Download as PDF, PPTX








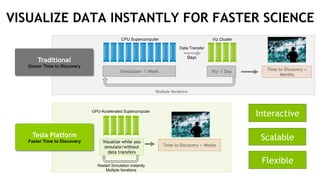









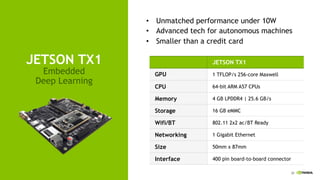
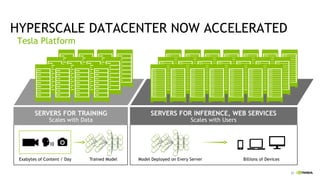



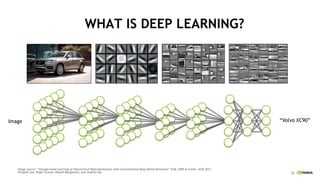
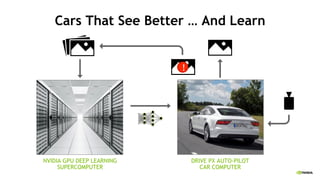
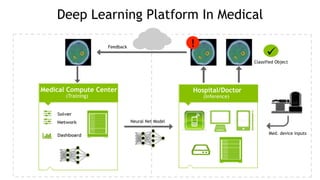

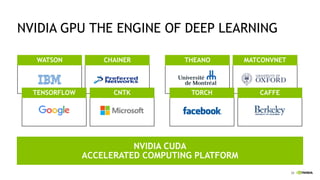
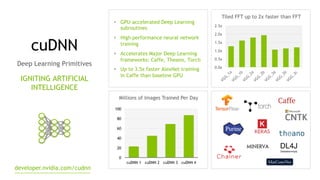








