KEMBAR78
Daftar
Login
Apache Hadoopの新機能Ozoneの現状 | PDF
Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
Submit search
EN
NS
Uploaded by
NTT DATA OSS Professional Services
6,251 views
Apache Hadoopの新機能Ozoneの現状
2017年11月29日に開催されたHadoopソースコードリーディング 第24回の講演資料です。
Technology
◦
Read more
7
Save
Share
Embed
1
/ 35
2
/ 35
3
/ 35
4
/ 35
5
/ 35
6
/ 35
7
/ 35
8
/ 35
9
/ 35
10
/ 35
11
/ 35
12
/ 35
13
/ 35
14
/ 35
15
/ 35
16
/ 35
17
/ 35
18
/ 35
19
/ 35
20
/ 35
21
/ 35
22
/ 35
23
/ 35
24
/ 35
25
/ 35
26
/ 35
27
/ 35
28
/ 35
29
/ 35
30
/ 35
31
/ 35
32
/ 35
33
/ 35
34
/ 35
35
/ 35
More Related Content
PDF
続・PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 #2
by
Preferred Networks
PDF
[Cloud OnAir] Bigtable に迫る!基本機能も含めユースケースまで丸ごと紹介 2018年8月30日 放送
by
Google Cloud Platform - Japan
PPTX
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
PDF
DockerとPodmanの比較
by
Akihiro Suda
PDF
入門 Kubeflow ~Kubernetesで機械学習をはじめるために~ (NTT Tech Conference #4 講演資料)
by
NTT DATA Technology & Innovation
PDF
macOSの仮想化技術について ~Virtualization-rs Rust bindings for virtualization.framework ~
by
NTT Communications Technology Development
PDF
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
PDF
Hadoop入門
by
Preferred Networks
続・PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜 #2
by
Preferred Networks
[Cloud OnAir] Bigtable に迫る!基本機能も含めユースケースまで丸ごと紹介 2018年8月30日 放送
by
Google Cloud Platform - Japan
Apache Bigtopによるオープンなビッグデータ処理基盤の構築(オープンデベロッパーズカンファレンス 2021 Online 発表資料)
by
NTT DATA Technology & Innovation
DockerとPodmanの比較
by
Akihiro Suda
入門 Kubeflow ~Kubernetesで機械学習をはじめるために~ (NTT Tech Conference #4 講演資料)
by
NTT DATA Technology & Innovation
macOSの仮想化技術について ~Virtualization-rs Rust bindings for virtualization.framework ~
by
NTT Communications Technology Development
Apache Spark の紹介(前半:Sparkのキホン)
by
NTT DATA OSS Professional Services
Hadoop入門
by
Preferred Networks
What's hot
PPTX
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
PDF
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
PDF
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
PDF
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PDF
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
PDF
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
PDF
Kubernetesによる機械学習基盤への挑戦
by
Preferred Networks
PDF
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
PPTX
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
PDF
Dockerイメージ管理の内部構造
by
Etsuji Nakai
PPTX
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
PPTX
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
PPT
Raft
by
Preferred Networks
PDF
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
詳説データベース輪読会: 分散合意その2
by
Sho Nakazono
PDF
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
PDF
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
by
Preferred Networks
PDF
Kubernetesのしくみ やさしく学ぶ 内部構造とアーキテクチャー
by
Toru Makabe
PDF
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
PDF
20191029 AWS Black Belt Online Seminar Elastic Load Balancing (ELB)
by
Amazon Web Services Japan
大量のデータ処理や分析に使えるOSS Apache Spark入門(Open Source Conference 2021 Online/Kyoto 発表資料)
by
NTT DATA Technology & Innovation
Grafana LokiではじめるKubernetesロギングハンズオン(NTT Tech Conference #4 ハンズオン資料)
by
NTT DATA Technology & Innovation
Apache Kafkaって本当に大丈夫?~故障検証のオーバービューと興味深い挙動の紹介~
by
NTT DATA OSS Professional Services
Hadoop/Spark で Amazon S3 を徹底的に使いこなすワザ (Hadoop / Spark Conference Japan 2019)
by
Noritaka Sekiyama
PFN のオンプレML基盤の取り組み / オンプレML基盤 on Kubernetes 〜PFN、ヤフー〜
by
Preferred Networks
Apache Hadoop YARNとマルチテナントにおけるリソース管理
by
Cloudera Japan
Kubernetesによる機械学習基盤への挑戦
by
Preferred Networks
PostgreSQLをKubernetes上で活用するためのOperator紹介!(Cloud Native Database Meetup #3 発表資料)
by
NTT DATA Technology & Innovation
分析指向データレイク実現の次の一手 ~Delta Lake、なにそれおいしいの?~(NTTデータ テクノロジーカンファレンス 2020 発表資料)
by
NTT DATA Technology & Innovation
Dockerイメージ管理の内部構造
by
Etsuji Nakai
Apache Spark on Kubernetes入門(Open Source Conference 2021 Online Hiroshima 発表資料)
by
NTT DATA Technology & Innovation
大規模データ処理の定番OSS Hadoop / Spark 最新動向 - 2021秋 -(db tech showcase 2021 / ONLINE 発...
by
NTT DATA Technology & Innovation
Raft
by
Preferred Networks
Apache Sparkに手を出してヤケドしないための基本 ~「Apache Spark入門より」~ (デブサミ 2016 講演資料)
by
NTT DATA OSS Professional Services
詳説データベース輪読会: 分散合意その2
by
Sho Nakazono
Apache Sparkにおけるメモリ - アプリケーションを落とさないメモリ設計手法 -
by
Yoshiyasu SAEKI
PFNのML/DL基盤を支えるKubernetesにおける自動化 / DevOpsDays Tokyo 2021
by
Preferred Networks
Kubernetesのしくみ やさしく学ぶ 内部構造とアーキテクチャー
by
Toru Makabe
IoT時代におけるストリームデータ処理と急成長の Apache Flink
by
Takanori Suzuki
20191029 AWS Black Belt Online Seminar Elastic Load Balancing (ELB)
by
Amazon Web Services Japan
Similar to Apache Hadoopの新機能Ozoneの現状
PPTX
Hadoop Compatible File Systems (Azure編) (セミナー「Big Data Developerに贈る第二弾 ‐ Azur...
by
NTT DATA Technology & Innovation
PDF
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
PDF
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
PDF
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
PDF
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
PDF
HDFS Router-based federation
by
NTT DATA OSS Professional Services
PDF
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
PDF
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
PPTX
[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化
by
Takahiro Moteki
PPTX
20170803 bigdataevent
by
Makoto Uehara
PDF
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
PDF
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
PDF
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
PDF
Red Hat OpenShift Container Storage
by
Takuya Utsunomiya
PPTX
クラウドデザイン パターンに見る クラウドファーストな アプリケーション設計 Data Management編
by
Takekazu Omi
PPTX
Cloudera大阪セミナー 20130219
by
Cloudera Japan
PDF
Hadoop Compatible File Systems 2019 (db tech showcase 2019 Tokyo講演資料、2019/09/25)
by
NTT DATA Technology & Innovation
PPTX
DeNA private cloud のその後 - OpenStack最新情報セミナー(2017年3月)
by
VirtualTech Japan Inc.
PDF
Storm×couchbase serverで作るリアルタイム解析基盤
by
NTT Communications Technology Development
Hadoop Compatible File Systems (Azure編) (セミナー「Big Data Developerに贈る第二弾 ‐ Azur...
by
NTT DATA Technology & Innovation
Distributed data stores in Hadoop ecosystem
by
NTT DATA OSS Professional Services
分散処理基盤Apache Hadoopの現状と、NTTデータのHadoopに対する取り組み
by
NTT DATA OSS Professional Services
HDFS新機能総まとめin 2015 (日本Hadoopユーザー会 ライトニングトーク@Cloudera World Tokyo 2015 講演資料)
by
NTT DATA OSS Professional Services
NTTデータ流 Hadoop活用のすすめ ~インフラ構築・運用の勘所~
by
NTT DATA OSS Professional Services
HDFS Router-based federation
by
NTT DATA OSS Professional Services
Hadoop ecosystem NTTDATA osc15tk
by
NTT DATA OSS Professional Services
分散処理基盤Apache Hadoop入門とHadoopエコシステムの最新技術動向 (オープンソースカンファレンス 2015 Tokyo/Spring 講...
by
NTT DATA OSS Professional Services
[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化
by
Takahiro Moteki
20170803 bigdataevent
by
Makoto Uehara
Hadoopのシステム設計・運用のポイント
by
Cloudera Japan
Hadoopエコシステムのデータストア振り返り
by
NTT DATA OSS Professional Services
Apache Hadoop HDFSの最新機能の紹介(2018)#dbts2018
by
Yahoo!デベロッパーネットワーク
HDFS basics from API perspective
by
NTT DATA OSS Professional Services
Red Hat OpenShift Container Storage
by
Takuya Utsunomiya
クラウドデザイン パターンに見る クラウドファーストな アプリケーション設計 Data Management編
by
Takekazu Omi
Cloudera大阪セミナー 20130219
by
Cloudera Japan
Hadoop Compatible File Systems 2019 (db tech showcase 2019 Tokyo講演資料、2019/09/25)
by
NTT DATA Technology & Innovation
DeNA private cloud のその後 - OpenStack最新情報セミナー(2017年3月)
by
VirtualTech Japan Inc.
Storm×couchbase serverで作るリアルタイム解析基盤
by
NTT Communications Technology Development
More from NTT DATA OSS Professional Services
PDF
Global Top 5 を目指す NTT DATA の確かで意外な技術力
by
NTT DATA OSS Professional Services
PDF
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
PDF
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
PDF
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
PDF
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
PDF
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~
by
NTT DATA OSS Professional Services
PDF
20170303 java9 hadoop
by
NTT DATA OSS Professional Services
PPTX
ブロックチェーンの仕組みと動向(入門編)
by
NTT DATA OSS Professional Services
PDF
Application of postgre sql to large social infrastructure jp
by
NTT DATA OSS Professional Services
PDF
Application of postgre sql to large social infrastructure
by
NTT DATA OSS Professional Services
PDF
Apache Hadoop 2.8.0 の新機能 (抜粋)
by
NTT DATA OSS Professional Services
PDF
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
PDF
商用ミドルウェアのPuppet化で気を付けたい5つのこと
by
NTT DATA OSS Professional Services
PPTX
今からはじめるPuppet 2016 ~ インフラエンジニアのたしなみ ~
by
NTT DATA OSS Professional Services
PDF
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
PDF
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料)
by
NTT DATA OSS Professional Services
PDF
本当にあったHadoopの恐い話 Blockはどこへきえた? (Hadoop / Spark Conference Japan 2016 ライトニングトー...
by
NTT DATA OSS Professional Services
PDF
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
PDF
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
Global Top 5 を目指す NTT DATA の確かで意外な技術力
by
NTT DATA OSS Professional Services
Spark SQL - The internal -
by
NTT DATA OSS Professional Services
PostgreSQL10を導入!大規模データ分析事例からみるDWHとしてのPostgreSQL活用のポイント
by
NTT DATA OSS Professional Services
Structured Streaming - The Internal -
by
NTT DATA OSS Professional Services
Apache Hadoopの未来 3系になって何が変わるのか?
by
NTT DATA OSS Professional Services
Apache Hadoop and YARN, current development status
by
NTT DATA OSS Professional Services
SIerとオープンソースの美味しい関係 ~コミュニティの力を活かして世界を目指そう~
by
NTT DATA OSS Professional Services
20170303 java9 hadoop
by
NTT DATA OSS Professional Services
ブロックチェーンの仕組みと動向(入門編)
by
NTT DATA OSS Professional Services
Application of postgre sql to large social infrastructure jp
by
NTT DATA OSS Professional Services
Application of postgre sql to large social infrastructure
by
NTT DATA OSS Professional Services
Apache Hadoop 2.8.0 の新機能 (抜粋)
by
NTT DATA OSS Professional Services
データ活用をもっともっと円滑に! ~データ処理・分析基盤編を少しだけ~
by
NTT DATA OSS Professional Services
商用ミドルウェアのPuppet化で気を付けたい5つのこと
by
NTT DATA OSS Professional Services
今からはじめるPuppet 2016 ~ インフラエンジニアのたしなみ ~
by
NTT DATA OSS Professional Services
Hadoopエコシステムの最新動向とNTTデータの取り組み (OSC 2016 Tokyo/Spring 講演資料)
by
NTT DATA OSS Professional Services
PostgreSQLでpg_bigmを使って日本語全文検索 (MySQLとPostgreSQLの日本語全文検索勉強会 発表資料)
by
NTT DATA OSS Professional Services
本当にあったHadoopの恐い話 Blockはどこへきえた? (Hadoop / Spark Conference Japan 2016 ライトニングトー...
by
NTT DATA OSS Professional Services
Apache Spark超入門 (Hadoop / Spark Conference Japan 2016 講演資料)
by
NTT DATA OSS Professional Services
サポートメンバは見た! Hadoopバグワースト10 (adoop / Spark Conference Japan 2016 ライトニングトーク発表資料)
by
NTT DATA OSS Professional Services
Recently uploaded
PPTX
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
PDF
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
PDF
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
PPTX
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
PDF
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
PDF
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PPTX
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
PDF
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
How to buy a used computer and use it with Windows 11
by
Atomu Hidaka
DX人材育成 サービスデザインで実現する「巻き込み力」の育て方 by Graat
by
Graat(グラーツ)
技育祭2025秋 サボろうとする生成AIの傾向と対策 登壇資料(フューチャー渋川)
by
Yoshiki Shibukawa
FOSS4G Japan 2025 - QGISでスムーズに地図を比較 - QMapCompareプラグインの紹介
by
Raymond Lay
FOSS4G Hokkaido - QFieldをランナーのために活用した - QField for runners
by
Raymond Lay
「似ているようで微妙に違う言葉」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
「Drupal SDCについて紹介」2025/10/17の勉強会で発表されたものです。
by
iPride Co., Ltd.
