Downloaded 204 times



















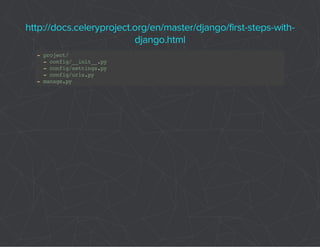
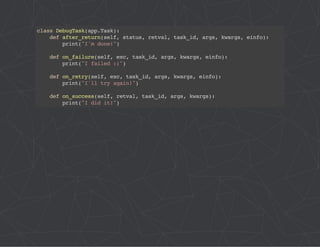
![# project/config/__init__.py
from __future__ import absolute_import
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ['celery_app']](https://image.slidesharecdn.com/practicalcelery-141029122350-conversion-gate02/85/Practical-Celery-26-320.jpg)




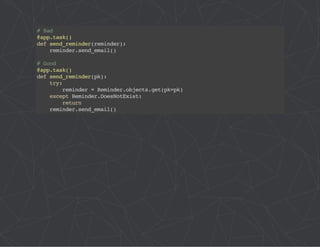


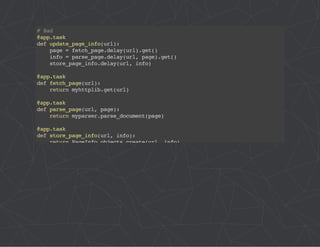














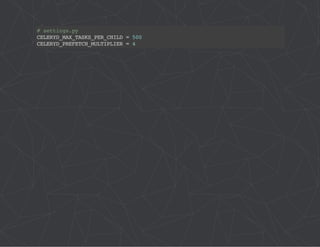










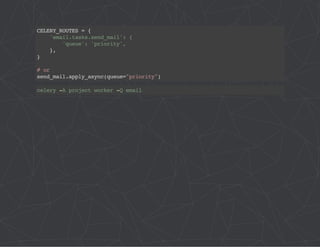

























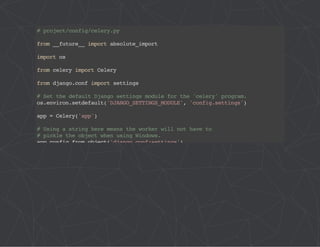
![# project/config/__init__.py
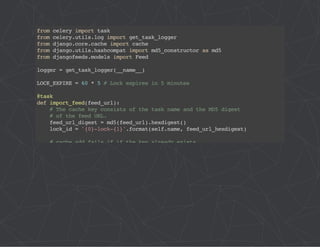
from __future__ import absolute_import
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ['celery_app']](https://image.slidesharecdn.com/practicalcelery-141029122350-conversion-gate02/75/Practical-Celery-26-2048.jpg)





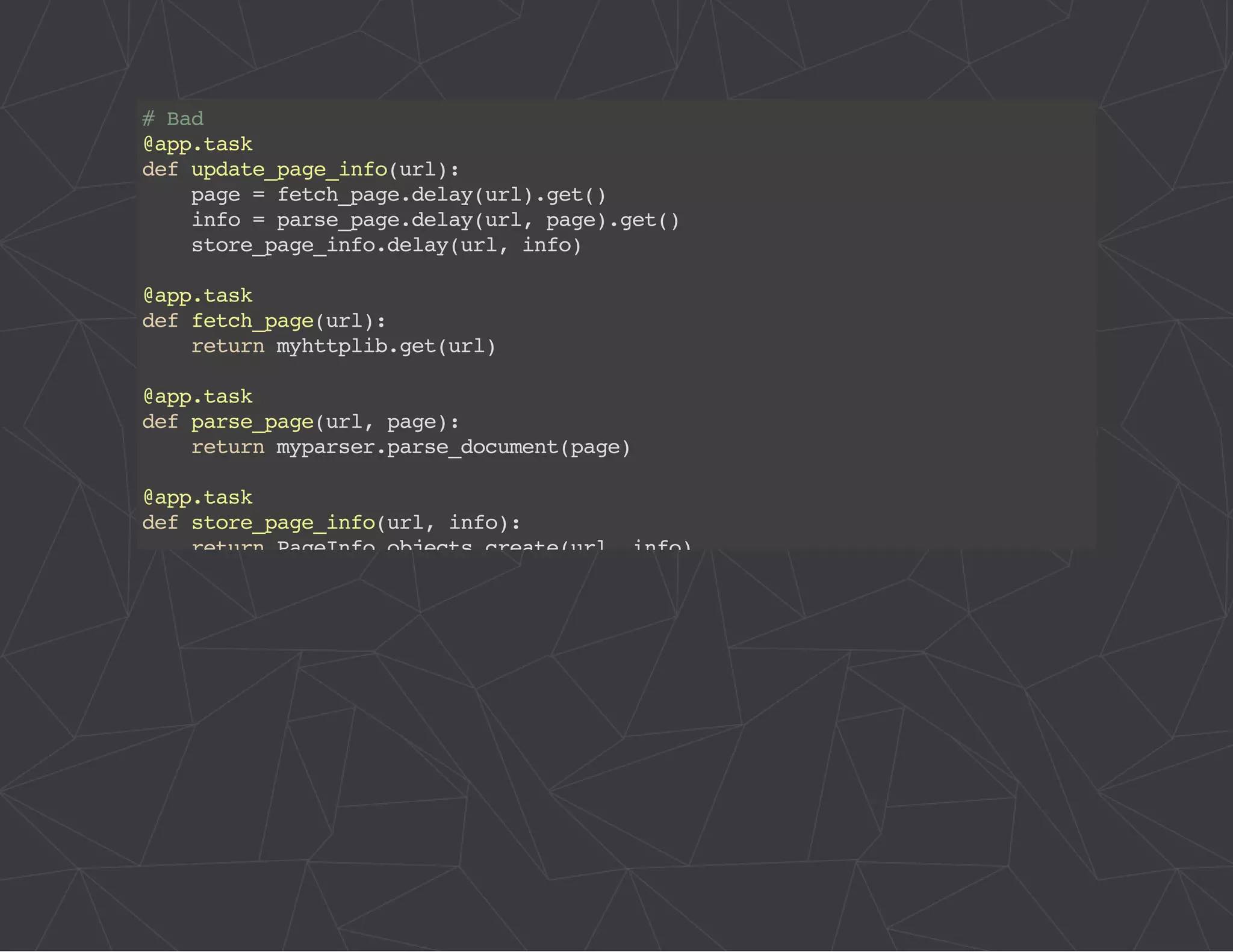
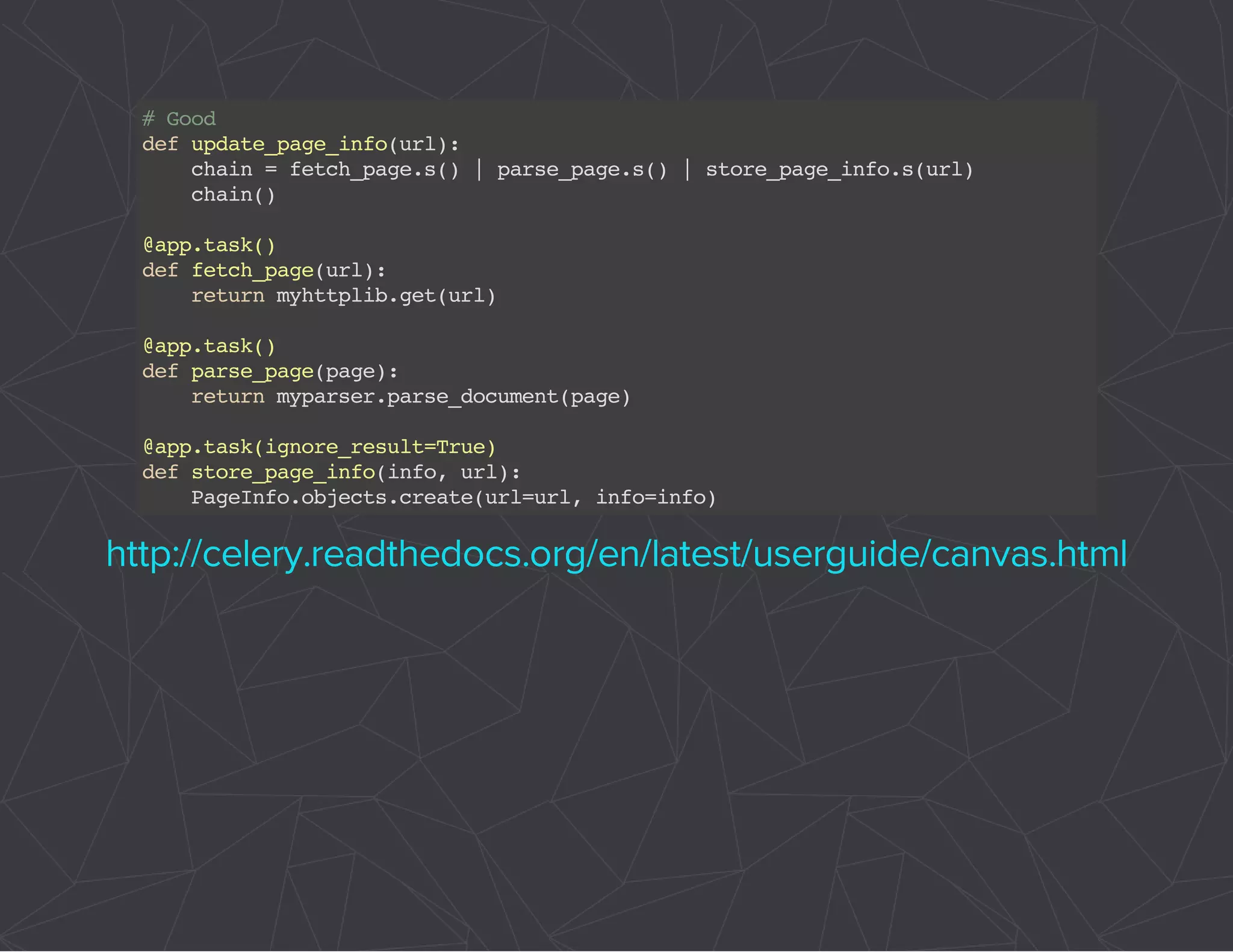

