This document discusses web mining and outlines its goals, types, and techniques. Web mining involves examining data from the world wide web and includes web content mining, web structure mining, and web usage mining. Content mining analyzes web page contents, structure mining analyzes hyperlink structures, and usage mining analyzes web server logs and user browsing patterns. Common techniques discussed include page ranking algorithms, focused crawlers, usage pattern discovery, and preprocessing of web server logs.
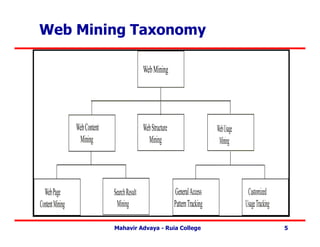
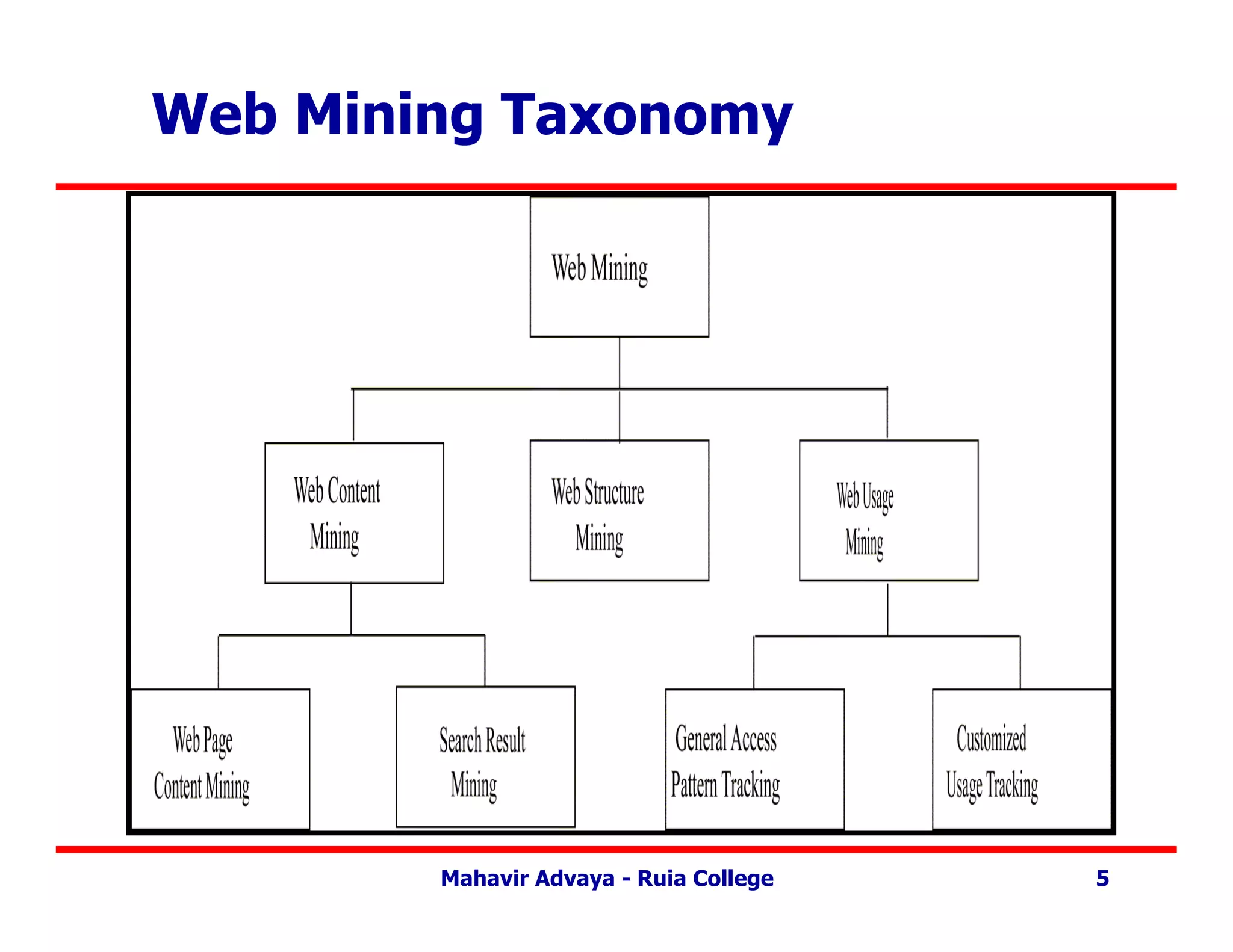
Web Mining Outline
•Goal –
– Examine the use of data mining on the World Wide
Web.