FOSS4G Japan 2024 ハザードマップゲームの作り方 Hazard Map Game QGIS Plugin
by
Raymond Lay
Apache Hadoopの新機能Ozoneの現状
1.
© 2017 NTT
DATA Corporation Apache Hadoopの新機能Ozoneの現状 2017/11/29 株式会社NTTデータ OSSプロフェッショナルサービス 鯵坂 明 Hadoopソースコードリーディング 第24回
2.
© 2017 NTT
DATA Corporation 2 鯵坂 明 (Akira Ajisaka, @ajis_ka) NTTデータ OSSプロフェッショナルサービス Apache Hadoopと関わり続けて6年が経過 Hadoopの新機能や、関連するミドルウェアの検証 プロジェクトへの技術支援 サポートサービス Apache Hadoop committer, PMC member HadoopのJava 9対応を実施中 自己紹介
3.
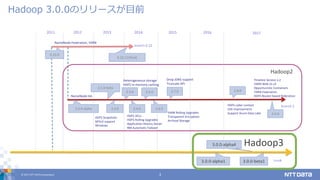
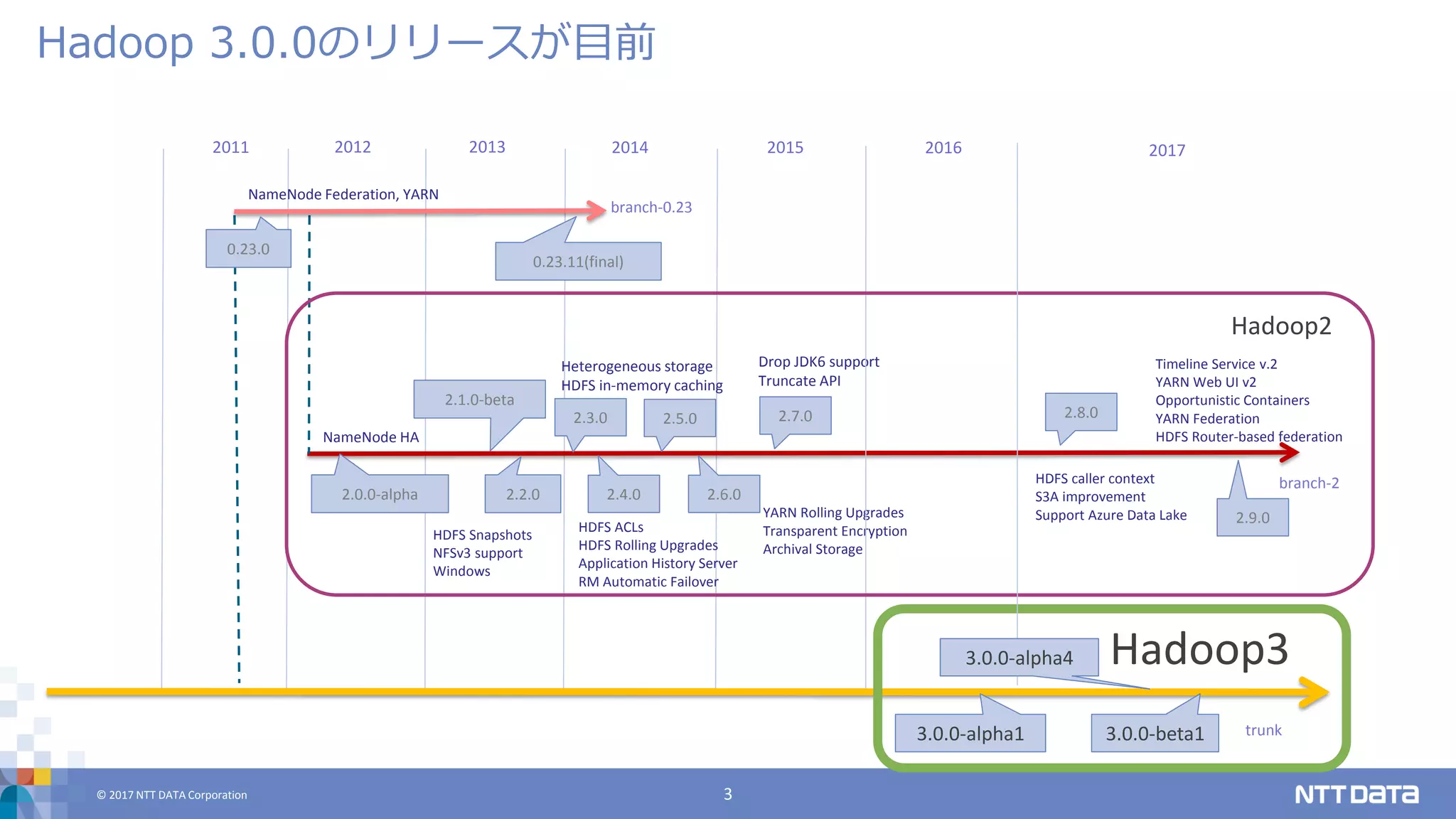
© 2017 NTT
DATA Corporation 3 Hadoop 3.0.0のリリースが目前 20142011 20132012 2015 2.2.0 2.3.0 2.4.02.0.0-alpha 2.1.0-beta 0.23.0 0.23.11(final) NameNode Federation, YARN NameNode HA HDFS Snapshots NFSv3 support Windows Heterogeneous storage HDFS in-memory caching HDFS ACLs HDFS Rolling Upgrades Application History Server RM Automatic Failover 2.5.0 2.6.0 YARN Rolling Upgrades Transparent Encryption Archival Storage 2.7.0 Drop JDK6 support Truncate API 2016 branch-0.23 branch-2 trunk Hadoop2 Hadoop3 2017 2.8.0 3.0.0-alpha1 3.0.0-beta1 HDFS caller context S3A improvement Support Azure Data Lake 3.0.0-alpha4 2.9.0 Timeline Service v.2 YARN Web UI v2 Opportunistic Containers YARN Federation HDFS Router-based federation
4.
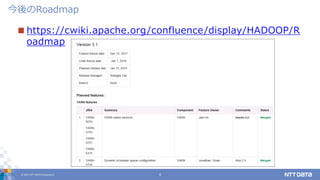
© 2017 NTT
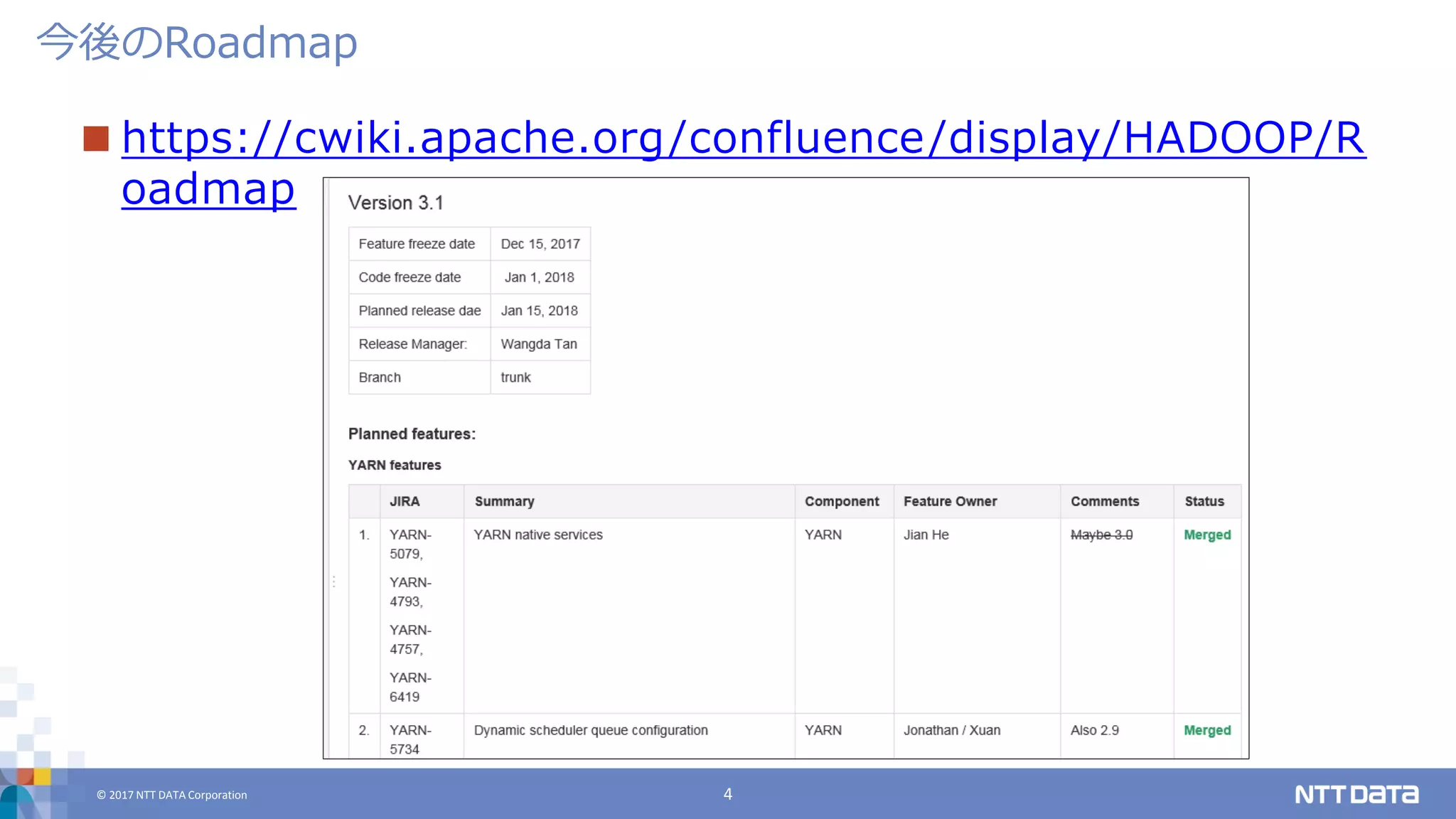
DATA Corporation 4 https://cwiki.apache.org/confluence/display/HADOOP/R oadmap 今後のRoadmap
5.
