Download as PDF, PPTX























![Reference:-
Example of Shortest-remaining-time-first
■ Now we add the concepts of varying arrival times and preemption to the analysis
ProcessAarri Arrival TimeT Burst Time
P1 0 8
P2 1 4
P3 2 9
P4 3 5
■ Preemptive SJF Gantt Chart
■ Average waiting time = [(10-1)+(1-1)+(17-2)+5-3)]/4 = 26/4 = 6.5 msec
P4
0 1 26
P1
P2
10
P3
P1
5 17](https://image.slidesharecdn.com/cpu-schedul-161225054822/85/Process-Scheduling-32-320.jpg)





















![Reference:-
Example of Shortest-remaining-time-first
■ Now we add the concepts of varying arrival times and preemption to the analysis
ProcessAarri Arrival TimeT Burst Time
P1 0 8
P2 1 4
P3 2 9
P4 3 5
■ Preemptive SJF Gantt Chart
■ Average waiting time = [(10-1)+(1-1)+(17-2)+5-3)]/4 = 26/4 = 6.5 msec
P4
0 1 26
P1
P2
10
P3
P1
5 17](https://image.slidesharecdn.com/cpu-schedul-161225054822/75/Process-Scheduling-32-2048.jpg)






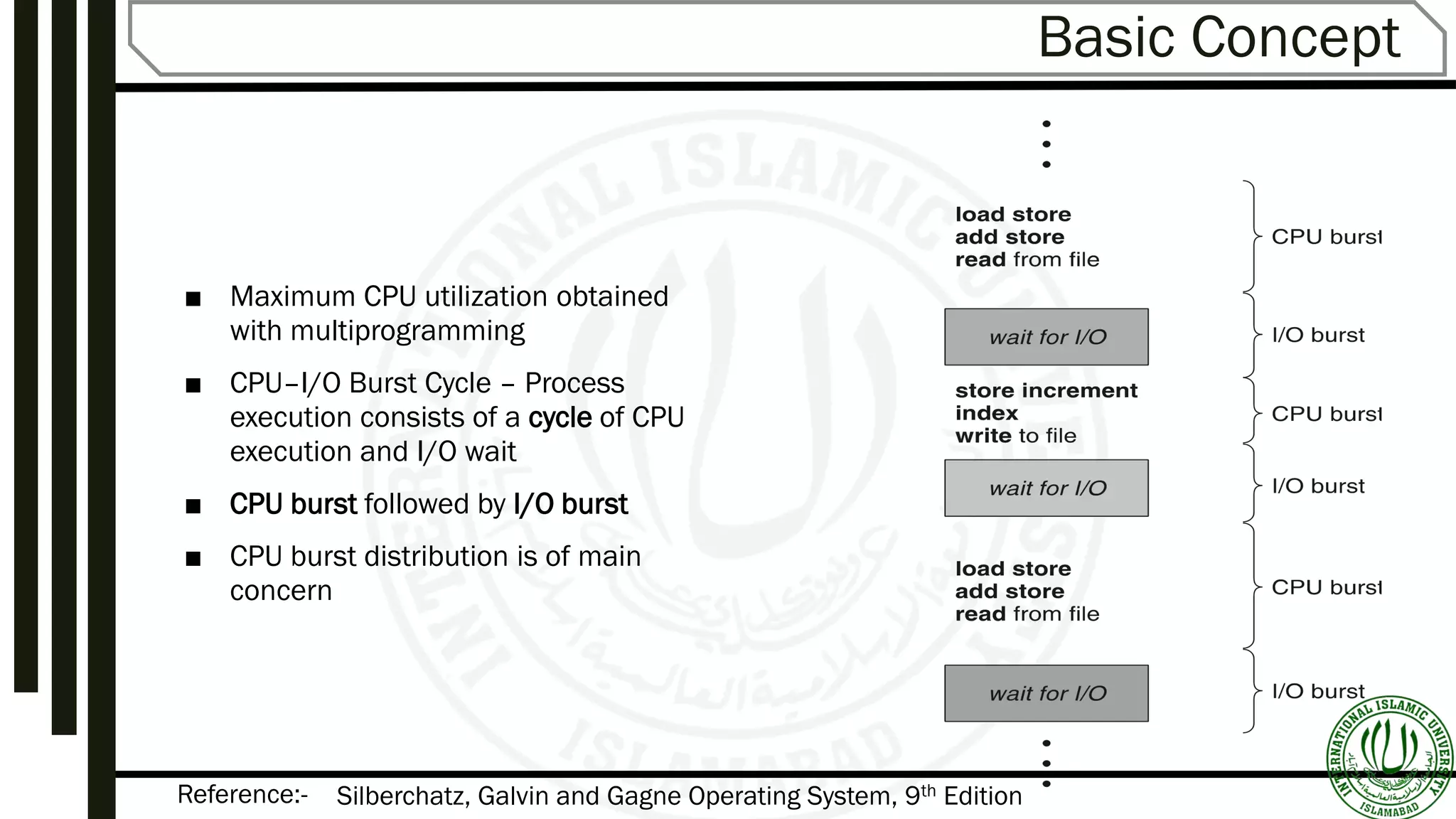
The document discusses various aspects of process scheduling, including the goals, types (preemptive vs. non-preemptive), and criteria for effective scheduling in operating systems. It elaborates on common scheduling algorithms, their advantages, and disadvantages, as well as the importance of optimizing CPU utilization, throughput, and response time. Additionally, the document covers advanced concepts like multilevel queues and multilevel feedback queues to address the needs of different processes.
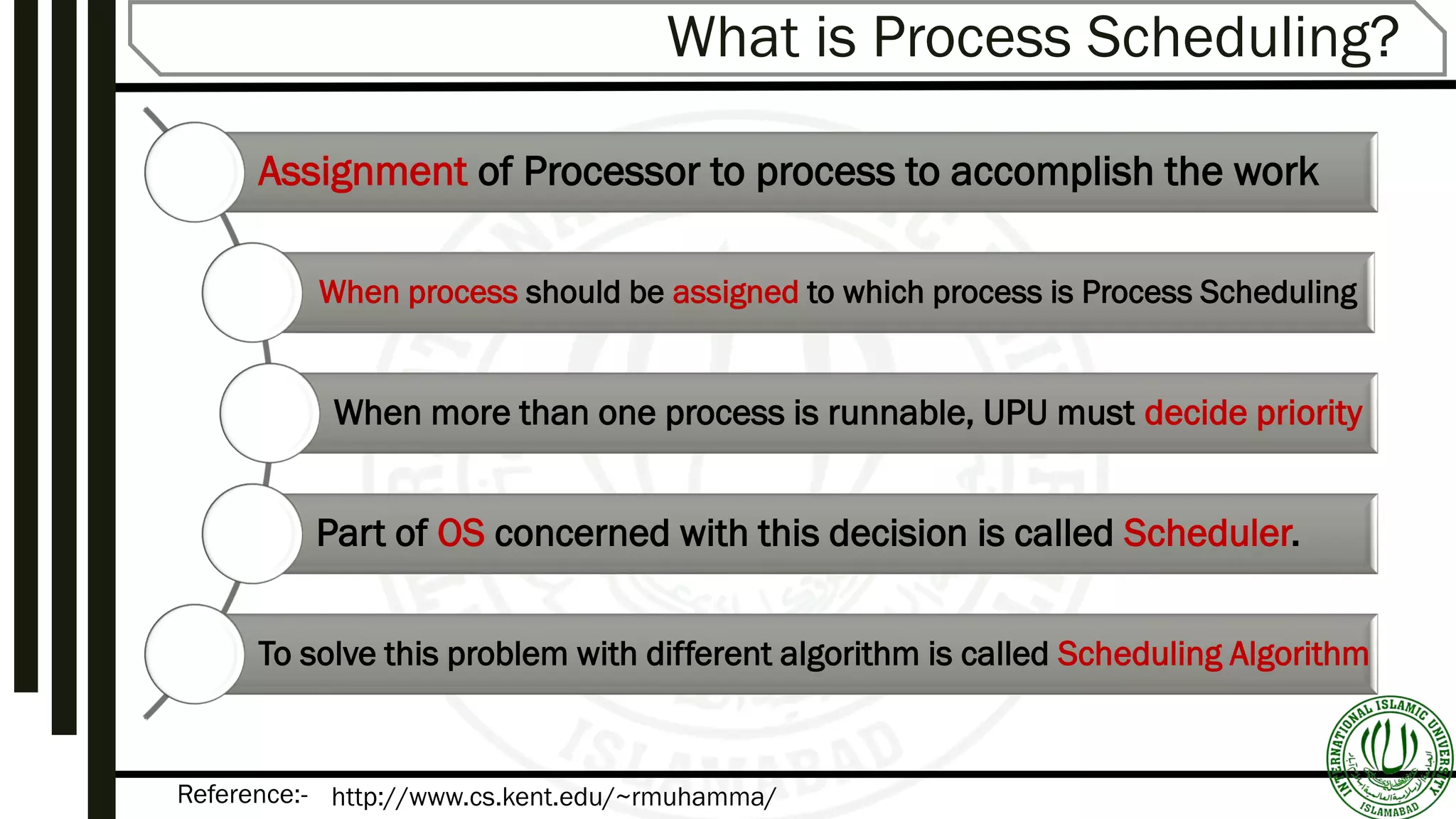
Overview of Process Scheduling presented by Sunawar Khan, highlighting its essential role in OS.
