Download as PDF, PPTX








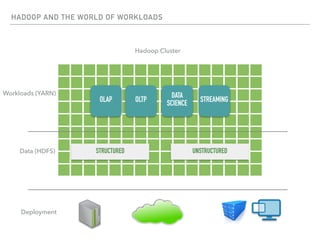
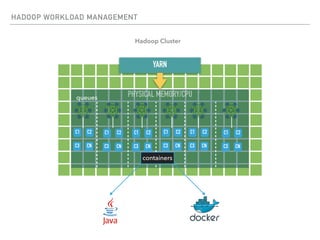




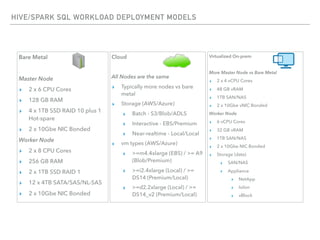



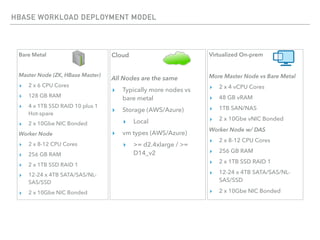

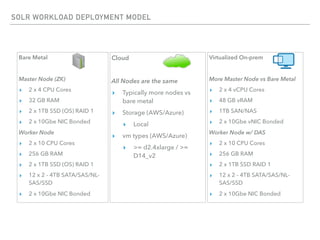



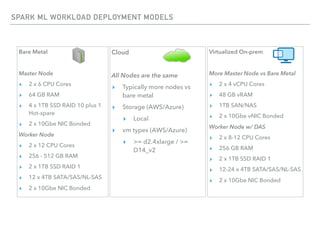





