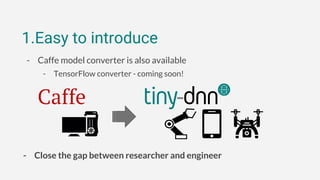
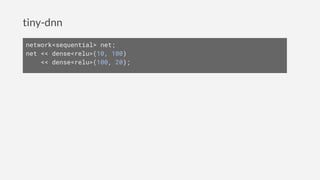
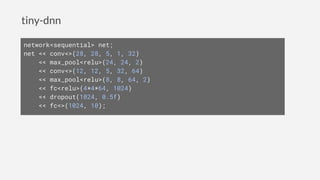
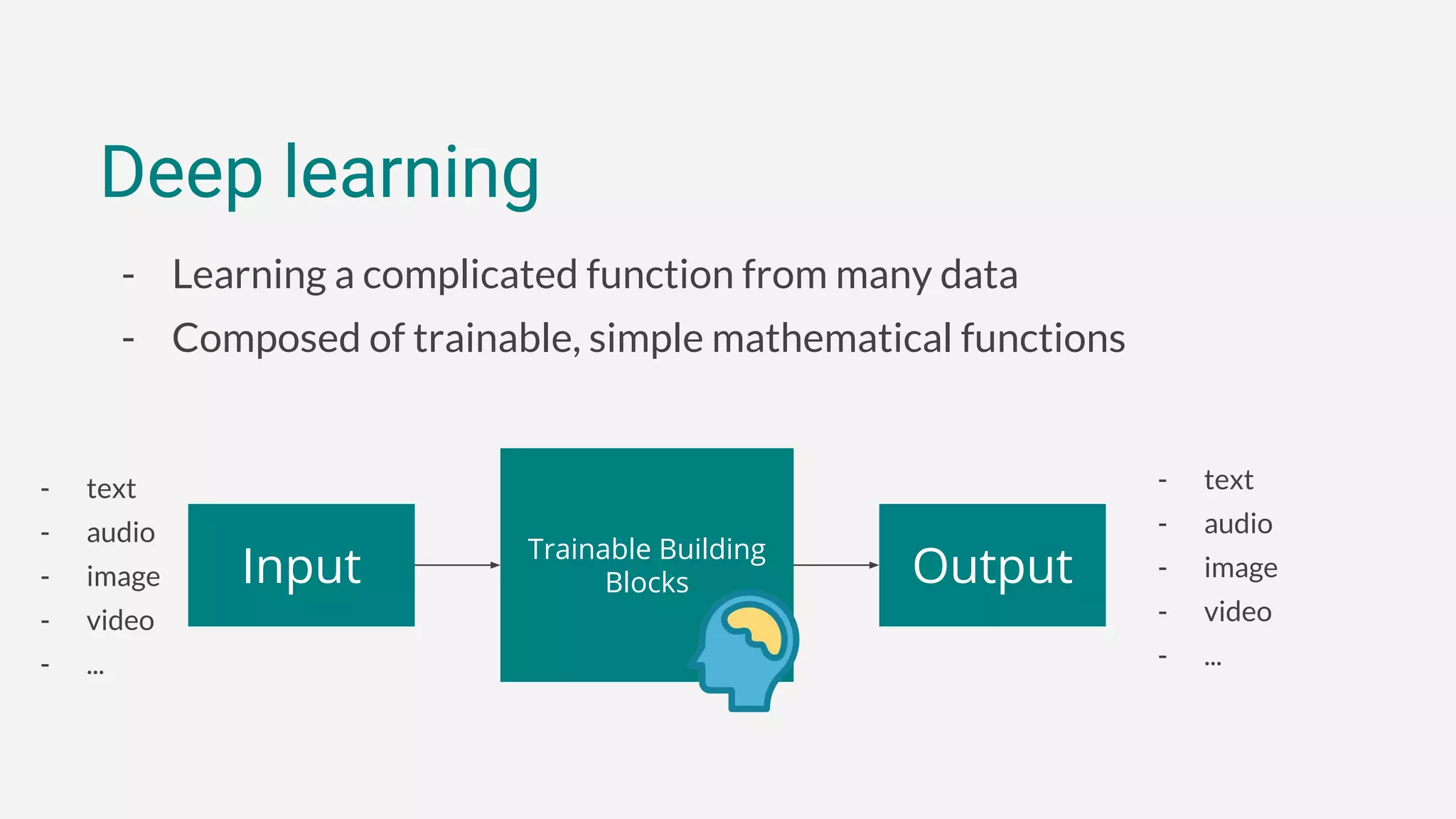