• Outline -
– Introduction.
– Web Content Mining.
– Web Structure Mining.
– Web Usage Mining.
Mahavir Advaya - Ruia College 2
3.
Web Mining Issues
•Size –
– >350 million pages (1999).
– Grows at about 1 million pages a day.
– Google indexes 3 billion documents.
• Diverse types of data.
Mahavir Advaya - Ruia College 3
4.
Web Data
• Web pages.
• Intra-page structures.
• Inter-page structures.
• Usage data.
• Supplemental data –
– Profiles.
– Registration information.
– Cookies.
Mahavir Advaya - Ruia College 4
Web Content Mining
•Extends work of basic search engines.
• Search Engines –
– IR application.
– Keyword based.
– Similarity between query and document.
– Crawlers.
– Indexing.
– Profiles.
– Link analysis.
Mahavir Advaya - Ruia College 6
7.
Crawlers (Spider)
• Robot(spider), a program, traverses the hypertext structure in
the Web.
– Collect information from visited pages.
– Used to construct indexes for search engines.
• Traditional Crawler – visits entire Web (?) and replaces index.
• Periodic Crawler – visits portions of the Web and updates subset
of index.
• Incremental Crawler – selectively searches the Web and
incrementally modifies index.
• Focused Crawler – visits pages related to a particular subject.
Mahavir Advaya - Ruia College 7
8.
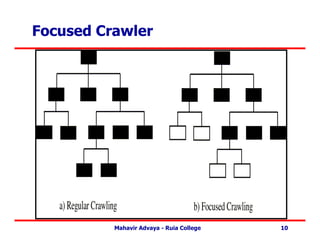
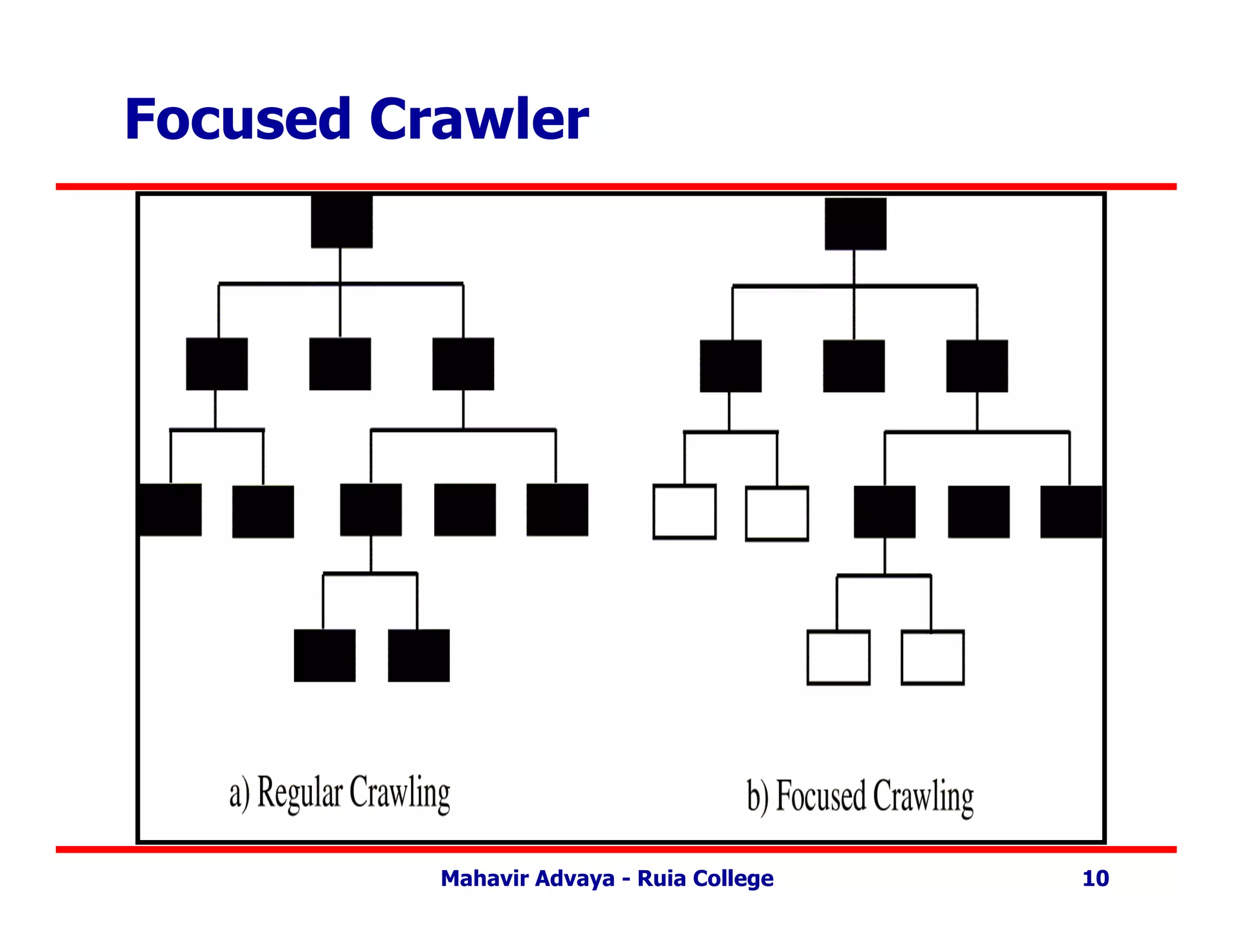
Focused Crawler
• Onlyvisit links from a page if that page is determined to
be relevant.
• Classifier is static after learning phase.
• Components –
– Hypertext Classifier which assigns relevance score to
each page based on crawl topic.
– Distiller to identify hub pages.
– Crawler visits pages to based on crawler and distiller
scores.
Mahavir Advaya - Ruia College 8
9.
Focused Crawler
• Classifierto related documents to topics.
• Classifier also determines how useful outgoing links are.
• Hub Pages contain links to many relevant pages. Must
be visited even if not high relevance score.