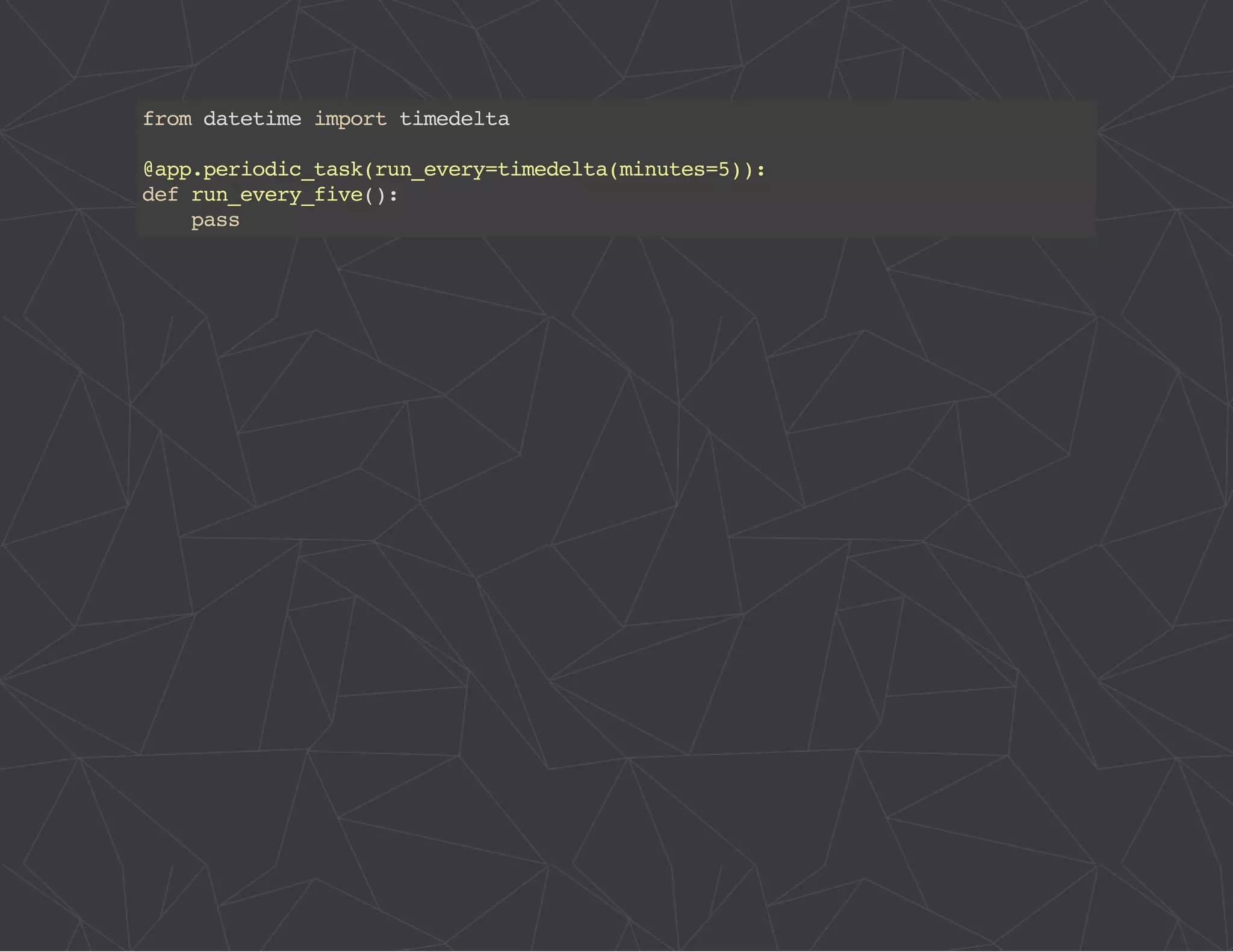
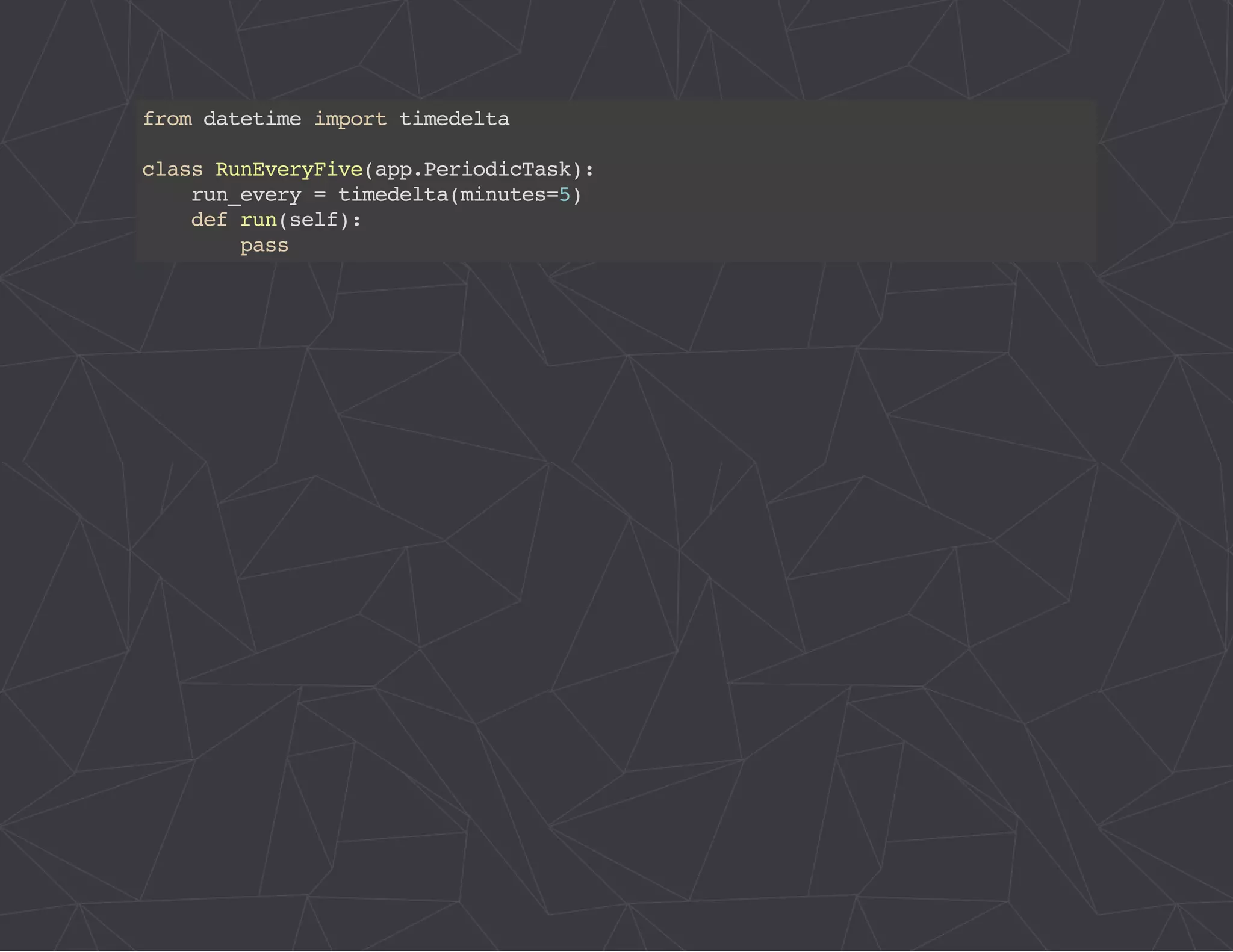
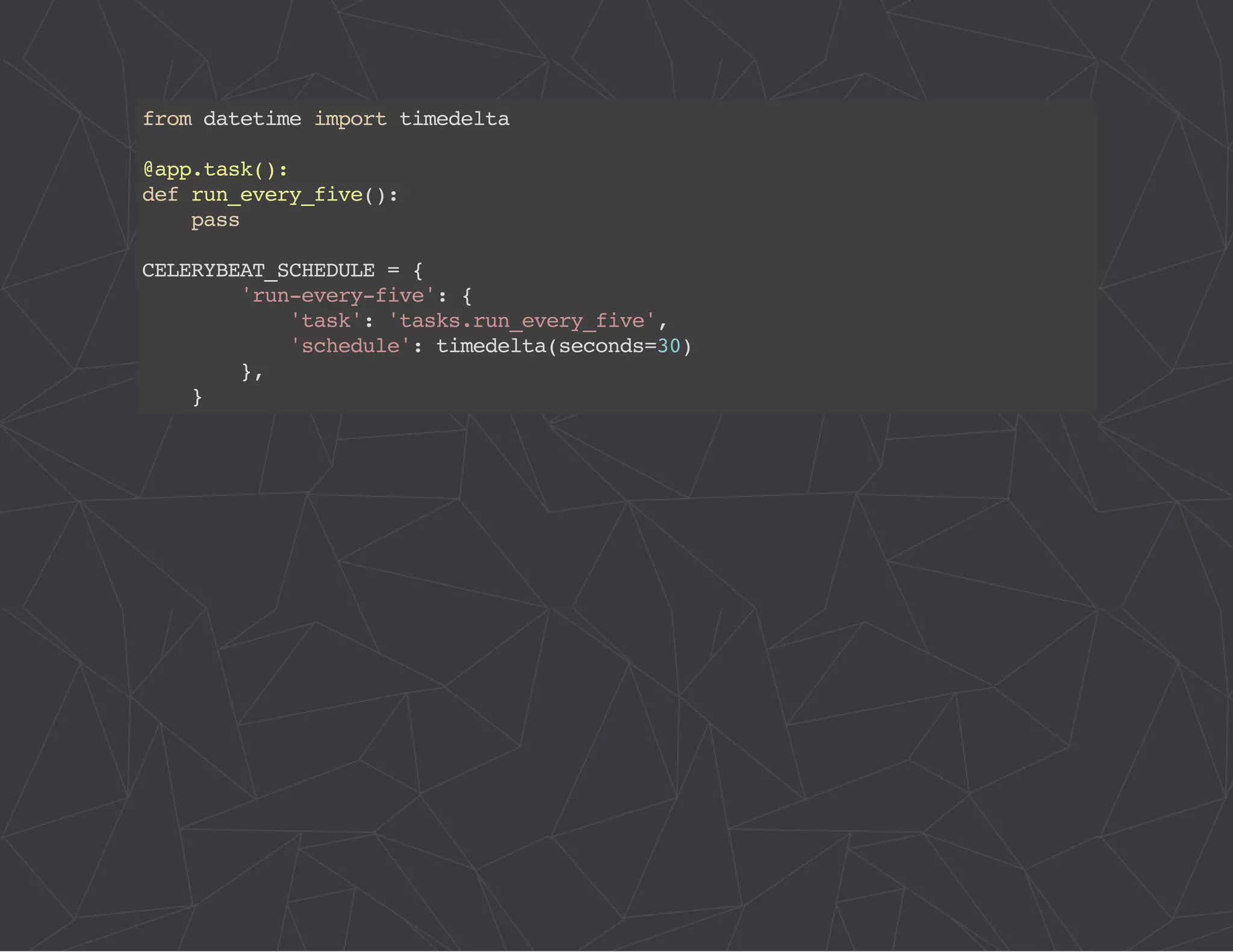
