Greedy algorithms make locally optimal choices at each step to arrive at a global optimum. The fractional knapsack problem uses a greedy approach of selecting items with the highest value per unit weight. Huffman coding also uses a greedy approach by iteratively combining the two least frequent symbols into a new node, building a prefix tree that assigns shorter codes to more frequent symbols. Both problems can be solved in O(n log n) time by using priority queues to efficiently select the best options at each step.



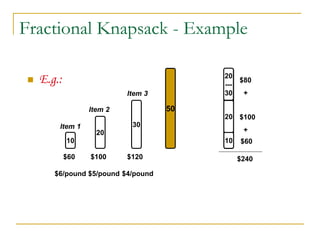


![Fractional Knapsack Problem
Alg.: Fractional-Knapsack (W, v[n], w[n])
1. While w > 0 and as long as there are items remaining
2. pick item with maximum vi/wi
3. xi min (1, w/wi)
4. remove item i from list
5. w w – xiwi
w – the amount of space remaining in the knapsack (w = W)
Running time: (n) if items already ordered; else (nlgn)](https://image.slidesharecdn.com/16greedyalgorithms-240311143355-3127e9f0/85/16_Greedy_Algorithms-Greedy_AlgorithmsGreedy_Algorithms-7-320.jpg)




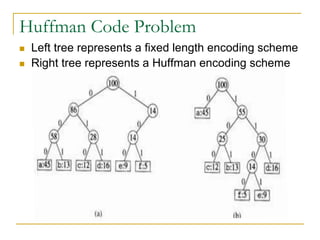
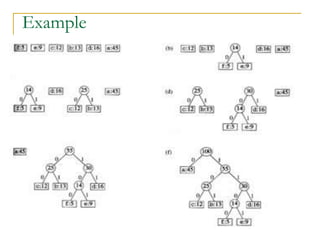


![Huffman Code Problem
In the pseudocode that follows:
we assume that C is a set of n characters and that
each character c €C is an object with a defined
frequency f [c].
The algorithm builds the tree T corresponding to the
optimal code
A min-priority queue Q, is used to identify the two
least-frequent objects to merge together.
The result of the merger of two objects is a new
object whose frequency is the sum of the
frequencies of the two objects that were merged.](https://image.slidesharecdn.com/16greedyalgorithms-240311143355-3127e9f0/85/16_Greedy_Algorithms-Greedy_AlgorithmsGreedy_Algorithms-16-320.jpg)