Mahavir Advaya - Ruia College 9
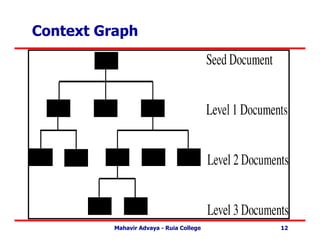
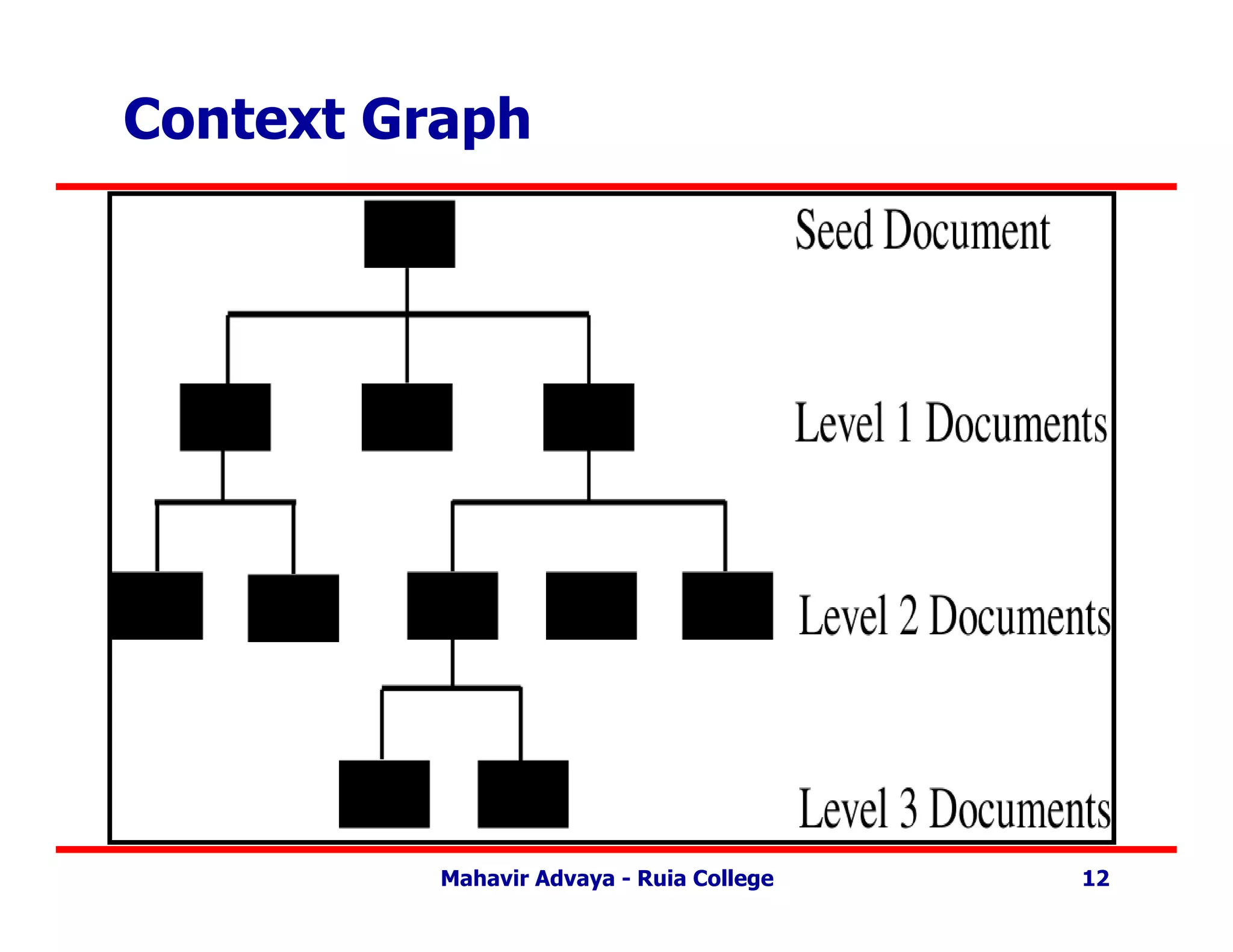
Context Focused Crawler
• Context Graph –
– Context graph created for each seed document .
– Root is the seed document.
– Nodes at each level show documents with links to
documents at next higher level.
– Updated during crawl itself .
• Approach –
1. Construct context graph and classifiers using seed
documents as training data.
2. Perform crawling using classifiers and context graph
created.
Mahavir Advaya - Ruia College 11
Virtual Web View
•Approach to handle unstructured data.
• Multiple Layered DataBase (MLDB) built on top of the
Web.
• Each layer of the database is more generalized (and
smaller) and centralized than the one beneath it.
• Upper layers of MLDB are structured and can be accessed
with SQL type queries.
• Does not require the use of spiders (Crawlers).
