Downloaded 38 times








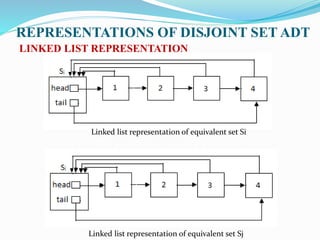

![REPRESENTATIONS OF DISJOINT SET ADT
TREE REPRESENTATION
A tree data structure can be used to represent a disjoint set ADT.
Each set is represented by a tree. The elements in the tree have
the same root and hence the root is used to name the set.
The trees do not have to be binary since we only need a parent
pointer.
Make-set (DISJ_SET S )
int i;
for( i = N; i > o; i-- )
p[i] = 0;
Tree representation of disjoint set ADT after Make-set operation](https://image.slidesharecdn.com/lecture6disjointset-181031065904/85/Lecture-6-disjoint-set-11-320.jpg)
![REPRESENTATIONS OF DISJOINT SET ADT
TREE REPRESENTATION
Initially, after the Make-set operation, each set contains one
element. The Make-set operation takes O(1) time.
set_type Find-set( element_type x, DISJ_SET S )
if( p[x] <= 0 )
return x;
else
return( find( p[x], S ) );
The Find-Set operation takes a time proportional to the depth
of the tree. This is inefficient for an unbalanced tree
void Union( DISJ_SET S, set_type root1, set_type root2 )
p[root2] = root1;
The union operation takes a constant time of O(1).](https://image.slidesharecdn.com/lecture6disjointset-181031065904/85/Lecture-6-disjoint-set-12-320.jpg)





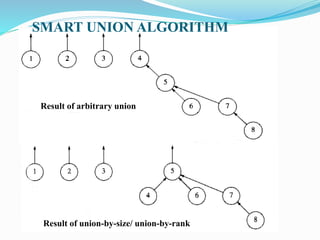
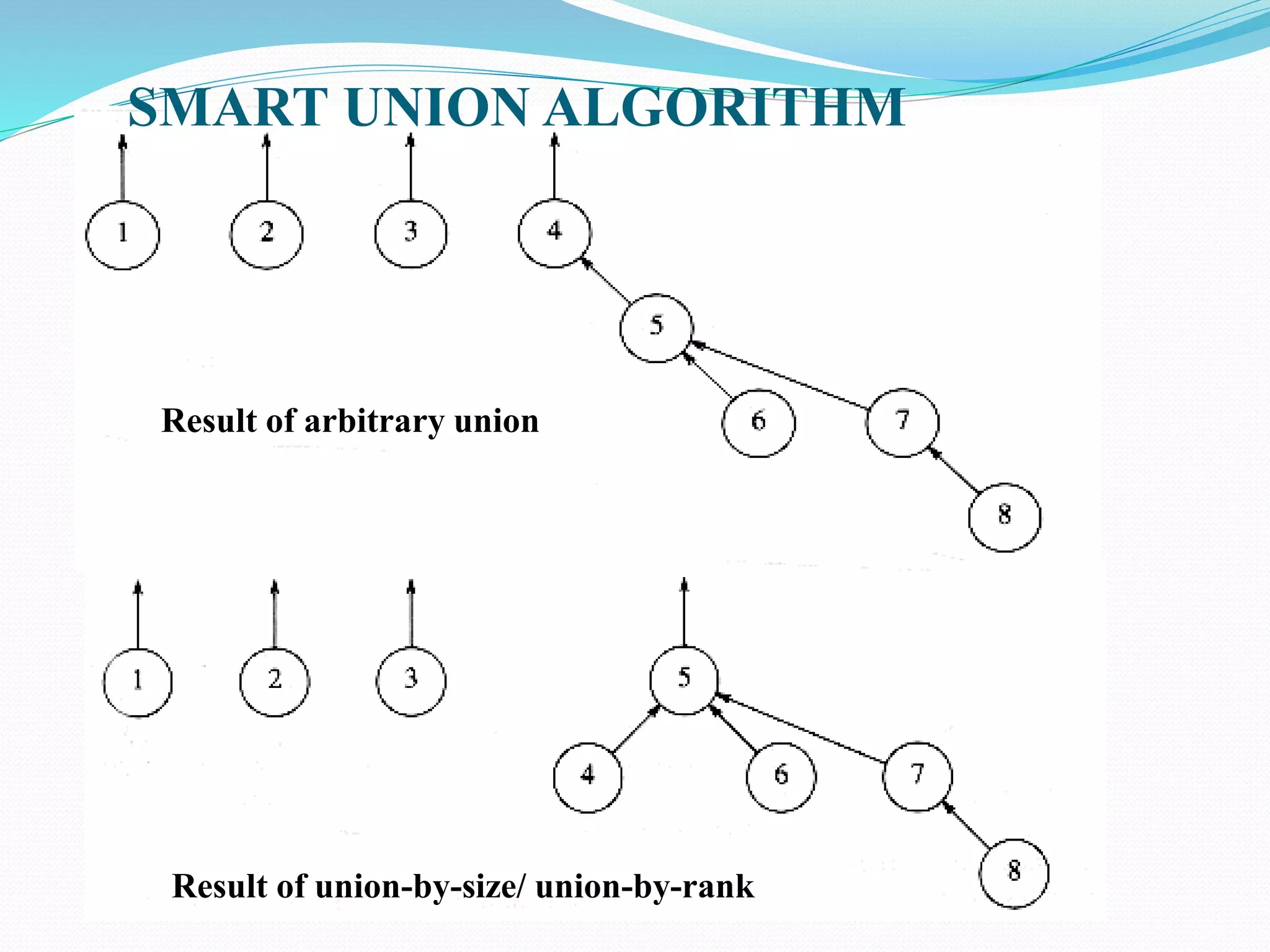
![SMART UNION ALGORITHM
Algorithm of union-by-rank : Assume x and y are two
nodes
Union(x, y)
Link(Find-set(x), Find-set(y))
Link(x, y)
if rank[x] > rank[y]
then p[y] = x
else p[x] = y
if rank[x] == rank[y]
then rank[y] = rank[y] + 1](https://image.slidesharecdn.com/lecture6disjointset-181031065904/85/Lecture-6-disjoint-set-19-320.jpg)