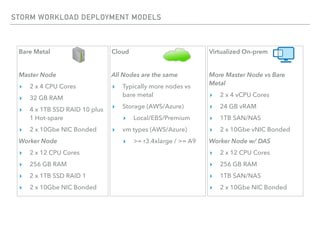







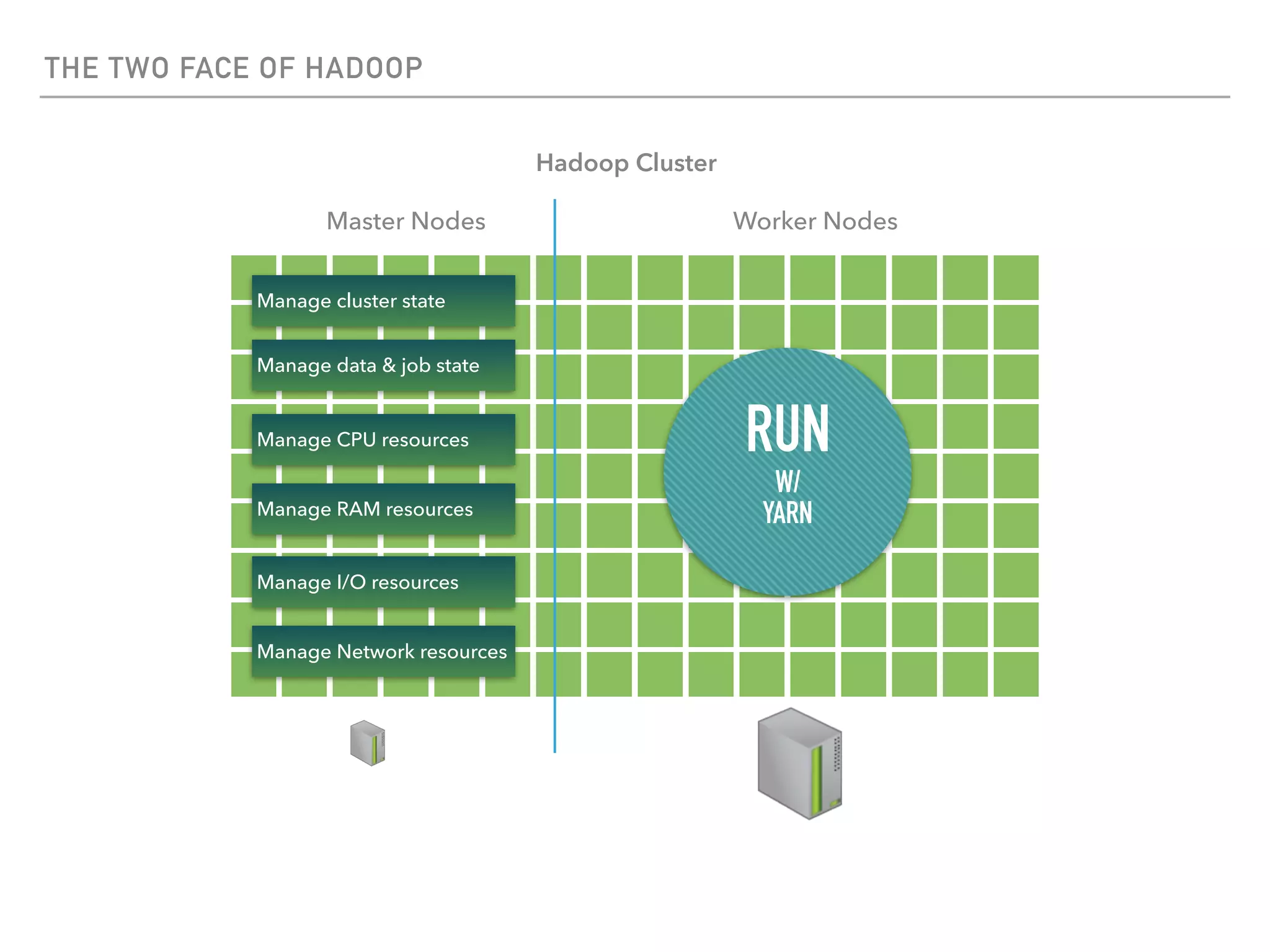



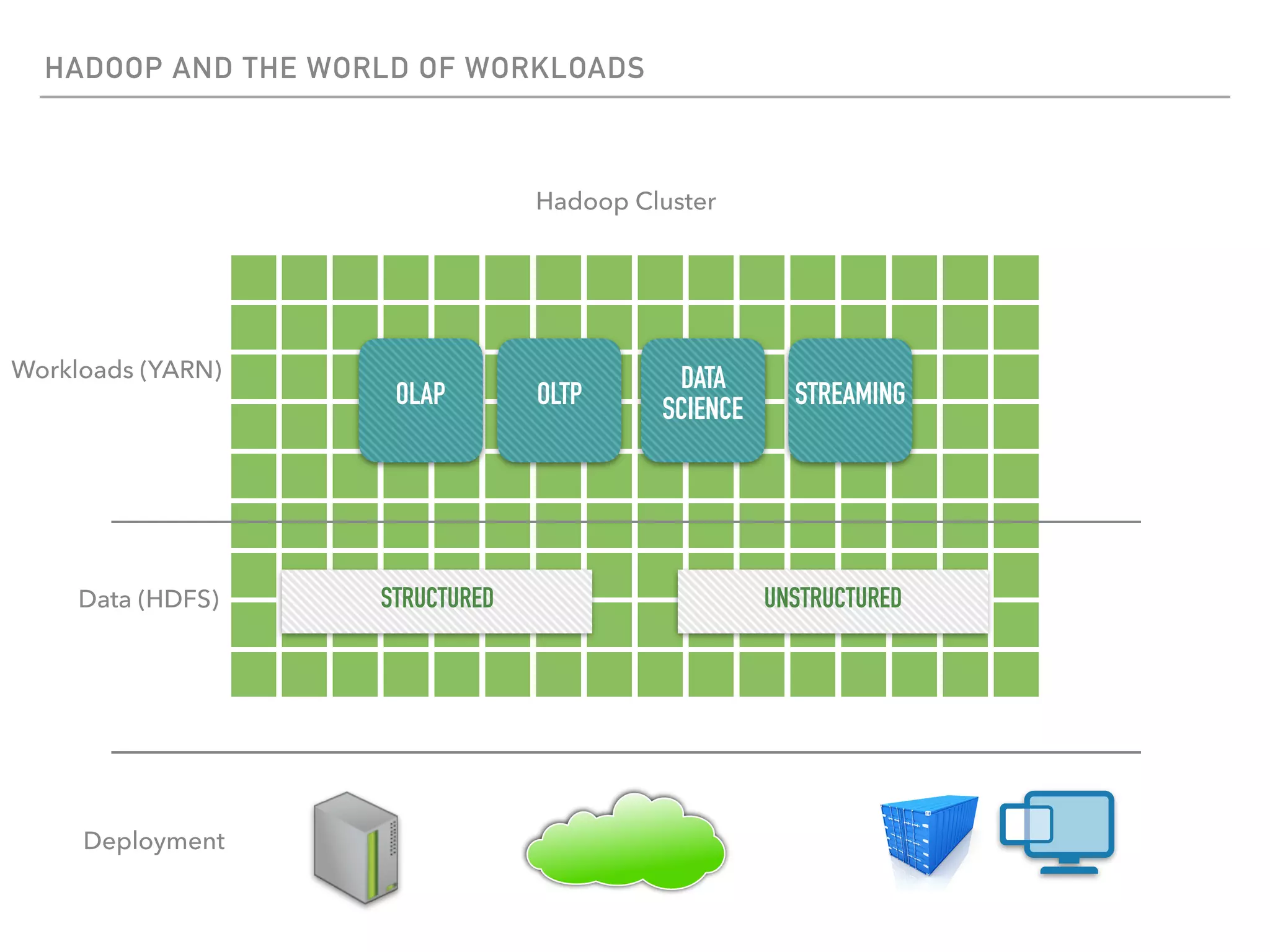
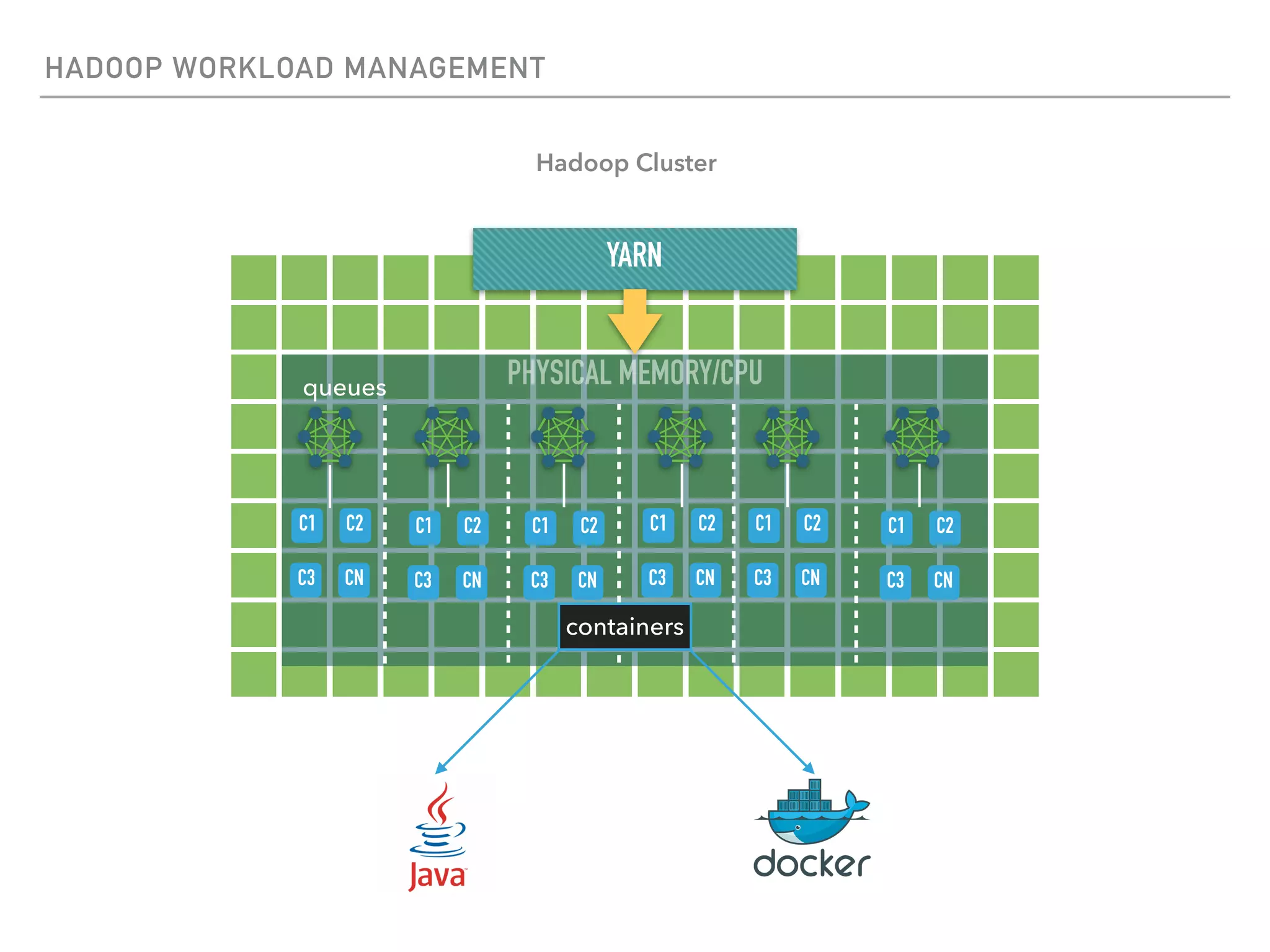




