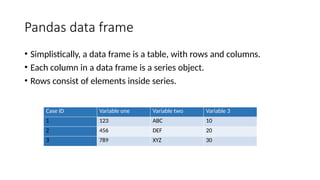
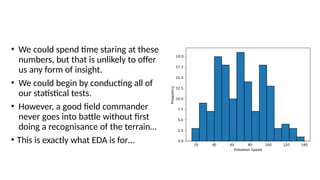
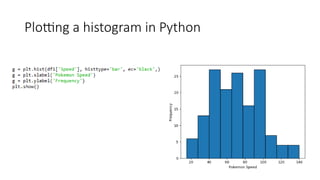
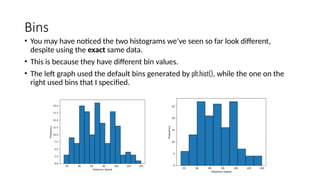
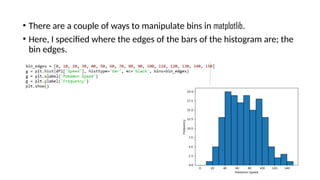
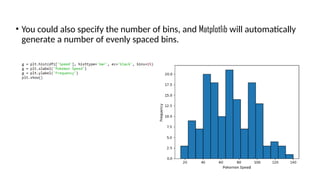
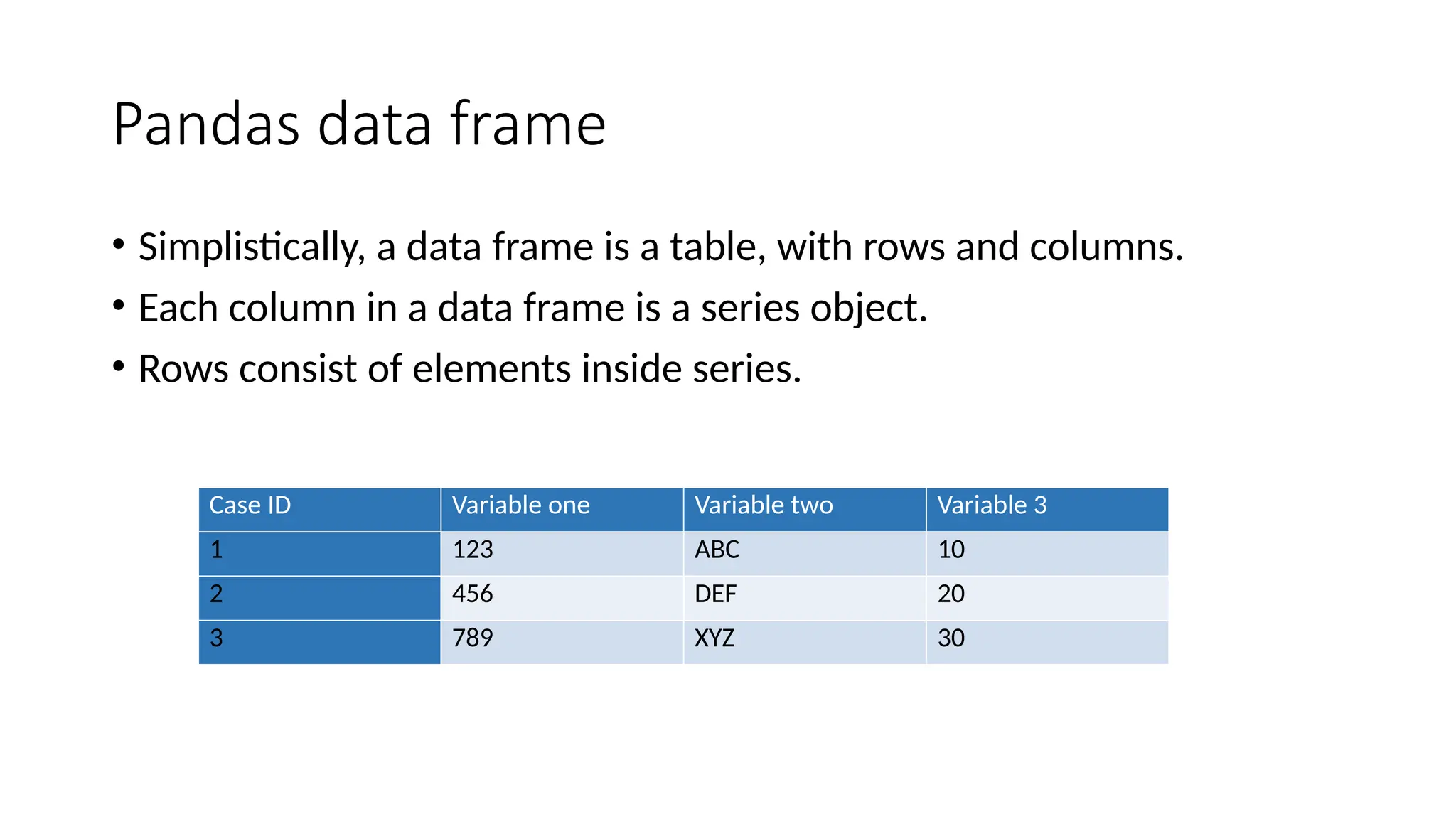
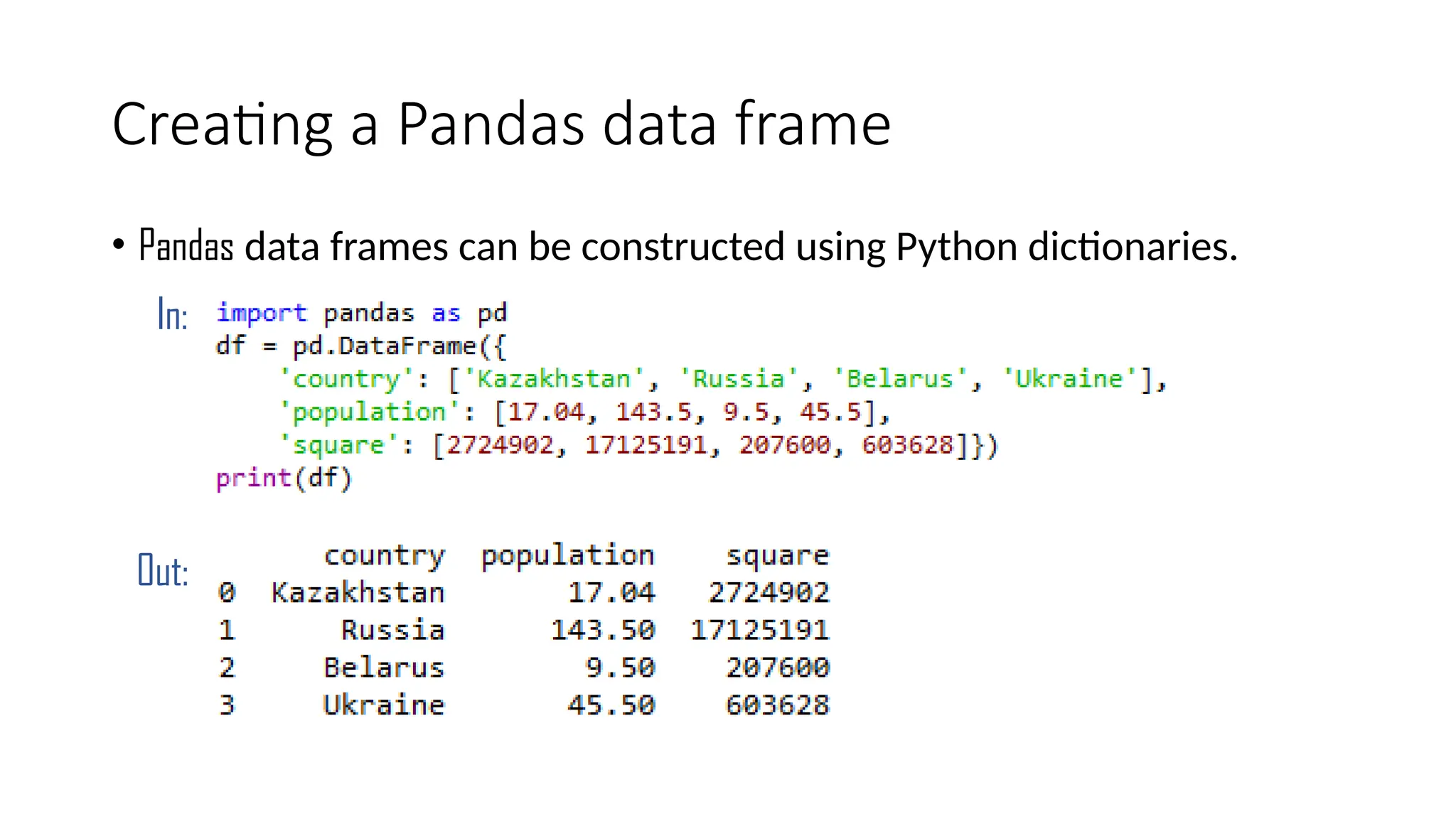
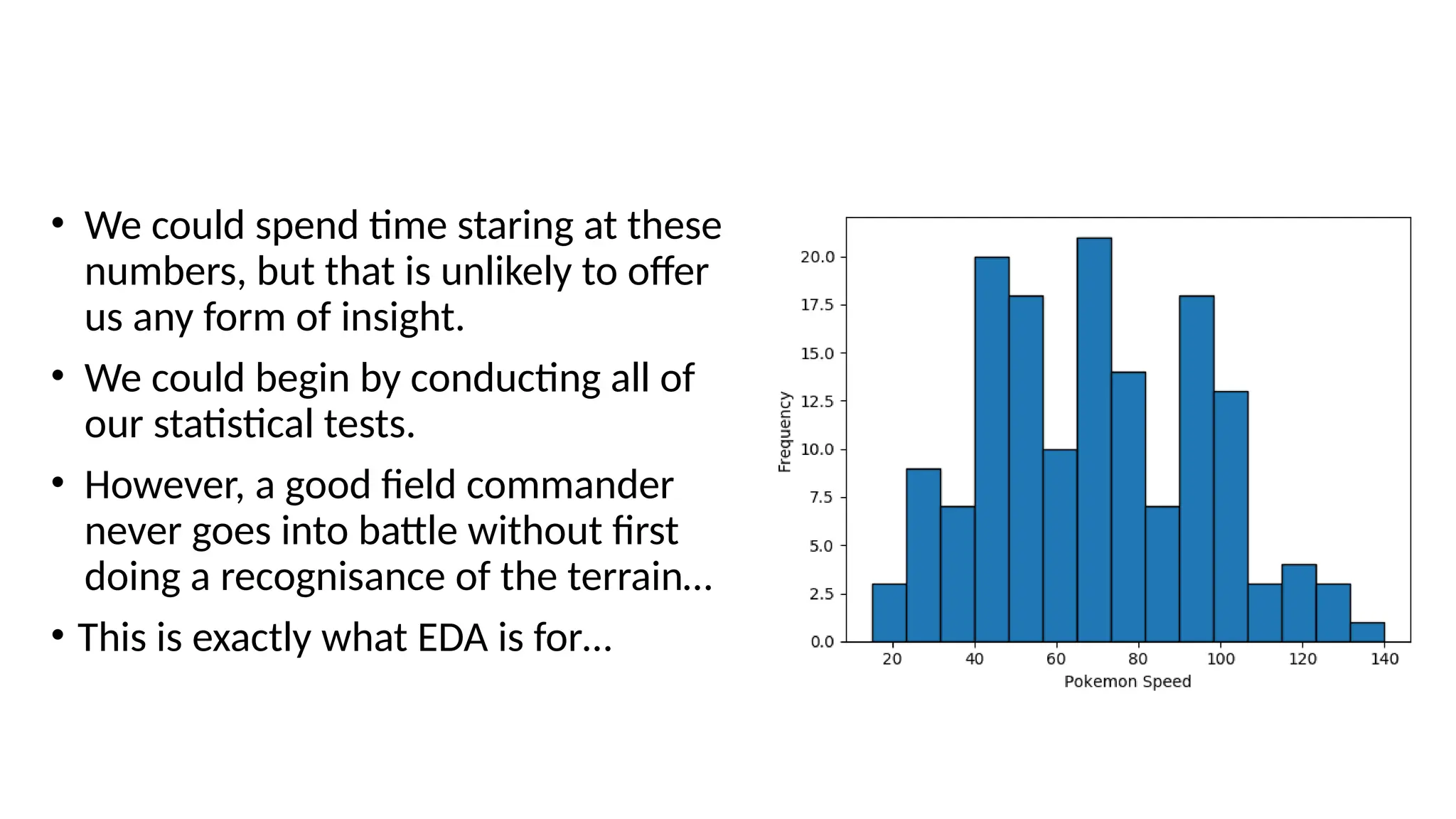
