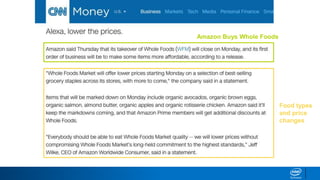
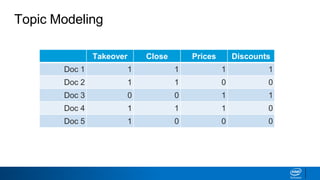
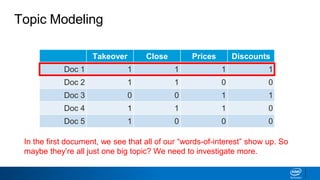
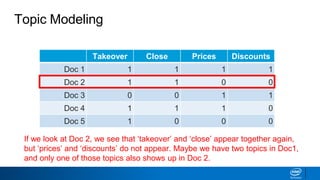
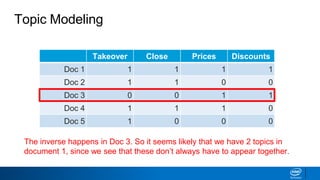
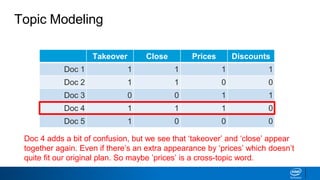
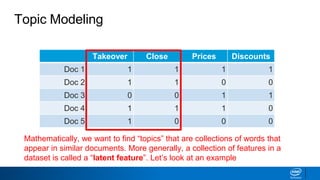
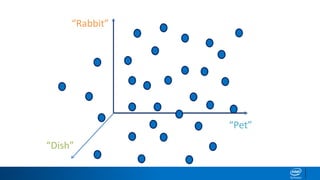
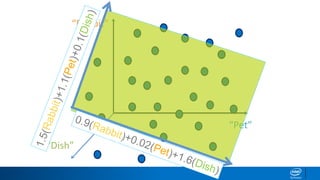
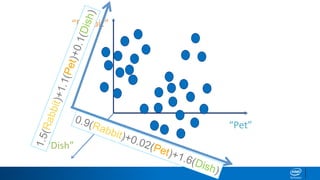
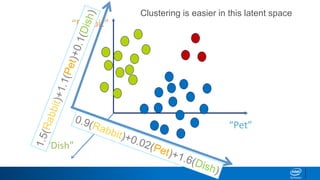
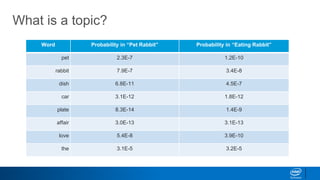
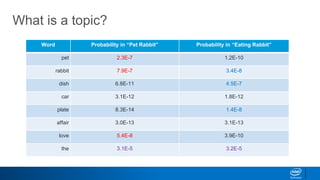
