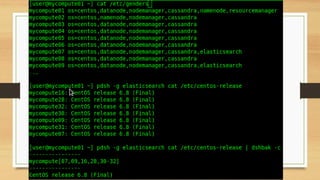
This document provides a high-level overview of key considerations for building a computer cluster, including:
- Gathering requirements for operations, dataflow, and compute needs.
- Designing for reliability, scalability, and failure tolerance.
- Choosing appropriate rack servers and network switches.
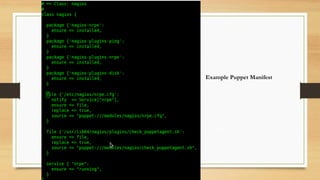
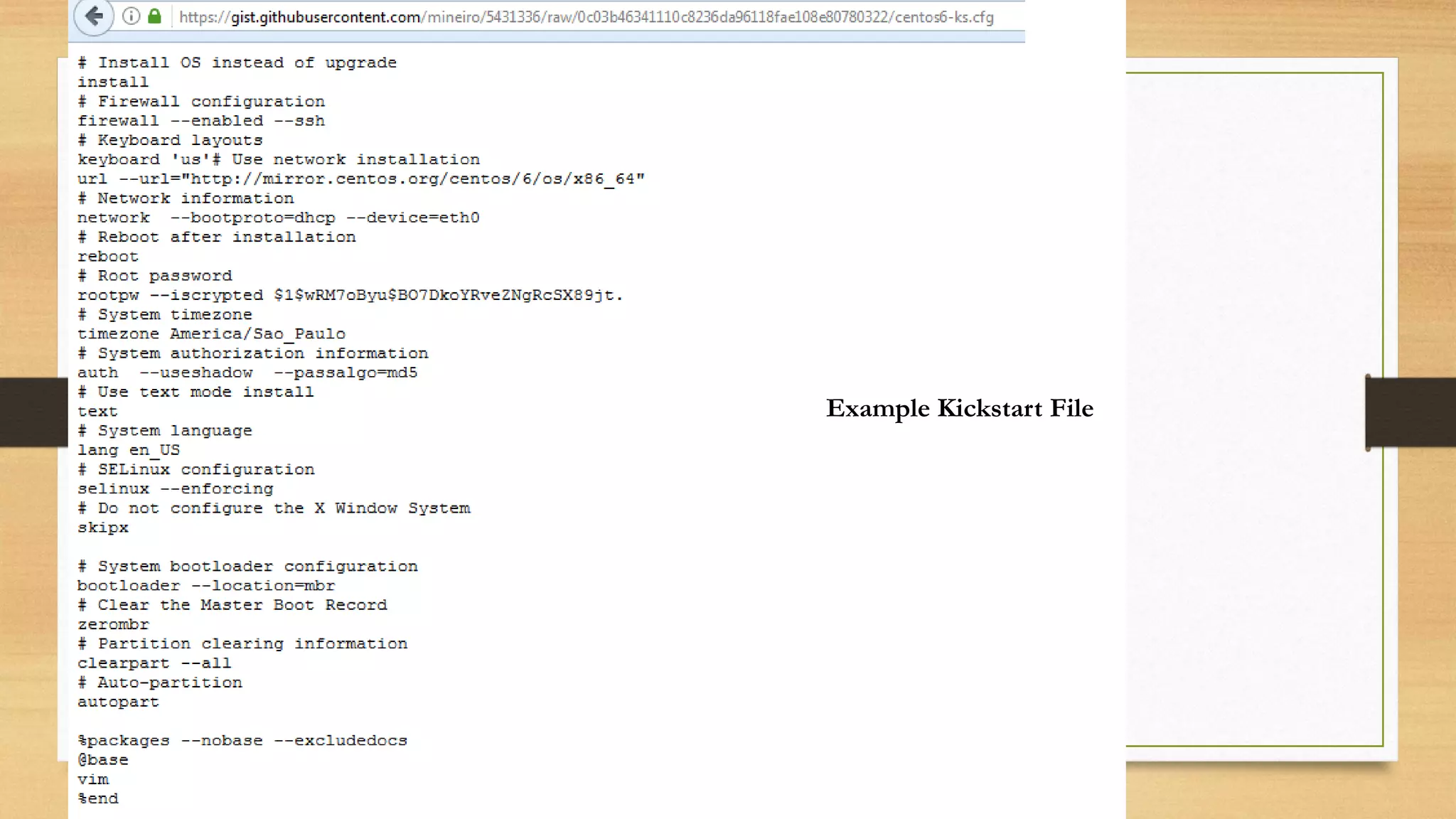
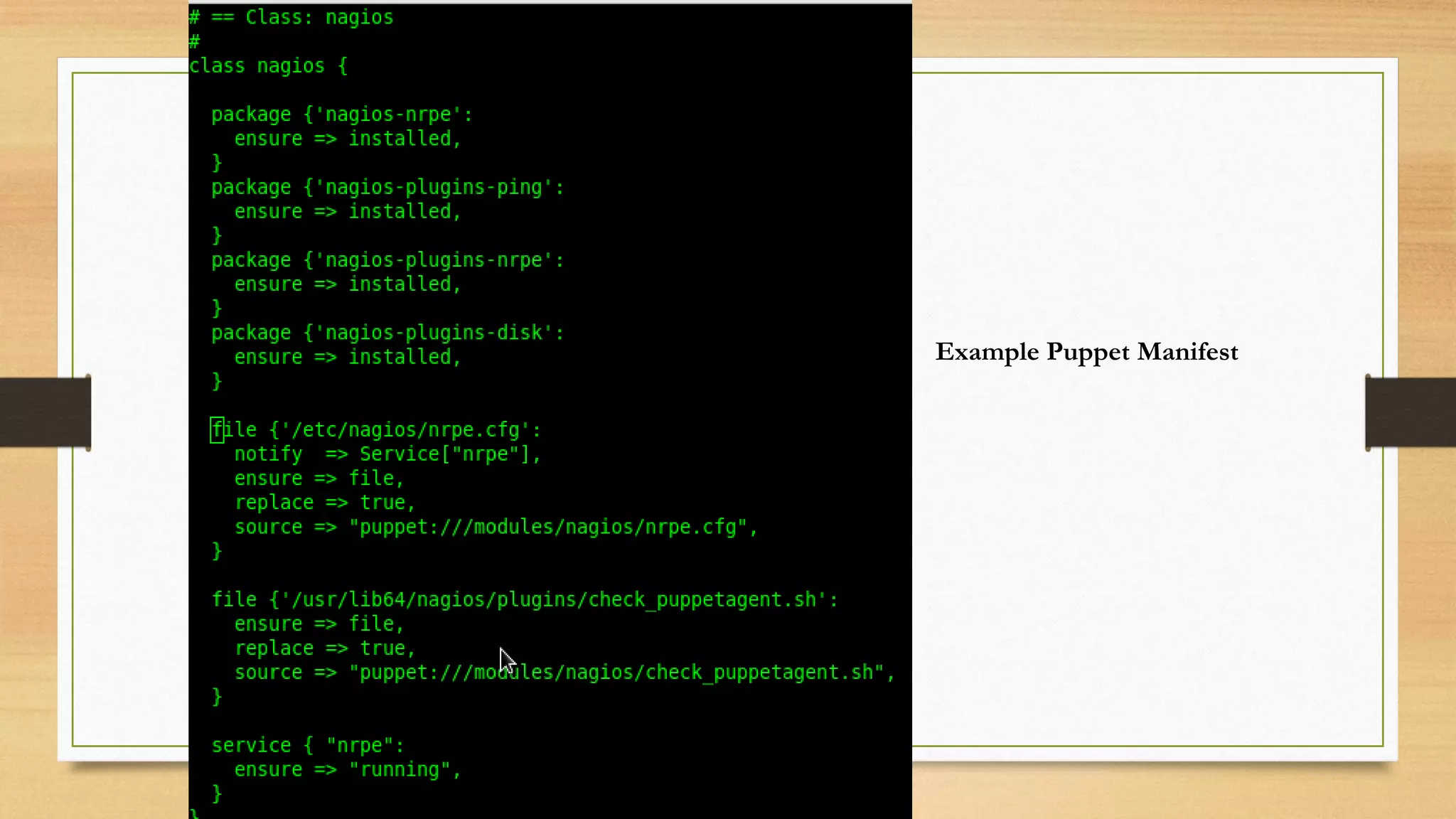
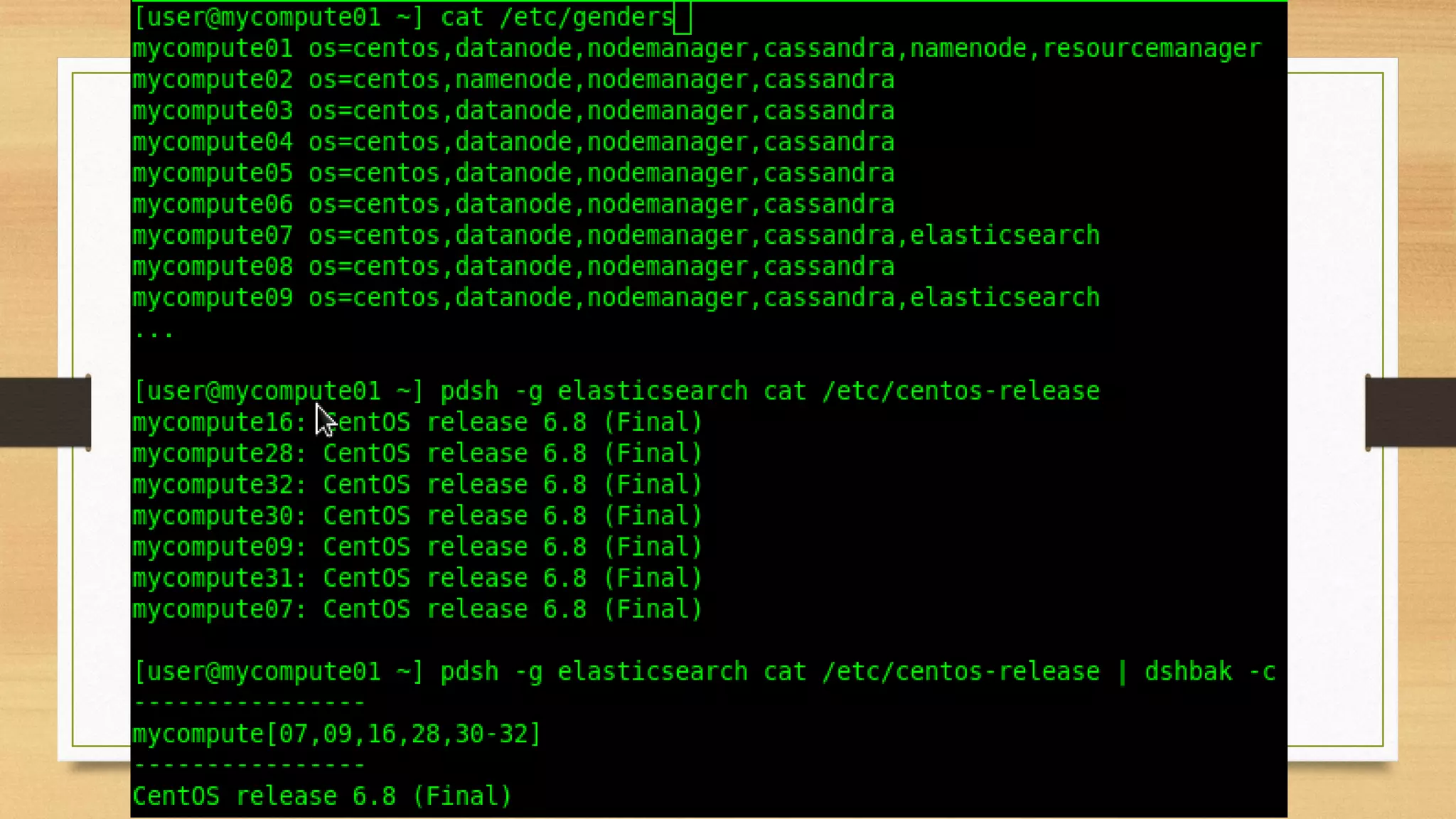
- Using configuration management tools to automate server provisioning and updates.
