Downloaded 16 times
















![Tri-mergeSort( a[L,....,R], L, R )
{ n=R-L+1 (number of element calculated from index position)
IF (n>2) THEN
{
m1 = n/3 (First midpoint)
m2 = 2*m1 (Second midpoint)
Tri-mergeSort ( a[L,….,m1], L, m1 )
Algorithm of Tri-merge sort
Tri-mergeSort ( a[m1+1,….,m2], m1+1, m2 )
Tri-mergeSort ( a[m2+1,….,R], m2+1, R )
Tri-merge ( a[L,….,R], L, m1+1, m2+1, R )
} in
ELSE IF (n = 2) THEN
{
Structural PseudoCode
IF ( a[L] > a[R] )
{
temp = a[L]
a[L] = a[R]
a[R] = temp
}
}
}](https://image.slidesharecdn.com/final25aprl-130225130232-phpapp01/85/Tri-Merge-Sorting-Algorithm-17-320.jpg)
![Tri-merge ( a[L,….,R], L, m1, m2, R)
{ part1 = a[L,…,m1-1]; part2 = a[m1,…,m2-1]; part3 = a[m2,…,R]
TempArray[L,…,R]; n = R-L+1
IF ( n > 2 )
{ WHILE( part1, part2 and part3 has elements )
Comparing from 3 parts find minimum and set to TempArray.
WHILE( part1 and part2 has elements )
Comparing from 2 parts find minimum and set to TempArray.
WHILE( part2 and part3 has elements )
Comparing from 2 parts find minimum and set to TempArray.
WHILE( part1 and part3 has elements )
Comparing from 2 parts find minimum and set to TempArray.
WHILE( part1 has elements )
set to TempArray.
WHILE( part2 has elements )
set to TempArray.
WHILE (part3 has elements)
set to TempArray.
}
RETURN TempArray
}](https://image.slidesharecdn.com/final25aprl-130225130232-phpapp01/85/Tri-Merge-Sorting-Algorithm-18-320.jpg)
![void TriMergeSort( int a[], int L, int R, long int asscount[],long int comcount[])
{
int noOfEle=R-L+1;
int m1,m2,part,t;
comcount[0]++;
if(noOfEle>2)
{
part=(R-L+1)/3;
m1 = L+part-1;
Complete program of
m2 = L+2*part-1;
asscount[0]+=3;
Tri-merge Sort
TriMergeSort(a,L,m1,asscount,comcount);
TriMergeSort(a, m1+1,m2,asscount,comcount);
TriMergeSort(a, m2+1,R,asscount,comcount);
TriMerge(a,L,m1+1,m2+1,R,asscount,comcount);
}
else if(noOfEle==2)
{
comcount[0]+=2;
if(a[L]>a[R])
{
asscount[0]+=3;
t=a[L];
a[L]=a[R];](https://image.slidesharecdn.com/final25aprl-130225130232-phpapp01/85/Tri-Merge-Sorting-Algorithm-19-320.jpg)



























![Tri-mergeSort( a[L,....,R], L, R )
{ n=R-L+1 (number of element calculated from index position)
IF (n>2) THEN
{
m1 = n/3 (First midpoint)
m2 = 2*m1 (Second midpoint)
Tri-mergeSort ( a[L,….,m1], L, m1 )
Algorithm of Tri-merge sort
Tri-mergeSort ( a[m1+1,….,m2], m1+1, m2 )
Tri-mergeSort ( a[m2+1,….,R], m2+1, R )
Tri-merge ( a[L,….,R], L, m1+1, m2+1, R )
} in
ELSE IF (n = 2) THEN
{
Structural PseudoCode
IF ( a[L] > a[R] )
{
temp = a[L]
a[L] = a[R]
a[R] = temp
}
}
}](https://image.slidesharecdn.com/final25aprl-130225130232-phpapp01/75/Tri-Merge-Sorting-Algorithm-17-2048.jpg)
![Tri-merge ( a[L,….,R], L, m1, m2, R)
{ part1 = a[L,…,m1-1]; part2 = a[m1,…,m2-1]; part3 = a[m2,…,R]
TempArray[L,…,R]; n = R-L+1
IF ( n > 2 )
{ WHILE( part1, part2 and part3 has elements )
Comparing from 3 parts find minimum and set to TempArray.