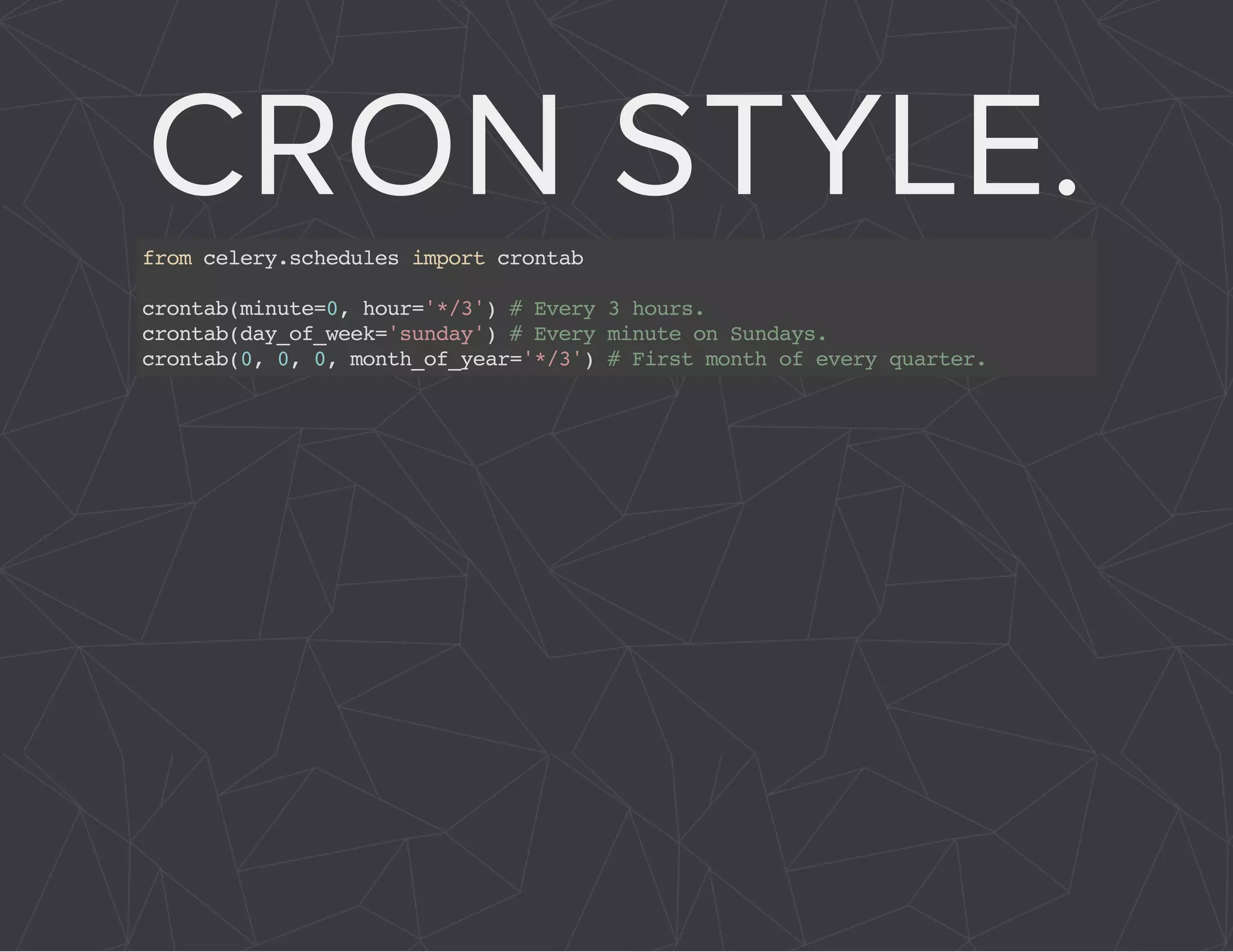
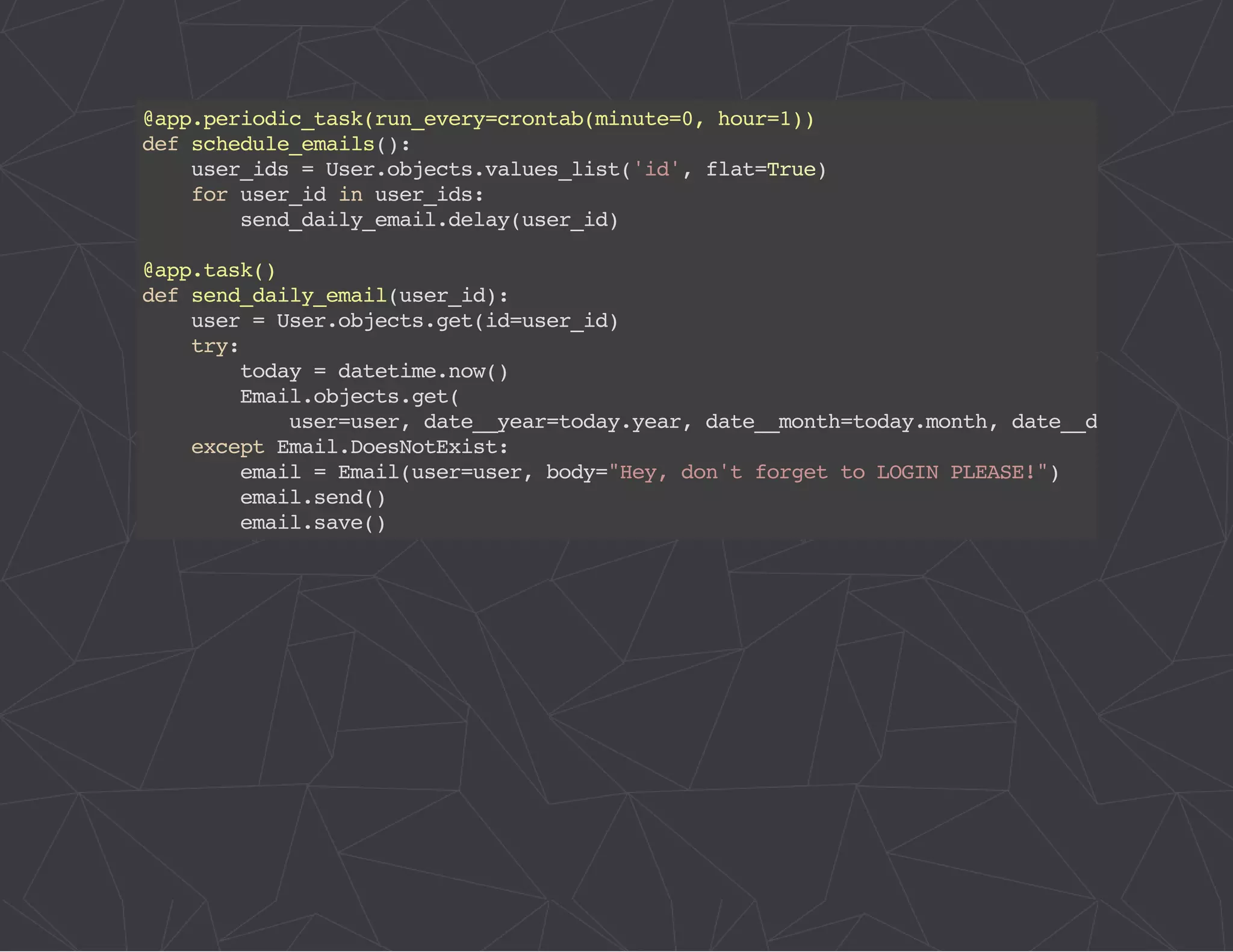




