Download to read offline






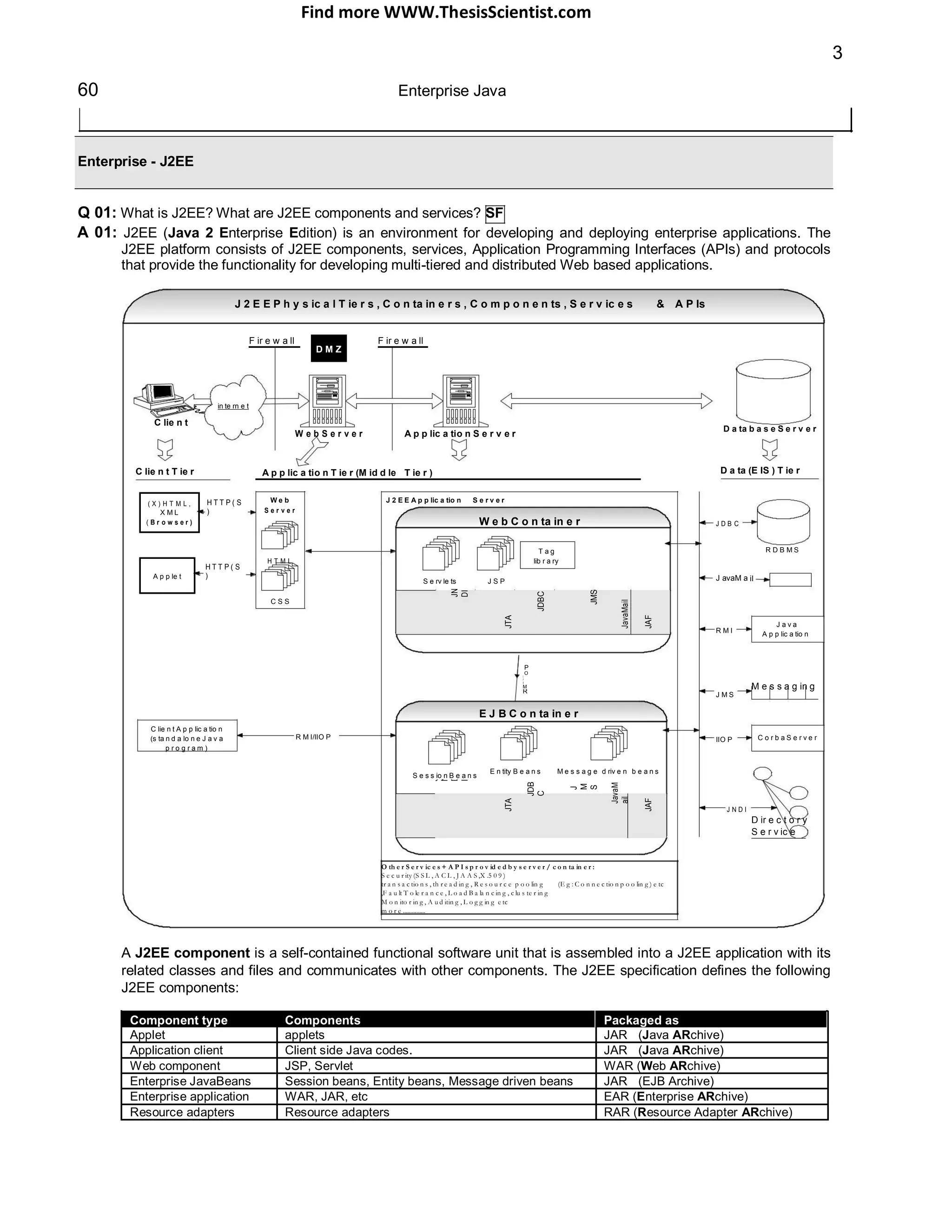
![Find more WWW.ThesisScientist.com
64 Enterprise Java
Q 04: How to package a module, which is, shared by both the WEB and the EJB modules? SF
A 04: Package the modules shared by both WEB and EJB modules as dependency jar files. Define the Class-Path:
property in the MANIFEST.MF file in the EJB jar and the Web war files to refer to the shared modules. [Refer Q7
in Enterprise section for diagram: J2EE deployment structure].
The MANIFEST.MF files in the EJB jar and WEB war modules should look like:
Manifest-Version: 1.0
Created-By: Apache Ant 1.5
Class-Path: myAppsUtil.jar
Q 05: Why use design patterns in a J2EE application? DP
A 05:
They have been proven. Patterns reflect the experience and knowledge of developers who have successfully
used these patterns in their own work. It lets you leverage the collective experience of the development
community.
Example Session facade and value object patterns evolved from performance problems experienced due to
multiple network calls to the EJB tier from the WEB tier. Fast lane reader and Data Access Object patterns
exist for improving database access performance. The flyweight pattern improves application performance
through object reuse (which minimises the overhead such as memory allocation, garbage collection etc).
They provide common vocabulary. Patterns provide software designers with a common vocabulary. Ideas
can be conveyed to developers using this common vocabulary and format.
Example Should we use a Data Access Object (DAO)? How about using a Business Delegate? Should we
use Value Objects to reduce network overhead? Etc.
Q 06: What is the difference between a Web server and an application server? SF
A 06:
Web Server Application Server
Supports HTTP protocol. When the Web server receives Exposes business logic and dynamic content to the client
an HTTP request, it responds with an HTTP response, through various protocols such as HTTP, TCP/IP, IIOP, JRMP etc.
such as sending back an HTML page (static content) or
delegates the dynamic response generation to some
other program such as CGI scripts or Servlets or JSPs in
the application server.
Uses various scalability and fault-tolerance techniques. Uses various scalability and fault-tolerance techniques. In addition
provides resource pooling, component life cycle management,
transaction management, messaging, security etc.
Provides services for components like Web container for servlet
components and EJB container for EJB components.
With the advent of XML Web services the line between application servers and Web servers is not clear-cut. By passing XML
documents between request and response the Web server can behave like an application server.
Q 07: What are ear, war and jar files? What are J2EE Deployment Descriptors? SF
A 07: ear, war and jar are standard application deployment archive files. Since they are a standard, any application
server (at least in theory) will know how to unpack and deploy them.
An EAR file is a standard JAR file with an “.ear” extension, named from Enterprise ARchive file. A J2EE
application with all of its modules is delivered in EAR file. JAR files can‟t have other JAR files. But EAR and WAR
(Web ARchive) files can have JAR files.
An EAR file contains all the JARs and WARs belonging to an application. JAR files contain the EJB classes and
WAR files contain the Web components (JSPs, static content (HTML, CSS, GIF etc), Servlets etc.). The J2EE
application client's class files are also stored in a JAR file. EARs, JARs, and WARs all contain an XML-based
deployment descriptor.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-7-320.jpg)




![Find more WWW.ThesisScientist.com
Enterprise Java 69
So if two different WEB modules want to use two different versions of the same EJB then we need to have two
different ear files. As was discussed in the Q4 in Java section the class loaders use a delegation model where
the child class loaders delegate the loading up the hierarchy to their parent before trying to load it itself only if the
parent can‟t load it. But with regards to WAR class loaders, some application servers provide a setting to turn this
behaviour off (DelegationMode=false). This delegation mode is recommended in the Servlet 2.3 specification.
As a general rule classes should not be deployed higher in the hierarchy than they are supposed to exist. This is because
if you move one class up the hierarchy then you will have to move other classes up the hierarchy as well. This is because
classes loaded by the parent class loader can‟t see the classes loaded by its child class loaders (uni-directional bottom-up
visibility).
Enterprise - Servlet
Q 09: What is the difference between CGI and Servlet? SF
Q 09:
Traditional CGI Java Servlet
(Common Gateway Interface)
Traditional CGI creates a heavy weight process to handle each Spawns a lightweight Java thread to handle each http
http request. N number of copies of the same traditional CGI request. Single copy of a type of servlet but N number of
programs is copied into memory to serve N number of threads (thread sizes can be configured in an application
requests. server).
In the Model 2 MVC architecture, servlets process requests and select JSP views. So servlets act as controller.
Servlets intercept the incoming HTTP requests from the client (browser) and then dispatch the request to the
business logic model (e.g. EJB, POJO - Plain Old Java Object, JavaBeans etc). Then select the next JSP view for
display and deliver the view to client as the presentation (response). It is the best practice to use Web tier UI
frameworks like Struts, JavaServer Faces etc, which uses proven and tested design patterns.
Q 10: HTTP is a stateless protocol, so how do you maintain state? How do you store user data between requests? SF
PIBP
A 10: This is a commonly asked question as well. You can retain the state information between different page requests
as follows:
HTTP Sessions are the recommended approach. A session identifies the requests that originate from the same
browser during the period of conversation. All the servlets can share the same session. The JSESSIONID is
generated by the server and can be passed to client through cookies, URL re-writing (if cookies are turned off) or
built-in SSL mechanism. Care should be taken to minimize size of objects stored in session and objects
stored in session should be serializable. In a Java servlet the session can be obtained as follows: CO
HttpSession session = request.getSession(); //returns current session or a new session
Sessions can be timed out (configured in web.xml) or manually invalidated.
Session Management
ServerClient
(Browser)
A new session is created on the Server
1. Initial Request[No session] side with JSESSIONID where JSESSIONID Name Value
state can be maintained as
xsder12345 Firstname Peter
2. JSESSIONID is passed to client with name/value pair.
e xsder12345 LastName Smith
the response through onfor thati
rm
fo
cookies or URL re-writing dstate
in
NIDre IO
e
sto S
S
v SE
trie ed J
re
3. Client uses the JSESSIONID pli
sup
for subsequent requests](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-12-320.jpg)

![Find more WWW.ThesisScientist.com
Enterprise Java 71
ready state to service requests from clients. The container calls the servlet‟s service() method for handling each
request by spawning a new thread for each request from the Web container‟s thread pool [It is also possible to
have a single threaded Servlet, refer Q16 in Enterprise section]. Before destroying the instance the container will
call the destroy() method. After destroy() the servlet becomes the potential candidate for garbage collection.
Note on servlet reloading:
Most servers can reload a servlet after its class file has been modified provided the servlets are deployed to
$server_root/servlets directory. This is achieved with the help of a custom class loader. This feature is handy for development
and test phases. This is not recommended for production since it can degrade performance because of timestamp comparison
for each request to determine if a class file has changed. So for production it is recommended to move the servlet to server‟s
class path ie $server_root/classes.
When a server dispatches a request to a servlet, the server first checks if the servlet's class file has changed on disk. If it has
changed, the server abandons the class loader used to load the old version and creates a new instance of the custom class
loader to load the new version. Old servlet versions can stay in memory indefinitely (so the effect is the other classes can still
hold references to the old servlet instances, causing odd side effects, but the old versions are not used to handle any more
requests. Servlet reloading is not performed for classes found in the server's classpath because the core, primordial class loader,
loads those classes. These classes are loaded once and retained in memory even when their class files change.
Servlet Life Cycle
called once
thread 1 : client request
thread 2 : client request
thread 3 : client request
called once
ins tan tiate
& call init()
init()
ready to serve requests
handle m ultiple
servic e() requests and send response.
destroy()
Q 12: Explain the directory structure of a WEB application? SFSE
A 12: Refer Q7 in Enterprise section for diagram: J2EE deployment structure and explanation in this section where
MyAppsWeb.war is depicting the Web application directory structure. The directory structure of a Web application
consists of two parts:
A public resource directory (document root): The document root is where JSP pages, client-side classes
and archives, and static Web resources are stored.
A private directory called WEB-INF: which contains following files and directories:
web.xml : Web application deployment descriptor.
*.tld : Tag library descriptor files.
classes : A directory that contains server side classes like servlets, utility classes, JavaBeans etc.
lib : A directory where JAR (archive files of tag libraries, utility libraries used by the server side
classes) files are stored.
Note: JSP resources usually reside directly or under subdirectories of the document root, which are directly
accessible to the user through the URL. If you want to protect your Web resources then hiding the JSP files
behind the WEB-INF directory can protect the JSP files from direct access. Refer Q35 in Enterprise section.
Q 13: What is the difference between doGet () and doPost () or GET and POST? SFSE](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-14-320.jpg)










![Find more WWW.ThesisScientist.com
82 Enterprise Java
Q 37: What is a TagExtraInfo class? SF
A 37: A TagExtraInfo class provides extra information about tag attributes to the JSP container at translation time.
Returns information about the scripting variables that the tag makes available to the rest of the JSP page
to use. The method used is:
VariableInfo[] getVariableInfo(TagData td)
Example
<html>
<myTag:addObjectsToArray name=”myArray” />
<myTag:displayArray name=”myArray” />
</html>
Without the use of TagExtraInfo, if you want to manipulate the attribute myArray in the above code in a
scriptlet it will not be possible. This is because it does not place the myArray object on the page. You can still
use pageContext.getAttribute() but that may not be a cleaner approach because it relies on the page
designer to correctly cast to object type. The TagExtraInfo can be used to make items stored in the
pageContext via setAttribute() method available to the scriptlet as shown below.
<html>
<myTag:addObjectsToArray name=”myArray” />
<%-- scriplet code %>
<% for(int i=0; i<myArray.length;i++){
html += <LI> + myArray[i] + </LI>;
%>
</html>
Validates the attributes passed to the Tag at translation time.
Example It can validate the myArray array list to have not more than 100 objects. The method used is:
boolean isValid(TagData data)
Q 38: What is the difference between custom JSP tags and JavaBeans? SF
A 38: In the context of a JSP page, both accomplish similar goals but the differences are:
Custom Tags JavaBeans
Can manipulate JSP content. Can‟t manipulate JSP content.
Custom tags can simplify the complex operations much Easier to set up.
better than the bean can. But require a bit more work to
set up.
Used only in JSPs in a relatively self-contained manner. Can be used in both Servlets and JSPs. You can define a bean in
one Servlet and use them in another Servlet or a JSP page.
JavaBeans declaration and usage example: CO
<jsp:useBean id="identifier" class="packageName.className"/> <jsp:setProperty
name="identifier" property="classField" value="someValue" />
<jsp:getProperty name="identifier" property="classField" /> <%=identifier.getclassField() %>
Q 39: Tell me about JSP best practices? BP
A 39:
Separate HTML code from the Java code: Combining HTML and Java code in the same source code can
make the code less readable. Mixing HTML and scriplet will make the code extremely difficult to read and
maintain. The display or behaviour logic can be implemented as a custom tags by the Java developers and
Web designers can use these Tags as the ordinary XHTML tags.
Place data access logic in JavaBeans: The code within the JavaBean is readily accessible to other JSPs
and Servlets.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-25-320.jpg)


