Lec 14 SystemsArchitecture 1
Systems Architecture
Lecture 14: Floating Point Arithmetic
Jeremy R. Johnson
Anatole D. Ruslanov
William M. Mongan
Some or all figures from Computer Organization and Design: The
Hardware/Software Approach, Third Edition, by David Patterson and
John Hennessy, are copyrighted material (COPYRIGHT 2004
MORGAN KAUFMANN PUBLISHERS, INC. ALL RIGHTS
RESERVED).
2.
Lec 14 SystemsArchitecture 2
Introduction
• Objective: To provide hardware support for floating point
arithmetic. To understand how to represent floating point
numbers in the computer and how to perform arithmetic with
them. Also to learn how to use floating point arithmetic in
MIPS.
• Approximate arithmetic
– Finite Range
– Limited Precision
• Topics
– IEEE format for single and double precision floating point numbers
– Floating point addition and multiplication
– Support for floating point computation in MIPS
3.
Lec 14 SystemsArchitecture 3
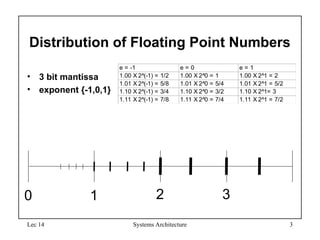
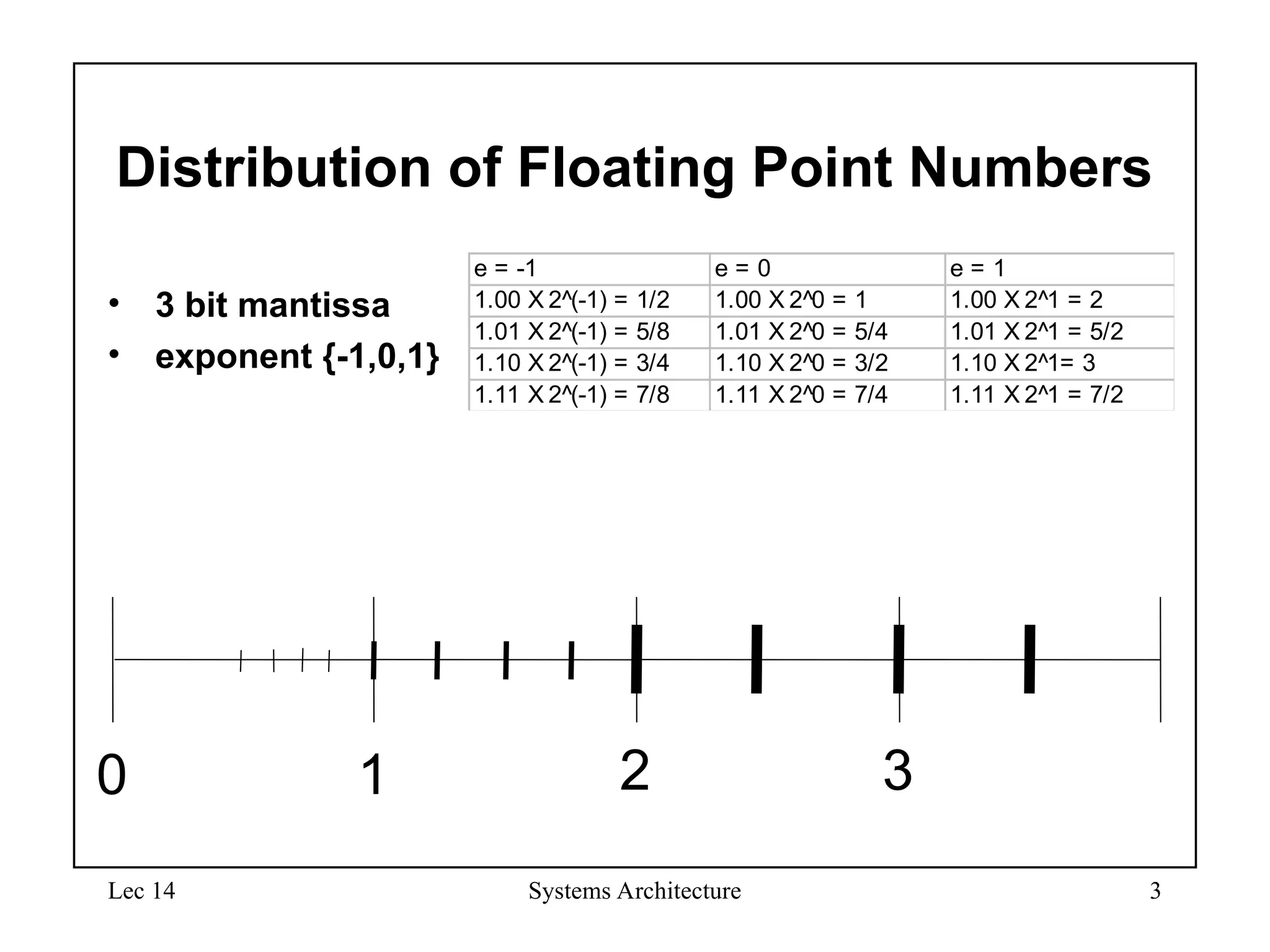
Distribution of Floating Point Numbers
• 3 bit mantissa
• exponent {-1,0,1}
e = -1 e = 0 e = 1
1.00 X 2^(-1) = 1/2 1.00 X 2^0 = 1 1.00 X 2^1 = 2
1.01 X 2^(-1) = 5/8 1.01 X 2^0 = 5/4 1.01 X 2^1 = 5/2
1.10 X 2^(-1) = 3/4 1.10 X 2^0 = 3/2 1.10 X 2^1= 3
1.11 X 2^(-1) = 7/8 1.11 X 2^0 = 7/4 1.11 X 2^1 = 7/2
0 1 2 3
4.
Lec 14 SystemsArchitecture 4
Floating Point
• An IEEE floating point representation consists of
– A Sign Bit (no surprise)
– An Exponent (“times 2 to the what?”)
