Downloaded 113 times




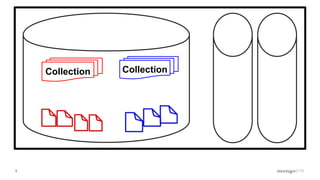
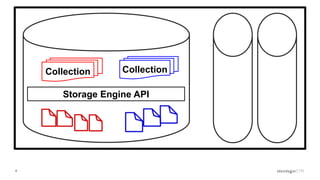








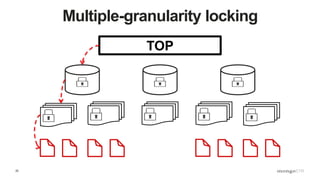









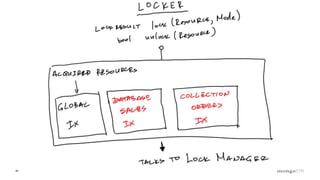




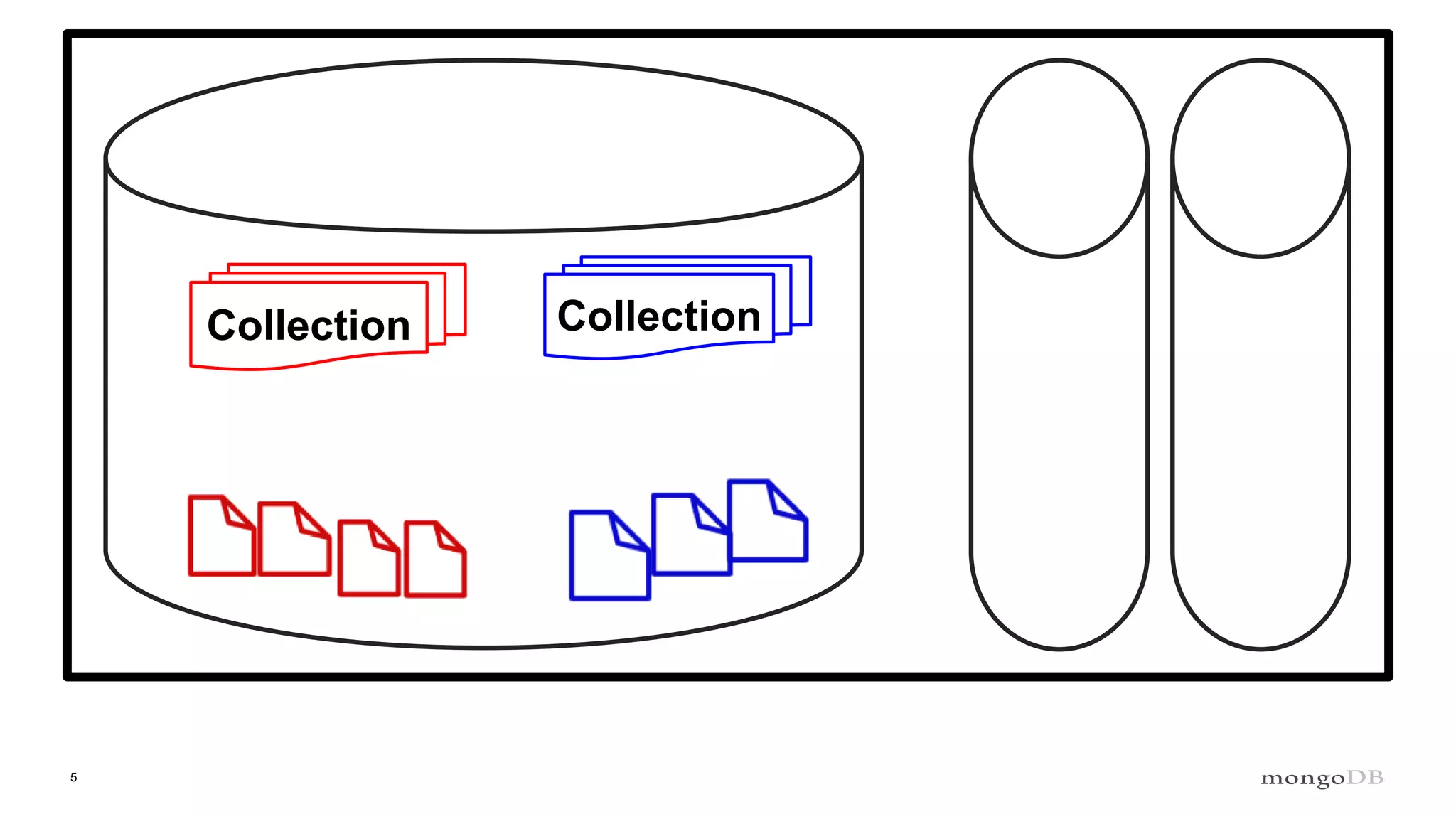
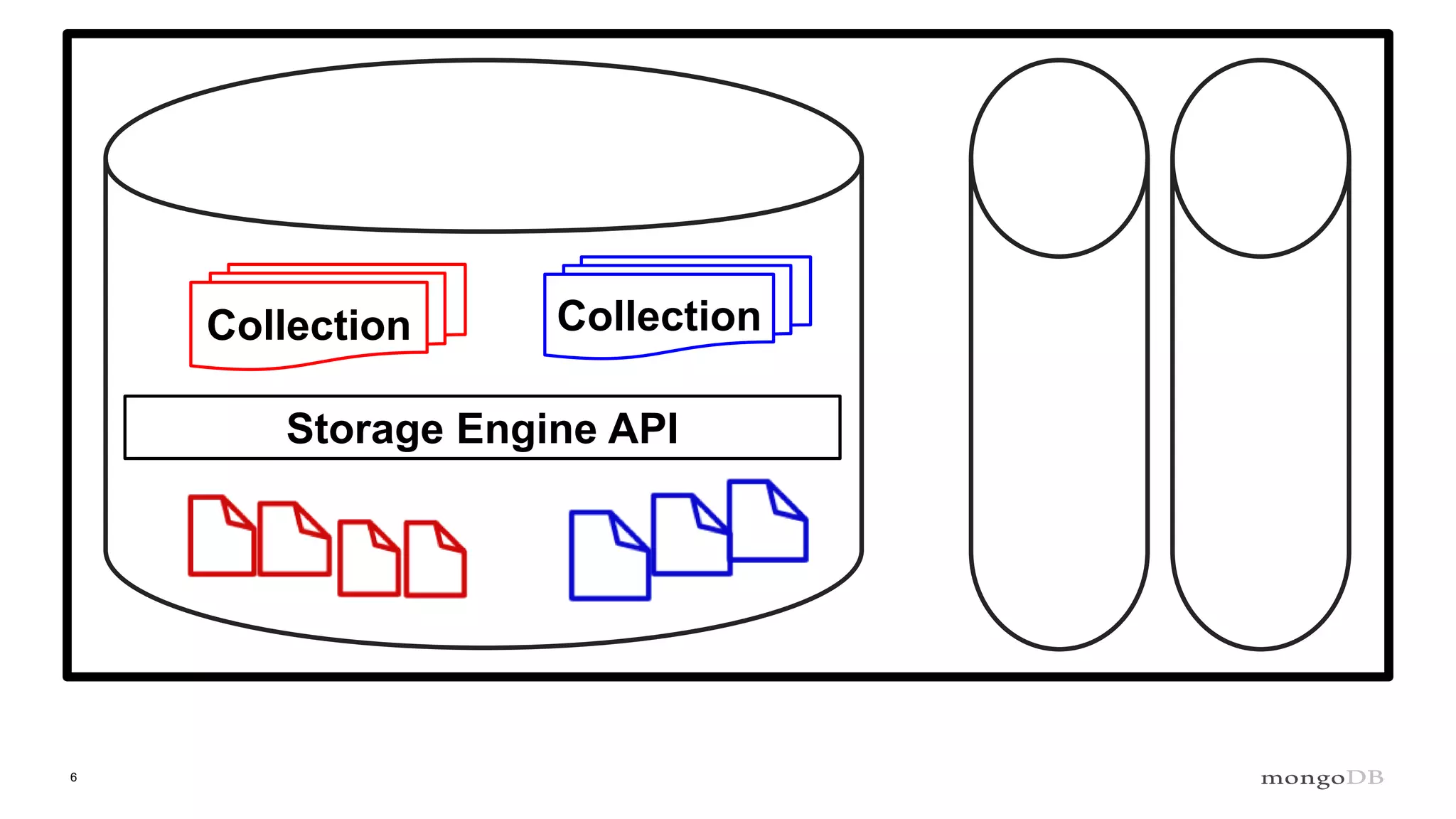






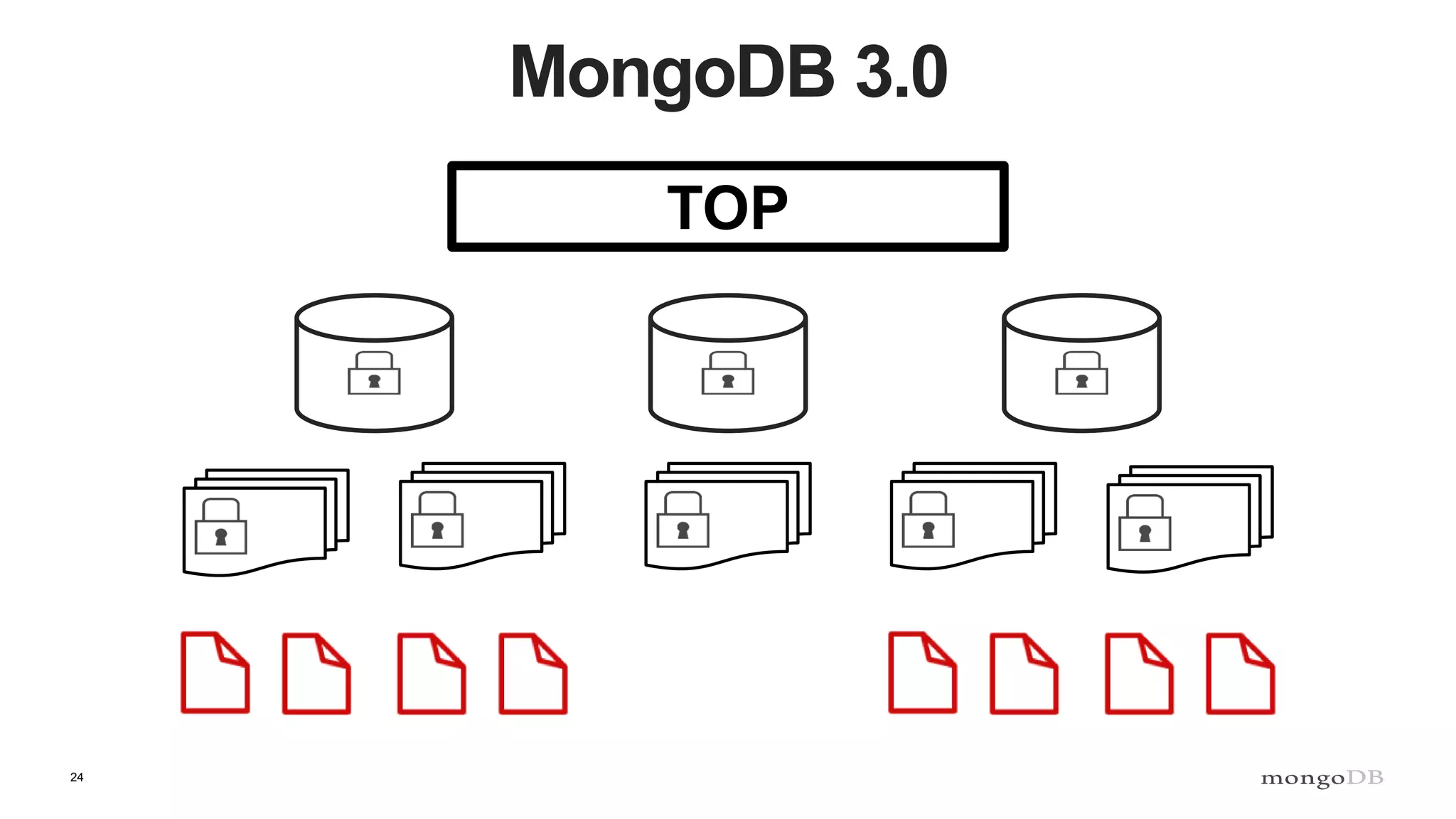
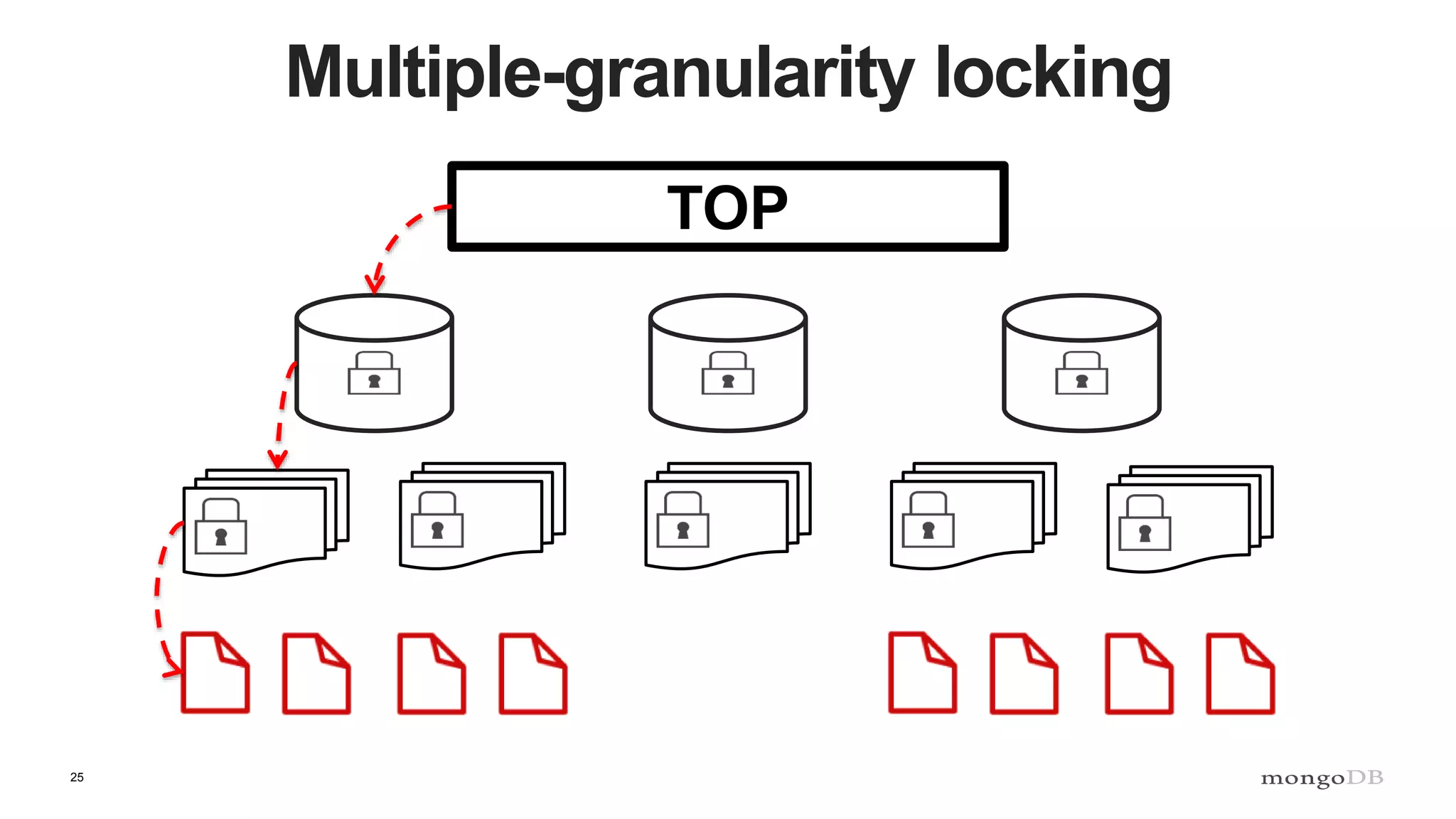












- MongoDB's concurrency control uses multiple-granularity locking at the instance, database, and collection level. This allows finer-grained locking than previous approaches. - The storage engine handles concurrency control at lower levels like the document level, using either MVCC or locking depending on the engine. WiredTiger uses MVCC while MMAPv1 uses locking at the collection level. - Intents signal the intention to access lower levels without acquiring locks upfront, improving concurrency compared to directly acquiring locks. The lock manager enforces the locking protocol and ensures consistency.
