Download as PDF, PPTX



















The document discusses the implementation of dynamic partition pruning in Apache Spark to enhance the performance of SQL analytics workloads. It outlines the benefits of this approach, leading to significant speedups in query execution, particularly with TPC-DS benchmarks like query 98. The innovation allows Spark to efficiently handle star-schema queries, reducing the need for complex ETL processes with denormalized tables.
Introduction to Dynamic Partition Pruning in Apache Spark as discussed by Bogdan Ghit and Juliusz Sompolski.
Presentation by the BI Experience team at Databricks, focusing on performance improvements for SQL analytics.
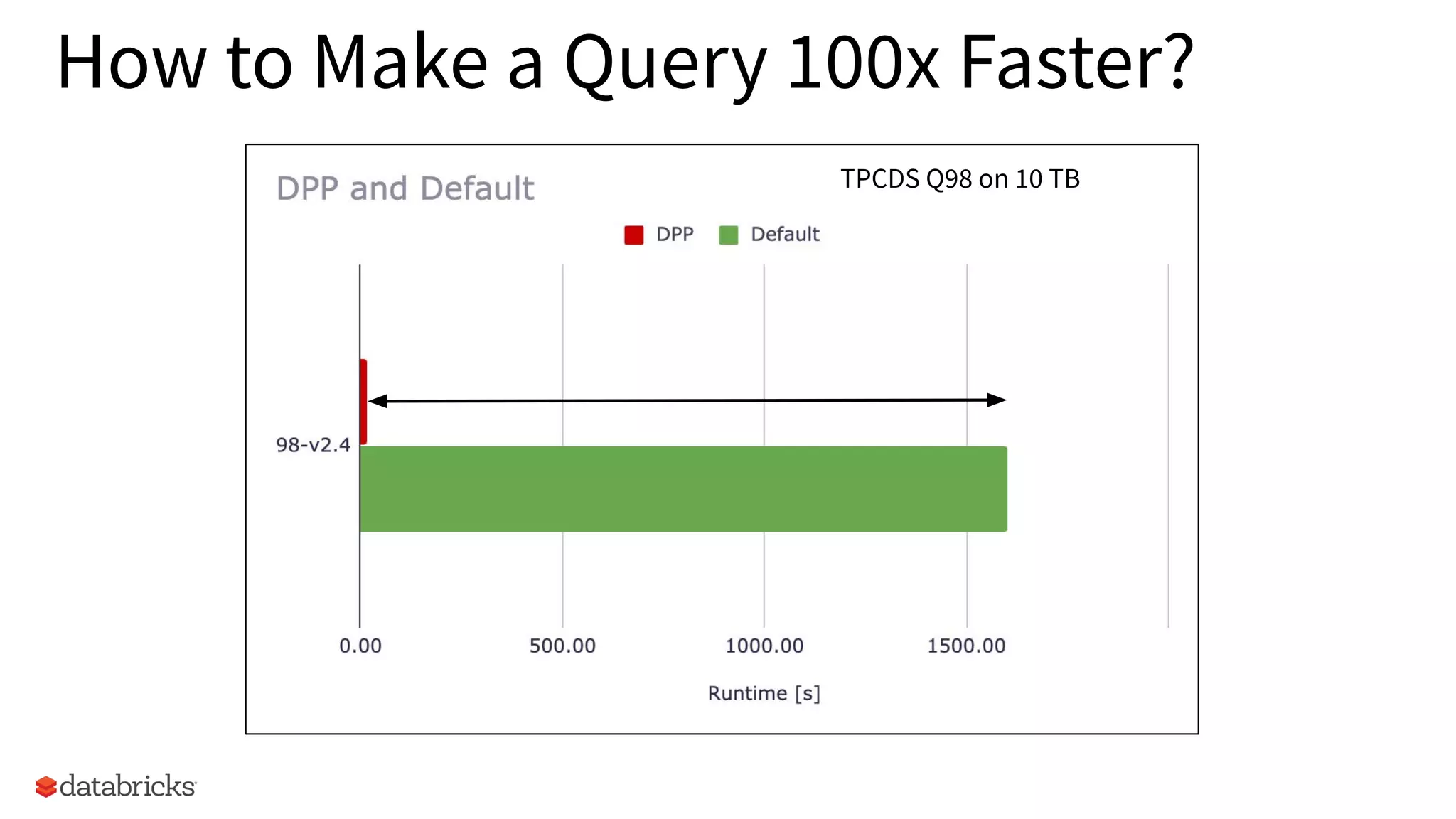
Exploration of making a TPCDS Q98 query 100x faster, highlighting performance challenges.