![PATH COMPRESSION
The Find-set procedure is a two-pass method: it makes
one pass up the find path to find the root, and it makes a
second pass back down the find path to update each
node so that it points directly to the root.
Find-set function using path compression:
Find-set(x)
if x ≠ p[x]
then p[x] = Find-set(p[x])
return p[x]](https://image.slidesharecdn.com/lecture6disjointset-181031065904/85/Lecture-6-disjoint-set-21-320.jpg)










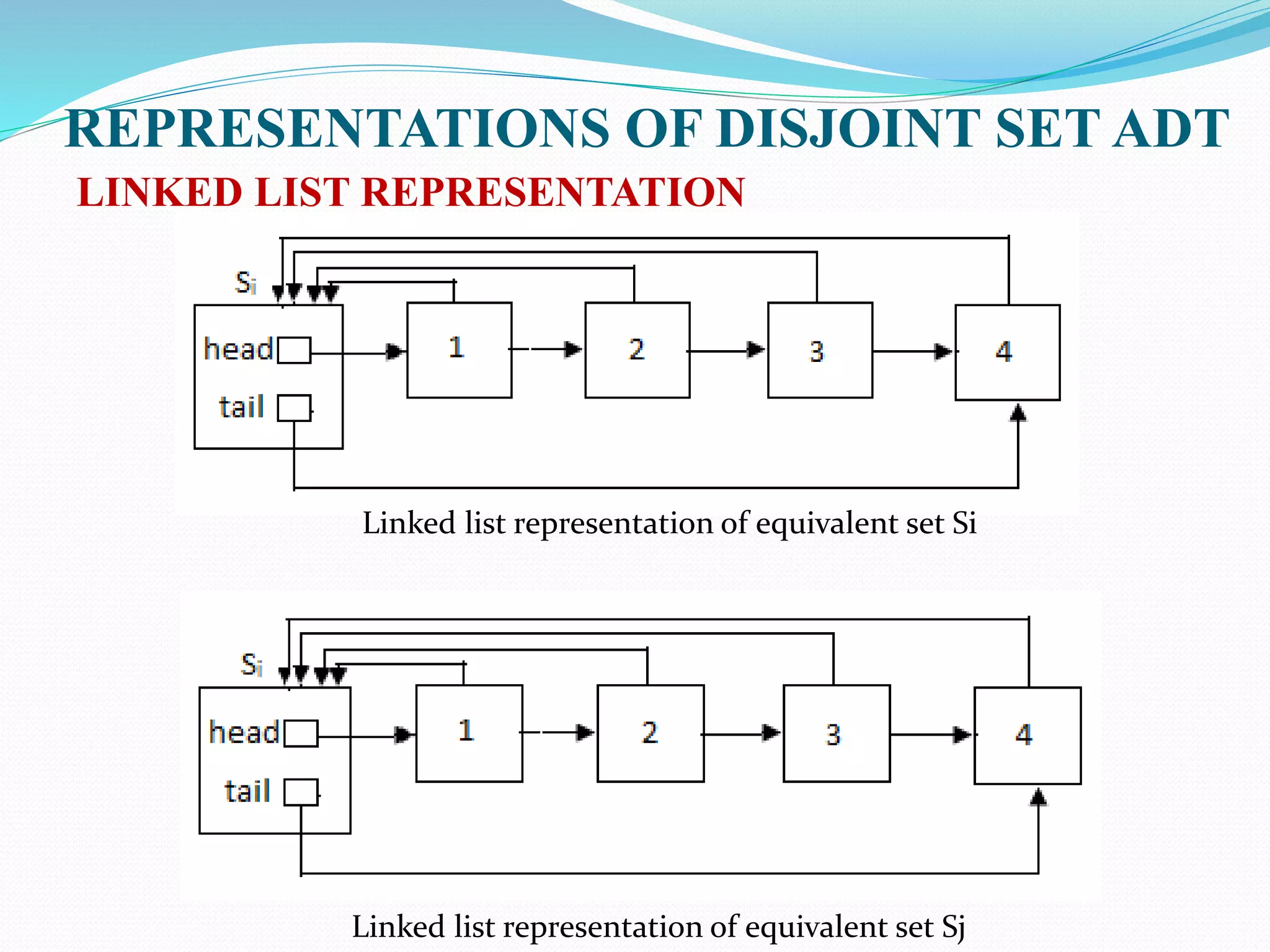
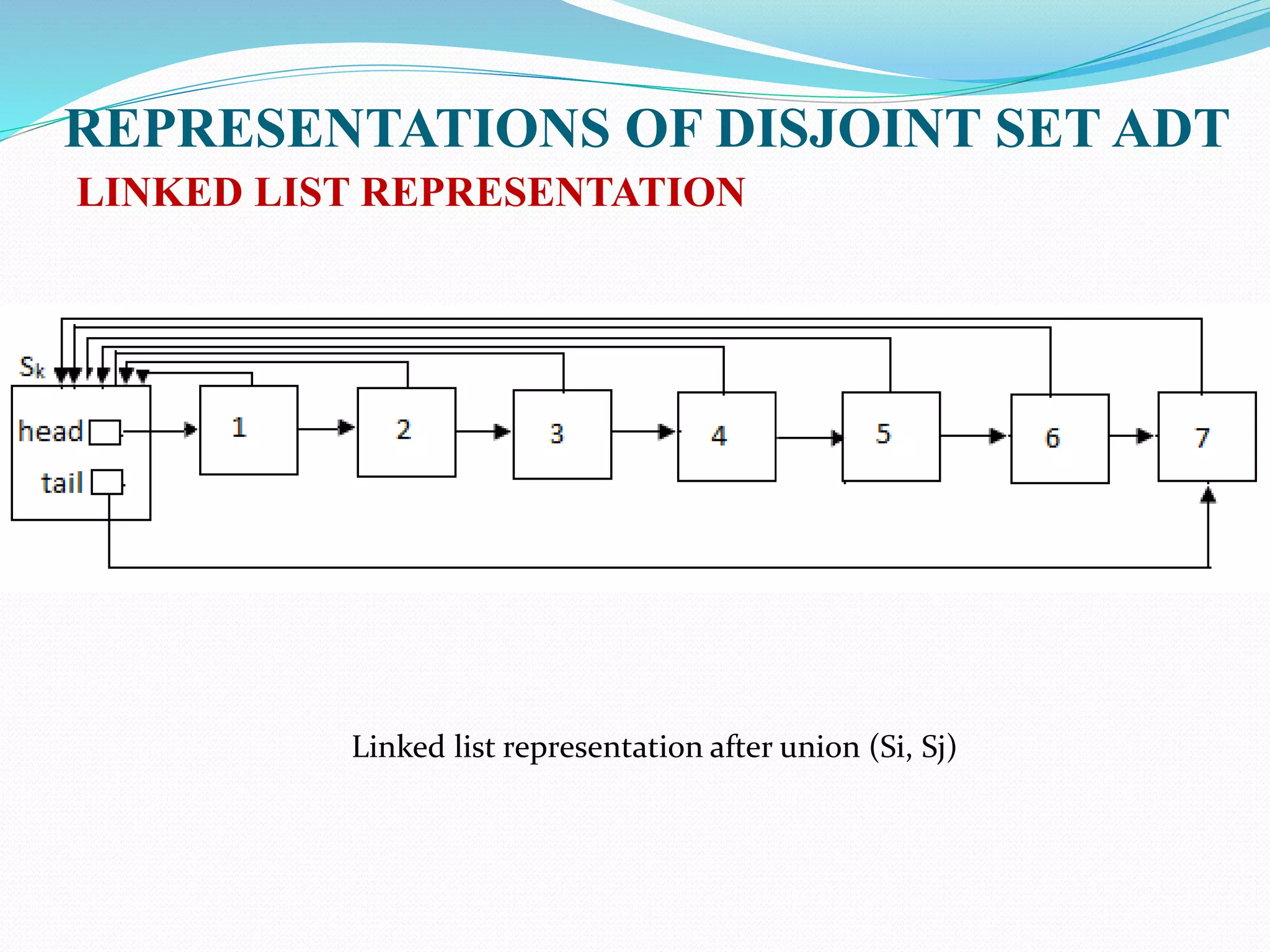
![REPRESENTATIONS OF DISJOINT SET ADT
TREE REPRESENTATION
A tree data structure can be used to represent a disjoint set ADT.
Each set is represented by a tree. The elements in the tree have
the same root and hence the root is used to name the set.
The trees do not have to be binary since we only need a parent
pointer.
Make-set (DISJ_SET S )
int i;
for( i = N; i > o; i-- )
p[i] = 0;
Tree representation of disjoint set ADT after Make-set operation](https://image.slidesharecdn.com/lecture6disjointset-181031065904/75/Lecture-6-disjoint-set-11-2048.jpg)
![REPRESENTATIONS OF DISJOINT SET ADT
TREE REPRESENTATION
Initially, after the Make-set operation, each set contains one
element. The Make-set operation takes O(1) time.
set_type Find-set( element_type x, DISJ_SET S )
if( p[x] <= 0 )
return x;
else
return( find( p[x], S ) );
The Find-Set operation takes a time proportional to the depth
of the tree. This is inefficient for an unbalanced tree
void Union( DISJ_SET S, set_type root1, set_type root2 )
p[root2] = root1;
The union operation takes a constant time of O(1).](https://image.slidesharecdn.com/lecture6disjointset-181031065904/75/Lecture-6-disjoint-set-12-2048.jpg)