© 2017 NTT
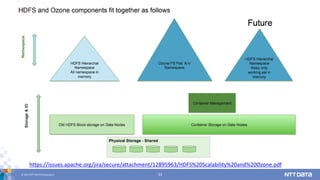
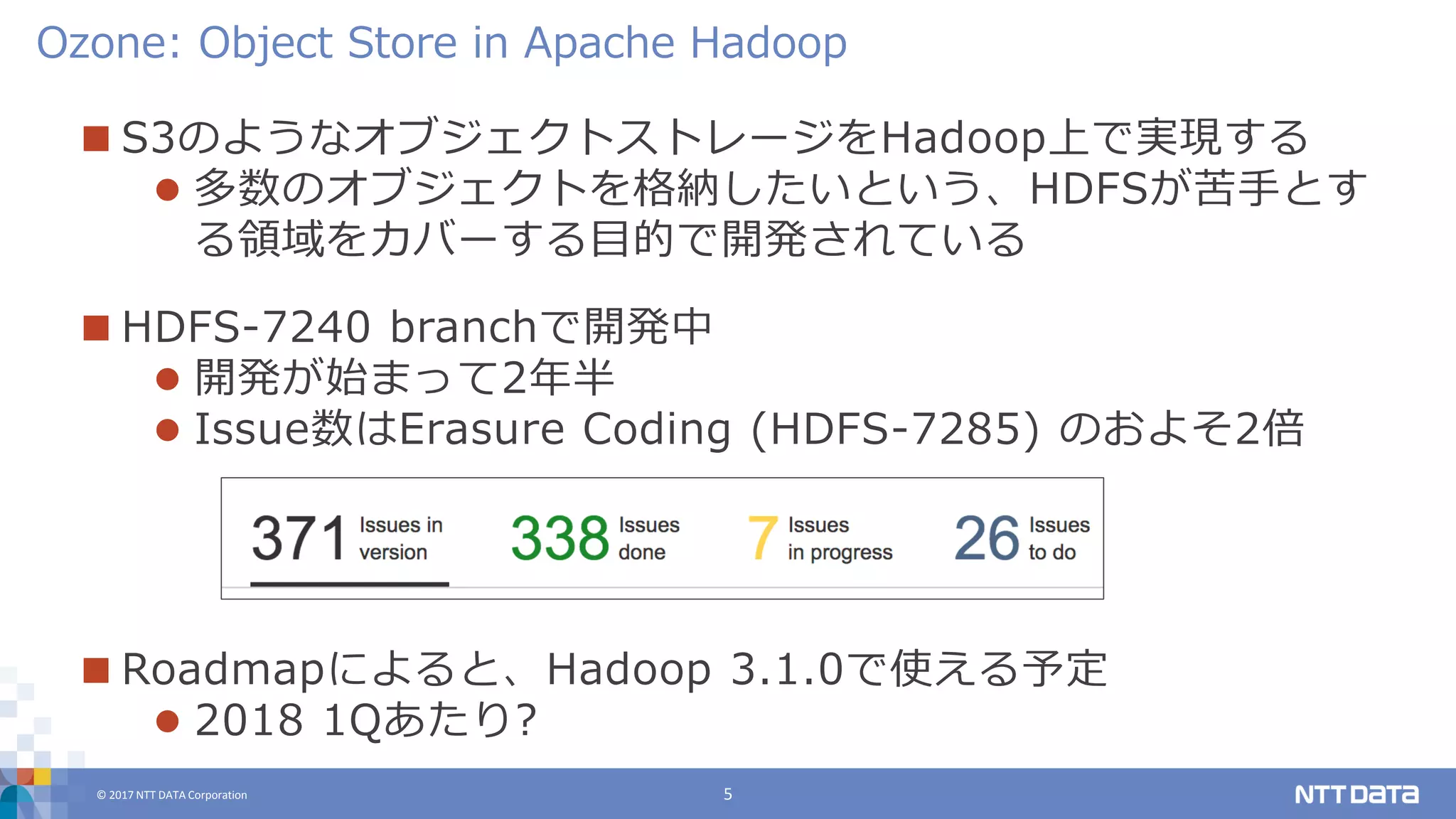
DATA Corporation 5 S3のようなオブジェクトストレージをHadoop上で実現する 多数のオブジェクトを格納したいという、HDFSが苦手とす る領域をカバーする目的で開発されている HDFS-7240 branchで開発中 開発が始まって2年半 Issue数はErasure Coding (HDFS-7285) のおよそ2倍 Roadmapによると、Hadoop 3.1.0で使える予定 2018 1Qあたり? Ozone: Object Store in Apache Hadoop
6.
© 2017 NTT
DATA Corporation 6 本スライドは、feature branchで開発中の機能 を紹介するものです 設定方法、コマンドなど全てにおいて、今後変更 される可能性が大いにあります Ozoneについて詳しく紹介する前に... 注意事項
7.
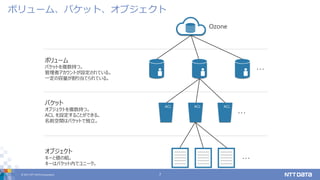
© 2017 NTT
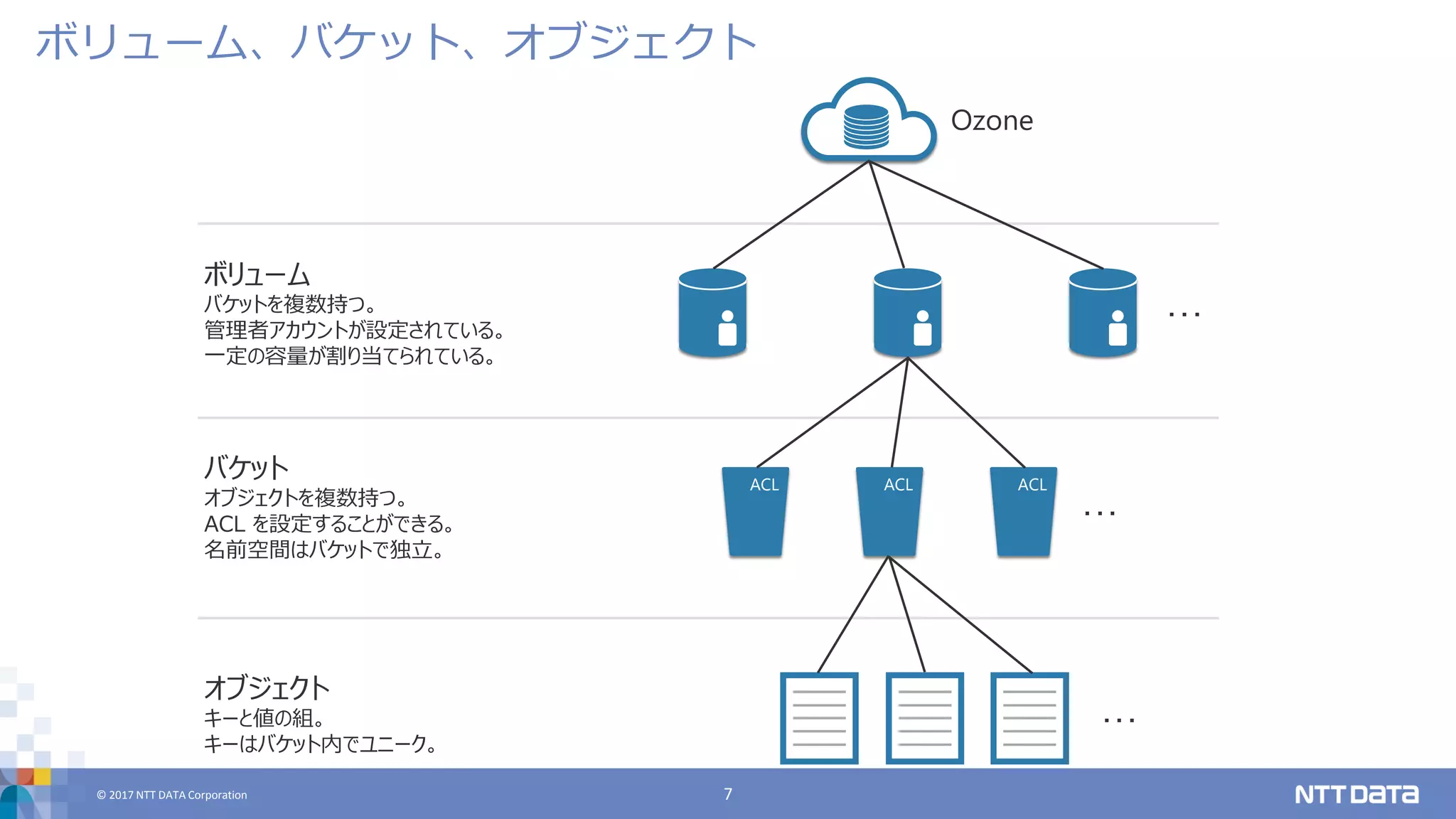
DATA Corporation 7 ボリューム、バケット、オブジェクト Ozone ACLACL ACL ボリューム バケットを複数持つ。 管理者アカウントが設定されている。 一定の容量が割り当てられている。 バケット オブジェクトを複数持つ。 ACL を設定することができる。 名前空間はバケットで独立。 オブジェクト キーと値の組。 キーはバケット内でユニーク。 ・・・ ・・・ ・・・
8.
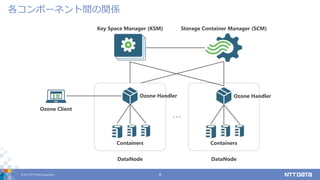
© 2017 NTT
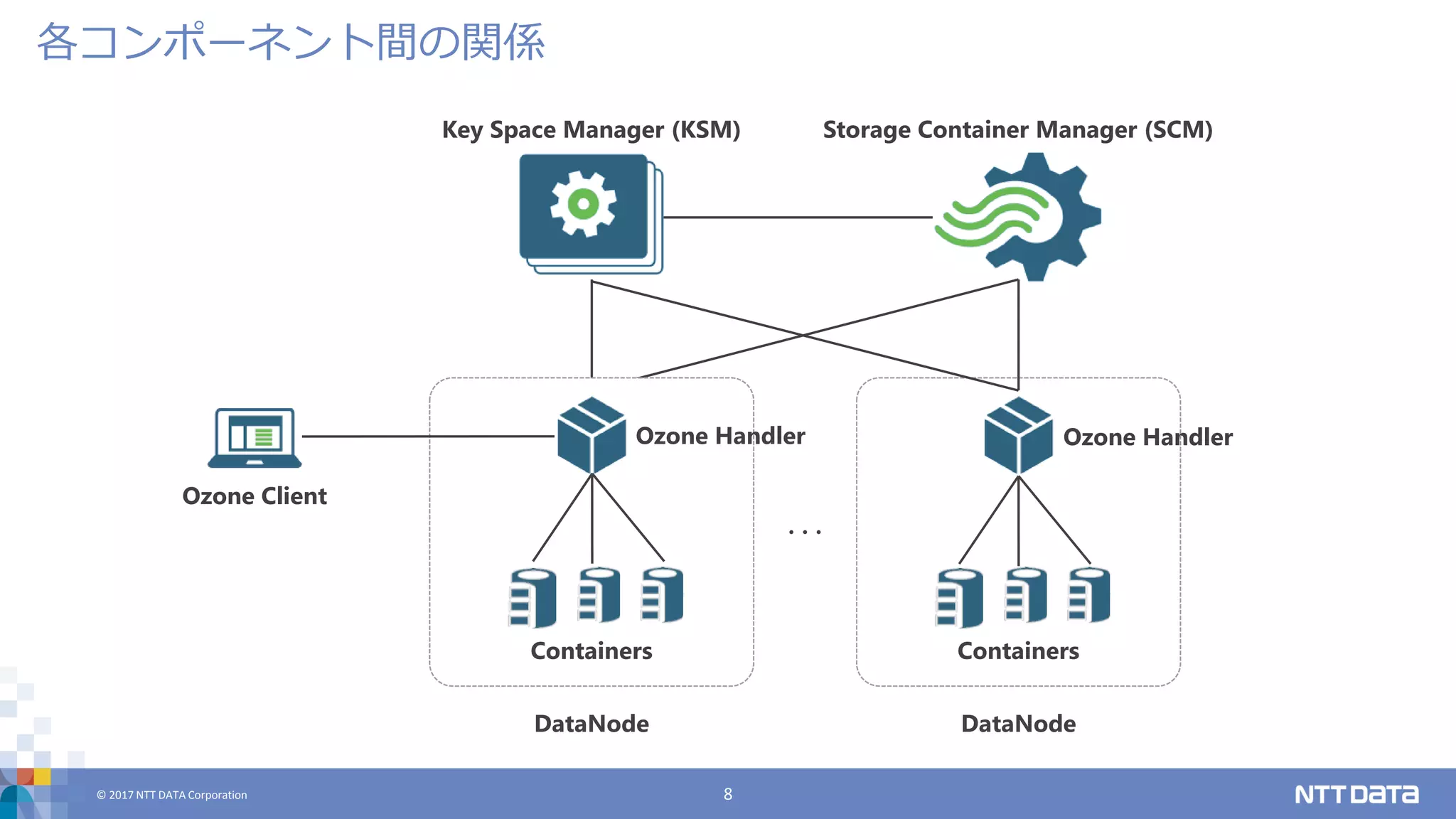
DATA Corporation 8 各コンポーネント間の関係 Key Space Manager (KSM) Storage Container Manager (SCM) Ozone Client Containers Ozone Handler DataNode Containers Ozone Handler DataNode ・・・
9.