– Mantissa (“Significand”), which is assumed to be 1.xxxxx (thus, one
bit of the mantissa is implied as 1)
– This is called a normalized representation
• So a mantissa = 0 really is interpreted to be 1.0, and a
mantissa of all 1111 is interpreted to be 1.1111
• Special cases are used to represent denormalized
mantissas (true mantissa = 0), NaN, etc., as will be
discussed.
5.
Lec 14 SystemsArchitecture 5
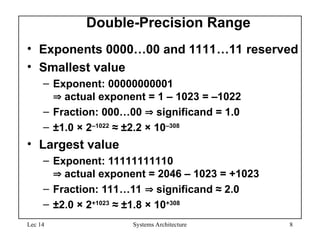
Floating Point Standard
• Defined by IEEE Std 754-1985
• Developed in response to divergence of representations
– Portability issues for scientific code
• Now almost universally adopted
• Two representations
– Single precision (32-bit)
– Double precision (64-bit)
6.
Lec 14 SystemsArchitecture 6
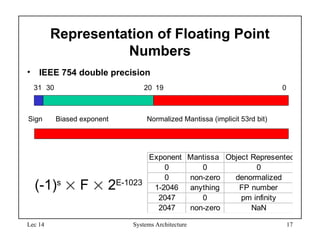
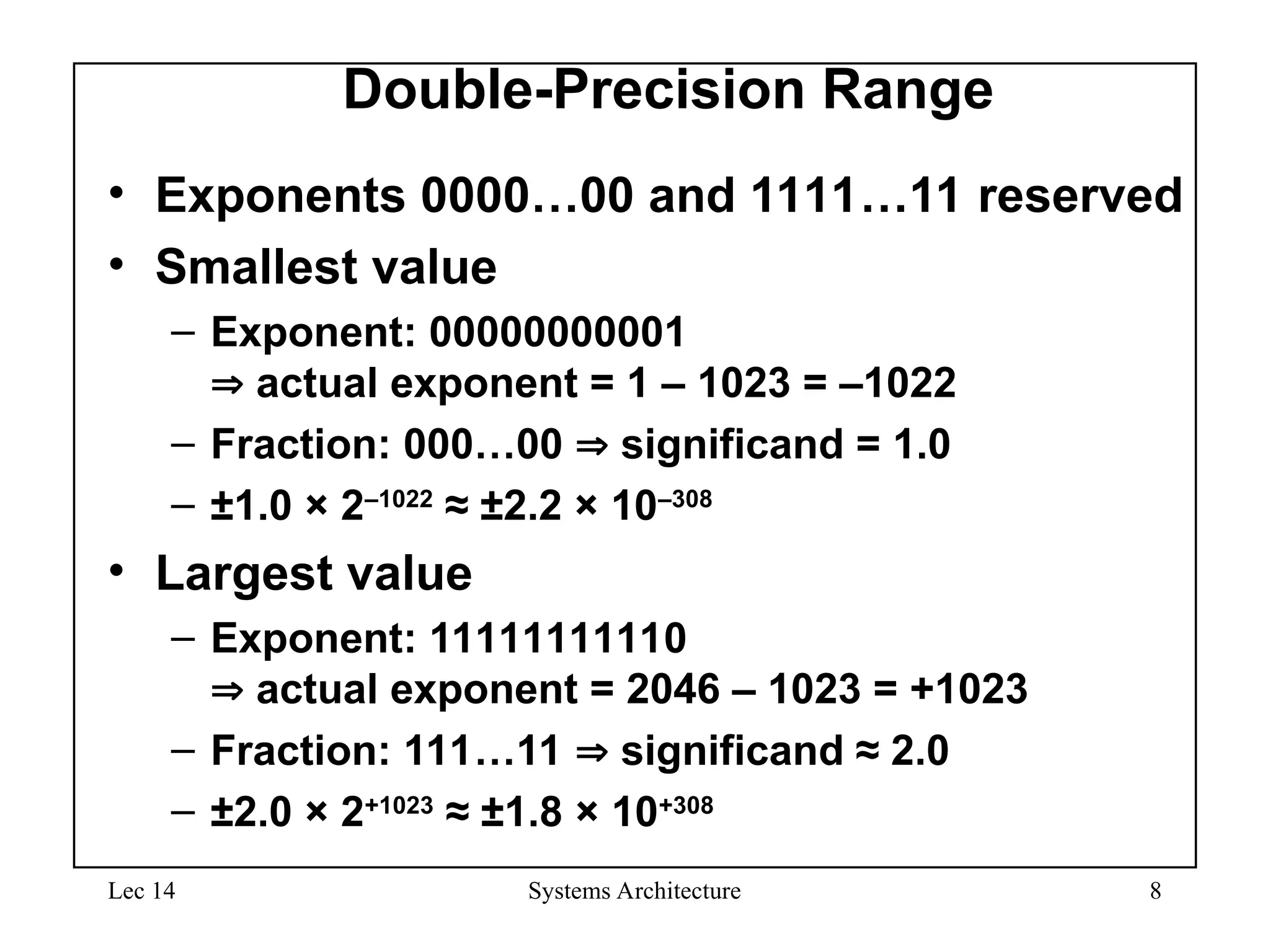
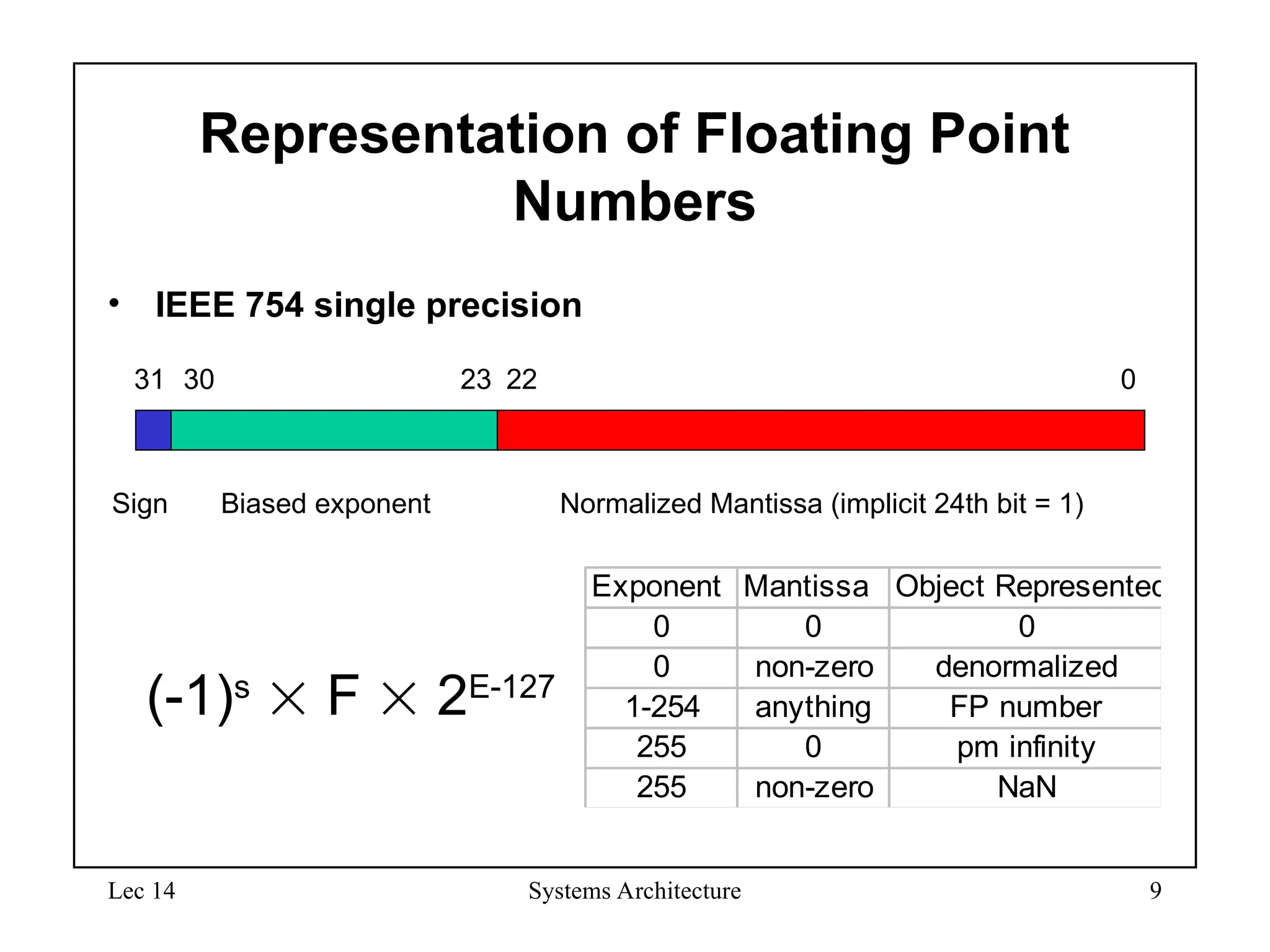
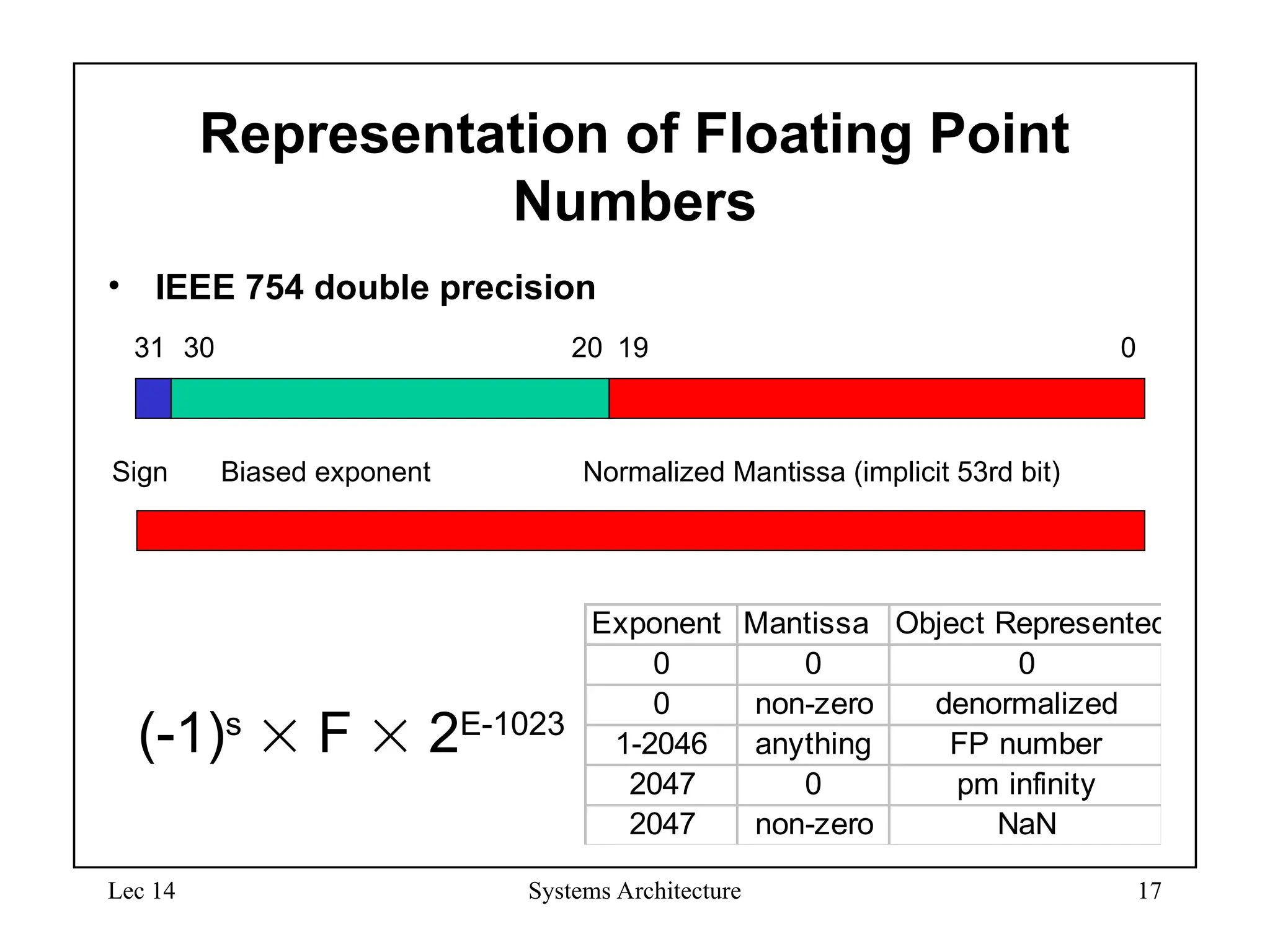
IEEE Floating-Point Format
• S: sign bit (0 non-negative, 1 negative)
• Normalize significand: 1.0 ≤ |significand| < 2.0
– Always has a leading pre-binary-point 1 bit, so no need to
represent it explicitly (hidden bit)
– Significand is Fraction with the “1.” restored
• Exponent: excess representation: actual exponent + Bias