WHILE( part1 and part2 has elements )
Comparing from 2 parts find minimum and set to TempArray.
WHILE( part2 and part3 has elements )
Comparing from 2 parts find minimum and set to TempArray.
WHILE( part1 and part3 has elements )
Comparing from 2 parts find minimum and set to TempArray.
WHILE( part1 has elements )
set to TempArray.
WHILE( part2 has elements )
set to TempArray.
WHILE (part3 has elements)
set to TempArray.
}
RETURN TempArray
}](https://image.slidesharecdn.com/final25aprl-130225130232-phpapp01/75/Tri-Merge-Sorting-Algorithm-18-2048.jpg)
![void TriMergeSort( int a[], int L, int R, long int asscount[],long int comcount[])
{
int noOfEle=R-L+1;
int m1,m2,part,t;
comcount[0]++;
if(noOfEle>2)
{
part=(R-L+1)/3;
m1 = L+part-1;
Complete program of
m2 = L+2*part-1;
asscount[0]+=3;
Tri-merge Sort
TriMergeSort(a,L,m1,asscount,comcount);
TriMergeSort(a, m1+1,m2,asscount,comcount);
TriMergeSort(a, m2+1,R,asscount,comcount);
TriMerge(a,L,m1+1,m2+1,R,asscount,comcount);
}
