
































This document provides an overview of KSQL, an open source streaming SQL engine for Apache Kafka. It describes the core concepts of Kafka and KSQL, including how KSQL can be used for streaming ETL, anomaly detection, real-time monitoring, and data transformation. It also discusses how KSQL fits into a streaming platform and can be run in both client-server and standalone modes.
Overview of KSQLOpen, an open-source streaming solution for Apache Kafka.
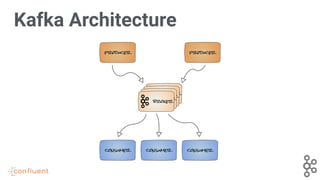
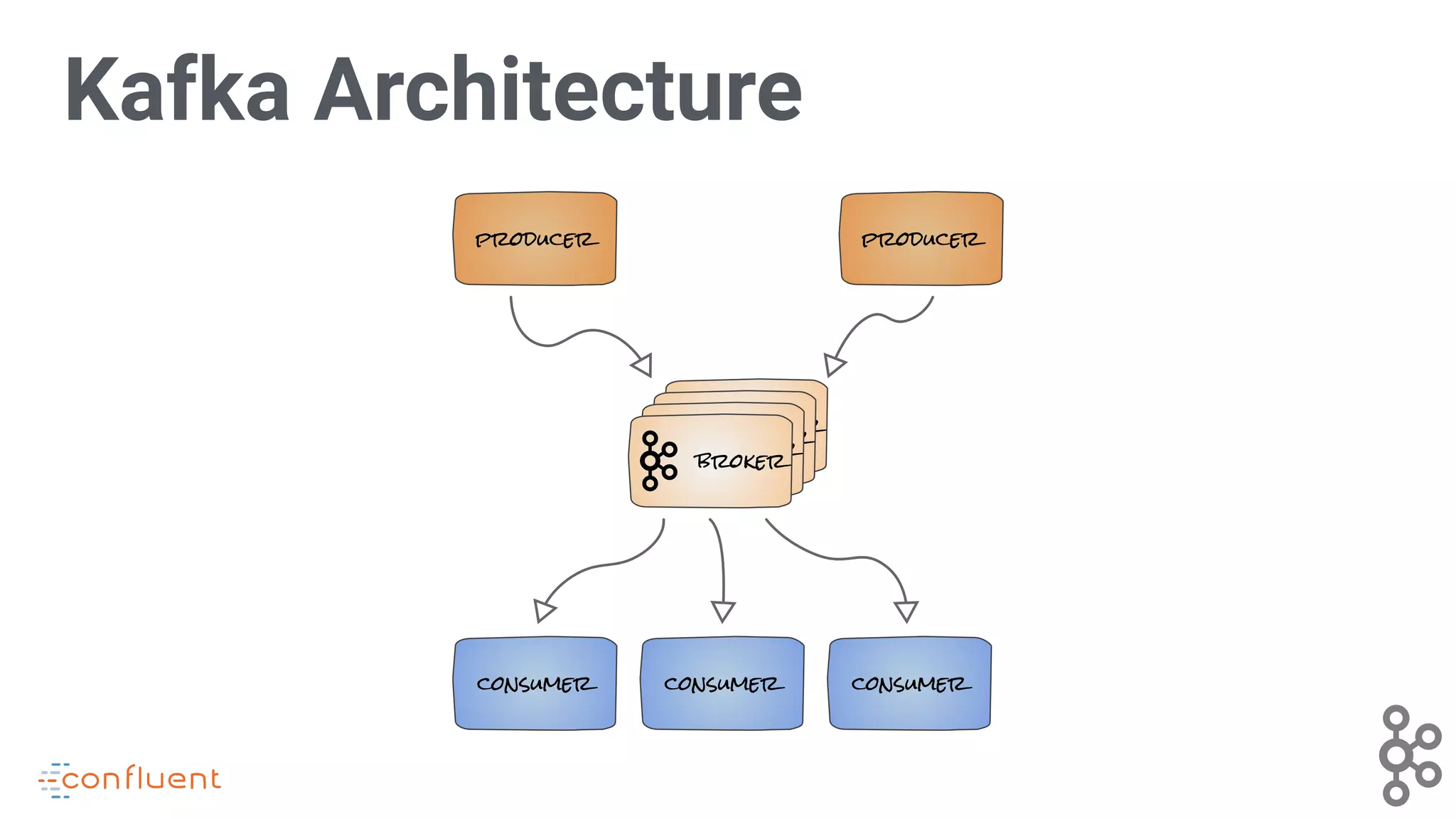
Details the components of Kafka architecture, highlighting producers, consumers, and brokers.