• Translation tools convert Web documents to XML.
• Extraction tools extract desired information to place in first
layer of MLDB. Convert web document to XML.
• Higher levels contain more summarized data obtained
through generalizations of the lower levels.
Mahavir Advaya - Ruia College 13
14.
WebML
• Web dataMining Query Language.
• Provides data mining operations on MLDB.
• Major feature – four operations –
– COVERS: one concept covers another if it is higher in
the hierarchy.
– COVERED BY: reverse of COVERS, reverses the
descendents.
– LIKE: concept is a synonym.
– CLOSE TO: One concept is close to another if it is a
sibling in the hierarchy.
Mahavir Advaya - Ruia College 14
15.
WebML
• Example –
– Find all the documents at the level of
www.engr.smu.edu.
• Query –
SELECT *
FROM document in ‘ ‘ www.engr.smu.edu ‘ ‘
WHERE ONE OF keywords COVERS ‘ ‘ cat ‘ ‘
Mahavir Advaya - Ruia College 15
16.
Personalization
• Example ofWeb Content Mining.
• Web access or contents tuned to better fit the desires of each
user.
• With personalization, advertisements to be sent to the customers
based on specific knowledge.
• Goal – Make the customer purchase something.
• Three basic types –
– Manual techniques – identify user’s preferences based on
profiles or demographics.
– Collaborative filtering identifies preferences based on ratings
from similar users.
– Content based filtering retrieves pages based on similarity
between pages and user profiles.
Mahavir Advaya - Ruia College 16
17.
Web Structure Mining
•Create a model of the Web organization or a portion of
it.
• Mine structure (links, graph) of the Web.
• Techniques –
– PageRank.
– CLEVER.
• May be combined with content mining to more
effectively retrieve important pages.
Mahavir Advaya - Ruia College 17
18.
PageRank
• Used byGoogle.
• Prioritize pages returned from search by looking at Web
structure.
• Importance of page is calculated based on number of
pages which point to it – Backlinks.
• Weighting is used to provide more importance to
backlinks coming form important pages.
Mahavir Advaya - Ruia College 18
19.
PageRank (cont’d)
• PR(p)= c (PR(1)/N1 + … + PR(n)/Nn)
– PR(i): PageRank for a page i which points to
target page p.
– Ni: number of links coming out of page i.
– c: constant value between 0 and 1 used for
normalization.
Mahavir Advaya - Ruia College 19
20.
CLEVER
• System developedby IBM.
• Finding both authoritative and hub pages.
• Authoritative Pages –
– Authors define an authority as the “best source” for
the request.
o Highly important pages.
o Best source for requested information.
• Hub Pages –
– Contain links to highly important pages.
– Clever, identifies authoritative and hub pages by
creating weights.
Mahavir Advaya - Ruia College 20
21.
HITS
• Hyperlink-Induces TopicSearch.
• Finds Hubs and Authoritative Pages.
• Two components –
– Based on a set of keywords, find set of relevant
pages – R.
– Identify hub and authority pages for these.
o Expand R to a base set, B, of pages linked to or
from R.
o Calculate weights for authorities and hubs.
• Pages with highest ranks in R are returned.
Mahavir Advaya - Ruia College 21
Web Usage Mining
•Extends work of basic search engines.
• Performs mining on Web usage data or Web logs.
• Search Engines –
– IR application.
– Keyword based.
– Similarity between query and document.
– Crawlers.
– Indexing.
– Profiles.
– Link analysis.
Mahavir Advaya - Ruia College 23
24.
Web Usage MiningApplications
• Personalization – tracking of previously accessed pages.
• Determining frequent access behavior for users.
• Improve structure of a site’s Web pages.
• Aid in caching and prediction of future page references.
• Improve design of individual pages.
• Improve effectiveness of e-commerce (sales and
advertising).
• Gathering Statistics – considering accessed pages may
or may not be viewed as part web mining .
Mahavir Advaya - Ruia College 24
25.
