Download as PDF, PPTX



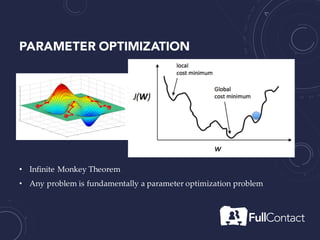
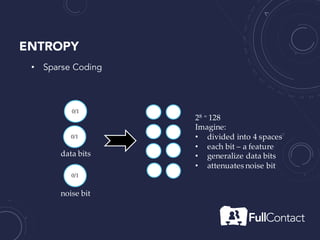
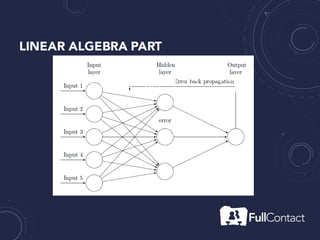

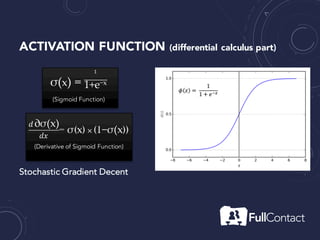


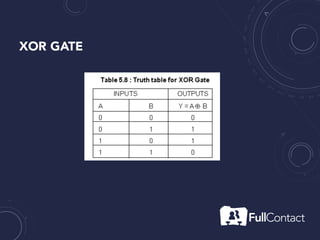

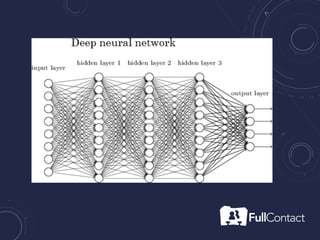

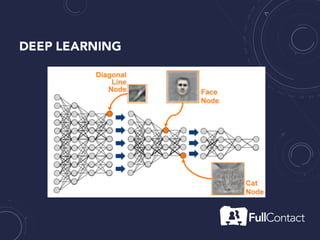






