This document discusses Huffman's algorithm for lossless data compression. It begins by defining Huffman's algorithm and explaining that it assigns variable-length codes to characters based on their frequency, with more frequent characters getting shorter codes. It then outlines the two main parts of the algorithm: 1) creating a Huffman tree from the character frequencies and 2) traversing the tree to find the Huffman codes. The document provides step-by-step explanations of how to build a Huffman tree and assign codes, including examples. It concludes by listing some important exam questions related to explaining and applying Huffman's algorithm.
Data Structure &Files
Unit 4: Tables
4.2 Huffman’s Algorithm
Ms. Vrushali Dhanokar
Assistant Professor
IT Department
2.
What is Huffman’sAlgorithm?
• Lossless data compression algorithm.
• Variable-length code is assigned to input different characters.
• The code length is related to how frequently characters are used.
• Most frequent characters have the smallest codes and longer codes for least frequent characters.
• Complexity for assigning the code for each character according to their frequency is
O(n log n).
• There are mainly two parts:
1. To create a Huffman tree,
2. To traverse the tree to find Huffman codes.
3.
Steps to buildHuffman Tree:
Input is an array of unique characters along with their frequency of occurrences
and output is Huffman Tree.
1. Create a leaf node for each unique character and build a min heap of all leaf
nodes (Min Heap is used as a priority queue. The value of frequency field is used
to compare two nodes in min heap. Initially, the least frequent character is at
root).
