This document provides an introduction to Hadoop, outlining its core components, ecosystem, and various programming models such as centralized and distributed computing. It discusses the principles of big data processing, including the need for scalability, fault tolerance, and resource management, while highlighting Hadoop's role in managing large volumes of structured and unstructured data. Key concepts such as HDFS, MapReduce, YARN, and the integration of additional ecosystem tools like Spark and Hive are also explored.


















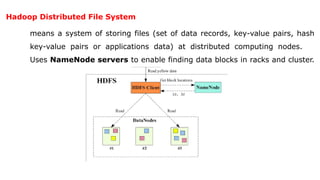




























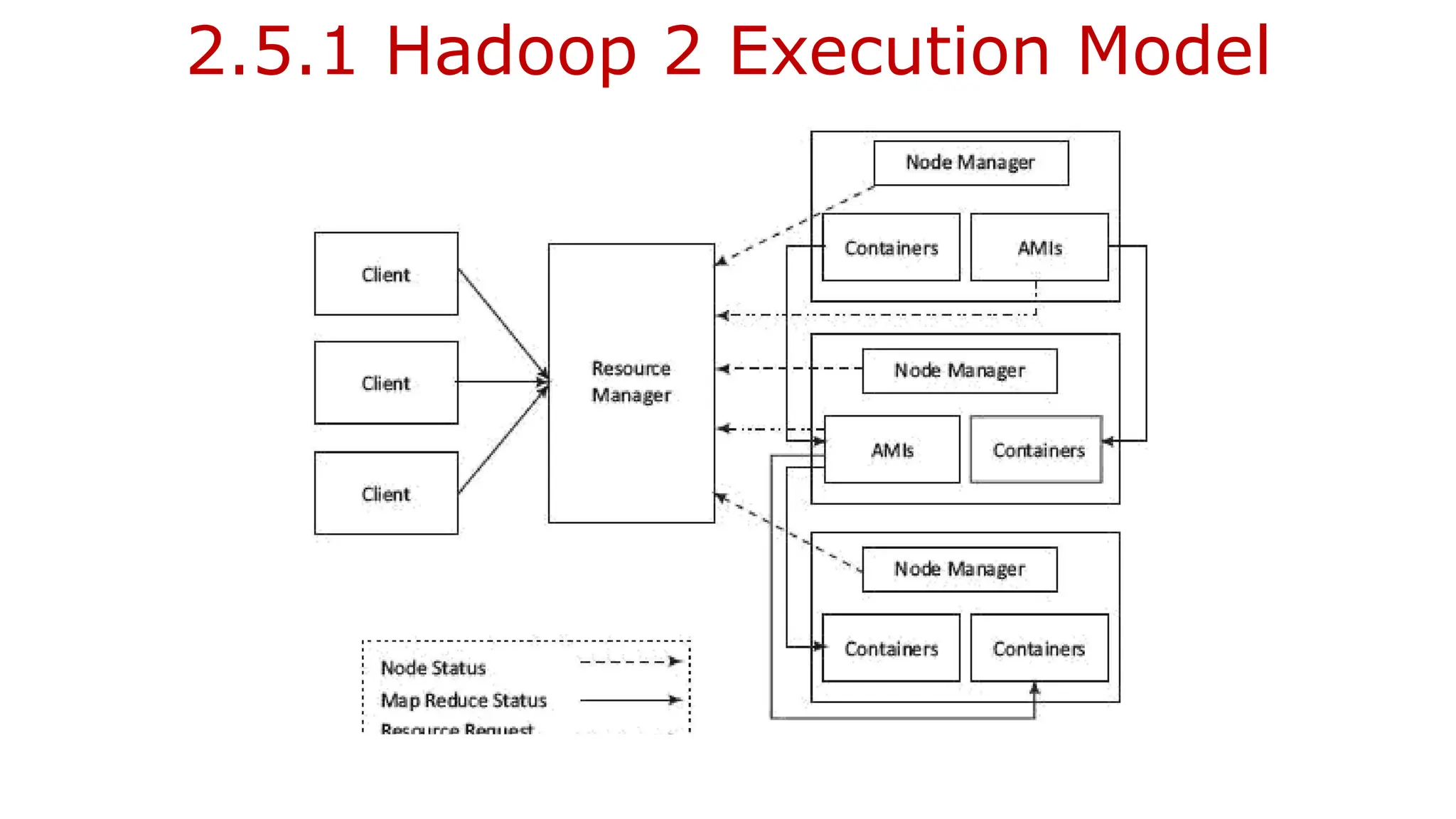
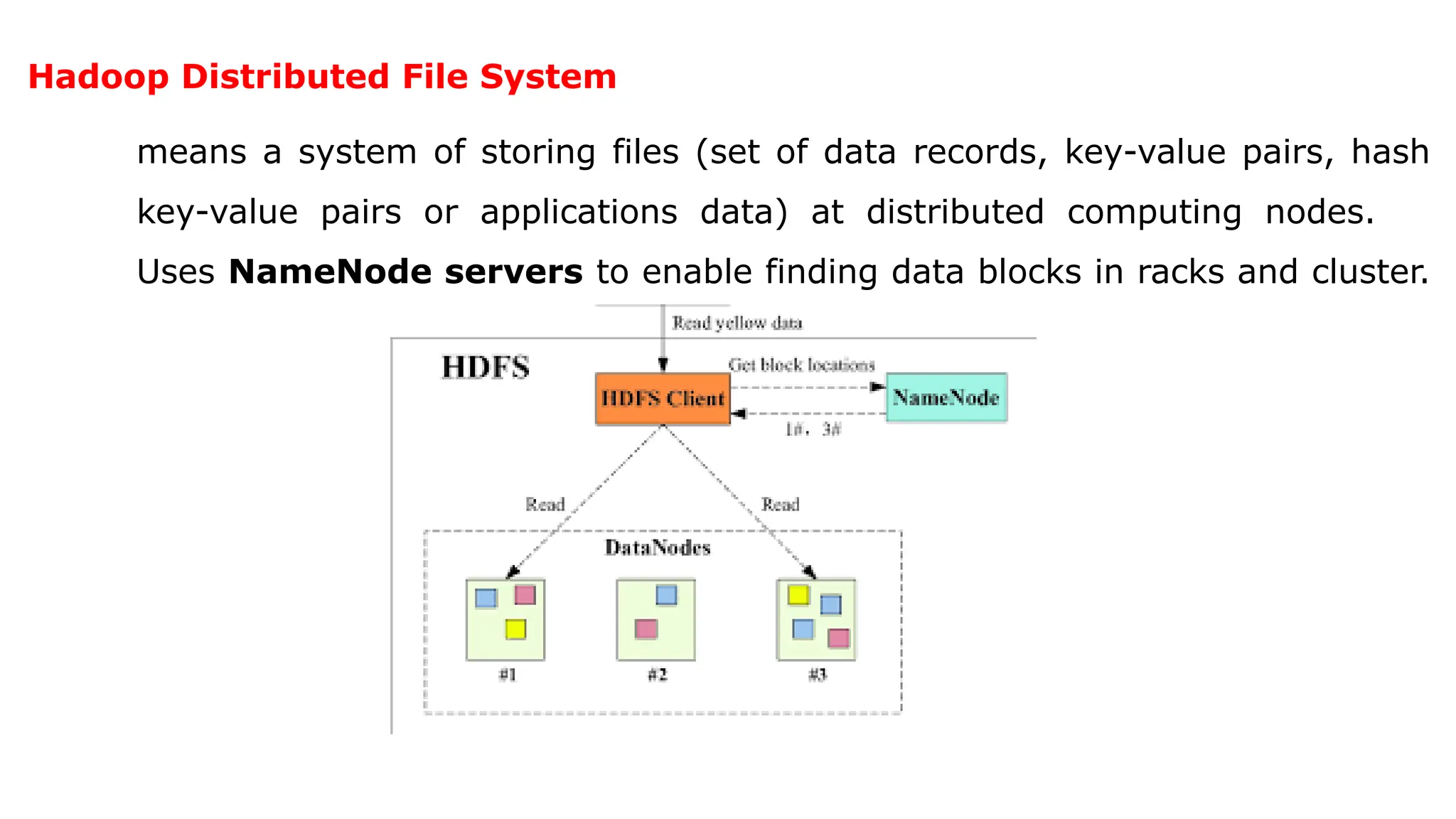
![2.3.1.1 Hadoop Physical Organization
Conventional File System:
• The conventional file system uses directories.