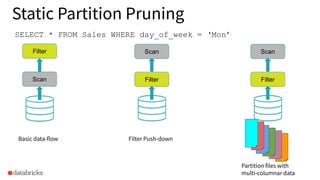
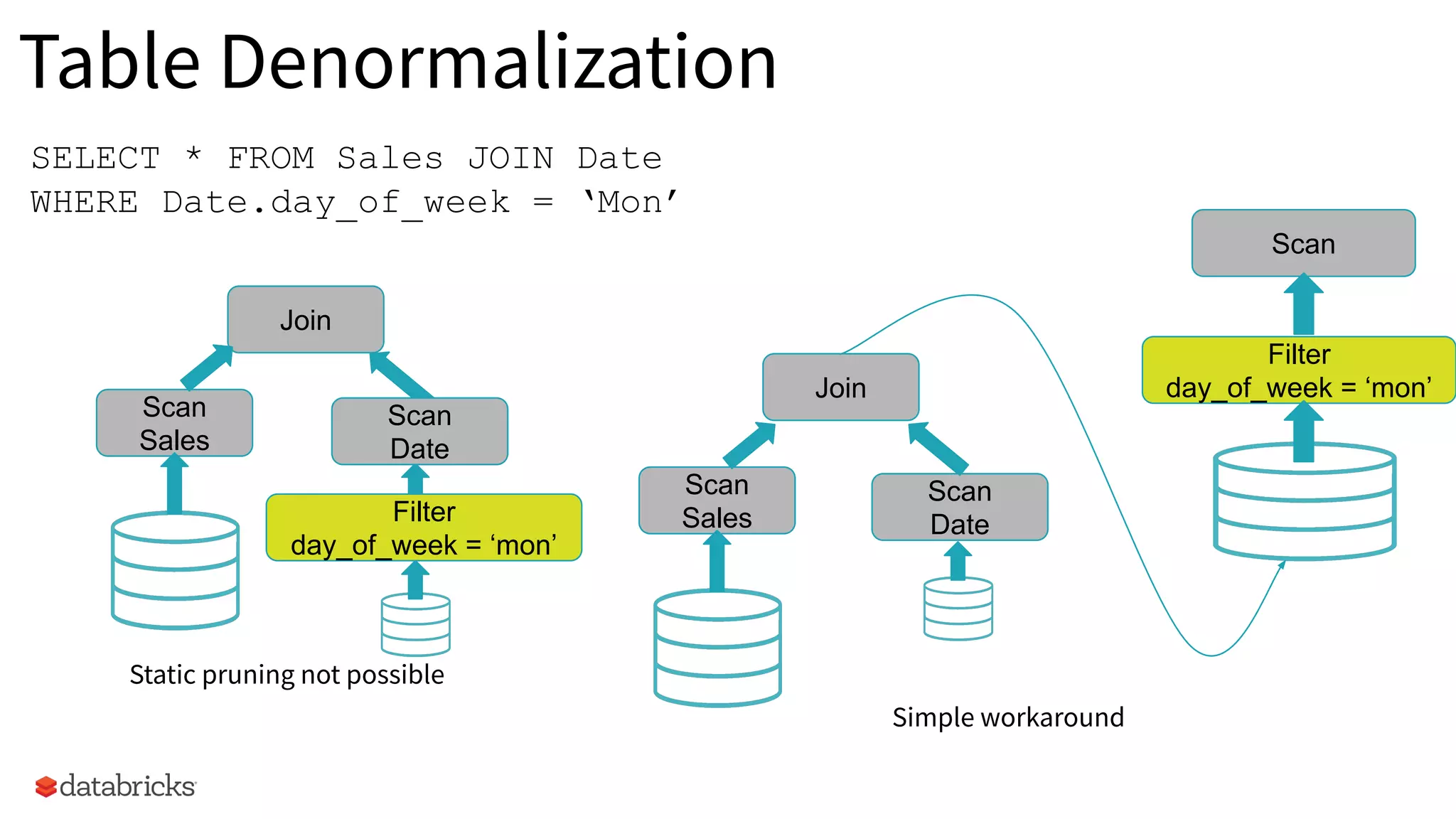
Example of a static partition pruning scenario using Sales data filtered by day_of_week to demonstrate basic data flow.
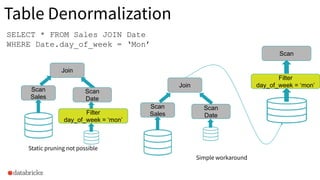
Scenario showcasing the need for table denormalization, indicating static pruning limitations.
