Downloaded 47 times




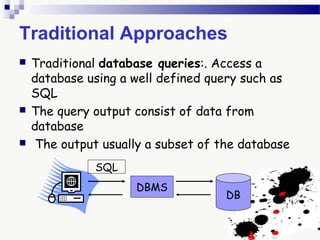

















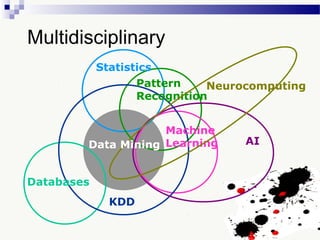
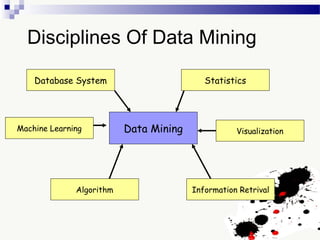
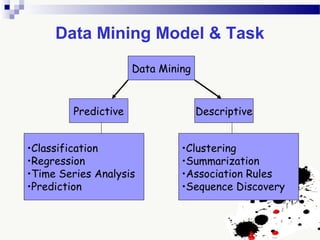


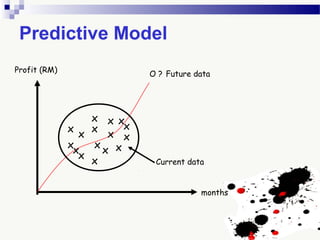


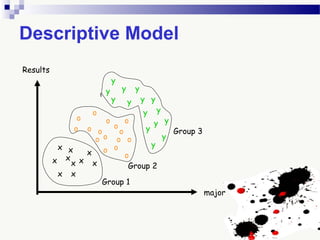







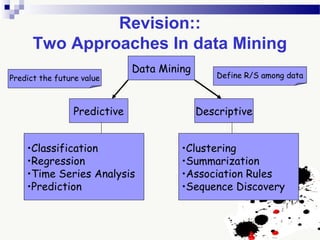
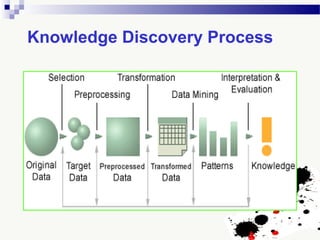





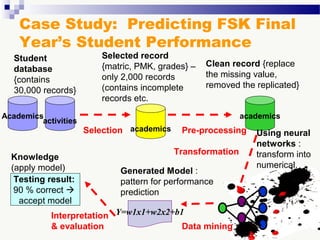