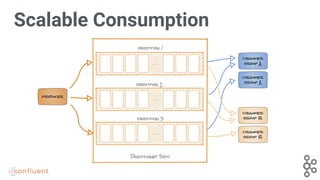
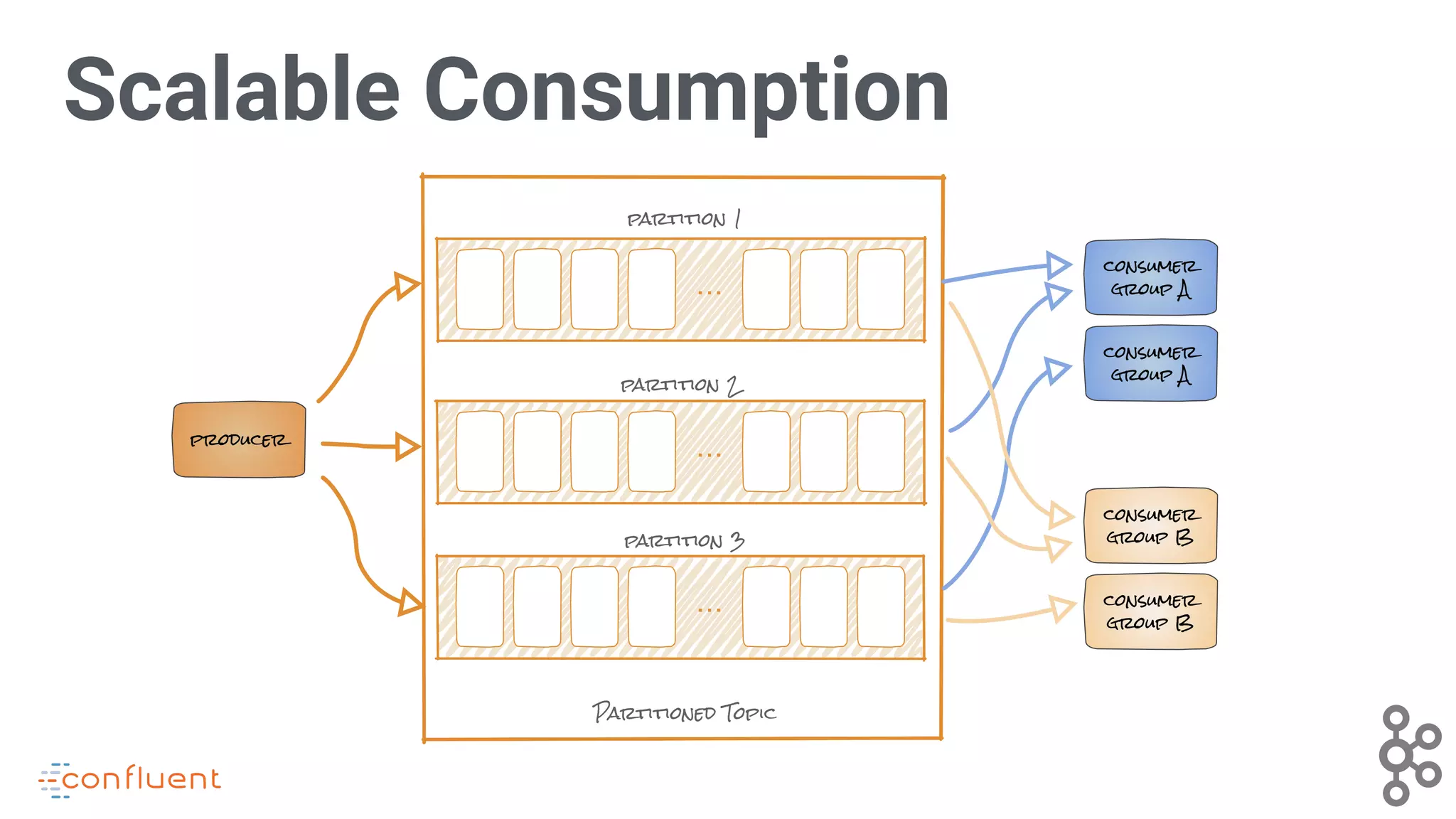
Demonstrates how Kafka supports scalable consumer groups and partitioned topics for efficient data consumption.
