Download as PDF, PPTX


















This document provides detailed instructions for processing nested JSON data using Apache Spark, specifically focusing on analyzing a public baby names dataset. It outlines the steps to read data from a URL, create a DataFrame, extract required fields, and analyze the data through queries and visualization. The document also highlights the integration services offered by Aegis Software Canada and includes company contact information.
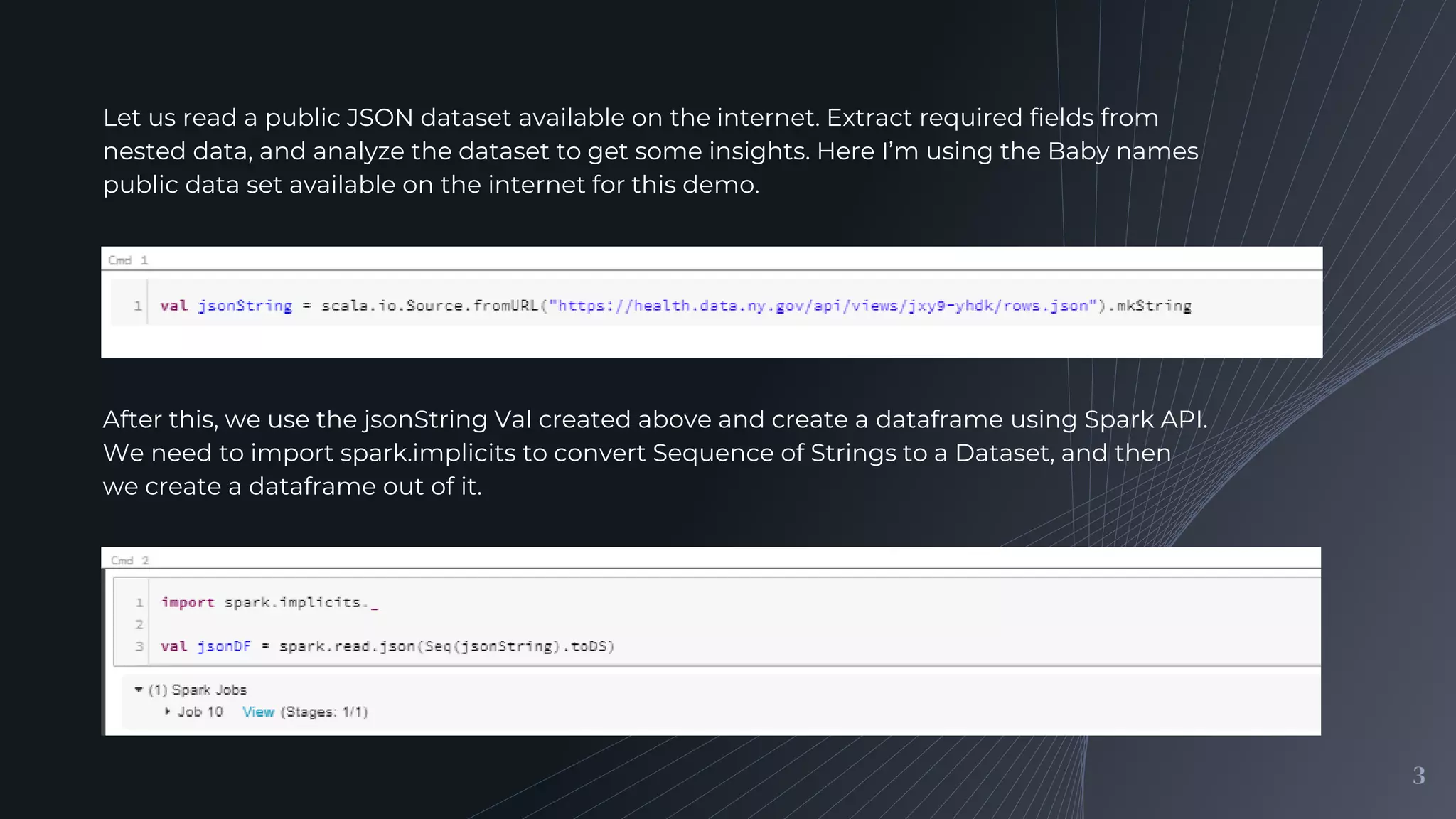
Introduction to processing nested JSON data using Apache Spark, focusing on reading, extracting, analyzing, and visualizing data from a Baby names public dataset.