Overview of the presentation and audience including operations engineers, developers, and curious individuals.
Definition of concurrency control involving locking, data consistency, and MVCC (Multi-Version Concurrency Control).
Learning objectives for top-level concurrency control, cooperation with the storage engine, and an outline of the talk.
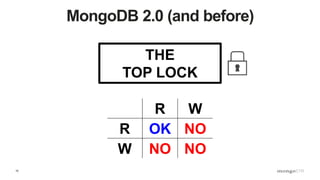
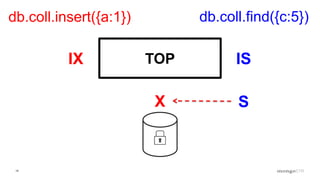
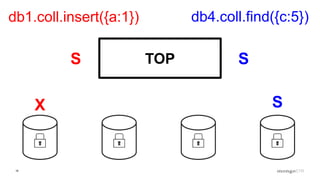
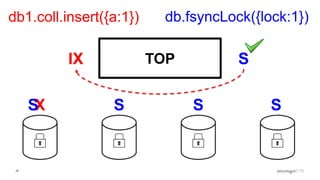
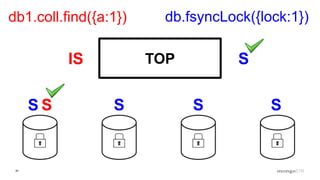
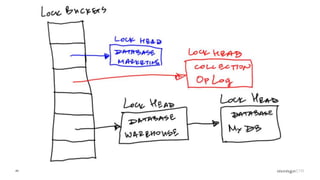
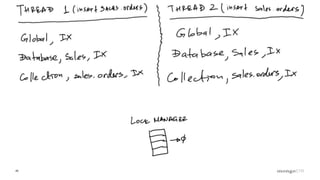
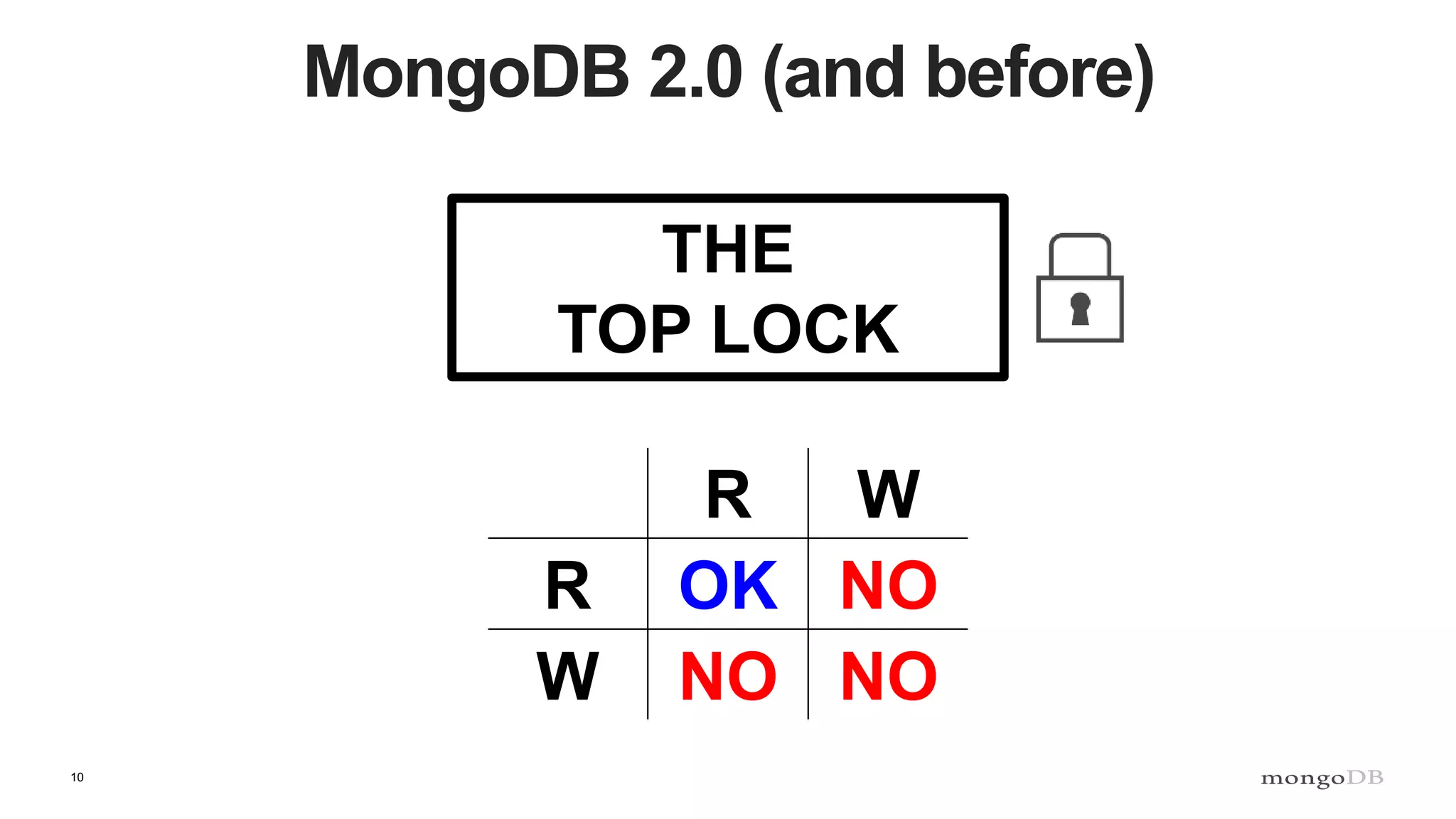
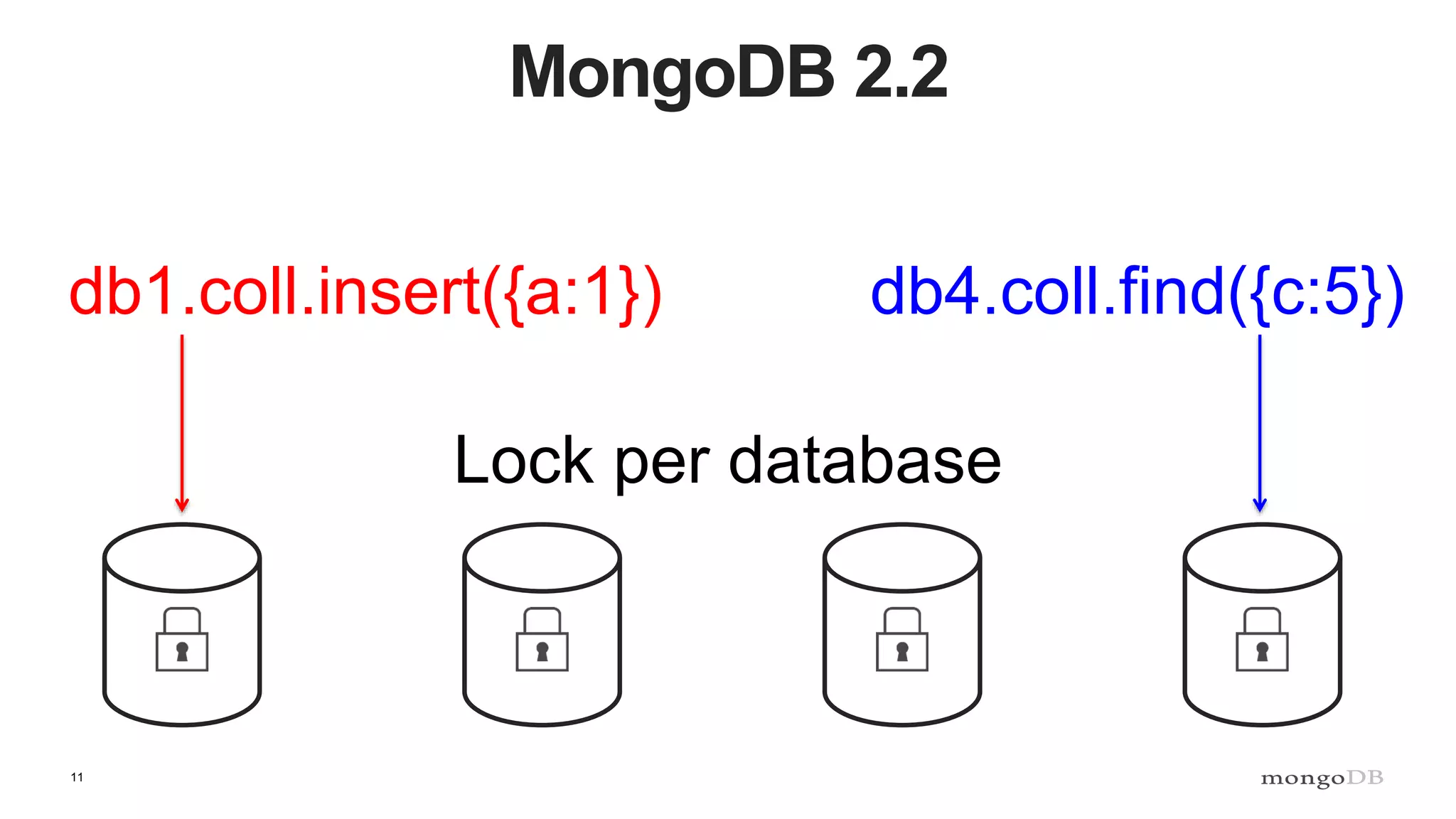
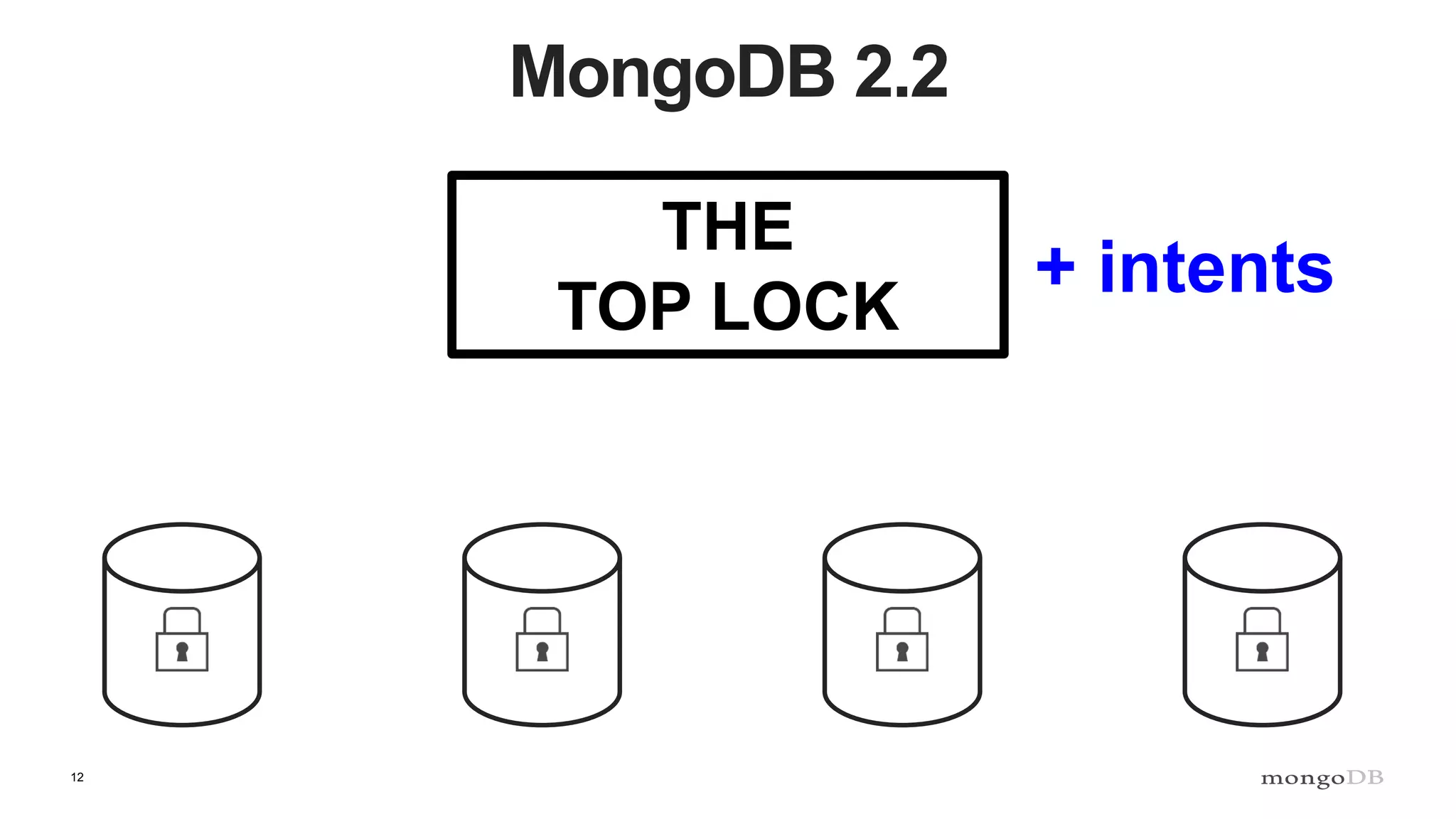
