0% found this document useful (0 votes)
10 views9 pagesA Data Science Project 2
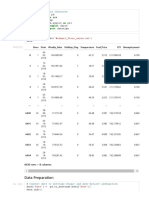
The document outlines a data science project involving a global super-store's sales data, focusing on data cleaning, analysis, and visualization using Python libraries such as Pandas, Matplotlib, and Seaborn. Key tasks include handling missing values, identifying duplicates, and performing statistical analysis, including correlation and regression modeling. The project culminates in a linear regression model to predict sales based on profit and discount variables.
Uploaded by
23stcs21Copyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
0% found this document useful (0 votes)
10 views9 pagesA Data Science Project 2
The document outlines a data science project involving a global super-store's sales data, focusing on data cleaning, analysis, and visualization using Python libraries such as Pandas, Matplotlib, and Seaborn. Key tasks include handling missing values, identifying duplicates, and performing statistical analysis, including correlation and regression modeling. The project culminates in a linear regression model to predict sales based on profit and discount variables.
Uploaded by
23stcs21Copyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
/ 9