© 2017 NTT
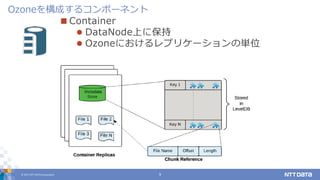
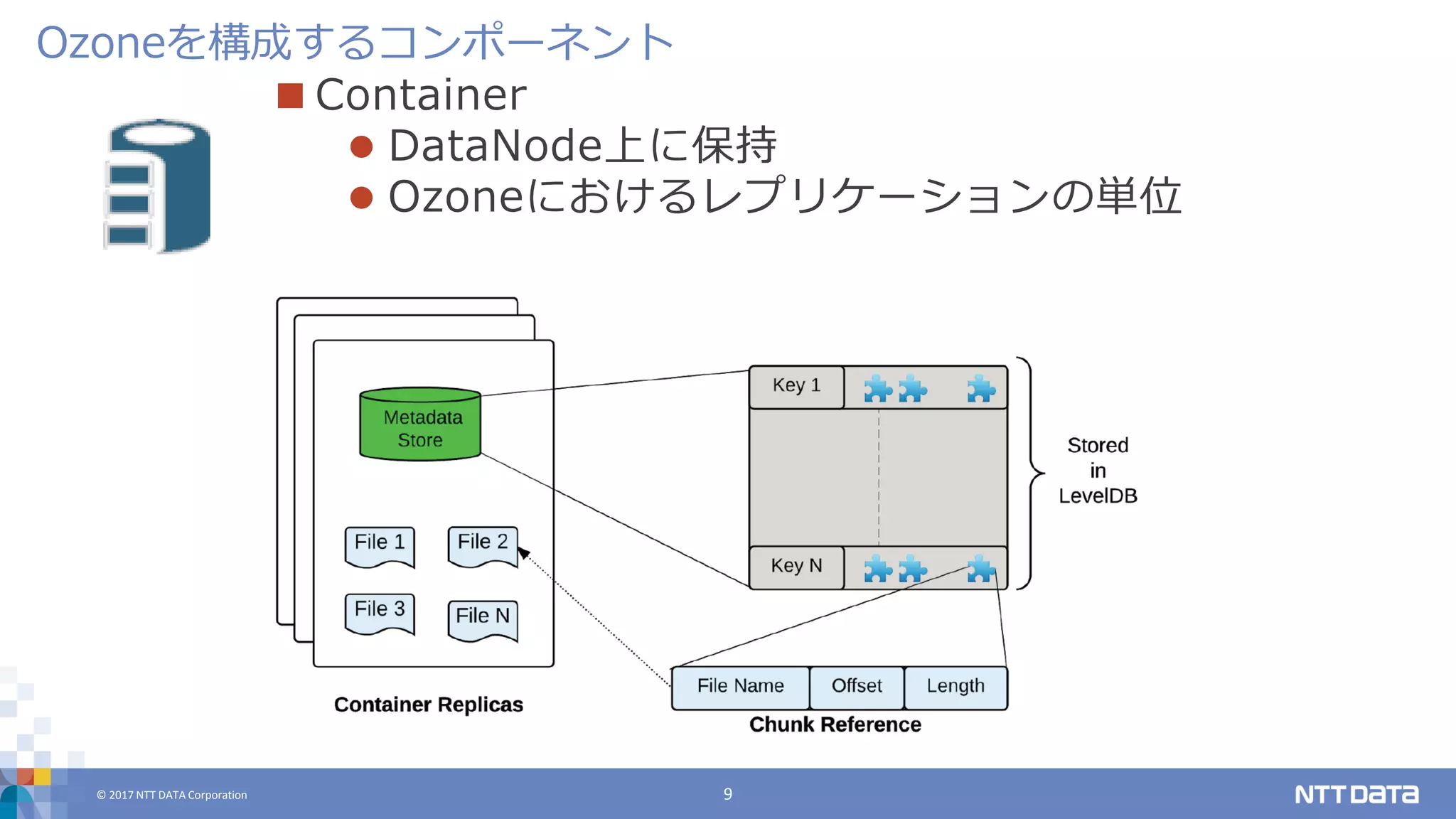
DATA Corporation 9 Container DataNode上に保持 Ozoneにおけるレプリケーションの単位 Ozoneを構成するコンポーネント
10.
© 2017 NTT
DATA Corporation 10 Ozone Handler クライアントに対してOzoneのREST APIを提供 各DataNode上で動作 Key Space Manager (KSM) 名前空間に関するクエリを処理 オブジェクトのキーやバケット名からcontainerを解決 Storage Container Manager (SCM) DataNodeとheartbeat通信し、各containerがどの DataNode上に存在するかをトラッキングする 障害時にcontainerのレプリケーションを実施 Ozoneを構成するコンポーネント
11.
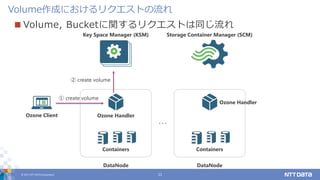
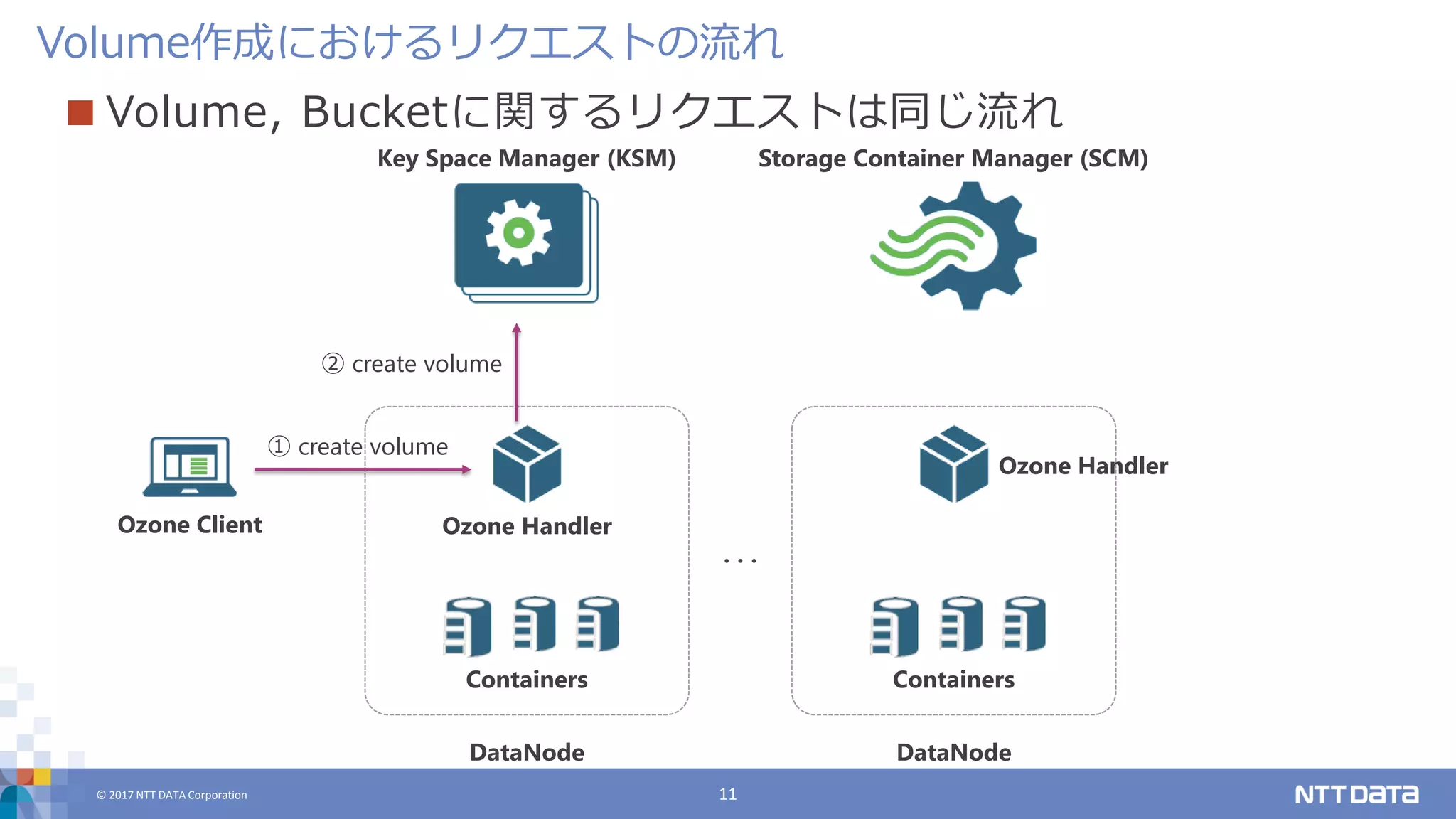
© 2017 NTT
DATA Corporation 11 Volume作成におけるリクエストの流れ Key Space Manager (KSM) Storage Container Manager (SCM) Ozone Client Containers Ozone Handler DataNode Containers Ozone Handler DataNode ・・・ ① create volume ② create volume Volume, Bucketに関するリクエストは同じ流れ
12.
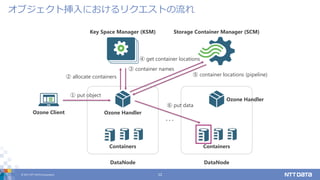
© 2017 NTT
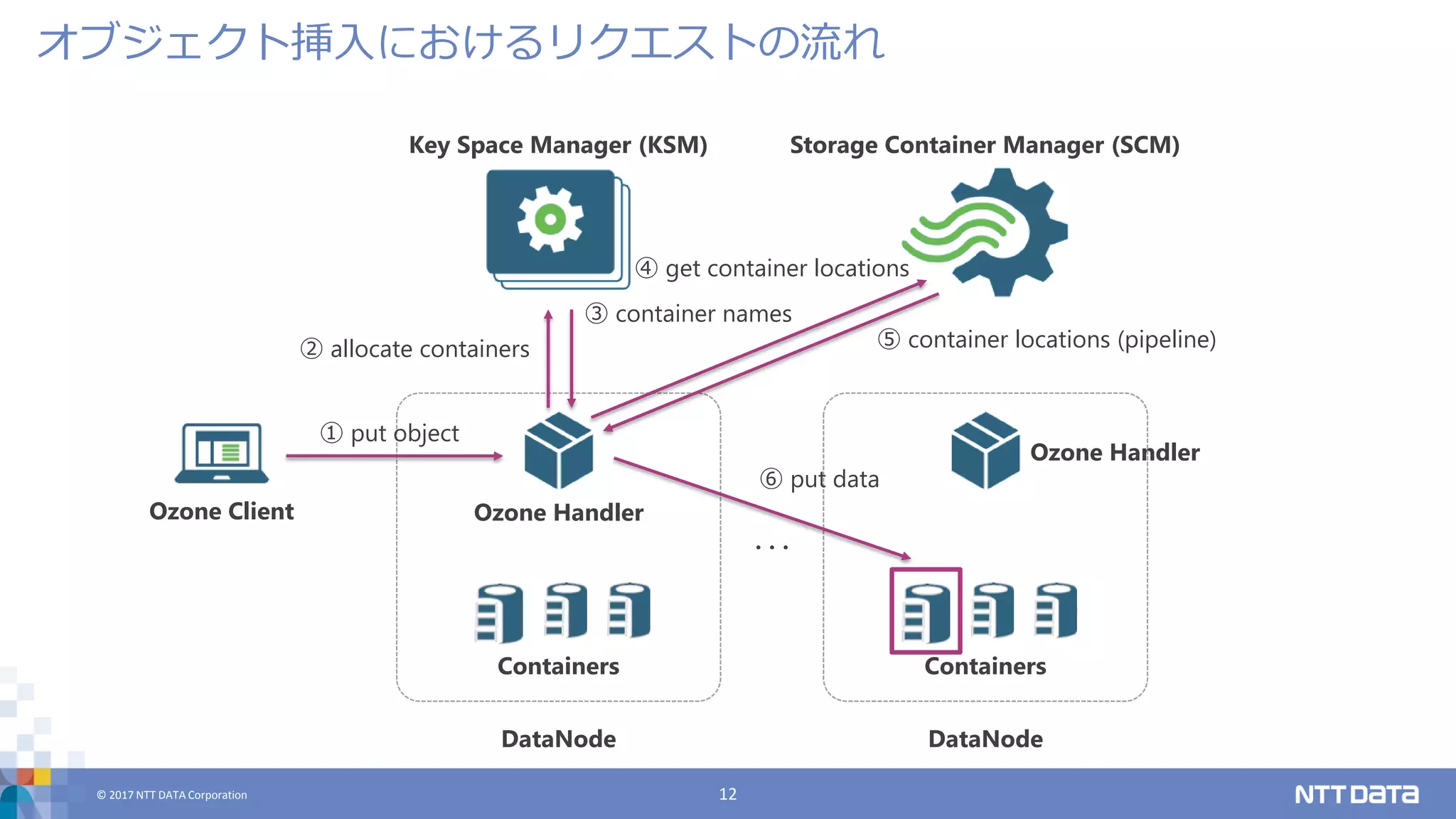
DATA Corporation 12 オブジェクト挿入におけるリクエストの流れ Key Space Manager (KSM) Storage Container Manager (SCM) Ozone Client Containers Ozone Handler DataNode Containers Ozone Handler DataNode ・・・ ① put object ② allocate containers ③ container names ⑥ put data ④ get container locations ⑤ container locations (pipeline)
13.
© 2017 NTT
DATA Corporation 13 DataNode -> ObjectStoreHandler -> DistributedStorageHandler という順番で追うことで、Ozone Handlerの全貌が掴める DistributedStorageHandler が クライアントからのリクエスト を受け付ける Volumeの作成 -> #createVolume オブジェクトの挿入 -> #newKeyWriter ... デモ ソースコードリーディング
14.
