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
![UNIT V Searching Sorting Hashing Techniques [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/unitvsearchingsortinghashingtechniquesautosaved-241126054304-95a69c51-thumbnail.jpg?width=600ounds&width=560&fit=bounds)














![Agentic Systems and Compliance - A brief intro [1.2]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticsystemsandcompliace-1-251018025303-958a42ec-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


