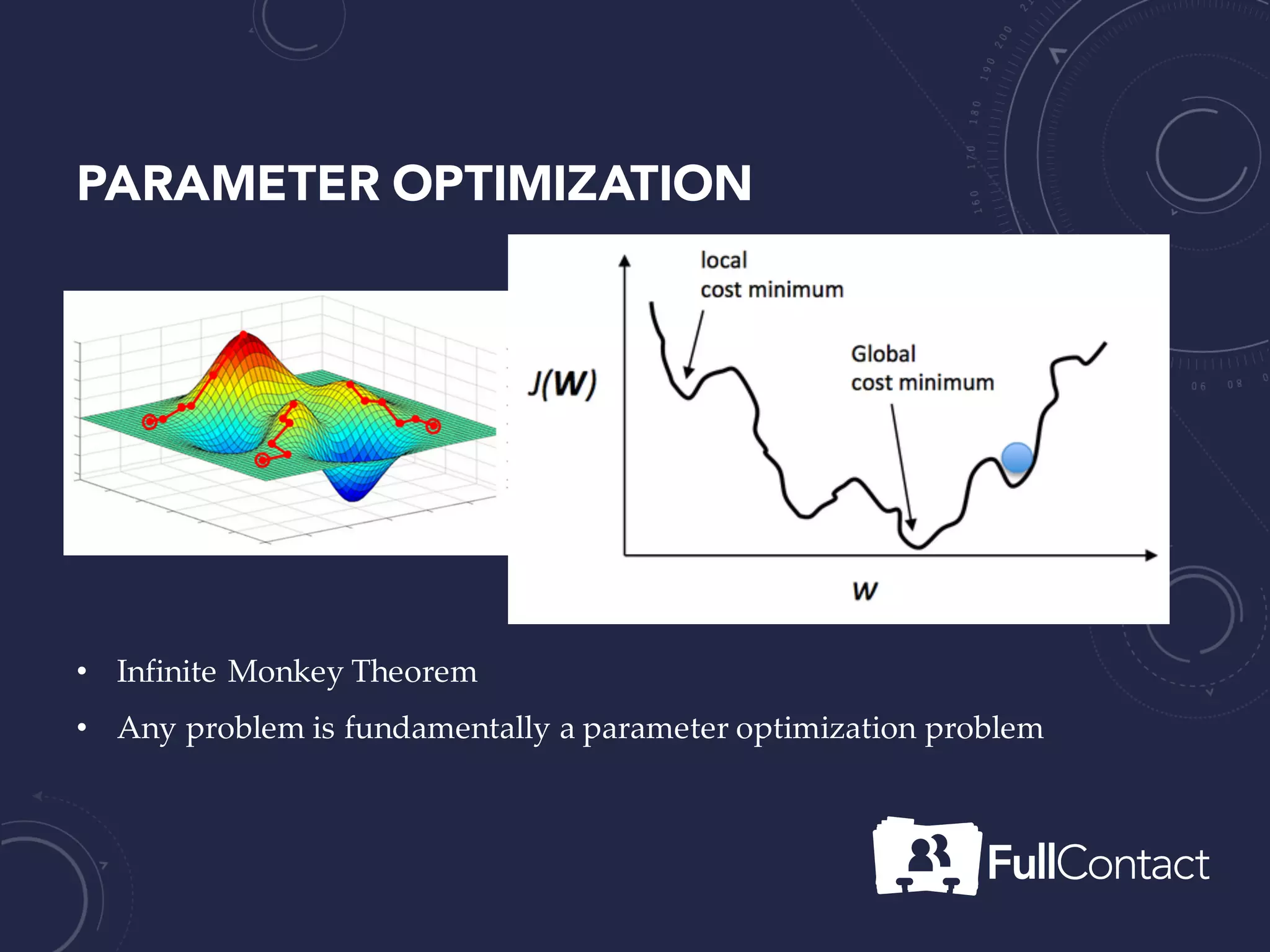
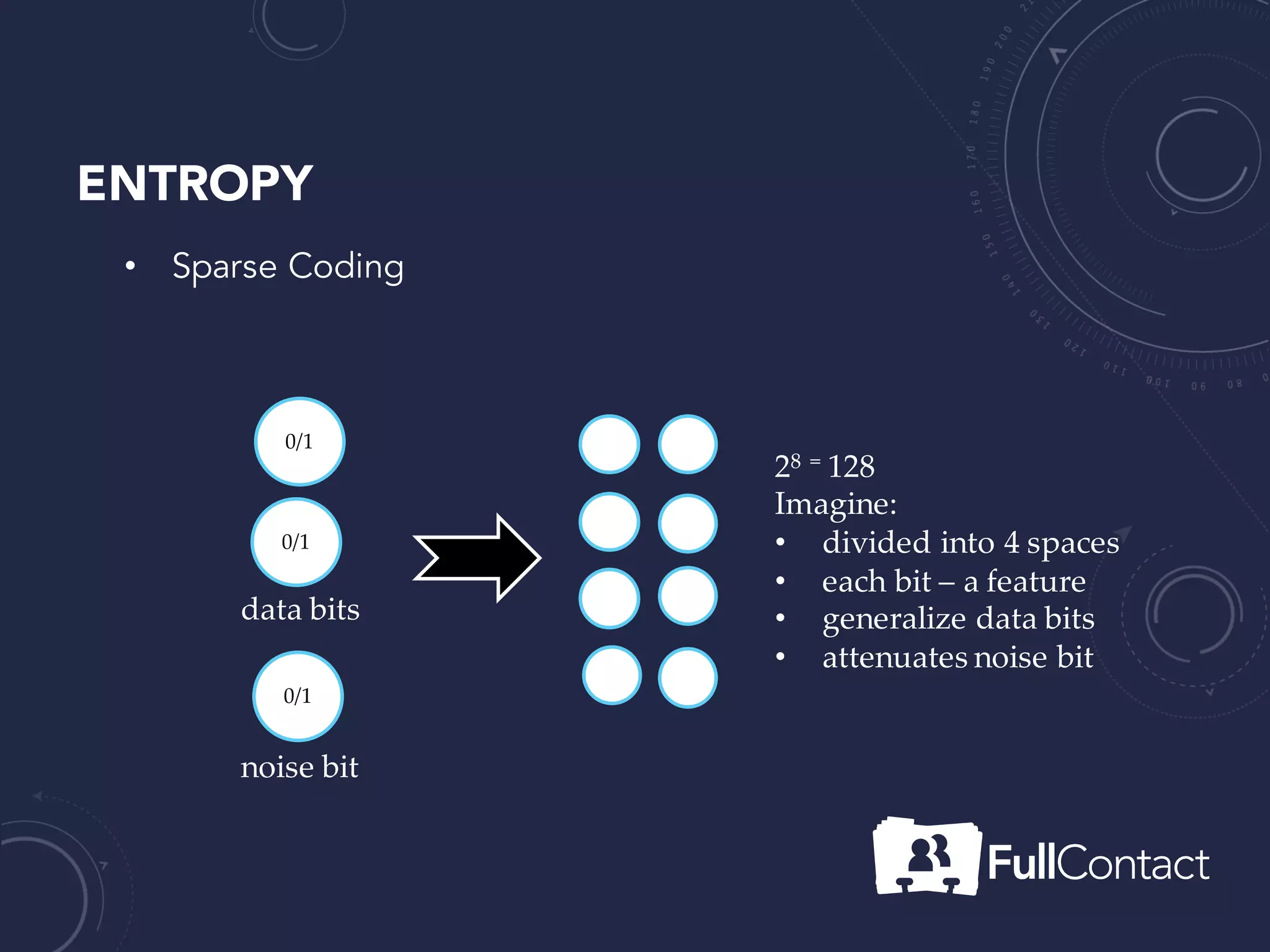
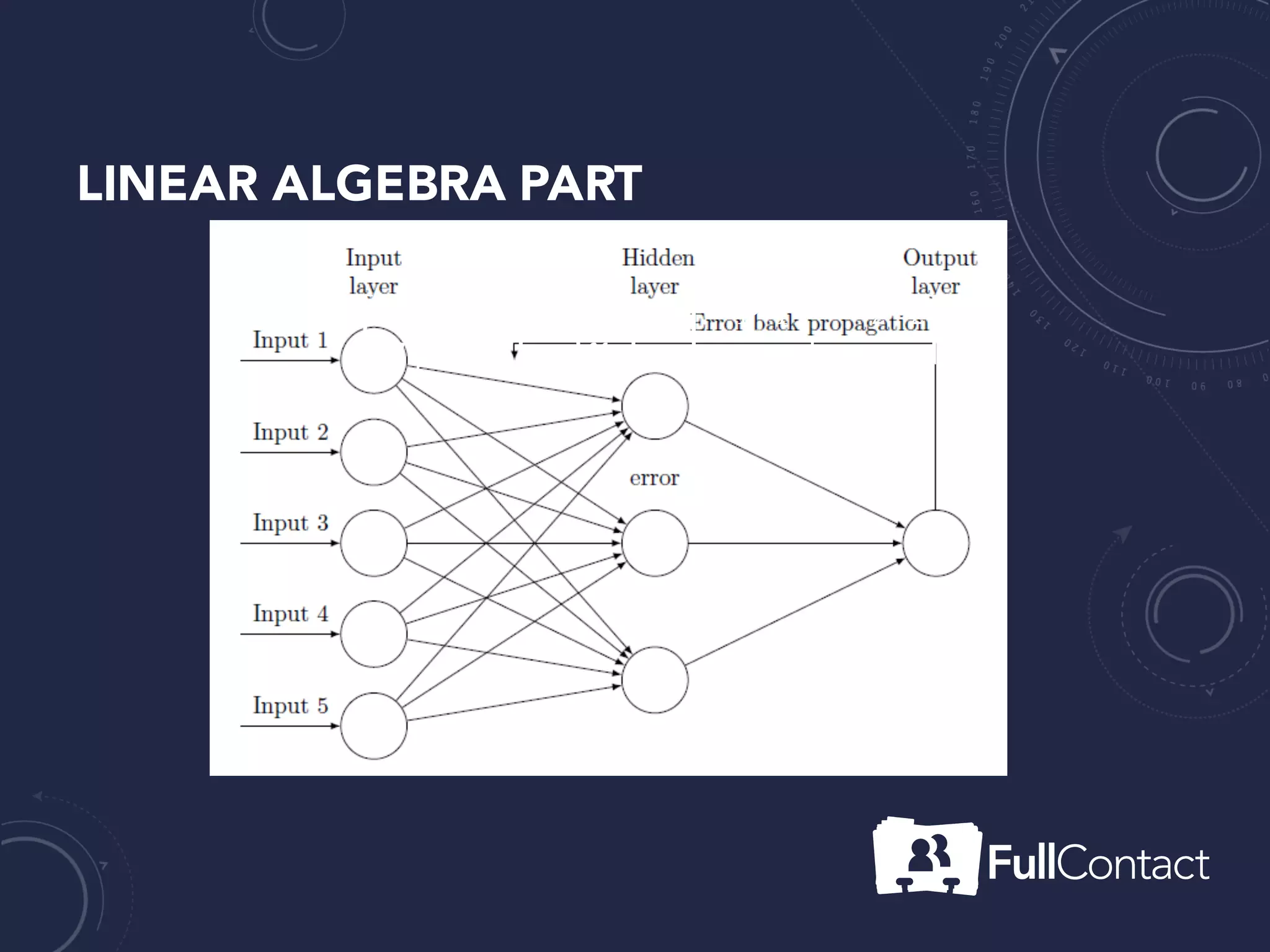

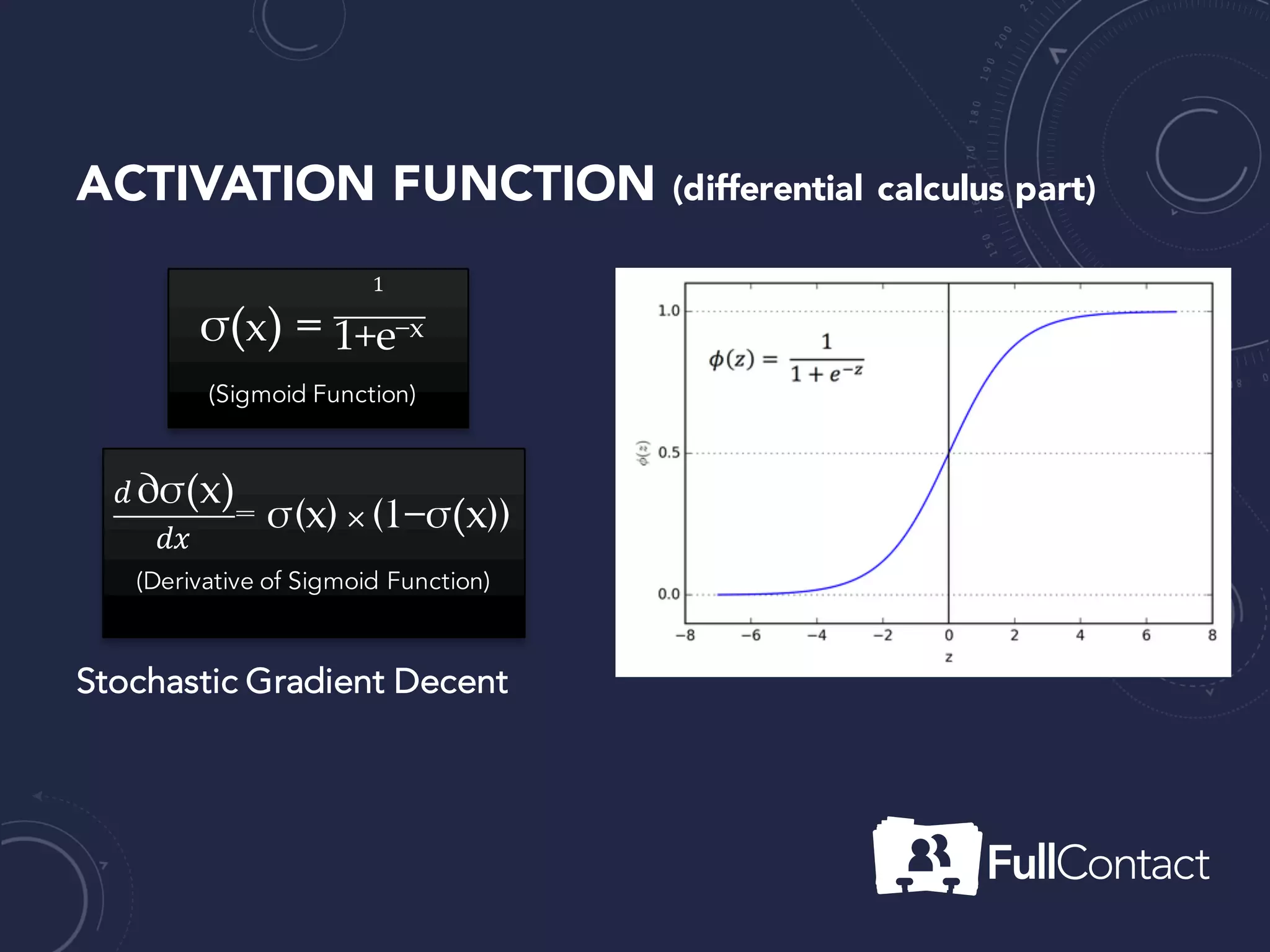