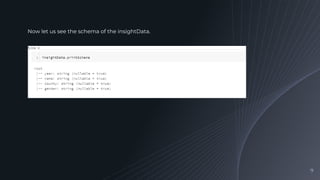
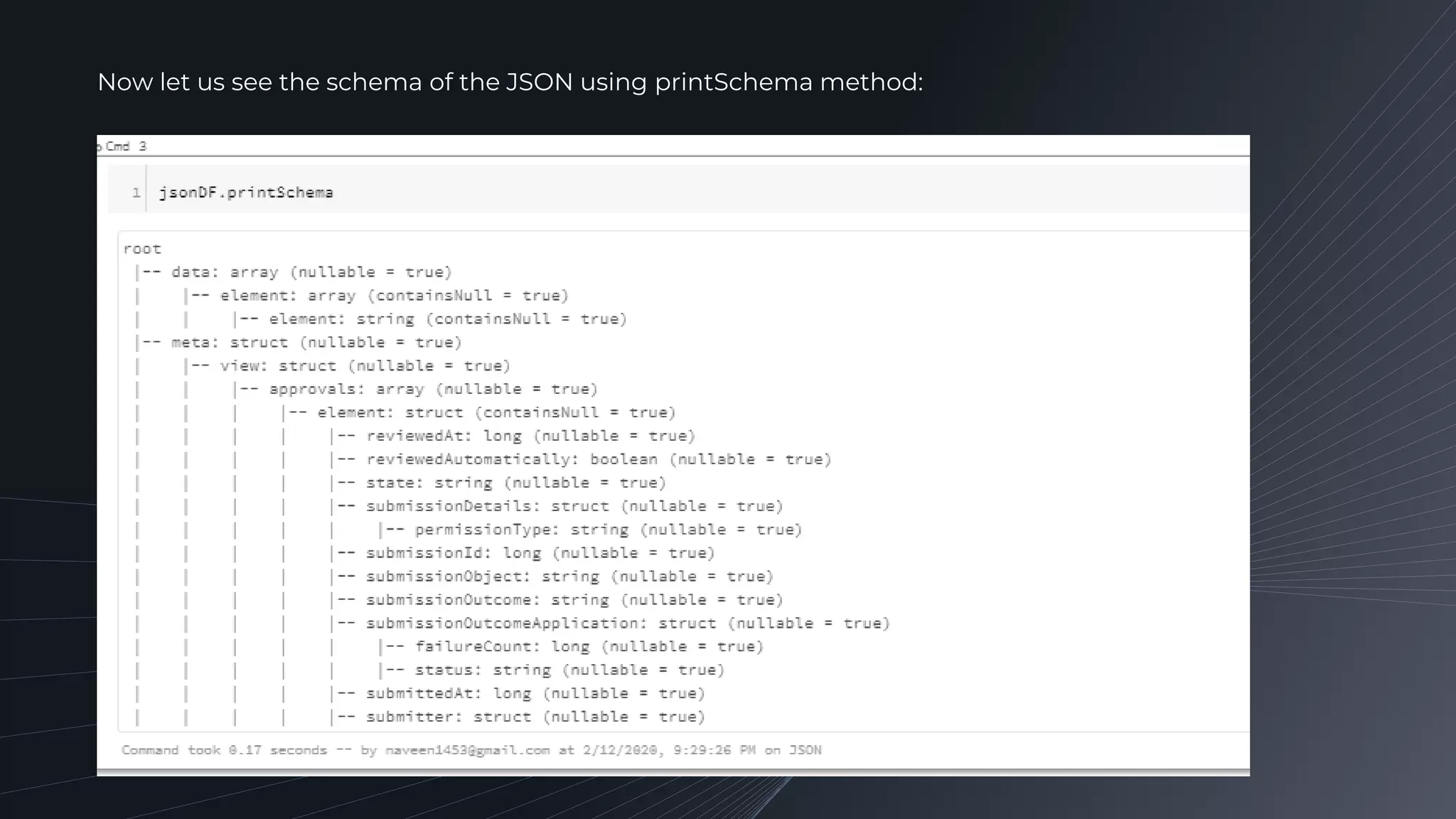
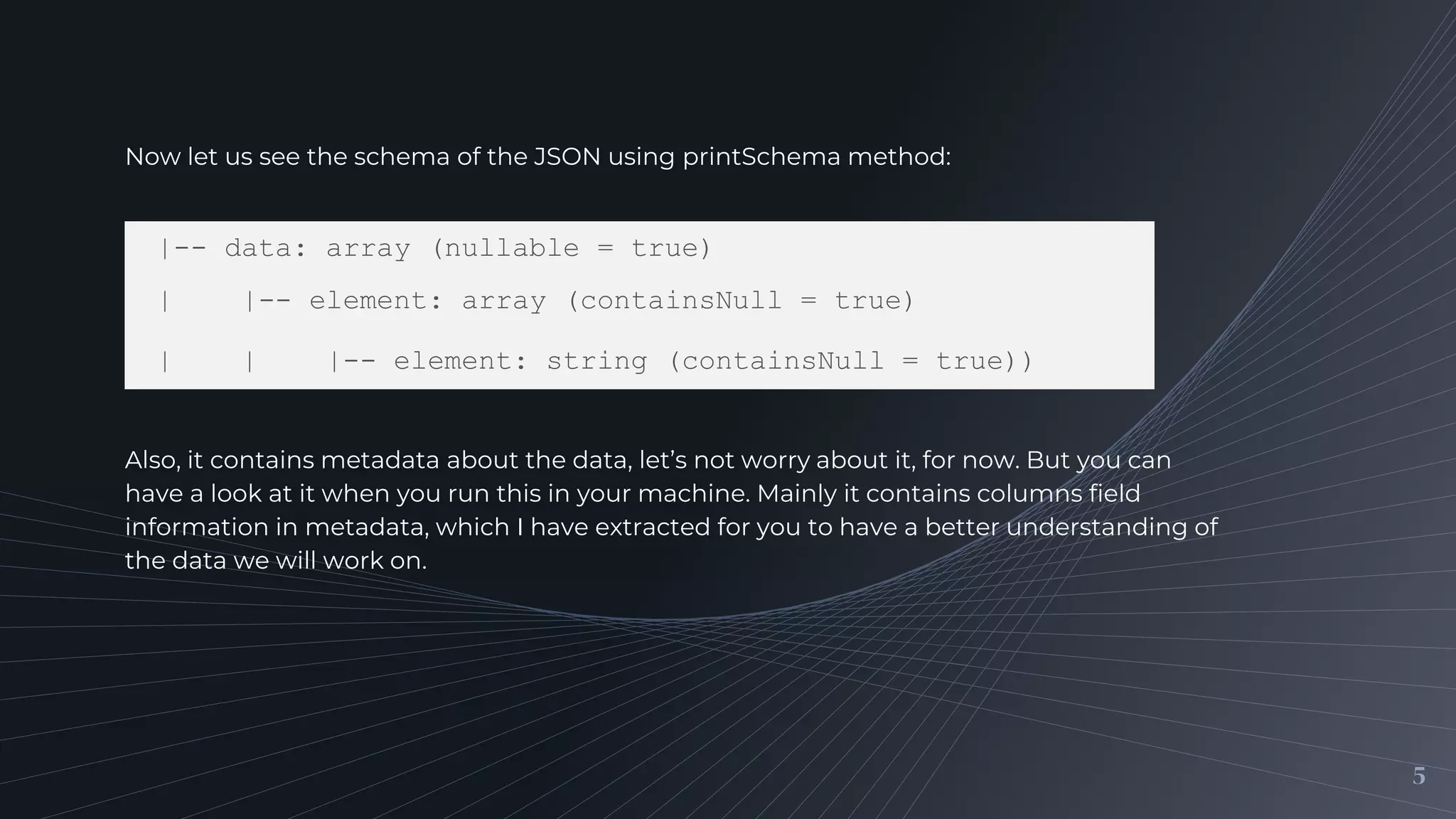