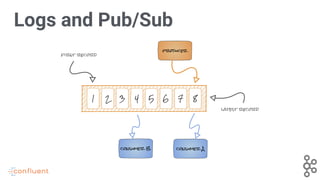
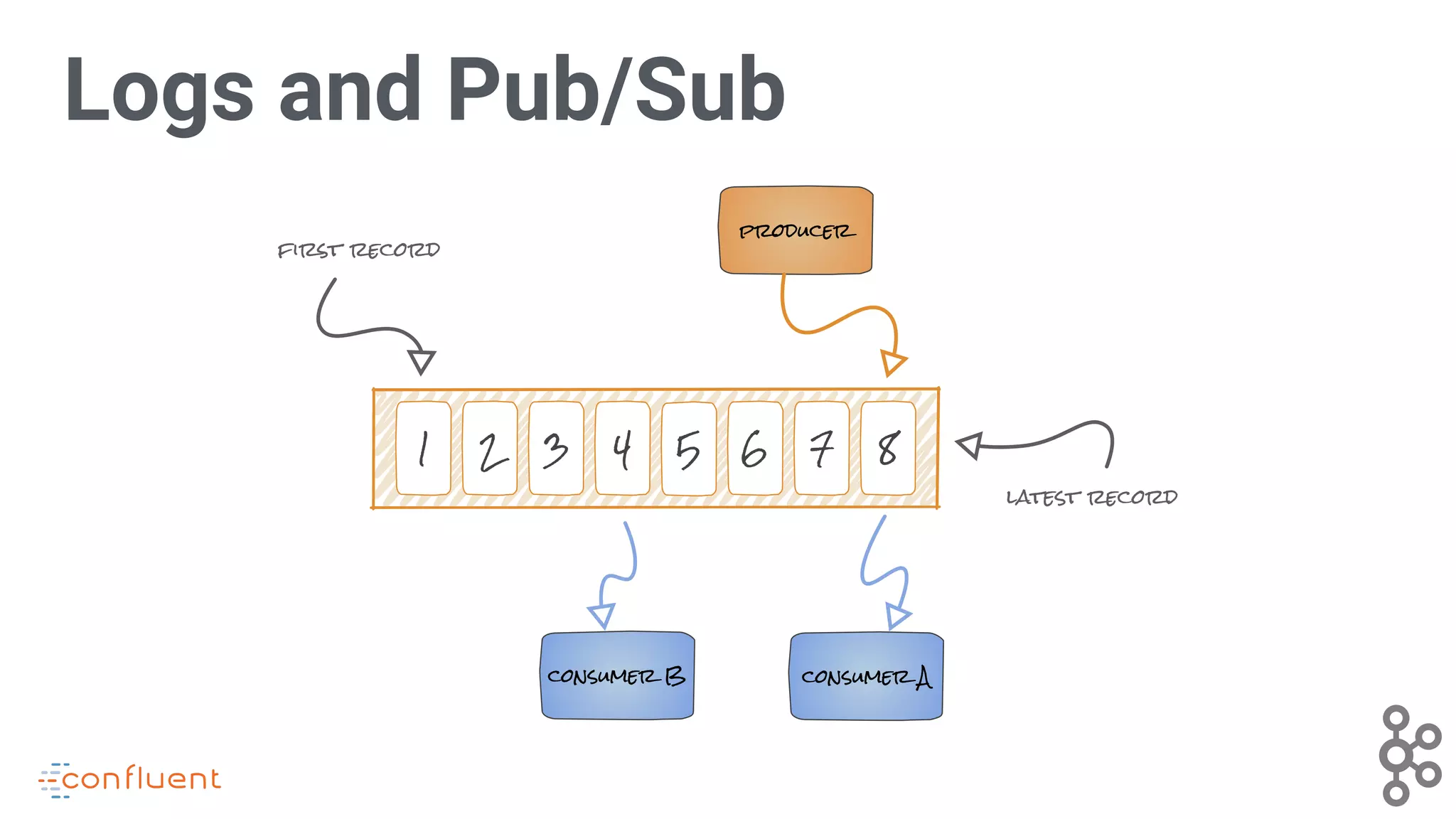
Explains the log and Pub/Sub dynamics in Kafka, showcasing record handling.
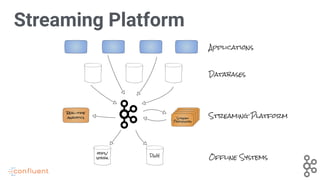
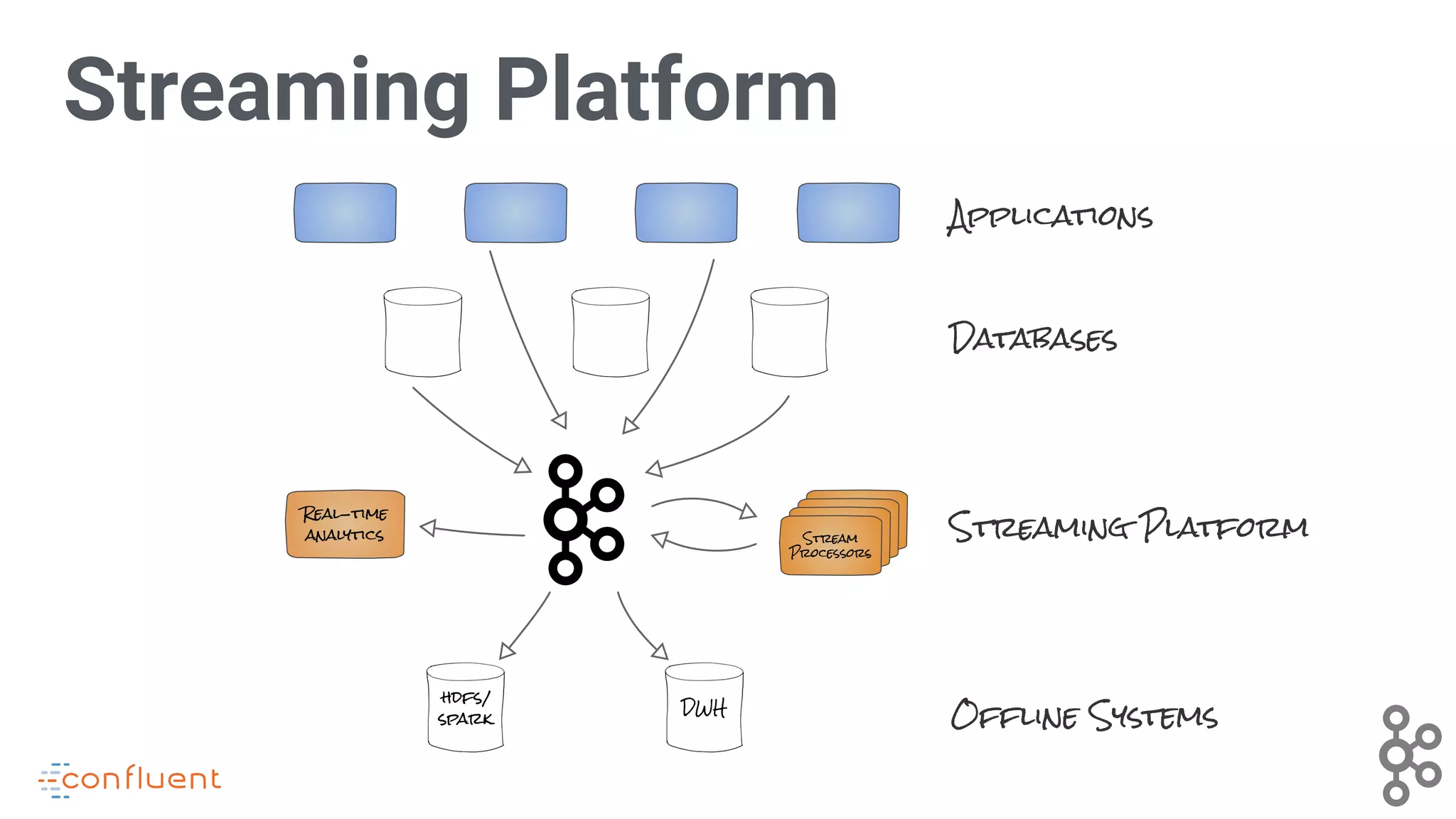
Discusses the integration of various applications, databases, and systems into a streaming platform.
