Downloaded 11 times


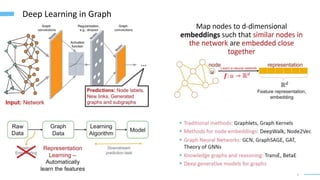
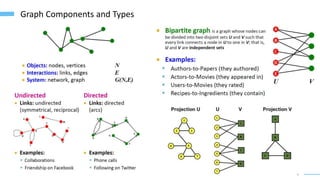
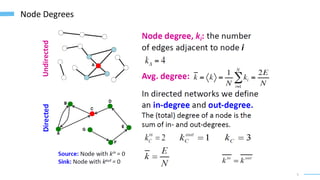
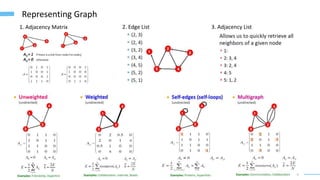
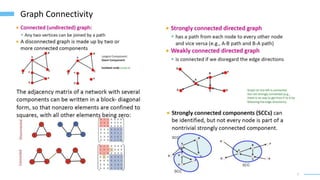
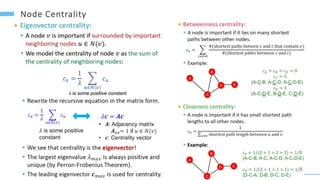
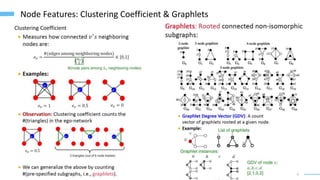
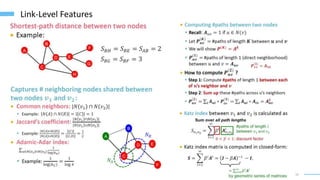


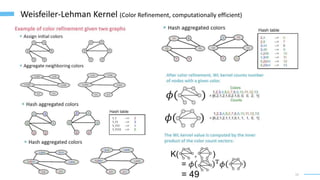
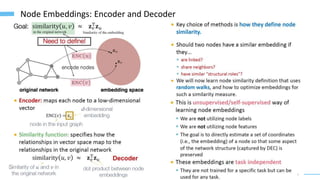
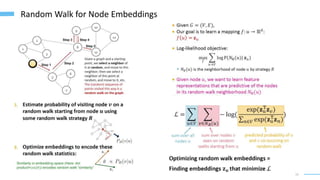


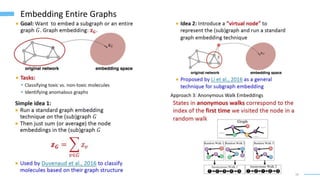





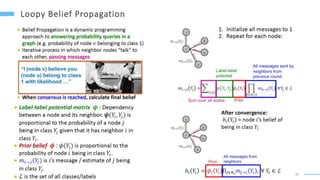
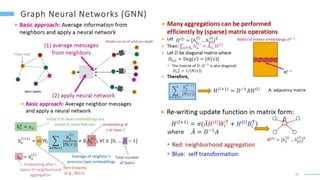
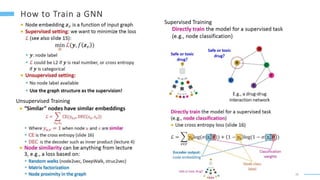
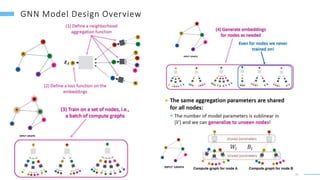







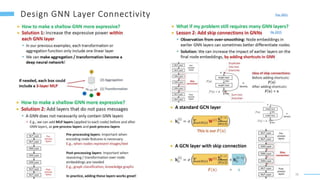
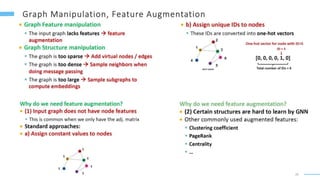
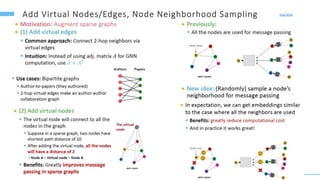


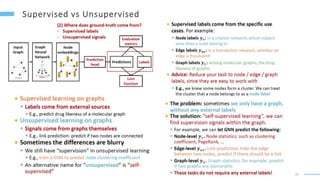
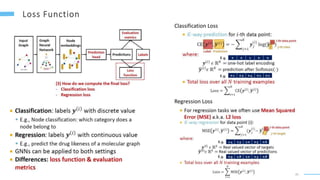
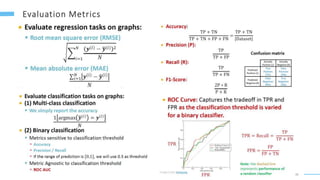

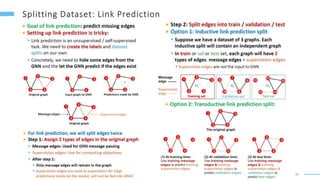

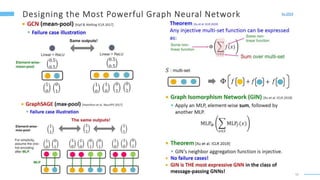
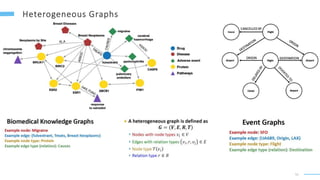

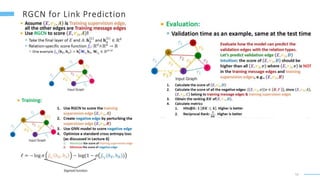
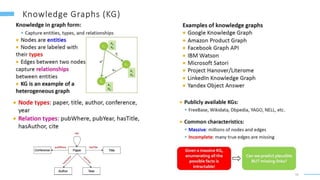








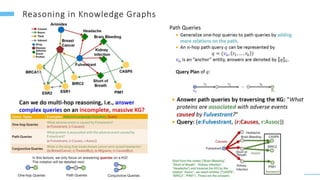
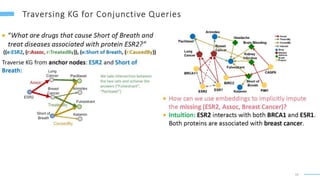
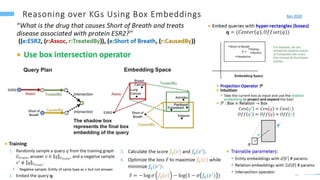

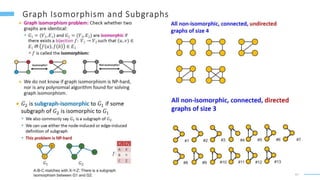



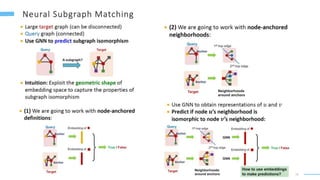
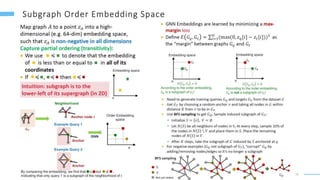

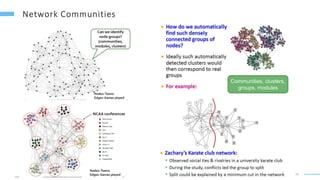

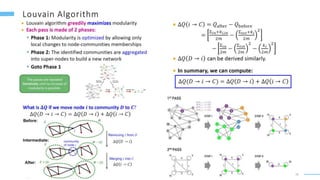
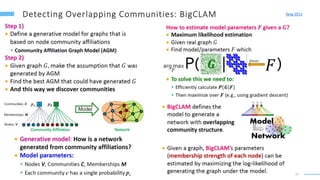
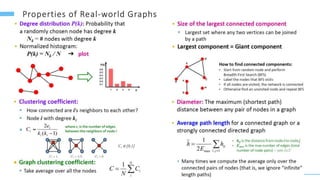
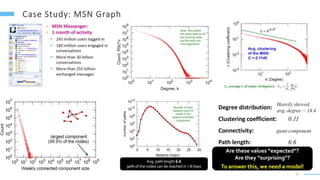
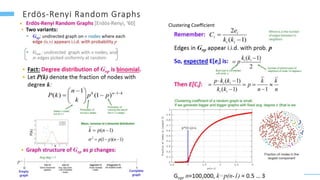
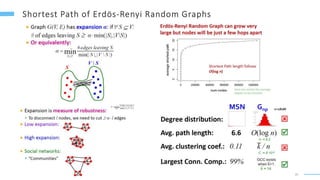
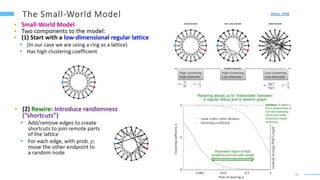
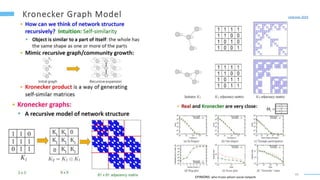
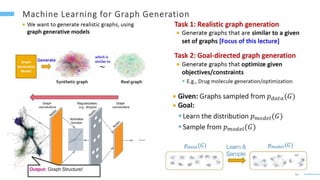

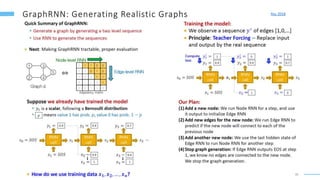
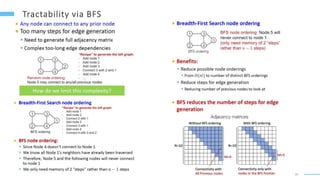

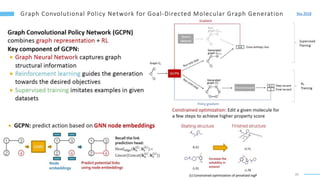
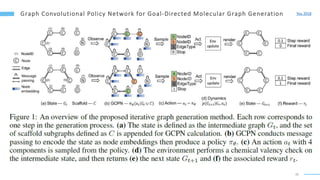
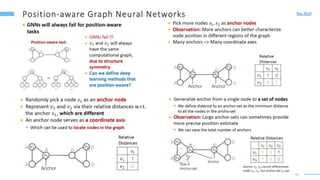
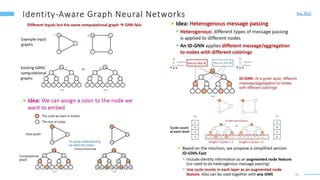