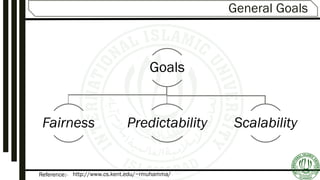
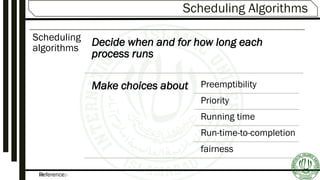
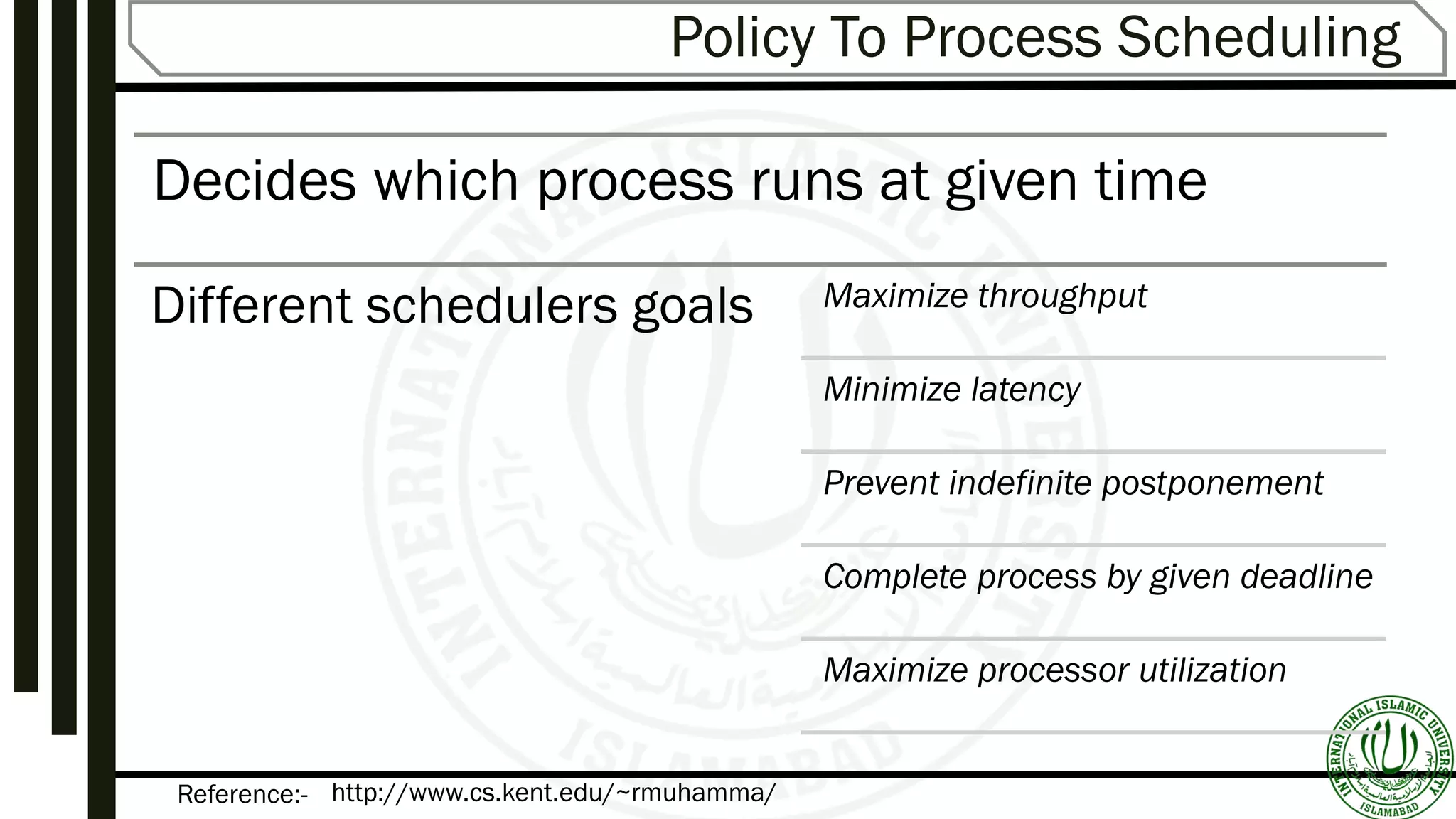
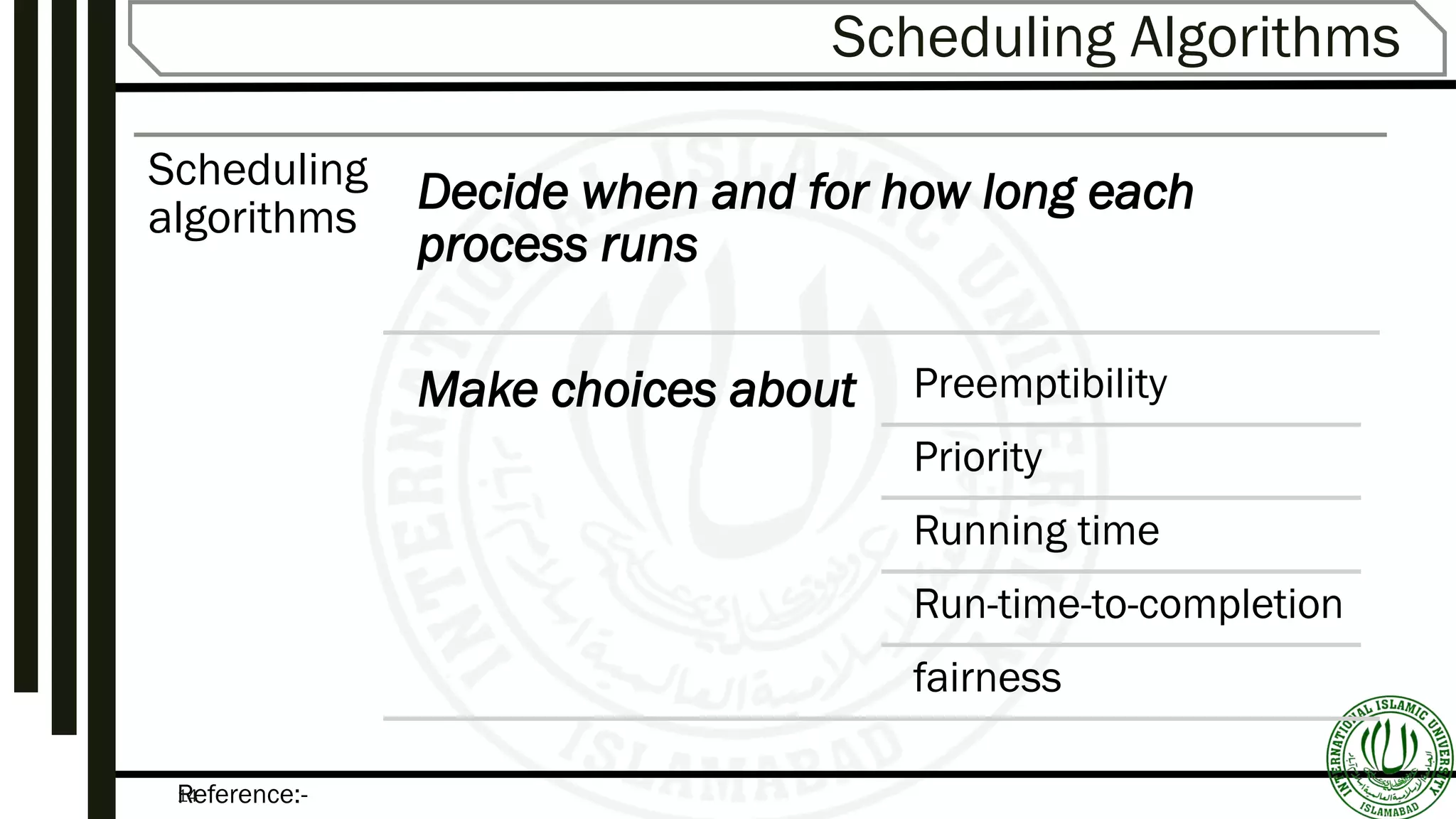
Discusses goals like maximizing CPU utilization, the concept of preemptive vs. non-preemptive scheduling, and the criteria and algorithms used in scheduling.