– Ensures exponent is unsigned
– Single: Bias = 127; Double: Bias = 1203
S Exponent Fraction
single: 8 bits
double: 11 bits
single: 23 bits
double: 52 bits
Bias)
(Exponent
S
2
Fraction)
(1
1)
(
x
Lec 14 SystemsArchitecture 11
Basic Technique
• Represent the decimal in the form +/- 1.xxxb x 2y
• And “fill in the fields”
– Remember biased exponent and implicit “1.” mantissa!
• Examples:
– 0.0: 0 00000000 00000000000000000000000
– 1.0 (1.0 x 2^0): 0 01111111 00000000000000000000000
– 0.5 (0.1 binary = 1.0 x 2^-1): 0 01111110 00000000000000000000000
– 0.75 (0.11 binary = 1.1 x 2^-1): 0 01111110 10000000000000000000000
– 3.0 (11 binary = 1.1*2^1): 0 10000000 10000000000000000000000
– -0.375 (-0.011 binary = -1.1*2^-2): 1 01111101 10000000000000000000000
– 1 10000011 01000000000000000000000 = - 1.01 * 2^4 = -20.0
http://www.math-cs.gordon.edu/courses/cs311/lectures-2003/
binary.html
12.
Lec 14 SystemsArchitecture 12
Basic Technique
• One can compute the mantissa just similar to the way one
would convert decimal whole numbers to binary.
• Take the decimal and repeatedly multiply the fractional
component by 2. The whole number portion is the next binary
bit.
• For whole numbers, append the binary whole number to the
mantissa and shift the exponent until the mantissa is in