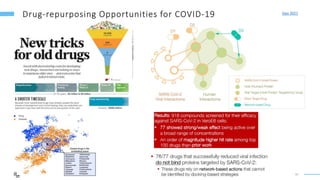



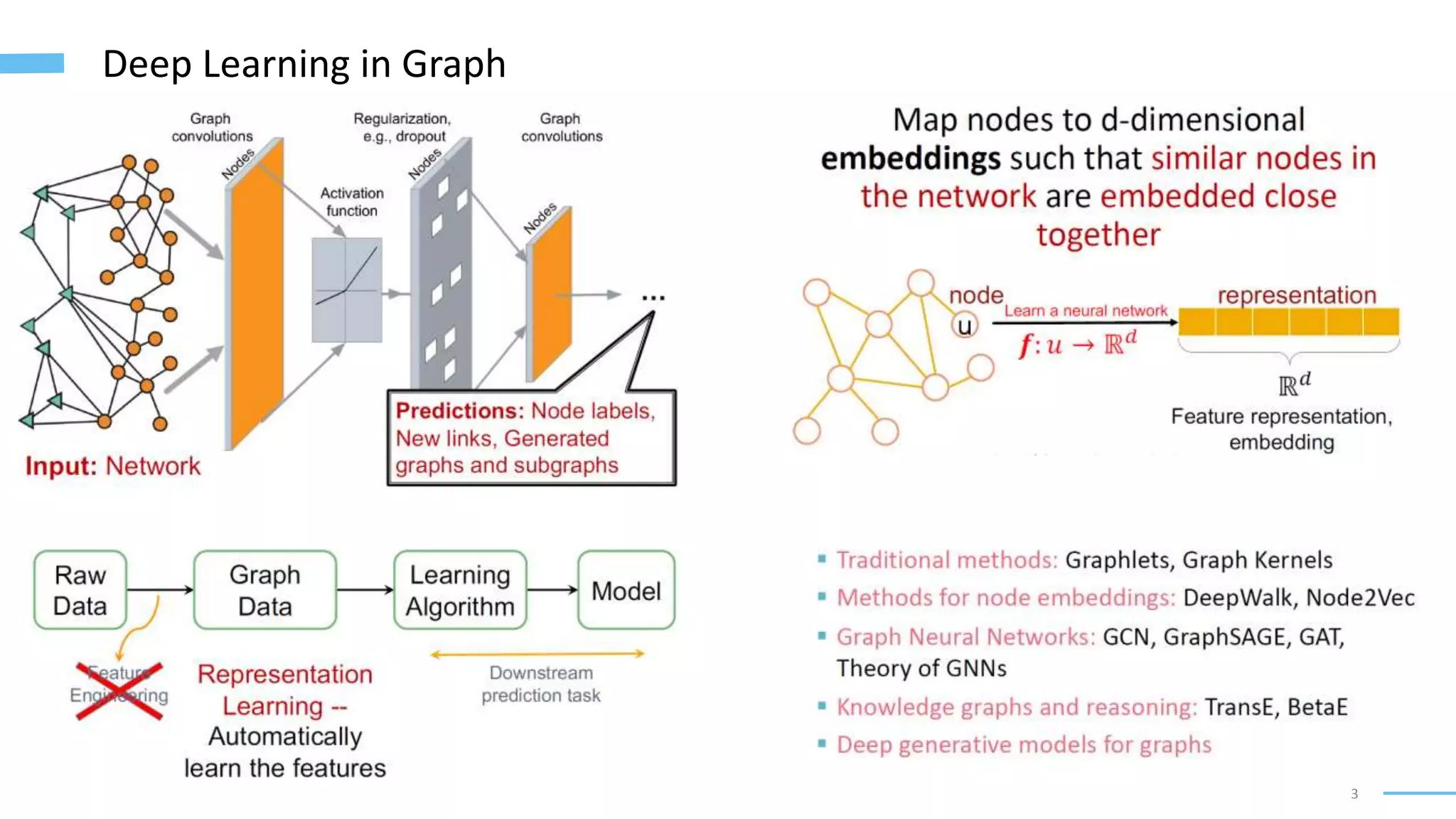
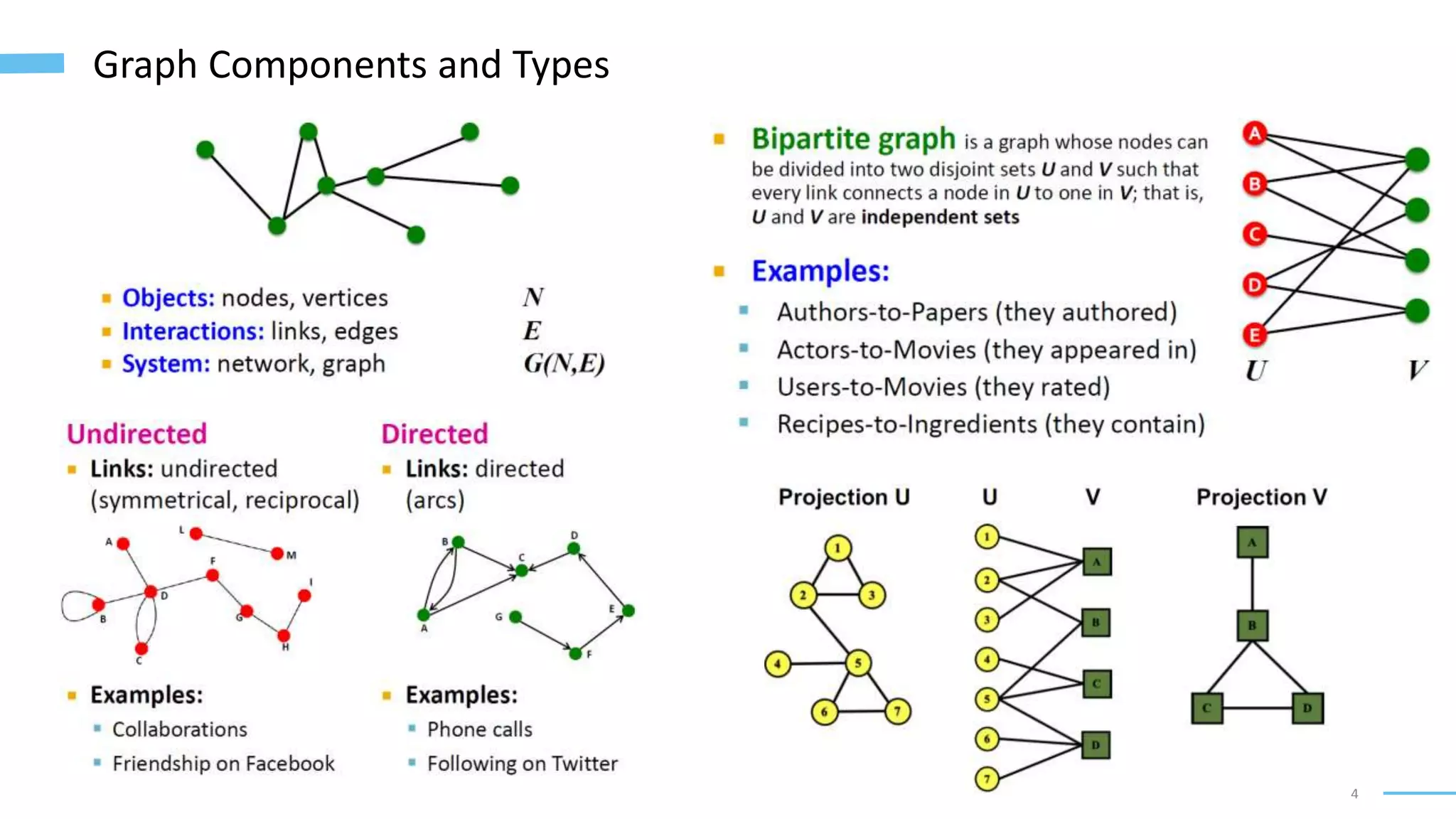
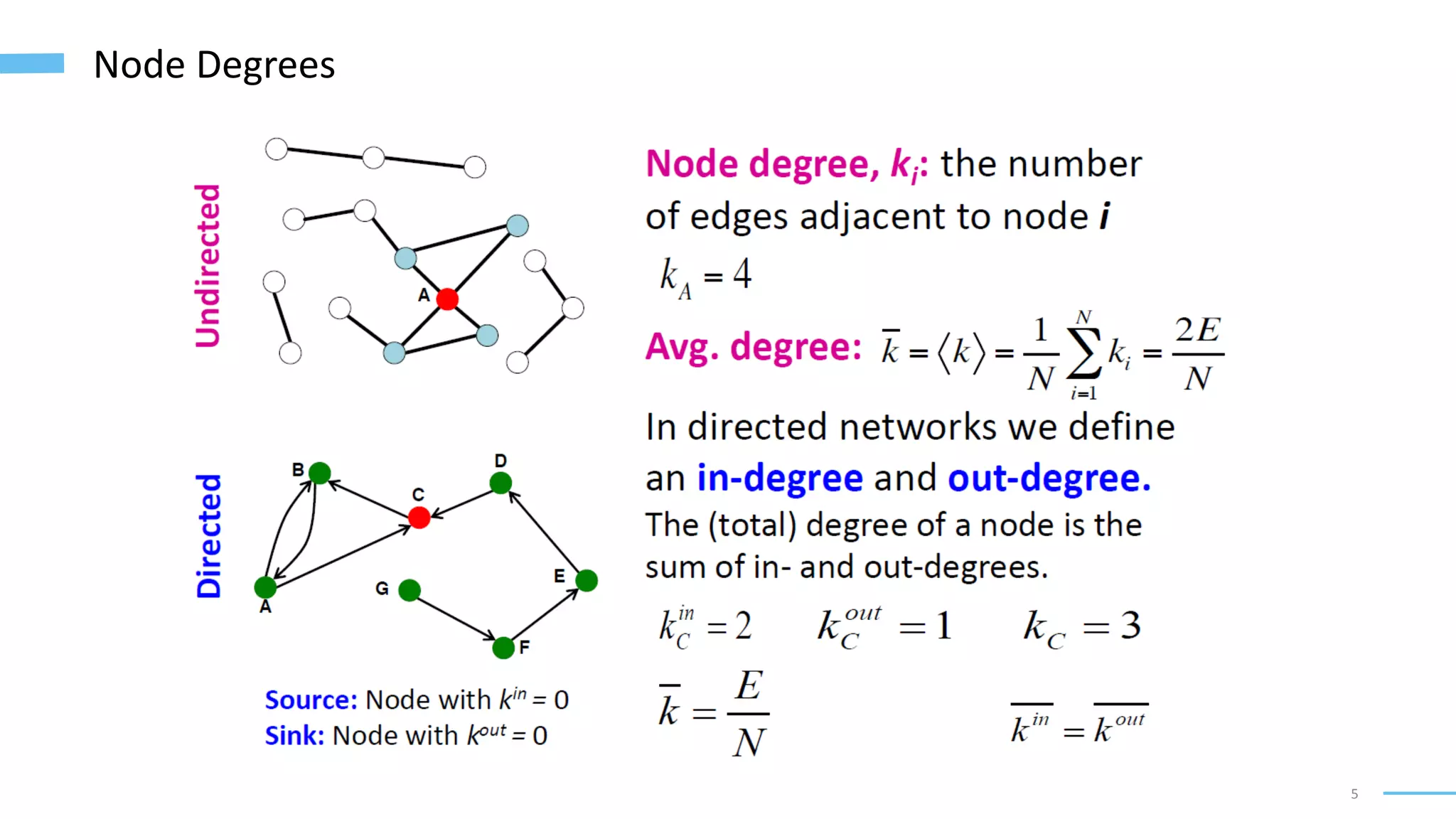
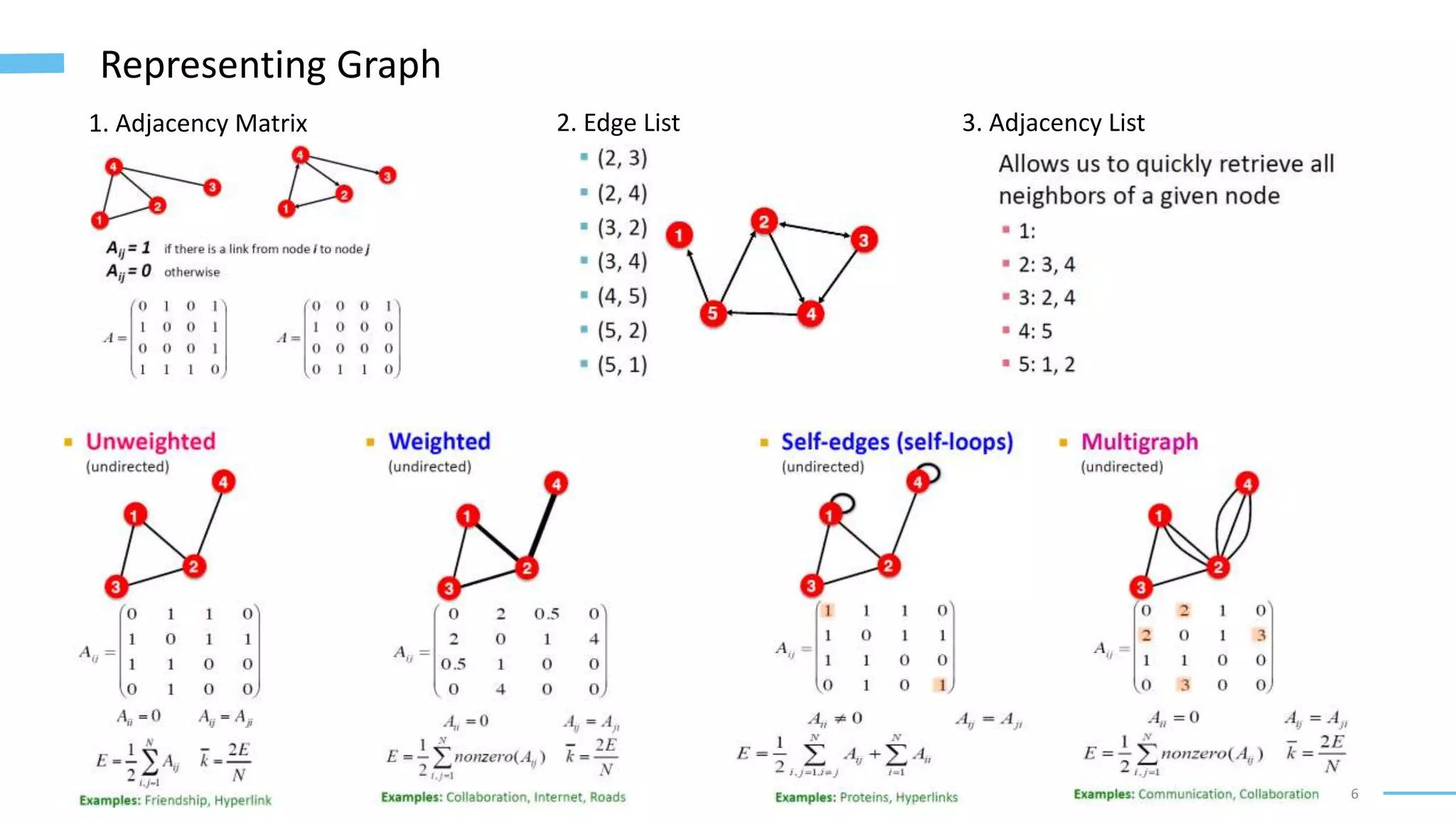
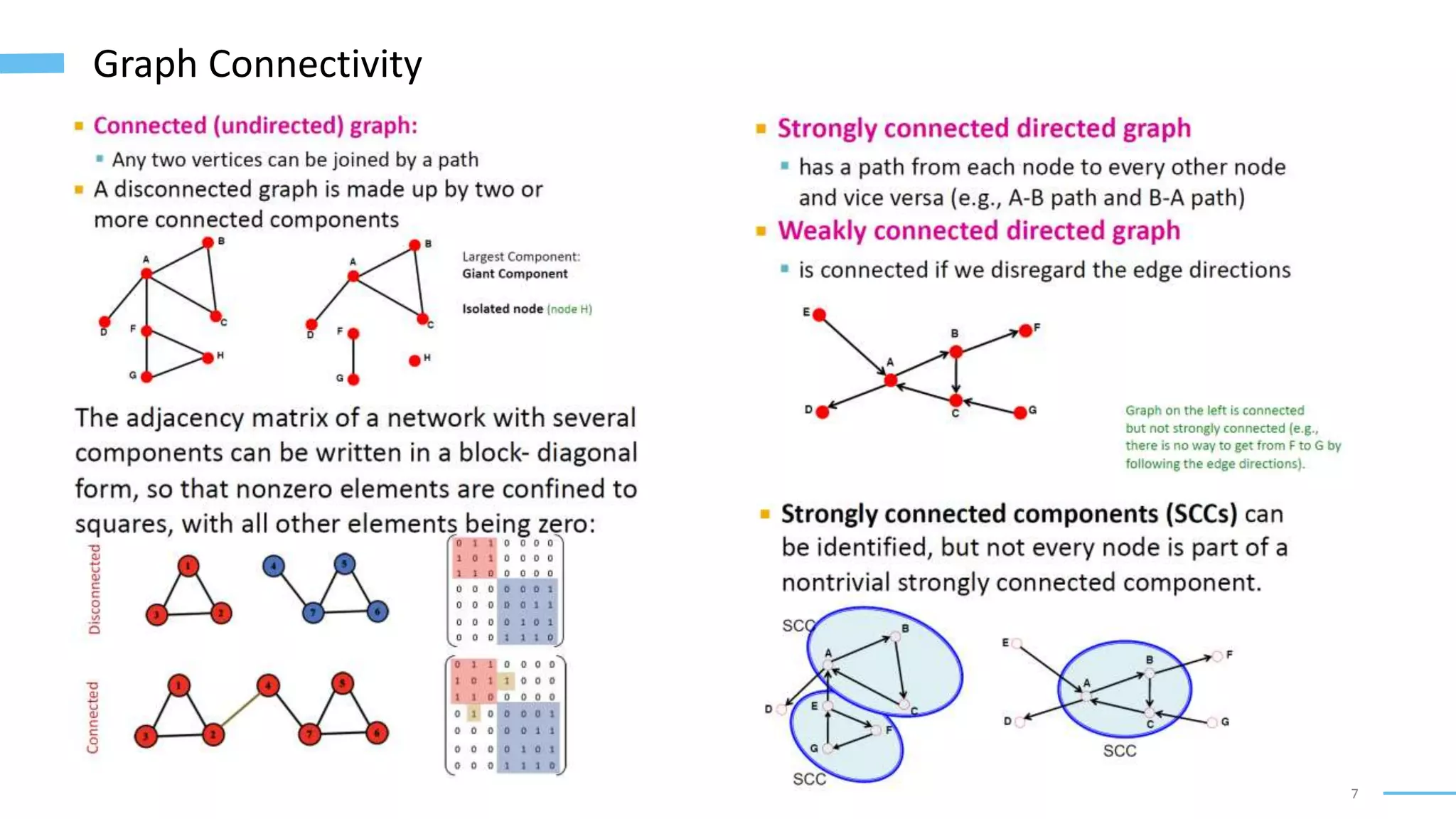
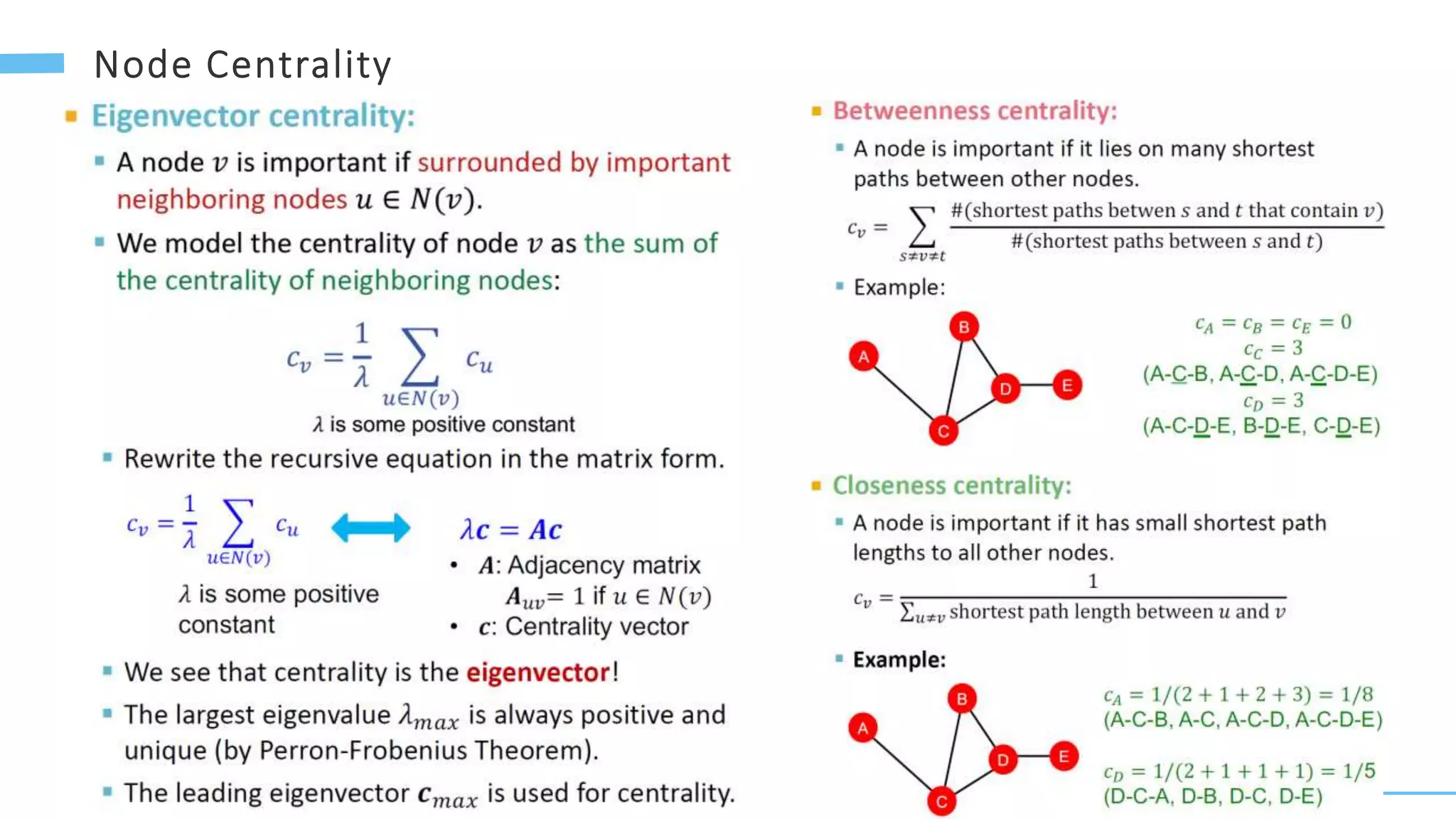
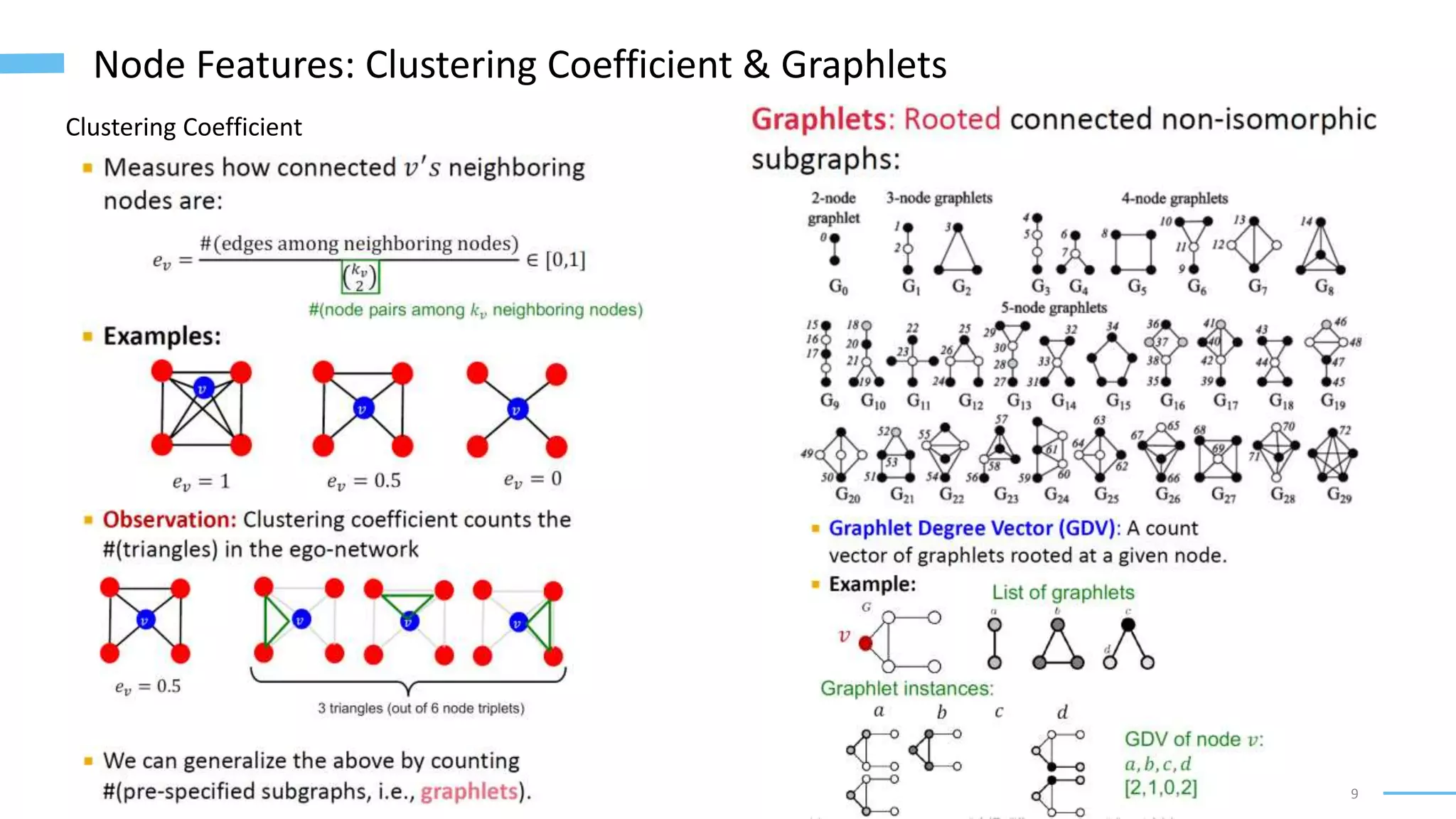
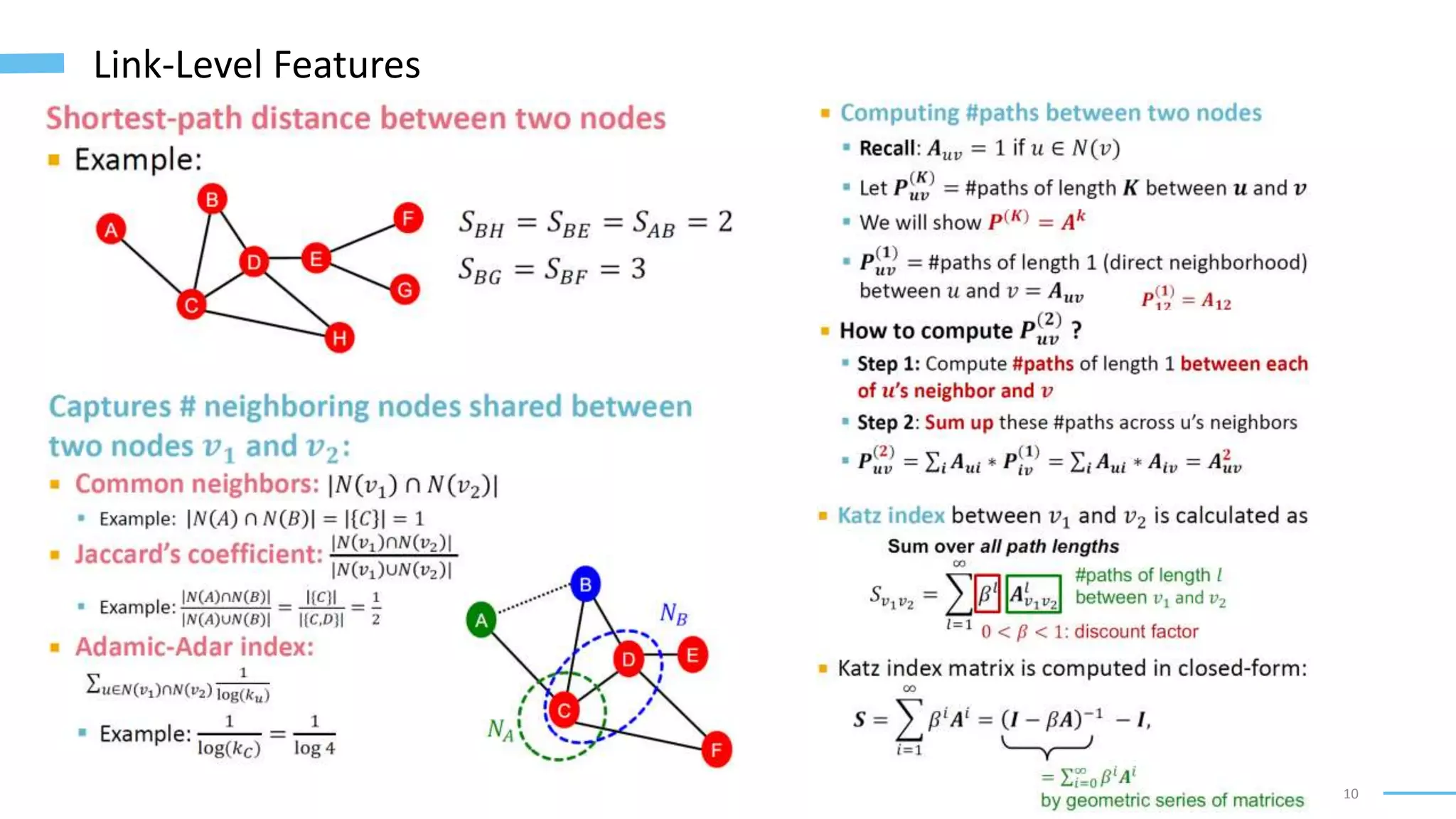