![Find more WWW.ThesisScientist.com
Enterprise Java 85
The above code ensures that both operation 1 and operation 2 succeed or fail as an atomic unit and consequently
leaves the database in a consistent state. Also turning auto-commit off will provide better performance.
Q 44: What is the difference between JDBC-1.0 and JDBC-2.0? What are Scrollable ResultSets, Updateable ResultSets,
RowSets, and Batch updates? SF
A 44: JDBC2.0 has the following additional features or functionality:
JDBC 1.0 JDBC 2.0
With JDBC-1.0 the With JDBC 2.0 ResultSets are updateable and also you can move forward and backward.
ResultSet functionality
was limited. There was no Example This example creates an updateable and scroll-sensitive ResultSet
support for updates of any
kind and scrolling through Statement stmt = myConnection.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,
the ResultSets was ResultSet.CONCUR_UPDATEABLE)
forward only (no going
back)
With JDBC-1.0 the With JDBC-2.0 statement objects can be grouped into a batch and executed at once. We call
statement objects submits addBatch() multiple times to create our batch and then we call executeBatch() to send the SQL
updates to the database statements off to database to be executed as a batch (this minimises the network overhead).
individually within same or
separate transactions. Example
This is very inefficient
large amounts of data Statement stmt = myConnection.createStatement();
need to be updated. stmt.addBatch(“INSERT INTO myTable1 VALUES (1,”ABC”)”);
stmt.addBatch(“INSERT INTO myTable1 VALUES (2,”DEF”)”);
stmt.addBatch(“INSERT INTO myTable1 VALUES (3,”XYZ”)”);
…
int[] countInserts = stmt.executeBatch();
- The JDBC-2.0 optional package provides a RowSet interface, which extends the ResultSet. One
of the implementations of the RowSet is the CachedRowSet, which can be considered as a
disconnected ResultSet.
Q 45: How to avoid the “running out of cursors” problem? DCPIMI
A 45: A database can run out of cursors if the connection is not closed properly or the DBA has not allocated enough
cursors. In a Java code it is essential that we close all the valuable resources in a try{} and finally{} block. The
finally{} block is always executed even if there is an exception thrown from the catch {} block. So the resources like
connections and statements should be closed in a finally {} block. CO
Try{} Finally {} blocks to close Exceptions
Wrong Approach - Right Approach -
Connections and statements will not be closed if there public void executeSQL() throws SQLException{
is an exception: try{
Connection con = DriverManager.getConnection(........);
public void executeSQL() throws SQLException{ .....
Statement stmt = con.createStatement();
Connection con = DriverManager.getConnection(........);
....
//line 20 where exception is thrown
..... ResultSet rs = stmt.executeQuery("SELECT * from myTable");
Statement stmt = con.createStatement(); .....
.... }
//line 20 where exception is thrown finally{
ResultSet rs = stmt.executeQuery("SELECT * from myTable"); try {
..... if(rs != null) rs.close();
rs.close(); if(stmt != null) stmt.close();
stmt.close(); if(con != null) con.close();
con.close(); }
} catch(Exception e){}
}
Note: if an exception is thrown at line 20 then the }
close() statements are never reached.
Note: if an exception is thrown at line 20 then the
finally clause is called before the exception is thrown to
the method.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-28-320.jpg)






























![Find more WWW.ThesisScientist.com
Enterprise Java 117
</head>
</html>
Now to convert the Sample.xml into a PDF file apply the
following FO (Formatting Objects) file Through the FOP
processor.
Sample.fo
<?xml version="1.0" encoding="ISO-8859-1"?>
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format">
<fo:layout-master-set>
<fo:simple-page-master master-name="A4">
</fo:simple-page-master>
</fo:layout-master-set>
<fo:page-sequence master-reference="A4">
<fo:flow flow-name="xsl-region-body">
<fo:block>
<xsl:value-of select="content[@language='English']">
</fo:block>
</fo:flow>
</fo:page-sequence>
</fo:root>
which gives a basic Sample.pdf which has the following line
Not Much
XPath Xml Path Language, a language for addressing parts of an As per Sample.xsl
XML document, designed to be used by both XSLT and
XPointer. We can write both the patterns (context-free) and <xsl:template match=”content[@language=‟English‟]”>
expressions using the XPATH Syntax. XPATH is also used ………
in XQuery. <td><xsl:value-of select=”content/@language” /></td>
JAXP Stands for Java API for XML Processing. This provides a DOM example using JAXP:
common interface for creating and using SAX, DOM, and
XSLT APIs in Java regardless of which vendor‟s DocumentBuilderFactory dbf =
implementation is actually being used (just like the JDBC, DocumentBuilderFactory.newInstance();
JNDI interfaces). JAXP has the following packages: DocumentBuilder db = dbf.newDocumentBuilder();
Document doc =
db.parse(new File("xml/Test.xml"));
NodeList nl = doc.getElementsByTagName("to");
Node n = nl.item(0);
System.out.println(n.getFirstChild().getNodeValue());
SAX example using JAXP:
SAXParserFactory spf =
SAXParserFactory.newInstance();
SAXParser sp = spf.newSAXParser();
SAXExample se = new SAXExample();
sp.parse(new File("xml/Sample.xml"),se);
where SAXExample.Java code snippet
public class SAXExample extends DefaultHandler {
public void startElement(
String uri,
String localName,
String qName,
Attributes attr)
throws SAXException {
System.out.println("--->" + qName);
}
...
}](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-62-320.jpg)










![Find more WWW.ThesisScientist.com
130 Enterprise Java
Class diagrams can have a conceptual perspective and an implementation perspective. During the analysis
draw the conceptual model and during implementation draw the implementation model.
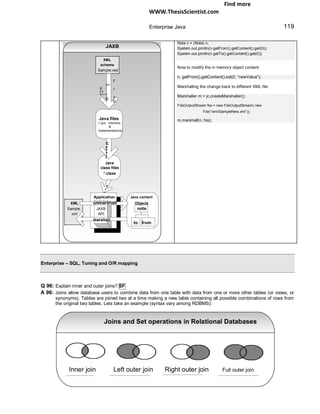
Package diagrams: To simplify complex class diagrams you can group classes into packages.
P a c k a g e D i a g r a m
A c c o u n t i n g O r d e r i n g
d e p e n d e n c y
d e p e n d e n c y
C u s t o m e r
When to use package diagrams?
Package diagrams are vital for large projects.
Object diagrams: Object diagrams show instances instead of classes. They are useful for explaining some
complicated objects in detail about their recursive relationships etc.
O b je c t D ia g r a m
O b je c t D ia g r a m
C la s s D ia g r a m
o b je c t n a m ep h y s ic s M a th s : D e p a r tm e n t
C la s s n a m e
1
0 . . *
im p r o v e c la r ity p h y s ic s : D e p a rtm e n t m a th : D e p a r tm e n t
D e p a r t m e n t
p u r e M a th : D e p a rtm e n t a p p lie d M a th : D e p a rtm e n t
R e c u r s iv e c la s s
d ia g ra m d iffic u lt to fu lly
u n d e r s ta n d S h o w s th e d e ta ils o f th e r e c u rs iv e o b je c t re la tio n s h ip
When to use object diagrams?
Object diagrams are a vital for large projects.
They are useful for explaining structural relationships in detail for complex objects.
Sequence diagrams: Sequence diagrams are interaction diagrams which detail what messages are sent and
when. The sequence diagrams are organized according to time. The time progresses as you move from top to
bottom of the diagram. The objects involved in the diagram are shown from left to right according to when they
take part.
S e q u e n c e D ia g r a m
c lie n t a n O r d e r : O r d e r
a n E n tr y : O r d e r E n tr y
c h e c k if s u ffic ie n t d e ta ils
m a k e A n O r d e r ( ) m a k e A n O r d e r ( ) a r e a v a ila b le
fo r e a c h lin e I te m
it e r a t io n [ f o r e a c h ... ] ( )
h a s S u ffic ie n tD e ta ils ( )
c o n fir m : C o n f ir m a tio n
p r in tC o n fir m a tio n ( )
N o te : E a c h v e r t ic a l d o tt e d lin e is a
lin e a r e c a lle d t h e a c t iv a t io n b a r
lif e lin e . E a c h a r r o w is a m e s s a g e . T h e r e c t a n g u la r b o x e s o n t h e lif e w h ic h
r e p r e s e n ts t h e d u r a t io n o f e x e c u t io n o f m e s s a g e .](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-75-320.jpg)







![Find more WWW.ThesisScientist.com
138 Enterprise Java
www.company1.com to the IP address 192.168.0.10. The Web server on the machine that has the IP address
192.168.0.10, so it receives the request. The Web server determines which virtual host to use by matching the
request URL It gets from an HTTP header submitted by the browser with the “ServerName” parameter in the
configuration file shown above.
Name-based virtual hosting is usually easier, since you have to only configure your DNS server to map each
hostname to a single IP address and then configure the Web server to recognize the different hostnames as
discussed in the previous paragraph. Name-based virtual hosting also eases the demand for scarce IP
addresses limited by physical network connections [but modern operation systems supports use of virtual
interfaces, which are also known as IP aliases]. Therefore you should use name-based virtual hosting unless
there is a specific reason to choose IP-based virtual hosting. Some reasons why you might consider using IP-
based virtual hosting:
Name-based virtual hosting cannot be used with SSL based secure servers because of the nature of the
SSL protocol.
Some operating systems and network equipment implement bandwidth management techniques that cannot
differentiate between hosts unless they are on separate IP addresses.
IP based virtual hosts are useful, when you want to manage more than one site (like live, demo, staging etc)
on the same server where hosts inherit the characteristics defined by your main host. But when using SSL
for example, a unique IP address is necessary.
For example in development environment when using the test client and the server on the same machine we can
define the host file as shown below:
UNIX user: /etc/hosts
Windows user: C:WINDOWSSYSTEM32DRIVERSETCHOSTS
localhost
www.company1.com
www.company2.com
[Reference: http://httpd.apache.org/docs/1.3/vhosts/]
Q 120: What is application server clustering? SI
A 120: An application server cluster consists of a number of application servers loosely coupled on a network. The
server cluster or server group is generally distributed over a number of machines or nodes. The important point
to note is that the cluster appears as a single server to its clients.
The goals of application server clustering are:
Scalability: should be able to add new servers on the existing node or add new additional nodes to
enable the server to handle increasing loads without performance degradation, and in a manner
transparent to the end users.
Load balancing: Each server in the cluster should process a fair share of client load, in proportion to its
processing power, to avoid overloading of some and under utilization of other server resources. Load
distribution should remain balanced even as load changes with time.
High availability: Clients should be able to access the server at almost all times. Server usage should be
transparent to hardware and software failures. If a server or node fails, its workload should be moved
over to other servers, automatically as fast as possible and the application should continue to run
uninterrupted. This method provides a fair degree of application system fault-tolerance. After failure, the
entire load should be redistributed equally among working servers of the system.
[Good read: Uncover the hood of J2EE clustering by Wang Yu on http://www.theserverside.com ]
Q 121: Explain Java Management Extensions (JMX)? SF
A 121: JMX framework can improve the manageability of your application by](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-83-320.jpg)