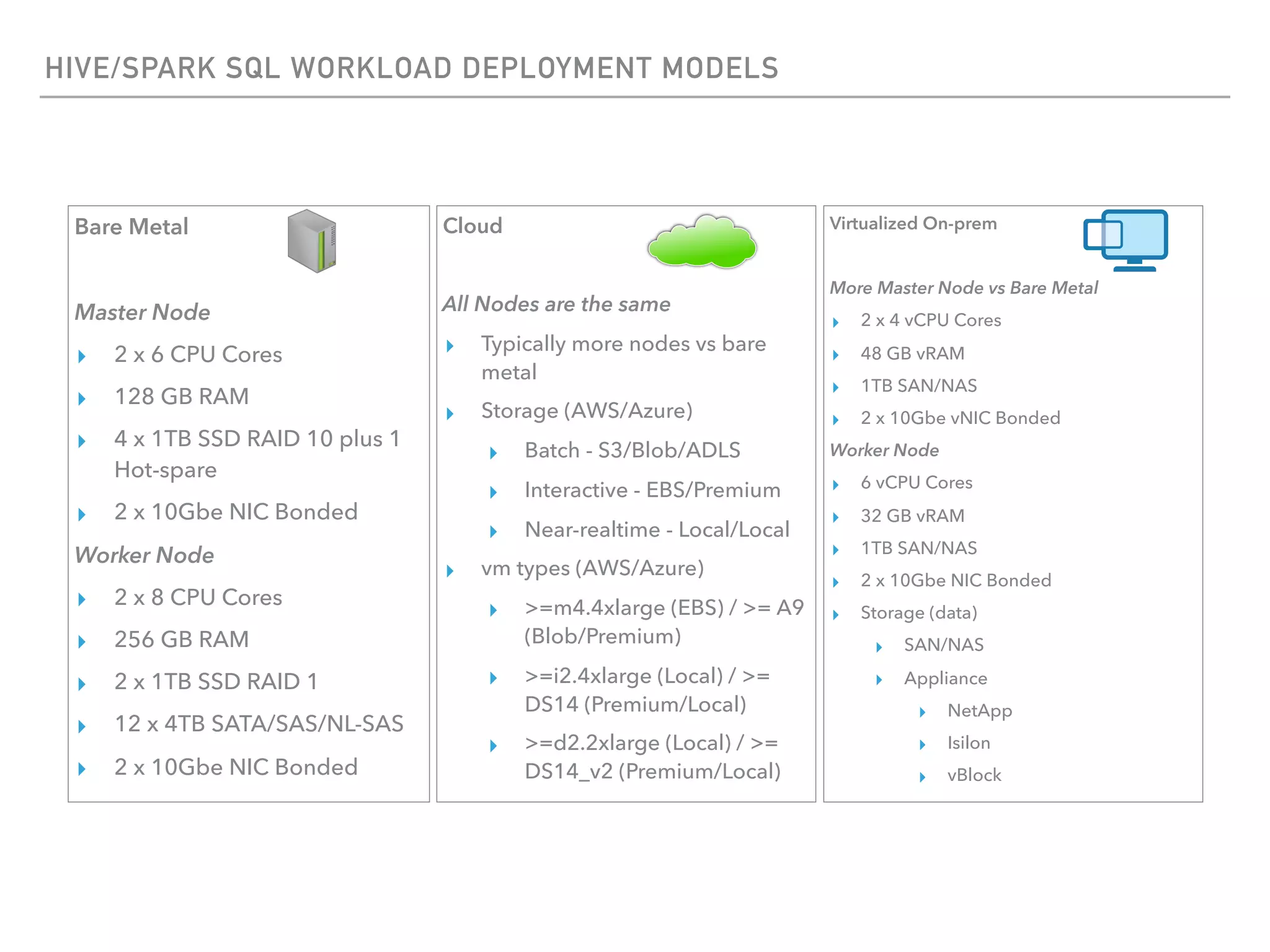



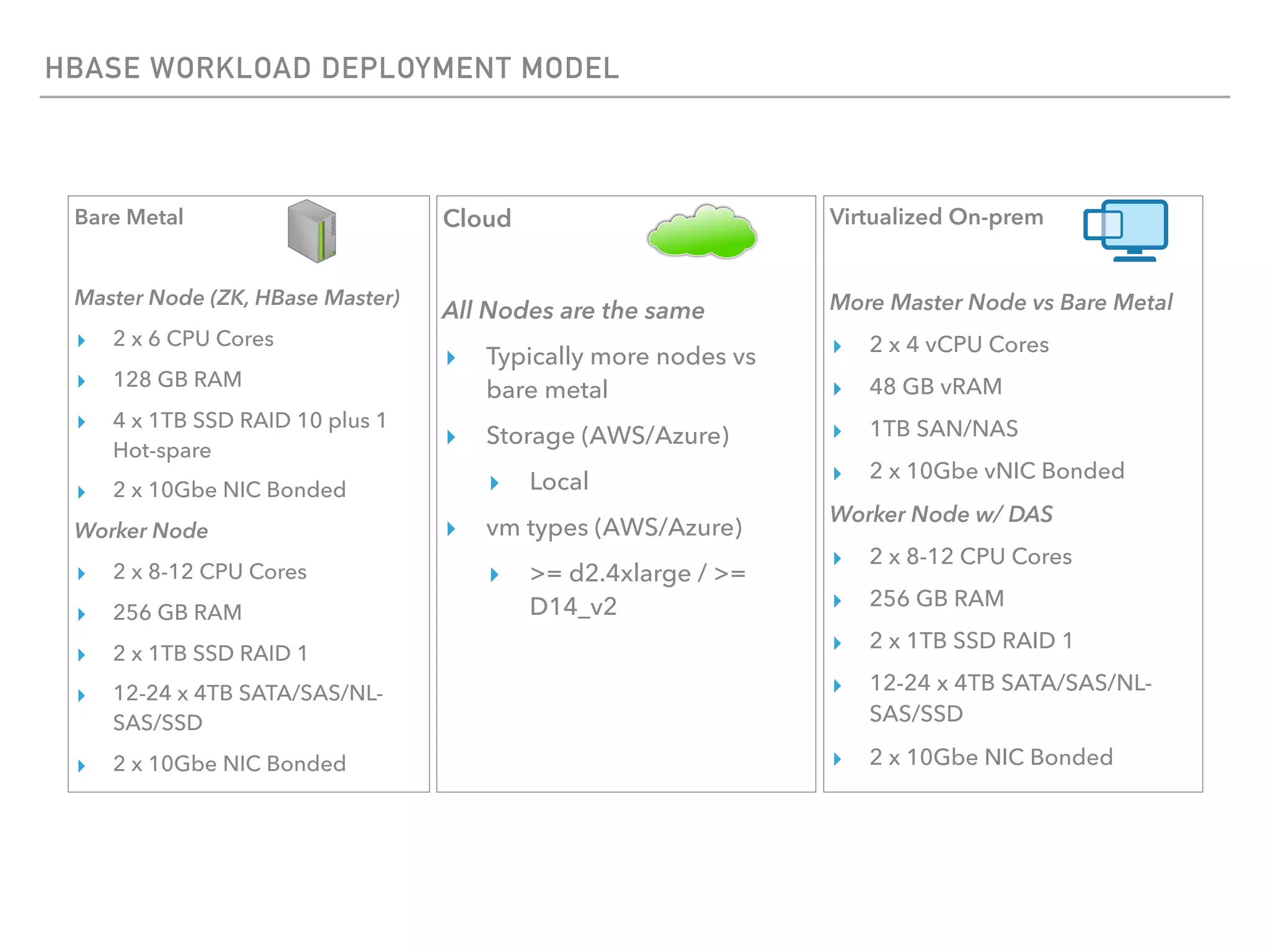

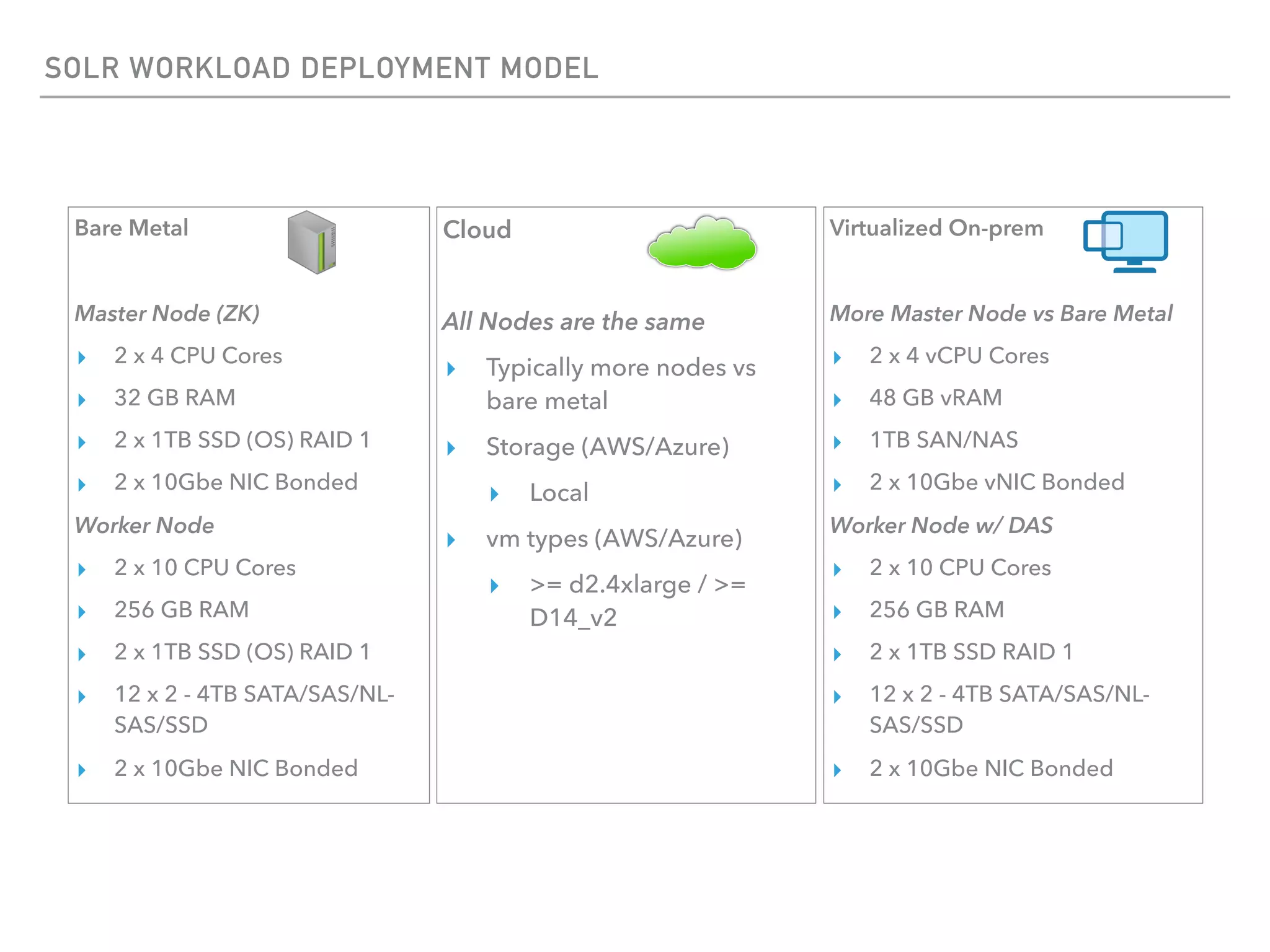



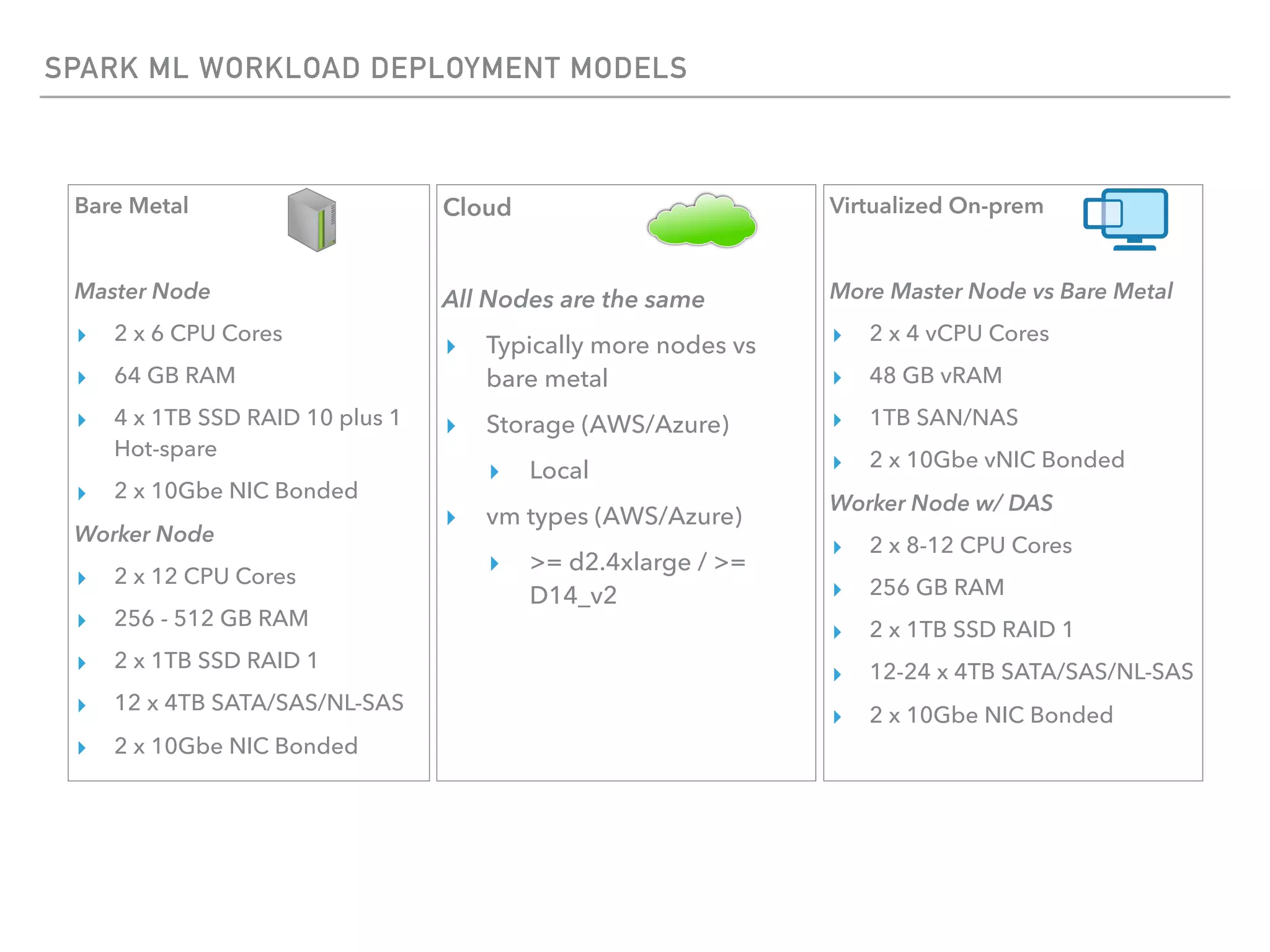