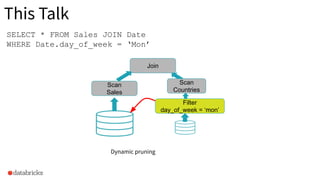
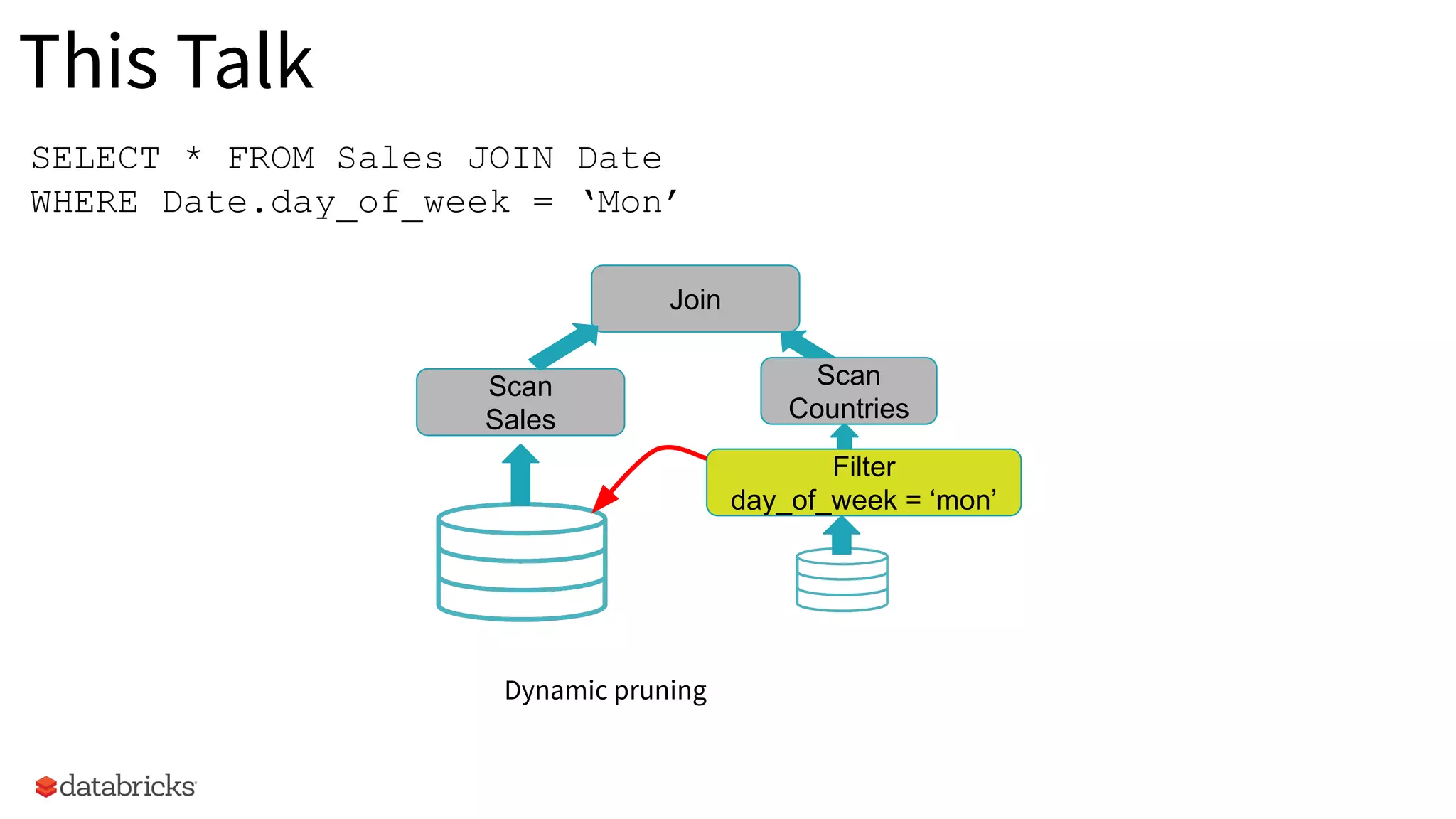
Illustration of dynamic pruning's application with a focus on filtering and joining Sales and Date tables.
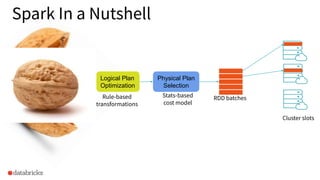
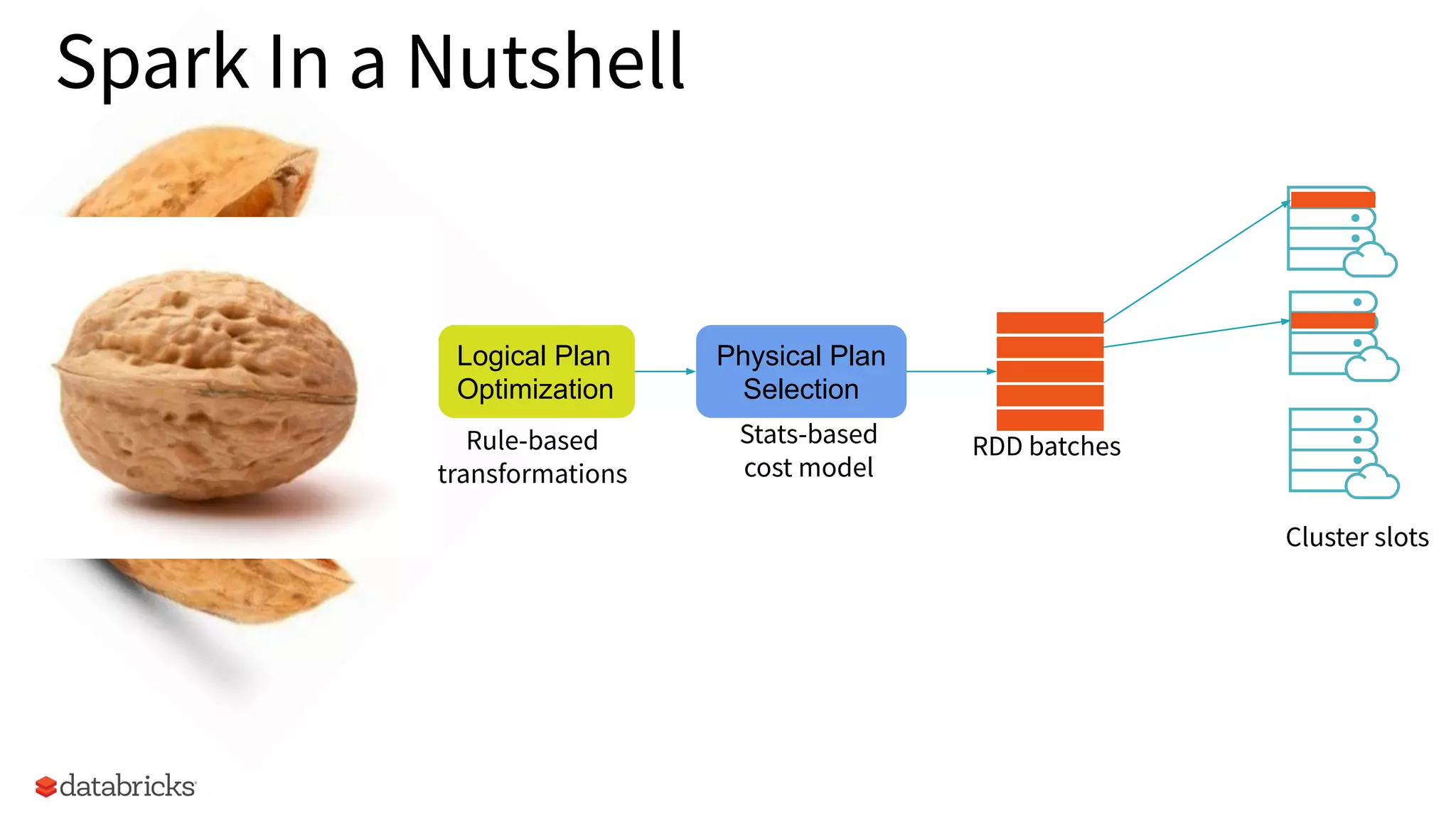
Overview of Spark's architecture including logical and physical planning, and optimization strategies.