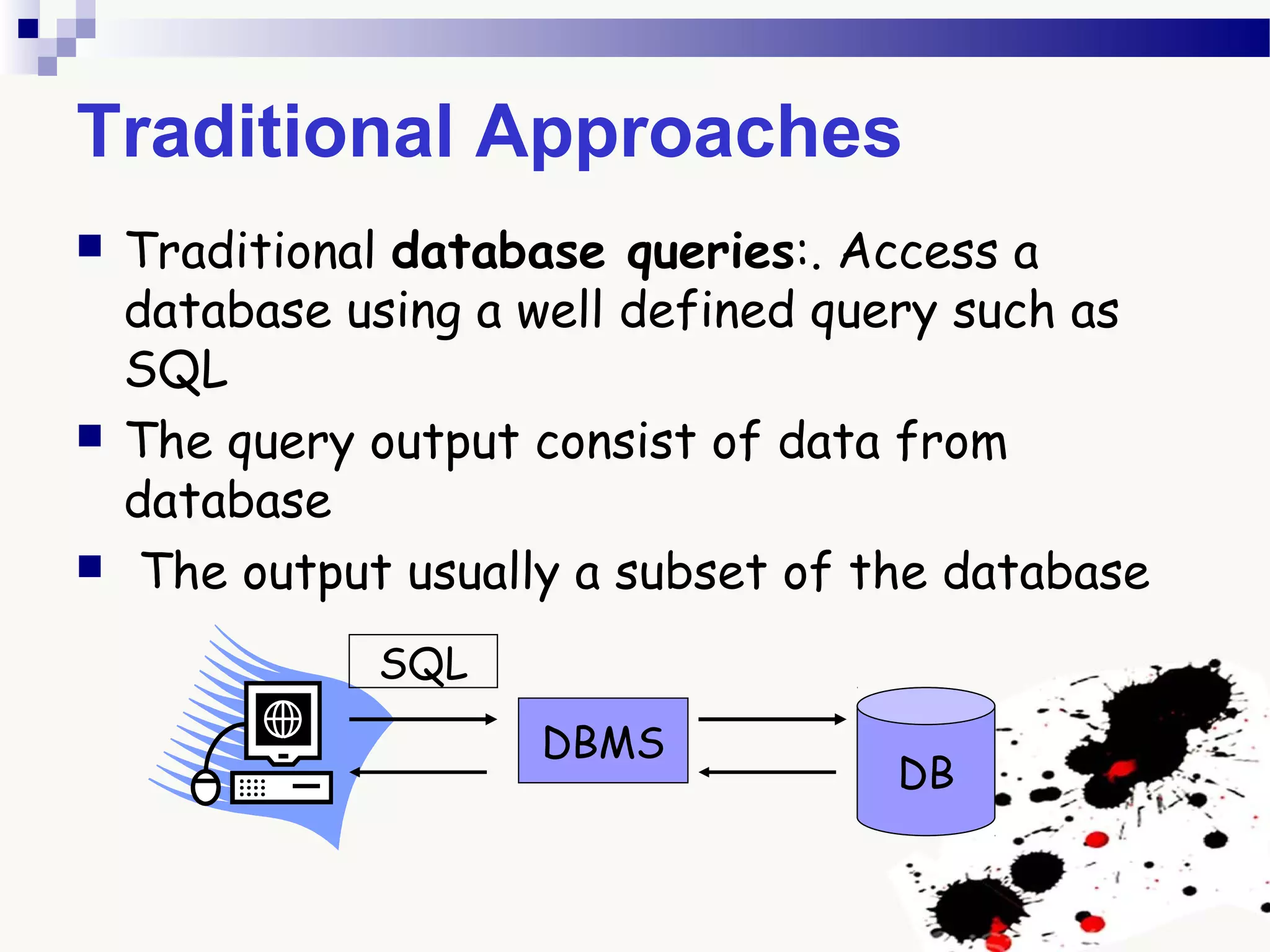

















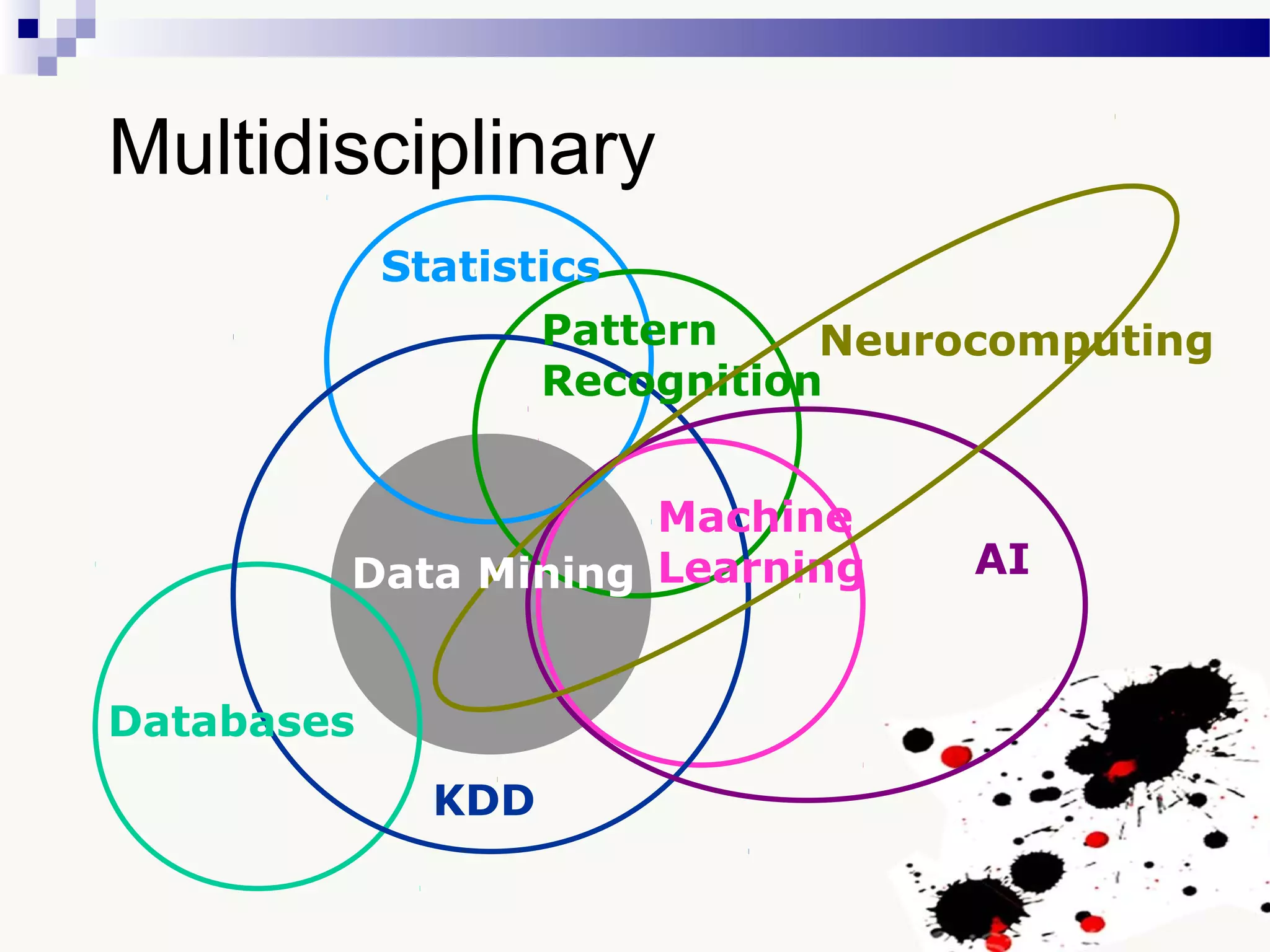
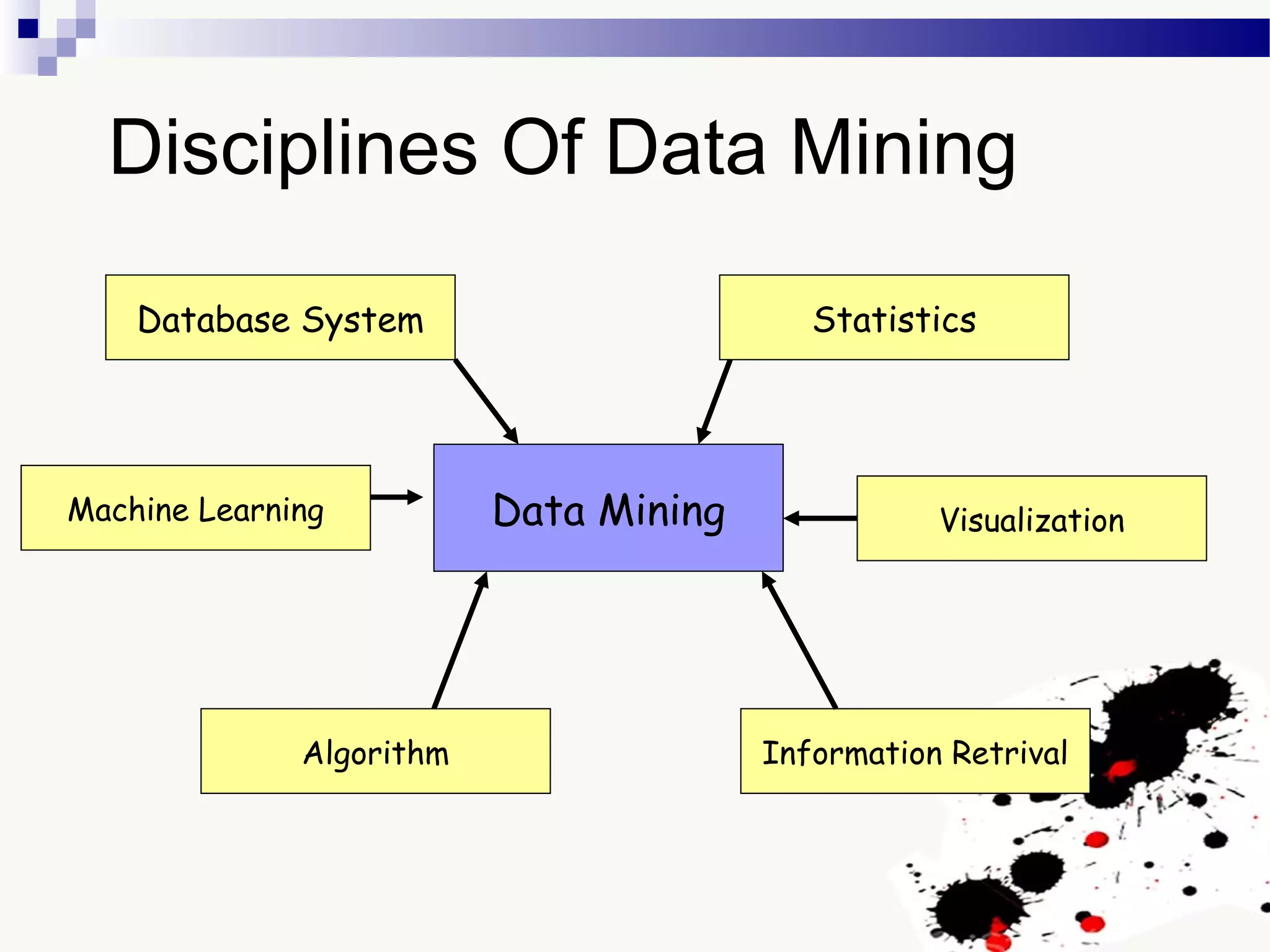
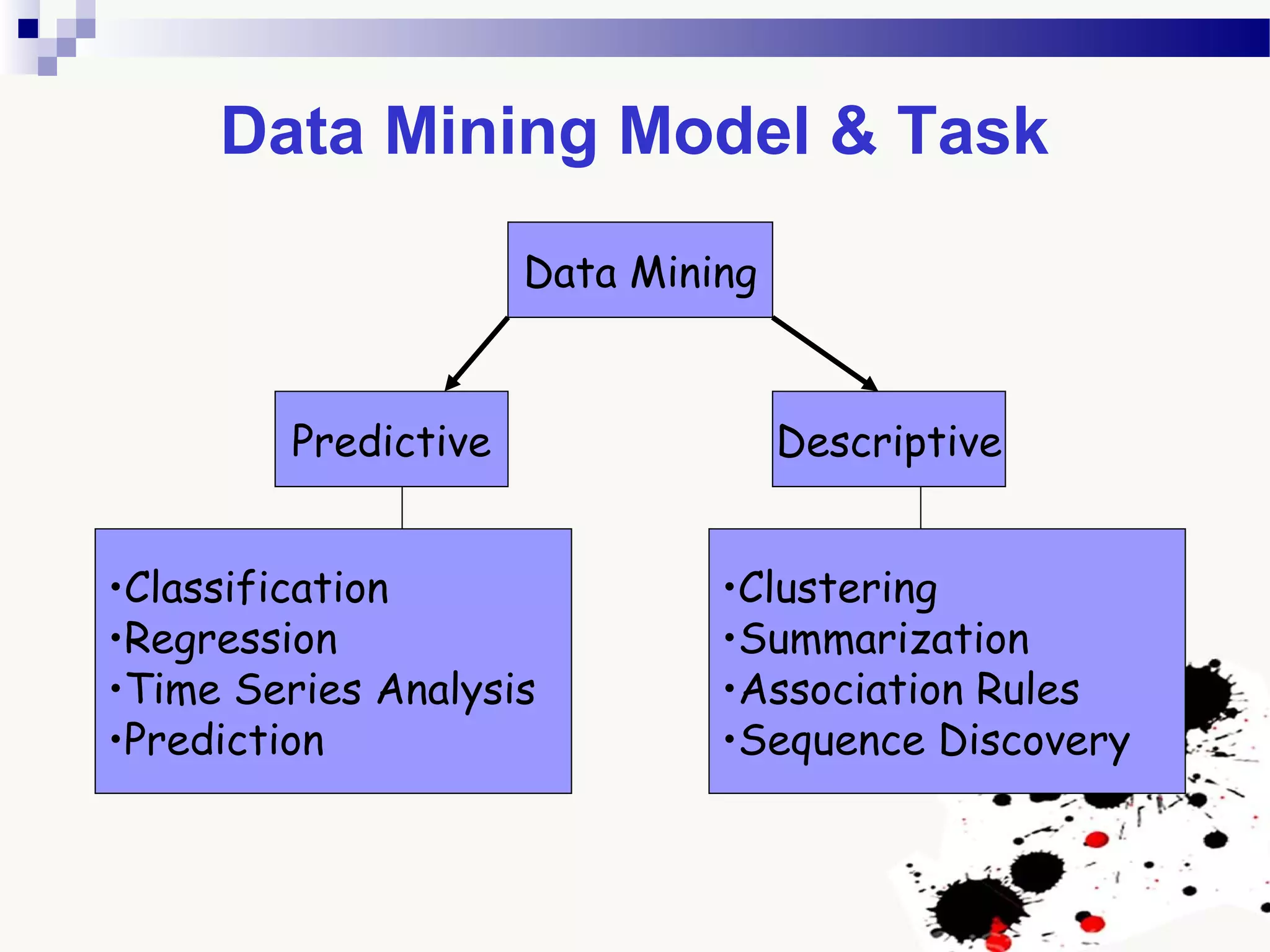


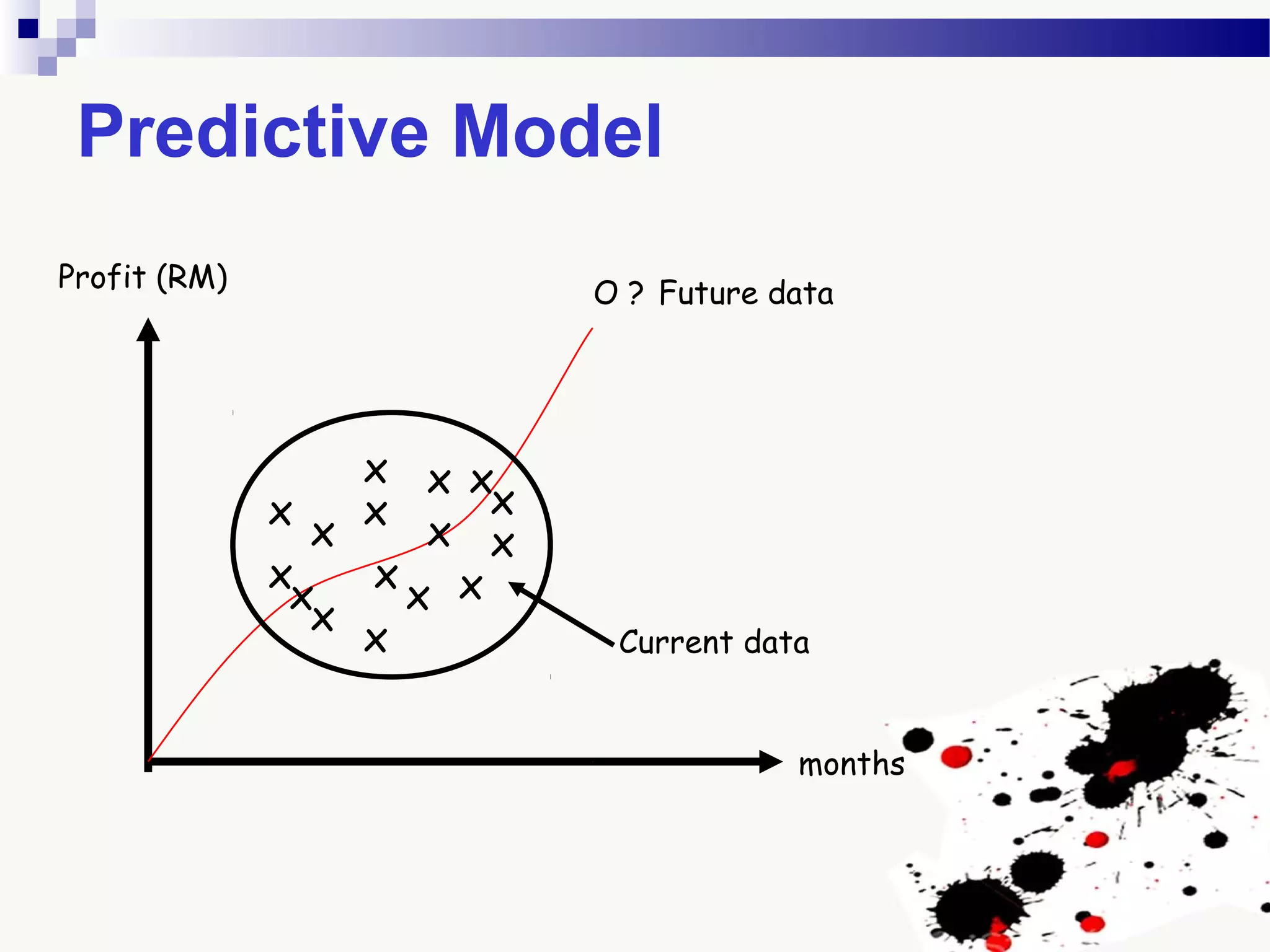