• A directory consists of files.
HDFS:
• HDFS use the NameNodes and DataNodes.
• A NameNode stores the file's meta data.
• Meta data gives information about the file [example location], but NameNodes does not
participate in the computations.
• The DataNode stores the actual data files in the data blocks and participate in computations](https://image.slidesharecdn.com/bigdataanalytics-module-2-240924052133-057eaef5/85/BIg-Data-Analytics-Module-2-as-per-vtu-syllabus-pptx-49-320.jpg)







![2.3.1.2 Hadoop 2
Hadoop 1
• is a Master-Slave architecture. [Suffers from single point of failure]
• It consists of a single master and multiple slaves.
• Suppose if master node got crashed then irrespective of your best slave nodes,
your cluster will be destroyed.
• Again for creating that cluster you need to copy system files, image files, etc.
on another system is too much time consuming which will not be tolerated by
organizations in today’s time.](https://image.slidesharecdn.com/bigdataanalytics-module-2-240924052133-057eaef5/85/BIg-Data-Analytics-Module-2-as-per-vtu-syllabus-pptx-58-320.jpg)

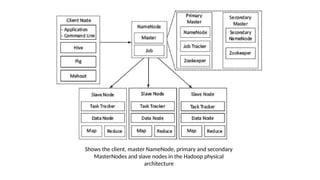
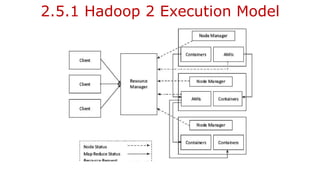
![2.3.1.2 Hadoop 2
Each MasterNode [MN] has the following components:
- An associated NameNode
- Zookeeper coordination (an associated NameNode), functions as a
centralized repository for distributed applications. Zookeeper uses
synchronization, serialization and coordination activities. It enables
functioning of a distributed system as a single function.