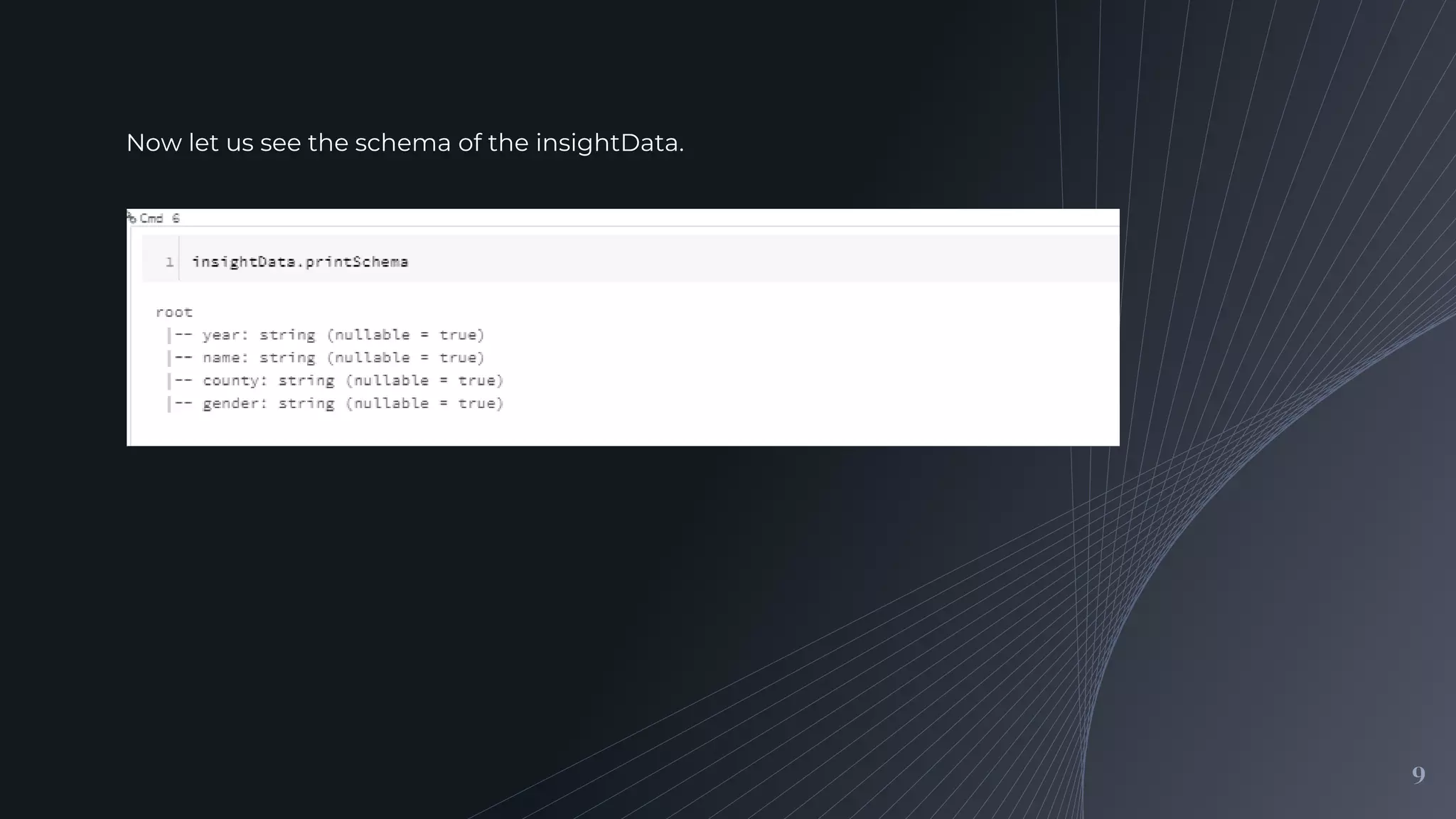
Demonstrating the structure of the JSON dataset using Spark's printSchema method and discussing the metadata it contains.