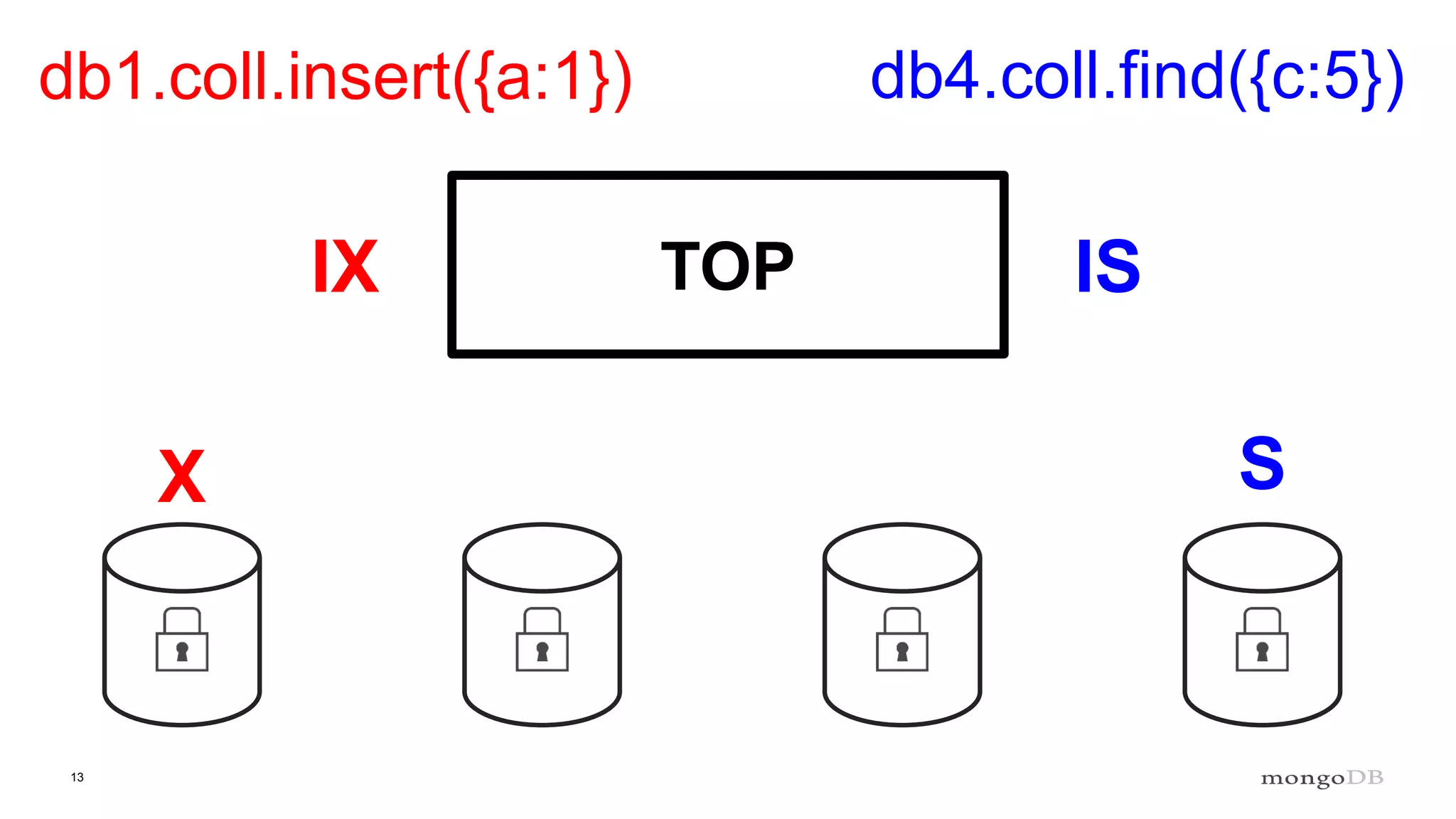
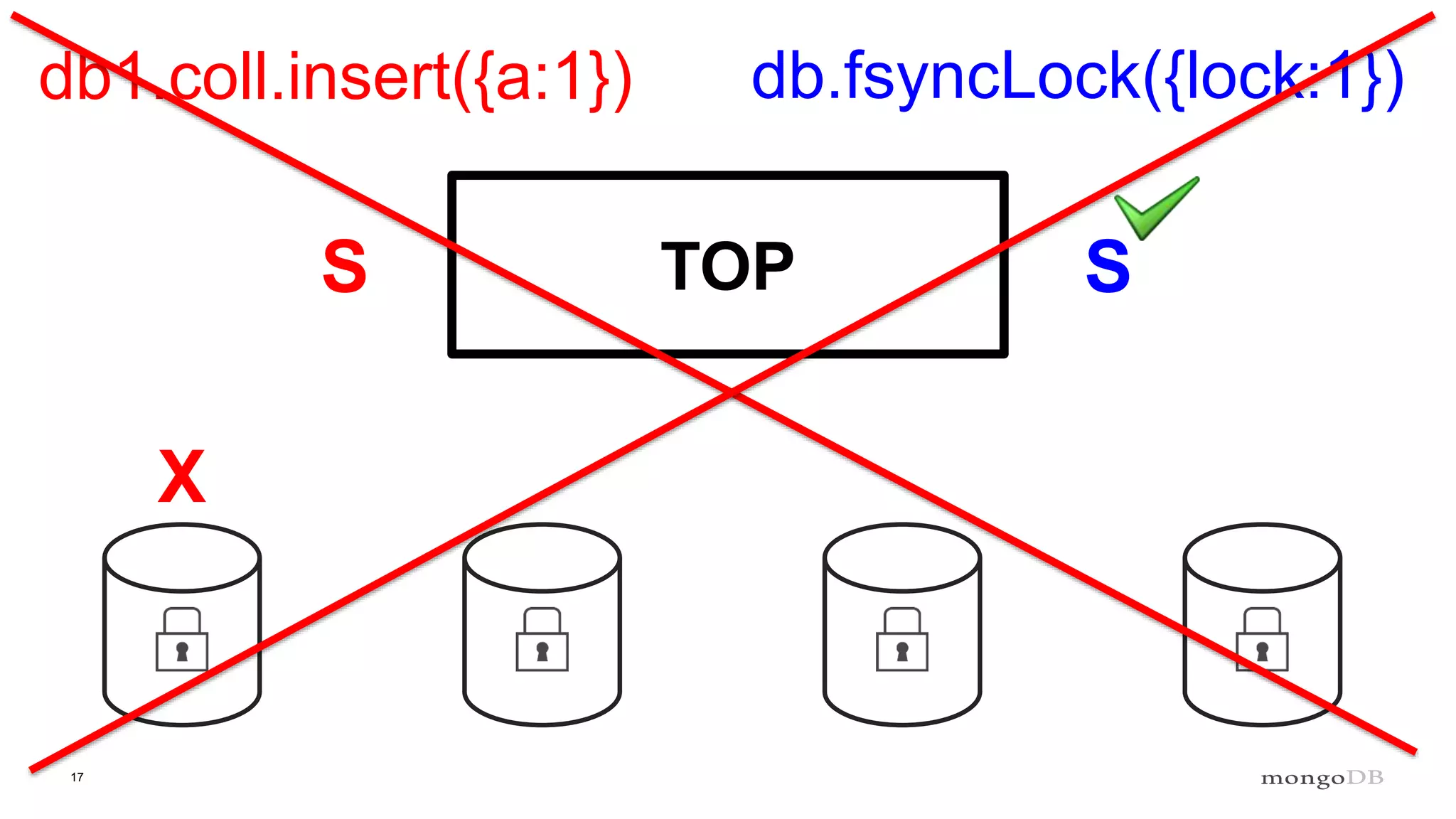
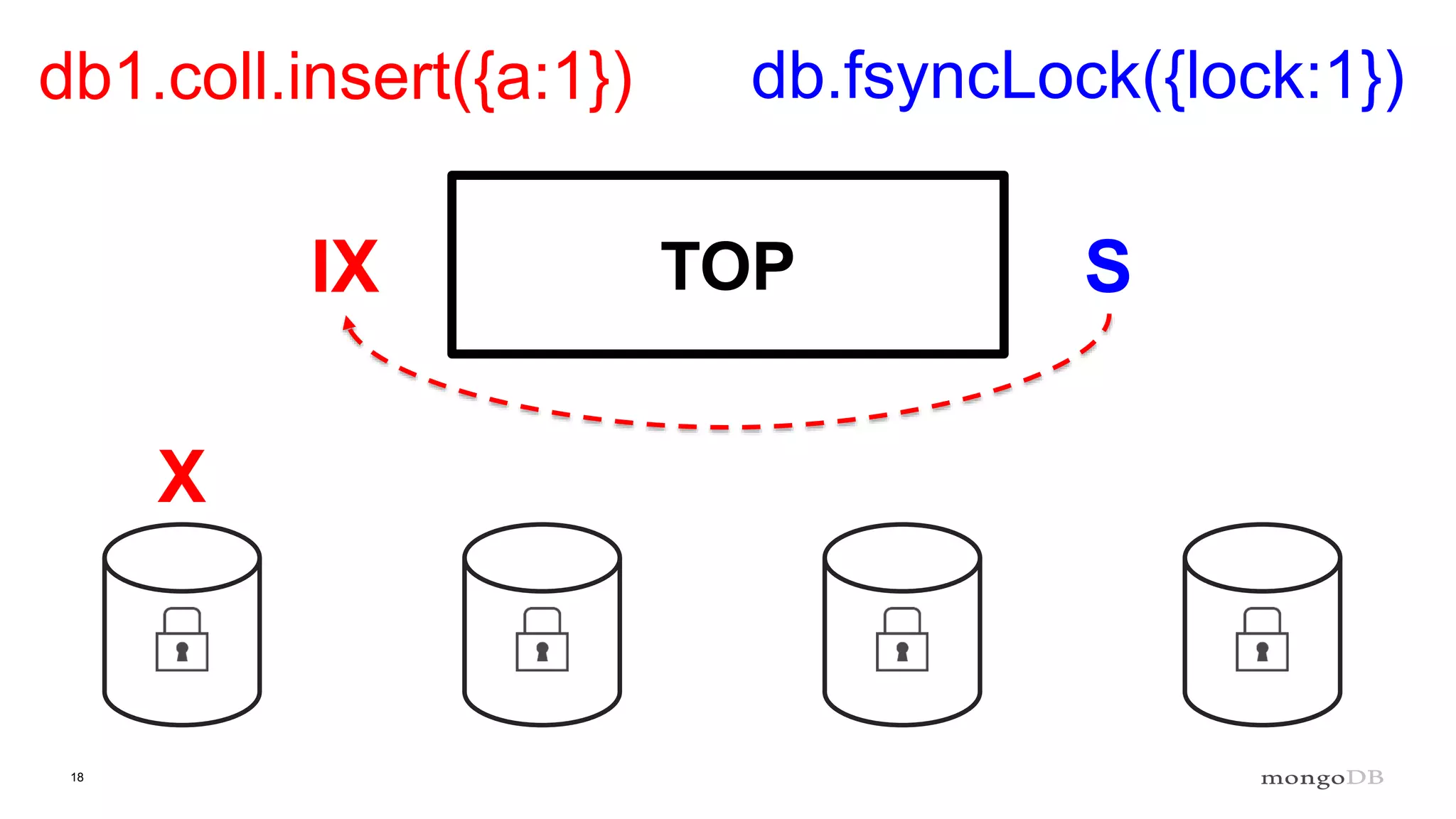
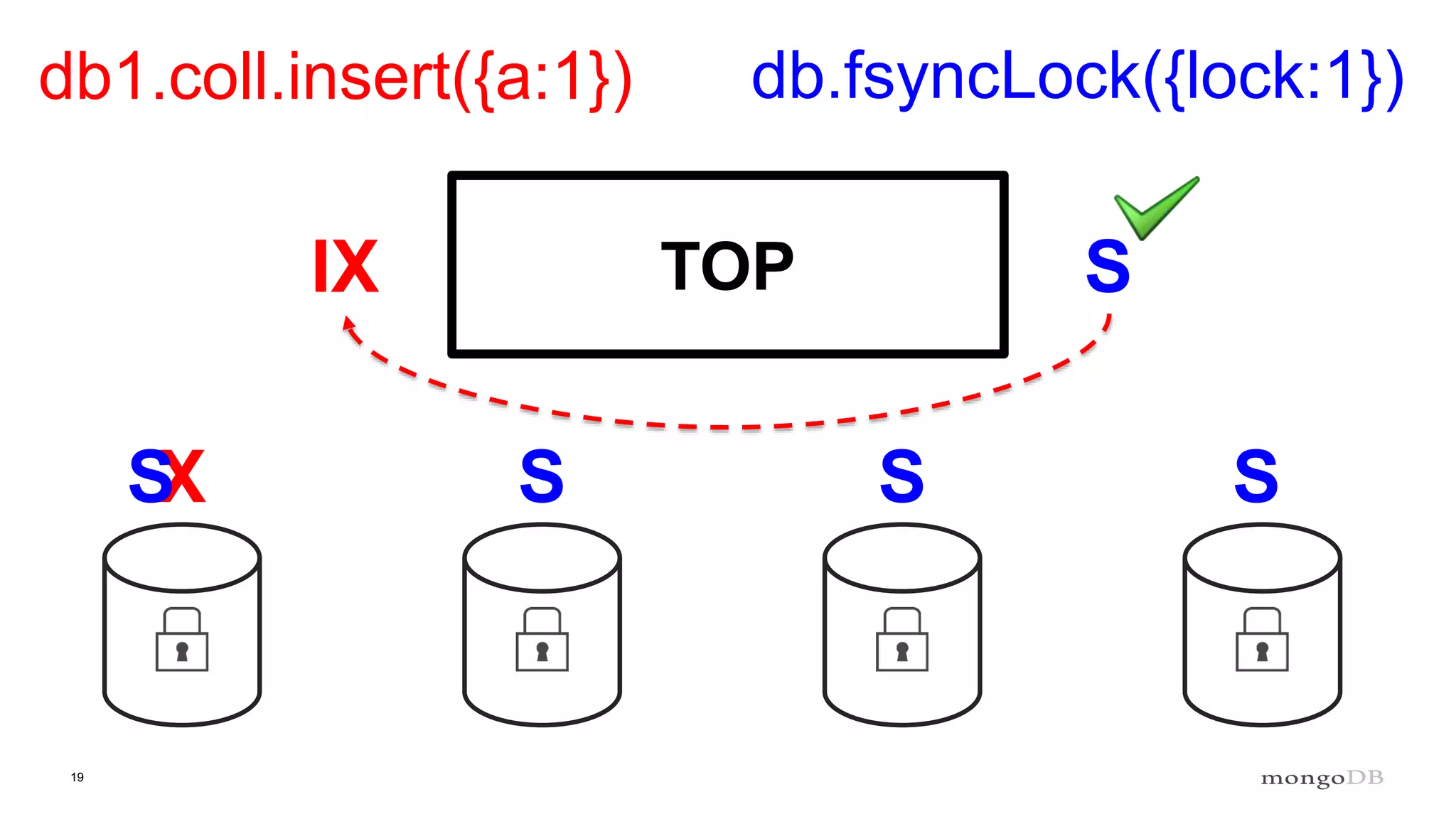
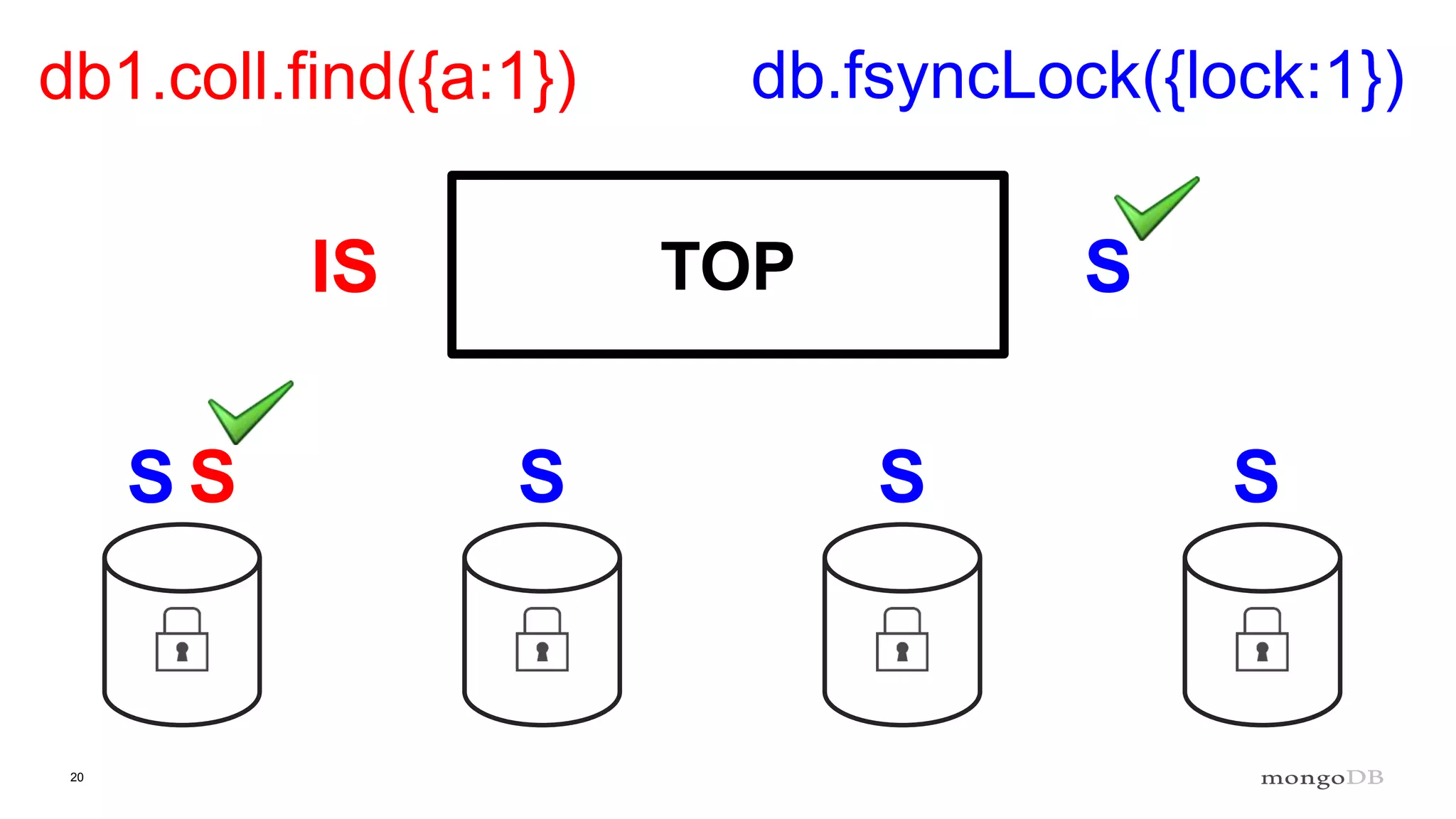
Description of locking mechanisms in MongoDB 2.0 and 2.2, including top-level locks and database-level locks with intents.
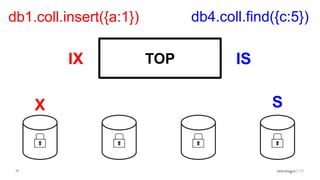
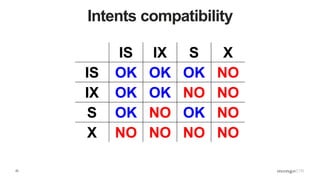