© 2017 NTT
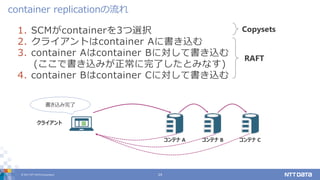
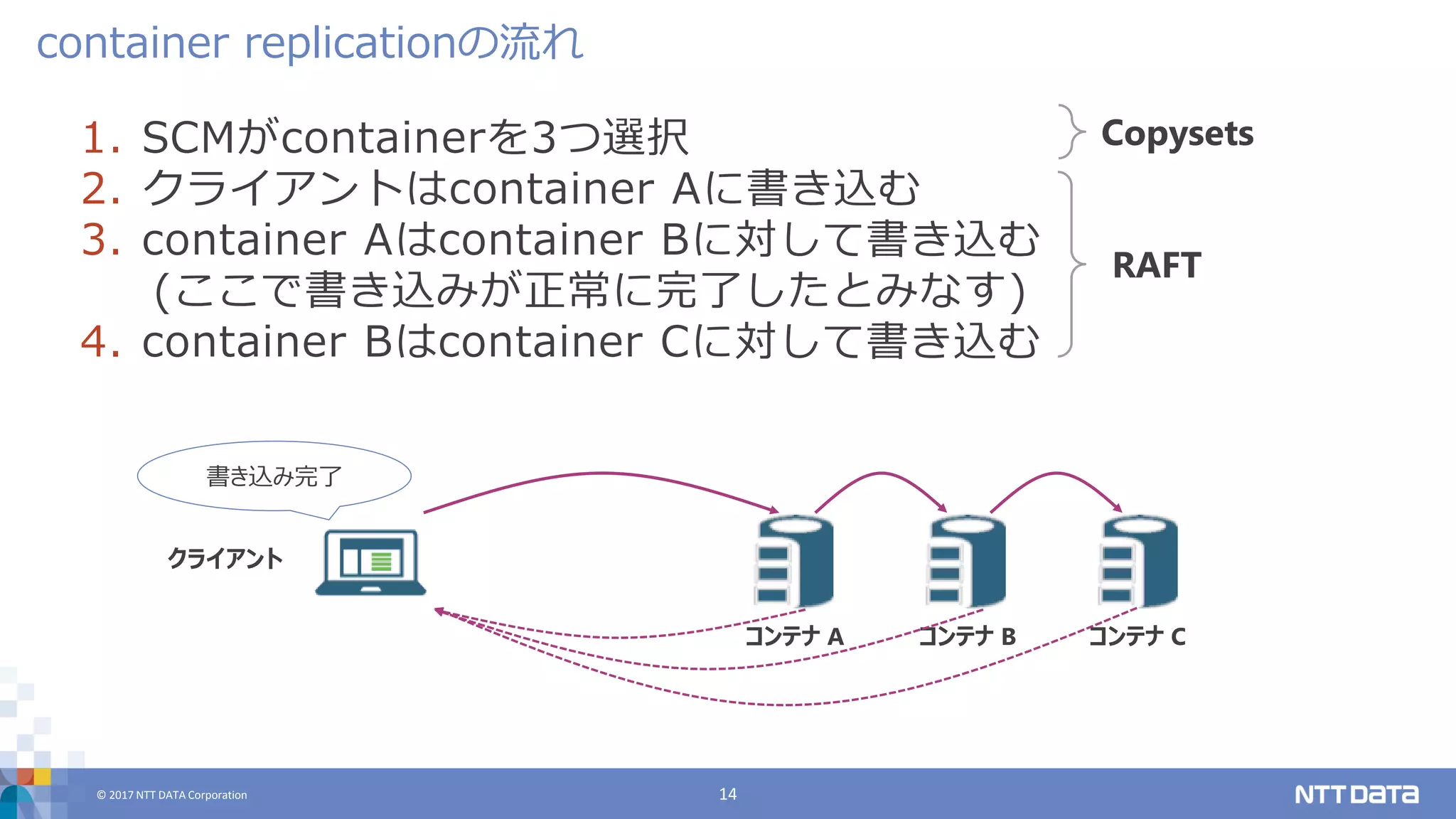
DATA Corporation 14 1. SCMがcontainerを3つ選択 2. クライアントはcontainer Aに書き込む 3. container Aはcontainer Bに対して書き込む (ここで書き込みが正常に完了したとみなす) 4. container Bはcontainer Cに対して書き込む container replicationの流れ Copysets RAFT コンテナ B クライアント 書き込み完了 コンテナ A コンテナ C
15.
© 2017 NTT
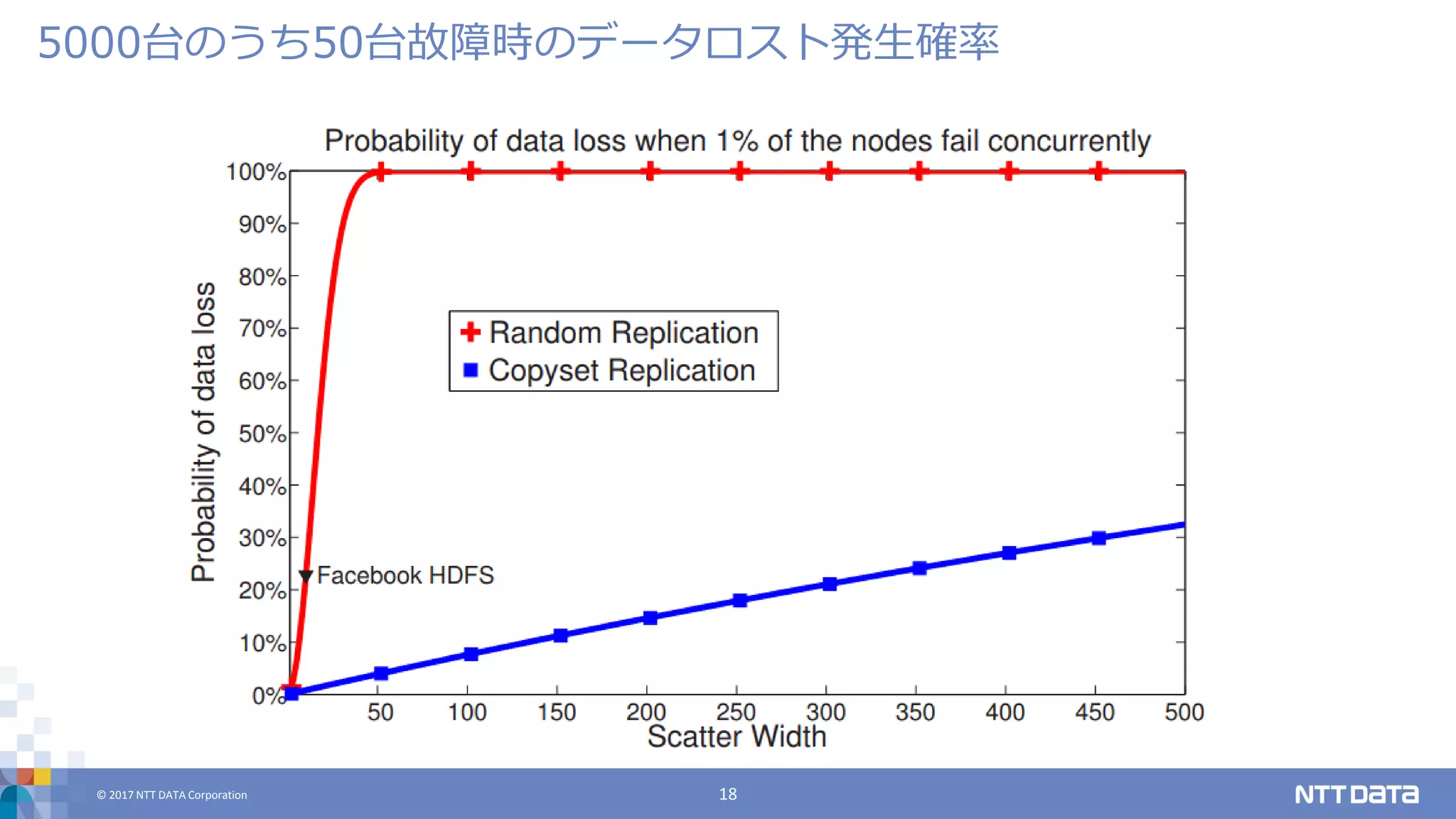
DATA Corporation 15 ランダムレプリケーションだと、データロストの確率が増える 5000ノードのクラスタで1%のサーバが同時に故障した場合、 ほぼ確実にデータロスト レプリケーションをするノードの組み合わせが増えすぎること が問題 ノードの組み合わせ: 5000C3 = 約208億通り データロストする組み合わせ: 50C3 = 19600通り あるblockが故障する確率: 208億/19600 = 約100万分の1 block数は億オーダー -> データロスト ノードの組み合わせを減らすしかない Copysets: Reducing the Frequency of Data Loss in Cloud Storage
16.
© 2017 NTT
DATA Corporation 16 Scatter width (以下 S) を定義 あるノードのデータのコピーを持っているノード数がS 9 nodeの場合、{1, 2, 3}, {4, 5, 6}, {7, 8, 9}, {1, 4, 7}, {2, 5, 8}, {3, 6, 9} という組み合わせは S=4 を満 たす ここで、{1, 2, 3}はあるデータが 1, 2, 3番のノードにそ れぞれレプリケーションされることを示す 1にあるデータは 2, 3, 4, 7の4ノードが持っている (S=4) Sを小さくすると組み合わせが減り、データロスト発生確率は 下がるが、小さくしすぎてもよくない 故障時の再レプリケーションが遅くなる Copysets: Reducing the Frequency of Data Loss in Cloud Storage
17.
© 2017 NTT
DATA Corporation 17 Sをなるべく保ったまま、組み合わせを減らすことが重要 以下はどちらもS=4だが、上のほうがよい {1, 2, 3}, {4, 5, 6}, {7, 8, 9}, {1, 4, 7}, {2, 5, 8}, {3, 6, 9} {1, 2, 3}, {2, 3, 4}, {3, 4, 5}, {4, 5, 6}, {5, 6, 7}, {6, 7, 8}, {7, 8, 9}, {8, 9, 1}, {9, 1, 2}, {1, 2, 4}, {1, 3, 4}, {2, 3, 5}, {2, 4, 5}, {3, 4, 6}, {3, 5, 6}, {4, 5, 7} 詳細は省くが、うまく作ると組み合わせ数は O(S) になる 完全ランダムの場合、O(SR-1 ) Copysets: Reducing the Frequency of Data Loss in Cloud Storage
18.
© 2017 NTT
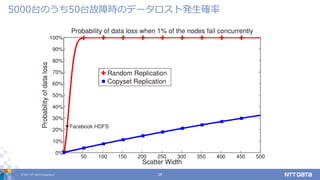
DATA Corporation 18 5000台のうち50台故障時のデータロスト発生確率
19.
© 2017 NTT
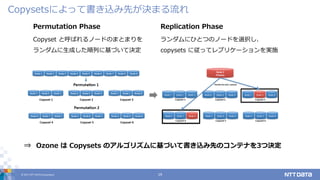
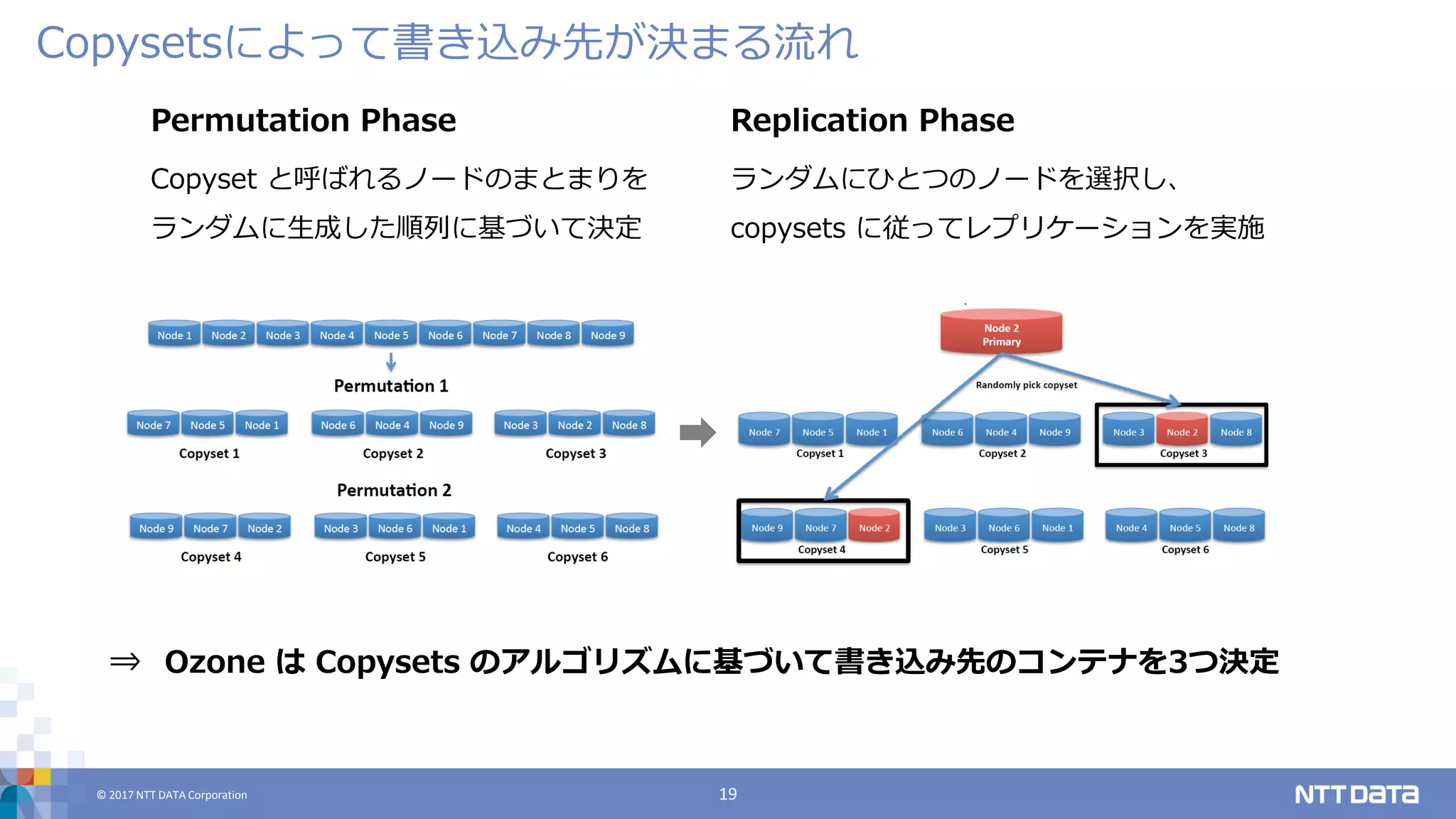
DATA Corporation 19 Copysetsによって書き込み先が決まる流れ Permutation Phase Copyset と呼ばれるノードのまとまりを ランダムに生成した順列に基づいて決定 Replication Phase ランダムにひとつのノードを選択し、 copysets に従ってレプリケーションを実施 ⇒ Ozone は Copysets のアルゴリズムに基づいて書き込み先のコンテナを3つ決定
20.