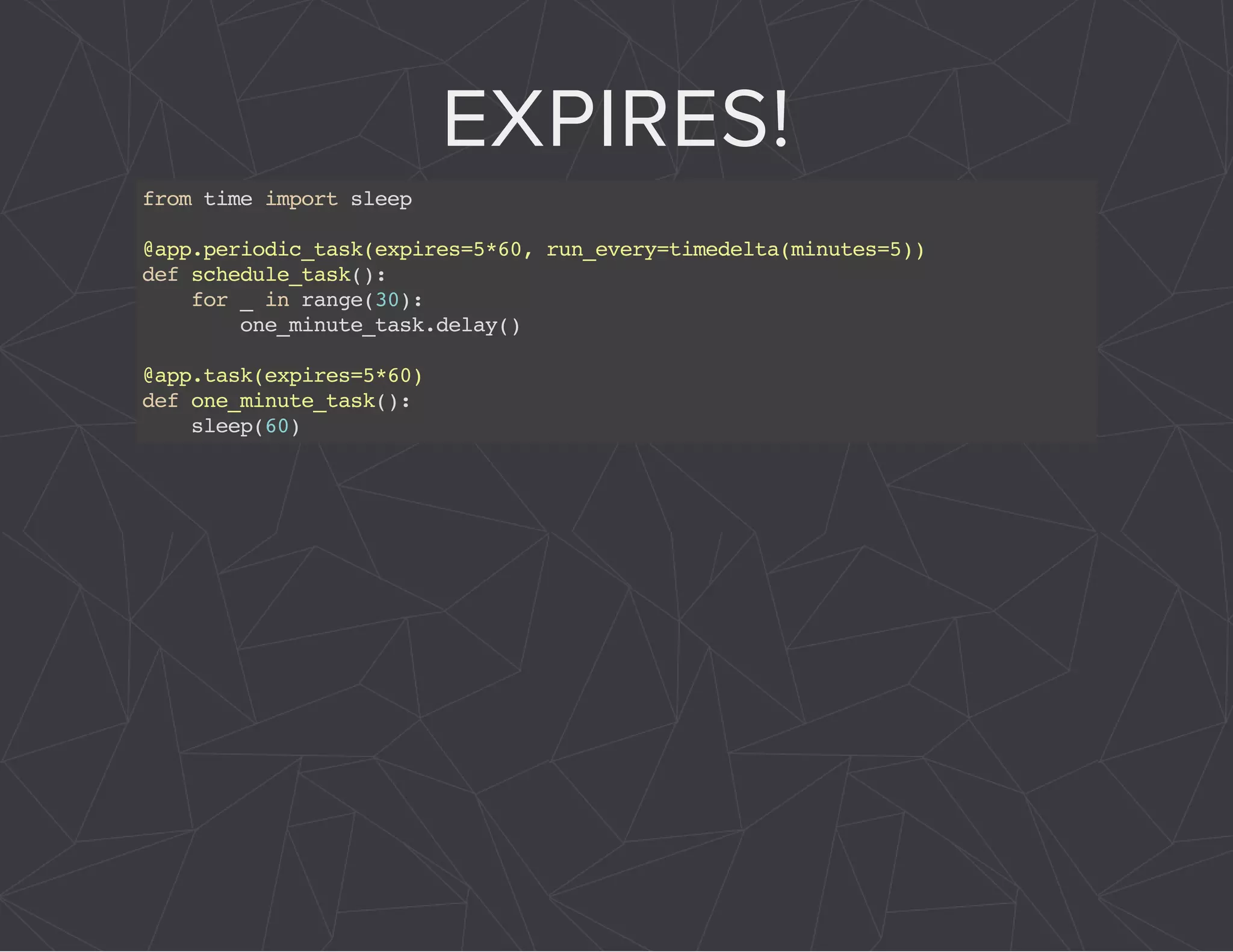


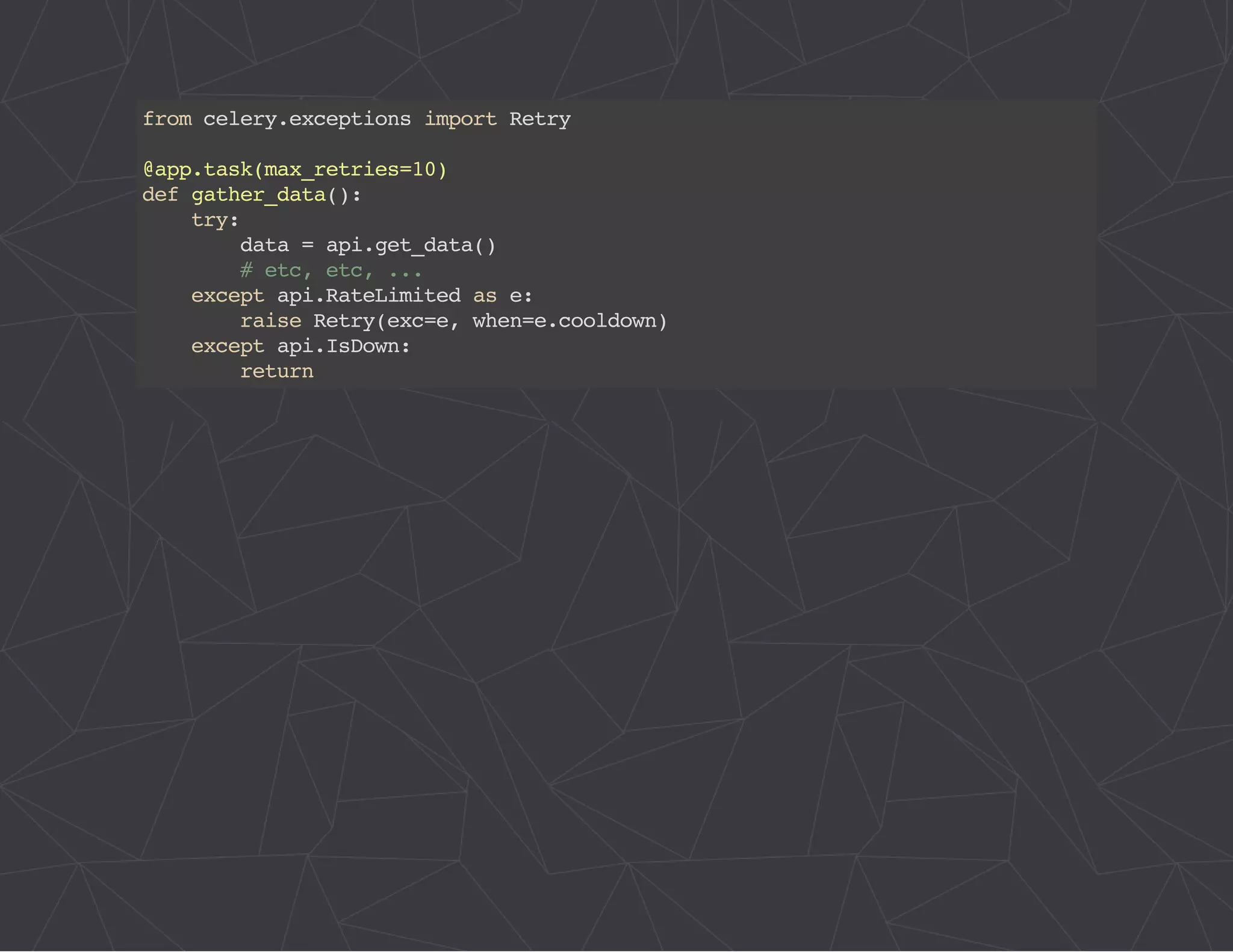