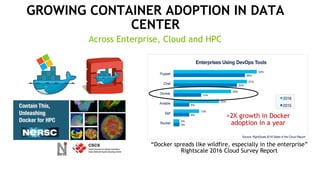








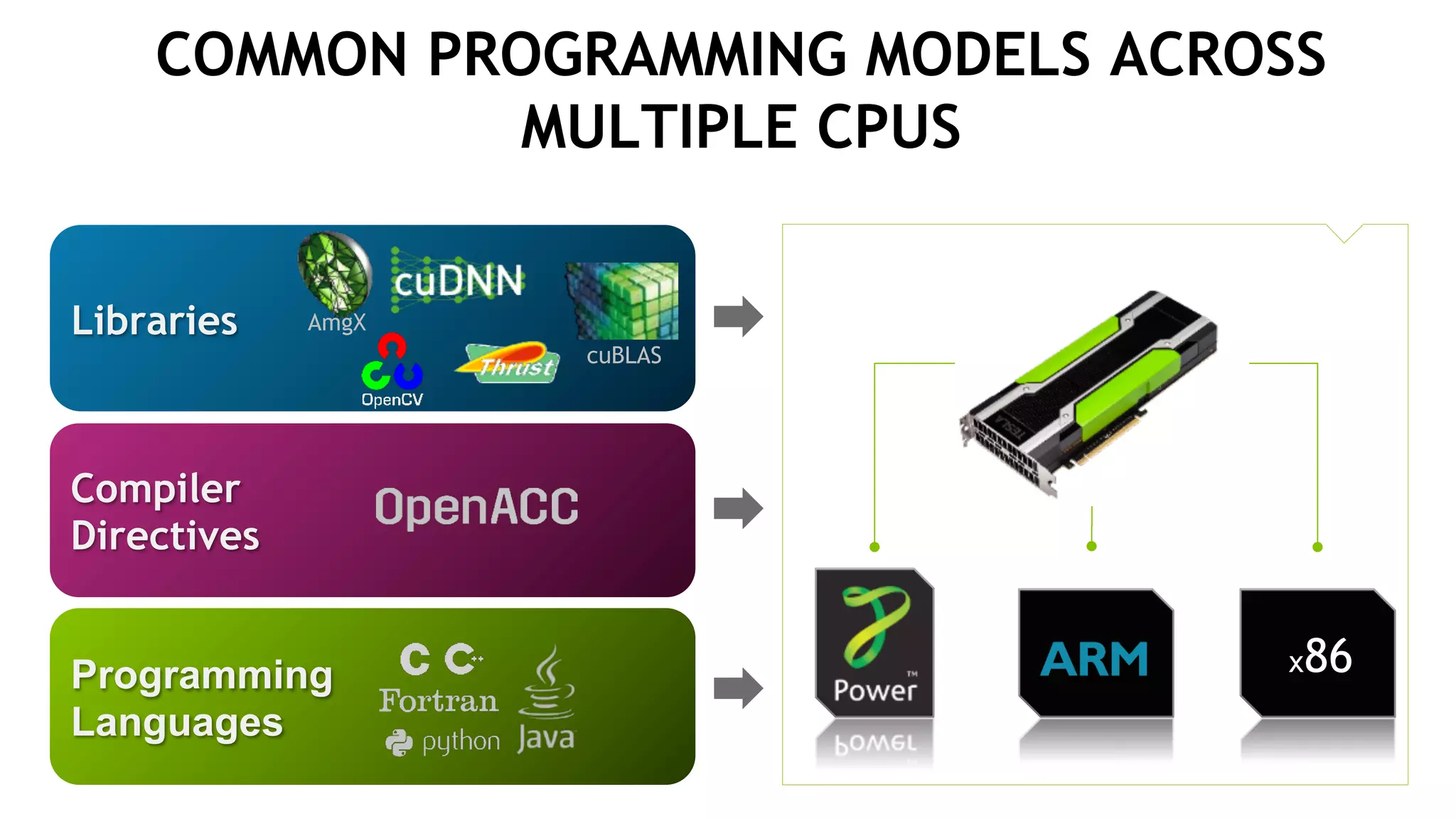


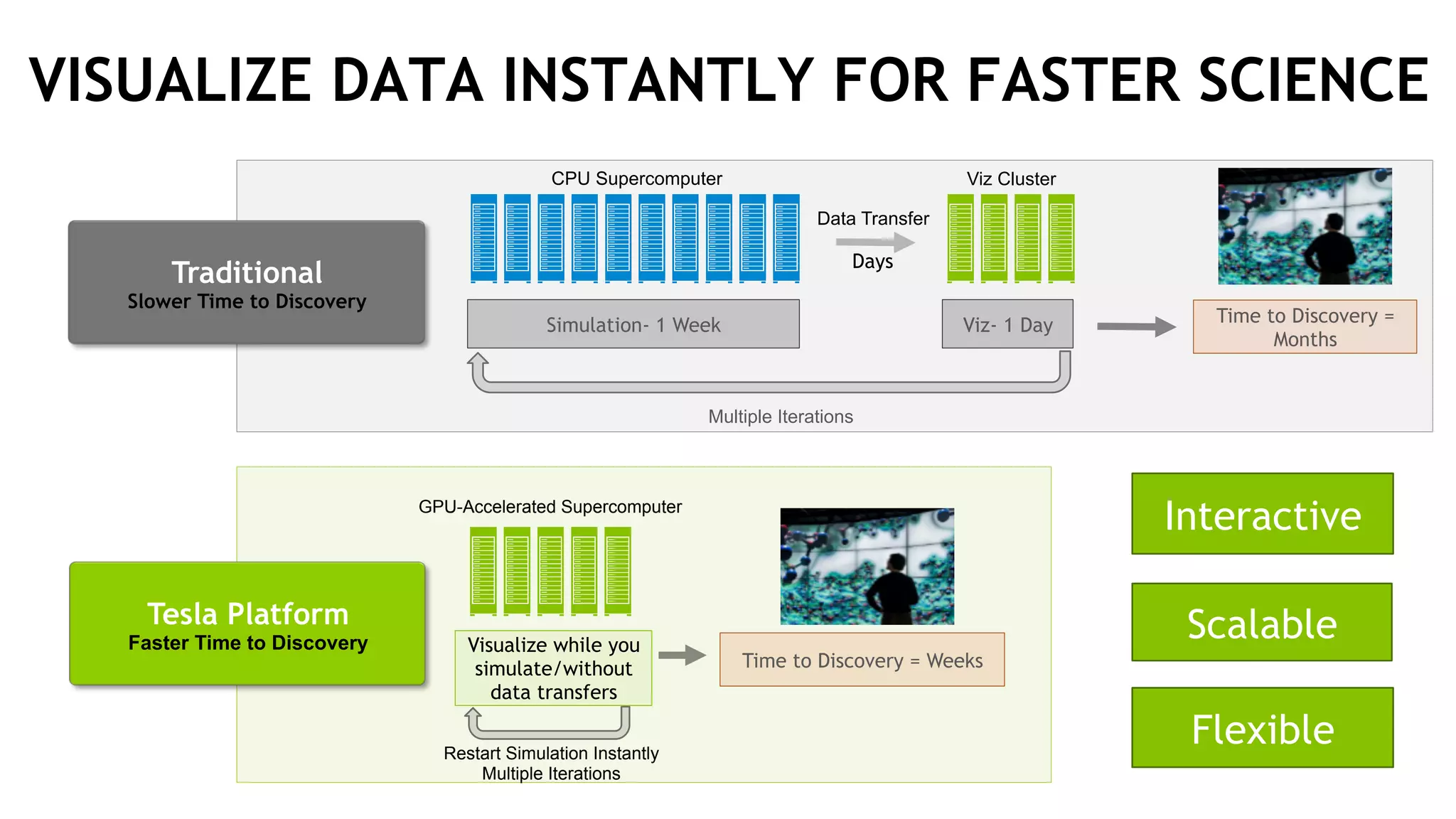










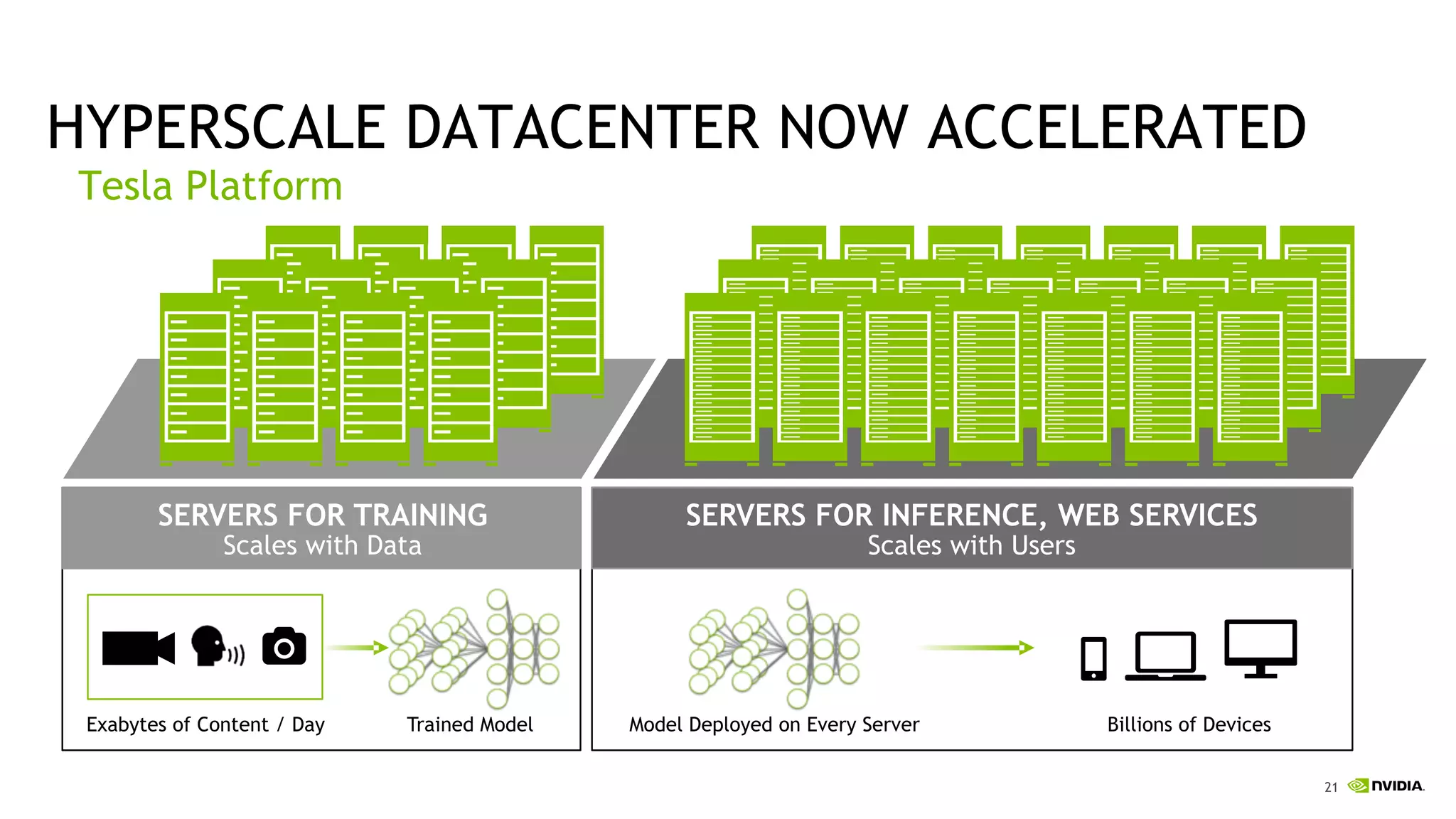



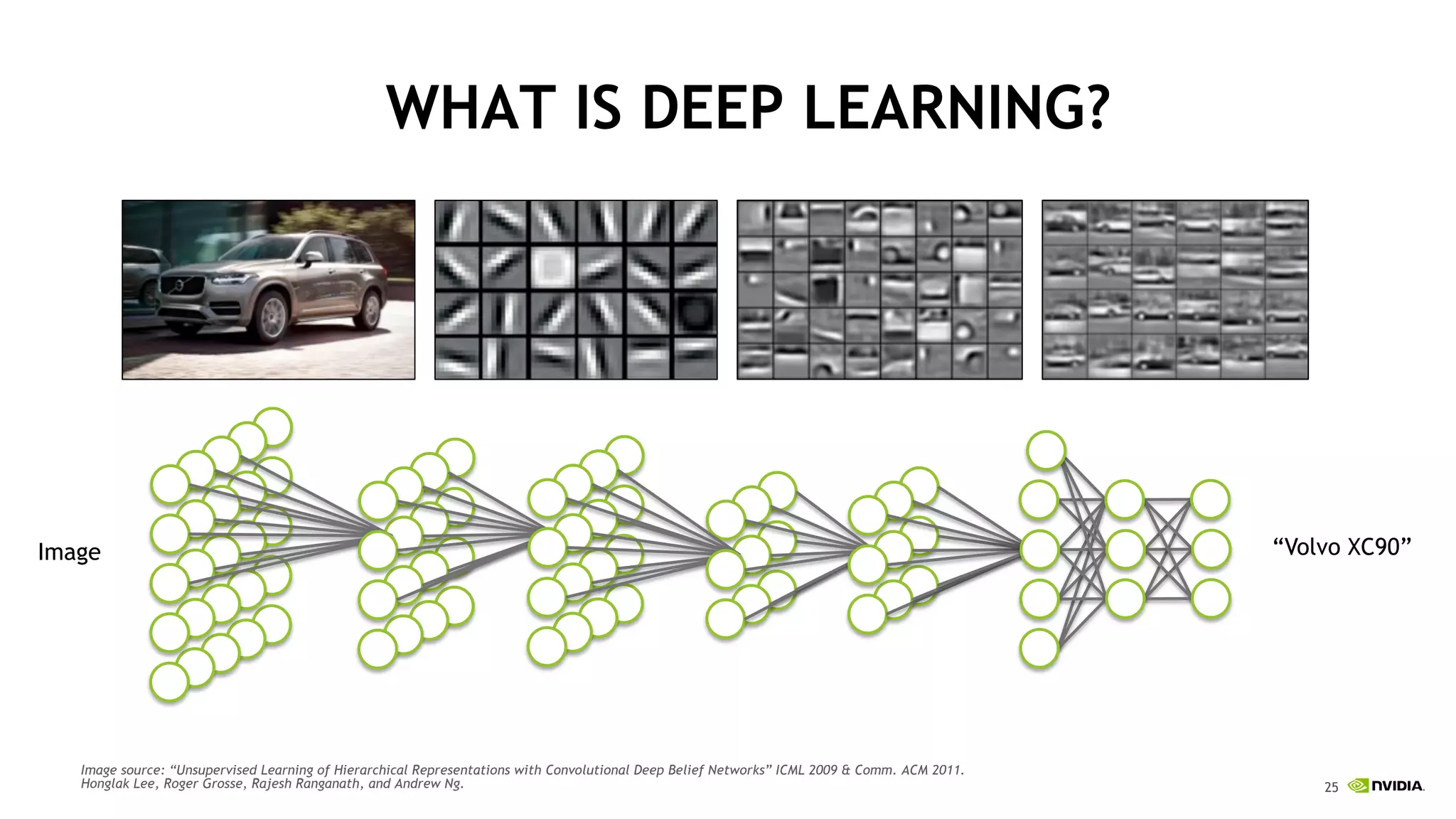