Discussion on data layout, query shape optimization, and handling multi-columnar data.
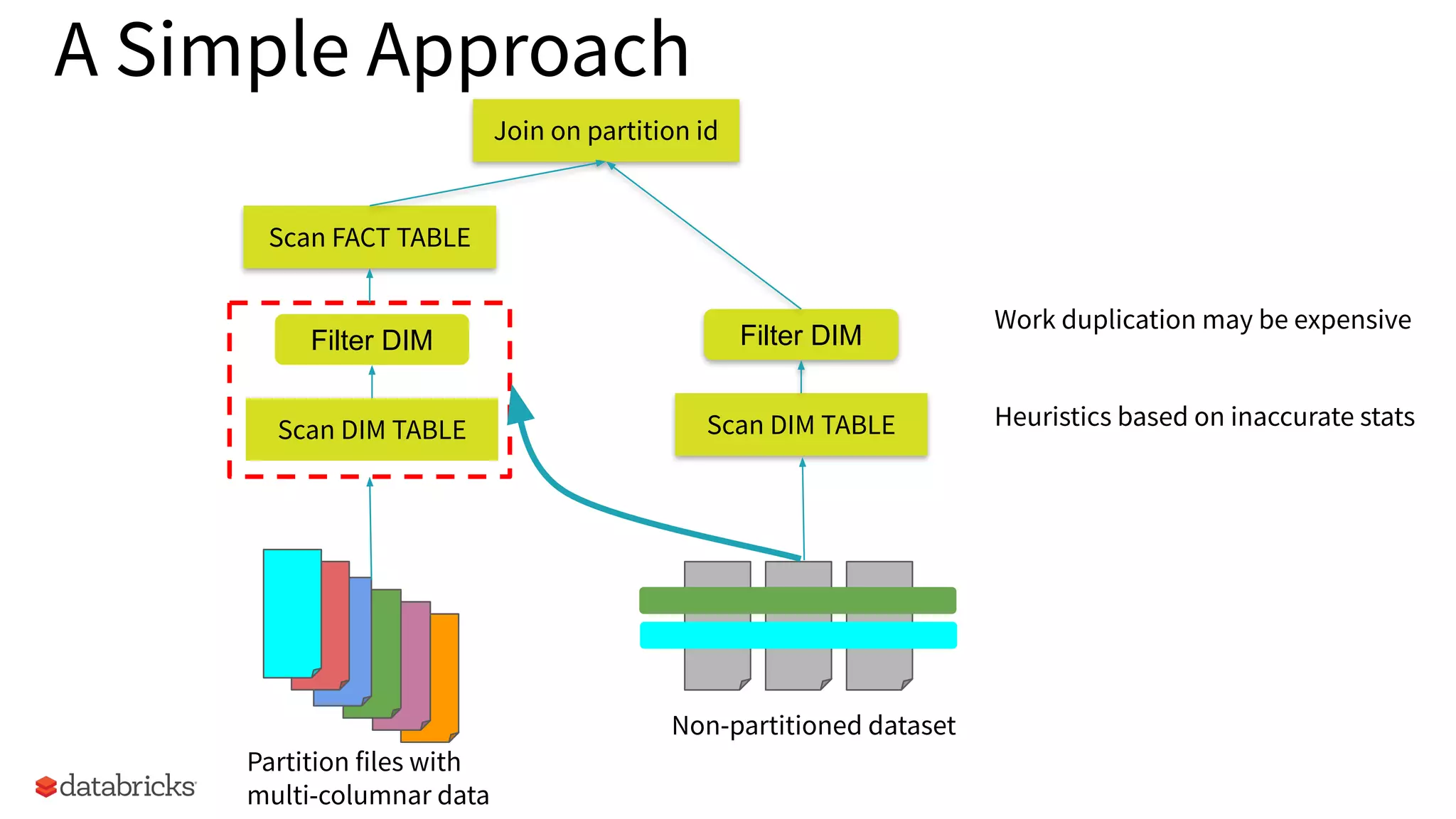
Presenting a simple yet ineffective approach for handling non-partitioned datasets and potential work duplication.