- Associated JournalNode (JN). The JN keeps the records of the state
information, resources assigned, and intermediate results or execution of
application tasks. Distributed applications can write and read data from a JN.](https://image.slidesharecdn.com/bigdataanalytics-module-2-240924052133-057eaef5/85/BIg-Data-Analytics-Module-2-as-per-vtu-syllabus-pptx-60-320.jpg)
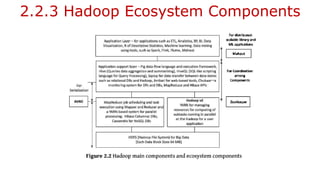
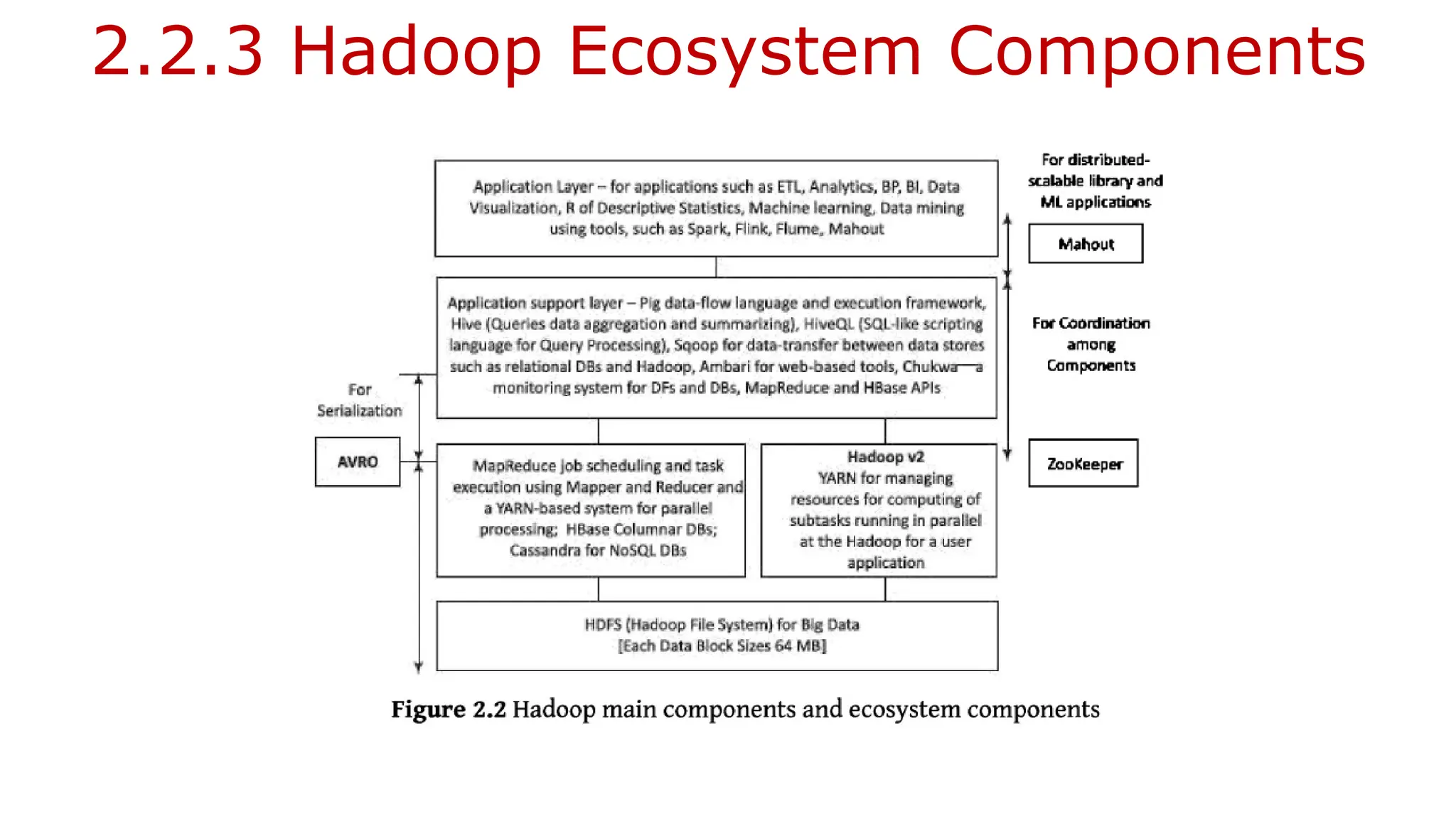
![2.3.2 HDFS Commands
• In Core components of Hadoop [Refer figure in 2.2.1 or slide no. 28].
• Hadoop common module, which contains the libraries and utilities is at the intersection
of MapReduce, HDFS and YARN [Yet Another Resource Navigator].
• The HDFS has a shell. But this shell is not POSIX confirming.
• Thus, the shell cannot interact similar to Unix or Linux.
• Commands for interacting with the files in HDFS require /bin/hdfs <args>,
Where, args stands for the command arguments.
Full set of the Hadoop shell commands can be found at Apache Software Foundation website. copyToLocal is the
command for copying a file at HDFS to the local.
-cat is command for copying to standard output (stdout).
All Hadoop commands are invoked by the bin/Hadoop script. % Hadoop fsck / -files -blocks](https://image.slidesharecdn.com/bigdataanalytics-module-2-240924052133-057eaef5/85/BIg-Data-Analytics-Module-2-as-per-vtu-syllabus-pptx-61-320.jpg)



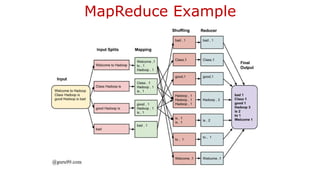

![2.4.1 Hadoop MapReduce Framework
MapReduce provides two important functions.