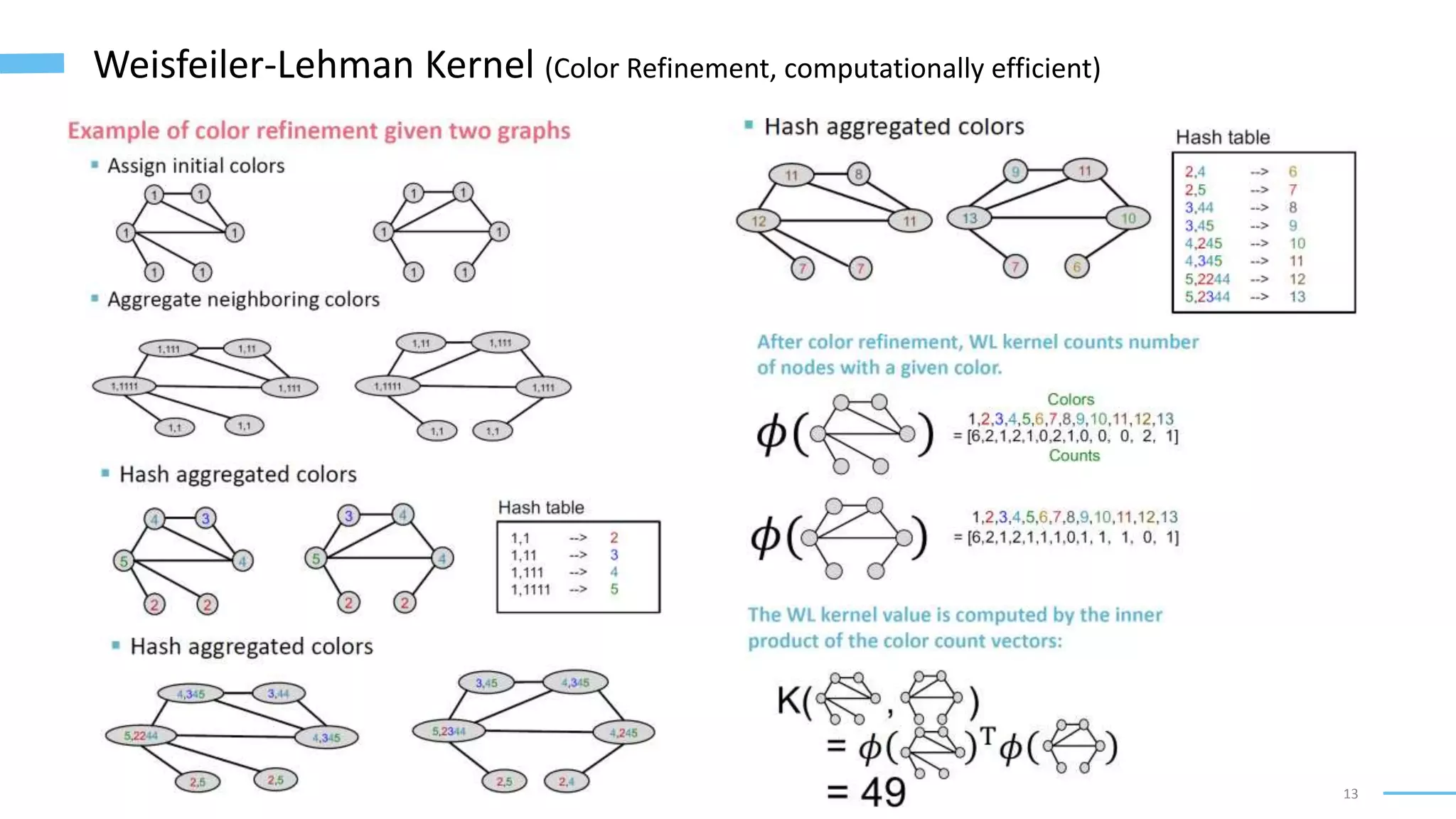
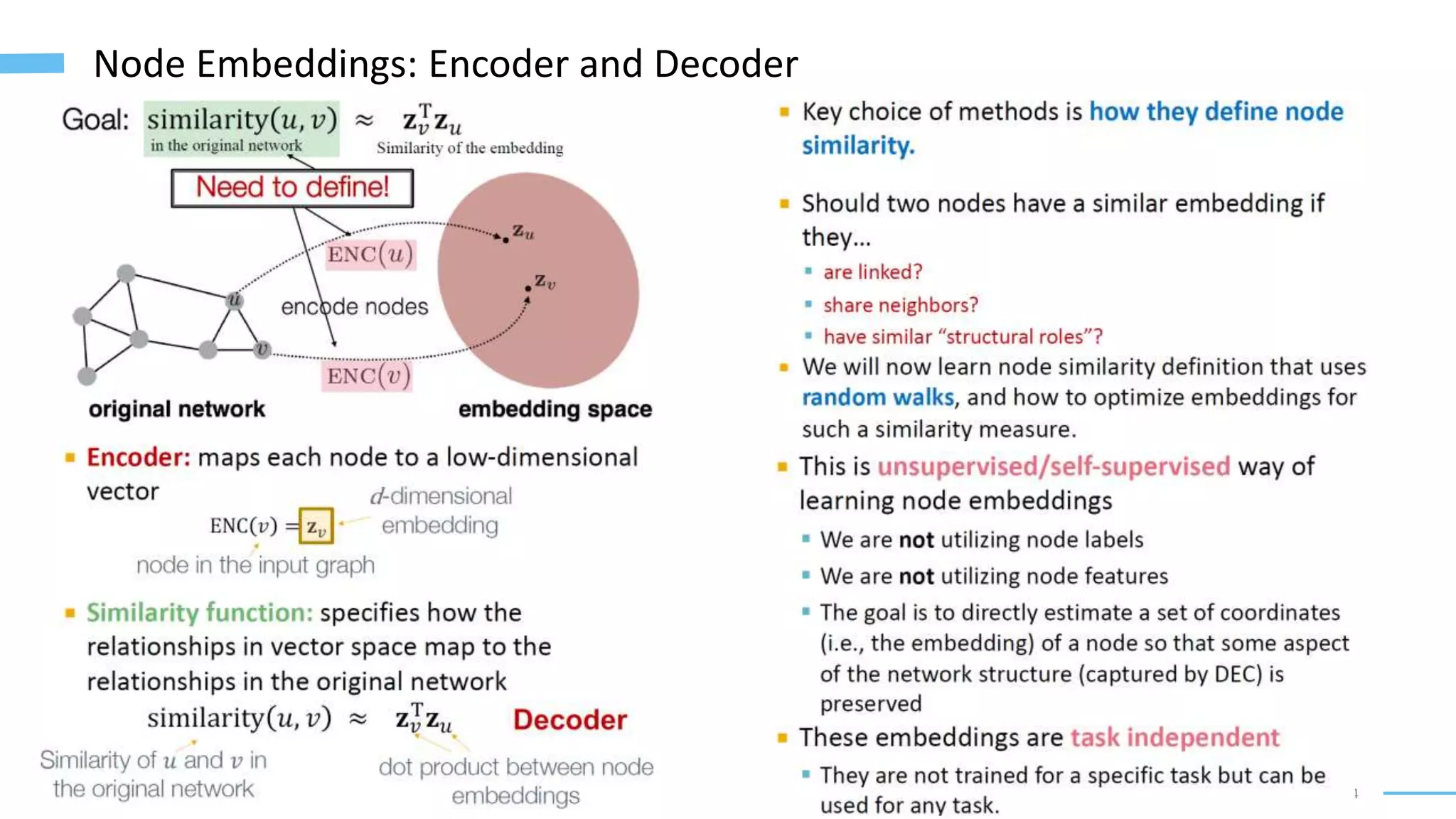
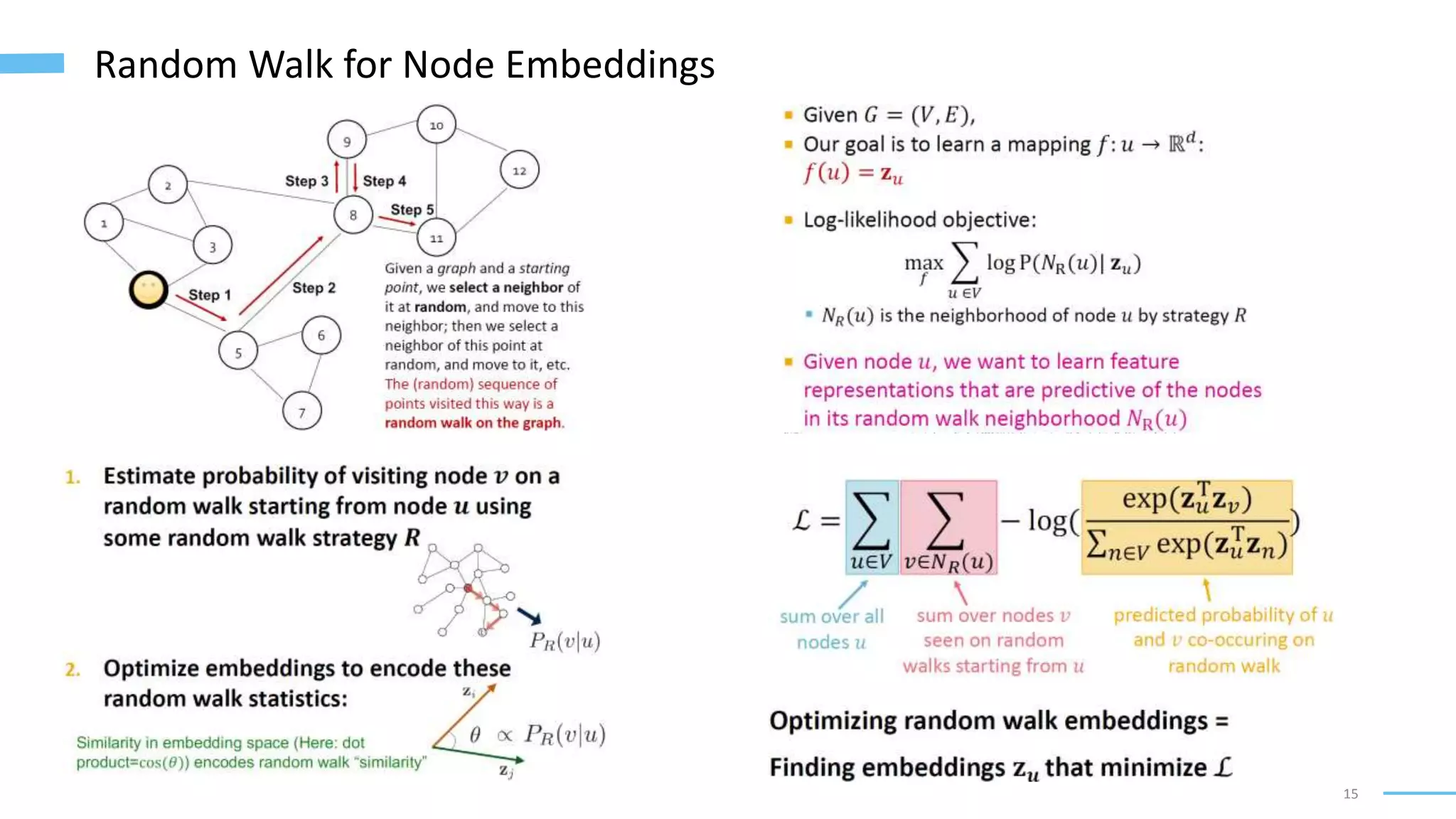