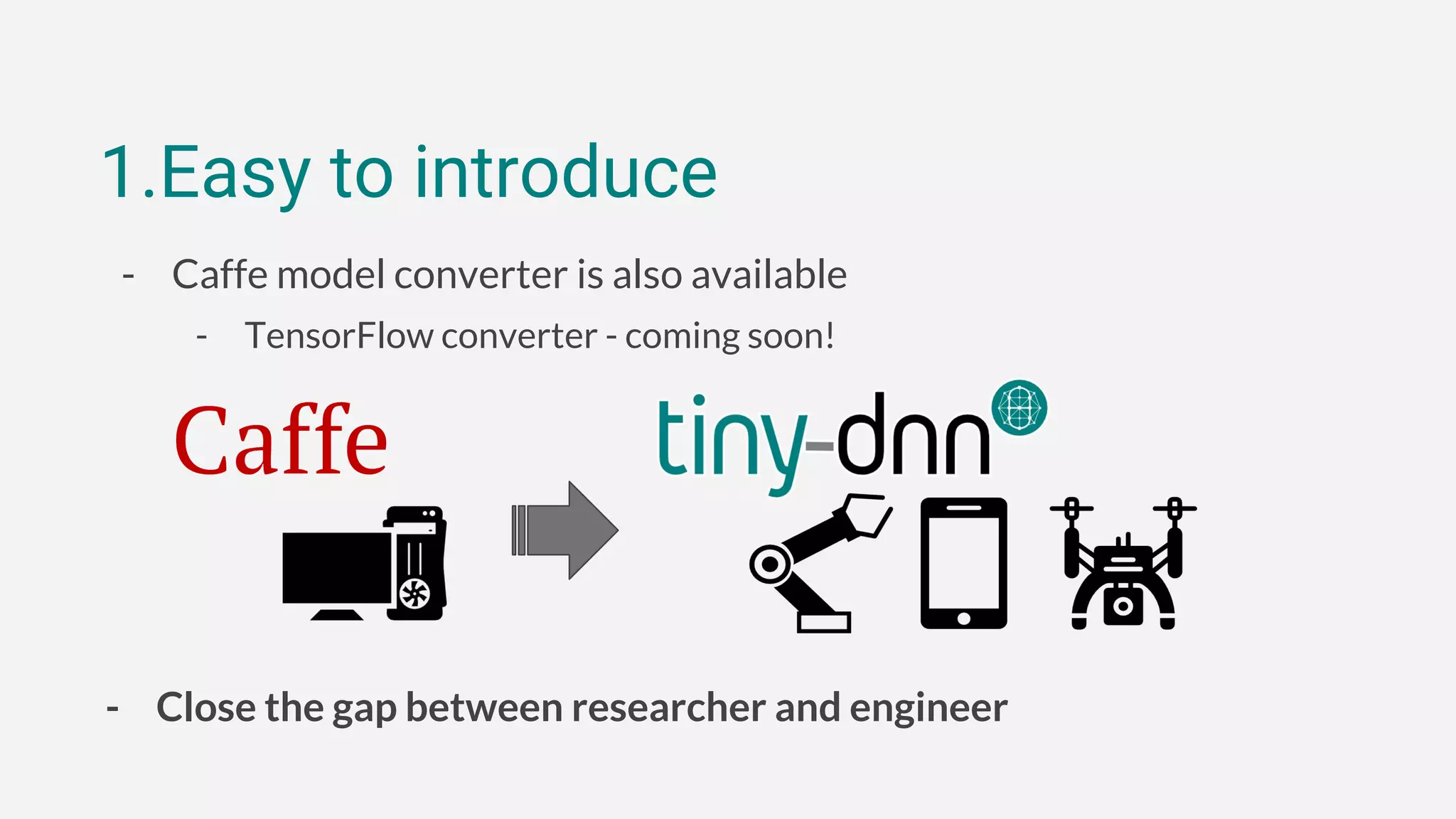
1. tiny-dnn is a header-only deep learning framework for C++ that aims to be easy to introduce, have simple syntax, and support extensible backends.