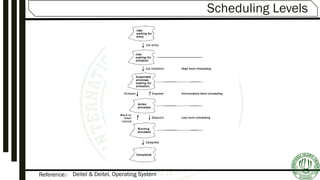
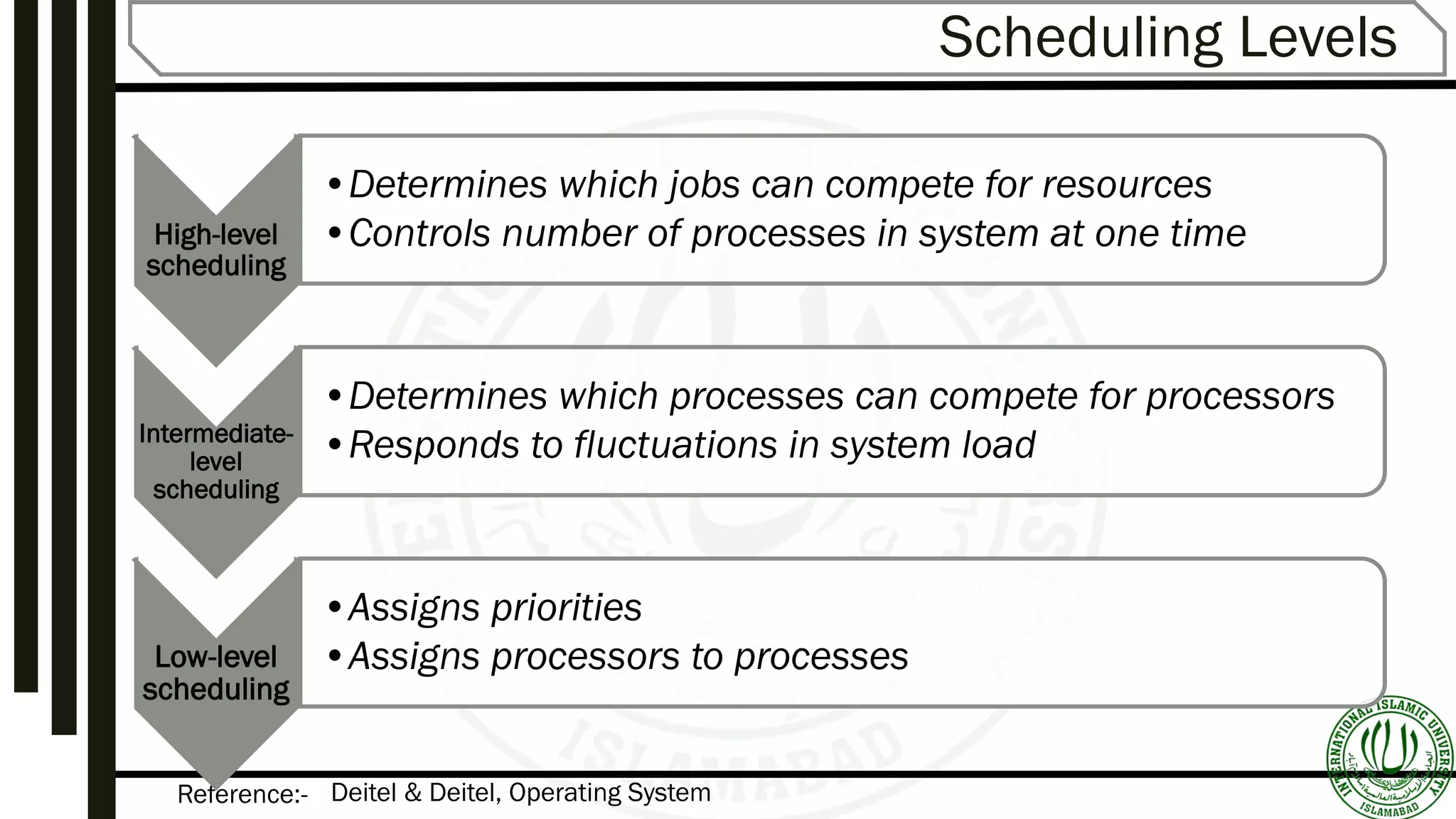
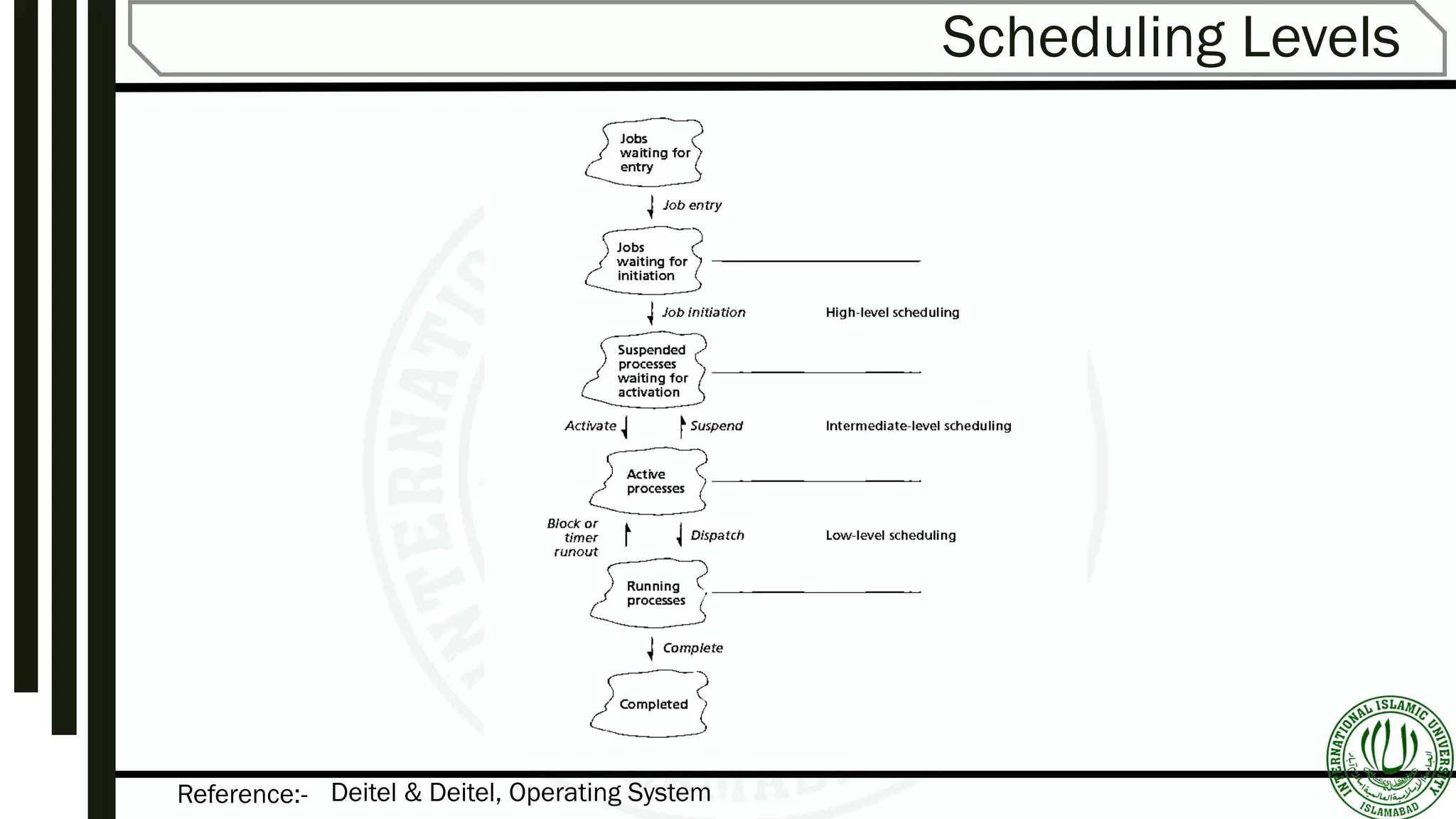
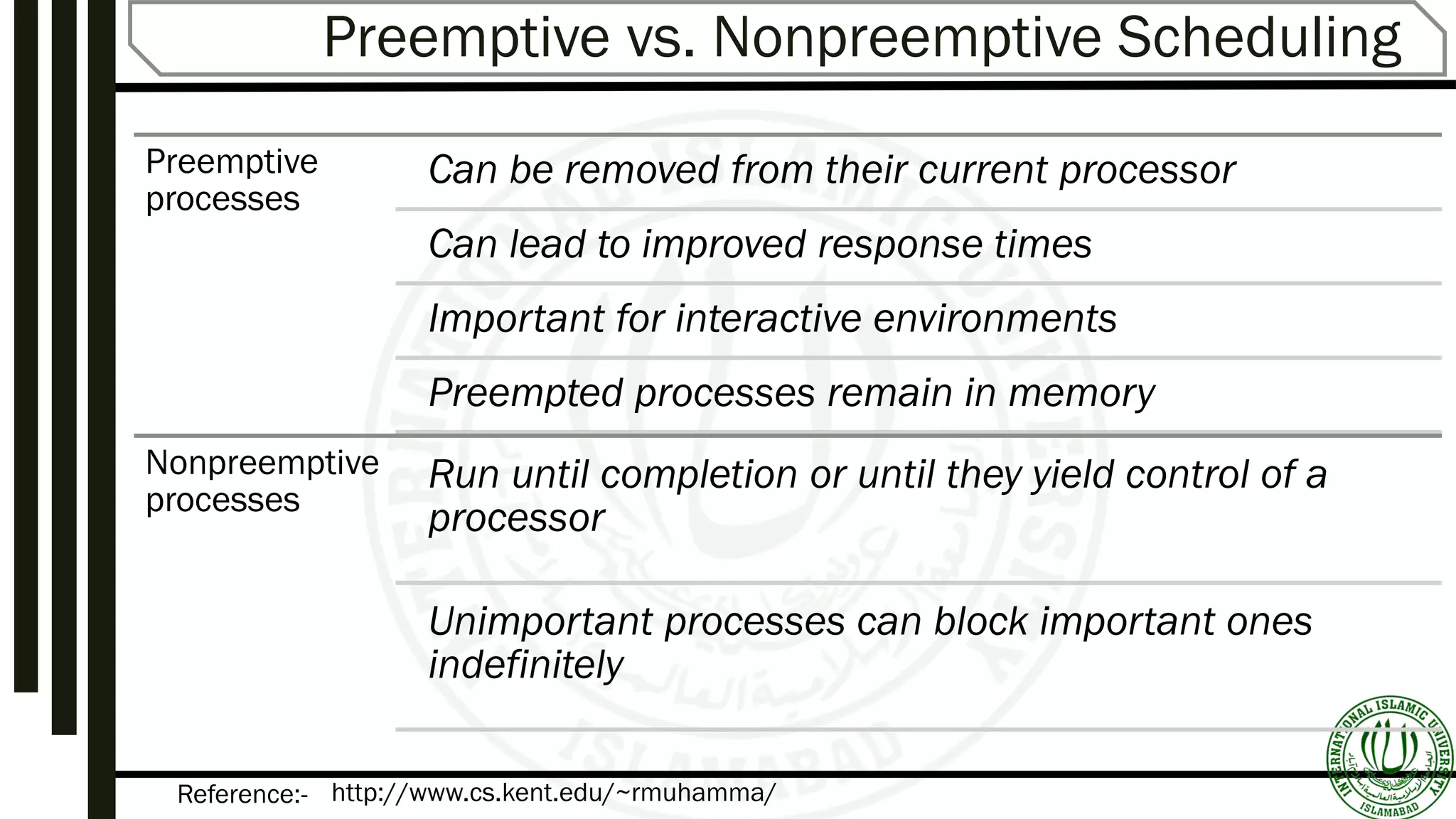
Details on scheduling levels: High, Intermediate, Low; and the differences between preemptive and non-preemptive scheduling.
Focuses on objectives of scheduling, listing criteria like CPU utilization, throughput, turnaround time, and response time.
Optimization criteria for scheduling algorithms, including utilization and throughput considerations.