![Find more WWW.ThesisScientist.com
140 Enterprise Java
Recycle your valuable resources by either pooling or caching. You should create a limited number of
resources and share them from a common pool (e.g. pool of threads, pool of database connections, pool of
objects etc). Caching is simply another type of pooling where instead of pooling a connection or object, you
are pooling remote data (database data) and placing it in the memory (using Hashtable etc).
Avoid embedding business logic in a protocol dependent manner like in JSPs, HttpServlets, Struts
action classes etc. This is because your business logic should be not only executed by your Web clients but
also required to be shared by various GUI clients like Swing based stand alone application, WAP clients etc.
Automate the build process with tools like Ant, CruiseControl, and Maven etc. In an enterprise application
the build process can become quite complex and confusing.
Build test cases first (i.e. Test Driven Development (TDD), refer section Emerging Technologies) using
tools like JUnit. Automate the testing process and integrate it with build process.
Separate HTML code from the Java code: Combining HTML and Java code in the same source code can
make the code less readable. Mixing HTML and scriplet will make the code extremely difficult to read and
maintain. The display or behaviour logic can be implemented as a custom tags by the Java developers and
Web designers can use these Tags as the ordinary XHTML tags.
It is best practice to use multi-threading and stay away from single threaded model of the servlet unless
otherwise there is a compelling reason for it. Shared resources can be synchronized or used in read-only
manner or shared values can be stored in a database table. Single threaded model can adversely affect
performance.
Apply the following JSP best practices:
Place data access logic in JavaBeans: The code within the JavaBean is readily accessible to other
JSPs and Servlets.
Factor shared behaviour out of Custom Tags into common JavaBeans classes: The custom tags
are not used outside JSPs. To avoid duplication of behaviour or business logic, move the logic into
JavaBeans and get the custom tags to utilize the beans.
Choose the right “include” mechanism: What are the differences between static and a dynamic
include? Using includes will improve code reuse and maintenance through modular design. Which one
to use? Refer Q31 in Enterprise section.
Use style sheets (e.g. css), template mechanism (e.g. struts tiles etc) and appropriate comments
(both hidden and output comments).
If you are using EJBs apply the EJB best practices as described in Q82 in Enterprise section.
Use the J2EE standard packaging specification to improve portability across Application Servers.
Use proven frameworks like Struts, Spring, Hibernate, JSF etc.
Apply appropriate proven J2EE design patterns to improve performance and minimise network
communications cost (Session façade pattern, Value Object pattern etc).
Batch database requests to improve performance. For example
Connection con = DriverManager.getConnection(……).
Statement stmt = con.createStatement().
stmt.addBatch(“INSERT INTO Address…………”);
stmt.addBatch(“INSERT INTO Contact…………”);
stmt.addBatch(“INSERT INTO Personal”);
int[] countUpdates = stmt.executeBatch();
Use “PreparedStatements” instead of ordinary “Statements” for repeated reads.
Avoid resource leaks by
Closing all database connections after you have used them.
Clean up objects after you have finished with them especially when an object having a long life cycle
refers to a number of objects with short life cycles (you have the potential for memory leak).](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-85-320.jpg)
![Find more WWW.ThesisScientist.com
Enterprise Java 141
Poor exception handling where the connections do not get closed properly and clean up code that
never gets called. You should put clean up code in a finally {} block.
Handle and propagate exceptions correctly. Decide between checked and unchecked (i.e RunTime
exceptions) exceptions.
Q 125: Explain some of the J2EE best practices to improve performance? BPPI
A 125: In short manage valuable resources wisely and recycle them where possible, minimise network overheads and
serialization cost, and optimise all your database operations.
Manage and recycle your valuable resources by either pooling or caching. You should create a limited
number of resources and share them from a common pool (e.g. pool of threads, pool of database
connections, pool of objects etc). Caching is simply another type of pooling where instead of pooling a
connection or object, you are pooling remote data (database data), and placing it in memory (using
Hashtable etc). Unused stateful session beans must be removed explicitly and appropriate idle timeout
should be set to control stateful session bean life cycle.
Use effective design patterns to minimise network overheads (Session facade, Value Object etc Refer
Q84, Q85 in Enterprise section), use of fast-lane reader pattern for database access (Refer Q86 in
Enterprise section). Caching of retrieved JNDI InitialContexts, factory objects (e.g. EJB homes) etc. using
the service locator design pattern, which reduces expensive JNDI access with the help of caching
strategies.
Minimise serialization costs by marking references (like file handles, database connections etc), which do
not required serialization by declaring them „transient‟ (Refer Q19 in Java section). Use pass-by-reference
where possible as opposed to pass by value.
Set appropriate timeouts: for the HttpSession objects, after which the session expires, set idle timeout for
stateful session beans etc.
Improve the performance of database operations with the following tips:
Database connections should be released when not needed anymore, otherwise there will be potential
resource leakage problems.
Apply least restrictive but valid transaction isolation level.
Use JDBC prepared statements for overall database efficiency and for batching repetitive inserts and
updates. Also batch database requests to improve performance.
When you first establish a connection with a database by default it is in auto-commit mode. For better
performance turn auto-commit off by calling the connection.setAutoCommit(false) method.
Where appropriate (you are loading 100 objects into memory but use only 5 objects) lazy load your
data to avoid loading the whole database into memory using the virtual proxy pattern. Virtual proxy is
an object, which looks like an object but actually contain no fields until when one of its methods is
called does it load the correct object from the database.
Where appropriate eager load your data to avoid frequently accessing the database every time over
the network.
Enterprise – Logging, testing and deployment
Q 126: Give an overview of log4J? SF
A 126: Log4j is a logging framework for Java. Log4J is designed to be fast and flexible. Log4J has 3 main components
which work together to enable developers to log messages:
Loggers [was called Category prior to version 1.2]
Appenders
Layout](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-86-320.jpg)
![Find more WWW.ThesisScientist.com
142 Enterprise Java
Logger: The foremost advantage of any logging API like log4J, apache commons logging etc over plain
System.out.println is its ability to disable certain log statements while allowing others to print unhindered.
Loggers are hierarchical. The root logger exists at the top of the hierarchy. The root logger always exists and it
cannot be retrieved by name. The hierarchical nature of the logger is denoted by “.” notation. For example the
logger “java.util” is the parent of child logger “java.util.Vector” and so on. Loggers may be assigned priorities
such as DEBUG, INFO, WARN, ERROR and FATAL. If a given logger is not assigned a priority, then it inherits
the priority from its closest ancestor. The logging requests are made by invoking one of the following printing
methods of the logger instance: debug(), info(), warn(), error(), fatal().
Appenders and Layouts: In addition to selectively enabling and disabling logging requests based on the logger,
the log4J allows logging requests to multiple destinations. In log4J terms the output destination is an appender.
There are appenders for console, files, remote sockets, JMS, etc. One logger can have more than one
appender. A logging request for a given logger will be forwarded to all the appenders in that logger plus the other
appenders higher in the hierarchy. In addition to the output destination the output format can be categorised as
well. This is accomplished by associating layout with an appender. The layout is responsible for formatting the
logging request according to user‟s settings.
Sample configuration file:
#set the root logger priority to DEBUG and its appender to App1
log4j.rootLogger=DEBUG, App1
#App1 is set to a console appender
log4j.appender.App1=org.apache.log4j.ConsoleAppender
#appender App1 uses a pattern layout
log4j.appender.App1.layout=org.apache.log4j.PatternLayout.
log4j.appender.App1.layout.ConversionPattern=%-4r [%t] %-5p %c %x -%m%n
# Print only messages of priority WARN or above in the package com.myapp
log4j.Logger.com.myapp=WARN
XML configuration for log4j is available, and is usually the best practise.
Q 127: How do you initialize and use Log4J? SFCO
A 127:
public class MyApp {
//Logger is a utility wrapper class to be written with appropriate printing
methods static Logger log = Logger.getLogger (MyApp.class.getName());
public void my method() {
if(log.isDebugEnabled())
log.debug(“This line is reached………………………..” + var1 + “-” + var2);
)
}
}
Q 128: What is the hidden cost of parameter construction when using Log4J? SFPI
A 128:
Do not use in frequently accessed methods or loops: CO
log.debug (“Line number” + intVal + “ is less than ” + String.valueOf(array[i]));
The above construction has a performance cost in frequently accessed methods and loops in constructing
the message parameter, concatenating the String etc regardless of whether the message will be logged or not.
Do use in frequently accessed methods or loops: CO
If (log.isDebugEnabled()) {
log.debug (“Line number” + intVal + “ is less than ” + String.valueOf(array[i]));
}](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-87-320.jpg)
![Find more WWW.ThesisScientist.com
Enterprise Java 143
The above construction will avoid the parameter construction cost by only constructing the message parameter
when you are in debug mode. But it is not a best practise to place log.isDebugEnabled() around all debug code.
Q 129: What is the test phases and cycles? SD
A 129:
Unit tests (e.g. JUnit etc, carried out by developers).
There are two popular approaches to testing server-side classes: mock objects, which test classes by
simulating the server container, and in-container testing, which tests classes running in the actual server
container. If you are using Struts framework, StrutsTestCase for JUnit allows you to use either approach,
with very minimal impact on your actual unit test code.
System tests or functional tests (carried out by business analysts and/or testers).
Integration tests (carried out by business analysts, testers, developers etc).
Regression tests (carried out by business analysts and testers).
Stress volume tests or load tests (carried out by technical staff).
User acceptance tests (UAT – carried out by end users).
Each of the above test phases will be carried out in cycles. Refer Q13 in How would you go about… section for
JUnit, which is an open source unit-testing framework.
Q 130: Brief on deployment environments you are familiar with?
A 130: Differ from project team to project team [Hint] :
Application environments where “ear” files get deployed.
Development box: can have the following instances of environments in the same machine (need not be
clustered).
Development environment Æ used by developers.
System testing environment Æ used by business analysts.
Staging box: can have the following instances of environments in the same machine (preferably clustered
servers with load balancing)
Integration testing environment Æ used for integration testing, user acceptance testing etc.
Pre-prod environment Æ used for user acceptance testing, regression testing, and load testing or stress
volume testing (SVT). [This environment should be exactly same as the production environment].
Production box:
Production environment Æ live site used by actual users.
Data environments (Database)
Note: Separate boxes [not the same boxes as where applications (i.e. ear files) are deployed]
Development box (database).
Used by applications on development and system testing environments. Separate instances can be
created on the same box for separate environments like development and system testing.
Staging Box (database)
Used by applications on integration testing and user acceptance testing environments. Separate
instances can be created on the same box for separate environments.
Production Box (database)
Live data used by actual users of the system.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-88-320.jpg)
![Find more WWW.ThesisScientist.com
144 Enterprise Java
Enterprise - Personal
Q 131: Tell me about yourself or about some of the recent projects you have worked with? What do you consider your
most significant achievement? Why do you think you are qualified for this position? Why should we hire you and
what kind of contributions will you make?
A 131: [Hint:] Pick your recent projects and give a brief overview of it. Also it is imperative that during your briefing that
you demonstrate how you applied your skills and knowledge in some of the following key areas and fixed any
issues.
Design Concepts: Refer Q02, Q03, Q19, Q20, Q21, Q91, Q98, and Q101.
Design Patterns: Refer Q03, Q24, Q25, Q83, Q84, Q85, Q86, Q87, Q88 and Q111.
Performance issues: Refer Q10, Q16, Q45, Q46, Q97, Q98, Q100, Q123, and Q125.
Memory issues: Refer Q45 and Q93
Multi-threading (Concurrency issues): Refer Q16, Q34, and Q113
Exception Handling: Refer Q76 and Q77
Transactional issues: Refer Q43, Q71, Q72, Q73, Q74, Q75 and Q77.
Security issues: Refer Q23, Q58, and Q81
Scalability issues: Refer Q20, Q21, Q120 and Q122.
Best practices: Refer Q10, Q16, Q39, Q40, Q46, Q82, Q124, and Q125
Refer Q66 – Q72 in Java section for frequently asked non-technical questions.
Q 132: Have you used any load testing tools?
A 132: Rational Robot, JMeter, LoadRunner, etc.
Q 133: What source control systems have you used? SD
A 133: CVS, VSS (Visual Source Safe), Rational clear case etc. Refer Q13 in How would you go about section…. for
CVS.
Q 134: What operating systems are you comfortable with? SD
A 134: NT, Unix, Linux, Solaris etc
Q 135: Which on-line technical resources do you use to resolve any design and/or development issues?
A 135: http://www.theserverside.com, http://www.javaworld.com, http://www-136.ibm.com/developerworks/Java/,
http://java.sun.com/, www.javaperformancetuning.com etc
Enterprise – Software development process
Q 136: What software development processes/principles are you familiar with? SD
A 136: Agile (i.e. lightweight) software development process is gaining popularity and momentum across
organizations.
Agile software development manifesto Æ [Good read: http://www.agilemanifesto.org/principles.html].
Highest priority is to satisfy the customer.
Welcome requirement changes even late in development life cycle.
Business people and developers should work collaboratively.
Form teams with motivated individuals who produce best designs and architectures.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-89-320.jpg)
![Find more WWW.ThesisScientist.com
Enterprise Java 145
Teams should be pro-active on how to become more effective without becoming complacent.
Quality working software is the primary measure of progress.
Why is iterative development with vertical slicing used in agile development? Your overall software quality
can be improved through iterative development, which provides you with constant feedback.
Traditional Vs Agile approach
Traditional approach
scop
e
1
2
Business Layer
technica
l
mileston
e
milestone
Data Layer Data Layer
project time
Agile (light w eight )approach
Present Presentatio
sc
op
e
ation
1
n Layer 2Layer
tech
nical
Busines
iterat
ion
Business
iteratio
n
s layesr Data L ayer
layesr
Data
Layer
project time
Presentation Layer
Business Layer
Data Layer
Presentation Layer
Business Layer
Data Layer
milestone3iteration3
With the tradional approach, Say for example
w e have a fundamental flaw in the data layer,
if this flaw gets only picked up after the
milestone 3, then there w ill be lot of rew ork to
be done to the business and the presentation
layer. This is the major draw back w ith the
traditional development approach w here there
is no vertical slicing.
As you can see w ith the agileiterative
approach, a vertical slice is built for each
iteration. So any fundamental flaw in design or
coding can be picked up early and rectified.
Even deployment and testing w ill be carried
out in vertical slices.
Several methodologies fit under this agile development methodology banner. All these methodologies share
many characteristics like iterative and incremental development, test driven development, stand up
meetings to improve communication, automatic testing, build and continuous integration of code etc.
Among all the agile methodologies XP is the one which has got the most attention. Different companies use
different flavours of agile methodologies by using different combinations of methodologies.
How does vertical slicing influence customer perception? With the iterative and incremental approach,
customer will be comfortable with the progress of the development as opposed to traditional big bang approach.
TradionalVsAgileperceivedfunctionality
As far as the developer is concerned As far as the developer is concerned
65% of coding has been completed and
Traditional
65% of coding has been completed but
Agile from the customer's view 65% of the
from the customer's view only 20% of
functionality has been completed. So
the functionality has been completed
the customer is happy.
Presentation Layer PresentationLayer
BusinessLayer BusinessLayer
DataLayer DataLayer
EXtreme Programming [XP] Æ simple design, pair programming, unit testing, refactoring, collective code
ownership, coding standards, etc. Refer Q10 in “How would you go about…” section. XP has four key
values: Communication, Feedback, Simplicity and Courage. It then builds up some tried and tested
practices and techniques. XP has a strong emphasis on testing where tests are integrated into continuous
integration and build process, which yields a highly stable platform. XP is designed for smaller teams of 20
– 30 people.
RUP (Rational Unified Process) Æ Model driven architecture, design and development; customizable
frameworks for scalable process; iterative development methodology; Re-use of architecture, code,
component, framework, patterns etc. RUP can be used as an agile process for smaller teams of 20-30](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-90-320.jpg)
![Find more WWW.ThesisScientist.com
146 Enterprise Java
people, or as a heavy weight process for larger teams of 50-100 people. Refer Q103 – Q105 in Enterprise
section.
Feature Driven Development [FDD] Æ Jeff De Luca and long time OO guru Peter Coad developed feature
Driven Development (FDD). Like the other adaptive methodologies, it focuses on short iterations that
deliver tangible functionality. FDD was originally designed for larger project teams of around 50 people. In
FDD's case the iterations are two weeks long. FDD has five processes. The first three are done at the
beginning of the project. The last two are done within each iteration.
Develop an Overall Model
Build a Features List
Plan by Feature
Design by Feature
Build by Feature
The developers come in two kinds: class owners and chief programmers. The chief programmers are the
most experienced developers. They are assigned features to be built. However they don't build them alone.
Instead the chief programmer identifies which classes are involved in implementing the feature and gathers
their class owners together to form a feature team for developing that feature. The chief programmer acts
as the coordinator, lead designer, and mentor while the class owners do much of the coding of the feature.
Test Driven Development [TDD] Æ TDD is an iterative software development process where you first write
the test with the idea that it must fail. Refer Q1 in Emerging Technologies/Frameworks section…
Scrum Æ Scrum divides a project into sprints (aka iterations) of 30 days. Before you begin a sprint you
define the functionality required for that sprint and leave the team to deliver it. But every day the team holds
a short (10 – 15 minute) meeting, called a scrum where the team runs through what it will achieve in the
next day. Some of the questions asked in the scrum meetings are:
What did you do since the last scrum meetings?
Do you have any obstacles?
What will you do before next meeting?
This is very similar to stand-up meetings in XP and iterative development process in RUP.
Enterprise – Key Points
J2EE is a 3-tier (or n-tier) system. Each tier is logically separated and loosely coupled from each other, and may be
distributed.
J2EE applications are developed using MVC architecture, which divides the functionality of displaying and
maintaining of the data to minimise the degree of coupling between enterprise components.
J2EE modules are deployed as ear, war and jar files, which are standard application deployment archive files.
HTTP is a stateless protocol and state can be maintained between client requests using HttpSession, URL rewriting,
hidden fields and cookies. HttpSession is the recommended approach.
Servlets and JSPs are by default multi-threaded, and care should be taken in declaring instance variables and
accessing shared resources. It is possible to have a single threaded model of a servlet or a JSP but this can
adversely affect performance.
Clustering promotes high availability and scalability. The considerations for servlet clustering are:
Objects stored in the session should be serializable.
Design for idempotence.
Avoid using instance and static variables in read and write mode.
Avoid storing values in the ServletContext.
Avoid using java.io.* and use getResourceAsStream() instead.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-91-320.jpg)




![Find more WWW.ThesisScientist.com
152 How would you go about…?
Q 01: How would you go about documenting your Java/J2EE application?
A 01: To be successful with a Java/J2EE project, proper documentation is vital.
Before embarking on coding get the business requirements down. Build a complete list of requested features,
sample screen shots (if available), use case diagrams, business rules etc as a functional specification
document. This is the phase where business analysts and developers will be asking questions about user
interface requirements, data tier integration requirements, use cases etc. Also prioritize the features based on
the business goals, lead-times and iterations required for implementation.
Prepare a technical specification document based on the functional specification. The technical
specification document should cover:
Purpose of the document: This document will emphasise the customer service functionality …
Overview: This section basically covers background information, scope, any inclusions and/or
exclusions, referenced documents etc.
Basic architecture: discusses or references baseline architecture document. Answers questions like
Will it scale? Can this performance be improved? Is it extendable and/or maintainable? Are there any
security issues? Describe the vertical slices to be used in the early iterations, and the concepts to be
proved by each slice. Etc. For example which MVC [model-1, model-2 etc] paradigms (Refer Q3 in
Enterprise section for MVC) should we use? Should we use Struts, JSF, Spring etc or build our own
framework? Should we use a business delegate (Refer Q83 in Enterprise section for business delegate)
to decouple middle tier with the client tier? Should we use AOP (Aspect Oriented Programming) (Refer
Q3 in Emerging Technologies/Frameworks)? Should we use dependency injection? Should we use
annotations? Do we require internationalization? Etc.
Assumptions, Dependencies, Risks and Issues: highlight all the assumptions, dependencies, risks
and issues. For example list all the risks you can identify.
Design alternatives for each key functional requirement. Also discuss why a particular design
alternative was chosen over the others. This process will encourage developers analyse the possible
design alternatives without having to jump at the obvious solution, which might not always be the best
one.
Processing logic: discuss the processing logic for the client tier, middle tier and the data tier. Where
required add process flow diagrams. Add any pre-process conditions and/or post-process conditions.
(Refer Q9 in Java section for design by contract).
UML diagrams to communicate the design to the fellow developers, solution designers, architects etc.
Usually class diagrams and sequence diagrams are required. The other diagrams may be added for any
special cases like (Refer Q107 in Enterprise section):
State chart diagram: useful to describe behaviour of an object across several usecases.
Activity diagram: useful to express complex operations. Supports and encourages parallel
behaviour. Activity and statechart diagrams are beneficial for workflow modelling with multi
threaded programming.
Collaboration and Sequence diagrams: Use a collaboration or sequence diagram when you
want to look at behaviour of several objects within a single use case. If you want to look at a single
object across multiple use cases then use statechart.
Object diagrams: The Object diagrams show instances instead of classes. They are useful for
explaining some complicated objects in detail such as highlighting recursive relationships etc.
List the package names, class names, database names and table names with a brief description of
their responsibility in a tabular form.
Prepare a coding standards document for the whole team to promote consistency and efficiency. Some
coding practices can degrade performance for example:
Inappropriate use of String class. Use StringBuffer instead of String for compute intensive mutations
(Refer Q17 in Java section).](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-97-320.jpg)