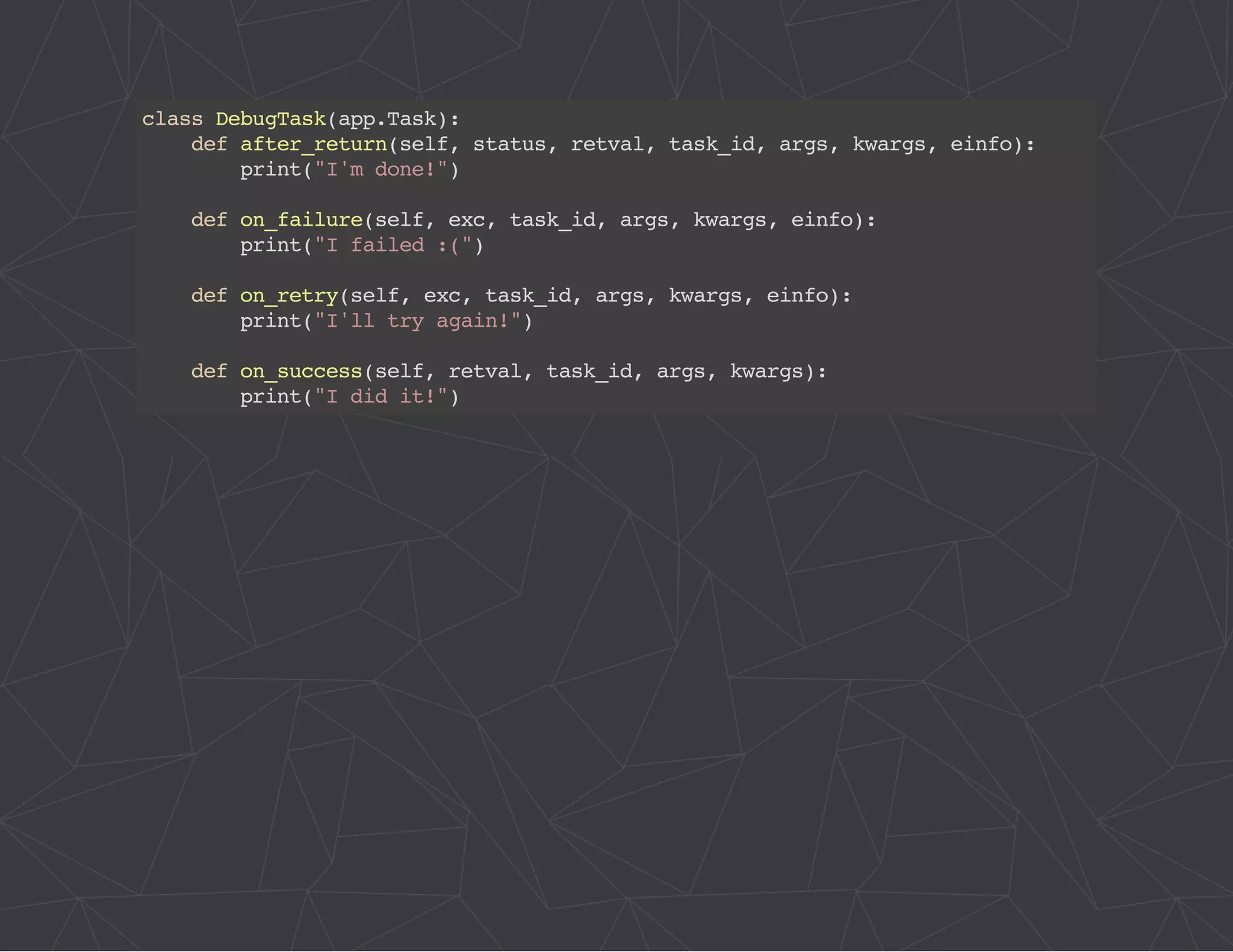



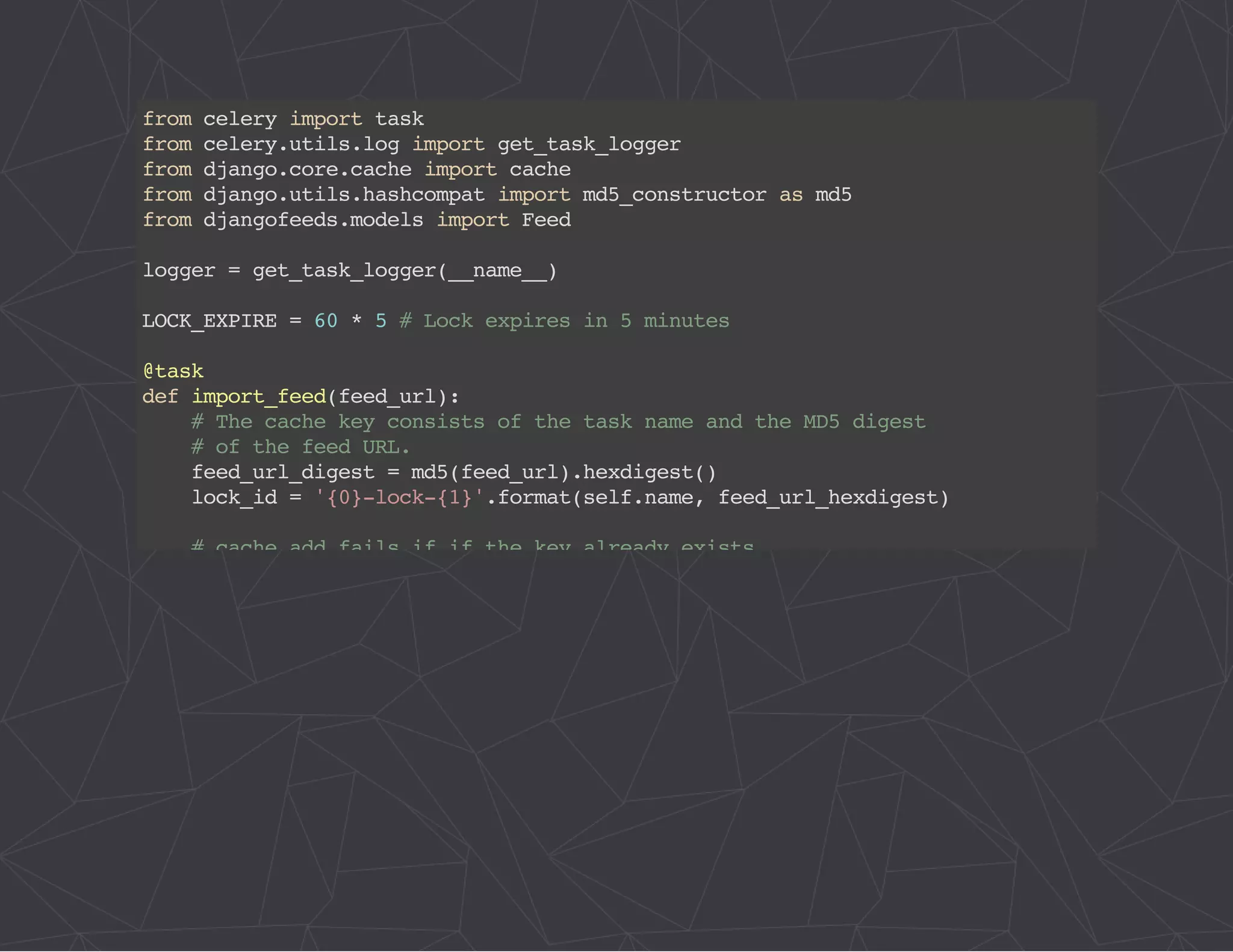

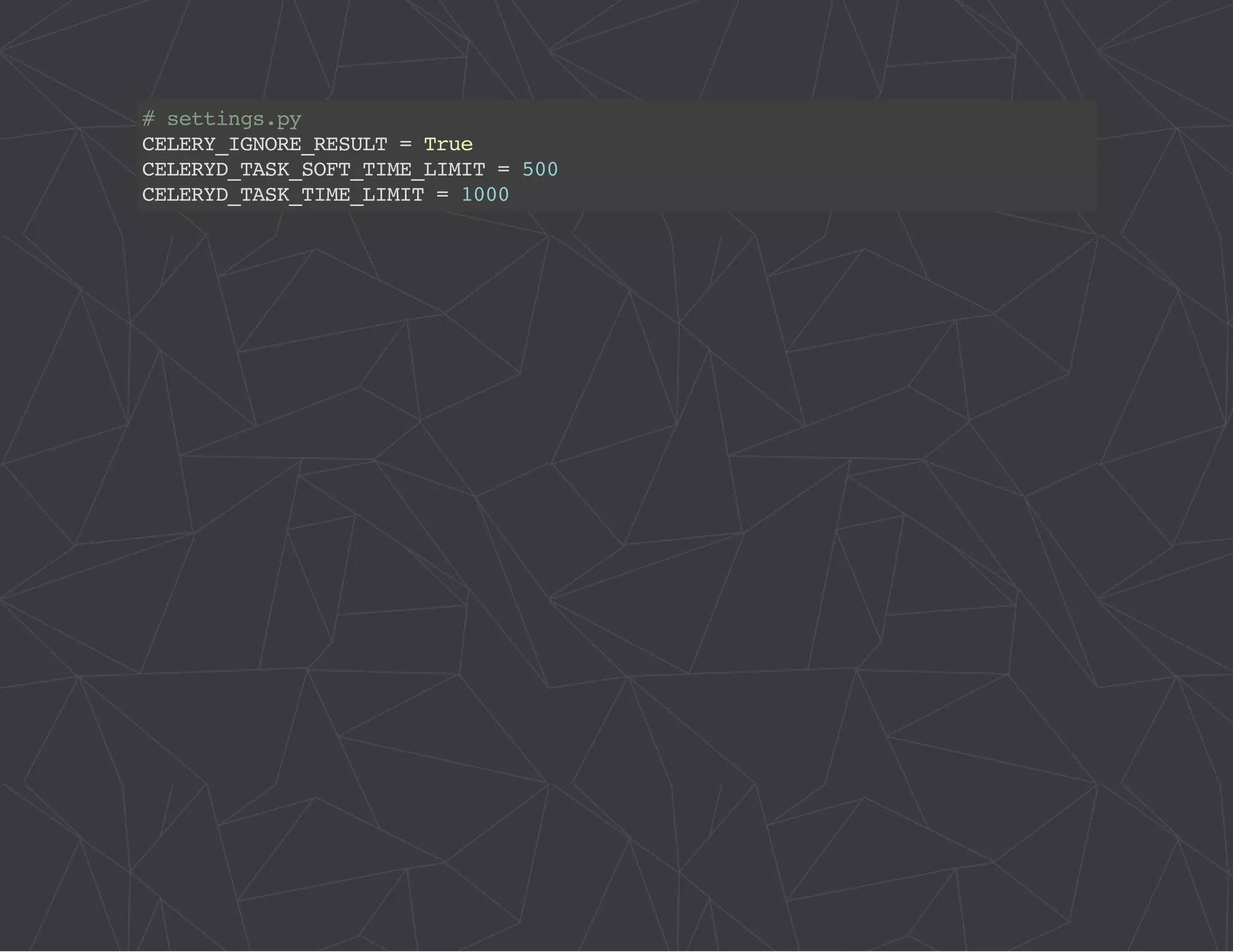