2. It allows defining neural networks concisely using modern C++ features and supports common network types like MLPs and CNNs through simple syntax similar to Keras and TensorFlow.
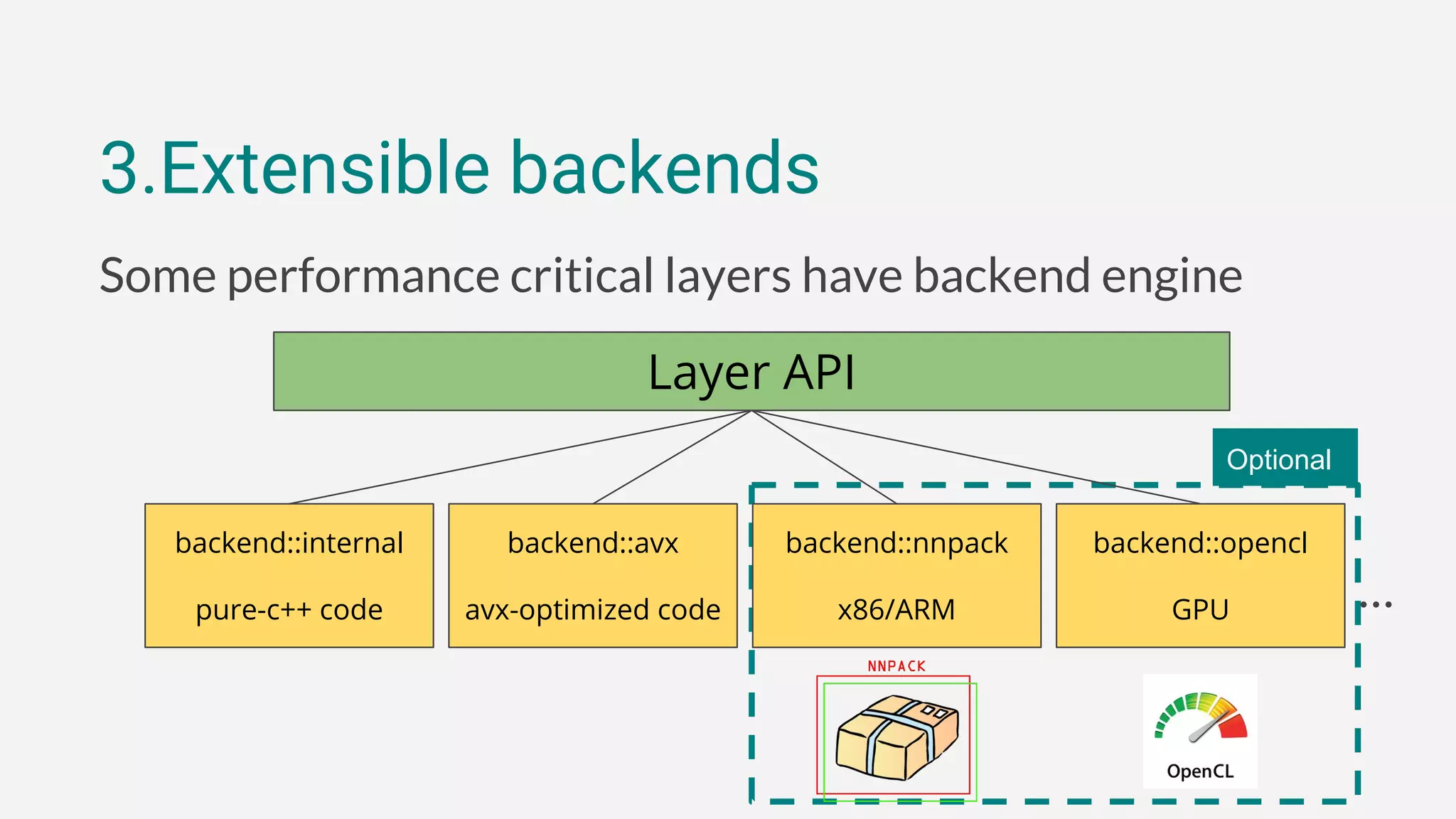
3. The framework has optional performance-oriented backends like AVX and NNPACK to accelerate computation on different hardware, and supports functions for model serialization, basic training, and more through additional modules.