normalized form.
http://www.newton.dep.anl.gov/newton/askasci/1995/math/MATH065.HTM
Lec 14 SystemsArchitecture 18
Floating Point Arithmetic
• fl(x) = nearest floating point number to x
• Relative error (precision = s digits)
–|x - fl(x)|/|x| 1/21-s
for = 2, 2-s
• Arithmetic
–x y = fl(x+y) = (x + y)(1 + ) for < u
–x y = fl(x y)(1 + ) for < u
ULP—Unit in the Last Place is the smallest possible increment
or decrement that can be made using the machine's FP
arithmetic.
17.
Lec 14 SystemsArchitecture 19
Floating-Point Precision
• Relative precision
– all fraction bits are significant
– Single: approx 2–23
• Equivalent to 23 × log102 ≈ 23 × 0.3 ≈ 6 decimal digits of precision
– Double: approx 2–52
• Equivalent to 52 × log102 ≈ 52 × 0.3 ≈ 16 decimal digits of precision
18.
Lec 14 SystemsArchitecture 20
Is FP addition associative?
• Associativity law for addition: a + (b + c) = (a + b) + c
• Let a = – 2.7 x 1023
, b = 2.7 x 1023
, and c = 1.0
• a + (b + c) = – 2.7 x 1023
+ ( 2.7 x 1023
+ 1.0 ) = – 2.7 x 1023
+ 2.7
x 1023
= 0.0
• (a + b) + c = ( – 2.7 x 1023
+ 2.7 x 1023
) + 1.0 = 0.0 + 1.0 = 1.0
• Beware – Floating Point addition not associative!
• The result is approximate…
• Why the smaller number disappeared?
19.