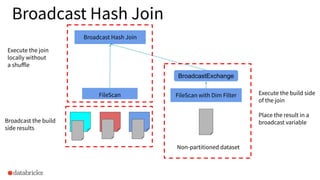
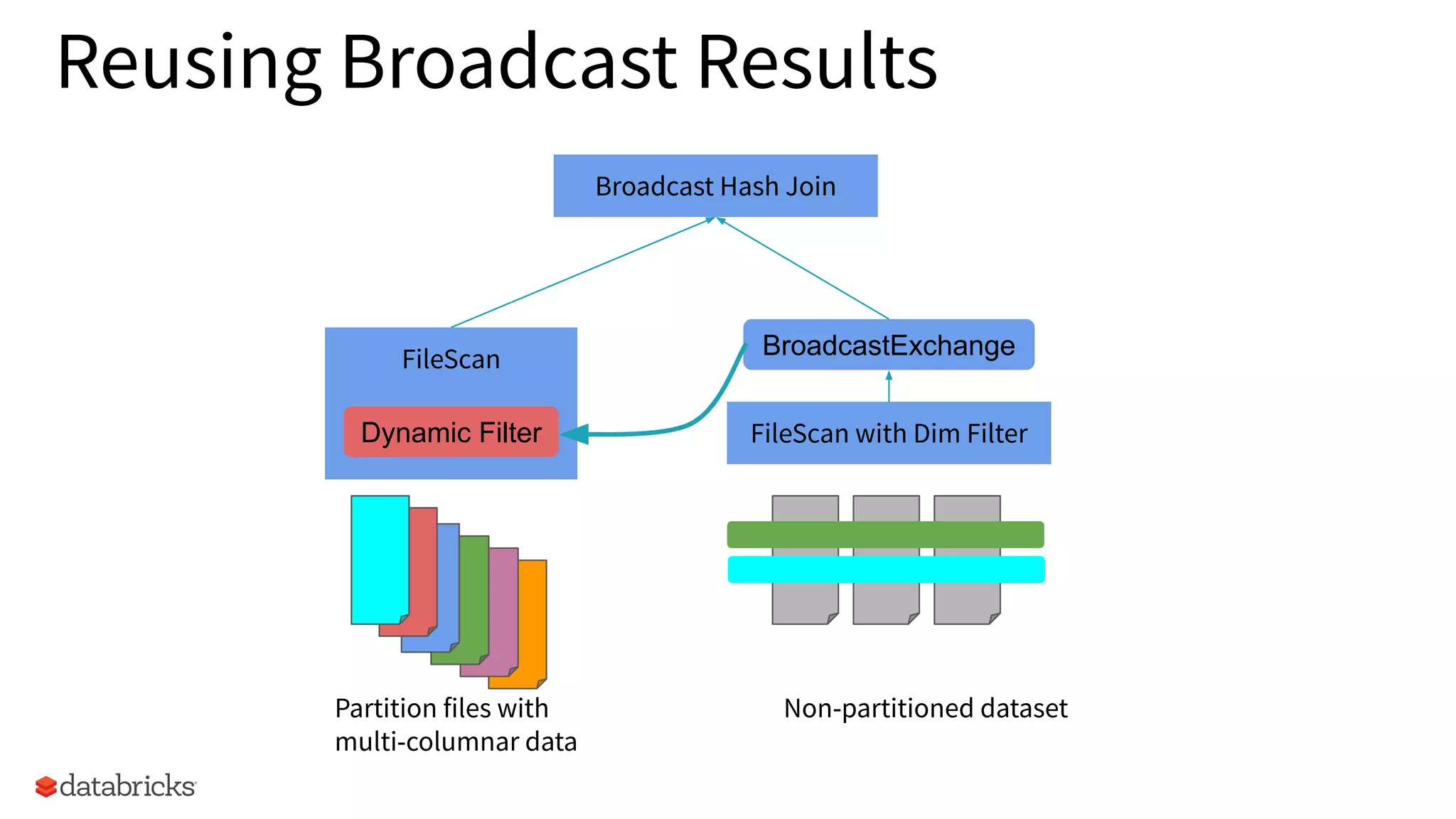
Description of Broadcast Hash Join strategy for optimizing joins on non-partitioned datasets.
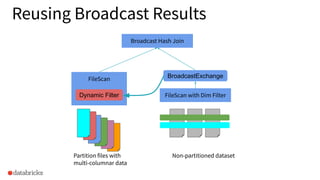
Explains how to reuse broadcast results in dynamic filtering scenarios for improved performance.
Details on the experimental setup for performance testing, including workload selection and cluster configuration.