![Tensorflow
w1 = tf.Variable(tf.random_normal([10, 100]))
w2 = tf.Variable(tf.random_normal([100, 20]))
b1 = tf.Variable(tf.random_normal([100]))
b2 = tf.Variable(tf.random_normal([20]))
layer1 = tf.add(tf.matmul(x, w1), b1)
layer1 = tf.nn.relu(layer1)
layer2 = tf.add(tf.matmul(x, w2), b2)
layer2 = tf.nn.relu(layer2)](https://image.slidesharecdn.com/deeplearningwithc-anintroductiontotiny-dnn-161127092855/85/Deep-learning-with-C-an-introduction-to-tiny-dnn-16-320.jpg)
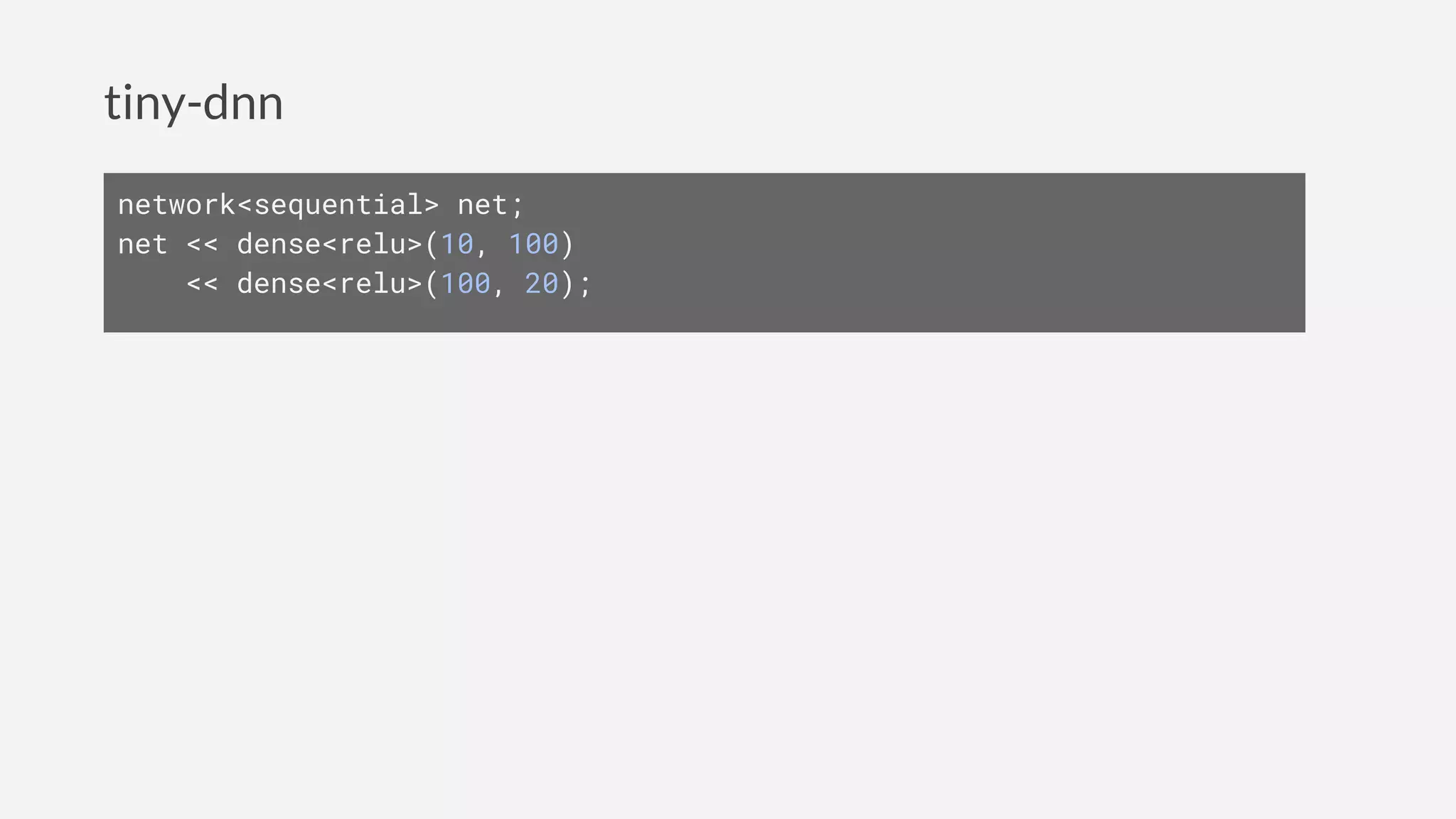
![Keras
model = Sequential([
Dense(100, input_dim=10),
Activation('relu'),
Dense(20),
Activation('relu'),
])](https://image.slidesharecdn.com/deeplearningwithc-anintroductiontotiny-dnn-161127092855/85/Deep-learning-with-C-an-introduction-to-tiny-dnn-17-320.jpg)



![Tensorflow
x = tf.Variable(tf.random_normal([-1, 28, 28, 1]))
wc1 = tf.Variable(tf.random_normal([5, 5, 1, 32]))
wc2 = tf.Variable(tf.random_normal([5, 5, 32, 64]))
wd1 = tf.Variable(tf.random_normal([7*7*64, 1024]))
wout = tf.Variable(tf.random_normal([1024, n_classes]))
bc1 = tf.Variable(tf.random_normal([32]))
bc2 = tf.Variable(tf.random_normal([64]))
bd1 = tf.Variable(tf.random_normal([1024]))
bout = tf.Variable(tf.random_normal([n_classes]))