Lec 14 SystemsArchitecture 21
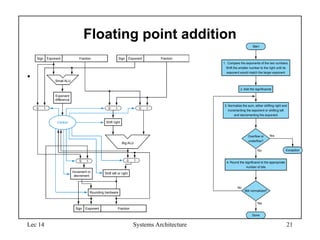
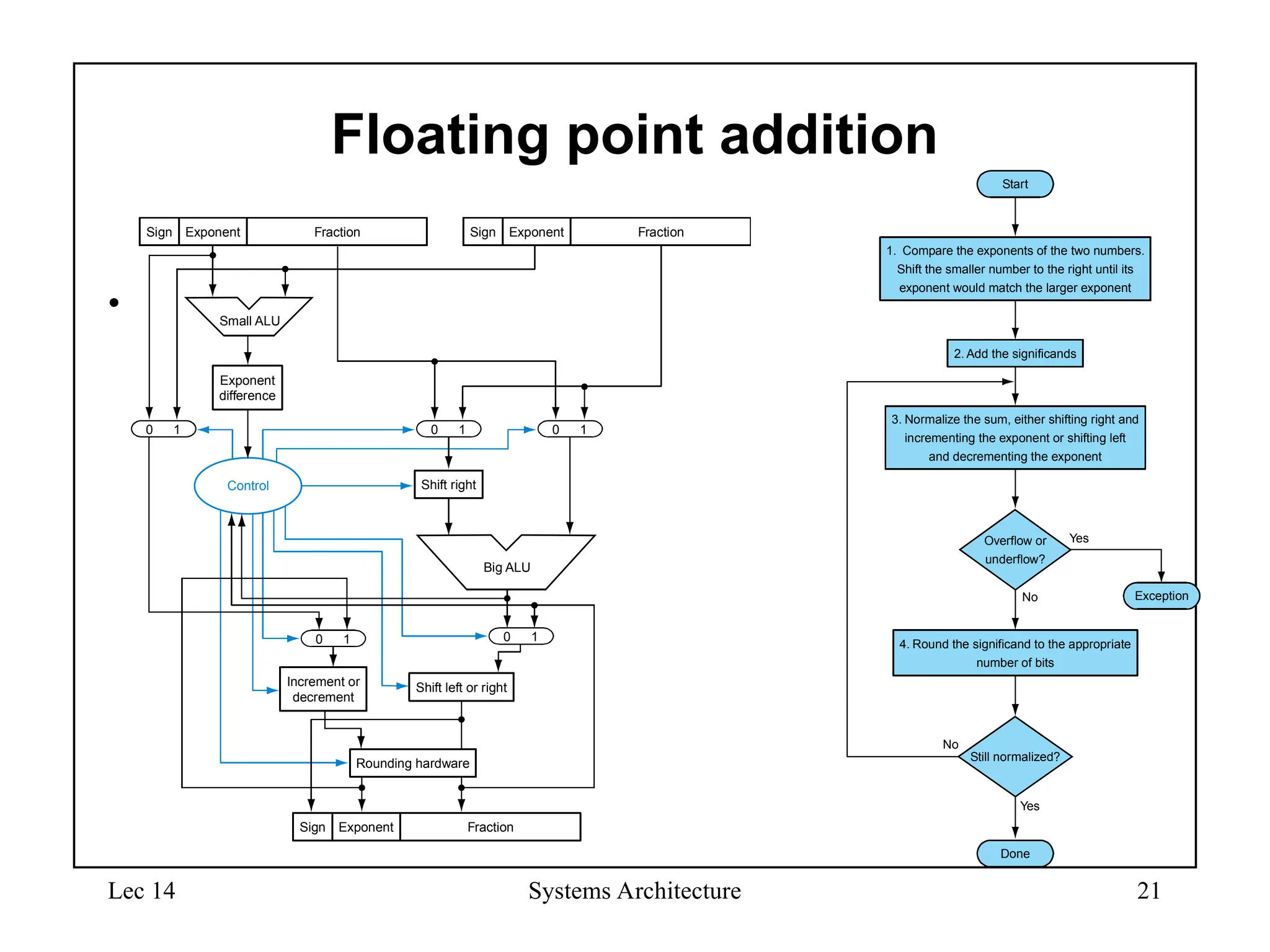
Floating point addition
•
Still normalized?
4. Round the significand to the appropriate
number of bits
Yes
Overflow or
underflow?
Start
No
Yes
Done
1. Compare the exponents of the two numbers.
Shift the smaller number to the right until its
exponent would match the larger exponent
2. Add the significands
3. Normalize the sum, either shifting right and
incrementing the exponent or shifting left
and decrementing the exponent
No Exception
Small ALU
Exponent
difference
Control
Exponent
Sign Fraction
Big ALU
Exponent
Sign Fraction
0 1 0 1 0 1
Shift right
0 1 0 1
Increment or
decrement
Shift left or right
Rounding hardware
Exponent
Sign Fraction
20.
Lec 14 SystemsArchitecture 22
Floating-Point Addition
• Consider a 4-digit decimal example
– 9.999 × 101
+ 1.610 × 10–1
• 1. Align decimal points
– Shift number with smaller exponent
– 9.999 × 101
+ 0.016 × 101
• 2. Add significands
– 9.999 × 101
+ 0.016 × 101
= 10.015 × 101
• 3. Normalize result & check for over/underflow
– 1.0015 × 102
• 4. Round and renormalize if necessary
– 1.002 × 102
21.
Lec 14 SystemsArchitecture 23
Floating-Point Addition
• Now consider a 4-digit binary example
– 1.0002 × 2–1
+ –1.1102 × 2–2
(0.5 + –0.4375)
• 1. Align binary points
– Shift number with smaller exponent
– 1.0002 × 2–1
+ –0.1112 × 2–1
• 2. Add significands
– 1.0002 × 2–1
+ –0.1112 × 2–
1 = 0.0012 × 2–1
• 3. Normalize result & check for over/underflow
– 1.0002 × 2–4
, with no over/underflow
• 4. Round and renormalize if necessary
– 1.0002 × 2–4
(no change) = 0.0625
22.