Introduces KSQL as a declarative stream processing language for handling streaming data.
Describes KSQL as an SQL engine tailored for stream processing with Apache Kafka.
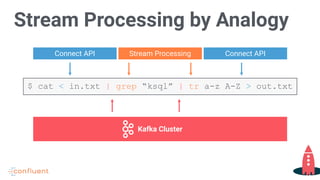
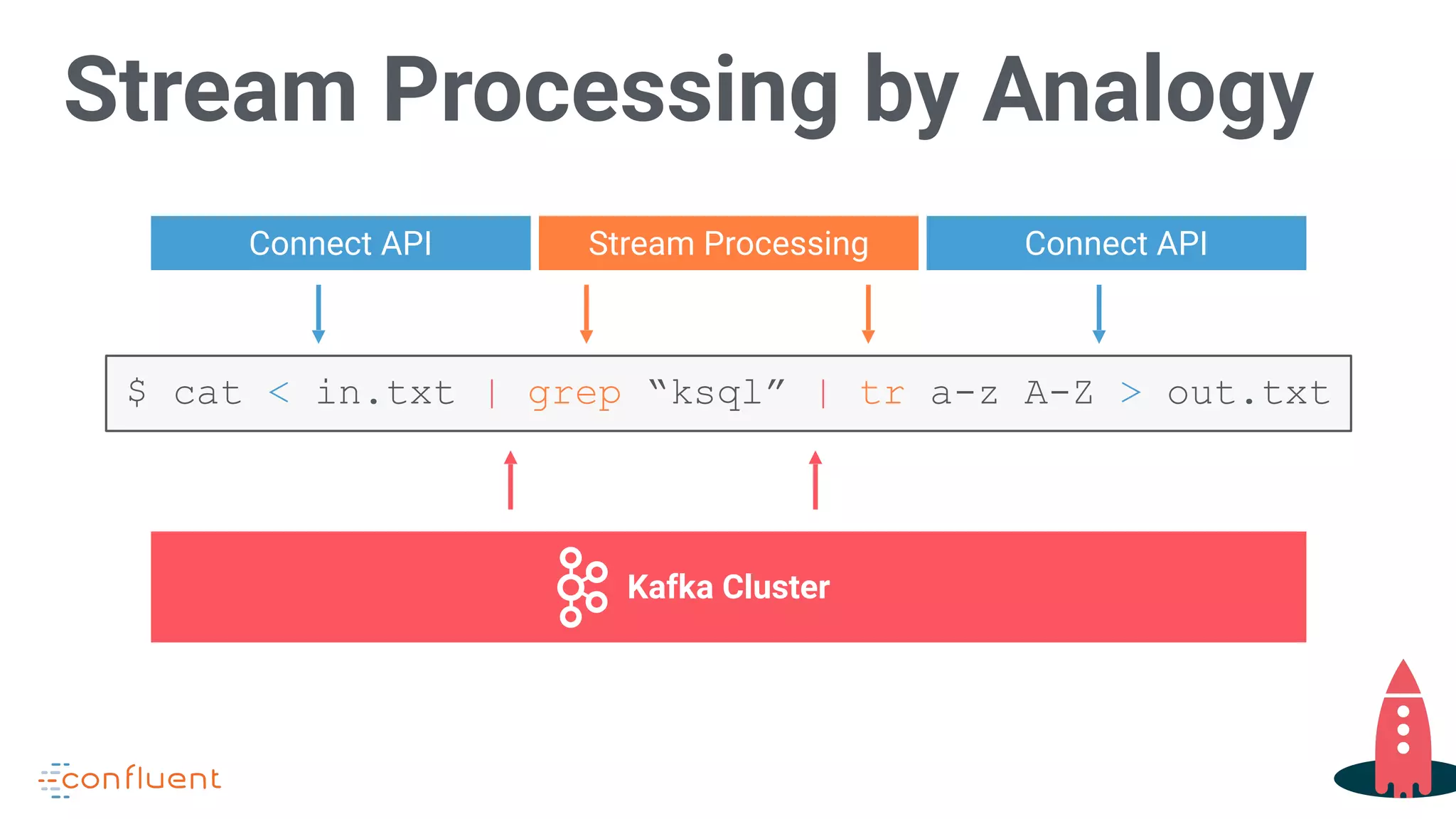