conv1 = conv2d(x, wc1, bc1)
conv1 = maxpool2d(conv1, k=2)
conv1 = tf.nn.relu(conv1)
conv2 = conv2d(conv1, wc2, bc2)
conv2 = maxpool2d(conv2, k=2)
conv2 = tf.nn.relu(conv2)
fc1 = tf.reshape(conv2, [-1, wd1.get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, wd1), bd1)
fc1 = tf.nn.relu(fc1)
fc1 = tf.nn.dropout(fc1, dropout)
out = tf.add(tf.matmul(fc1, wout), bout)](https://image.slidesharecdn.com/deeplearningwithc-anintroductiontotiny-dnn-161127092855/85/Deep-learning-with-C-an-introduction-to-tiny-dnn-22-320.jpg)
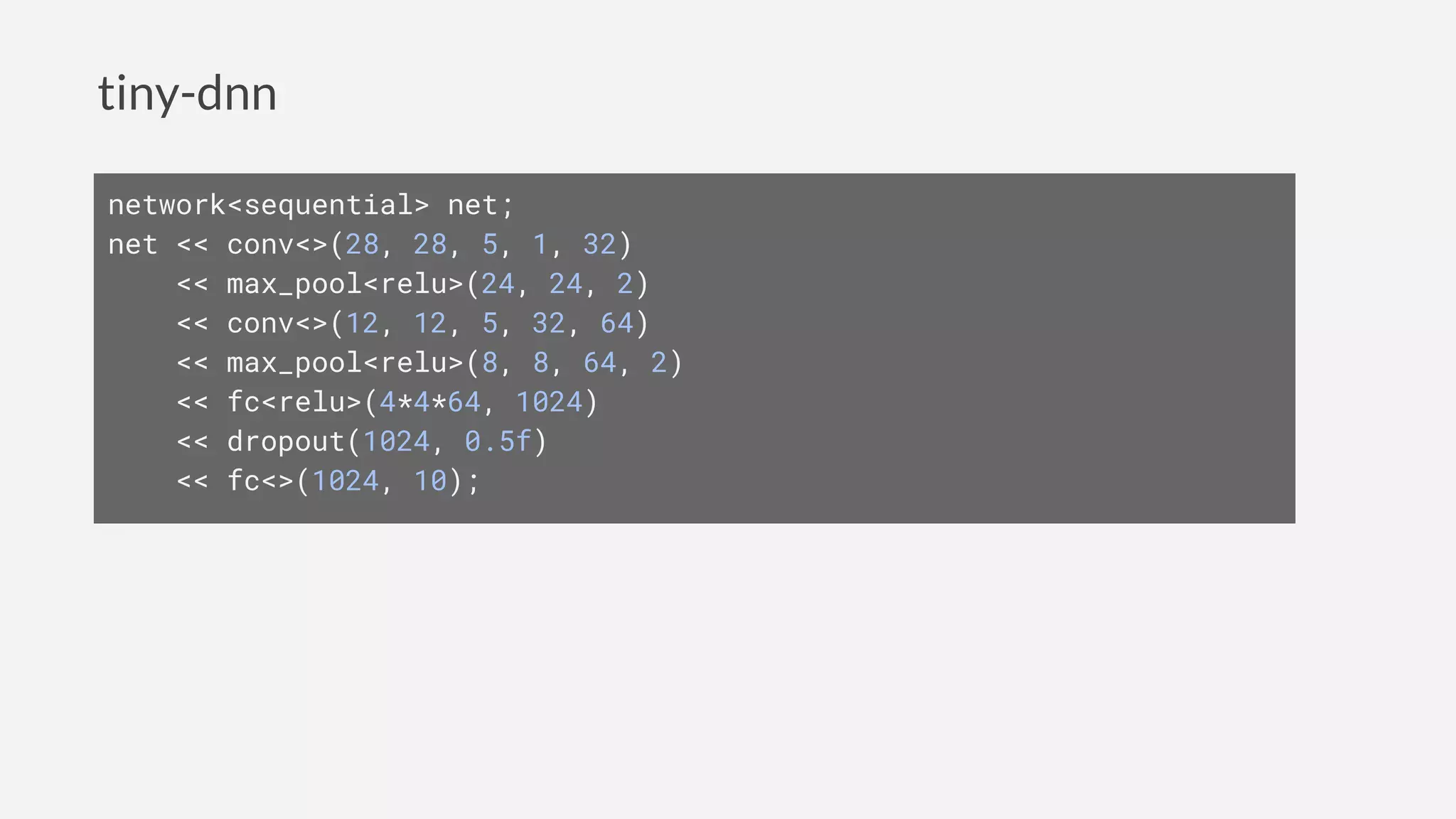
![Keras
model = Sequential([
Convolution2D(32, 5, 5, input_shape=[28,28,5]),
MaxPooling2D(pool_size=2),
Activation('relu'),
Convolution2D(64, 5, 5),
MaxPooling2D(pool_size=2),
Activation('relu'),
Dense(1024),
Dropout(0.5),
Dense(10),
])](https://image.slidesharecdn.com/deeplearningwithc-anintroductiontotiny-dnn-161127092855/85/Deep-learning-with-C-an-introduction-to-tiny-dnn-23-320.jpg)


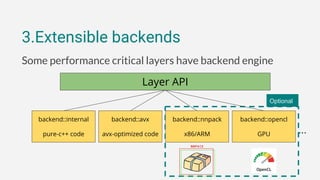
![3.Extensible backends
// select an engine explicitly
net << conv<>(28, 28, 5, 1, 32, backend::avx)
<< ...;
// switch them seamlessly
net[0]->set_backend_type(backend::opencl);](https://image.slidesharecdn.com/deeplearningwithc-anintroductiontotiny-dnn-161127092855/85/Deep-learning-with-C-an-introduction-to-tiny-dnn-28-320.jpg)

