© 2017 NTT
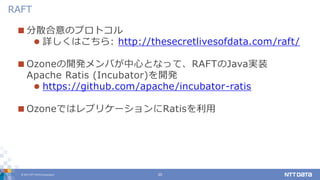
DATA Corporation 20 分散合意のプロトコル 詳しくはこちら: http://thesecretlivesofdata.com/raft/ Ozoneの開発メンバが中心となって、RAFTのJava実装 Apache Ratis (Incubator)を開発 https://github.com/apache/incubator-ratis OzoneではレプリケーションにRatisを利用 RAFT
21.
© 2017 NTT
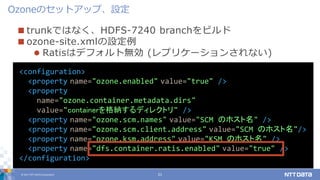
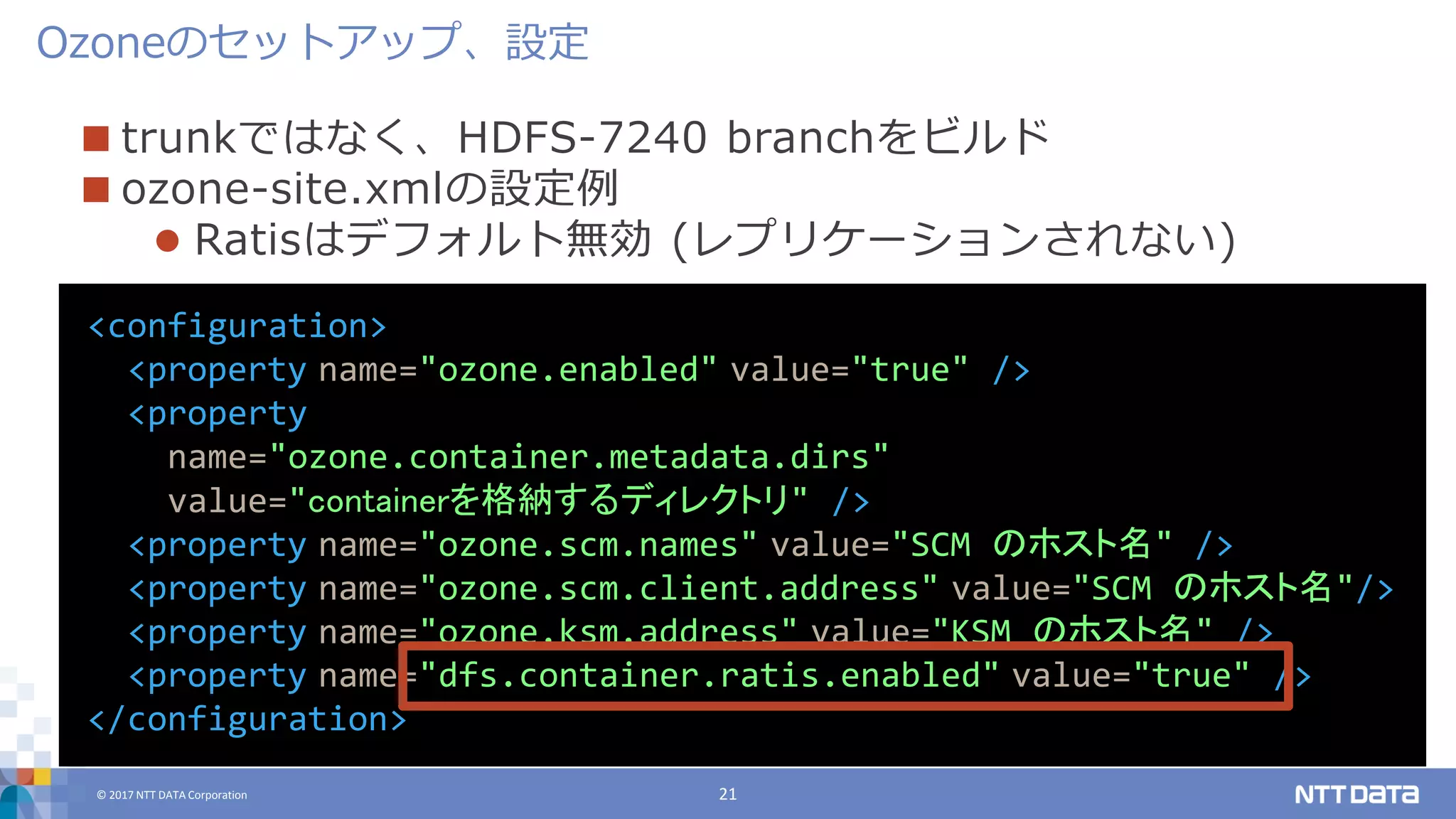
DATA Corporation 21 trunkではなく、HDFS-7240 branchをビルド ozone-site.xmlの設定例 Ratisはデフォルト無効 (レプリケーションされない) Ozoneのセットアップ、設定 <configuration> <property name="ozone.enabled" value="true" /> <property name="ozone.container.metadata.dirs" value="containerを格納するディレクトリ" /> <property name="ozone.scm.names" value="SCM のホスト名" /> <property name="ozone.scm.client.address" value="SCM のホスト名"/> <property name="ozone.ksm.address" value="KSM のホスト名" /> <property name="dfs.container.ratis.enabled" value="true" /> </configuration>
22.
© 2017 NTT
DATA Corporation 22 SCM KSM Ozoneの起動 $ hdfs --daemon start scm $ hdfs --daemon start ksm
23.
© 2017 NTT
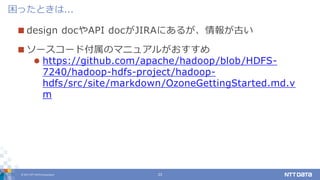
DATA Corporation 23 design docやAPI docがJIRAにあるが、情報が古い ソースコード付属のマニュアルがおすすめ https://github.com/apache/hadoop/blob/HDFS- 7240/hadoop-hdfs-project/hadoop- hdfs/src/site/markdown/OzoneGettingStarted.md.v m 困ったときは...
24.
© 2017 NTT
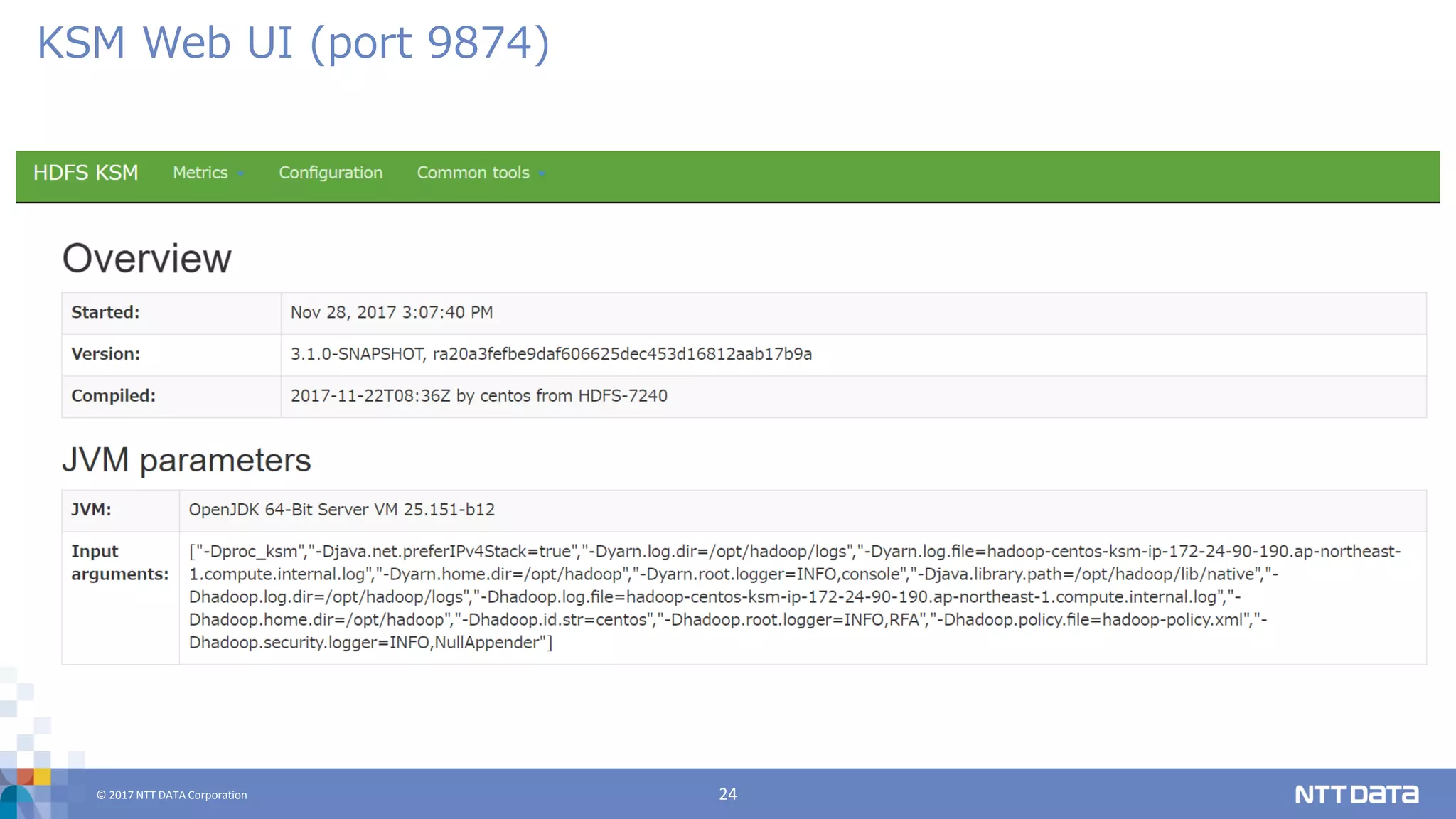
DATA Corporation 24 KSM Web UI (port 9874)
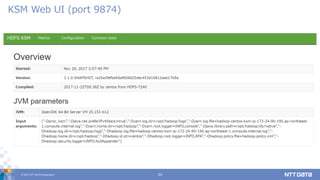
25.