![Find more WWW.ThesisScientist.com
How would you go about…? 155
Definition of class interfaces and inheritance hierarchy: Should we use an abstract class or an
interface? Is there any common functionality that we can move to the super class (or parent class)?
Should we use interface inheritance with object composition for code reuse as opposed to
implementation inheritance? Etc. (Refer Q8, Q10 in Java section).
Establishing key relationships (aggregation, composition, association etc): Should we use
aggregation or composition? [composition may require cascade delete] (Refer Q107, Q108 in Enterprise
section – under class diagrams). Should we use an “is a” (generalization) relationship or a “has a”
(composition) relationship? (Refer Q7 in Java section).
Applying polymorphism and encapsulation: Should we hide the member variables to improve
integrity and security? (Refer Q8 in Java section). Can we get a polymorphic behaviour so that we can
easily add new classes in the future? (Refer Q8 in Java section).
Applying well-proven design patterns (like Gang of four design patterns, J2EE design patterns, EJB
design patterns etc) help designers to base new designs on prior experience. Design patterns also help
you to choose design alternatives (Refer Q11 in How would you go about…).
Scalability of the system: Vertical scaling is achieved by increasing the number of servers running on
a single machine. Horizontal scaling is achieved by increasing the number of machines in the cluster.
Horizontal scaling is more reliable than the vertical scaling because there are multiple machines
involved in the cluster. In vertical scaling the number of server instances that can be run on one machine
are determined by the CPU usage and the JVM heap memory.
How do we replicate the session state? Should we use stateful session beans or HTTP session?
Should we serialize this object so that it can be replicated?
Internationalization requirements for multi-language support: Should we support other languages?
Should we support multi-byte characters in the database?
Vertical slicing: Getting the reusable and flexible design the first time is impossible. By developing the initial
vertical slice of your design you eliminate any nasty integration issues later in your project. Also get the
design patterns right early on by building the vertical slice. It will give you experience with what does work and
what does not work with Java/J2EE. Once you are happy with the initial vertical slice then you can apply it
across the application. The initial vertical slice should be based on a typical business use case. Refer Q136 in
Enterprise section.
Ensure the system is configurable through property files, xml descriptor files, annotations etc. This will
improve flexibility and maintainability. Avoid hard coding any values. Use a constant class for values, which
rarely change and use property files, xml descriptor files, annotations etc for values, which can change more
frequently (e.g. process flow steps etc) and/or environment related configurations(e.g. server name, server
port, LDAP server location etc).
Design considerations during design, development and deployment phases: designing a fast, secured,
reliable, robust, reusable and flexible system require considerations in the following key areas:
Performance issues (network overheads, quality of the code etc): Can I make a single coarse-grained
network call to my remote object instead of 3 fine-grained calls?
Concurrency issues (multi-threading etc): What if two threads access my object simultaneously will it
corrupt the state of my object?
Transactional issues (ACID properties): What if two clients access the same data simultaneously?
What if one part of the transaction fails, do we rollback the whole transaction? What if the client
resubmits the same transactional page again?
Security issues: Are there any potential security holes for SQL injection or URL injection by hackers?
Memory issues: Is there any potential memory leak problems? Have we allocated enough heap size for
the JVM? Have we got enough perm space allocated since we are using 3
rd
party libraries, which
generate classes dynamically? (e.g. JAXB, XSLT, JasperReports etc)
Scalability issues: Will this application scale vertically and horizontally if the load increases? Should
this object be serializable? Does this object get stored in the HttpSession?](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-100-320.jpg)
![Find more WWW.ThesisScientist.com
156 How would you go about…?
Maintainability, reuse, extensibility etc: How can we make the software reusable, maintainable and
extensible? What design patterns can we use? How often do we have to refactor our code?
Logging and auditing if something goes wrong can we look at the logs to determine the root cause of
the problem?
Object life cycles: Can the objects within the server be created, destroyed, activated or passivated
depending on the memory usage on the server? (e.g. EJB).
Resource pooling: Creating and destroying valuable resources like database connections, threads etc
can be expensive. So if a client is not using a resource can it be returned to a pool to be reused when
other clients connect? What is the optimum pool size?
Caching can we save network trips by storing the data in the server‟s memory? How often do we have
to clear the cache to prevent the in memory data from becoming stale?
Load balancing: Can we redirect the users to a server with the lightest load if the other server is
overloaded?
Transparent fail over: If one server crashes can the clients be routed to another server without any
interruptions?
Clustering: What if the server maintains a state when it crashes? Is this state replicated across the
other servers?
Back-end integration: How do we connect to the databases and/or legacy systems?
Clean shutdown: Can we shut down the server without affecting the clients who are currently using the
system?
Systems management: In the event of a catastrophic system failure who is monitoring the system? Any
alerts or alarms? Should we use JMX? Should we use any performance monitoring tools like Tivoli etc?
Dynamic redeployment: How do we perform the software deployment while the site is running? (Mainly
for mission critical applications 24hrs X 7days).
Portability issues: Can I port this application to a different server 2 years from now?
Q 03: How would you go about identifying performance and/or memory issues in your Java/J2EE application?
A 03: Profiling can be used to identify any performance issues or memory leaks. Profiling can identify what lines of code
the program is spending the most time in? What call or invocation paths are used to reach at these lines? What
kinds of objects are sitting in the heap? Where is the memory leak? Etc.
There are many tools available for the optimization of Java code like JProfiler, Borland OptimizeIt etc.
These tools are very powerful and easy to use. They also produce various reports with graphs.
Optimizeit™ Request Analyzer provides advanced profiling techniques that allow developers to analyse the
performance behaviour of code across J2EE application tiers. Developers can efficiently prioritize the
performance of Web requests, JDBC, JMS, JNDI, JSP, RMI, and EJB so that trouble spots can be
proactively isolated earlier in the development lifecycle.
Thread Debugger tools can be used to identify threading issues like thread starvation and contention issues
that can lead to system crash.
Code coverage tools can assist developers with identifying and removing any dead code from the
applications.
Hprof which comes with JDK for free. Simple tool.
Java –Xprof myClass
java -Xrunhprof:[help]|[<option>=<value>]
java -Xrunhprof:cpu=samples, depth=6, heap=sites](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/85/Java-Interview-Questions-Answers-Guide-Section-2-101-320.jpg)














![Find more WWW.ThesisScientist.com
64 Enterprise Java
Q 04: How to package a module, which is, shared by both the WEB and the EJB modules? SF
A 04: Package the modules shared by both WEB and EJB modules as dependency jar files. Define the Class-Path:
property in the MANIFEST.MF file in the EJB jar and the Web war files to refer to the shared modules. [Refer Q7
in Enterprise section for diagram: J2EE deployment structure].
The MANIFEST.MF files in the EJB jar and WEB war modules should look like:
Manifest-Version: 1.0
Created-By: Apache Ant 1.5
Class-Path: myAppsUtil.jar
Q 05: Why use design patterns in a J2EE application? DP
A 05:
They have been proven. Patterns reflect the experience and knowledge of developers who have successfully
used these patterns in their own work. It lets you leverage the collective experience of the development
community.
Example Session facade and value object patterns evolved from performance problems experienced due to
multiple network calls to the EJB tier from the WEB tier. Fast lane reader and Data Access Object patterns
exist for improving database access performance. The flyweight pattern improves application performance
through object reuse (which minimises the overhead such as memory allocation, garbage collection etc).
They provide common vocabulary. Patterns provide software designers with a common vocabulary. Ideas
can be conveyed to developers using this common vocabulary and format.
Example Should we use a Data Access Object (DAO)? How about using a Business Delegate? Should we
use Value Objects to reduce network overhead? Etc.
Q 06: What is the difference between a Web server and an application server? SF
A 06:
Web Server Application Server
Supports HTTP protocol. When the Web server receives Exposes business logic and dynamic content to the client
an HTTP request, it responds with an HTTP response, through various protocols such as HTTP, TCP/IP, IIOP, JRMP etc.
such as sending back an HTML page (static content) or
delegates the dynamic response generation to some
other program such as CGI scripts or Servlets or JSPs in
the application server.
Uses various scalability and fault-tolerance techniques. Uses various scalability and fault-tolerance techniques. In addition
provides resource pooling, component life cycle management,
transaction management, messaging, security etc.
Provides services for components like Web container for servlet
components and EJB container for EJB components.
With the advent of XML Web services the line between application servers and Web servers is not clear-cut. By passing XML
documents between request and response the Web server can behave like an application server.
Q 07: What are ear, war and jar files? What are J2EE Deployment Descriptors? SF
A 07: ear, war and jar are standard application deployment archive files. Since they are a standard, any application
server (at least in theory) will know how to unpack and deploy them.
An EAR file is a standard JAR file with an “.ear” extension, named from Enterprise ARchive file. A J2EE
application with all of its modules is delivered in EAR file. JAR files can‟t have other JAR files. But EAR and WAR
(Web ARchive) files can have JAR files.
An EAR file contains all the JARs and WARs belonging to an application. JAR files contain the EJB classes and
WAR files contain the Web components (JSPs, static content (HTML, CSS, GIF etc), Servlets etc.). The J2EE
application client's class files are also stored in a JAR file. EARs, JARs, and WARs all contain an XML-based
deployment descriptor.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-7-2048.jpg)




![Find more WWW.ThesisScientist.com
Enterprise Java 69
So if two different WEB modules want to use two different versions of the same EJB then we need to have two
different ear files. As was discussed in the Q4 in Java section the class loaders use a delegation model where
the child class loaders delegate the loading up the hierarchy to their parent before trying to load it itself only if the
parent can‟t load it. But with regards to WAR class loaders, some application servers provide a setting to turn this
behaviour off (DelegationMode=false). This delegation mode is recommended in the Servlet 2.3 specification.
As a general rule classes should not be deployed higher in the hierarchy than they are supposed to exist. This is because
if you move one class up the hierarchy then you will have to move other classes up the hierarchy as well. This is because
classes loaded by the parent class loader can‟t see the classes loaded by its child class loaders (uni-directional bottom-up
visibility).
Enterprise - Servlet
Q 09: What is the difference between CGI and Servlet? SF
Q 09:
Traditional CGI Java Servlet
(Common Gateway Interface)
Traditional CGI creates a heavy weight process to handle each Spawns a lightweight Java thread to handle each http
http request. N number of copies of the same traditional CGI request. Single copy of a type of servlet but N number of
programs is copied into memory to serve N number of threads (thread sizes can be configured in an application
requests. server).
In the Model 2 MVC architecture, servlets process requests and select JSP views. So servlets act as controller.
Servlets intercept the incoming HTTP requests from the client (browser) and then dispatch the request to the
business logic model (e.g. EJB, POJO - Plain Old Java Object, JavaBeans etc). Then select the next JSP view for
display and deliver the view to client as the presentation (response). It is the best practice to use Web tier UI
frameworks like Struts, JavaServer Faces etc, which uses proven and tested design patterns.
Q 10: HTTP is a stateless protocol, so how do you maintain state? How do you store user data between requests? SF
PIBP
A 10: This is a commonly asked question as well. You can retain the state information between different page requests
as follows:
HTTP Sessions are the recommended approach. A session identifies the requests that originate from the same
browser during the period of conversation. All the servlets can share the same session. The JSESSIONID is
generated by the server and can be passed to client through cookies, URL re-writing (if cookies are turned off) or
built-in SSL mechanism. Care should be taken to minimize size of objects stored in session and objects
stored in session should be serializable. In a Java servlet the session can be obtained as follows: CO
HttpSession session = request.getSession(); //returns current session or a new session
Sessions can be timed out (configured in web.xml) or manually invalidated.
Session Management
ServerClient
(Browser)
A new session is created on the Server
1. Initial Request[No session] side with JSESSIONID where JSESSIONID Name Value
state can be maintained as
xsder12345 Firstname Peter
2. JSESSIONID is passed to client with name/value pair.
e xsder12345 LastName Smith
the response through onfor thati
rm
fo
cookies or URL re-writing dstate
in
NIDre IO
e
sto S
S
v SE
trie ed J
re
3. Client uses the JSESSIONID pli
sup
for subsequent requests](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-12-2048.jpg)

![Find more WWW.ThesisScientist.com
Enterprise Java 71
ready state to service requests from clients. The container calls the servlet‟s service() method for handling each
request by spawning a new thread for each request from the Web container‟s thread pool [It is also possible to
have a single threaded Servlet, refer Q16 in Enterprise section]. Before destroying the instance the container will
call the destroy() method. After destroy() the servlet becomes the potential candidate for garbage collection.
Note on servlet reloading:
Most servers can reload a servlet after its class file has been modified provided the servlets are deployed to
$server_root/servlets directory. This is achieved with the help of a custom class loader. This feature is handy for development
and test phases. This is not recommended for production since it can degrade performance because of timestamp comparison
for each request to determine if a class file has changed. So for production it is recommended to move the servlet to server‟s
class path ie $server_root/classes.
When a server dispatches a request to a servlet, the server first checks if the servlet's class file has changed on disk. If it has
changed, the server abandons the class loader used to load the old version and creates a new instance of the custom class
loader to load the new version. Old servlet versions can stay in memory indefinitely (so the effect is the other classes can still
hold references to the old servlet instances, causing odd side effects, but the old versions are not used to handle any more
requests. Servlet reloading is not performed for classes found in the server's classpath because the core, primordial class loader,
loads those classes. These classes are loaded once and retained in memory even when their class files change.
Servlet Life Cycle
called once
thread 1 : client request
thread 2 : client request
thread 3 : client request
called once
ins tan tiate
& call init()
init()
ready to serve requests
handle m ultiple
servic e() requests and send response.
destroy()
Q 12: Explain the directory structure of a WEB application? SFSE
A 12: Refer Q7 in Enterprise section for diagram: J2EE deployment structure and explanation in this section where
MyAppsWeb.war is depicting the Web application directory structure. The directory structure of a Web application
consists of two parts:
A public resource directory (document root): The document root is where JSP pages, client-side classes
and archives, and static Web resources are stored.
A private directory called WEB-INF: which contains following files and directories:
web.xml : Web application deployment descriptor.
*.tld : Tag library descriptor files.
classes : A directory that contains server side classes like servlets, utility classes, JavaBeans etc.
lib : A directory where JAR (archive files of tag libraries, utility libraries used by the server side
classes) files are stored.
Note: JSP resources usually reside directly or under subdirectories of the document root, which are directly
accessible to the user through the URL. If you want to protect your Web resources then hiding the JSP files
behind the WEB-INF directory can protect the JSP files from direct access. Refer Q35 in Enterprise section.
Q 13: What is the difference between doGet () and doPost () or GET and POST? SFSE](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-14-2048.jpg)