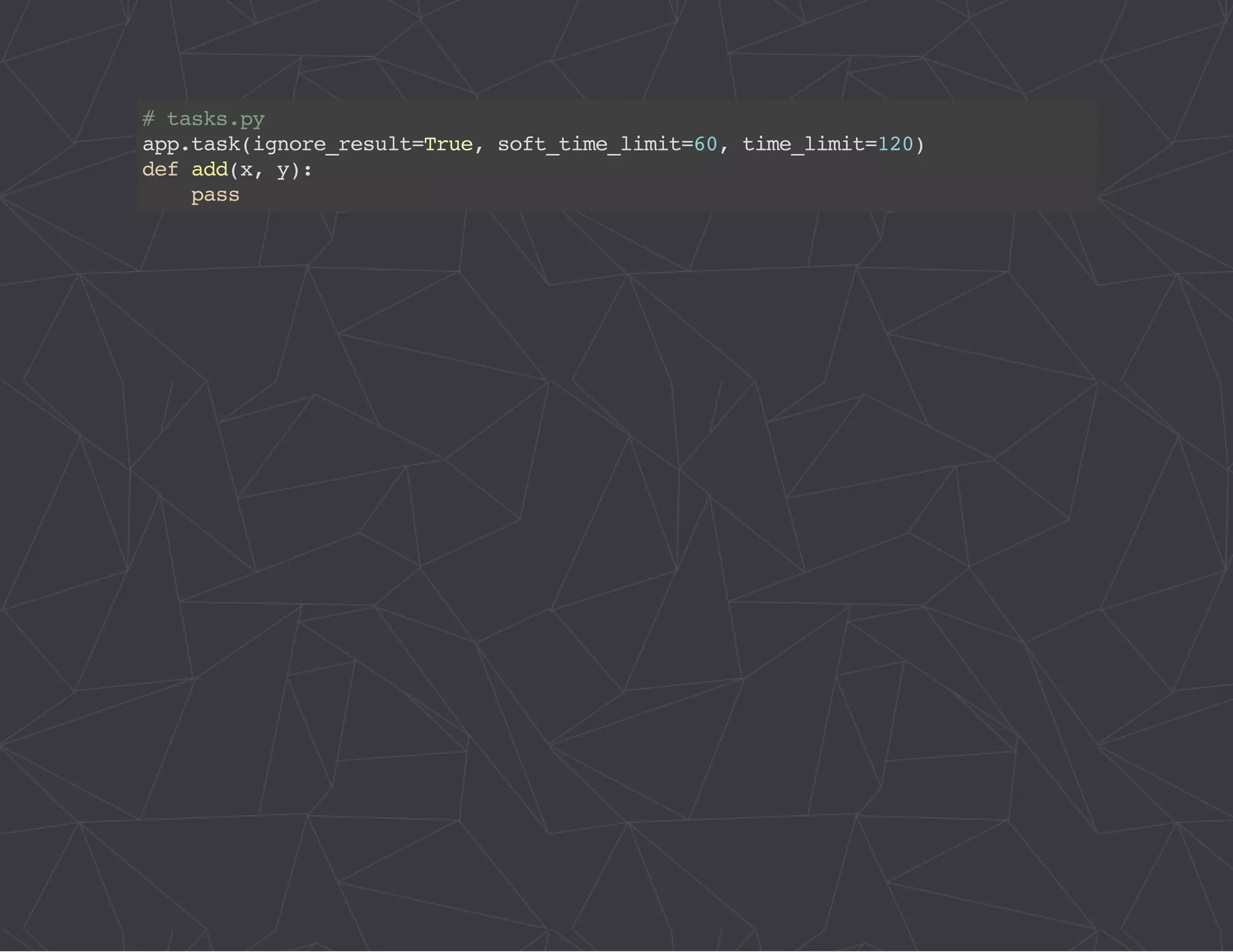
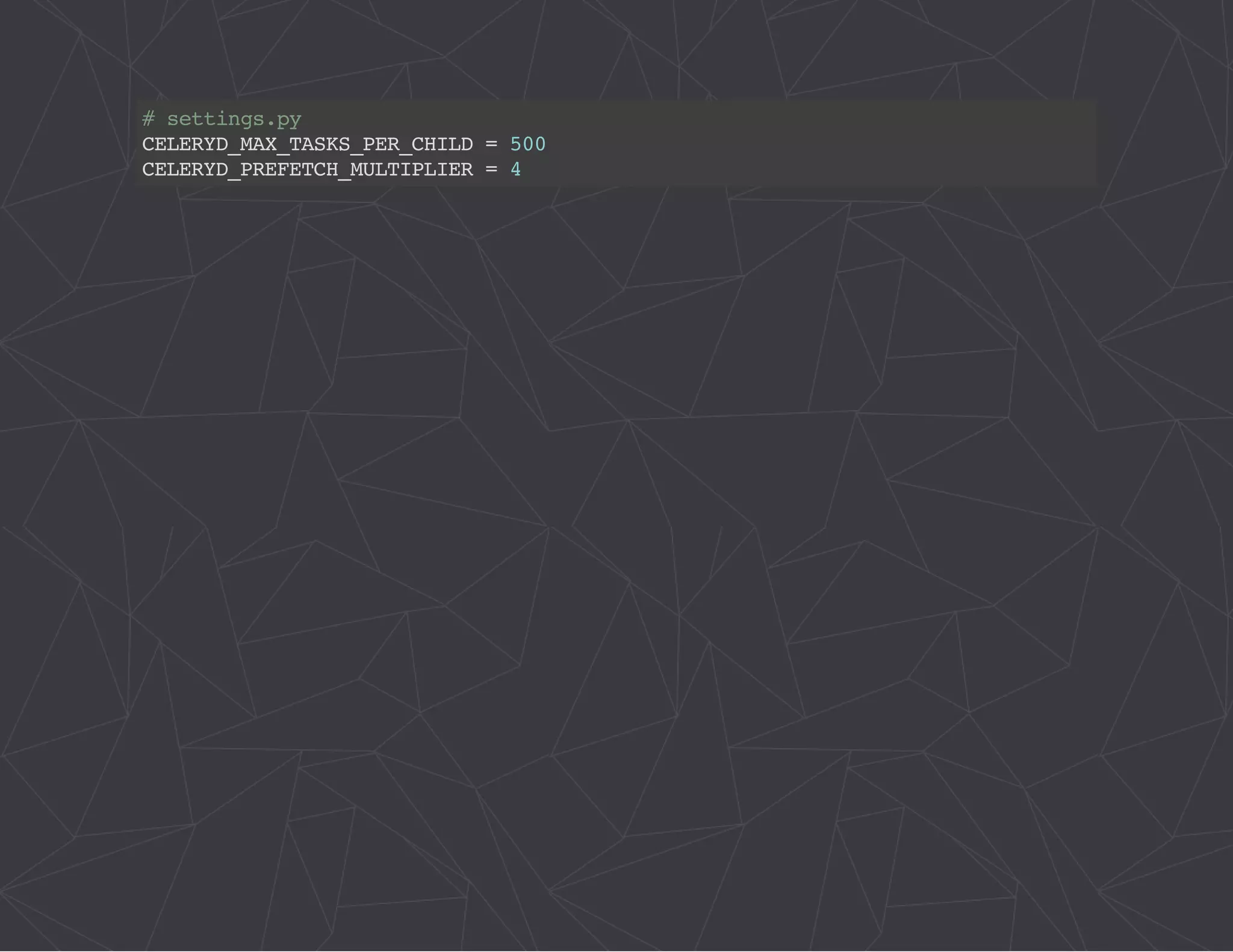