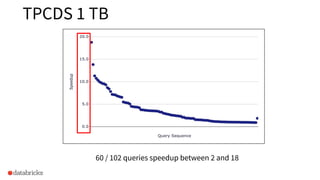
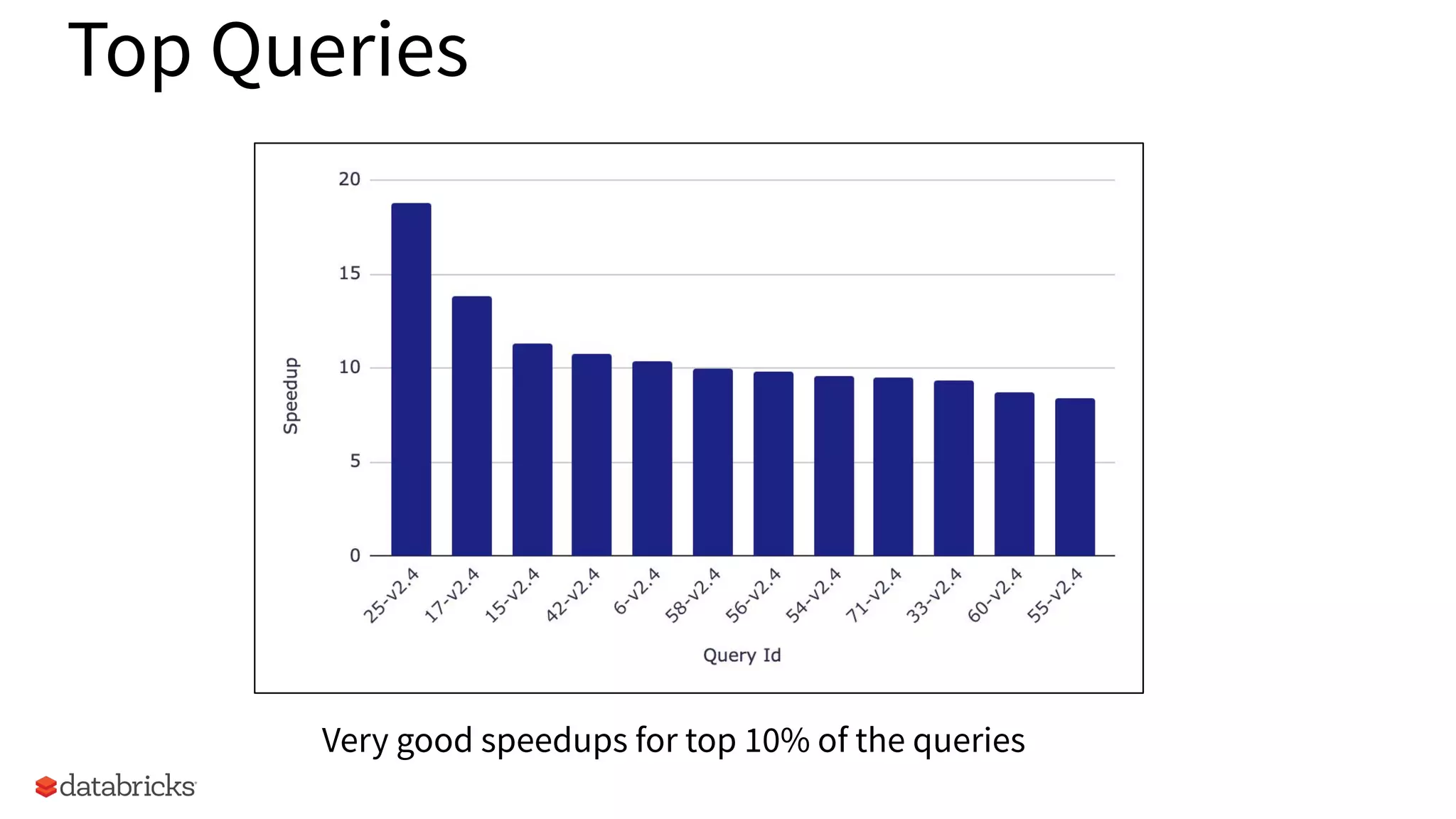
Results of TPCDS 1 TB queries showcasing speedups between 2 to 18 times.
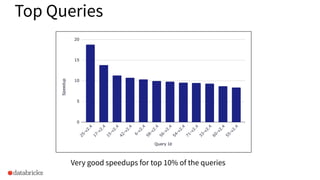
Identifies significant speedups observed for the top 10% of queries in the dataset.
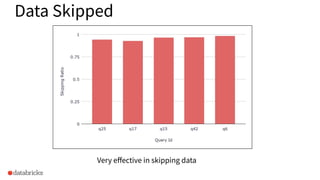