![Find more WWW.ThesisScientist.com
82 Enterprise Java
Q 37: What is a TagExtraInfo class? SF
A 37: A TagExtraInfo class provides extra information about tag attributes to the JSP container at translation time.
Returns information about the scripting variables that the tag makes available to the rest of the JSP page
to use. The method used is:
VariableInfo[] getVariableInfo(TagData td)
Example
<html>
<myTag:addObjectsToArray name=”myArray” />
<myTag:displayArray name=”myArray” />
</html>
Without the use of TagExtraInfo, if you want to manipulate the attribute myArray in the above code in a
scriptlet it will not be possible. This is because it does not place the myArray object on the page. You can still
use pageContext.getAttribute() but that may not be a cleaner approach because it relies on the page
designer to correctly cast to object type. The TagExtraInfo can be used to make items stored in the
pageContext via setAttribute() method available to the scriptlet as shown below.
<html>
<myTag:addObjectsToArray name=”myArray” />
<%-- scriplet code %>
<% for(int i=0; i<myArray.length;i++){
html += <LI> + myArray[i] + </LI>;
%>
</html>
Validates the attributes passed to the Tag at translation time.
Example It can validate the myArray array list to have not more than 100 objects. The method used is:
boolean isValid(TagData data)
Q 38: What is the difference between custom JSP tags and JavaBeans? SF
A 38: In the context of a JSP page, both accomplish similar goals but the differences are:
Custom Tags JavaBeans
Can manipulate JSP content. Can‟t manipulate JSP content.
Custom tags can simplify the complex operations much Easier to set up.
better than the bean can. But require a bit more work to
set up.
Used only in JSPs in a relatively self-contained manner. Can be used in both Servlets and JSPs. You can define a bean in
one Servlet and use them in another Servlet or a JSP page.
JavaBeans declaration and usage example: CO
<jsp:useBean id="identifier" class="packageName.className"/> <jsp:setProperty
name="identifier" property="classField" value="someValue" />
<jsp:getProperty name="identifier" property="classField" /> <%=identifier.getclassField() %>
Q 39: Tell me about JSP best practices? BP
A 39:
Separate HTML code from the Java code: Combining HTML and Java code in the same source code can
make the code less readable. Mixing HTML and scriplet will make the code extremely difficult to read and
maintain. The display or behaviour logic can be implemented as a custom tags by the Java developers and
Web designers can use these Tags as the ordinary XHTML tags.
Place data access logic in JavaBeans: The code within the JavaBean is readily accessible to other JSPs
and Servlets.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-25-2048.jpg)


![Find more WWW.ThesisScientist.com
Enterprise Java 85
The above code ensures that both operation 1 and operation 2 succeed or fail as an atomic unit and consequently
leaves the database in a consistent state. Also turning auto-commit off will provide better performance.
Q 44: What is the difference between JDBC-1.0 and JDBC-2.0? What are Scrollable ResultSets, Updateable ResultSets,
RowSets, and Batch updates? SF
A 44: JDBC2.0 has the following additional features or functionality:
JDBC 1.0 JDBC 2.0
With JDBC-1.0 the With JDBC 2.0 ResultSets are updateable and also you can move forward and backward.
ResultSet functionality
was limited. There was no Example This example creates an updateable and scroll-sensitive ResultSet
support for updates of any
kind and scrolling through Statement stmt = myConnection.createStatement(ResultSet.TYPE_SCROLL_SENSITIVE,
the ResultSets was ResultSet.CONCUR_UPDATEABLE)
forward only (no going
back)
With JDBC-1.0 the With JDBC-2.0 statement objects can be grouped into a batch and executed at once. We call
statement objects submits addBatch() multiple times to create our batch and then we call executeBatch() to send the SQL
updates to the database statements off to database to be executed as a batch (this minimises the network overhead).
individually within same or
separate transactions. Example
This is very inefficient
large amounts of data Statement stmt = myConnection.createStatement();
need to be updated. stmt.addBatch(“INSERT INTO myTable1 VALUES (1,”ABC”)”);
stmt.addBatch(“INSERT INTO myTable1 VALUES (2,”DEF”)”);
stmt.addBatch(“INSERT INTO myTable1 VALUES (3,”XYZ”)”);
…
int[] countInserts = stmt.executeBatch();
- The JDBC-2.0 optional package provides a RowSet interface, which extends the ResultSet. One
of the implementations of the RowSet is the CachedRowSet, which can be considered as a
disconnected ResultSet.
Q 45: How to avoid the “running out of cursors” problem? DCPIMI
A 45: A database can run out of cursors if the connection is not closed properly or the DBA has not allocated enough
cursors. In a Java code it is essential that we close all the valuable resources in a try{} and finally{} block. The
finally{} block is always executed even if there is an exception thrown from the catch {} block. So the resources like
connections and statements should be closed in a finally {} block. CO
Try{} Finally {} blocks to close Exceptions
Wrong Approach - Right Approach -
Connections and statements will not be closed if there public void executeSQL() throws SQLException{
is an exception: try{
Connection con = DriverManager.getConnection(........);
public void executeSQL() throws SQLException{ .....
Statement stmt = con.createStatement();
Connection con = DriverManager.getConnection(........);
....
//line 20 where exception is thrown
..... ResultSet rs = stmt.executeQuery("SELECT * from myTable");
Statement stmt = con.createStatement(); .....
.... }
//line 20 where exception is thrown finally{
ResultSet rs = stmt.executeQuery("SELECT * from myTable"); try {
..... if(rs != null) rs.close();
rs.close(); if(stmt != null) stmt.close();
stmt.close(); if(con != null) con.close();
con.close(); }
} catch(Exception e){}
}
Note: if an exception is thrown at line 20 then the }
close() statements are never reached.
Note: if an exception is thrown at line 20 then the
finally clause is called before the exception is thrown to
the method.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-28-2048.jpg)





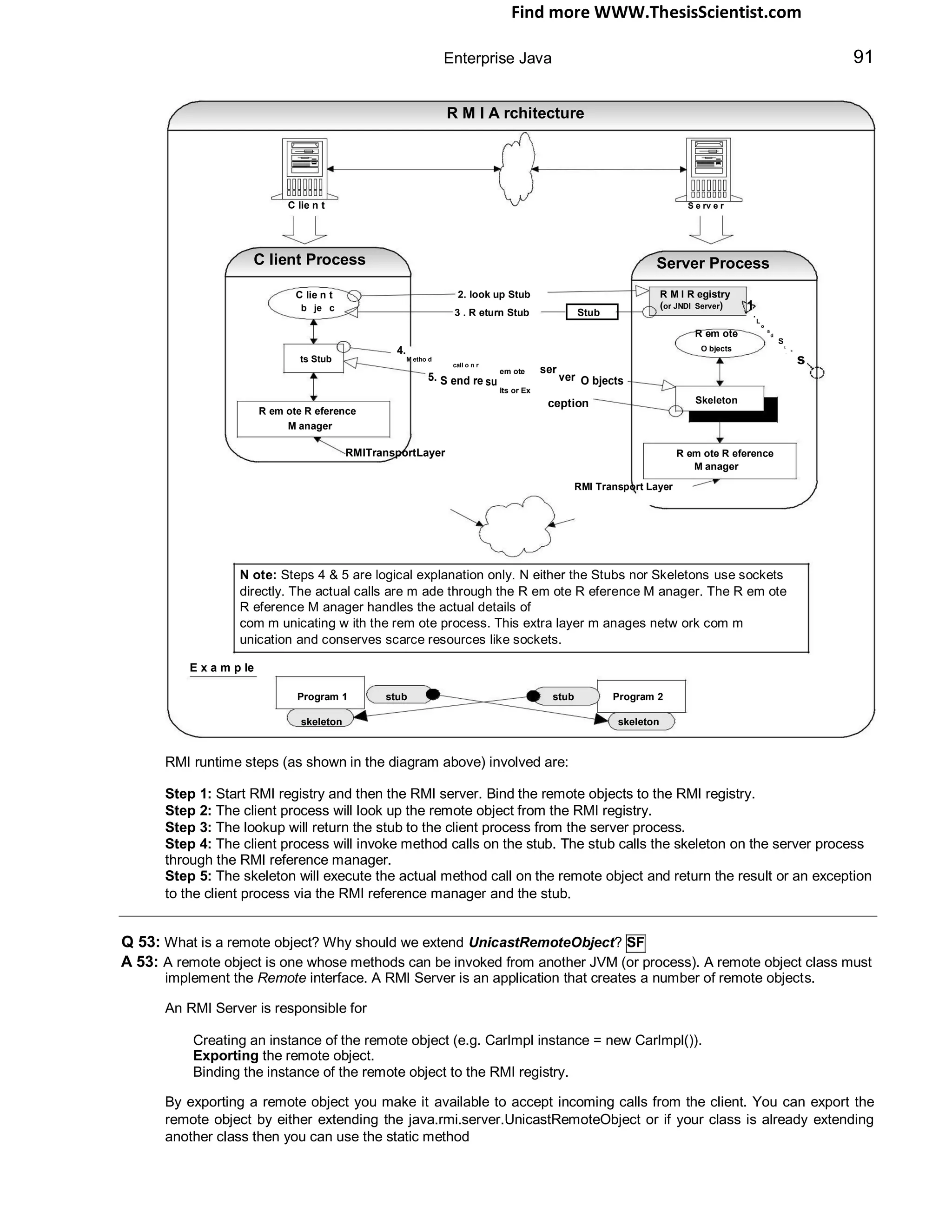
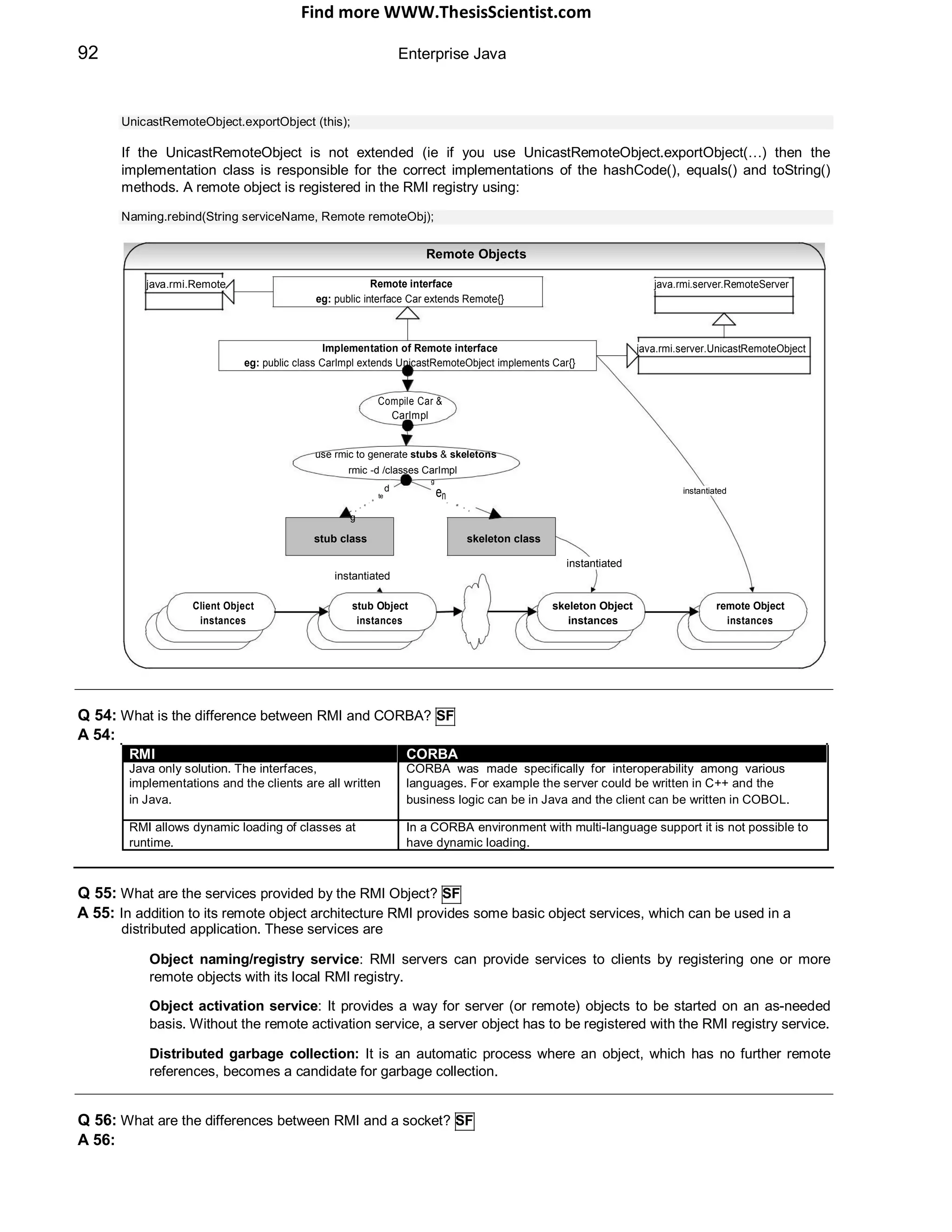
























![Find more WWW.ThesisScientist.com
Enterprise Java 117
</head>
</html>
Now to convert the Sample.xml into a PDF file apply the
following FO (Formatting Objects) file Through the FOP
processor.
Sample.fo
<?xml version="1.0" encoding="ISO-8859-1"?>
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format">
<fo:layout-master-set>
<fo:simple-page-master master-name="A4">
</fo:simple-page-master>
</fo:layout-master-set>
<fo:page-sequence master-reference="A4">
<fo:flow flow-name="xsl-region-body">
<fo:block>
<xsl:value-of select="content[@language='English']">
</fo:block>
</fo:flow>
</fo:page-sequence>
</fo:root>
which gives a basic Sample.pdf which has the following line
Not Much
XPath Xml Path Language, a language for addressing parts of an As per Sample.xsl
XML document, designed to be used by both XSLT and
XPointer. We can write both the patterns (context-free) and <xsl:template match=”content[@language=‟English‟]”>
expressions using the XPATH Syntax. XPATH is also used ………
in XQuery. <td><xsl:value-of select=”content/@language” /></td>
JAXP Stands for Java API for XML Processing. This provides a DOM example using JAXP:
common interface for creating and using SAX, DOM, and
XSLT APIs in Java regardless of which vendor‟s DocumentBuilderFactory dbf =
implementation is actually being used (just like the JDBC, DocumentBuilderFactory.newInstance();
JNDI interfaces). JAXP has the following packages: DocumentBuilder db = dbf.newDocumentBuilder();
Document doc =
db.parse(new File("xml/Test.xml"));
NodeList nl = doc.getElementsByTagName("to");
Node n = nl.item(0);
System.out.println(n.getFirstChild().getNodeValue());
SAX example using JAXP:
SAXParserFactory spf =
SAXParserFactory.newInstance();
SAXParser sp = spf.newSAXParser();
SAXExample se = new SAXExample();
sp.parse(new File("xml/Sample.xml"),se);
where SAXExample.Java code snippet
public class SAXExample extends DefaultHandler {
public void startElement(
String uri,
String localName,
String qName,
Attributes attr)
throws SAXException {
System.out.println("--->" + qName);
}
...
}](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-62-2048.jpg)