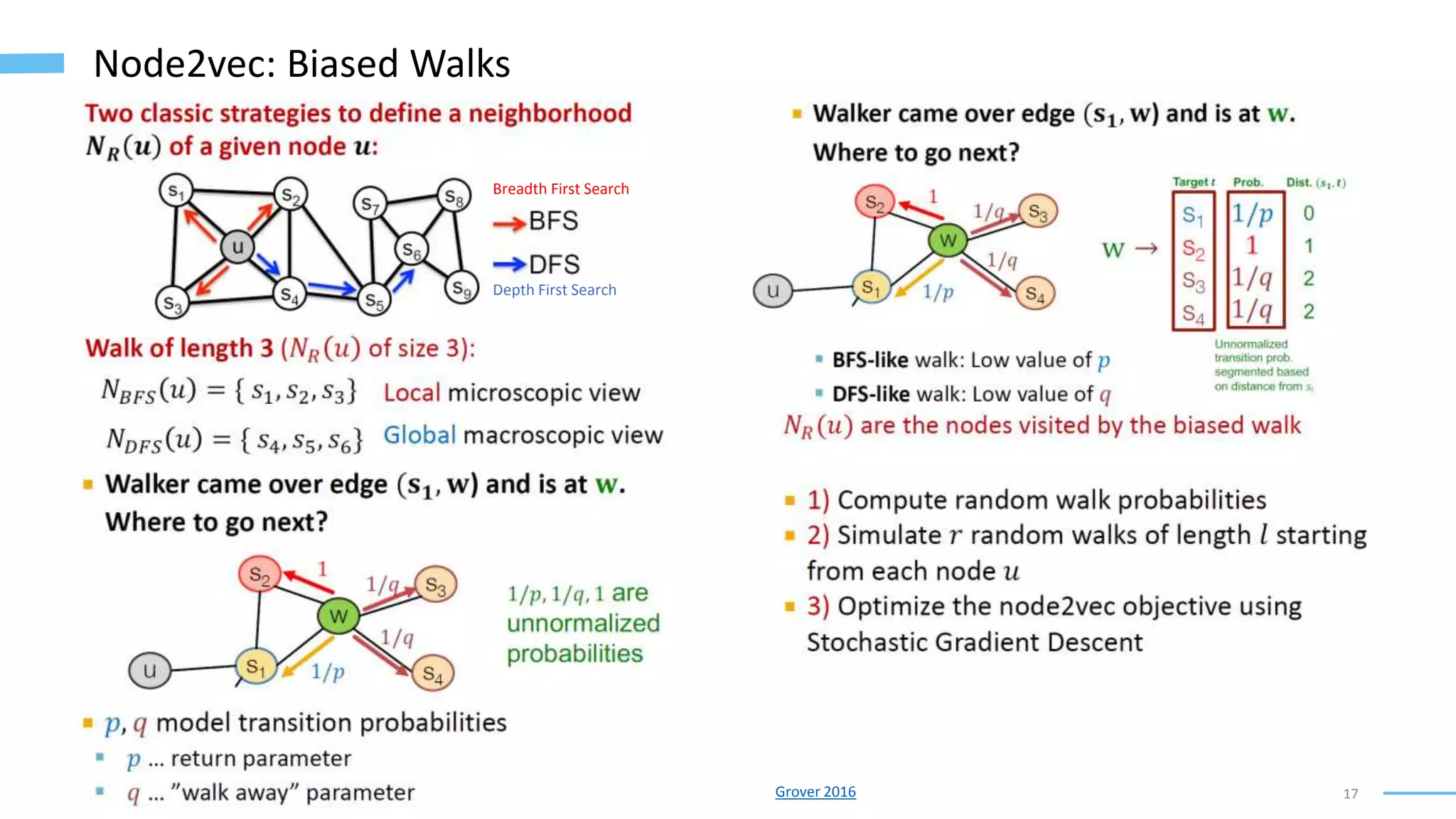

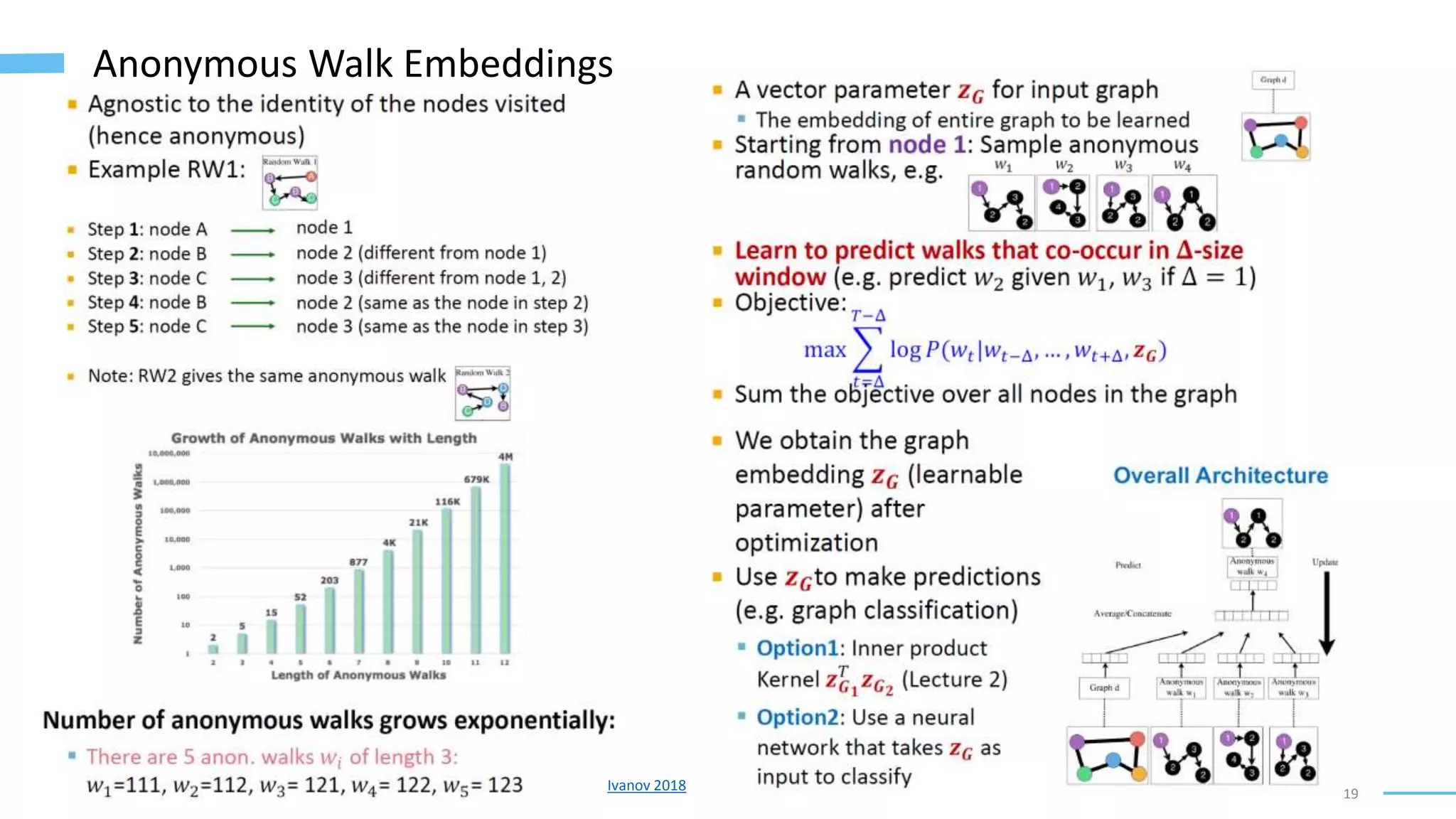
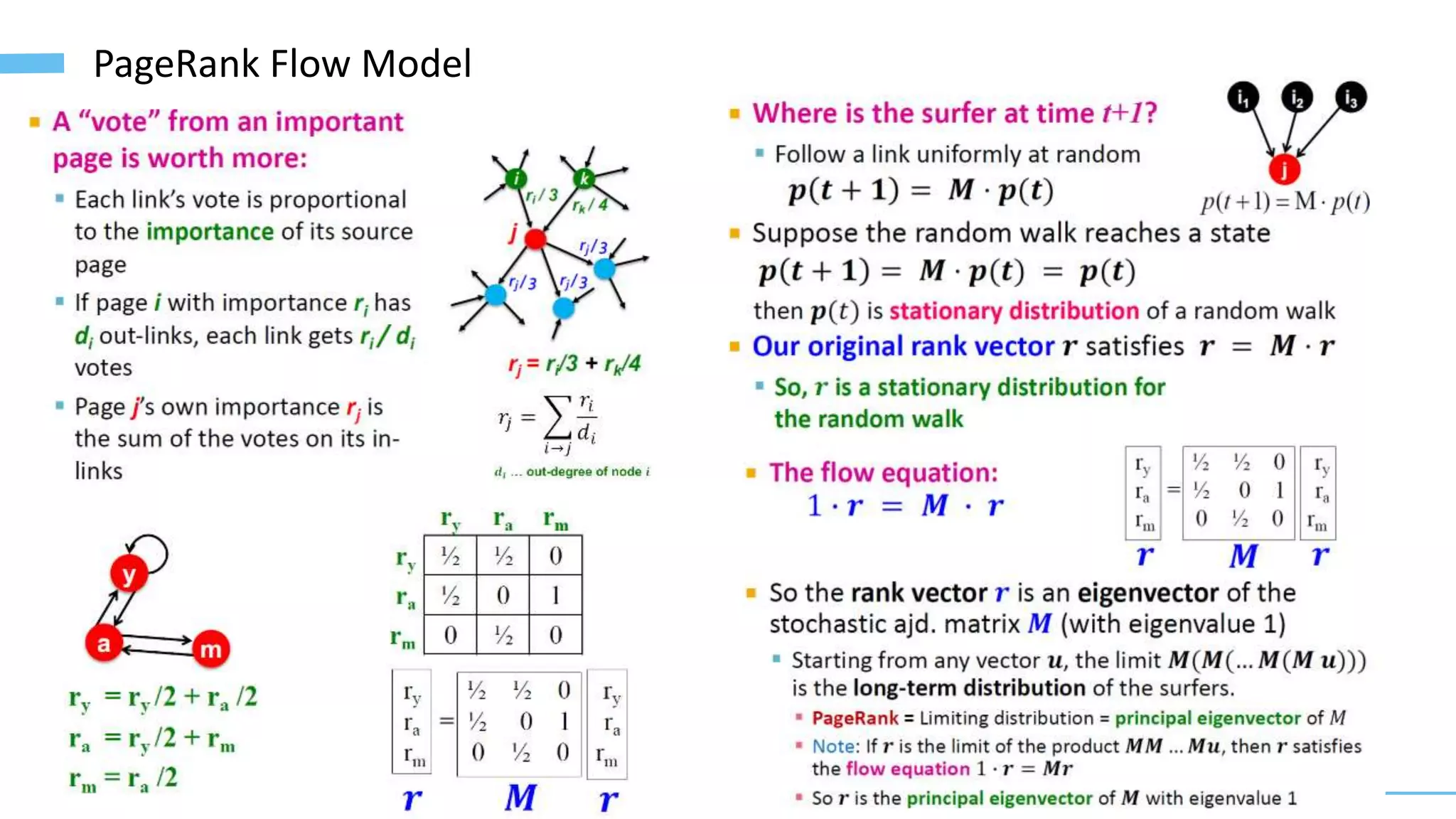