2. Extract two nodes with the minimum frequency from the min heap.
3. Create a new internal node with a frequency equal to the sum of the two
nodes frequencies. Make the first extracted node as its left child and the other
extracted node as its right child. Add this node to the min heap.
4. Repeat steps#2 and #3 until the heap contains only one node. The remaining
node is the root node and the tree is complete.
4.
Steps to BuildingHuffman’s Tree:
Let’s understand the algorithm with example:
Example 1:
Character Frequency
a 5
b 9 1. 5+9=14(Internal Node)
c 12 2. 12+13=25(Internal Node)
d 13 3. 14+16=30(Internal Node)
e 16 4. 25+30=55.(Internal Node)
f 45 5. 55+45=100.(Root Node)
5.
Continue..
Step 1: BuildMin Heap DS, Which contains 6 Nodes(Given example having 6 Char.) Each node represent as
root.
Step 2: Extract two minimum frequency nodes from min heap. Add a new internal node with frequency
5 + 9 = 14. Now 14 becomes internal root node.
Step 3: Again extract two minimum frequency nodes from heap.
Add a new internal node with frequency
12 + 13 = 25. Now 25 becomes internal root node.
Step 4: Again extract two minimum frequency nodes. Add a new internal node with frequency 14 + 16 = 30.
Now 30 becomes internal root node.
Now min heap contains 3 nodes.
6.
Continue..
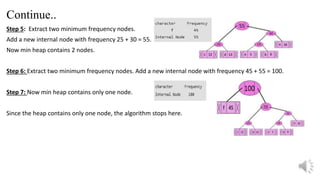
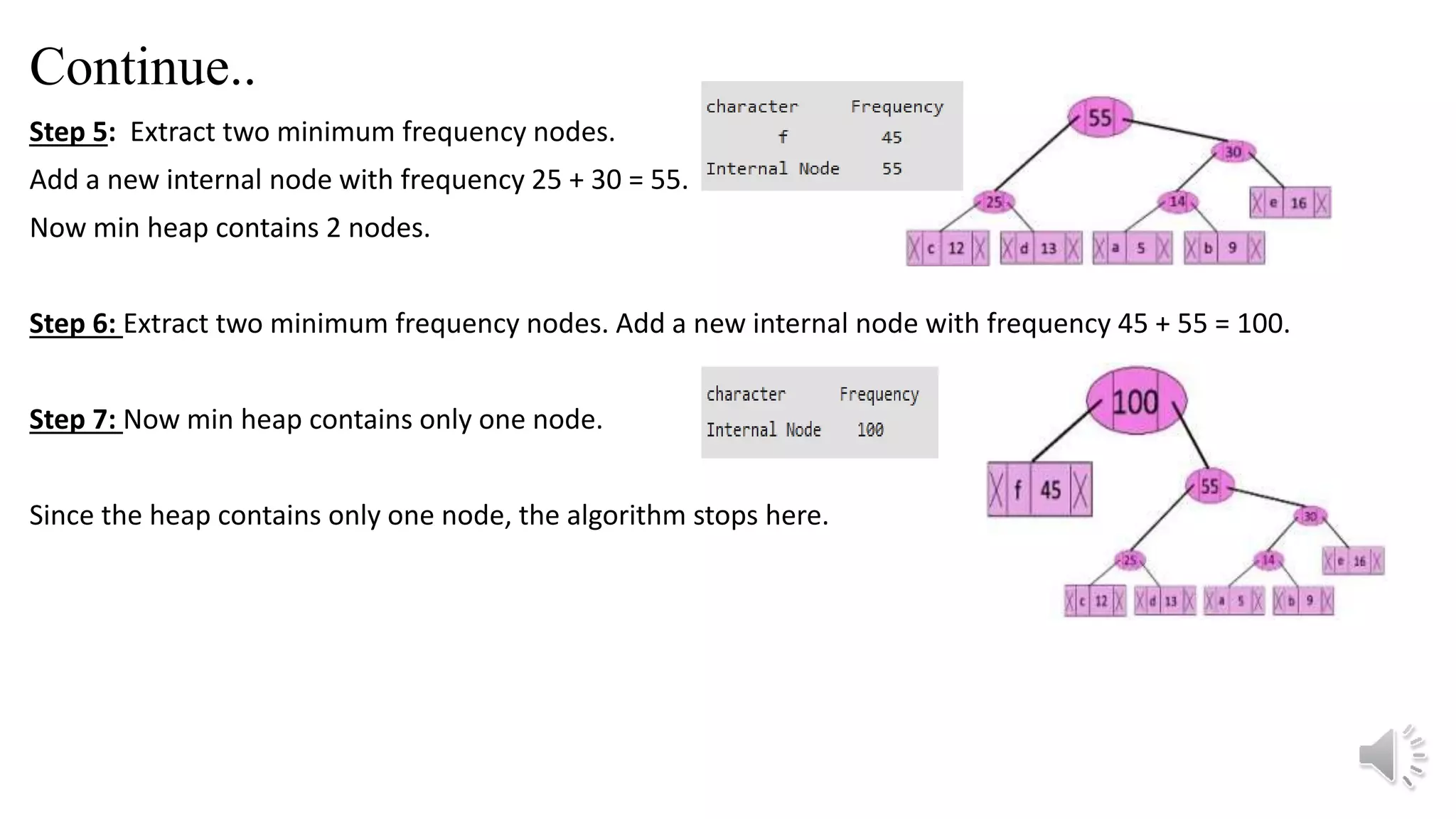
Step 5: Extracttwo minimum frequency nodes.
Add a new internal node with frequency 25 + 30 = 55.
Now min heap contains 2 nodes.
Step 6: Extract two minimum frequency nodes. Add a new internal node with frequency 45 + 55 = 100.
Step 7: Now min heap contains only one node.
Since the heap contains only one node, the algorithm stops here.
7.