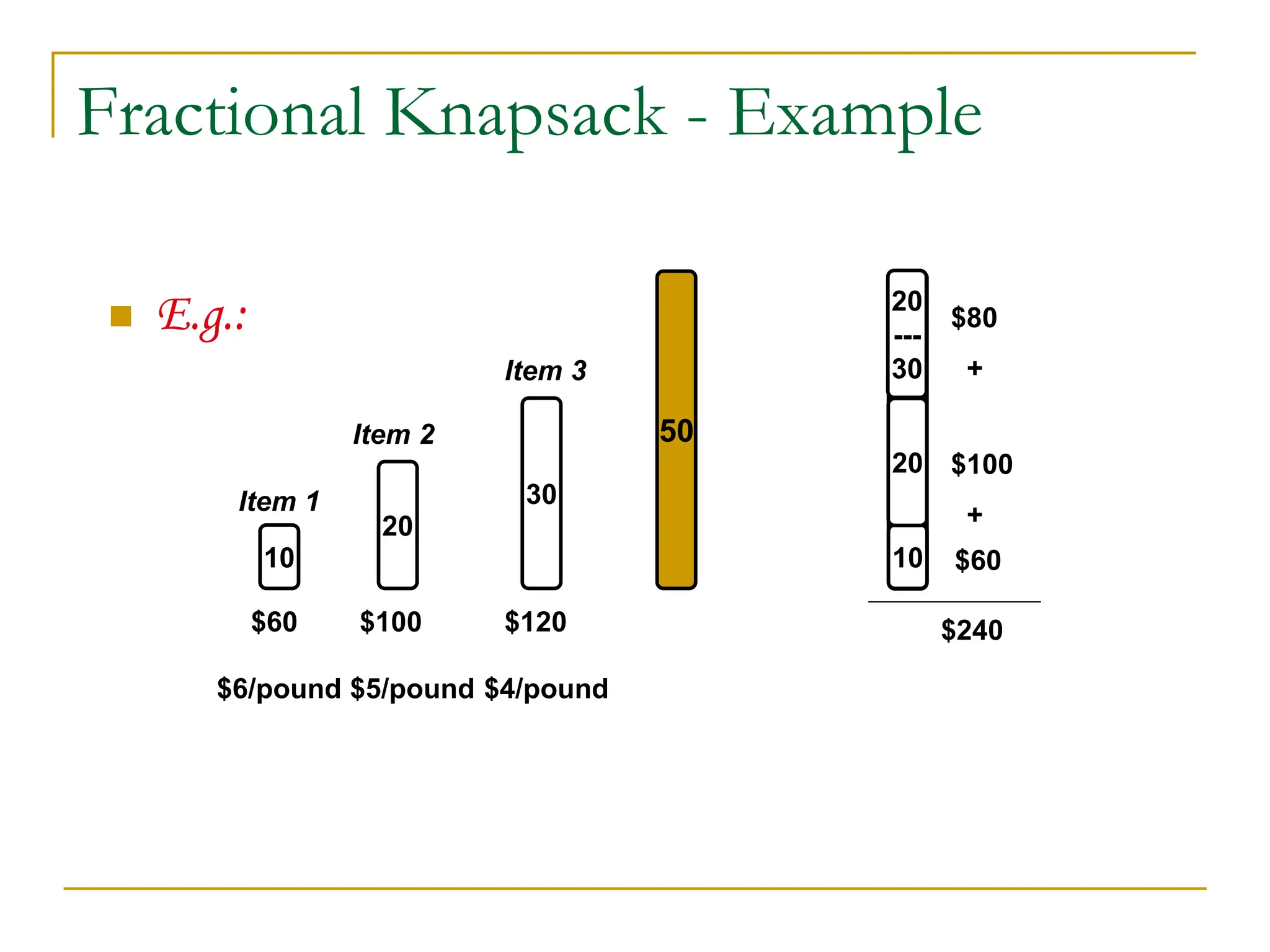


![Fractional Knapsack Problem
Alg.: Fractional-Knapsack (W, v[n], w[n])
1. While w > 0 and as long as there are items remaining
2. pick item with maximum vi/wi
3. xi min (1, w/wi)
4. remove item i from list
5. w w – xiwi
w – the amount of space remaining in the knapsack (w = W)
Running time: (n) if items already ordered; else (nlgn)](https://image.slidesharecdn.com/16greedyalgorithms-240311143355-3127e9f0/75/16_Greedy_Algorithms-Greedy_AlgorithmsGreedy_Algorithms-7-2048.jpg)