© 2017 NTT
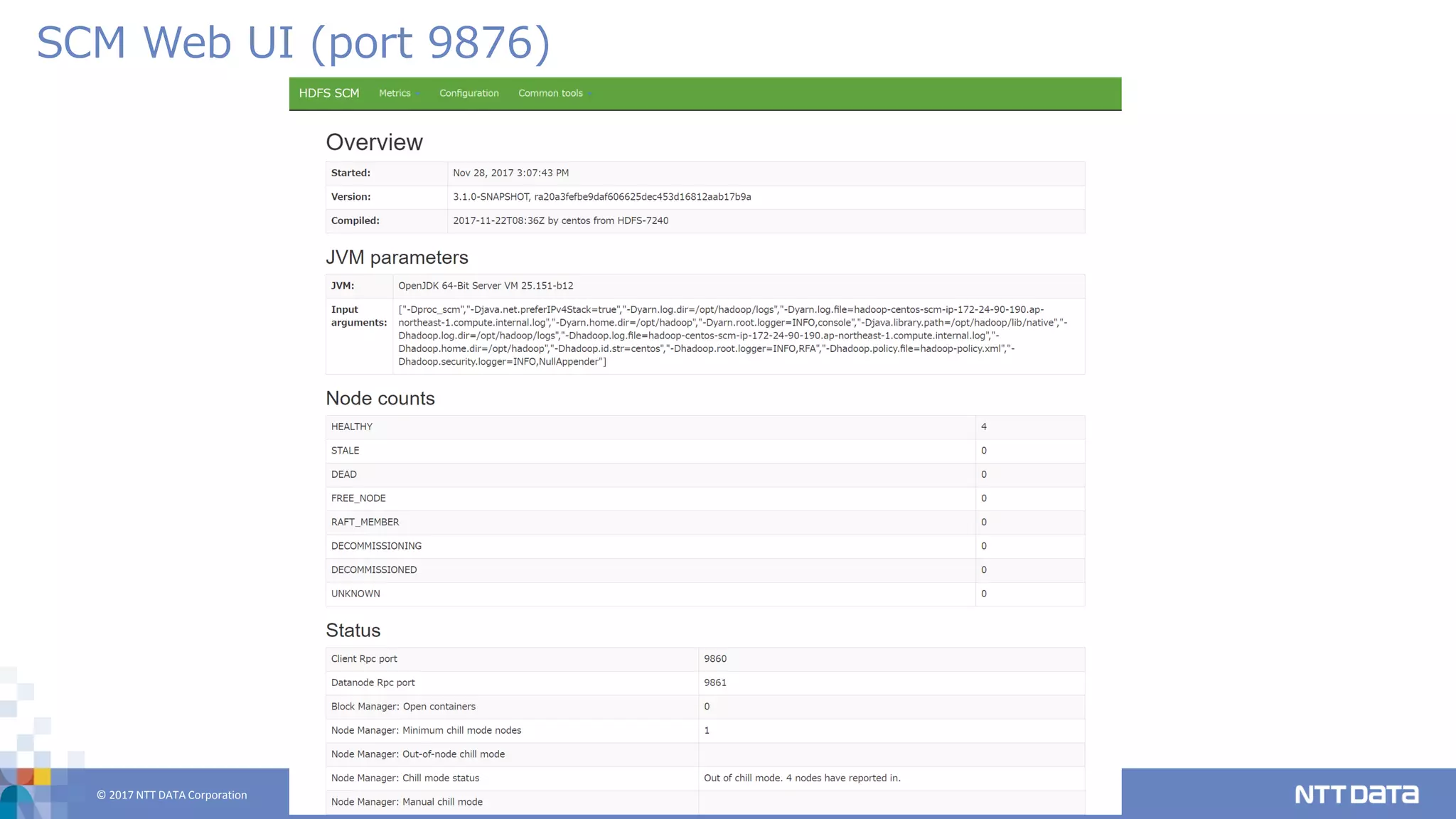
DATA Corporation 25 SCM Web UI (port 9876)
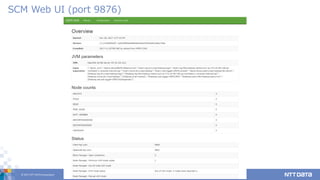
26.
© 2017 NTT
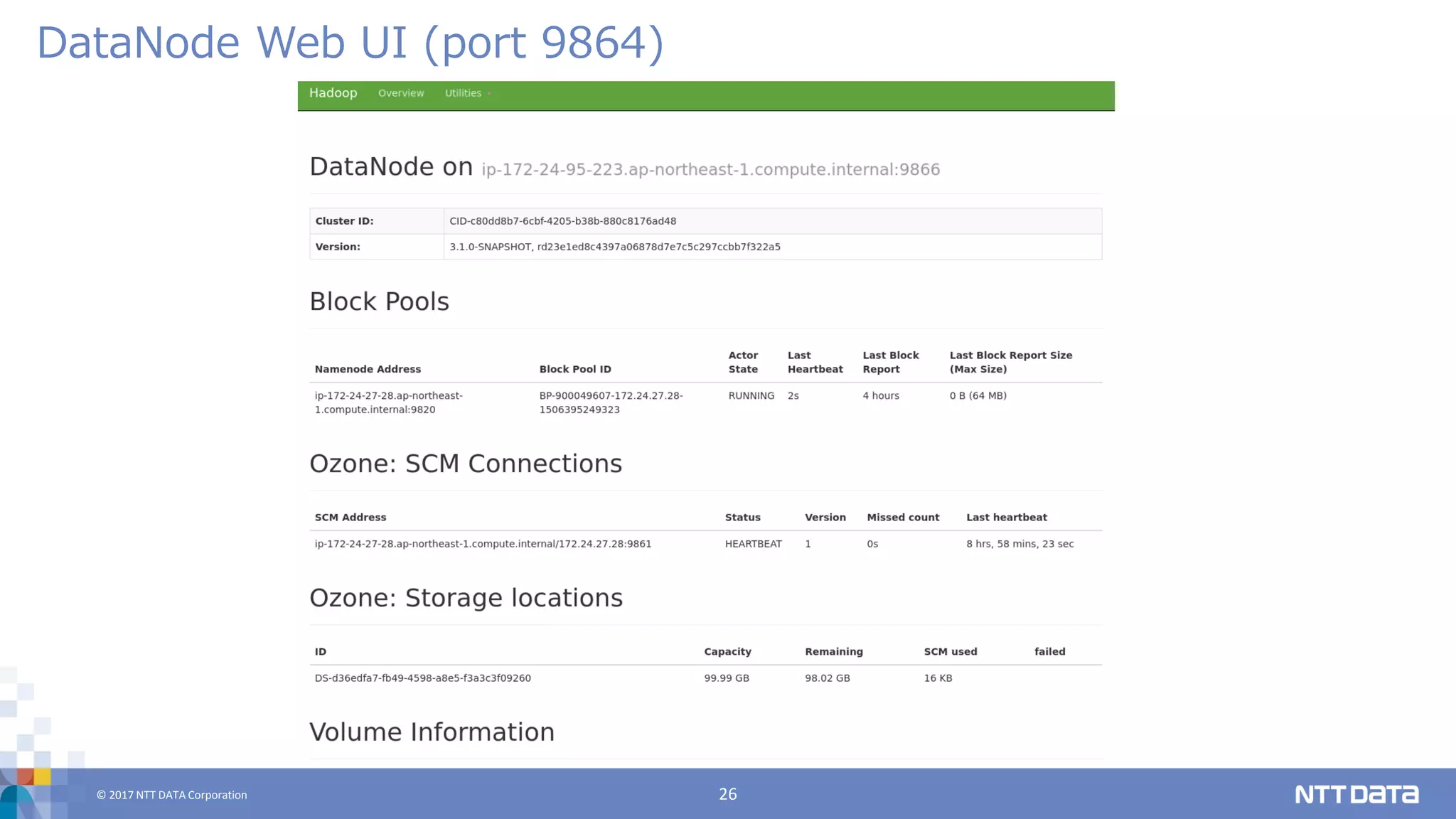
DATA Corporation 26 DataNode Web UI (port 9864)
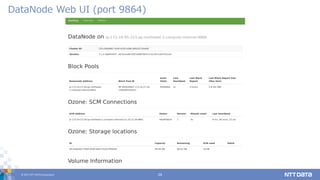
27.
© 2017 NTT
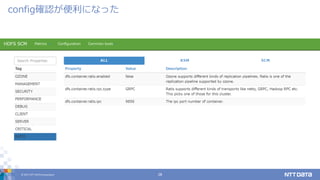
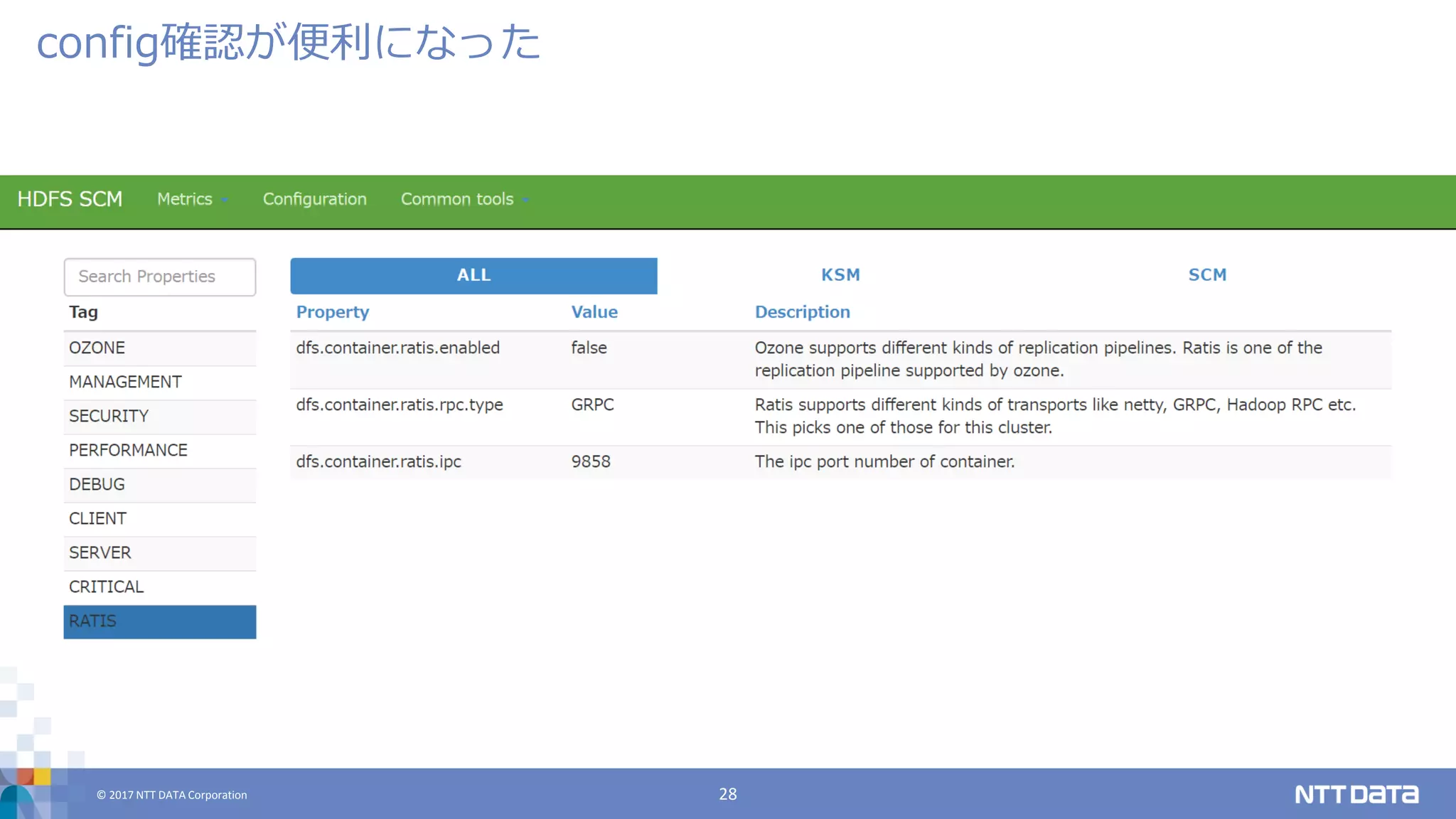
DATA Corporation 27 config確認が便利になった
28.
© 2017 NTT
DATA Corporation 28 config確認が便利になった
29.
© 2017 NTT
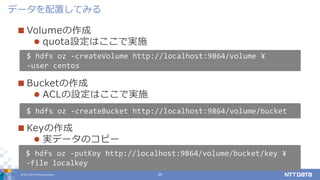
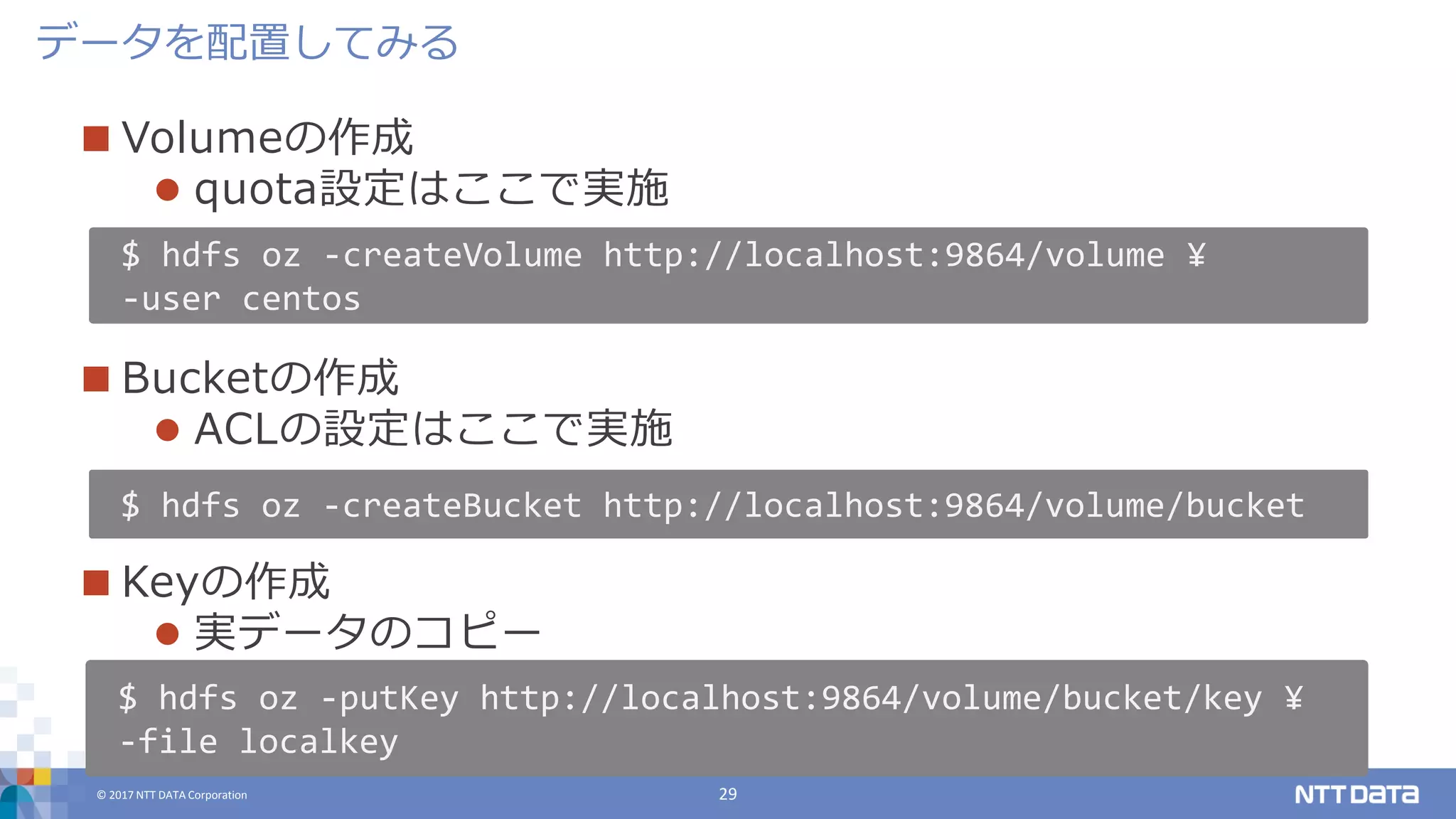
DATA Corporation 29 Volumeの作成 quota設定はここで実施 Bucketの作成 ACLの設定はここで実施 Keyの作成 実データのコピー データを配置してみる $ hdfs oz -createVolume http://localhost:9864/volume ¥ -user centos $ hdfs oz -createBucket http://localhost:9864/volume/bucket $ hdfs oz -putKey http://localhost:9864/volume/bucket/key ¥ -file localkey
30.