else if(noOfEle==2)
{
comcount[0]+=2;
if(a[L]>a[R])
{
asscount[0]+=3;
t=a[L];
a[L]=a[R];](https://image.slidesharecdn.com/final25aprl-130225130232-phpapp01/75/Tri-Merge-Sorting-Algorithm-19-2048.jpg)





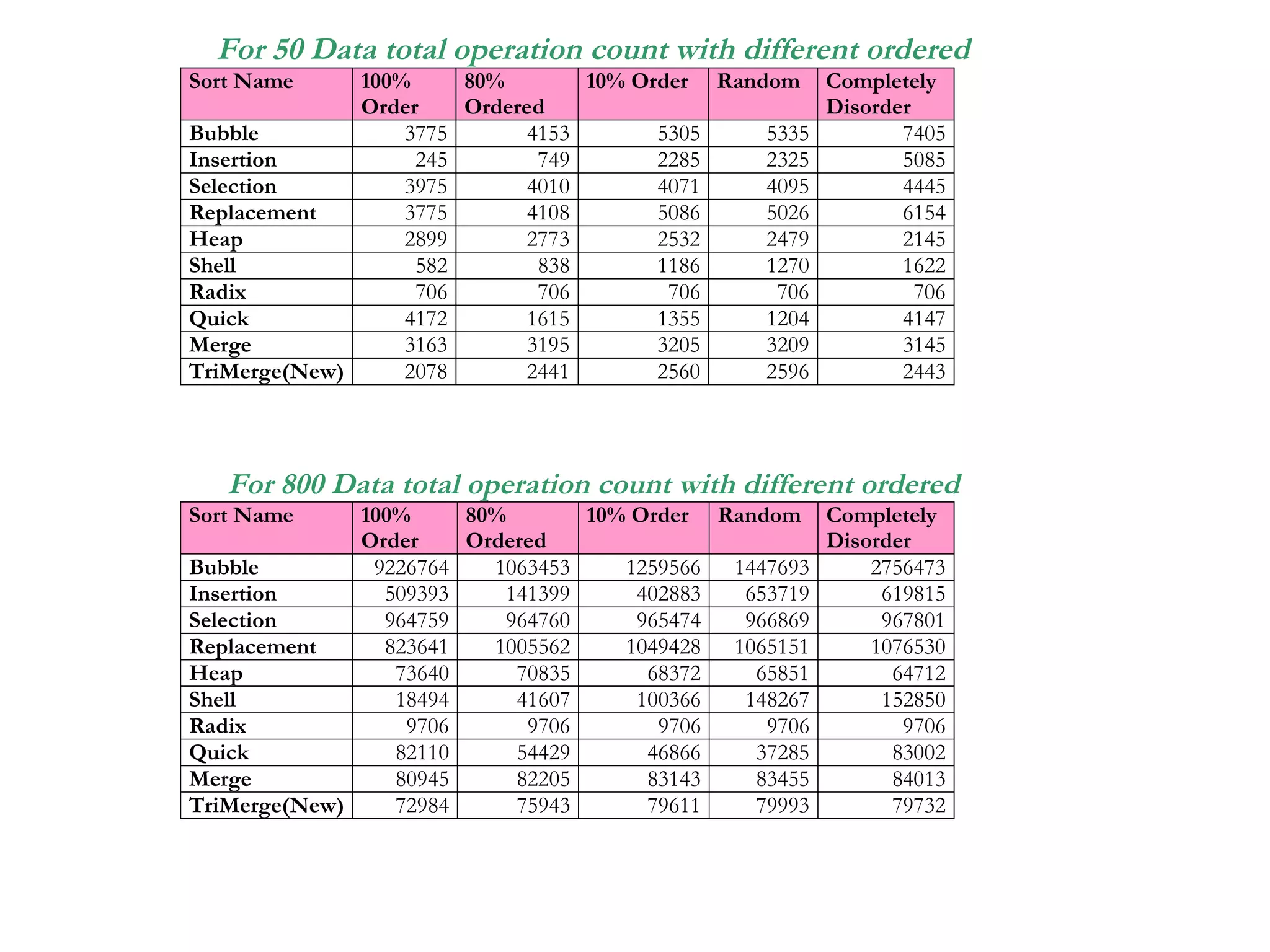
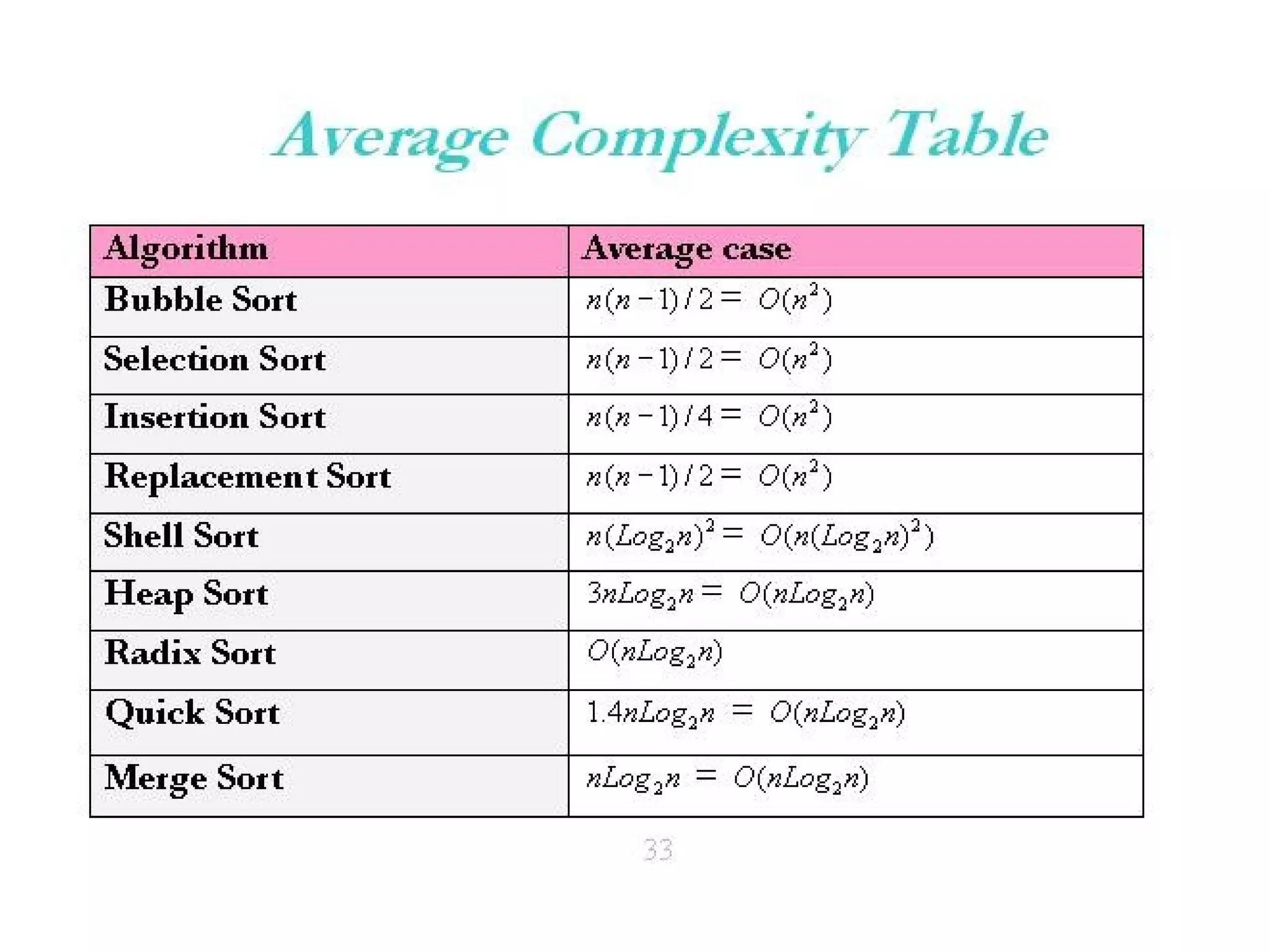

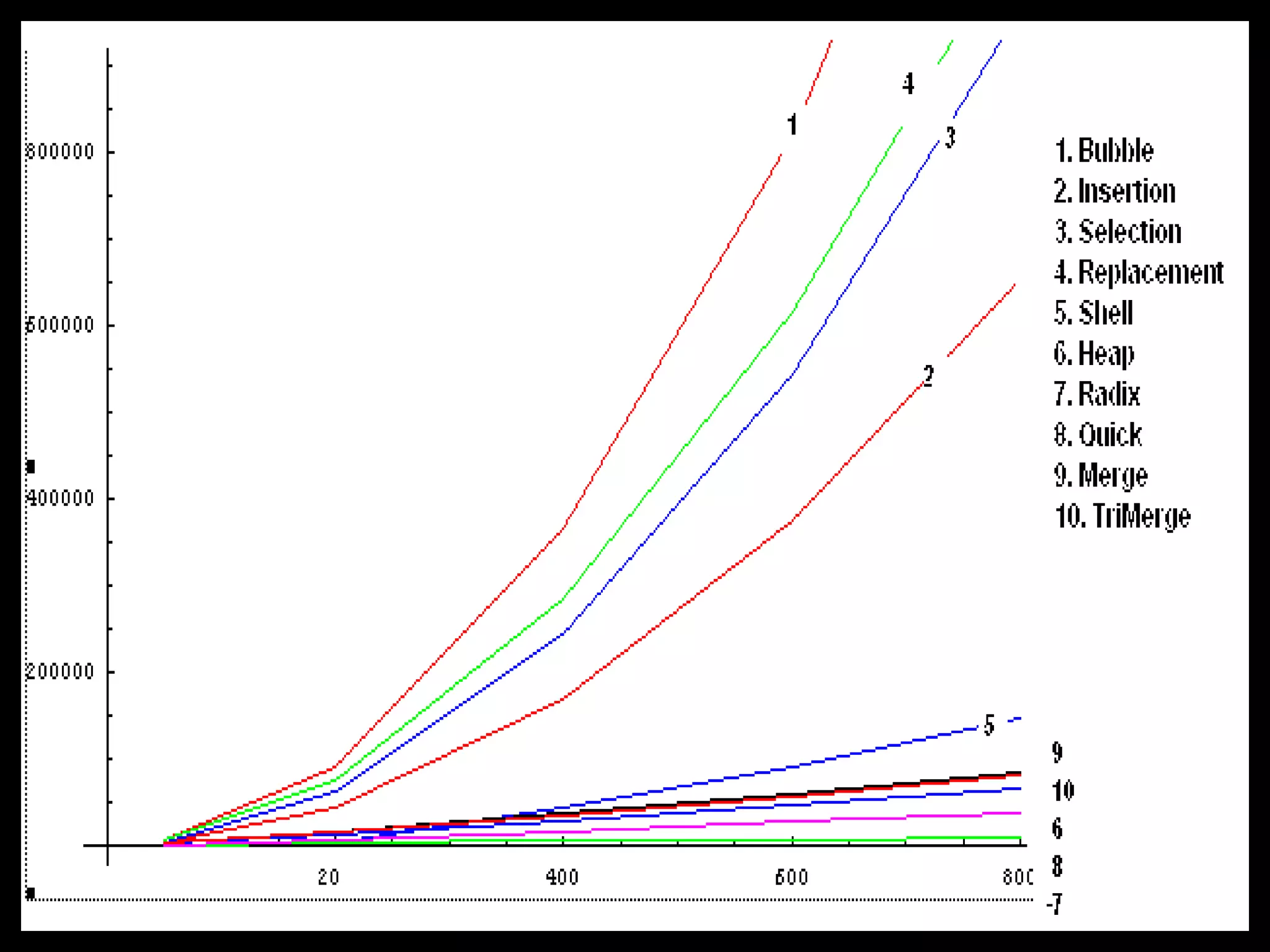