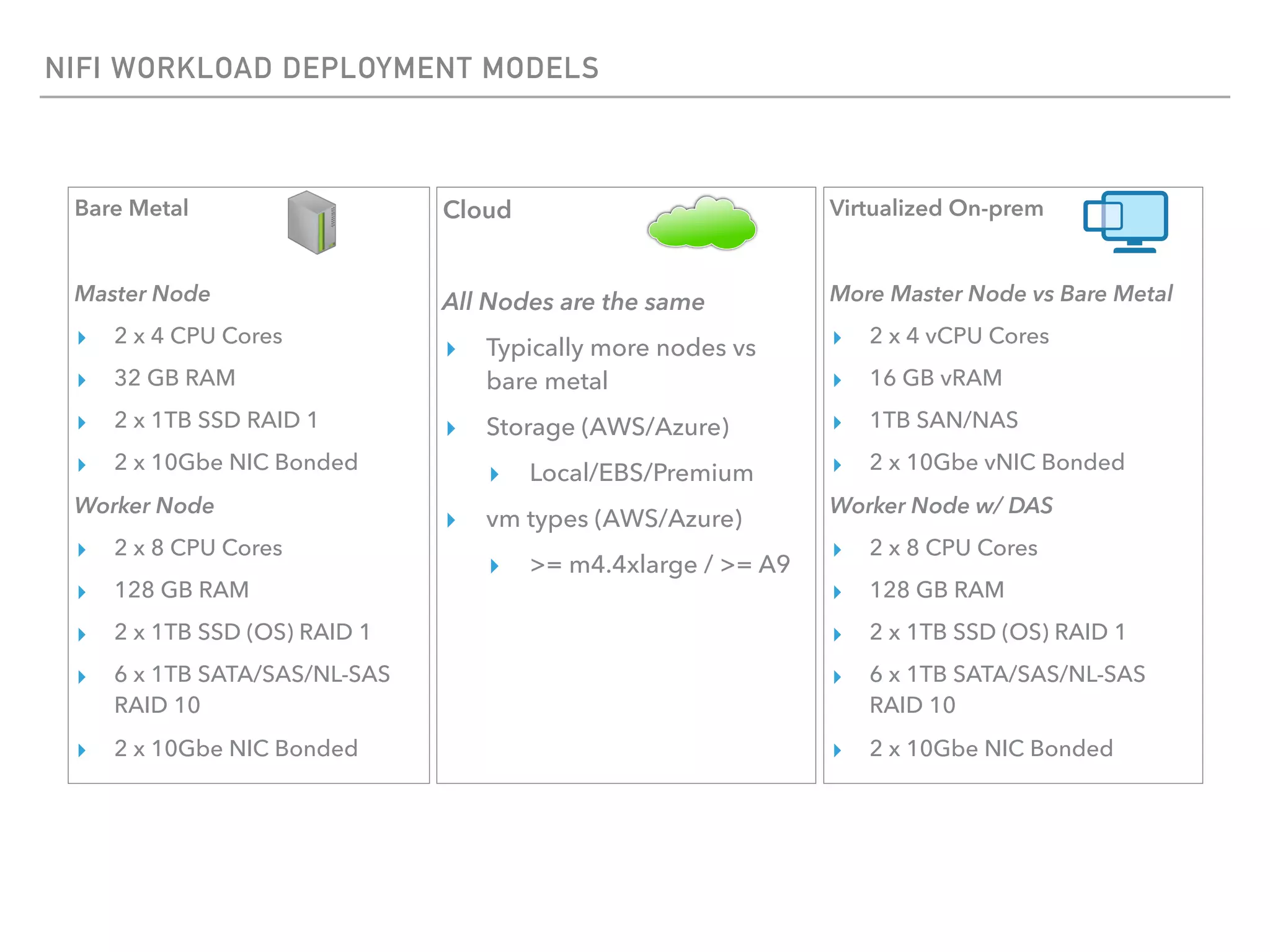

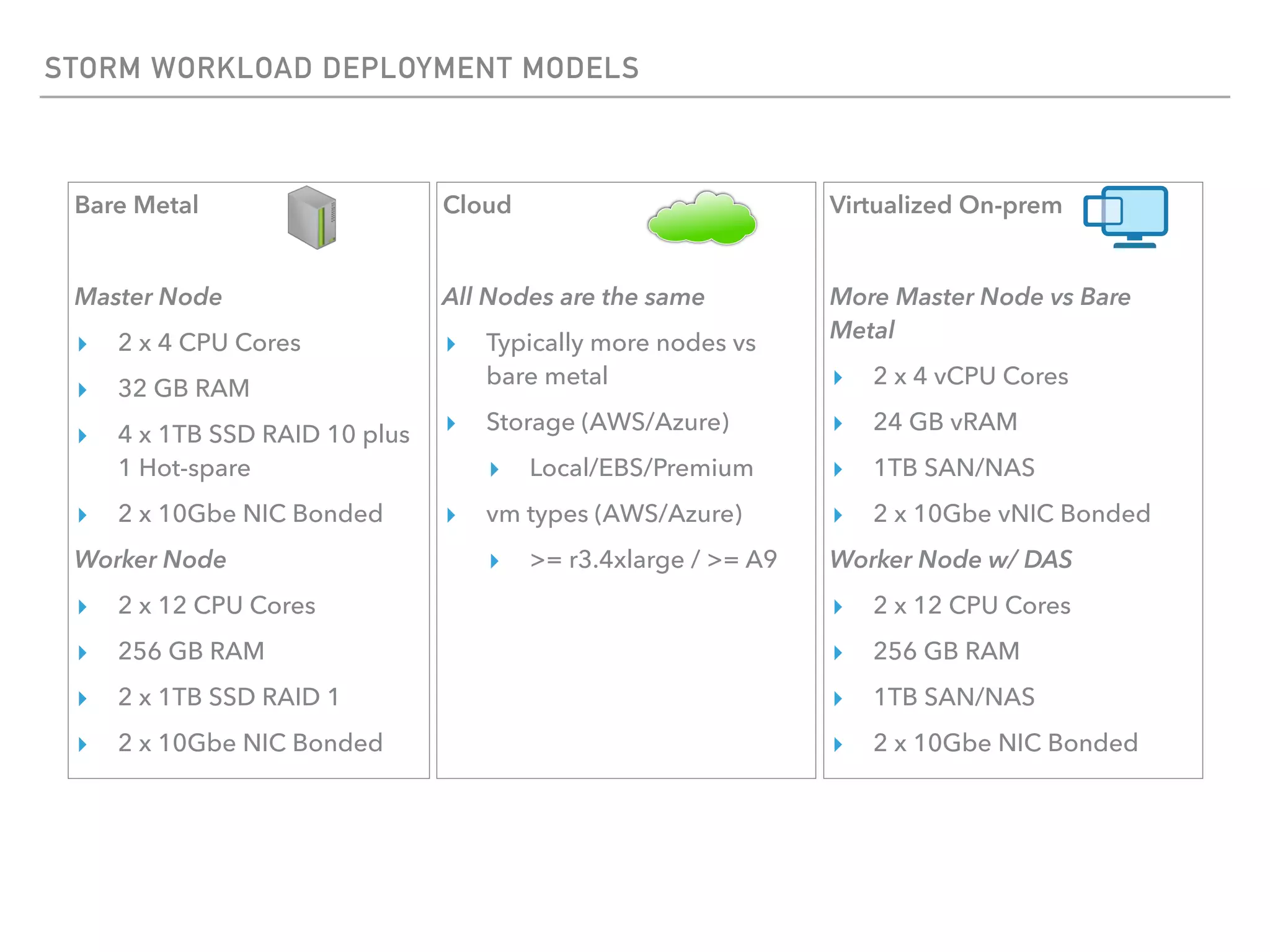




The document outlines the architecture and deployment models for Hadoop and its various workloads, including OLAP, OLTP, data science, and streaming. It discusses performance considerations such as resource management, scaling, and network configuration, as well as specific recommendations for hardware configurations across bare metal, cloud, and virtualized environments. Key focus areas include workload management, resource allocation, and system resilience to ensure efficient Hadoop cluster operations.










































































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)