![Tensorflow
w1 = tf.Variable(tf.random_normal([10, 100]))
w2 = tf.Variable(tf.random_normal([100, 20]))
b1 = tf.Variable(tf.random_normal([100]))
b2 = tf.Variable(tf.random_normal([20]))
layer1 = tf.add(tf.matmul(x, w1), b1)
layer1 = tf.nn.relu(layer1)
layer2 = tf.add(tf.matmul(x, w2), b2)
layer2 = tf.nn.relu(layer2)](https://image.slidesharecdn.com/deeplearningwithc-anintroductiontotiny-dnn-161127092855/75/Deep-learning-with-C-an-introduction-to-tiny-dnn-16-2048.jpg)
![Keras
model = Sequential([
Dense(100, input_dim=10),
Activation('relu'),
Dense(20),
Activation('relu'),
])](https://image.slidesharecdn.com/deeplearningwithc-anintroductiontotiny-dnn-161127092855/75/Deep-learning-with-C-an-introduction-to-tiny-dnn-17-2048.jpg)



![Tensorflow
x = tf.Variable(tf.random_normal([-1, 28, 28, 1]))
wc1 = tf.Variable(tf.random_normal([5, 5, 1, 32]))
wc2 = tf.Variable(tf.random_normal([5, 5, 32, 64]))
wd1 = tf.Variable(tf.random_normal([7*7*64, 1024]))
wout = tf.Variable(tf.random_normal([1024, n_classes]))
bc1 = tf.Variable(tf.random_normal([32]))
bc2 = tf.Variable(tf.random_normal([64]))
bd1 = tf.Variable(tf.random_normal([1024]))
bout = tf.Variable(tf.random_normal([n_classes]))