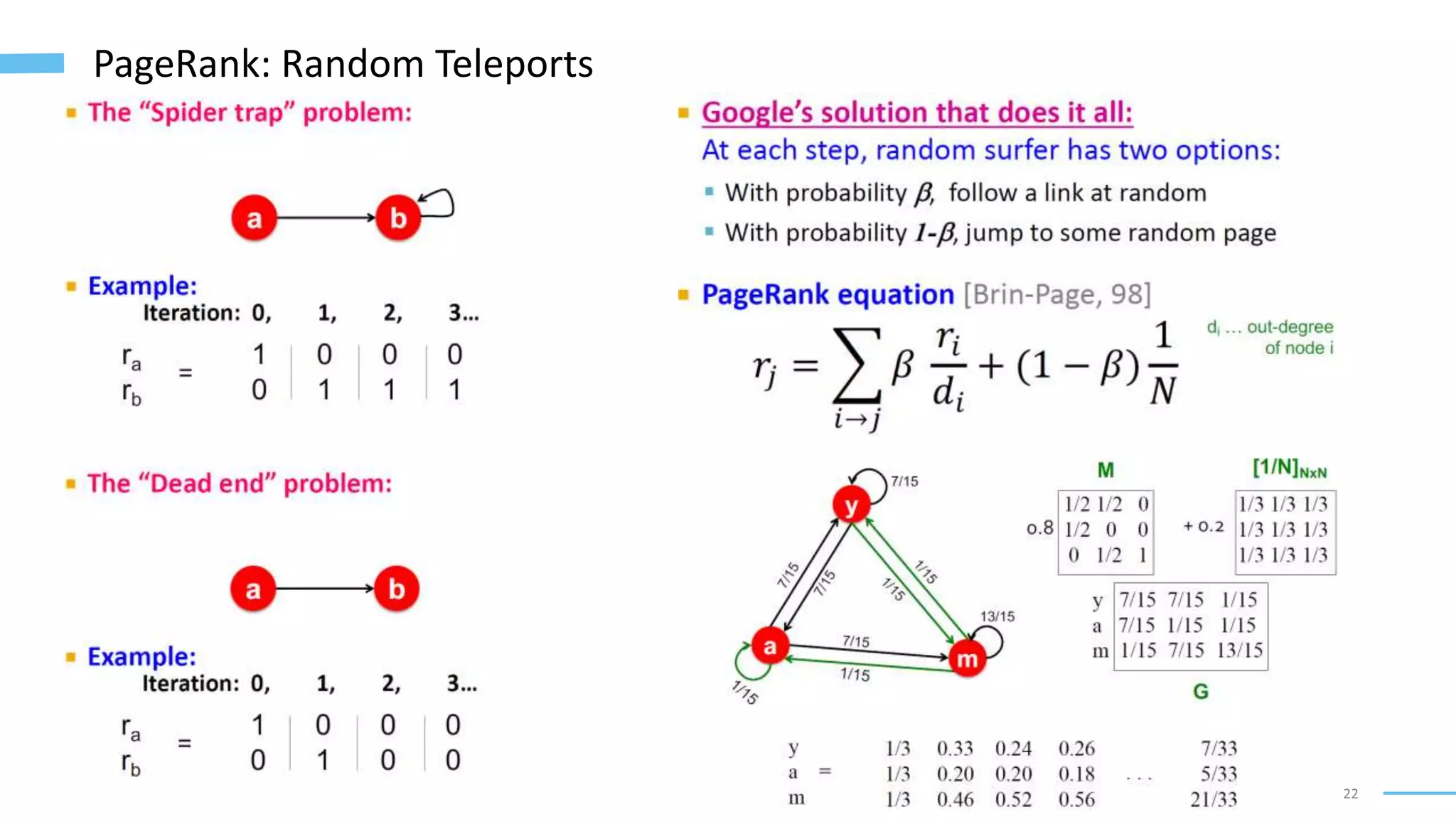
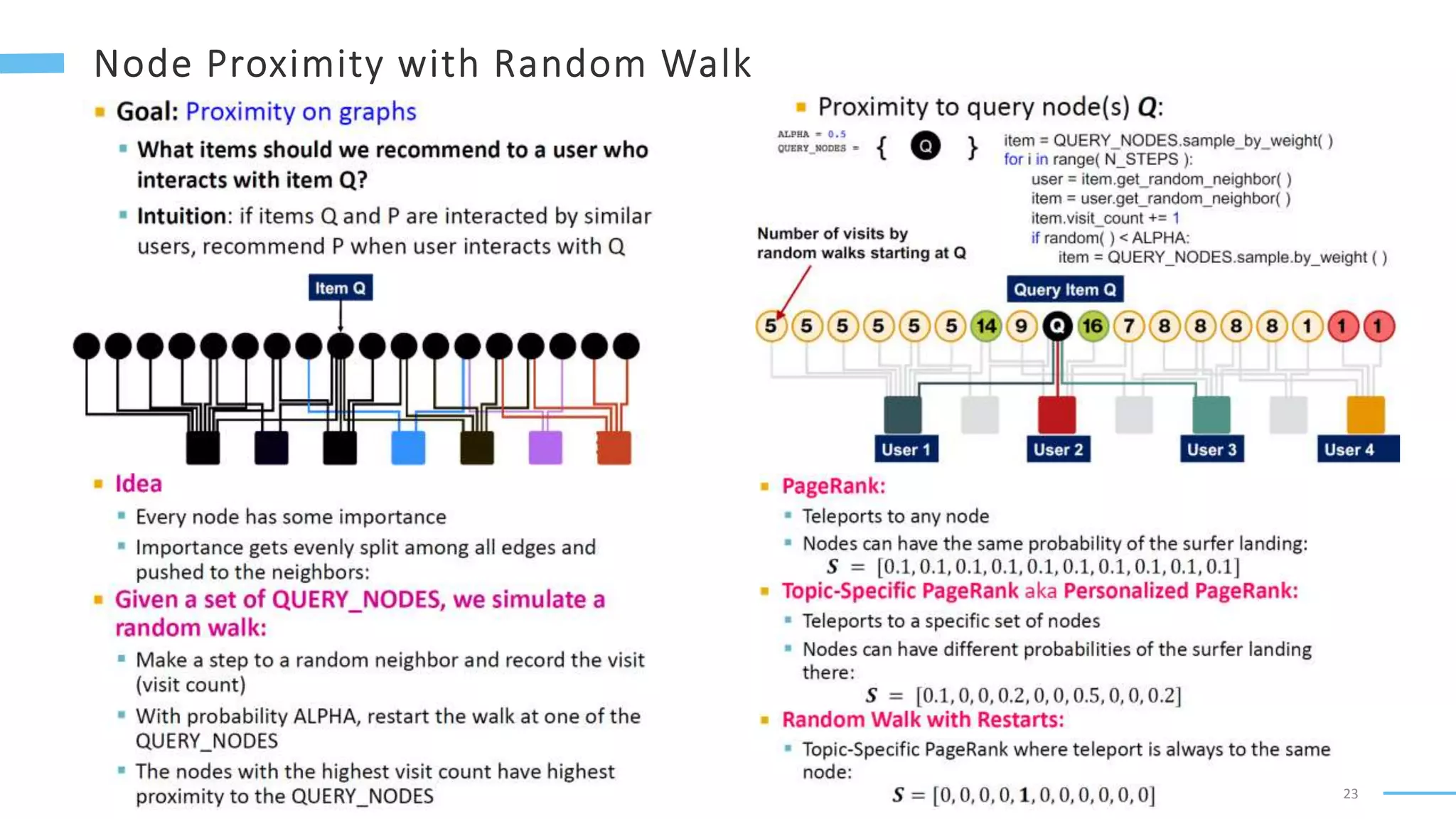
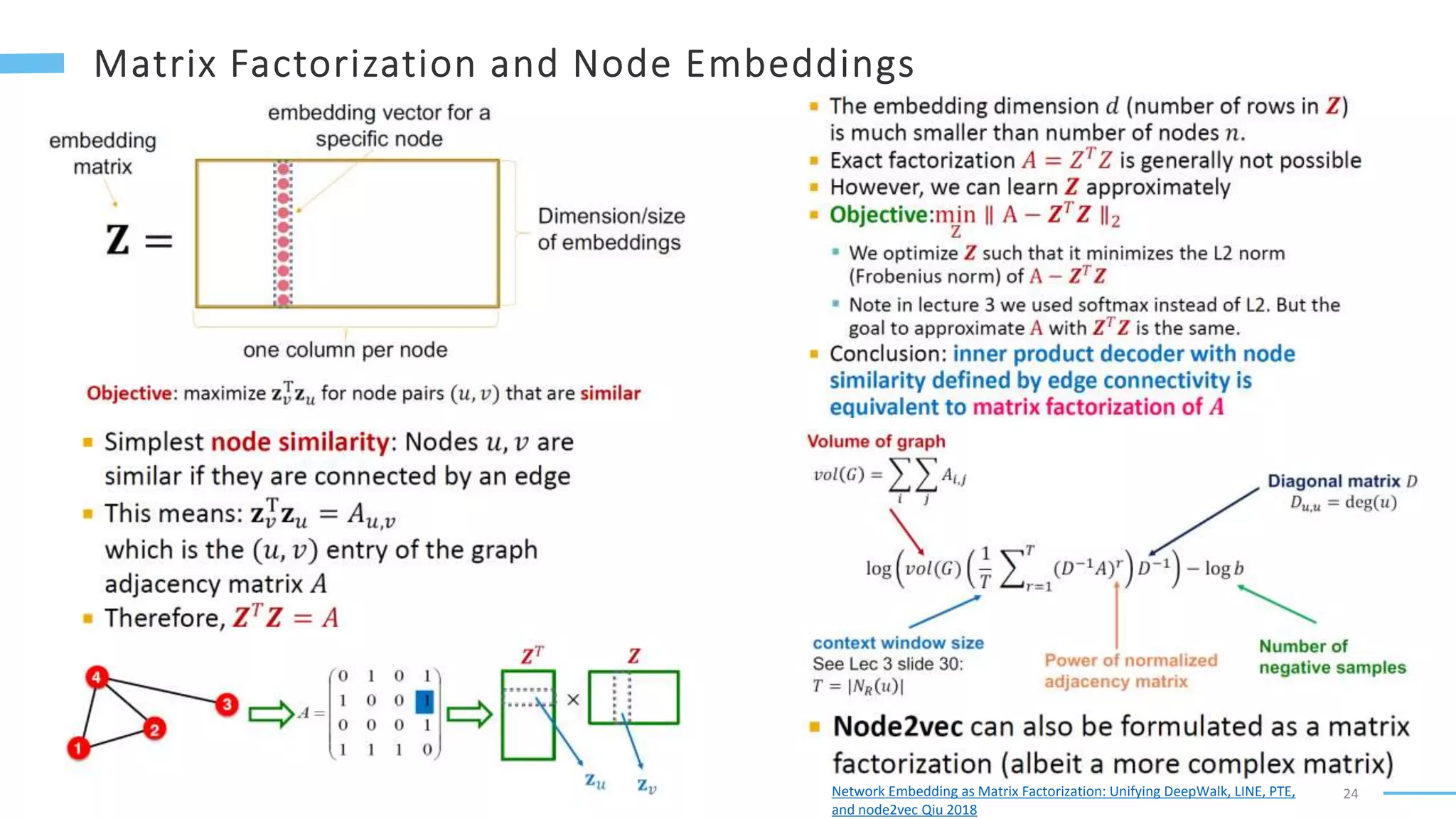
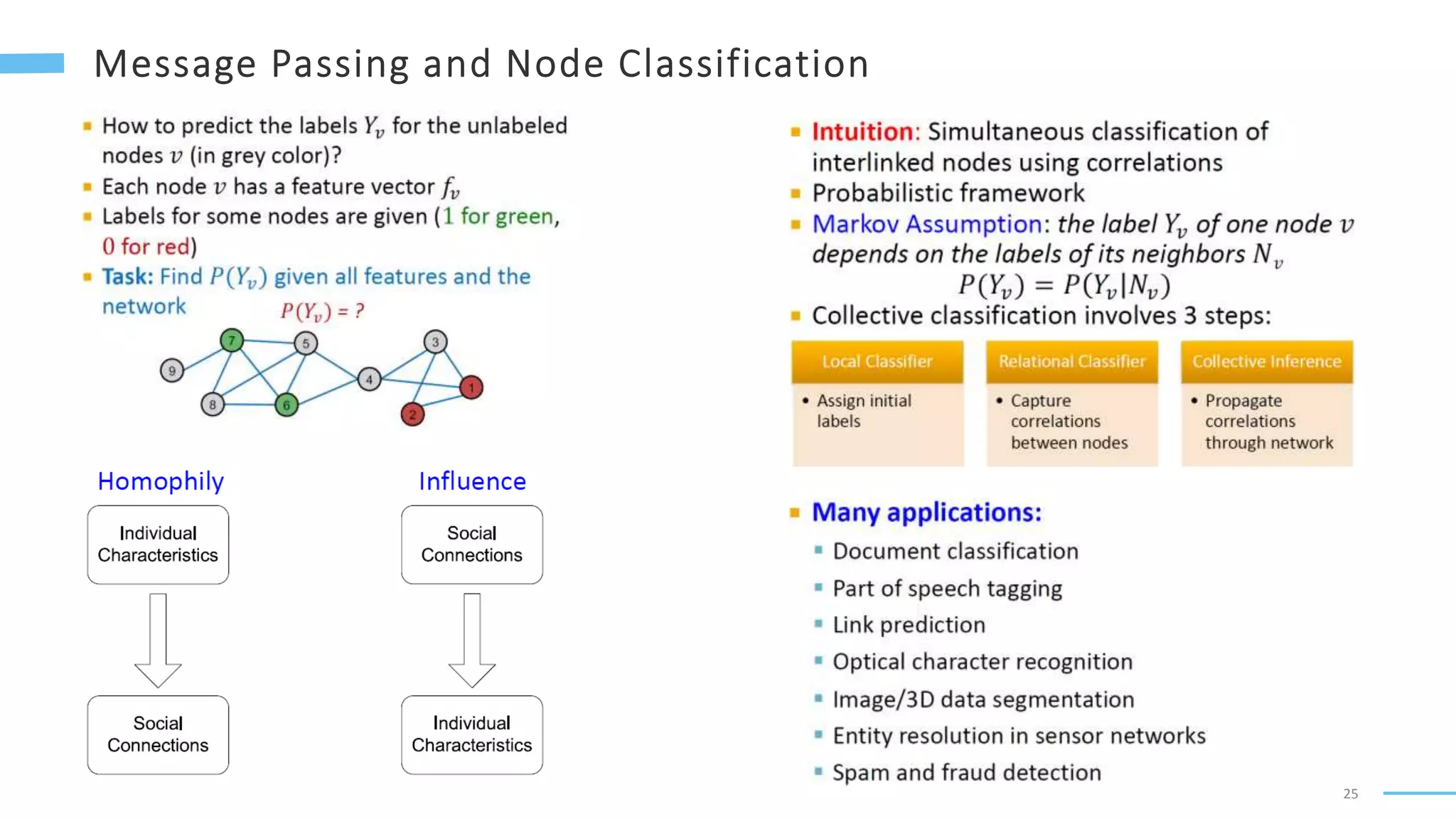
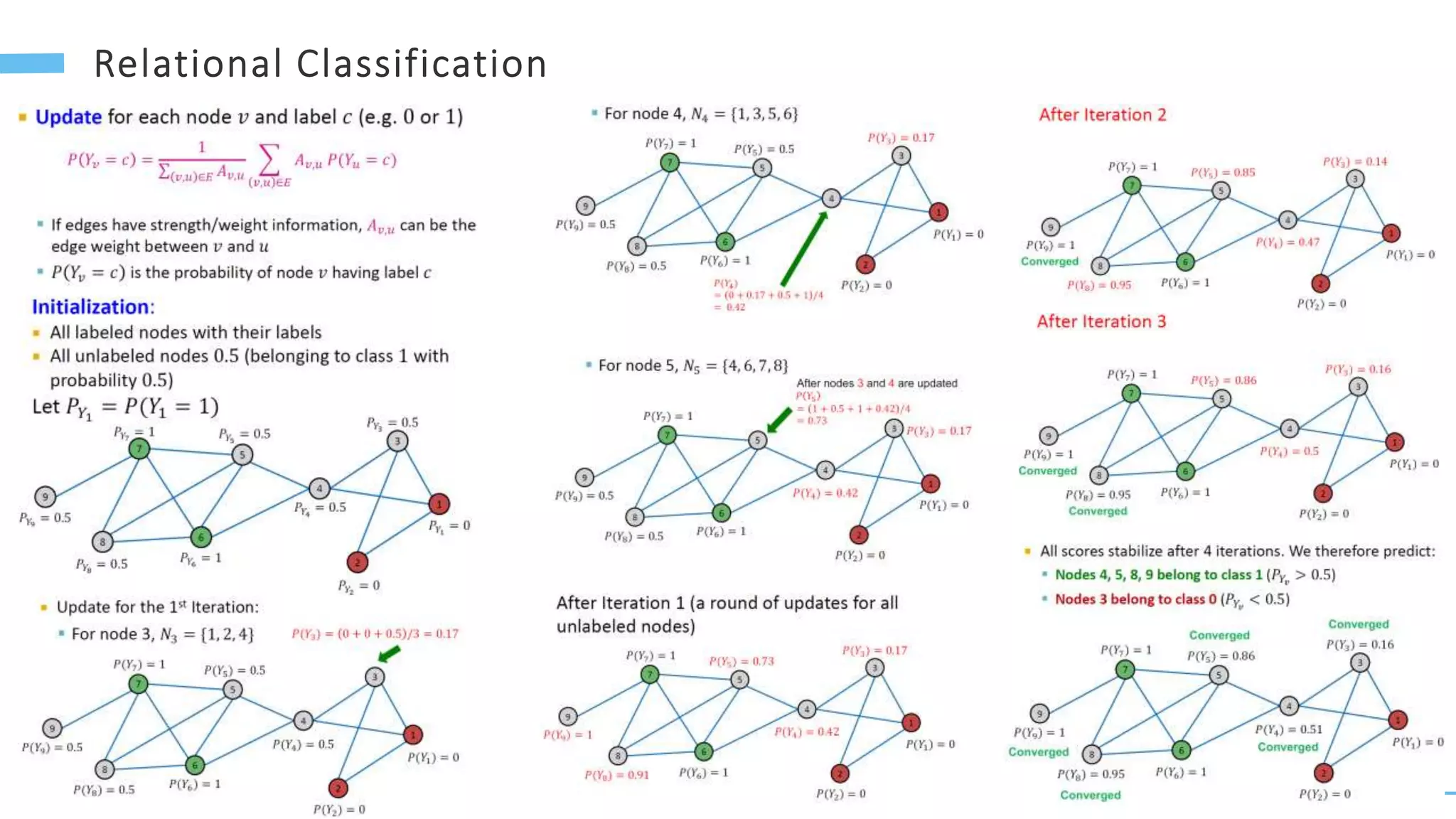
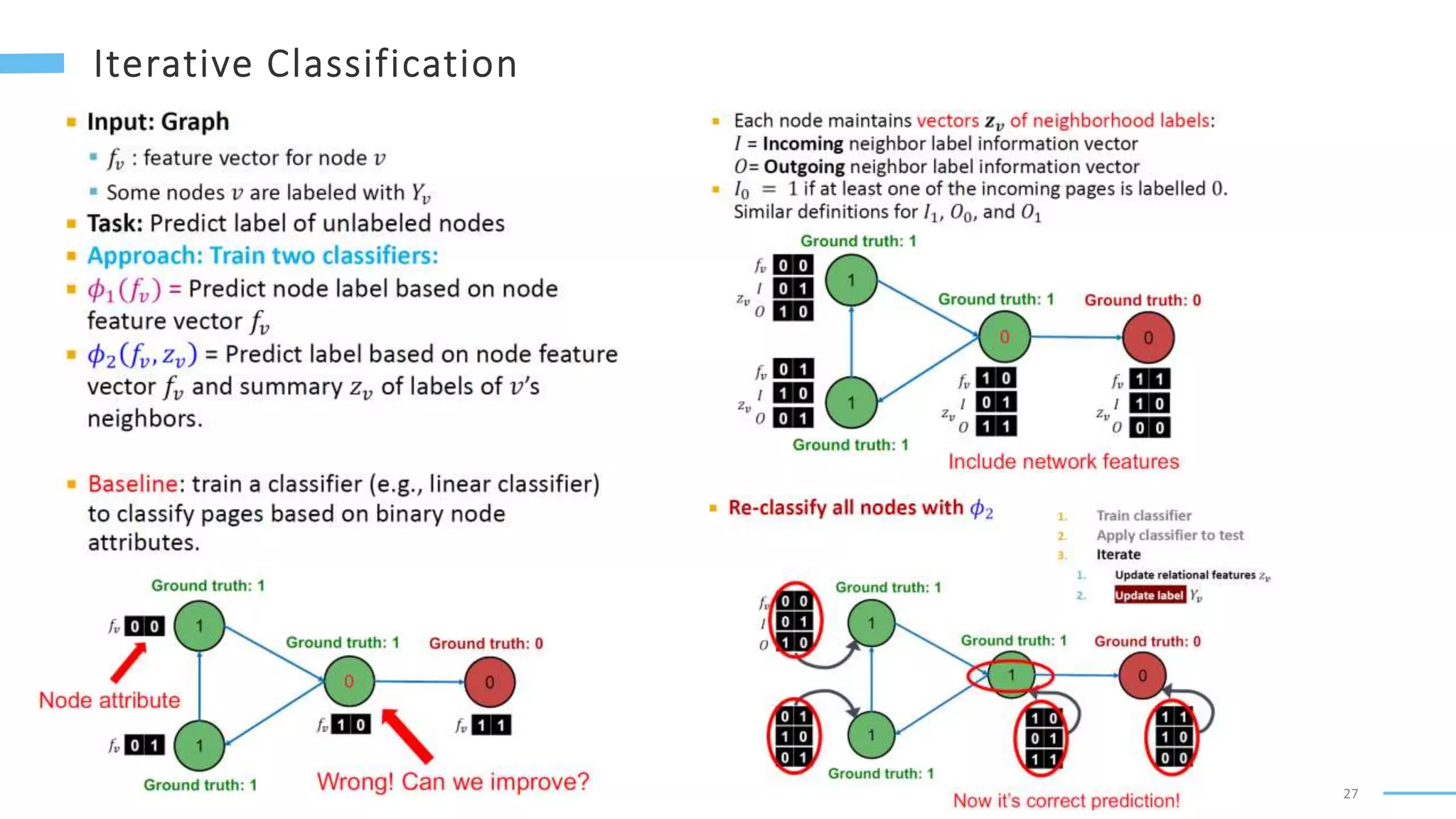
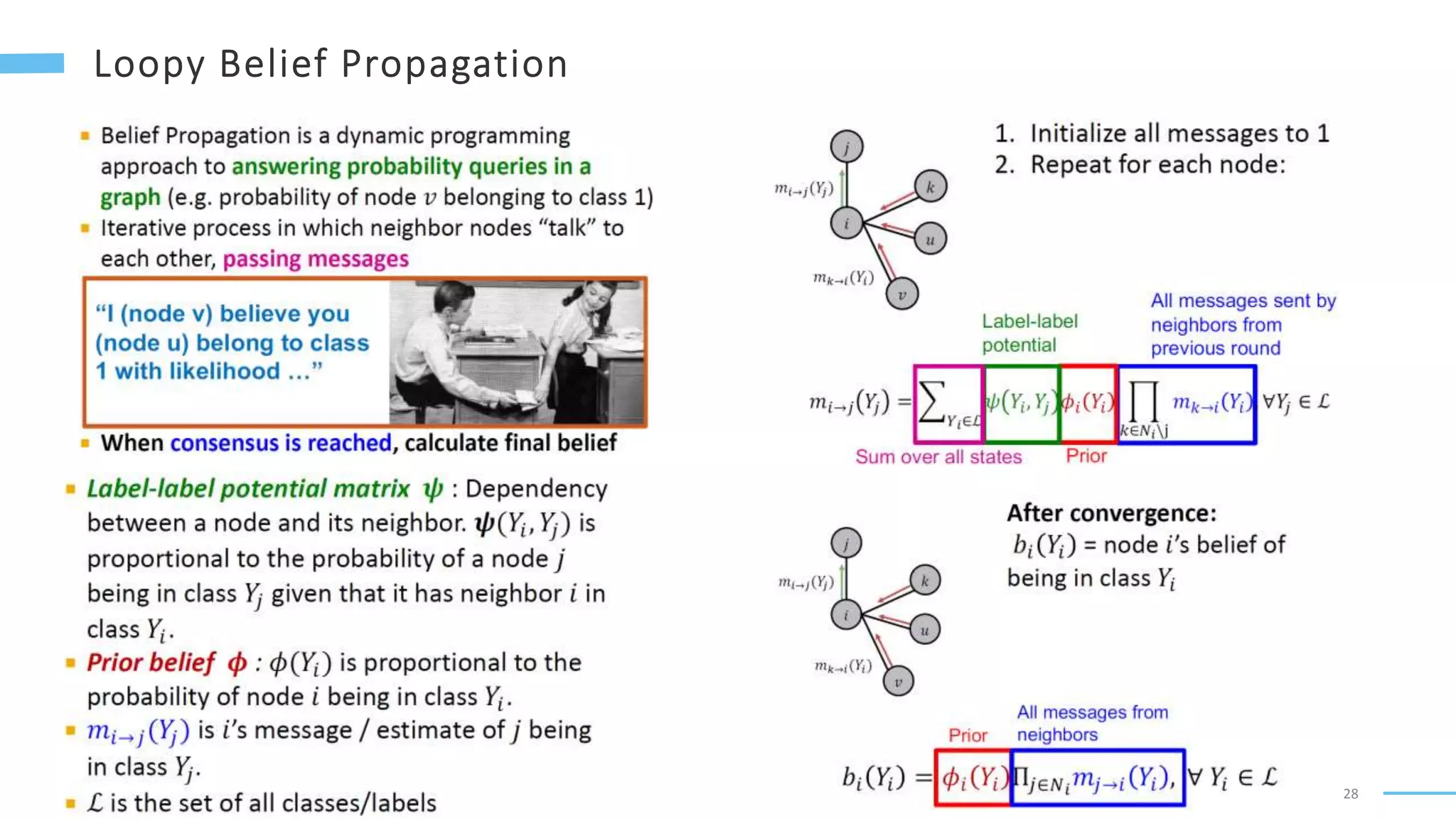
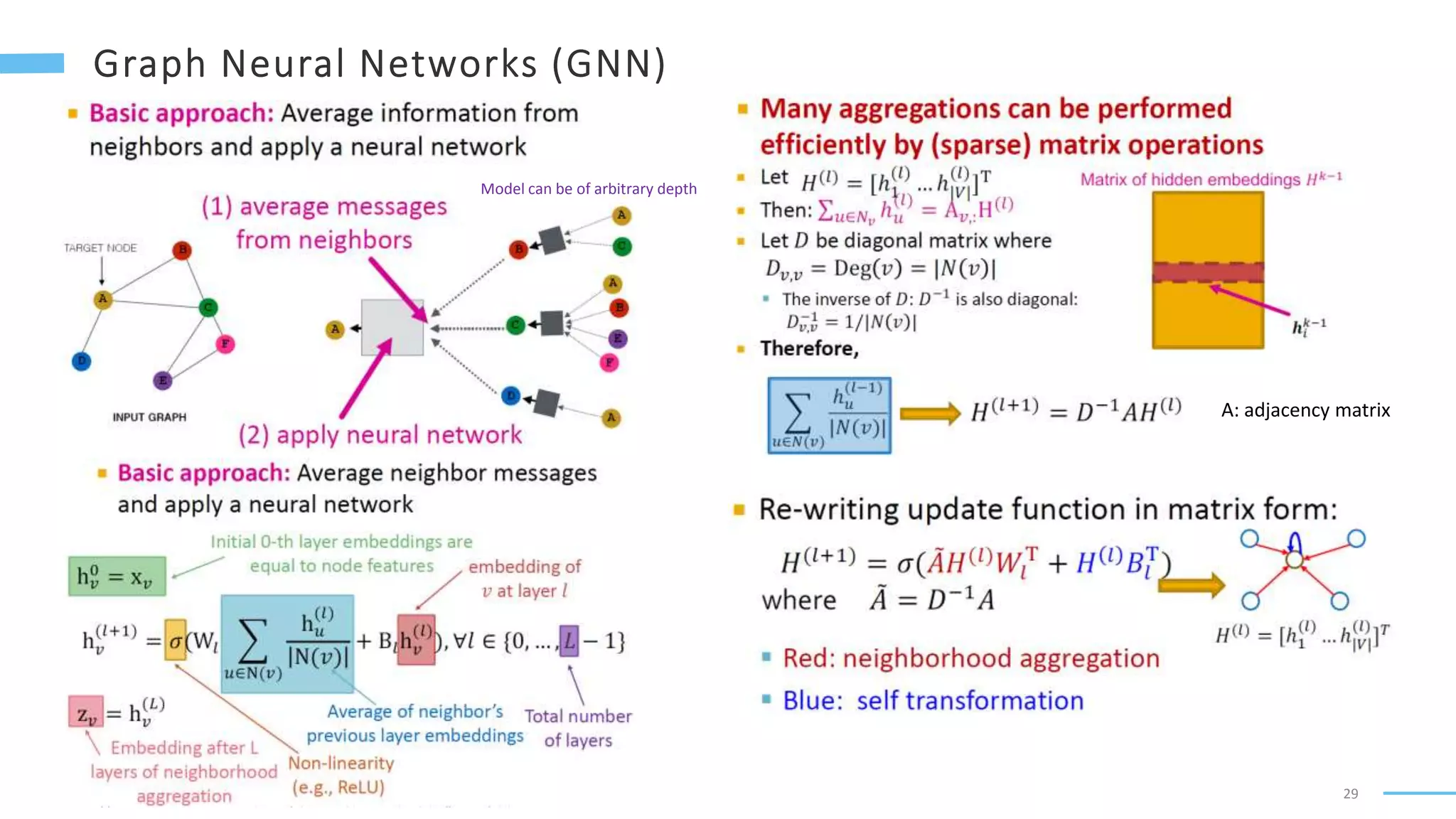
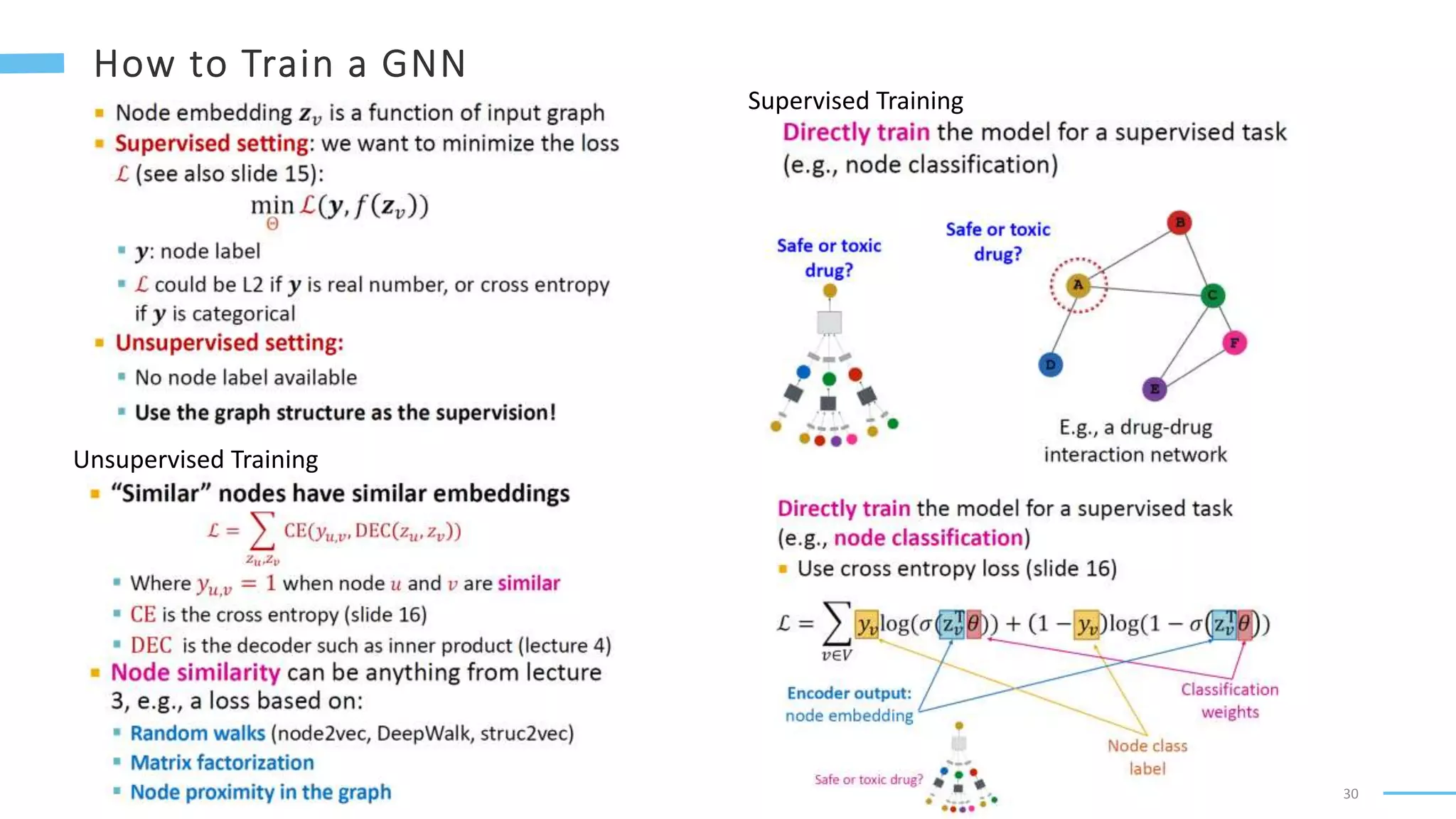