Insight into the effectiveness of data skipping in improving query performance.
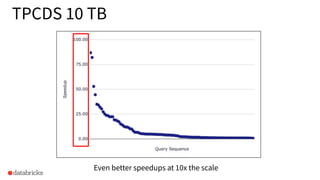
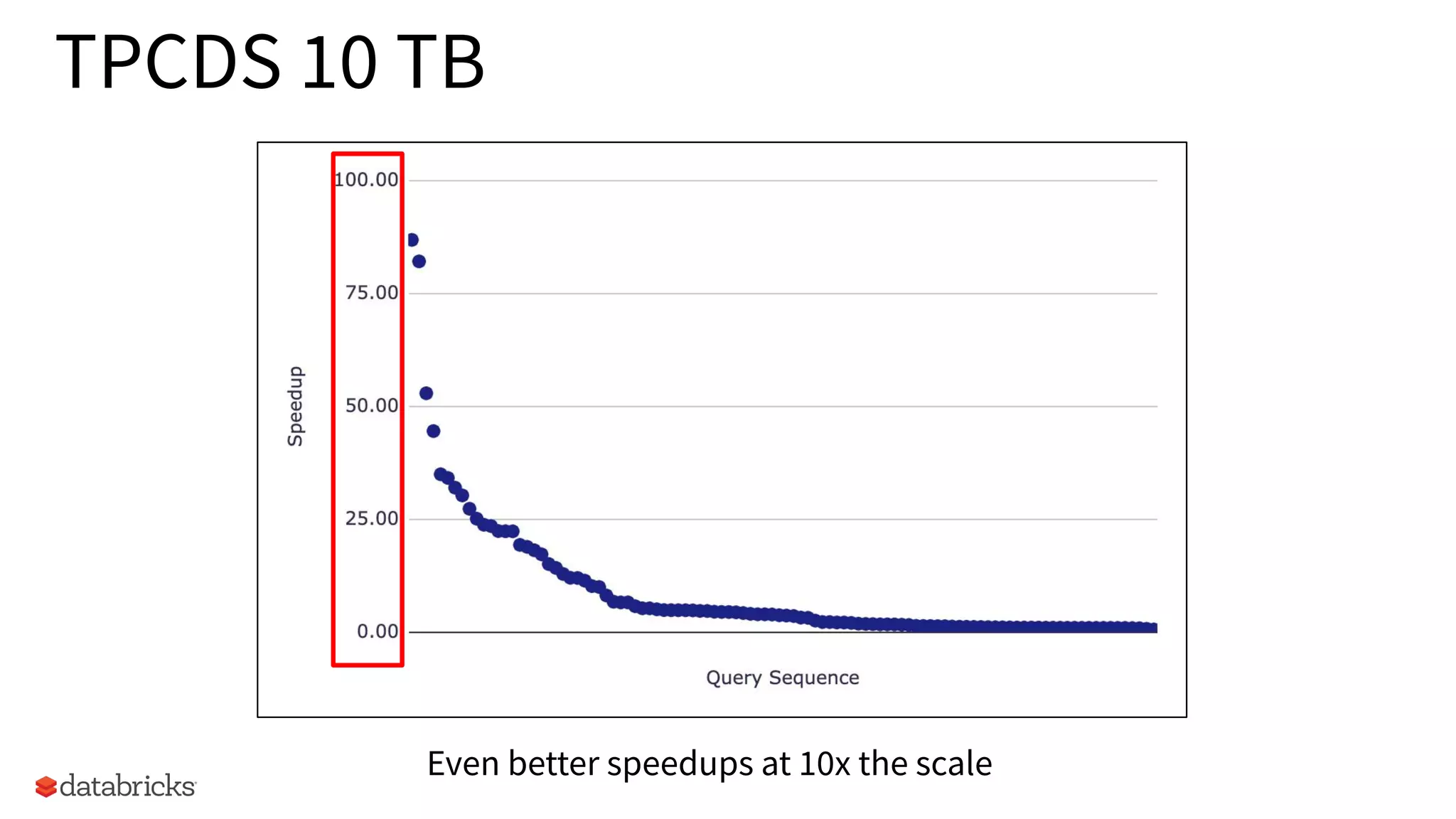
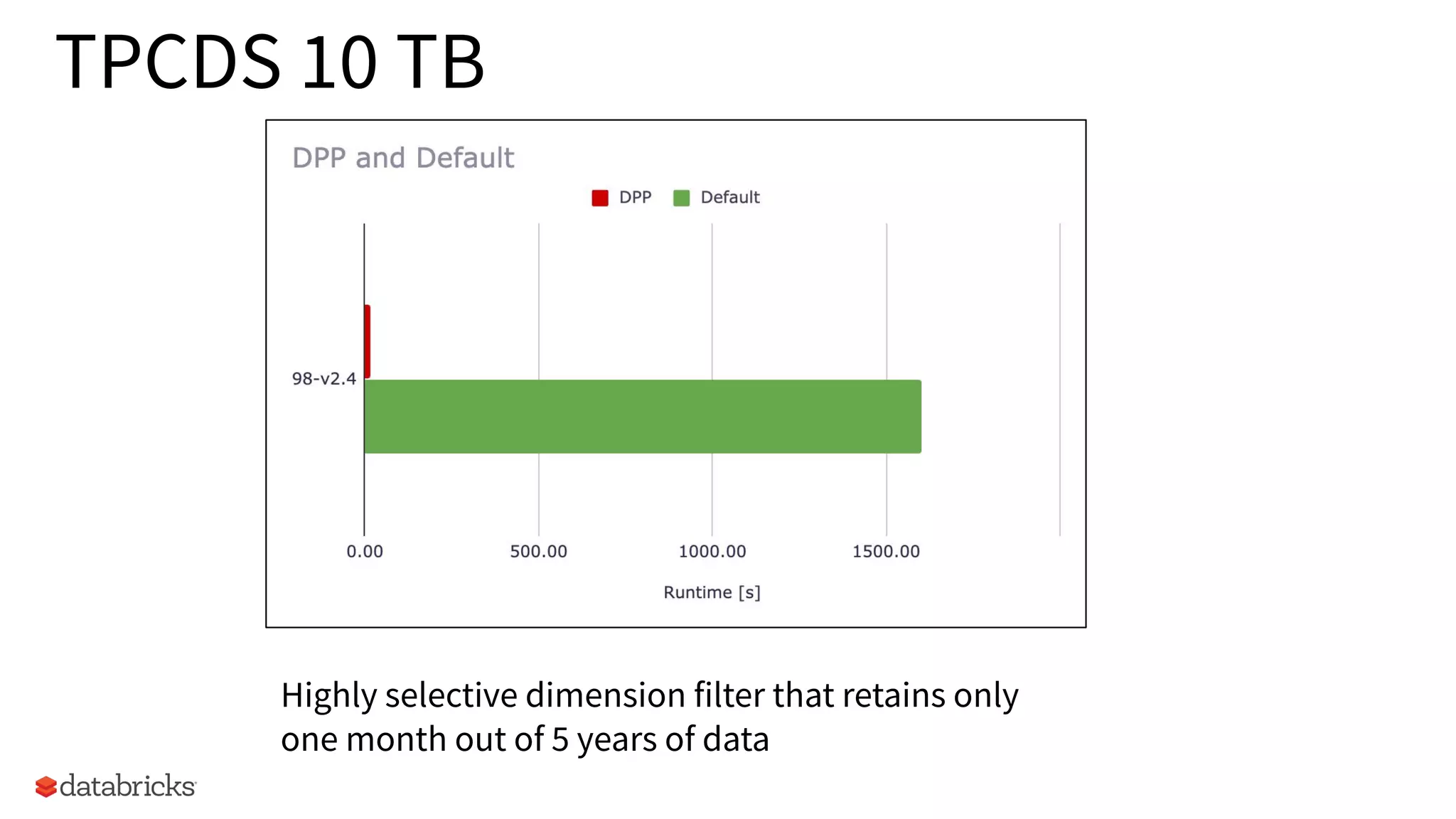
Performance evaluations achieving better speedups in TPCDS queries at 10 TB scale.
