Downloaded 181 times




















![Ugly Demo IV: Frequent Pattern MiningData: http://fimi.cs.helsinki.fi/data/./mahout fpg -i <PATH>/content/freqitemset/accidents.dat -o patterns -k 50 -method mapreduce -g 10 -regex [\ ] ./mahout seqdump --seqFile patterns/fpgrowth/part-r-00000](https://image.slidesharecdn.com/intro-mahout-110529200909-phpapp01/85/mahout-introduction-24-320.jpg)


























![Ugly Demo IV: Frequent Pattern MiningData: http://fimi.cs.helsinki.fi/data/./mahout fpg -i <PATH>/content/freqitemset/accidents.dat -o patterns -k 50 -method mapreduce -g 10 -regex [\ ] ./mahout seqdump --seqFile patterns/fpgrowth/part-r-00000](https://image.slidesharecdn.com/intro-mahout-110529200909-phpapp01/75/mahout-introduction-24-2048.jpg)






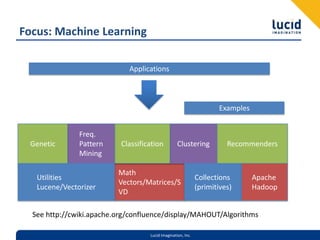
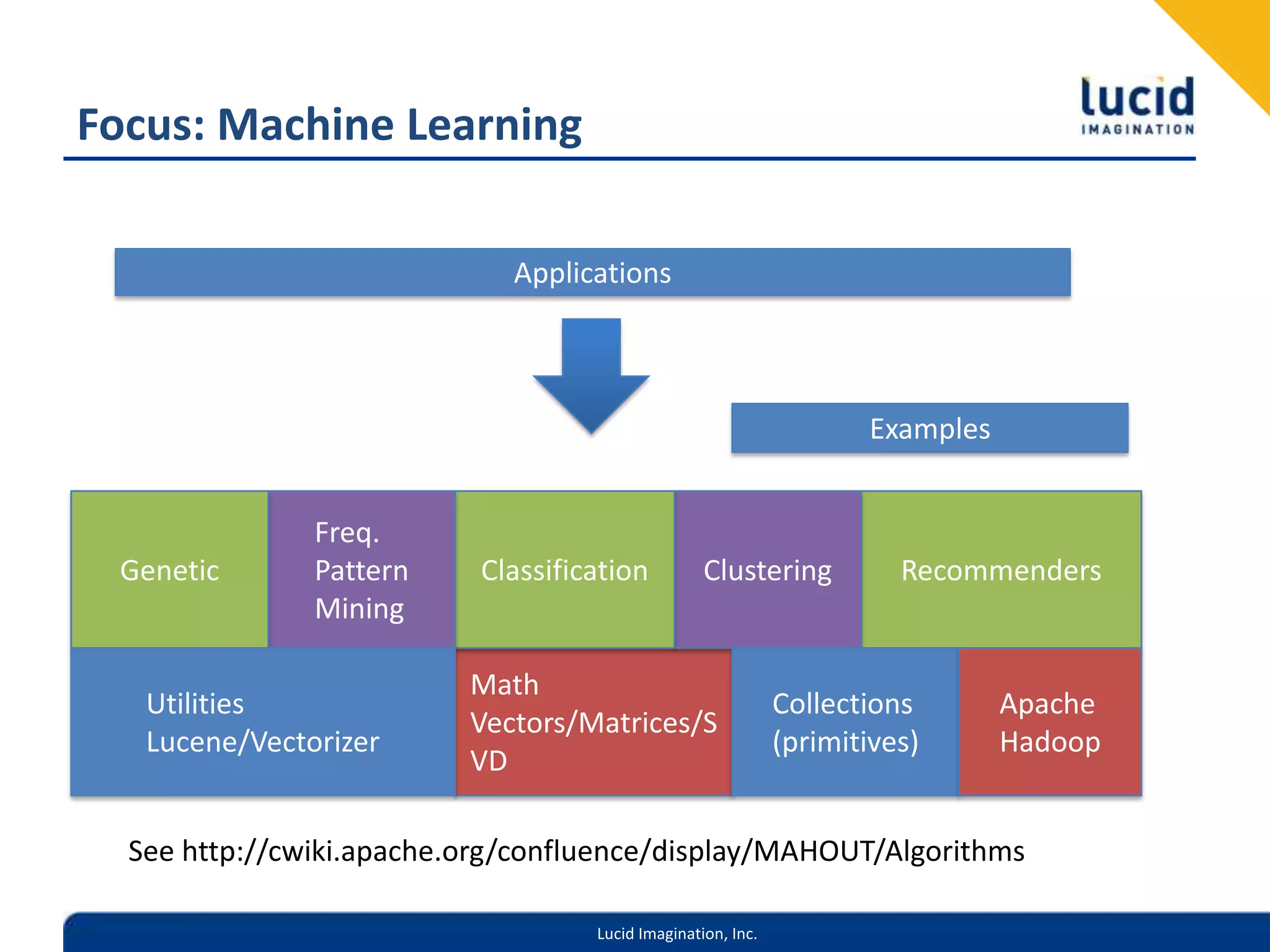
This document introduces Apache Mahout, an open source machine learning library. It discusses common machine learning use cases like recommendations, classification, and clustering. It explains how Mahout implements scalable machine learning algorithms using Apache Hadoop. Finally, it provides examples of using Mahout's recommender systems, topic modeling, clustering and frequent pattern mining capabilities.















