Uses analogy to explain stream processing, emphasizing Kafka Cluster's role and process flow.
Presents various use cases where KSQL can be effectively utilized.
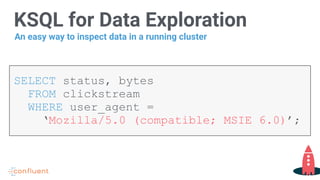
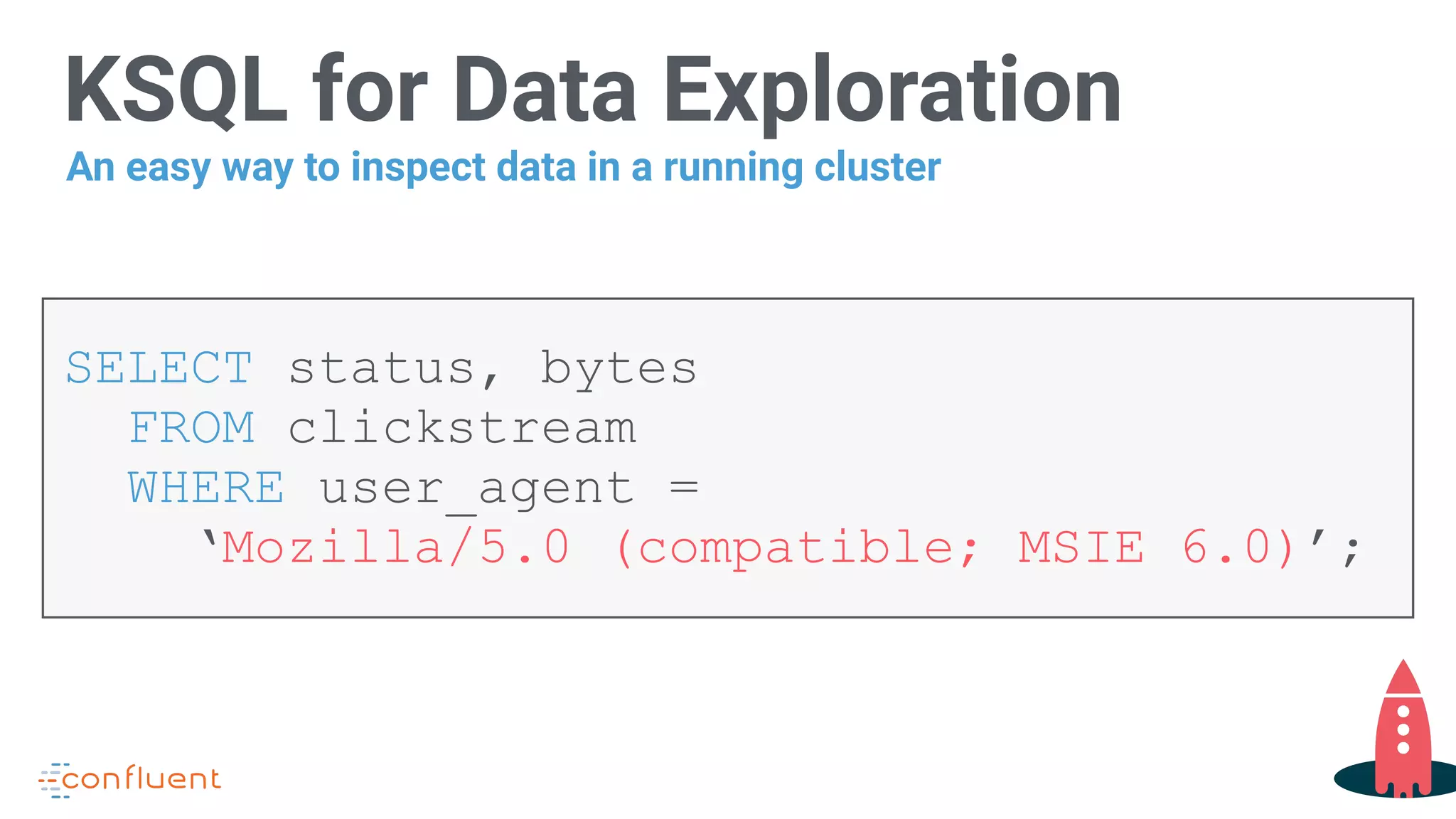
Showcases how to perform data exploration using KSQL for querying clickstream data.