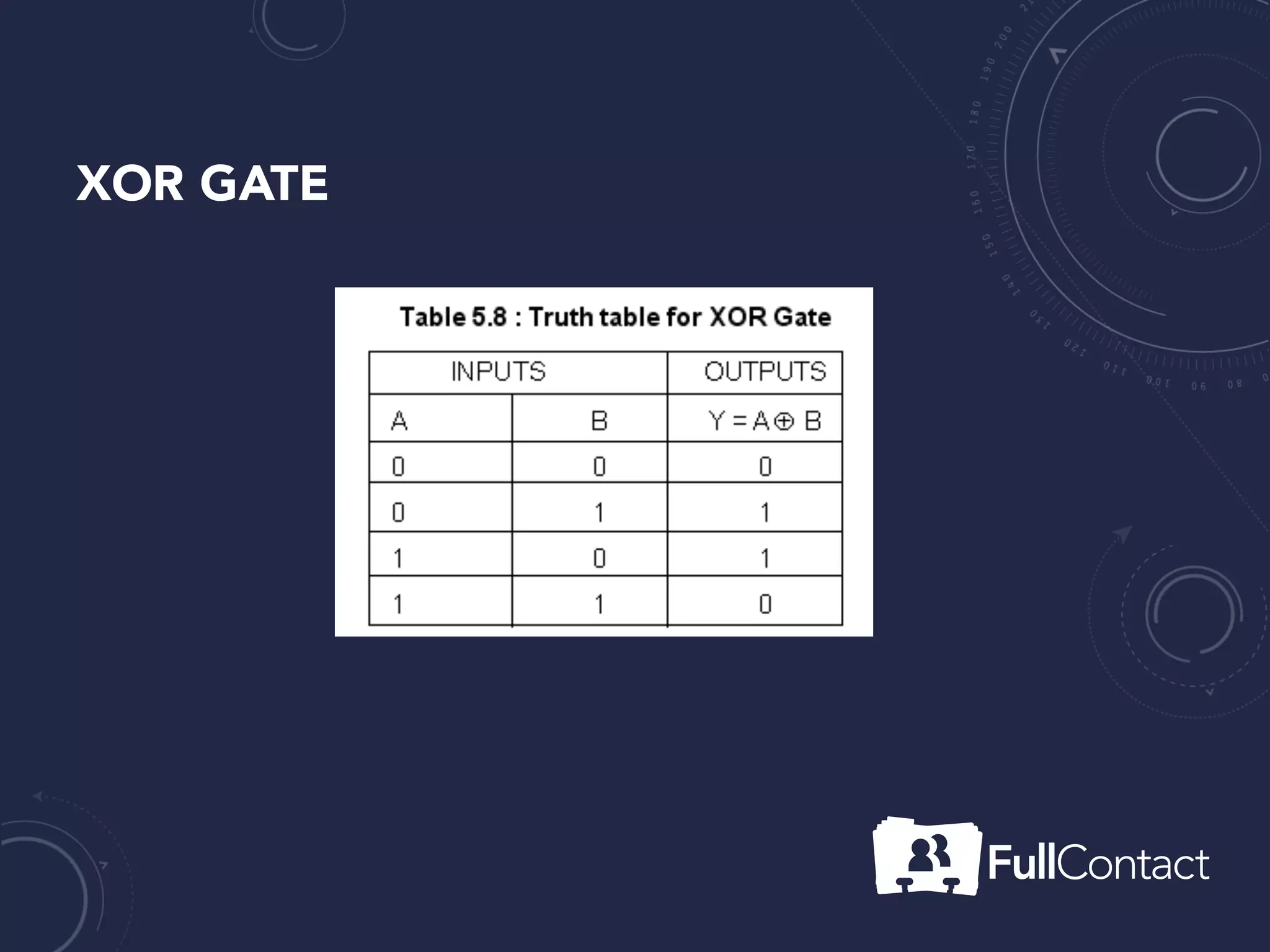

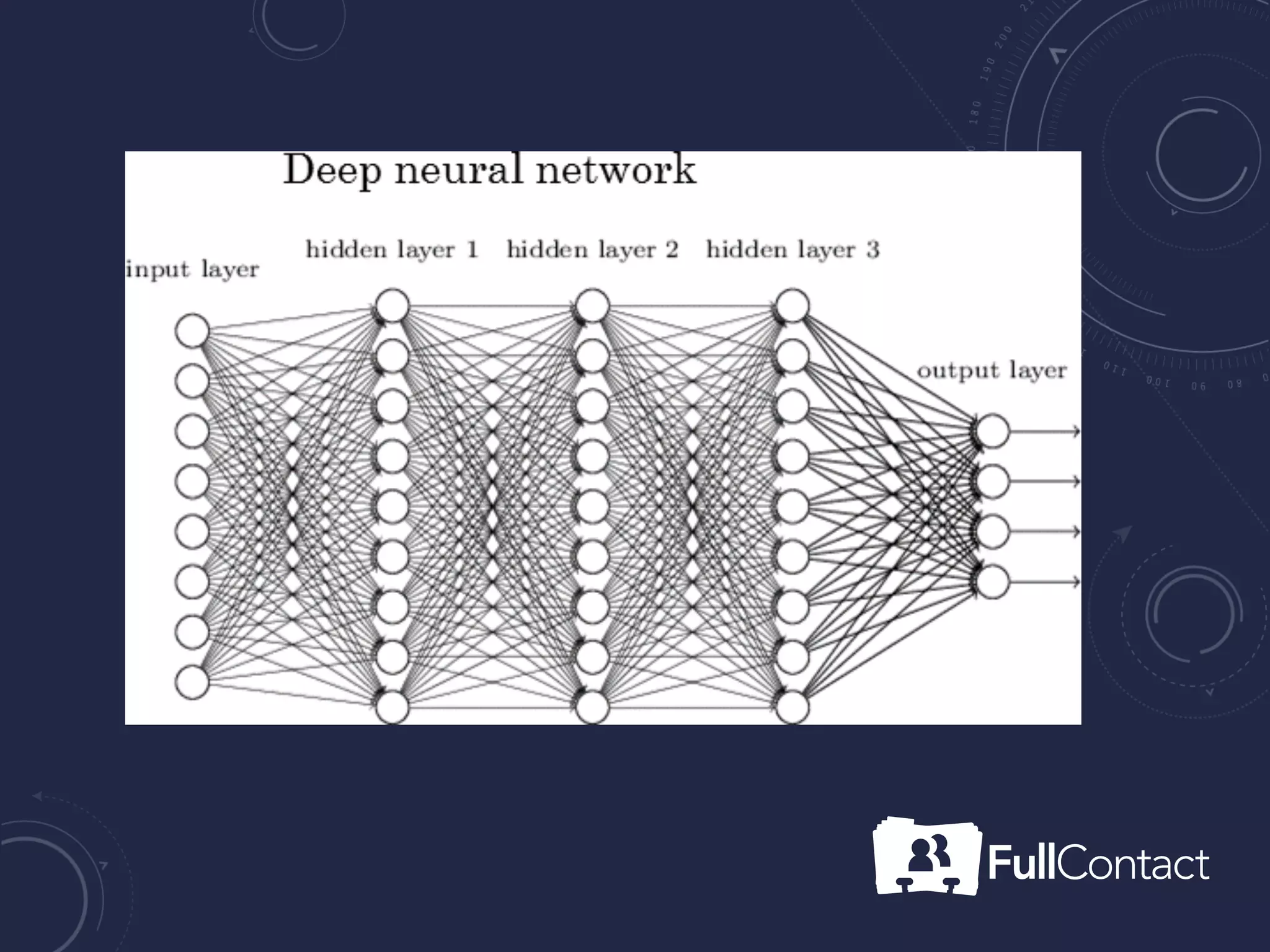

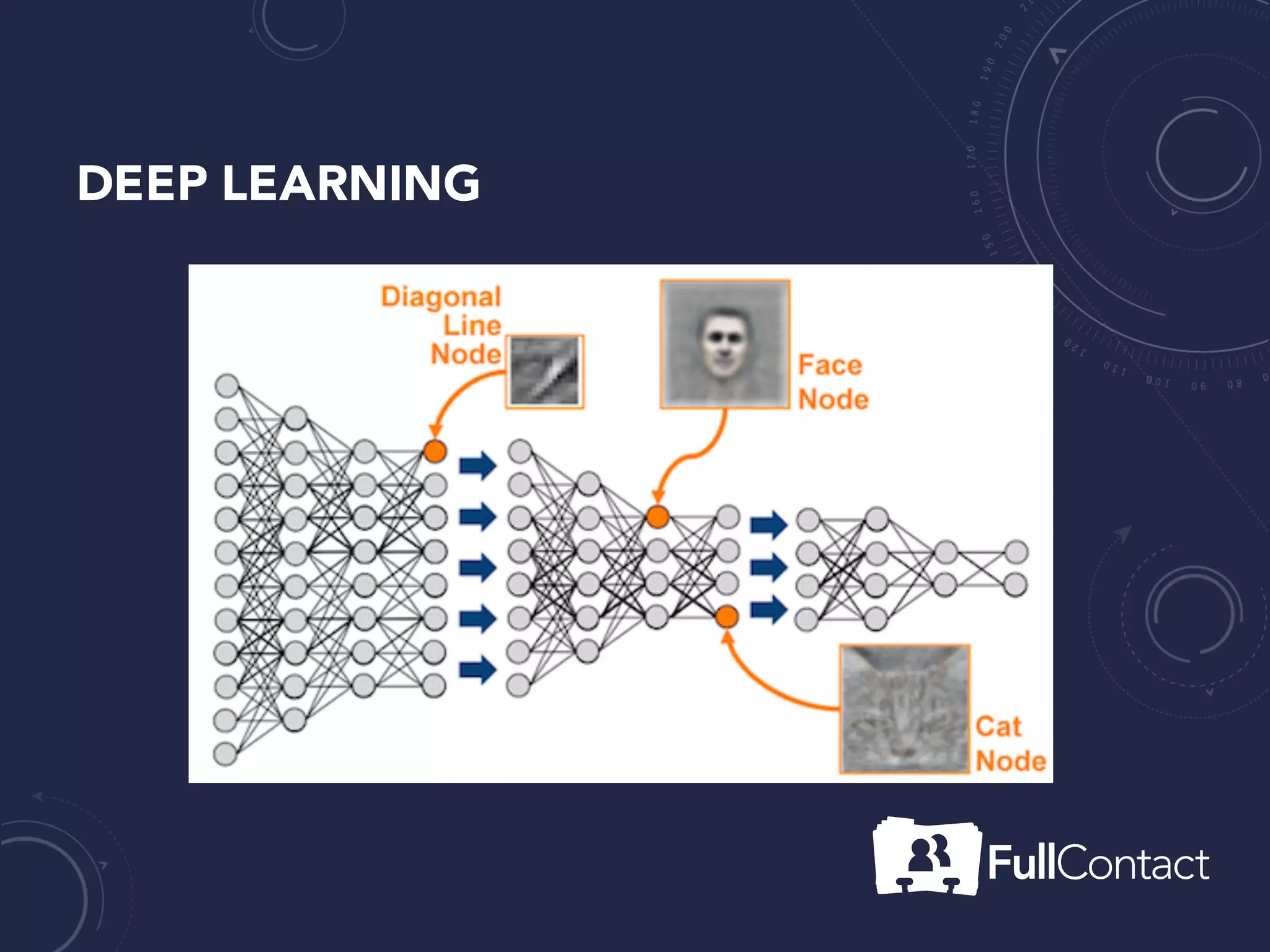




The document is a guide on the basics of neural networks, focusing on parameter optimization, sparse coding, and foundational mathematics like linear algebra and calculus. It includes practical elements like building a simple neural network and applying the XOR truth table example. Additionally, it provides resources and links for further learning in the field of deep learning.




































































