1. The distribution of client application task or users query to various nodes
within a cluster is one function.
2. The second function is organizing and reducing [aggregating] the results
from each node into a one cohesive response/answer.
The Hadoop framework in turns manages the task of issuing jobs, job
completion, and copying intermediate data results from the cluster
DataNodes with the help of JobTracker which is a daemon process.](https://image.slidesharecdn.com/bigdataanalytics-module-2-240924052133-057eaef5/85/BIg-Data-Analytics-Module-2-as-per-vtu-syllabus-pptx-67-320.jpg)





































































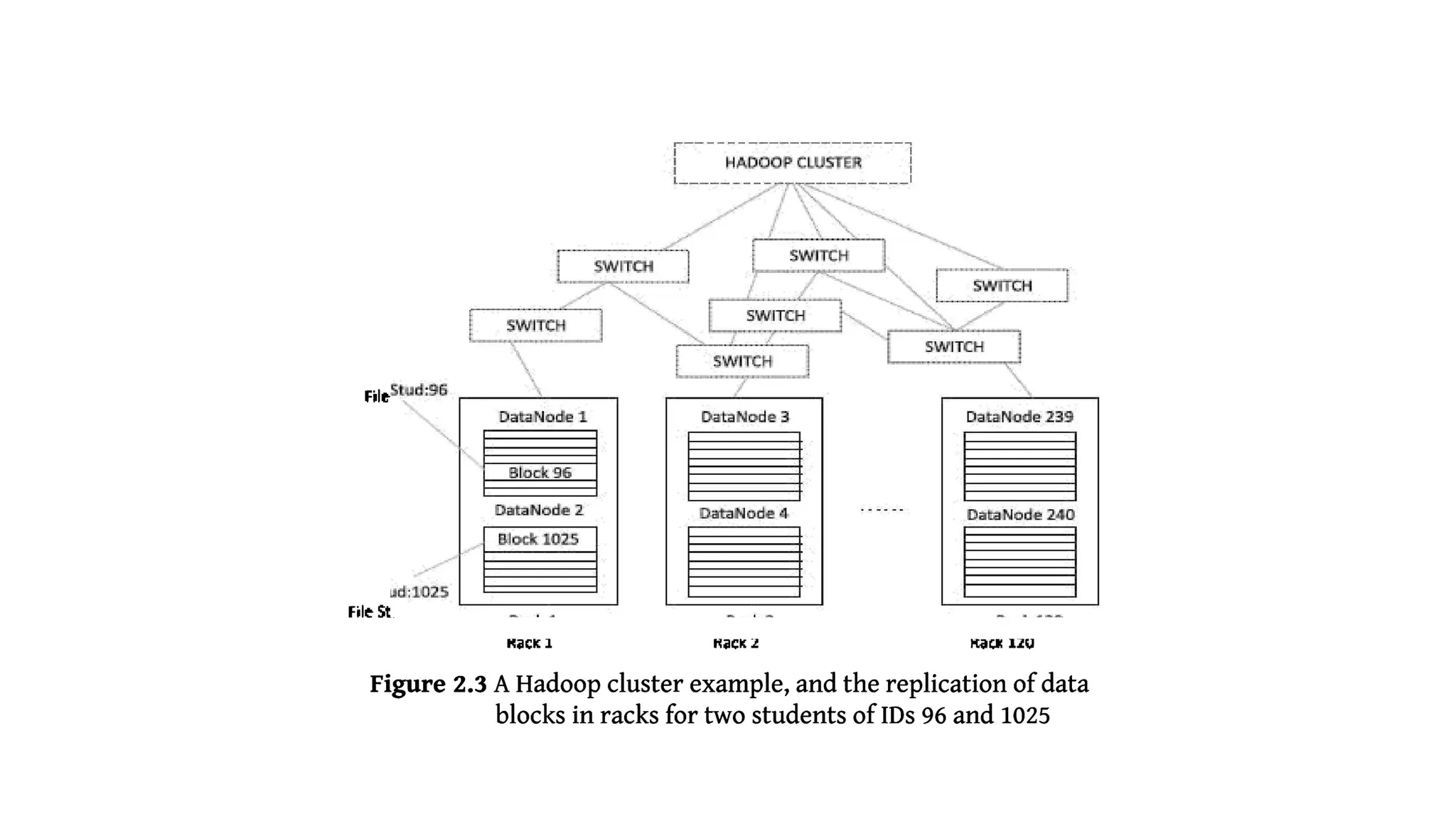
![2.3.1.1 Hadoop Physical Organization
Conventional File System:
• The conventional file system uses directories.