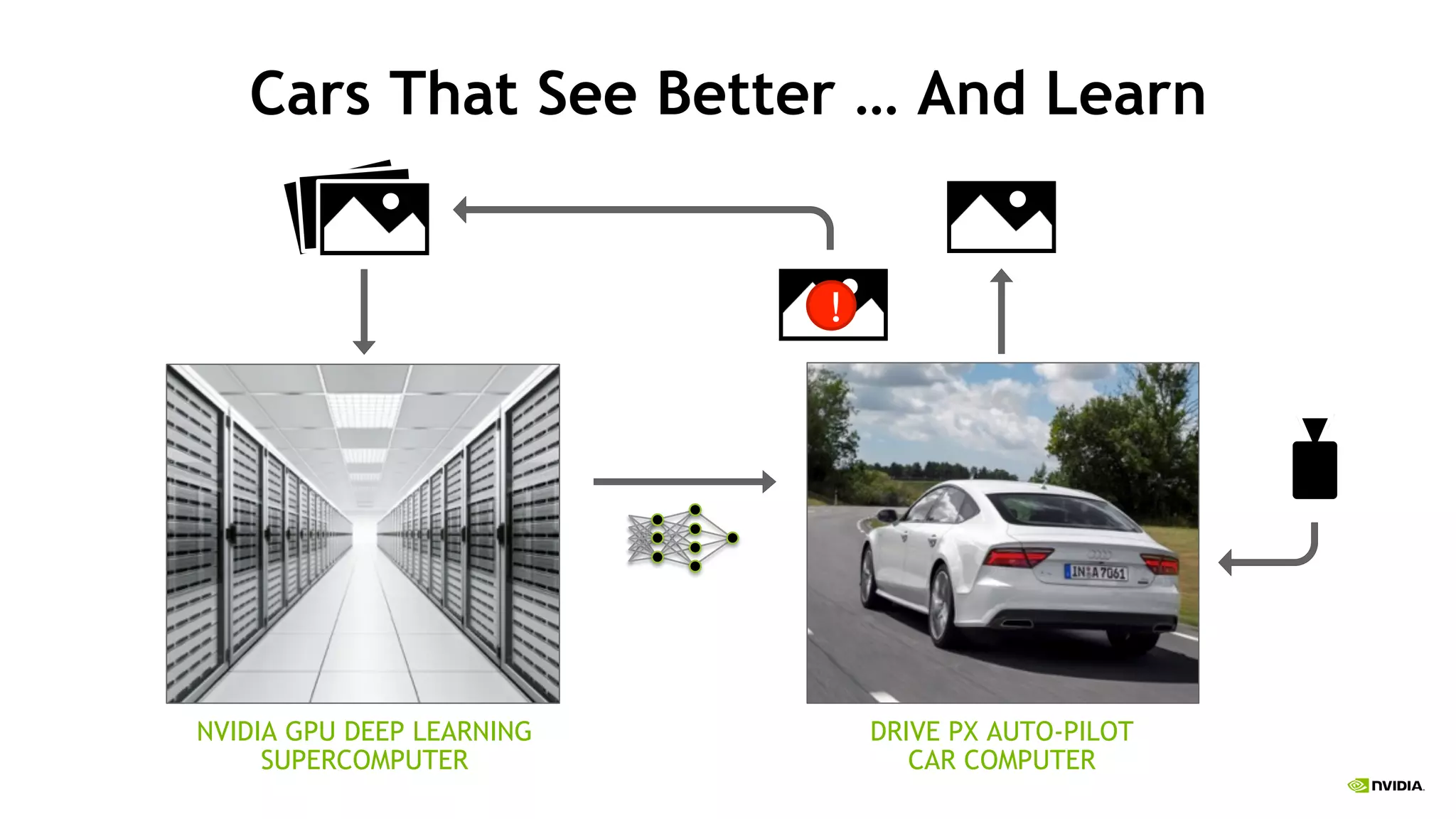
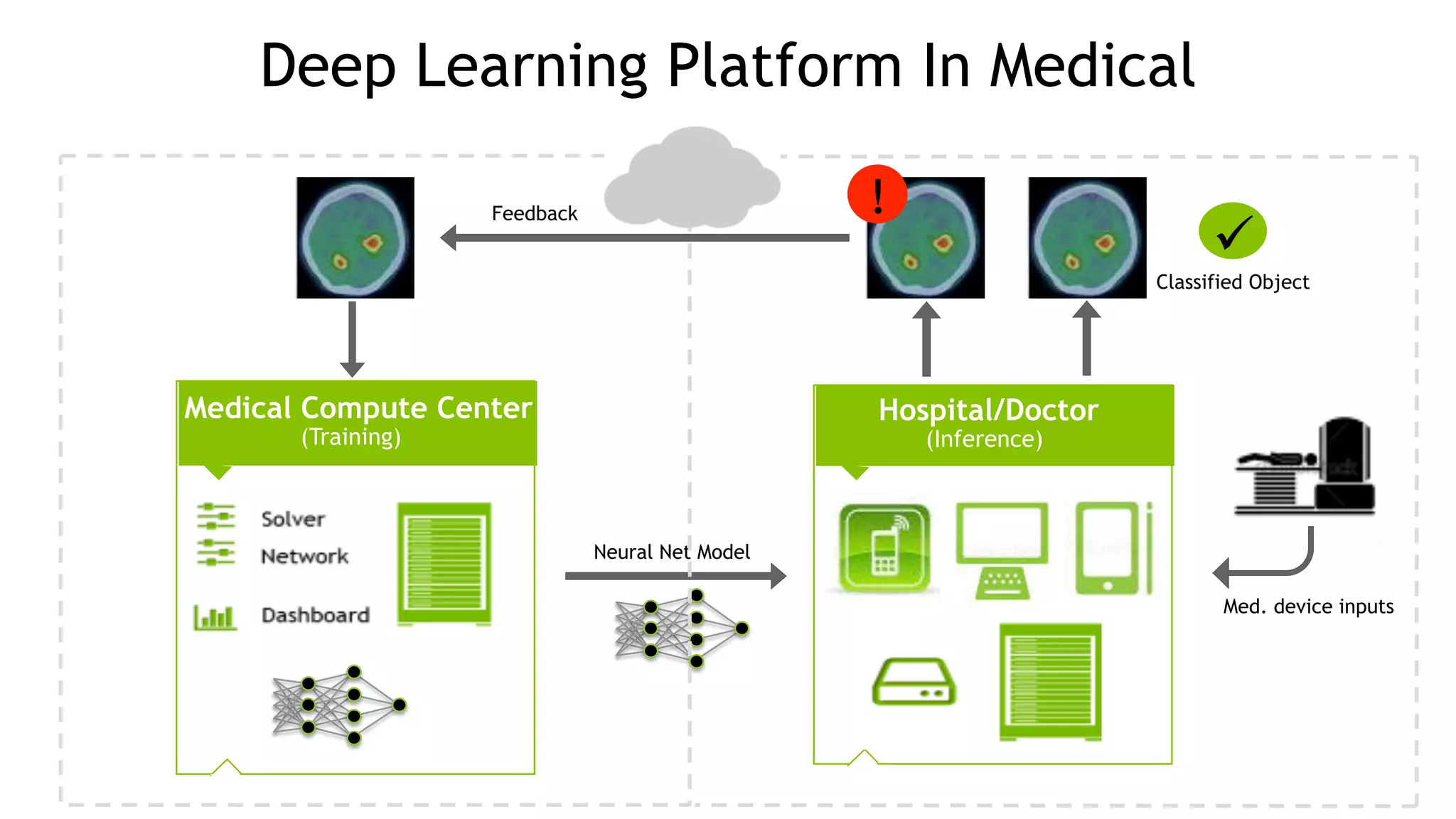
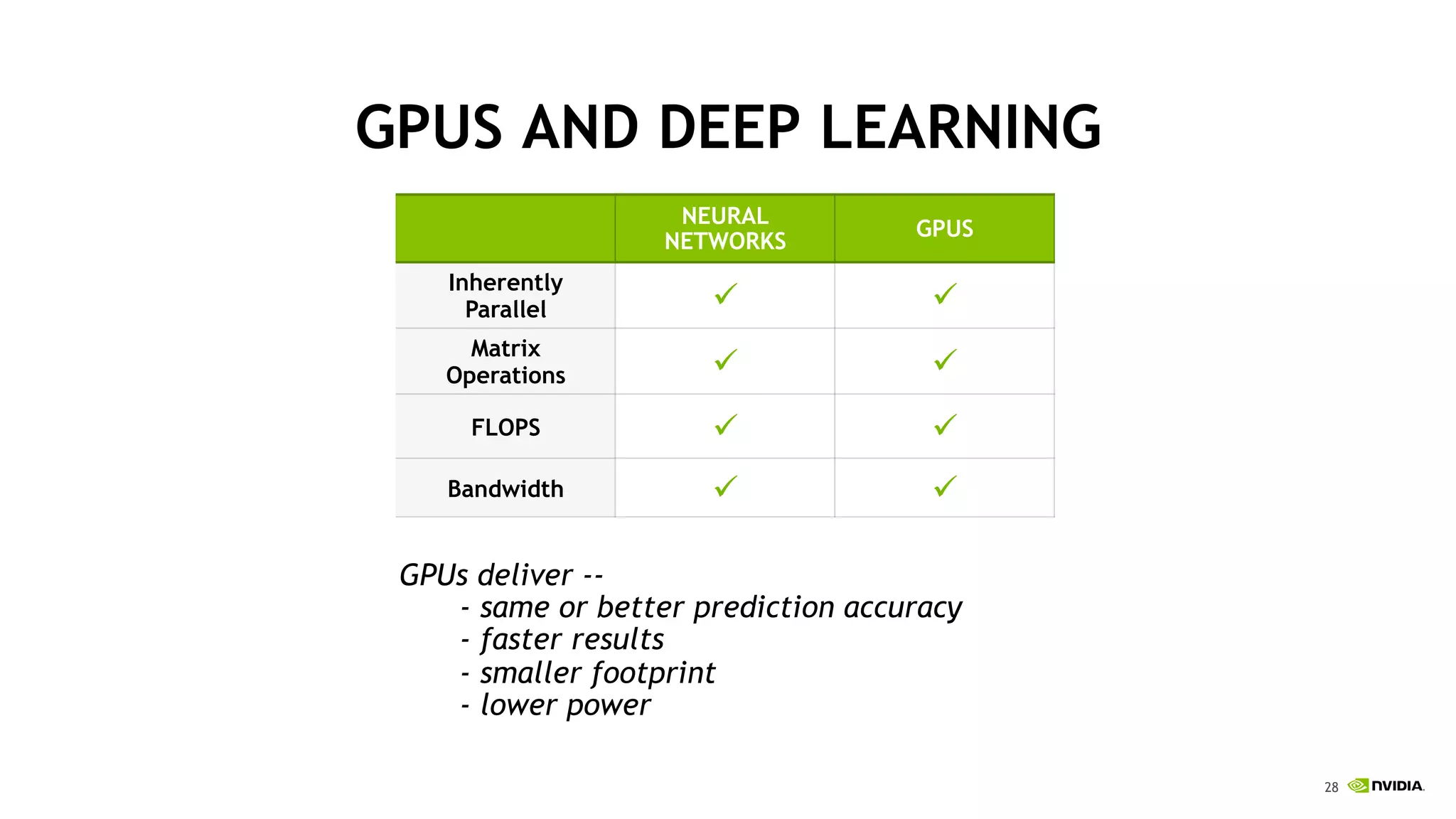
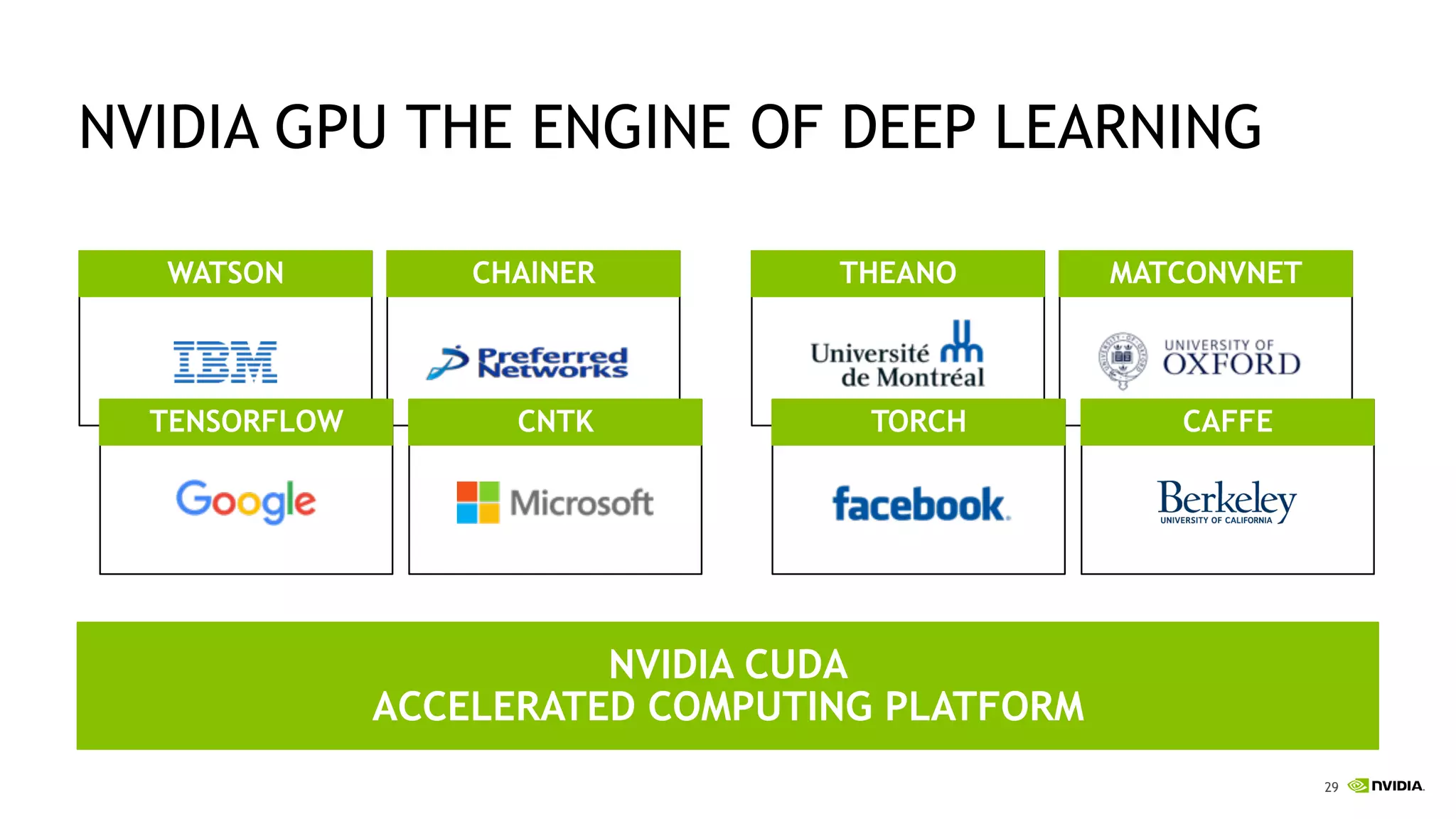