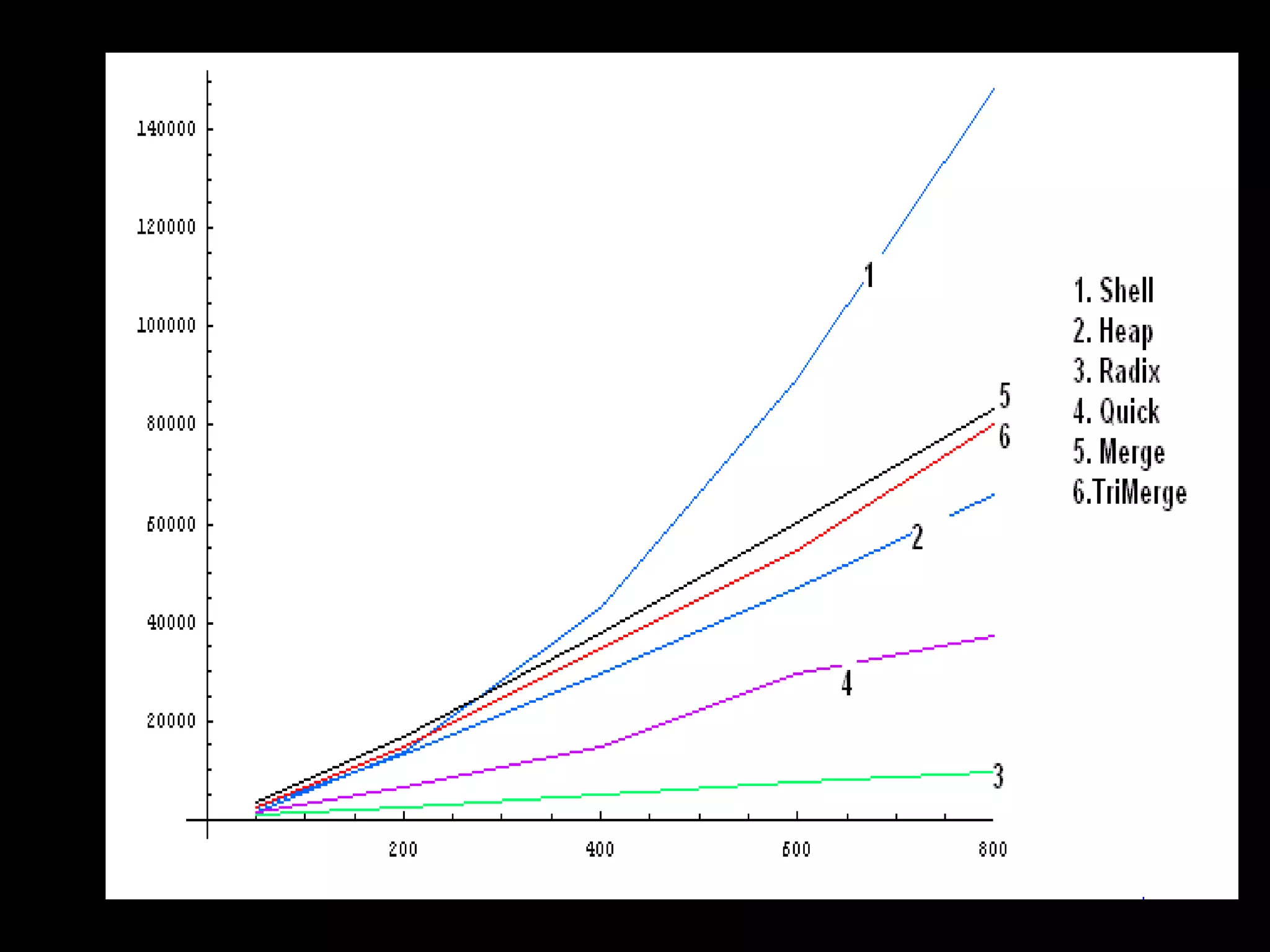




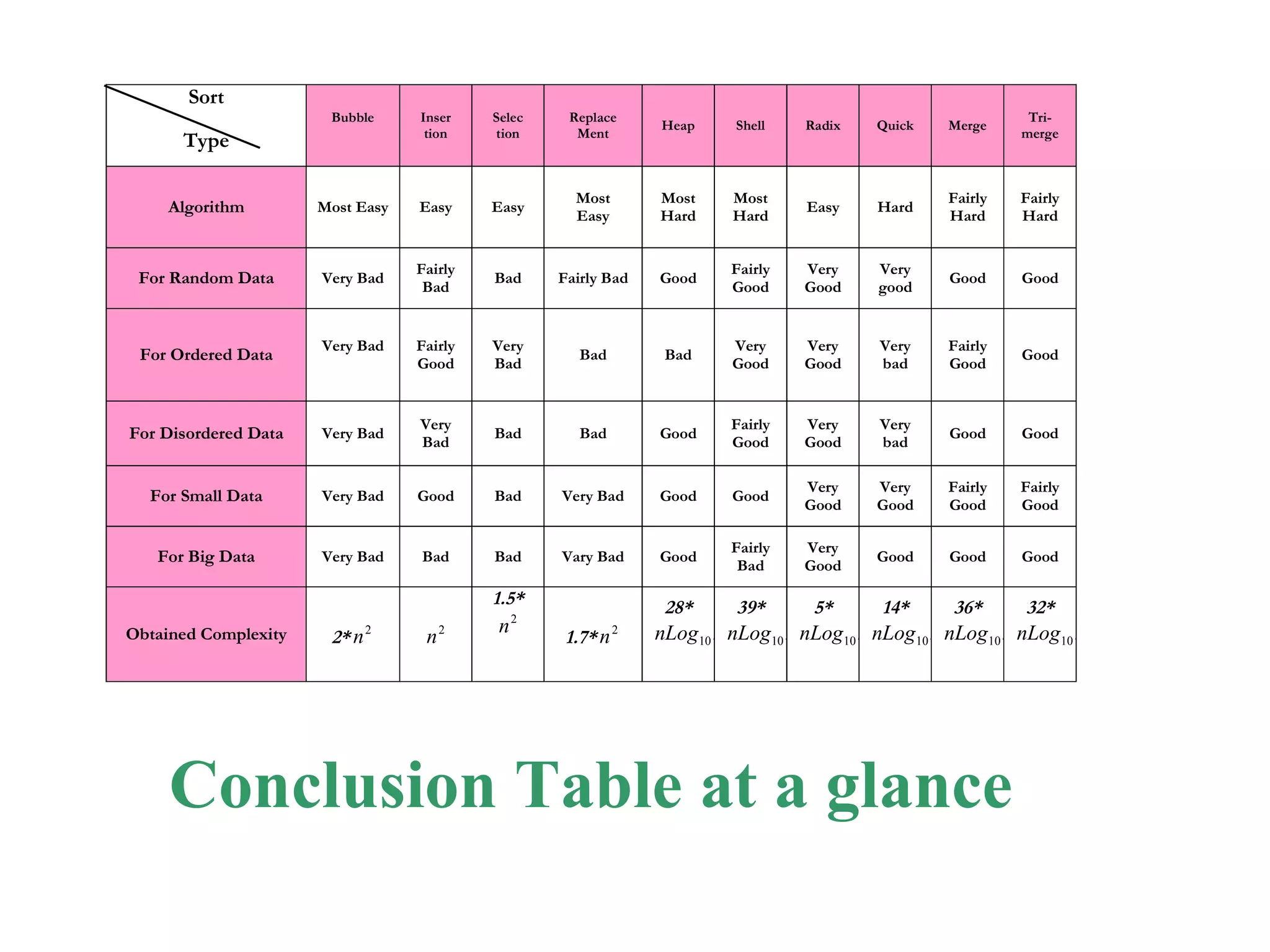


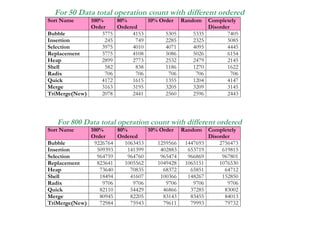
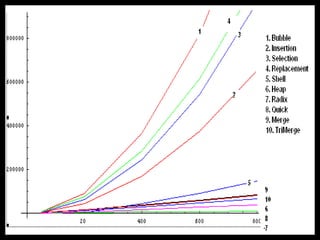
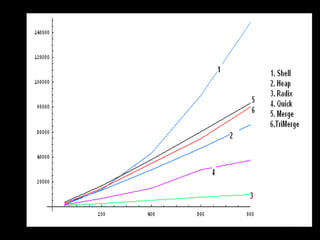
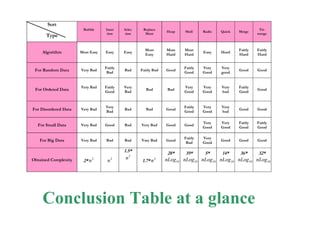
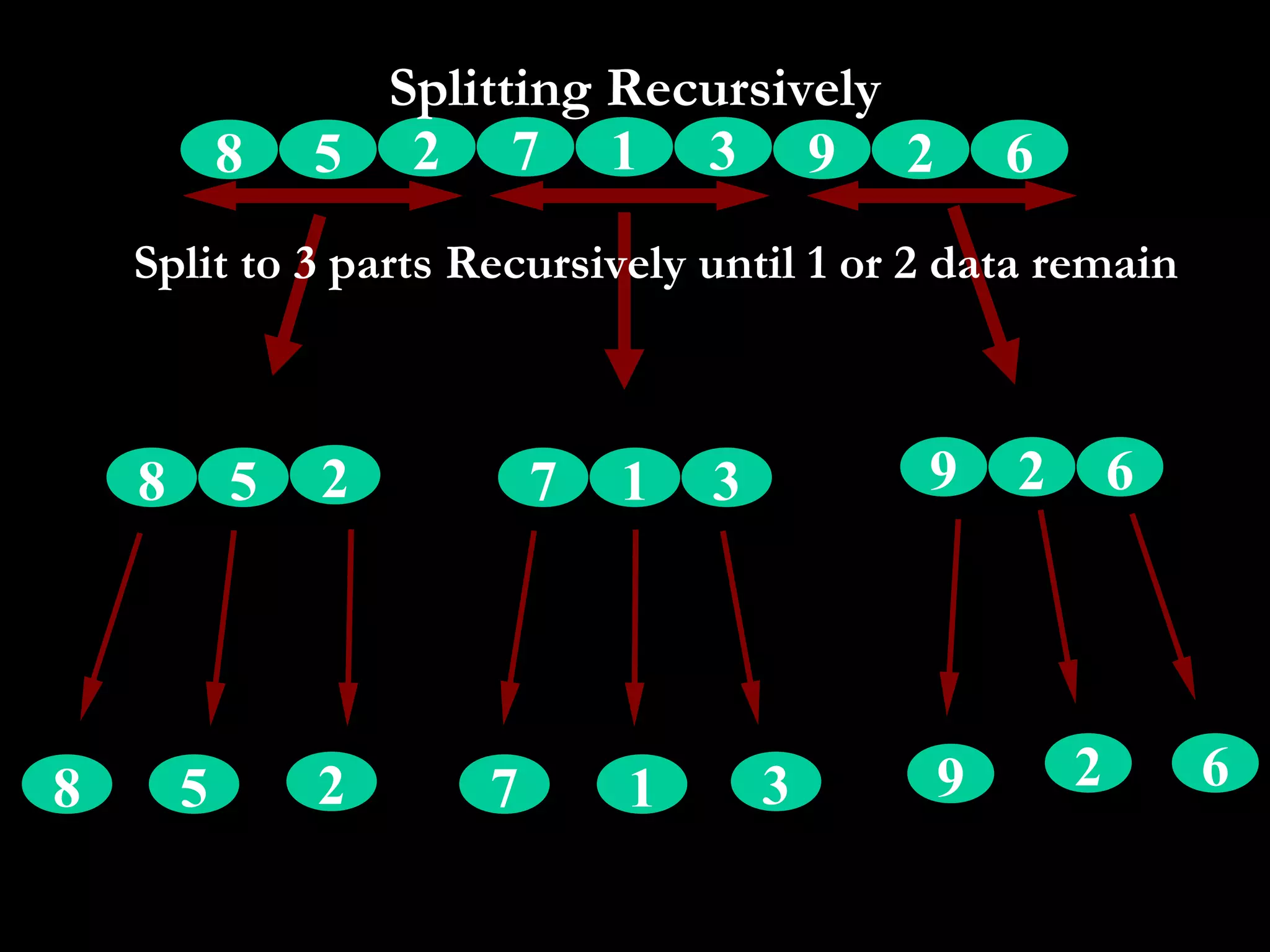
The document presents a project on the efficiency of sorting algorithms, covering various sorting methods, their classifications, and a new algorithm named tri-merge sort, which utilizes a ternary tree structure for improved performance. It includes implementation and comparative analysis of different algorithms through programming in C/C++, highlighting efficiency based on various data types and sizes. The findings suggest that while traditional algorithms like quick and radix sort perform well under certain conditions, the newly proposed tri-merge sort shows significant benefits in merging efficiency.
































































































