Download to read offline






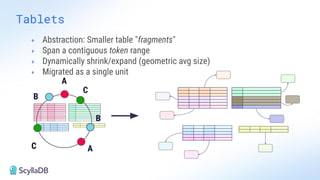
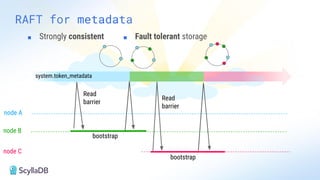
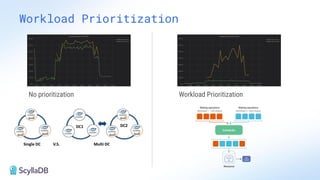









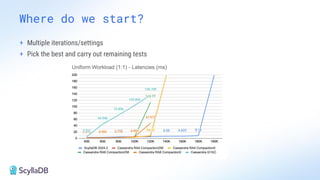
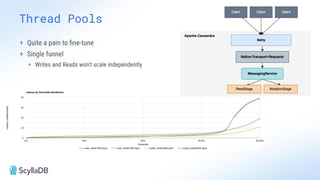
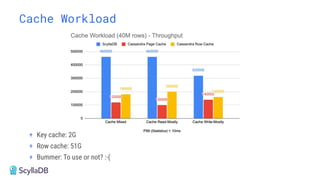
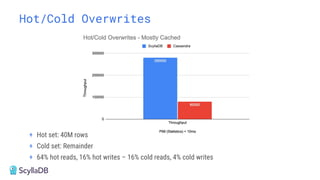