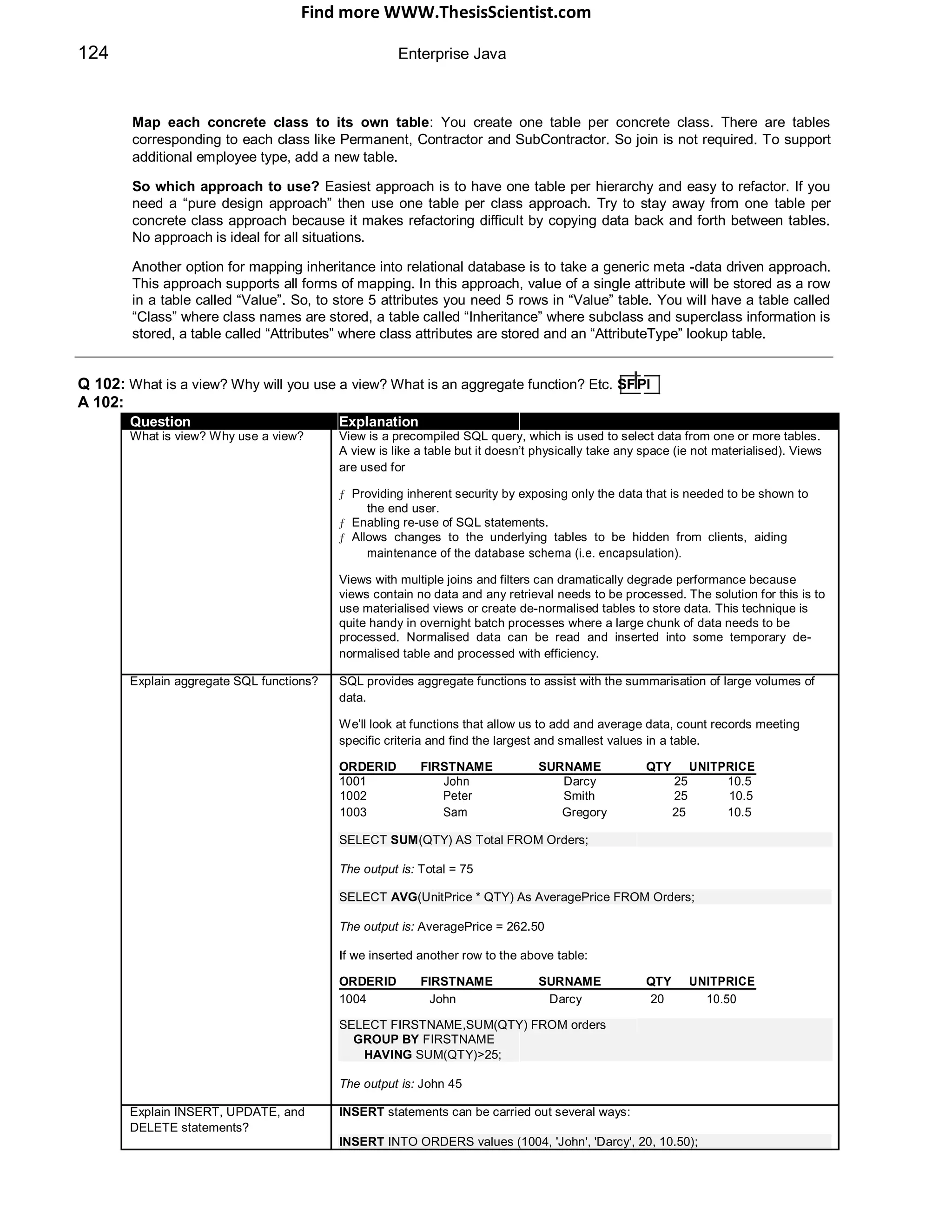
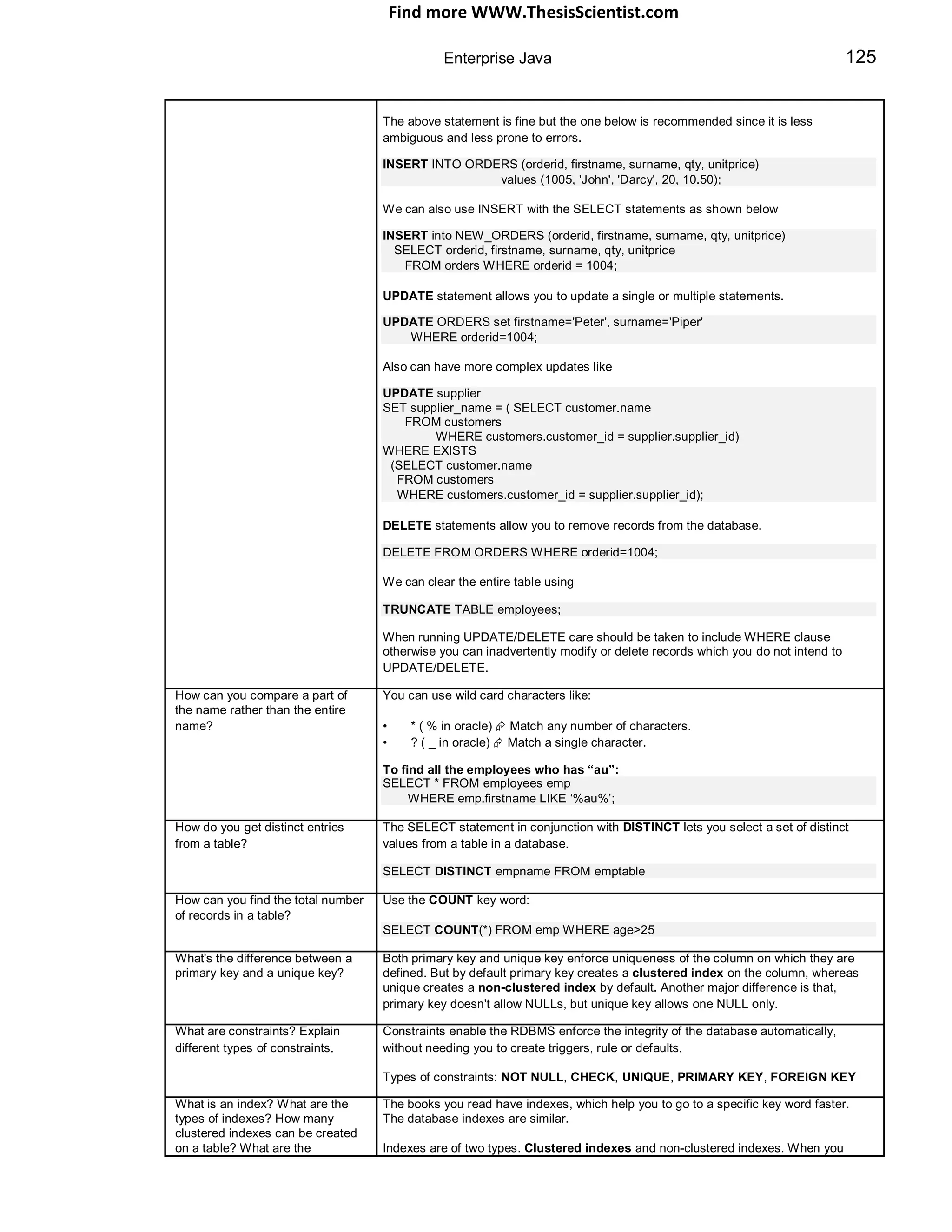



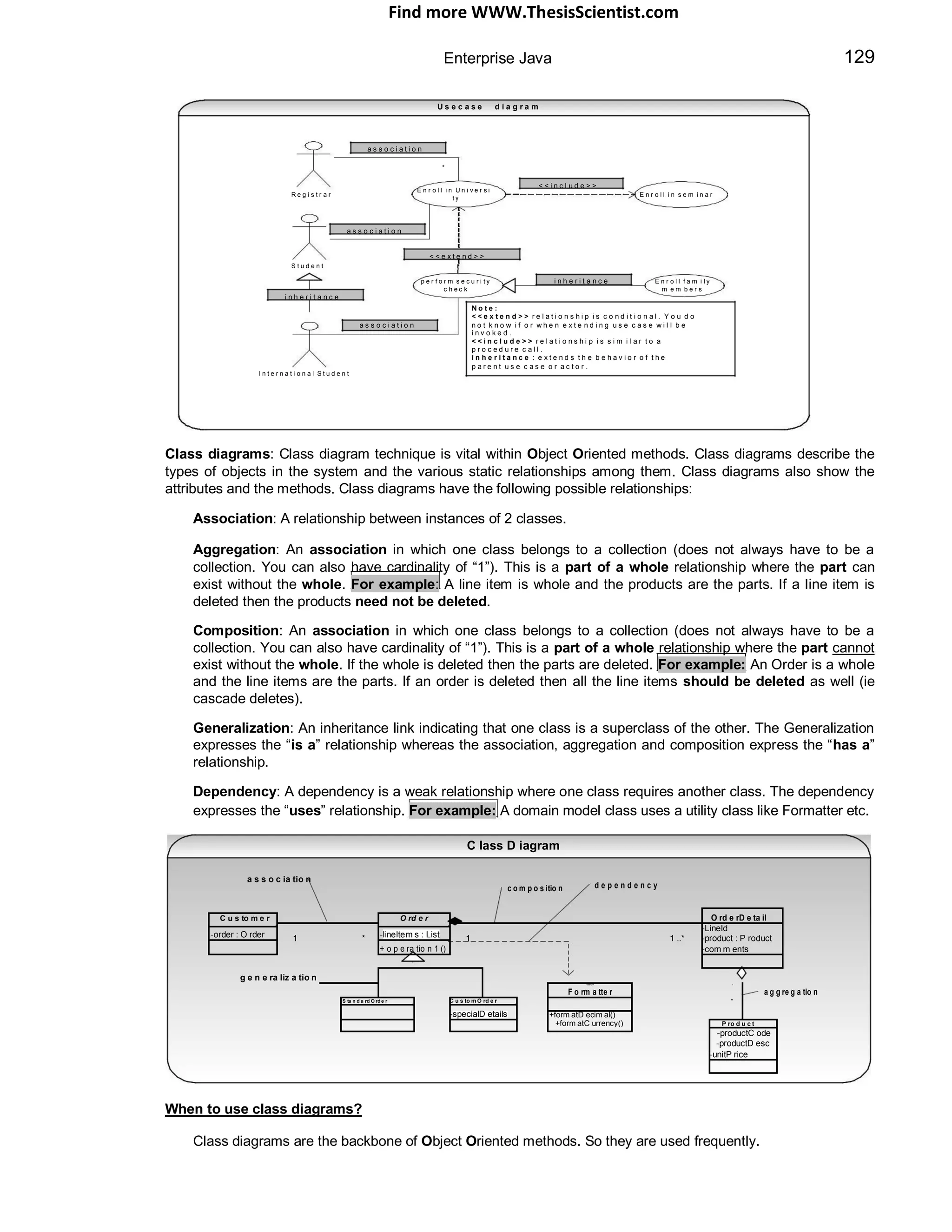
![Find more WWW.ThesisScientist.com
130 Enterprise Java
Class diagrams can have a conceptual perspective and an implementation perspective. During the analysis
draw the conceptual model and during implementation draw the implementation model.
Package diagrams: To simplify complex class diagrams you can group classes into packages.
P a c k a g e D i a g r a m
A c c o u n t i n g O r d e r i n g
d e p e n d e n c y
d e p e n d e n c y
C u s t o m e r
When to use package diagrams?
Package diagrams are vital for large projects.
Object diagrams: Object diagrams show instances instead of classes. They are useful for explaining some
complicated objects in detail about their recursive relationships etc.
O b je c t D ia g r a m
O b je c t D ia g r a m
C la s s D ia g r a m
o b je c t n a m ep h y s ic s M a th s : D e p a r tm e n t
C la s s n a m e
1
0 . . *
im p r o v e c la r ity p h y s ic s : D e p a rtm e n t m a th : D e p a r tm e n t
D e p a r t m e n t
p u r e M a th : D e p a rtm e n t a p p lie d M a th : D e p a rtm e n t
R e c u r s iv e c la s s
d ia g ra m d iffic u lt to fu lly
u n d e r s ta n d S h o w s th e d e ta ils o f th e r e c u rs iv e o b je c t re la tio n s h ip
When to use object diagrams?
Object diagrams are a vital for large projects.
They are useful for explaining structural relationships in detail for complex objects.
Sequence diagrams: Sequence diagrams are interaction diagrams which detail what messages are sent and
when. The sequence diagrams are organized according to time. The time progresses as you move from top to
bottom of the diagram. The objects involved in the diagram are shown from left to right according to when they
take part.
S e q u e n c e D ia g r a m
c lie n t a n O r d e r : O r d e r
a n E n tr y : O r d e r E n tr y
c h e c k if s u ffic ie n t d e ta ils
m a k e A n O r d e r ( ) m a k e A n O r d e r ( ) a r e a v a ila b le
fo r e a c h lin e I te m
it e r a t io n [ f o r e a c h ... ] ( )
h a s S u ffic ie n tD e ta ils ( )
c o n fir m : C o n f ir m a tio n
p r in tC o n fir m a tio n ( )
N o te : E a c h v e r t ic a l d o tt e d lin e is a
lin e a r e c a lle d t h e a c t iv a t io n b a r
lif e lin e . E a c h a r r o w is a m e s s a g e . T h e r e c t a n g u la r b o x e s o n t h e lif e w h ic h
r e p r e s e n ts t h e d u r a t io n o f e x e c u t io n o f m e s s a g e .](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-75-2048.jpg)







![Find more WWW.ThesisScientist.com
138 Enterprise Java
www.company1.com to the IP address 192.168.0.10. The Web server on the machine that has the IP address
192.168.0.10, so it receives the request. The Web server determines which virtual host to use by matching the
request URL It gets from an HTTP header submitted by the browser with the “ServerName” parameter in the
configuration file shown above.
Name-based virtual hosting is usually easier, since you have to only configure your DNS server to map each
hostname to a single IP address and then configure the Web server to recognize the different hostnames as
discussed in the previous paragraph. Name-based virtual hosting also eases the demand for scarce IP
addresses limited by physical network connections [but modern operation systems supports use of virtual
interfaces, which are also known as IP aliases]. Therefore you should use name-based virtual hosting unless
there is a specific reason to choose IP-based virtual hosting. Some reasons why you might consider using IP-
based virtual hosting:
Name-based virtual hosting cannot be used with SSL based secure servers because of the nature of the
SSL protocol.
Some operating systems and network equipment implement bandwidth management techniques that cannot
differentiate between hosts unless they are on separate IP addresses.
IP based virtual hosts are useful, when you want to manage more than one site (like live, demo, staging etc)
on the same server where hosts inherit the characteristics defined by your main host. But when using SSL
for example, a unique IP address is necessary.
For example in development environment when using the test client and the server on the same machine we can
define the host file as shown below:
UNIX user: /etc/hosts
Windows user: C:WINDOWSSYSTEM32DRIVERSETCHOSTS
localhost
www.company1.com
www.company2.com
[Reference: http://httpd.apache.org/docs/1.3/vhosts/]
Q 120: What is application server clustering? SI
A 120: An application server cluster consists of a number of application servers loosely coupled on a network. The
server cluster or server group is generally distributed over a number of machines or nodes. The important point
to note is that the cluster appears as a single server to its clients.
The goals of application server clustering are:
Scalability: should be able to add new servers on the existing node or add new additional nodes to
enable the server to handle increasing loads without performance degradation, and in a manner
transparent to the end users.
Load balancing: Each server in the cluster should process a fair share of client load, in proportion to its
processing power, to avoid overloading of some and under utilization of other server resources. Load
distribution should remain balanced even as load changes with time.
High availability: Clients should be able to access the server at almost all times. Server usage should be
transparent to hardware and software failures. If a server or node fails, its workload should be moved
over to other servers, automatically as fast as possible and the application should continue to run
uninterrupted. This method provides a fair degree of application system fault-tolerance. After failure, the
entire load should be redistributed equally among working servers of the system.
[Good read: Uncover the hood of J2EE clustering by Wang Yu on http://www.theserverside.com ]
Q 121: Explain Java Management Extensions (JMX)? SF
A 121: JMX framework can improve the manageability of your application by](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-83-2048.jpg)