Lec 14 SystemsArchitecture 24
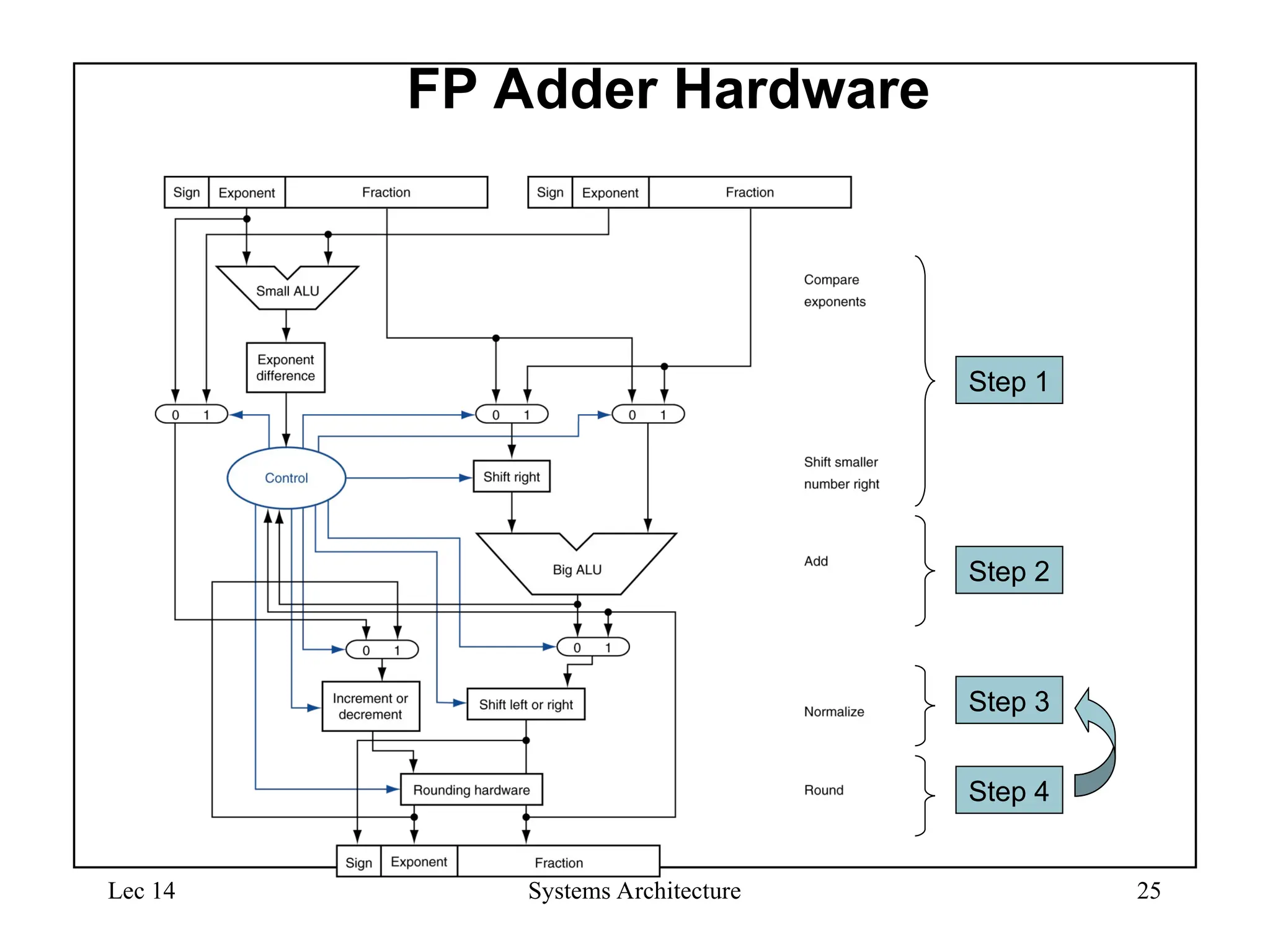
FP Adder Hardware
• Much more complex than integer adder
• Doing it in one clock cycle would take too long
– Much longer than integer operations
– Slower clock would penalize all instructions
• FP adder usually takes several cycles
– Can be pipelined
Lec 14 SystemsArchitecture 26
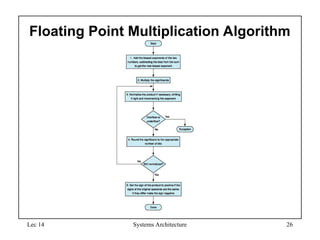
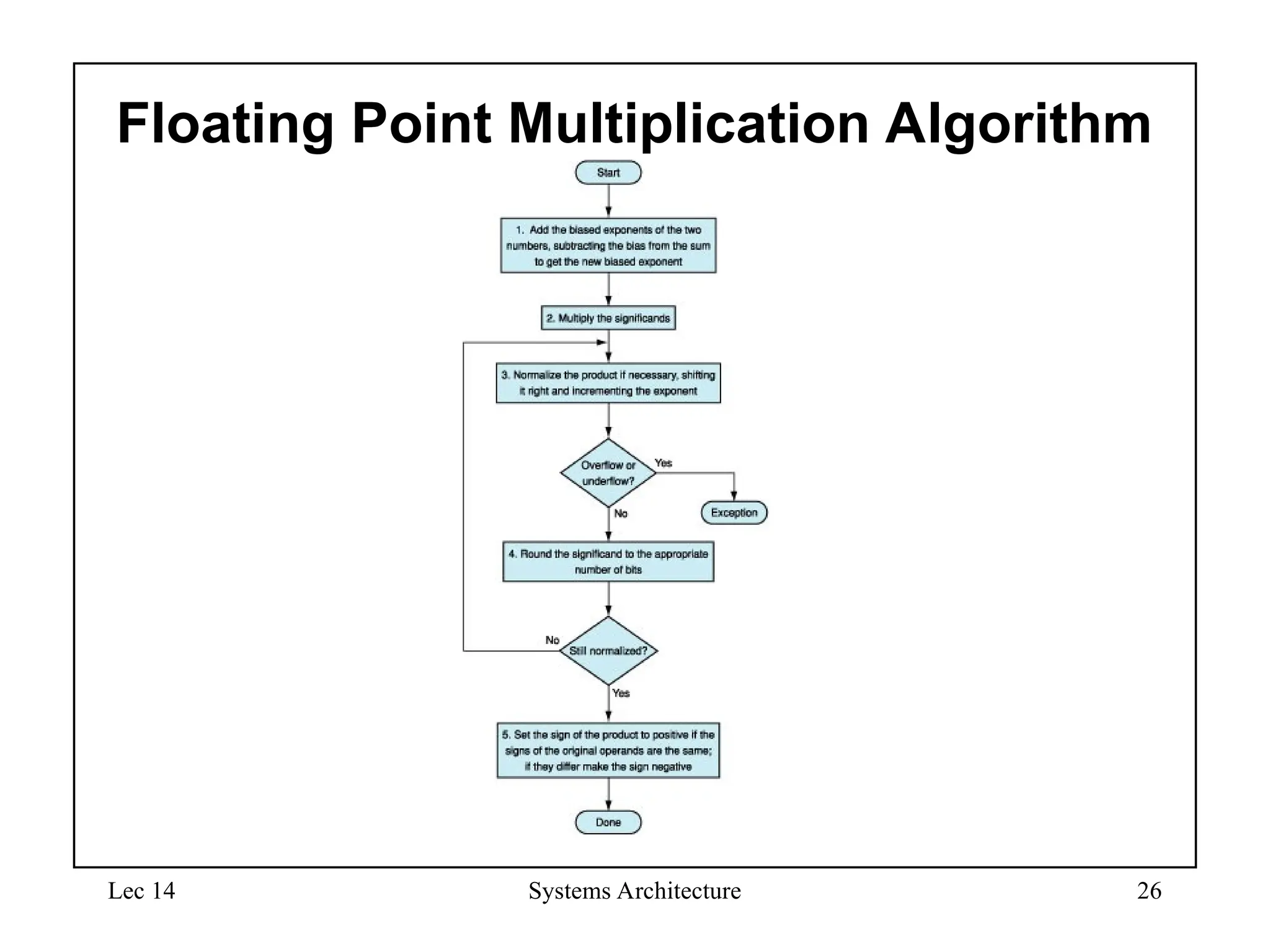
Floating Point Multiplication Algorithm
25.