Details KSQL's capabilities in enabling data transformations within streaming ETL processes.
Illustrates how to detect anomalies in streaming data using KSQL with real-time insights.
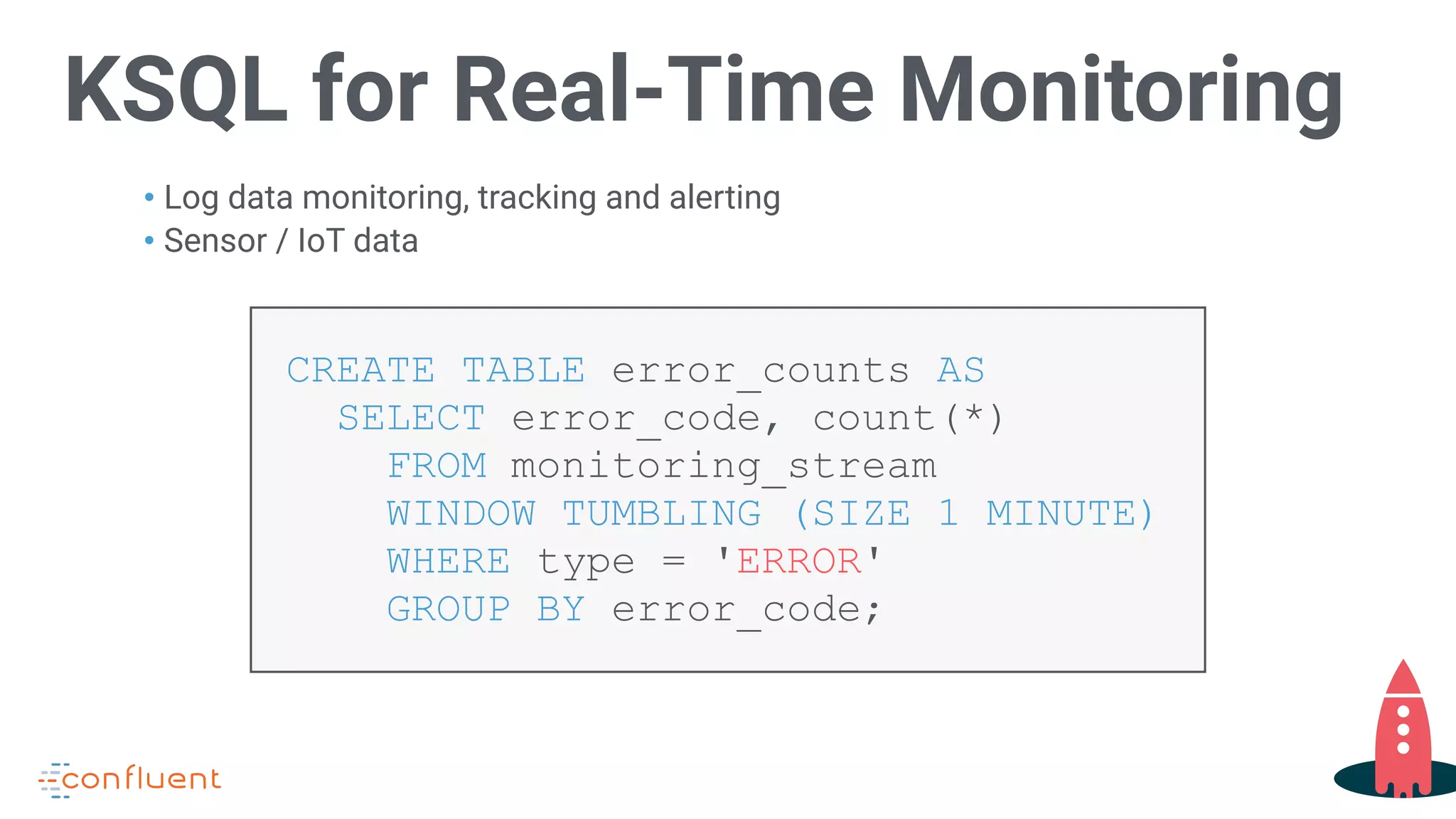
Describes KSQL applications in real-time monitoring of log and IoT data.