Steps to printcodes from Huffman Tree:
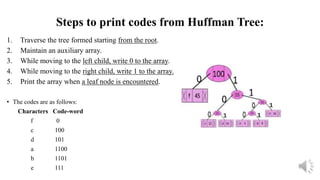
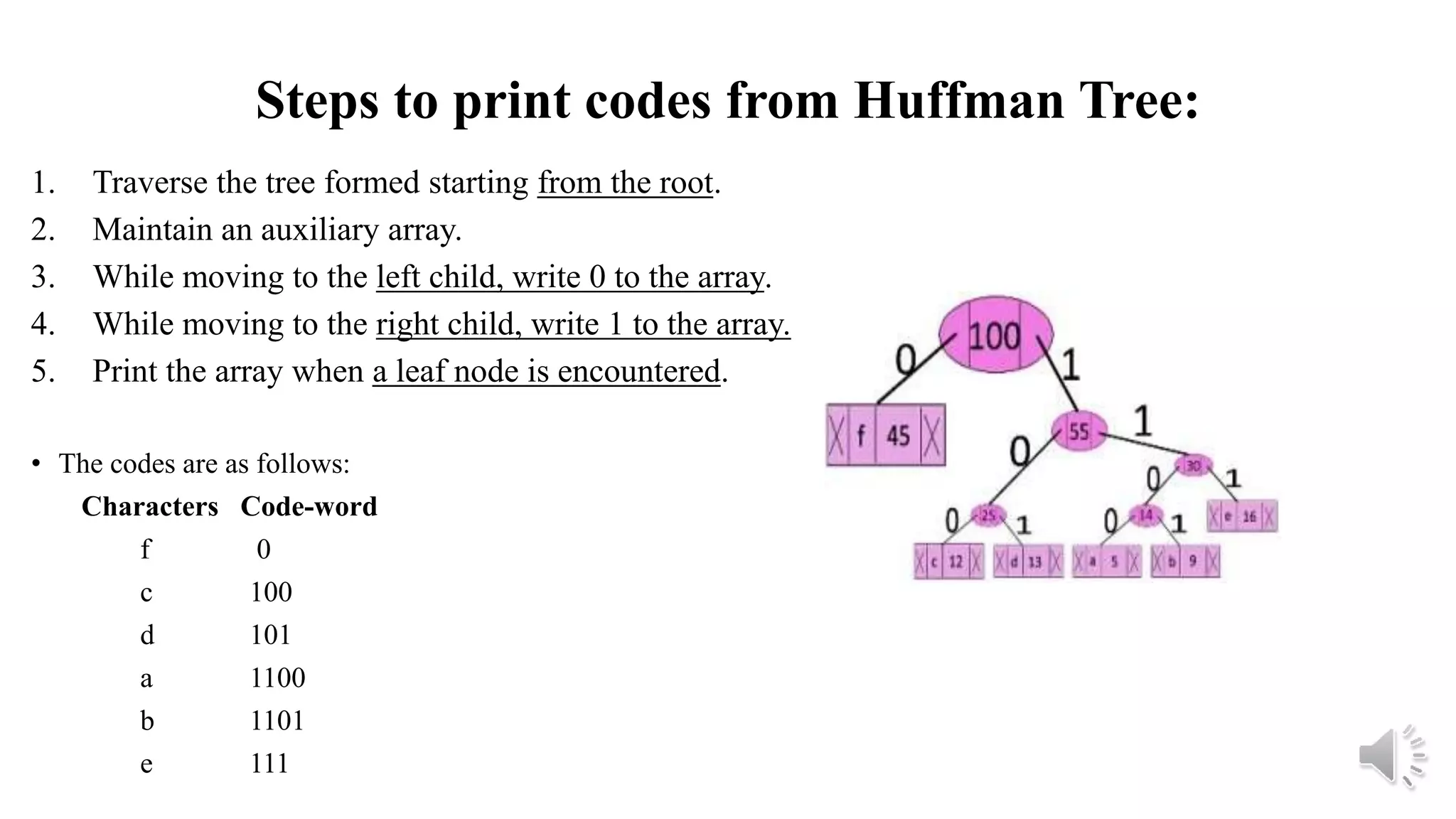
1. Traverse the tree formed starting from the root.
2. Maintain an auxiliary array.
3. While moving to the left child, write 0 to the array.
4. While moving to the right child, write 1 to the array.
5. Print the array when a leaf node is encountered.
• The codes are as follows:
Characters Code-word
f 0
c 100
d 101
a 1100
b 1101
e 111
Important Questions
• BySPPU Exam Pattern
1. Explain Huffman algorithm with example. 4M
1. Construct Huffman Tree and Code with following data
Character A B C D E
Frequency20 10 10 30 30 5M
3. Apply Huffman Coding for the word ‘ENGINEERING’.
Give Huffman Code for each symbol. 6M