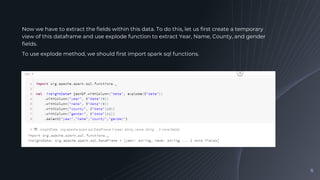
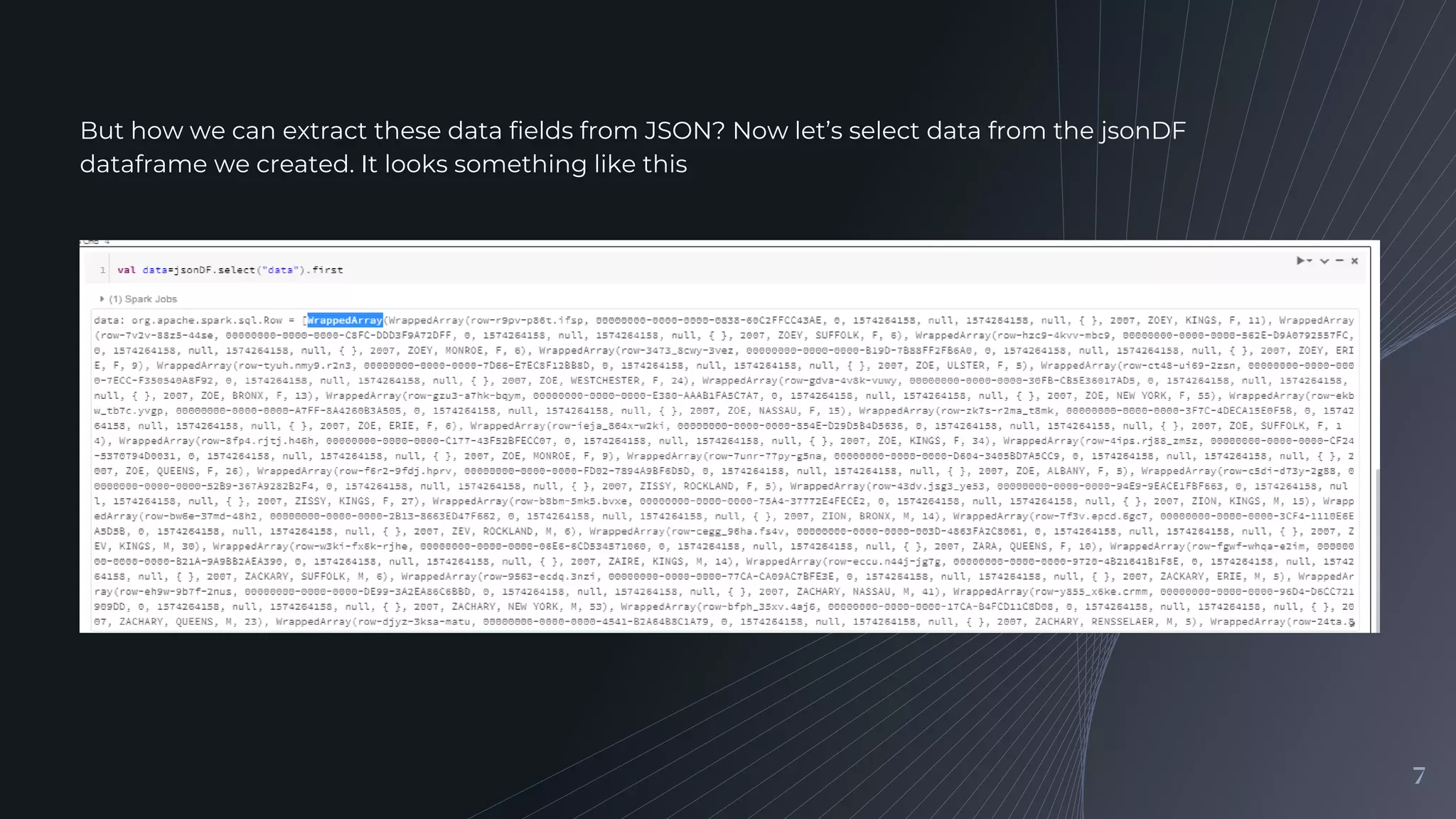
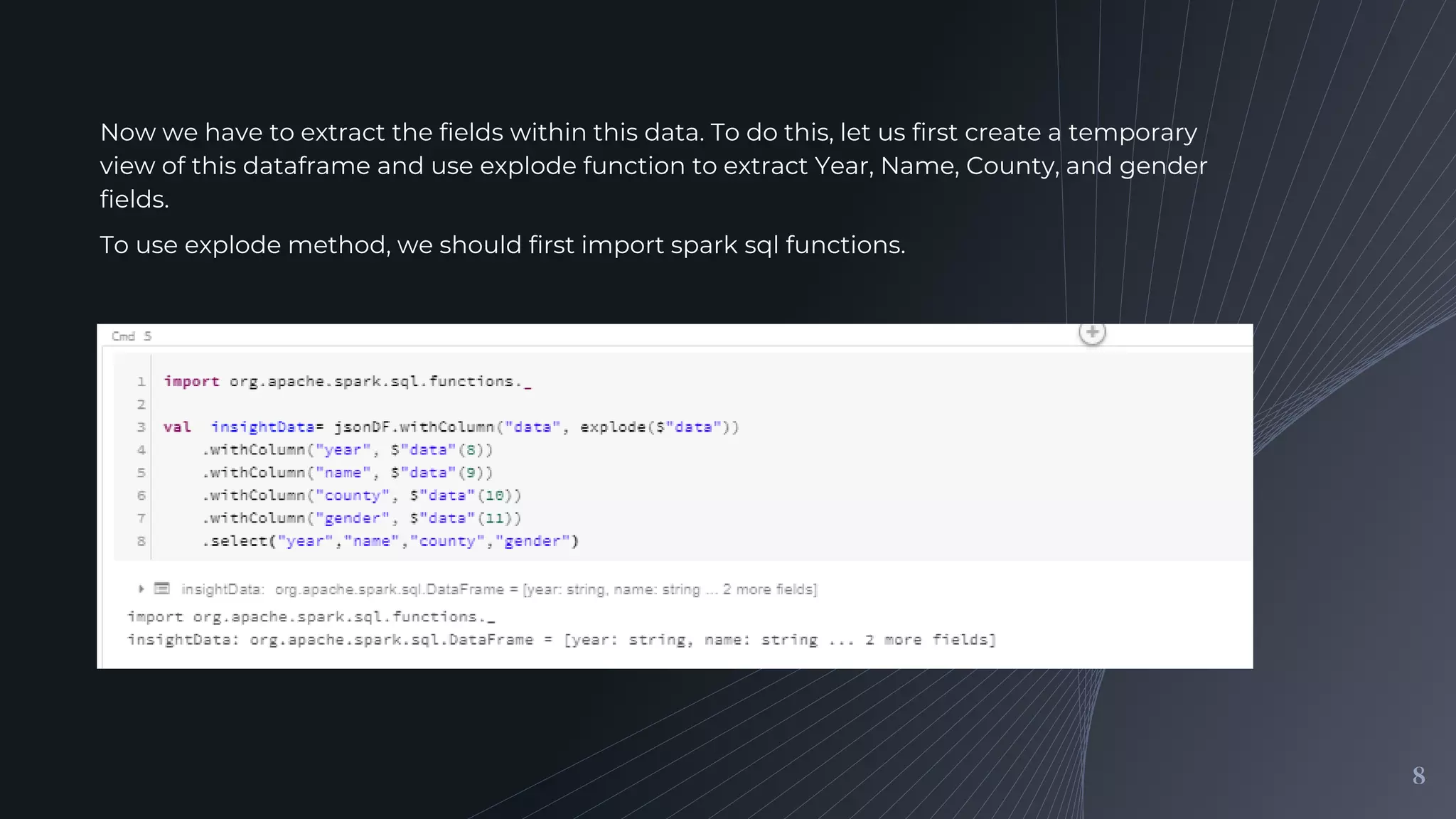
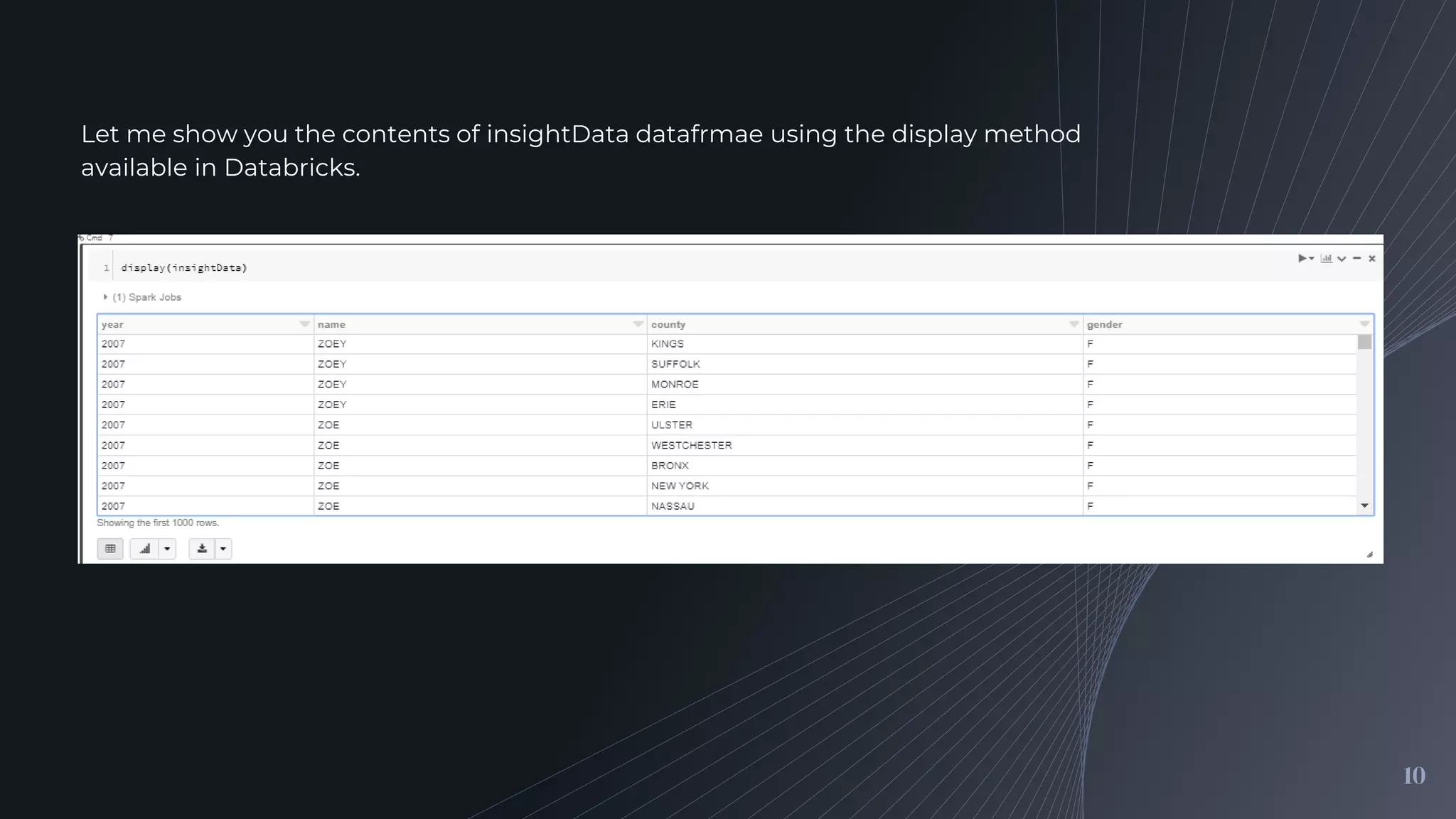