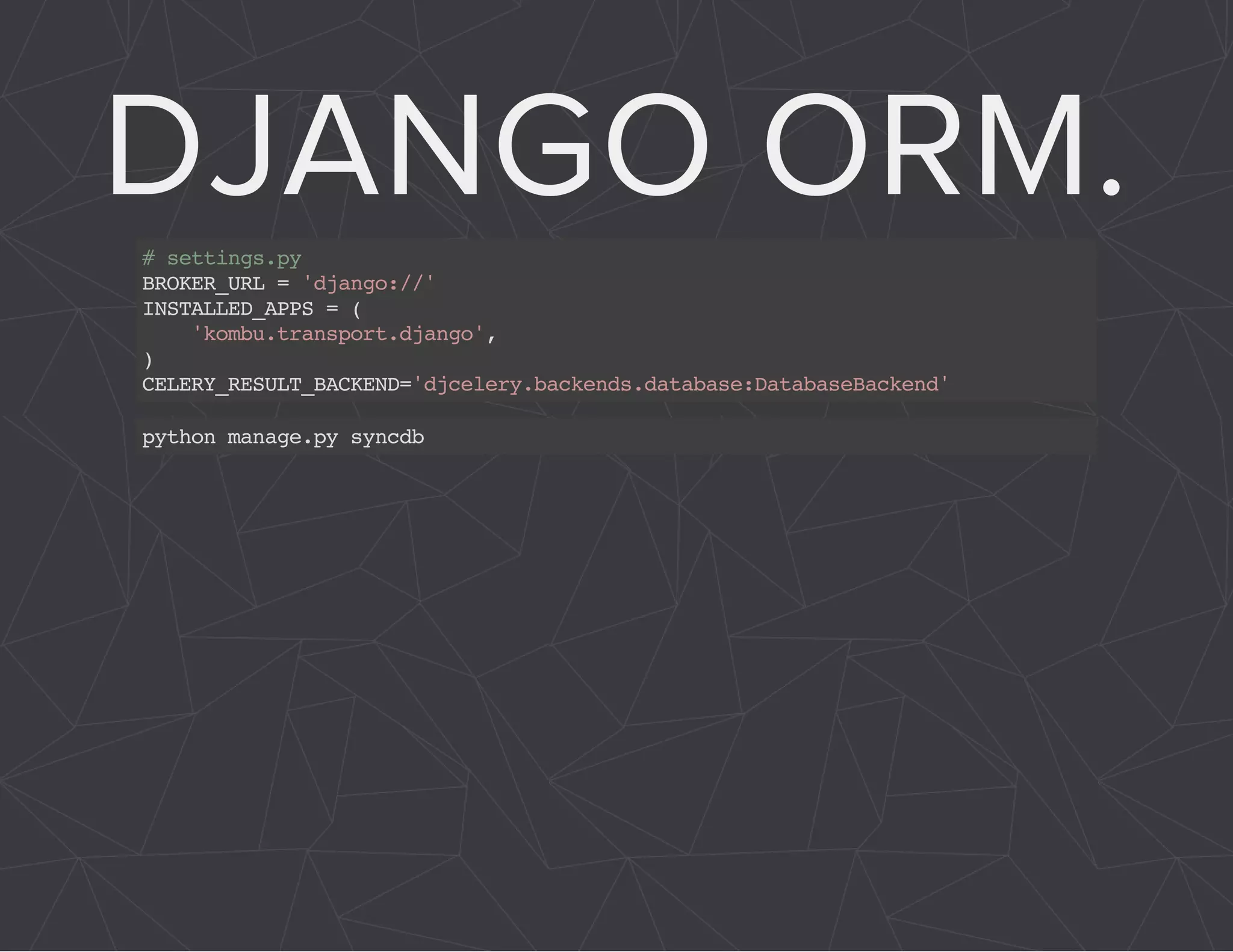







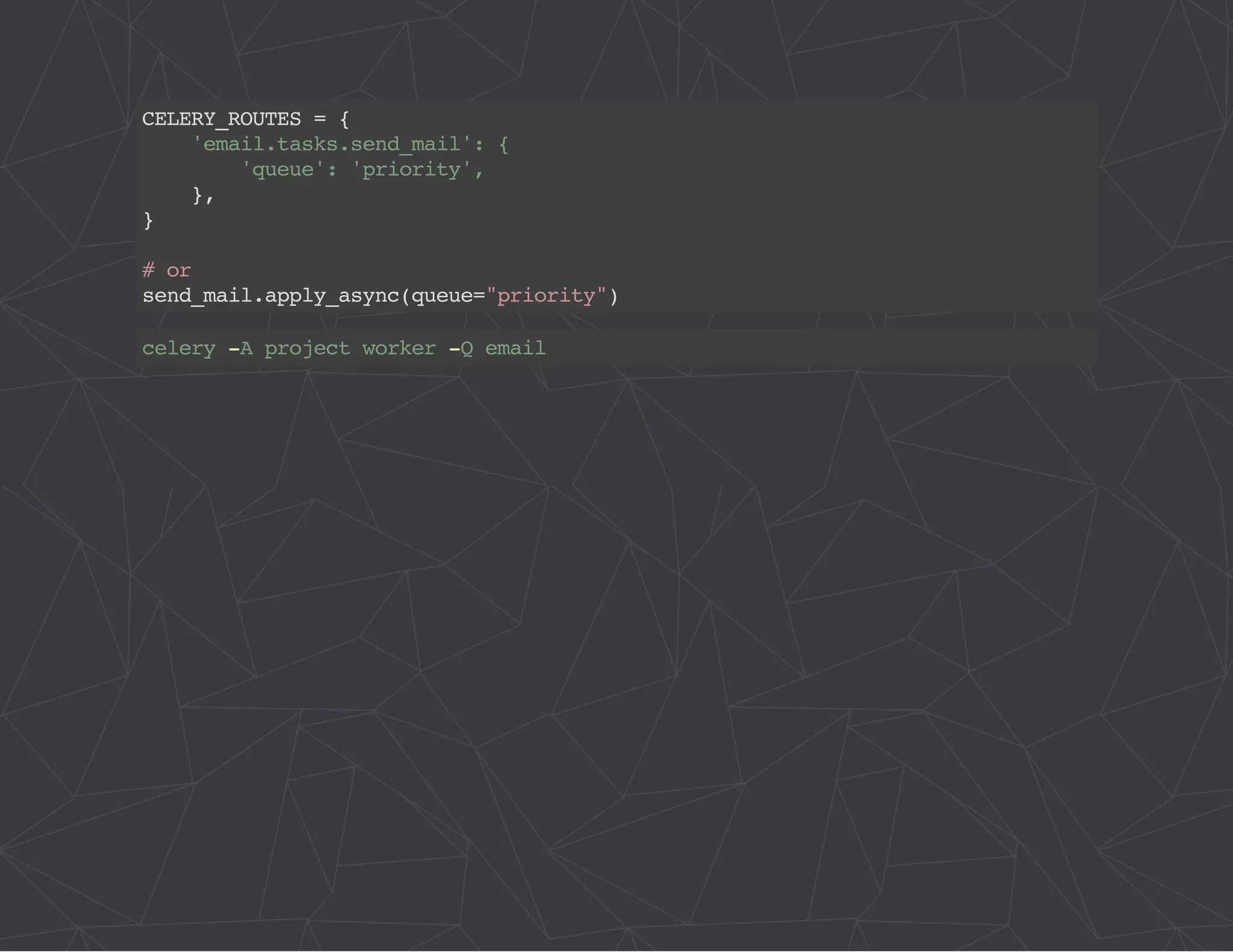




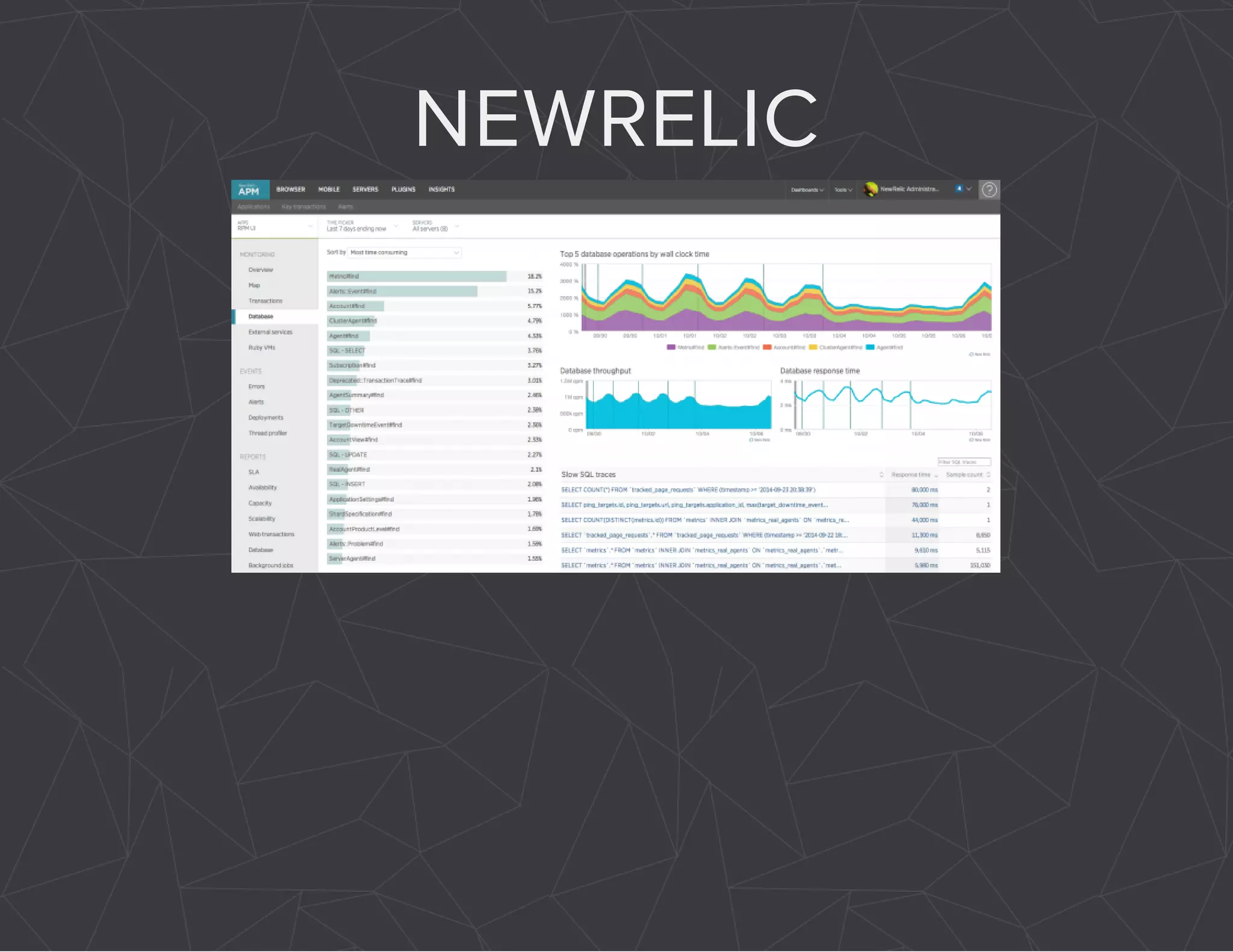
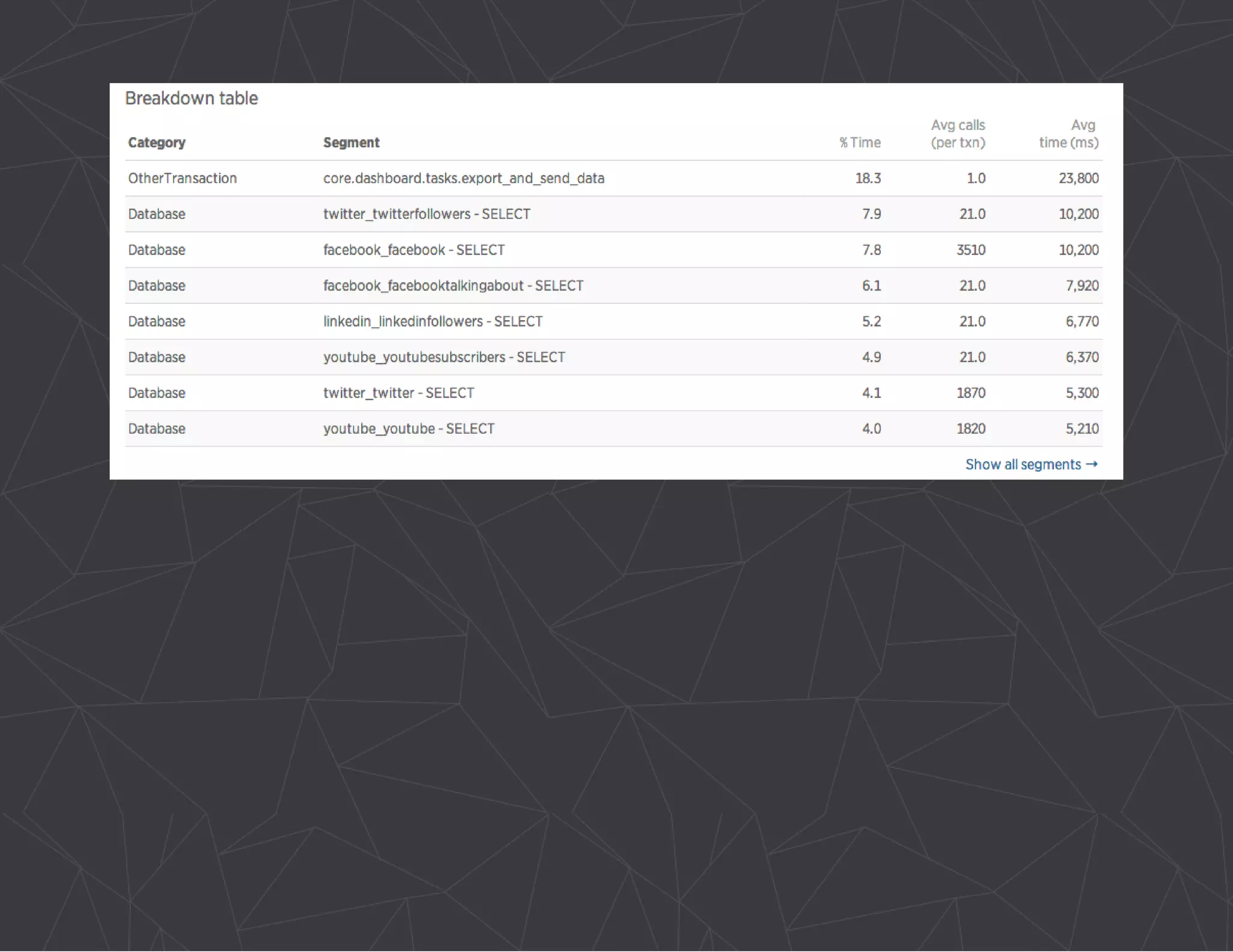