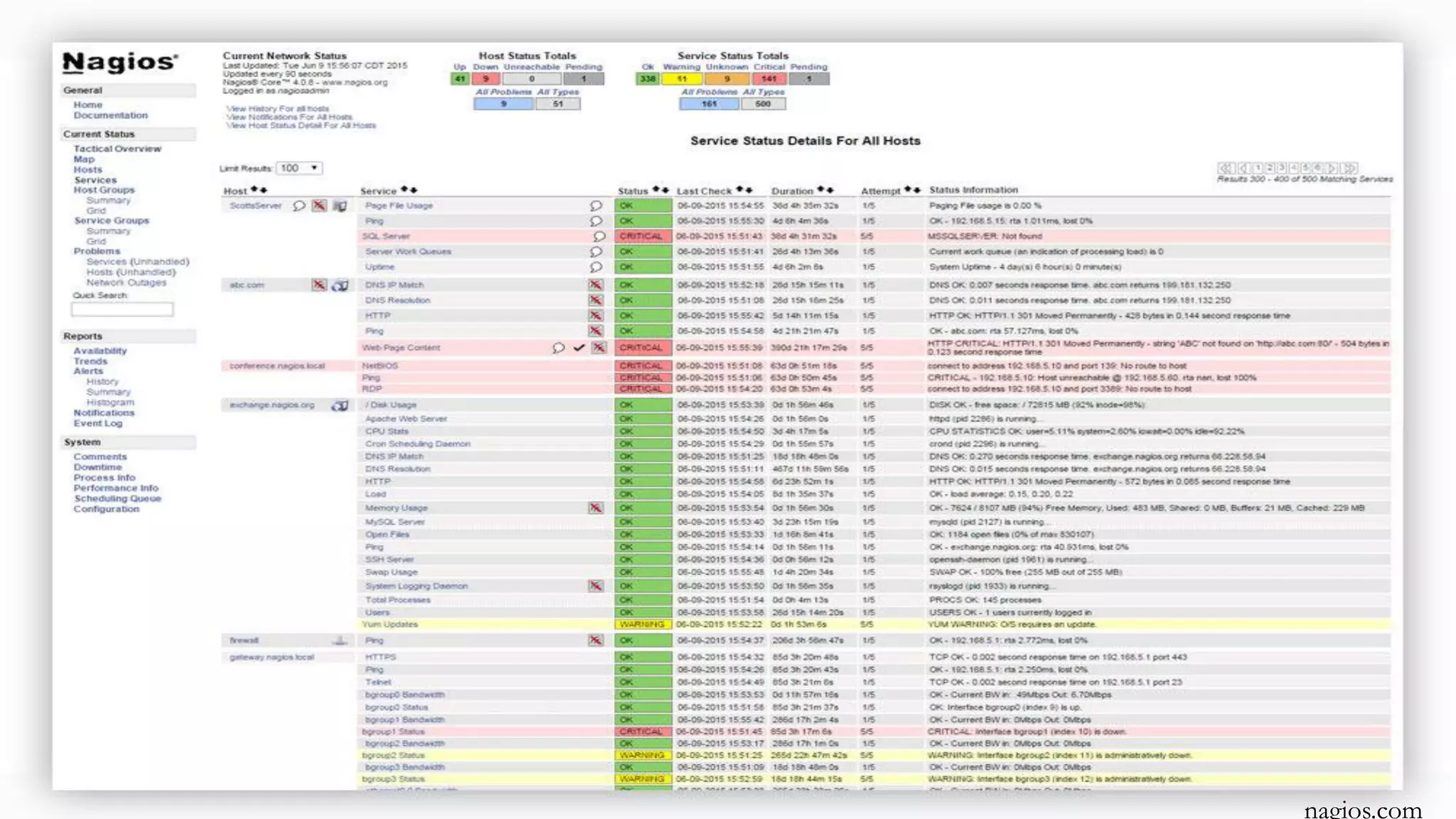
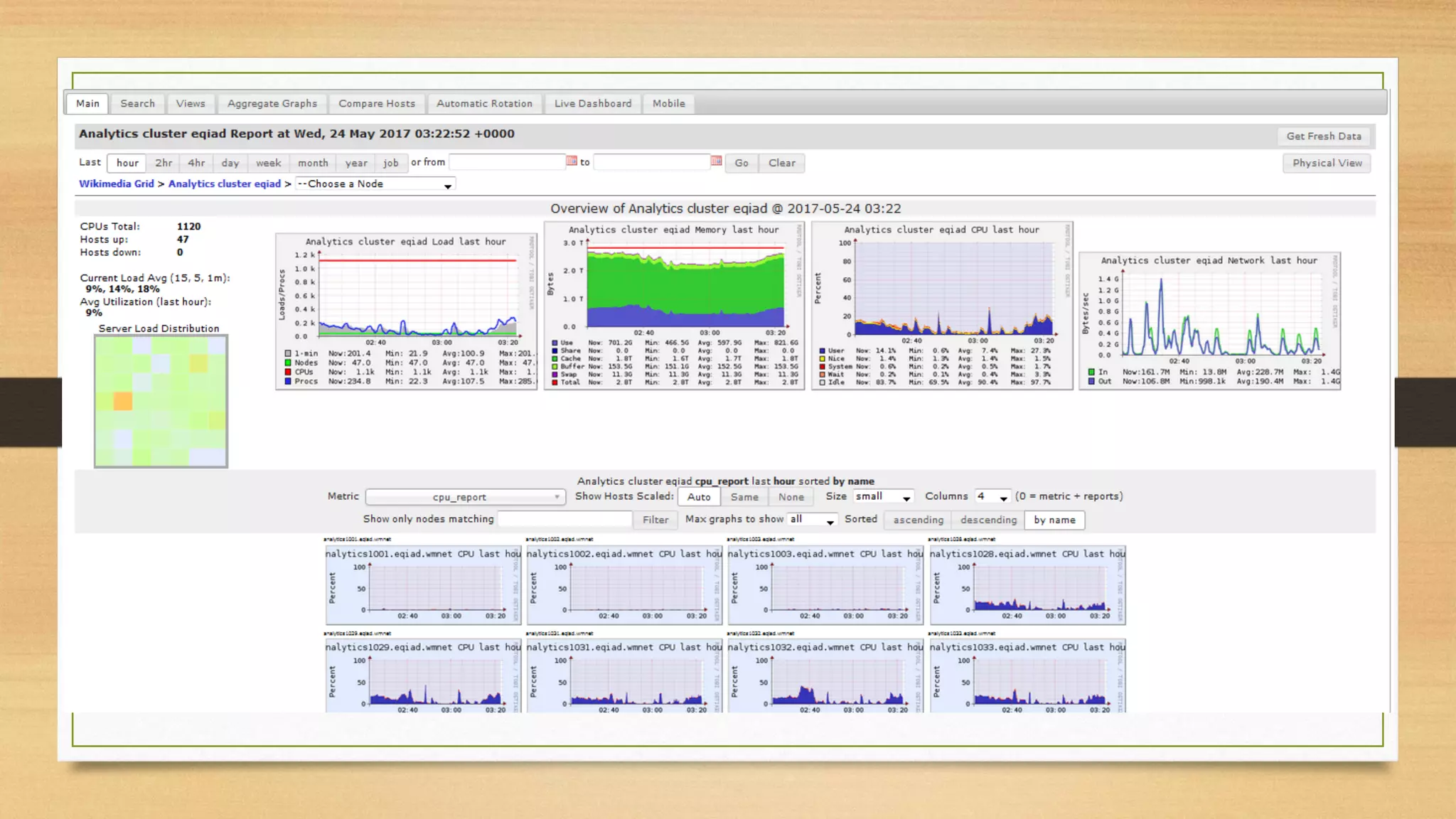
- Implementing monitoring and metrics collection to detect and diagnose issues.
- Deploying software in a controlled, repeatable manner across integration, test, and production environments.