Demonstrates how to create KSQL streams for simple transformations of existing data.
Identifies scenarios where KSQL may not be ideal, such as for BI reports and ad-hoc queries.
Provides a KSQL command example for creating a streaming topic from Kafka data.
Shows how to create a table in KSQL for users, specifying necessary data structures.
Explains using KSQL command for enriching data through joins between streams.
Live demonstration to showcase KSQL functionalities.
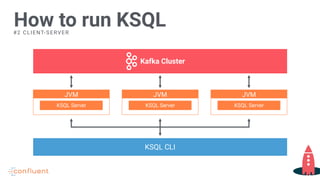
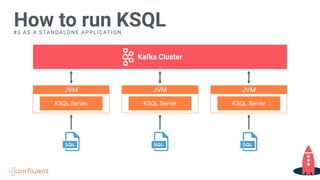
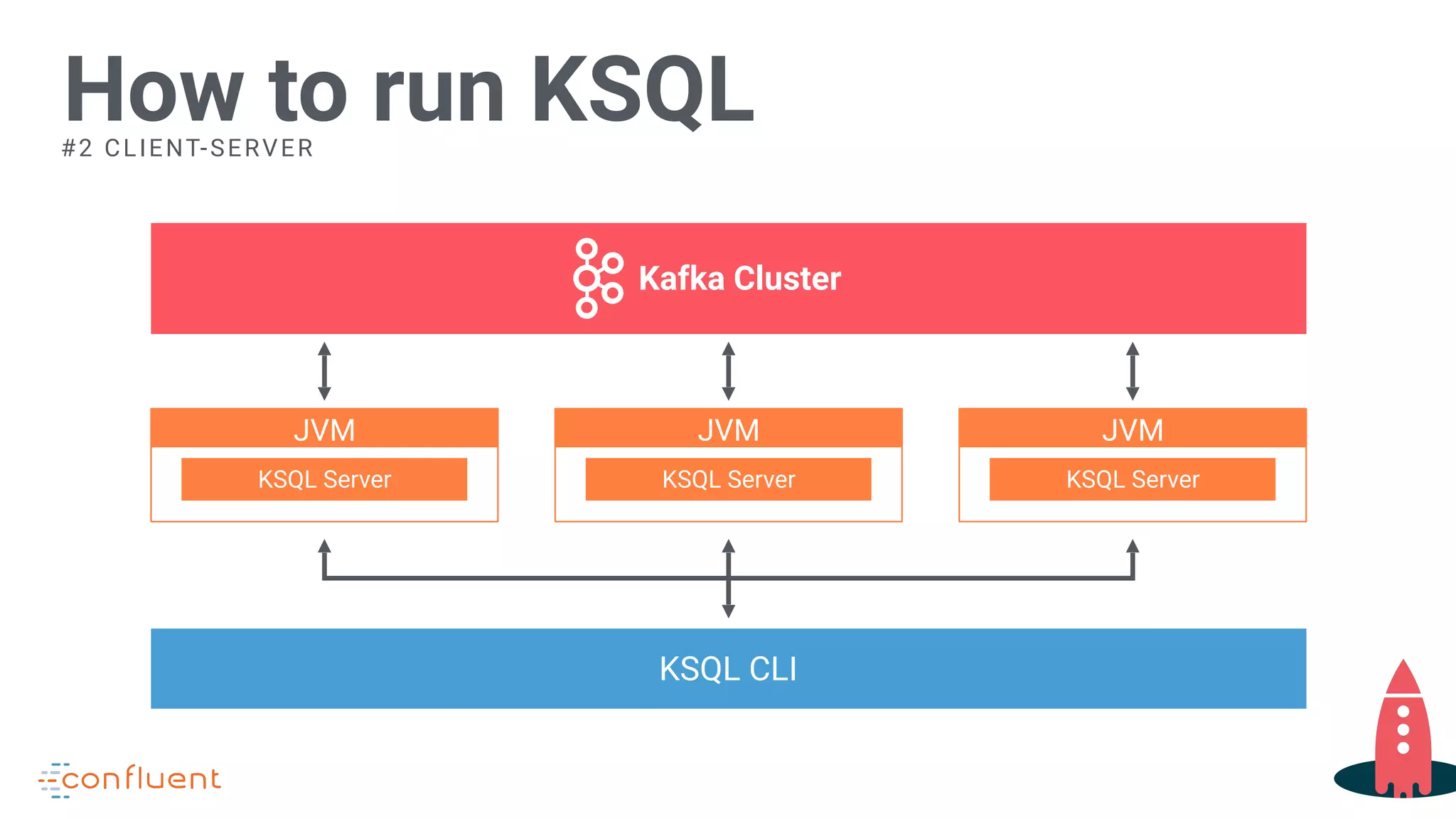
Instructions for running KSQL on various server configurations.