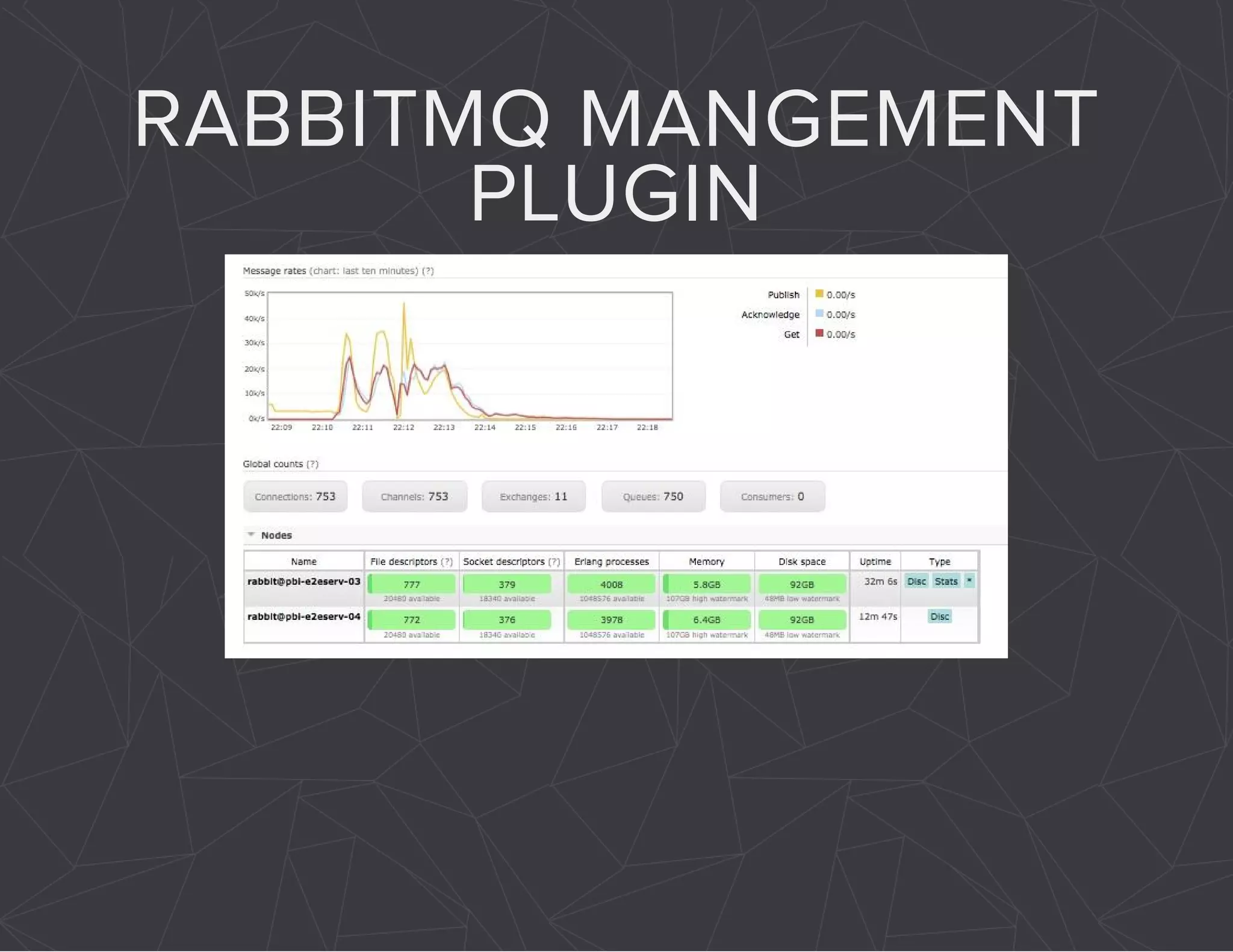



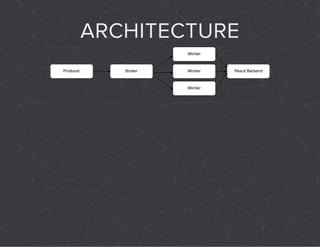
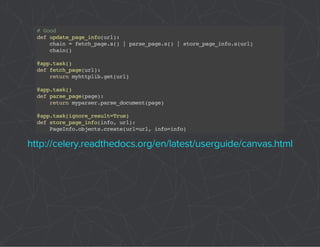
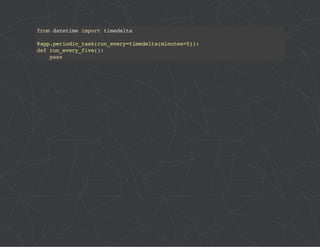
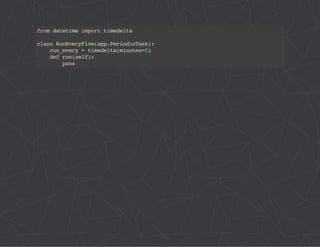
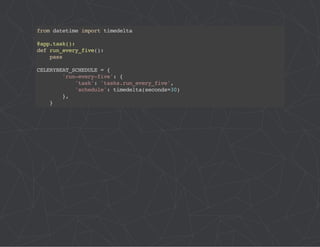
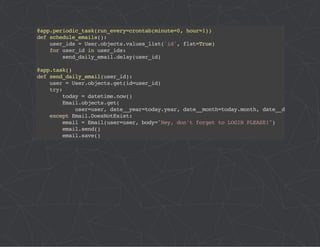
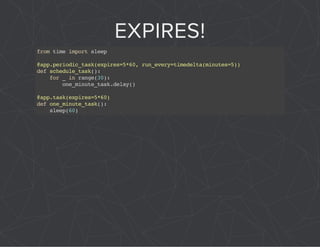
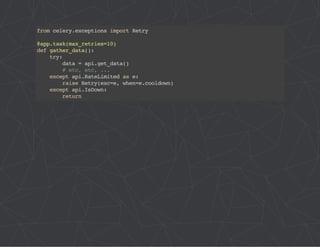
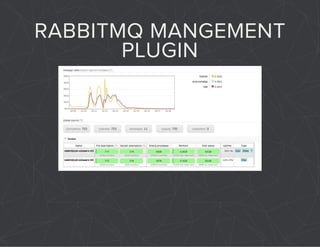
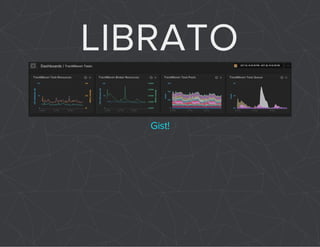
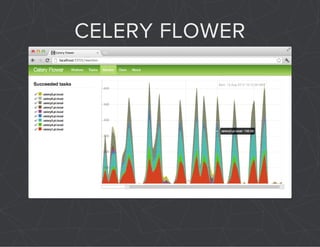
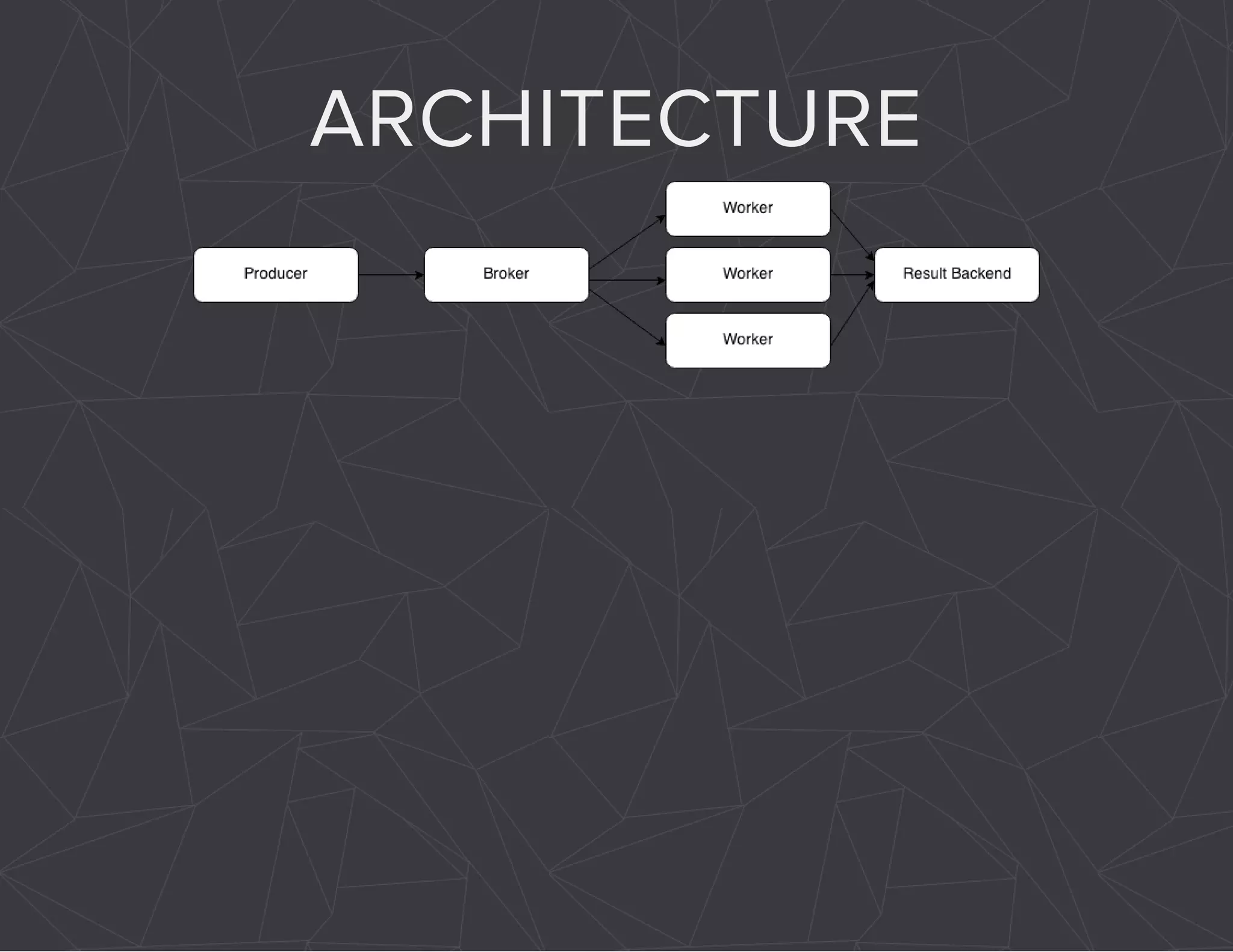
The document provides a comprehensive overview of Celery, an asynchronous distributed task queue system developed in Python. It covers various aspects including architecture, task management, and best practices for using Celery in applications, particularly with Django. Additionally, the document discusses periodic tasks, error handling, and configuration options to optimize performance.






































![[Quase] Tudo que você precisa saber sobre tarefas assíncronas](https://cdn.slidesharecdn.com/ss_thumbnails/tarefasasincronas-170505123700-thumbnail.jpg?width=600ounds&width=560&fit=bounds)




