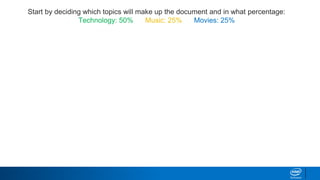
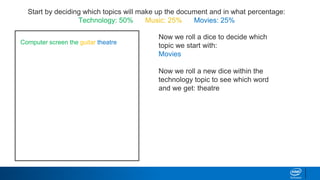
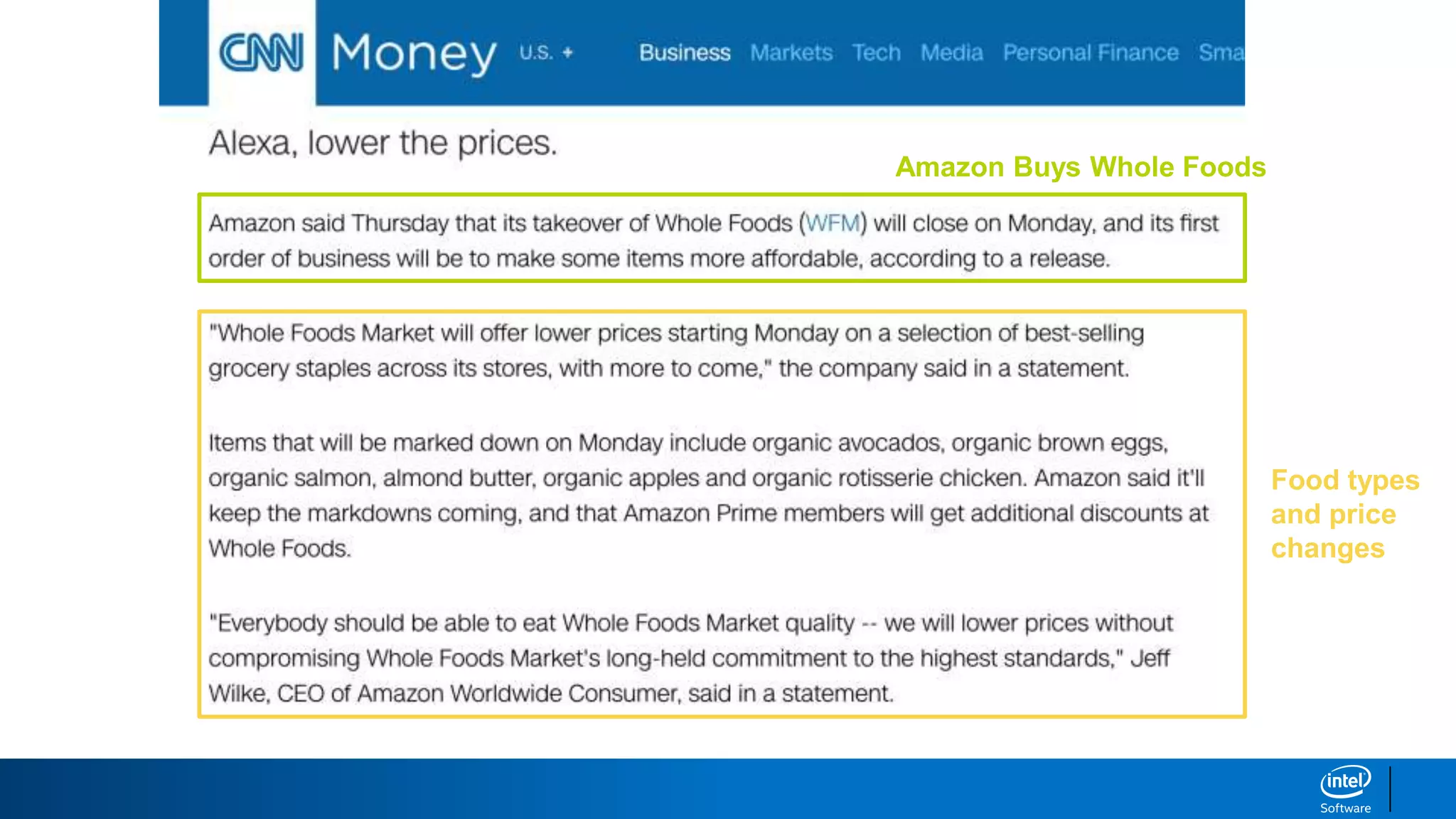
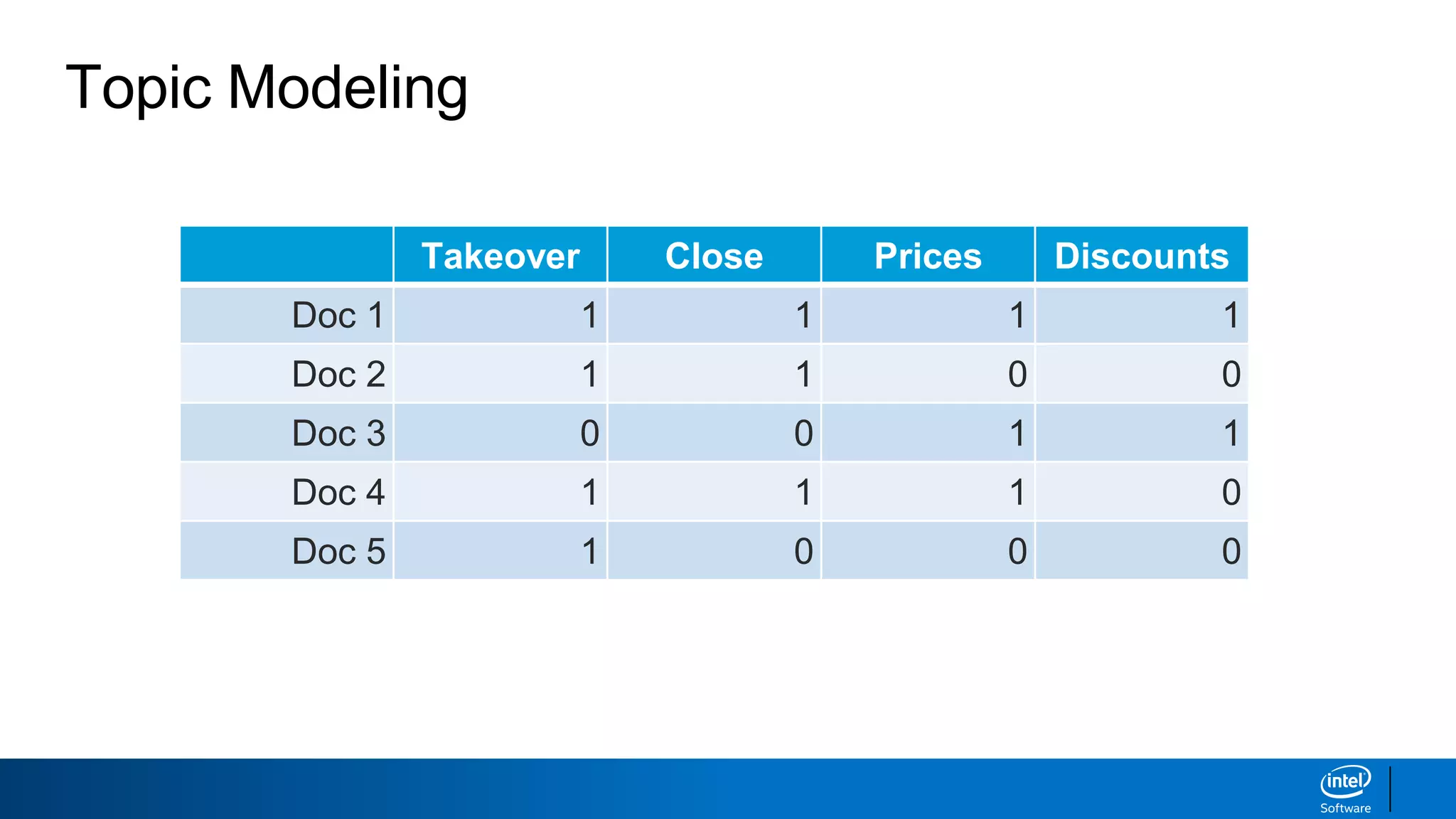
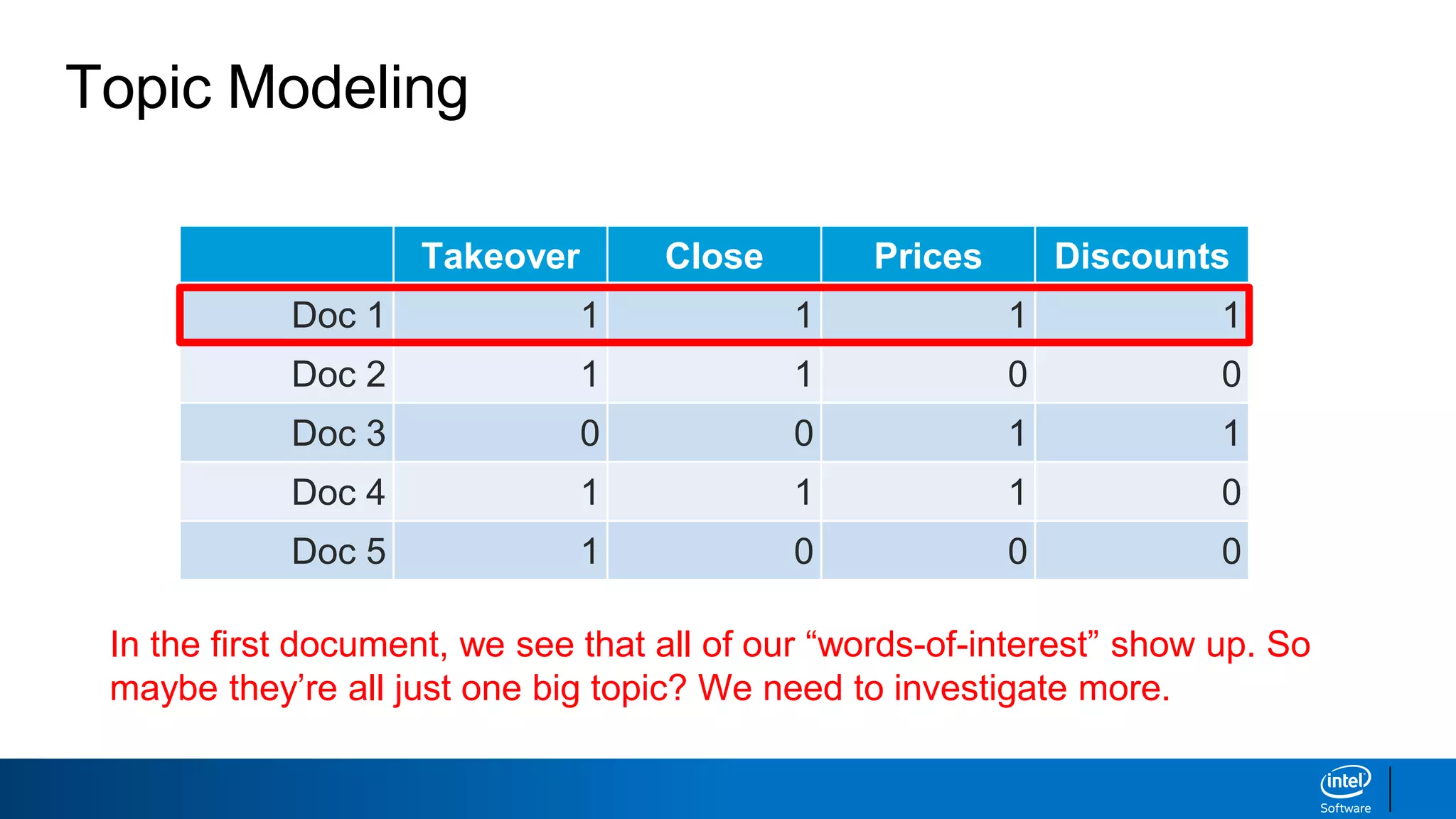
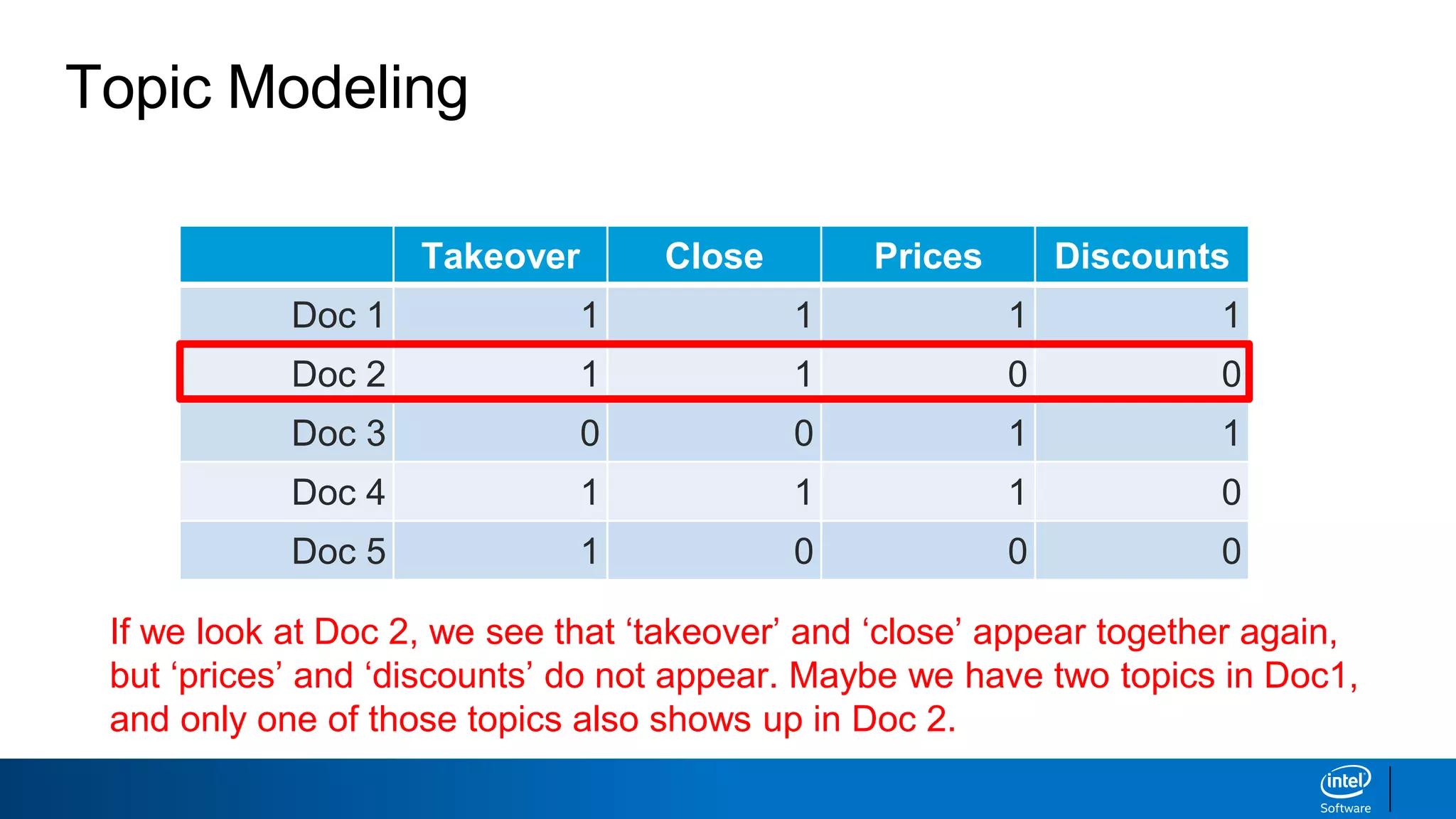
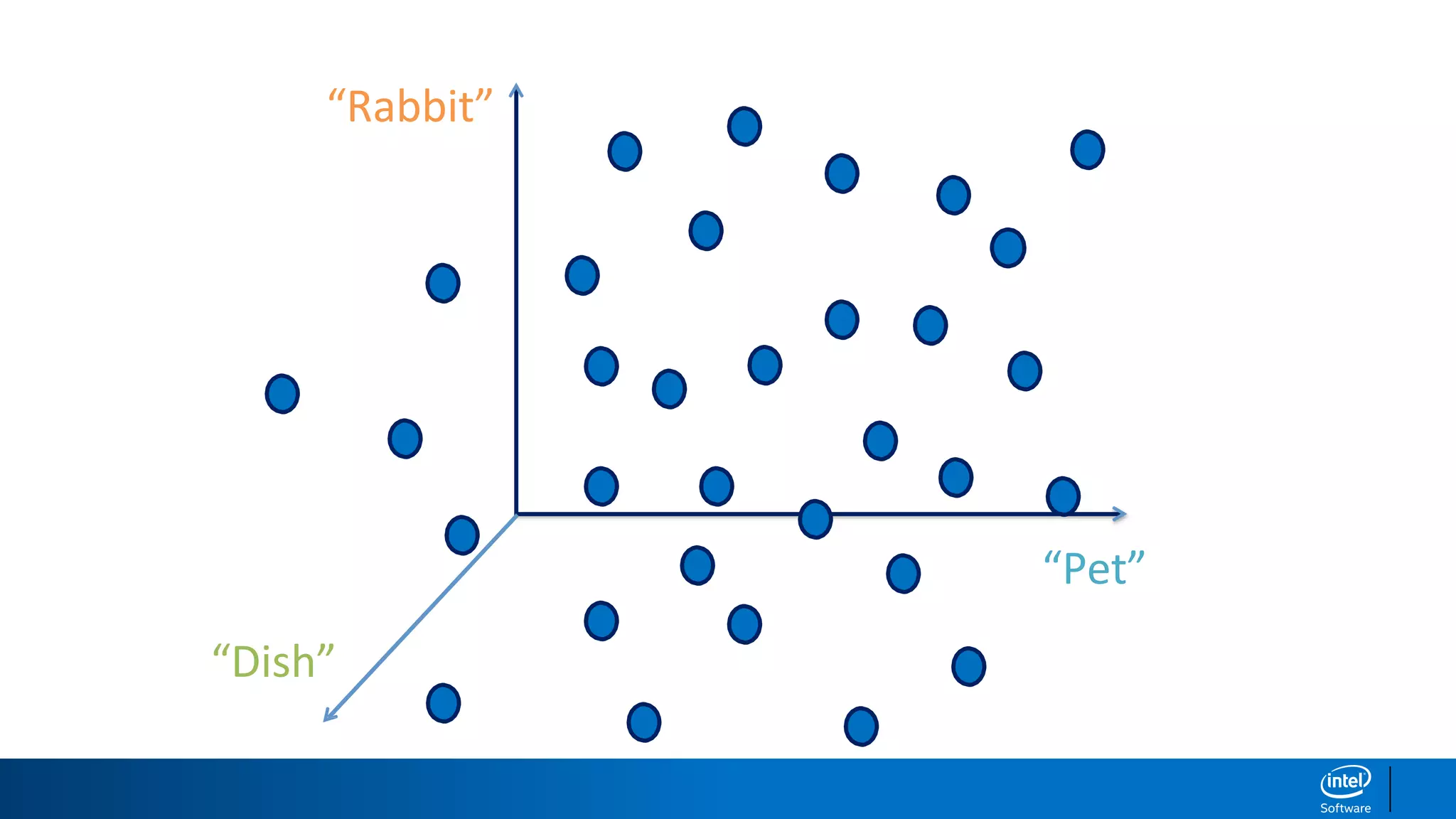
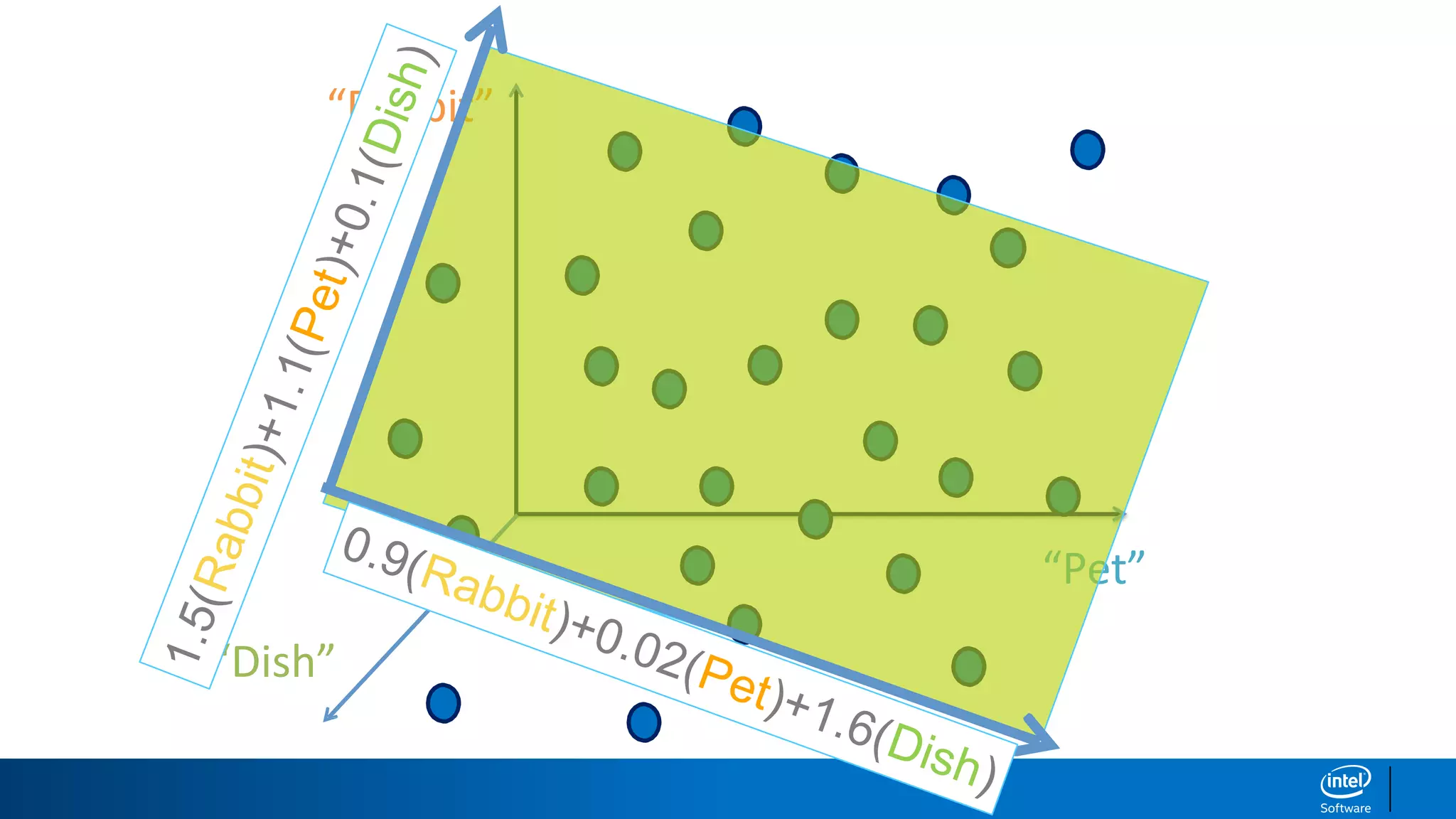
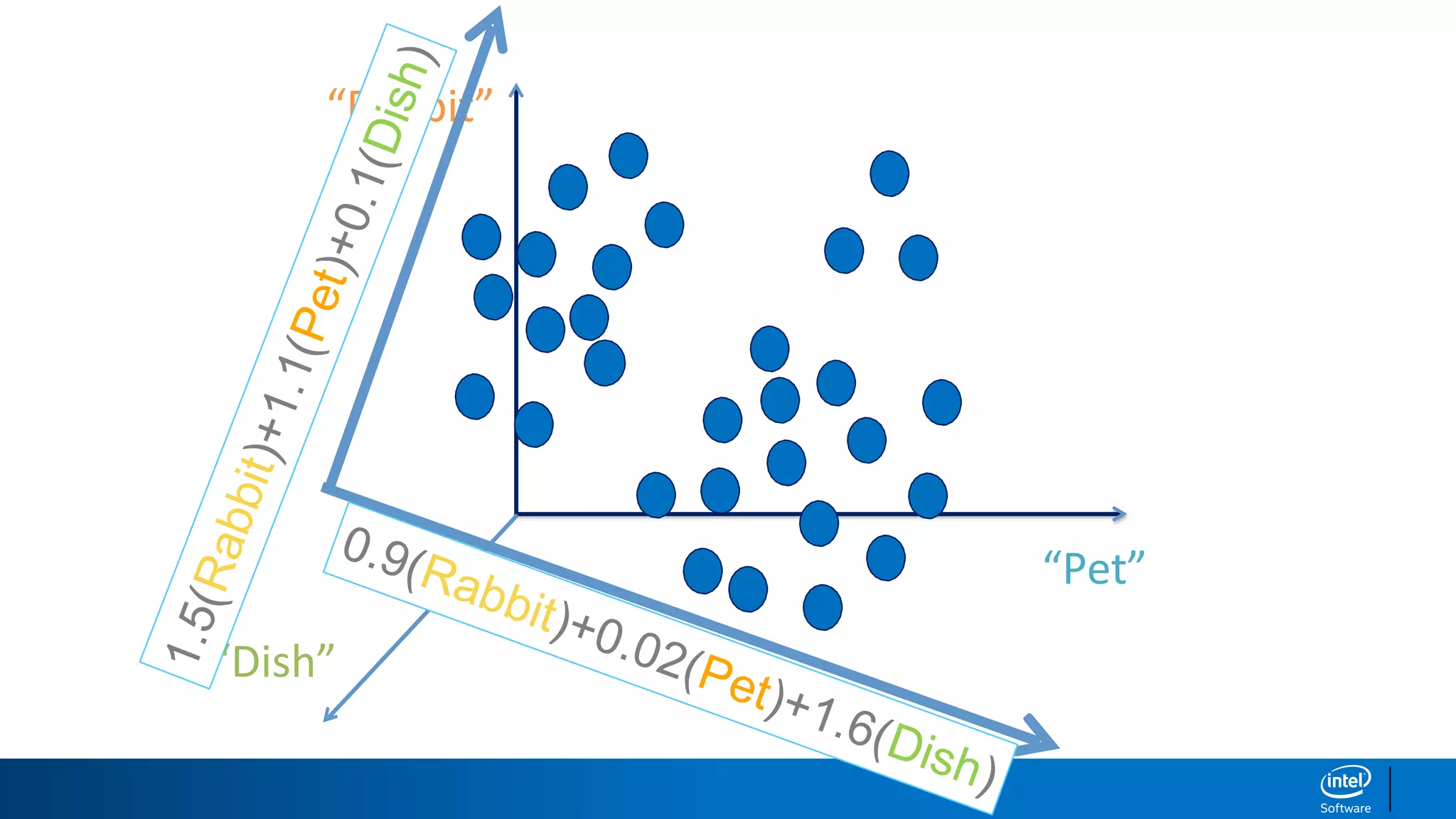
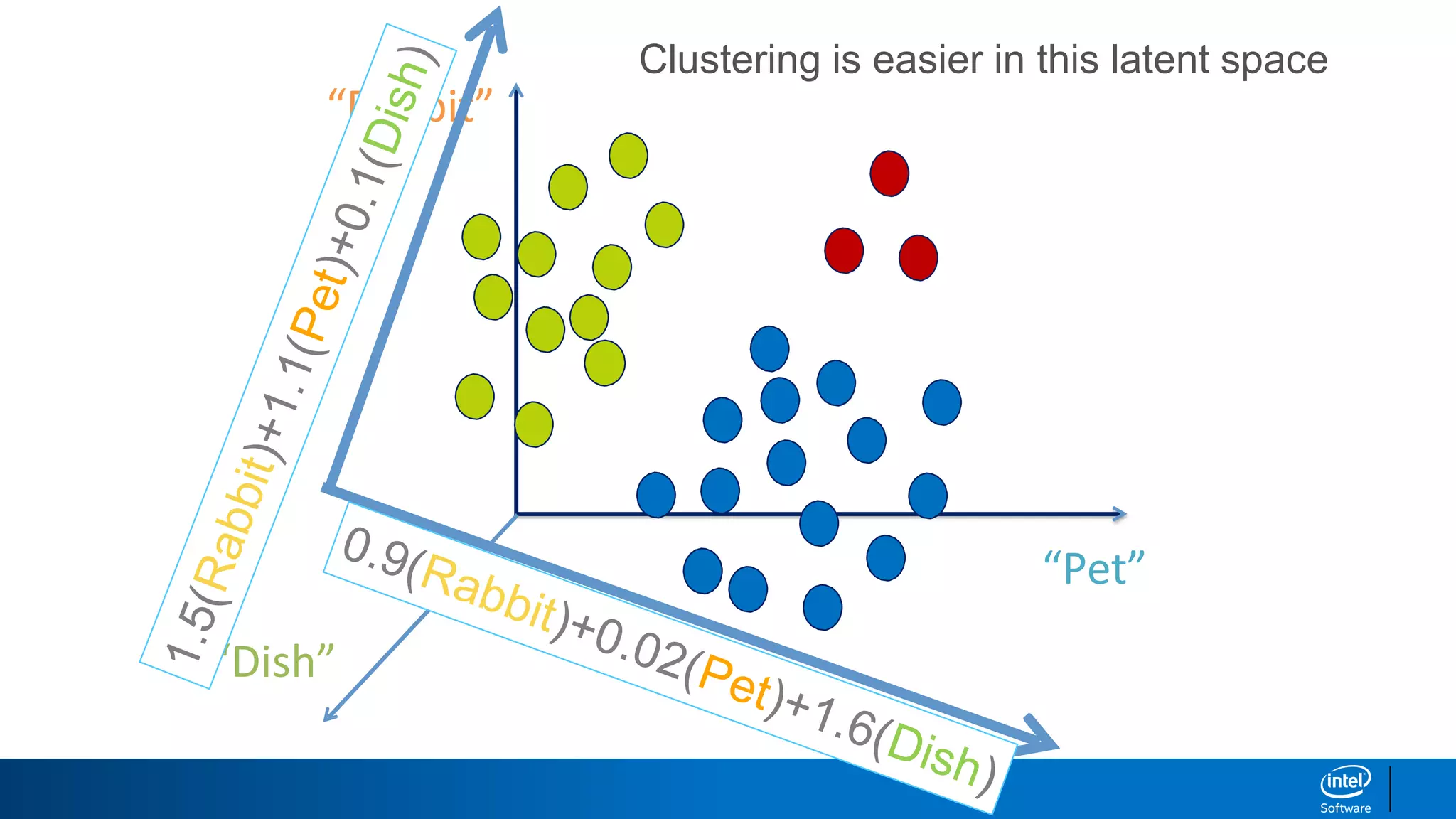
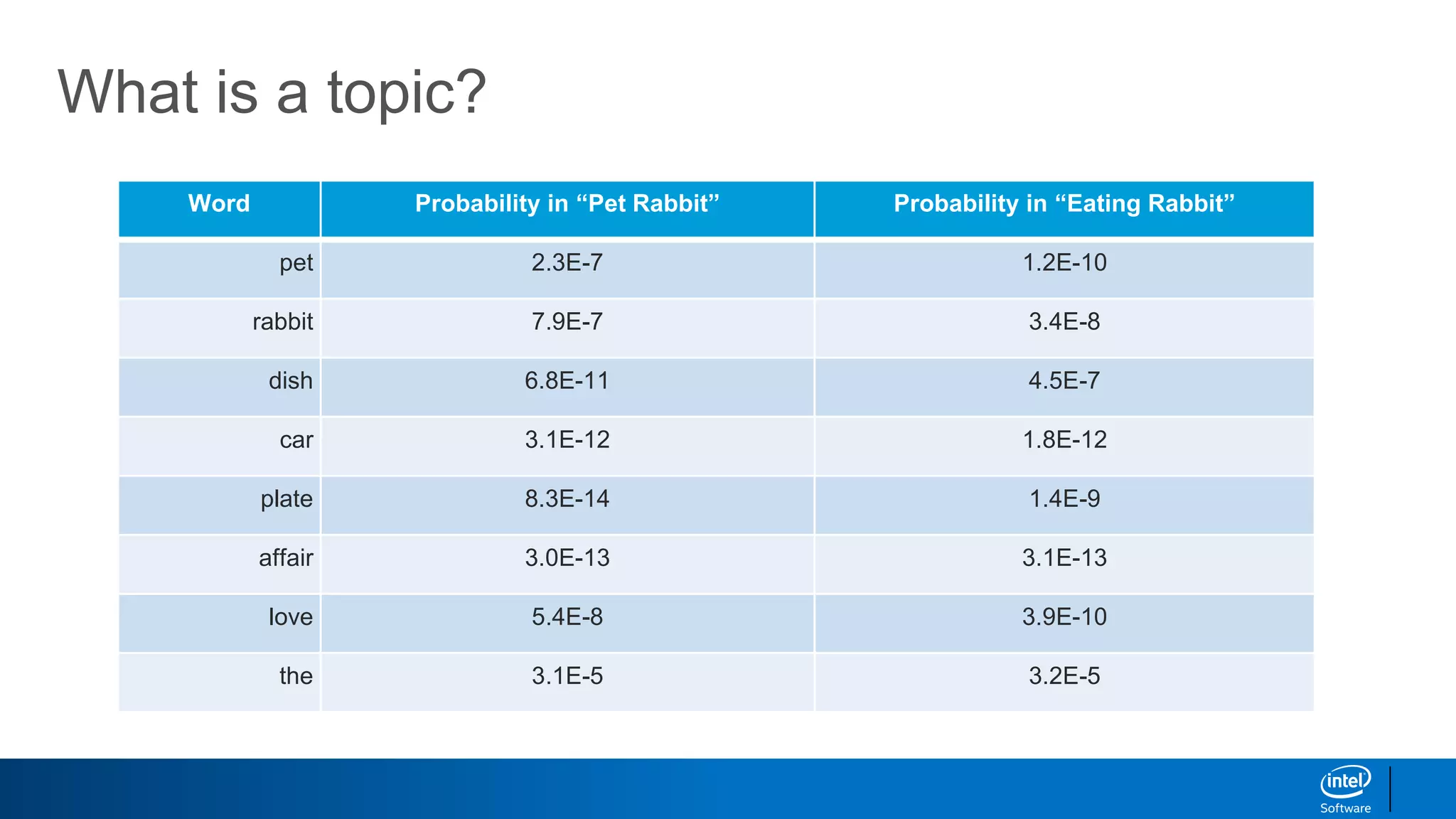
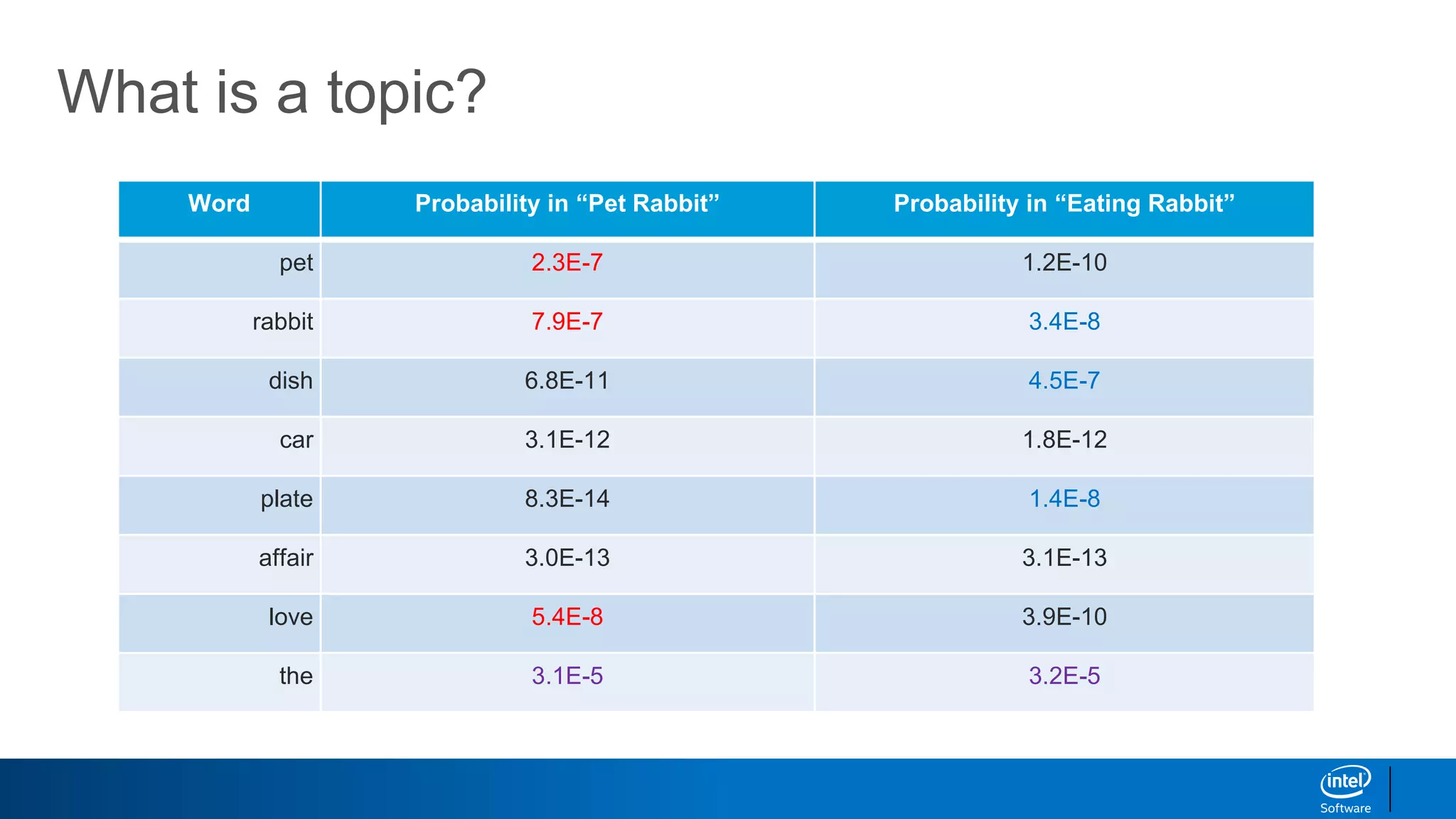
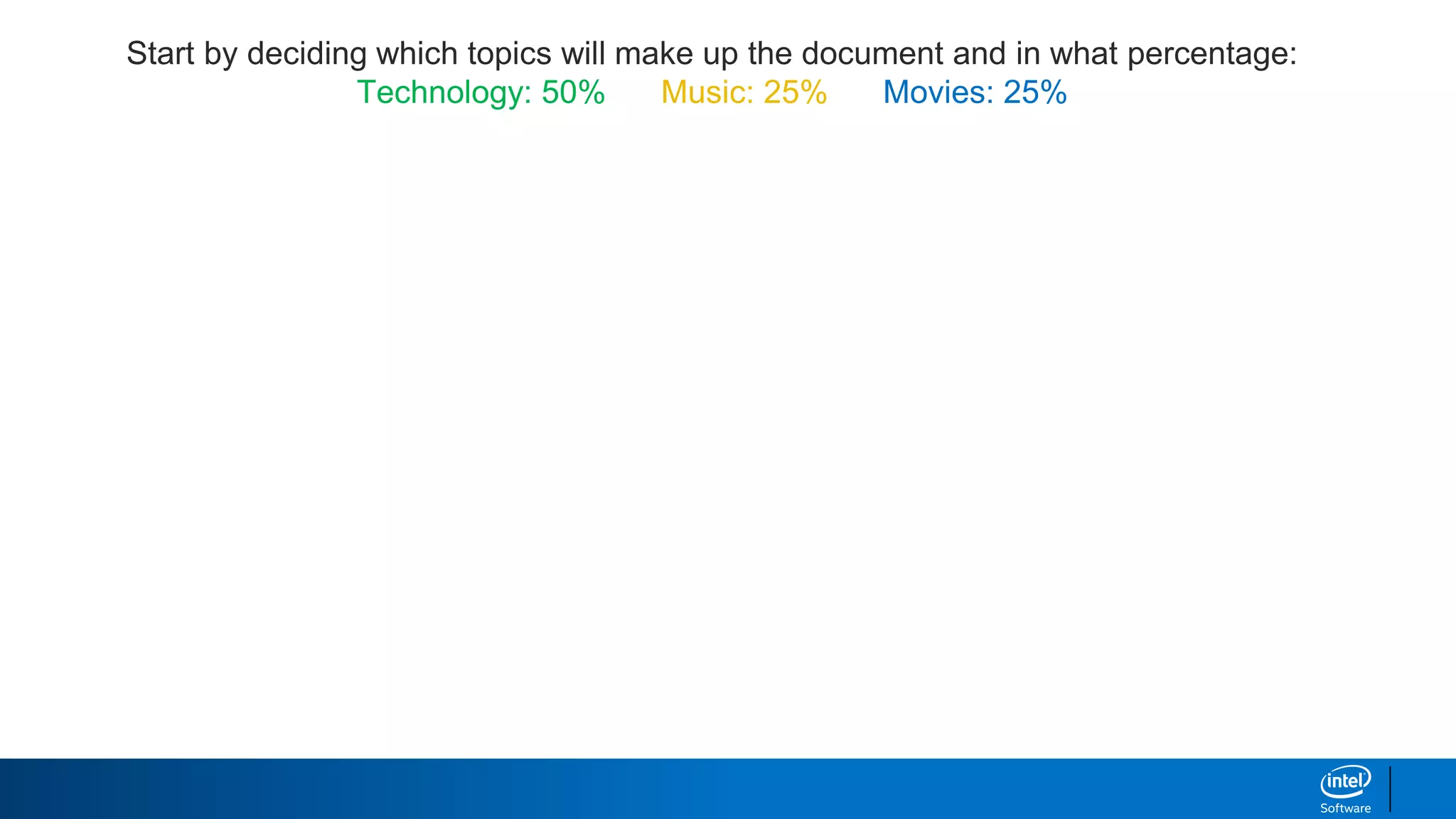