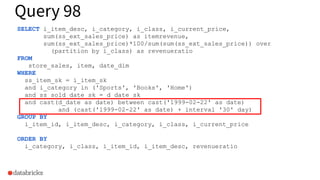
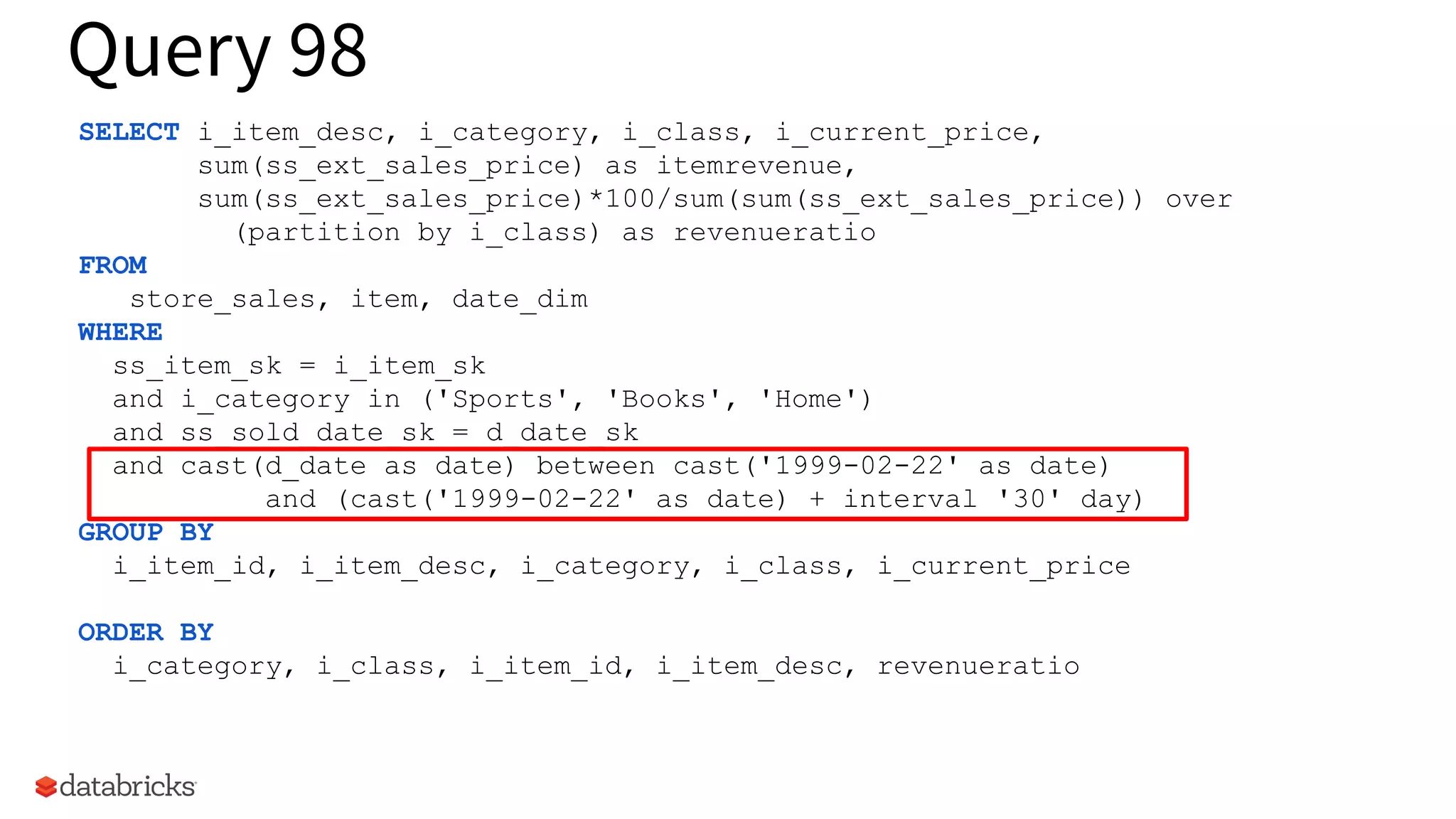
Sample TPCDS query illustrating complex aggregations and filters based on item sales.
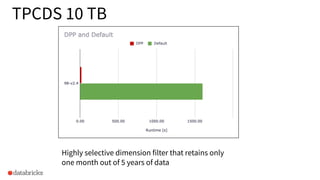
Highlights highly selective filters in query examples retaining minimal data for processing.
Summary of Apache Spark 3.0 improvements with Dynamic Partition Pruning, emphasizing its significance.
Conclusion and thanks from presenters Bogdan Ghit and Juliusz Sompolski, with contact information.























































