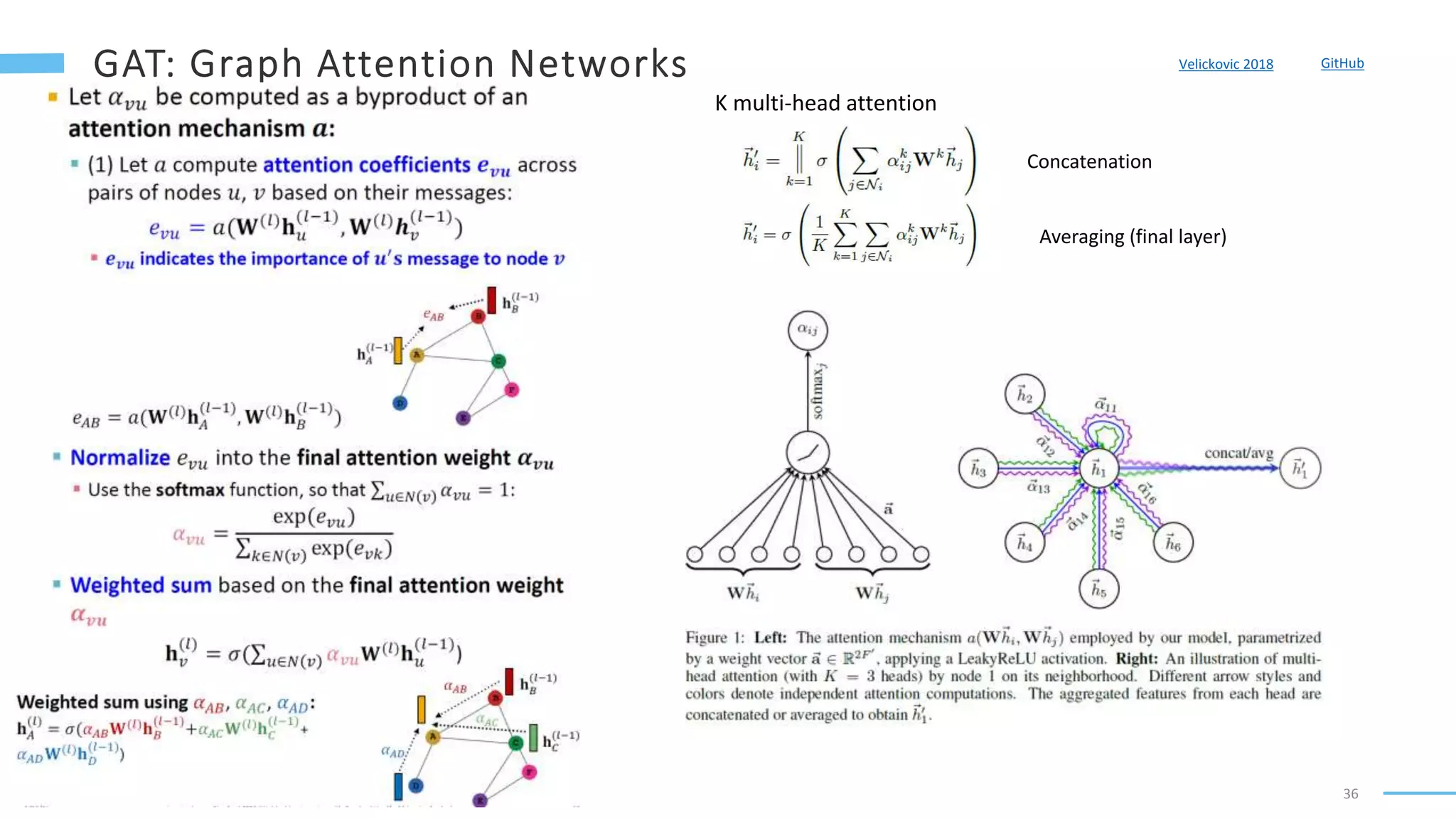
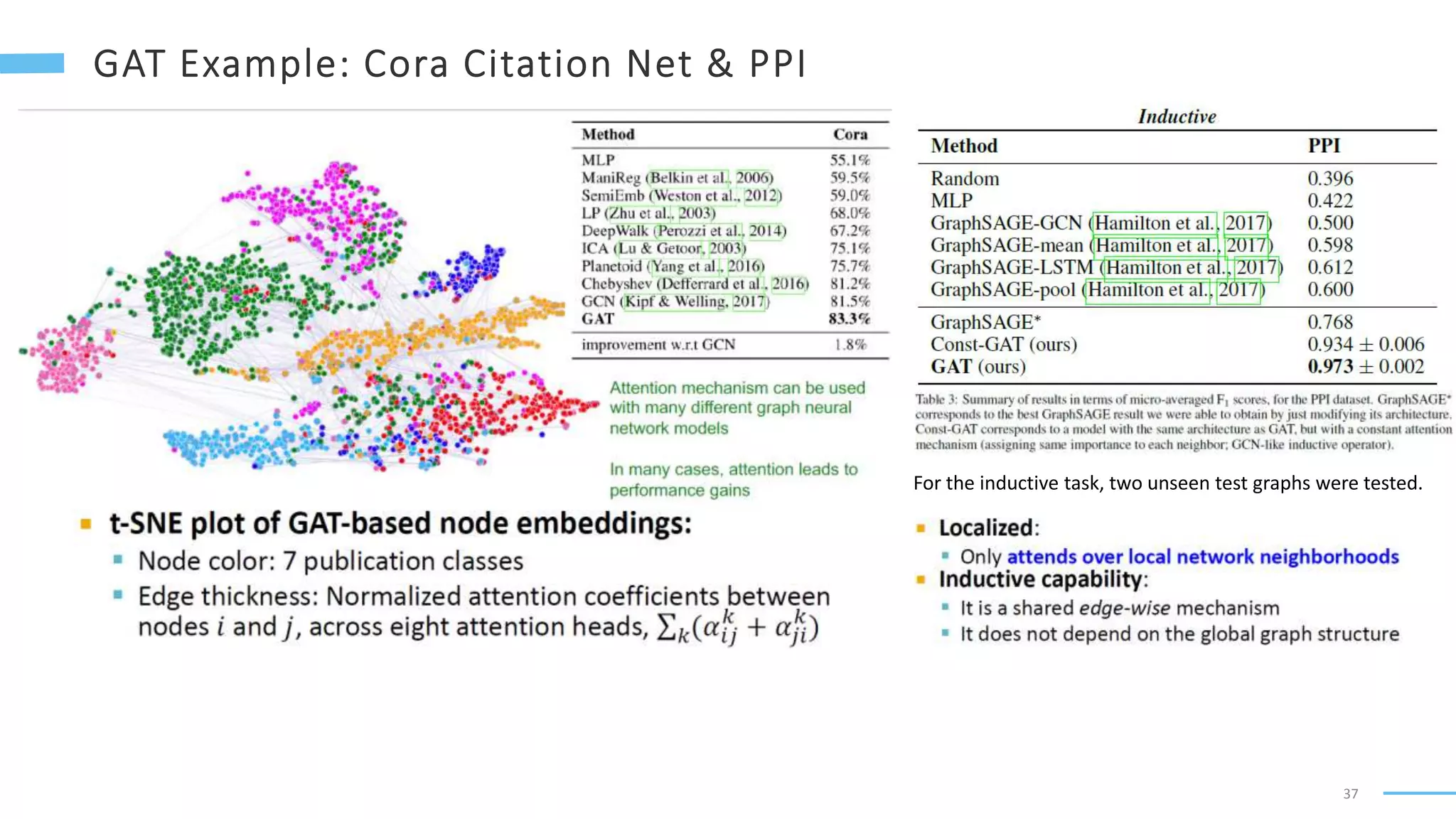
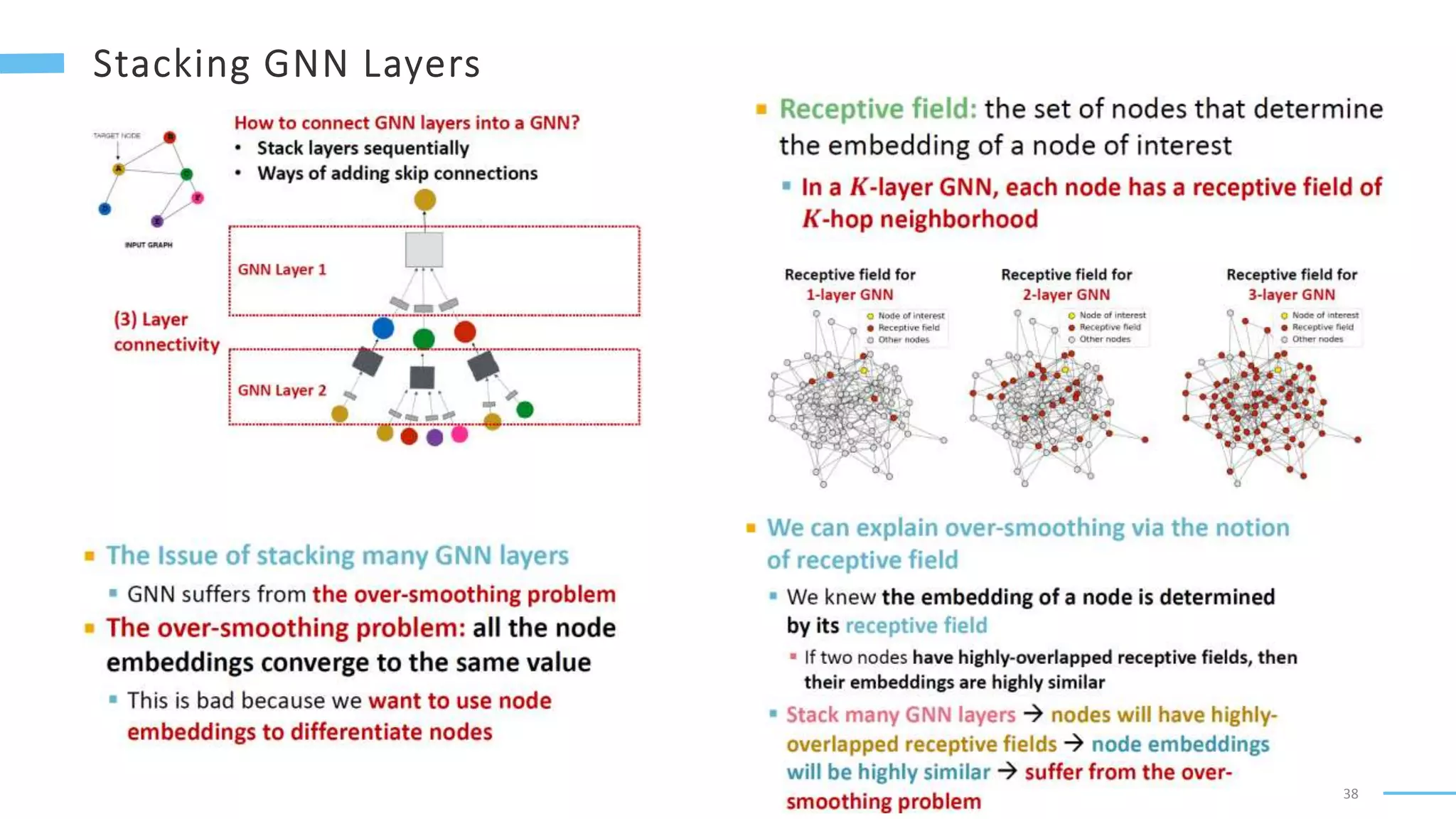



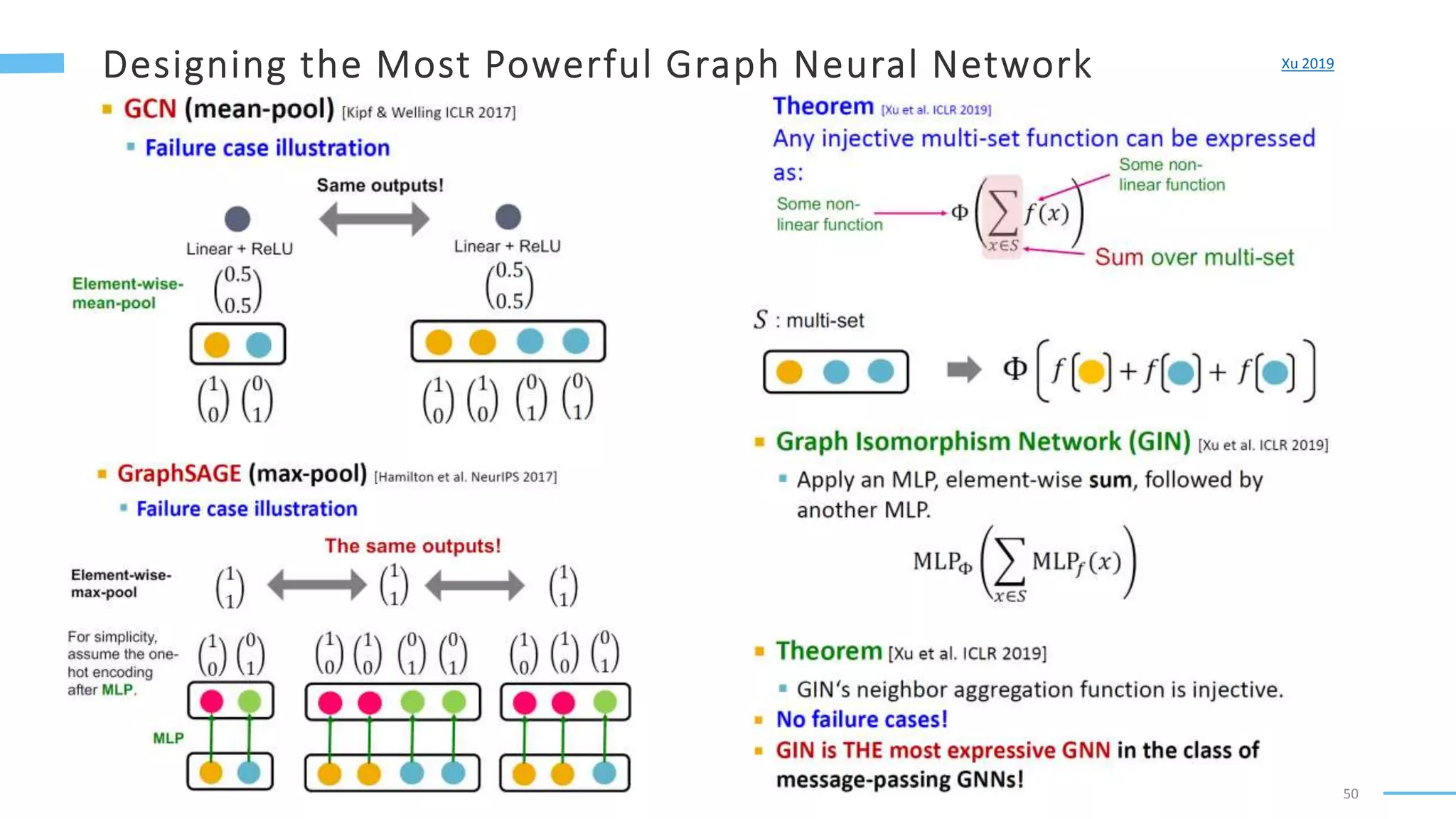
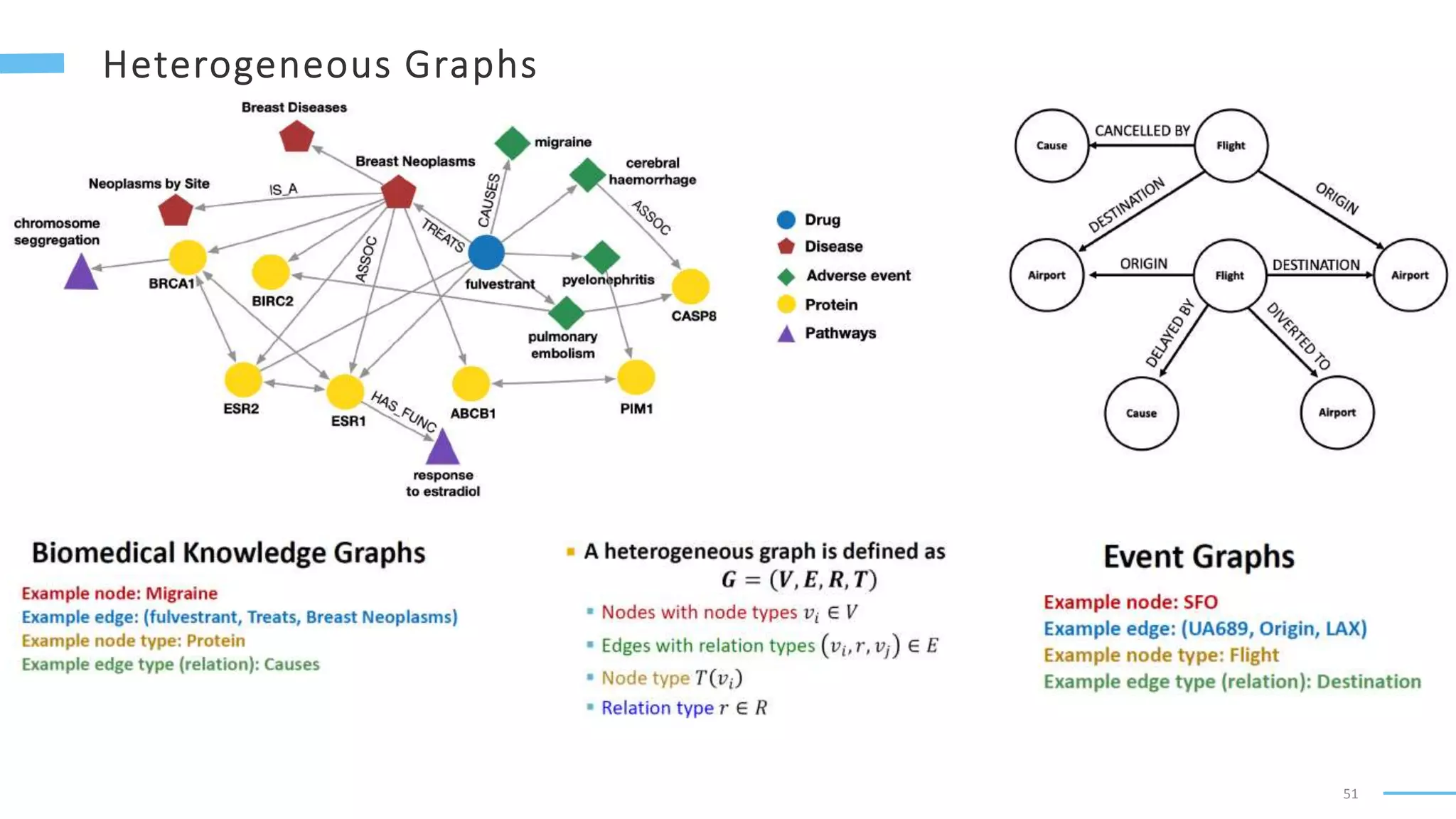