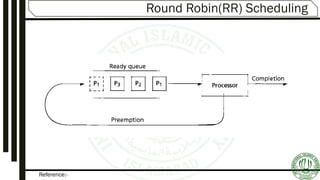
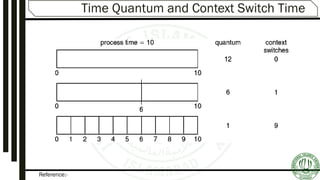
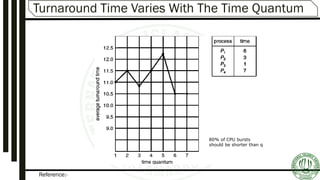
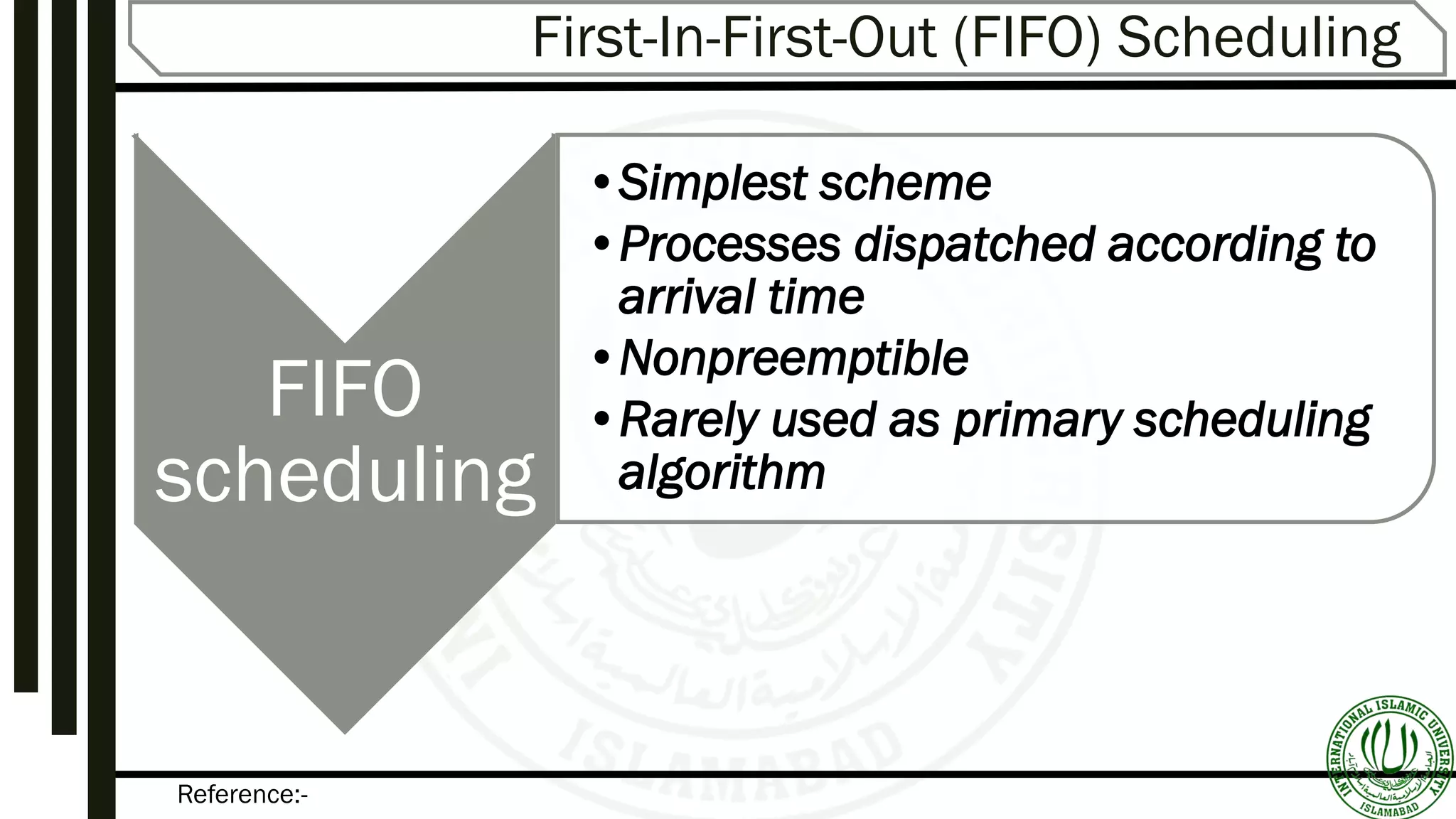
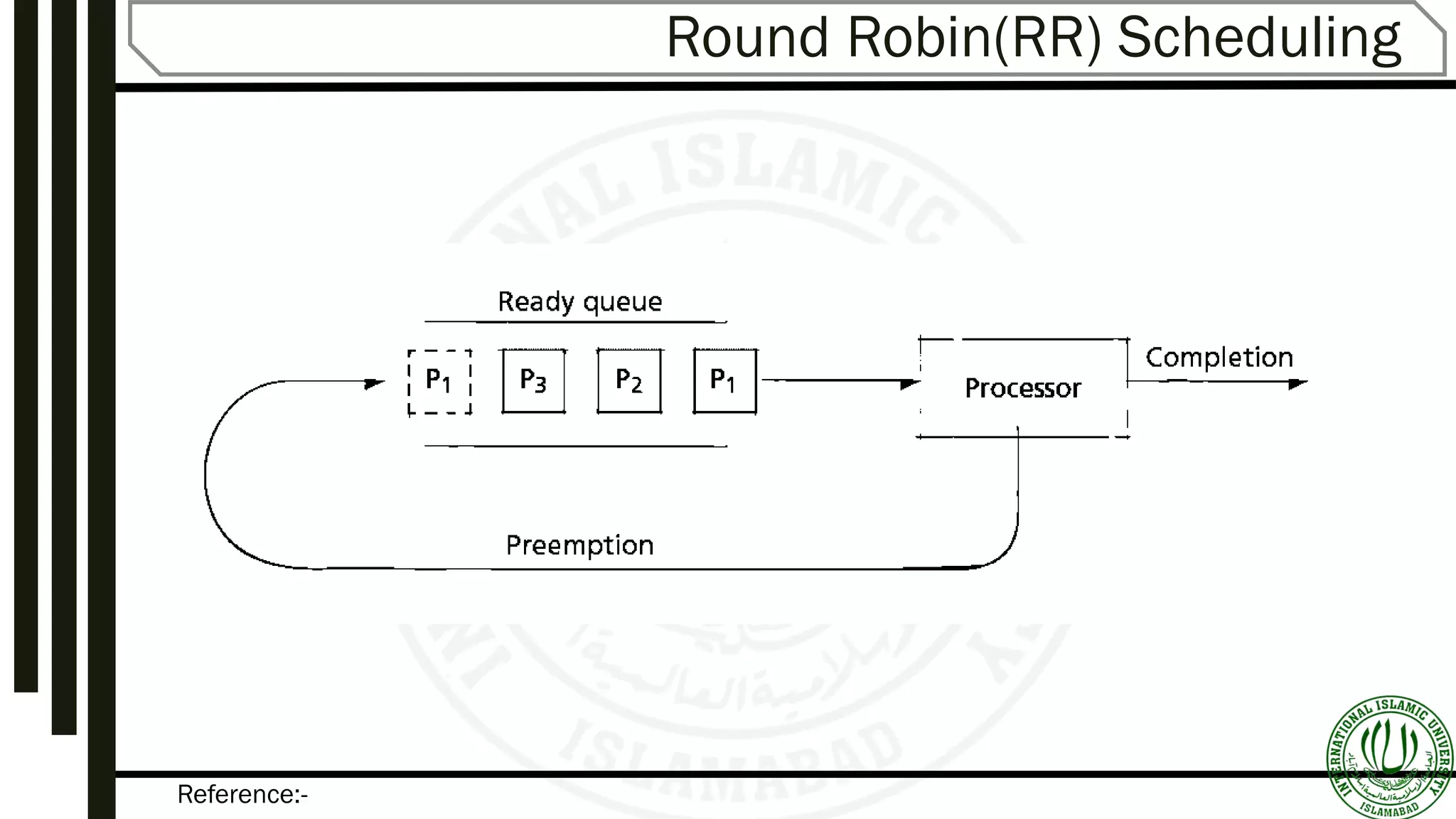
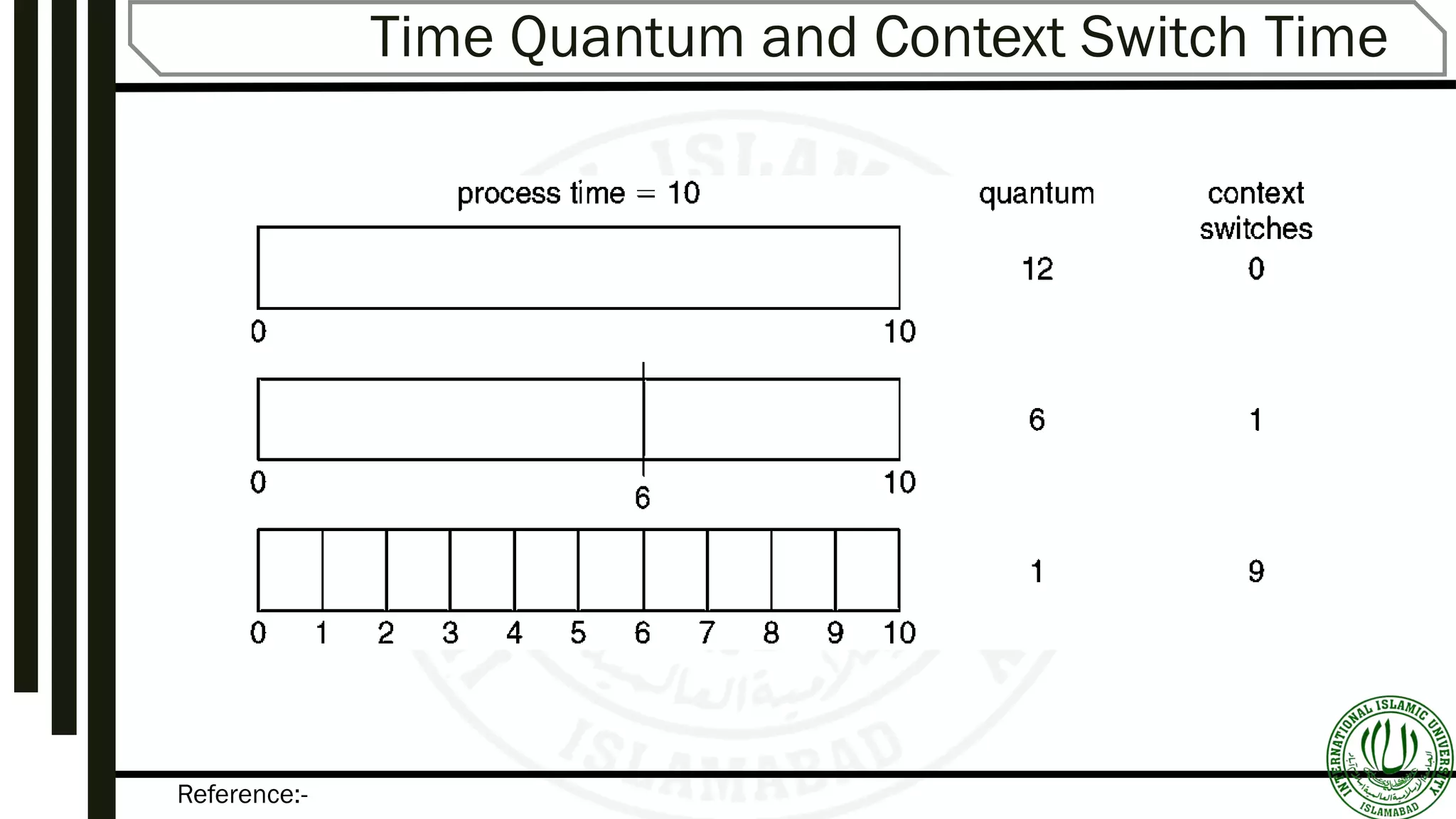
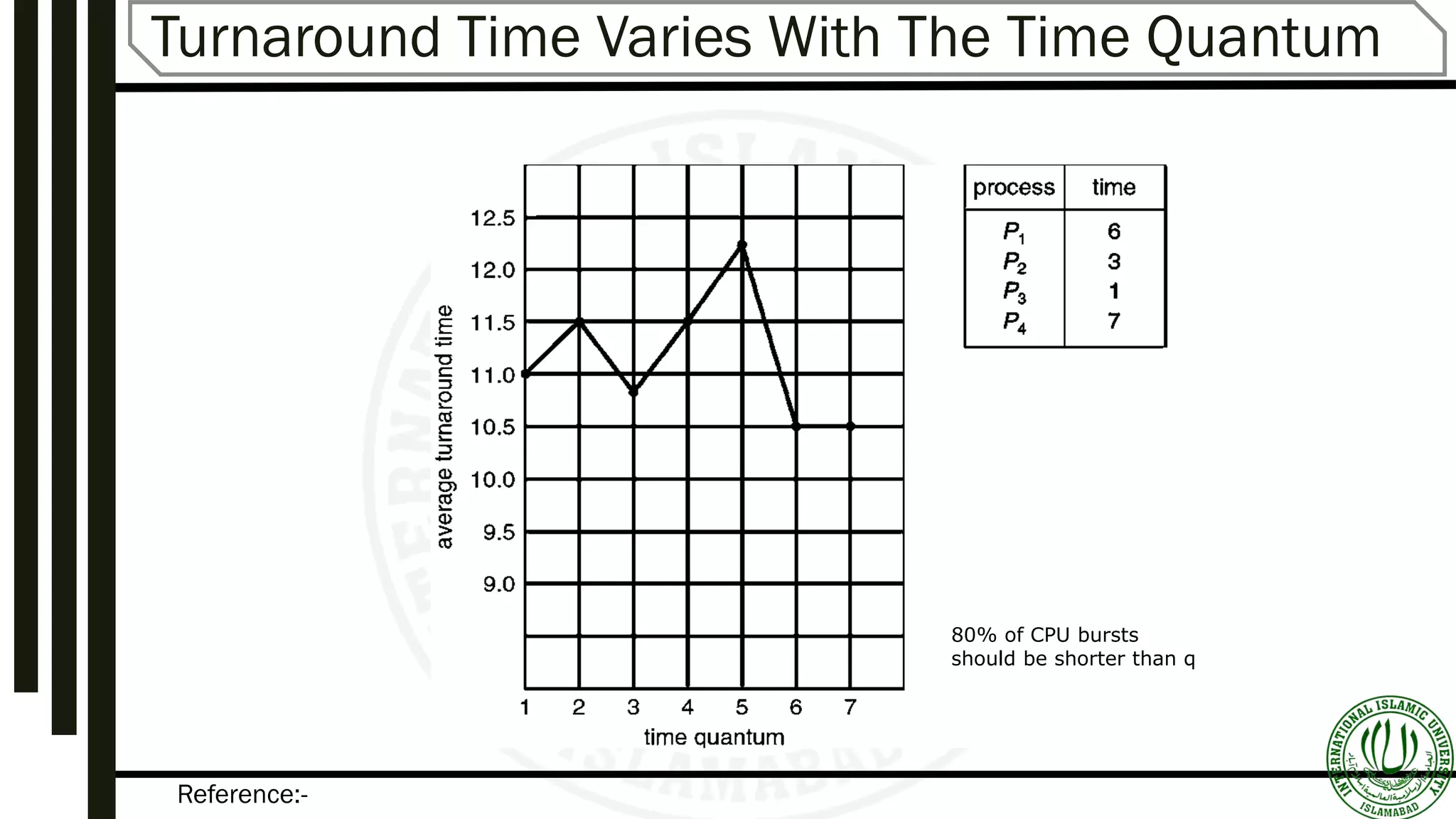
Describes FIFO (First-In-First-Out) scheduling, its mechanism, and provides example scenarios illustrating its functionality.Round-Robin scheduling mechanisms, time quantum specifications, advantages, and examples illustrating performance variation.