conv1 = conv2d(x, wc1, bc1)
conv1 = maxpool2d(conv1, k=2)
conv1 = tf.nn.relu(conv1)
conv2 = conv2d(conv1, wc2, bc2)
conv2 = maxpool2d(conv2, k=2)
conv2 = tf.nn.relu(conv2)
fc1 = tf.reshape(conv2, [-1, wd1.get_shape().as_list()[0]])
fc1 = tf.add(tf.matmul(fc1, wd1), bd1)
fc1 = tf.nn.relu(fc1)
fc1 = tf.nn.dropout(fc1, dropout)
out = tf.add(tf.matmul(fc1, wout), bout)](https://image.slidesharecdn.com/deeplearningwithc-anintroductiontotiny-dnn-161127092855/75/Deep-learning-with-C-an-introduction-to-tiny-dnn-22-2048.jpg)
![Keras
model = Sequential([
Convolution2D(32, 5, 5, input_shape=[28,28,5]),
MaxPooling2D(pool_size=2),
Activation('relu'),
Convolution2D(64, 5, 5),
MaxPooling2D(pool_size=2),
Activation('relu'),
Dense(1024),
Dropout(0.5),
Dense(10),
])](https://image.slidesharecdn.com/deeplearningwithc-anintroductiontotiny-dnn-161127092855/75/Deep-learning-with-C-an-introduction-to-tiny-dnn-23-2048.jpg)


![3.Extensible backends
// select an engine explicitly
net << conv<>(28, 28, 5, 1, 32, backend::avx)
<< ...;
// switch them seamlessly
net[0]->set_backend_type(backend::opencl);](https://image.slidesharecdn.com/deeplearningwithc-anintroductiontotiny-dnn-161127092855/75/Deep-learning-with-C-an-introduction-to-tiny-dnn-28-2048.jpg)