Web Usage MiningActivities
• Preprocessing Web log –
– Cleanse.
– Remove extraneous information.
– Sessionize –
o Session: Sequence of pages referenced by one user at a
sitting.
• Pattern Discovery –
– Count patterns that occur in sessions.
– Pattern is sequence of pages references in session.
– Similar to association rules –
o Transaction: session.
o Itemset: pattern (or subset).
o Order is important.
• Pattern Analysis.
Mahavir Advaya - Ruia College 25
26.
ARs in WebMining
• Web Mining –
– Content.
– Structure.
– Usage.
• Frequent patterns of sequential page references in Web
searching.
• Uses –
– Caching
– Clustering users
– Develop user profiles
– Identify important pages
Mahavir Advaya - Ruia College 26
27.
Web Usage MiningIssues
• Identification of exact user not possible.
• Exact sequence of pages referenced by a user not
possible due to caching.
• Session not well defined.
• Security, privacy, and legal issues.
Mahavir Advaya - Ruia College 27
28.
Web Log Cleansing
•Replace source IP address with unique but non-
identifying ID.
• Replace exact URL of pages referenced with unique but
non-identifying ID.
• Delete error records and records containing not page
data (such as figures and code).
Mahavir Advaya - Ruia College 28
29.
Sessionizing
• Divide Weblog into sessions.
• Two common techniques –
– Number of consecutive page references from a source
IP address occurring within a predefined time interval
(e.g. 25 minutes).
– All consecutive page references from a source IP
address where the interclick time is less than a
predefined threshold.
Mahavir Advaya - Ruia College 29
30.
Data Structures
• Keeptrack of patterns identified during Web usage
mining process.
• Common techniques –
– Trie.
– Suffix Tree.
– Generalized Suffix Tree.
– WAP Tree.
Mahavir Advaya - Ruia College 30
31.
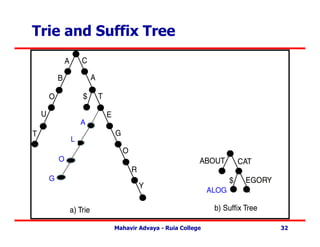