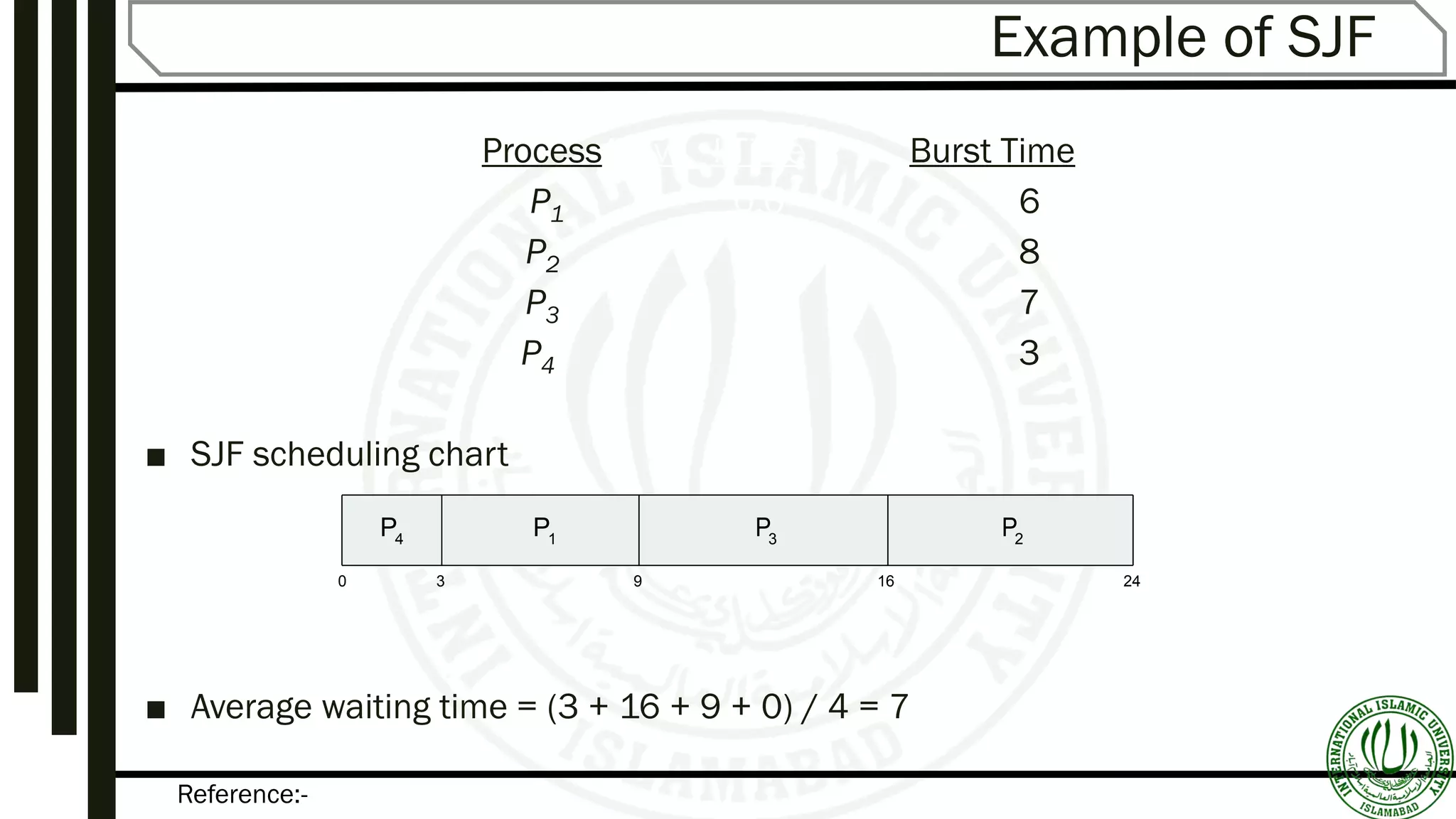
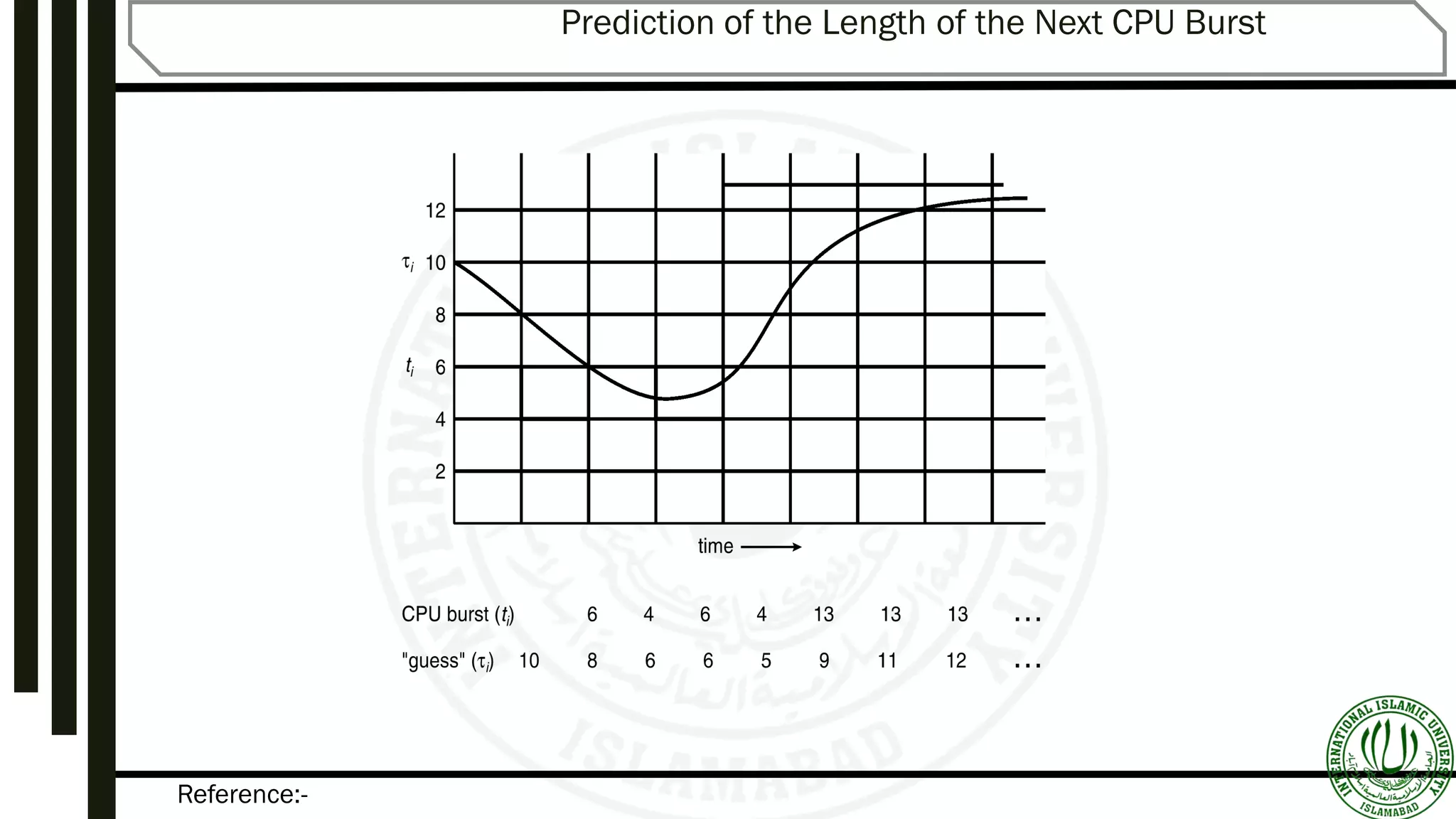
Discussion on SPF scheduling, its advantages, challenges in predicting CPU burst times, and examples demonstrating scheduling impact.