Explanation of deployment options scaling across multiple server nodes for KSQL.
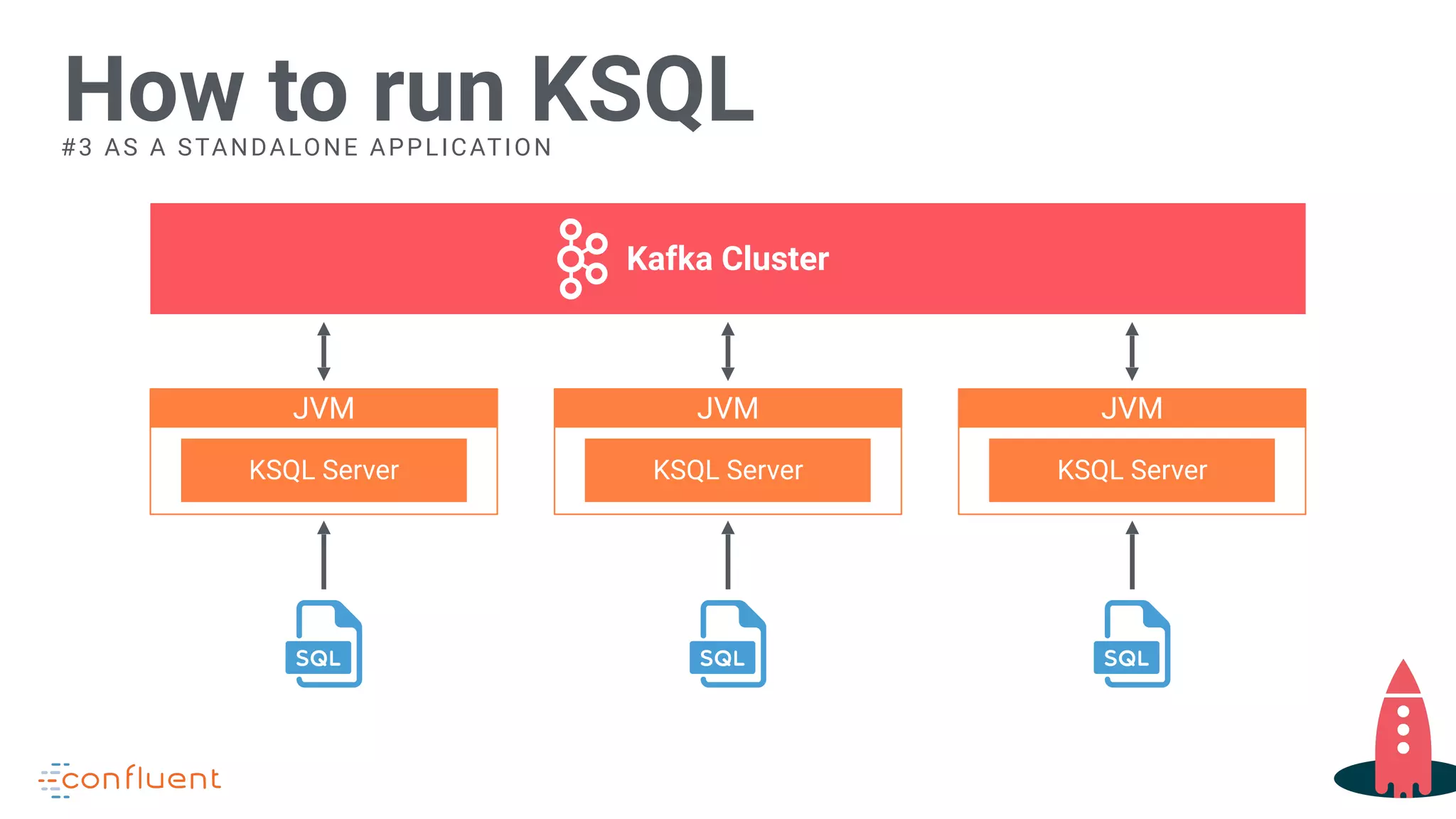
Describes running KSQL as a standalone application using predefined queries.
Provides resources and next steps for learning more about KSQL.
Thank you note along with contact information for further inquiries.





































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)

