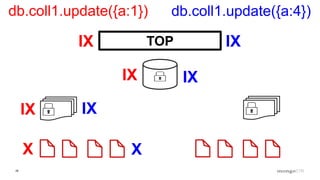
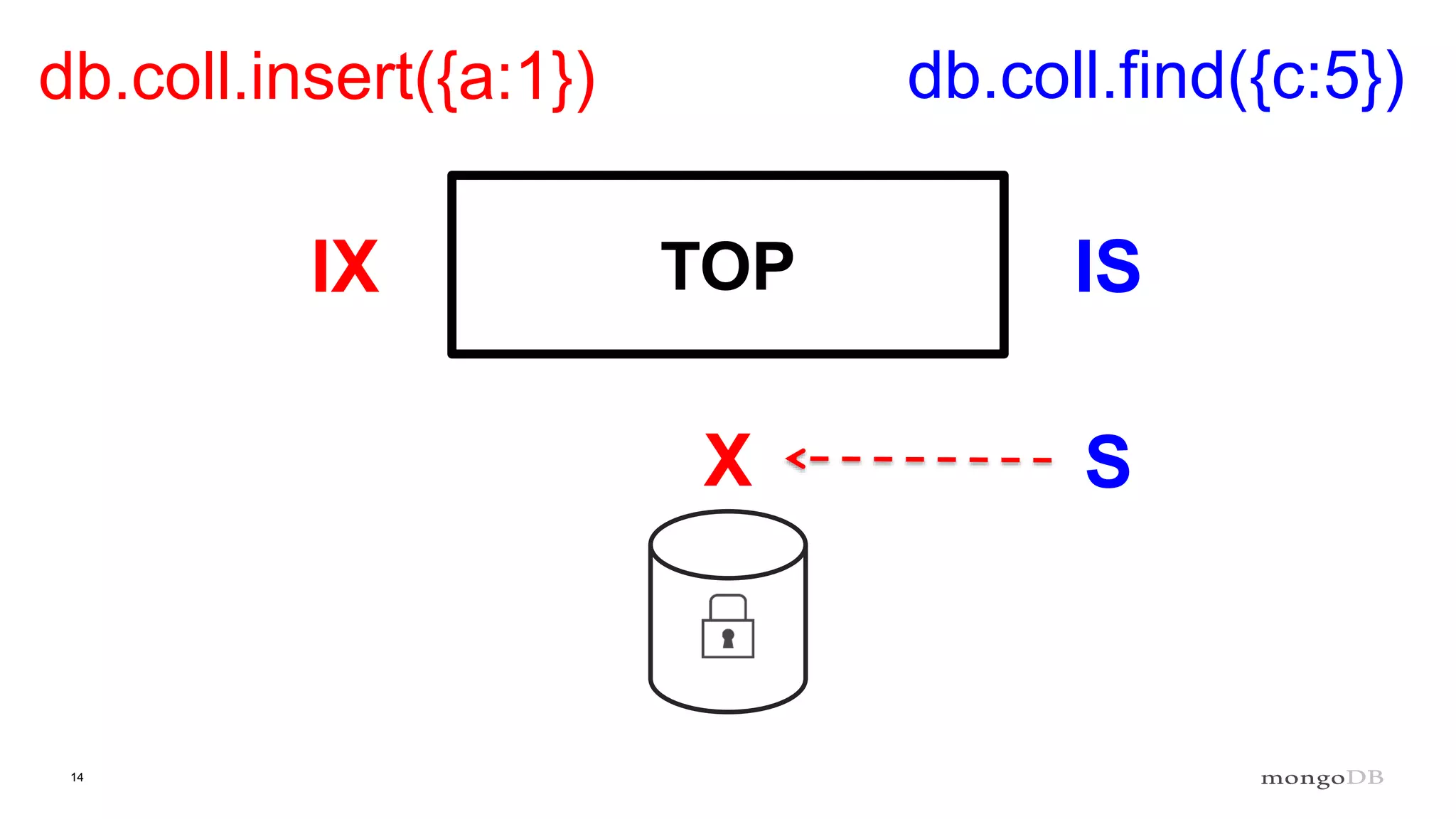
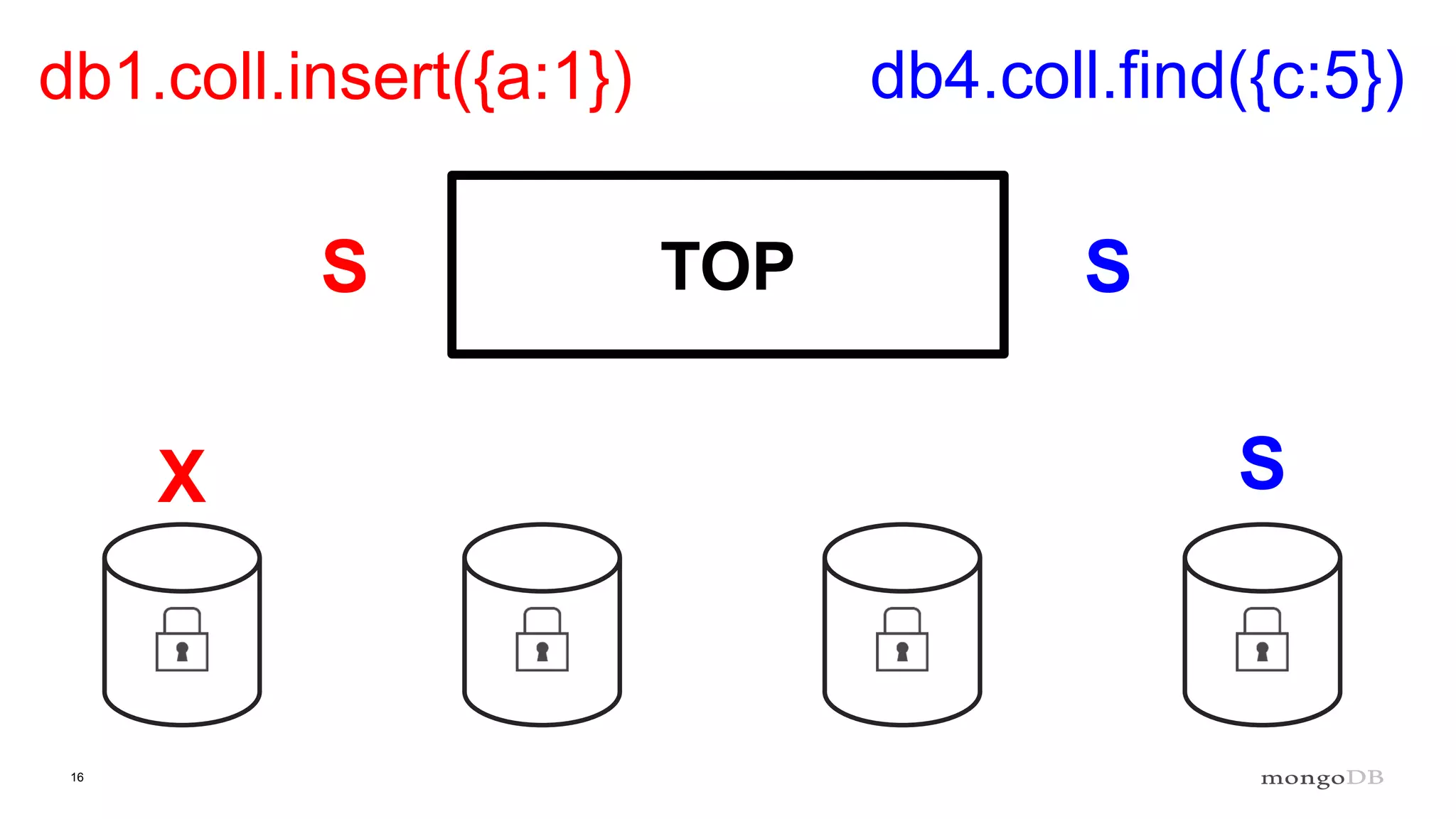
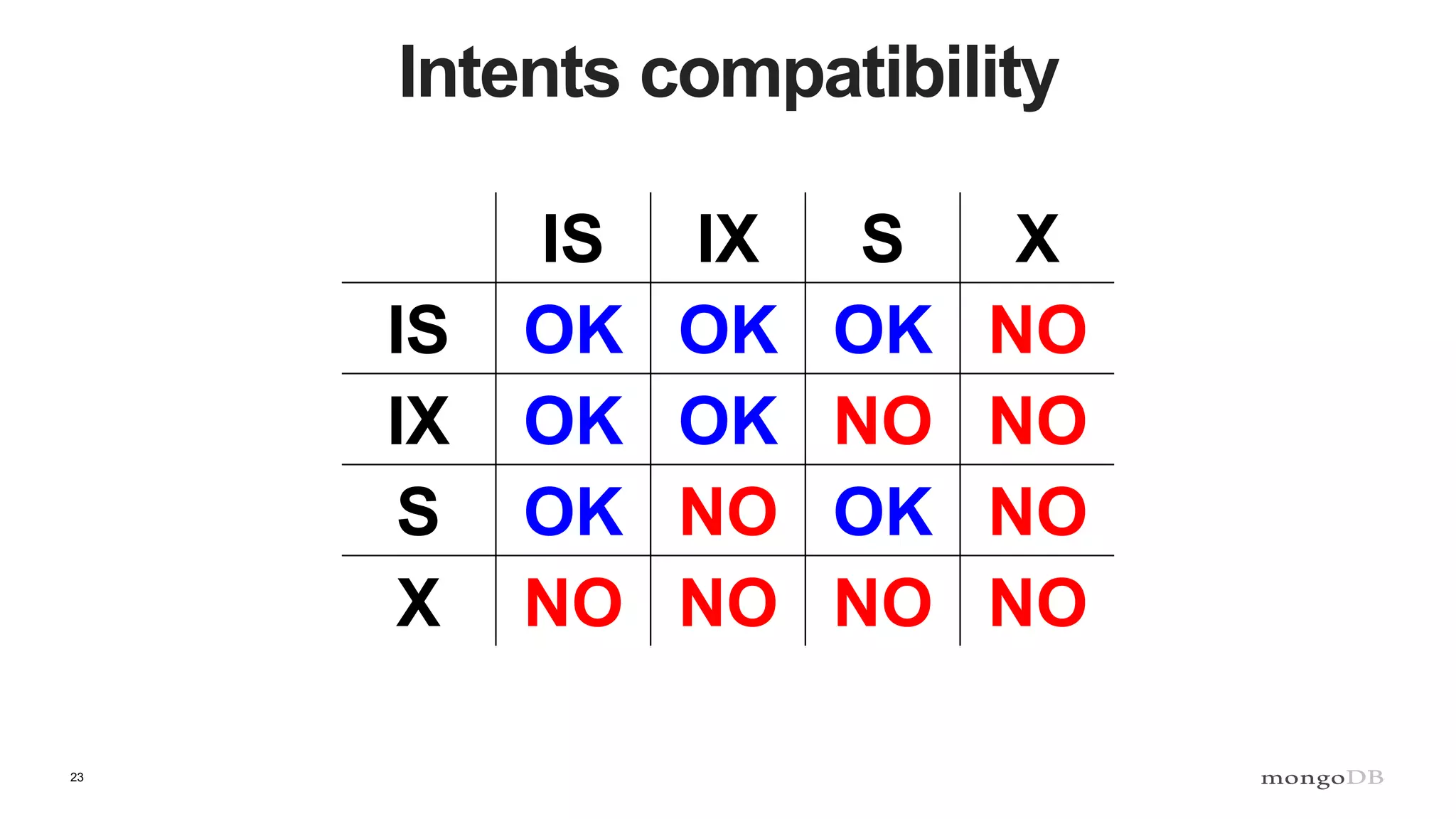
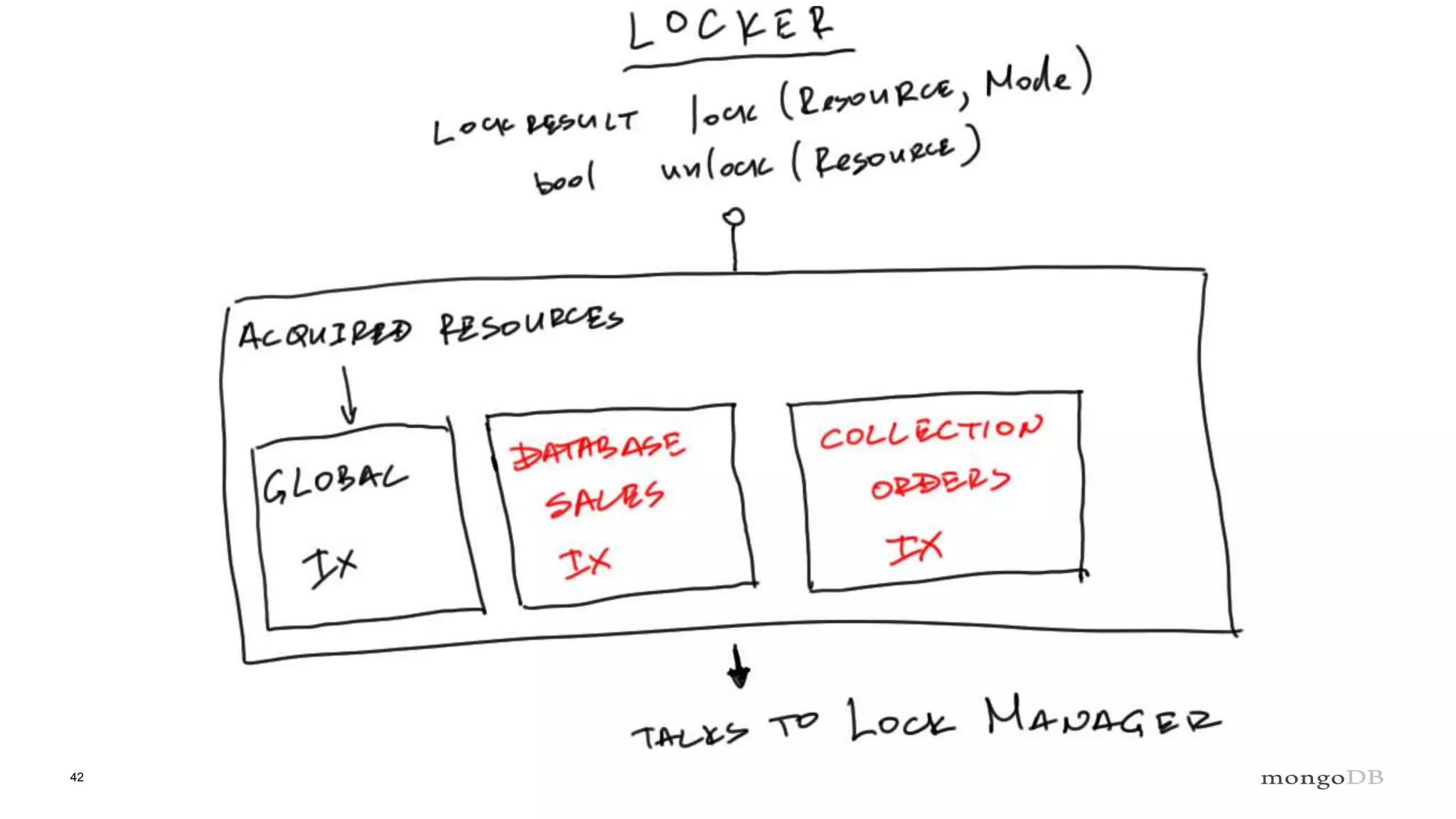
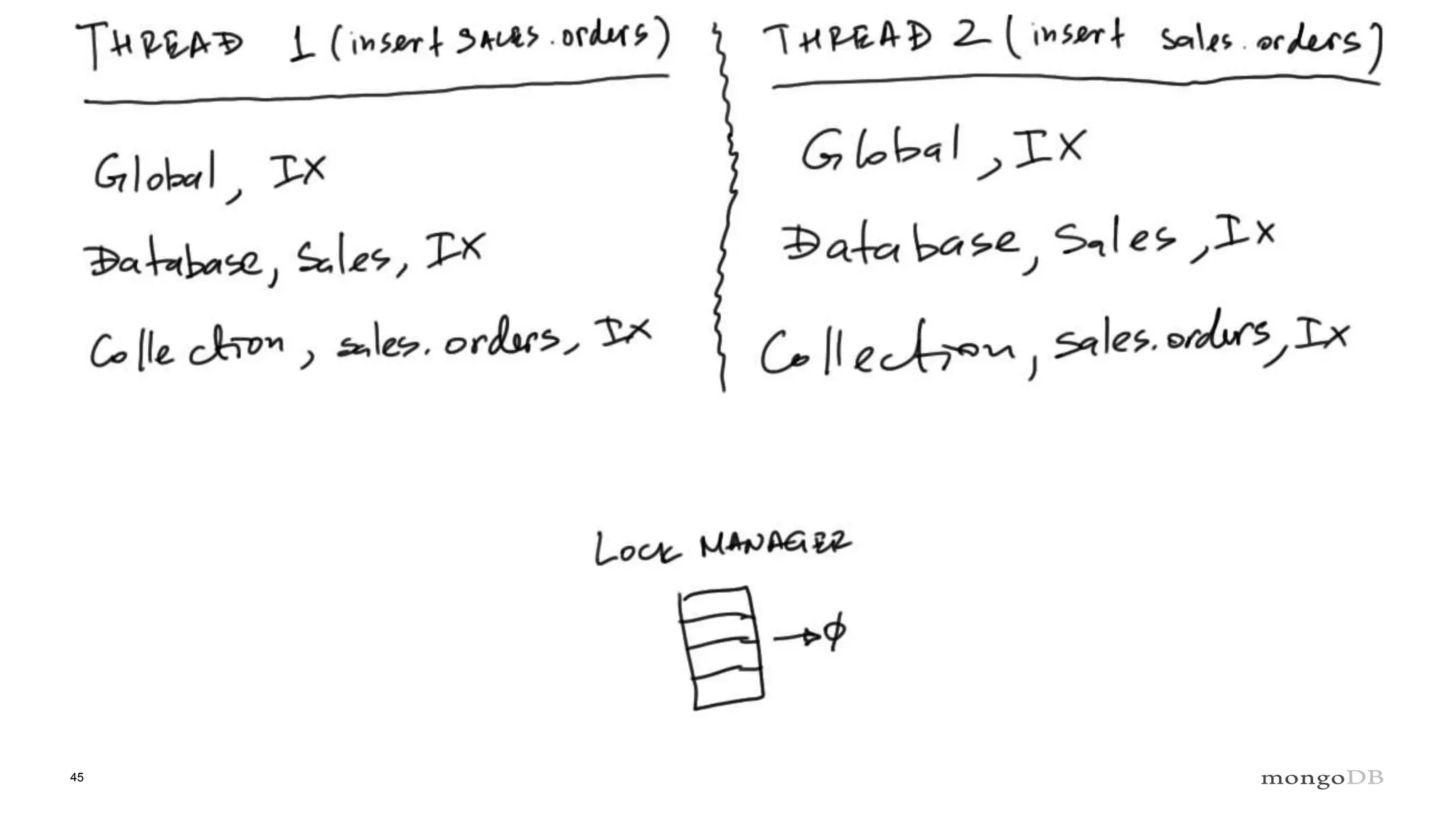
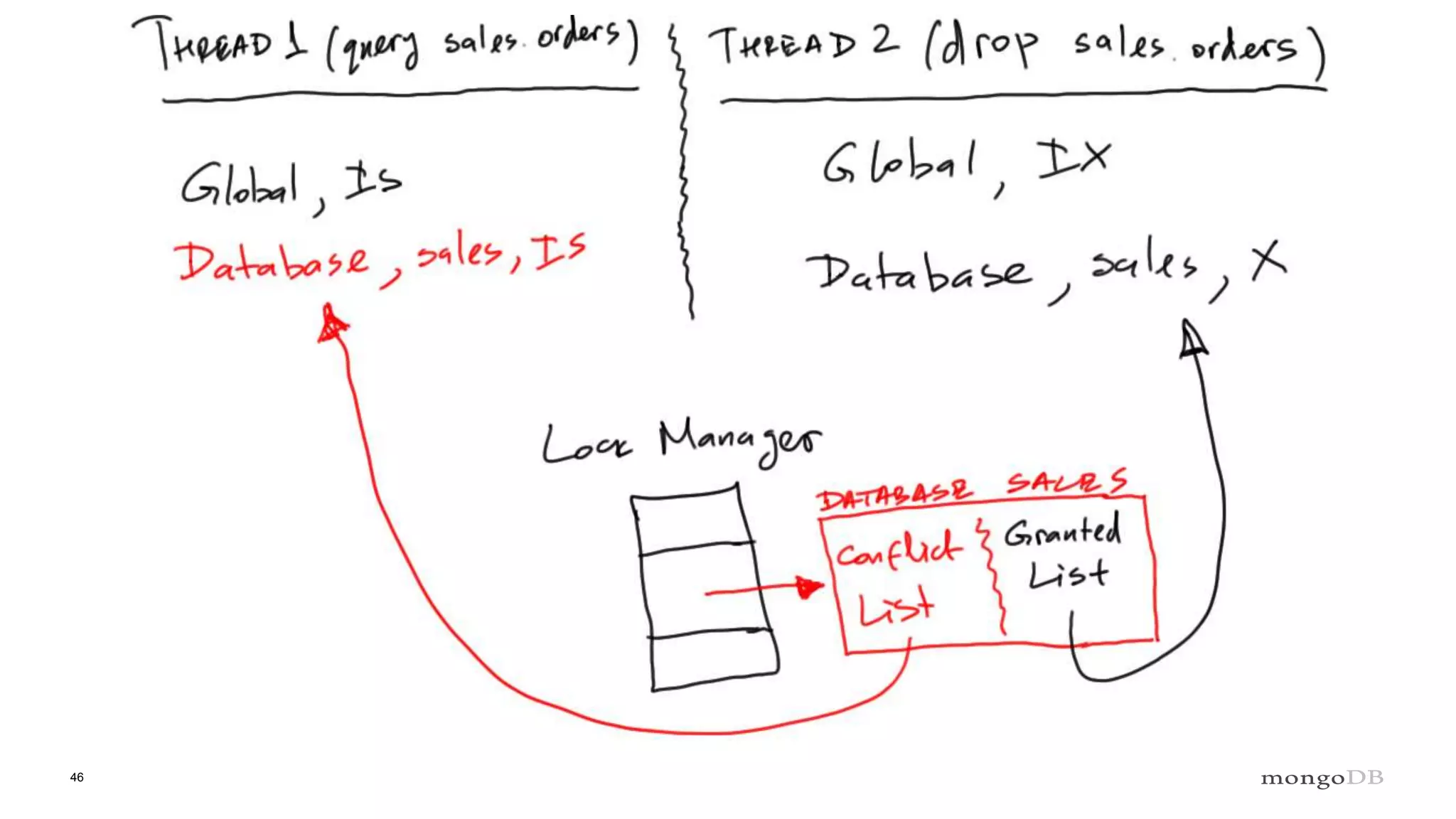
Explanation of intents in MongoDB, their compatibility, and necessity to optimize locking mechanisms.