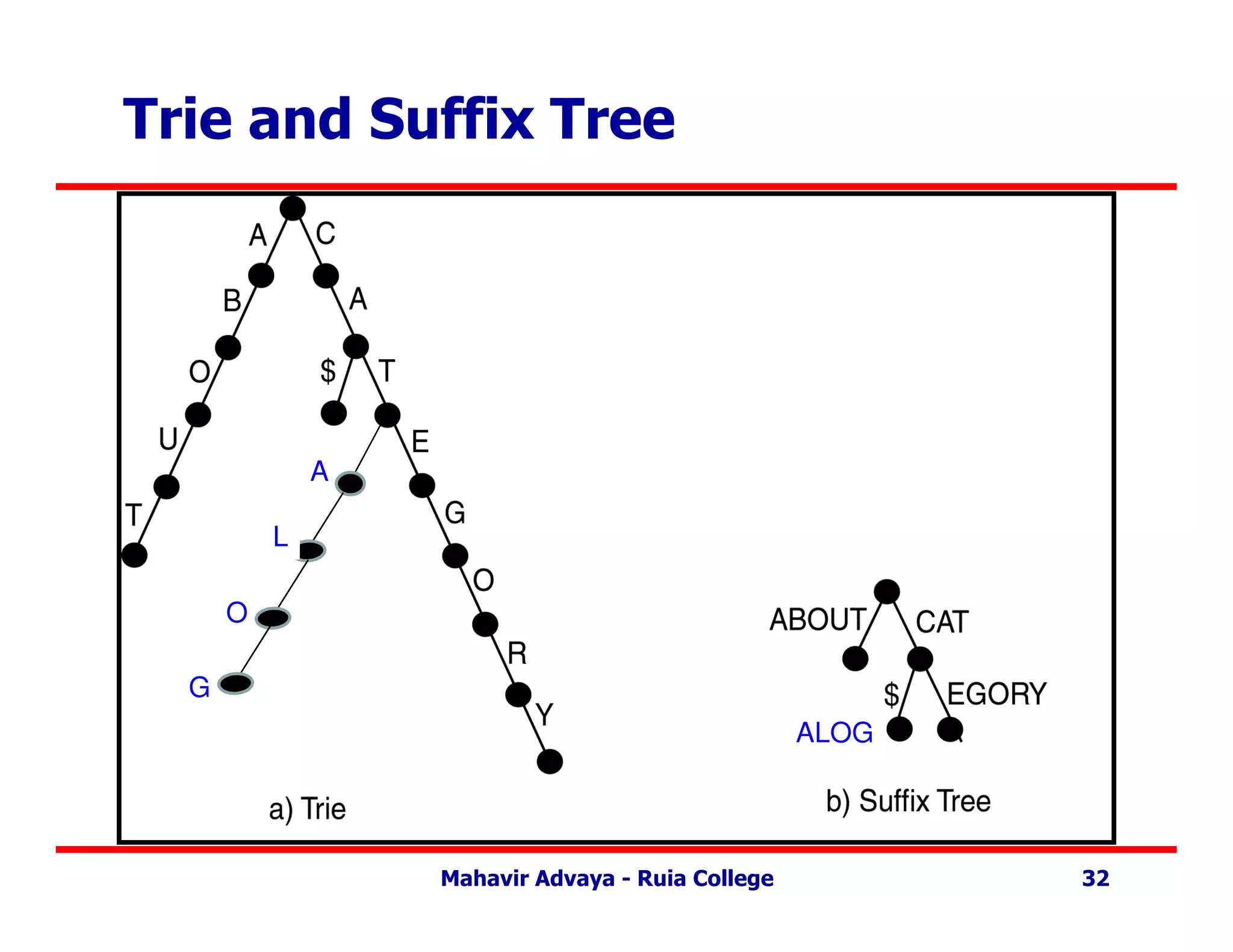
Trie vs. SuffixTree
• Trie –
– Rooted tree.
– Edges labeled which character (page) from pattern.
– Path from root to leaf represents pattern.
• Suffix Tree –
– Single child collapsed with parent. Edge contains
labels of both prior edges.
Mahavir Advaya - Ruia College 31
32.
Trie and SuffixTree
A
L
O
G
ALOG
Mahavir Advaya - Ruia College 32
33.
Generalized Suffix Tree
•Suffix tree for multiple sessions.
• Contains patterns from all sessions.
• Maintains count of frequency of occurrence of a pattern
in the node.
• WAP Tree –
– Web Access Pattern.
– Compressed version of generalized suffix tree.
– Tree stores sequences and their counts.
Mahavir Advaya - Ruia College 33
34.
Types of Patterns
•Algorithms have been developed to discover different
types of patterns.
• Properties –
– Ordered – Characters (pages) must occur in the exact
order in the original session.
– Duplicates – Duplicate characters are allowed in the
pattern.
– Consecutive – All characters in pattern must occur
consecutive in given session.
– Maximal – Not subsequence of another pattern.
Mahavir Advaya - Ruia College 34
Questions???
• Write ashort note on Web Content Mining.
• What is Web Mining? Give web mining taxonomy.
• What do you mean by Web Usage Mining? Explain rule with
examples.
• Write a short note on Harvest System.
• Define crawler. State and explain different types of crawlers.
• Write a short note on crawlers.
• Give taxonomy of web mining activities. For what purpose web
usage mining is used? What activities are involved in web usage
mining?
• What do you understand by the term “Web Usage Mining”.
• Explain the term crawlers in web mining.
• Discuss the importance of establishing a standardized WebML.
• Write a short note on web structure mining.
Mahavir Advaya - Ruia College 36