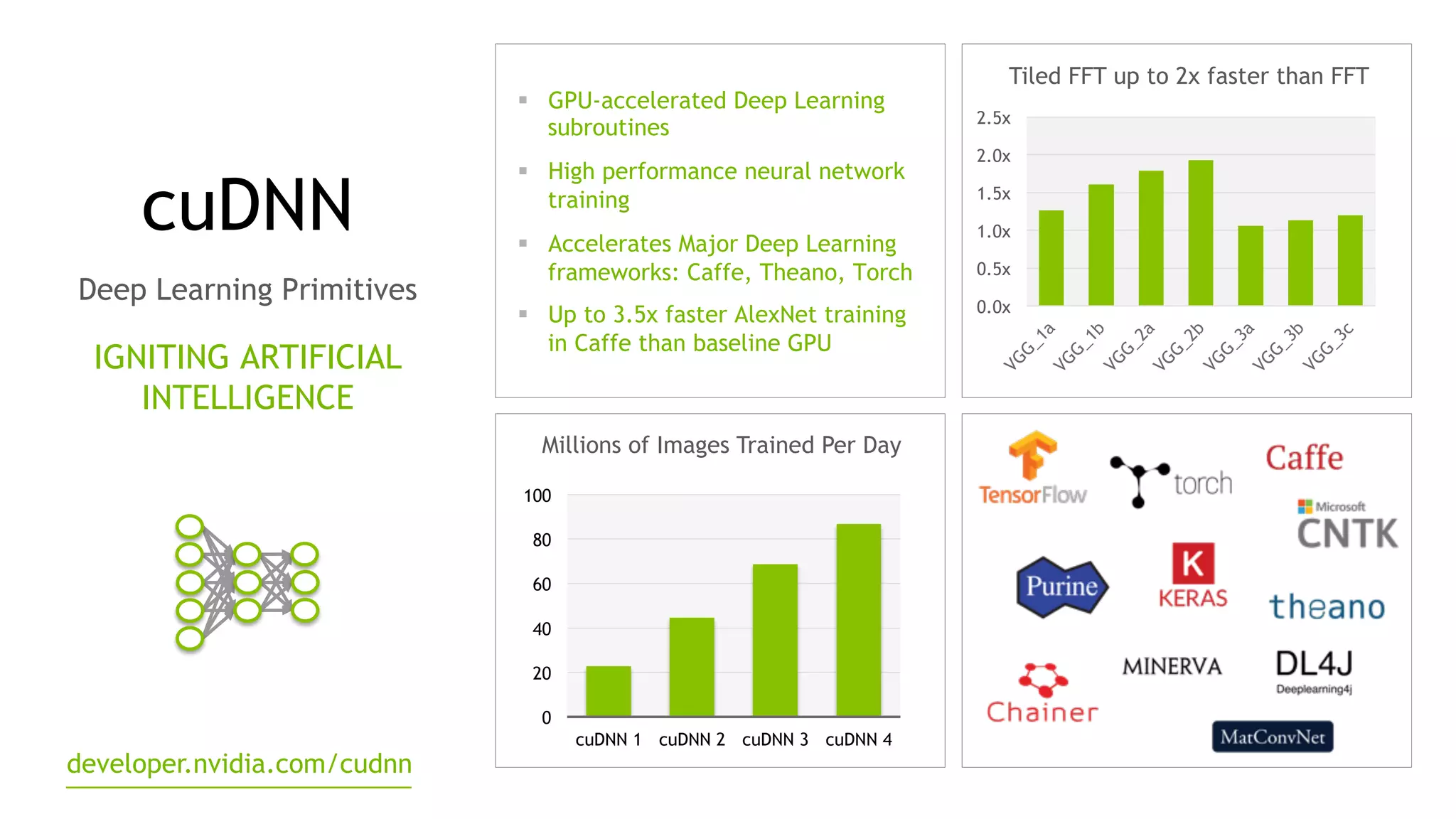












The document discusses the Tesla Accelerated Computing Platform presented at the HPC Advisory Council meeting in Lugano, covering various applications in high-performance computing (HPC), hyperscale environments, and machine learning. It highlights the capabilities and performance metrics of Tesla GPUs, including the K80 and M40, detailing their advantages in processing speed and efficiency for data visualization and deep learning tasks. Additionally, the report emphasizes NVIDIA's technological innovations like NVLink and GPU management software to enhance data center operations and support deep learning frameworks.



























































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)