Identifying the fields in the JSON data we will analyze and explaining how to extract these fields using a temporary view and the explode function.
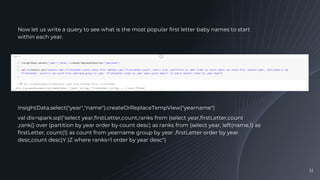
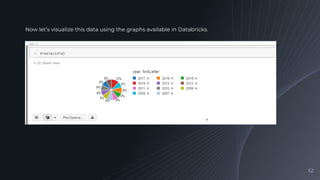
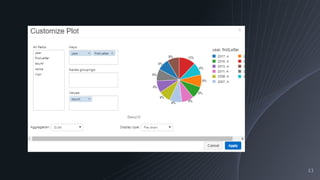
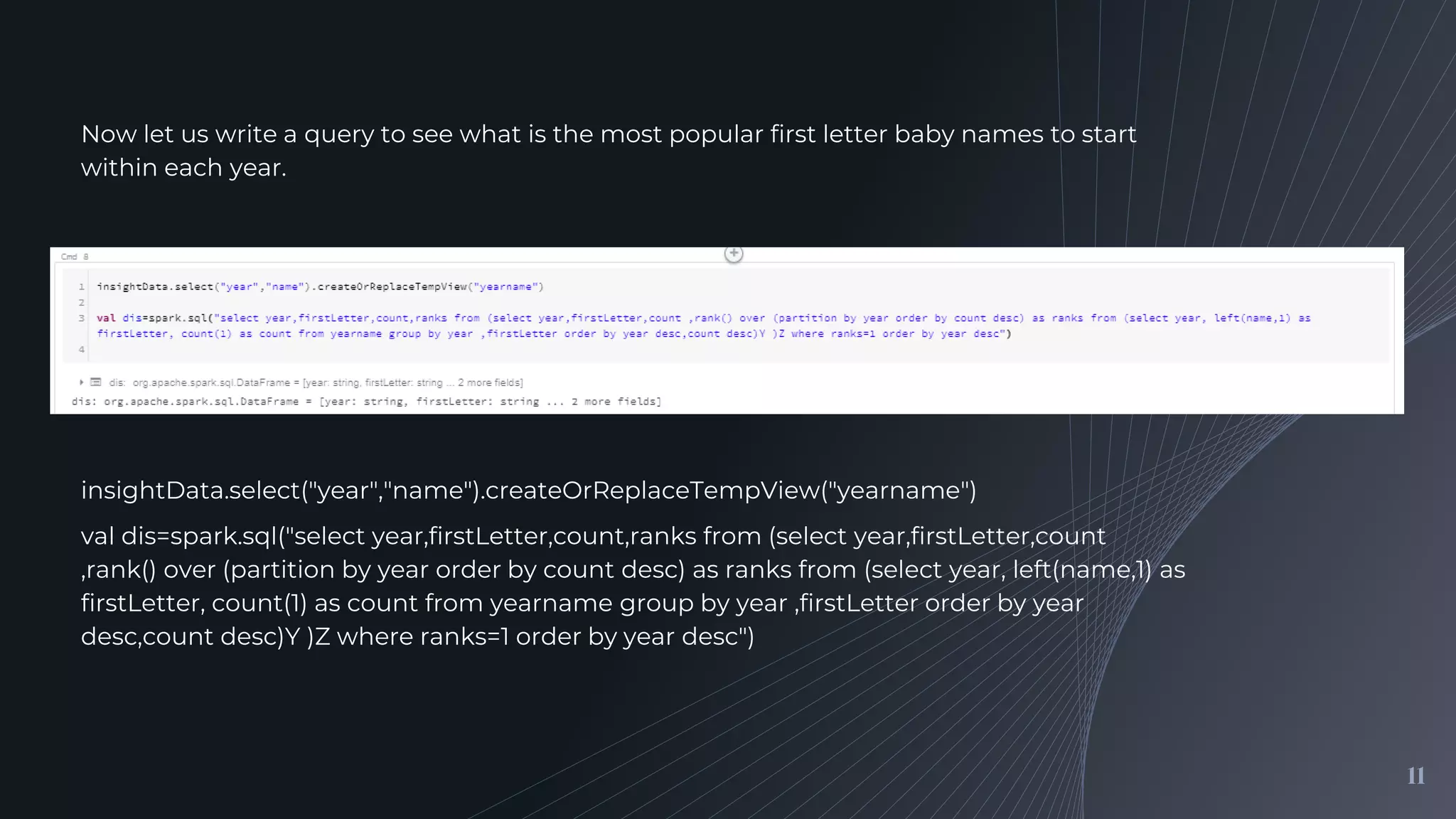
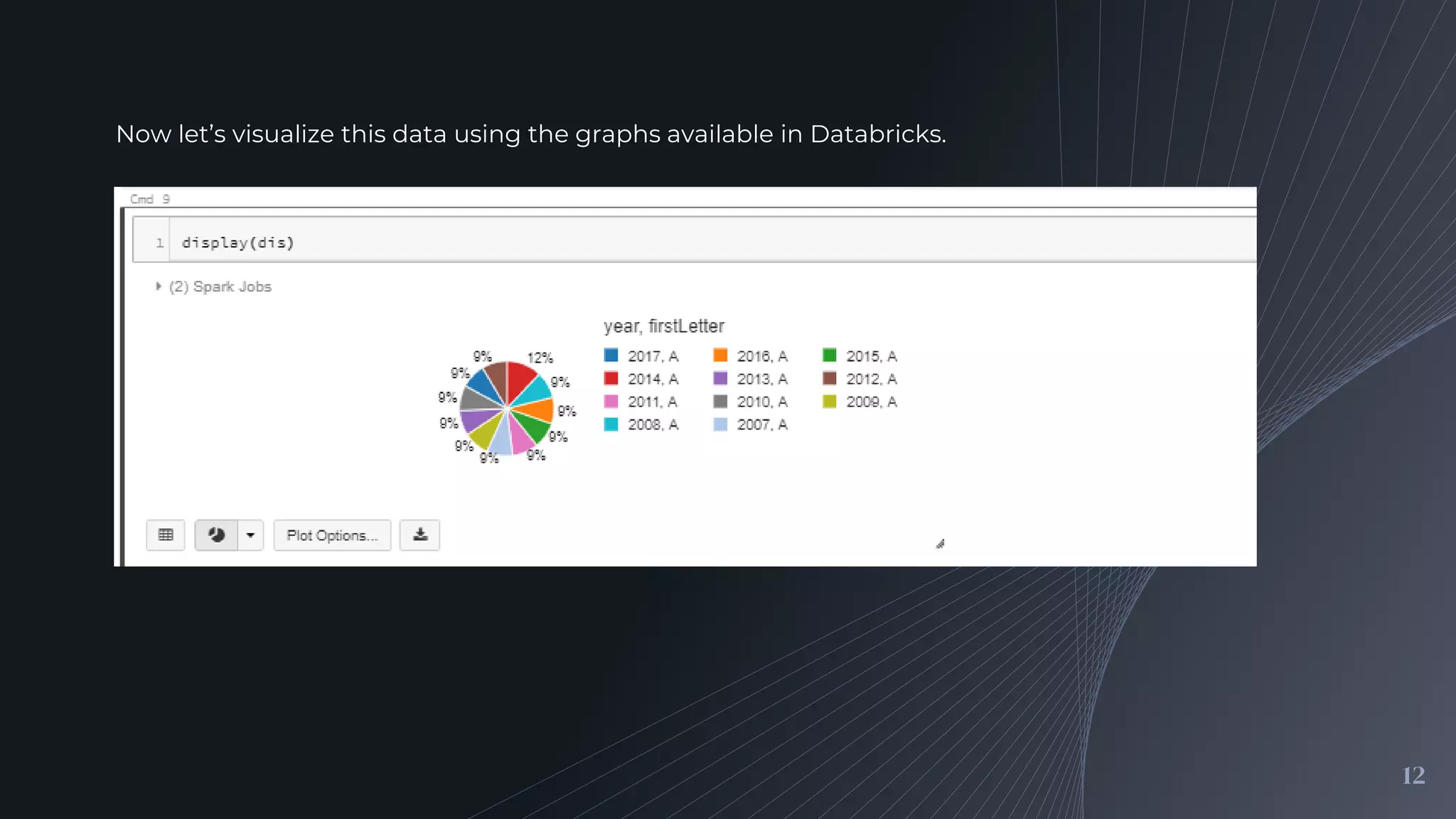