![Find more WWW.ThesisScientist.com
140 Enterprise Java
Recycle your valuable resources by either pooling or caching. You should create a limited number of
resources and share them from a common pool (e.g. pool of threads, pool of database connections, pool of
objects etc). Caching is simply another type of pooling where instead of pooling a connection or object, you
are pooling remote data (database data) and placing it in the memory (using Hashtable etc).
Avoid embedding business logic in a protocol dependent manner like in JSPs, HttpServlets, Struts
action classes etc. This is because your business logic should be not only executed by your Web clients but
also required to be shared by various GUI clients like Swing based stand alone application, WAP clients etc.
Automate the build process with tools like Ant, CruiseControl, and Maven etc. In an enterprise application
the build process can become quite complex and confusing.
Build test cases first (i.e. Test Driven Development (TDD), refer section Emerging Technologies) using
tools like JUnit. Automate the testing process and integrate it with build process.
Separate HTML code from the Java code: Combining HTML and Java code in the same source code can
make the code less readable. Mixing HTML and scriplet will make the code extremely difficult to read and
maintain. The display or behaviour logic can be implemented as a custom tags by the Java developers and
Web designers can use these Tags as the ordinary XHTML tags.
It is best practice to use multi-threading and stay away from single threaded model of the servlet unless
otherwise there is a compelling reason for it. Shared resources can be synchronized or used in read-only
manner or shared values can be stored in a database table. Single threaded model can adversely affect
performance.
Apply the following JSP best practices:
Place data access logic in JavaBeans: The code within the JavaBean is readily accessible to other
JSPs and Servlets.
Factor shared behaviour out of Custom Tags into common JavaBeans classes: The custom tags
are not used outside JSPs. To avoid duplication of behaviour or business logic, move the logic into
JavaBeans and get the custom tags to utilize the beans.
Choose the right “include” mechanism: What are the differences between static and a dynamic
include? Using includes will improve code reuse and maintenance through modular design. Which one
to use? Refer Q31 in Enterprise section.
Use style sheets (e.g. css), template mechanism (e.g. struts tiles etc) and appropriate comments
(both hidden and output comments).
If you are using EJBs apply the EJB best practices as described in Q82 in Enterprise section.
Use the J2EE standard packaging specification to improve portability across Application Servers.
Use proven frameworks like Struts, Spring, Hibernate, JSF etc.
Apply appropriate proven J2EE design patterns to improve performance and minimise network
communications cost (Session façade pattern, Value Object pattern etc).
Batch database requests to improve performance. For example
Connection con = DriverManager.getConnection(……).
Statement stmt = con.createStatement().
stmt.addBatch(“INSERT INTO Address…………”);
stmt.addBatch(“INSERT INTO Contact…………”);
stmt.addBatch(“INSERT INTO Personal”);
int[] countUpdates = stmt.executeBatch();
Use “PreparedStatements” instead of ordinary “Statements” for repeated reads.
Avoid resource leaks by
Closing all database connections after you have used them.
Clean up objects after you have finished with them especially when an object having a long life cycle
refers to a number of objects with short life cycles (you have the potential for memory leak).](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-85-2048.jpg)
![Find more WWW.ThesisScientist.com
Enterprise Java 141
Poor exception handling where the connections do not get closed properly and clean up code that
never gets called. You should put clean up code in a finally {} block.
Handle and propagate exceptions correctly. Decide between checked and unchecked (i.e RunTime
exceptions) exceptions.
Q 125: Explain some of the J2EE best practices to improve performance? BPPI
A 125: In short manage valuable resources wisely and recycle them where possible, minimise network overheads and
serialization cost, and optimise all your database operations.
Manage and recycle your valuable resources by either pooling or caching. You should create a limited
number of resources and share them from a common pool (e.g. pool of threads, pool of database
connections, pool of objects etc). Caching is simply another type of pooling where instead of pooling a
connection or object, you are pooling remote data (database data), and placing it in memory (using
Hashtable etc). Unused stateful session beans must be removed explicitly and appropriate idle timeout
should be set to control stateful session bean life cycle.
Use effective design patterns to minimise network overheads (Session facade, Value Object etc Refer
Q84, Q85 in Enterprise section), use of fast-lane reader pattern for database access (Refer Q86 in
Enterprise section). Caching of retrieved JNDI InitialContexts, factory objects (e.g. EJB homes) etc. using
the service locator design pattern, which reduces expensive JNDI access with the help of caching
strategies.
Minimise serialization costs by marking references (like file handles, database connections etc), which do
not required serialization by declaring them „transient‟ (Refer Q19 in Java section). Use pass-by-reference
where possible as opposed to pass by value.
Set appropriate timeouts: for the HttpSession objects, after which the session expires, set idle timeout for
stateful session beans etc.
Improve the performance of database operations with the following tips:
Database connections should be released when not needed anymore, otherwise there will be potential
resource leakage problems.
Apply least restrictive but valid transaction isolation level.
Use JDBC prepared statements for overall database efficiency and for batching repetitive inserts and
updates. Also batch database requests to improve performance.
When you first establish a connection with a database by default it is in auto-commit mode. For better
performance turn auto-commit off by calling the connection.setAutoCommit(false) method.
Where appropriate (you are loading 100 objects into memory but use only 5 objects) lazy load your
data to avoid loading the whole database into memory using the virtual proxy pattern. Virtual proxy is
an object, which looks like an object but actually contain no fields until when one of its methods is
called does it load the correct object from the database.
Where appropriate eager load your data to avoid frequently accessing the database every time over
the network.
Enterprise – Logging, testing and deployment
Q 126: Give an overview of log4J? SF
A 126: Log4j is a logging framework for Java. Log4J is designed to be fast and flexible. Log4J has 3 main components
which work together to enable developers to log messages:
Loggers [was called Category prior to version 1.2]
Appenders
Layout](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-86-2048.jpg)
![Find more WWW.ThesisScientist.com
142 Enterprise Java
Logger: The foremost advantage of any logging API like log4J, apache commons logging etc over plain
System.out.println is its ability to disable certain log statements while allowing others to print unhindered.
Loggers are hierarchical. The root logger exists at the top of the hierarchy. The root logger always exists and it
cannot be retrieved by name. The hierarchical nature of the logger is denoted by “.” notation. For example the
logger “java.util” is the parent of child logger “java.util.Vector” and so on. Loggers may be assigned priorities
such as DEBUG, INFO, WARN, ERROR and FATAL. If a given logger is not assigned a priority, then it inherits
the priority from its closest ancestor. The logging requests are made by invoking one of the following printing
methods of the logger instance: debug(), info(), warn(), error(), fatal().
Appenders and Layouts: In addition to selectively enabling and disabling logging requests based on the logger,
the log4J allows logging requests to multiple destinations. In log4J terms the output destination is an appender.
There are appenders for console, files, remote sockets, JMS, etc. One logger can have more than one
appender. A logging request for a given logger will be forwarded to all the appenders in that logger plus the other
appenders higher in the hierarchy. In addition to the output destination the output format can be categorised as
well. This is accomplished by associating layout with an appender. The layout is responsible for formatting the
logging request according to user‟s settings.
Sample configuration file:
#set the root logger priority to DEBUG and its appender to App1
log4j.rootLogger=DEBUG, App1
#App1 is set to a console appender
log4j.appender.App1=org.apache.log4j.ConsoleAppender
#appender App1 uses a pattern layout
log4j.appender.App1.layout=org.apache.log4j.PatternLayout.
log4j.appender.App1.layout.ConversionPattern=%-4r [%t] %-5p %c %x -%m%n
# Print only messages of priority WARN or above in the package com.myapp
log4j.Logger.com.myapp=WARN
XML configuration for log4j is available, and is usually the best practise.
Q 127: How do you initialize and use Log4J? SFCO
A 127:
public class MyApp {
//Logger is a utility wrapper class to be written with appropriate printing
methods static Logger log = Logger.getLogger (MyApp.class.getName());
public void my method() {
if(log.isDebugEnabled())
log.debug(“This line is reached………………………..” + var1 + “-” + var2);
)
}
}
Q 128: What is the hidden cost of parameter construction when using Log4J? SFPI
A 128:
Do not use in frequently accessed methods or loops: CO
log.debug (“Line number” + intVal + “ is less than ” + String.valueOf(array[i]));
The above construction has a performance cost in frequently accessed methods and loops in constructing
the message parameter, concatenating the String etc regardless of whether the message will be logged or not.
Do use in frequently accessed methods or loops: CO
If (log.isDebugEnabled()) {
log.debug (“Line number” + intVal + “ is less than ” + String.valueOf(array[i]));
}](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-87-2048.jpg)
![Find more WWW.ThesisScientist.com
Enterprise Java 143
The above construction will avoid the parameter construction cost by only constructing the message parameter
when you are in debug mode. But it is not a best practise to place log.isDebugEnabled() around all debug code.
Q 129: What is the test phases and cycles? SD
A 129:
Unit tests (e.g. JUnit etc, carried out by developers).
There are two popular approaches to testing server-side classes: mock objects, which test classes by
simulating the server container, and in-container testing, which tests classes running in the actual server
container. If you are using Struts framework, StrutsTestCase for JUnit allows you to use either approach,
with very minimal impact on your actual unit test code.
System tests or functional tests (carried out by business analysts and/or testers).
Integration tests (carried out by business analysts, testers, developers etc).
Regression tests (carried out by business analysts and testers).
Stress volume tests or load tests (carried out by technical staff).
User acceptance tests (UAT – carried out by end users).
Each of the above test phases will be carried out in cycles. Refer Q13 in How would you go about… section for
JUnit, which is an open source unit-testing framework.
Q 130: Brief on deployment environments you are familiar with?
A 130: Differ from project team to project team [Hint] :
Application environments where “ear” files get deployed.
Development box: can have the following instances of environments in the same machine (need not be
clustered).
Development environment Æ used by developers.
System testing environment Æ used by business analysts.
Staging box: can have the following instances of environments in the same machine (preferably clustered
servers with load balancing)
Integration testing environment Æ used for integration testing, user acceptance testing etc.
Pre-prod environment Æ used for user acceptance testing, regression testing, and load testing or stress
volume testing (SVT). [This environment should be exactly same as the production environment].
Production box:
Production environment Æ live site used by actual users.
Data environments (Database)
Note: Separate boxes [not the same boxes as where applications (i.e. ear files) are deployed]
Development box (database).
Used by applications on development and system testing environments. Separate instances can be
created on the same box for separate environments like development and system testing.
Staging Box (database)
Used by applications on integration testing and user acceptance testing environments. Separate
instances can be created on the same box for separate environments.
Production Box (database)
Live data used by actual users of the system.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-88-2048.jpg)
![Find more WWW.ThesisScientist.com
144 Enterprise Java
Enterprise - Personal
Q 131: Tell me about yourself or about some of the recent projects you have worked with? What do you consider your
most significant achievement? Why do you think you are qualified for this position? Why should we hire you and
what kind of contributions will you make?
A 131: [Hint:] Pick your recent projects and give a brief overview of it. Also it is imperative that during your briefing that
you demonstrate how you applied your skills and knowledge in some of the following key areas and fixed any
issues.
Design Concepts: Refer Q02, Q03, Q19, Q20, Q21, Q91, Q98, and Q101.
Design Patterns: Refer Q03, Q24, Q25, Q83, Q84, Q85, Q86, Q87, Q88 and Q111.
Performance issues: Refer Q10, Q16, Q45, Q46, Q97, Q98, Q100, Q123, and Q125.
Memory issues: Refer Q45 and Q93
Multi-threading (Concurrency issues): Refer Q16, Q34, and Q113
Exception Handling: Refer Q76 and Q77
Transactional issues: Refer Q43, Q71, Q72, Q73, Q74, Q75 and Q77.
Security issues: Refer Q23, Q58, and Q81
Scalability issues: Refer Q20, Q21, Q120 and Q122.
Best practices: Refer Q10, Q16, Q39, Q40, Q46, Q82, Q124, and Q125
Refer Q66 – Q72 in Java section for frequently asked non-technical questions.
Q 132: Have you used any load testing tools?
A 132: Rational Robot, JMeter, LoadRunner, etc.
Q 133: What source control systems have you used? SD
A 133: CVS, VSS (Visual Source Safe), Rational clear case etc. Refer Q13 in How would you go about section…. for
CVS.
Q 134: What operating systems are you comfortable with? SD
A 134: NT, Unix, Linux, Solaris etc
Q 135: Which on-line technical resources do you use to resolve any design and/or development issues?
A 135: http://www.theserverside.com, http://www.javaworld.com, http://www-136.ibm.com/developerworks/Java/,
http://java.sun.com/, www.javaperformancetuning.com etc
Enterprise – Software development process
Q 136: What software development processes/principles are you familiar with? SD
A 136: Agile (i.e. lightweight) software development process is gaining popularity and momentum across
organizations.
Agile software development manifesto Æ [Good read: http://www.agilemanifesto.org/principles.html].
Highest priority is to satisfy the customer.
Welcome requirement changes even late in development life cycle.
Business people and developers should work collaboratively.
Form teams with motivated individuals who produce best designs and architectures.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-89-2048.jpg)
![Find more WWW.ThesisScientist.com
Enterprise Java 145
Teams should be pro-active on how to become more effective without becoming complacent.
Quality working software is the primary measure of progress.
Why is iterative development with vertical slicing used in agile development? Your overall software quality
can be improved through iterative development, which provides you with constant feedback.
Traditional Vs Agile approach
Traditional approach
scop
e
1
2
Business Layer
technica
l
mileston
e
milestone
Data Layer Data Layer
project time
Agile (light w eight )approach
Present Presentatio
sc
op
e
ation
1
n Layer 2Layer
tech
nical
Busines
iterat
ion
Business
iteratio
n
s layesr Data L ayer
layesr
Data
Layer
project time
Presentation Layer
Business Layer
Data Layer
Presentation Layer
Business Layer
Data Layer
milestone3iteration3
With the tradional approach, Say for example
w e have a fundamental flaw in the data layer,
if this flaw gets only picked up after the
milestone 3, then there w ill be lot of rew ork to
be done to the business and the presentation
layer. This is the major draw back w ith the
traditional development approach w here there
is no vertical slicing.
As you can see w ith the agileiterative
approach, a vertical slice is built for each
iteration. So any fundamental flaw in design or
coding can be picked up early and rectified.
Even deployment and testing w ill be carried
out in vertical slices.
Several methodologies fit under this agile development methodology banner. All these methodologies share
many characteristics like iterative and incremental development, test driven development, stand up
meetings to improve communication, automatic testing, build and continuous integration of code etc.
Among all the agile methodologies XP is the one which has got the most attention. Different companies use
different flavours of agile methodologies by using different combinations of methodologies.
How does vertical slicing influence customer perception? With the iterative and incremental approach,
customer will be comfortable with the progress of the development as opposed to traditional big bang approach.
TradionalVsAgileperceivedfunctionality
As far as the developer is concerned As far as the developer is concerned
65% of coding has been completed and
Traditional
65% of coding has been completed but
Agile from the customer's view 65% of the
from the customer's view only 20% of
functionality has been completed. So
the functionality has been completed
the customer is happy.
Presentation Layer PresentationLayer
BusinessLayer BusinessLayer
DataLayer DataLayer
EXtreme Programming [XP] Æ simple design, pair programming, unit testing, refactoring, collective code
ownership, coding standards, etc. Refer Q10 in “How would you go about…” section. XP has four key
values: Communication, Feedback, Simplicity and Courage. It then builds up some tried and tested
practices and techniques. XP has a strong emphasis on testing where tests are integrated into continuous
integration and build process, which yields a highly stable platform. XP is designed for smaller teams of 20
– 30 people.
RUP (Rational Unified Process) Æ Model driven architecture, design and development; customizable
frameworks for scalable process; iterative development methodology; Re-use of architecture, code,
component, framework, patterns etc. RUP can be used as an agile process for smaller teams of 20-30](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-90-2048.jpg)
![Find more WWW.ThesisScientist.com
146 Enterprise Java
people, or as a heavy weight process for larger teams of 50-100 people. Refer Q103 – Q105 in Enterprise
section.
Feature Driven Development [FDD] Æ Jeff De Luca and long time OO guru Peter Coad developed feature
Driven Development (FDD). Like the other adaptive methodologies, it focuses on short iterations that
deliver tangible functionality. FDD was originally designed for larger project teams of around 50 people. In
FDD's case the iterations are two weeks long. FDD has five processes. The first three are done at the
beginning of the project. The last two are done within each iteration.
Develop an Overall Model
Build a Features List
Plan by Feature
Design by Feature
Build by Feature
The developers come in two kinds: class owners and chief programmers. The chief programmers are the
most experienced developers. They are assigned features to be built. However they don't build them alone.
Instead the chief programmer identifies which classes are involved in implementing the feature and gathers
their class owners together to form a feature team for developing that feature. The chief programmer acts
as the coordinator, lead designer, and mentor while the class owners do much of the coding of the feature.
Test Driven Development [TDD] Æ TDD is an iterative software development process where you first write
the test with the idea that it must fail. Refer Q1 in Emerging Technologies/Frameworks section…
Scrum Æ Scrum divides a project into sprints (aka iterations) of 30 days. Before you begin a sprint you
define the functionality required for that sprint and leave the team to deliver it. But every day the team holds
a short (10 – 15 minute) meeting, called a scrum where the team runs through what it will achieve in the
next day. Some of the questions asked in the scrum meetings are:
What did you do since the last scrum meetings?
Do you have any obstacles?
What will you do before next meeting?
This is very similar to stand-up meetings in XP and iterative development process in RUP.
Enterprise – Key Points
J2EE is a 3-tier (or n-tier) system. Each tier is logically separated and loosely coupled from each other, and may be
distributed.
J2EE applications are developed using MVC architecture, which divides the functionality of displaying and
maintaining of the data to minimise the degree of coupling between enterprise components.
J2EE modules are deployed as ear, war and jar files, which are standard application deployment archive files.
HTTP is a stateless protocol and state can be maintained between client requests using HttpSession, URL rewriting,
hidden fields and cookies. HttpSession is the recommended approach.
Servlets and JSPs are by default multi-threaded, and care should be taken in declaring instance variables and
accessing shared resources. It is possible to have a single threaded model of a servlet or a JSP but this can
adversely affect performance.
Clustering promotes high availability and scalability. The considerations for servlet clustering are:
Objects stored in the session should be serializable.
Design for idempotence.
Avoid using instance and static variables in read and write mode.
Avoid storing values in the ServletContext.
Avoid using java.io.* and use getResourceAsStream() instead.](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-91-2048.jpg)