1. LDA represents documents as mixtures of topics and topics as mixtures of words.
2. It assumes documents are generated by first choosing a topic distribution, then choosing words from that topic.
3. The algorithm estimates topic distributions for each document and word distributions for each topic that are most likely to have generated the observed document-word matrix.

























![Code: LDA (Scikit-learn)
from sklearn.datasets import fetch_20newsgroups
ng_train = fetch_20newsgroups(subset=‘train’,
remove=(‘headers’, ‘footers’, ‘quotes’))
print("Data has {0:d} documents".format(len(ng_train.data)))
print(ng_train.data[0][:100]) # print requires Python 3
Data has 11314 documents
'I was wondering if anyone out there could enlighten me on this car I sawnthe
other day. It was a 2-d’
Output:
Input:](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/85/Latent-dirichlet-allocation_and_topic_modeling-42-320.jpg)
![Code: LDA (Scikit-learn)
from sklearn.feature_extraction.text import CountVectorizer
count_vectorizer = CountVectorizer(ngram_range=(1, 2),
stop_words='english',
token_pattern=“b[a-z][a-z]+b",
lowercase=True,
max_features=1000)
X = count_vectorizer.fit_transform(ng_train.data)
# “X” is now our transformed data
Input:](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/85/Latent-dirichlet-allocation_and_topic_modeling-43-320.jpg)
![Code: LDA (Scikit-learn)
import pandas as pd
print(count_vectorizer.get_feature_names()[92:97]) # print 5 random columns
df = pd.DataFrame(X.toarray(), columns=count_vectorizer.get_feature_names())
# create data frame
print(df.iloc[10:15, 92:97]) # values of these features on documents 10-15
“['bhj', 'bible', 'big', 'bike', ‘bios']"
Output:
Input:
df:](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/85/Latent-dirichlet-allocation_and_topic_modeling-44-320.jpg)
![Code: LDA (Scikit-learn)
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_topics=4, random_state=42,
learning_method='online')
data = lda.fit_transform(X)
print(data[0])
[ 0.00246896, 0.00251041, 0.99253159, 0.00248904]
Output:
Input:](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/85/Latent-dirichlet-allocation_and_topic_modeling-45-320.jpg)
![Code: LDA (Scikit-learn)
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_topics=4, random_state=42,
learning_method='online')
data = lda.fit_transform(X)
print(data[0])
[ 0.00246896, 0.00251041, 0.99253159, 0.00248904]
Output:
Input:
This document is 99% topic 3!](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/85/Latent-dirichlet-allocation_and_topic_modeling-46-320.jpg)
![Code: LDA (Scikit-learn)
year game good team think don just games like players
Output:
Input:
The top 10 words for topic 2!