![SMART UNION ALGORITHM
Algorithm of union-by-rank : Assume x and y are two
nodes
Union(x, y)
Link(Find-set(x), Find-set(y))
Link(x, y)
if rank[x] > rank[y]
then p[y] = x
else p[x] = y
if rank[x] == rank[y]
then rank[y] = rank[y] + 1](https://image.slidesharecdn.com/lecture6disjointset-181031065904/75/Lecture-6-disjoint-set-19-2048.jpg)

![PATH COMPRESSION
The Find-set procedure is a two-pass method: it makes
one pass up the find path to find the root, and it makes a
second pass back down the find path to update each
node so that it points directly to the root.
Find-set function using path compression:
Find-set(x)
if x ≠ p[x]
then p[x] = Find-set(p[x])
return p[x]](https://image.slidesharecdn.com/lecture6disjointset-181031065904/75/Lecture-6-disjoint-set-21-2048.jpg)



The document discusses the disjoint set abstract data type (ADT). It can be used to represent equivalence relations and solve the dynamic equivalence problem. There are three main representations - array, linked list, and tree. The tree representation can be improved using two heuristics: smart union algorithm (e.g. union-by-rank) and path compression. Together these optimizations allow the disjoint set operations to run in near-linear time with respect to the total number of operations.













![Data Structures - Lecture 7 [Linked List]](https://cdn.slidesharecdn.com/ss_thumbnails/lecture-7linkedlists-150121011916-conversion-gate02-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

































