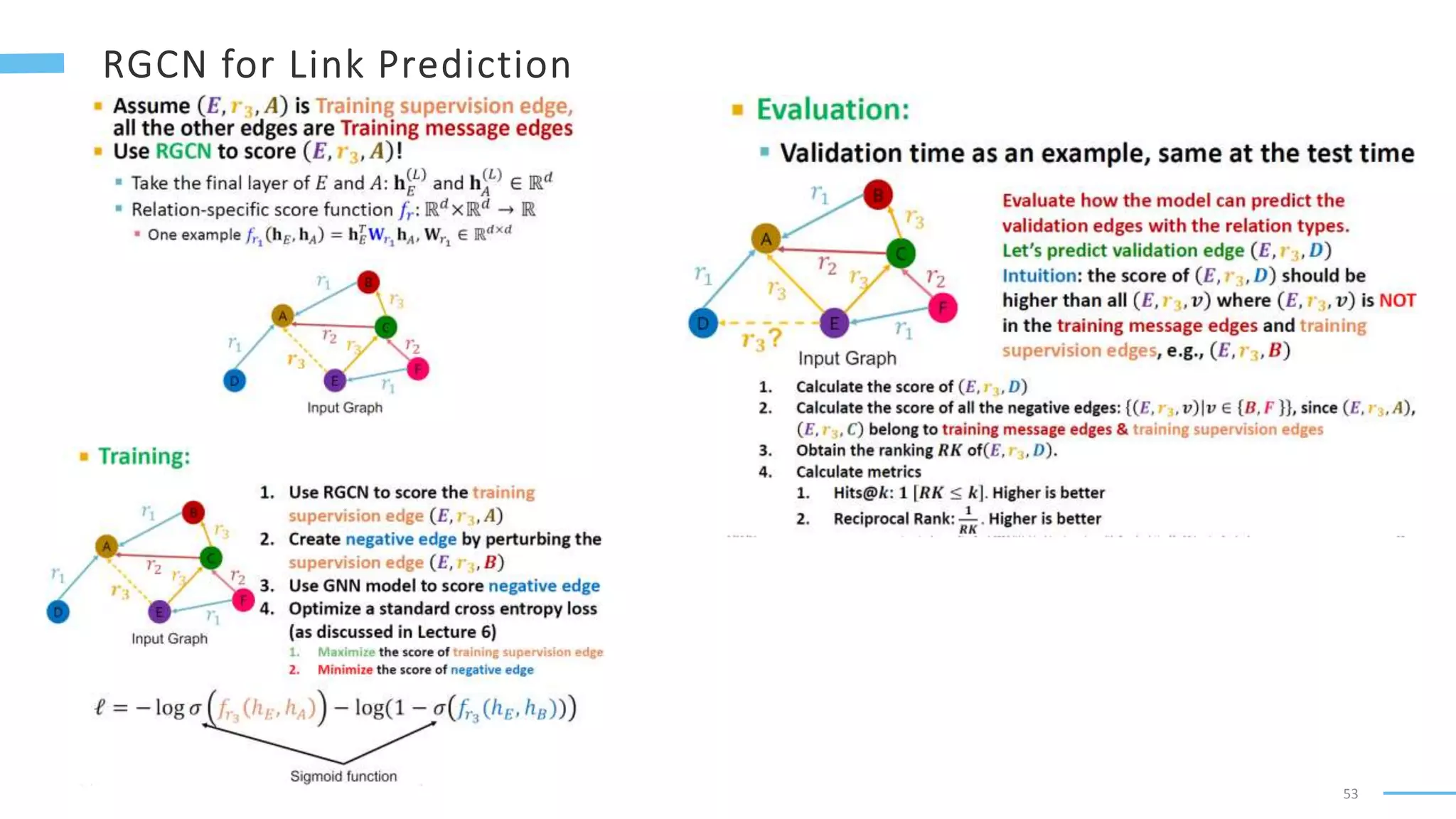
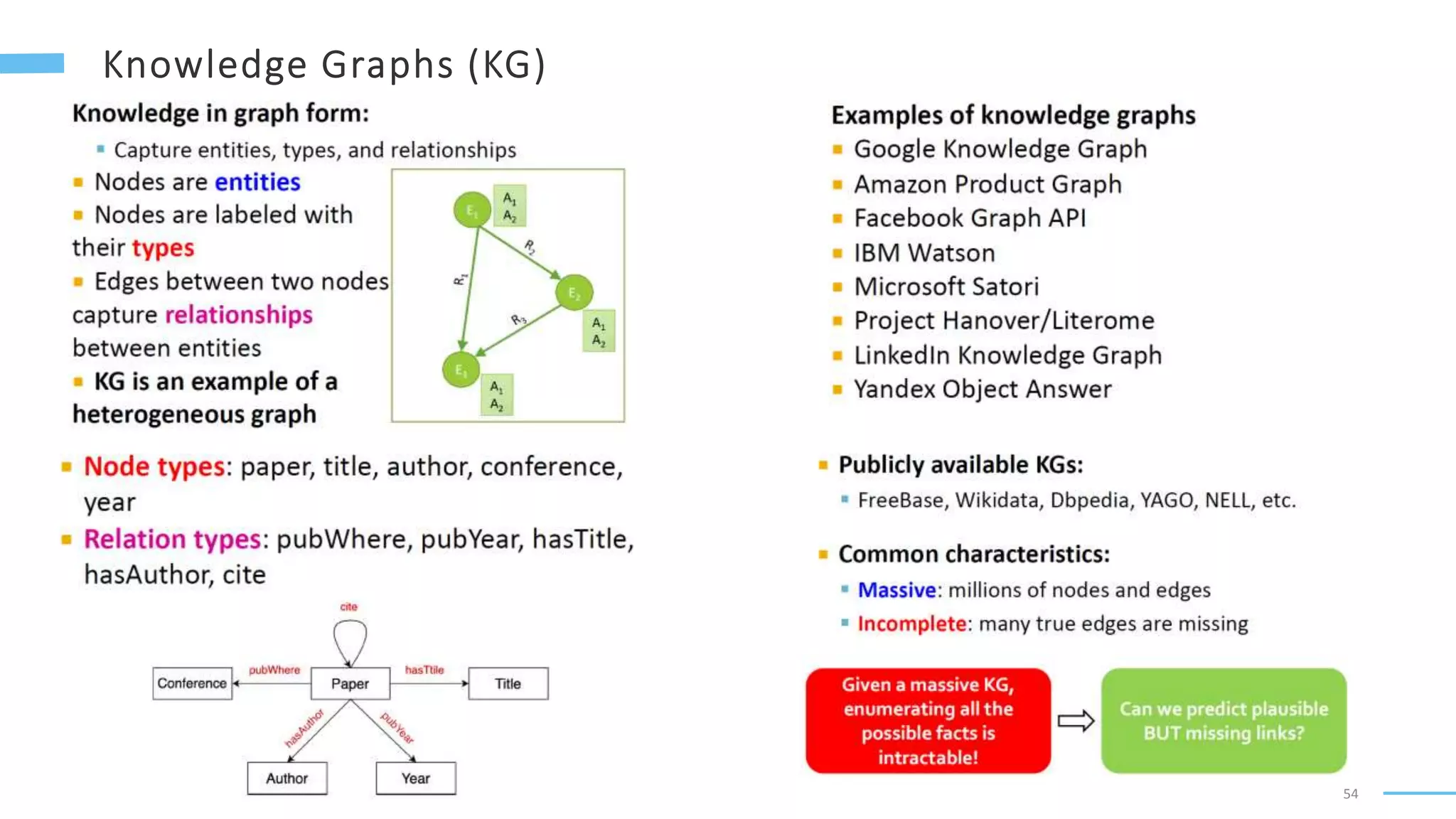









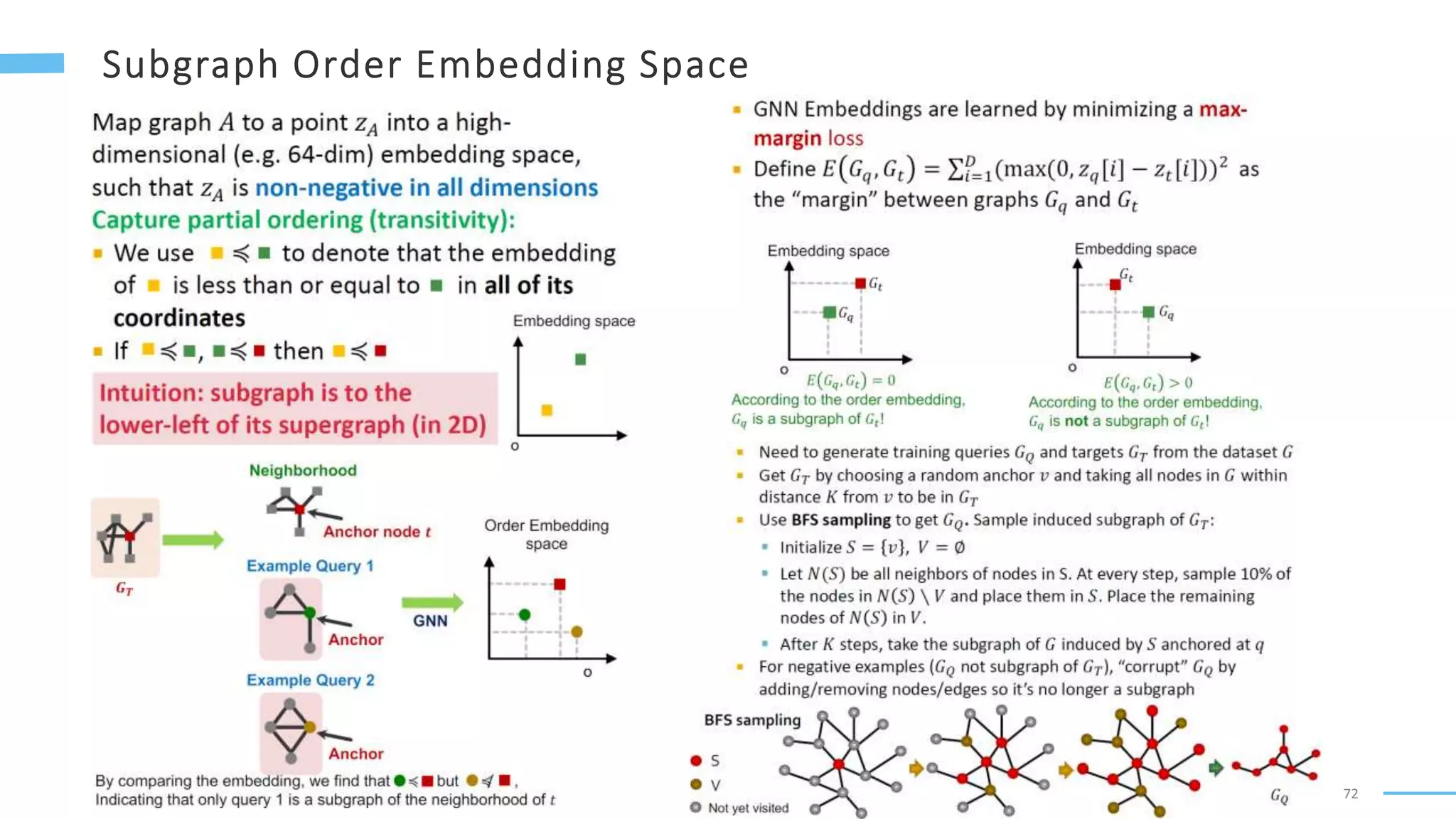
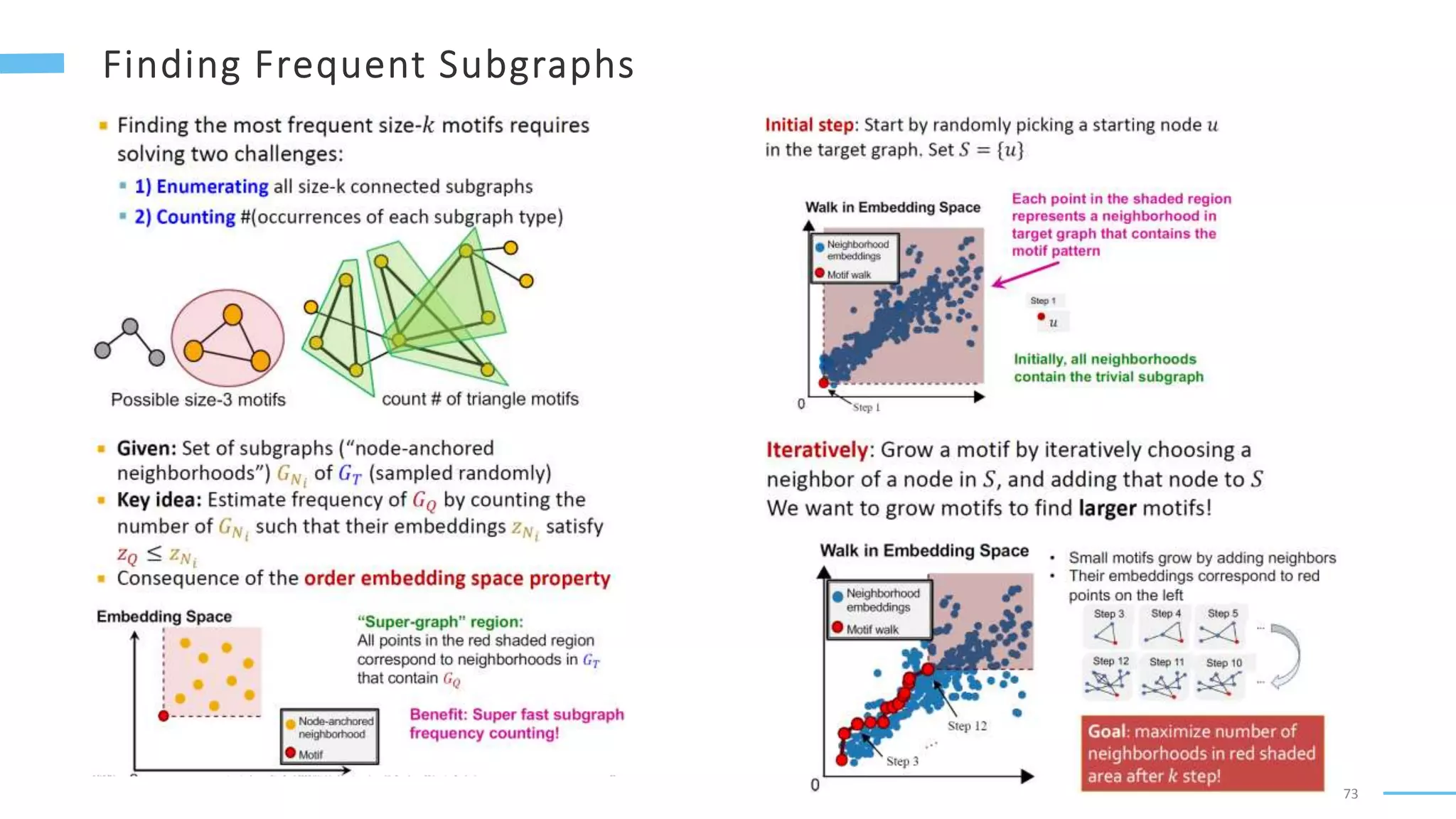
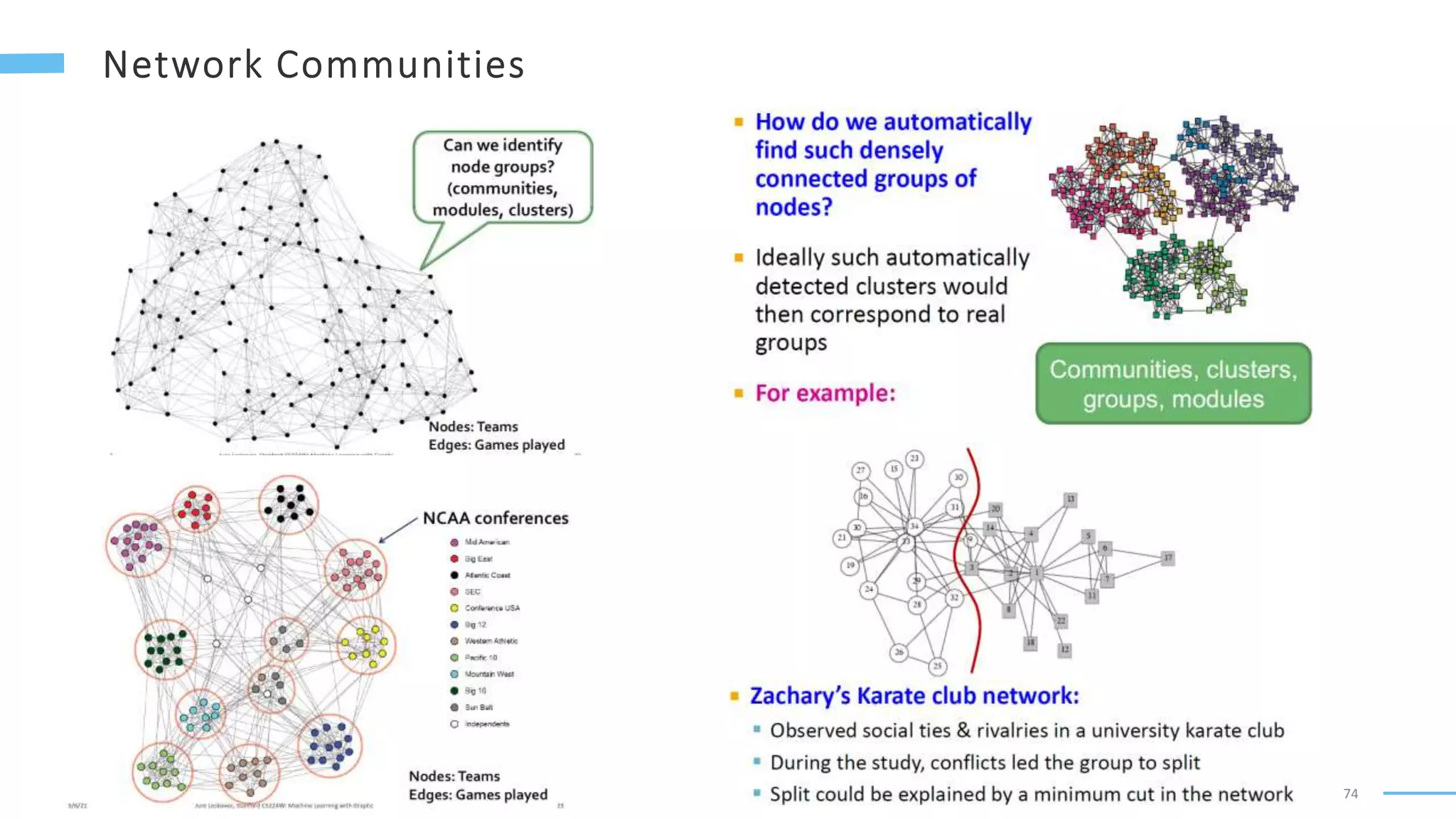