• A directory consists of files.
HDFS:
• HDFS use the NameNodes and DataNodes.
• A NameNode stores the file's meta data.
• Meta data gives information about the file [example location], but NameNodes does not
participate in the computations.
• The DataNode stores the actual data files in the data blocks and participate in computations](https://image.slidesharecdn.com/bigdataanalytics-module-2-240924052133-057eaef5/75/BIg-Data-Analytics-Module-2-as-per-vtu-syllabus-pptx-49-2048.jpg)


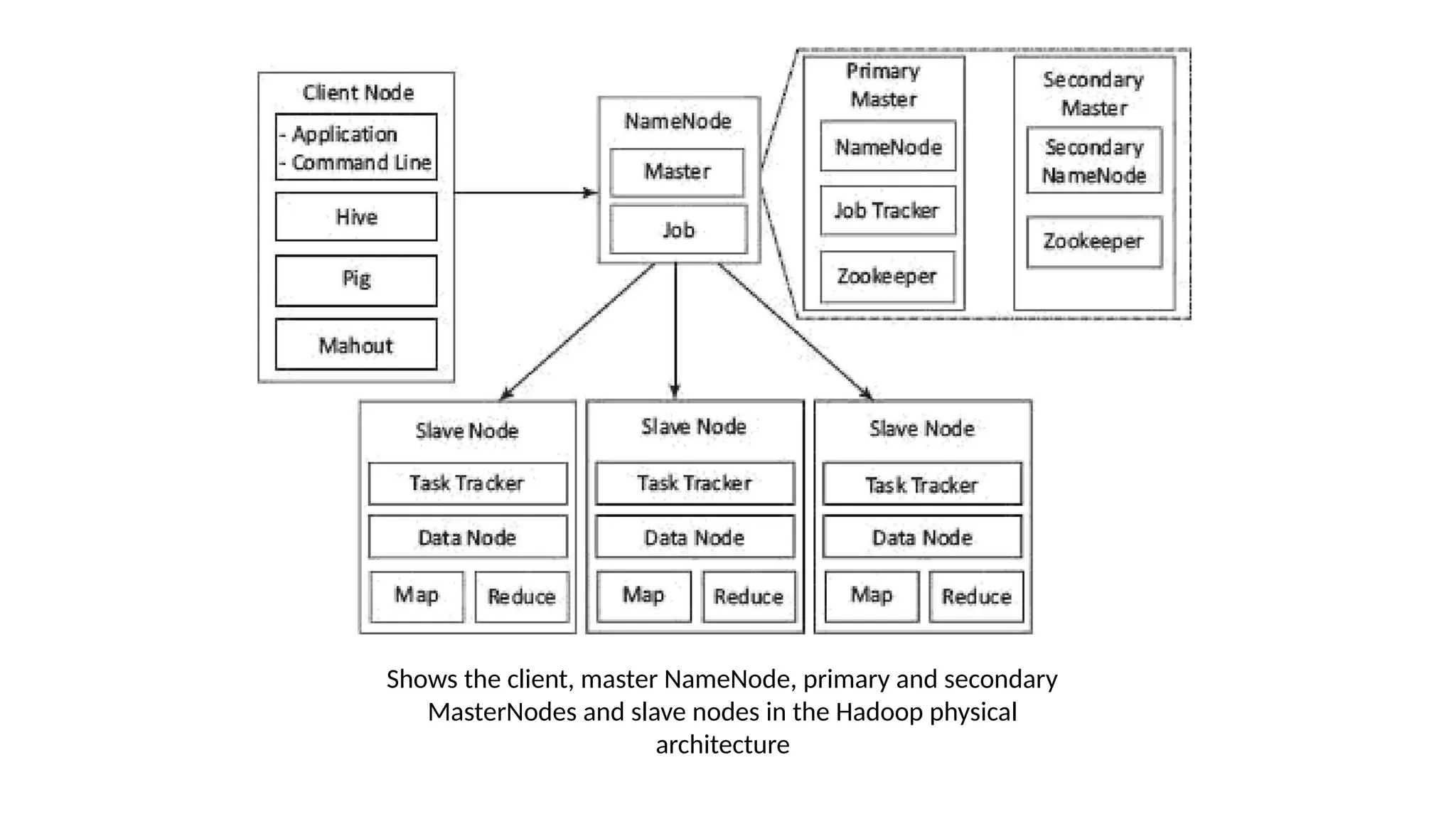





![2.3.1.2 Hadoop 2
Hadoop 1
• is a Master-Slave architecture. [Suffers from single point of failure]
• It consists of a single master and multiple slaves.
• Suppose if master node got crashed then irrespective of your best slave nodes,
your cluster will be destroyed.
• Again for creating that cluster you need to copy system files, image files, etc.
on another system is too much time consuming which will not be tolerated by
organizations in today’s time.](https://image.slidesharecdn.com/bigdataanalytics-module-2-240924052133-057eaef5/75/BIg-Data-Analytics-Module-2-as-per-vtu-syllabus-pptx-58-2048.jpg)

![2.3.1.2 Hadoop 2
Each MasterNode [MN] has the following components:
- An associated NameNode
- Zookeeper coordination (an associated NameNode), functions as a
centralized repository for distributed applications. Zookeeper uses
synchronization, serialization and coordination activities. It enables
functioning of a distributed system as a single function.
- Associated JournalNode (JN). The JN keeps the records of the state
information, resources assigned, and intermediate results or execution of
application tasks. Distributed applications can write and read data from a JN.](https://image.slidesharecdn.com/bigdataanalytics-module-2-240924052133-057eaef5/75/BIg-Data-Analytics-Module-2-as-per-vtu-syllabus-pptx-60-2048.jpg)
![2.3.2 HDFS Commands
• In Core components of Hadoop [Refer figure in 2.2.1 or slide no. 28].
• Hadoop common module, which contains the libraries and utilities is at the intersection
of MapReduce, HDFS and YARN [Yet Another Resource Navigator].
• The HDFS has a shell. But this shell is not POSIX confirming.
• Thus, the shell cannot interact similar to Unix or Linux.
• Commands for interacting with the files in HDFS require /bin/hdfs <args>,
Where, args stands for the command arguments.
Full set of the Hadoop shell commands can be found at Apache Software Foundation website. copyToLocal is the
command for copying a file at HDFS to the local.
-cat is command for copying to standard output (stdout).