Lec 14 SystemsArchitecture 29
FP Arithmetic Hardware
• FP multiplier is of similar complexity to FP adder
– But uses a multiplier for significands instead of an adder
• FP arithmetic hardware usually does
– Addition, subtraction, multiplication, division, reciprocal, square-root
– FP integer conversion
• Operations usually takes several cycles
– Can be pipelined
26.
Lec 14 SystemsArchitecture 30
FP Instructions in MIPS
• FP hardware is coprocessor 1
– Adjunct processor that extends the ISA
• Separate FP registers
– 32 single-precision: $f0, $f1, … $f31
– Paired for double-precision: $f0/$f1, $f2/$f3, …
• Release 2 of MIPs ISA supports 32 × 64-bit FP reg’s
• FP instructions operate only on FP registers
– Programs generally don’t do integer ops on FP
data, or vice versa
– More registers with minimal code-size impact
• FP load and store instructions
– lwc1, ldc1, swc1, sdc1
• e.g., ldc1 $f8, 32($sp)
27.
Lec 14 SystemsArchitecture 31
FP Instructions in MIPS
• Single-precision arithmetic
– add.s, sub.s, mul.s, div.s
• e.g., add.s $f0, $f1, $f6
• Double-precision arithmetic
– add.d, sub.d, mul.d, div.d
• e.g., mul.d $f4, $f4, $f6
• Single- and double-precision comparison
– c.xx.s, c.xx.d (xx is eq, lt, le, …)
– Sets or clears FP condition-code bit
• e.g. c.lt.s $f3, $f4
• Branch on FP condition code true or false
– bc1t, bc1f
• e.g., bc1t TargetLabel
28.
Lec 14 SystemsArchitecture 32
FP Example: °F to °C
• C code:
float f2c (float fahr) {
return ((5.0/9.0)*(fahr - 32.0));
}
– fahr in $f12, result in $f0, literals in global memory
space
• Compiled MIPS code:
f2c: lwc1 $f16, const5($gp)
lwc2 $f18, const9($gp)
div.s $f16, $f16, $f18
lwc1 $f18, const32($gp)
sub.s $f18, $f12, $f18
mul.s $f0, $f16, $f18
jr $ra
29.
Lec 14 SystemsArchitecture 33
Rounding
• Guard and round digits and sticky bit
– When computing result, assume there are several extra digits available
for shifting and computation. This improves accuracy of computation.
– Guard digit: first extra digit/bit to the right of mantissa -- used for
rounding addition results
– Round digit: second extra digit/bit to the right of mantissa -- used for
rounding multiplication results
– Sticky bit: third extra digit/bit to the right of mantissa – used for
resolving ties such as 0.50...00 vs. 0.50...01
30.
Lec 14 SystemsArchitecture 34
Rounding
examples
• An example without guard and round digits
– Add 9.76 x 1025
and 2.59 x 1024
assuming 3 digit mantissa
• Shift mantissa of the smaller number to the right: 0.25 x 1025
• Add mantissas: 10.01x 1025
• Check and normalize mantissa if necessary: 1.00x 1026
• An example with guard and round digits
– Add 9.76 x 1025
and 2.59 x 1024
assuming 3 digit mantissa
• Internal registers have extra two digits: 9.7600 x 1025
and 2.5900 x 1024
• Shift mantissa of the smaller number to the right: 0.2590 x 1025
• Add mantissas: 10.0190 x 1025
• Check and normalize mantissa if necessary: 1.0019 x 1026
• Round the result: 1.00 x 1026
31.
Lec 14 SystemsArchitecture 35
Rounding
examples
• An example without guard and round digits
– Add 9.78 x 1025
and 8.79 x 1024
assuming 3 digit mantissa
• Shift mantissa of the smaller number to the right: 0.87 x 1025
• Add mantissas: 10.65 x 1025
• Normalize mantissa if necessary: 1.06 x 1026
• An example with guard and round digits
– Add 9.78 x 1025
and 8.79 x 1024
assuming 3 digit mantissa
• Internal registers have extra two digits: 9.7800 x 1025
and 8.7900 x 1024
• Shift mantissa of the smaller number to the right: 0.8790 x 1025
• Add mantissas (note extra digit on the left): 10.6590 x 1025
• Check and normalize mantissa if necessary: 1.0659 x 1026
• Round the result: 1.07 x 1026
32.
