Downloaded 20 times


![ Definitions
- Formal Definition of String Matching Problem- Formal Definition of String Matching Problem
- Assume text is an array T[1..n] of length n and- Assume text is an array T[1..n] of length n and
the pattern is an array P[1..m] of length m ≤ nthe pattern is an array P[1..m] of length m ≤ n
Explanation:Explanation:
This basically means that there is a string array T which contains a certainThis basically means that there is a string array T which contains a certain
number of characters that is larger than the number of characters in stringnumber of characters that is larger than the number of characters in string
array P. P is said to be the pattern array because it contains a pattern ofarray P. P is said to be the pattern array because it contains a pattern of
characters to be searched for in the larger array T.characters to be searched for in the larger array T.](https://image.slidesharecdn.com/stringmatchingalgorithms-171108075656/85/String-matching-algorithms-3-320.jpg)

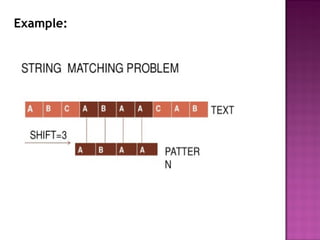

![1.Naive Algorithm
The idea of the naive solution is just to make a comparison character
by character of the text T[s...s + m − 1] for all s {0, . . . , n − m + 1}∈
and the pattern P[0...m − 1]. It returns all the valid shifts found.
Figure 2 shows how the algorithm work in a practical example.
For example if the pattern to search is a m and the text is a n, then
we need M operation of comparison by shift. For all the text, we need
(N − M + 1) × M operation, generally M is very small compared to N, it is
why we can simply considered the complexity as O(M × N). 2](https://image.slidesharecdn.com/stringmatchingalgorithms-171108075656/85/String-matching-algorithms-7-320.jpg)



![3. Boyer-Moore Algorithm (BM)
The basic idea behind this solution is that the match is performed
from right to left.
This characteristic allows the algorithm to skip more characters than
the other algorithms,
for example if the first character matched of the text is not
contained in the pattern P[0...m − 1], we can skip m characters
immediately. As the KMP algorithm, this algorithm preprocesses the
pattern to obtain a table which contains information to skip characters
for each character of the pattern. But BM algorithm use also another
table based on the alphabet. It contains as many entries as there are
characters in the alphabet
. In the example below, we can easily persuade the advantage of BM
algorithm over KMP and the naive one, we only need four attempts to
find the valid shift.](https://image.slidesharecdn.com/stringmatchingalgorithms-171108075656/85/String-matching-algorithms-11-320.jpg)

![4. Rabin-Karp Algorithm
(RK)
The Rabin-Karp algorithm uses a totally different approach to solve the
string matching problem.
This method is based on hashing techniques. We compute a hash function
h(x) for the pattern P[0...m−1] and then look for a match by using the same
hash function for each substring of length m − 1 of the text .
The Rabin-Karp also use preprocessing technique before the search
operation. Its preprocessing operation is the hashing of the pattern, which is
O(M) complexity. So, the running time of the algorithm is O(M × (N − M + 1)),
but in general, we will see, that the algorithms will run with a complexity
O(N).
Let’s introduce following notations:
• h(p) : the hashed value of the pattern
• h(ts) : the hashed value of the substring [s, ..., s + M − 1]](https://image.slidesharecdn.com/stringmatchingalgorithms-171108075656/85/String-matching-algorithms-13-320.jpg)



![ Definitions
- Formal Definition of String Matching Problem- Formal Definition of String Matching Problem
- Assume text is an array T[1..n] of length n and- Assume text is an array T[1..n] of length n and
the pattern is an array P[1..m] of length m ≤ nthe pattern is an array P[1..m] of length m ≤ n
Explanation:Explanation:
This basically means that there is a string array T which contains a certainThis basically means that there is a string array T which contains a certain
number of characters that is larger than the number of characters in stringnumber of characters that is larger than the number of characters in string
array P. P is said to be the pattern array because it contains a pattern ofarray P. P is said to be the pattern array because it contains a pattern of
characters to be searched for in the larger array T.characters to be searched for in the larger array T.](https://image.slidesharecdn.com/stringmatchingalgorithms-171108075656/75/String-matching-algorithms-3-2048.jpg)


![1.Naive Algorithm
The idea of the naive solution is just to make a comparison character
by character of the text T[s...s + m − 1] for all s {0, . . . , n − m + 1}∈
and the pattern P[0...m − 1]. It returns all the valid shifts found.
Figure 2 shows how the algorithm work in a practical example.
For example if the pattern to search is a m and the text is a n, then
we need M operation of comparison by shift. For all the text, we need
(N − M + 1) × M operation, generally M is very small compared to N, it is
why we can simply considered the complexity as O(M × N). 2](https://image.slidesharecdn.com/stringmatchingalgorithms-171108075656/75/String-matching-algorithms-7-2048.jpg)



![3. Boyer-Moore Algorithm (BM)
The basic idea behind this solution is that the match is performed
from right to left.
This characteristic allows the algorithm to skip more characters than
the other algorithms,
for example if the first character matched of the text is not
contained in the pattern P[0...m − 1], we can skip m characters
immediately. As the KMP algorithm, this algorithm preprocesses the
pattern to obtain a table which contains information to skip characters
for each character of the pattern. But BM algorithm use also another
table based on the alphabet. It contains as many entries as there are
characters in the alphabet
. In the example below, we can easily persuade the advantage of BM
algorithm over KMP and the naive one, we only need four attempts to
find the valid shift.](https://image.slidesharecdn.com/stringmatchingalgorithms-171108075656/75/String-matching-algorithms-11-2048.jpg)

![4. Rabin-Karp Algorithm
(RK)
The Rabin-Karp algorithm uses a totally different approach to solve the
string matching problem.
This method is based on hashing techniques. We compute a hash function
h(x) for the pattern P[0...m−1] and then look for a match by using the same
hash function for each substring of length m − 1 of the text .
The Rabin-Karp also use preprocessing technique before the search
operation. Its preprocessing operation is the hashing of the pattern, which is
O(M) complexity. So, the running time of the algorithm is O(M × (N − M + 1)),
but in general, we will see, that the algorithms will run with a complexity
O(N).
Let’s introduce following notations:
• h(p) : the hashed value of the pattern
• h(ts) : the hashed value of the substring [s, ..., s + M − 1]](https://image.slidesharecdn.com/stringmatchingalgorithms-171108075656/75/String-matching-algorithms-13-2048.jpg)


This document discusses and defines four common algorithms for string matching: 1. The naive algorithm compares characters one by one with a time complexity of O(MN). 2. The Knuth-Morris-Pratt (KMP) algorithm uses pattern preprocessing to skip previously checked characters, achieving linear time complexity of O(N+M). 3. The Boyer-Moore (BM) algorithm matches strings from right to left and uses pattern preprocessing tables to skip more characters than KMP, with sublinear worst-case time complexity of O(N/M). 4. The Rabin-Karp (RK) algorithm uses hashing techniques to find matches in text substrings, with time complexity of



































![Gp 27[string matching].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/gp27stringmatching-230422183348-6f0879e9-thumbnail.jpg?width=600ounds&width=560&fit=bounds)



















