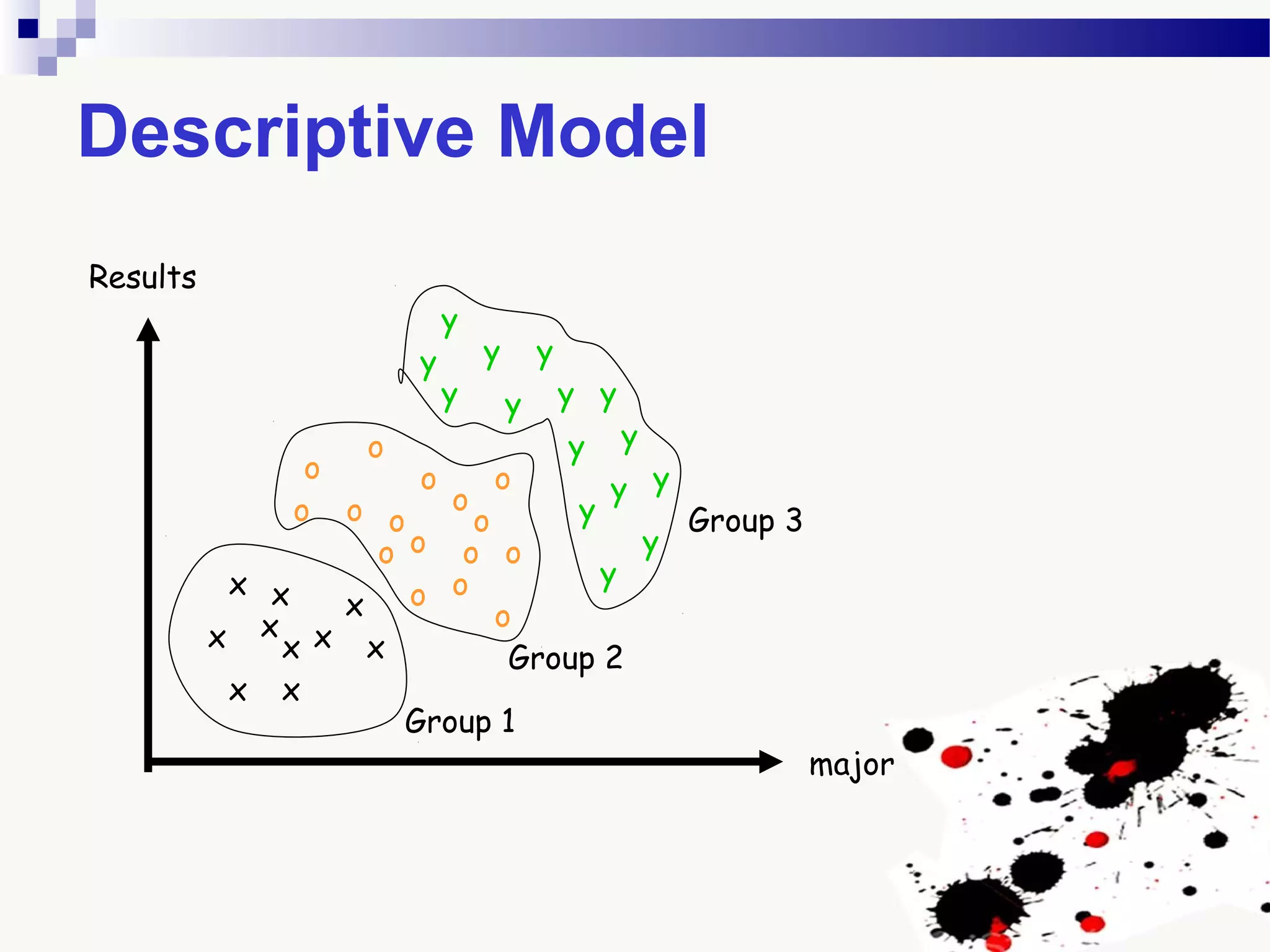







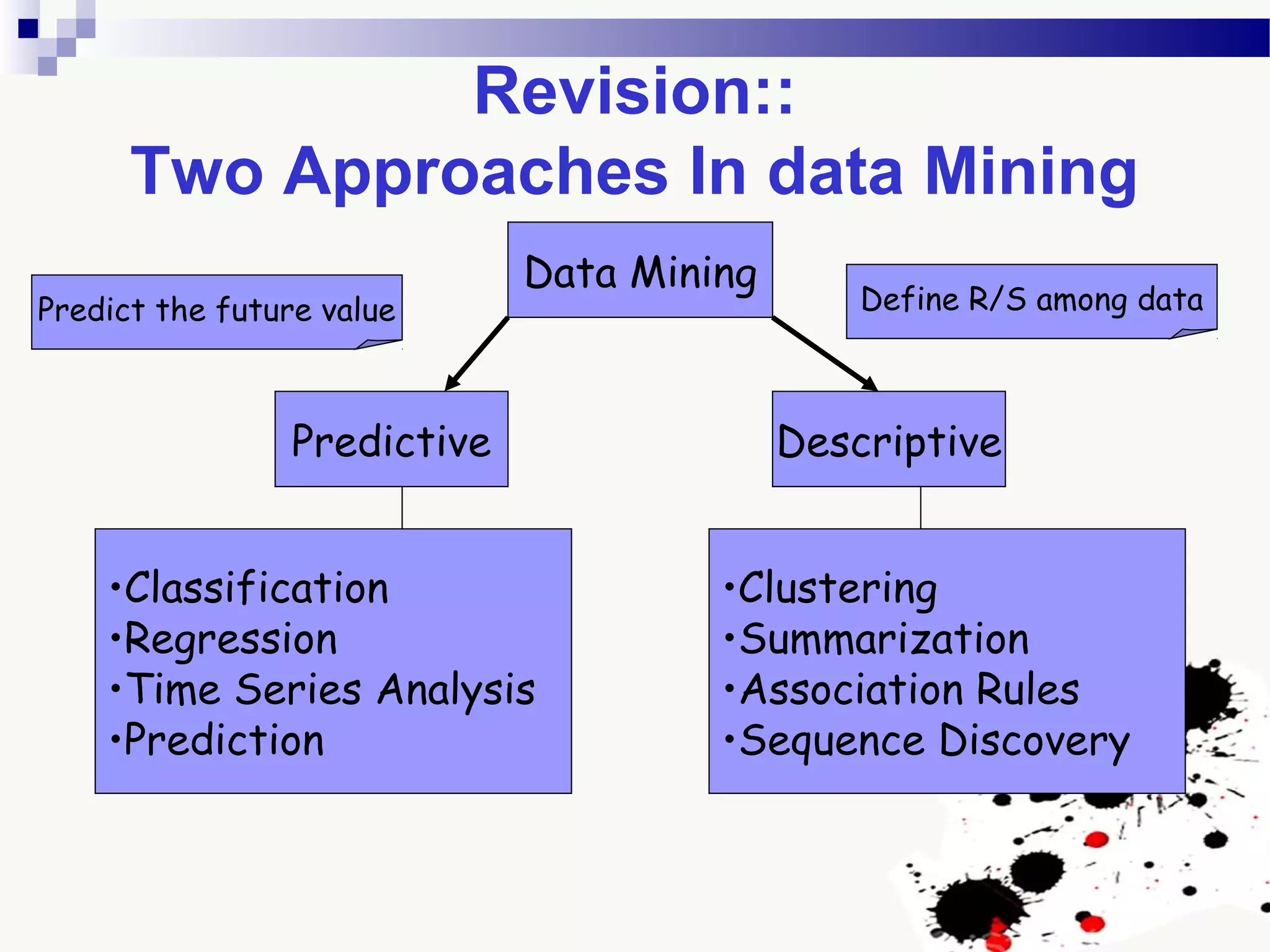
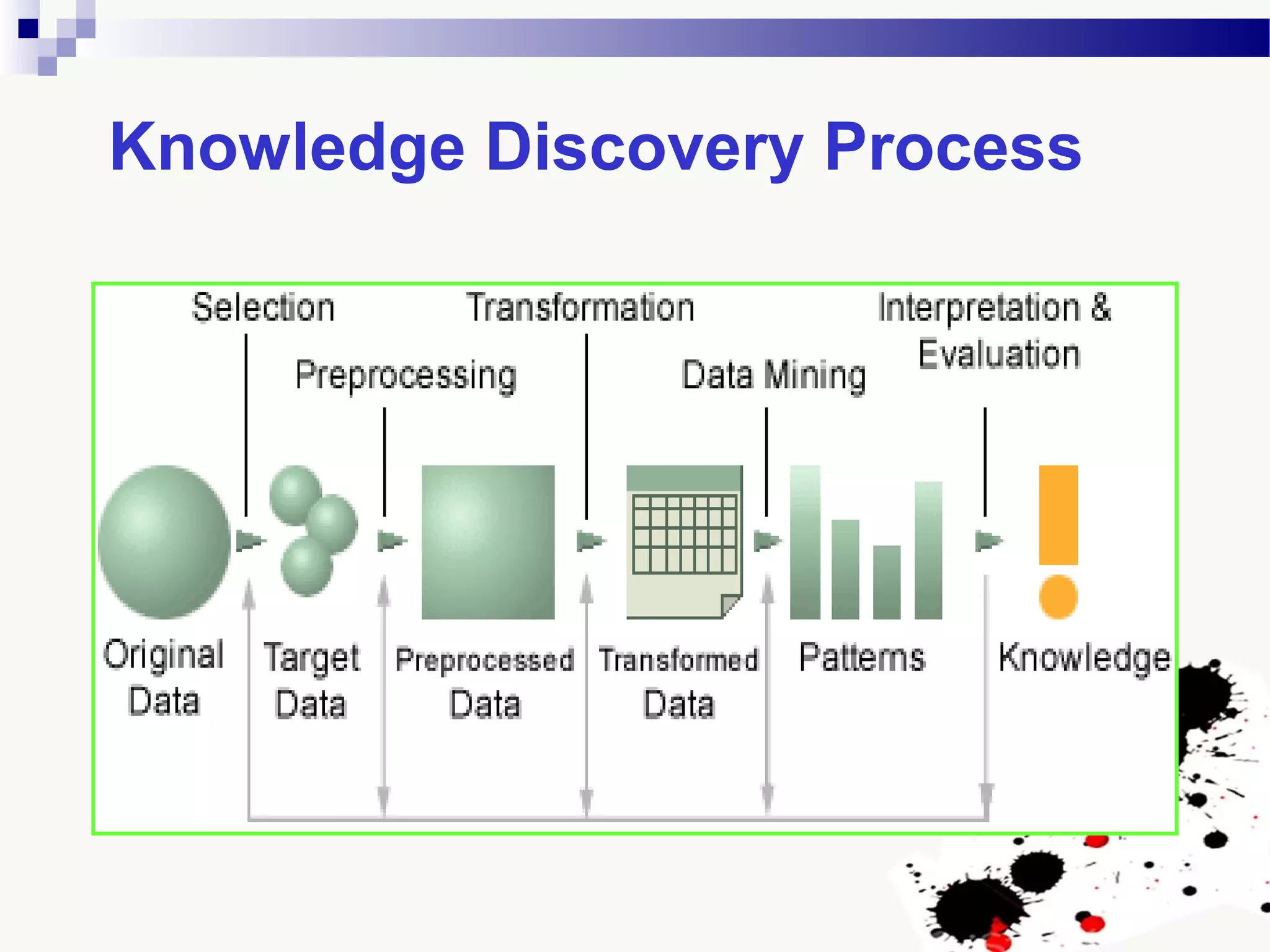





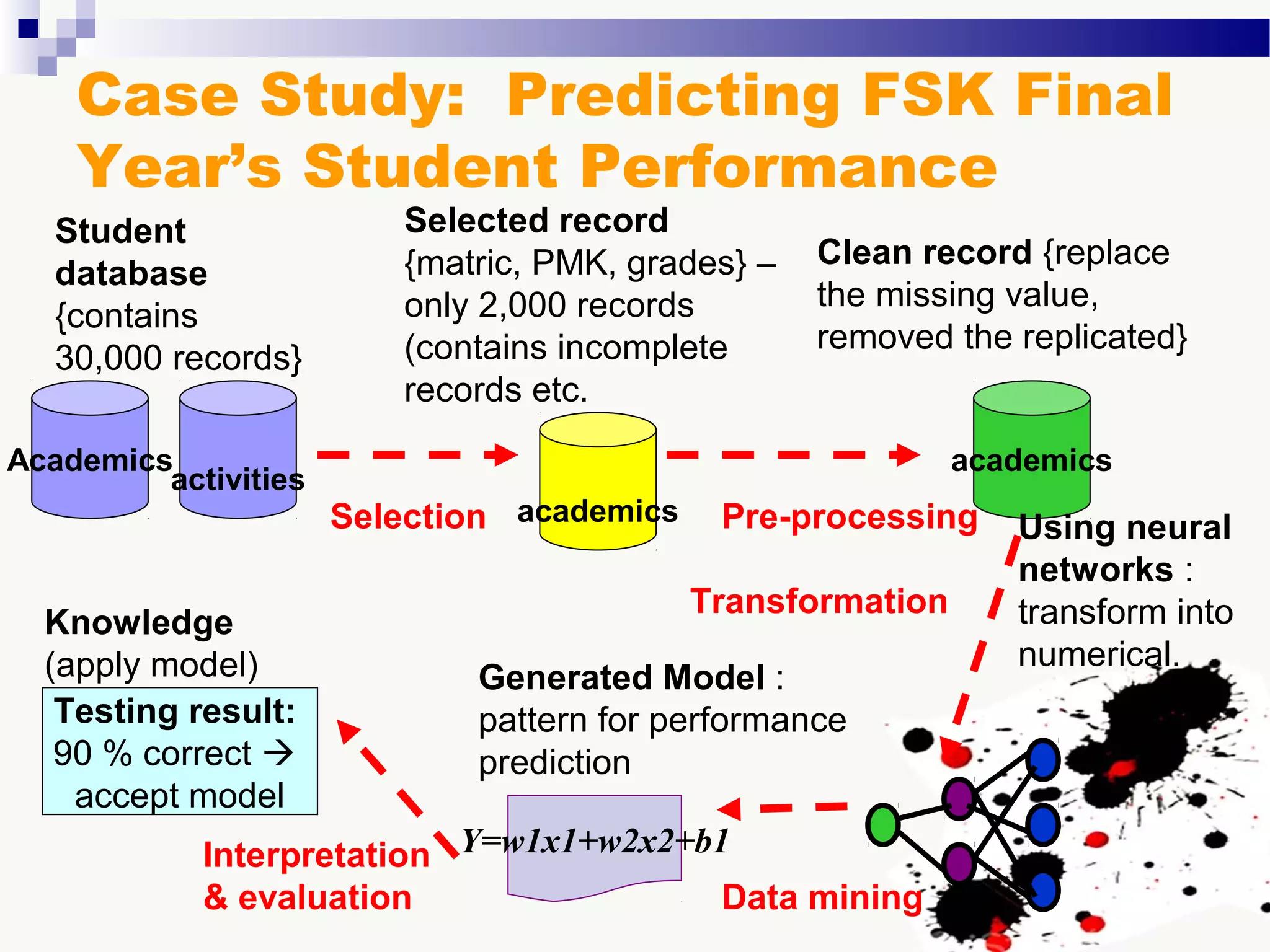

The document discusses knowledge acquisition and data mining. It begins by defining knowledge acquisition as the process of discovering useful patterns or rules in large quantities of data through automatic or semi-automatic means. It then discusses why knowledge acquisition is important due to factors like data explosion and competitive pressure. The document also discusses different types of knowledge that can be mined, including classes, clusters, associations and sequential patterns. It outlines the predictive and descriptive approaches in data mining and common tasks like classification, clustering and association rule mining. Finally, it presents the typical steps in the knowledge discovery process including data selection, pre-processing, transformation, data mining, and interpretation.











































































