![Find more WWW.ThesisScientist.com
152 How would you go about…?
Q 01: How would you go about documenting your Java/J2EE application?
A 01: To be successful with a Java/J2EE project, proper documentation is vital.
Before embarking on coding get the business requirements down. Build a complete list of requested features,
sample screen shots (if available), use case diagrams, business rules etc as a functional specification
document. This is the phase where business analysts and developers will be asking questions about user
interface requirements, data tier integration requirements, use cases etc. Also prioritize the features based on
the business goals, lead-times and iterations required for implementation.
Prepare a technical specification document based on the functional specification. The technical
specification document should cover:
Purpose of the document: This document will emphasise the customer service functionality …
Overview: This section basically covers background information, scope, any inclusions and/or
exclusions, referenced documents etc.
Basic architecture: discusses or references baseline architecture document. Answers questions like
Will it scale? Can this performance be improved? Is it extendable and/or maintainable? Are there any
security issues? Describe the vertical slices to be used in the early iterations, and the concepts to be
proved by each slice. Etc. For example which MVC [model-1, model-2 etc] paradigms (Refer Q3 in
Enterprise section for MVC) should we use? Should we use Struts, JSF, Spring etc or build our own
framework? Should we use a business delegate (Refer Q83 in Enterprise section for business delegate)
to decouple middle tier with the client tier? Should we use AOP (Aspect Oriented Programming) (Refer
Q3 in Emerging Technologies/Frameworks)? Should we use dependency injection? Should we use
annotations? Do we require internationalization? Etc.
Assumptions, Dependencies, Risks and Issues: highlight all the assumptions, dependencies, risks
and issues. For example list all the risks you can identify.
Design alternatives for each key functional requirement. Also discuss why a particular design
alternative was chosen over the others. This process will encourage developers analyse the possible
design alternatives without having to jump at the obvious solution, which might not always be the best
one.
Processing logic: discuss the processing logic for the client tier, middle tier and the data tier. Where
required add process flow diagrams. Add any pre-process conditions and/or post-process conditions.
(Refer Q9 in Java section for design by contract).
UML diagrams to communicate the design to the fellow developers, solution designers, architects etc.
Usually class diagrams and sequence diagrams are required. The other diagrams may be added for any
special cases like (Refer Q107 in Enterprise section):
State chart diagram: useful to describe behaviour of an object across several usecases.
Activity diagram: useful to express complex operations. Supports and encourages parallel
behaviour. Activity and statechart diagrams are beneficial for workflow modelling with multi
threaded programming.
Collaboration and Sequence diagrams: Use a collaboration or sequence diagram when you
want to look at behaviour of several objects within a single use case. If you want to look at a single
object across multiple use cases then use statechart.
Object diagrams: The Object diagrams show instances instead of classes. They are useful for
explaining some complicated objects in detail such as highlighting recursive relationships etc.
List the package names, class names, database names and table names with a brief description of
their responsibility in a tabular form.
Prepare a coding standards document for the whole team to promote consistency and efficiency. Some
coding practices can degrade performance for example:
Inappropriate use of String class. Use StringBuffer instead of String for compute intensive mutations
(Refer Q17 in Java section).](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-97-2048.jpg)


![Find more WWW.ThesisScientist.com
How would you go about…? 155
Definition of class interfaces and inheritance hierarchy: Should we use an abstract class or an
interface? Is there any common functionality that we can move to the super class (or parent class)?
Should we use interface inheritance with object composition for code reuse as opposed to
implementation inheritance? Etc. (Refer Q8, Q10 in Java section).
Establishing key relationships (aggregation, composition, association etc): Should we use
aggregation or composition? [composition may require cascade delete] (Refer Q107, Q108 in Enterprise
section – under class diagrams). Should we use an “is a” (generalization) relationship or a “has a”
(composition) relationship? (Refer Q7 in Java section).
Applying polymorphism and encapsulation: Should we hide the member variables to improve
integrity and security? (Refer Q8 in Java section). Can we get a polymorphic behaviour so that we can
easily add new classes in the future? (Refer Q8 in Java section).
Applying well-proven design patterns (like Gang of four design patterns, J2EE design patterns, EJB
design patterns etc) help designers to base new designs on prior experience. Design patterns also help
you to choose design alternatives (Refer Q11 in How would you go about…).
Scalability of the system: Vertical scaling is achieved by increasing the number of servers running on
a single machine. Horizontal scaling is achieved by increasing the number of machines in the cluster.
Horizontal scaling is more reliable than the vertical scaling because there are multiple machines
involved in the cluster. In vertical scaling the number of server instances that can be run on one machine
are determined by the CPU usage and the JVM heap memory.
How do we replicate the session state? Should we use stateful session beans or HTTP session?
Should we serialize this object so that it can be replicated?
Internationalization requirements for multi-language support: Should we support other languages?
Should we support multi-byte characters in the database?
Vertical slicing: Getting the reusable and flexible design the first time is impossible. By developing the initial
vertical slice of your design you eliminate any nasty integration issues later in your project. Also get the
design patterns right early on by building the vertical slice. It will give you experience with what does work and
what does not work with Java/J2EE. Once you are happy with the initial vertical slice then you can apply it
across the application. The initial vertical slice should be based on a typical business use case. Refer Q136 in
Enterprise section.
Ensure the system is configurable through property files, xml descriptor files, annotations etc. This will
improve flexibility and maintainability. Avoid hard coding any values. Use a constant class for values, which
rarely change and use property files, xml descriptor files, annotations etc for values, which can change more
frequently (e.g. process flow steps etc) and/or environment related configurations(e.g. server name, server
port, LDAP server location etc).
Design considerations during design, development and deployment phases: designing a fast, secured,
reliable, robust, reusable and flexible system require considerations in the following key areas:
Performance issues (network overheads, quality of the code etc): Can I make a single coarse-grained
network call to my remote object instead of 3 fine-grained calls?
Concurrency issues (multi-threading etc): What if two threads access my object simultaneously will it
corrupt the state of my object?
Transactional issues (ACID properties): What if two clients access the same data simultaneously?
What if one part of the transaction fails, do we rollback the whole transaction? What if the client
resubmits the same transactional page again?
Security issues: Are there any potential security holes for SQL injection or URL injection by hackers?
Memory issues: Is there any potential memory leak problems? Have we allocated enough heap size for
the JVM? Have we got enough perm space allocated since we are using 3
rd
party libraries, which
generate classes dynamically? (e.g. JAXB, XSLT, JasperReports etc)
Scalability issues: Will this application scale vertically and horizontally if the load increases? Should
this object be serializable? Does this object get stored in the HttpSession?](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-100-2048.jpg)
![Find more WWW.ThesisScientist.com
156 How would you go about…?
Maintainability, reuse, extensibility etc: How can we make the software reusable, maintainable and
extensible? What design patterns can we use? How often do we have to refactor our code?
Logging and auditing if something goes wrong can we look at the logs to determine the root cause of
the problem?
Object life cycles: Can the objects within the server be created, destroyed, activated or passivated
depending on the memory usage on the server? (e.g. EJB).
Resource pooling: Creating and destroying valuable resources like database connections, threads etc
can be expensive. So if a client is not using a resource can it be returned to a pool to be reused when
other clients connect? What is the optimum pool size?
Caching can we save network trips by storing the data in the server‟s memory? How often do we have
to clear the cache to prevent the in memory data from becoming stale?
Load balancing: Can we redirect the users to a server with the lightest load if the other server is
overloaded?
Transparent fail over: If one server crashes can the clients be routed to another server without any
interruptions?
Clustering: What if the server maintains a state when it crashes? Is this state replicated across the
other servers?
Back-end integration: How do we connect to the databases and/or legacy systems?
Clean shutdown: Can we shut down the server without affecting the clients who are currently using the
system?
Systems management: In the event of a catastrophic system failure who is monitoring the system? Any
alerts or alarms? Should we use JMX? Should we use any performance monitoring tools like Tivoli etc?
Dynamic redeployment: How do we perform the software deployment while the site is running? (Mainly
for mission critical applications 24hrs X 7days).
Portability issues: Can I port this application to a different server 2 years from now?
Q 03: How would you go about identifying performance and/or memory issues in your Java/J2EE application?
A 03: Profiling can be used to identify any performance issues or memory leaks. Profiling can identify what lines of code
the program is spending the most time in? What call or invocation paths are used to reach at these lines? What
kinds of objects are sitting in the heap? Where is the memory leak? Etc.
There are many tools available for the optimization of Java code like JProfiler, Borland OptimizeIt etc.
These tools are very powerful and easy to use. They also produce various reports with graphs.
Optimizeit™ Request Analyzer provides advanced profiling techniques that allow developers to analyse the
performance behaviour of code across J2EE application tiers. Developers can efficiently prioritize the
performance of Web requests, JDBC, JMS, JNDI, JSP, RMI, and EJB so that trouble spots can be
proactively isolated earlier in the development lifecycle.
Thread Debugger tools can be used to identify threading issues like thread starvation and contention issues
that can lead to system crash.
Code coverage tools can assist developers with identifying and removing any dead code from the
applications.
Hprof which comes with JDK for free. Simple tool.
Java –Xprof myClass
java -Xrunhprof:[help]|[<option>=<value>]
java -Xrunhprof:cpu=samples, depth=6, heap=sites](https://image.slidesharecdn.com/javainterviewquestion3-170527052901/75/Java-Interview-Questions-Answers-Guide-Section-2-101-2048.jpg)




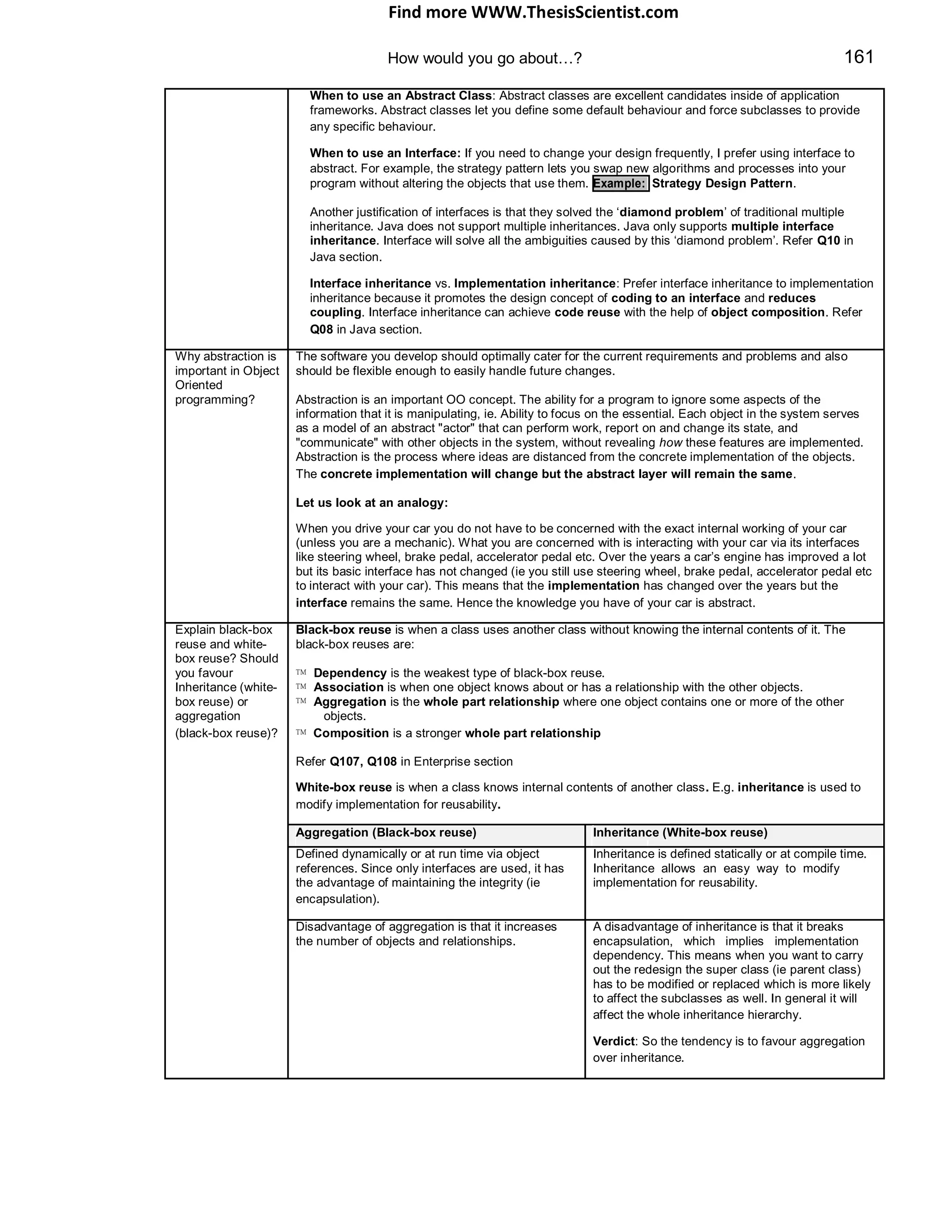





The document provides an overview of J2EE (Java 2 Enterprise Edition), detailing its components, architecture, services, and APIs used for developing enterprise applications. It explains the multi-tier architecture, emphasizing the separation of user interface logic, business logic, and database logic that enhances maintainability and scalability. Additionally, it discusses the role of MVC (Model-View-Controller) architecture in promoting loose coupling within J2EE applications.






















