© 2017 NTT
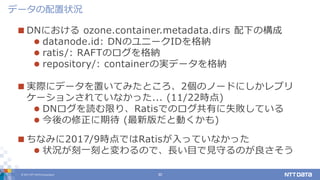
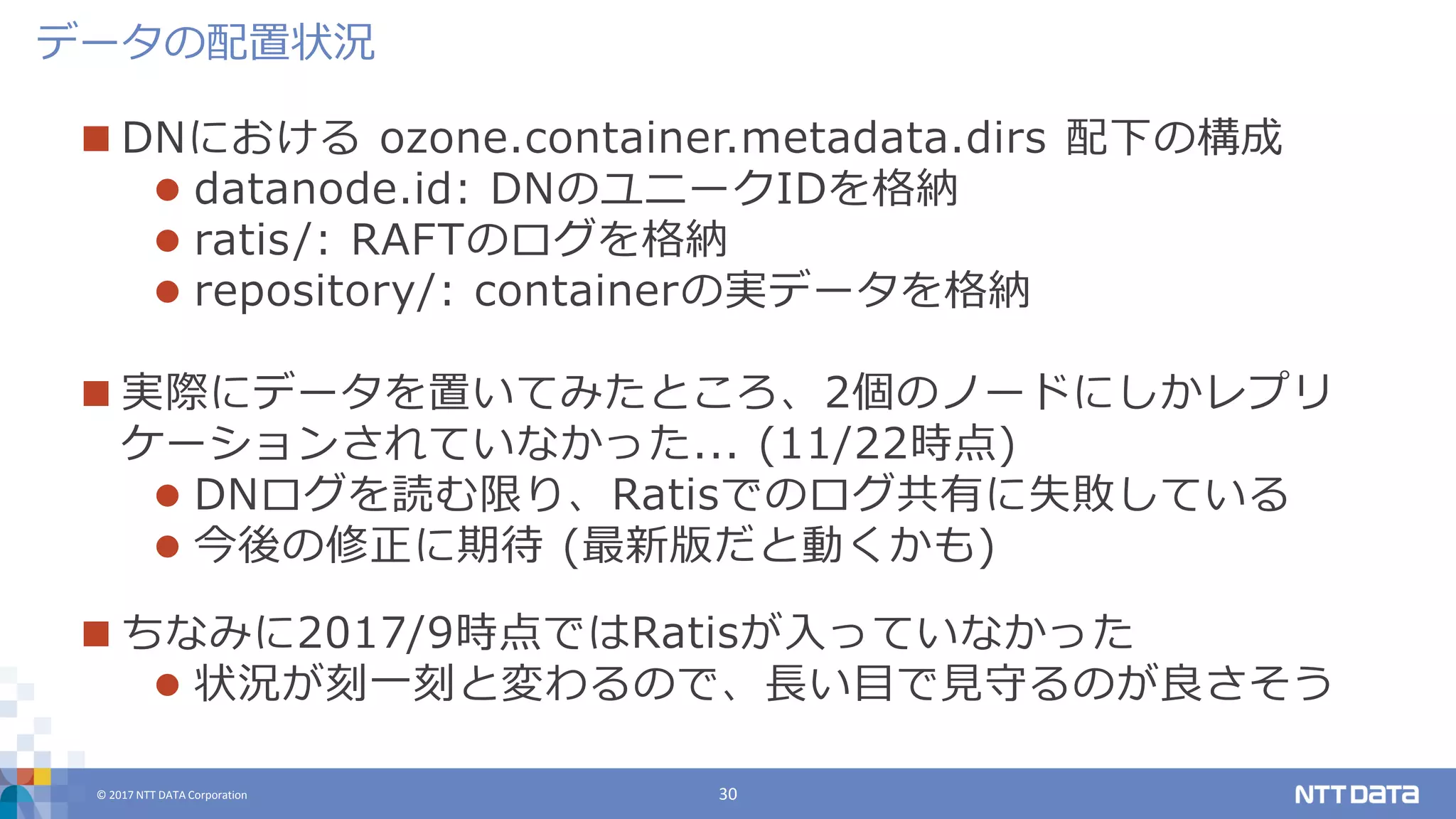
DATA Corporation 30 DNにおける ozone.container.metadata.dirs 配下の構成 datanode.id: DNのユニークIDを格納 ratis/: RAFTのログを格納 repository/: containerの実データを格納 実際にデータを置いてみたところ、2個のノードにしかレプリ ケーションされていなかった... (11/22時点) DNログを読む限り、Ratisでのログ共有に失敗している 今後の修正に期待 (最新版だと動くかも) ちなみに2017/9時点ではRatisが入っていなかった 状況が刻一刻と変わるので、長い目で見守るのが良さそう データの配置状況
31.
© 2017 NTT
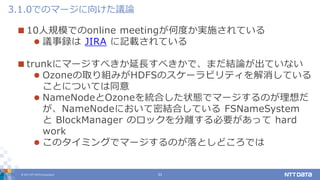
DATA Corporation 31 10人規模でのonline meetingが何度か実施されている 議事録は JIRA に記載されている trunkにマージすべきか延長すべきかで、まだ結論が出ていない Ozoneの取り組みがHDFSのスケーラビリティを解消している ことについては同意 NameNodeとOzoneを統合した状態でマージするのが理想だ が、NameNodeにおいて密結合している FSNameSystem と BlockManager のロックを分離する必要があって hard work このタイミングでマージするのが落としどころでは 3.1.0でのマージに向けた議論
32.
© 2017 NTT
DATA Corporation 32 NameNodeにおけるFSNameSystemとBlockManagerの密結合は、 HDFS append APIを実装した2010年にもたらされた 当時は、RAFTのようなメンバの追加/削除が可能な分散合意プロトコルが 一般的ではなかったため、中央集権的に実装された Ozoneのマージを機に、7年続いた密結合が取り崩されることに期待が膨ら む 私も開発に参加して、取り組みを加速させたい 最後に
33.
© 2017 NTT
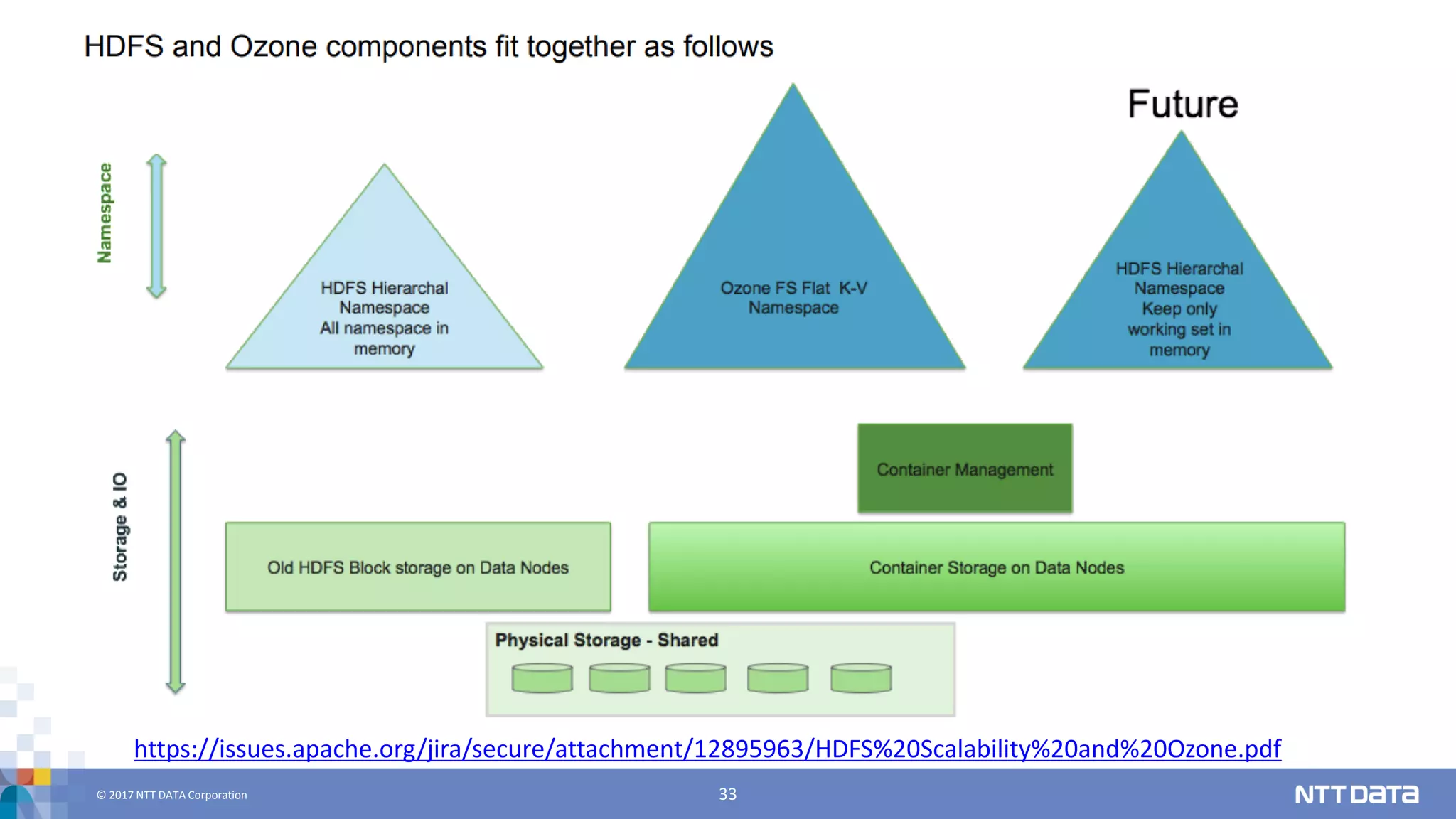
DATA Corporation 33 https://issues.apache.org/jira/secure/attachment/12895963/HDFS%20Scalability%20and%20Ozone.pdf
34.
© 2017 NTT
DATA Corporation 34 Copysets: Reducing the Frequency of Data Loss in Cloud Storage https://www.usenix.org/node/174509 References
35.
© 2017 NTT
DATA Corporation 本資料中に記載されている会社名、商品名、ロゴは、各社の商標または登録商標です。




























![[Cloud OnAir] Bigtable に迫る!基本機能も含めユースケースまで丸ごと紹介 2018年8月30日 放送](https://cdn.slidesharecdn.com/ss_thumbnails/1111111-180830075720-thumbnail.jpg?width=600ounds&width=560&fit=bounds)


































![[CWT2017]Infrastructure as Codeを活用したF.O.Xのクラウドビッグデータ環境の変化](https://cdn.slidesharecdn.com/ss_thumbnails/dlcwt2017infrastructureascodef-171108044056-thumbnail.jpg?width=600ounds&width=560&fit=bounds)






