All Hadoop commands are invoked by the bin/Hadoop script. % Hadoop fsck / -files -blocks](https://image.slidesharecdn.com/bigdataanalytics-module-2-240924052133-057eaef5/75/BIg-Data-Analytics-Module-2-as-per-vtu-syllabus-pptx-61-2048.jpg)



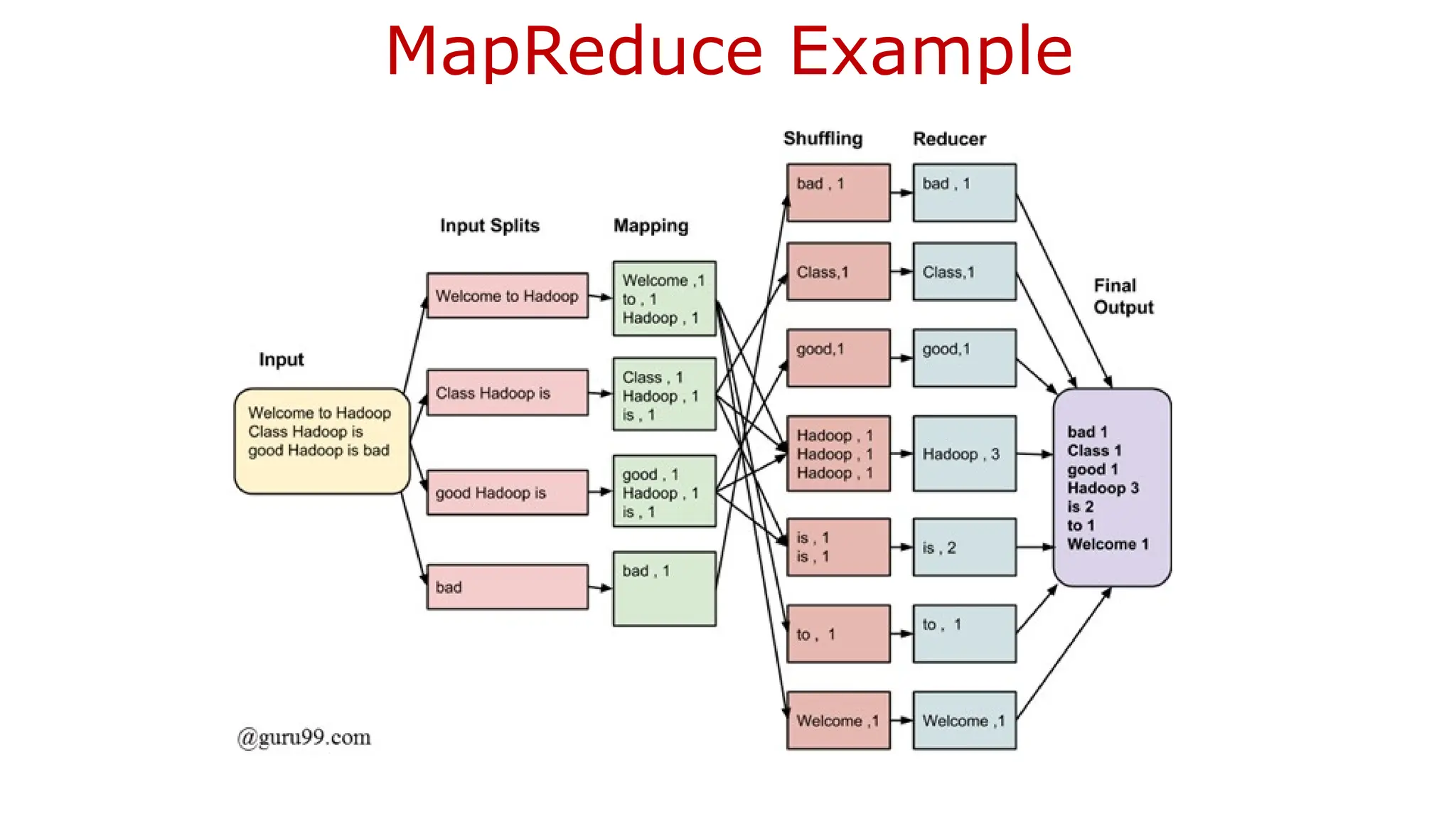

![2.4.1 Hadoop MapReduce Framework
MapReduce provides two important functions.
1. The distribution of client application task or users query to various nodes
within a cluster is one function.
2. The second function is organizing and reducing [aggregating] the results
from each node into a one cohesive response/answer.
The Hadoop framework in turns manages the task of issuing jobs, job
completion, and copying intermediate data results from the cluster
DataNodes with the help of JobTracker which is a daemon process.](https://image.slidesharecdn.com/bigdataanalytics-module-2-240924052133-057eaef5/75/BIg-Data-Analytics-Module-2-as-per-vtu-syllabus-pptx-67-2048.jpg)