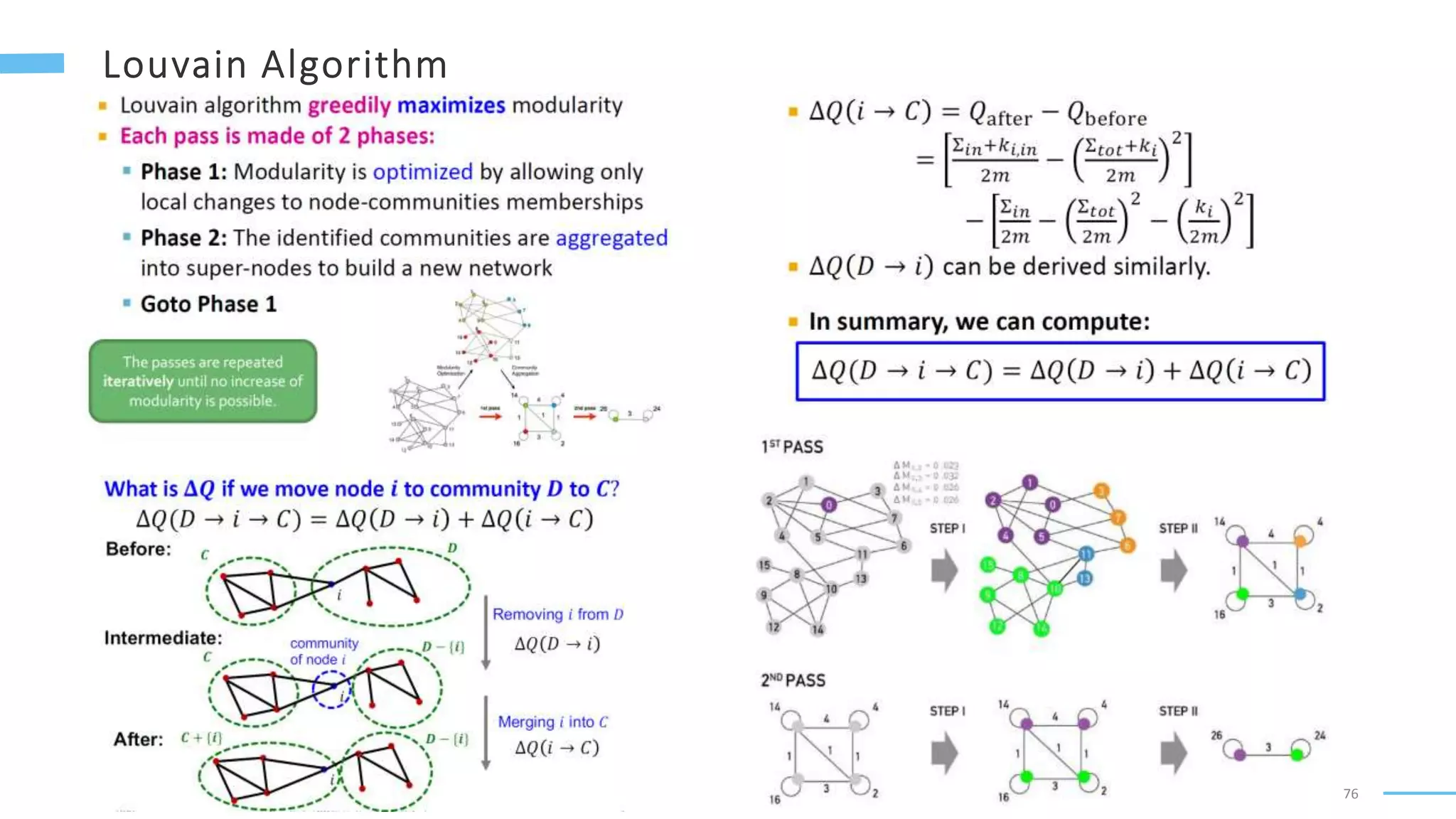
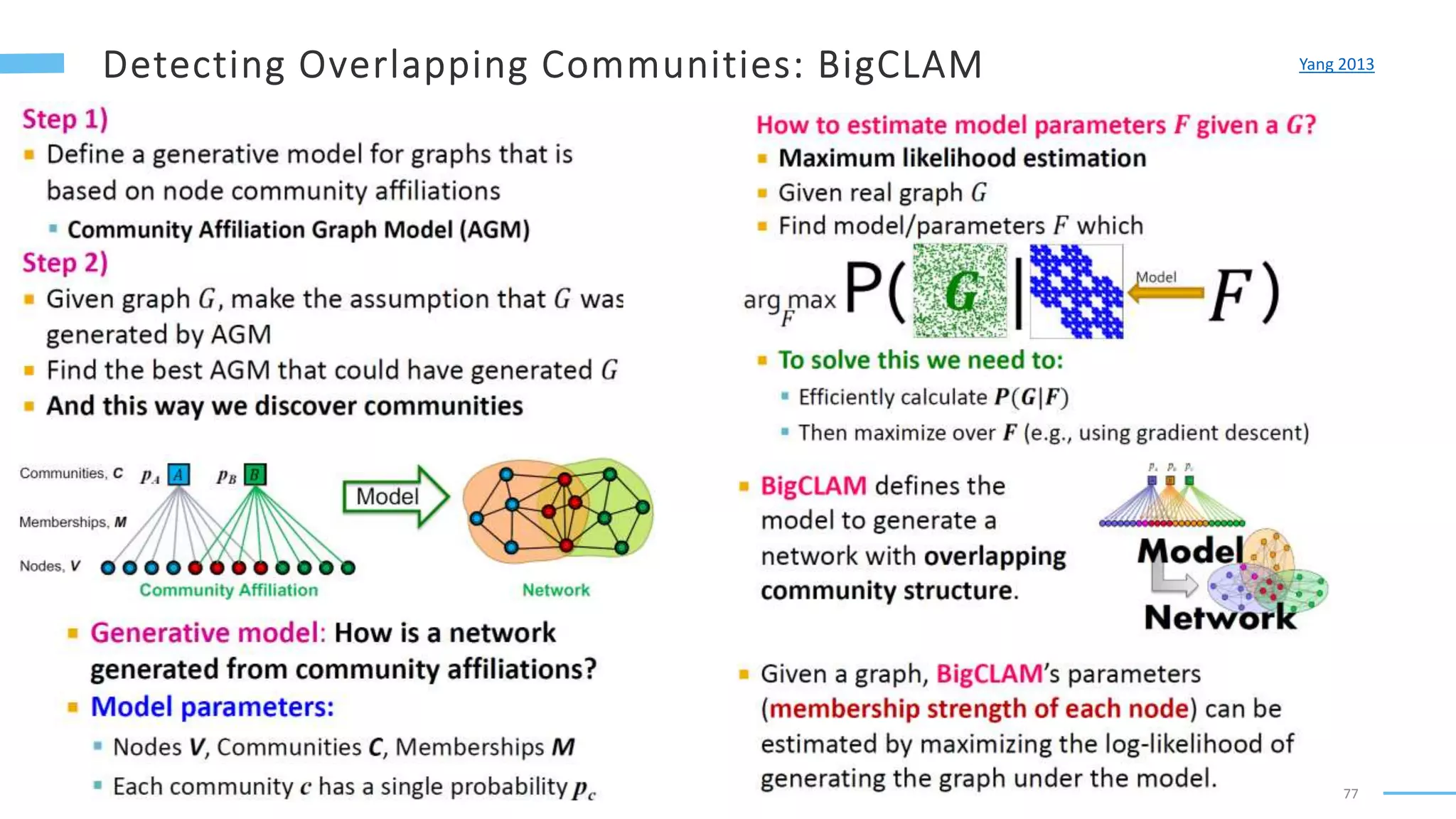

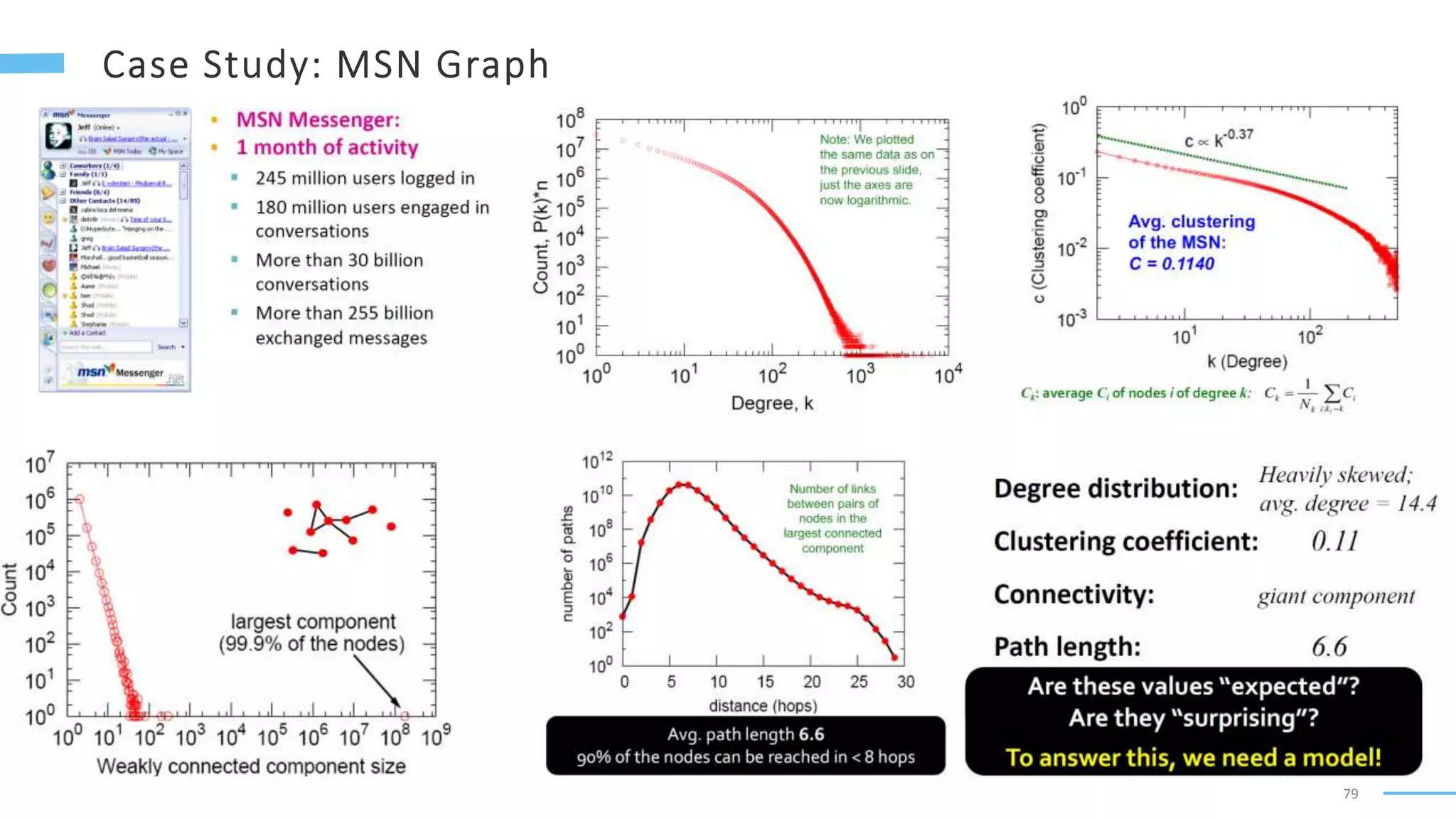
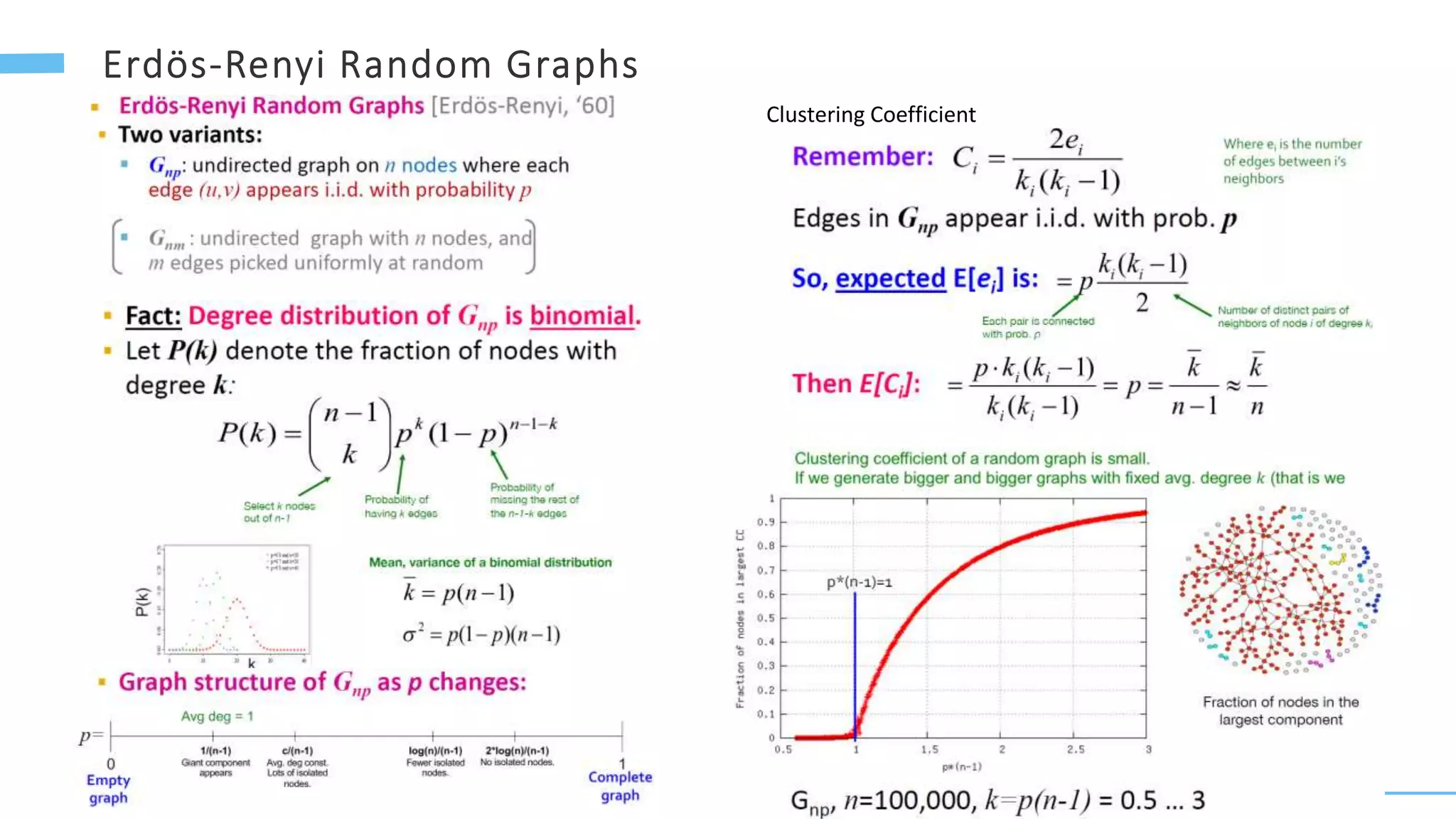
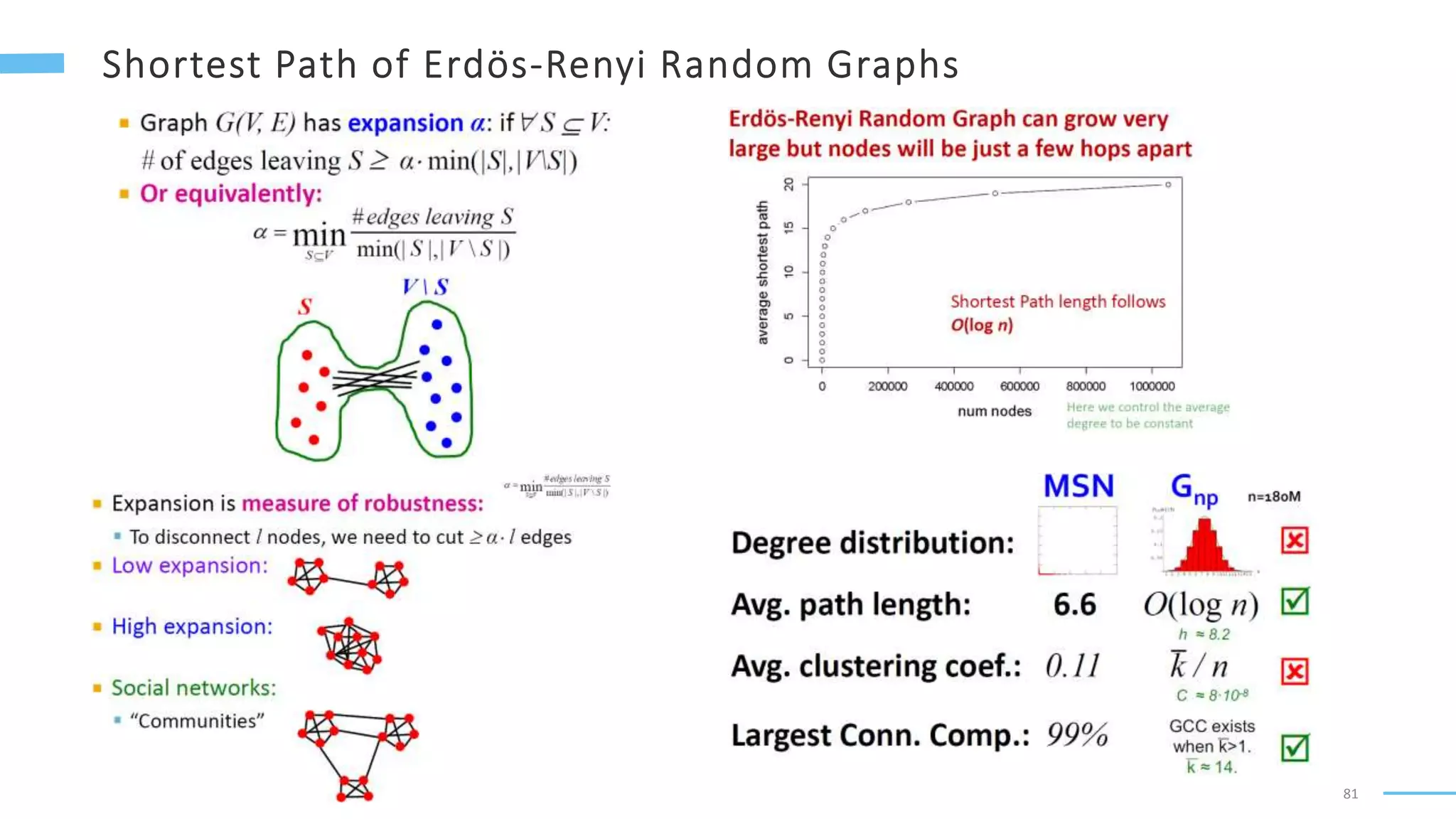






This document provides an overview of machine learning with graphs. It discusses graph neural networks and deep learning in graphs. It covers representing graphs using adjacency matrices and lists. It also discusses node and graph level features, as well as node embeddings using random walks. Finally, it summarizes several graph neural network models like GCN and GraphSAGE and their applications to citation networks, social networks, and knowledge graphs.
















































































