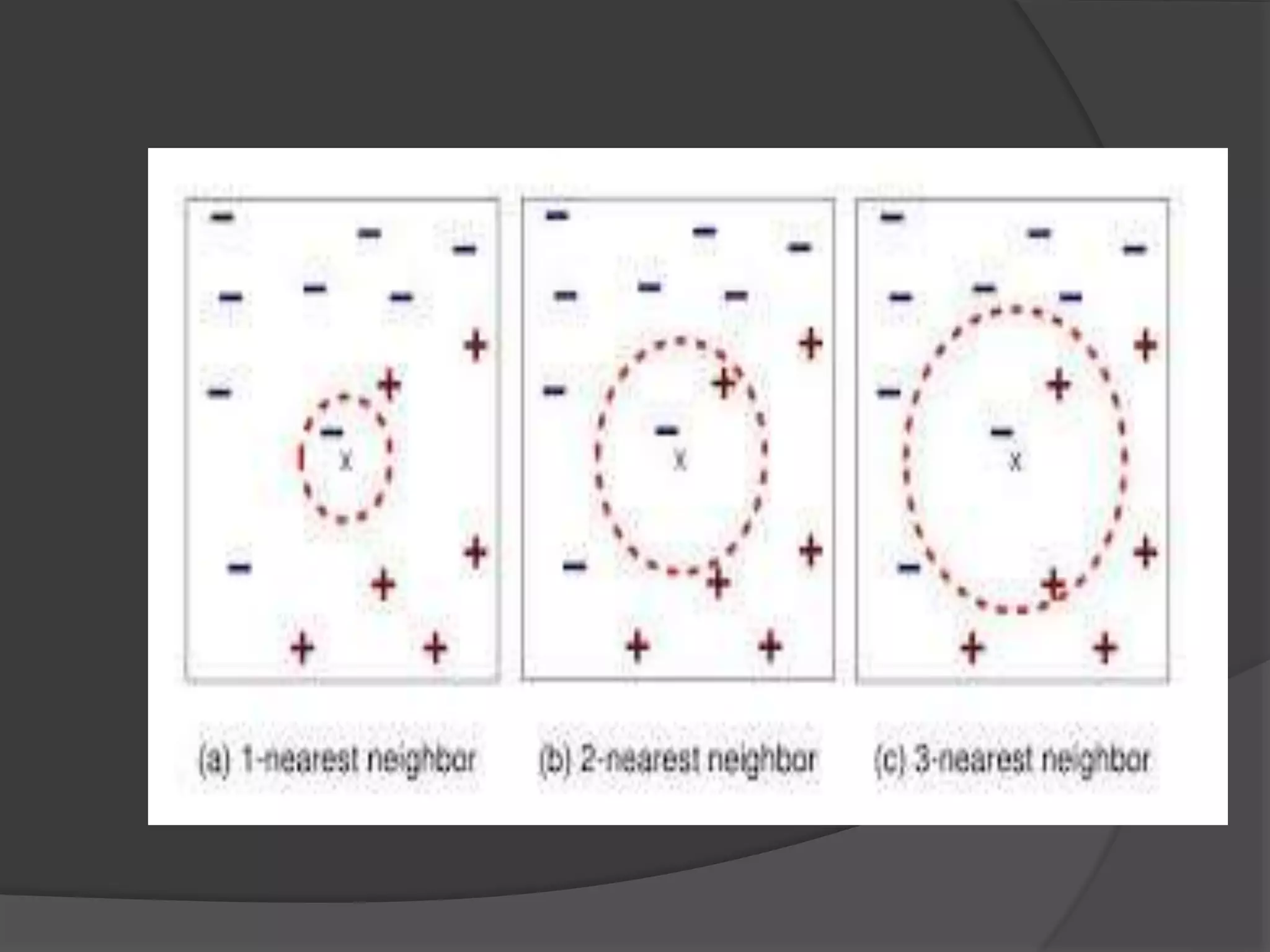
Lazy learning is a machine learning method where generalization of training data is delayed until a query is made, unlike eager learning which generalizes before queries. K-nearest neighbors and case-based reasoning are examples of lazy learners, which store training data and classify new data based on similarity. Case-based reasoning specifically stores prior problem solutions to solve new problems by combining similar past case solutions.







































































































![UiPath Automation Suite Installation (Hands-On) [2/3]](https://cdn.slidesharecdn.com/ss_thumbnails/automationsuitecommunitysession2-251015095633-a6d862f1-thumbnail.jpg?width=600ounds&width=560&fit=bounds)