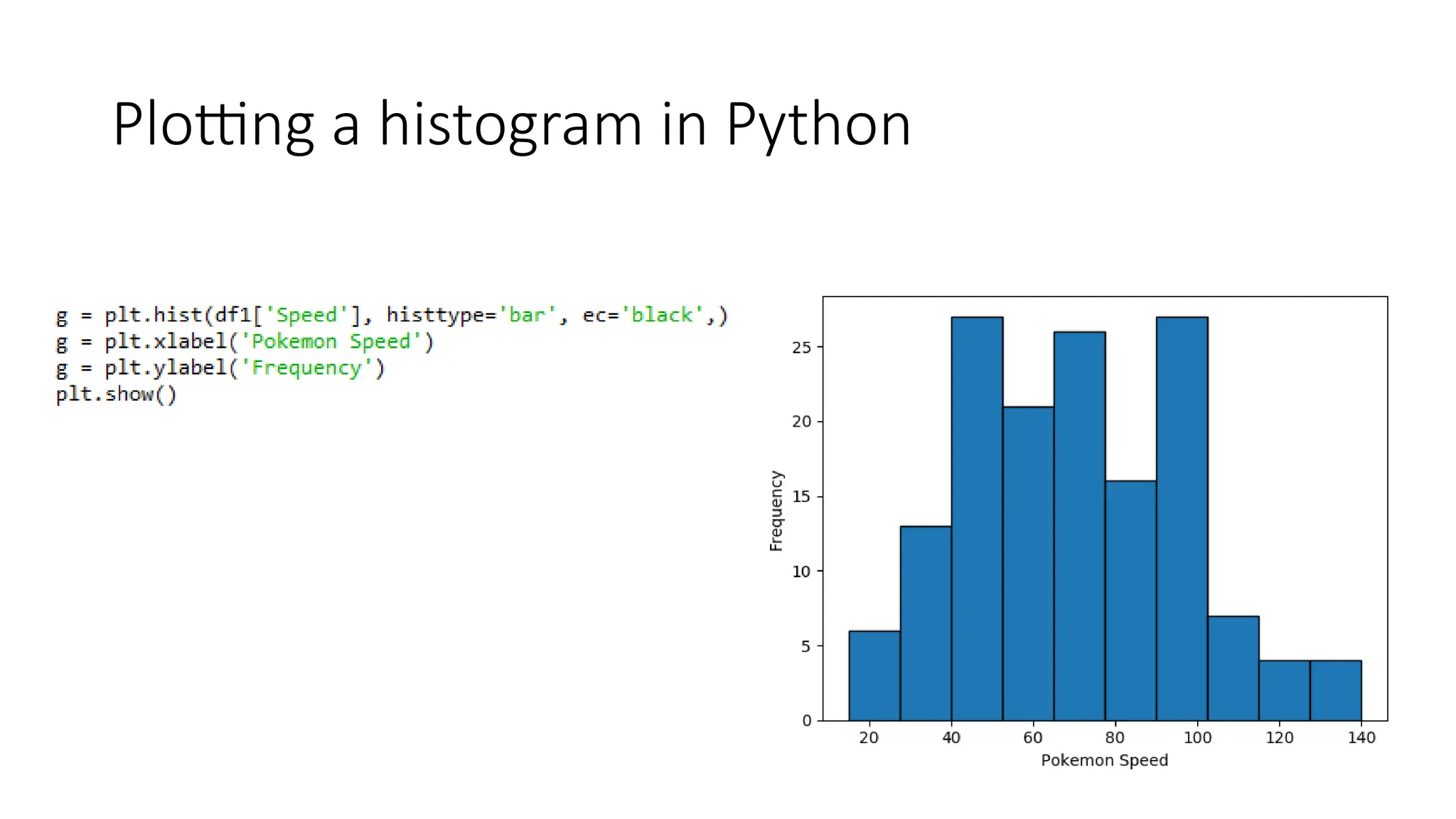
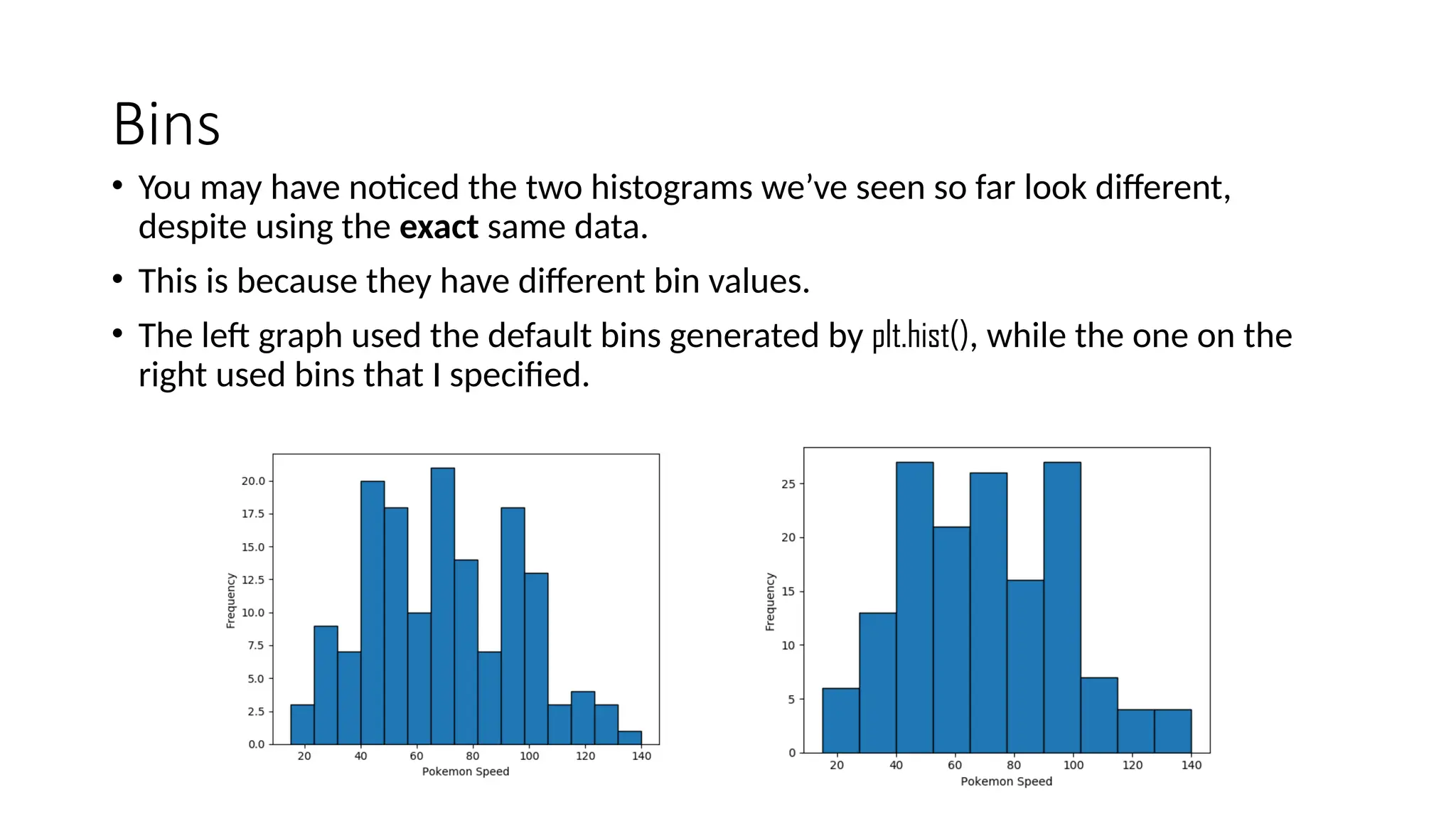
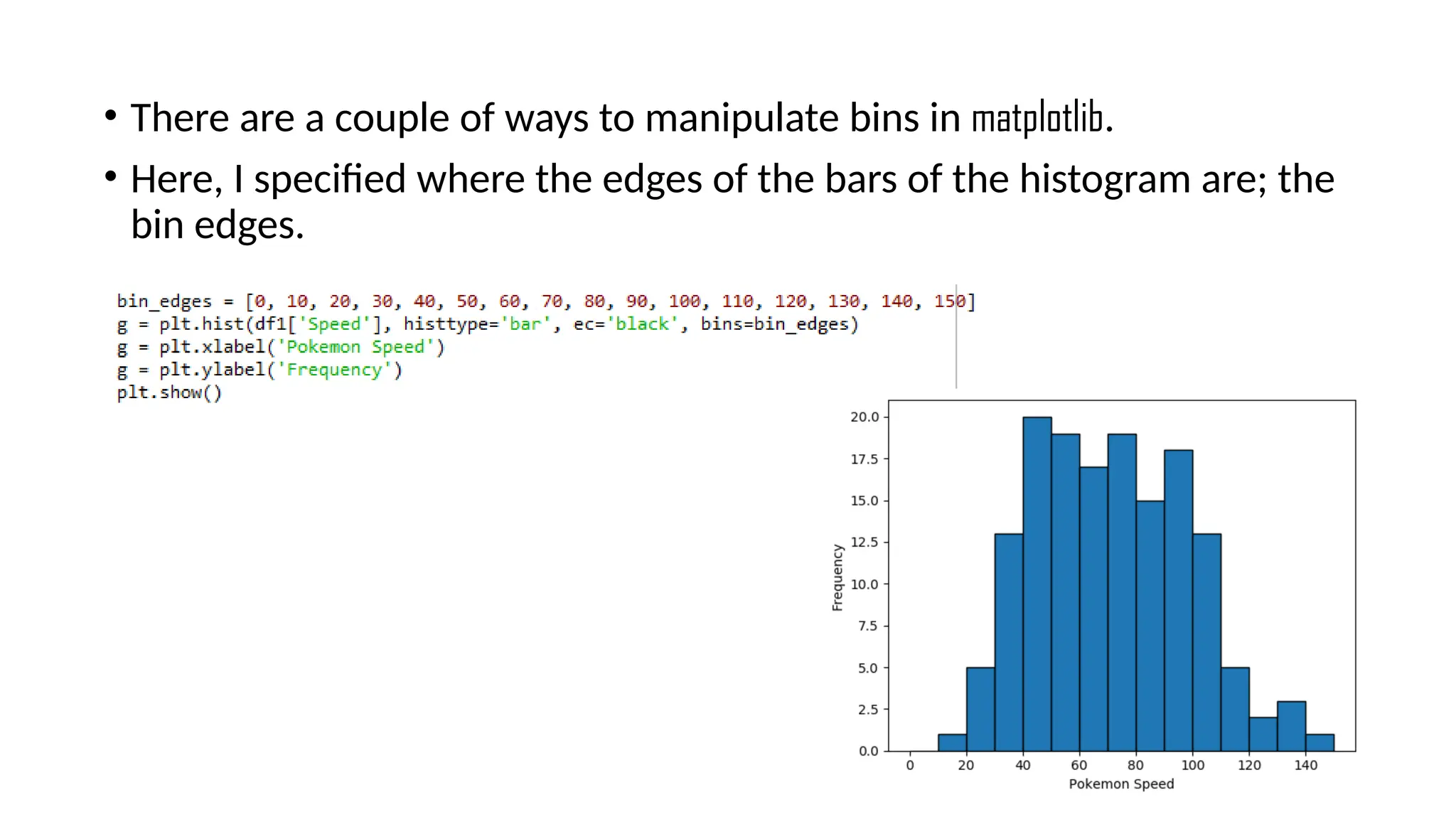
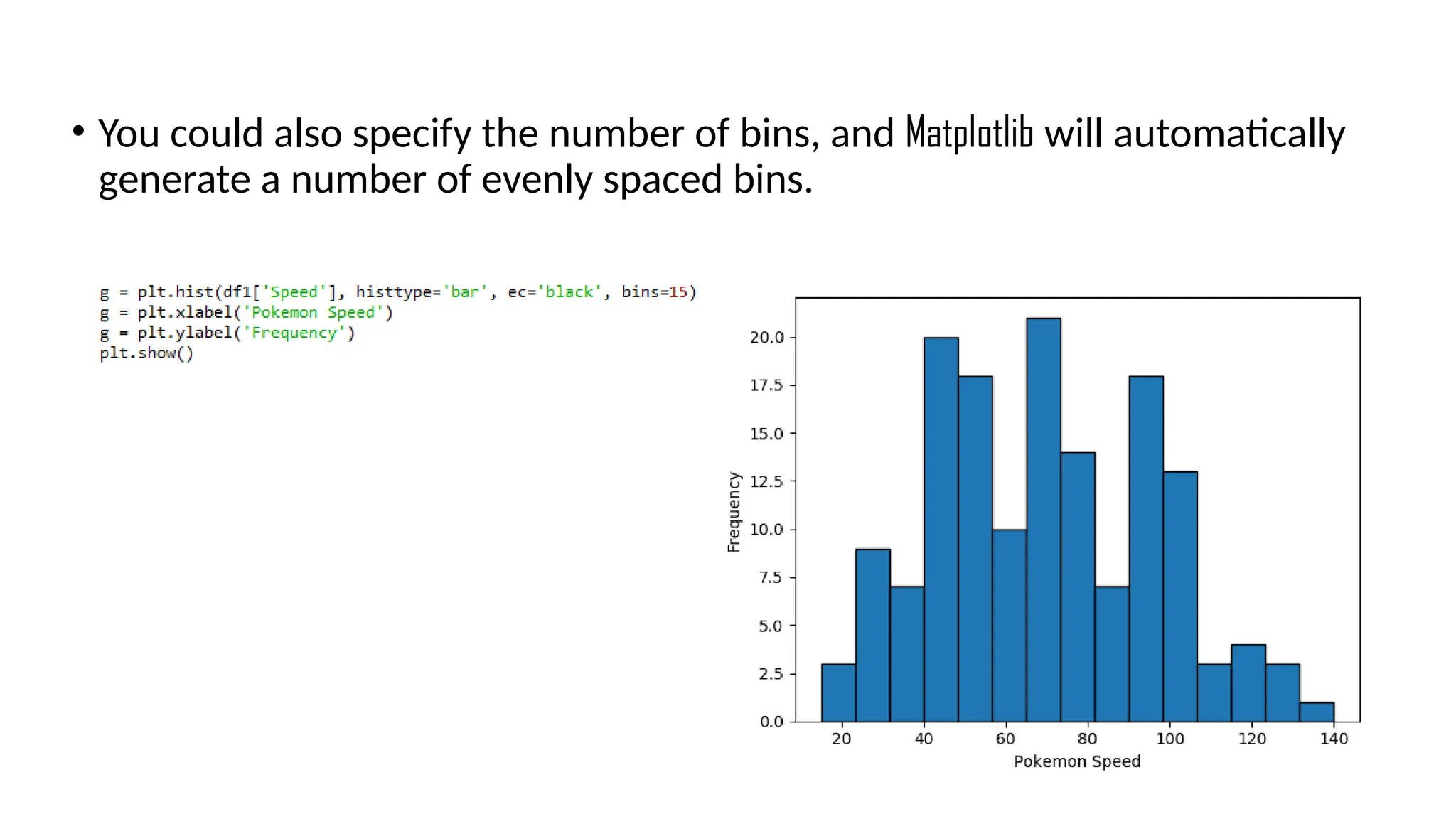
Pandas is a popular Python library for data analysis, providing high-performance data structures like DataFrames and Series, which can be easily manipulated and filtered. It supports various file formats for reading and writing data, with CSV being the most commonly used. Exploratory Data Analysis (EDA) involves organizing and visualizing data to derive insights, with techniques such as plotting histograms utilizing specified bin values.


































































![RTP_AR_Basic_Learners' Workbook_KS2 [FOR REPRODUCTION] (1).pdf](https://cdn.slidesharecdn.com/ss_thumbnails/rtparbasiclearnersworkbookks2forreproduction1-251016024943-e51a16ac-thumbnail.jpg?width=600ounds&width=560&fit=bounds)