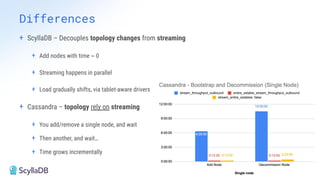
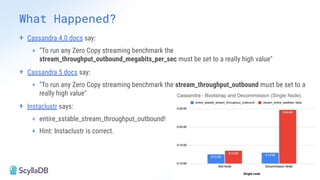
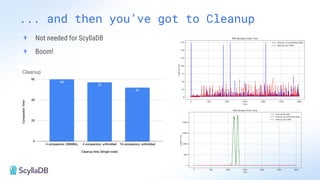
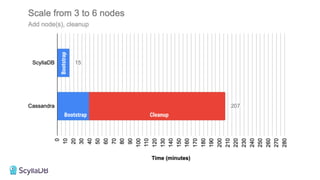
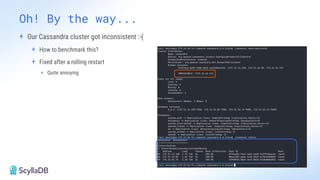


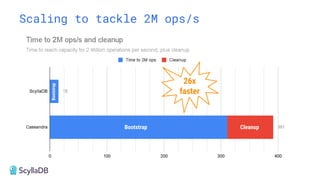
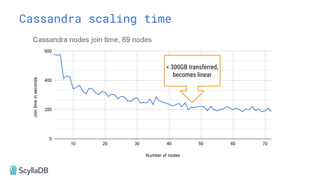
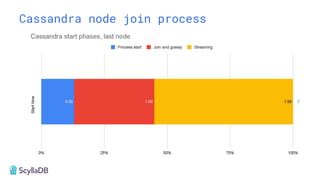
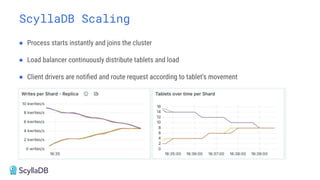