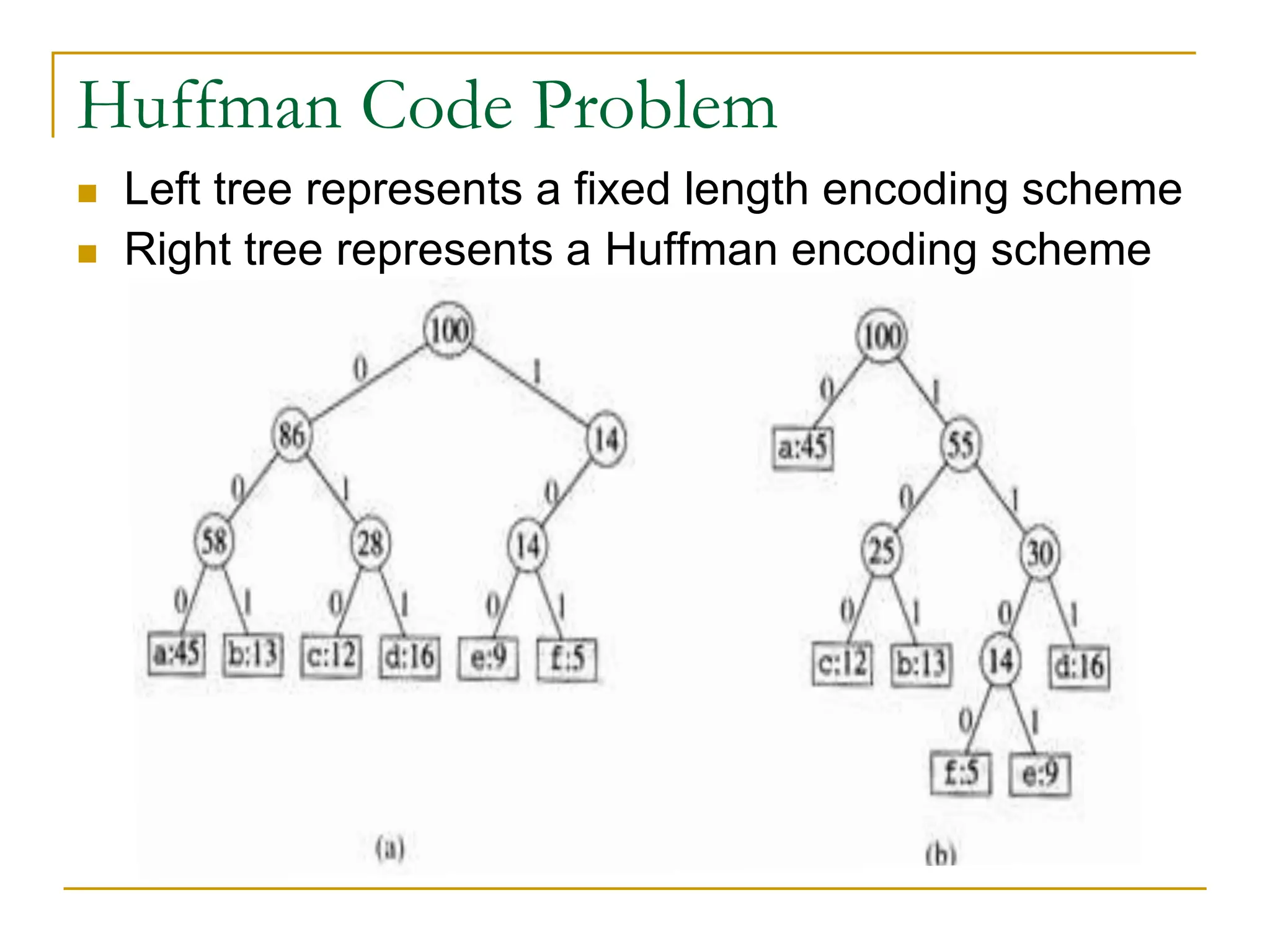
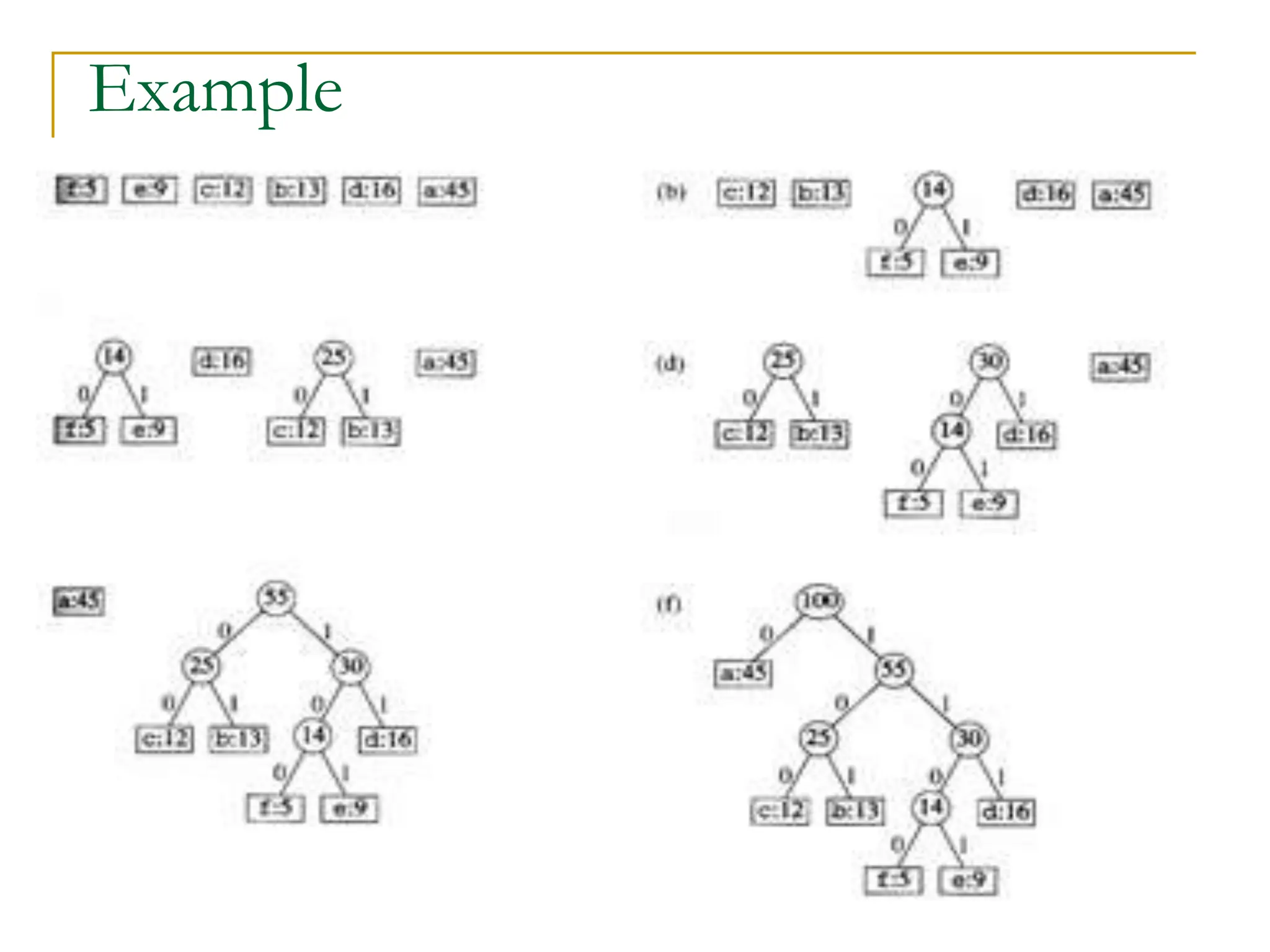


![Huffman Code Problem
In the pseudocode that follows:
we assume that C is a set of n characters and that
each character c €C is an object with a defined
frequency f [c].
The algorithm builds the tree T corresponding to the
optimal code
A min-priority queue Q, is used to identify the two
least-frequent objects to merge together.
The result of the merger of two objects is a new
object whose frequency is the sum of the
frequencies of the two objects that were merged.](https://image.slidesharecdn.com/16greedyalgorithms-240311143355-3127e9f0/75/16_Greedy_Algorithms-Greedy_AlgorithmsGreedy_Algorithms-16-2048.jpg)



































