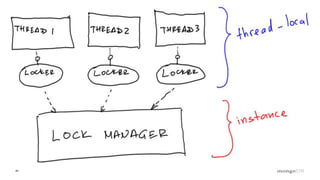
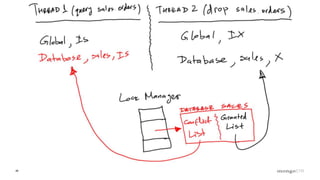
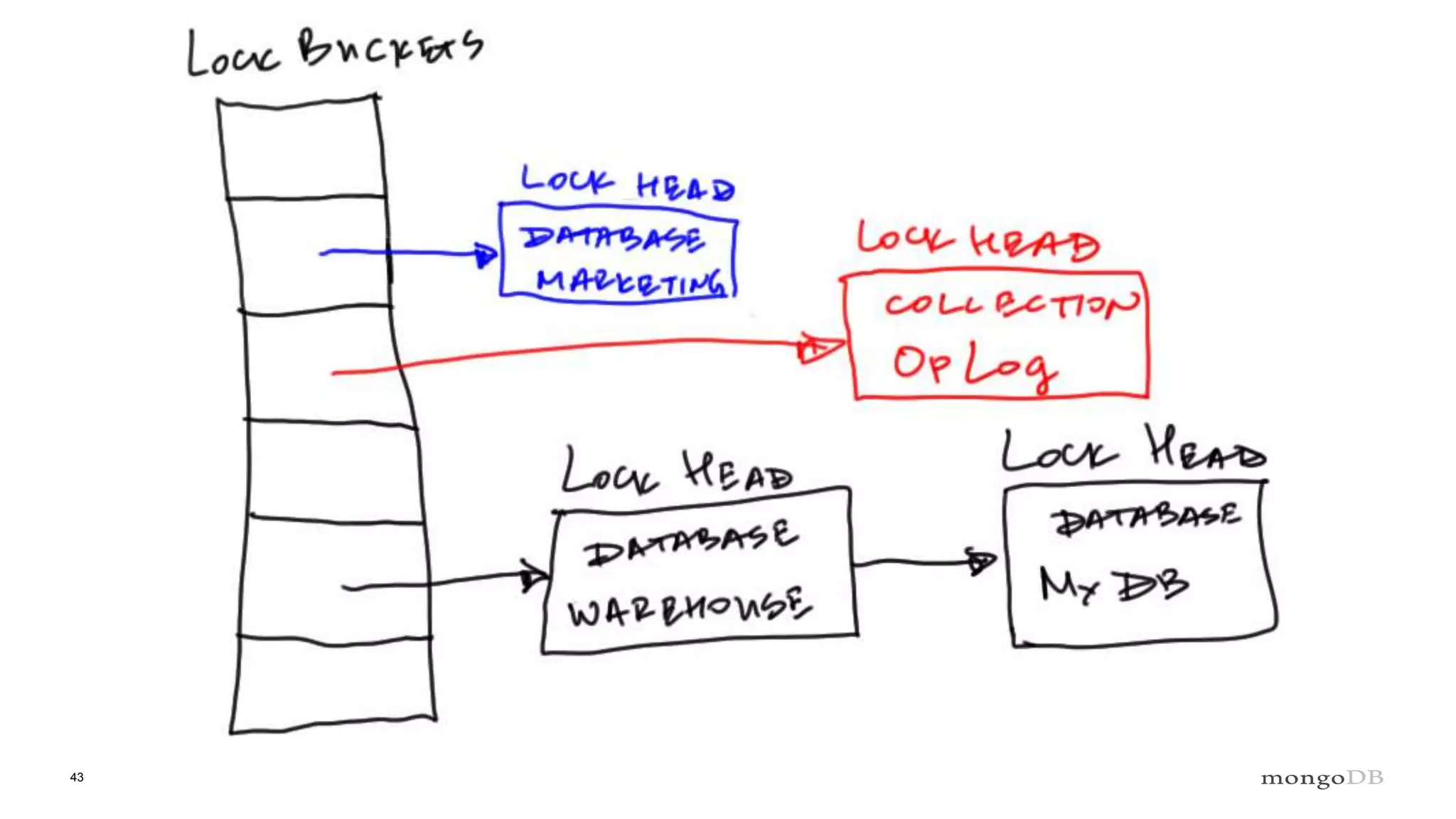
Role of the Lock Manager that ensures protocol adherence with low overhead, fairness, and statistics collection.
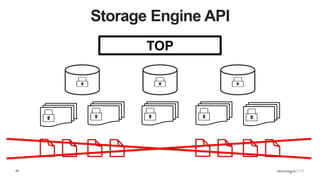
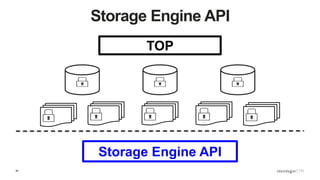
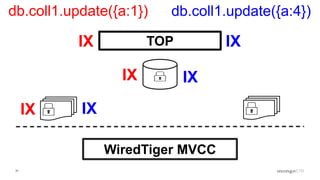
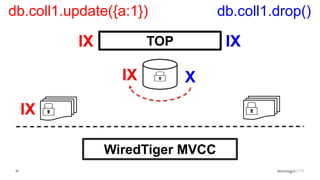
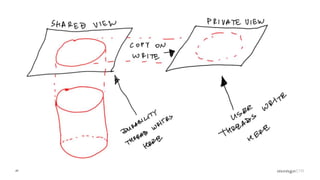