Lec 14 SystemsArchitecture 36
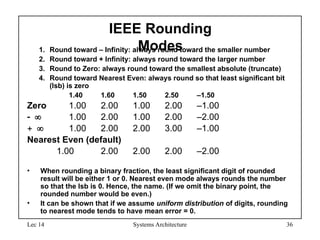
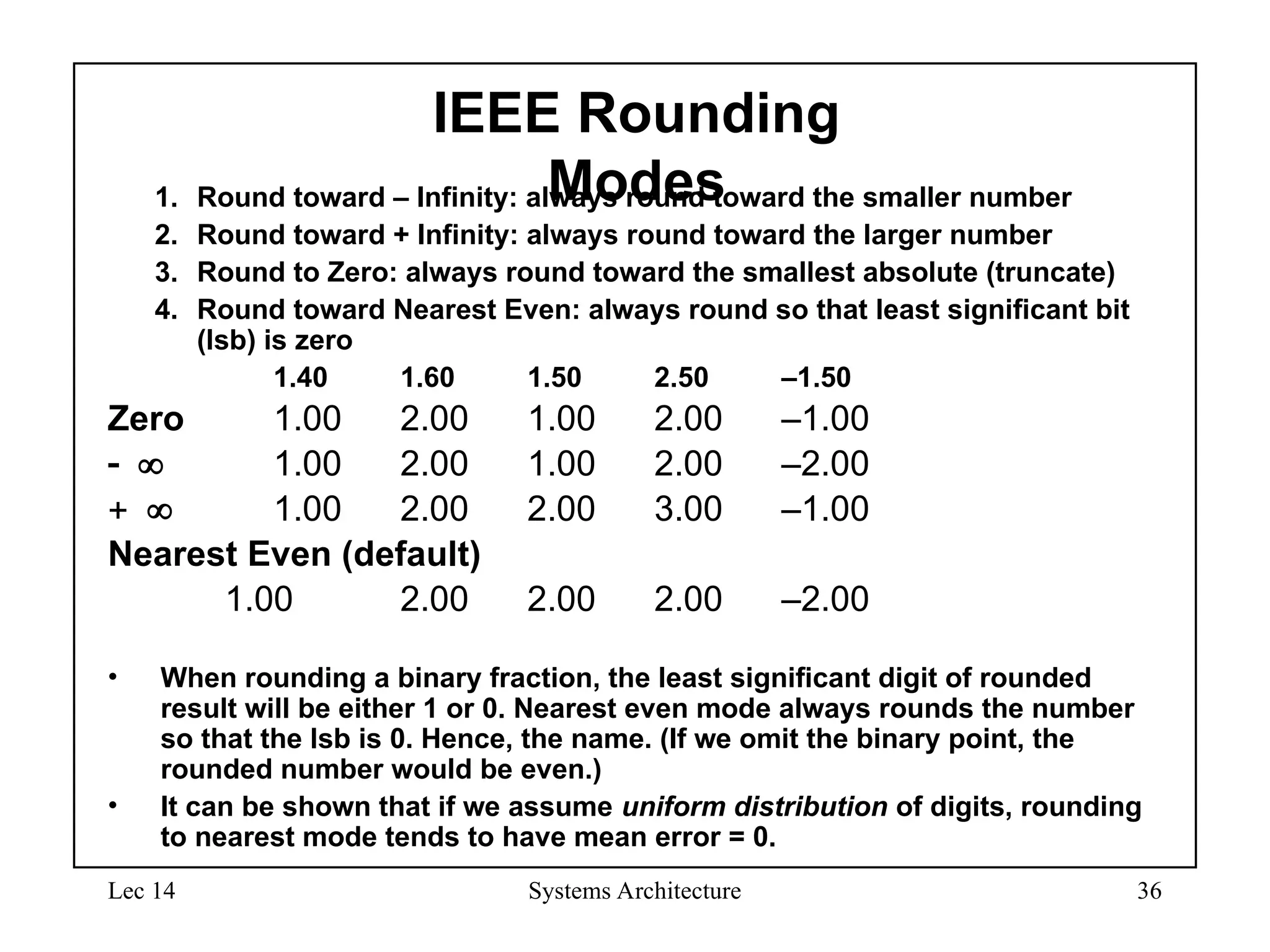
IEEE Rounding
Modes
1. Round toward – Infinity: always round toward the smaller number
2. Round toward + Infinity: always round toward the larger number
3. Round to Zero: always round toward the smallest absolute (truncate)
4. Round toward Nearest Even: always round so that least significant bit
(lsb) is zero
1.40 1.60 1.50 2.50 –1.50
Zero 1.00 2.00 1.00 2.00 –1.00
1.00 2.00 1.00 2.00 –2.00
1.00 2.00 2.00 3.00 –1.00
Nearest Even (default)
1.00 2.00 2.00 2.00 –2.00
• When rounding a binary fraction, the least significant digit of rounded
result will be either 1 or 0. Nearest even mode always rounds the number
so that the lsb is 0. Hence, the name. (If we omit the binary point, the
rounded number would be even.)
• It can be shown that if we assume uniform distribution of digits, rounding
to nearest mode tends to have mean error = 0.
33.
Lec 14 SystemsArchitecture 37
FP Instructions in
MIPS
• Floating point operations are slower than integer operations
• Data is rarely converted from integers to float within the same
procedure
• 1980’s solution – place FP processing unit in a separate chip
• Today’s solution – imbed FP processing unit in processor chip
• Co-processor 1 features:
– Contains 32 single precision floating point registers: $f0, $f1, … $f31
– These registers can also act as 16 double precision registers:
$f0/$f1, $f2/$f3, … , $f30/$f31 (only the first one is specified in the instructions)
– Uses special floating point instructions, which are similar (in format) to integer
instructions but have .s or .d attached to signify that they work on fp numbers
– Several special instructions to move between “regular” registers and the co-
processor registers
34.
Lec 14 SystemsArchitecture 38
FP Instructions in
MIPS
• lwc1 / swc1 – load/store word coprocessor 1
• Move instructions (between processors)
mfc1 rt, rd Move floating point register rd to CPU register rt
mtc1 rd, rt Move CPU register rt to floating point register rd
mfc1.d rdest, frsrc1
Move frsrc1 & frsrc1 + 1 to regs rdest & rdest
+ 1
• Single and double precision arithmetic instructions
Single add.s, sub.s, mul.s, div.s, c.lt.s
Double add.d, sub.d, mul.d, div.d, c.lt.d
• Examples: add.s $f0, $f1, $f2 sub.d $f0, $f2, $f4