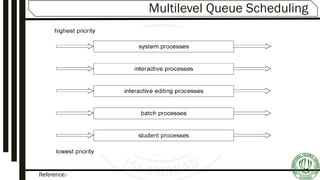
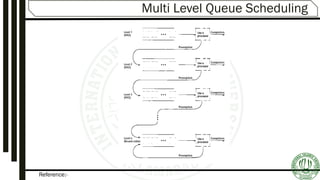
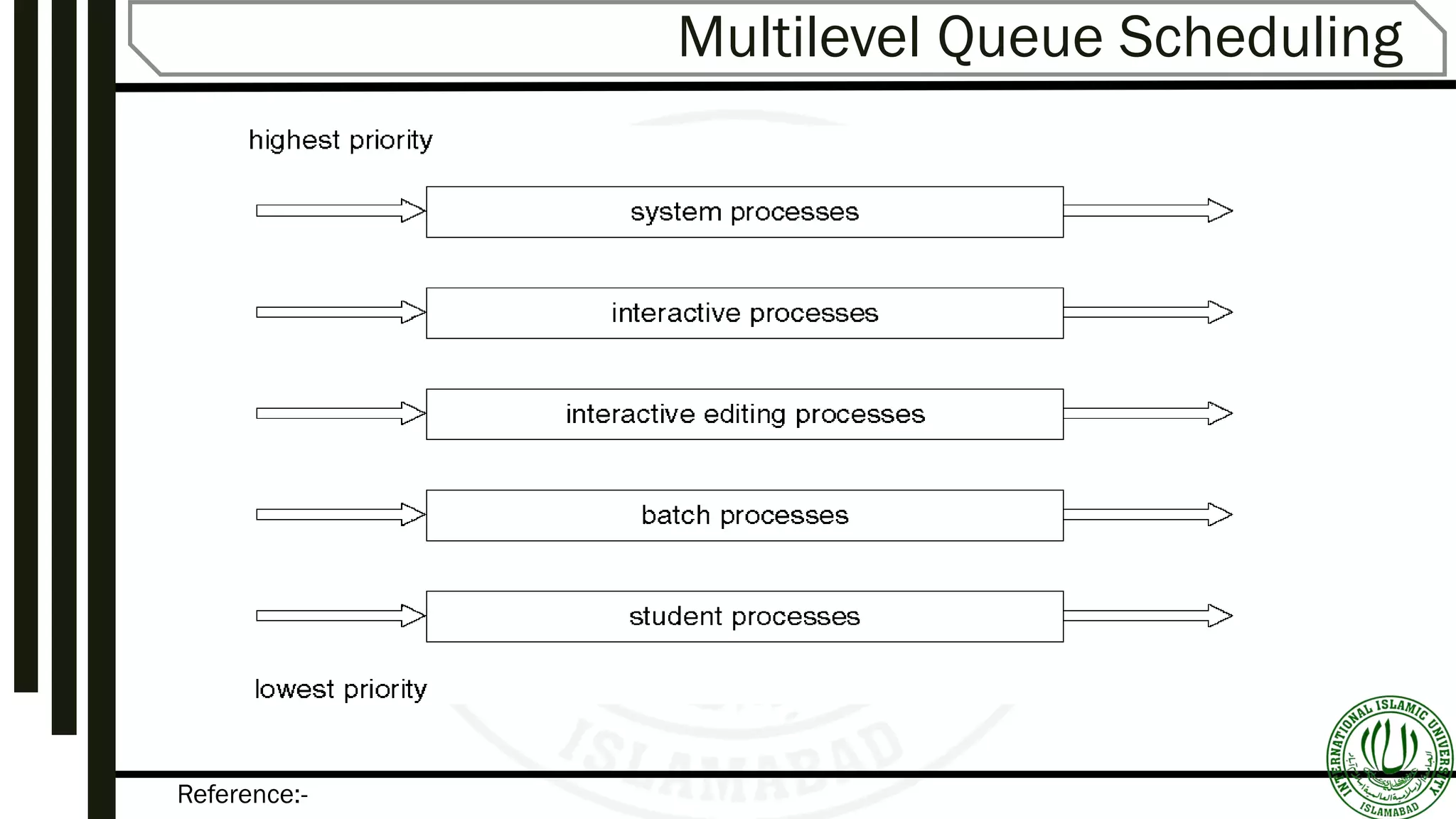
Explains Multilevel Queue and Multilevel Feedback Queues, detailing their structure, algorithms, and approaches for optimizing process management.
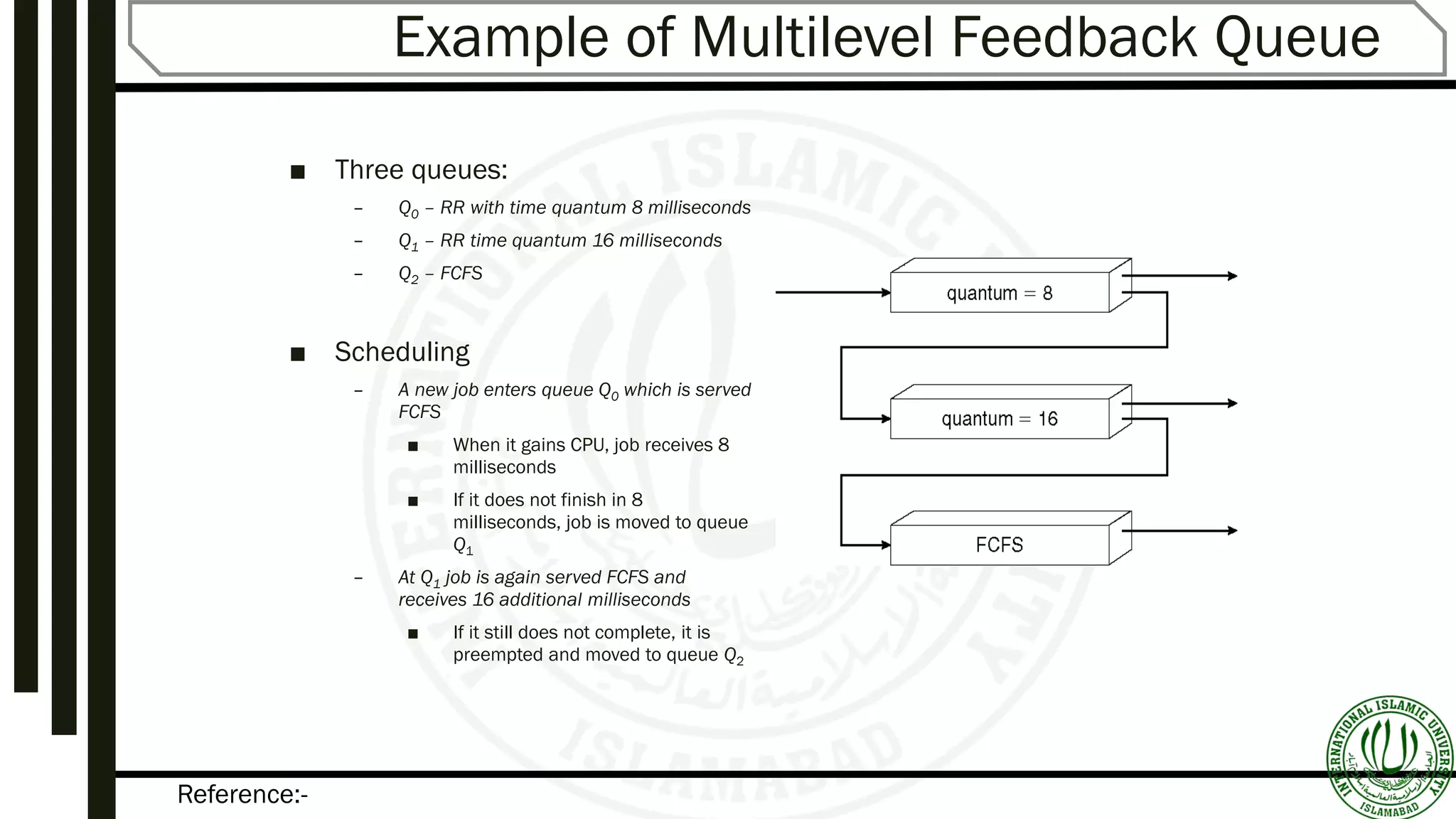
Illustrative example showing the implementation of multilevel feedback queues with various time quantum and execution rules.
































































