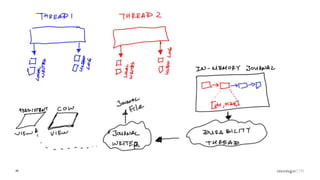
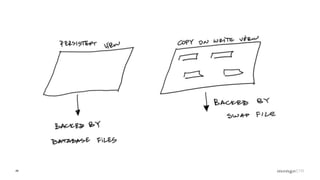
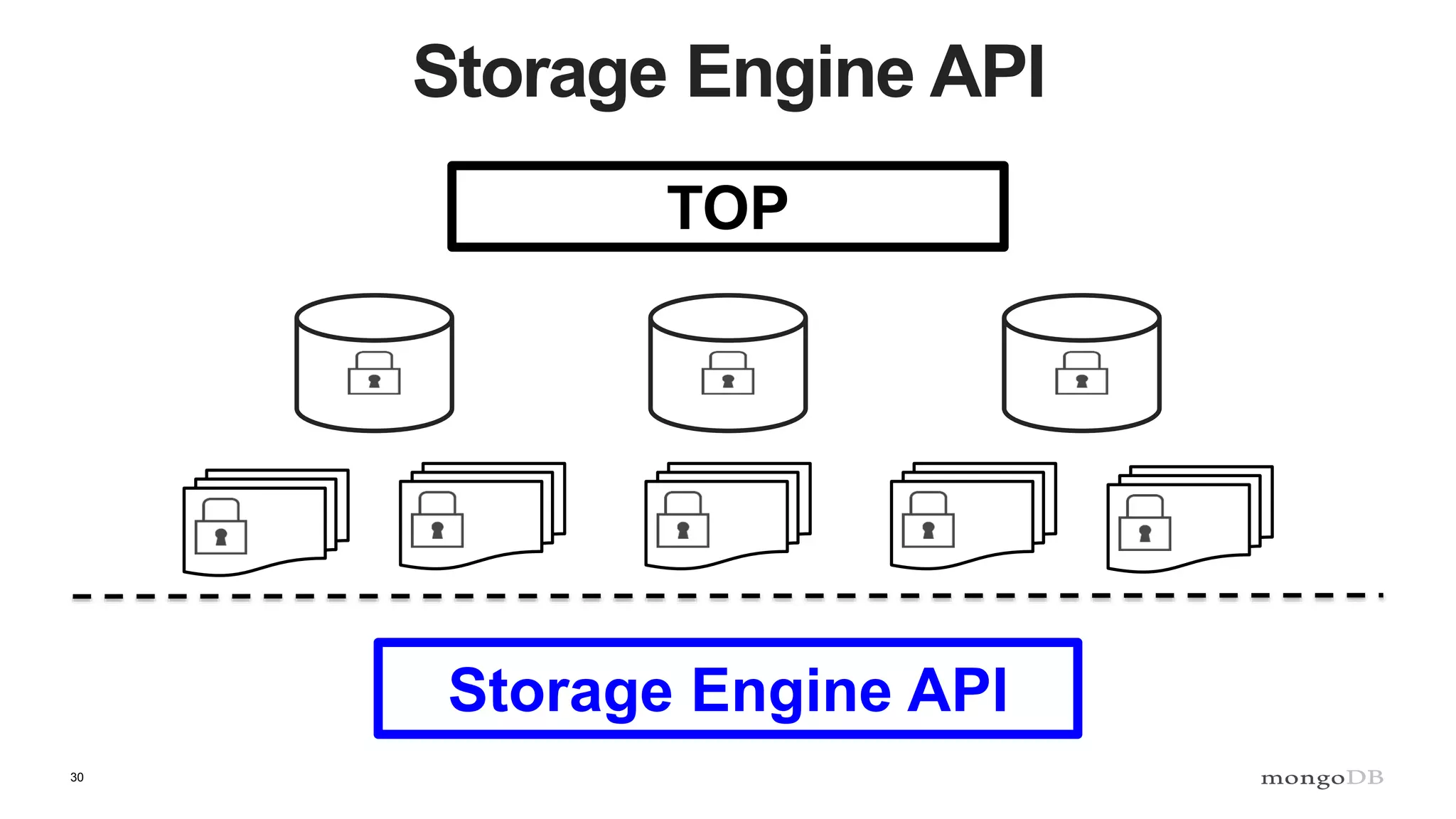
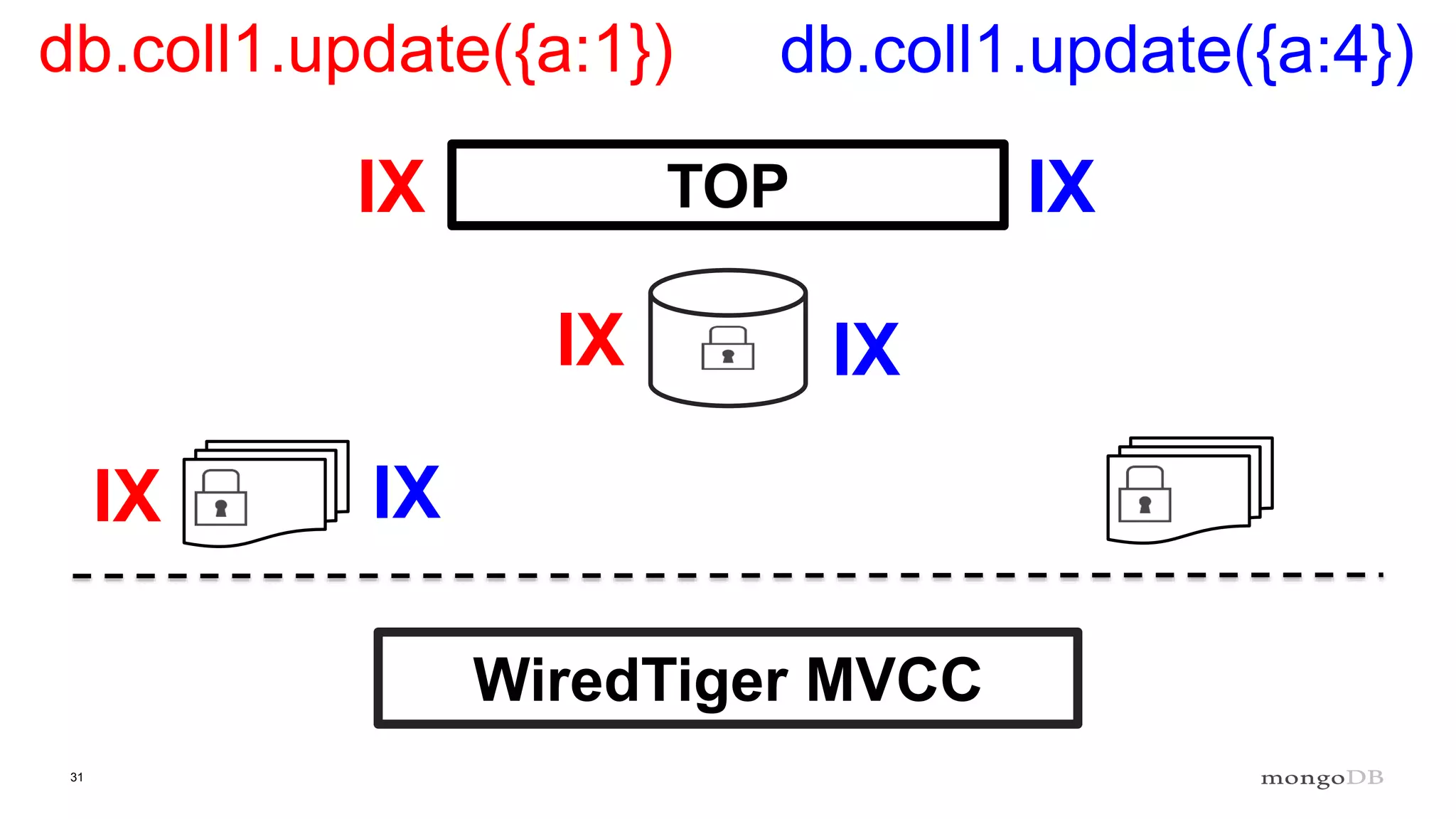
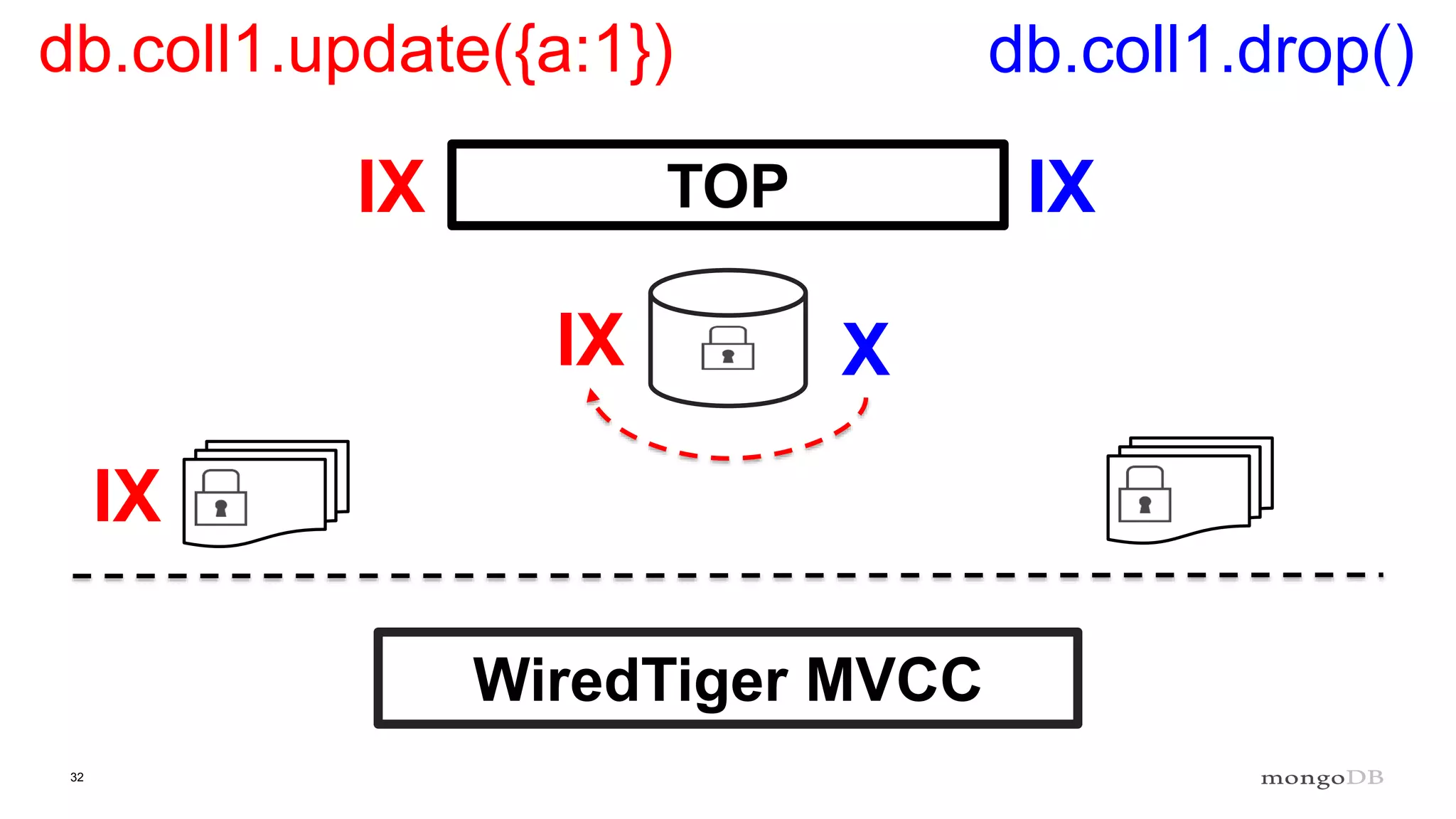
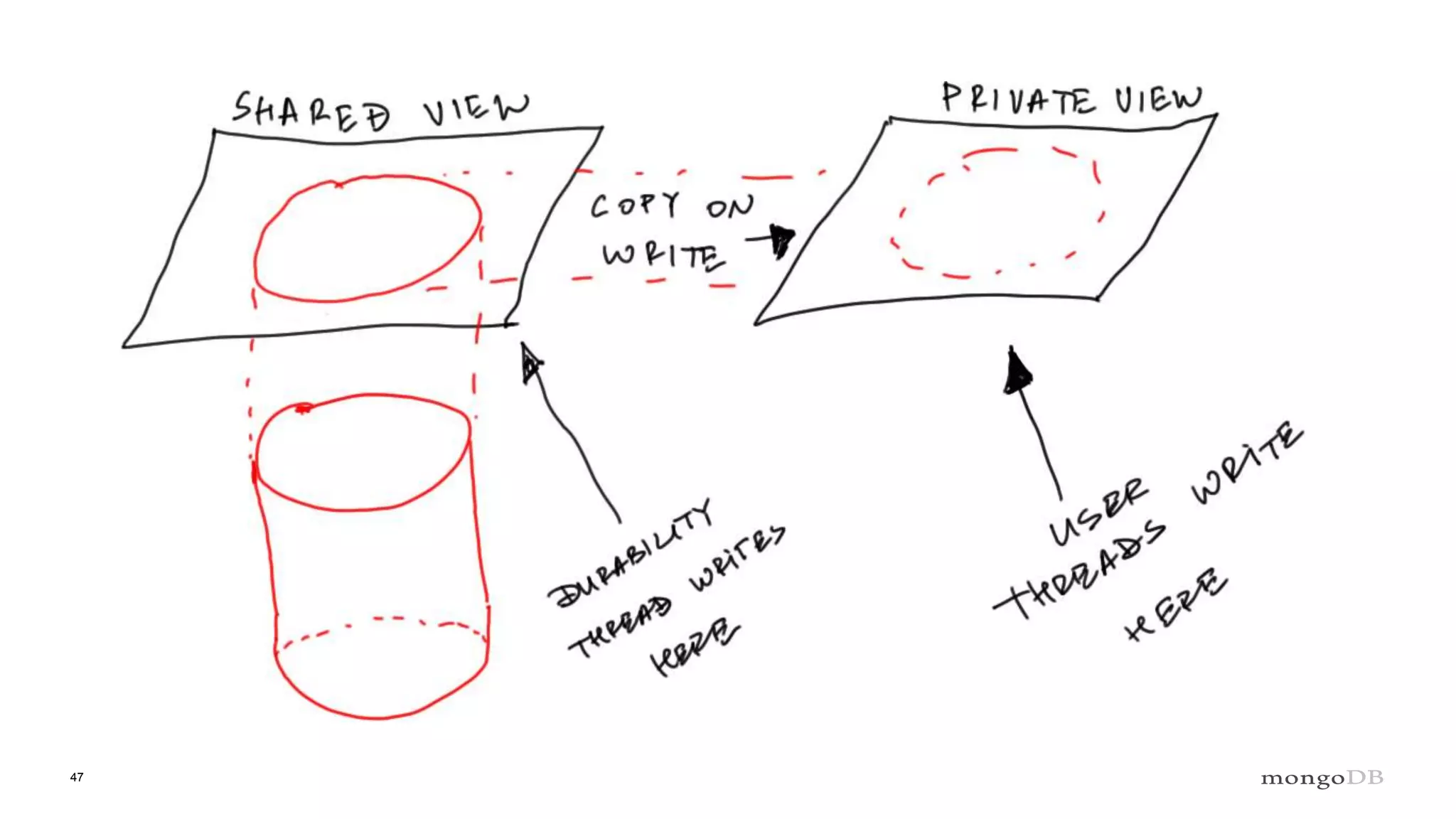
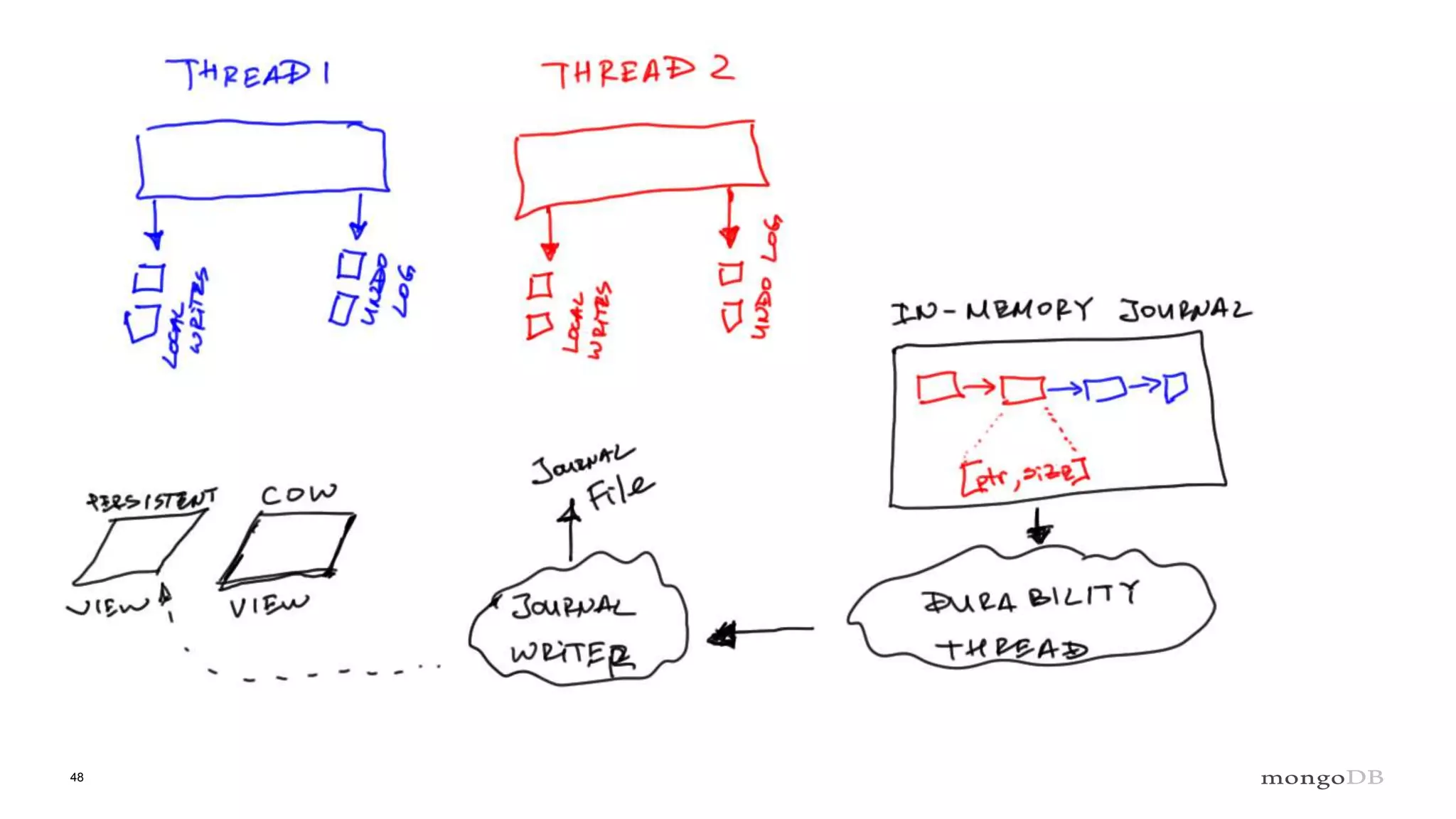
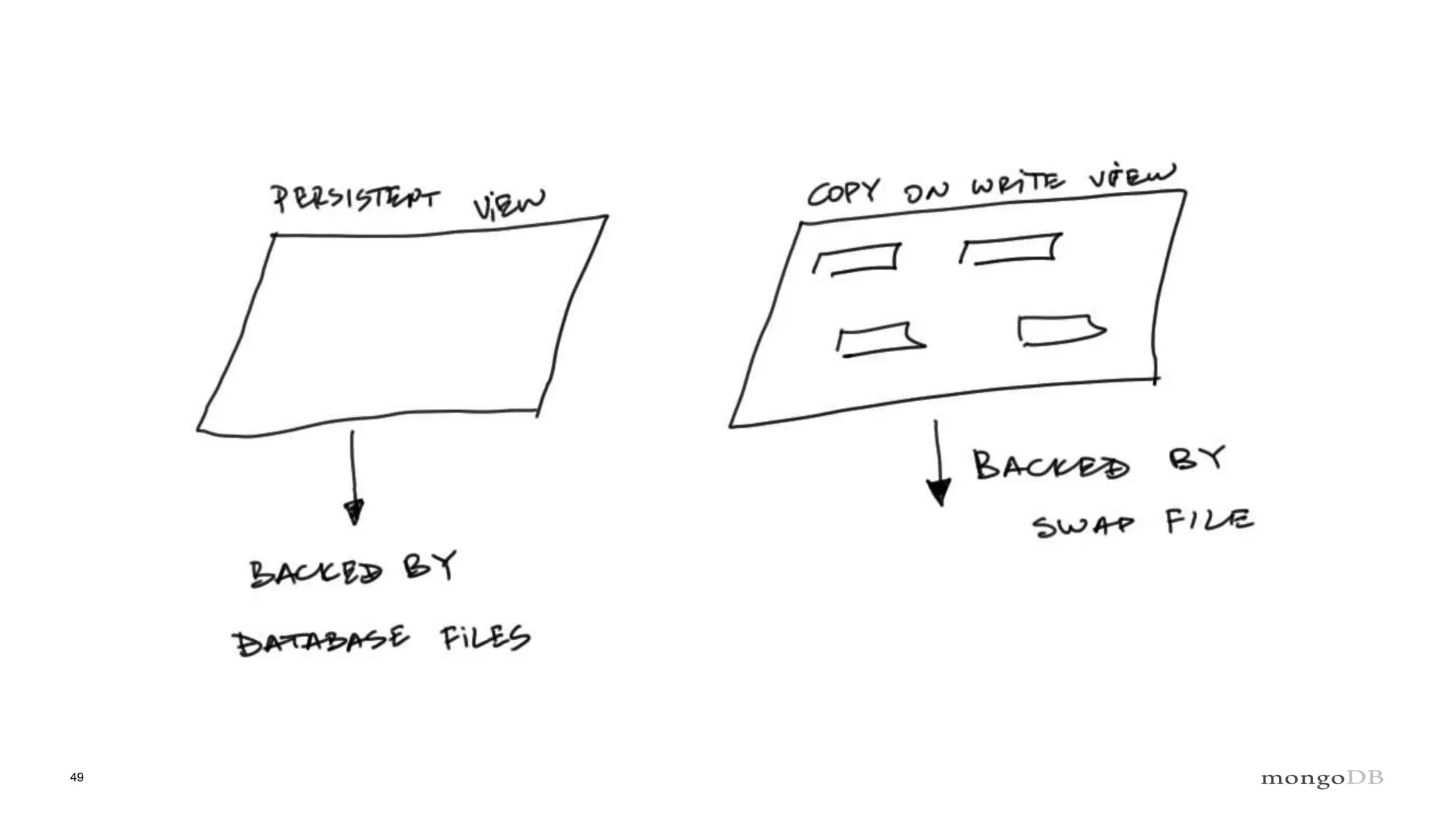
Overview of the Storage Engine API and comparing operations using wiredTiger's MVCC (Multi-Version Concurrency Control).