for word in lda.components_[2].argsort()[:10:-1]:
print(word)](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/85/Latent-dirichlet-allocation_and_topic_modeling-47-320.jpg)


![Code: LDA (gensim)
[(2: 0.95, 4: 0.21)]
[(0: 0.75, 1: 0.15, 5: 0.11)]
Output:
Input:
from gensim import corpora, models, similarities, matutils
lda = LdaModel(corpus, num_topics=5) # train model
print(lda[doc_bow]) # get topic probability distribution for a document
lda.update(corpus2) # update the LDA model with additional documents
print(lda[doc_bow])](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/85/Latent-dirichlet-allocation_and_topic_modeling-50-320.jpg)
![Code: LDA (gensim)
[(0, u'0.002*"image" + 0.002*"don" + 0.002*"jpeg" + 0.002*"good" +
0.001*"think" + 0.001*"people" + 0.001*"file" + 0.001*"year" + 0.001*"just" +
0.001*"like"'),
(1, u'0.002*"graphics" + 0.002*"edu" + 0.002*"god" + 0.001*"just" +
0.001*"like" + 0.001*"does" + 0.001*"people" + 0.001*"know" + 0.001*"data" +
0.001*"jesus"'),
(2, u'0.002*"think" + 0.002*"don" + 0.002*"just" + 0.002*"like" + 0.002*"does"
+ 0.002*"god" + 0.001*"know" + 0.001*"people" + 0.001*"time" + 0.001*"good"')
… ]
Output:
Input:
lda.print_topics()](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/85/Latent-dirichlet-allocation_and_topic_modeling-51-320.jpg)


























![Code: LDA (Scikit-learn)
from sklearn.datasets import fetch_20newsgroups
ng_train = fetch_20newsgroups(subset=‘train’,
remove=(‘headers’, ‘footers’, ‘quotes’))
print("Data has {0:d} documents".format(len(ng_train.data)))
print(ng_train.data[0][:100]) # print requires Python 3
Data has 11314 documents
'I was wondering if anyone out there could enlighten me on this car I sawnthe
other day. It was a 2-d’
Output:
Input:](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/75/Latent-dirichlet-allocation_and_topic_modeling-42-2048.jpg)
![Code: LDA (Scikit-learn)
from sklearn.feature_extraction.text import CountVectorizer
count_vectorizer = CountVectorizer(ngram_range=(1, 2),
stop_words='english',
token_pattern=“b[a-z][a-z]+b",
lowercase=True,
max_features=1000)
X = count_vectorizer.fit_transform(ng_train.data)
# “X” is now our transformed data
Input:](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/75/Latent-dirichlet-allocation_and_topic_modeling-43-2048.jpg)
![Code: LDA (Scikit-learn)
import pandas as pd
print(count_vectorizer.get_feature_names()[92:97]) # print 5 random columns
df = pd.DataFrame(X.toarray(), columns=count_vectorizer.get_feature_names())
# create data frame
print(df.iloc[10:15, 92:97]) # values of these features on documents 10-15
“['bhj', 'bible', 'big', 'bike', ‘bios']"
Output:
Input:
df:](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/75/Latent-dirichlet-allocation_and_topic_modeling-44-2048.jpg)
![Code: LDA (Scikit-learn)
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_topics=4, random_state=42,
learning_method='online')
data = lda.fit_transform(X)
print(data[0])
[ 0.00246896, 0.00251041, 0.99253159, 0.00248904]
Output:
Input:](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/75/Latent-dirichlet-allocation_and_topic_modeling-45-2048.jpg)
![Code: LDA (Scikit-learn)
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_topics=4, random_state=42,
learning_method='online')
data = lda.fit_transform(X)
print(data[0])
[ 0.00246896, 0.00251041, 0.99253159, 0.00248904]
Output:
Input:
This document is 99% topic 3!](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/75/Latent-dirichlet-allocation_and_topic_modeling-46-2048.jpg)
![Code: LDA (Scikit-learn)
year game good team think don just games like players
Output:
Input:
The top 10 words for topic 2!
for word in lda.components_[2].argsort()[:10:-1]:
print(word)](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/75/Latent-dirichlet-allocation_and_topic_modeling-47-2048.jpg)


![Code: LDA (gensim)
[(2: 0.95, 4: 0.21)]
[(0: 0.75, 1: 0.15, 5: 0.11)]
Output:
Input:
from gensim import corpora, models, similarities, matutils
lda = LdaModel(corpus, num_topics=5) # train model
print(lda[doc_bow]) # get topic probability distribution for a document
lda.update(corpus2) # update the LDA model with additional documents
print(lda[doc_bow])](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/75/Latent-dirichlet-allocation_and_topic_modeling-50-2048.jpg)
![Code: LDA (gensim)
[(0, u'0.002*"image" + 0.002*"don" + 0.002*"jpeg" + 0.002*"good" +
0.001*"think" + 0.001*"people" + 0.001*"file" + 0.001*"year" + 0.001*"just" +
0.001*"like"'),
(1, u'0.002*"graphics" + 0.002*"edu" + 0.002*"god" + 0.001*"just" +
0.001*"like" + 0.001*"does" + 0.001*"people" + 0.001*"know" + 0.001*"data" +
0.001*"jesus"'),
(2, u'0.002*"think" + 0.002*"don" + 0.002*"just" + 0.002*"like" + 0.002*"does"
+ 0.002*"god" + 0.001*"know" + 0.001*"people" + 0.001*"time" + 0.001*"good"')
… ]
Output:
Input:
lda.print_topics()](https://image.slidesharecdn.com/latentdirichletallocationandtopicmodeling-190218095527/75/Latent-dirichlet-allocation_and_topic_modeling-51-2048.jpg)



































