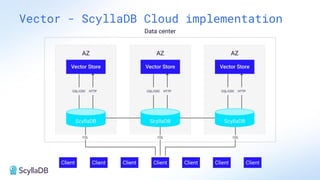










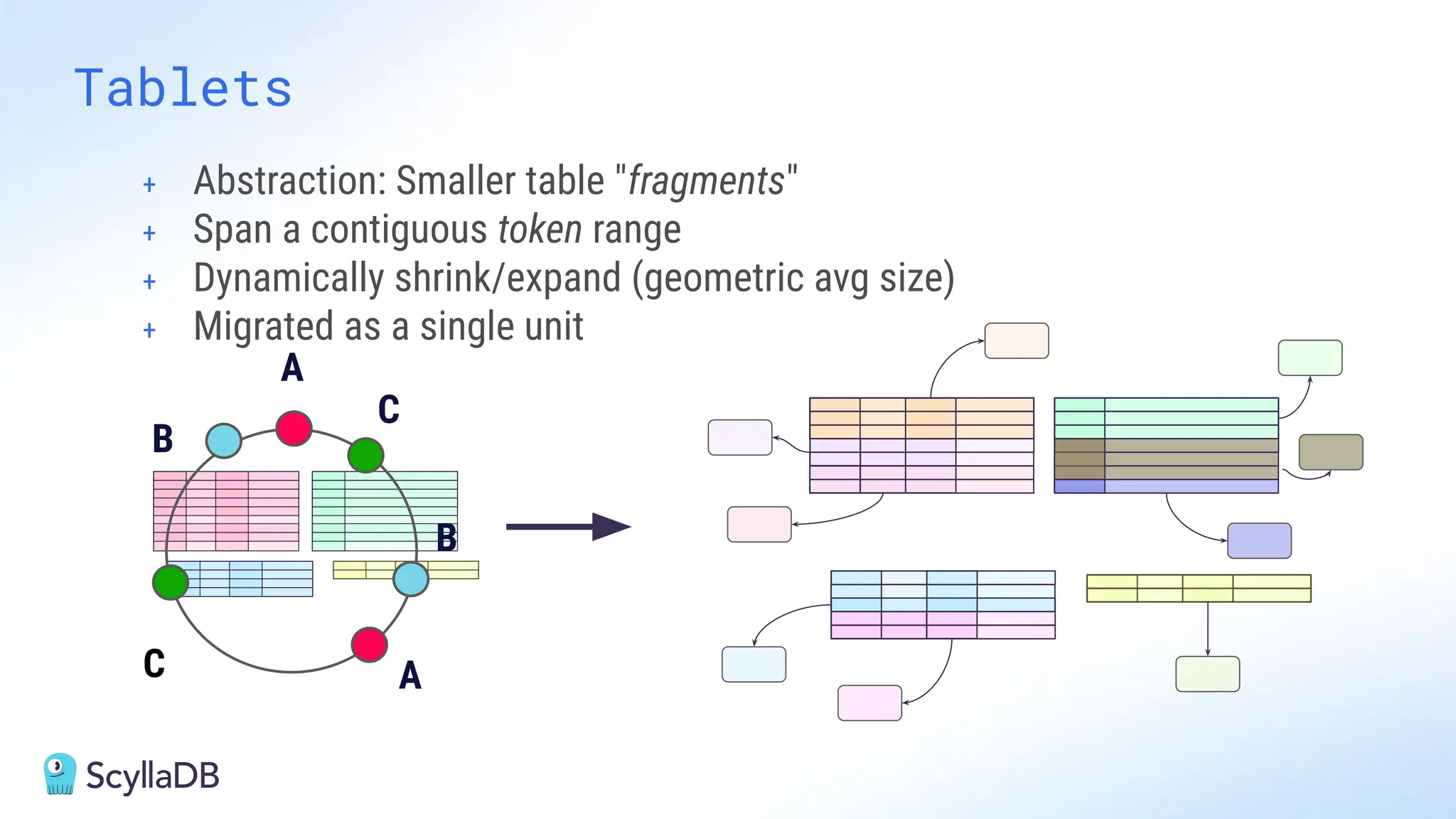
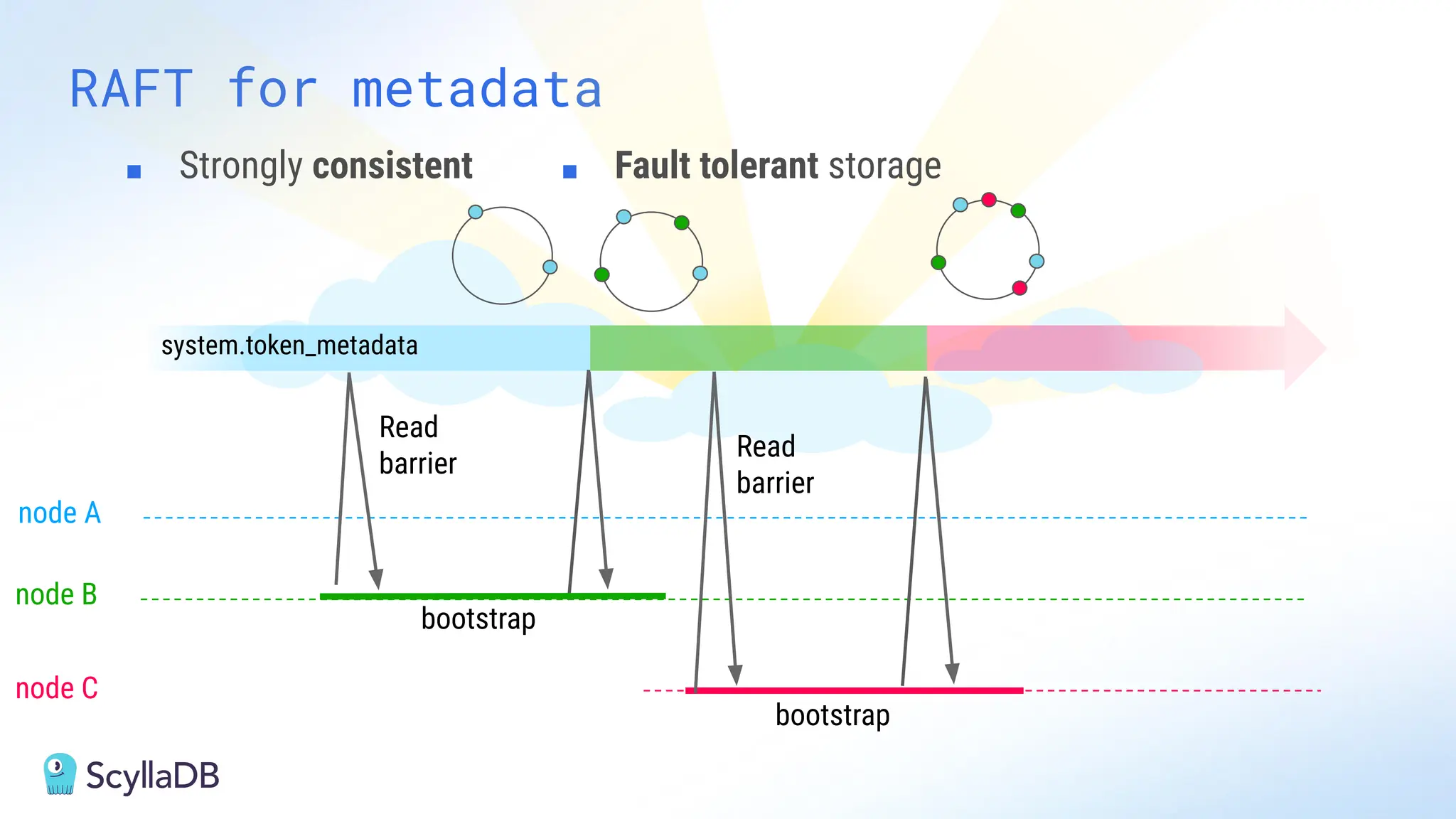











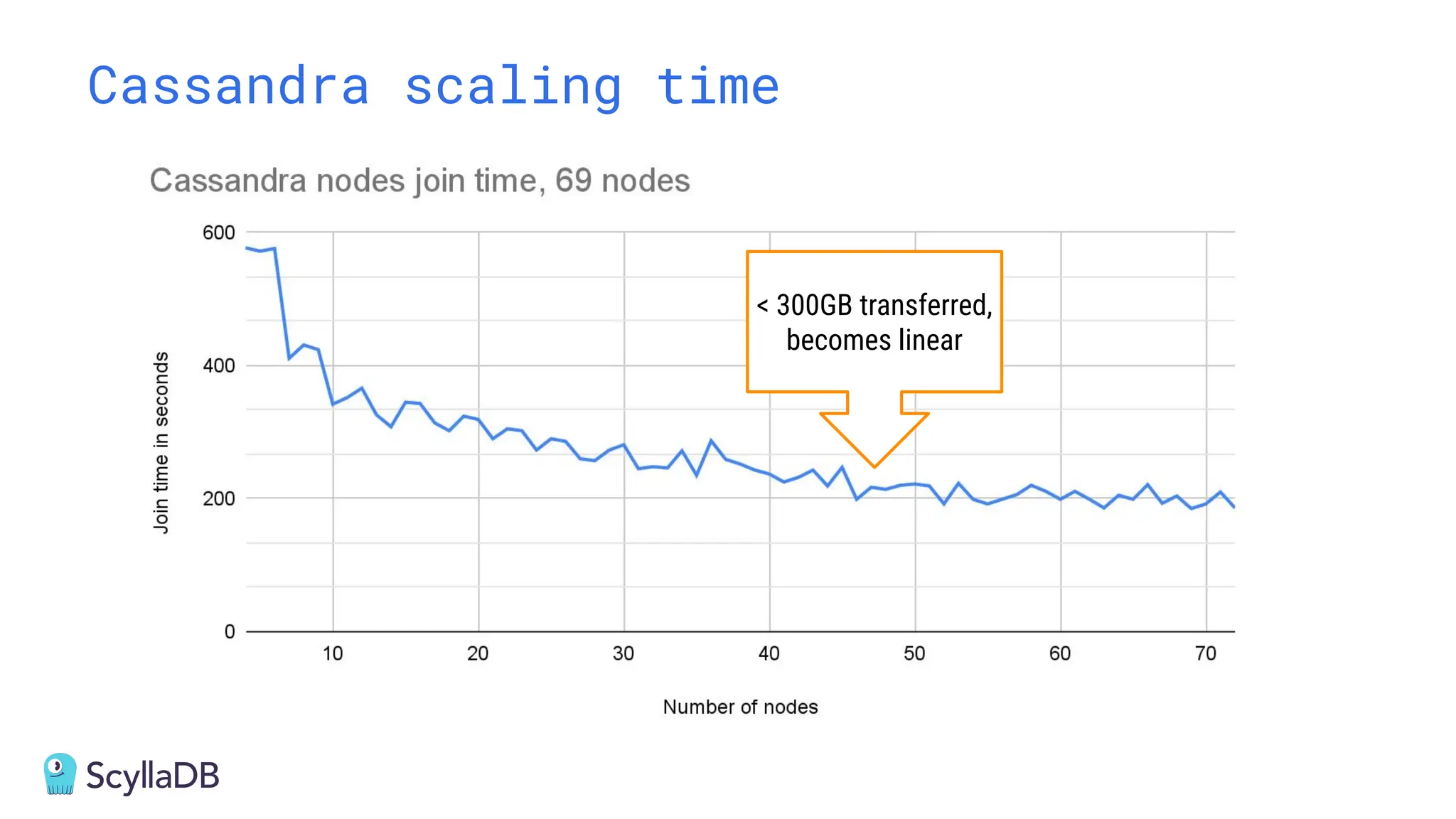
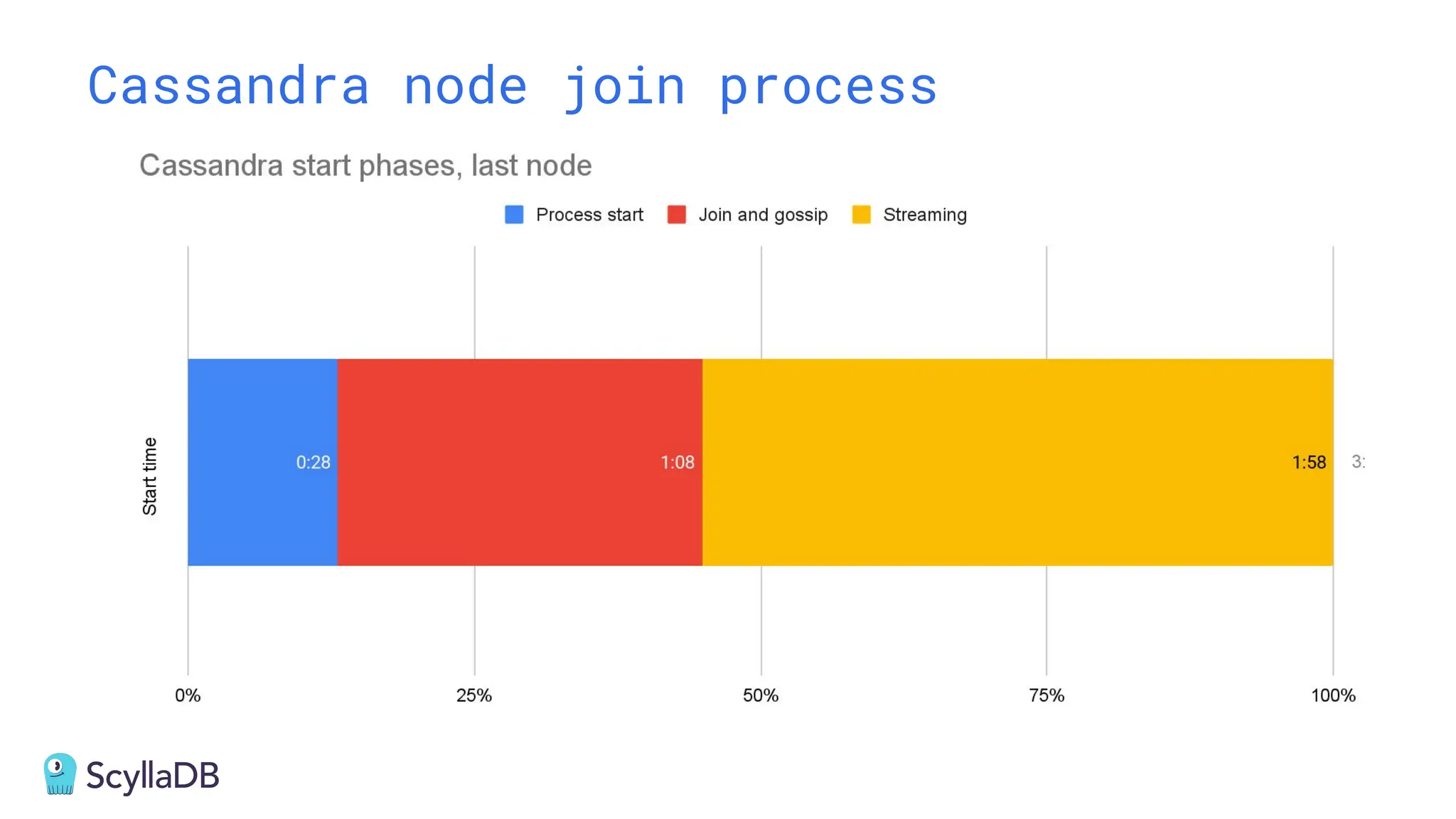
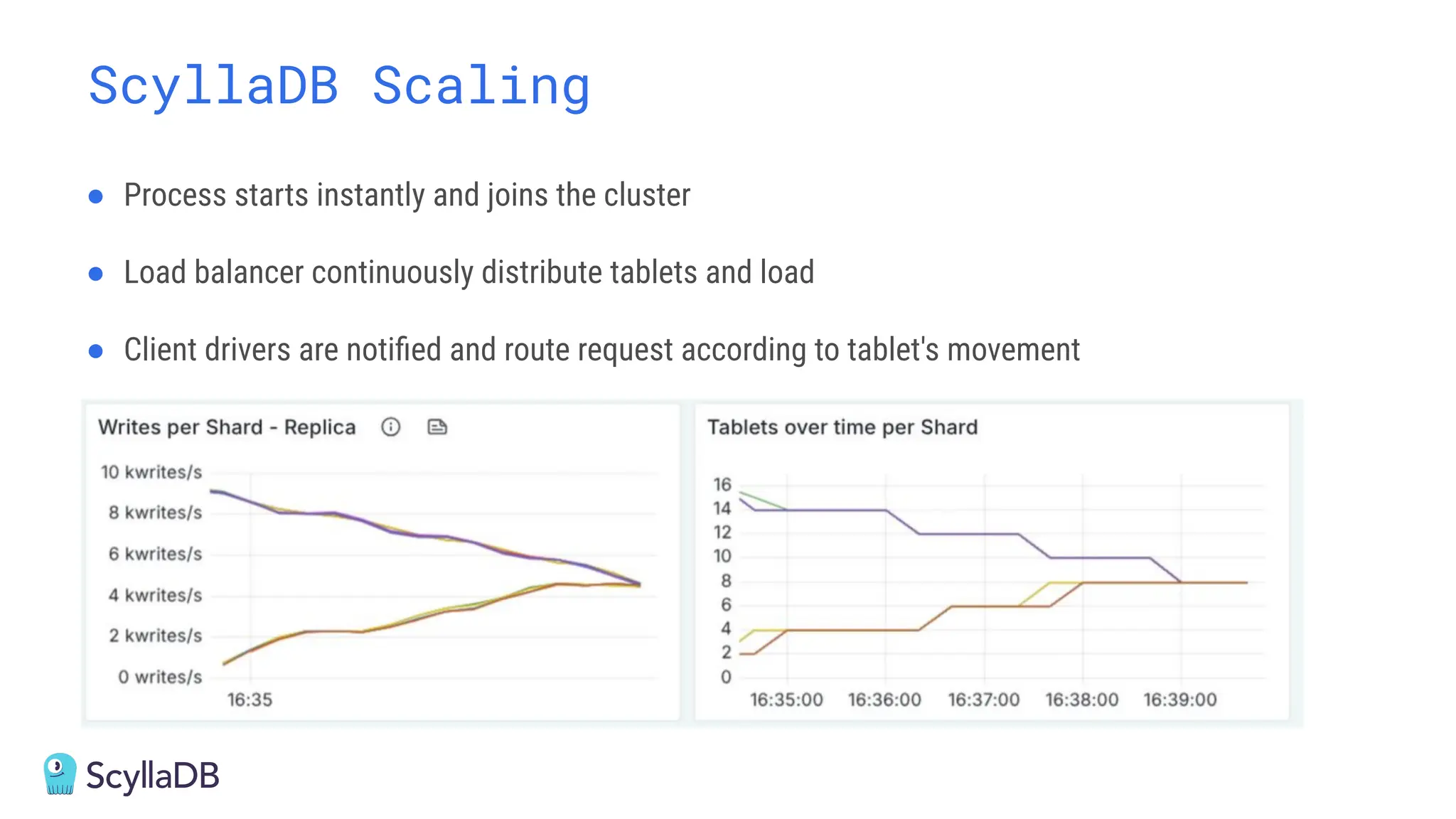














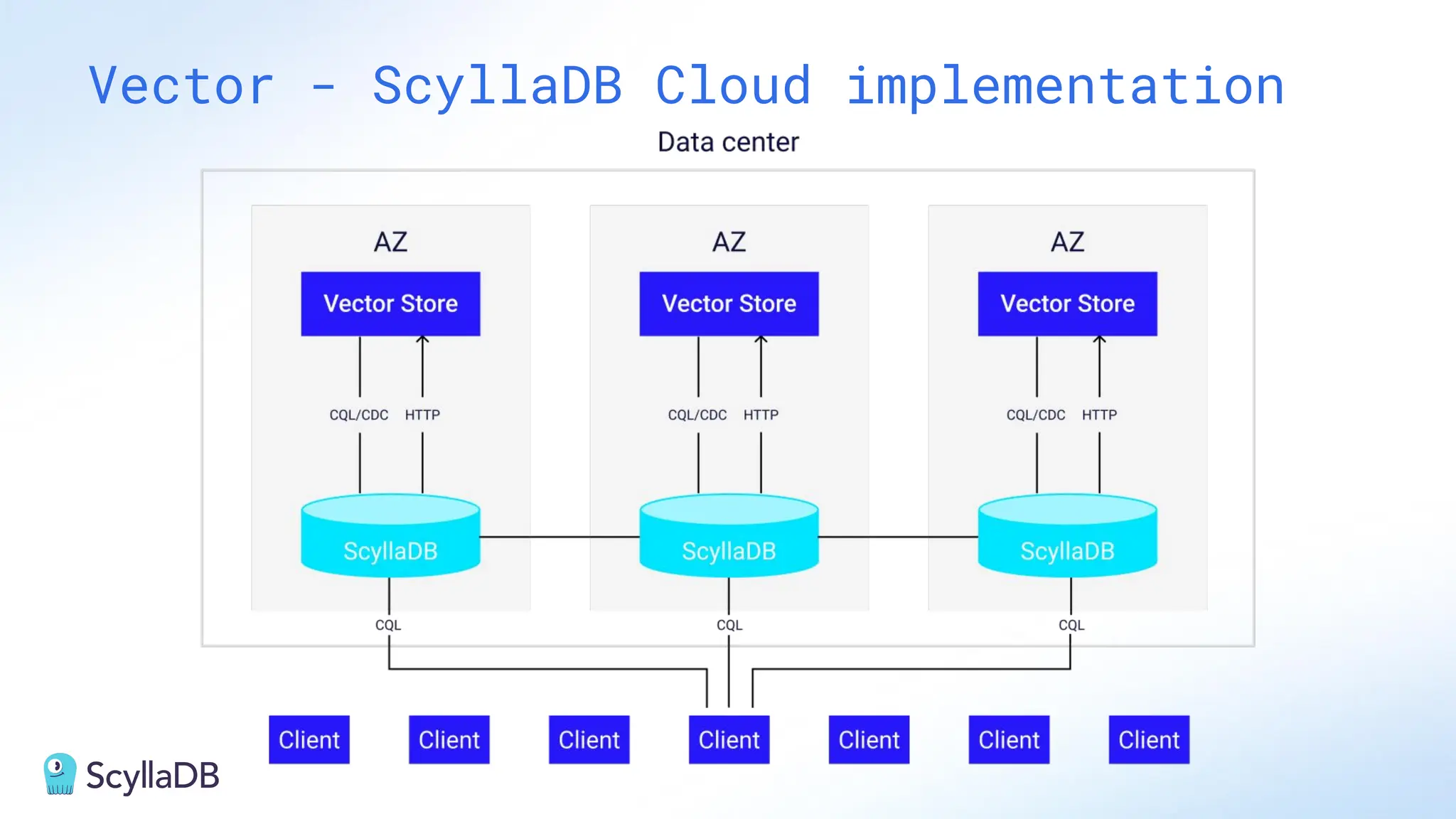






Comparing design decisions, performance, and use case fit Apache Cassandra and ScyllaDB are distributed databases designed to handle massive globally-distributed workloads. They were both created with a highly scalable architecture and both use the same CQL query language. But their priorities and design decisions have diverged quite a bit over the past decade. From the start, there have been notable differences in fundamentals such as sharding, caching, and indexing. The differences have become more significant with the most recent releases. For example, Cassandra 5 introduced Storage‑Attached Indexes, Trie‑based Memtables & SSTables and Unified Compaction Strategy. Meanwhile, ScyllaDB added tablets elasticity (vs. vNodes), Raft, support for up to 90% storage utilization, and ZSTD dictionary-based compression for both network and storage. And both are now taking distinctly different approaches to vector search. Join this webinar for a side-by-side analysis of the key differences and what it means for teams working with high-performance databases. We’ll cover: - A look inside each database’s architecture and internal operations - How performance, features, and deployment options compare - What’s unique in each and what use cases / technical requirements benefit most from each database’s differentiators



































