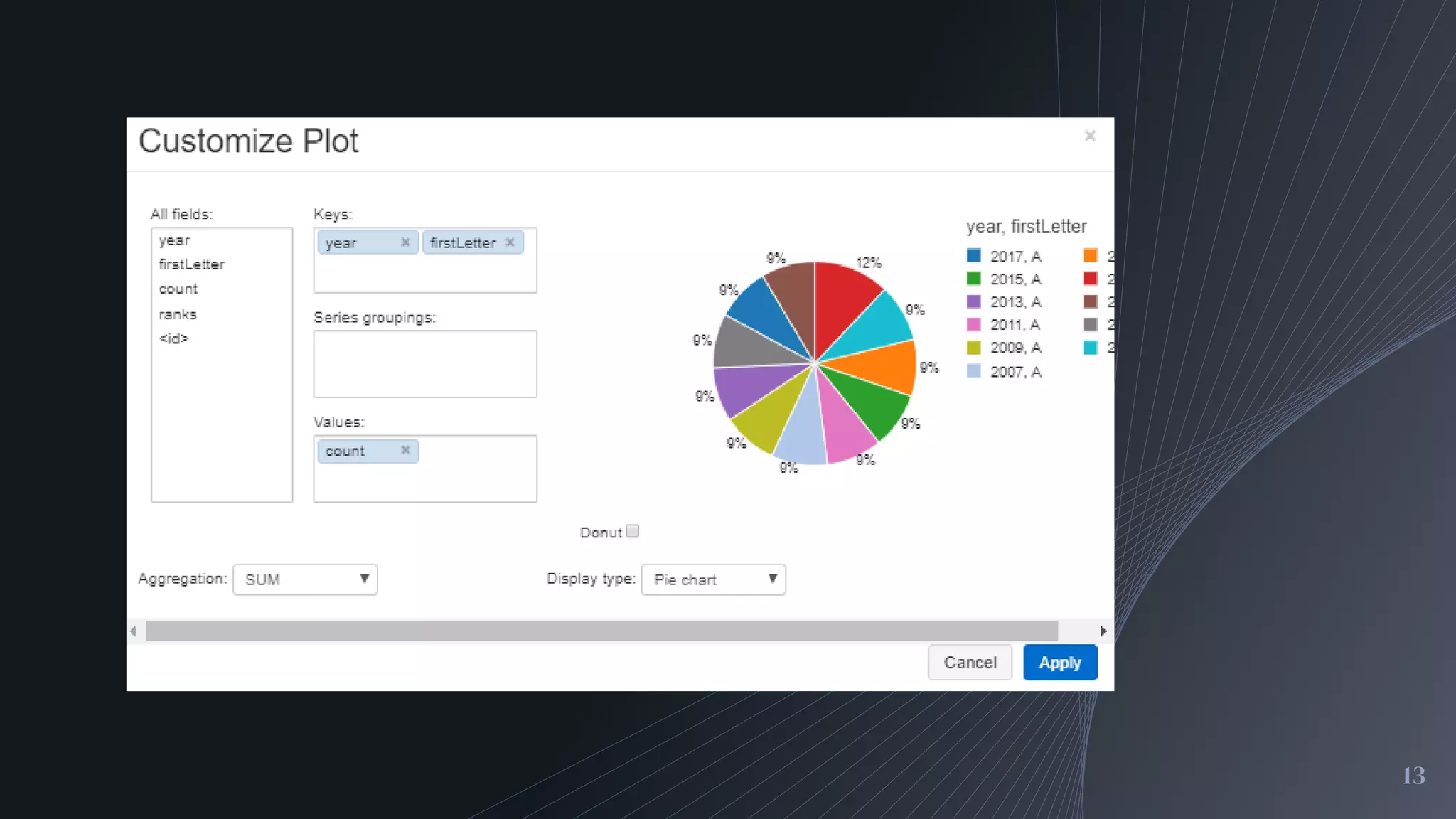
Performing queries to find popular baby name trends and visualizing the results using Databricks graphing tools.
Introduction to Aegis Software Canada, highlighting their expertise in Apache Spark integration and providing contact information.











































