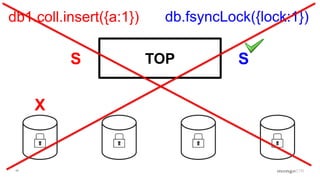
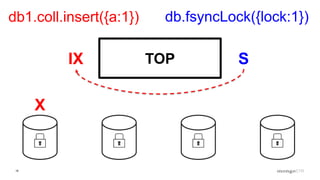
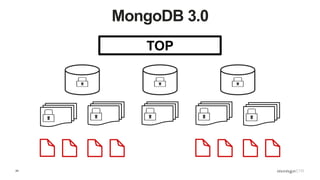
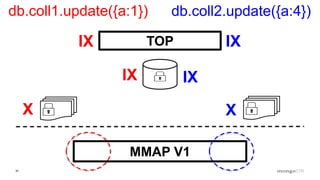
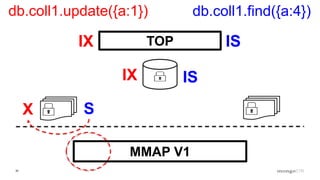
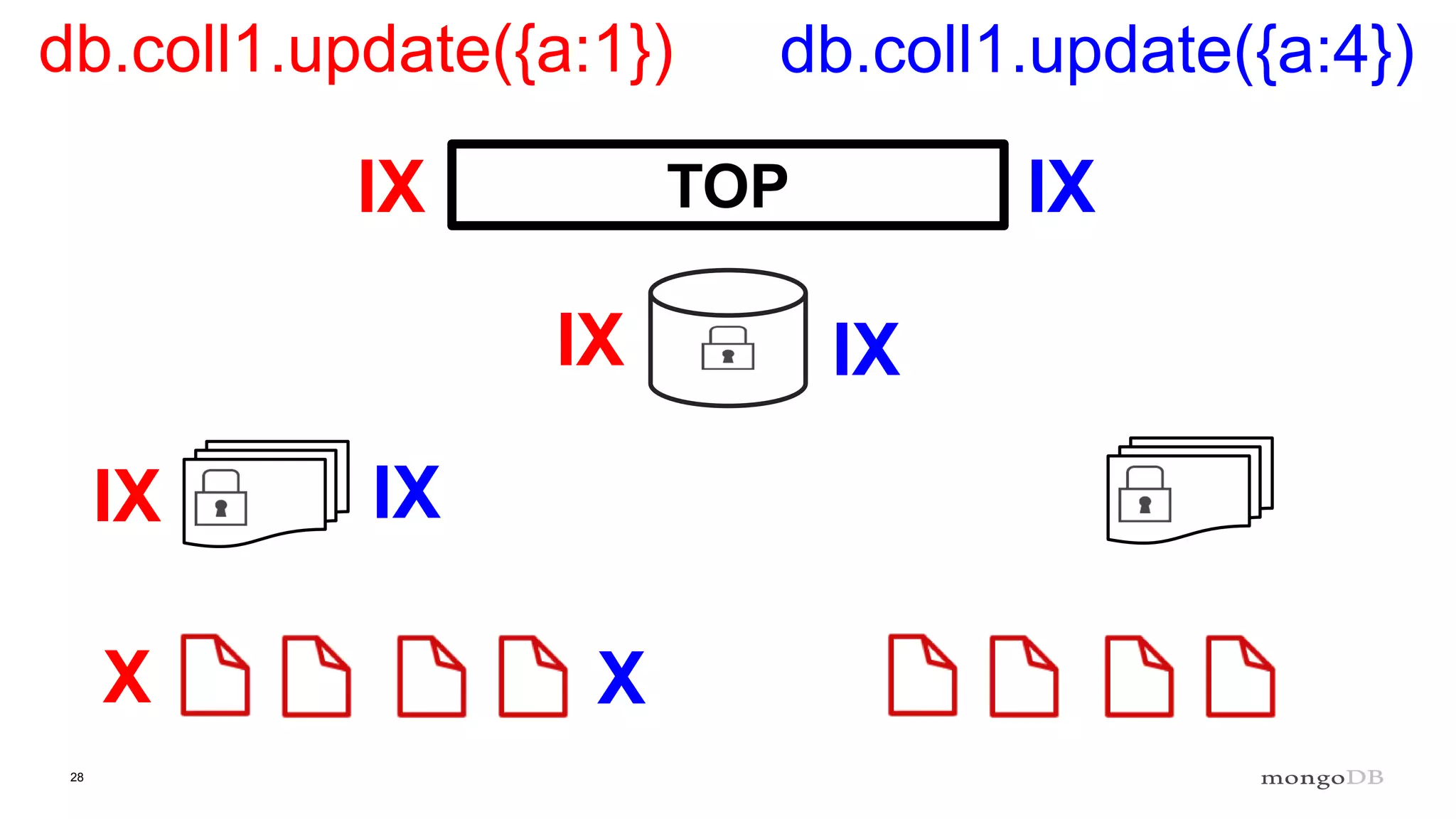
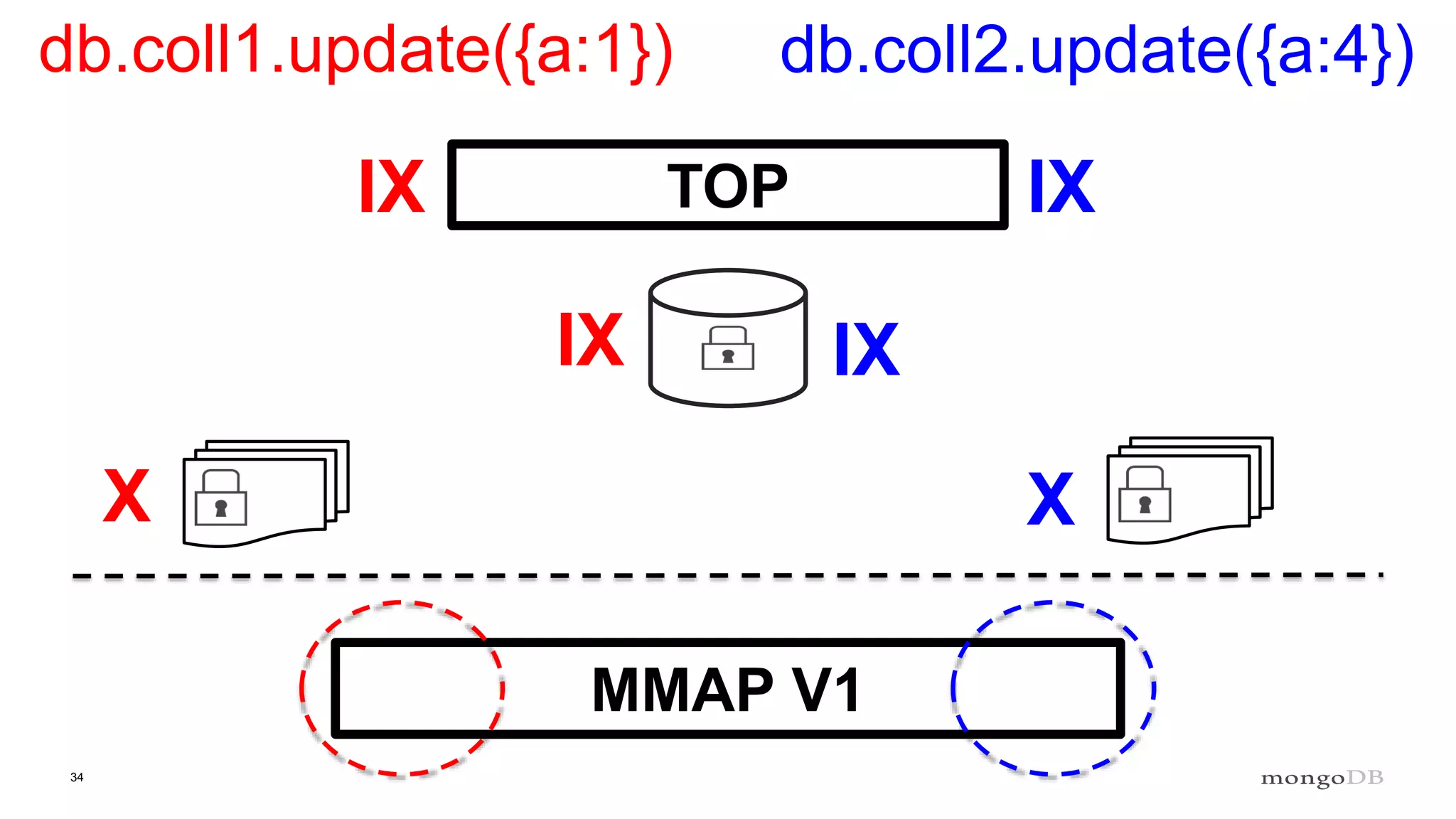
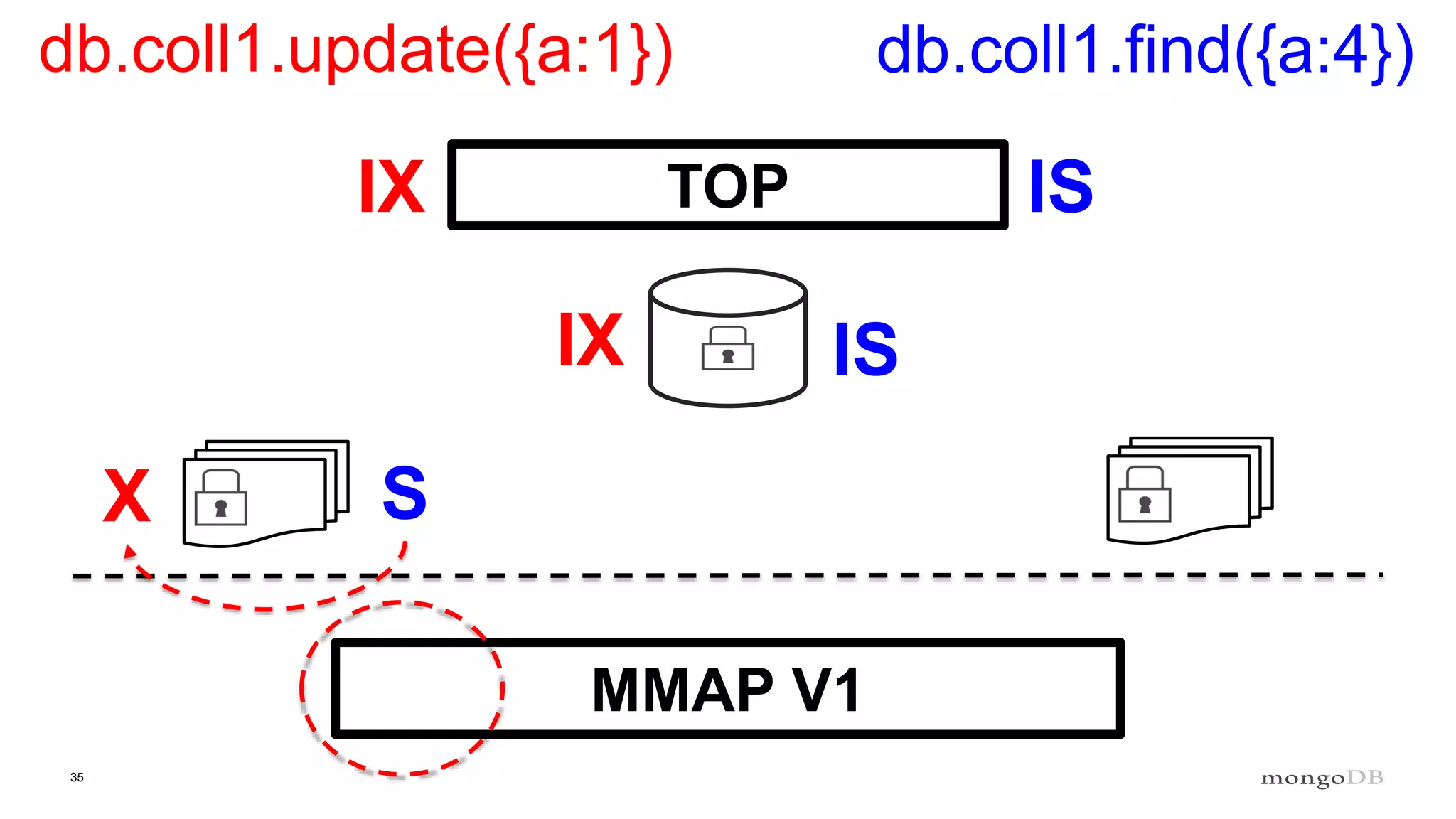
Discussion of MMAP V1's handling of concurrency through collection-level locking and the roles of intents.
Conclusions on storage engines controlling concurrency, decoupling from top-level locking, and improvements in MMAP V1.
Opportunity for audience questions regarding the topics covered in the presentation.
Additional slides that may not contain further significant content related to the main presentation.























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=600ounds&width=560&fit=bounds)











